Download presentation
Presentation is loading. Please wait.

1
第一章 C语言概述

2
C语言的特点 C程序的结构 在计算机上运行C程序的方法
本章要点 C语言的特点 C程序的结构 在计算机上运行C程序的方法

3
1.1 C语言出现的历史背景 1.2 C程序的特点 1.3 简单的C语言程序介绍 1.4 运行C程序的步骤和方法
主要内容 1.1 C语言出现的历史背景 1.2 C程序的特点 1.3 简单的C语言程序介绍 1.4 运行C程序的步骤和方法

4
1.1 C语言出现的历史背景 C语言是国际上广泛流行的高级语言。 C语言是在B语言的基础上发展起来的。
B (BCPL)语言是1970年由美国贝尔实验室设计的, 并用于编写了第一个UNIX操作系统,在PDP 7上实现。优点:精练,接近硬件,缺点:过于简单,数据无类型。 1973年贝尔实验室的D.M.Ritchie 在B语言的基础上设计出了C语言,对B取长补短,并用之改写了原来用汇编编写的UNIX,(即UNIX第5版),但仅在贝尔实验室使用。
语言是1970年由美国贝尔实验室设计的, 并用于编写了第一个UNIX操作系统,在PDP 7上实现。优点:精练,接近硬件,缺点:过于简单,数据无类型。 1973年贝尔实验室的D.M.Ritchie 在B语言的基础上设计出了C语言,对B取长补短,并用之改写了原来用汇编编写的UNIX,(即UNIX第5版),但仅在贝尔实验室使用。")
5
1.1C语言出现的历史背景 1975年UNIX第6版发布,C优点突出引起关注。
1977年出现了《可移植C语言编译程序》 ,推动了UNIX在各种机器上实现 ,C语言也得到推广,其发展相辅相成。 1978年影响深远的名著《The C Programming Language》由 Brian W.Kernighan和Dennis M.Ritchie 合著,被称为标准C。 之后,C语言先后移植到大、中、小、微型计算机上,已独立于UNIX和PDP,风靡世界,成为最广泛的几种计算机语言之一。

6
1.1C语言出现的历史背景 1983年,美国国家标准化协会(ANSI)根据C语言各种版本对C的发展和扩充,制定了新的标准ANSI C ,比标准C有了很大的发展。 1988年K & R按照 ANSI C修改了他们的《The C Programming Language》。 1987年,ANSI公布了新标准——87 ANSI C。 1990年,国际标准化组织接受了87 ANSI C为ISO C 的标准(ISO9899—1990)。 1994年,ISO又修订了C语言标准。 目前流行的C语言编译系统大多是以ANSI C为基础进行开发的。
。 1994年,ISO又修订了C语言标准。 目前流行的C语言编译系统大多是以ANSI C为基础进行开发的。")
7
1.1C语言出现的历史背景 说明: 不同版本的C编译系统所实现的语言功能和语法规则又略有差别,因此读者应了解所用的C语言编译系统的特点(可以参阅有关手册)。本书的叙述基本上以ANSI C 为基础。
。本书的叙述基本上以ANSI C 为基础。")
8
1.2 C语言的特点 (1)语言简洁、紧凑,使用方便、灵活。 32个关键字、9种控制语句,程序形式自由。 (2)运算符丰富。34种运算符 。
(3)数据类型丰富,具有现代语言的各种数据结构。 (4)具有结构化的控制语句 ,是完全模块化和结构化的语言。 (5)语法限制不太严格,程序设计自由度大。
数据类型丰富,具有现代语言的各种数据结构。 (4)具有结构化的控制语句 ,是完全模块化和结构化的语言。 (5)语法限制不太严格,程序设计自由度大。")
9
1.2 C语言的特点 (6)允许直接访问物理地址,能进行位操作,能实现汇编语言的大部分功能,可直接对硬件进行操作。兼有高级和低级语言的特点 。 (7)目标代码质量高,程序执行效率高。只比汇编程序生成的目标代码效率低10%-20%。 (8)程序可移植性好(与汇编语言比)。基本上不做修改就能用于各种型号的计算机和各种操作系统。
程序可移植性好(与汇编语言比)。基本上不做修改就能用于各种型号的计算机和各种操作系统。")
10
1.2 C语言的特点 问题:既然有了面向对象的C++语言,为什么还要学习C语言?
解释2:面向对象的基础是面向过程。C++是面向对象的语言,C是面向过程的,学起来比C语言困难得多,所以不太适合程序设计的初学者。

11
#include <stdio.h> void main( ) {
说明: 本程序的作用是输出一行信息: This is a C program. 1.3 简单的C语言程序介绍 #include <stdio.h> void main( ) { printf ("This is a C program.\n"); } /*文件包含*/ /*主函数 */ /*函数体开始*/ /*输出语句*/ /*函数体结束*/ 说明: main-主函数名, void-函数类型 每个C程序必须有一个主函数main { }是函数开始和结束的标志,不可省 每个C语句以分号结束 使用标准库函数时应在程序开头一行写: #include <stdio.h>
 { printf ( This is a C program.\n ); } /*文件包含*/ /*主函数 */ /*函数体开始*/ /*输出语句*/ /*函数体结束*/ 说明: main-主函数名, void-函数类型. 每个C程序必须有一个主函数main. { }是函数开始和结束的标志,不可省. 每个C语句以分号结束. 使用标准库函数时应在程序开头一行写: #include <stdio.h>")
12
说明: 输出一行信息:sum is 579 例1.2 求两数之和 #include <stdio.h> void main( ) /*求两数之和*/ { int a,b,sum; /*声明,定义变量为整型*/ /*以下3行为C语句 */ a=123; b=456; sum=a+b; printf(″sum is %d\n″,sum); } 说明: /*……*/表示注释。注释只是给人看的,对编译和运行不起作用。所以可以用汉字或英文字符表示,可以出现在一行中的最右侧,也可以单独成为一行。
 /*求两数之和*/ { int a,b,sum; /*声明,定义变量为整型*/ /*以下3行为C语句 */ a=123; b=456; sum=a+b; printf(″sum is %d\n″,sum); } 说明: /*……*/表示注释。注释只是给人看的,对编译和运行不起作用。所以可以用汉字或英文字符表示,可以出现在一行中的最右侧,也可以单独成为一行。")
13
int max(int x, int y) max(int x,int y); { int z; if (x>y) z=x;
程序运行情况如下: 8,5 ↙(输入8和5赋给a和b) max=8 (输出c的值) 例1.3 求3个数中较大者。 #include <stdio.h> void main( ) /* 主函数*/ { int max(int x,int y); / 对被调用函数max的声明 */ int a, b, c; /*定义变量a、b、c */ scanf(″%d,%d″,&a,&b); /*输入变量a和b的值*/ c=max(a,b); /*调用max函数,将得到的值赋给c */ printf(″max=%d\\n″,c); /*输出c的值*/ } max(a,b); int max(int x, int y) { int z; if (x>y) z=x; else z=y; return (z); } max(int x,int y); 说明:本程序包括main和被调用函数max两个函数。max函数的作用是将x和y中较大者的值赋给变量z。return语句将z的值返回给主调函数main。
 max=8 (输出c的值) 例1.3 求3个数中较大者。 #include <stdio.h> void main( ) /* 主函数*/ { int max(int x,int y); / 对被调用函数max的声明 */ int a, b, c; /*定义变量a、b、c */ scanf(″%d,%d″,&a,&b); /*输入变量a和b的值*/ c=max(a,b); /*调用max函数,将得到的值赋给c */ printf(″max=%d\\n″,c); /*输出c的值*/ } max(a,b); int max(int x, int y) { int z; if (x>y) z=x; else z=y; return (z); } max(int x,int y); 说明:本程序包括main和被调用函数max两个函数。max函数的作用是将x和y中较大者的值赋给变量z。return语句将z的值返回给主调函数main。")
14
1.3 简单的C语言程序介绍 C程序: (1) C程序是由函数构成的。 这使得程序容易实现模块化。 (2) 一个函数由两部分组成:
函数的首部:例1.3中的max函数首部 int max(int x,int y ) 函数体:花括号内的部分。若一个函数有多个花括号,则最外层的一对花括号为函数体的范围。 函数体包括两部分 : 声明部分:int a,b,c; 可缺省 执行部分:由若干个语句组成。可缺省
 函数体:花括号内的部分。若一个函数有多个花括号,则最外层的一对花括号为函数体的范围。 函数体包括两部分 : 声明部分:int a,b,c; 可缺省. 执行部分:由若干个语句组成。可缺省.")
15
这是一个空函数,什么也不做,但是合法的函数。
1.3 简单的C语言程序介绍 注意: 函数的声明部分和执行部分都可缺省,例如: void dump ( ) { } 这是一个空函数,什么也不做,但是合法的函数。
 { } 这是一个空函数,什么也不做,但是合法的函数。")
16
1.3 简单的C语言程序介绍 小结: (3) C程序总是从main函数开始执行的,与main函数的位置无关。
(5) 每个语句和数据声明的最后必须有一个分号。 (6) C语言本身没有输入输出语句。输入和输出的操作是由库函数scanf和printf等函数来完成的。C对输入输出实行“函数化”。
 每个语句和数据声明的最后必须有一个分号。 (6) C语言本身没有输入输出语句。输入和输出的操作是由库函数scanf和printf等函数来完成的。C对输入输出实行 函数化 。")
17
1.4 运行C程序的步骤和方法 1.4.1 运行C程序的步骤 上机输入与编辑源程序 对源程序进行编译 与库函数连接 运行目标程序

18
1.4 运行C程序的步骤和方法 1.4.2上机运行C程序的方法
目前使用的大多数C编译系统都是集成环境(IDE)的。可以用不同的编译系统对C程序进行操作。 常用的有Turbo C 2.0、Turbo C++ 3.0、Visual C++等。 Turbo C++ 3.0:是一个集成环境,它具有方便、直观和易用的界面,虽然它也是DOS环境下的集成环境,但是可以把启动Turbo C 集成环境的DOS执行文件tc.exe生成快捷方式,也可以用鼠标操作。 Visual C++:也可以用Visual C++对C程序进行编译。
的。可以用不同的编译系统对C程序进行操作。 常用的有Turbo C 2.0、Turbo C++ 3.0、Visual C++等。 Turbo C++ 3.0:是一个集成环境,它具有方便、直观和易用的界面,虽然它也是DOS环境下的集成环境,但是可以把启动Turbo C 集成环境的DOS执行文件tc.exe生成快捷方式,也可以用鼠标操作。 Visual C++:也可以用Visual C++对C程序进行编译。")
19
例:Turbo C++ 3.0的使用 将Turbo C++ 3.0编译程序装入磁盘某一目录下 例如: 放在C盘根目录下一级TC3.0子目录下。 进入Turbo C++ 3.0集成环境 ①在DOS环境下 C:\TC3.0>tc ↙

20
② 在Windows环境下 找到可执行文件tc.exe,执行该文件。 主菜单:11个菜单项: File Edit Search Run Compile Debug Project Options Window Help

21
(2) 编辑源文件 新建:单击“File”菜单下 的“New”, 修改:选择“File”→“Open”(即单击“File” 的下拉菜单中的“Open”项,修改已有的源程序。
 编辑源文件 新建:单击 File 菜单下 的 New , 修改:选择 File → Open (即单击 File 的下拉菜单中的 Open 项,修改已有的源程序。")
22
在编辑(EDIT) 状态下光标表示当前进行编辑的位置,在此位置可以进行插入、删除或修改,直到自已满意为止。
 状态下光标表示当前进行编辑的位置,在此位置可以进行插入、删除或修改,直到自已满意为止。")
23
保存:在编辑(EDIT) 状态下光标表示当前进行编辑的位置,在此位置可以进行插入、删除或修改,直到自已满意为止。
 状态下光标表示当前进行编辑的位置,在此位置可以进行插入、删除或修改,直到自已满意为止。")
24
(3) 对源程序进行编译 选择“Compile”(或“Alt+F9”)对源程序进行编译。 c1.cpp源程序,出现1个错误(error) ,0个警告(warming)。
 对源程序进行编译 选择 Compile (或 Alt+F9 )对源程序进行编译。 c1.cpp源程序,出现1个错误(error) ,0个警告(warming)。")
25
(4) 将目标程序进行连接 选择菜单“Compile” →“Link” ,如果不出现错误,会得到一个后缀为.exe的可执行文件。 (5) 执行程序 选菜单“Run” →“Run”( 或按“Ctrl+F9” 键)。 (6) 退出Turbo C++ 3.0环境 选择“File”→“Quit” 。
 退出Turbo C++ 3.0环境. 选择 File → Quit 。")
26
第二章 程序的灵魂--算法

27
本章要点 算法的概念 算法的表示 结构化程序设计方法

28
2.1 算法的概念 2.2 简单算法举例 2.3 算法的特性 2.4 怎样表示一个算法 2.5 化程序设计方法
主要内容 2.1 算法的概念 2.2 简单算法举例 2.3 算法的特性 2.4 怎样表示一个算法 2.5 化程序设计方法

29
一个程序应包括两个方面的内容: 对数据的描述:数据结构(data structure) 对操作的描述:算法(algorithm) 著名计算机科学家沃思提出一个公式: 数据结构 + 算法 = 程序 完整的程序设计应该是: 数据结构+算法+程序设计方法+语言工具

30
2.1 算法的概念 广义地说,为解决一个问题而采取的方法和步骤,就称为“算法”。 对同一个问题,可有不同的解题方法和步骤 例: 求
例: 求 方法1:1+2,+3,+4,一直加到100 加99次 方法2:100+(1+99)+(2+98)+…+(49 +51)+50 = × 加51次
+(2+98)+…+(49 +51)+50. = × 加51次.")
31
2.1 算法的概念 为了有效地进行解题,不仅需要保证算法正确,还要考虑算法的质量,选择合适的算法。希望方法简单,运算步骤少。
计算机算法可分为两大类别: 数值运算算法:求数值解,例如求方程的根、求函数的定积分等。 非数值运算:包括的面十分广泛,最常见的是用于事务管理领域,例如图书检索、人事管理、行车调度管理等。

32
太繁琐 2.2 简单算法举例 例2.1: 求1×2×3×4×5 如果要求1×2×…×1000,则要写999个步骤
例2.1: 求1×2×3×4×5 步骤1:先求1×2,得到结果2 步骤2:将步骤1得到的乘积2再乘以3,得到结果6 步骤3:将6再乘以4,得24 步骤4:将24再乘以5,得120 如果要求1×2×…×1000,则要写999个步骤 太繁琐

33
可以设两个变量:一个变量代表被乘数,一个变量代表乘数。不另设变量存放乘积结果,而直接将每一步骤的乘积放在被乘数变量中。设p为被乘数,i为乘数。用循环算法来求结果, 算法可改写:
S1:使p=1。 S2:使i=2。 S3:使p×i,乘积仍放在变量p中,可表示为:p×ip S4:使i的值加1,即i+1i。 S5:如果i不大于5,返回重新执行步骤S3以及其后的步骤S4和S5;否则,算法结束。最后得到p的值就是5!的值。

34
如果题目改为:求1×3×5×……×1000算法只需作很少的改动:
算法简练 S1:1→p S2:3 → i S3:p×i → p S4:i+2 → p S5:若i≤11,返回S3。否则,结束。

35
用这种方法表示的算法具有通用性、灵活性。S3到S5组成一个循环,在实现算法时 要反复多次执行S3,S4,S5等步骤,直到某一时刻,执行S5步骤时经过判断,乘数i已超过规定的数值而不返回S3步骤为止。此时算法结束,变量p的值就是所求结果。

36
例2.2 有50个学生,要求将他们之中成绩在80分以上者打印出来。设n表示学号, n1代表第一个学生学号, 代表第i个学生学号。用G代表学生成绩 , gi代表第i个学生成绩,算法表示如下:
S1:1 → i S2:如果≥80,则打印和,否则不打印。 S3:i+1 → i S4:如果i≤50,返回S2,继续执行。否则算法结束 变量i作为下标,用来控制序号(第几个学生,第几个成绩)。当i超过50时,表示 已对50个学生的成绩处理完毕,算法结束。
。当i超过50时,表示 已对50个学生的成绩处理完毕,算法结束。")
37
例2.3 判定2000~2500年中的每一年是否闰年,将结果输出。
分析:闰年的条件是:(1)能被4整除,但不能被100整除的年份都是闰年,如1996,2004年是闰年;(2)能被100整除,又能被400整除的年份是闰年。如1600,2000年是闰年。不符合这两个条件的年份不是闰年。 变量i作为下标,用来控制序号(第几个学生,第几个成绩)。当i超过50时,表示 已对50个学生的成绩处理完毕,算法结束。
能被4整除,但不能被100整除的年份都是闰年,如1996,2004年是闰年;(2)能被100整除,又能被400整除的年份是闰年。如1600,2000年是闰年。不符合这两个条件的年份不是闰年。 变量i作为下标,用来控制序号(第几个学生,第几个成绩)。当i超过50时,表示 已对50个学生的成绩处理完毕,算法结束。")
38
设y为被检测的年份,算法可表示如下 : S1:2000 → y S2:若y不能被4整除,则输出y “不是闰年”。然后转到S6。 S3:若y能被4整除,不能被100整除,则输出y “是闰年”。然后转到S6。 S4:若y能被100整除,又能被400整除,输出y“是闰年”,否则输出“不是闰年”。 然后转到S6。 S5: 输出y “不是闰年”。 S6:y+1 → y S7:当y≤2500时,转S2继续执行,如y>2500,算法停止。

39
以上算法中每做一步都分别分离出一些范围(巳能判定为闰年或非闰年),逐步缩小范围,直至执行S5时,只可能是非闰年。
“其它” 包括能被4整除,又能被100整除,而不能被400整除的那些年份(如1990) 是非闰年。
 是非闰年。")
40
S1:sign=1 例2.4 求 算法如下 : 单词作变量名,以使算法更易于理解: S2:sum=1 S3:deno=2
S4:sign=(-1)×sign S5:term=sign×(1/deno) S6:sum=sum+term S7:deno=deno+1 S8:若deno≤100返回S4,否则算法结束。 单词作变量名,以使算法更易于理解: sum表示累加和,deno是英文分母(denom inator)缩写,sign代表数值的符号,term代表某一项。 反复执行S4到S8步骤,直到分母大于100为止。一共执行了99次循环,向sum累加入了99个分数。sum最后的值就是多项式的值。
×sign S5:term=sign×(1/deno) S6:sum=sum+term S7:deno=deno+1 S8:若deno≤100返回S4,否则算法结束。 单词作变量名,以使算法更易于理解: sum表示累加和,deno是英文分母(denom inator)缩写,sign代表数值的符号,term代表某一项。 反复执行S4到S8步骤,直到分母大于100为止。一共执行了99次循环,向sum累加入了99个分数。sum最后的值就是多项式的值。")
41
例2.5 对一个大于或等于3的正整数,判断它是不是一个素数。
概念:所谓素数,是指除了1和该数本身之外,不能被其它任何整数整除的数。例如,13是素数。因为它不能被2,3,4,…,12整除。 分析:判断一个数n(n≥3)是否素数的方法: 将n作为被除数,将2到(n-1)各个整数轮流作为除数,如果都不能被整除,则n为素数。
是否素数的方法: 将n作为被除数,将2到(n-1)各个整数轮流作为除数,如果都不能被整除,则n为素数。")
42
实际上,n不必被2到(n-1)的整数除,只需被2到n/2间整数除,甚至只需被2到 之间的整数除即可。
算法如下 : S1:输入n的值 S2:i=2 (i作为除数) S3:n被i除,得余数r S4:如果r=0,表示n能被i整除,则打印n“不是素数”,算法结束。否则执行S5 S5:i+1→i S6:如果i≤n-1,返回S3。否则打印 n “是素数”。然后结束。 实际上,n不必被2到(n-1)的整数除,只需被2到n/2间整数除,甚至只需被2到 之间的整数除即可。
 S3:n被i除,得余数r S4:如果r=0,表示n能被i整除,则打印n 不是素数 ,算法结束。否则执行S5 S5:i+1→i S6:如果i≤n-1,返回S3。否则打印 n 是素数 。然后结束。 实际上,n不必被2到(n-1)的整数除,只需被2到n/2间整数除,甚至只需被2到 之间的整数除即可。")
43
2.3 算法的特性 一个算法应该具有以下特点: 有穷性:包含有限的操作步骤。 确定性:算法中的每一个步骤都应当是确定的。
有零个或多个输入:输入是指在执行算法时需要从外界取得必要的信息。 有一个或多个输出:算法的目的是为了求解,“解” 就是输出。 有效性:算法中的每一个步骤都应当能有效地执行,并得到确定的结果 。

44
2.4 算法的表示 可以用不同的方法表示算法,常用的有: 自然语言 传统流程图 结构化流程图 伪代码 PAD图

45
2.4.1 用自然语言表示算法 自然语言就是人们日常使用的语言,可以是汉语或英语或其它语言。用自然语言表示通俗易懂,但文字冗长,容易出现“歧义性”。自然语言表示的含义往往不大严格,要根据上下文才能判断其正确含义,描述包含分支和循环的算法时也不很方便。因此,除了那些很简单的问题外,一般不用自然语言描述算法。

46
美国国家标准化协会ANSI(American National Standard Institute)规定了一些常用的流程图符号:
2.4.2 用流程图表示算法 美国国家标准化协会ANSI(American National Standard Institute)规定了一些常用的流程图符号: 起止框 判断框 处理框 输入/输出框 注释框 流向线 连接点
规定了一些常用的流程图符号: 起止框. 判断框. 处理框. 输入/输出框. 注释框. 流向线. 连接点.")
47
例2.6 将求5!的算法用流程图表示 如果需要将最后结果打印出来,可在菱形框的下面加一个输出框。

48
例2.7 将例2.2的算法用流程图表示。打印50名 学生中成绩在80分以上者的学号和成绩。

49
如果如果包括这个输入数据的部分,流程图为

50
用流程图表示算法要比用文字描述算法逻辑清晰、易于理解。
例2.8 将例2.3判定闰年的算法用流程图表示

51
例2.9 将例2.4的算法用流程图表示

52
例2.10 将例2.5判断素数的算法用流程图表示

53
小结: 流程图是表示算法的较好的工具。一个流程图包括以下几部分 : (1)表示相应操作的框; (2)带箭头的流程线; (3)框内外必要的文字说明。
表示相应操作的框; (2)带箭头的流程线; (3)框内外必要的文字说明。")
54
2.4.3 三种基本结构和改进的流程图 1.传统流程图的弊端 传统流程图用流程线指出各框的执行顺序,对流程线的使用没有严格限制。因此,使用者可以毫不受限制地使流程随意地转向,使流程图变得毫无规律,阅读者要花很大精力去追踪流程,使人难以理解算法的逻辑。如图:

55
缺点:难以阅读、修改,使算法的可靠性和可维护性难以保证。
解决办法:必须限制箭头的滥用,即不允许无规律地使流程随意转向,只能顺序地进行下去。 传统流程图的流程可以是: 这种如同乱麻一样的算法称为BS型算法,意为一碗面条(A Bowl of Spaghetti),乱无头绪。
,乱无头绪。")
56
2.三种基本结构 Bohra和Jacopini提出了以下三种基本结构: 顺序结构、选择结构、循环结构 用这三种基本结构作为表示一个良好算法的基本单元。

57
三种基本结构的图示: 顺序结构 选择结构

58
循环结构的图示: 当型(While型)循环结构 直到型(Until型)循环
循环结构 直到型(Until型)循环")
59
三种基本结构的共同特点: (1)只有一个入口。 (2)只有一个出口。(请注意:一个菱形判断框有两个出口,而一个选择结构只有一个出口。不要将菱形框的出口和选择结构的出口混淆。) (3)结构内的每一部分都有机会被执行到。 (4)结构内不存在“死循环”(无终止的循环)。
结构内不存在 死循环 (无终止的循环)。")
60
不正确的流程表示: 图中没有一条从入口到出口的路径通过A框 流程内的死循环

61
小结: 由三种基本结构顺序组成的算法结构,可以解决任何复杂的问题。由基本结构所构成的算法属于“结构化”的算法,它不存在无规律的转向,只在本基本结构内才允许存在分支和向前或向后的跳转。

62
扩展: 只要具有上述四个特点的都可以作为基本结构。可以自己定义基本结构,并由这些基本结构组成结构化程序。 此图符合基本结构的特点

63
这是一个多分支选择结构,根据表达式的值决定执行路线。虚线框内的结构是一个入口一个出口,并且有上述全部的四个特点。由此构成的算法结构也是结构化的算法。可以认为这是由三种基本结构所派生出来的。

64
2.4.4 用N-S流程图表示算法 1973年美国学者I.Nassi和B.Shneiderman提出了一种新的流程图形式。在这种流程图中,完全去掉了带箭头的流程线。全部算法写在一个矩形框内,在该框内还可以包含其它的从属于它的框,或者说,由一些基本的框组成一个大的框。这种流程图又称N--S结构化流程图。

65
N-S流程图用以下的流程图符号: (1)顺序结构 (2)选择结构 (3)循环结构
顺序结构 (2)选择结构 (3)循环结构")
66
用三种N-S流程图中的基本框,可以组成复杂的N-S流程图。图中的A框或B框,可以是一个简单的操作,也可以是三个基本结构之一。

67
例2.11 将例2.1的求5!算法用N-S图表示

68
例2.12 将例2.2的算法用N-S图表示。(打印50名学生中成绩高于80分的学号和成绩)
没有输入数据

69
例2.12 将例2.2的算法用N-S图表示。(打印50名学生中成绩高于80分的学号和成绩)
有输入数据

70
例2.13 将例2.3判定闰年的算法用N-S图表示

71
例2.14 将例2.4的算法用N-S图表示

72
例2.15 将例2.5判别素数的算法用N-S流程图表示。
传统流程图分析: 出口1 此图不符合基本结构特点!由于不能分解为三种基本结构,就无法直接用N--S流程图的三种基本结构的符号来表示。因此,应当先作必要的变换。 出口2

73
例2.15 将例2.5判别素数的算法用N-S流程图表示。
传统流程图变换为: 一个出口

74
用N-S流程图表示:

75
N-S图表示算法的优点 比文字描述直观、形象、 易于理解;比传统流程图紧凑易画。尤其是它废除了流程线,整个算法结构是由各个基本结构按顺序组成的,N--S流程图中的上下顺序就是执行时的顺序。用N--S图表示的算法都是结构化的算法,因为它不可能出现流程无规律的跳转,而只能自上而下地顺序执行。

76
小结: 一个结构化的算法是由一些基本结构顺序组成的。在基本结构之间不存在向前或向后的跳转,流程的转移只存在于一个基本结构范围之内(如循环中流程的跳转);一 个非结构化的算法可以用一个等价的结构化算法代替,其功能不变 。如果一个算法不能分解为若干个基本结构,则它必然不是一个结构化的算法。
;一 个非结构化的算法可以用一个等价的结构化算法代替,其功能不变 。如果一个算法不能分解为若干个基本结构,则它必然不是一个结构化的算法。")
77
2.4.5 用位代码表示算法 概念:伪代码是用介于自然语言和计算机语言之间的文字和符号来描述算法。 特点:它如同一篇文章一样 ,自上而下地写下来。每一行(或几行)表示一个基本操作。它不用图形符号,因此书写方便 、格式紧凑,也比较好懂,也便于向计算机语言算法(即程序)过渡。 用处:适用于设计过程中需要反复修改时的流程描述。

78
例: “打印x的绝对值”的算法可以用伪代码表示为:
IF x is positive THEN print x ELSE print -x 也可以用汉字伪代码表示: 若 x为正 打印 x 否则 打印 -x 也可以中英文混用,如: IF x 为正 print -x 例: “打印x的绝对值”的算法可以用伪代码表示为:

79
置t的初值为1 例2.16 求5!。用伪代码表示算法: 也可以写成以下形式: 开始 置i的初值为2 当i<=5,执行下面操作:
使t=t×i 使i=i+1 {循环体到此结束} 输出t的值 结束 例2.16 求5!。用伪代码表示算法: 也可以写成以下形式: BEGIN{算法开始} 1t 2 i while i≤5 {t×i t i+1 i} print t END{算法结束}

80
例2.17 输出50个学生中成绩高于80分者的学号和成绩。
用伪代码表示算法: BEGIN{算法开始} 1 i while i≤50 {input ni and gi i+1 i} 1 i {if gi≥80 print ni and gi END{算法结束}

81
2.4.6 用计算机语言表示算法 概念:用计算机实现算法。计算机是无法识别流程图和伪代码的。只有用计算机语言编写的程序才能被计算机执行。因此在用流程图或伪代码描述出一个算法后,还要将它转换成计算机语言程序。 特点:用计算机语言表示算法必须严格遵循所用的语言的语法规则,这是和伪代码不同的。 用处:要完成一件工作,包括设计算法和实现算法两个部分。设计算法的目的是为了实现算法。

82
例 2.20 将例2.16表示的算法(求5!)用C语言表示。 #include <stdio.h> void main( )
{int i,t; t=1; i=2; while(i<=5) {t=t*i; i=i+1; } printf(″%d\n″,t);
 {t=t*i; i=i+1; } printf(″%d\n″,t);")
83
应当强调说明:写出了C程序,仍然只是描述了算法,并未实现算法。只有运行程序才是实现算法。应该说,用计算机语言表示的算法是计算机能够执行的算法。

84
结构化程序设计强调程序设计风格和程序结构的规范化,提倡清晰的结构。
2.5 结构化程序设计方法 一个结构化程序 就是用高级语言表示的结构化算法。用三种基本结构组成的程序必然是结构化的程序,这种程序便于编写、便于阅读、便于修改和维护。 结构化程序设计强调程序设计风格和程序结构的规范化,提倡清晰的结构。 结构化程序设计方法的基本思路是:把一个复杂问题的求解过程 分阶段进行,每个阶段处理的问题都控制在人们容易理解和处理的范围内。

85
采取以下方法来保证得到结构化的程序: 自顶向下; 逐步细化; 模块化设计; 结构化编码。 两种不同的方法: 自顶向下,逐步细化; 自下而上,逐步积累。

86
用这种方法逐步分解,直到作者认为可以直接将各小段表达为文字语句为止。这种方法就叫 做“自顶向下,逐步细化”。

87
自顶向下,逐步细化方法的优点: 考虑周全,结构清晰,层次分明,作者容易写,读者容易看。如果发现某一部分中有一段内容不妥,需要修改,只需找出该部分修改有关段落即可,与其它部分无关。我们提倡用这种方法设计程序。这就是用工程的方法设计程序。

88
模块设计的方法: 模块化设计的思想实际上是一种“分而治之”的思想,把一个大任务分为若干个子任务,每一个子任务就相对简单了。 在拿到一个程序模块以后,根据程序模块的功能将它划分为若干个子模块,如果这些子模块的规模还嫌大,还再可以划分为更小的模块。这个过程采用自顶向下方法来实现。 子模块一般不超过50行。 划分子模块时应注意模块的独立性,即:使一个模块完成一项功能,耦合性愈少愈好。

89
第三章 数据类型、运算符与表达式

90
本章要点 数据的描述规则 数据的操作规则

91
3.1 C的数据类型 3.2 常量与变量 3.3 整型数据 3.4 浮点型数据运行 3.5 字符型数据
主要内容 3.1 C的数据类型 3.2 常量与变量 3.3 整型数据 3.4 浮点型数据运行 3.5 字符型数据

92
主要内容 3.6变量赋初值 3.7 各类数值型数据间的混合运算 3.8 算术运算符和算术表达式 3.9 赋值运算符和赋值表达式
3.10 逗号运算符和逗号表达式

93
3.1 C的数据类型 C语言提供了以下一些数据类型。 基本类型 数据类型 构造类型 指针类型 空类型(无值类型) void 整型 int
字符型 char 实型(浮点型) 单精度实型 float 双精度实型 double 枚举类型 enum 数组类型 结构类型 struct 联合类型 union 数据类型 构造类型 指针类型 空类型(无值类型) void
 单精度实型. float. 双精度实型. double. 枚举类型 enum. 数组类型. 结构类型 struct. 联合类型 union. 数据类型. 构造类型. 指针类型. 空类型(无值类型) void.")
94
3.2 常量与变量 3.2.1 常量和符号常量 整型 100,125,-100,0 实型 3.14 , 0.125,-3.789
常量和符号常量 在程序运行过程中,其值不能被改变的量称为常量 常量区分为不同的类型: 整型 100,125,-100,0 实型 3.14 , 0.125,-3.789 字符型 ‘a’, ‘b’,‘2’ 字符串 ‘a’, ‘ab’,‘1232’

95
运行结果: total=300 例3.1 符号常量的使用 #define PRICE 30 #include <stdio.h> void main ( ) { int num, total; num=10; total=num * PRICE; printf(″total=%d\n ″,total); } 说明:如再用赋值语句给PRICE赋值是错的 PRICE=40;/* 错误,不能给符号常量赋值 说明: 程序中用#define命令行定义PRICE代表常量30,此后凡在本文件中出现的PRICE都代表30,可以和常量一样进行运算 符号常量: 用一个标识符代表一个常量。符号常量的值在其作用域内不能改变,也不能再被赋值。
 { int num, total; num=10; total=num * PRICE; printf(″total=%d\n ″,total); } 说明:如再用赋值语句给PRICE赋值是错的. PRICE=40;/* 错误,不能给符号常量赋值. 说明: 程序中用#define命令行定义PRICE代表常量30,此后凡在本文件中出现的PRICE都代表30,可以和常量一样进行运算. 符号常量: 用一个标识符代表一个常量。符号常量的值在其作用域内不能改变,也不能再被赋值。")
96
3.2 常量与变量 3.2.2 变量 变量代表内存中具有特定属性的一个存储单元,它用来存放数据,这就是变量的值,在程序运行期间,这些值是可以改变的。 变量名实际上是一个以一个名字对应代表一个地址,在对程序编译连接时由编译系统给每一个变量名分配对应的内存地址。从变量中取值,实际上是通过变量名找到相应的内存地址,从该存储单元中读取数据。

97
3.2 常量与变量 变量命名的规定:C语言规定标识符只能由字母、数字和下划线三种字符组成,且第一个字符必须为字母或下划线。
例:sum,_total, month, Student_name, lotus_1_2_3,BASIC, li_ling M.D.John, ¥123,3D64,a>b

98
3.2 常量与变量 注意: 编译系统将大写字母和小写字母认为是两个不同的字符。 建议变量名的长度最好不要超过8个字符。
在选择变量名和其它标识符时,应注意做到“见名知意”,即选有含意的英文单词 (或其缩写)作标识符。 要求对所有用到的变量作强制定义,也就是“先定义,后使用” 。
作标识符。 要求对所有用到的变量作强制定义,也就是 先定义,后使用 。")
99
3.3 整型数据 3.3.1整型常量的表示方法 可用以下三种形式表示: 整型常量即整常数。在C语言中,整常数 (1)十进制整数。
3.3 整型数据 3.3.1整型常量的表示方法 整型常量即整常数。在C语言中,整常数 可用以下三种形式表示: (1)十进制整数。 如:123, 。 (2)八进制整数。以0头的数是八进制数。 如:0123表示八进制数123,等于十进制数83,-011表示八进制数-11,即十进制数-9。
十进制整数。 如:123, 。 (2)八进制整数。以0头的数是八进制数。 如:0123表示八进制数123,等于十进制数83,-011表示八进制数-11,即十进制数-9。")
100
3.3 整型数据 3.3.2 整型变量 (1)整型数据在内存中的存放形式 (3)十六进制整数。以0x开头的数是16进制数。
3.3 整型数据 (3)十六进制整数。以0x开头的数是16进制数。 如:0x123,代表16进制数123,等于十进制数 291。 -0x12等于十进制数-10。 3.3.2 整型变量 (1)整型数据在内存中的存放形式 数据在内存中是以二进制形式存放的。 如: int i; /* 定义为整型变量 */ i=10; /* 给i赋以整数10 */
十六进制整数。以0x开头的数是16进制数。 如:0x123,代表16进制数123,等于十进制数 291。 -0x12等于十进制数-10。 整型变量. (1)整型数据在内存中的存放形式. 数据在内存中是以二进制形式存放的。 如: int i; /* 定义为整型变量 */ i=10; /* 给i赋以整数10 */")
101
3.3 整型数据 注意: 十进制数10的二进制形式为1010,Turbo C 2.0和Turbo C++ 3.0为一个整型变量在内存中分配2个字节的存储单元(不同的编译系统为整型数据分配的字节数是不相同的,VC++ 6.0则分配4个字节)。 数值是以补码(complement) 表示的。
 表示的。")
102
3.3 整型数据 (2)整型变量的分类 有符号基本整型 (signed)int 有符号短整型 (signed)short (int )
3.3 整型数据 (2)整型变量的分类 有符号基本整型 有符号短整型 有符号长整型 无符号基本整型 无符号短整型 无符号长整型 (signed)int (signed)short (int ) (signed) long (int) unsigned int unsigned short (int) unsigned long (int) 共六种 注意:括号表示其中的内容是可选的。
整型变量的分类. 有符号基本整型. 有符号短整型. 有符号长整型. 无符号基本整型. 无符号短整型. 无符号长整型. (signed)int. (signed)short (int ) (signed) long (int) unsigned int. unsigned short (int) unsigned long (int) 共六种. 注意:括号表示其中的内容是可选的。")
103
3.3 整型数据 整数类型的有关数据: 类型 类型说明符 长度 数的范围 基本型 int 2字节 -32768~32767
3.3 整型数据 整数类型的有关数据: 类型 类型说明符 长度 数的范围 基本型 int 字节 ~32767 短整型 short 字节 -215~215-1 长整型 long 字节 -231~231-1 无符号整型 unsigned 字节 0~65535 无符号短整型 unsigned short 2字节 0~65535 无符号长整型 unsigned long 4字节 0~(232-1)
")
104
3.3 整型数据 例如:整数13在内存中实际存放的情况:

105
3.3 整型数据 (3)整型变量的定义: C规定在程序中所有用到的变量都必须在程序中定义,即“强制类型定义”。 例如:
3.3 整型数据 (3)整型变量的定义: C规定在程序中所有用到的变量都必须在程序中定义,即“强制类型定义”。 例如: int a,b(指定变量a、b为整型) unsigned short c,d;(指定变量c、d为无符号短整型) long e,f;(指定变量e、f为长整型)
整型变量的定义: C规定在程序中所有用到的变量都必须在程序中定义,即 强制类型定义 。 例如: int a,b(指定变量a、b为整型) unsigned short c,d;(指定变量c、d为无符号短整型) long e,f;(指定变量e、f为长整型)")
106
例3. 2 整型变量的定义与使用 #include <stdio. h> void main() {int a,b,c,d; /
例3.2 整型变量的定义与使用 #include <stdio.h> void main() {int a,b,c,d; /*指定a、b、c、d为整型变量*/ unsigned u; /*指定u为无符号整型变量*/ a=12;b=-24;u=10; c=a+u;d=b+u; printf(″a+u=%d,b+u=%d\n″,c,d); } 运行结果: a+u=22,b+u=-14 说明: 可以看到不同种类的整型数据可以进行算术运算
 {int a,b,c,d; /*指定a、b、c、d为整型变量*/ unsigned u; /*指定u为无符号整型变量*/ a=12;b=-24;u=10; c=a+u;d=b+u; printf(″a+u=%d,b+u=%d\n″,c,d); } 运行结果: a+u=22,b+u=-14. 说明: 可以看到不同种类的整型数据可以进行算术运算.")
107
例3. 3 整型数据的溢出 #include <stdio
例3.3 整型数据的溢出 #include <stdio.h> void main() {int a,b; a=32767; b=a+1; printf(“%d,%d\n”,a,b); } 运行结果: 32767,-32768 说明:数值是以补码表示的。一个整型变量只能容纳-32768~32767范围内的数,无法表示大于32767或小于-32768的数。遇此情况就发生“溢出”。
 {int a,b; a=32767; b=a+1; printf( %d,%d\n ,a,b); } 运行结果: 32767, 说明:数值是以补码表示的。一个整型变量只能容纳-32768~32767范围内的数,无法表示大于32767或小于-32768的数。遇此情况就发生 溢出 。")
108
3.3 整型数据 整型常量的类型 (1)一个整数,如果其值在-32768~+32767范围内,认为它是int型,它可以赋值给int型和long int型变量。 (2) 一个整数,如果其值超过了上述范围,而在 ~ 范围内,则认为它是为长整型。可以将它赋值给一个long int型变量。
 一个整数,如果其值超过了上述范围,而在 ~ 范围内,则认为它是为长整型。可以将它赋值给一个long int型变量。")
109
3.3 整型数据 (3) 如果所用的C版本(如Turbo C)分配给 short int与int型数据在内存中占据的长度
3.3 整型数据 (3) 如果所用的C版本(如Turbo C)分配给 short int与int型数据在内存中占据的长度 相同,则它的表数范围与int型相同。因此 一个int型的常量同时也是一个short int型 常量,可以赋给int型或short int型变量。
 如果所用的C版本(如Turbo C)分配给. short int与int型数据在内存中占据的长度. 相同,则它的表数范围与int型相同。因此. 一个int型的常量同时也是一个short int型. 常量,可以赋给int型或short int型变量。")
110
3.3 整型数据 (4) 一个整常量后面加一个字母u或U,认 为是unsigned int型,如12345u,在内存
3.3 整型数据 (4) 一个整常量后面加一个字母u或U,认 为是unsigned int型,如12345u,在内存 中按unsigned int规定的方式存放(存储 单元中最高位不作为符号位,而用来存储 数据)。如果写成-12345u,则先将-12345 转换成其补码53191,然后按无符号数存 储。
 一个整常量后面加一个字母u或U,认. 为是unsigned int型,如12345u,在内存. 中按unsigned int规定的方式存放(存储. 单元中最高位不作为符号位,而用来存储. 数据)。如果写成-12345u,则先将 转换成其补码53191,然后按无符号数存. 储。")
111
3.3 整型数据 (5) 在一个整常量后面加一个字母l或L,则认为是long int型常量。 例如: 123l.432L.0L
3.3 整型数据 (5) 在一个整常量后面加一个字母l或L,则认为是long int型常量。 例如: 123l.432L.0L 用于函数调用中。 如果函数的形参为long int型,则要求实参也为long int型。
 在一个整常量后面加一个字母l或L,则认为是long int型常量。 例如: 123l.432L.0L. 用于函数调用中。 如果函数的形参为long int型,则要求实参也为long int型。")
112
3.4 浮点型数据 小数 0.123 指数 3e-3 3.4.1浮点型常量的表示方法 两种表 示形式
注意:字母e(或E)之前必须有数字,且e后面的指数必须为整数: 1e3、1.8e-3、-123e-6、-.1e-3 e3、2.1e3.5、.e3、e
之前必须有数字,且e后面的指数必须为整数: 1e3、1.8e-3、-123e-6、-.1e-3. e3、2.1e3.5、.e3、e. ")
113
例如: 123.456可以表示为: 3.4 浮点型数据 规范化的指数形式: 在字母e(或E)之前的小数部分中,小数点左边
应有一位(且只能有一位)非零的数字。 例如: 可以表示为: e0, e1, e2, e3, e4, e 其中的 e3称为“规范化的指数形式”。
非零的数字。 例如: 可以表示为: e0, e1, e2, e3, e4, e. 其中的 e3称为 规范化的指数形式 。")
114
3.4 浮点型数据 3.4.2 浮点型变量 (1)浮点型数据在内存中的存放形式
一个浮点型数据一般在内存中占4个字节(32位)。与整型数据的存储方式不同,浮点型数据是按照指数形式存储的。系统把一个浮点型数据分成小数部分和指数部分,分别存放。指数部分采用规范化的指数形式。
。与整型数据的存储方式不同,浮点型数据是按照指数形式存储的。系统把一个浮点型数据分成小数部分和指数部分,分别存放。指数部分采用规范化的指数形式。")
115
3.4 浮点型数据 (2) 浮点型变量的分类 浮点型变量分为单精度(float型)、双精度(double型)和长双精度型(long double)三类形式。 类型 位数 数的范围 有效数字 float ~ ~7 位 double型 ~ ~16位 long double ~ ~19位

116
例3. 4 浮点型数据的舍入误差 #include <stdio
例3.4 浮点型数据的舍入误差 #include <stdio.h> void main() {float a,b; a = e5; b = a + 20 ; printf(“%f\n”,b); } 运行结果: e5 说明:一个浮点型变量只能保证的有效数字是7位有效数字,后面的数字是无意义的,并不准确地表示该数。应当避免将一个很大的数和一个很小的数直接相加或相减,否则就会“丢失”小的数
 {float a,b; a = e5; b = a + 20 ; printf( %f\n ,b); } 运行结果: e5. 说明:一个浮点型变量只能保证的有效数字是7位有效数字,后面的数字是无意义的,并不准确地表示该数。应当避免将一个很大的数和一个很小的数直接相加或相减,否则就会 丢失 小的数.")
117
3.4 浮点型数据 3.4.3 浮点型常量的类型 C编译系统将浮点型常量作为双精度来处理。 例如:f = 2.45678 * 4523.65
系统先把 和 作为双精度数,然后进行相乘的运算,得到的乘也是一个双精度数。最后取其前7位赋给浮点型变量f。如是在数的后面加字母f或F(如1.65f, F),这样编译系统就会把它们按单精度(32位)处理。
,这样编译系统就会把它们按单精度(32位)处理。")
118
3.5 字符型数据 3.5.1 字符常量 ‘a’,’A’, ‘1’ 例 ‘abc’、“a” (1)用单引号包含的一个字符是字符型常量
(2)只能包含一个字符 ‘a’,’A’, ‘1’ ‘abc’、“a” 例
只能包含一个字符. ‘a’,’A’, ‘1’ ‘abc’、 a 例. ")
119
3.5 字符型数据 有些以“\”开头的特殊字符称为转义字符 \n 换行 \t 横向跳格 \r 回车 \\ 反斜杠
\\ 反斜杠 \ddd ddd表示1到3位八进制数字 \xhh hh表示1到2位十六进制数字

120
例3. 5 转义字符的使用 #include <stdio
例3.5 转义字符的使用 #include <stdio.h> void main() {printf(″ ab c\t de\rf\tg\n″); printf(″h\ti\b\bj k\n″); } 显示屏上的运行结果: f gde h j k 打印机上的显示结果: fab c gde h jik
 {printf(″ ab c\t de\rf\tg\n″); printf(″h\ti\b\bj k\n″); } 显示屏上的运行结果: f gde. h j k. 打印机上的显示结果: fab c gde. h jik.")
121
3.5 字符型数据 3.5.2字符变量 字符型变量用来存放字符常量,注意只能放一个字符。 字符变量的定义形式如下:char c1,c2;
c1=‘a’;c2= ‘b’ ; 一个字符变量在内存中占一个字节。

122
3.5 字符型数据 3.5.3字符数据在内存中的存储形式及其使用方法
图 3.5.3字符数据在内存中的存储形式及其使用方法 将一个字符常量放到一个字符变量中,实际上并不是把该字符本身放到内存单元中去,而是将该字符的相应的ASCII代码放到存储单元中。 这样使字符型数据和整型数据 之间可以通用。一个字符数据 既可以以字符形式输出,也可 以以整数形式输出。

123
例3. 6 向字符变量赋以整数。 #include <stdio
例3.6 向字符变量赋以整数。 #include <stdio.h> void main() {char c1,c2; c1=97; c2=98; printf(“%c %c\n”,c1,c2); printf(“%d %d\n”,c1,c2); } 运行结果: a b 97 98 说明:在第3和第4行中,将整数97和98分别赋给c1和c2,它的作用相当于以下两个赋值语句: c1=′a′;c2=′b′; 因为’a’和’b’的ASCII码为97和98
 {char c1,c2; c1=97; c2=98; printf( %c %c\n ,c1,c2); printf( %d %d\n ,c1,c2); } 运行结果: a b 说明:在第3和第4行中,将整数97和98分别赋给c1和c2,它的作用相当于以下两个赋值语句: c1=′a′;c2=′b′; 因为’a’和’b’的ASCII码为97和98.")
124
例3. 7 大小写字母的转换 #include <stdio
例3.7 大小写字母的转换 #include <stdio.h> void main() {char c1,c2; c1=’a’; c2=’b’; c1=c1-32; c2=c2-32; printf(“%c %c″,c1,c2); } 运行结果:A B 说明:程序的作用是将两个小写字母a和b转换成大写字母A和B。从ASCII代码表中可以看到每一个小写字母比它相应的大写字母的ASCII码大32。C语言允许字符数据与整数直接进行算术运算。
 {char c1,c2; c1=’a’; c2=’b’; c1=c1-32; c2=c2-32; printf( %c %c″,c1,c2); } 运行结果:A B. 说明:程序的作用是将两个小写字母a和b转换成大写字母A和B。从ASCII代码表中可以看到每一个小写字母比它相应的大写字母的ASCII码大32。C语言允许字符数据与整数直接进行算术运算。")
125
3.5 字符型数据 说明: 有些系统(如Turbo C)将字符变量定义为signed char型。其存储单元中的最高位作为符号位,它的取值范围是-128~127。如果在字符变量中存放一个ASCII码为0~127间的字符,由于字节中最高位为0,因此用%d输出字符变量时,输出的是一个正整数。如果在字符变量中存放一个ASCII码为128~255间的字符,由于在字节中最高位为1,用%d格式符输出时,就会得到一个负整数。
将字符变量定义为signed char型。其存储单元中的最高位作为符号位,它的取值范围是-128~127。如果在字符变量中存放一个ASCII码为0~127间的字符,由于字节中最高位为0,因此用%d输出字符变量时,输出的是一个正整数。如果在字符变量中存放一个ASCII码为128~255间的字符,由于在字节中最高位为1,用%d格式符输出时,就会得到一个负整数。")
126
3.5 字符型数据 3.5.4字符串常量 字符串常量是一对双撇号括起来的字符序列 合法的字符串常量:
“How do you do.”, “CHINA”, “a” , “$123.45” 可以输出一个字符串,如 printf(“How do you do.”);
;")
127
3.5 字符型数据 ‘a’是字符常量,”a”是字符串常量,二者不 同。 如:假设C被指定为字符变量 :char c c=’a’;
c=”a”;c=”CHINA”; 结论:不能把一个字符串常量赋给一个字符变量。

128
3.5 字符型数据 如:如果有一个字符串常量”CHINA” ,实际上在内存中是:
C规定:在每一个字符串常量的结尾加一个 “字符 串结束标志”,以便系统据此判断字符串是否结束。 C规定以字符’\0’作为字符串结束标志。 如:如果有一个字符串常量”CHINA” ,实际上在内存中是: C H I N A \0 它占内存单元不是5个字符,而是6个字符,最后一个字符为’\0’。但在输出时不输出’\0’。

129
3.6 变量赋初值 字符串常量 (1)C语言允许在定义变量的同时使变量初始化。 如: int a=3; // 指定a为整型变量,初值为3
float f=3.56; // 指定f为浮点型变量,初值为3.56 char c= ‘a’; // 指定c为字符变量,初值为‘a’

130
3.6 变量赋初值 (2)可以使被定义的变量的一部分赋初值。
如: int a,b,c=5; 表示指定a、b、c为整型变量,但只对c初始化,c的初值为5 (3)如果对几个变量赋以同一个初值, 应写成:int a=3,b=3,c=3; 表示a、b、c的初值都是3。 不能写成∶ int a=b=c3; 注意:初始化不是在编译阶段完成的而是在程序运行时执行本函数时赋初值的,相当于有一个赋值语句。
如果对几个变量赋以同一个初值, 应写成:int a=3,b=3,c=3; 表示a、b、c的初值都是3。 不能写成∶ int a=b=c3; 注意:初始化不是在编译阶段完成的而是在程序运行时执行本函数时赋初值的,相当于有一个赋值语句。")
131
3.7 各类数值型数据间的混合运算 整型(包括int,short,long)、浮点型(包括
图 整型(包括int,short,long)、浮点型(包括 float,double)可以混合运算。在进行运算时 ,不同类型的数据要先转换成同一类型,然后 进行运算。 上述的类型转换是由 系统自动进行的
、浮点型(包括. float,double)可以混合运算。在进行运算时. ,不同类型的数据要先转换成同一类型,然后. 进行运算。 上述的类型转换是由. 系统自动进行的.")
132
3.8 术运算符和算术表达式 3.8.1 C运算符简介 C的运算符有以下几类: (1)算术运算符 (+ - * / %)
(2)关系运算符 (><==>=<=!=) (3)逻辑运算符 (!&&||) (4)位运算符 (<< >> ~ |∧&) (5)赋值运算符 (=及其扩展赋值运算符) (6)条件运算符 (?:) (7)逗号运算符 (,)
关系运算符 (><==>=<=!=) (3)逻辑运算符 (!&&||) (4)位运算符 (<< >> ~ |∧&) (5)赋值运算符 (=及其扩展赋值运算符) (6)条件运算符 (?:) (7)逗号运算符 (,)")
133
3.8 算术运算符和算术表达式 (8)指针运算符 (*和&) (9)求字节数运算符(sizeof)
(10)强制类型转换运算符( (类型) ) (11)分量运算符(.->) (12)下标运算符([ ]) (13)其他 (如函数调用运算符())
强制类型转换运算符( (类型) ) (11)分量运算符(.->) (12)下标运算符([ ]) (13)其他 (如函数调用运算符())")
134
3.8 算术运算符和算术表达式 3.8.2 算术运算符和算术表达式 (1)基本的算术运算符:
+ (加法运算符,或正值运算符,如:3+5、+3) - (减法运算符,或负值运算符,如:5-2、-3) * (乘法运算符,如:3*5) / (除法运算符,如:5/3) % (模运算符,或称求余运算符,%两侧均应为整型数据,如:7%4的值为3)。
 - (减法运算符,或负值运算符,如:5-2、-3) * (乘法运算符,如:3*5) / (除法运算符,如:5/3) % (模运算符,或称求余运算符,%两侧均应为整型数据,如:7%4的值为3)。")
135
3.8 算术运算符和算术表达式 (2) 算术表达式和运算符的优先级与结合性基本的算术运算符: 例如: a*b/c-1.5+′a′
用算术运算符和括号将运算对象(也称操作数)连接起来的、符合C语法规则的式子,称为C算术表达式。运算对象包括常量、变量、函数等。 例如: a*b/c-1.5+′a′ 是一个合法的表达式。
连接起来的、符合C语法规则的式子,称为C算术表达式。运算对象包括常量、变量、函数等。 例如: a*b/c-1.5+′a′ 是一个合法的表达式。")
136
3.8 算术运算符和算术表达式 C语言规定了运算符的优先级和结合性。 C规定了各种运算符的结合方向(结合性)
在表达式求值时,先按运算符的优先级别高低次序执行,例如先乘除后加减。 C规定了各种运算符的结合方向(结合性) 算术运算符的结合方向为“自左至右”,即先左后右 。
 算术运算符的结合方向为 自左至右 ,即先左后右 。")
137
3.8 算术运算符和算术表达式 (3)强制类型转换运算符 可以利用强制类型转换运算符将一个表达式转换成 所需类型。
一般形式:(类型名)(表达式) 例如: (double)a 将a转换成double类型 (int)(x+y) 将x+y的值转换成整型 (float)(5%3) 将5%3的值转换成float型
(表达式) 例如: (double)a 将a转换成double类型. (int)(x+y) 将x+y的值转换成整型. (float)(5%3) 将5%3的值转换成float型.")
138
例3. 8 强制类型转换。 #include <stdio
例3.8 强制类型转换。 #include <stdio.h> voidmain() {float x; int i; x=3.6; i=(int)x; printf("x=%f, i=%d\n",x,i); } 运行结果: x= , i=3 说明:有两种类型转换,一种是在运算时不必用户指定,系统自动进行的类型转换,如3+6.5。第二种是强制类型转换。当自动类型转换不能实现目的时,可以用强制类型转换。
 {float x; int i; x=3.6; i=(int)x; printf( x=%f, i=%d\n ,x,i); } 运行结果: x= , i=3. 说明:有两种类型转换,一种是在运算时不必用户指定,系统自动进行的类型转换,如3+6.5。第二种是强制类型转换。当自动类型转换不能实现目的时,可以用强制类型转换。")
139
3.8 算术运算符和算术表达式 (4) 自增、自减运算符 如: 作用是使变量的值增1或减1 ++i,--i(在使用i之前,先使i的值加
(减)1) i++,i--(在使用i之后,使i的值加( 减)1)
1) i++,i--(在使用i之后,使i的值加( 减)1)")
140
3.8 算术运算符和算术表达式 i++与++i的区别: 例如: ++i是先执行i=i+1后,再使用i的值;
i++是先使用i的值后,再执行i=i+1。 例如: ①j=++i; i的值先变成4, 再赋给j,j的值均为4 ②j=i++; 先将 i的值3赋给j,j的值为3,然后i变为4

141
3.8 算术运算符和算术表达式 注意: (1)自增运算符(++),自减运算符(--),只能用于变量,而不能用于常量或表达式,
(2)++和--的结合方向是“自右至左”。 自增(减)运算符常用于循环语句中使循环变量 自动加1。也用于指针变量,使指针指向下一个地址
++和--的结合方向是 自右至左 。 自增(减)运算符常用于循环语句中使循环变量. 自动加1。也用于指针变量,使指针指向下一个地址.")
142
3.8 算术运算符和算术表达式 例如:对表达式 a = f1( )+f2( ) (5) 有关表达式使用中的问题说明
①ANSI C并没有具体规定表达式中的子表达式的求值顺序,允许各编译系统自己安排。 例如:对表达式 a = f1( )+f2( ) 并不是所有的编译系统都先调用f1( ), 然后 调用f2( )。在有的情况下结果可能不同。有时会出 现一些令人容易搞混的问题,因此务必要小心谨慎。
+f2( ) 并不是所有的编译系统都先调用f1( ), 然后. 调用f2( )。在有的情况下结果可能不同。有时会出. 现一些令人容易搞混的问题,因此务必要小心谨慎。")
143
3.8 算术运算符和算术表达式 例如:不要写成i+++j的形式,而应写成 ②C语言中有的运算符为一个字符,有的运算符由
两个字符组成 ,为避免误解,最好采取大家都能理 解的写法。 例如:不要写成i+++j的形式,而应写成 (i++)+j的形式
+j的形式.")
144
3.8 算术运算符和算术表达式 不要写出别人看不懂的也 不知道系统会怎样执行程 序 ③在调用函数时,实参数的求值顺序,C标准并无统 一规定。
例如:i的初值为3,如果有下面的函数调用: printf(″%d,%d″,i,i++) 在有的系统中,从左至右求值,输出“3,3”。在多数系统中对函数参数的求值顺序是自右而左,printf函数输出的是“4,3”。以上这种写法不宜提倡, 最好改写成 j = i++; printf("%d, %d", j,i) 不要写出别人看不懂的也 不知道系统会怎样执行程 序
 在有的系统中,从左至右求值,输出 3,3 。在多数系统中对函数参数的求值顺序是自右而左,printf函数输出的是 4,3 。以上这种写法不宜提倡, 最好改写成. j = i++; printf( %d, %d , j,i) 不要写出别人看不懂的也. 不知道系统会怎样执行程. 序.")
145
3.9 赋值运算符和赋值表达式 (1)赋值运算符 赋值符号“=”就是赋值运算符,它的作用是 将一个数据赋给一个变量。如“a=3”的作用
是执行一次赋值操作(或称赋值运算)。把常 量3赋给变量a。也可以将一个表达式的值赋 给一个变量。
。把常. 量3赋给变量a。也可以将一个表达式的值赋. 给一个变量。")
146
3.9 赋值运算符和赋值表达式 (2)类型转换 是数值型或字符型时,在赋值时要进行类型 转换。
如果赋值运算符两侧的类型不一致,但都 是数值型或字符型时,在赋值时要进行类型 转换。 ①将浮点型数据(包括单、双精度)赋给整 型变量时,舍弃浮点数的小数部分。 如:i为整型变量,执行“i=3.56”的结果是使 i的值为3,以整数形式存储在整型变量中。
赋给整. 型变量时,舍弃浮点数的小数部分。 如:i为整型变量,执行 i=3.56 的结果是使. i的值为3,以整数形式存储在整型变量中。")
147
3.9 赋值运算符和赋值表达式 ②将整型数据赋给单、双精度变量时,数值不变, 但以浮点数形式存储到变量中。
如: 将23赋给float变量f,即执行f=23,先 将23转换成23.00000,再存储在f中。 将23赋给double型变量d,即执行d= 23,则将23补足有效位数字为23.00000 000000000,然后以双精度浮点数形式存储 到变量d中。

148
3.9 赋值运算符和赋值表达式 如:float f;double d=123.456789e100; f=d;
③将一个double型数据赋给float变量时,截取其前 面7位有效数字,存放到float变量的存储单元(4个 字节)中。但应注意数值范围不能溢出。 如:float f;double d= e100; f=d; 就出现溢出的错误。 如果将一个float型数据赋给double变量时,数值不 变,有效位数扩展到16位,在内存中以8个字节存储
中。但应注意数值范围不能溢出。 如:float f;double d= e100; f=d; 就出现溢出的错误。 如果将一个float型数据赋给double变量时,数值不. 变,有效位数扩展到16位,在内存中以8个字节存储.")
149
3.9 赋值运算符和赋值表达式 ④字符型数据赋给整型变量时,由于字符只占1个字 节,而整型变量为2个字节,因此将字符数据(8个
图 ④字符型数据赋给整型变量时,由于字符只占1个字 节,而整型变量为2个字节,因此将字符数据(8个 二进位)放到整型变量存储单元的低8位中。 第一种情况: 如果所用系统将字符处理为无符号的字符类型,或程 序已将字符变量定义为unsigned char 型,则将字符的8位放到整型变量低8位,高8位补 零 例如:将字符‘\376’赋给int型变量i
放到整型变量存储单元的低8位中。 第一种情况: 如果所用系统将字符处理为无符号的字符类型,或程. 序已将字符变量定义为unsigned char. 型,则将字符的8位放到整型变量低8位,高8位补. 零. 例如:将字符‘\376’赋给int型变量i.")
150
如果所用系统(如Turbo C++)将字符处理为带符号
3.9 赋值运算符和赋值表达式 图 第二种情况: 如果所用系统(如Turbo C++)将字符处理为带符号 的(即signed char),若字符最高位为0,则整型 变量高8位补0;若字符最高位为1,则高8位全补 1。这称为“符号扩展”,这样做的目的是使数值保持 不变,如变量c(字符‘\376’)以整数形式输出 为-2,i的值也是-2。
将字符处理为带符号. 的(即signed char),若字符最高位为0,则整型. 变量高8位补0;若字符最高位为1,则高8位全补. 1。这称为 符号扩展 ,这样做的目的是使数值保持. 不变,如变量c(字符‘\376’)以整数形式输出. 为-2,i的值也是-2。")
151
3.9 赋值运算符和赋值表达式 例如:int i=289;char c=′a′;c=i;
图 ⑤将一个int、short、long型数据赋给一个char型变 量时,只将其低8位原封不动地送到char型变量(即 截断)。 例如:int i=289;char c=′a′;c=i; 赋值情况 : c的值为33, 如果用“%c”输 出c,将得到字符“!” (其 ASCII码为33)。
。 例如:int i=289;char c=′a′;c=i; 赋值情况 : c的值为33, 如果用 %c 输. 出c,将得到字符 ! (其. ASCII码为33)。")
152
3.9 赋值运算符和赋值表达式 将带符号的整型数据(int型)赋给long型变量时,要进行符号扩展,将整型数的16位送到long型低16位中: 如果int型数据为正值(符号位为0),则long型变量的高16位补0; 如果int型变量为负值(符号位为1),则long型变量的高16位补1,以保持数值不改变。 反之,若将一个long型数据赋给一个int型变量,只将long型数据中低16位原封不动地送到整型变量(即截断)。
,则long型变量的高16位补1,以保持数值不改变。 反之,若将一个long型数据赋给一个int型变量,只将long型数据中低16位原封不动地送到整型变量(即截断)。")
153
3.9 赋值运算符和赋值表达式 例如:int a; long b=8;a=b 赋值情况如图 : 图 图3.14
如果b=65536(八进制数0200000),则赋值后a值为0。见图3.14
,则赋值后a值为0。见图3.14.")
154
3.9 赋值运算符和赋值表达式 ⑦将unsigned int型数据赋给long int型变量时,不
存在符号扩展问题,只需将高位补0即可。将一个 unsigned类型数据赋给一个占字节数相同的非 unsigned型整型变量(例如:unsigned int ->int,unsigned long->long,unsigned short ->short),将unsigned型变量的内容原样送到非 unsigned型变量中,但如果数据范围超过相应整型的 范围,则会出现数据错误。
,将unsigned型变量的内容原样送到非. unsigned型变量中,但如果数据范围超过相应整型的. 范围,则会出现数据错误。")
155
3.9 赋值运算符和赋值表达式 例如:unsigned int a=65535; int b;b=a; 将a整个送到b中,由于b是int,
图 例如:unsigned int a=65535; int b;b=a; 将a整个送到b中,由于b是int, 第1位是符号位,因此b成了 负数。根据补码知识可知,b的 值为-1,可以用printf(″%d″,b);来验证。 ⑧将非unsigned型数据赋给长度相同的unsigned型变量,也是原样照赋(连原有的符号位也作为数值一起传送)。
;来验证。 ⑧将非unsigned型数据赋给长度相同的unsigned型变量,也是原样照赋(连原有的符号位也作为数值一起传送)。")
156
例3. 9 有符号数据传送给无符号变量。 #include <stdio
例3.9 有符号数据传送给无符号变量。 #include <stdio.h> void main() {unsigned a; int b=-1; a=b; printf(″%u\n″,a); } 运行结果: 65535 图 说明:“%u”是输出无符号数时所用的格式符。如果b为正值,且在0~32767之间,则赋值后数值不变。赋值情况见图
 {unsigned a; int b=-1; a=b; printf(″%u\n″,a); } 运行结果: 65535. 图. 说明: %u 是输出无符号数时所用的格式符。如果b为正值,且在0~32767之间,则赋值后数值不变。赋值情况见图.")
157
以“a+=3”为例来说明,它相当于使a进行一次自加(3)的操作。即先使a加3,再赋给a。
3.9 赋值运算符和赋值表达式 (3) 复合的赋值运算符 在赋值符“=”之前加上其他运算符,可以构成复 合的运算符。 例如: a+=3 等价于 a=a+3 x*=y+8 等价于 x=x*(y+8) x%=3 等价于 x=x%3 以“a+=3”为例来说明,它相当于使a进行一次自加(3)的操作。即先使a加3,再赋给a。
 复合的赋值运算符. 在赋值符 = 之前加上其他运算符,可以构成复. 合的运算符。 例如: a+=3 等价于 a=a+3. x*=y+8 等价于 x=x*(y+8) x%=3 等价于 x=x%3. 以 a+=3 为例来说明,它相当于使a进行一次自加(3)的操作。即先使a加3,再赋给a。")
158
3.9 赋值运算符和赋值表达式 为便于记忆,可以这样理解: ① a += b (其中a为变量,b为表达式)
|___↑ ③ a = a + b (在“=”左侧补上变量名a)
")
159
凡是二元(二目)运算符,都可以与赋值符一起组合成复合赋值符。
3.9 赋值运算符和赋值表达式 注意:如果b是包含若干项的表达式,则相当于它有 括号。 如: ① x %= y+3 ② x %= (y+3) |__↑ ③ x = x %(y+3)(不要错写成x=x%y+3) 凡是二元(二目)运算符,都可以与赋值符一起组合成复合赋值符。 C语言规定可以使用10种复合赋值运算符: +=,-=,*=,/=,%=,<<=,>>=,&=,∧=,|=
 |__↑ ③ x = x %(y+3)(不要错写成x=x%y+3) 凡是二元(二目)运算符,都可以与赋值符一起组合成复合赋值符。 C语言规定可以使用10种复合赋值运算符: +=,-=,*=,/=,%=,<<=,>>=,&=,∧=,|=")
160
例如: “a=5”是一个赋值表达式 3.9 赋值运算符和赋值表达式 (4) 赋值表达式 由赋值运算符将一个变量和一个表达式连接
起来的式子称为“赋值表达式”。 一般形式为: <变量><赋值运算符><表达式> 例如: “a=5”是一个赋值表达式

161
3.9 赋值运算符和赋值表达式 对赋值表达式求解的过程是: ②赋给赋值运算符左侧的变量。
①求赋值运算符右侧的“表达式”的值; ②赋给赋值运算符左侧的变量。 例如: 赋值表达式“a=3*5”的值为15,执行表达式后,变量a的值也是15。 注意: 一个表达式应该有一个值

162
3.9 赋值运算符和赋值表达式 左值 (lvalue) : 赋值运算符左侧的标识符 变量可以作为左值; 而表达式就不能作为左值(如a+b);
常变量也不能作为左值。 右值 (lvalue) :出现在赋值运算符右侧的表达式 左值也可以出现在赋值运算符右侧,因而左值 都可以作为右值。
 :出现在赋值运算符右侧的表达式. 左值也可以出现在赋值运算符右侧,因而左值. 都可以作为右值。")
163
3.9 赋值运算符和赋值表达式 分析:括弧内的“b=5”是一个赋值表达式,它 赋值表达式中的“表达式”,又可以是一个赋值表
达式。例如: a=(b=5) 分析:括弧内的“b=5”是一个赋值表达式,它 的值等于5。执行表达式“a=(b=5)”相当于执行 “b=5”和“a=b”两个赋值表达式。 赋值运算符 按照“自右而左”的结合顺序,因此,“(b=5)” 外面的括弧可以不要,即“a=(b=5)”和“a=b=5” 等价。
 分析:括弧内的 b=5 是一个赋值表达式,它. 的值等于5。执行表达式 a=(b=5) 相当于执行. b=5 和 a=b 两个赋值表达式。 赋值运算符. 按照 自右而左 的结合顺序,因此, (b=5) 外面的括弧可以不要,即 a=(b=5) 和 a=b=5 等价。")
164
3.9 赋值运算符和赋值表达式 分析:先执行括弧内的运算,将15赋给a,然后执行 注意:在对赋值表达式(a=3*5)求解后,变量a得到值
不能写成: a=3*5=4*3 注意:在对赋值表达式(a=3*5)求解后,变量a得到值 15执行(a=3*5)=4*3时,实际上是将4*3的积12赋给变 量a,而不是赋给3*5。
求解后,变量a得到值. 15执行(a=3*5)=4*3时,实际上是将4*3的积12赋给变. 量a,而不是赋给3*5。")
165
3.9 赋值运算符和赋值表达式 赋值表达式也可以包含复合的赋值运算符。 如:a+=a-=a*a 分析:此赋值表达式的求解步骤如下∶

166
3.9 赋值运算符和赋值表达式 如:printf("%d",a=b);
将赋值表达式作为表达式的一种,使赋值操作不仅可以出现在赋值语句中,而且可以以表达式形式出现在其他语句(如输出语句、循环语句等)中。 如:printf("%d",a=b); 分析:如果b的值为3, 则输出a的值(也是表达式a=b的值)为3。在一个语句中完成了赋值和输出双重功能。
中。 如:printf( %d ,a=b); 分析:如果b的值为3, 则输出a的值(也是表达式a=b的值)为3。在一个语句中完成了赋值和输出双重功能。")
167
3.10 逗号运算符和逗号表达式 如:3+5,6+8 一般形式: 表达式1,表达式2 逗号运算符:将两个表达式连接起来,又称为“顺序求
逗号表达式 的值为14 逗号运算符:将两个表达式连接起来,又称为“顺序求 值运算符” 如:3+5,6+8 一般形式: 表达式1,表达式2 求解过程: 先求解表达式1,再求解表达式2。整个逗号表达式的值是表达式2的值。

168
3.10 逗号运算符和逗号表达式 例:逗号表达式a=3*5,a*4 分析:赋值运算符的优先级别高于逗号运算符, 因 此应先求解a=3*5。
a的值为15,然后求解a*4,得60。整个逗号表达式的值为60。 例:逗号表达式a=3*5,a*4 分析:赋值运算符的优先级别高于逗号运算符, 因 此应先求解a=3*5。 一个逗号表达式又可以与另一个表达式组成一 个新的逗号表达式 如:(a=3*5,a*4) a+5先计算出a的值等于15,再进行a*4的运算得60(但a值未变,仍为15),再进行a+5得20,即整个表达式的值为20。
 a+5先计算出a的值等于15,再进行a*4的运算得60(但a值未变,仍为15),再进行a+5得20,即整个表达式的值为20。")
169
3.10 逗号运算符和逗号表达式 逗号表达式的一般形式可以扩展为 它的值为表达式n的值。 表达式1,表达式2,表达式3,……,表达式n
赋值表达式,将一个逗号表达式的值赋给x,x的值等于18 逗号运算符是所有运算符中级别最低的 例: ① x=(a=3,6*3) ② x=a=3,6*3 逗号表达式,包括一个赋值表达式和一个算术表达式,x的值为3,整个逗号表达式的值为18。
 ② x=a=3,6*3. 逗号表达式,包括一个赋值表达式和一个算术表达式,x的值为3,整个逗号表达式的值为18。")
170
3.10 逗号运算符和逗号表达式 注意:并不是任何地方出现的逗号都是作为逗号运算符。例如函数参数也是用逗号来间隔的。
“a,b,c”并不是一个逗号表达式,它是printf函数的3个参数 注意:并不是任何地方出现的逗号都是作为逗号运算符。例如函数参数也是用逗号来间隔的。 如: printf(“%d,%d,%d”,a,b,c); printf(“%d,%d,%d”,(a,b,c),b,c) “(a,b,c)”是一个逗号表达式,它的值等于c的值。
; printf( %d,%d,%d ,(a,b,c),b,c) (a,b,c) 是一个逗号表达式,它的值等于c的值。")
171
第四章 最简单的c程序设计

172
主要内容 4.1 C语句概述 4.2 赋值语句 4.3 数据输入输出的概念及在c语言中的实现 4.4 字符数据的输入输出
4.2 赋值语句 4.3 数据输入输出的概念及在c语言中的实现 4.4 字符数据的输入输出 4.5 格式输入与输出 4.6 顺序结构程序设计举例

173
4.1 C语句概述

174
4.1 C语句概述 一个c程序可以有若干个源程序文件组成 一个源文件可以有若干个函数和预处理命令以及全局变量声明部分组成
一个函数有函数首部和函数体组成 函数体由数据声明和执行语句组成 C语句分为 5类 控制语句 函数调用语句 表达式语句 空语句 复合语句

175
4.1 C语句概述 (一)控制语句 完成一定的控制功能 1 if() ~else 条件语句 6 break 间断语句
(一)控制语句 完成一定的控制功能 1 if() ~else 条件语句 break 间断语句 2 for()~ 循环语句 switch() 开关语句 3 while()~循环语句 goto 转向语句 4 do ~while();循环语句 return 返回语句 5 continue 继续语句
控制语句 完成一定的控制功能. 1 if() ~else 条件语句 6 break 间断语句. 2 for()~ 循环语句 7 switch() 开关语句. 3 while()~循环语句 8 goto 转向语句. 4 do ~while();循环语句 9 return 返回语句. 5 continue 继续语句.")
176
例: 4.1 C语句概述 (二)函数调用语句 有一个函数调用加一个分号构成一个语句
Printf(“This is a C statement.”); 例:
; 例:")
177
4.1 C语句概述 (三)表达式语句 有一个表达式加一个分号构成一个语句 a = 3 ; 例: 分号 赋值表达式 表达式语句 + =
表达式语句 有一个表达式加一个分号构成一个语句 a = 3 ; 例: 分号 赋值表达式 表达式语句 + =")
178
4.1 C语句概述 (四)空语句 只有一个分号的语句 (什么也不做) 用来做流程的转向点 用来作为循环语句中的循环体 ;
空语句 只有一个分号的语句 (什么也不做) 用来做流程的转向点 用来作为循环语句中的循环体 ;")
179
4.1 C语句概述 (五)复合语句 用一对{}括起来的语句 { z=x+y; t=z/100; printf(“%f”,t); } 例:
复合语句 用一对{}括起来的语句 { z=x+y; t=z/100; printf( %f ,t); } 例:")
180
4.2 赋值语句 赋值语句是由赋值表达式加上一个分号构成 例:a=100 赋值表达式 a=100; 赋值语句
4.2 赋值语句 赋值语句是由赋值表达式加上一个分号构成 例:a= 赋值表达式 a=100; 赋值语句 条件中不能含有赋值符号,但是赋值表达式可以 包含于条件表达式中 例:if(a=b) t=a; 错误 if((a=b)>0) t=a; 正确
 t=a; 错误. if((a=b)>0) t=a; 正确.")
181
4.2 赋值语句 问题:c语言中的赋值语句于其他高级语言的赋值语句有什么不同点?
4.2 赋值语句 问题:c语言中的赋值语句于其他高级语言的赋值语句有什么不同点? 1:C语言中的赋值号“=”是一个运算符,在其他大多数语言中赋值号不是运算。 2:其他大多数高级语言没有“赋值表达式”这一概念。

182
4.3 数据输入输出的概念及在C 语言中的实现 (一)所谓输入输出是以计算机主机为主体而言的 输出:从计算机向外部输出设备(显示器,打印机) 输出数据。 输入:从输入设备(键盘,鼠标,扫描仪)向计算机 输入数据。

183
4.3 数据输入输出的概念及在C 语言中的实现 (二)C语言本身不提供输入输出语句,输入和输出操作是由C函数库中的函数来实现的。 例如:
字符输入函数: getchar 字符输出函数:putchar 格式输入函数: scanf 格式输出函数: printf 字符串输入函数:gets 字数穿输出函数:puts

184
(三)在使用系统库函数时,要用预编译命令“#include”将有关的“头文件”包括到用户源文件中。
例如:在调用标准输入输出库函数时,文件开头应该有: #include “stdio.h” 或: #include <stdio.h> 头文件

185
4.4 字符数据的输入输出 (一)字符输出函数 一般形式:putchar(c) 函数作用:向终端输出一个字符 字符型变量整型变量
字符输出函数 一般形式:putchar(c) 函数作用:向终端输出一个字符 字符型变量整型变量")
186
4.4 字符数据的输入输出 例4.1 输出单个字符。 #include<stdio.h> void main() { char a,b,c; a=‘B’;b=‘O’;c=‘Y’; putchar(a);putchar(b);putchar(c);putchar(‘\n’); } 运行结果:B O Y putchar(a);putchar(‘\n’);putchar(b);putchar(‘\n’);putchar(c);putchar(‘\n’); 运行结果:BOY
;putchar(‘\n’);putchar(b);putchar(‘\n’);putchar(c);putchar(‘\n’); 运行结果:BOY.")
187
4.4 字符数据的输入输出 (二)字符输入函数 一般形式:getchar() 函数作用:从终端(或系统隐含指定的输入设备)输入一个字符。
4.4 字符数据的输入输出 (二)字符输入函数 一般形式:getchar() 函数作用:从终端(或系统隐含指定的输入设备)输入一个字符。 函数值: 从输入设备得到的字符。
字符输入函数. 一般形式:getchar() 函数作用:从终端(或系统隐含指定的输入设备)输入一个字符。 函数值: 从输入设备得到的字符。")
188
4.4 字符数据的输入输出 例4.2 输入单个字符。 #include<stdio.h> void main() { char c; c=getchar(); putchar(c); putchar(‘\n’); } 运行程序: 从键盘输入字符‘a’ 按Enter键 屏幕上将显示输出的字符‘a’ a a

189
4.5 格式输入与输出 (一)格式输出函数 函数作用:向终端(或系统隐含指定的输出设备)输出若干个任意类型的数据。
4.5 格式输入与输出 (一)格式输出函数 函数作用:向终端(或系统隐含指定的输出设备)输出若干个任意类型的数据。 一般格式:printf(格式控制,输出表列) %d:以带符号的十进制形式输出整数 %o:以八进制无符号形式输出整数 %x:以十六进制无符号形式输出整数 To be continued……
格式输出函数. 函数作用:向终端(或系统隐含指定的输出设备)输出若干个任意类型的数据。 一般格式:printf(格式控制,输出表列) %d:以带符号的十进制形式输出整数. %o:以八进制无符号形式输出整数. %x:以十六进制无符号形式输出整数. To be continued……")
190
4.5 格式输入与输出 %u:以无符号十进制形式输出整数 %c:以字符形式输出,只输出一个字符 %s:输出字符串
4.5 格式输入与输出 %u:以无符号十进制形式输出整数 %c:以字符形式输出,只输出一个字符 %s:输出字符串 %f:以小数形式输出单,双精度数,隐含输出六位小数 %e:以指数形式输出实数 %g:选用%f或%e格式中输出宽度较短的一种格式,不输 出无意义的0

191
4.5 格式输入与输出 几种常见的格式符的修饰符: L:用于长整型整数,可加在格式符d,o,x,u前面 M(代表一个正整数):数据最小宽度
4.5 格式输入与输出 几种常见的格式符的修饰符: L:用于长整型整数,可加在格式符d,o,x,u前面 M(代表一个正整数):数据最小宽度 N(代表一个正整数):对实数,表示输出n位小数; 对字符串,表示截取的字符个数 —:输出的数字或字符在域内向左靠
:数据最小宽度. N(代表一个正整数):对实数,表示输出n位小数; 对字符串,表示截取的字符个数. —:输出的数字或字符在域内向左靠.")
192
4.5 格式输入与输出 d格式符。用来输出十进制整数。 几种用法: ① %d:按十进制整型数据的实际长度输出。
4.5 格式输入与输出 d格式符。用来输出十进制整数。 几种用法: ① %d:按十进制整型数据的实际长度输出。 ② %md:m为指定的输出字段的宽度。如果数据的位数小于m, 则左端补以空格,若大于m,则按实际位数输出。 例: printf(″%4d,%4d″,a,b); 若a=123,d=12345,则输出结果为 123,12345 ③ %ld:输出长整型数据。 例: long a=135790;/* 定义a为长整型变量*/ printf(″%ld″,a);
; 若a=123,d=12345,则输出结果为. 123,12345. ③ %ld:输出长整型数据。 例: long a=135790;/* 定义a为长整型变量*/ printf(″%ld″,a);")
193
4.5 格式输入与输出 (2) o格式符。以八进制整数形式输出。 输出的数值不带符号,符号位也一起作为八进制数的一部分输出。
4.5 格式输入与输出 (2) o格式符。以八进制整数形式输出。 输出的数值不带符号,符号位也一起作为八进制数的一部分输出。 例:int a=-1; printf("%d,%o",a,a); -1在内存单元中的存放形式(以补码形式存放)如下: 输出为: -1,177777 不会输出带负号的八进制整数。对长整数(long型)可以 用“%lo”格式输出。还可以指定字段宽度。 例:printf("%8o",a); 输出为: 。 (数字前有2个空格)
 o格式符。以八进制整数形式输出。 输出的数值不带符号,符号位也一起作为八进制数的一部分输出。 例:int a=-1; printf( %d,%o ,a,a); -1在内存单元中的存放形式(以补码形式存放)如下: 输出为: -1,177777. 不会输出带负号的八进制整数。对长整数(long型)可以. 用 %lo 格式输出。还可以指定字段宽度。 例:printf( %8o ,a); 输出为: 。 (数字前有2个空格)")
194
4.5 格式输入与输出 (3)x格式符。以十六进制数形式输出整数。同样不会出 现负的十六进制数。 例: int a=-1;
4.5 格式输入与输出 (3)x格式符。以十六进制数形式输出整数。同样不会出 现负的十六进制数。 例: int a=-1; printf(″%x,%o,%d″,a,a,a); 输出结果为: ffff,177777,-1 可以用“%lx”输出长整型数,也可以指定输出字段的宽度。 例: “%12x”
x格式符。以十六进制数形式输出整数。同样不会出. 现负的十六进制数。 例: int a=-1; printf(″%x,%o,%d″,a,a,a); 输出结果为: ffff,177777,-1. 可以用 %lx 输出长整型数,也可以指定输出字段的宽度。 例: %12x")
195
4.5 格式输入与输出 (4)u格式符,用来输出unsigned型数据。 (5)c格式符,用来输出一个字符。
4.5 格式输入与输出 (4)u格式符,用来输出unsigned型数据。 一个有符号整数(int型)也可以用%u格式输出; 一个unsigned型数据也可以用%d格式输出; unsigned型数据也可用%o或%x格式输出。 (5)c格式符,用来输出一个字符。 如:char d=′a′; printf(″%c″,d); 输出字符′a′. 一个整数,只要它的值在0~255范围内,可以用 “%c”使之按字符形式输出,在输出前,系统会将该整数 作为ASCII码转换成相应的字符;一个字符数据也可以用 整数形式输出。
u格式符,用来输出unsigned型数据。 一个有符号整数(int型)也可以用%u格式输出; 一个unsigned型数据也可以用%d格式输出; unsigned型数据也可用%o或%x格式输出。 (5)c格式符,用来输出一个字符。 如:char d=′a′; printf(″%c″,d); 输出字符′a′. 一个整数,只要它的值在0~255范围内,可以用. %c 使之按字符形式输出,在输出前,系统会将该整数. 作为ASCII码转换成相应的字符;一个字符数据也可以用. 整数形式输出。")
196
4.5 格式输入与输出 例4.3 无符号数据的输出。 #include<stdio.h> void main() { unsigned int a=65535;int b=-2; printf(“a=%d,%o,%x,%u\n”,a,a,a,a); printf(“b=%d,%o,%x,%u\n”,b,b,b,b); } 运行结果: a=-1,177777,ffff,65535 b=-2,177776,fffe,65534
 { unsigned int a=65535;int b=-2; printf( a=%d,%o,%x,%u\n ,a,a,a,a); printf( b=%d,%o,%x,%u\n ,b,b,b,b); } 运行结果: a=-1,177777,ffff,65535 b=-2,177776,fffe,")
197
指定输出字数的宽度, printf(“%3c”,c); 则输出: a
4.5 格式输入与输出 指定输出字数的宽度, printf(“%3c”,c); 则输出: a 例4.4 字符数据的输出。 #include<stdio.h> void main() { char c=‘a’; int i=97; printf(“%c,%d\n”,c,c); printf(“%c,%d\n”,i,i); } 运行结果: a,97 a,97
; 则输出: a. 例4.4 字符数据的输出。 #include<stdio.h> void main() { char c=‘a’; int i=97; printf( %c,%d\n ,c,c); printf( %c,%d\n ,i,i); } 运行结果: a,97 a,97.")
198
4.5 格式输入与输出 (6)s格式符 输出字符串. ① %s。例如: printf(″%s″,″CHINA″)
4.5 格式输入与输出 (6)s格式符 输出字符串. ① %s。例如: printf(″%s″,″CHINA″) 输出字符串“CHINA”(不包括双引号)。 ② %ms,输出的字符串占m列,若串长大于m,则全部输出,若串长 小于m,则左补空格。 ③ %-ms,若串长小于m,字符串向左靠,右补空格。 ④ %m. ns,输出占m列,只取字符串中左端n个字符,输出在m列的 右侧,左补空格。 ⑤ %-m.ns,n个字符输出在m列的左侧,右补空格,若n〉m,m自 动取n值。
s格式符 输出字符串. ① %s。例如: printf(″%s″,″CHINA″) 输出字符串 CHINA (不包括双引号)。 ② %ms,输出的字符串占m列,若串长大于m,则全部输出,若串长. 小于m,则左补空格。 ③ %-ms,若串长小于m,字符串向左靠,右补空格。 ④ %m. ns,输出占m列,只取字符串中左端n个字符,输出在m列的. 右侧,左补空格。 ⑤ %-m.ns,n个字符输出在m列的左侧,右补空格,若n〉m,m自. 动取n值。")
199
4.5 格式输入与输出 例4.5字符串的输出。 #include<stdio.h> void main() { printf(“%3s,%7.2s,%.4s,%-5.3s\n”, “CHINA”, “CHINA”, “CHINA”, “CHINA”); } 运行结果: CHINA, CH ,CHIN,CHI

200
4.5 格式输入与输出 (7)f格式符。用来以小数形式输出实数(包括单双精度) 有以下几种用法:
4.5 格式输入与输出 (7)f格式符。用来以小数形式输出实数(包括单双精度) 有以下几种用法: ① %f。不指定字段宽度,由系统自动指定字段宽度,使整数 部分全部输出,并输出6位小数。应当注意,在输出的数字中 并非全部数字都是有效数字。单精度实数的有效位数一般为7位。 ②%m.nf。指定输出的数据共占m列,其中有n位小数。如果 数值长度小于m,则左端补空格。 ③%-m.nf与%m.nf基本相同,只是使输出的数值向左端 靠,右端补空格。
f格式符。用来以小数形式输出实数(包括单双精度) 有以下几种用法: ① %f。不指定字段宽度,由系统自动指定字段宽度,使整数. 部分全部输出,并输出6位小数。应当注意,在输出的数字中. 并非全部数字都是有效数字。单精度实数的有效位数一般为7位。 ②%m.nf。指定输出的数据共占m列,其中有n位小数。如果. 数值长度小于m,则左端补空格。 ③%-m.nf与%m.nf基本相同,只是使输出的数值向左端. 靠,右端补空格。")
201
4.5 格式输入与输出 例4.6 输出实数时的有效位数。 #include <stdio.h> void main() { float x,y; x=111111.111;y=222222.222; printf(″%f″,x+y); } 运行结果: 333333.328125

202
4.5 格式输入与输出 例4.7输出双精度数时的有效位数。 #include <stdio.h> void main() {double x,y; x= ; y= ; printf(“%f”,x+y); } 运行结果:
 {double x,y; x= ; y= ; printf( %f ,x+y); } 运行结果:")
203
4.5 格式输入与输出 例4.8 输出实数时指定小数位数。 #include <stdio.h> void main() { float f= ; printf(“%f%10f%10.2f%.2f%-10.2f\n”,f,f,f,f,f); } 运行结果:

204
4.5 格式输入与输出 (8)e格式符,以指数形式输出实数。 可用以下形式: ① %e。不指定输出数据所占的宽度和数字部分的小数位数. 例:
4.5 格式输入与输出 (8)e格式符,以指数形式输出实数。 可用以下形式: ① %e。不指定输出数据所占的宽度和数字部分的小数位数. 例: printf(″%e″,123.456); 输出: 1.234560 e+002 6列 列 所输出的实数共占13列宽度。(注:不同系统的规定略有不同)
e格式符,以指数形式输出实数。 可用以下形式: ① %e。不指定输出数据所占的宽度和数字部分的小数位数. 例: printf(″%e″,123.456); 输出: 1.234560 e+002. 6列 5列. 所输出的实数共占13列宽度。(注:不同系统的规定略有不同)")
205
4.5 格式输入与输出 说明: ② %m.ne和%-m.ne。 m、n和“-”字符的含义与前相同。
4.5 格式输入与输出 ② %m.ne和%-m.ne。 m、n和“-”字符的含义与前相同。 此处n指拟输出的数据的小数部分(又称尾数)的小数位数。 若f=123.456,则: printf("%e %10e %10.2e %.2e %-10.2e",f,f,f,f,f); 输出如下: e e e e+002 13列 列 列 列 1.23e+002 10列 说明: 未指定n,自动使n=6. 超过给定的10列,乃突破10列的限制,按实际长度输出。 第3个数据共占10列,小数部分占2列。 只指定n=2,未指定m,自动使m等于数据应占的长度。 第5个数据应占10列,数值只有9列,由于是“%-10.2e”, 数值向左靠,右补一个空格。 (注:有的C系统的输出格式与此略有不同)
的小数位数。 若f=123.456,则: printf( %e %10e %10.2e %.2e %-10.2e ,f,f,f,f,f); 输出如下: e e e e 列 13列 10列 9列. 1.23e 列. 说明: 未指定n,自动使n=6. 超过给定的10列,乃突破10列的限制,按实际长度输出。 第3个数据共占10列,小数部分占2列。 只指定n=2,未指定m,自动使m等于数据应占的长度。 第5个数据应占10列,数值只有9列,由于是 %-10.2e , 数值向左靠,右补一个空格。 (注:有的C系统的输出格式与此略有不同)")
206
4.5 格式输入与输出 说明: (9)g格式符,用来输出实数. 它根据数值的大小,自动选f格式或e格式(选择输出时占宽度
4.5 格式输入与输出 (9)g格式符,用来输出实数. 它根据数值的大小,自动选f格式或e格式(选择输出时占宽度 较小的一种),且不输出无意义的零。 例:若f=123.468,则 printf(″%f %e %g″,f,f,f); 输出如下: e 10列 列 列 说明: 用%f格式输出占10列,用%e格式输出占13列,用%g 格式时,自动从上面两种格式中选择短者(今以%f格式为短) 故占10列,并按%f格式用小数形式输出,最后3个小数位为 无意义的0,不输出,因此输出 ,然后右补3个空格。 %g格式用得较少。
g格式符,用来输出实数. 它根据数值的大小,自动选f格式或e格式(选择输出时占宽度. 较小的一种),且不输出无意义的零。 例:若f=123.468,则. printf(″%f %e %g″,f,f,f); 输出如下: e 列 13列 10列. 说明: 用%f格式输出占10列,用%e格式输出占13列,用%g. 格式时,自动从上面两种格式中选择短者(今以%f格式为短) 故占10列,并按%f格式用小数形式输出,最后3个小数位为. 无意义的0,不输出,因此输出 ,然后右补3个空格。 %g格式用得较少。")
207
4.5 格式输入与输出 说明: 除了X,E,G外,其他各式字符必须用小写。 可以在printf函数中的“格式控制”字符串中包含转义字符。
4.5 格式输入与输出 说明: 除了X,E,G外,其他各式字符必须用小写。 可以在printf函数中的“格式控制”字符串中包含转义字符。 一个格式说明必须以“%”开头,以9个格式字符之一为结束,中间可以插入附加格式字符。 想输出%,则应该在格式控制字符串中用连续两个%表示。

208
是由若干个地址组成的表列,可以是变量的地址,或字符串的首地址
4.5 格式输入与输出 (一).格式输入函数 函数作用:按照变量在内存的地址将变量值存 进去。 一般格式:scanf(格式控制,地址表列) 同printf函数 是由若干个地址组成的表列,可以是变量的地址,或字符串的首地址
.格式输入函数. 函数作用:按照变量在内存的地址将变量值存 进去。 一般格式:scanf(格式控制,地址表列) 同printf函数. 是由若干个地址组成的表列,可以是变量的地址,或字符串的首地址.")
209
4.5 格式输入与输出 例4.9 用scanf函数输入数据。 #include<stdio.h> void main() { int a,b,c; scanf(“%d%d%d”,&a,&b,&c); printf(“%d,%d,%d\n”,a,b,c); } a在内存中的地址 &是地址运算符 运行情况: (输入a,b,c的值) 3,4, (输出a,b,c的值)
 3,4,5 (输出a,b,c的值)")
210
4.5 格式输入与输出 说明: 对unsigned型变量所需要的数据,可以用%u,%d或%o,%x格式输入。
4.5 格式输入与输出 说明: 对unsigned型变量所需要的数据,可以用%u,%d或%o,%x格式输入。 可以指定输入数据所占的列数,系统自动按它截取所需数据。 如果在%后有一个“*”附加说明符,表示跳过它指定的列数。 输入数据时不能规定精度。

211
4.5 格式输入与输出 使用scanf函数时应注意的问题 : (1)scanf函数中的“格式控制”后面应当是变量地址,而不应 是变量名。
4.5 格式输入与输出 使用scanf函数时应注意的问题 : (1)scanf函数中的“格式控制”后面应当是变量地址,而不应 是变量名。 (2) 如果在“格式控制”字符串中除了格式说明以外还有其他字符, 则在输入数据时在对应位置应输入与这些字符相同的字符。 (3) 在用“%c”格式输入字符时,空格字符和“转义字符”都作为 有效字符输入 。 (4) 在输入数据时,遇以下情况时认为该数据结束。 ① 遇空格,或按“回车”或“跳格”(Tab)键; ② 按指定的宽度结束,如“%3d”,只取3列; ③ 遇非法输入。
scanf函数中的 格式控制 后面应当是变量地址,而不应. 是变量名。 (2) 如果在 格式控制 字符串中除了格式说明以外还有其他字符, 则在输入数据时在对应位置应输入与这些字符相同的字符。 (3) 在用 %c 格式输入字符时,空格字符和 转义字符 都作为. 有效字符输入 。 (4) 在输入数据时,遇以下情况时认为该数据结束。 ① 遇空格,或按 回车 或 跳格 (Tab)键; ② 按指定的宽度结束,如 %3d ,只取3列; ③ 遇非法输入。")
212
4.6 顺序结构程序设计举例 例4.10 输入三角形的三边 长,求三角形面积。 假设:三个边长a,b,c能构 成三角形。 已知面积公式:
area= s=(a+b+c)*0.5 开始 输入三边长 计算s 计算面积 结束
*0.5. 开始. 输入三边长. 计算s. 计算面积. 结束.")
213
4.6 顺序结构程序设计举例 #include<stdio.h> #include<math.h> void main() {float a,b,c,s,area; scanf(″%f,%f,%f″,&a,&b,&c); s=1.0/2*(a+b+c); area=sqrt(s*(s-a)*(s-b)*(s-c)); printf(″a=%7.2f, b=%7.2f, c=%7.2f, s=%7.2f\n″,a,b,c,s); printf(″area=%7.2f\n″,area);} 数学函数库 因为要用到其中的sqrt函数 运行情况: 3,4,6 a= , b= , c= , s= area=
 {float a,b,c,s,area; scanf(″%f,%f,%f″,&a,&b,&c); s=1.0/2*(a+b+c); area=sqrt(s*(s-a)*(s-b)*(s-c)); printf(″a=%7.2f, b=%7.2f, c=%7.2f, s=%7.2f\n″,a,b,c,s); printf(″area=%7.2f\n″,area);} 数学函数库. 因为要用到其中的sqrt函数. 运行情况: 3,4,6 a= 3.00, b= 4.00, c= 6.00, s= 6.50 area=")
214
4.6 顺序结构程序设计举例 例4.11 从键盘输入一个大写字母,要求改用小写字母输出。 #include <stdio.h> void main() { char cl,c2; cl=getchar(); printf(″%c,%d\n″,cl,cl); c2=cl+32; printf(″%c,%d\n″,c2,c2); } 运行情况: A↙ A,65 a,97
 { char cl,c2; cl=getchar(); printf(″%c,%d\n″,cl,cl); c2=cl+32; printf(″%c,%d\n″,c2,c2); } 运行情况: A↙ A,65 a,97.")
215
4.6 顺序结构程序设计举例 例4.12 求ax2+bx+c=0方程的根。 a,b,c由键盘输入,设 >0。 众所周知,一元二次方程式的根为 x1= x2= 可以将上面的分式分为两项: p= , q= x1=p+q, x2=p-q

216
4.6 顺序结构程序设计举例 运行情况: a=1,b=3,c=2↙ x1=-1.00 x2=-2.00
#include <stdio.h> #include <math.h> void main ( ) { float a,b,c,disc,x1,x2,p,q; scanf("a=%f,b=%f,c=%f",&a,&b,&c); disc=b*b-4*a*c; p=-b/(2*a); q=sqrt(disc)/(2*a); x1=p+q;x2=p-q; printf("\n\nx1=%5.2f\nx2=%5.2f\n",x1,x2); } 运行情况: a=1,b=3,c=2↙ x1=-1.00 x2=-2.00
 { float a,b,c,disc,x1,x2,p,q; scanf( a=%f,b=%f,c=%f ,&a,&b,&c); disc=b*b-4*a*c; p=-b/(2*a); q=sqrt(disc)/(2*a); x1=p+q;x2=p-q; printf( \n\nx1=%5.2f\nx2=%5.2f\n ,x1,x2); } 运行情况: a=1,b=3,c=2↙ x1=-1.00 x2=-2.00.")
217
第五章 选择结构程序设计

218
本章要点 关系表达式 逻辑表达式 选择结构程序设计

219
5.1 关系运算符和关系表达式 5.2 逻辑运算符和逻辑表达式 5.3 if语句 5.4 switch语句 5.5 程序举例
主要内容 5.1 关系运算符和关系表达式 5.2 逻辑运算符和逻辑表达式 5.3 if语句 5.4 switch语句 5.5 程序举例

220
5.1 关系运算符和关系表达式 说明: 1.关系运算符及其优先次序 < (小于) <= (小于或等于) > (大于)
< (小于) <= (小于或等于) > (大于) >= (大于或等于) == (等于) != (不等于) 优先级相同(高) 优先级相同(低) 说明: 关系运算符的优先级低于算术运算符 关系运算符的优先级高于赋值运算符
 <= (小于或等于) > (大于) >= (大于或等于) == (等于) != (不等于) 优先级相同(高) 优先级相同(低) 说明: 关系运算符的优先级低于算术运算符. 关系运算符的优先级高于赋值运算符.")
221
C语言中没有专用的逻辑值,1代表真,0代表假
5.1 关系运算符和关系表达式 2.关系表达式 用关系运算符将两个表达式(可以是算术表达式或 关系表达式,逻辑表达式,赋值表达式,字符表达式) 接起来的式子,称关系表达式 例:a>b,a+b>b+c,(a=3)>(b=5),’a’<‘b’,(a>b)>(b<c) 关系表达式的值是一个逻辑值,即“真”或“假”。 例:关系表达式”a>b”的值为“真”,表达式的值为1。 C语言中没有专用的逻辑值,1代表真,0代表假
 接起来的式子,称关系表达式. 例:a>b,a+b>b+c,(a=3)>(b=5),’a’<‘b’,(a>b)>(b<c) 关系表达式的值是一个逻辑值,即 真 或 假 。 例:关系表达式 a>b 的值为 真 ,表达式的值为1。 C语言中没有专用的逻辑值,1代表真,0代表假.")
222
5.2 逻辑运算符和逻辑表达式 1.逻辑运算符及其优先次序 (1)&& (逻辑与) 相当于其他语言中的AND
(2)|| (逻辑或) 相当于其他语言中的OR (3)! (逻辑非) 相当于其他语言中的NOT 例:a&&b 若a,b为真,则a&&b为真。 a||b 若a,b之一为真,则a||b为真。 !a 若a为真,则!a为假。 优先次序: !(非)->&&()->||() 逻辑运算符中的“&&”和“||”低于关系运算符,“!”高于算 术运算符
|| (逻辑或) 相当于其他语言中的OR. (3)! (逻辑非) 相当于其他语言中的NOT. 例:a&&b 若a,b为真,则a&&b为真。 a||b 若a,b之一为真,则a||b为真。 !a 若a为真,则!a为假。 优先次序: !(非)->&&()->||() 逻辑运算符中的 && 和 || 低于关系运算符, ! 高于算. 术运算符.")
223
5.2 逻辑运算符和逻辑表达式 2.逻辑表达式 用逻辑运算符将关系表达式或逻辑量连接起来的式子就 是逻辑表达式。
逻辑表达式的值应该是一个逻辑量“真”或“假”。 任何非零的数值被认作“真” 例:设a=4,b=5: !a的值为 a&&b的值为1 a||b的值为 !a||b的值为1 4&&0||2的值为1

224
5.2 逻辑运算符和逻辑表达式 例:5>3&&8<4-!0 自左向右运算 5>3逻辑值为1 !0逻辑值为1 4-1值为3
8<3逻辑值为0 表达式值为0 1&&0逻辑值为0

225
5.2 逻辑运算符和逻辑表达式 例:(m=a>b)&&(n=c>d)
在逻辑表达式的求解中,并不是所有的逻辑运算符都要被执行。 (1)a&&b&&c 只有a为真时,才需要判断b的值,只有a和b都为真时, 才需要判断c的值。 (2)a||b||c 只要a为真,就不必判断b和c的值,只有a为假,才 判断b。a和b都为假才判断c 例:(m=a>b)&&(n=c>d) 当a=1,b=2,c=3,d=4,m和n的原值为1时,由于“a>b”的值 为0,因此m=0,而“n=c>d”不被执行,因此n的值不是0而 仍保持原值1。
a&&b&&c 只有a为真时,才需要判断b的值,只有a和b都为真时, 才需要判断c的值。 (2)a||b||c 只要a为真,就不必判断b和c的值,只有a为假,才. 判断b。a和b都为假才判断c. 例:(m=a>b)&&(n=c>d) 当a=1,b=2,c=3,d=4,m和n的原值为1时,由于 a>b 的值. 为0,因此m=0,而 n=c>d 不被执行,因此n的值不是0而. 仍保持原值1。")
226
答 (year%4==0&&year%100!=0)||year%400==0 案 值为真(1)是闰年,否则为非闰年。
5.2 逻辑运算符和逻辑表达式 用逻辑表达式来表示闰年的条件 能被4整除,但不能被100整除。 能被4整除,又能被400整除。 ? 答 (year%4==0&&year%100!=0)||year%400==0 案 值为真(1)是闰年,否则为非闰年。
||year%400==0. 案 值为真(1)是闰年,否则为非闰年。")
227
5.3 if语句 1.If语句的三种基本形式 (1)if (表达式) 语句 例: if(x>y) printf(“%d”,x);
真(非0) 假 (0)
 假. (0)")
228
5.3 if语句 (2)if(表达式) 语句1 else 语句2 例: if (x>y) printf(“%d”,x);
else printf(“%d”,y); 条件 语句1 语句2 Y N
; 条件. 语句1. 语句2. Y. N.")
229
5.3 if语句 (3)if(表达式1)语句1 else if(表达式2)语句2 else if(表达式3)语句3 ……
else if(表达式m)语句m else 语句n
语句m. else 语句n.")
230
5.3 if语句 例: else if(number>300)cost=0.10;
else cost=0;

231
5.3 if语句 说明: (1)3种形式的if语句中在if后面都有表达式, 一般为逻辑表达式或关系表达式。
else前面有一个分号,整个语句结束处有一 个分号。 (3)在if和else后面可以只含有一个内嵌的操 作语句,也可以由多个操作语句,此时用花 括号将几个语句括起来成为一个复合语句。
在if和else后面可以只含有一个内嵌的操. 作语句,也可以由多个操作语句,此时用花. 括号将几个语句括起来成为一个复合语句。")
232
5.3 if语句 例5.1 输入两个实数,按代数值由小到大的顺序输出这两个数。 #include<stdio.h> void main() {float a,b,t; scanf(″%f,%f″,&a,&b); if(a>b) {t=a; a=b; b=t;} printf(″%5.2f,%5.2f\n″,a,b);} y n a>b T=a A=b B=t
 {float a,b,t; scanf(″%f,%f″,&a,&b); if(a>b) {t=a; a=b; b=t;} printf(″%5.2f,%5.2f\n″,a,b);} y. n. a>b. T=a. A=b. B=t.")
233
5.3 if语句 例5.2 输入三个数a,b,c,要求按由小到大的顺序输出。 If a>b 将a和b对换
a>c b>c a和b交换 a和c交换 c和b交换 y n If a>b 将a和b对换 If a>c 将a和c对换 If b>c 将b和c对换

234
5.3 if语句 #include <stdio.h> void main ( ) { float a,b,c,t; scanf(″%f,%f,%f″,&a,&b,&c); if(a>b) {t=a;a=b;b=t;} if(a>c) {t=a;a=c;c=t;} if(b>c) {t=b;b=c;c=t;} printf("%5.2f,%5.2f,%5.2f\n",a,b,c); }
 { float a,b,c,t; scanf(″%f,%f,%f″,&a,&b,&c); if(a>b) {t=a;a=b;b=t;} if(a>c) {t=a;a=c;c=t;} if(b>c) {t=b;b=c;c=t;} printf( %5.2f,%5.2f,%5.2f\n ,a,b,c); }")
235
5.3 if语句 2.If语句的嵌套 在if语句中又包含一个或多个if语句称为if语句的嵌套。 形式: If() if() 语句1
else 语句2 Else if() 语句3 else 语句4 内嵌if
 语句3. else 语句4. 内嵌if.")
236
5.3 if语句 例: 例: 匹配规则: Else总是与它上面的,最近的,统一复合语句中的,未配 对的if语句配对。 If()
")
237
5.3 if语句 -1 (x<0) 例 5.3 有一个函数 y= 0 (x=0),编一程序,输入一个x
算法1: 算法1: 输入x 输入x 若x<0,则y= 若x<0,则y=-1 若x=0,则y= 否则: 若x>0,则y= 若x=0,则y=0 输出y 若x>0,则y=1 输出y

238
5.3 if语句 #include<stdio.h> void main() { int x,y;
scanf(“%d”,&x); 程序段 } printf(“x=%d,y=%d\n”,x,y);
; 程序段. } printf( x=%d,y=%d\n ,x,y);")
239
5.3 if语句 上例中的程序段有四个,请判断哪个是正确的? 正 正 确 确 程序1: 程序2:
程序1: 程序2: If(x<0) if(x>=0) Y=-1; if(x>0) y=1; Else else y=0; If(x==0) y=0; else y=-1; Else y=1; 程序3: 程序4: Y=-1; y=0; If(x!=0) if(x>=0) If(x>0) y=1; if(x>0) y=1; Else y=0; Else y=-1; 正 确 正 确
 if(x>=0) Y=-1; if(x>0) y=1; Else else y=0; If(x==0) y=0; else y=-1; Else y=1; 程序3: 程序4: Y=-1; y=0; If(x!=0) if(x>=0) If(x>0) y=1; if(x>0) y=1; Else y=0; Else y=-1; 正. 确. 正. 确.")
240
5.3 if语句 3.条件运算符 格式: 表达式1?表达式2∶表达式3 功能: 判断表达式1的值,如果成立就执行表
格式: 表达式1?表达式2∶表达式3 功能: 判断表达式1的值,如果成立就执行表 达式2,否则就执行表达式3 使用场合:若在if语句中,当被判别的表达式的 值为“真”或“假” 时,都执行一个赋值语 句且向同一个变量赋值时,可以用一个 条件运算符来处理。

241
5.3 if语句 例: else max=b; 当a>b时将a的值赋给max,当a≤b时将b的值赋给max,
if (a>b) max=a; else max=b; 当a>b时将a的值赋给max,当a≤b时将b的值赋给max, 可以看到无论a>b是否满足,都是向同一个变量赋值。 可以用下面的条件运算符来处理: max=(a>b)?a∶b;
 max=a; else max=b; 当a>b时将a的值赋给max,当a≤b时将b的值赋给max, 可以看到无论a>b是否满足,都是向同一个变量赋值。 可以用下面的条件运算符来处理: max=(a>b)?a∶b;")
242
5.3 if语句 说明: (1)条件运算符的执行顺序:先求解表达式1,若为非0(真) 则求解表达式2,此时表达式2的值就作为整个条件表达式
的值。若表达式1的值为0(假),则求解表达式3,表达 式3的值就是整个条件表达式的值。 (2)条件运算符优先级高于赋值运算符 ,低于关系运算符 和算术运算符。 (3)条件运算符的结合方向为“自右至左”。 (4)“表达式2”和“表达式3”不仅可以是数值表达式,还可以 是赋值表达式或函数表达式。 (5)条件表达式中,表达式1的类型可以与表达式2和表达 式3的类型不同。
,则求解表达式3,表达. 式3的值就是整个条件表达式的值。 (2)条件运算符优先级高于赋值运算符 ,低于关系运算符. 和算术运算符。 (3)条件运算符的结合方向为 自右至左 。 (4) 表达式2 和 表达式3 不仅可以是数值表达式,还可以. 是赋值表达式或函数表达式。 (5)条件表达式中,表达式1的类型可以与表达式2和表达. 式3的类型不同。")
243
5.3 if语句 例5.4输入一个字符,判别它是否大写字母,如果是,将它转换成小写字母;如果不是,不转换。然后输出最后得到的字符。 #include <stdio.h> void main ( ) { char ch; scanf("%c",& ch); ch=(ch>='A'&& ch<='Z')?(ch+32):ch; printf("%c\n",ch); } 如果字符变量ch的值为大写字母,则条件表达式的值为(ch+32),即相应的小写字母。如果ch的值不是大写字母,则条件表达式的值为ch,即不进行转换。
 { char ch; scanf( %c ,& ch); ch=(ch>= A && ch<= Z ) (ch+32):ch; printf( %c\n ,ch); } 如果字符变量ch的值为大写字母,则条件表达式的值为(ch+32),即相应的小写字母。如果ch的值不是大写字母,则条件表达式的值为ch,即不进行转换。")
244
5.4 switch语句 switch语句的格式: switch (表达式) {case 常量表达式1:语句1
… case 常量表达式n:语句n default :语句n+1 }

245
5.4 switch语句 例: 要求按照考试成绩的等级输出百分制分数段,用 switch语句实现: switch(grade)
{ case ′A′∶printf(″85~100\n″); case ′B′∶ printf (″70~84\n″); case ′C′∶ printf (″60~69\n″); case ′D′∶ printf (″<60\n″); default∶( printf ″error\n″); }
; case ′B′∶ printf (″70~84\n″); case ′C′∶ printf (″60~69\n″); case ′D′∶ printf (″<60\n″); default∶( printf ″error\n″); }")
246
5.4 switch语句 说明: switch后面括弧内的“表达式”, ANSI标准允许它为任何类型。
(2) 当表达式的值与某一个case后面的常量表达式的值相等时,就执行此case后面的语句,若所有的case中的常量表达式的值都没有与表达式的值匹配的,就执行default后面的语句。 (3) 每一个case的常量表达式的值必须互不相同,否则就 会出现互相矛盾的现象(对表达式的同一个值,有两种或多种执行方案)。
 当表达式的值与某一个case后面的常量表达式的值相等时,就执行此case后面的语句,若所有的case中的常量表达式的值都没有与表达式的值匹配的,就执行default后面的语句。 (3) 每一个case的常量表达式的值必须互不相同,否则就 会出现互相矛盾的现象(对表达式的同一个值,有两种或多种执行方案)。")
247
5.4 switch语句 (4) 各个case和default的出现次序不影响执行结 果。例如,可以先出现“default:…”,再出现
“case ′D′:…”,然后是“case′A′:…”。 (5) 执行完一个case后面的语句后,流程控制转移到下一 个case继续执行。“case常量表达式”只是起语句标号作用,并不是在条件判断。在执行 switch语句时,根据switch后面表达式的值 找到匹配的入口标号,就从此标号开始执行下去,不再进行判断。应该在执行一个case分支后,可以用一个 break语句来终止switch语句的执行。 (6) 多个可以共用一组执行语句。
 执行完一个case后面的语句后,流程控制转移到下一 个case继续执行。 case常量表达式 只是起语句标号作用,并不是在条件判断。在执行 switch语句时,根据switch后面表达式的值 找到匹配的入口标号,就从此标号开始执行下去,不再进行判断。应该在执行一个case分支后,可以用一个. break语句来终止switch语句的执行。 (6) 多个可以共用一组执行语句。")
248
5.5 程序举例 例5.5 写程序,判断某一年是否闰年。 用下图来表示判断闰年的算法。

249
5.5 程序举例 运行情况: 1989↙ 1989 is not a leap year. 2000↙
2000 is a leap year. #include <stdio.h> void main() {int year, leap; scanf("%d",&year); if (year%4==0) {if (year%100==0) {if (year%400==0) leap=1; else leap=0;} else leap=1;} else leap=0; if (leap) printf("%d is ",year); else printf("%d is not ",year); printf("a leap year.\n");} if(year%4!=0) leap=0; else if(year%100!=0) leap=1; else if(year%400!=0) leap=0; else leap=1;
 {int year, leap; scanf( %d ,&year); if (year%4==0) {if (year%100==0) {if (year%400==0) leap=1; else leap=0;} else leap=1;} else leap=0; if (leap) printf( %d is ,year); else printf( %d is not ,year); printf( a leap year.\n );} if(year%4!=0) leap=0; else if(year%100!=0) leap=1; else if(year%400!=0) leap=0; else leap=1;")
250
5.5 程序举例 例5.6 求a+bx+c=0方程的解。 基本的算法: ① a=0,不是二次方程。 ② -4ac=0,有两个相等实根。
③ -4ac>0,有两个不等实根。 ④ -4ac<0,有两个共轭复根。

252
5.5 程序举例 #include <stdio.h> #include <math.h> void main ( ) {float a,b,c,disc,x1,x2,realpart,imagpart; scanf("%f,%f,%f",&a,&b,&c); printf("the equation "); if(fabs(a)<=1e-6) printf("is not a quadratic\\n"); else { disc=b*b-4*a*c; if(fabs(disc)<=1e-6) printf("has two equal roots:%8.4f\n",-b/(2*a));
 {float a,b,c,disc,x1,x2,realpart,imagpart; scanf( %f,%f,%f ,&a,&b,&c); printf( the equation ); if(fabs(a)<=1e-6) printf( is not a quadratic\\n ); else { disc=b*b-4*a*c; if(fabs(disc)<=1e-6) printf( has two equal roots:%8.4f\n ,-b/(2*a));")
253
5.5 程序举例 else if(disc>1e-6) {x1=(-b+sqrt(disc))/(2*a); x2=(-b-sqrt(disc))/(2*a); printf(″has distinct real roots:%8.4f and %8.4f\n″,x1,x2); } else {realpart=-b/(2*a); imagpart=sqrt(-disc)/(2*a); printf(″has complex roots∶\n″); printf(″%8.4f+%8.4fi\n″,realpart,imagpart); printf(″%8.4f-%8.4fi\n″,realpart,imagpart); } }}
 {x1=(-b+sqrt(disc))/(2*a); x2=(-b-sqrt(disc))/(2*a); printf(″has distinct real roots:%8.4f and %8.4f\n″,x1,x2); } else {realpart=-b/(2*a); imagpart=sqrt(-disc)/(2*a); printf(″has complex roots∶\n″); printf(″%8.4f+%8.4fi\n″,realpart,imagpart); printf(″%8.4f-%8.4fi\n″,realpart,imagpart); } }}")
254
5.5 程序举例 例5.7 运输公司对用户计算运费。 路程(s)越远,每公里运费越低。标准如下: s<250km 没有折扣
s<250km 没有折扣 250≤s<500 2%折扣 500≤s<1000 5%折扣 1000≤s<2000 8%折扣 2000≤s<3000 10%折扣 3000≤s 15%折扣 设每公里每吨货物的基本运费为p,货物重为w, 距离为s,折扣为d,则总运费f的计算公式为: f=p*w*s*(1-d)
")
255
5.5 程序举例 分析折扣变化的规律性: 折扣的“变化点”都是250的倍数 在横轴上加一种坐标c,c的值为s/250。 c代表250的倍数。
c<1,无折扣; 1≤c<2,折扣d=2%; 2≤c<4,d=5%; 4≤c<8,d=8%; 8≤c<12,d=10%; c≥12,d=15%。

256
#include <stdio. h> void main ( ) {int c,s;. float p,w,d,f;
#include <stdio.h> void main ( ) {int c,s; float p,w,d,f; scanf("%f,%f,%d",&p,&w,&s); if(s>=3000) c=12; else c=s/250; switch(c){ case 0:d=0;break; case 1:d=2;break; case 2:case 3:d=5;break; case 4:case 5:case 6:case 7:d=8;break; case 8:case 9:case 10: case 11:d=10;break; case 12:d=15;break; } f=p*w*s*(1-d/100.0); printf("freight=%15.4f\n",f);} §5.5 程序举例(续)
 {int c,s; float p,w,d,f; scanf( %f,%f,%d ,&p,&w,&s); if(s>=3000) c=12; else c=s/250; switch(c){ case 0:d=0;break; case 1:d=2;break; case 2:case 3:d=5;break; case 4:case 5:case 6:case 7:d=8;break; case 8:case 9:case 10: case 11:d=10;break; case 12:d=15;break; } f=p*w*s*(1-d/100.0); printf( freight=%15.4f\n ,f);} §5.5 程序举例(续)")
257
第六章 循环控制

258
循环的基本概念 不同形式的循环控制 多重循环问题
本章要点 循环的基本概念 不同形式的循环控制 多重循环问题

259
主要内容 6.1 概述 6.2 goto语句以及用goto语句构成循环 6.3 用while语句实现循环
6.4 用do-while语句实现循环 6.5 用for 语句实现循环 6.6 循环的嵌套 6.7 几种循环的比较 6.8 break语句continue和语句 6.9 程 序 举 例

260
6.1 概述 什么是循环? 为什么要使用循环? 问题1: 问题2:求学生平均成绩 分数相加后除以课数
问题2:求学生平均成绩 分数相加后除以课数 在许多问题中需要用到循环控制。循环结构是结构化程序设计的基本结构之一,它和顺序结构、选择结构共同作为各种复杂程序的基本构造单元。

261
6.2 goto语句以及用goto语句构成循环 goto语句——无条件转向语句 goto 语句标号;
语句标号用标识符表示,它的定名规则与变量名相同,即由字母、数字和下划线组成,其第一个字符必须为字母或下划线。 例如:goto label_1; 合法; goto 123; 不合法.

262
6.2 goto语句以及用goto语句构成循环 结构化程序设计方法主张限制使用goto语句,因 (1) 与if语句一起构成循环结构;
一般来说,可以有两种用途: (1) 与if语句一起构成循环结构; (2) 从循环体中跳转到循环体外。 但是这种用法不符合结构化原则,一般不宜采用,只有在不得已时(例如能大大提高效率)才使用。
 与if语句一起构成循环结构; (2) 从循环体中跳转到循环体外。 但是这种用法不符合结构化原则,一般不宜采用,只有在不得已时(例如能大大提高效率)才使用。")
263
运行结果:5050 例6.1 用if语句和goto语句构成循环,求1到100的和 void main( ) { int i, sum=0; i=1; loop: if(i<=100) { sum=sum+i; i++; goto loop; } printf("%d\\n″,sum); } 说明:这里用的是“当型”循环结构,当满足“i<=100” 时执行花括弧内的循环体。
 { int i, sum=0; i=1; loop: if(i<=100) { sum=sum+i; i++; goto loop; } printf( %d\\n″,sum); } 说明:这里用的是 当型 循环结构,当满足 i<=100 时执行花括弧内的循环体。")
264
while语句用来实现“当型”循环结构。
一般形式: while (表达式) 语句 当表达式为非0值时,执行while语句中的内嵌语句。其特点是:先判断表达式,后执行语句。
 语句. 当表达式为非0值时,执行while语句中的内嵌语句。其特点是:先判断表达式,后执行语句。")
265
例6. 2 求1到100的和 #include <stdio
例6.2 求1到100的和 #include <stdio.h> void main() {int i,sum=0; i=1; while (i<=100) { sum=sum+i; i++; } printf(″%d\\n″,sum); } 运行结果:5050 说明:(1)循环体如果包含一个以上的语句,应该用花括弧括起来,以复合语句形式出现.(2)在循环体中应有使循环趋向于结束的语句 。
 {int i,sum=0; i=1; while (i<=100) { sum=sum+i; i++; } printf(″%d\\n″,sum); } 运行结果:5050. 说明:(1)循环体如果包含一个以上的语句,应该用花括弧括起来,以复合语句形式出现.(2)在循环体中应有使循环趋向于结束的语句. 。")
266
注意: 6.3 用while语句实现循环 循环体如果包含一个以上的语句,应该用花括弧括起来,以复合语句形式出现。

267
6.4 用do-while语句实现循环 do-while语句的特点:先执行循环体,然后判断循环条件是否成立。 一般形式: do 循环体语句
执行过程:先执行一次指定的循环体语句,然后判别表达式,当表达式的值为非零(“真”) 时,返回重新执行循环体语句,如此反复,直到表达式的值等于0为止,此时循环结束。
 时,返回重新执行循环体语句,如此反复,直到表达式的值等于0为止,此时循环结束。")
268
例6. 3 求1到100的和 #include <stdio
例6.3 求1到100的和 #include <stdio.h> void main() { int i,sum=0; i=1; do {sum=sum+i; i++; } while(i<=100); printf("%d\\n″,sum); } 运行结果:5050
 { int i,sum=0; i=1; do {sum=sum+i; i++; } while(i<=100); printf( %d\\n″,sum); } 运行结果:5050.")
269
6.4 用do-while语句实现循环 while语句和用do-while语句的比较: 在一般情况下,用while语句和用do-while语
句处理同一问题时,若二者的循环体部分是一 样的,它们的结果也一样。但是如果while后面 的表达式一开始就为假(0值)时,两种循环的结 果是不同的。
时,两种循环的结. 果是不同的。")
270
例6. 4 while和do-while循环的比较 (1) #include <stdio
例6.4 while和do-while循环的比较 (1) #include <stdio.h> (2) #include <stdio.h> void main ( ) void main( ) {int sum=0,i; {int sum=0,i; scanf(“%d″,&i); scanf(”%d″,&i); while (i<=10) do {sum=sum+I; { sum=sum+i; i++; i++; } while (i<=10); printf(“sum=%d\\n″ ,sum); } printf(“sum=%d\\n”,sum); } 运行结果: 1↙ sum=55 再运行一次: 11↙ sum=11 运行结果: 1↙ sum=55 再运行一次: 11↙ sum=0 说明:(1)当while后面的表达式的第一次的值为“真”时,两种循环得到的结果相同。否则,二者结果不相同。
 #include <stdio.h> (2) #include <stdio.h> void main ( ) void main( ) {int sum=0,i; {int sum=0,i; scanf( %d″,&i); scanf( %d″,&i); while (i<=10) do {sum=sum+I; { sum=sum+i; i++; i++; } while (i<=10); printf( sum=%d\\n″ ,sum); } printf( sum=%d\\n ,sum); } 运行结果: 1↙ sum=55. 再运行一次: 11↙ sum=11. 运行结果: 1↙ sum=55. 再运行一次: 11↙ sum=0. 说明:(1)当while后面的表达式的第一次的值为 真 时,两种循环得到的结果相同。否则,二者结果不相同。")
271
6.5 用for 语句实现循环 C语言中的for语句使用最为灵活,不仅可以用于循环次数已经确定的情况,而且可以用于循环次数不确定而只给出循环结束条件的情况,它完全可以代替while语句。 一般形式: for(表达式1;表达式2;表达式3) 语句
 语句.")
272
6.5 用for 语句实现循环 for语句的执行过程: (1) 先求解表达式1。 (2) 求解表达式2,若其值为真(值为非0),则执
面第(3)步。若为假(值为0),则结束循环, 转到第(5)步。 (3) 求解表达式3。 (4) 转回上面第(2)步骤继续执行。 (5) 循环结束,执行for语句下面的一个语句
步。若为假(值为0),则结束循环, 转到第(5)步。 (3) 求解表达式3。 (4) 转回上面第(2)步骤继续执行。 (5) 循环结束,执行for语句下面的一个语句.")
273
6.5 用for 语句实现循环 执行表达式1 循环初始条件 表达式2? 循环控制条件 执行语句 循环体 for语句等价于下列语句:
成立 不成立 执行for循环之后的语句 执行表达式3 执行表达式1 循环初始条件 循环控制条件 循环体 for语句等价于下列语句: 表达式1; while (表达式2) { 语句; 表达式3; }
 { 语句; 表达式3; }")
274
6.5 用for 语句实现循环 for语句最简单的形式: for(循环变量赋初值;循环条件;循环变量增值)
例如: for(i=1;i<=100;i++) sum=sum+i; 相当于: i=1; while(i<=100) {sum=sum+i;i++;} 用for语句 简单、方便。
 sum=sum+i; 相当于: i=1; while(i<=100) {sum=sum+i;i++;} 用for语句. 简单、方便。")
275
6.5 用for 语句实现循环 说明: (1) for语句的一般形式中的“表达式1”可以省略,此时应在for语句之前给循环变量赋初值。注意省略表达式1时,其后的分号不能省略。如 for(;i<=100;i++) sum=sum+i; 执行时,跳过“求解表达式1”这一步,其他不变。

276
6.5 用for 语句实现循环 说明: (2) 如果表达式2省略,即不判断循环条件,循环无终 止地进行下去。也就是认为表达式2始终为真。
例如:for(i=1; ;i++) sum=sum+i; 表达式1是一个赋值表达式,表达式2空缺。它相当于: i=1; while(1) {sum=sum+1;i++;}
 sum=sum+i; 表达式1是一个赋值表达式,表达式2空缺。它相当于: i=1; while(1) {sum=sum+1;i++;}")
277
6.5 用for 语句实现循环 说明: (3) 表达式3也可以省略,但此时程序设计者应另外设法保证循环能正常结束。如:
for(i=1;i<=100;) {sum=sum+i;i++;} 在上面的for语句中只有表达式1和表达式2,而没有表达式3。i++的操作不放在for语句的表达式3的位置处,而作为循环体的一部分,效果是一样的,都能使循环正常结束。
 {sum=sum+i;i++;} 在上面的for语句中只有表达式1和表达式2,而没有表达式3。i++的操作不放在for语句的表达式3的位置处,而作为循环体的一部分,效果是一样的,都能使循环正常结束。")
278
6.5 用for 语句实现循环 说明: (4) 可以省略表达式1和表达式3,只有表达式2,即只 给循环条件。如:
for(;i<=100;) while(i<=100) {sum=sum+i; 相当于 {sum=sum+i; i++;} i++;} 在这种情况下,完全等同于while语句。可见for语句 比while语句功能强,除了可以给出循环条件外,还可 以赋初值,使循环变量自动增值等。
 while(i<=100) {sum=sum+i; 相当于 {sum=sum+i; i++;} i++;} 在这种情况下,完全等同于while语句。可见for语句. 比while语句功能强,除了可以给出循环条件外,还可. 以赋初值,使循环变量自动增值等。")
279
6.5 用for 语句实现循环 说明: (5) 3个表达式都可省略,如: for(; ;) 语句 相当于 while(1) 语句
即不设初值,不判断条件(认为表达式2为真值), 循环变量不增值。无终止地执行循环体。
, 循环变量不增值。无终止地执行循环体。")
280
6.5 用for 语句实现循环 说明: (6) 表达式1可以是设置循环变量初值的赋值表达式,也可以是与循环变量无关的其他表达式。如:
for (sum=0;i<=100;i++) sum=sum+i; 表达式3也可以是与循环控制无关的任意表达式。
 sum=sum+i; 表达式3也可以是与循环控制无关的任意表达式。")
281
6.5 用for 语句实现循环 说明: 表达式1和表达式3可以是一个简单的表达式,也可以 是逗号表达式,即包含一个以上的简单表达式,中间用
逗号间隔。如: for(sum=0,i=1;i<=100;i++) sum=sum+i; 或 for(i=0,j=100;i<=j;i++,j--) k=i+j; 表达式1和表达式3都是逗号表达式,各包含两个赋值 表达式,即同时设两个初值,使两个变量增值.
 sum=sum+i; 或. for(i=0,j=100;i<=j;i++,j--) k=i+j; 表达式1和表达式3都是逗号表达式,各包含两个赋值. 表达式,即同时设两个初值,使两个变量增值.")
282
6.5 用for 语句实现循环 说明: 在逗号表达式内按自左至右顺序求解,整个逗号表达 式的值为其中最右边的表达式的值。如:
for(i=1;i<=100;i++,i++) sum=sum+i; 相当于 for(i=1;i<=100;i=i+2) sum=sum+i;
 sum=sum+i; 相当于. for(i=1;i<=100;i=i+2) sum=sum+i;")
283
6.5 用for 语句实现循环 说明: (7) 表达式一般是关系表达式(如i<=100)或逻辑表达式
(如a<b && x<y),但也可以是数值表达式或字符表达 式,只要其值为非零,就执行循环体。
,但也可以是数值表达式或字符表达. 式,只要其值为非零,就执行循环体。")
284
6.5 用for 语句实现循环 说明: 注意:此for语句的循环体为空语句,把本来要在循环
① for(i=0;(c=getchar())!=′\n′;i+=c); 在表达式2中先从终端接收一个字符赋给c,然后判断 此赋值表达式的值是否不等于′\n′(换行符),如果 不等于′\n′,就执行循环体。 注意:此for语句的循环体为空语句,把本来要在循环 体内处理的内容放在表达式3中,作用是一样的。可见 for语句功能强,可以在表达式中完成本来应在循环体 内完成的操作。
)!=′\n′;i+=c); 在表达式2中先从终端接收一个字符赋给c,然后判断. 此赋值表达式的值是否不等于′\n′(换行符),如果. 不等于′\n′,就执行循环体。 注意:此for语句的循环体为空语句,把本来要在循环. 体内处理的内容放在表达式3中,作用是一样的。可见. for语句功能强,可以在表达式中完成本来应在循环体. 内完成的操作。")
285
6.5 用for 语句实现循环 说明: 运行情况: Computer↙ (输入)
而不是 Ccoommppuutteerr 说明: ② for( ;(c=getchar())!=′\n′;) printf(″%c″,c); for语句中只有表达式2,而无表达式1和表达式3。 其作用是每读入一个字符后立即输出该字符,直到输入 一个“换行”为止。请注意,从终端键盘向计算机输入 时,是在按Enter键以后才将一批数据一起送到内存缓 冲区中去的。
)!=′\n′;) printf(″%c″,c); for语句中只有表达式2,而无表达式1和表达式3。 其作用是每读入一个字符后立即输出该字符,直到输入. 一个 换行 为止。请注意,从终端键盘向计算机输入. 时,是在按Enter键以后才将一批数据一起送到内存缓. 冲区中去的。")
286
6.5 用for 语句实现循环 注意: C语言中的for语句比其他语言(如BASIC, PASCAL)中的FOR语句功能强得多。可以把循环体
和一些与循环控制无关的操作也作为表达式1或 表达式3出现,这样程序可以短小简洁。但过分 地利用这一特点会使for语句显得杂乱,可读性 降低,最好不要把与循环控制无关的内容放到 for语句中。

287
6.6 循环的嵌套 一个循环体内又包含另一个完整的循环结构 称为循环的嵌套。内嵌的循环中还可以嵌套 循环,这就是多层循环。
三种循环(while循环、do-while循环和for循 环)可以互相嵌套。
可以互相嵌套。")
288
6.6 循环的嵌套 下面几种都是合法的形式: (1) while( ) (2) do (3) for(;;) {… {… {
{… {… { while( ) do for(;;) {…} {… } {… } } while( ); } } while( );
 do for(;;) {…} {… } {… } } while( ); } } while( );")
289
6.6 循环的嵌套 (4) while( ) (5) for(;;) (6) do {… {… {…
6.6 循环的嵌套 (4) while( ) (5) for(;;) (6) do {… {… {… do{…} while( ) for(;;){ } while( ) { } … {…} … } } } while( )
 while( ) (5) for(;;) (6) do. {… {… {… do{…} while( ) for(;;){ } while( ) { } … {…} … } } } while( )")
290
6.7 几种循环的比较 (1)四种循环都可以用来处理同一问题,一般情况下它们可以互相代替。但一般不提倡用goto型循环。
(2)在while循环和do-while循环中,只在while后面的括号内指定循环条件,因此为了使循环能正常结束,应在循环体中包含使循环趋于结束的语句(如i++,或i=i+1等)。
在while循环和do-while循环中,只在while后面的括号内指定循环条件,因此为了使循环能正常结束,应在循环体中包含使循环趋于结束的语句(如i++,或i=i+1等)。")
291
6.7 几种循环的比较 for循环可以在表达式3中包含使循环趋于结束的操作,甚至可以将循环体中的操作全部放到表达式3中。因此for语句的功能更强,凡用while循环能完成的,用for循环都能实现。 (3)用while和do-while循环时,循环变量初始化的操作应在while和do-while语句之前完成。而for语句可以在表达式1中实现循环变量的初始化。
用while和do-while循环时,循环变量初始化的操作应在while和do-while语句之前完成。而for语句可以在表达式1中实现循环变量的初始化。")
292
6.7 几种循环的比较 (4)while循环、do-while循环和for循环,可以 用break语句跳出循环,用continue语句结束本
对用goto语句和if语句构成的循环,不能用 break语句和continue语句进行控制。

293
6.8 break语句和continue语句 6.8.1 break语句
一般形式: break; 注意:break语句不能用于循环语句和switch语句之外的任何其他语句中。

294
6.8 break语句和continue语句 例: float pi=3.14159; for(r=1;r<=10;r++)
{ area=pi*r*r; if(area>100) break; printf(″r=%f,area=%f\n″,r,area); } 程序的作用是计算r=1到r=10时的圆面积,直到面积area大于100为止。从上面的for循环可以看到:当area>100时,执行break语句,提前结束循环,即不再继续执行其余的几次循环。
 break; printf(″r=%f,area=%f\n″,r,area); } 程序的作用是计算r=1到r=10时的圆面积,直到面积area大于100为止。从上面的for循环可以看到:当area>100时,执行break语句,提前结束循环,即不再继续执行其余的几次循环。")
295
6.8 break语句和continue语句 6.8.2 continue语句
作用为结束本次循环,即跳过循环体中下面尚未执行的语句,接着进行下一次是否执行循环的判定. 一般形式: continue;

296
6.8 break语句和continue语句 continue语句和break语句的区别
while(表达式1) for { … if(表达式2) continue; … }0
 for. { … if(表达式2) continue; … }0.")
297
while(表达式1) for 6.8 break语句和continue语句 continue和break的区别
{ … if(表达式2) break; … }
 break; … }")
298
例6. 5 把100~200之间的不能被3整除的数输出。 #include <stdio
例6.5 把100~200之间的不能被3整除的数输出。 #include <stdio.h> void main() {int n; for (n=100;n<=200;n++) {if (n%3==0) continue; printf("%d ″,n); } } 说明:当n能被3整除时,执行continue语句,结束本次循环(即跳过printf函数语句),只有n不能被3整除时才执行printf函数。
 {int n; for (n=100;n<=200;n++) {if (n%3==0) continue; printf( %d ″,n); } } 说明:当n能被3整除时,执行continue语句,结束本次循环(即跳过printf函数语句),只有n不能被3整除时才执行printf函数。")
299
6.9 程序举例 例6.6用π/4≈1-1/3+1/5-1/7+…公式求π的近似值,直到某一项的绝对值小于为止。 N-S图表示算法

300
运行结果: pi= 例6.6 求pi的近似值 #include <stdio.h> #include<math.h> void main() { int s;float n,t,pi; t=1;pi=0;n=1.0;s=1; while(fabs(t)>1e-6) {pi=pi+t;n=n+2;s=-s;t=s/n;} pi=pi*4; printf(″pi=%10.6f\n″,pi); }
 { int s;float n,t,pi; t=1;pi=0;n=1.0;s=1; while(fabs(t)>1e-6) {pi=pi+t;n=n+2;s=-s;t=s/n;} pi=pi*4; printf(″pi=%10.6f\n″,pi); }")
301
6.9 程序举例 例6.7 求Fibonacci数列前40个数。这个数列有如下特点:第1,2两个数为1,1。从第3个数开始,该数是其前面两个数之和。即: F(1)= (n=1) F(2)= (n=2) F(n)=F(n-1)+F(n-2) (n≥3) 算法如图所示:
=1 (n=2) F(n)=F(n-1)+F(n-2) (n≥3) 算法如图所示:")
302
例6. 7求Fibonacci数列前40个数。 #include <stdio
例6.7求Fibonacci数列前40个数。 #include <stdio.h> void main() { long int f1,f2; int i; f1=1;f2=1; for(i=1; i<=20; i++) { printf(″%12ld %12ld ″,f1,f2); if(i%2==0) printf(″\n″); f1=f1+f2; f2=f2+f1;} } 运行结果:
 { long int f1,f2; int i; f1=1;f2=1; for(i=1; i<=20; i++) { printf(″%12ld %12ld ″,f1,f2); if(i%2==0) printf(″\n″); f1=f1+f2; f2=f2+f1;} } 运行结果:")
303
6.9 程序举例 例6.8 判断m是否素数。 算法思想:让m被2到除,如果m能被2~之中任何一个整数整除,则提前结束循环,此时i必然小于或等于k(即);如果m不能被2~k(即)之间的任一整数整除,则在完成最后一次循环后,i还要加1,因此i=k+1,然后才终止循环。在循环之后判别i的值是否大于或等于k+1,若是,则表明未曾被2~k之间任一整数整除过,因此输出“是素数”。
;如果m不能被2~k(即)之间的任一整数整除,则在完成最后一次循环后,i还要加1,因此i=k+1,然后才终止循环。在循环之后判别i的值是否大于或等于k+1,若是,则表明未曾被2~k之间任一整数整除过,因此输出 是素数 。")
305
例6. 8 判断m是否素数。 #include <stdio. h> #include <math
例6.8 判断m是否素数。 #include <stdio.h> #include <math.h> void main() {int m,i,k; scanf(″%d″,&m);k=sqrt(m); for (i=2;i<=k;i++) if(m%i==0) break; if(i>k) printf("%d is a prime number\n″,m); else printf("%d is not a prime number\n″,m); } 运行结果: 17↙ 17 is a prime number
 {int m,i,k; scanf(″%d″,&m);k=sqrt(m); for (i=2;i<=k;i++) if(m%i==0) break; if(i>k) printf( %d is a prime number\n″,m); else printf( %d is not a prime number\n″,m); } 运行结果: 17↙ 17 is a prime number.")
306
例6. 9 求100~200间的全部素数。 #include <stdio. h> # include <math
例6.9 求100~200间的全部素数。 #include <stdio.h> # include <math.h> void main() {int m,k,i,n=0; for(m=101;m<=200;m=m+2) { k=sqrt(m); for (i=2;i<=k;i++) if (m%i==0) break; if (i>=k+1){printf("%d ″,m);n=n+1;} if(n%10==0) printf(″\n″); } printf ("\n");} 运行结果:
 {int m,k,i,n=0; for(m=101;m<=200;m=m+2) { k=sqrt(m); for (i=2;i<=k;i++) if (m%i==0) break; if (i>=k+1){printf( %d ″,m);n=n+1;} if(n%10==0) printf(″\n″); } printf ( \n );} 运行结果:")
307
6.9 程序举例 例6.10 译密码。为使电文保密,往往按一定规律将其转换成密码,收报人再按约定的规律将其译回原文。
思路:可以按以下规律将电文变成密码: 将字母A变成字母E,a变成e,即变成其后的第4个字母,W变成A,X变成B,Y变成C,Z变成D。

308
例6. 10输入一行字符,要求输出其相应的密码 include <stdio
例6.10输入一行字符,要求输出其相应的密码 include <stdio.h> void main() {char c; while((c=getchar())!=′\n′) {if((c>=′a′ && c<=′z′) || (c>=′A′ && c<=′Z′)) { c=c+4; if(c>′Z′ && c<=′Z′+4 || c>′z′) c=c-26; } printf(″%c\n″,c); } } 运行结果: China!↙ Glmre!
 {char c; while((c=getchar())!=′\n′) {if((c>=′a′ && c<=′z′) || (c>=′A′ && c<=′Z′)) { c=c+4; if(c>′Z′ && c<=′Z′+4 || c>′z′) c=c-26; } printf(″%c\n″,c); } } 运行结果: China!↙ Glmre!")
310
第七章 数组

311
? ??? 这些数据如何存放才便于排序 这便是本章所要解决的问题 问题:给一组数排序,这组 数该 如何存放呢 1 1 1 1 1 1 1 1
8 2 9 4 5 6 3 7 1 8 1 8 1 8 8 8 8 8 8 8 8 8 8 8 ??? 这些数据如何存放才便于排序 8 8 8 8 8 8 8 ? 这便是本章所要解决的问题

312
本章要点 掌握一维、二维数组的定义和引用方法、存储结构和初始化方法。 掌握有关一维数组的有关算法 掌握数组的运算。

313
7.1 一维数组的定义和引用 7.2 二维数组的定义和引用 7.3 字符数组
主要内容 7.1 一维数组的定义和引用 7.2 二维数组的定义和引用 7.3 字符数组

314
7.1 一维数组的定义和引用 C语言为这些数据,提供了一种构造数据类型:数组。所谓数组就是一组具有相同数据类型的数据的有序集合。
一个班学生的学习成绩 一行文字 一个矩阵 这些数据的特点是: 1.具有相同的数据类型 2.使用过程中需要保留原始数据 C语言为这些数据,提供了一种构造数据类型:数组。所谓数组就是一组具有相同数据类型的数据的有序集合。

315
7.1.1一维数组的定义 例如: int a[10]; 说明: 1.一维数组的定义格式为: 类型说明符 数组名[常量表达式];
类型说明符 数组名[常量表达式]; 例如: int a[10]; 它表示定义了一个整形数组,数组名为a,此数组有10个元素。 说明: 1.数组名定名规则和变量名相同,遵循标识符定名规则。
![7.1.1一维数组的定义 例如: int a[10]; 说明: 1.一维数组的定义格式为: 类型说明符 数组名[常量表达式];](http://slidesplayer.com/slide/11113381/60/images/315/7.1.1%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89+%E4%BE%8B%E5%A6%82%EF%BC%9A+int+a%EF%BC%BB10%EF%BC%BD%3B+%E8%AF%B4%E6%98%8E%EF%BC%9A+1.%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89%E6%A0%BC%E5%BC%8F%E4%B8%BA%EF%BC%9A+%E7%B1%BB%E5%9E%8B%E8%AF%B4%E6%98%8E%E7%AC%A6+%E6%95%B0%E7%BB%84%E5%90%8D%EF%BC%BB%E5%B8%B8%E9%87%8F%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%BD%EF%BC%9B.jpg "类型说明符 数组名[常量表达式]; 例如: int a[10]; 它表示定义了一个整形数组,数组名为a,此数组有10个元素。 说明: 1.数组名定名规则和变量名相同,遵循标识符定名规则。")
316
2.在定义数组时,需要指定数组中元素的个数,方括弧中的常量表达式用来表示元素的个数,即数组长度。
3.常量表达式中可以包括常量和符号常量,但不能包含变量。也就是说,C语言不允许对数组的大小作动态定义,即数组的大小不依赖于程序运行过程中变量的值。

317
例如: int n; scanf(“%d″,&n); /*在程序中临时输入数 组的大小 */ int a[n]; 数组说明中其他常见的错误:
① float a[0]; /* 数组大小为0没有意义 */ ② int b(2)(3); /* 不能使用圆括号 */ ③ int k, a[k]; /* 不能用变量说明数组大小*/
![例如: int n; scanf( %d″,&n); /*在程序中临时输入数 组的大小 */ int a[n]; 数组说明中其他常见的错误:](http://slidesplayer.com/slide/11113381/60/images/317/%E4%BE%8B%E5%A6%82%EF%BC%9A+int+n%3B+scanf%28+%25d%E2%80%B3%EF%BC%8C%26n%29%3B+%2F%2A%E5%9C%A8%E7%A8%8B%E5%BA%8F%E4%B8%AD%E4%B8%B4%E6%97%B6%E8%BE%93%E5%85%A5%E6%95%B0+%E7%BB%84%E7%9A%84%E5%A4%A7%E5%B0%8F+%2A%2F+int+a%EF%BC%BBn%EF%BC%BD%3B+%E6%95%B0%E7%BB%84%E8%AF%B4%E6%98%8E%E4%B8%AD%E5%85%B6%E4%BB%96%E5%B8%B8%E8%A7%81%E7%9A%84%E9%94%99%E8%AF%AF%EF%BC%9A.jpg "① float a[0]; /* 数组大小为0没有意义 */ ② int b(2)(3); /* 不能使用圆括号 */ ③ int k, a[k]; /* 不能用变量说明数组大小*/")
318
每个数据元素占用的字节数,就是基类型的字节数
2.一维数组在内存中的存放 一维数组: float mark[100]; mark[0] mark[1] mark[2] mark[3] . mark[99] 86.5 92.0 77.5 52.0 94.0 低地址 高地址 每个数据元素占用的字节数,就是基类型的字节数 一个元素占4个字节

319
7.1.2一维数组元素的引用 注意: 1.数组元素的引用方式 数组名[下标] 下标可以是整型常量或整型表达式。
例如: a[0]=a[5]+a[7]-a[2*3] 注意: 定义数组时用到的“数组名[常量表达式]” 和引用数组元素时用到的“数组名[下标]” 是有区别的。 例如∶ int a[10]; t=a[6];
![7.1.2一维数组元素的引用 注意: 1.数组元素的引用方式 数组名[下标] 下标可以是整型常量或整型表达式。](http://slidesplayer.com/slide/11113381/60/images/319/7.1.2%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E5%BC%95%E7%94%A8+%E6%B3%A8%E6%84%8F%EF%BC%9A+1.%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E5%BC%95%E7%94%A8%E6%96%B9%E5%BC%8F+%E6%95%B0%E7%BB%84%E5%90%8D%EF%BC%BB%E4%B8%8B%E6%A0%87%EF%BC%BD+%E4%B8%8B%E6%A0%87%E5%8F%AF%E4%BB%A5%E6%98%AF%E6%95%B4%E5%9E%8B%E5%B8%B8%E9%87%8F%E6%88%96%E6%95%B4%E5%9E%8B%E8%A1%A8%E8%BE%BE%E5%BC%8F%E3%80%82.jpg "例如: a[0]=a[5]+a[7]-a[2*3] 注意: 定义数组时用到的 数组名[常量表达式] 和引用数组元素时用到的 数组名[下标] 是有区别的。 例如∶ int a[10]; t=a[6];")
320
2.一维数组元素引用的程序实例 #include <stdio.h> void main() { int i,a[10];
for (i=0; i<=9;i++) a[i]=i; for(i=9;i>=0; i--) printf("%d ″,a[i]); printf("\n″); } 运行结果如下: 程序使a[0]到 a[9]的值为0~9,然后按逆序输出。
![2.一维数组元素引用的程序实例 #include <stdio.h> void main() { int i,a[10];](http://slidesplayer.com/slide/11113381/60/images/320/2.%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E5%BC%95%E7%94%A8%E7%9A%84%E7%A8%8B%E5%BA%8F%E5%AE%9E%E4%BE%8B+%23include+%3Cstdio.h%3E+void+main%28%29+%7B+int+i%EF%BC%8Ca%EF%BC%BB10%EF%BC%BD%3B.jpg "for (i=0; i<=9;i++) a[i]=i; for(i=9;i>=0; i--) printf( %d ″,a[i]); printf( \n″); } 运行结果如下: 程序使a[0]到. a[9]的值为0~9,然后按逆序输出。")
321
7.1.3一维数组的初始化 对数组元素初始化的实现方法: 例如:int a[10]={0,1,2,3,4,5,6,7,8,9};
1.在定义数组时对数组元素赋以初值。 例如:int a[10]={0,1,2,3,4,5,6,7,8,9}; 将数组元素的初值依次放在一对花括弧内。经过上面的定义和初始化之后,a[0]=0,a[1]=1,a[2]=2,a[3]=3,a[4]=4,a[5]=5,a[6]=6,a[7]=7,a[8]=8,a[9]=9。
![7.1.3一维数组的初始化 对数组元素初始化的实现方法: 例如:int a[10]={0,1,2,3,4,5,6,7,8,9};](http://slidesplayer.com/slide/11113381/60/images/321/7.1.3%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%88%9D%E5%A7%8B%E5%8C%96+%E5%AF%B9%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E5%88%9D%E5%A7%8B%E5%8C%96%E7%9A%84%E5%AE%9E%E7%8E%B0%E6%96%B9%E6%B3%95%EF%BC%9A+%E4%BE%8B%E5%A6%82%3Aint+a%EF%BC%BB10%EF%BC%BD%3D%7B0%2C1%2C2%2C3%2C4%2C5%2C6%2C7%2C8%2C9%7D%3B.jpg "1.在定义数组时对数组元素赋以初值。 例如:int a[10]={0,1,2,3,4,5,6,7,8,9}; 将数组元素的初值依次放在一对花括弧内。经过上面的定义和初始化之后,a[0]=0,a[1]=1,a[2]=2,a[3]=3,a[4]=4,a[5]=5,a[6]=6,a[7]=7,a[8]=8,a[9]=9。")
322
定义a数组有10个元素,但花括弧内只提供5个初值,这表示只给前面5个元素赋初值,后5个元素值为0。
2. 可以只给一部分元素赋值。 例如: int a[10]={0,1,2,3,4}; 定义a数组有10个元素,但花括弧内只提供5个初值,这表示只给前面5个元素赋初值,后5个元素值为0。 3. 如果想使一个数组中全部元素值为0,可以写成: int a[10]={0,0,0,0,0,0,0,0,0,0}; 或inta[10]={0}; 不能写成:int a[10]={0*10};

323
4. 在对全部数组元素赋初值时,由于数据的个数已经确定,因此可以不指定数组长度。
例如:int a[5]={1,2,3,4,5}; 也可以写成 int a[]={1,2,3,4,5}; int a[10]={1,2,3,4,5}; 只初始化前5个元素,后5个元素为0。

324
Fibonacci数列公式:已知: a1=a2=1 an=an-1+an-2
7.1.4一维数组程序举例 例7-1:用数组来处理,求解Fibonacci数列。 Fibonacci数列公式:已知: a1=a2=1 an=an-1+an-2 即:1,1,2,3,5,8,13 程序实例: #include <stdio.h> void main() { int i; int f[20]={1,1};
 { int i; int f[20]={1,1};")
325
for(i=2;i<20;i++) f[i]=f[i-2]+f[i-1]; for(i=0;i<20;i++) { if(i%5==0) printf(″\n″); printf(″%12d″,f[i]) } /*For循环结束*/ } /*程序结束*/ if语句用来控制换行,每行输出5个数据。 运行结果如下:
![for(i=2;i<20;i++) f[i]=f[i-2]+f[i-1]; for(i=0;i<20;i++) { if(i%5==0) printf(″\n″); printf(″%12d″,f[i])](http://slidesplayer.com/slide/11113381/60/images/325/for%28i%3D2%3Bi%3C20%3Bi%2B%2B%29+f%EF%BC%BBi%EF%BC%BD%3Df%EF%BC%BBi-2%EF%BC%BD%2Bf%EF%BC%BBi-1%EF%BC%BD%3B+for%28i%3D0%3Bi%3C20%3Bi%2B%2B%29+%7B+if%28i%255%3D%3D0%29+printf%28%E2%80%B3%EF%BC%BCn%E2%80%B3%29%3B+printf%28%E2%80%B3%2512d%E2%80%B3%EF%BC%8Cf%EF%BC%BBi%EF%BC%BD%29.jpg "} /*For循环结束*/ } /*程序结束*/ if语句用来控制换行,每行输出5个数据。 运行结果如下:")
326
程序举例2:用起泡法对10个数排序(由小到大)。
第 一 趟 比 较 经过第一趟(共5次比较与交换)后,最大的数9已“沉底” 。然后进行对余下的前面5个数第二趟比较,
后,最大的数9已 沉底 。然后进行对余下的前面5个数第二趟比较,")
327
第 二 趟 比 较 如果有n个数,则要进行n-1趟比较。在第1趟比较中要进行n-1次两两比较,在第j趟比较中要进行n-j次两两比较。

328
程序流程图如下:

329
程序实例7.3: #include <stdio.h> void main() { int a[10]; int i,j,t; printf(″input 10 numbers :\n″); for (i=0;i<10;i++) scanf("%d",&a[i]); printf("\n");
![程序实例7.3: #include <stdio.h> void main() { int a[10]; int i,j,t; printf(″input 10 numbers :\n″);](http://slidesplayer.com/slide/11113381/60/images/329/%E7%A8%8B%E5%BA%8F%E5%AE%9E%E4%BE%8B7.3%EF%BC%9A+%23include+%3Cstdio.h%3E+void+main%28%29+%7B+int+a%EF%BC%BB10%EF%BC%BD%3B+int+i%2Cj%2Ct%3B+printf%28%E2%80%B3input+10+numbers+%3A%5Cn%E2%80%B3%29%3B.jpg "for (i=0;i<10;i++) scanf( %d ,&a[i]); printf( \n );")
330
for(j=0;j<9;j++) for(i=0;i<9-j;i++) if (a[i]>a[i+1]) { t=a[i];a[i]=a[i+1]; a[i+1]=t; } printf(″the sorted numbers :\n″); for(i=0;i<10;i++) printf(″%d ″,a[i]); printf(″\n″); }/*程序结束*/ 程序运行结果如下: input 10 numbers: ↙ the sorted numbers:
![for(j=0;j<9;j++) for(i=0;i<9-j;i++) if (a[i]>a[i+1]) { t=a[i];a[i]=a[i+1]; a[i+1]=t; } printf(″the sorted numbers :\n″);](http://slidesplayer.com/slide/11113381/60/images/330/for%28j%3D0%3Bj%3C9%3Bj%2B%2B%29+for%28i%3D0%3Bi%3C9-j%3Bi%2B%2B%29+if+%28a%EF%BC%BBi%EF%BC%BD%3Ea%EF%BC%BBi%2B1%EF%BC%BD%29+%7B+t%3Da%5Bi%5D%3Ba%5Bi%5D%3Da%5Bi%2B1%5D%3B+a%EF%BC%BBi%2B1%EF%BC%BD%3Dt%3B+%7D+printf%28%E2%80%B3the+sorted+numbers+%3A%5Cn%E2%80%B3%29%3B.jpg "for(i=0;i<10;i++) printf(″%d ″,a[i]); printf(″\n″); }/*程序结束*/ 程序运行结果如下: input 10 numbers: ↙ the sorted numbers:")
331
7.2 二维数组的定义和引用 7.2.1二维数组的定义 二维数组定义的一般形式为 类型说明符 数组名[常量表达式][常量表达式];
例如:定义a为3×4(3行4列)的数组,b为5×10(5行10列)的数组。如下: float a[3][4],b[5][10]; 不能写成 float a[3,4],b[5,10];
![7.2 二维数组的定义和引用 7.2.1二维数组的定义 二维数组定义的一般形式为 类型说明符 数组名[常量表达式][常量表达式];](http://slidesplayer.com/slide/11113381/60/images/331/7.2+%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89%E5%92%8C%E5%BC%95%E7%94%A8+7.2.1%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89+%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E5%AE%9A%E4%B9%89%E7%9A%84%E4%B8%80%E8%88%AC%E5%BD%A2%E5%BC%8F%E4%B8%BA+%E7%B1%BB%E5%9E%8B%E8%AF%B4%E6%98%8E%E7%AC%A6+%E6%95%B0%E7%BB%84%E5%90%8D%EF%BC%BB%E5%B8%B8%E9%87%8F%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%BD%EF%BC%BB%E5%B8%B8%E9%87%8F%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%BD%EF%BC%9B.jpg "例如:定义a为3×4(3行4列)的数组,b为5×10(5行10列)的数组。如下: float a[3][4],b[5][10]; 不能写成 float a[3,4],b[5,10];")
332
注意:我们可以把二维数组看作是一种特殊的一维数组:它的元素又是一个一维数组。
例如:可以把a看作是一个一维数组,它有3个元素:a[0]、a[1]、a[2],每个元素又是一个包含4个元素的一维数组。

333
7.2.1二维数组的定义 一维数组在内存中的存放 下图表示对a[3][4]数组存放的顺序
二维数组中的元素在内存中的排列顺序是:按行存放,即先顺序存放第一行的元素,再存放第二行的元素……
![7.2.1二维数组的定义 一维数组在内存中的存放 下图表示对a[3][4]数组存放的顺序](http://slidesplayer.com/slide/11113381/60/images/333/7.2.1%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89+%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84%E5%9C%A8%E5%86%85%E5%AD%98%E4%B8%AD%E7%9A%84%E5%AD%98%E6%94%BE+%E4%B8%8B%E5%9B%BE%E8%A1%A8%E7%A4%BA%E5%AF%B9a%EF%BC%BB3%EF%BC%BD%EF%BC%BB4%EF%BC%BD%E6%95%B0%E7%BB%84%E5%AD%98%E6%94%BE%E7%9A%84%E9%A1%BA%E5%BA%8F.jpg "二维数组中的元素在内存中的排列顺序是:按行存放,即先顺序存放第一行的元素,再存放第二行的元素……")
334
例如:整型数组 b[3][3]={ {1,2,3}, {4,5,6}, {7,8,9} }; 地址 值 数组元素
地址 值 数组元素 3000H 3002H 3004H 3006H 3008H 300AH 300CH 300EH 3010H b[0][0] b[0][1] b[0][2] b[1][0] b[1][1] b[1][2] b[2][0] b[2][1] b[2][2] 1 2 3 4 5 6 789
![例如:整型数组 b[3][3]={ {1,2,3}, {4,5,6}, {7,8,9} }; 地址 值 数组元素](http://slidesplayer.com/slide/11113381/60/images/334/%E4%BE%8B%E5%A6%82%EF%BC%9A%E6%95%B4%E5%9E%8B%E6%95%B0%E7%BB%84+b%5B3%5D%5B3%5D%3D%7B+%7B1%2C2%2C3%7D%2C+%7B4%2C5%2C6%7D%2C+%7B7%2C8%2C9%7D+%7D%3B+%E5%9C%B0%E5%9D%80+%E5%80%BC+%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0.jpg "地址 值 数组元素. 3000H. 3002H. 3004H. 3006H. 3008H. 300AH. 300CH. 300EH. 3010H. b[0][0] b[0][1] b[0][2] b[1][0] b[1][1] b[1][2] b[2][0] b[2][1] b[2][2]")
335
7.2.1二维数组的定义 问题:有了二维数组的基础,那么多维数组如何定义呢? 定义三维数组: float a[2][3][4];
注意:多维数组元素在内存中的排列顺序: 第一维的下标变化最慢,最右边的下标变化最快。
![7.2.1二维数组的定义 问题:有了二维数组的基础,那么多维数组如何定义呢? 定义三维数组: float a[2][3][4];](http://slidesplayer.com/slide/11113381/60/images/335/7.2.1%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89+%E9%97%AE%E9%A2%98%EF%BC%9A%E6%9C%89%E4%BA%86%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%9F%BA%E7%A1%80%EF%BC%8C%E9%82%A3%E4%B9%88%E5%A4%9A%E7%BB%B4%E6%95%B0%E7%BB%84%E5%A6%82%E4%BD%95%E5%AE%9A%E4%B9%89%E5%91%A2%EF%BC%9F+%E5%AE%9A%E4%B9%89%E4%B8%89%E7%BB%B4%E6%95%B0%E7%BB%84%EF%BC%9A+float+a%EF%BC%BB2%EF%BC%BD%EF%BC%BB3%EF%BC%BD%EF%BC%BB4%EF%BC%BD%3B.jpg "注意:多维数组元素在内存中的排列顺序: 第一维的下标变化最慢,最右边的下标变化最快。")
336
三维数组的元素排列顺序 a[0][0][0]→a[0][0][1]→a[0][0][2]→a[0][0][3]→
![三维数组的元素排列顺序 a[0][0][0]→a[0][0][1]→a[0][0][2]→a[0][0][3]→](http://slidesplayer.com/slide/11113381/60/images/336/%E4%B8%89%E7%BB%B4%E6%95%B0%E7%BB%84%E7%9A%84%E5%85%83%E7%B4%A0%E6%8E%92%E5%88%97%E9%A1%BA%E5%BA%8F+a%5B0%5D%5B0%5D%5B0%5D%E2%86%92a%5B0%5D%5B0%5D%5B1%5D%E2%86%92a%5B0%5D%5B0%5D%5B2%5D%E2%86%92a%5B0%5D%5B0%5D%5B3%5D%E2%86%92.jpg "三维数组的元素排列顺序 a[0][0][0]→a[0][0][1]→a[0][0][2]→a[0][0][3]→")
337
下标可以是整型表达式,如 a[2-1][2*2-1]
7.2.2 二维数组的引用 二维数组元素的表示形式为: 数组名[下标][下标] 例如: a[2][3] 下标可以是整型表达式,如 a[2-1][2*2-1] 不要写成 a[2,3],a[2-1,2*2-1]形式 数组元素可以出现在表达式中,也可以被赋值 例如:b[1][2]=a[2][3]/2
![下标可以是整型表达式,如 a[2-1][2*2-1]](http://slidesplayer.com/slide/11113381/60/images/337/%E4%B8%8B%E6%A0%87%E5%8F%AF%E4%BB%A5%E6%98%AF%E6%95%B4%E5%9E%8B%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%8C%E5%A6%82+a%EF%BC%BB2-1%EF%BC%BD%EF%BC%BB2%2A2-1%EF%BC%BD.jpg "7.2.2 二维数组的引用. 二维数组元素的表示形式为: 数组名[下标][下标] 例如: a[2][3] 下标可以是整型表达式,如 a[2-1][2*2-1] 不要写成 a[2,3],a[2-1,2*2-1]形式. 数组元素可以出现在表达式中,也可以被赋值. 例如:b[1][2]=a[2][3]/2.")
338
在使用数组元素时,应该注意下标值应在已定义的数组大小的范围内。
常出现的错误有: int a[3][4]; /* 定义a为3×4的数组 */ ┆ a[3][4]=3;

339
7.2.3二维数组的引用 数据类型 可以用下面4种方法对二维数组初始化: 1.分行给二维数组赋初值。
数组名 [常量表达式1][常量表达式2]={ 初始化数据 }; 可以用下面4种方法对二维数组初始化: 1.分行给二维数组赋初值。 例如: int a[3][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12}}; 2.可以将所有数据写在一个花括号内,按数组排列的顺序对各元素赋初值。 例如:int a[3][4]={1,2,3,4,5,6,7,8,9,10,11,12};

340
3.可以对部分元素赋初值。 例如: int a[3][4]={{1},{5},{9}}; 也可以对各行中的某一元素赋初值,如 int a[3][4]={{1},{0,6},{0,0,11}}; 也可以只对某几行元素赋初值。如: int a[3][4]={{1},{5,6}};
![3.可以对部分元素赋初值。 例如: int a[3][4]={{1},{5},{9}}; 也可以对各行中的某一元素赋初值,如. int a[3][4]={{1},{0,6},{0,0,11}};](http://slidesplayer.com/slide/11113381/60/images/340/%EF%BC%93.%E5%8F%AF%E4%BB%A5%E5%AF%B9%E9%83%A8%E5%88%86%E5%85%83%E7%B4%A0%E8%B5%8B%E5%88%9D%E5%80%BC%E3%80%82+%E4%BE%8B%E5%A6%82%EF%BC%9A+int+a%EF%BC%BB3%EF%BC%BD%EF%BC%BB4%EF%BC%BD%3D%7B%7B1%7D%EF%BC%8C%7B5%7D%EF%BC%8C%7B9%7D%7D%3B+%E4%B9%9F%E5%8F%AF%E4%BB%A5%E5%AF%B9%E5%90%84%E8%A1%8C%E4%B8%AD%E7%9A%84%E6%9F%90%E4%B8%80%E5%85%83%E7%B4%A0%E8%B5%8B%E5%88%9D%E5%80%BC%EF%BC%8C%E5%A6%82.+int+a%EF%BC%BB3%EF%BC%BD%EF%BC%BB4%EF%BC%BD%3D%7B%7B1%7D%EF%BC%8C%7B0%EF%BC%8C6%7D%EF%BC%8C%7B0%EF%BC%8C0%EF%BC%8C11%7D%7D%3B.jpg "也可以只对某几行元素赋初值。如: int a[3][4]={{1},{5,6}};")
341
4.如果对全部元素都赋初值,则定义数组时对第一维的长度可以不指定,但第二维的长度不能省。
例如:int a[3][4]={1,2,3,4,5,6,7,8,9,10,11,12};它等价于:int a[][4]={1,2,3,4,5,6,7,8,9,10,11,12}; 在定义时也可以只对部分元素赋初值而省略第一维的长度,但应分行赋初值。 例如:int a[][4]={{0,0,3},{},{0,10}};

342
7.2.4二维数组程序举例 例7.4 将一个二维数组行和列元素互换,存到另一个 二维数组中。 例如:a= 1 2 3 1 4
b= 2 5 3 6 #include <stdio.h> void main() { int a[2][3]={{1,2,3},{4,5,6}}; int b[3][2],i,j; printf(″array a:\n″); for (i=0;i<=1;i++) for (j=0;j<=2;j++)
 { int a[2][3]={{1,2,3},{4,5,6}}; int b[3][2],i,j; printf(″array a:\n″); for (i=0;i<=1;i++) for (j=0;j<=2;j++)")
343
printf(″%5d″,a[i][j]);
b[j][i]=a[i][j]; } printf(″\n″); printf(″array b:\n″); for (i=0;i<=2;i++) { for(j=0;j<=1;j++) printf("%5d″,b[i][j]); } /*程序结束*/ 运行结果如下: array a: array b: 1 4 2 5 6
![printf(″%5d″,a[i][j]);](http://slidesplayer.com/slide/11113381/60/images/343/printf%28%E2%80%B3%255d%E2%80%B3%EF%BC%8Ca%EF%BC%BBi%EF%BC%BD%EF%BC%BBj%EF%BC%BD%29%3B.jpg "b[j][i]=a[i][j]; } printf(″\n″); printf(″array b:\n″); for (i=0;i<=2;i++) { for(j=0;j<=1;j++) printf( %5d″,b[i][j]); } /*程序结束*/ 运行结果如下: array a: array b:")
344
例7.5: 有一个3×4的矩阵,要求编程序求出其中值最大的那个元素的值,以及其所在的行号和列号。
N-S流程图表示算法 如下:

345
程序: #include <stdio.h> void main() { int i,j,row=0,colum=0,max; int a[3][4]={{1,2,3,4},{9,8,7,6}, {-10,10,-5,2}}; max=a[0][0];
![程序: #include <stdio.h> void main() { int i,j,row=0,colum=0,max; int a[3][4]={{1,2,3,4},{9,8,7,6},](http://slidesplayer.com/slide/11113381/60/images/345/%E7%A8%8B%E5%BA%8F%EF%BC%9A+%23include+%3Cstdio.h%3E+void+main%28%29+%7B+int+i%EF%BC%8Cj%EF%BC%8Crow%3D0%EF%BC%8Ccolum%3D0%EF%BC%8Cmax%3B+int+a%5B3%5D%5B4%5D%3D%7B%7B1%EF%BC%8C2%EF%BC%8C3%EF%BC%8C4%7D%EF%BC%8C%7B9%EF%BC%8C8%EF%BC%8C7%EF%BC%8C6%7D%EF%BC%8C.jpg "{-10,10,-5,2}}; max=a[0][0];")
346
for (i=0;i<=2;i++) for (j=0;j<=3;j++) if (a[i][j]>max) { max=a[i][j]; row=i; colum=j; } printf(″max=%d,row=%d,colum=%d\n″, max,row,colum); } /*程序结束*/
![for (i=0;i<=2;i++) for (j=0;j<=3;j++) if (a[i][j]>max) { max=a[i][j]; row=i; colum=j; } printf(″max=%d,row=%d,colum=%d\n″,](http://slidesplayer.com/slide/11113381/60/images/346/for+%28i%3D0%3Bi%3C%3D2%3Bi%2B%2B%29+for+%28j%3D0%3Bj%3C%3D3%3Bj%2B%2B%29+if+%28a%EF%BC%BBi%EF%BC%BD%EF%BC%BBj%EF%BC%BD%3Emax%29+%7B+max%3Da%5Bi%5D%5Bj%5D%3B+row%3Di%3B+colum%3Dj%3B+%7D+printf%28%E2%80%B3max%3D%25d%EF%BC%8Crow%3D%25d%EF%BC%8Ccolum%3D%25d%EF%BC%BCn%E2%80%B3%EF%BC%8C.jpg "max,row,colum); } /*程序结束*/")
347
7.3 字符数组 7.3.1字符数组的定义 定义方法与前面介绍的类似。例如: char c[10];
c[0]=′I′;c[1]=′ ′;c[2]=′a′; c[3]=′m′;c[4]=′ ′;c[5]=′h′;c[6]=′a′; c[7]=′p′;c[8]=′p′;c[9]=′y′;
![7.3 字符数组 7.3.1字符数组的定义 定义方法与前面介绍的类似。例如: char c[10];](http://slidesplayer.com/slide/11113381/60/images/347/7.3+%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%84+7.3.1%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%84%E7%9A%84%E5%AE%9A%E4%B9%89+%E5%AE%9A%E4%B9%89%E6%96%B9%E6%B3%95%E4%B8%8E%E5%89%8D%E9%9D%A2%E4%BB%8B%E7%BB%8D%E7%9A%84%E7%B1%BB%E4%BC%BC%E3%80%82%E4%BE%8B%E5%A6%82%EF%BC%9A+char+c%EF%BC%BB10%EF%BC%BD%3B.jpg "c[0]=′I′;c[1]=′ ′;c[2]=′a′; c[3]=′m′;c[4]=′ ′;c[5]=′h′;c[6]=′a′; c[7]=′p′;c[8]=′p′;c[9]=′y′;")
348
7.3.2字符数组的初始化 对字符数组初始化,可逐个字符赋给数组中各元素。 例如:
char c[10]={‘I’,’a’,’m’,’h’,’a’,’p’,’p’,’y’}

349
如果初值个数小于数组长度,则只将这些字符赋给数
组中前面那些元素,其余的元素自动定为空字符。 char c[10]={′c′,′ ′,′p′,′r′,′o′, ′g′,′r′,′a′,′m′};

350
如果提供的初值个数与预定的数组长度相同,在定义
时可以省略数组长度,系统会自动根据初值个数确定 数组长度。 char c[]={′I′,′ ′,′a′,′m′,′ ′,′h′, ′a′,′p′,′p′,′y′};数组c的长度自动定为10。

351
定义和初始化一个二维字符数组 char diamond[5][5]={{′ ′,′ ′,*′},{′ ′,′*′,′ ′,′*′},{′*′,′ ′,′ ′,′ ′,′*′},{′ ′,′*′,′ ′,′*′},{′ ′,′ ′,′*′}}
![定义和初始化一个二维字符数组 char diamond[5][5]={{′ ′,′ ′,*′},{′ ′,′*′,′ ′,′*′},{′*′,′ ′,′ ′,′ ′,′*′},{′ ′,′*′,′ ′,′*′},{′ ′,′ ′,′*′}}](http://slidesplayer.com/slide/11113381/60/images/351/%E5%AE%9A%E4%B9%89%E5%92%8C%E5%88%9D%E5%A7%8B%E5%8C%96%E4%B8%80%E4%B8%AA%E4%BA%8C%E7%BB%B4%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%84+char+diamond%EF%BC%BB5%EF%BC%BD%EF%BC%BB5%EF%BC%BD%3D%7B%7B%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%2A%E2%80%B2%7D%EF%BC%8C%7B%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2%2A%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2%2A%E2%80%B2%7D%EF%BC%8C%7B%E2%80%B2%2A%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2%2A%E2%80%B2%7D%EF%BC%8C%7B%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2%2A%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2%2A%E2%80%B2%7D%EF%BC%8C%7B%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2+%E2%80%B2%EF%BC%8C%E2%80%B2%2A%E2%80%B2%7D%7D.jpg "定义和初始化一个二维字符数组 char diamond[5][5]={{′ ′,′ ′,*′},{′ ′,′*′,′ ′,′*′},{′*′,′ ′,′ ′,′ ′,′*′},{′ ′,′*′,′ ′,′*′},{′ ′,′ ′,′*′}}")
352
7.3.3字符数组的引用 例7.6 输出一个字符串。 程序如下: #include <stdio.h> void main()
{ char c[10]={’I’,’ ’,’a’,’m’,’ ’,’a’,’ ’, ’b’,’o’,′y′}; int i; for(i=0;i<10;i++) printf(″%c″,c[i]); printf(″\n″); } 运行结果:I am a boy
 printf(″%c″,c[i]); printf(″\n″); } 运行结果:I am a boy.")
353
#include <stdio.h> void main()
例7.7 输出一个钻石图形 #include <stdio.h> void main() { char diamond[][5]={{′ ′,′ ′,′*′},{′′,′*′,′ ′,′*′},{′*′,′ ′,′ ′,′ ′,′*′},{′ ′,′*′,′ ′,′*′},{′ ′,′ ′,′*′}}; int i,j; for (i=0;i<5;i++) { for (j=0;j<5;j++) printf(″%c″,diamond[i][j]); printf(″\n″); } } 运行结果 * * * * *
 { char diamond[][5]={{′ ′,′ ′,′*′},{′′,′*′,′ ′,′*′},{′*′,′ ′,′ ′,′ ′,′*′},{′ ′,′*′,′ ′,′*′},{′ ′,′ ′,′*′}}; int i,j; for (i=0;i<5;i++) { for (j=0;j<5;j++) printf(″%c″,diamond[i][j]); printf(″\n″); } } 运行结果. * * * * *")
354
7.3.4字符串和字符串结束标志 为了测定字符串的实际长度,C语言规定了一个“字符串结束标志”——‘\0’。
字符数组并不要求它的最后一个字符为′\0′,甚至可以不包含′\0′。 例如:char c[5]={′C′,′h′,′i′,′n′,′a′};

355
但是由于系统对字符串常量自动加一个′\0′。因此,为了使处理方法一致,在字符数组中也常人为地加上一个′\0′。
例如:char c[6]={′C′,′h′,′i′,′n′,′a′,′\0′};

356
char c[]={“Pascal program”};
例如: 定义字符数组∶ char c[]={“Pascal program”}; 要用一个新的字符串代替原有的字符串”Pascal program” ,从键盘向字符数组输入∶Hello 如果不加′\0′的话,字符数组中的字符如下∶ Hellol program
![char c[]={ Pascal program };](http://slidesplayer.com/slide/11113381/60/images/356/char+c%EF%BC%BB%EF%BC%BD%3D%7B+Pascal+program+%7D%3B.jpg "例如: 定义字符数组∶ char c[]={ Pascal program }; 要用一个新的字符串代替原有的字符串 Pascal program ,从键盘向字符数组输入∶Hello. 如果不加′\0′的话,字符数组中的字符如下∶ Hellol program.")
357
7.3.5字符数组的输入输出 字符数组的输入输出可以有两种方法: 逐个字符输入输出。用格式符“%c”输入或输出一个字符。
将整个字符串一次输入或输出。用“%s”格式符,意思是对字符串的输入输出。

358
char c[]={″China″}; printf(″%s″,c); 例如 在内存中数组c的状态
![char c[]={″China″}; printf(″%s″,c); 例如 在内存中数组c的状态](http://slidesplayer.com/slide/11113381/60/images/358/char+c%EF%BC%BB%EF%BC%BD%3D%7B%E2%80%B3China%E2%80%B3%7D%3B+printf%28%E2%80%B3%25s%E2%80%B3%EF%BC%8Cc%29%3B+%E4%BE%8B%E5%A6%82+%E5%9C%A8%E5%86%85%E5%AD%98%E4%B8%AD%E6%95%B0%E7%BB%84c%E7%9A%84%E7%8A%B6%E6%80%81.jpg "char c[]={″China″}; printf(″%s″,c); 例如 在内存中数组c的状态")
359
说明: (1)用“%s”格式符输出字符串时,printf函数中的输出项是字符数组名,而不是数组元素名。 (2)如果数组长度大于字符串实际长度,也只输出到遇′\0′结束。 (3)输出字符不包括结束符′\0′。 (4)如果一个字符数组中包含一个以上′\0′,则遇第一个′\0′时输出就结束。 (5)可以用scanf函数输入一个字符串。
如果一个字符数组中包含一个以上′\0′,则遇第一个′\0′时输出就结束。 (5)可以用scanf函数输入一个字符串。")
360
如果利用一个scanf函数输入多个字符串,则在输入时以空格分隔。
例如: char strl[5],str2[5],str3[5]; scanf(″%s %s %s″,str1,str2,str3); 输入数据: How are you? 数组中未被赋值的元素的值自动置′\0′。
; 输入数据: How are you 数组中未被赋值的元素的值自动置′\0′。")
361
注意:scanf函数中的输入项如果字符数组名。不要再加地址符&,因为在C语言中数组名代表该数组的起始地址。下面写法不对:
scanf(″%s″,&str); 分析图中所示的字符数组 用8进制形式输出数组c的起始地址 printf(″%o″,c); printf(″%s″,c);
; 分析图中所示的字符数组. 用8进制形式输出数组c的起始地址. printf(″%o″,c); printf(″%s″,c);")
362
7.3.6字符串处理函数 1. puts函数 其一般形式为: puts (字符数组)
其作用是将一个字符串(以′\0′结束的字符序列)输出到终端。假如已定义str是一个字符数组名,且该数组已被初始化为"China"。则执行puts(str);其结果是在终端上输出China。
输出到终端。假如已定义str是一个字符数组名,且该数组已被初始化为 China 。则执行puts(str);其结果是在终端上输出China。")
363
用puts函数输出的字符串中可以包含转义字符。例如: char str[]={″China\nBeijing″}; puts(str);
输出结果: China Beijing 在输出时,将字符串 结束标志′\0′ 转换成′\n′, 即输出完字符串后换行。
![用puts函数输出的字符串中可以包含转义字符。例如: char str[]={″China\nBeijing″}; puts(str);](http://slidesplayer.com/slide/11113381/60/images/363/%E7%94%A8puts%E5%87%BD%E6%95%B0%E8%BE%93%E5%87%BA%E7%9A%84%E5%AD%97%E7%AC%A6%E4%B8%B2%E4%B8%AD%E5%8F%AF%E4%BB%A5%E5%8C%85%E5%90%AB%E8%BD%AC%E4%B9%89%E5%AD%97%E7%AC%A6%E3%80%82%E4%BE%8B%E5%A6%82%EF%BC%9A+char+str%EF%BC%BB%EF%BC%BD%3D%7B%E2%80%B3China%5CnBeijing%E2%80%B3%7D%3B+puts%28str%29%3B.jpg "输出结果: China. Beijing. 在输出时,将字符串. 结束标志′\0′ 转换成′\n′, 即输出完字符串后换行。")
364
2. gets函数 其一般形式为:gets(字符数组) 其作用是从终端输入一个字符串到字符数组,并且得到一个函数值。该函数值是字符数组的起始地址。如执行下面的函数: gets(str) 从键盘输入: Computer↙将输入的字符串"Computer"送给字符数组str

365
说明: 函数值为字符数组str的起始地址。一般利用gets函数的目的是向字符数组输入一个字符串,而不大关心其函数值。 注意:用puts和gets函数只能输入或输出一个字符串,不能写成 puts(str1,str2) 或 gets(str1,str2)
")
366
3. strcat函数 其一般形式为:strcat(字符数组1,字符数组2) Strcat的作用是连接两个字符数组中的字符串,把字符串2接到字符串1的后面,结果放在字符数组1中,函数调用后得到一个函数值——字符数组1的地址。
 Strcat的作用是连接两个字符数组中的字符串,把字符串2接到字符串1的后面,结果放在字符数组1中,函数调用后得到一个函数值——字符数组1的地址。 .")
367
例如: char str1[30]={″People′s Republic of ″}; char str2[]={″China″}; print(″%s″,strcat(str1,str2)); 输出: People′s Republic of China
![例如: char str1[30]={″People′s Republic of ″}; char str2[]={″China″}; print(″%s″,strcat(str1,str2));](http://slidesplayer.com/slide/11113381/60/images/367/%E4%BE%8B%E5%A6%82%EF%BC%9A+char+str1%EF%BC%BB30%EF%BC%BD%3D%7B%E2%80%B3People%E2%80%B2s+Republic+of+%E2%80%B3%7D%3B+char+str2%EF%BC%BB%EF%BC%BD%3D%7B%E2%80%B3China%E2%80%B3%7D%3B+print%28%E2%80%B3%25s%E2%80%B3%EF%BC%8Cstrcat%28str1%EF%BC%8Cstr2%29%29%3B.jpg "输出: People′s Republic of China.")
368
4. strcpy函数 其一般形式为:strcpy(字符数组1,字符串2) strcpy是“字符串复制函数”。作用是将字符串2复制到字符数组1中去。例如: char str1[10],str2[]={″China″}; strcpy(str1,str2);
![4. strcpy函数 其一般形式为:strcpy(字符数组1,字符串2) strcpy是 字符串复制函数 。作用是将字符串2复制到字符数组1中去。例如: char str1[10],str2[]={″China″};](http://slidesplayer.com/slide/11113381/60/images/368/4.+strcpy%E5%87%BD%E6%95%B0+%E5%85%B6%E4%B8%80%E8%88%AC%E5%BD%A2%E5%BC%8F%E4%B8%BA%EF%BC%9Astrcpy%28%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%841%EF%BC%8C%E5%AD%97%E7%AC%A6%E4%B8%B22%29+strcpy%E6%98%AF+%E5%AD%97%E7%AC%A6%E4%B8%B2%E5%A4%8D%E5%88%B6%E5%87%BD%E6%95%B0+%E3%80%82%E4%BD%9C%E7%94%A8%E6%98%AF%E5%B0%86%E5%AD%97%E7%AC%A6%E4%B8%B22%E5%A4%8D%E5%88%B6%E5%88%B0%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%841%E4%B8%AD%E5%8E%BB%E3%80%82%E4%BE%8B%E5%A6%82%EF%BC%9A+char+str1%EF%BC%BB10%EF%BC%BD%EF%BC%8Cstr2%EF%BC%BB%EF%BC%BD%3D%7B%E2%80%B3China%E2%80%B3%7D%3B.jpg "strcpy(str1,str2);")
369
关于strcpy函数的几点说明 (1)字符数组1必须定义得足够大,以便容纳被复制的字符串。字符数组1的长度不应小于字符串2的长度。 (2)“字符数组1”必须写成数组名形式(如str1),“字符串2”可以是字符数组名,也可以是一个字符串常量。如strcpy(str1,″China″);
字符数组1必须定义得足够大,以便容纳被复制的字符串。字符数组1的长度不应小于字符串2的长度。 (2) 字符数组1 必须写成数组名形式(如str1), 字符串2 可以是字符数组名,也可以是一个字符串常量。如strcpy(str1,″China″);")
370
(3)复制时连同字符串后面的′\0′一起复制到字符数组1中。
(4)可以用strcpy函数将字符串2中前面若干个字符复制到字符数组1中去。例如:strcpy(str1,str2,2); 作用是将str2中前面2个字符复制到str1中去,然后再加一个‘\0’。
可以用strcpy函数将字符串2中前面若干个字符复制到字符数组1中去。例如:strcpy(str1,str2,2); 作用是将str2中前面2个字符复制到str1中去,然后再加一个‘\0’。")
371
(5)不能用赋值语句将一个字符串常量或字符数组直接给一个字符数组。如:
str1=″China″; 不合法 str1=str2; 不合法 用strcpy函数只能将一个字符串复制到另一个字符数组中去。 用赋值语句只能将一个字符赋给一个字符型变量或字符数组元素。下面是合法的使用: char a[5],c1,c2; c1=′A′; c2=′B′; a[0]=′C′; a[1]=′h′; a[2]=′i′; a[3]=′n′; a[4]=′a′;

372
5. strcmp函数 其一般形式为:strcmp(字符串1,字符串2) strcmp的作用是比较字符串1和字符串2。 例如:strcmp(str1,str2); strcmp(″China″,″Korea″); strcmp(str1,″Beijing″);
;")
373
比较的结果由函数值带回 (1) 如果字符串1=字符串2,函数值为0。 (2) 如果字符串1>字符串2,函数值为一正整数。 (3) 如果字符串1<字符串2,函数值为一负整数。 注意:对两个字符串比较,不能用以下形式: if(str1>str2) printf(″yes″); 而只能用 if(strcmp(str1,str2)>0) printf(″yes″);
 printf(″yes″); 而只能用. if(strcmp(str1,str2)>0) printf(″yes″);")
374
6. strlen函数 其一般形式为:strlen (字符数组) strlen是测试字符串长度的函数。函数的值为字符串中的实际长度(不包括′\0′在内)。 例如:char str[10]={″China″}; printf(″%d″,strlen(str)); 输出结果不是10,也不是6,而是5。也可以直接测试字符串常量的长度,如strlen(″China″);
![6. strlen函数 其一般形式为:strlen (字符数组) strlen是测试字符串长度的函数。函数的值为字符串中的实际长度(不包括′\0′在内)。 例如:char str[10]={″China″};](http://slidesplayer.com/slide/11113381/60/images/374/6.+strlen%E5%87%BD%E6%95%B0+%E5%85%B6%E4%B8%80%E8%88%AC%E5%BD%A2%E5%BC%8F%E4%B8%BA%EF%BC%9Astrlen+%28%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%84%29+strlen%E6%98%AF%E6%B5%8B%E8%AF%95%E5%AD%97%E7%AC%A6%E4%B8%B2%E9%95%BF%E5%BA%A6%E7%9A%84%E5%87%BD%E6%95%B0%E3%80%82%E5%87%BD%E6%95%B0%E7%9A%84%E5%80%BC%E4%B8%BA%E5%AD%97%E7%AC%A6%E4%B8%B2%E4%B8%AD%E7%9A%84%E5%AE%9E%E9%99%85%E9%95%BF%E5%BA%A6%28%E4%B8%8D%E5%8C%85%E6%8B%AC%E2%80%B2%EF%BC%BC0%E2%80%B2%E5%9C%A8%E5%86%85%29%E3%80%82+%E4%BE%8B%E5%A6%82%EF%BC%9Achar+str%EF%BC%BB10%EF%BC%BD%3D%7B%E2%80%B3China%E2%80%B3%7D%3B.jpg "printf(″%d″,strlen(str)); 输出结果不是10,也不是6,而是5。也可以直接测试字符串常量的长度,如strlen(″China″);")
375
7. strlwr函数 其一般形式为:strlwr (字符串) strlwr函数的作用是将字符串中大写字母换成小写字母。 8. strupr函数 其一般形式为:strupr (字符串) strupr函数的作用是将字符串中小写字母换成大写字母。
 strupr函数的作用是将字符串中小写字母换成大写字母。 .")
376
7.3.7字符数组应用举例 例 输入一行字符,统计其中有多少个单词,单 词之间用空格分隔开。

377
程序如下: #include <stdio.h> void main() { char string[81]; int i,num=0,word=0; char c; gets(string); for (i=0;(c=string[i])!=′\ 0′;i++)
![程序如下: #include <stdio.h> void main() { char string[81]; int i,num=0,word=0; char c; gets(string);](http://slidesplayer.com/slide/11113381/60/images/377/%E7%A8%8B%E5%BA%8F%E5%A6%82%E4%B8%8B%EF%BC%9A+%23include+%3Cstdio.h%3E+void+main%28%29+%7B+char+string%EF%BC%BB81%EF%BC%BD%3B+int+i%EF%BC%8Cnum%3D0%EF%BC%8Cword%3D0%3B+char+c%3B+gets%28string%29%3B.jpg "for (i=0;(c=string[i])!=′\ 0′;i++)")
378
printf(″There are %d words in the line.\n″,num);
if(c==′ ′) word=0; else if(word==0) { word=1; num++; } printf(″There are %d words in the line.\n″,num); 运行情况如下: I am a boy.↙ There are 4 words in the line.
 word=0; else if(word==0) { word=1; num++; } printf(″There are %d words in the. line.\n″,num); 运行情况如下: I am a boy.↙ There are 4 words in the line.")
379
#include<stdio.h> #include<string.h> void main ( ) {
例7.9 有3个字符串,要求找出其中最大者 程序如下: #include<stdio.h> #include<string.h> void main ( ) { char string[20]; char str[3][20]; int i; for (i=0;i<3;i++) gets (str[i]);
 { char string[20]; char str[3][20]; int i; for (i=0;i<3;i++) gets (str[i]);")
380
if (strcmp(str[0],str[1])>0)
strcpy(string,str[0]) else strcpy(string,str[1]); if (strcmp(str[2],string)>0) strcpy(string,str[2]); printf(″\nthe largest string is∶ \n%s\n″,string); }
![if (strcmp(str[0],str[1])>0)](http://slidesplayer.com/slide/11113381/60/images/380/if+%28strcmp%28str%EF%BC%BB0%EF%BC%BD%2Cstr%EF%BC%BB1%EF%BC%BD%29%3E0%29.jpg "strcpy(string,str[0]) else strcpy(string,str[1]); if (strcmp(str[2],string)>0) strcpy(string,str[2]); printf(″\nthe largest string is∶ \n%s\n″,string); }")
381
运行结果如下: CHINA↙ HOLLAND↙ AMERICA↙ the largest string is∶ HOLLAND

382
第八章 函数

383
本章要点 函数的概念 函数的定义与调用 函数的递归调用 变量的作用域 函数的作用域

384
主要内容 § 8.1 概述 § 8.2函数定义的一般形式 § 8.3函数参数和函数的值 § 8.4 函数的调用 § 8.5 函数的嵌套调用
§ 8.6函数的递归调用 § 8.7数组作为函数参数 § 8.8 局部变量和全局变量 § 8.9变量的存储类别 § 8.10 内部函数和外部函数

385
§8.1概述 一个较大的程序可分为若干个程序模块,每一个模块用来实现一个特定的功能。在高级语言中用子程序实现模块的功能。子程序由函数来完成。一个C程序可由一个主函数和若干个其他函数构成。 函数间的调用关系 由主函数调用其他函数,其他函数也可以互相调用。同一个函数可以被一个或多个函数调用任意多次。

386
例8.1先举一个函数调用的简单例子 # include <stdio.h> void main() {
void printstar(); /*对printstar函数声明*/ void print_message(); /*对print_message函数声明*/ printstar(); /*调用printstar函数*/ print_message(); /*调用print_message函数*/ printstar(); /*调用printstar函数*/ }
; /*对printstar函数声明*/ void print_message(); /*对print_message函数声明*/ printstar(); /*调用printstar函数*/ print_message(); /*调用print_message函数*/ printstar(); /*调用printstar函数*/ }")
387
void printstar() /*定义printstar函数*/
{ printf("* * * * * * * * * * * * * * * *\n"); } void print_message() /*定义print_message函数*/ printf("How do you do!\n"); 运行情况如下: * * * * * * * * * * * * * * * * How do you do!
; } void print_message() /*定义print_message函数*/ printf( How do you do!\n ); 运行情况如下: * * * * * * * * * * * * * * * * How do you do!")
388
说明: (1)一个C程序由一个或多个程序模块组成,每一个程序模块作为一个源程序文件。对较大的程序,一般不希望把所有内容全放在一个文件中,而是将他们分别放在若干个源文件中,再由若干源程序文件组成一个C程序。这样便于分别编写、分别编译,提高调试效率。一个源程序文件可以为多个C程序公用。
一个C程序由一个或多个程序模块组成,每一个程序模块作为一个源程序文件。对较大的程序,一般不希望把所有内容全放在一个文件中,而是将他们分别放在若干个源文件中,再由若干源程序文件组成一个C程序。这样便于分别编写、分别编译,提高调试效率。一个源程序文件可以为多个C程序公用。")
389
(2) 一个源程序文件由一个或多个函数以及其他有关内容(如命令行、数据定义等)组成。一个源程序文件是一个编译单位,在程序编译时是以源程序文件为单位进行编译的,而不是以函数为单位进行编译的。
(3)C程序的执行是从main函数开始的,如是在main函数中调用其他函数,在调用后流程返回到main函数,在main函数中结束整个程序的运行。
C程序的执行是从main函数开始的,如是在main函数中调用其他函数,在调用后流程返回到main函数,在main函数中结束整个程序的运行。")
390
(4) 所有函数都是平行的,即在定义函数时是分别进行的,是互相独立的。一个函数并不从属于另一函数,即函数不能嵌套定义。函数间可以互相调用,但不能调用main函数。main函数是系统调用的。
 所有函数都是平行的,即在定义函数时是分别进行的,是互相独立的。一个函数并不从属于另一函数,即函数不能嵌套定义。函数间可以互相调用,但不能调用main函数。main函数是系统调用的。")
391
(5)从用户使用的角度看,函数有两种: ① 标准函数,即库函数。这是由系统提供的,用户不必自己定义这些函数,可以直接使用它们。应该说明,不同的C系统提供的库函数的数量和功能会有一些不同,当然许多基本的函数是共同的。 ② 用户自己定义的函数。用以解决用户的专门需要。

392
(6) 从函数的形式看,函数分两类: ①无参函数。如例8.1中的printstar和print_message就是无参函数。在调用无参函数时,主调函数不向被调用函数传递数据。无参函数一般用来执行指定的一组操作。例如,例8.1程序中的printstar函数。 ②有参函数。在调用函数时,主调函数在调用被调用函数时,通过参数向被调用函数传递数据,一般情况下,执行被调用函数时会得到一个函数值,供主调函数使用。

393
§8.2函数定义的一般形式 §8.2.1. 无参函数的定义一般形式 定义无参函数的一般形式为: 类型标识符 函数名() { 声明部分
在定义函数时要用“类型标识符”指定函数值的类型,即函数带回来的值的类型。例8.1中的printstar和print_message函数为void类型,表示不需要带回函数值。 定义无参函数的一般形式为: 类型标识符 函数名() { 声明部分 语句部分 }
 { 声明部分. 语句部分. }")
394
§8.2.2. 有参函数定义的一般形式 定义有参函数的一般形式为: 类型标识符 函数名(形式参数表列) { 声明部分 语句部分 } 例如:
类型标识符 函数名(形式参数表列) { 声明部分 语句部分 } 例如: int max(int x,int y) {int z;/ *函数体中的声明部分*/ z=x>y?x∶y; return(z); }
 { 声明部分. 语句部分. } 例如: int max(int x,int y) {int z;/ *函数体中的声明部分*/ z=x>y?x∶y; return(z); }")
395
§8.2.3 空函数 定义空函数的一般形式为: 类型标识符 函数名() { } 例如: dummy()
调用此函数时,什么工作也不做,没有任何实际作用。在主调函数中写上“dummy();”表明“这里要调用一个函数”,而现在这个函数没有起作用,等以后扩充函数功能时补充上。 定义空函数的一般形式为: 类型标识符 函数名() { } 例如: dummy()
; 表明 这里要调用一个函数 ,而现在这个函数没有起作用,等以后扩充函数功能时补充上。 定义空函数的一般形式为: 类型标识符 函数名() { } 例如: dummy()")
396
§8.3函数参数和函数的值 §8.3.1形式参数和实际参数
在前面提到的有参函数中,在定义函数时函数名后面括弧中的变量名称为“形式参数”(简称“形参”),在主调函数中调用一个函数时,函数名后面括弧中的参数(可以是一个表达式)称为“实际参数”(简称“实参”)。return后面的括弧中的值()作为函数带回的值(称函数返回值)。
,在主调函数中调用一个函数时,函数名后面括弧中的参数(可以是一个表达式)称为 实际参数 (简称 实参 )。return后面的括弧中的值()作为函数带回的值(称函数返回值)。")
397
大多数情况下,主调函数和被调用函数之间有数据传递的关系。
在不同的函数之间传递数据,可以使用的法: 参数:通过形式参数和实际参数 返回值:用return语句返回计算结果 全局变量:外部变量

398
例8.2调用函数时的数据传递 #include <stdio.h> void main() { int max(int x,int y); /* 对max函数的声明 */ int a,b,c; scanf("%d,%d",&a,&b); c=max(a,b); printf("Max is %d",c); }
; c=max(a,b); printf("Max is %d",c); }")
399
运行情况如下: 7,8↙ Max is 8 int max(int x,int y)/*定义有参函数max */ { int z;
z=x>y?x∶y; return(z); } 运行情况如下: 7,8↙ Max is 8
; } 运行情况如下: 7,8↙ Max is 8.")
400
通过函数调用,使两个函数中的数据发生联系

401
关于形参与实参的说明: (1) 在定义函数中指定的形参,在未出现函数调用时,它们并不占内存中的存储单元。只有在发生函数调用时,函数max中的形参才被分配内存单元。在调用结束后,形参所占的内存单元也被释放。 (2) 实参可以是常量、变量或表达式,如: max(3,a+b); 但要求它们有确定的值。在调用时将实参的值赋给形参。
 实参可以是常量、变量或表达式,如: max(3,a+b); 但要求它们有确定的值。在调用时将实参的值赋给形参。")
402
(3) 在被定义的函数中,必须指定形参的类型(见例8.2程序中的 “c=max(a,b);” )。
(4) 实参与形参的类型应相同或赋值兼容。例8.2中实参和形参都是整型。如果实参为整型而形参x为实型,或者相反,则按第3章介绍的不同类型数值的赋值规则进行转换。 例如实参值a为3.5,而形参x为整型,则将实数3.5转换成整数3,然后送到形参b。字符型与整型可以互相通用。
 实参与形参的类型应相同或赋值兼容。例8.2中实参和形参都是整型。如果实参为整型而形参x为实型,或者相反,则按第3章介绍的不同类型数值的赋值规则进行转换。 例如实参值a为3.5,而形参x为整型,则将实数3.5转换成整数3,然后送到形参b。字符型与整型可以互相通用。")
403
(5) 在C语言中,实参向对形参的数据传递是“值传递”,单向传递,只由实参传给形参,而不能由形参传回来给实参。在内存中,实参单元与形参单元是不同的单元。
 在C语言中,实参向对形参的数据传递是 值传递 ,单向传递,只由实参传给形参,而不能由形参传回来给实参。在内存中,实参单元与形参单元是不同的单元。")
404
在调用函数时,给形参分配存储单元,并将实参对应的值传递给形参,调用结束后,形参单元被释放,实参单元仍保留并维持原值。因此,在执行一个被调用函数时,形参的值如果发生改变,并不会改变主调函数的实参的值。例如,若在执行函数过程中x和y的值变为10和15,而a和b仍为2和3。

405
§8.3.2 函数的返回值 (1)函数的返回值是通过函数中的return语句获得的。 关于函数返回值的一些说明:
通常,希望通过函数调用使主调函数能得到一个确定的值,这就是函数的返回值。例如,例8.2中,max(2,3)的值是3,max(5,2)的值是5。赋值语句将这个函数值赋给变量c。 关于函数返回值的一些说明: (1)函数的返回值是通过函数中的return语句获得的。
的值是3,max(5,2)的值是5。赋值语句将这个函数值赋给变量c。 关于函数返回值的一些说明: (1)函数的返回值是通过函数中的return语句获得的。")
406
如: “return z;” 等价于 “return (z);”
一个函数中可以有一个以上的return语句,执行到哪一个return语句,哪一个语句起作用。return语句后面的括弧也可以不要, 如: “return z;” 等价于 “return (z);”
;")
407
(2) 函数的返回值应当属于某一个确定的类型,在定义函数时指定函数返回值的类型。
return后面的值可以是一个表达式。 例如,例8.2中的函数max可以改写成: max(int x,int y) { return(x>y?x∶y); } (2) 函数的返回值应当属于某一个确定的类型,在定义函数时指定函数返回值的类型。
 { return(x>y?x∶y); } (2) 函数的返回值应当属于某一个确定的类型,在定义函数时指定函数返回值的类型。")
408
例如:下面是3个函数的首行: int max(float x,float y) /* 函数值为整型 */
char letter(char c1,char c2) /* 函数值为字符型 */ double min(int x,int y) /* 函数值为双精度型 */ 在C语言中,凡不加类型说明的函数,自动按整型处理。例8.2中的max函数首行的函数类型int可以省写,用Turbo C 2.0编译程序时能通过,但用Turbo C++ 3.0编译程序时不能通过,因为C++要求所有函数都必须指定函数类型。因此,建议在定义时对所有函数都指定函数类型。
 /* 函数值为字符型 */ double min(int x,int y) /* 函数值为双精度型 */ 在C语言中,凡不加类型说明的函数,自动按整型处理。例8.2中的max函数首行的函数类型int可以省写,用Turbo C 2.0编译程序时能通过,但用Turbo C++ 3.0编译程序时不能通过,因为C++要求所有函数都必须指定函数类型。因此,建议在定义时对所有函数都指定函数类型。")
409
(3)在定义函数时指定的函数类型一般应该和return语句中的表达式类型一致。
(4)对于不带回值的函数,应当用“void”定义函数为“无类型”(或称“空类型”)。这样,系统就保证不使函数带回任何值,即禁止在调用函数中使用被调用函数的返回值。此时在函数体中不得出现return语句。
对于不带回值的函数,应当用 void 定义函数为 无类型 (或称 空类型 )。这样,系统就保证不使函数带回任何值,即禁止在调用函数中使用被调用函数的返回值。此时在函数体中不得出现return语句。")
410
运行情况如下: 1.5, 2.5↙ Max is 2 例 8.3 返回值类型与函数类型不同
# include <stdio.h> void main() { int max(float x,float y); float a,b; int c; scanf("%f,%f,",&a,&b); c=max(a,b); printf("Max is %d\n",c); } int max(float x,float y) { float z; /* z为实型变量 */ z=x>y?x∶y; return(z);
 { int max(float x,float y); float a,b; int c; scanf("%f,%f,",&a,&b); c=max(a,b); printf("Max is %d\n",c); } int max(float x,float y) { float z; /* z为实型变量 */ z=x>y?x∶y; return(z);")
411
§8.4 函数的调用 §8.4.1 函数调用的一般形式 函数调用的一般形式为: 函数名(实参表列)
如果是调用无参函数,则“实参表列”可以没有,但括弧不能省略。 如果实参表列包含多个实参,则各参数间用逗号隔开。实参与形参的个数应相等,类型应匹配。实参与形参按顺序对应,一一传递数据。

412
如果实参表列包括多个实参,对实参求值的顺序并不是确定的,有的系统按自左至右顺序求实参的值,有的系统则按自右至左顺序。许多C版本是按自右而左的顺序求值,例如Tubro C++。

413
例 8.4 实参求值的顺序 #include <stdio.h> void main() { int f(int a,int b); /* 函数声明 */ int i=2,p; p=f(i,++i); /* 函数调用 */ printf("%d\n",p); }
; }")
414
int f(int a,int b) /* 函数定义 */
{ int c; if(a>b) c=1; else if(a==b) c=0; else c=-1; return(c); }
 c=1; else if(a==b) c=0; else c=-1; return(c); }")
415
int i=2,p; p=f(i,++i); 对于函数调用 如果按自左至右顺序求实参的值,则函数调用相当于f(2,3)
如果按自左至右顺序求实参的值,则函数调用相当于f(3,3)
")
416
按函数在程序中出现的位置来分,可以有以下三种函数调用方式:
§8.4.2函数调用的方式 按函数在程序中出现的位置来分,可以有以下三种函数调用方式: 1.函数语句 把函数调用作为一个语句。如例8.1中的printstar(),这时不要求函数带回值,只要求函数完成一定的操作。 2.函数表达式 函数出现在一个表达式中,这种表达式称为函数表达式。这时要求函数带回一个确定的值以参加表达式的运算。例如:c=2*max(a,b);
,这时不要求函数带回值,只要求函数完成一定的操作。 2.函数表达式. 函数出现在一个表达式中,这种表达式称为函数表达式。这时要求函数带回一个确定的值以参加表达式的运算。例如:c=2*max(a,b);")
417
m = max (a , max ( b , c ) ) ; 3.函数参数 函数调用作为一个函数的实参。例如:
其中max ( b , c )是一次函数调用,它的值作为max另一次调用的实参。m的值是a、b、c三者中的最大者。又如: printf ("%d", max (a,b));也是把max ( a , b )作为printf函数的一个参数。 函数调用作为函数的参数,实质上也是函数表达式形式调用的一种,因为函数的参数本来就要求是表达式形式。
是一次函数调用,它的值作为max另一次调用的实参。m的值是a、b、c三者中的最大者。又如: printf ( %d , max (a,b));也是把max ( a , b )作为printf函数的一个参数。 函数调用作为函数的参数,实质上也是函数表达式形式调用的一种,因为函数的参数本来就要求是表达式形式。")
418
在一个函数中调用另一函数(即被调用函数)需要具备哪些条件呢 ?
§8.4.3对被调用函数的声明和函数原型 §8.4.3对被调用函数的声明和函数原型 在一个函数中调用另一函数(即被调用函数)需要具备哪些条件呢 ? (1) 首先被调用的函数必须是已经存在的函数(是库函数或用户自己定义的函数)。但光有这一条件还不够。
需要具备哪些条件呢 ? (1) 首先被调用的函数必须是已经存在的函数(是库函数或用户自己定义的函数)。但光有这一条件还不够。")
419
(2) 如果使用库函数,还应该在本文件开头用#include命令将调用有关库函数时所需用到的信息“包含”到本文件中来。
(3) 如果使用用户自己定义的函数,而该函数的位置在调用它的函数(即主调函数)的后面(在同一个文件中),应该在主调函数中对被调用的函数作声明。
 如果使用用户自己定义的函数,而该函数的位置在调用它的函数(即主调函数)的后面(在同一个文件中),应该在主调函数中对被调用的函数作声明。")
420
函数原型的一般形式为 (1) 函数类型 函数名(参数类型1,参数类型2……); (2) 函数类型 函数名(参数类型1,参数名1,参数类型2,参数名2……);
 函数类型 函数名(参数类型1,参数类型2……); (2) 函数类型 函数名(参数类型1,参数名1,参数类型2,参数名2……);")
421
“声明”一词的原文是delaration,过去在许多书中把它译为“说明”。声明的作用是把函数名、函数参数的个数和参数类型等信息通知编译系统,以便在遇到函数调用时,编译系统能正确识别函数并检查调用是否合法。 (例如函数名是否正确,实参与形参的类型和个数是否一致)。
。")
422
注意:函数的“定义”和“声明”不是一回事。函数的定义是指对函数功能的确立,包括指定函数名,函数值类型、形参及其类型、函数体等,它是一个完整的、独立的函数单位。而函数的声明的作用则是把函数的名字、函数类型以及形参的类型、个数和顺序通知编译系统,以便在调用该函数时系统按此进行对照检查。

423
例8.5 对被调用的函数作声明 # include <stdio.h> void main()
{ float add(float x, float y); /*对被调用函数add的声明*/ float a,b,c; scanf("%f,%f",&a,&b); c=add(a,b); printf("sum is %f \n",c); } float add(float x,float y) /*函数首部*/ { float z; /* 函数体 */ z=x+y; return(z);
; /*对被调用函数add的声明*/ float a,b,c; scanf("%f,%f",&a,&b); c=add(a,b); printf("sum is %f \n",c); } float add(float x,float y) /*函数首部*/ { float z; /* 函数体 */ z=x+y; return(z);")
424
如果 被调用函数的定义出现在主调函数之前,可以不必加以声明。因为编译系统已经先知道了已定义函数的有关情况,会根据函数首部提供的信息对函数的调用作正确性检查。

425
改写例 8.5 # include <stdio.h> float add(float x,float y) /*函数首部*/
z=x+y; return(z); } void main() { float a,b,c; scanf("%f,%f",&a,&b); c=add(a,b); printf("sum is %f \n",c);
; } void main() { float a,b,c; scanf("%f,%f",&a,&b); c=add(a,b); printf("sum is %f \n",c);")
426
§8.5 函数的嵌套调用 嵌套定义就是在定义一个函数时,其函数体内又包含另一个函数的完整定义 。
C语言不能嵌套定义函数,但可以嵌套调用函数,也就是说,在调用一个函数的过程中,又调用另一个函数。

428
例 8.6 用弦截法求方程 f(x)=x3-5x2+16x-80=0 的根
=x3-5x2+16x-80=0 的根")
429
(2) 连接(x1,f(x1))和(x2,f(x2))两点,此线(即弦)交x轴于x。
方法: (1) 取两个不同点x1,x2,如果f(x1)和f(x2)符号相反,则(x1,x2)区间内必有一个根。如果f(x1)与f(x2)同符号,则应改变x1,x2,直到f(x1)、f(x2)异号为止。注意x1、x2的值不应差太大,以保证(x1,x2)区间内只有一个根。 (2) 连接(x1,f(x1))和(x2,f(x2))两点,此线(即弦)交x轴于x。
 取两个不同点x1,x2,如果f(x1)和f(x2)符号相反,则(x1,x2)区间内必有一个根。如果f(x1)与f(x2)同符号,则应改变x1,x2,直到f(x1)、f(x2)异号为止。注意x1、x2的值不应差太大,以保证(x1,x2)区间内只有一个根。 (2) 连接(x1,f(x1))和(x2,f(x2))两点,此线(即弦)交x轴于x。")
430
(3) 若f(x)与f(x1)同符号,则根必在(x,x2)区间内,此时将x作为新的x1。如果f(x)与f(x2)同符号,则表示根在(x1,x)区间内,将x作为新的x2。
 若f(x)与f(x1)同符号,则根必在(x,x2)区间内,此时将x作为新的x1。如果f(x)与f(x2)同符号,则表示根在(x1,x)区间内,将x作为新的x2。")
431
N-S流程图

432
分别用几个函数来实现各部分功能: (1) 用函数f(x)代表x的函数:x3-5x2+16x-80. (2) 用函数调用xpoint (x1,x2)来求(x1,f(x1))和 (x2,f(x2))的连线与x轴的交点x的坐标。 (3) 用函数调用root (x1,x2)来求(x1,x2)区间的 那个实根。显然,执行root函数过程中要用 到函数xpoint,而执行xpoint函数过程中要用 到f函数。
 用函数调用root (x1,x2)来求(x1,x2)区间的. 那个实根。显然,执行root函数过程中要用. 到函数xpoint,而执行xpoint函数过程中要用. 到f函数。")
433
#include <stdio.h>
#include <math.h> float f(float x) /* 定义f函数,以实 现f(x) =x3-5x2+16x-80 */ {float y; y=((x-5.0)*x+16.0)*x-80.0; return(y); }
 /* 定义f函数,以实. 现f(x) =x3-5x2+16x-80 */ {float y; y=((x-5.0)*x+16.0)*x-80.0; return(y); }")
434
float xpoint(float x1,float x2)
/*定义xpoint函数,求出弦与x轴交点 */{float y; y=(x1*f(x2)-x2*f(x1)) /f(x2)-f(x1)); return(y); }
-x2*f(x1)) /f(x2)-f(x1)); return(y); }")
435
float root(float x1,float x2)
{float x,y,y1; y1=f(x1); do { x=xpoint(x1,x2); y=f(x); if(y*y1>0) /*f(x)与f(x1)同符号 */ { y1=y; x1=x;} else x2=x; } while(fabs(y)>=0.0001); return(x); }
; do. { x=xpoint(x1,x2); y=f(x); if(y*y1>0) /*f(x)与f(x1)同符号 */ { y1=y; x1=x;} else. x2=x; } while(fabs(y)>=0.0001); return(x); }")
436
运行情况如下: input x1,x2: 2,6 void main() /主函数/ {float x1,x2,f1,f2,x; do
{printf("input x1,x2:\n"); scanf("%f,%f",&x1,&x2); f1=f(x1); f2=f(x2); }while(f1*f2>=0); x=root(x1,x2); printf("A root of equation is %8.4f\n",x); } 运行情况如下: input x1,x2: 2,6 A root of equation is 5.0000
; scanf("%f,%f",&x1,&x2); f1=f(x1); f2=f(x2); }while(f1*f2>=0); x=root(x1,x2); printf("A root of equation is %8.4f\n",x); } 运行情况如下: input x1,x2: 2,6. A root of equation is 5.0000.")
437
§8.6函数的递归调用 在调用一个函数的过程中又出现直接或间接地调用该函数本身,称为函数的递归调用。C语言的特点之一就在于允许函数的递归调用。例如: int f(int x) { int y,z; z=f(y); return(2*z); }
; return(2*z); }")
439
age(5)=age(4)+2 age(4)=age(3)+2 age(3)=age(2)+2 age(2)=age(1)+2
例 8.7 有5个人坐在一起,问第5个人多少岁?他说比第4个人大2岁。问第4个人岁数,他说比第3个人大2岁。问第3个人,又说比第2个人大2岁。问第2个人,说比第1个人大2岁。最后问第1个人,他说是10岁。请问第5个人多大。 age(5)=age(4)+2 age(4)=age(3)+2 age(3)=age(2)+2 age(2)=age(1)+2 age(1)=10 可以用数学公式表述如下: age(n)=10 (n=1) age(n-1)+2 (n>1)
=age(4)+2. age(4)=age(3)+2. age(3)=age(2)+2. age(2)=age(1)+2. age(1)=10. 可以用数学公式表述如下: age(n)=10 (n=1) age(n-1)+2 (n>1)")
440
运行结果如下: 18 可以用一个函数来描述上述递归过程: int age(int n) /*求年龄的递归函数*/
if(n==1) c=10; else c=age(n-1)+2; return(c); } 用一个主函数调用age函数,求得第5人的年龄。 #include <stdio.h> void main() { printf(″%d″,age(5)); 运行结果如下: 18
 c=10; else c=age(n-1)+2; return(c); } 用一个主函数调用age函数,求得第5人的年龄。 #include <stdio.h> void main() { printf(″%d″,age(5)); 运行结果如下: 18.")
441
例 8.8用递归方法求n! 求n!也可以用递归方法,即5!等于4!×5,而4!=3!×4…1!=1。可用下面的递归公式表示: n!=1 (n=0,1) n·(n-1)! (n>1)
 n·(n-1)! (n>1)")
442
例 8.9 Hanoi(汉诺)塔问题。这是一个古典的数学问题,是一个用递归方法解题的典型例子。问题是这样的:古代有一个梵塔,塔内有3个座A、B、C,开始时A座上有64个盘子,盘子大小不等,大的在下,小的在上(见图8.13)。有一个老和尚想把这64个盘子从A座移到C座,但每次只允许移动一个盘,且在移动过程中在3个座上都始终保持大盘在下,小盘在上。在移动过程中可以利用B座,要求编程序打印出移动的步骤。
塔问题。这是一个古典的数学问题,是一个用递归方法解题的典型例子。问题是这样的:古代有一个梵塔,塔内有3个座A、B、C,开始时A座上有64个盘子,盘子大小不等,大的在下,小的在上(见图8.13)。有一个老和尚想把这64个盘子从A座移到C座,但每次只允许移动一个盘,且在移动过程中在3个座上都始终保持大盘在下,小盘在上。在移动过程中可以利用B座,要求编程序打印出移动的步骤。")
444
为便于理解,我们先分析将A座上3个盘子移到C座上的过程:
将以上综合起来,可得到移动3个盘子的步骤为 A→C,A→B,C→B,A→C,B→A,B→C,A→C。 (1) 将A座上2个盘子移到B座上(借助C); (2) 将A座上1个盘子移到C座上; (3) 将B座上2个盘子移到C座上(借助A)。 其中第(2)步可以直接实现。第1步又可用递归方法分解为: 1.1 将A上1个盘子从A移到C; 1.2 将A上1个盘子从A移到B; 1.3 将C上1个盘子从C移到B。 第(3)步可以分解为: 3.1 将B上1个盘子从B移到A上; 3.2 将B上1个盘子从B移到C上; 3.3 将A上1个盘子从A移到C上。
 将A座上2个盘子移到B座上(借助C); (2) 将A座上1个盘子移到C座上; (3) 将B座上2个盘子移到C座上(借助A)。 其中第(2)步可以直接实现。第1步又可用递归方法分解为: 1.1 将A上1个盘子从A移到C; 1.2 将A上1个盘子从A移到B; 1.3 将C上1个盘子从C移到B。 第(3)步可以分解为: 3.1 将B上1个盘子从B移到A上; 3.2 将B上1个盘子从B移到C上; 3.3 将A上1个盘子从A移到C上。")
445
由上面的分析可知:将n个盘子从A座移到C座可以分解为以下3个步骤:
(1) 将A上n-1个盘借助C座先移到B座上。 (2) 把A座上剩下的一个盘移到C座上。 (3) 将n-1个盘从B座借助于A座移到C座上。
 将A上n-1个盘借助C座先移到B座上。 (2) 把A座上剩下的一个盘移到C座上。 (3) 将n-1个盘从B座借助于A座移到C座上。")
446
程序如下: #include <stdio.h> void main() { void hanoi(int n,char one,char two,char three); /* 对hanoi函数的声明 */ int m; printf("input the number of diskes:"); scanf(“%d”,&m); printf("The step to moveing %d diskes:\n",m); hanoi(m,'A','B','C'); }
; scanf( %d ,&m); printf( The step to moveing %d diskes:\n ,m); hanoi(m, A , B , C ); }")
447
void hanoi(int n,char one,char two,char three)
/* 定义hanoi函数,将n个盘从one座借助two座,移到three座 */ { void move(char x,char y); /* 对move函数的声明 */ if(n==1) move(one,three); else { hanoi(n-1,one,three,two); move(one,three); hanoi(n-1,two,one,three); } } void move(char x,char y) /* 定义move函数 */ printf(“%c-->%c\n",x,y);
; /* 对move函数的声明 */ if(n==1) move(one,three); else. { hanoi(n-1,one,three,two); move(one,three); hanoi(n-1,two,one,three); } } void move(char x,char y) /* 定义move函数 */ printf( %c-->%c\n ,x,y);")
448
运行情况如下: input the number of diskes:3↙ The steps to noving 3 diskes: A-->C A-->B C-->B B-->A B-->C

449
§8.7数组作为函数参数 §8.7.1 数组元素作函数实参 由于实参可以是表达式,而数组元素可以是表达式的组成部分,因此数组元素当然可以作为函数的实参,与用变量作实参一样,是单向传递,即“值传送”方式。 例8.10 有两个数组a和b,各有10个元素,将它们对应地逐个相比(即a[0]与b[0]比,a[1]与b[1]比……)。如果a数组中的元素大于b数组中的相应元素的数目多于b数组中元素大于a数组中相应元素的数目(例如,a[i]>b[i]6次,b[i]>a[i]3次,其中i每次为不同的值),则认为a数组大于b数组,并分别统计出两个数组相应元素大于、等于、小于的次数。
。如果a数组中的元素大于b数组中的相应元素的数目多于b数组中元素大于a数组中相应元素的数目(例如,a[i]>b[i]6次,b[i]>a[i]3次,其中i每次为不同的值),则认为a数组大于b数组,并分别统计出两个数组相应元素大于、等于、小于的次数。")
450
#include <stdio.h>
void main() { int large(int x,int y); /* 函数声明 */ int a[10],b[10],i,n=0,m=0,k=0; printf(″enter array a∶\n″); for(i=0;i<10;i++=) scanf(″%d″,&a[i]); printf(″\n″); printf(″ enter arrayb∶\n″); scanf (″%d″,&b[i]); for(i=0;i<10;i++) { if(large (a[i],b[i] )== 1) n=n+1; else if( large (a[i],b[i] )==0) m=m+1; else k=k+1;}
 { int large(int x,int y); /* 函数声明 */ int a[10],b[10],i,n=0,m=0,k=0; printf(″enter array a∶\n″); for(i=0;i<10;i++=) scanf(″%d″,&a[i]); printf(″\n″); printf(″ enter arrayb∶\n″); scanf (″%d″,&b[i]); for(i=0;i<10;i++) { if(large (a[i],b[i] )== 1) n=n+1; else if( large (a[i],b[i] )==0) m=m+1; else k=k+1;}")
451
printf("a[i]>b[i] %d times\na[i]=b[i] %d
times\na[i]<b[i] %d times\n",n,m,k); if(n>k) printf("array a is larger than array b\n"); else if (n<k) printf("array a is smaller than array b\n"); else printf("array a is equal to array b\n"); } large(int x,int y) { int flag; if(x>y)flag=1; else if(x<y)flag=-1; else flag=0; return(flag);
![printf( a[i]>b[i] %d times\na[i]=b[i] %d](http://slidesplayer.com/slide/11113381/60/images/451/printf%28+a%5Bi%5D%3Eb%5Bi%5D+%25d+times%5Cna%5Bi%5D%3Db%5Bi%5D+%25d.jpg "times\na[i]<b[i] %d times\n ,n,m,k); if(n>k) printf( array a is larger than array b\n ); else if (n<k) printf( array a is smaller than array b\n ); else printf( array a is equal to array b\n ); } large(int x,int y) { int flag; if(x>y)flag=1; else if(x<y)flag=-1; else flag=0; return(flag);")
452
运行情况如下: enter array a: 1 3 5 7 9 8 6 4 2 0↙ enter array b∶ –1 – ↙ a[i]>b[i] 4 times a[i]=b[i] 1 times a[i]<b[i] 5 times array a is smaller thann array b
![运行情况如下: enter array a: 1 3 5 7 9 8 6 4 2 0↙ enter array b∶ –1 – ↙ a[i]>b[i] 4 times.](http://slidesplayer.com/slide/11113381/60/images/452/%E8%BF%90%E8%A1%8C%E6%83%85%E5%86%B5%E5%A6%82%E4%B8%8B%EF%BC%9A+enter+array+a%EF%BC%9A+%EF%BC%91+%EF%BC%93+%EF%BC%95+%EF%BC%97+%EF%BC%99+%EF%BC%98+%EF%BC%96+%EF%BC%94+%EF%BC%92+%EF%BC%90%E2%86%99%EE%81%85+%EF%BD%85%EF%BD%8E%EF%BD%94%EF%BD%85%EF%BD%92+%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99+%EF%BD%82%E2%88%B6+%E2%80%931+%E2%80%93+%E2%86%99%EE%81%85+%EF%BD%81%EF%BC%BB%EF%BD%89%EF%BC%BD%EF%BC%9E%EF%BD%82%EF%BC%BB%EF%BD%89%EF%BC%BD+%EF%BC%94+%EF%BD%94%EF%BD%89%EF%BD%8D%EF%BD%85%EF%BD%93..jpg "a[i]=b[i] 1 times. a[i]<b[i] 5 times. array a is smaller thann array b.")
453
例8.11 有一个一维数组score,内放10个学生成绩,求平均成绩。
§8.7.2 数组名作函数参数 可以用数组名作函数参数,此时形参应当用数组名或用指针变量 。 例8.11 有一个一维数组score,内放10个学生成绩,求平均成绩。

454
#include <stdio.h>
void main() { float average(float array[10]); /* 函数声明 */ float score[10] , aver; int i; printf(″input 10 scores:\n″); for(i=0;i<10;i++= scanf(″%f″,&score[i]); printf(″\n″); aver=average( score ); printf (″ average score is %5.2f\n″, aver); }
 { float average(float array[10]); /* 函数声明 */ float score[10] , aver; int i; printf(″input 10 scores:\n″); for(i=0;i<10;i++= scanf(″%f″,&score[i]); printf(″\n″); aver=average( score ); printf (″ average score is %5.2f\n″, aver); }")
455
float average (float array[10]) { int i; float aver,sum=array[0];
for (i=1;i<10;i++=) sum=sum+array[i]; aver=sum/10; return(aver); } 运行情况如下: input 10 scores: 100 56 78 98.5 76 87 99 67.5 75 97↙ average score is 83.40
![float average (float array[10]) { int i; float aver,sum=array[0];](http://slidesplayer.com/slide/11113381/60/images/455/float+average+%EF%BC%88float+array%EF%BC%BB10%EF%BC%BD%EF%BC%89+%EF%BD%9B+int+%EF%BD%89%EF%BC%9B+float+aver%EF%BC%8C%EF%BD%93%EF%BD%95%EF%BD%8D%EF%BC%9D%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%EF%BC%BB%EF%BC%90%EF%BC%BD%EF%BC%9B.jpg "for (i=1;i<10;i++=) sum=sum+array[i]; aver=sum/10; return(aver); } 运行情况如下: input 10 scores: 100 56 78 98.5 76 87 99 67.5 75 97↙ average score is")
456
例 8.12形参数组不定义长度 #include <stdio.h> void main()
{ float average(float array[ ],int n) float score_1[5] ={98.5,97,9 1.5,60,55}; float score_2[10]={ 67.5,89.5,99,69.5, 77,89.5,76.5,54,60,99.5}; printf(“the average of class A is %6.2f\n”, average(score_1,5)); printf(“the average of class B is %6.2f\n”, average(score_2,10)); }
 float score_1[5] ={98.5,97,9. 1.5,60,55}; float score_2[10]={ 67.5,89.5,99,69.5, 77,89.5,76.5,54,60,99.5}; printf( the average of class A is %6.2f\n , average(score_1,5)); printf( the average of class B is %6.2f\n , average(score_2,10)); }")
457
float average(float array[ ],int n) { int i; float aver,sum=array[0];
for(i=1;i<n;i++= sum=sum+array[i]; aver=sum/n; return(aver); } 运行结果如下: the average of class A is 80.40 The average of class B is
![float average(float array[ ],int n) { int i; float aver,sum=array[0];](http://slidesplayer.com/slide/11113381/60/images/457/float+average%EF%BC%88float+%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%EF%BC%BB+%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89+%EF%BD%9B+int+%EF%BD%89%EF%BC%9B+float+aver%EF%BC%8C%EF%BD%93%EF%BD%95%EF%BD%8D%EF%BC%9D%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%EF%BC%BB%EF%BC%90%EF%BC%BD%EF%BC%9B.jpg "for(i=1;i<n;i++= sum=sum+array[i]; aver=sum/n; return(aver); } 运行结果如下: the average of class A is The average of class B is")
458
例 8.13 用选择法对数组中10个整数按由小到大排序。所谓选择法就是先将10个数中最小的数与a[0]对换;再将a[1]到a[9]中最小的数与a[1]对换……每比较一轮,找出一个未经排序的数中最小的一个。共比较9轮。
![例 8.13 用选择法对数组中10个整数按由小到大排序。所谓选择法就是先将10个数中最小的数与a[0]对换;再将a[1]到a[9]中最小的数与a[1]对换……每比较一轮,找出一个未经排序的数中最小的一个。共比较9轮。](http://slidesplayer.com/slide/11113381/60/images/458/%E4%BE%8B+8.13+%E7%94%A8%E9%80%89%E6%8B%A9%E6%B3%95%E5%AF%B9%E6%95%B0%E7%BB%84%E4%B8%AD10%E4%B8%AA%E6%95%B4%E6%95%B0%E6%8C%89%E7%94%B1%E5%B0%8F%E5%88%B0%E5%A4%A7%E6%8E%92%E5%BA%8F%E3%80%82%E6%89%80%E8%B0%93%E9%80%89%E6%8B%A9%E6%B3%95%E5%B0%B1%E6%98%AF%E5%85%88%E5%B0%8610%E4%B8%AA%E6%95%B0%E4%B8%AD%E6%9C%80%E5%B0%8F%E7%9A%84%E6%95%B0%E4%B8%8Ea%EF%BC%BB0%EF%BC%BD%E5%AF%B9%E6%8D%A2%3B%E5%86%8D%E5%B0%86a%EF%BC%BB1%EF%BC%BD%E5%88%B0a%EF%BC%BB9%EF%BC%BD%E4%B8%AD%E6%9C%80%E5%B0%8F%E7%9A%84%E6%95%B0%E4%B8%8Ea%EF%BC%BB1%EF%BC%BD%E5%AF%B9%E6%8D%A2%E2%80%A6%E2%80%A6%E6%AF%8F%E6%AF%94%E8%BE%83%E4%B8%80%E8%BD%AE%2C%E6%89%BE%E5%87%BA%E4%B8%80%E4%B8%AA%E6%9C%AA%E7%BB%8F%E6%8E%92%E5%BA%8F%E7%9A%84%E6%95%B0%E4%B8%AD%E6%9C%80%E5%B0%8F%E7%9A%84%E4%B8%80%E4%B8%AA%E3%80%82%E5%85%B1%E6%AF%94%E8%BE%839%E8%BD%AE%E3%80%82.jpg "例 8.13 用选择法对数组中10个整数按由小到大排序。所谓选择法就是先将10个数中最小的数与a[0]对换;再将a[1]到a[9]中最小的数与a[1]对换……每比较一轮,找出一个未经排序的数中最小的一个。共比较9轮。")
459
a[0] a[1] a[2] a[3] a[4] 未排序时的情况 将5个数中最小的数1与a[0]对换 将余下的4个数中最小的数3与a[1]对换 将余下的3个数中最小的数4与a[2]对换 将余下的2个数中最小的数6与a[3]对 换,至此完成排序
![a[0] a[1] a[2] a[3] a[4] 未排序时的情况](http://slidesplayer.com/slide/11113381/60/images/459/a%5B0%5D+a%5B1%5D+a%5B2%5D+a%5B3%5D+a%5B4%5D+%E6%9C%AA%E6%8E%92%E5%BA%8F%E6%97%B6%E7%9A%84%E6%83%85%E5%86%B5.jpg "将5个数中最小的数1与a[0]对换 将余下的4个数中最小的数3与a[1]对换 将余下的3个数中最小的数4与a[2]对换 将余下的2个数中最小的数6与a[3]对. 换,至此完成排序.")
460
程序实例 #include <stdio.h> void main() { void sort(int array[],int n); int a[10],i; printf(″enter the array\n″); for(i=0;i<10;i++= scanf(″%d″,&a[i]); sort(a,10); printf(″the sorted array∶\n″); printf(″%d″,a[i]); printf(″\n″); }
![程序实例 #include <stdio.h> void main() { void sort(int array[],int n); int a[10],i; printf(″enter the array\n″);](http://slidesplayer.com/slide/11113381/60/images/460/%E7%A8%8B%E5%BA%8F%E5%AE%9E%E4%BE%8B+%23include+%3Cstdio.h%3E+void+main%EF%BC%88%EF%BC%89+%EF%BD%9B+void+sort%EF%BC%88int+%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%EF%BC%BB%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89%3B+int+%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%EF%BC%8C%EF%BD%89%EF%BC%9B+printf%EF%BC%88%E2%80%B3enter+the+array%EF%BC%BC%EF%BD%8E%E2%80%B3%EF%BC%89%EF%BC%9B.jpg "for(i=0;i<10;i++= scanf(″%d″,&a[i]); sort(a,10); printf(″the sorted array∶\n″); printf(″%d″,a[i]); printf(″\n″); }")
461
void sort(int array[],int n)
for(i=0;i<n-1;i++) { k=i; for(j=i+1;j<n;j++) if(array[j] < array[k]=k=j; t=array[k]; array[k]=array[i];array[i]=t }
![void sort(int array[],int n)](http://slidesplayer.com/slide/11113381/60/images/461/void+sort%EF%BC%88int+%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%EF%BC%BB%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "for(i=0;i<n-1;i++) { k=i; for(j=i+1;j<n;j++) if(array[j] < array[k]=k=j; t=array[k]; array[k]=array[i];array[i]=t. }")
462
§8.7.3. 多维数组名作函数参数 程序如下: #include <stdio.h> void main()
{ max_value ( int array[ ][4]); int [3][4]={{1,3,5,7},{2,4,6,8},{15,17,34,12}}; printf(″max value is %d\n″, max_value(a) ); }
; int [3][4]={{1,3,5,7},{2,4,6,8},{15,17,34,12}}; printf(″max value is %d\n″, max_value(a) ); }")
463
运行结果如下: Max value is 34 max_value ( int array[ ][4]) { int i,j,k,max;
max=array[0][0]; for(i=0;i<3;i++) for(j=0;j<4;j++= if(array[i][j]>max) max= array [i][j]; return(max); } 运行结果如下: Max value is 34
![运行结果如下: Max value is 34 max_value ( int array[ ][4]) { int i,j,k,max;](http://slidesplayer.com/slide/11113381/60/images/463/%E8%BF%90%E8%A1%8C%E7%BB%93%E6%9E%9C%E5%A6%82%E4%B8%8B%EF%BC%9A+Max+value+is+34+max_value+%EF%BC%88+int+array%EF%BC%BB+%EF%BC%BD%EF%BC%BB4%EF%BC%BD%EF%BC%89+%EF%BD%9B+int+%EF%BD%89%EF%BC%8C%EF%BD%8A%EF%BC%8C%EF%BD%8B%EF%BC%8C%EF%BD%8D%EF%BD%81%EF%BD%98%EF%BC%9B.jpg "max=array[0][0]; for(i=0;i<3;i++) for(j=0;j<4;j++= if(array[i][j]>max) max= array [i][j]; return(max); } 运行结果如下: Max value is 34.")
464
§8.8局部变量和全局变量 §8.8.1局部变量 在一个函数内部定义的变量是内部变量,它只在本函数范围内有效,也就是说只有在本函数内才能使用它们,在此函数以外是不能使用这些变量的。这称为“局部变量”。

465
float f1( int a) /*函数f1 */
{int b,c; … a、b、c有效 } char f2(int x,int y) /*函数f2 */ {int i,j; x、y、i、j有效 void main( ) /*主函数*/ {int m,n; … m、n有效 }
 /*函数f2 */ {int i,j; x、y、i、j有效. void main( ) /*主函数*/ {int m,n; … m、n有效. }")
466
(1) 主函数中定义的变量(m,n)也只在主函数中有效,而不因为在主函数中定义而在整个文件或程序中有效。主函数也不能使用其他函数中定义的变量。
说 明 (2) 不同函数中可以使用相同名字的变量,它们代表不同的对象,互不干扰。例如, 上面在f1函数中定义了变量b和c,倘若在f2函数中也定义变量b和c,它们在内存中占不同的单元,互不混淆。 (3) 形式参数也是局部变量。例如上面f1函数中的形参a,也只在f1函数中有效。其他函数可以调用f1函数,但不能引用f1函数的形参a。 (4) 在一个函数内部,可以在复合语句中定义变量,这些变量只在本复合语句中有效,这种复合语句也称为“分程序”或“程序块”。
 不同函数中可以使用相同名字的变量,它们代表不同的对象,互不干扰。例如, 上面在f1函数中定义了变量b和c,倘若在f2函数中也定义变量b和c,它们在内存中占不同的单元,互不混淆。 (3) 形式参数也是局部变量。例如上面f1函数中的形参a,也只在f1函数中有效。其他函数可以调用f1函数,但不能引用f1函数的形参a。 (4) 在一个函数内部,可以在复合语句中定义变量,这些变量只在本复合语句中有效,这种复合语句也称为 分程序 或 程序块 。")
467
void main ( ) {int a,b; … {int c; c=a+b; c在此范围内有效 a,b在此范围内有效 } }
 {int a,b; … {int c; c=a+b; c在此范围内有效 a,b在此范围内有效 } }")
468
§8.8.2 全局变量 在函数内定义的变量是局部变量,而在函数之外定义的变量称为外部变量,外部变量是全局变量(也称全程变量)。全局变量可以为本文件中其他函数所共用。它的有效范围为从定义变量的位置开始到本源文件结束。
。全局变量可以为本文件中其他函数所共用。它的有效范围为从定义变量的位置开始到本源文件结束。")
469
int p=1,q=5; /* 外部变量 */ float f1(int a) /* 定义函数f1 */ {int b,c; … } char c1,c2; /* 外部变量*/ char f2 (int x, int y) /* 定义函数f2 */ {int i,j; 全局变量p,q的作用范围 … 全局变量c1,c2的作用范围 void main ( ) /*主函数*/ {int m,n; }
 /* 定义函数f2 */ {int i,j; 全局变量p,q的作用范围. … 全局变量c1,c2的作用范围. void main ( ) /*主函数*/ {int m,n; }")
470
例 8.15 有一个一维数组,内放10个学生成绩,写一个函数,求出平均分、最高分和最低分。
#include <stdio.h> float Max=0,Min=0; /*全局变量*/ void main() { float average(float array[ ],int n); float ave,score[10]; int i; for(i=0;i<10;i++) scanf(″%f″,&score[i]); ave= average(score,10); printf(“max=%6.2f\nmin=%6.2f\n average=%6.2f\n“,Max,Min,ave); }
 { float average(float array[ ],int n); float ave,score[10]; int i; for(i=0;i<10;i++) scanf(″%f″,&score[i]); ave= average(score,10); printf( max=%6.2f\nmin=%6.2f\n. average=%6.2f\n ,Max,Min,ave); }")
471
float average(float array[ ],int n)
/* 定义函数,形参为数组 */ { int i; float aver,sum=array[0]; Max=Min=array[0]; for(i=1;i<n;i++) { if(array[i]>Max)Max=array[i]; else if(array[i]<Min)Min= array[i]; sum=sum+array[i]; } aver=sum/n; return(aver); } 运行情况如下: 99 45 78 97 100 67.5 89 92 66 43↙ max=100.00 min=43.00 average=77.65
![float average(float array[ ],int n)](http://slidesplayer.com/slide/11113381/60/images/471/float+average%EF%BC%88float+array%EF%BC%BB+%EF%BC%BD%EF%BC%8Cint+n%EF%BC%89.jpg "/* 定义函数,形参为数组 */ { int i; float aver,sum=array[0]; Max=Min=array[0]; for(i=1;i<n;i++) { if(array[i]>Max)Max=array[i]; else if(array[i]<Min)Min= array[i]; sum=sum+array[i]; } aver=sum/n; return(aver); } 运行情况如下: 99 45 78 97 100 67.5 89 92 66 43↙ max=100.00. min=43.00. average=77.65.")
473
建议不在必要时不要使用全局变量,原因如下:
① 全局变量在程序的全部执行过程中都占用存储单元,而不是仅在需要时才开辟单元。 ② 使用全局变量过多,会降低程序的清晰性,人们往往难以清楚地判断出每个瞬时各个外部变量的值。在各个函数执行时都可能改变外部变量的值,程序容易出错。因此,要限制使用全局变量。

474
③它使函数的通用性降低了,因为函数在执行时要依赖于其所在的外部变量。如果将一个函数移到另一个文件中,还要将有关的外部变量及其值一起移过去。但若该外部变量与其他文件的变量同名时,就会出现问题,降低了程序的可靠性和通用性。一般要求把C程序中的函数做成一个封闭体,除了可以通过“实参——形参”的渠道与外界发生联系外,没有其他渠道。

475
例 8.16 外部变量与局部变量同名 #include <stdio.h> int a=3,b=5; /* a,b为外部变量*/ a,b作用范围 void main ( ) { int a=8; /*a为局部变量 */ 局部变量a作用范围 printf (″%d″, max (a,b)); 全局变量b的作用范围 } max (int a, int b) /*a,b为局部变量 */ { int c; c=a>b?a∶b; 形参a、b作用范围 return (c); 运行结果为 8
); 全局变量b的作用范围. } max (int a, int b) /*a,b为局部变量 */ { int c; c=a>b a∶b; 形参a、b作用范围. return (c); 运行结果为. 8.")
476
§8.9 变量的存储类别 §8.9.1 动态存储方式与静态存储方式
前面已介绍了从变量的作用域(即从空间)角度来分,可以分为全局变量和局部变量。那么从变量值存在的时间(即生存期)角度来分,又可以分为静态存储方式和动态存储方式。 所谓静态存储方式是指在程序运行期间由系统分配固定的存储空间的方式。而动态存储方式则是在程序运行期间根据需要进行动态的分配存储空间的方式。这个存储空间可以分为三部分: 程序区 静态存储区 动态存储区
角度来分,可以分为全局变量和局部变量。那么从变量值存在的时间(即生存期)角度来分,又可以分为静态存储方式和动态存储方式。 所谓静态存储方式是指在程序运行期间由系统分配固定的存储空间的方式。而动态存储方式则是在程序运行期间根据需要进行动态的分配存储空间的方式。这个存储空间可以分为三部分: 程序区. 静态存储区. 动态存储区.")
477
在C语言中每一个变量和函数有两个属性:数据类型和数据的存储类别。对数据类型,读者已熟悉(如整型、字符型等)。存储类别指的是数据在内存中存储的方式。存储方式分为两大类:静态存储类和动态存储类。具体包含四种:自动的(auto),静态的(static),寄存器的(register),外部的(extern)。根据变量的存储类别,可以知道变量的作用域和生存期。
。存储类别指的是数据在内存中存储的方式。存储方式分为两大类:静态存储类和动态存储类。具体包含四种:自动的(auto),静态的(static),寄存器的(register),外部的(extern)。根据变量的存储类别,可以知道变量的作用域和生存期。")
478
§8.9.2 auto变量 函数中的局部变量,如不专门声明为static存储类别,都是动态地分配存储空间的,数据存储在动态存储区中。函数中的形参和在函数中定义的变量(包括在复合语句中定义的变量),都属此类,在调用该函数时系统会给它们分配存储空间,在函数调用结束时就自动释放这些存储空间。因此这类局部变量称为自动变量。自动变量用关键字auto作存储类别的声明。例如: int f(int a) /*定义f函数,a为形参 */ {auto int b,c=3; /*定义b、c为自动变量 */ … }
,都属此类,在调用该函数时系统会给它们分配存储空间,在函数调用结束时就自动释放这些存储空间。因此这类局部变量称为自动变量。自动变量用关键字auto作存储类别的声明。例如: int f(int a) /*定义f函数,a为形参 */ {auto int b,c=3; /*定义b、c为自动变量 */ … }")
479
8.9.3用static声明局部变量 有时希望函数中的局部变量的值在函数调用结束后不消失而保留原值,即其占用的存储单元不释放,在下一次该函数调用时,该变量已有值,就是上一次函数调用结束时的值。这时就应该指定该局部变量为“静态局部变量”,用关键字static进行声明。通过下面简单的例子可以了解它的特点。

480
例8.17 考察静态局部变量的值。 #include <stdio.h> void main() {int f(int); int a=2,i; for(i=0;i<3;i++= printf(″%d ″,f(a)); } int f(int a) {auto int b=0; static c=3; b=b+1; c=c+1; return(a+b+c); }
 {auto int b=0; static c=3; b=b+1; c=c+1; return(a+b+c); }")
481
对静态局部变量的说明: (1) 静态局部变量属于静态存储类别,在静态存储区内分配存储单元。在程序整个运行期间都不释放。而自动变量(即动态局部变量)属于动态存储类别,占动态存储区空间而不占静态存储区空间,函数调用结束后即释放。 (2) 对静态局部变量是在编译时赋初值的,即只赋初值一次,在程序运行时它已有初值。以后每次调用函数时不再重新赋初值而只是保留上次函数调用结束时的值。而对自动变量赋初值,不是在编译时进行的,而是在函数调用时进行,每调用一次函数重新给一次初值,相当于执行一次赋值语句。
 对静态局部变量是在编译时赋初值的,即只赋初值一次,在程序运行时它已有初值。以后每次调用函数时不再重新赋初值而只是保留上次函数调用结束时的值。而对自动变量赋初值,不是在编译时进行的,而是在函数调用时进行,每调用一次函数重新给一次初值,相当于执行一次赋值语句。")
482
(3)如在定义局部变量时不赋初值的话,则对静态局部变量来说,编译时自动赋初值0(对数值型变量)或空字符(对字符变量)。而对自动变量来说,如果不赋初值则它的值是一个不确定的值。这是由于每次函数调用结束后存储单元已释放,下次调用时又重新另分配存储单元,而所分配的单元中的值是不确定的。 (4) 虽然静态局部变量在函数调用结束后仍然存在,但其他函数是不能引用它的。
 虽然静态局部变量在函数调用结束后仍然存在,但其他函数是不能引用它的。")
483
例8.18 输出1到5的阶乘值。 #include <stdio.h> void main() {int fac(int n); int i; for(i=1;i<=5;i++) printf(″%d!=%d\n″,i,fac(i)); } Int fac(int n) {static int f=1; f=f*n; return(f);
 {static int f=1; f=f*n; return(f);")
484
8.9.4 register变量 一般情况下,变量(包括静态存储方式和动态存储方式)的值是存放在内存中的。当程序中用到哪一个变量的值时,由控制器发出指令将内存中该变量的值送到运算器中。 经过运算器进行运算,如果需要存数,再从运算器将数据送到内存存放。
的值是存放在内存中的。当程序中用到哪一个变量的值时,由控制器发出指令将内存中该变量的值送到运算器中。 经过运算器进行运算,如果需要存数,再从运算器将数据送到内存存放。")
485
如果有一些变量使用频繁(例如在一个函数中执行10000次循环,每次循环中都要引用某局部变量),则为存取变量的值要花费不少时间。为提高执行效率,C语言允许将局部变量的值放在CPU中的寄存器中,需要用时直接从寄存器取出参加运算,不必再到内存中去存取。由于对寄存器的存取速度远高于对内存的存取速度,因此这样做可以提高执行效率。这种变量叫做寄存器变量,用关键字register作声明。例如,例8.19中的程序是输出1到n的阶乘的值。
,则为存取变量的值要花费不少时间。为提高执行效率,C语言允许将局部变量的值放在CPU中的寄存器中,需要用时直接从寄存器取出参加运算,不必再到内存中去存取。由于对寄存器的存取速度远高于对内存的存取速度,因此这样做可以提高执行效率。这种变量叫做寄存器变量,用关键字register作声明。例如,例8.19中的程序是输出1到n的阶乘的值。")
486
例8.19使用寄存器变量 #include <stdio.h> void main ( ) {long fac(long); long i,n; scanf("%ld",&n); for(i=1;i<=n;i++) printf("%ld!=%ld\n",i,fac(i)); } long fac(long n) {register long i,f=1; /*定义寄存器变量*/ for (i=1;i<=n;i++) f=f*i; return (f);
); } long fac(long n) {register long i,f=1; /*定义寄存器变量*/ for (i=1;i<=n;i++) f=f*i; return (f);")
487
8.9.5用extern声明外部变量 外部变量是在函数的外部定义的全局变量,它的作用域是从变量的定义处开始,到本程序文件的末尾。在此作用域内,全局变量可以为程序中各个函数所引用。编译时将外部变量分配在静态存储区。 有时需要用extern来声明外部变量,以扩展外部变量的作用城。

488
1. 在一个文件内声明外部变量 例8.20 用extern声明外部变量,扩展它在程序文件中的作用域。 #include <stdio.h> void main() { int max(int,int); /*外部变量声明*/ extern A,B; printf("%d\n",max(A,B)); } int A=13,B=-8; /*定义外部变量*/ int max(int x,int y) /*定义max函数 */ { int z; z=x>y?x:y; return(z);
); } int A=13,B=-8; /*定义外部变量*/ int max(int x,int y) /*定义max函数 */ { int z; z=x>y x:y; return(z);")
489
2. 在多文件的程序中声明外部变量 例8.21 用extern将外部变量的作用域扩展到其他文件。 本程序的作用是给定b的值,输入a和m,求a×b和am的值。文件file1.c中的内容为: #include <stdio.h> int A; /*定义外部变量*/ void main() {int power(int); /*函数声明*/ int b=3,c,d,m; printf(″enter the number a and its power m:\n″); scanf(″%d,%d″,&A,&m); c=A*b; printf(″%d*%d=%d\n″,A,b,c); d=power(m); printf(″%d**%d=%d\n″,A,m,d); }
 {int power(int); /*函数声明*/ int b=3,c,d,m; printf(″enter the number a and its power m:\n″); scanf(″%d,%d″,&A,&m); c=A*b; printf(″%d*%d=%d\n″,A,b,c); d=power(m); printf(″%d**%d=%d\n″,A,m,d); }")
490
文件file2.c中的内容为: extern A; /*声明A为一个已定义的外部变量*/ int power(int n); {int i,y=1; for(i=1;i<=n;i++) y*=A; return(y); }
; }")
491
8.9.6用static声明外部变量 有时在程序设计中希望某些外部变量只限于被本文件引用,而不能被其他文件引用。这时可以在定义外部变量时加一个static声明。 例如: file1.c file2.c static int A; extern int A; void main ( ) void fun (int n) { {… … A=A*n; }
 void fun (int n) { {… … A=A*n; }")
492
8.9.7关于变量的声明和定义 对变量而言,声明与定义的关系稍微复杂一些。在声明部分出现的变量有两种情况:一种是需要建立存储空间的(如:int a; ),另一种是不需要建立存储空间的(如:extern a;)。前者称为“定义性声明”(defining declaration) ,或简称定义(definition)。 后者称为“引用性声明”(referencing declaration)。广义地说,声明包括定义,但并非所有的声明都是定义。对“int a;” 而言,它既是声明,又是定义。而对“extern a;” 而言,它是声明而不是定义。
,另一种是不需要建立存储空间的(如:extern a;)。前者称为 定义性声明 (defining declaration) ,或简称定义(definition)。 后者称为 引用性声明 (referencing declaration)。广义地说,声明包括定义,但并非所有的声明都是定义。对 int a; 而言,它既是声明,又是定义。而对 extern a; 而言,它是声明而不是定义。")
493
一般为了叙述方便,把建立存储空间的声明称定义,而把不需要建立存储空间的声明称为声明。显然这里指的声明是狭义的,即非定义性声明。例如:
void main() {extern A; /*是声明不是定义。声明A是一 个已定义的外部变量*/ … } int A;
 {extern A; /*是声明不是定义。声明A是一. 个已定义的外部变量*/ … } int A;")
494
§8.9.8存储类别小结 (1) 从作用域角度分,有局部变量和全局变量。它们采用的存储类别如下: 局部变量 |自动变量,即动态局部变量
局部变量 |自动变量,即动态局部变量 (离开函数,值就消失) |静态局部变量(离开函数,值仍保留) |寄存器变量(离开函数,值就消失) |(形式参数可以定义为自动变量或寄存 器变量) 全局变量 |静态外部变量(只限本文件引用) |外部变量 (即非静态的外部变量,允许其他文件引用)
 |静态局部变量(离开函数,值仍保留) |寄存器变量(离开函数,值就消失) |(形式参数可以定义为自动变量或寄存. 器变量) 全局变量 |静态外部变量(只限本文件引用) |外部变量. (即非静态的外部变量,允许其他文件引用)")
495
(2) 从变量存在的时间(生存期)来区分,有动态存储和静态存储两种类型。静态存储是程序整个运行时间都存在,而动态存储则是在调用函数时临时分配单元。
动态存储 |自动变量(本函数内有效) |寄存器变量(本函数内有效) |形式参数(本函数内有效) 静态存储 |静态局部变量(函数内有效) |静态外部变量(本文件内有效) |外部变量(其他文件可引用)
 |寄存器变量(本函数内有效) |形式参数(本函数内有效) 静态存储 |静态局部变量(函数内有效) |静态外部变量(本文件内有效) |外部变量(其他文件可引用)")
496
(3) 从变量值存放的位置来区分,可分为: 内存中静态存储区 |静态局部变量 |静态外部变量(函数外部静态变量) |外部变量(可为其他文件引用) 内存中动态存储区:自动变量和形式参数 CPU中的寄存器:寄存器变量

497
(4) 关于作用域和生存期的概念。从前面叙述可以知道,对一个变量的性质可以从两个方面分析,一是变量的作用域,一是变量值存在时间的长短,即生存期。前者是从空间的角度,后者是从时间的角度。二者有联系但不是同一回事。 (5) static对局部变量和全局变量的作用不同。对局部变量来说,它使变量由动态存储方式改变为静态存储方式。而对全局变量来说,它使变量局部化(局部于本文件),但仍为静态存储方式。从作用域角度看,凡有static声明的,其作用域都是局限的,或者是局限于本函数内(静态局部变量),或者局限于本文件内(静态外部变量)。
 static对局部变量和全局变量的作用不同。对局部变量来说,它使变量由动态存储方式改变为静态存储方式。而对全局变量来说,它使变量局部化(局部于本文件),但仍为静态存储方式。从作用域角度看,凡有static声明的,其作用域都是局限的,或者是局限于本函数内(静态局部变量),或者局限于本文件内(静态外部变量)。")
498
§8.10 内部函数和外部函数 函数本质上是全局的,因为一个函数要被另外的函数调用,但是,也可以指定函数不能被其他文件调用。根据函数能否被其他源文件调用,将函数区分为内部函数和外部函数。 §8.10.1内部函数 如果一个函数只能被本文件中其他函数所调用,它称为内部函数。在定义内部函数时,在函数名和函数类型的前面加static。即 static 类型标识符 函数名(形参表) 如 static int fun ( int a , int b )
 如 static int fun ( int a , int b )")
499
§8.10.2外部函数 (1) 在定义函数时,如果在函数首部的最左端加关键字extern,则表示此函数是外部函数,可供其他文件调用。如函数首部可以写为extern int fun (int a, int b) 这样,函数fun就可以为其他文件调用。C语言规定,如果在定义函数时省略extern,则隐含为外部函数。本书前面所用的函数都是外部函数。 (2) 在需要调用此函数的文件中,用extern对函数作声明,表示该函数是在其他文件中定义的外部函数
 在需要调用此函数的文件中,用extern对函数作声明,表示该函数是在其他文件中定义的外部函数.")
500
例 8.22 有一个字符串,内有若干个字符,今输入一个字符,要求程序将字符串中该字符删去。用外部函数实现
File.c(文件1) #include <stdio.h> void main() { extern void enter_string(char str[]); extern void detele_string(char str[],char ch); extern void print_string(char str[]);/*以上3行声明在本函数中将要调用的在其他文件中定义的3个函数*/ char c; char str[80]; scanf("%c",&c); detele_string(str,c); print_string(str); }
 #include <stdio.h> void main() { extern void enter_string(char str[]); extern void detele_string(char str[],char ch); extern void print_string(char str[]);/*以上3行声明在本函数中将要调用的在其他文件中定义的3个函数*/ char c; char str[80]; scanf( %c ,&c); detele_string(str,c); print_string(str); }")
501
file2.c(文件2) #include <stdio.h> void enter_string(char str[80]) /* 定义外部函数 enter-string*/ { gets(str); /*向字符数组输入字符串*/ } file3.c(文件3) void delete_string(char str[],char ch) /*定义外部函数 delete_string */ { int i,j; for(i=j=0;str[i]!='\0';i++) if(str[i]!=ch) str[j++]=str[i]; str[i]='\0'; }
![file2.c(文件2) #include <stdio.h> void enter_string(char str[80]) /* 定义外部函数. enter-string*/ { gets(str); /*向字符数组输入字符串*/](http://slidesplayer.com/slide/11113381/60/images/501/file%EF%BC%92%EF%BC%8E%EF%BD%83%EF%BC%88%E6%96%87%E4%BB%B6%EF%BC%92%EF%BC%89+%23include+%3Cstdio.h%3E+void+enter_string%28char+str%5B80%5D%29+%EF%BC%8F%2A+%E5%AE%9A%E4%B9%89%E5%A4%96%E9%83%A8%E5%87%BD%E6%95%B0.+enter-string%2A%EF%BC%8F+%7B+gets%28str%29%3B+%EF%BC%8F%2A%E5%90%91%E5%AD%97%E7%AC%A6%E6%95%B0%E7%BB%84%E8%BE%93%E5%85%A5%E5%AD%97%E7%AC%A6%E4%B8%B2%2A%EF%BC%8F.jpg "} file3.c(文件3) void delete_string(char str[],char ch) /*定义外部函数. delete_string */ { int i,j; for(i=j=0;str[i]!= \0 ;i++) if(str[i]!=ch) str[j++]=str[i]; str[i]= \0 ; }")
502
#include <stdio.h> void print_string(char str[]) {
file4.c(文件4) #include <stdio.h> void print_string(char str[]) { printf("%s\n",str); } 运行情况如下: abcdefgc↙ (输入str) c↙ (输入要删去的字符) abdefg (输出已删去指定字符的字符串)
![#include <stdio.h> void print_string(char str[]) {](http://slidesplayer.com/slide/11113381/60/images/502/%23include+%3Cstdio.h%3E+void+print_string%28char+str%5B%5D%29+%7B.jpg "file4.c(文件4) #include <stdio.h> void print_string(char str[]) { printf( %s\n ,str); } 运行情况如下: abcdefgc↙ (输入str) c↙ (输入要删去的字符) abdefg (输出已删去指定字符的字符串)")
503
第九章 预处理命令

504
预处理的概念 C语言处理系统的预处理功能 预处理命令的使用
本章要点 预处理的概念 C语言处理系统的预处理功能 预处理命令的使用

505
主要内容 9.1 宏定义 9.2“文件包含”处理 9.3 条件编译

506
基本概念 ANSI C标准规定可以在C源程序中加入一些“预处理命令” ,以改进程序设计环境,提高编程效率。
这些预处理命令是由ANSI C统一规定的,但是它不是C语言本身的组成部分,不能直接对它们进行编译(因为编译程序不能识别它们)。必须在对程序进行通常的编译之前,先对程序中这些特殊的命令进行“预处理” 经过预处理后程序可由编译程序对预处理后的源程序进行通常的编译处理,得到可供执行的目标代码。
。必须在对程序进行通常的编译之前,先对程序中这些特殊的命令进行 预处理 经过预处理后程序可由编译程序对预处理后的源程序进行通常的编译处理,得到可供执行的目标代码。")
507
基本概念 C语言与其他高级语言的一个重要区别是可以使用预处理命令和具有预处理的功能。 C提供的预处理功能主要有以下三种: 1.宏定义
1.宏定义 2.文件包含 3.条件编译 这些功能分别用宏定义命令、文件包含命令、条件编译命令来实现。为了与一般C语句相区别,这些命令以符号“#”开头。例如: #define #include

508
§9.1 宏定义 9.1.1 不带参数的宏定义 宏定义一般形式为: #define 标识符 字符串
例如:# define PI 宏定义的作用是在本程序文件中用指定的标识符PI来代替“ ”这个字符串,在编译预处理时,将程序中在该命令以后出现的所有的PI都用“ ”代替。这种方法使用户能以一个简单的名字代替一个长的字符串. 这个标识符(名字)称为“宏名” 在预编译时将宏名替换成字符串的过程称为“宏展开”。#define是宏定义命令。
称为 宏名 在预编译时将宏名替换成字符串的过程称为 宏展开 。#define是宏定义命令。")
509
例9.1 使用不带参数的宏定义 #include <stdio.h> #define PI 3.1415926
void main() {float l,s,r,v; printf("input radius:"); scanf("%f",&r); l=2.0*PI*r; s=PI*r*r; v=4.0/3*PI*r*r*r; printf("l=%10.4f\ns=%10.4f\nv=%10.4f\n",l,s,v); }
 {float l,s,r,v; printf( input radius: ); scanf( %f ,&r); l=2.0*PI*r; s=PI*r*r; v=4.0/3*PI*r*r*r; printf( l=%10.4f\ns=%10.4f\nv=%10.4f\n ,l,s,v); }")
510
运行情况如下: 说明: 1=25.1328 s=50.2655 v=150.7966 input radius: 4↙
(1) 宏名一般习惯用大写字母表示,以便与变量名相区别。但这并非规定,也可用小写字母。 (2) 使用宏名代替一个字符串,可以减少程序中重复书写某些字符串的工作量。 (3) 宏定义是用宏名代替一个字符串,只作简单置换,不作正确性检查。只有在编译已被宏展开后的源程序时才会发现语法错误并报错。
 宏名一般习惯用大写字母表示,以便与变量名相区别。但这并非规定,也可用小写字母。 (2) 使用宏名代替一个字符串,可以减少程序中重复书写某些字符串的工作量。 (3) 宏定义是用宏名代替一个字符串,只作简单置换,不作正确性检查。只有在编译已被宏展开后的源程序时才会发现语法错误并报错。")
511
说明: (4) 宏定义不是C语句,不必在行末加分号。如果加了分号则会连分号一起进行置换。
(5) #define命令出现在程序中函数的外面,宏名的有效范围为定义命令之后到本源文件结束。通常,#define命令写在文件开头,函数之前,作为文件一部分,在此文件范围内有效。 (6) 可以用#undef命令终止宏定义的作用域。 例如:
 #define命令出现在程序中函数的外面,宏名的有效范围为定义命令之后到本源文件结束。通常,#define命令写在文件开头,函数之前,作为文件一部分,在此文件范围内有效。 (6) 可以用#undef命令终止宏定义的作用域。 例如:")
512
在f1函数中,G不再代表9.8。这样可以灵活控制宏定义的作用范围。
#define G _______ void main() ↑ { G的有效范围 … } ↓---- #undef G f1() { } 在f1函数中,G不再代表9.8。这样可以灵活控制宏定义的作用范围。
 ↑ { G的有效范围. … } -----↓---- #undef G. f1() { } 在f1函数中,G不再代表9.8。这样可以灵活控制宏定义的作用范围。")
513
说明: 例9.2 在宏定义中引用已定义的宏名 运行情况如下: (7) 在进行宏定义时,可以引用已定义的宏名,可以层层置换。
#include <stdio.h> #define R 3.0 #define PI #define L 2*PI*R #define S PI*R*R void main() { printf("L=%f\nS=%f\n",L,S); } 运行情况如下: L= S=
 { printf( L=%f\nS=%f\n ,L,S); } 运行情况如下: L= S=")
514
printf(“L=%F\NS=%f\n”, 2*3.1415926*3.0,3.1415926*3.0*3.0);
S展开为 *3.0*3.0 printf函数调用语句展开为: printf(“L=%F\NS=%f\n”, 2* *3.0, *3.0*3.0);
;")
515
说明: (8) 对程序中用双撇号括起来的字符串内的字符,即使与宏名相同,也不进行置换。
(9) 宏定义是专门用于预处理命令的一个专用名词,它与定义变量的含义不同,只作字符替换,不分配内存空间。
 宏定义是专门用于预处理命令的一个专用名词,它与定义变量的含义不同,只作字符替换,不分配内存空间。")
516
9.1.2 带参数的宏定义 作用:不是进行简单的字符串替换,还要进行参数替换。 带参数的宏定义一般形式为: 例:
#define 宏名(参数表) 字符串 字符串中包含在括弧中所指定的参数 例: 程序中用3和2分别代替宏定义中的形式参数a和b,用3*2代替S(3,2) 。因此赋值语句展开为: area=3*2 #define S(a,b) a*b area=S(3,2);
 字符串. 字符串中包含在括弧中所指定的参数. 例: 程序中用3和2分别代替宏定义中的形式参数a和b,用3*2代替S(3,2) 。因此赋值语句展开为: area=3*2. #define S(a,b) a*b. area=S(3,2);")
517
对带参的宏定义是这样展开置换的: 对带实参的宏(如S(3,2),则按#define命令行中指定的字符串从左到右进行置换。若串中包含宏中的形参(如a、b),则将程序中相应的实参(可以是常量、变量或表达式)代替形参。如果宏定义中的字符串中的字符不是参数字符(如a*b中的*号),则保留。这样就形成了置换的字符串。
,则按#define命令行中指定的字符串从左到右进行置换。若串中包含宏中的形参(如a、b),则将程序中相应的实参(可以是常量、变量或表达式)代替形参。如果宏定义中的字符串中的字符不是参数字符(如a*b中的*号),则保留。这样就形成了置换的字符串。")
518
赋值语句“area=S(a); ” 经宏展开后为:
例9.3 使用带参的宏 运行情况如下: #include <stdio.h> #define PI #define S(r) PI*r*r void main() {float a,area; a=3.6; area=S(a); printf("r=%f\narea=%f\n",a,area); } r= area= 赋值语句“area=S(a); ” 经宏展开后为: area= *a*a;
 PI*r*r. void main() {float a,area; a=3.6; area=S(a); printf( r=%f\narea=%f\n ,a,area); } r= area= 赋值语句 area=S(a); 经宏展开后为: area= *a*a;")
519
说明: (1)对带参数的宏展开只是将语句中的宏名后面括号内的实参字符串代替#define 命令行中的形参。
(2) 在宏定义时,在宏名与带参数的括弧之间不应加空格,否则将空格以后的字符都作为替代字符串的一部分。
 在宏定义时,在宏名与带参数的括弧之间不应加空格,否则将空格以后的字符都作为替代字符串的一部分。")
520
带参数的宏和函数的区别: (1) 函数调用时,先求出实参表达式的值,然后代入形参。而使用带参的宏只是进行简单的字符替换。
(2) 函数调用是在程序运行时处理的,为形参分配临时的内存单元。而宏展开则是在编译前进行的,在展开时并不分配内存单元,不进行值的传递处理,也没有“返回值”的概念。 (3) 对函数中的实参和形参类型要求一致。而宏名无类型,它的参数也无类型,只是一个符号代表,展开时代入指定的字符串即可。宏定义时,字符串可以是任何类型的数据。 (4) 调用函数只可得到一个返回值,而用宏可以设法得到几个结果。
 函数调用是在程序运行时处理的,为形参分配临时的内存单元。而宏展开则是在编译前进行的,在展开时并不分配内存单元,不进行值的传递处理,也没有 返回值 的概念。 (3) 对函数中的实参和形参类型要求一致。而宏名无类型,它的参数也无类型,只是一个符号代表,展开时代入指定的字符串即可。宏定义时,字符串可以是任何类型的数据。 (4) 调用函数只可得到一个返回值,而用宏可以设法得到几个结果。")
521
例9.4 通过宏展开得到若干个结果 #include <stdio.h> #define PI 3.1415926
#define CIRCLE(R,L,S,V) L=2*PI*R;S=PI*R*R;V=4.0/3.0*PI*R*R*R void main() {float r,l,s,v; scanf("%f",&r); CIRCLE(r,l,s,v); printf("r=%6.2f,l=%6.2f,s=%6.2f,v=%6.2f\n",r,l,s,v); }
 L=2*PI*R;S=PI*R*R;V=4.0/3.0*PI*R*R*R. void main() {float r,l,s,v; scanf( %f ,&r); CIRCLE(r,l,s,v); printf( r=%6.2f,l=%6.2f,s=%6.2f,v=%6.2f\n ,r,l,s,v); }")
522
对宏进行预编译,展开后的main函数如下:
void main() { float r,l,s,v; scanf("%f",&r); l=2* *r; s= *r*r; v=4.0/3/0* *r*r*r; printf(”r=%6.2f,l=%6.2f,s=%6.2f,v=%6.2f\n”,r,l,s,v); } 运行情况如下: 3.5↙ r=3.50,l=21.99,s=38.48,v=179.59
 { float r,l,s,v; scanf( %f ,&r); l=2* *r; s= *r*r; v=4.0/3/0* *r*r*r; printf( r=%6.2f,l=%6.2f,s=%6.2f,v=%6.2f\n ,r,l,s,v); } 运行情况如下: 3.5↙ r=3.50,l=21.99,s=38.48,v=")
523
带参数的宏和函数的区别: (5) 使用宏次数多时,宏展开后源程序长,因为每展开一次都使程序增长,而函数调用不会使源程序变长。
(6) 宏替换不占运行时间,只占编译时间。而函数调用则占运行时间(分配单元、保留现场、值传递、返回)。 如果善于利用宏定义,可以实现程序的简化,如事先将程序中的“输出格式”定义好,以减少在输出语句中每次都要写出具体的输出格式的麻烦。
 宏替换不占运行时间,只占编译时间。而函数调用则占运行时间(分配单元、保留现场、值传递、返回)。 如果善于利用宏定义,可以实现程序的简化,如事先将程序中的 输出格式 定义好,以减少在输出语句中每次都要写出具体的输出格式的麻烦。")
524
例9.5 通过宏展开得到若干个结果 #include <stdio.h> #define PR printf
#define NL "\n" #define D "%d" #define D1 D NL #define D2 D D NL #define D3 D D D NL #define D4 D D D D NL #define S "%s" void main() { int a,b,c,d; char string[]="CHINA"; a=1;b=2;c=3;d=4; PR(D1,a); PR(D2,a,b); PR(D3,a,b,c); PR(D4,a,b,c,d); PR(S,string); } 运行时输出结果: 1 12 123 1234 CHINA
 { int a,b,c,d; char string[]= CHINA ; a=1;b=2;c=3;d=4; PR(D1,a); PR(D2,a,b); PR(D3,a,b,c); PR(D4,a,b,c,d); PR(S,string); } 运行时输出结果: 1. 12. 123. 1234. CHINA.")
525
§9.2 “文件包含”处理 所谓“文件包含”处理是指一个源文件可以将另外一个源文件的全部内容包含进来。C语言提供了#include命令用来实现“文件包含”的操作。 其一般形式为: #include "文件名" 或 #include <文件名>

526
例9.6 将例9.5时格式宏做成头文件,把它包含在用户程序中。
(2)主文件file1.c #include <stdio.h> #include "format.h" void main() { int a,b,c,d; char string[]="CHINA"; a=1;b=2;c=3;d=4; PR(D1,a); PR(D2,a,b); PR(D3,a,b,c); PR(D4,a,b,c,d); PR(S,string); } (1)将格式宏做成头文件format.h #include <stdio.h> #define PR printf #define NL "\n" #define D "%d" #define D1 D NL #define D2 D D NL #define D3 D D D NL #define D4 D D D D NL #define S "%s"
主文件file1.c. #include <stdio.h> #include format.h void main() { int a,b,c,d; char string[]= CHINA ; a=1;b=2;c=3;d=4; PR(D1,a); PR(D2,a,b); PR(D3,a,b,c); PR(D4,a,b,c,d); PR(S,string); } (1)将格式宏做成头文件format.h. #include <stdio.h> #define PR printf. #define NL \n #define D %d #define D1 D NL. #define D2 D D NL. #define D3 D D D NL. #define D4 D D D D NL. #define S %s")
527
注意: 在编译时并不是分别对两个文件分别进行编译,然后再将它们的目标程序连接的,而是在经过编译预处理后将头文件format.h包含到主文件中,得到一个新的源程序,然后对这个文件进行编译,得到一个目标(.obj)文件。被包含的文件成为新的源文件的一部分,而单独生成目标文件。
文件。被包含的文件成为新的源文件的一部分,而单独生成目标文件。")
528
说明: (1) 一个#include命令只能指定一个被包含文件,如果要包含n个文件,要用n个#include命令。
(2) 如果文件1包含文件2,而在文件2中要用到文件3的内容,则可在文件1中用两个include命令分别包含文件2和文件3,而且文件3应出现在文件2之前,即在file1.c中定义。 (3) 在一个被包含文件中又可以包含另一个被包含文件,即文件包含是可以嵌套的。
 如果文件1包含文件2,而在文件2中要用到文件3的内容,则可在文件1中用两个include命令分别包含文件2和文件3,而且文件3应出现在文件2之前,即在file1.c中定义。 (3) 在一个被包含文件中又可以包含另一个被包含文件,即文件包含是可以嵌套的。")
530
说明: (4) 在#include命令中,文件名可以用双撇号或尖括号括起来。
(5) 被包含文件(file2.h)与其所在的文件(即用#include命令的源文件file2.c),在预编译后已成为同一个文件(而不是两个文件)。因此,如果file2.h中有全局静态变量,它也在file1.h文件中有效,不必用extern声明。
 被包含文件(file2.h)与其所在的文件(即用#include命令的源文件file2.c),在预编译后已成为同一个文件(而不是两个文件)。因此,如果file2.h中有全局静态变量,它也在file1.h文件中有效,不必用extern声明。")
531
§9.3 条件编译 (3) #if 表达式 程序段1 #else 程序段2 #endif
概念:所谓“条件编译”,是对部分内容指定编译的条件,使其只在满足一定条件才进行编译。 条件编译命令的几种形式: (1)#ifdef 标识符 程序段1 #else 程序段2 #endif (2)#ifndef 标识符 程序段1 #else 程序段2 #endif
#ifdef 标识符. 程序段1. #else. 程序段2. #endif. (2)#ifndef 标识符. 程序段1. #else. 程序段2. #endif.")
532
运行结果为: C LANGUAGE 例9.7 输入一行字母字符,根据需要设置条件编译,使之能将字母全改为大写输出,或全改为小写字母输出。
#include <stdio.h> #define LETTER 1 void main() {char str[20]="C Language",c; int i; i=0; while((c=str[i])!='\0') { i++; #if LETTER if(c>='a' && c<='z') c=c-32; #else if(c>='A' && c<='Z') c=c+32; #endif printf("%c",c); } 例9.7 输入一行字母字符,根据需要设置条件编译,使之能将字母全改为大写输出,或全改为小写字母输出。 运行结果为: C LANGUAGE
 {char str[20]= C Language ,c; int i; i=0; while((c=str[i])!= \0 ) { i++; #if LETTER. if(c>= a && c<= z ) c=c-32; #else. if(c>= A && c<= Z ) c=c+32; #endif. printf( %c ,c); } 例9.7 输入一行字母字符,根据需要设置条件编译,使之能将字母全改为大写输出,或全改为小写字母输出。 运行结果为: C LANGUAGE.")
533
第十章 指针

534
主要内容 10.1地址和指针的概念 10.2变量的指针和指向变量的 指针变量 10.3数组与指针 10.4字符串与指针
10.5指向函数的指针 10.6返回指针值的函数 10.7指针数组和指向指针的指针 10.8有关指针的数据类型和指针运算的小结

535
10.1地址和指针的概念 内存区的每一个字节有一个编号,这就是“地址” 。如果在程序中定义了一个变量,在对程序进行编译时,系统就会给这个变量分配内存单元。 1.按变量地址存取变量值的方式称为“直接访问”方式 printf(″%d″,i); scanf(″%d″,&i); k=i+j;
; scanf(″%d″,&i); k=i+j;")
537
2. 另一种存取变量值的方式称为“间接访问”的方式。即,将变量i的地址存放在另一个变量中。
在C语言中,指针是一种特殊的变量,它是存放地址的。

538
指针和指针变量的定义: 一个变量的地址称为该变量的“指针”。
例如,地址2000是变量i的指针。如果有一个变量专门用来存放另一变量的地址(即指针),则它称为“指针变量”。上述的i_pointer就是一个指针变量。
,则它称为 指针变量 。上述的i_pointer就是一个指针变量。")
539
10.2 变量的指针和指向变量的指 针变量 10.2.1 定义一个指针变量 定义指针变量的一般形式为 基类型 *指针变量名;

540
下面都是合法的定义: float *pointer_3; char *pointer_4; 可以用赋值语句使一个指针变量得到另一个变 量的地址,从而使它指向一个该变量。 例如: pointer_1=&i; pointer_2=&j;

541
在定义指针变量时要注意两点: 指针变量前面的“*”,表示该变量的类型为指针型变量。 例: float *pointer_1; 指针变量名是pointer_1 ,而不是* pointer_1 。 (2) 在定义指针变量时必须指定基类型。 需要特别注意的是,只有整型变量的地址才能放到指向整型变量的指针变量中。下面的赋值是错误的∶ float a; int * pointer_1; pointer_1=&a;
 在定义指针变量时必须指定基类型。 需要特别注意的是,只有整型变量的地址才能放到指向整型变量的指针变量中。下面的赋值是错误的∶ float a; int * pointer_1; pointer_1=&a;")
542
10.2.2 指针变量的引用 注意:指针变量中只能存放地址(指针), 不要将一个整数(或任何其他非地址类型的数据) 赋给一个指针变量。
例10.1 通过指针变量访问整型变量 #include <stdio.h> void main ( ) { int a,b; int*pointer_1, *pointer_2; a=100;b=10; pointer_1=&a; /*把变量a的地址赋给 pointer_1 */
 { int a,b; int*pointer_1, *pointer_2; a=100;b=10; pointer_1=&a; /*把变量a的地址赋给. pointer_1 */")
543
pointer_2=&b; /*把变量b的地址赋给
printf(″%d,%d\n″,a,b); printf(″%d,%d\n″,*pointer_1, *pointer_2); }
; printf(″%d,%d\n″,*pointer_1, *pointer_2); }")
544
对“&”和“*”运算符说明: 如果已执行了语句 pointer_1=&a; (1)&* pointer_1的含义是什么?
“&”和“*”两个运算符的优先级别相同,但按自右而左方向结合。因此,&* pointer_1与&a相同,即变量a的地址。 如果有pointer_2 =&* pointer_1 ;它的作用是将&a(a的地址)赋给pointer_2 ,如果pointer_2原来指向b,经过重新赋值后它已不再指向b了,而指向了a。
赋给pointer_2 ,如果pointer_2原来指向b,经过重新赋值后它已不再指向b了,而指向了a。")
546
(2) *&a的含义是什么? 先进行&a运算,得a的地址,再进行*运算。*&a和*pointer_1的作用是一样的,它们都等价于变量a。即*&a与a等价。 (3) (*pointer_1)++相当于a++。
 *&a的含义是什么? 先进行&a运算,得a的地址,再进行*运算。*&a和*pointer_1的作用是一样的,它们都等价于变量a。即*&a与a等价。 (3) (*pointer_1)++相当于a++。")
547
例10 . 2 输入a和b两个整数,按先大后小的顺序输出
a和b。 #include <stdio.h> void main() { int *p1,*p2,*p,a,b; scanf(″%d,%d″,&a,&b); p1=&a;p2=&b; if(a<b) {p=p1;p1=p2;p2=p;} printf(″a=%d,b=%d\n\n″,a,b); printf(″max=%d,min=%d\n″,*p1,*p2); }
 { int *p1,*p2,*p,a,b; scanf(″%d,%d″,&a,&b); p1=&a;p2=&b; if(a<b) {p=p1;p1=p2;p2=p;} printf(″a=%d,b=%d\n\n″,a,b); printf(″max=%d,min=%d\n″,*p1,*p2); }")
548
运行情况如下: 5,9↙ a=5,b=9 max=9,min=5 当输入a=5,b=9时,由于a<b,将p1和p2交换。交换前的情况见图(a),交换后见图(b)。
,交换后见图(b)。")
550
10.2.3 指针变量作为函数参数 例10 . 3 对输入的两个整数按大小顺序输出 #include <stdio.h>
例 对输入的两个整数按大小顺序输出 #include <stdio.h> void main() {void swap(int *p1,int *p2); int a,b; int *pointer_1,*pointer_2; scanf(″%d,%d″,&a,&b); pointer_1 =&a; pointer_2 =&b; if(a<b= swap( pointer_1 , pointer_2 ); printf(″\n%d,%d\n″,a,b); }
 {void swap(int *p1,int *p2); int a,b; int *pointer_1,*pointer_2; scanf(″%d,%d″,&a,&b); pointer_1 =&a; pointer_2 =&b; if(a<b= swap( pointer_1 , pointer_2 ); printf(″\n%d,%d\n″,a,b); }")
551
void swap(int *p1,int *p2)
{ int temp; temp=*p1; *p1=*p2; *p2=temp; }

553
例10.4 输入a、b、c 3个整数,按大小顺序输出。
#include <stdio.h> void main() { void exchange(int *q1, int *q2, int *q3); int a,b,c,*p1,*p2,*p3; scanf(″%d,%d,%d″,&a, &b, &c); p1=&a;p2=&b;p3=&c; exchange (p1,p2,p3); printf(″\n%d,%d,%d\n″,a,b,c); }
 { void exchange(int *q1, int *q2, int *q3); int a,b,c,*p1,*p2,*p3; scanf(″%d,%d,%d″,&a, &b, &c); p1=&a;p2=&b;p3=&c; exchange (p1,p2,p3); printf(″\n%d,%d,%d\n″,a,b,c); }")
554
void exchange(int *q1, int *q2, int *q3)
{ void swap(int *pt1, int *pt2); if(*q1<*q2) swap(q1,q2); if(*q1<*q3) swap(q1,q3); if(*q2<*q3= swap(q2,q3); } void swap(int *pt1, int *pt2) {int temp; temp=*pt1; *pt1=*pt2; *pt2=temp;
; if(*q1<*q2) swap(q1,q2); if(*q1<*q3) swap(q1,q3); if(*q2<*q3= swap(q2,q3); } void swap(int *pt1, int *pt2) {int temp; temp=*pt1; *pt1=*pt2; *pt2=temp;")
555
10.3 数组与指针 一个变量有地址,一个数组包含若干元素,每个数组元素都在内存中占用存储单元,它们都有相应的地址。指针变量既然可以指向变量,当然也可以指向数组元素(把某一元素的地址放到一个指针变量中)。所谓数组元素的指针就是数组元素的地址。
。所谓数组元素的指针就是数组元素的地址。")
556
10.3.1 指向数组元素的指针 定义一个指向数组元素的指针变量的方法,与以前介绍的指向变量的指针变量相同。 例如:int a[10];
(定义a为包含10个整型数据的数组) int*p; (定义p为指向整型变量的指针变量) 应当注意,如果数组为int型,则指针变量的基类型亦应为int型。
![指向数组元素的指针 定义一个指向数组元素的指针变量的方法,与以前介绍的指向变量的指针变量相同。 例如:int a[10];](http://slidesplayer.com/slide/11113381/60/images/556/%E6%8C%87%E5%90%91%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E6%8C%87%E9%92%88+%E5%AE%9A%E4%B9%89%E4%B8%80%E4%B8%AA%E6%8C%87%E5%90%91%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E7%9A%84%E6%96%B9%E6%B3%95%EF%BC%8C%E4%B8%8E%E4%BB%A5%E5%89%8D%E4%BB%8B%E7%BB%8D%E7%9A%84%E6%8C%87%E5%90%91%E5%8F%98%E9%87%8F%E7%9A%84%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E7%9B%B8%E5%90%8C%E3%80%82+%E4%BE%8B%E5%A6%82%EF%BC%9A%EF%BD%89%EF%BD%8E%EF%BD%94+%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%EF%BC%9B.jpg "(定义a为包含10个整型数据的数组) int*p; (定义p为指向整型变量的指针变量) 应当注意,如果数组为int型,则指针变量的基类型亦应为int型。")
557
对该指针变量赋值: p=&a[0]; 把a[0]元素的地址赋给指针变量p。也就是使p指向a数组的第0号元素,如图:
![对该指针变量赋值: p=&a[0]; 把a[0]元素的地址赋给指针变量p。也就是使p指向a数组的第0号元素,如图:](http://slidesplayer.com/slide/11113381/60/images/557/%E5%AF%B9%E8%AF%A5%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E8%B5%8B%E5%80%BC%EF%BC%9A+%EF%BD%90%EF%BC%9D%EF%BC%86%EF%BD%81%EF%BC%BB%EF%BC%90%EF%BC%BD%EF%BC%9B+%E6%8A%8A%EF%BD%81%EF%BC%BB%EF%BC%90%EF%BC%BD%E5%85%83%E7%B4%A0%E7%9A%84%E5%9C%B0%E5%9D%80%E8%B5%8B%E7%BB%99%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%EF%BD%90%E3%80%82%E4%B9%9F%E5%B0%B1%E6%98%AF%E4%BD%BF%EF%BD%90%E6%8C%87%E5%90%91%EF%BD%81%E6%95%B0%E7%BB%84%E7%9A%84%E7%AC%AC%EF%BC%90%E5%8F%B7%E5%85%83%E7%B4%A0%EF%BC%8C%E5%A6%82%E5%9B%BE%EF%BC%9A.jpg "对该指针变量赋值: p=&a[0]; 把a[0]元素的地址赋给指针变量p。也就是使p指向a数组的第0号元素,如图:")
558
10.3.2通过指针引用数组元素 引用一个数组元素,可以用: (1) 下标法,如a[i]形式;
(1) 下标法,如a[i]形式; (2) 指针法,如*(a+i)或*(p+i)。其中a是数组名,p是指向数组元素的指针变量,其初值p=a。 例10.5 输出数组中的全部元素。 假设有一个a数组,整型,有10个元素。要输出各元素的值有三种方法:
![10.3.2通过指针引用数组元素 引用一个数组元素,可以用: (1) 下标法,如a[i]形式;](http://slidesplayer.com/slide/11113381/60/images/558/10.%EF%BC%93.%EF%BC%92%E9%80%9A%E8%BF%87%E6%8C%87%E9%92%88%E5%BC%95%E7%94%A8%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0+%E5%BC%95%E7%94%A8%E4%B8%80%E4%B8%AA%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%EF%BC%8C%E5%8F%AF%E4%BB%A5%E7%94%A8%EF%BC%9A+%EF%BC%88%EF%BC%91%EF%BC%89+%E4%B8%8B%E6%A0%87%E6%B3%95%EF%BC%8C%E5%A6%82%EF%BD%81%EF%BC%BB%EF%BD%89%EF%BC%BD%E5%BD%A2%E5%BC%8F%EF%BC%9B.jpg "(1) 下标法,如a[i]形式; (2) 指针法,如*(a+i)或*(p+i)。其中a是数组名,p是指向数组元素的指针变量,其初值p=a。 例10.5 输出数组中的全部元素。 假设有一个a数组,整型,有10个元素。要输出各元素的值有三种方法:")
559
(1)下标法。 #include <stdio.h> void main() { int a[10]; int i; for(i=0;i<10;i++) scanf(″%d″,&a[i]); printf(″\n″); printf(″%d″,a[i]); }
![(1)下标法。 #include <stdio.h> void main() { int a[10]; int i; for(i=0;i<10;i++) scanf(″%d″,&a[i]);](http://slidesplayer.com/slide/11113381/60/images/559/%281%29%E4%B8%8B%E6%A0%87%E6%B3%95%E3%80%82+%23include+%3Cstdio.h%3E+void+main%EF%BC%88%EF%BC%89+%EF%BD%9B+int+%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%EF%BC%9B+int+%EF%BD%89%EF%BC%9B+for%EF%BC%88%EF%BD%89%EF%BC%9D%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%9C%EF%BC%91%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%8B%EF%BC%8B%EF%BC%89+scanf%EF%BC%88%E2%80%B3%EF%BC%85%EF%BD%84%E2%80%B3%EF%BC%8C%EF%BC%86%EF%BD%81%EF%BC%BB%EF%BD%89%EF%BC%BD%EF%BC%89%EF%BC%9B.jpg "printf(″\n″); printf(″%d″,a[i]); }")
560
(2) 通过数组名计算数组元素地址,找出元素的值。
#include <stdio.h> void main() { int a[10]; int i; for(i=0;i<10;i++ ) scanf(″%d″,&a[i]); printf(″\n″); for(i=0;i<10;i++) printf(″%d″,*(a+i)); }
 { int a[10]; int i; for(i=0;i<10;i++ ) scanf(″%d″,&a[i]); printf(″\n″); for(i=0;i<10;i++) printf(″%d″,*(a+i)); }")
561
(3) 用指针变量指向数组元素。 #include <stdio.h> void main() { int a[10]; int *p,i; for(i=0;i<10;i++) scanf(″%d″,&a[i]); printf(″\n″); for(p=a;p<(a+10);p++) printf(″%d ″,*p); }
![(3) 用指针变量指向数组元素。 #include <stdio.h> void main() { int a[10]; int *p,i; for(i=0;i<10;i++)](http://slidesplayer.com/slide/11113381/60/images/561/%283%29+%E7%94%A8%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E6%8C%87%E5%90%91%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E3%80%82+%23include+%3Cstdio.h%3E+void+main%EF%BC%88%EF%BC%89+%EF%BD%9B+int+%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%EF%BC%9B+int+%2A%EF%BD%90%EF%BC%8C%EF%BD%89%EF%BC%9B+for%EF%BC%88%EF%BD%89%EF%BC%9D%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%9C%EF%BC%91%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%8B%EF%BC%8B%EF%BC%89.jpg "scanf(″%d″,&a[i]); printf(″\n″); for(p=a;p<(a+10);p++) printf(″%d ″,*p); }")
562
例10.6 通过指针变量输出a数组的10个元素。 #include <stdio.h> void main() { int*p,i,a[10]; p=a; for(i=0;i<10;i++ ) scanf(″%d″,p++); printf(″\n″); for(i=0;i<10;i++,p++ ) printf(″%d″,*p); } 程序运行情况: ↙ 显然输出的数值并不是a数组中各元素的值
![例10.6 通过指针变量输出a数组的10个元素。 #include <stdio.h> void main() { int*p,i,a[10]; p=a; for(i=0;i<10;i++ )](http://slidesplayer.com/slide/11113381/60/images/562/%E4%BE%8B10.%EF%BC%96+%E9%80%9A%E8%BF%87%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E8%BE%93%E5%87%BA%EF%BD%81%E6%95%B0%E7%BB%84%E7%9A%84%EF%BC%91%EF%BC%90%E4%B8%AA%E5%85%83%E7%B4%A0%E3%80%82+%23include+%3Cstdio.h%3E+void+main%EF%BC%88%EF%BC%89+%EF%BD%9B+int%EE%80%92%2A%EF%BD%90%EF%BC%8C%EF%BD%89%EF%BC%8C%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%EF%BC%9B+%EF%BD%90%EF%BC%9D%EF%BD%81%EF%BC%9B+for%EF%BC%88%EF%BD%89%EF%BC%9D%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%9C%EF%BC%91%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%8B%EF%BC%8B+%EF%BC%89.jpg "scanf(″%d″,p++); printf(″\n″); for(i=0;i<10;i++,p++ ) printf(″%d″,*p); } 程序运行情况: ↙ 显然输出的数值并不是a数组中各元素的值.")
563
#include <stdio.h>
void main() { int*p,i,a[10]; p=a; for(i=0;i<10;i++) scanf(″%d″,p++); printg(″\n″); p=a; for(i=0;i<10;i++,p++ ) printf(″%d″,*p); }
 { int*p,i,a[10]; p=a; for(i=0;i<10;i++) scanf(″%d″,p++); printg(″\n″); p=a; for(i=0;i<10;i++,p++ ) printf(″%d″,*p); }")
564
10.3.3 用数组名作函数参数 在第8章8.7节中介绍过可以用数组名作函数的参数 如: void main()
10.3.3 用数组名作函数参数 在第8章8.7节中介绍过可以用数组名作函数的参数 如: void main() {if(int arr[],int n); int array[10]; ┇ f(array,10); } void f(int arr[ ],int n) { }
 {if(int arr[],int n); int array[10]; ┇ f(array,10); } void f(int arr[ ],int n) { }")
565
例10.7 将数组a中n个整数按相反顺序存放。

566
#include <stdio.h>
void main() { void inv(int x[ ],int n); int i,a[10]={3,7,9,11,0, 6,7,5,4,2}; printf(″The original array:\n″); for(i=0;i<10;i++) printf (″%d,″,a[i]); printf(″\n″); inv (a,10); printf(″The array has been in verted:\n″); for(i=0;i<10;i++) printf (″%d,″,a[i]); printf (″\n″); }
 { void inv(int x[ ],int n); int i,a[10]={3,7,9,11,0, 6,7,5,4,2}; printf(″The original array:\n″); for(i=0;i<10;i++) printf (″%d,″,a[i]); printf(″\n″); inv (a,10); printf(″The array has been in verted:\n″); for(i=0;i<10;i++) printf (″%d,″,a[i]); printf (″\n″); }")
567
void inv(int x[ ],int n) /*形参x是数组名*/
{ int temp,i,j,m=(n-1)/2; for(i=0;i<=m;i++) { j=n-1-i; temp=x[i]; x[i]=x[j]; x[j]=temp; } return; 运行情况如下: The original array: 3,7,9,11,0,6,7,5,4,2 The array has been inverted: 2,4,5,7,6,0,11,9,7,3
![void inv(int x[ ],int n) /*形参x是数组名*/](http://slidesplayer.com/slide/11113381/60/images/567/void+inv%EF%BC%88int+%EF%BD%98%EF%BC%BB+%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89+%2F%2A%E5%BD%A2%E5%8F%82x%E6%98%AF%E6%95%B0%E7%BB%84%E5%90%8D%2A%2F.jpg "{ int temp,i,j,m=(n-1)/2; for(i=0;i<=m;i++) { j=n-1-i; temp=x[i]; x[i]=x[j]; x[j]=temp; } return; 运行情况如下: The original array: 3,7,9,11,0,6,7,5,4,2. The array has been inverted: 2,4,5,7,6,0,11,9,7,3.")
569
对刚才的程序可以作一些改动。将函数inv中的形参x改成指针变量。
#include <stdio.h> void main() {void inv(int *x,int n); int i,a[10]={3,7,9,11,0, 6,7,5,4,2}; printf( ″The original array:\n″ ); for(i=0;i<10;i++) printf (″%d,″,a[i]); printf (″\n″); inv(a,10); printf ( ″The array has been in verted:\n″ ); printf (″%d,″,a[i]); printf (″\n″);}
 {void inv(int *x,int n); int i,a[10]={3,7,9,11,0, 6,7,5,4,2}; printf( ″The original array:\n″ ); for(i=0;i<10;i++) printf (″%d,″,a[i]); printf (″\n″); inv(a,10); printf ( ″The array has been in verted:\n″ ); printf (″%d,″,a[i]); printf (″\n″);}")
570
void inv(int *x,int n) /*形参x为指针变量*/
{intp,temp,*i,*j,m=(n-1)/2; i=x;j=x+n-1;p=x+m; for(;i<=p;i++,j--) {temp=*i;*i=*j;*j=temp;} return; }
/2; i=x;j=x+n-1;p=x+m; for(;i<=p;i++,j--) {temp=*i;*i=*j;*j=temp;} return; }")
571
如果有一个实参数组,想在函数中改变此数组中的元素的值,实参与形参的对应关系有以下4种情况:
(1) 形参和实参都用数组名,如: void main() void f(int x[ ],int n) { int a[10]; { … … f(a,10); } }
 形参和实参都用数组名,如: void main() void f(int x[ ],int n) { int a[10]; { … … f(a,10); } }")
573
(2) 实参用数组名,形参用指针变量。如: void main() void f(int *x,int n) {int a[10]; { … … f(a,10); } } (3)实参形参都用指针变量。例如: void main() void f(int *x,int n) {int a[10], *p=a; { ┇ ┇ f(p,10); } }
![(2) 实参用数组名,形参用指针变量。如: void main() void f(int *x,int n) {int a[10]; {](http://slidesplayer.com/slide/11113381/60/images/573/%282%29+%E5%AE%9E%E5%8F%82%E7%94%A8%E6%95%B0%E7%BB%84%E5%90%8D%EF%BC%8C%E5%BD%A2%E5%8F%82%E7%94%A8%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E3%80%82%E5%A6%82%EF%BC%9A+void+%EF%BD%8D%EF%BD%81%EF%BD%89%EF%BD%8E%EF%BC%88%EF%BC%89+void+%EF%BD%86%EF%BC%88int+%2A%EF%BD%98%EF%BC%8Cint+%EF%BD%8E%EF%BC%89+%EF%BD%9Bint+%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%EF%BC%9B+%7B.jpg "… … f(a,10); } } (3)实参形参都用指针变量。例如: void main() void f(int *x,int n) {int a[10], *p=a; { ┇ ┇ f(p,10); } }")
575
(4) 实参为指针变量,形参为数组名。如: void main() void f(int x[ ],int n) {int a[10],*p=a; { ┇ ┇ f(p,10); } }
![(4) 实参为指针变量,形参为数组名。如: void main() void f(int x[ ],int n) {int a[10],*p=a; {](http://slidesplayer.com/slide/11113381/60/images/575/%284%29+%E5%AE%9E%E5%8F%82%E4%B8%BA%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%EF%BC%8C%E5%BD%A2%E5%8F%82%E4%B8%BA%E6%95%B0%E7%BB%84%E5%90%8D%E3%80%82%E5%A6%82%EF%BC%9A+void+main%EF%BC%88%EF%BC%89+void+%EF%BD%86%EF%BC%88int+x%5B+%5D%EF%BC%8Cint+%EF%BD%8E%EF%BC%89+%EF%BD%9B%EF%BD%89%EF%BD%8E%EF%BD%94+%EF%BD%81%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%BD%2C%2Ap%3Da%EF%BC%9B+%7B.jpg "┇ ┇ f(p,10); } }")
576
#include <stdio.h>
void main() { void inv(int *x,int n); int i,arr[10],*p=arr; printf(″The original array:\n ″); for(i=0;i<10;i++,p++) scanf(″%d″,p); printf(″\n″); p=arr; inv(p,10); /* 实参为指针变量 */ printf(″The array has been inverted :\n″); for(p=arr;p<arr+10;p++ ) printf(″%d″,*p); printf(″\n″); }
 { void inv(int *x,int n); int i,arr[10],*p=arr; printf(″The original array:\n ″); for(i=0;i<10;i++,p++) scanf(″%d″,p); printf(″\n″); p=arr; inv(p,10); /* 实参为指针变量 */ printf(″The array has been inverted :\n″); for(p=arr;p<arr+10;p++ ) printf(″%d″,*p); printf(″\n″); }")
577
void inv(int *x,int n) {intp,m,temp,*i,*j; m=(n-1)/2; i=x;j=x+n-1;p=x+m; for(;i<=p;i++,j--) {temp=*i;*i=*j;*j=temp;} return; }

578
例10.9 用选择法对10个整数按由大到小顺序排序。
#include <stdio.h> void main() { void sort(int x[ ],int n); int*p,i,a[10]; p=a; for(i=0;i<10;i++) scanf(″%d″,p++); sort(p,10); for(p=a,i=0;i<10;i++) {printf(″%d″,*p);p++;} }
 { void sort(int x[ ],int n); int*p,i,a[10]; p=a; for(i=0;i<10;i++) scanf(″%d″,p++); sort(p,10); for(p=a,i=0;i<10;i++) {printf(″%d″,*p);p++;} }")
579
void sort(int x[ ],int n)
for(i=0;i<n-1;i++) {k=i; for(j=i+1;j<n;j++) if(x[j]>x[k]) k=j; if(k!=i) {t=x[i]; x[i]=x[k]; x[k]=t;} } }
![void sort(int x[ ],int n)](http://slidesplayer.com/slide/11113381/60/images/579/void+sort%EF%BC%88int+%EF%BD%98%5B+%5D%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "for(i=0;i<n-1;i++) {k=i; for(j=i+1;j<n;j++) if(x[j]>x[k]) k=j; if(k!=i) {t=x[i]; x[i]=x[k]; x[k]=t;} } }")
580
多维数组与指针 用指针变量可以指向一维数组中的元素,也可以指向多维数组中的元素。但在概念上和使用上,多维数组的指针比一维数组的指针要复杂一些。 1. 多维数组元素的地址 先回顾一下多维数组的性质,可以认为二维数组是“数组的数组”,例 : 定义int a[3][4]={{1,3,5,7},{9,11,13,15},{17,19,21,23}}; 则二维数组a是由3个一维数组所组成的。设二维数组的首行的首地址为2000 ,则

581
表 示 形 式 含义 地 址 a 二维数组名,指向一维数组a[0],即0行首地址 2000 a[0], *(a+0), *a 0行0列元素地址 a+1,&a[1] 1行首地址 2008 a[1],*(a+1) 1行0列元素a[1][0]的地址 A[1]+2, *(a+1)+2, &a[1][2] 1行2列元素a[1][2] 的地址 2012 *(a[1]+2), *(*(a+1)+2), a[1][2] 1行2列元素a[1][2]的值 元素值为13
![表 示 形 式 含义. 地 址. a. 二维数组名,指向一维数组a[0],即0行首地址 a[0], *(a+0), *a. 0行0列元素地址. a+1,&a[1] 1行首地址.](http://slidesplayer.com/slide/11113381/60/images/581/%E8%A1%A8+%E7%A4%BA+%E5%BD%A2+%E5%BC%8F+%E5%90%AB%E4%B9%89.+%E5%9C%B0+%E5%9D%80.+a.+%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E5%90%8D%EF%BC%8C%E6%8C%87%E5%90%91%E4%B8%80%E7%BB%B4%E6%95%B0%E7%BB%84a%5B0%EF%BC%BD%EF%BC%8C%E5%8D%B30%E8%A1%8C%E9%A6%96%E5%9C%B0%E5%9D%80+a%5B0%EF%BC%BD%2C+%2A%28a%2B0%29%2C+%2Aa.+0%E8%A1%8C0%E5%88%97%E5%85%83%E7%B4%A0%E5%9C%B0%E5%9D%80.+a%2B1%EF%BC%8C%26a%EF%BC%BB1%EF%BC%BD+1%E8%A1%8C%E9%A6%96%E5%9C%B0%E5%9D%80..jpg "2008. a[1],*(a+1) 1行0列元素a[1][0]的地址. A[1]+2, *(a+1)+2, &a[1][2] 1行2列元素a[1][2] 的地址 *(a[1]+2), *(*(a+1)+2), a[1][2] 1行2列元素a[1][2]的值. 元素值为13.")
582
例10.10 输出二维数组有关的值 #include <stdio.h> #define FROMAT ″%d,%d\n″
void main() { int a[3][4]={1,3,5,7,9,11,13, 15,17,19,21,23}; printf(FORMAT,a,*a); printf(FORMAT,a[0] , *(a+0)); printf(FORMAT,&a[0],&a[0][0]); printf(FORMAT,a[1],a+1); printf(FORMAT,&a[1][0],*(a+1)+0); printf(FORMAT,a[2],*(a+2)); printf(FORMAT,&a[2],a+2); printf(FORMAT,a[1][0],*(*(a+ 1)+0)); }
 { int a[3][4]={1,3,5,7,9,11,13, 15,17,19,21,23}; printf(FORMAT,a,*a); printf(FORMAT,a[0] , *(a+0)); printf(FORMAT,&a[0],&a[0][0]); printf(FORMAT,a[1],a+1); printf(FORMAT,&a[1][0],*(a+1)+0); printf(FORMAT,a[2],*(a+2)); printf(FORMAT,&a[2],a+2); printf(FORMAT,a[1][0],*(*(a+ 1)+0)); }")
583
某一次运行结果如下: 158,158 (0行首地址和0行0列元素地址) 158,158 (0行0列元素地址) 158,158 (0行0首地址和0行0列元素地址) 166,166 (1行0列元素地址和1行首地址) 166,166 (1行0列元素地址) 174,174 (2行0列元素地址) 174,174 (2行首地址) 9,9 (1行0列元素的值)
 166,166 (1行0列元素地址) 174,174 (2行0列元素地址) 174,174 (2行首地址) 9,9 (1行0列元素的值)")
584
2 . 指向多维数组元素的指针变量 (1) 指向数组元素的指针变量 例10.11 用指针变量输出二维数组元素的值 #include <stdio.h> void main() { int a[3][4]={1,3,5,7,9,11,13,15,17,19,21,23}; int*p; for(p=a[0];p<a[0]+12;p++) {if((p-a[0])%4==0) printf(″\n″); printf(″%4d″,*p); } } 运行结果如下:
![2 . 指向多维数组元素的指针变量 (1) 指向数组元素的指针变量. 例10.11 用指针变量输出二维数组元素的值. #include <stdio.h> void main() { int a[3][4]={1,3,5,7,9,11,13,15,17,19,21,23};](http://slidesplayer.com/slide/11113381/60/images/584/2+.+%E6%8C%87%E5%90%91%E5%A4%9A%E7%BB%B4%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F+%281%29+%E6%8C%87%E5%90%91%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F.+%E4%BE%8B10.11+%E7%94%A8%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E8%BE%93%E5%87%BA%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84%E5%85%83%E7%B4%A0%E7%9A%84%E5%80%BC.+%23include+%3Cstdio.h%3E+void+main%EF%BC%88%EF%BC%89+%EF%BD%9B+int+%EF%BD%81%5B3%5D%5B4%5D%EF%BC%9D%EF%BD%9B1%2C3%2C5%2C7%2C9%2C11%2C13%2C15%2C17%2C19%2C21%2C23%EF%BD%9D%EF%BC%9B.jpg "int*p; for(p=a[0];p<a[0]+12;p++) {if((p-a[0])%4==0) printf(″\n″); printf(″%4d″,*p); } } 运行结果如下:")
585
(2) 指向由m个元素组成的一维数组的指针变量
例10.13 出二维数组任一行任一列元素的值 #include <stdio.h> void main ( ) { int a[3][4]={1,3,5,7,9,11, 13,15,17,19,21,23}; int (*p)[4],i,j; p=a; scanf(″ i=%d,j=%d″,&i,&j); printf(″a[%d,%d]=%d\n″,i, j,*(*(p+i)+j)); } 运行情况如下: i=1,j=2↙(本行为键盘输入) a[1,2]=13
 { int a[3][4]={1,3,5,7,9,11, 13,15,17,19,21,23}; int (*p)[4],i,j; p=a; scanf(″ i=%d,j=%d″,&i,&j); printf(″a[%d,%d]=%d\n″,i, j,*(*(p+i)+j)); } 运行情况如下: i=1,j=2↙(本行为键盘输入) a[1,2]=13.")
586
3. 用指向数组的指针作函数参数 例 有一个班,3个学生,各学4门课,计算总平均分数以及第n个学生的成绩。这个题目是很简单的。只是为了说明用指向数组的指针作函数参数而举的例子。用函数average求总平均成绩,用函数search找出并输出第i个学生的成绩。

587
#include <sydio.h>
void main() { void average(float *p,int n); void search(float (*p)[4],int n); float score[3][4]={{65,67,70,60},{80, 87,90,81},{90,99,100,98}}; average(*score,12);/*求12个分数的平均分*/ search(score,2);/*求序号为2的学生的成绩*/ }
 { void average(float *p,int n); void search(float (*p)[4],int n); float score[3][4]={{65,67,70,60},{80, 87,90,81},{90,99,100,98}}; average(*score,12);/*求12个分数的平均分*/ search(score,2);/*求序号为2的学生的成绩*/ }")
588
void average(float *p,int n)
float sum=0,aver; p_end=p+n-1; for(;p<=p_end;p++) sum=sum+(*p); aver=sum/n; printf(″average=%5.2f\n″,aver); }
 sum=sum+(*p); aver=sum/n; printf(″average=%5.2f\n″,aver); }")
589
void search(float (*p)[4],int n)
/ * p是指向具有4个元素的一维数组的指针 */{int i; printf(″the score of No. %d are:\n″,n); for(i=0;i<4;i++) printf(″%5.2f″,*(*(p+n)+i)); } 程序运行结果如下: average=82.25 The score of No.2 are: 90.00 99.00 100.00 98.00
![void search(float (*p)[4],int n)](http://slidesplayer.com/slide/11113381/60/images/589/void+search%EF%BC%88float+%28%2A%EF%BD%90%29%5B4%5D%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "/ * p是指向具有4个元素的一维数组的指针 */{int i; printf(″the score of No. %d are:\n″,n); for(i=0;i<4;i++) printf(″%5.2f″,*(*(p+n)+i)); } 程序运行结果如下: average=82.25. The score of No.2 are: 90.00 99.00 100.00 98.00.")
590
例10.14 在上题基础上,查找有一门以上课程不及格的学生,打印出他们的全部课程的成绩。
#include <stdio.h> void main() {void search(float (*p)[4],int n);/*函数声明*/ float score[3][4]={{65,57,70,60},{58,87, 90,81},{90,99,100,98}}; search(score,3); }
 {void search(float (*p)[4],int n);/*函数声明*/ float score[3][4]={{65,57,70,60},{58,87, 90,81},{90,99,100,98}}; search(score,3); }")
591
void search(float (*p)[4],int n)
for(j=0;j<n;j++) {flag=0; for(i=0;i<4;i++) if(*(*(p+j)+i)<60) flag=1; if(flag==1) { printf("No.%d fails,his scores are:\n",j+1); for(i=0;i<4;i++) printf(″%5.1f″,*(*(p+j)+i)); printf(″\n″); } } } 程序运行结果如下: No.1 fails, his scores are: 65.0 57.0 70.0 60.0 No.2 fails, his scores are: 58.0 87.0 90.0 81.0
![void search(float (*p)[4],int n)](http://slidesplayer.com/slide/11113381/60/images/591/void+search%EF%BC%88float+%28%2Ap%29%EF%BC%BB4%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "for(j=0;j<n;j++) {flag=0; for(i=0;i<4;i++) if(*(*(p+j)+i)<60) flag=1; if(flag==1) { printf( No.%d fails,his scores are:\n ,j+1); for(i=0;i<4;i++) printf(″%5.1f″,*(*(p+j)+i)); printf(″\n″); } } } 程序运行结果如下: No.1 fails, his scores are: 65.0 57.0 70.0 60.0. No.2 fails, his scores are: 58.0 87.0 90.0 81.0.")
592
(1) 用字符数组存放一个字符串,然后输出该字符串。
10.4 字符串与指针 10.4.1字符串的表示形式 (1) 用字符数组存放一个字符串,然后输出该字符串。 例 10.15 定义一个字符数组,对它初始化, 然后输出该字符串 #include <stdio.h> void main() {char string[]=″I love China!″; printf(″%s\n″,string); }
 用字符数组存放一个字符串,然后输出该字符串。 例 10.15 定义一个字符数组,对它初始化, 然后输出该字符串. #include <stdio.h> void main() {char string[]=″I love China!″; printf(″%s\n″,string); }")
593
(2) 用字符指针指向一个字符串。 可以不定义字符数组,而定义一个字符指针。用字符指针指向字符串中的字符。 例10.16 定义字符指针 #include <stdio.h> void main() {charstring=″ I love China!″; printf(″%s\n″,string); }
; }")
594
例10.17 将字符串a复制为字符串b。 #include <stdio.h> void main() {char a[ ]=″I am a boy.″,b[20]; int i; for(i=0;*(a+i)!=′\0′;i++) *(b+i)=*(a+i); *(b+i)=′\0′; printf(″string a is :%s\n″,a); printf(″string b is:″); for(i=0;b[i]!=′\0′;i++) printf(″%c″,b[i]); printf(″\n″); }
![例10.17 将字符串a复制为字符串b。 #include <stdio.h> void main() {char a[ ]=″I am a boy.″,b[20]; int i; for(i=0;*(a+i)!=′\0′;i++)](http://slidesplayer.com/slide/11113381/60/images/594/%E4%BE%8B10.%EF%BC%917+%E5%B0%86%E5%AD%97%E7%AC%A6%E4%B8%B2%EF%BD%81%E5%A4%8D%E5%88%B6%E4%B8%BA%E5%AD%97%E7%AC%A6%E4%B8%B2%EF%BD%82%E3%80%82+%23include+%3Cstdio.h%3E+void+%EF%BD%8D%EF%BD%81%EF%BD%89%EF%BD%8E%EF%BC%88%EF%BC%89+%EF%BD%9Bchar+%EF%BD%81%5B+%5D%EF%BC%9D%E2%80%B3%EF%BC%A9+am+a+boy%EF%BC%8E%E2%80%B3%EF%BC%8C%EF%BD%82%5B20%5D%EF%BC%9B+int+%EF%BD%89%EF%BC%9B+for%EF%BC%88%EF%BD%89%EF%BC%9D%EF%BC%90%EF%BC%9B%2A%EF%BC%88%EF%BD%81%EF%BC%8B%EF%BD%89%EF%BC%89%EF%BC%81%EF%BC%9D%E2%80%B2%EF%BC%BC%EF%BC%90%E2%80%B2%EF%BC%9B%EF%BD%89%EF%BC%8B%EF%BC%8B%EF%BC%89.jpg "*(b+i)=*(a+i); *(b+i)=′\0′; printf(″string a is :%s\n″,a); printf(″string b is:″); for(i=0;b[i]!=′\0′;i++) printf(″%c″,b[i]); printf(″\n″); }")
595
也可以设指针变量,用它的值的改变来指向字符串中的不同的字符。
例10.18 用指针变量来处理例10.17问题。 #include <stdio.h> void main() {char a[ ] =″I am a boy. ″,b[20],*p1,*p2; int i; p1=a;p2=b; for(;*p1!=′\0′;p1++,p2++)
 {char a[ ] =″I am a boy. ″,b[20],*p1,*p2; int i; p1=a;p2=b; for(;*p1!=′\0′;p1++,p2++)")
596
*p2=*p1; *p2=′\0′; printf(″string a is:%s\n″,a); printf(″string b is:″); for(i=0;b[i]!=′\0′;i++) printf(″%c″,b[i]); printf(″\n″); } 程序必须保证使p1和p2同步移动
![*p2=*p1; *p2=′\0′; printf(″string a is:%s\n″,a); printf(″string b is:″); for(i=0;b[i]!=′\0′;i++)](http://slidesplayer.com/slide/11113381/60/images/596/%2A%EF%BD%90%EF%BC%92%EF%BC%9D%2A%EF%BD%90%EF%BC%91%EF%BC%9B+%2A%EF%BD%90%EF%BC%92%EF%BC%9D%E2%80%B2%EF%BC%BC%EF%BC%90%E2%80%B2%EF%BC%9B+printf%EF%BC%88%E2%80%B3string+%EF%BD%81+is%EF%BC%9A%EF%BC%85%EF%BD%93%EF%BC%BC%EF%BD%8E%E2%80%B3%EF%BC%8C%EF%BD%81%EF%BC%89%EF%BC%9B+printf%EF%BC%88%E2%80%B3%EF%BD%93%EF%BD%94%EF%BD%92%EF%BD%89%EF%BD%8E%EF%BD%87+%EF%BD%82+%EF%BD%89%EF%BD%93%EF%BC%9A%E2%80%B3%EF%BC%89%EF%BC%9B+for%EF%BC%88%EF%BD%89%EF%BC%9D%EF%BC%90%EF%BC%9B%EF%BD%82%EF%BC%BB%EF%BD%89%EF%BC%BD%EF%BC%81%EF%BC%9D%E2%80%B2%EF%BC%BC%EF%BC%90%E2%80%B2%EF%BC%9B%EF%BD%89%EF%BC%8B%EF%BC%8B%EF%BC%89.jpg "printf(″%c″,b[i]); printf(″\n″); } 程序必须保证使p1和p2同步移动.")
598
10.4.2 字符指针作函数参数 (1) 用字符数组作参数 例10.19 用函数调用实现字符串的复制
(1) 用字符数组作参数 例 用函数调用实现字符串的复制 #include <stdio.h> void main() { void copy_string(char from[ ], char to[ ]); char a[ ]=″I am a teacher.″; char b[ ]=″you are a student.″; printf(“string a=%s\n string b=%s\n″, a,b); printf(“copy string a to string b:\n ”); copy_string (a,b); printf("\nstring a=%s\nstring b=%s\n",a,b); }
 用字符数组作参数. 例10.19 用函数调用实现字符串的复制. #include <stdio.h> void main() { void copy_string(char from[ ], char to[ ]); char a[ ]=″I am a teacher.″; char b[ ]=″you are a student.″; printf( string a=%s\n string b=%s\n″, a,b); printf( copy string a to string b:\n ); copy_string (a,b); printf( \nstring a=%s\nstring b=%s\n ,a,b); }")
599
void copy_string(char from[ ], char to[ ])
{ int i=0; while(from[i]!=′\0′) {to[i]=from[i];i++;} to[i]=′\0′; } 程序运行结果如下: string a=I am a teacher. string b =you are a student. copy string a to string b: string a =I am a teacher. stringb=I am a teacher.
![void copy_string(char from[ ], char to[ ])](http://slidesplayer.com/slide/11113381/60/images/599/void+copy_string%EF%BC%88char+from%EF%BC%BB+%EF%BC%BD%EF%BC%8C+char+to%EF%BC%BB+%EF%BC%BD%EF%BC%89.jpg "{ int i=0; while(from[i]!=′\0′) {to[i]=from[i];i++;} to[i]=′\0′; } 程序运行结果如下: string a=I am a teacher. string b =you are a student. copy string a to string b: string a =I am a teacher. stringb=I am a teacher.")
600
(2) 形参用字符指针变量 #include <stdio.h> void main() { void copy_string(char * from, char *to); char *a=″I am a teacher .″; char *b=″you are a student .″; printf("string a=%s\nstring b=%s\n″,a,b); printf("copy string a to string b:\n "); copy_string(a,b); printf("\nstring a=%s\nstring b=%s\n",a,b); }
; printf( copy string a to string b:\n ); copy_string(a,b); printf( \nstring a=%s\nstring b=%s\n ,a,b); }")
601
(3) 对copy string 函数还可作简化
void copy_string(char *from,char *to) { for(;*from!=′\0′;from++,to++) *to=from; *to=′\0′; } (3) 对copy string 函数还可作简化 1、将copy_string函数改写为 void copy_string (char *from,char *to) {while((*to=*from)!=′\0′) {to++;from++;} }
 { for(;*from!=′\0′;from++,to++) *to=from; *to=′\0′; } (3) 对copy string 函数还可作简化. 1、将copy_string函数改写为. void copy_string (char *from,char *to) {while((*to=*from)!=′\0′) {to++;from++;} }")
602
• copy_string函数的函数体还可改为
{ while((*to++=*from++)!=′\0′); } •copy_string函数的函数体还可写成 { while(*from!=′\0′) *to++=*from++; *to=′\0′; }
!=′\0′); } •copy_string函数的函数体还可写成. { while(*from!=′\0′) *to++=*from++; *to=′\0′; }")
603
•上面的while语句还可以进一步简化为下面的while语句:
while(*to++=*from++); 它与下面语句等价: while((*to++=*from++)!=′\0′); 将*from赋给*to,如果赋值后的*to值等于′\0′则循环终止(′\0′已赋给*to) •函数体中while语句也可以改用for语句: for(;(*to++=*from++)!=0;); 或 for(;*to++=*from++;);
; 它与下面语句等价: while((*to++=*from++)!=′\0′); 将*from赋给*to,如果赋值后的*to值等于′\0′则循环终止(′\0′已赋给*to) •函数体中while语句也可以改用for语句: for(;(*to++=*from++)!=0;); 或. for(;*to++=*from++;);")
604
•也可用指针变量,函数copy_string可写为
void copy_string (char from[ ],char to[ ]) {char*p1,*p2; p1=from;p2=to; while((*p2++=*p1++)!=′\0′); }
 {char*p1,*p2; p1=from;p2=to; while((*p2++=*p1++)!=′\0′); }")
605
10.4.3 对使用字符指针变量和字符数组的讨论 字符数组和字符指针变量二者之间的区别:
(1) 字符数组由若干个元素组成,每个元素中放一个字符,而字符指针变量中存放的是地址(字符串第1个字符的地址),决不是将字符串放到字符指针变量中。 (2)赋值方式。对字符数组只能对各个元素赋值,不 能用以下办法对字符数组赋值。 char str[14]; str=″I love China!″; 而对字符指针变量,可以采用下面方法赋值: char*a; a=″I love China!″;
 字符数组由若干个元素组成,每个元素中放一个字符,而字符指针变量中存放的是地址(字符串第1个字符的地址),决不是将字符串放到字符指针变量中。 (2)赋值方式。对字符数组只能对各个元素赋值,不. 能用以下办法对字符数组赋值。 char str[14]; str=″I love China!″; 而对字符指针变量,可以采用下面方法赋值: char*a; a=″I love China!″;")
606
(3)对字符指针变量赋初值: char *a=″I love China!″;等价于 char*a; a=″I love Chian!″; 而对数组的初始化: char str[14]={″I love China!″}; 不能等价于 char str[14]; str[ ]=″I love China!″;
![(3)对字符指针变量赋初值: char *a=″I love China!″;等价于. char*a; a=″I love Chian!″; 而对数组的初始化: char str[14]={″I love China!″};](http://slidesplayer.com/slide/11113381/60/images/606/%283%29%E5%AF%B9%E5%AD%97%E7%AC%A6%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E8%B5%8B%E5%88%9D%E5%80%BC%EF%BC%9A+char+%2A%EF%BD%81%EF%BC%9D%E2%80%B3%EF%BC%A9+love+China%EF%BC%81%E2%80%B3%EF%BC%9B%E7%AD%89%E4%BB%B7%E4%BA%8E.+char%EE%80%92%2A%EF%BD%81%EF%BC%9B+%EF%BD%81%EF%BC%9D%E2%80%B3I+love+Chian%EF%BC%81%E2%80%B3%EF%BC%9B+%E8%80%8C%E5%AF%B9%E6%95%B0%E7%BB%84%E7%9A%84%E5%88%9D%E5%A7%8B%E5%8C%96%EF%BC%9A+char+str%EF%BC%BB%EF%BC%91%EF%BC%94%EF%BC%BD%EF%BC%9D%EF%BD%9B%E2%80%B3%EF%BC%A9+love+China%EF%BC%81%E2%80%B3%EF%BD%9D%3B.jpg "不能等价于. char str[14]; str[ ]=″I love China!″;")
607
(4) 定义了一个字符数组,在编译时为它分配内存单元,它有确定的地址。而定义一个字符指针变量时,给指针变量分配内存单元,在其中可以放一个字符变量的地址。
例如: char str[10]; scanf(″%s″,str);
;")
608
#include <stdio.h> void main() {char*a=″I love China!″; a=a+7;
(5) 指针变量的值是可以改变的,例如: 例10.20 改变指针变量的值 #include <stdio.h> void main() {char*a=″I love China!″; a=a+7; printf(″%s″,a); }
 指针变量的值是可以改变的,例如: 例10.20 改变指针变量的值. #include <stdio.h> void main() {char*a=″I love China!″; a=a+7; printf(″%s″,a); }")
609
若定义了一个指针变量,并使它指向一个字符串,就可以用下标形式引用指针变量所指的字符串中的字符。例如:
#include <stdio.h> void main() {char*a=″I love China!″; int i; printf ( “ The sixth character is %c\n",a[5]); for(i=0;a[i]!=′\0′;i++) printf(″%c″,a[i]); }
 {char*a=″I love China!″; int i; printf ( The sixth character is %c\n ,a[5]); for(i=0;a[i]!=′\0′;i++) printf(″%c″,a[i]); }")
610
10.5 指向函数的指针 10.5.1 用函数指针变量调用函数 用指针变量可以指向一个函数。
函数在编译时被分配给一个入口地址。这个函数的入口地址就称为函数的指针。

611
#include <stdio.h>
void main() { int max(int,int); int a,b,c; scanf(″%d,%d″,&a,&b); c=max(a,b); printf(″a=%d,b=%d,max=%d ″,a,b,c); } int max(int x,int y) { int z; if(x>y)z=x; else z=y; return(z);
 { int max(int,int); int a,b,c; scanf(″%d,%d″,&a,&b); c=max(a,b); printf(″a=%d,b=%d,max=%d. ″,a,b,c); } int max(int x,int y) { int z; if(x>y)z=x; else z=y; return(z);")
612
将 main 函数改写为 #include <stdio.h> void main() { int max(int,int); int (*p)(); int a,b,c; p=max; scanf(″%d,%d″,&a,&b); c=(*p)(a,b); printf(″a=%d,b=%d,max=% d″,a,b,c); }
; c=(*p)(a,b); printf(″a=%d,b=%d,max=% d″,a,b,c); }")
613
用指向函数的指针作函数参数 函数指针变量常用的用途之一是把指针作为参数传递到其他函数。指向函数的指针也可以作为参数,以实现函数地址的传递,这样就能够在被调用的函数中使用实参函数。

614
实参函数名 f f2 ↓ ↓ void sub(int (*x1)(int),int (*x2)(int,int)) { int a,b,i,j; a=(*x1)(i); /*调用f1函数*/ b=(*x2)(i,j);/*调用f2函数*/ … }
(i); /*调用f1函数*/ b=(*x2)(i,j);/*调用f2函数*/ … }")
615
例10.23 设一个函数process,在调用它的时候,每次实现不同的功能。输入a和b两个数,第一次调用process时找出a和b中大者,第二次找出其中小者,第三次求a与b之和。
#include <stdio.h> void main() { int max(int,int); /* 函数声明 */ int min(int,int); /* 函数声明 */ int add(int,int); /* 函数声明 */ void process (int , int , int(*fun)(); /* 函数声明 */ int a,b; printf(″enter a and b:″); scanf(″%d,%d″,&a,&b);
 { int max(int,int); /* 函数声明 */ int min(int,int); /* 函数声明 */ int add(int,int); /* 函数声明 */ void process (int , int , int(*fun)(); /* 函数声明 */ int a,b; printf(″enter a and b:″); scanf(″%d,%d″,&a,&b);")
616
printf(″max=″); process(a,b,max); printf(″min=″); process(a,b,min); printf(″sum=″); process(a,b,add); }

617
int max(int x,int y) /* 函数定义 */
if(x>y)z=x; else z=y; return(z); } int min(int x,int y) /* 函数定义 */ { int z; if(x<y)z=x; else z=y; return(z);
z=x; else z=y; return(z); } int min(int x,int y) /* 函数定义 */ { int z; if(x<y)z=x; else z=y; return(z);")
618
int add(int x,int y) /* 函数定义 */
z=x+y; return(z); } void process(int x,int y,int (*fun)(int,int)) { int result; result=(*fun)(x,y); printf(″%d\n″, result);
; } void process(int x,int y,int (*fun)(int,int)) { int result; result=(*fun)(x,y); printf(″%d\n″, result);")
619
10.6 返回指针值的函数 一个函数可以带回一个整型值、字符值、实型值等,也可以带回指针型的数据,即地址。其概念与以前类似,只是带回的值的类型是指针类型而已。 这种带回指针值的函数,一般定义形式为 类型名 *函数名(参数表列); 例如: int *a(int x,int y);
; 例如: int *a(int x,int y);")
620
例10.24 有若干个学生的成绩(每个学生有4门课程),要求在用户输入学生序号以后,能输出该学生的全部成绩。用指针函数来实现。
#include <stdio.h> void main() {float *score[ ][4]={{60,70,80,90}, {56,89,67,88},{34,78,90,66}}; float*search(float (*pointer)[4],int n); float*p; int i,m; printf(″enter the number of student:″); scanf(″%d″,&m); printf(″The scores of No.%d are:\n″,m);
 {float *score[ ][4]={{60,70,80,90}, {56,89,67,88},{34,78,90,66}}; float*search(float (*pointer)[4],int n); float*p; int i,m; printf(″enter the number of student:″); scanf(″%d″,&m); printf(″The scores of No.%d are:\n″,m);")
621
p=search(score,m); for(i=0;i<4;i++= printf(″%5.2f\t″,*(p+i)); } float * search(float (*pointer)[4],int n) { float *pt; pt=*(pointer+n); return(pt); 运行情况如下: enter the number of student:1↙ The scores of No. 1 are:
![p=search(score,m); for(i=0;i<4;i++= printf(″%5.2f\t″,*(p+i)); } float * search(float (*pointer)[4],int n)](http://slidesplayer.com/slide/11113381/60/images/621/%EF%BD%90%EF%BC%9Dsearch%EF%BC%88%EF%BD%93%EF%BD%83%EF%BD%8F%EF%BD%92%EF%BD%85%EF%BC%8C%EF%BD%8D%EF%BC%89%EF%BC%9B+for%EF%BC%88%EF%BD%89%EF%BC%9D%EF%BC%90%EF%BC%9B%EF%BD%89%EF%BC%9C%EF%BC%94%EF%BC%9B%EF%BD%89%EF%BC%8B%EF%BC%8B%EF%BC%9D+printf%EF%BC%88%E2%80%B3%EF%BC%85%EF%BC%95%EF%BC%8E%EF%BC%92%EF%BD%86%EF%BC%BC%EF%BD%94%E2%80%B3%EF%BC%8C%2A%EF%BC%88%EF%BD%90%EF%BC%8B%EF%BD%89%EF%BC%89%EF%BC%89%EF%BC%9B+%EF%BD%9D+float+%2A+search%EF%BC%88float+%28%2A%EF%BD%90%EF%BD%8F%EF%BD%89%EF%BD%8E%EF%BD%94%EF%BD%85%EF%BD%92%29%EF%BC%BB4%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "{ float *pt; pt=*(pointer+n); return(pt); 运行情况如下: enter the number of student:1↙ The scores of No. 1 are:")
622
例10.25 对上例中的学生,找出其中有不及格课程的学生及其学生号。
#include <stdio.h> void main() {float score[ ][4]={{60,70,80,90},{56, 89,67,88},{34,78,90,66}}; float search(float (*pointer)[4]); float*p; int i,j;
 {float score[ ][4]={{60,70,80,90},{56, 89,67,88},{34,78,90,66}}; float search(float (*pointer)[4]); float*p; int i,j;")
623
for(i=0;i<3;i++) {p=search(score +i); if(p==*(score+i)) {printf(″No.%d scores:″,i); for(j=0;j<4;j++) printf(″%5.2f″,*(p+j)); printf(″\n″);} } }
); printf(″\n″);} } }")
624
10.7 指针数组和指向指针的指针 指针数组的概念 一个数组,若其元素均为指针类型数据,称为指针数组,也就是说,指针数组中的每一个元素都相当于一个指针变量。 一维指针数组的定义形式为: 类型名数组名[数组长度]; 例如: int*p[4];

626
例10.26 将若干字符串按字母顺序(由小到大)输出。
例10.26 将若干字符串按字母顺序(由小到大)输出。 #include <stdio.h> #include <string.h> void main() {void sort(char *name[ ],int n); void printf(char *name[ ],int n); char *name[ ]={"Follow me","BASIC","Great Wall″,"FORTRAN","Computer design"}; int n=5; sort(name,n); print(name,n); }
输出。 #include <stdio.h> #include <string.h> void main() {void sort(char *name[ ],int n); void printf(char *name[ ],int n); char *name[ ]={ Follow me , BASIC , Great Wall″, FORTRAN , Computer design }; int n=5; sort(name,n); print(name,n); }")
627
void sort(char *name[ ],int n)
for(i=0;i<n-1;i++= {k=i; for(j=i+1;j<n;j++= if(strcmp(name[k],name[j])>0)k=j; if(k!=i) temp=name[i]; name[i]=name[k]; name[k]=temp;} } }
![void sort(char *name[ ],int n)](http://slidesplayer.com/slide/11113381/60/images/627/void+sort%EF%BC%88char+%2A%EF%BD%8E%EF%BD%81%EF%BD%8D%EF%BD%85%EF%BC%BB+%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "for(i=0;i<n-1;i++= {k=i; for(j=i+1;j<n;j++= if(strcmp(name[k],name[j])>0)k=j; if(k!=i) temp=name[i]; name[i]=name[k]; name[k]=temp;} } }")
628
void print(char *name[ ],int n)
{int i; for(i=0;i<n;i++) printf(″%s\n″,name[i]); } 运行结果为: BASIC Computer design FORTRAN Follow me Great Wall
![void print(char *name[ ],int n)](http://slidesplayer.com/slide/11113381/60/images/628/void+print%EF%BC%88char+%2A%EF%BD%8E%EF%BD%81%EF%BD%8D%EF%BD%85%EF%BC%BB+%EF%BC%BD%EF%BC%8Cint+%EF%BD%8E%EF%BC%89.jpg "{int i; for(i=0;i<n;i++) printf(″%s\n″,name[i]); } 运行结果为: BASIC. Computer design. FORTRAN. Follow me. Great Wall.")
629
10.7.2 指向指针的指针 定义一个指向指针数据的指针变量: char**p;
指向指针的指针 定义一个指向指针数据的指针变量: char**p; p的前面有两个*号。*运算符的结合性是从右到左,因此**p相当于*(*p),显然*p是指针变量的定义形式。如果没有最前面的*,那就是定义了一个指向字符数据的指针变量。现在它前面又有一个*号,表示指针变量p是指向一个字符指针变量的。*p就是p所指向的另一个指针变量。
,显然*p是指针变量的定义形式。如果没有最前面的*,那就是定义了一个指向字符数据的指针变量。现在它前面又有一个*号,表示指针变量p是指向一个字符指针变量的。*p就是p所指向的另一个指针变量。")
630
例10.27 使用指向指针的指针。 #include <stdio.h> void main() {char *name[]={"Follow me","BASIC","Great Wall″,"FORTRAN","Computer design"}; char **p; int i; for(i=0;i<5;i++) {p=name+i; printf(″%s\n″,*p); }
![例10.27 使用指向指针的指针。 #include <stdio.h> void main() {char *name[]={ Follow me , BASIC , Great. Wall″, FORTRAN , Computer design };](http://slidesplayer.com/slide/11113381/60/images/630/%E4%BE%8B10.%EF%BC%927+%E4%BD%BF%E7%94%A8%E6%8C%87%E5%90%91%E6%8C%87%E9%92%88%E7%9A%84%E6%8C%87%E9%92%88%E3%80%82+%23include+%3Cstdio.h%3E+void+main%EF%BC%88%EF%BC%89+%EF%BD%9Bchar+%2Aname%EF%BC%BB%EF%BC%BD%3D%7B+Follow+me+%EF%BC%8C+BASIC+%EF%BC%8C+Great.+Wall%E2%80%B3%EF%BC%8C+FORTRAN+%EF%BC%8C+Computer+design+%7D%3B.jpg "char **p; int i; for(i=0;i<5;i++) {p=name+i; printf(″%s\n″,*p); }")
631
例10.28 一个指针数组的元素指向整型数据的简单例子。
例 一个指针数组的元素指向整型数据的简单例子。 #include <stdio.h> void main() {int a[5]={1,3,5,7,9}; int *num[5]={&a[0],&a[1], &a[2],&a[3],&a[4]}; int **p,i; p=num; for(i=0;i<5;i++= { printf(″%d ″,**p); p++; }
 {int a[5]={1,3,5,7,9}; int *num[5]={&a[0],&a[1], &a[2],&a[3],&a[4]}; int **p,i; p=num; for(i=0;i<5;i++= { printf(″%d ″,**p); p++; }")
632
指针数组作main函数的形参 指针数组的一个重要应用是作为main函数的形参。在以往的程序中,main函数的第一行一般写成以下形式:void main()括弧中是空的。 main函数可以有参数,例如: void main(int argc,char *argv[ ])。 命令行的一般形式为命令名 参数1 参数2……参数n
。 命令行的一般形式为命令名 参数1 参数2……参数n.")
633
例如一个名为file1的文件,它包含以下的main函数:
void main(int argc,char *argv[ ]) {while(argc>1) {++argv; printf(″%s\n″,argv); --argc; } 在DOS命令状态下输入的命令行为 file1 China Beijing 则执行以上命令行将会输出以下信息: China Beijing
 {while(argc>1) {++argv; printf(″%s\n″,argv); --argc; } 在DOS命令状态下输入的命令行为. file1 China Beijing. 则执行以上命令行将会输出以下信息: China. Beijing.")
634
10.8有关指针的数据类型和 指针运算的小结 10.8.1有关指针的数据类型的小结

635
定义 含义 int i; 定义整型变量i int*p; p为指向整型数据的指针变量 int a[n]; 定义整型数组a,它有n个元素 int *p[n]; 定义指针数组p,它由n个指向整型数据的指针元素组成 int (*p)[n]; p为指向含n个元素的一维数组的指针变量 int f(); f为带回整型函数值的函数 int *p(); p为带回一个指针的函数,该指针指向整型数据 int (*p)(); p为指向函数的指针,该函数返回一个整型值 int **p; p是一个指针变量,它指向一个指向整型数据的指针变量
![定义 含义. int i; 定义整型变量i. int*p; p为指向整型数据的指针变量. int a[n]; 定义整型数组a,它有n个元素. int *p[n]; 定义指针数组p,它由n个指向整型数据的指针元素组成.](http://slidesplayer.com/slide/11113381/60/images/635/%E5%AE%9A%E4%B9%89+%E5%90%AB%E4%B9%89.+%EF%BD%89%EF%BD%8E%EF%BD%94+%EF%BD%89%EF%BC%9B+%E5%AE%9A%E4%B9%89%E6%95%B4%E5%9E%8B%E5%8F%98%E9%87%8F%EF%BD%89.+%EF%BD%89%EF%BD%8E%EF%BD%94%EE%80%92%2A%EF%BD%90%EF%BC%9B+%EF%BD%90%E4%B8%BA%E6%8C%87%E5%90%91%E6%95%B4%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%9A%84%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F.+int+a%EF%BC%BBn%EF%BC%BD%3B+%E5%AE%9A%E4%B9%89%E6%95%B4%E5%9E%8B%E6%95%B0%E7%BB%84%EF%BD%81%EF%BC%8C%E5%AE%83%E6%9C%89%EF%BD%8E%E4%B8%AA%E5%85%83%E7%B4%A0.+%EF%BD%89%EF%BD%8E%EF%BD%94+%EE%80%92%2A%EF%BD%90%EF%BC%BB%EF%BD%8E%EF%BC%BD%EF%BC%9B+%E5%AE%9A%E4%B9%89%E6%8C%87%E9%92%88%E6%95%B0%E7%BB%84%EF%BD%90%EF%BC%8C%E5%AE%83%E7%94%B1%EF%BD%8E%E4%B8%AA%E6%8C%87%E5%90%91%E6%95%B4%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%9A%84%E6%8C%87%E9%92%88%E5%85%83%E7%B4%A0%E7%BB%84%E6%88%90..jpg "int (*p)[n]; p为指向含n个元素的一维数组的指针变量. int f(); f为带回整型函数值的函数. int *p(); p为带回一个指针的函数,该指针指向整型数据. int (*p)(); p为指向函数的指针,该函数返回一个整型值. int **p; p是一个指针变量,它指向一个指向整型数据的指针变量.")
636
指针运算小结 (1) 指针变量加(减)一个整数 例如:p++、p--、p+i、p-i、p+=i、p-=i等。
 指针变量加(减)一个整数 例如:p++、p--、p+i、p-i、p+=i、p-=i等。")
637
(2) 指针变量赋值 将一个变量地址赋给一个指针变量。如: p=&a; (将变量a的地址赋给p) p=array; (将数组array首元素地址赋给p) p=&array[i];(将数组array第i个元素 的地址赋给p) p=max;(max为已定义的函数,将max的入口 地址赋给p) p1=p2;(p1和p2都是指针变量,将p2的 值赋给p1)
![(2) 指针变量赋值 将一个变量地址赋给一个指针变量。如: p=&a; (将变量a的地址赋给p) p=array; (将数组array首元素地址赋给p) p=&array[i];(将数组array第i个元素.](http://slidesplayer.com/slide/11113381/60/images/637/%282%29+%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E8%B5%8B%E5%80%BC+%E5%B0%86%E4%B8%80%E4%B8%AA%E5%8F%98%E9%87%8F%E5%9C%B0%E5%9D%80%E8%B5%8B%E7%BB%99%E4%B8%80%E4%B8%AA%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%E3%80%82%E5%A6%82%EF%BC%9A+%EF%BD%90%EF%BC%9D%EF%BC%86%EF%BD%81%EF%BC%9B+%EF%BC%88%E5%B0%86%E5%8F%98%E9%87%8F%EF%BD%81%E7%9A%84%E5%9C%B0%E5%9D%80%E8%B5%8B%E7%BB%99%EF%BD%90%EF%BC%89+%EF%BD%90%EF%BC%9Darray%EF%BC%9B+%EF%BC%88%E5%B0%86%E6%95%B0%E7%BB%84%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%E9%A6%96%E5%85%83%E7%B4%A0%E5%9C%B0%E5%9D%80%E8%B5%8B%E7%BB%99%EF%BD%90%EF%BC%89+%EF%BD%90%EF%BC%9D%EF%BC%86array%EF%BC%BB%EF%BD%89%EF%BC%BD%EF%BC%9B%EF%BC%88%E5%B0%86%E6%95%B0%E7%BB%84%EF%BD%81%EF%BD%92%EF%BD%92%EF%BD%81%EF%BD%99%E7%AC%AC%EF%BD%89%E4%B8%AA%E5%85%83%E7%B4%A0..jpg "的地址赋给p) p=max;(max为已定义的函数,将max的入口. 地址赋给p) p1=p2;(p1和p2都是指针变量,将p2的. 值赋给p1)")
638
(3) 指针变量可以有空值,即该指针变量不指向任何变量。
(4) 两个指针变量可以相减 如果两个指针变量都指向同一个数组中的元素,则两个指针变量值之差是两个指针之间的元素个数 。
 两个指针变量可以相减. 如果两个指针变量都指向同一个数组中的元素,则两个指针变量值之差是两个指针之间的元素个数 。")
639
(5) 两个指针变量比较 若两个指针指向同一个数组的元素,则可以进行比较。指向前面的元素的指针变量“小于”指向后面元素的指针变量。
 两个指针变量比较 若两个指针指向同一个数组的元素,则可以进行比较。指向前面的元素的指针变量 小于 指向后面元素的指针变量。")
640
void指针类型 ANSIC新标准增加了一种“void”指针类型,即可定义一个指针变量,但不指定它是指向哪一种类型数据的。ANSIC标准规定用动态存储分配函数时返回void指针,它可以用来指向一个抽象的类型的数据,在将它的值赋给另一指针变量时要进行强制类型转换使之适合于被赋值的变量的类型。例如: char*p1; void*p2; … p1=(char *)p2;
p2;")
641
同样可以用(void *)p1将p1的值转换成void *类型。如:
p2=(void *)p1; 也可以将一个函数定义为void *类型,如: void *fun(char ch1,char ch2) 表示函数fun返回的是一个地址,它指向“空类型”,如需要引用此地址,也需要根据情况对之进行类型转换,如对该函数调用得到的地址要进行以下转换: p1=(char *)fun(ch1,ch2);
p1; 也可以将一个函数定义为void *类型,如: void *fun(char ch1,char ch2) 表示函数fun返回的是一个地址,它指向 空类型 ,如需要引用此地址,也需要根据情况对之进行类型转换,如对该函数调用得到的地址要进行以下转换: p1=(char *)fun(ch1,ch2);")
642
第十一章 结构体与共用体

643
结构体的概念 结构体的定义和引用 结构体数组
本章要点 结构体的概念 结构体的定义和引用 结构体数组

644
主要内容 11.1 概述 11.2 定义结构体类型变量的方法 11.3 结构体变量的引用 11.4 结构体变量的初始化 11.5 结构体数组
11.1 概述 11.2 定义结构体类型变量的方法 11.3 结构体变量的引用 11.4 结构体变量的初始化 11.5 结构体数组 11.6指向结构体类型数据的指针 11.7 用指针处理链表 11.8 共用体 11.9 枚举类型 11.10 用typedef定义类型

645
11.1 概述 问题定义: 有时需要将不同类型的数据组合成一个有机 的整体,以便于引用。如:
11.1 概述 问题定义: 有时需要将不同类型的数据组合成一个有机 的整体,以便于引用。如: 一个学生有学号/姓名/性别/年龄/地址等属性 int num; char name[20]; char sex; int age; int char addr[30]; 图11-1 Li Fun M Beijing Num name sex age score addr 应当把它们组织成一个组合项,在一个组合 项中包含若干个类型不同(当然也可以相同) 的数据项。
 的数据项。")
646
11.1 概述 如:struct student 声明一个结构体类型的一般形式为: struct 结构体名 {成员表列}; {
11.1 概述 声明一个结构体类型的一般形式为: struct 结构体名 {成员表列}; 如:struct student { int num;char name[20];char sex; int age;float score;char addr[30]; } 结构体名 成员名 类型名

647
11.2 定义结构体类型变量的方法 例如:struct student student1, student2;
11.2 定义结构体类型变量的方法 可以采取以下3种方法定义结构体类型变量: (1)先声明结构体类型再定义变量名 例如:struct student student1, student2; | | | 结构体类型名 结构体变量名 定义了student1和student2为struct student类型的变量,即它们具有struct student类型的结构. 图11-2 student1 ZhangXin M Shanghai WangLi F Beijing student2
先声明结构体类型再定义变量名. 例如:struct student student1, student2; | | | 结构体类型名 结构体变量名. 定义了student1和student2为struct student类型的变量,即它们具有struct student类型的结构. 图11-2. student ZhangXin M Shanghai WangLi F Beijing. student2.")
648
11.2 定义结构体类型变量的方法 注意: 在定义了结构体变量后,系统会为之分配内存单元。
11.2 定义结构体类型变量的方法 在定义了结构体变量后,系统会为之分配内存单元。 例如:student1和student2在内存中各占59个字节( =59)。 注意: 将一个变量定义为标准类型(基本数据类型)与定义为结构体类型不同之处在于后者不仅要求指定变量为结构体类型,而且要求指定为某一特定的结构体类型,因为可以定义出许许多多种具体的结构体类型。
。 注意: 将一个变量定义为标准类型(基本数据类型)与定义为结构体类型不同之处在于后者不仅要求指定变量为结构体类型,而且要求指定为某一特定的结构体类型,因为可以定义出许许多多种具体的结构体类型。")
649
11.2 定义结构体类型变量的方法 (2)在声明类型的同时定义变量 这种形式的定义的一般形式为: struct 结构体名 { 成员表列
11.2 定义结构体类型变量的方法 (2)在声明类型的同时定义变量 这种形式的定义的一般形式为: struct 结构体名 { 成员表列 }变量名表列;
在声明类型的同时定义变量. 这种形式的定义的一般形式为: struct 结构体名. { 成员表列. }变量名表列;")
650
11.2 定义结构体类型变量的方法 例如: 它的作用与第一种方法相同,即定义了两个struct student 类型的变量student1,
11.2 定义结构体类型变量的方法 它的作用与第一种方法相同,即定义了两个struct student 类型的变量student1, student2 例如: struct student { int num; char name[20]; char sex; int age; float score; char addr[30]; }student1,student2;

651
11.2 定义结构体类型变量的方法 注意: (1) 类型与变量是不同的概念,不要混同。只能对变量赋值、存取或运算,而不能对一个类型赋值、存取或运算。在编译时,对类型是不分配空间的,只对变量分配空间。 注意: (2)对结构体中的成员(即“域”),可以单独使用,它的作用与地位相当于普通变量。 (3)成员也可以是一个结构体变量。 (4) 成员名可以与程序中的变量名相同,二者不代表同一对象。 (3) 直接定义结构体类型变量 其一般形式为: struct { 成员表列 }变量名表列; 即不出现结构体名。
对结构体中的成员(即 域 ),可以单独使用,它的作用与地位相当于普通变量。 (3)成员也可以是一个结构体变量。 (4) 成员名可以与程序中的变量名相同,二者不代表同一对象。 (3) 直接定义结构体类型变量. 其一般形式为: struct. { 成员表列. }变量名表列; 即不出现结构体名。")
652
11.2 定义结构体类型变量的方法 例如:struct date /*声明一个结构体类型*/
11.2 定义结构体类型变量的方法 先声明一个struct date类型,它代表“日期”,包括3个成员:month(月)、day(日)、year(年)。然后在声明struct student类型时,将成员birthday指定为struct date类型。 例如:struct date /*声明一个结构体类型*/ int num; char name[20]; char sex; int age; float score; struct date birthday; /*birthday是struct date类型*/ char addr[30]; }student1,student2; 图11-3 birthday addr Num name sex age Month day year
、day(日)、year(年)。然后在声明struct student类型时,将成员birthday指定为struct date类型。 例如:struct date /*声明一个结构体类型*/ int num; char name[20]; char sex; int age; float score; struct date birthday; /*birthday是struct date类型*/ char addr[30]; }student1,student2; 图11-3. birthday addr. Num name sex age. Month day year.")
653
11.3结构体变量的引用 在定义了结构体变量以后,当然可以引用这个变量。但应遵守以下规则:
(1)不能将一个结构体变量作为一个整体进行输入和输出。 例如: 已定义student1和student2为结构体变量并且它们已有值。 printf(″%d,%s,%c,%d,%f,%\n″,student1);
不能将一个结构体变量作为一个整体进行输入和输出。 例如: 已定义student1和student2为结构体变量并且它们已有值。 printf(″%d,%s,%c,%d,%f,%\n″,student1); ")
654
11.3结构体变量的引用 引用结构体变量中成员的方式为 结构体变量名.成员名
例如, student1.num表示student1变量中的num成员,即student1的num(学号)项。可以对变量的成员赋值,例如:student1.num=10010;“.”是成员(分量)运算符,它在所有的运算符中优先级最高,因此可以把student1.num作为一个整体来看待。上面赋值语句的作用是将整数10010赋给student1变量中的成员num。
项。可以对变量的成员赋值,例如:student1.num=10010; . 是成员(分量)运算符,它在所有的运算符中优先级最高,因此可以把student1.num作为一个整体来看待。上面赋值语句的作用是将整数10010赋给student1变量中的成员num。")
655
11.3结构体变量的引用 注意: 不能用student1.birthday来访问student1变量中的成员birthday,因为birthday本身是一个结构体变量。 (2) 如果成员本身又属一个结构体类型,则要用若干个成员运算符,一级一级地找到最低的一级的成员。只能对最低级的成员进行赋值或存取以及运算。 例如: 对上面定义的结构体变量student1, 可以这样访问各成员: student1.num student1.birthday.month
 如果成员本身又属一个结构体类型,则要用若干个成员运算符,一级一级地找到最低的一级的成员。只能对最低级的成员进行赋值或存取以及运算。 例如: 对上面定义的结构体变量student1, 可以这样访问各成员: student1.num. student1.birthday.month.")
656
11.3结构体变量的引用 (3) 对结构体变量的成员可以像普通变量一样进行各种运算(根据其类型决定可以进行的运算)。
由于“.”运算符的优先级最高,因此student1.age++是对student1.age进行自加运算,而不是先对age进行自加运算。 (3) 对结构体变量的成员可以像普通变量一样进行各种运算(根据其类型决定可以进行的运算)。 例如: student2.score=student1.score; sum=student1.score+student2.score; student1.age++; ++student2.age;
 对结构体变量的成员可以像普通变量一样进行各种运算(根据其类型决定可以进行的运算)。 例如: student2.score=student1.score; sum=student1.score+student2.score; student1.age++; ++student2.age;")
657
11.3结构体变量的引用 (4) 可以引用结构体变量成员的地址,也可以引用结构体变量的地址。 例如:
scanf(″%d″,&student1.num); (输入student1.num的值) printf(″%o″,&student1); (输出student1的首地址)
; (输入student1.num的值) printf(″%o″,&student1); (输出student1的首地址)")
658
11.3结构体变量的引用 传递结构体变量的地址。 但不能用以下语句整体读入结构体变量, 例如:
scanf(″%d,%s,%c,%d,%f,%s″,&student1); 结构体变量的地址主要用作函数参数, 传递结构体变量的地址。
; 结构体变量的地址主要用作函数参数, 传递结构体变量的地址。")
659
11.4结构体变量的初始化 运行结果: No.:10101 name:LiLin sex:M address:123 Beijing Road 例11.1 对结构体变量初始化. #include <stdio.h> void main() {struct student {long int num; char name[20]; char sex; char addr[20]; }a={10101,″LiLin″,′M′,″123 Beijing Road″}; /* 对结构体变量a赋初值*/ printf(″No.:%ld\nname:%s\nsex:%c\naddress:%s\n″,a.num,a.name,a.sex,a.addr); } 但不能用以下语句整体读入结构体变量, 例如: scanf(″%d,%s,%c,%d,%f,%s″,&student1); 结构体变量的地址主要用作函数参数,传递结构体变量的地址。
 {struct student {long int num; char name[20]; char sex; char addr[20]; }a={10101,″LiLin″,′M′,″123 Beijing Road″}; /* 对结构体变量a赋初值*/ printf(″No.:%ld\nname:%s\nsex:%c\naddress:%s\n″,a.num,a.name,a.sex,a.addr); } 但不能用以下语句整体读入结构体变量, 例如: scanf(″%d,%s,%c,%d,%f,%s″,&student1); 结构体变量的地址主要用作函数参数,传递结构体变量的地址。")
660
11.5 结构体数组 一个结构体变量中可以存放一组数 据(如一个学生的学号、姓名、成绩等 数据)。如果有10个学生的数据需要
参加运算,显然应该用数组,这就是结 构体数组。结构体数组与以前介绍过的 数值型数组不同之处在于每个数组元素 都是一个结构体类型的数据,它们都分 别包括各个成员(分量)项。
项。")
661
11.5 结构体数组 11.5.1定义结构体数组 和定义结构体变量的方法相仿,只需说明其为数组即可。例如: struct student
{int num;char name[20];char sex;int age; float score;char addr[30]; };struct student[3]; 以上定义了一个数组stu,数组有3个元素,均为struct student类型数据。

662
11.5 结构体数组 或: 也可以直接定义一个结构体数组,例如: struct student {int num; …};stu[3];
strcut student 图11-4
![11.5 结构体数组 或: 也可以直接定义一个结构体数组,例如: struct student {int num; …};stu[3];](http://slidesplayer.com/slide/11113381/60/images/662/11.5+%E7%BB%93%E6%9E%84%E4%BD%93%E6%95%B0%E7%BB%84+%E6%88%96%EF%BC%9A+%E4%B9%9F%E5%8F%AF%E4%BB%A5%E7%9B%B4%E6%8E%A5%E5%AE%9A%E4%B9%89%E4%B8%80%E4%B8%AA%E7%BB%93%E6%9E%84%E4%BD%93%E6%95%B0%E7%BB%84%EF%BC%8C%E4%BE%8B%E5%A6%82%EF%BC%9A+struct+student+%7Bint+num%3B+%E2%80%A6%7D%3Bstu%5B3%5D%3B.jpg "strcut student. 图11-4.")
663
11.5 结构体数组 11.5.2 结构体数组的初始化 与其他类型的数组一样,对结构体数组可以初始化。例如: struct student
图11-5 结构体数组的初始化 与其他类型的数组一样,对结构体数组可以初始化。例如: struct student {int num;char name[20]; char sex; int age; float score; char addr[30]; };stu[2]={{10101,″LiLin″,′M′,18,87.5,″103 BeijingRoad″},{10102,″Zhang Fun″,′M′,19,99,″130 Shanghai Road″}};

664
11.5 结构体数组 当然,数组的初始化也可以用以下形式: struct student {int num;
… }; struct student str[]{{…},{…},{…}}; 即先声明结构体类型,然后定义数组为该结构体类型,在定义数组时初始化。 结构体数组初始化的一般形式是在定义数组的后面加上“={初值表列};”。

665
11.5 结构体数组 结构体数组应用举例 例11.2对候选人得票的统计程序。设有3个候选人,每次输入一个得票的候选人的名字,要求最后输出各人得票结果。 #include <string.h> #include <stdio.h> struct person { char name[20];in count; }; leader[3]={“Li”,0, “ Zhang”,0, “ Fun”,0}

666
例11.2 void main() { int i,j; char leader_name[20]; for(i=1;i<=10;i++) { scanf(“%s”,leader_name); for(j=0;j<3;j++) if(strcmp(leader_name,leader[j].name)==0) leader[j].count++; } printf(“\n”); for(i=0;i<3;i++) printf(“%5s:%d\n”,leader[i].name,leader[i].count);} 运行结果: Li↙ Fun↙ Zhang↙ Fun↙ Li↙ Li:4 Zhang:3 Fun:3
![例11.2 void main() { int i,j; char leader_name[20]; for(i=1;i<=10;i++) { scanf( %s ,leader_name); for(j=0;j<3;j++) if(strcmp(leader_name,leader[j].name)==0) leader[j].count++; } printf( \n ); for(i=0;i<3;i++) printf( %5s:%d\n ,leader[i].name,leader[i].count);}](http://slidesplayer.com/slide/11113381/60/images/666/%E4%BE%8B11.2+void+main%28%29+%7B+int+i%2Cj%3B+char+leader_name%5B20%5D%3B+for%28i%3D1%3Bi%3C%3D10%3Bi%2B%2B%29+%7B+scanf%28+%25s+%2Cleader_name%29%3B+for%28j%3D0%3Bj%3C3%3Bj%2B%2B%29+if%28strcmp%28leader_name%2Cleader%5Bj%5D.name%29%3D%3D0%29+leader%5Bj%5D.count%2B%2B%3B+%7D+printf%28+%5Cn+%29%3B+for%28i%3D0%3Bi%3C3%3Bi%2B%2B%29+printf%28+%255s%3A%25d%5Cn+%2Cleader%5Bi%5D.name%2Cleader%5Bi%5D.count%29%3B%7D.jpg "运行结果: Li↙ Fun↙ Zhang↙ Fun↙ Li↙ Li:4. Zhang:3. Fun:3.")
667
11.5 结构体数组 程序定义一个全局的结构体数组leader,它有3个元素,每一个元素包含两个成员name(姓名)和count(票数)。在定义数组时使之初始化,使3位候选人的票数都先置零。 在主函数中定义字符数组leader-name,它代表被选人的姓名,在10次循环中每次先输入一个被选人的具体人名,然后把它与3个候选人姓名相比,看它和哪一个候选人的名字相同。在输入和统计结束之后,将3人的名字和得票数输出。 图11-6 Li Zhang Fun name count

668
11.6 指向结构体类型数据的指针 11.6.1 指向结构体变量的指针
一个结构体变量的指针就是该变量所占据的内存段的起始地址。可以设一个指针变量,用来指向一个结构体变量,此时该指针变量的值是结构体变量的起始地址。指针变量也可以用来指向结构体数组中的元素。 指向结构体变量的指针 下面通过一个简单例子来说明指向结构体变量的指针变量的应用。

669
定义指针变量p,指向struct student 类型的数据
例11.3指向结构体变量的指针的应用 #include <string.h> #include <stdio.h> void main() {struct student{long num;char name[20]; char sex; float score;}; struct student stu_1; struct student* p; p=&stu_1; stu_1.num=89101;strcpy(stu_1.name,”LiLin”); stu_1.sex=‘M’;stu_1.score=89.5; printf(″No.:%ld\nname:%s\nsex:%c\nscore:%f\n″,stu-1.num,stu-1.name,stu-1.sex,stu-1.score); printf(″No.:%ld\nname:%s\nsex:%c\nscore:%f\n″,(*p).num,(*p).name,(*p).sex,(*p).score); } 运行结果: No.:89101 name:LiLin sex:M score: 定义指针变量p,指向struct student 类型的数据 p指向的结构体变量中的成员
 {struct student{long num;char name[20]; char sex; float score;}; struct student stu_1; struct student* p; p=&stu_1; stu_1.num=89101;strcpy(stu_1.name, LiLin ); stu_1.sex=‘M’;stu_1.score=89.5; printf(″No.:%ld\nname:%s\nsex:%c\nscore:%f\n″,stu-1.num,stu-1.name,stu-1.sex,stu-1.score); printf(″No.:%ld\nname:%s\nsex:%c\nscore:%f\n″,(*p).num,(*p).name,(*p).sex,(*p).score); } 运行结果: No.:89101 name:LiLin. sex:M. score: 定义指针变量p,指向struct student 类型的数据. p指向的结构体变量中的成员.")
670
11.6 指向结构体类型数据的指针 图11-7 程序分析: 在函数的执行部分将结构体变量stu-1的起始地址赋给指针变量p,也就是使p指向stu-1,然后对stu-1的各成员赋值。第一个printf函数是输出stu-1的各个成员的值。用stu-1.num表示stu-1中的成员num,依此类推。第二个printf函数也是用来输出stu-1各成员的值,但使用的是(*p).num这样的形式。
.num这样的形式。")
671
11.6 指向结构体类型数据的指针 以下3种形式等价: 其中->称为指向运算符。 ① 结构体变量.成员名 ②(*p).成员名
p->成员名 其中->称为指向运算符。 请分析以下几种运算: p->n得到p指向的结构体变量中的成员n的值。 p->n++ 得到p指向的结构体变量中的成员n的值,用完该值后使它加1。 ++p->n 得到p指向的结构体变量中的成员n的值加1,然后再使用它。

672
11.6 指向结构体类型数据的指针 11.6.2 指向结构体数组的指针 运行结果:
例11.4 指向结构体数组的指针的应用 #include <stdio.h> struct student {int num;char name[20];char sex;int age;}; struct student stu[3]={{10101,″Li Lin″,′M′,18},{10102,″Zhang Fun″,′M′,19},{10104,″WangMing″,′F′,20}}; void main() { struct student *p; printf(″ No Name sex age\n″); for (p=str;p<str+3;p++) printf(″%5d %-20s %2c %4d\n″,p->num, p->name, p->sex, p->age); } 指向结构体数组的指针 运行结果: No. Name sex age 10101 LiLin M 10102 Zhang Fun M 10104 WangMing F
 { struct student *p; printf(″ No. Name sex age\n″); for (p=str;p<str+3;p++) printf(″%5d %-20s %2c %4d\n″,p->num, p->name, p->sex, p->age); } 指向结构体数组的指针. 运行结果: No. Name sex age 10101 LiLin M 18 10102 Zhang Fun M 19 10104 WangMing F 20")
673
11.6 指向结构体类型数据的指针 图11-8 程序分析: p是指向struct student结构体类型数据的指针变量。在for语句中先使p的初值为stu,也就是数组stu第一个元素的起始地址。在第一次循环中输出stu[0]的各个成员值。然后执行p++,使p自加1。p加1意味着p所增加的值为结构体数组stu的一个元素所占的字节数。执行p++后p的值等于stu +1,p指向stu[1]。在第二次循环中输出stu[1]的各成员值。在执行p++后,p的值等于stu+2,再输出stu [2]的各成员值。在执行p++后,p的值变为stu +3, 已不再小于stu+3了,不再执行循环。

674
11.6 指向结构体类型数据的指针 注意: 请注意以上二者的不同。
(1) 如果p的初值为stu,即指向第一个元素,则p加1后p就指向下一个元素。例如: (++p)->num 先使p自加1,然后得到它指向的元素中的num成员值(即10102)。 (p++)->num 先得到p->num的值(即10101),然后使p自加1,指向stu[1]。 请注意以上二者的不同。
 如果p的初值为stu,即指向第一个元素,则p加1后p就指向下一个元素。例如: (++p)->num 先使p自加1,然后得到它指向的元素中的num成员值(即10102)。 (p++)->num 先得到p->num的值(即10101),然后使p自加1,指向stu[1]。 请注意以上二者的不同。")
675
11.6 指向结构体类型数据的指针 注意: 例如: p=stu[1].name;
(2) 程序已定义了p是一个指向struct student类型数据的指针变量,它用来指向一个struct student类型的数据,不应用来指向stu数组元素中的某一成员。 例如: p=stu[1].name; 如果要将某一成员的地址赋给p,可以用强制类型转换,先将成员的地址转换成p的类型。 例如:p=(struct student *)stu[0].name;
![ 11.6 指向结构体类型数据的指针 注意: 例如: p=stu[1].name;](http://slidesplayer.com/slide/11113381/60/images/675/%EF%81%B2+11.6+%E6%8C%87%E5%90%91%E7%BB%93%E6%9E%84%E4%BD%93%E7%B1%BB%E5%9E%8B%E6%95%B0%E6%8D%AE%E7%9A%84%E6%8C%87%E9%92%88+%E6%B3%A8%E6%84%8F%EF%BC%9A+%E4%BE%8B%E5%A6%82%3A+%EF%BD%90%EF%BC%9D%EF%BD%93%EF%BD%94%EF%BD%95%EF%BC%BB1%EF%BC%BD%EF%BC%8E%EF%BD%8Ea%EF%BD%8D%EF%BD%85%3B.jpg "(2) 程序已定义了p是一个指向struct student类型数据的指针变量,它用来指向一个struct student类型的数据,不应用来指向stu数组元素中的某一成员。 例如: p=stu[1].name; 如果要将某一成员的地址赋给p,可以用强制类型转换,先将成员的地址转换成p的类型。 例如:p=(struct student *)stu[0].name; ")
676
11.6 指向结构体类型数据的指针 11.6.3 用结构体变量和指向结构体的指针 作函数参数
将一个结构体变量的值传递给另一个函数,有3个方法: 用结构体变量的成员作参数。 (2) 用结构体变量作实参。 (3) 用指向结构体变量(或数组)的指针作实参,将结构体变量(或数组)的地址传给形参。
 用结构体变量作实参。 (3) 用指向结构体变量(或数组)的指针作实参,将结构体变量(或数组)的地址传给形参。")
677
11.6 指向结构体类型数据的指针 11.6.2 指向结构体数组的指针
例11.5 有一个结构体变量stu,内含学生学号、姓名和3门课程的成绩。要求在main函数中赋予值,在另一函数print中将它们输出。今用结构体变量作函数参数。 指向结构体数组的指针 #include <stdio.h> struct student { int num; char name[20]; float score[3]; };

678
11.6 指向结构体类型数据的指针 void main() { void print(struct student); struct student stu; stu.num=12345;strcpy(stu.name, ″LiLin″;stu.score[0]=67.5;stu.score[1]=89;stu.score[2] =78.6); print(stu); } void print(struct student stu) { printf(FORMAT,stu.num,stu.name, stu.score[0], stu.score[1],stu.score[2]); printf(″\n″);} 运行结果: 12345 Li Li
 { void print(struct student); struct student stu; stu.num=12345;strcpy(stu.name, ″LiLin″;stu.score[0]=67.5;stu.score[1]=89;stu.score[2] =78.6); print(stu); } void print(struct student stu) { printf(FORMAT,stu.num,stu.name, stu.score[0], stu.score[1],stu.score[2]); printf(″\n″);} 运行结果: 12345. Li Li")
679
例11. 6 将上题改用指向结构体变量的指针作实参。 #include <stdio
例 将上题改用指向结构体变量的指针作实参。 #include <stdio.h> struct student { int num; char name[20]; float score[3]; };stu={12345, ″LiLi″,67.5,89,78.6}; void main() {void print(struct student *); /*形参类型修改成指向结构体的指针变量*/ print(&stu);} /*实参改为stu的起始地址*/ void print(struct student *p) /*形参类型修改了*/ { printf(FORMAT,p->num,p->name, p->score[0],p->score[1],p->score[2]); /*用指针变量调用各成员的值*/ printf(″\n″);} 运行结果: 12345 Li Li
 {void print(struct student *); /*形参类型修改成指向结构体的指针变量*/ print(&stu);} /*实参改为stu的起始地址*/ void print(struct student *p) /*形参类型修改了*/ { printf(FORMAT,p->num,p->name, p->score[0],p->score[1],p->score[2]); /*用指针变量调用各成员的值*/ printf(″\n″);} 运行结果: 12345. Li Li")
680
11.6 指向结构体类型数据的指针 图11-9 程序分析: 此程序改用在定义结构体变量stu时赋初值,这样程序可简化些。print函数中的形参p被定义为指向struct student类型数据的指针变量。注意在调用print函数时,用结构体变量str的起始地址&stu作实参。在调用函数时将该地址传送给形参p(p是指针变量)。这样p就指向stu。在print函数中输出p所指向的结构体变量的各个成员值,它们也就是stu的成员值。 main函数中的对各成员赋值也可以改用scanf函数输入。
。这样p就指向stu。在print函数中输出p所指向的结构体变量的各个成员值,它们也就是stu的成员值。 main函数中的对各成员赋值也可以改用scanf函数输入。")
681
§11.7 用指针处理链表 11.7.1 链表概述 链表的组成: 链表是一种常见的重要的数据结构,是动 态地进行存储分配的一种结构。
头指针:存放一个地址,该地址指向一个元素 结点:用户需要的实际数据和链接节点的指针 图11-10

682
§11.7 用指针处理链表 用结构体建立链表: struct student { int num; float score;
struct student *next ;}; 其中成员num和score用来存放结点中的有用数据(用户需要用到的数据),next是指针类型的成员,它指向struct student类型数据(这就是next所在的结构体类型) 图11-11
,next是指针类型的成员,它指向struct student类型数据(这就是next所在的结构体类型) 图")
683
11.7 用指针处理链表 运行结果: 简单链表 #include <stdio.h> #define NULL struct student {long num; float score; struct student *next; }; main() { struct student a,b,c,*head,*p; a. num=99101; a.score=89.5; b. num=99103; b.score=90; c. num=99107; c.score=85; head=&a; a.next=&b; b.next=&c; c.next=NULL; p=head; do {printf("%ld %5.1f\n",p->num,p->score); p=p->next; } while(p!=NULL); }
 { struct student a,b,c,*head,*p; a. num=99101; a.score=89.5; b. num=99103; b.score=90; c. num=99107; c.score=85; head=&a; a.next=&b; b.next=&c; c.next=NULL; p=head; do {printf( %ld %5.1f\n ,p->num,p->score); p=p->next; } while(p!=NULL); }")
684
11.7 用指针处理链表 程序分析: 开始时使head指向a结点,a.next指向b结点,b.next指向c结点,这就构成链表关系。“c.next=NULL” 的作用是使c.next不指向任何有用的存储单元。在输出链表时要借助p,先使p指向a结点,然后输出a结点中的数据,“p=p->next” 是为输出下一个结点作准备。p->next的值是b结点的地址,因此执行“p=p->next”后p就指向b结点,所以在下一次循环时输出的是b结点中的数据。

685
11.7 用指针处理链表 11.7.3处理动态链表所需的函数 库函数提供动态地开辟和释放存储单元的 有关函数: malloc函数
其函数原型为void *malloc(unsigned int size);其 作用是在内存的动态存储区中分配一个长度为 size的连续空间。此函数的值(即“返回值”) 是一个指向分配域起始地址的指针(类型为 void)。如果此函数未能成功地执行(例如内 存空间不足),则返回空指针(NULL)。
;其. 作用是在内存的动态存储区中分配一个长度为. size的连续空间。此函数的值(即 返回值 ) 是一个指向分配域起始地址的指针(类型为. void)。如果此函数未能成功地执行(例如内. 存空间不足),则返回空指针(NULL)。")
686
11.7 用指针处理链表 (2) calloc函数 其函数原型为void *calloc(unsigned n,
unsigned size);其作用是在内存的动态存储区 中分配n个长度为size的连续空间。函数返回 一个指向分配域起始地址的指针;如果分配不 成功,返回NULL。 用calloc函数可以为一维数组开辟动态存 储空间,n为数组元素个数,每个元素长度为 Size。
;其作用是在内存的动态存储区. 中分配n个长度为size的连续空间。函数返回. 一个指向分配域起始地址的指针;如果分配不. 成功,返回NULL。 用calloc函数可以为一维数组开辟动态存. 储空间,n为数组元素个数,每个元素长度为. Size。")
687
11.7 用指针处理链表 (3) free函数 其函数原型为void free(void *p);其作用
是释放由p指向的内存区,使这部分内存区能 被其他变量使用。p是最近一次调用calloc或 malloc函数时返回的值。free函数无返回值。 以前的C版本提供的malloc和calloc函数 得到的是指向字符型数据的指针。 ANSI C提 供的malloc和calloc函数规定为void类型。

688
11.7 用指针处理链表 11.7.4 建立动态链表 所谓建立动态链表是指在程序执行过程中从 无到有地建立起一个链表,即一个一个地开辟结
图11-12 建立动态链表 所谓建立动态链表是指在程序执行过程中从 无到有地建立起一个链表,即一个一个地开辟结 点和输入各结点数据,并建立起前后相链的关系 例11.5 写一函数建立一个有3名学生数据的单向动 态链表。 算法如图

689
11.7 用指针处理链表 算法的实现: 我们约定学号不会为零,如果输入的学号为 0,则表示建立链表的过程完成,该结点不应连 接到链表中。
如果输入的p1->num不等于0,则输入的是第 一个结点数据(n=1),令head=p1,即把p1的值 赋给head,也就是使head也指向新开辟的结点p1 所指向的新开辟的结点就成为链表中第一个结点 图11-13
,令head=p1,即把p1的值. 赋给head,也就是使head也指向新开辟的结点p1. 所指向的新开辟的结点就成为链表中第一个结点. 图")
690
11.7 用指针处理链表 算法的实现: 再开辟另一个结点并使p1指向它,接着输入该 结点的数据.
图11-14 如果输入的p1->num≠0,则应链入第2个结点 (n=2), 将新结点的地址赋给第一个结点的 next成员. 接着使p2=p1,也就是使p2指向刚才建 立的结点
, 将新结点的地址赋给第一个结点的. next成员. 接着使p2=p1,也就是使p2指向刚才建. 立的结点.")
691
11.7 用指针处理链表 算法的实现: 再开辟一个结点并使p1指向它,并输入该结点的 数据。 在第三次循环中,由于n=3(n≠1),又
将p1的值赋给p2->next,也就是将第 3个结点连接到第2个结点之后,并使p2= p1,使p2指向最后一个结点. 图11-15

692
11.7 用指针处理链表 算法的实现: 再开辟一个新结点,并使p1指向它,输入该结 点的数据。由于p1->num的值为0,不再执行循环
,此新结点不应被连接到链表中. 图11-16 将NULL赋给p2->next. 建立链表过程至此结束,p1最后所指的结点 未链入链表中,第三个结点的next成员的值 为NULL,它不指向任何结点。

693
11.7 用指针处理链表 建立链表的函数如下: #include <stdio.h>
#include <malloc.h> #define NULL 0 //令NULL代表0,用它表示“空地址 #define LEN sizeof(struct student) //令LEN代表struct //student类型数据的长度 struct student { long num; float score; struct student *next; };int n; //n为全局变量,本文件模块中各函数均可使用它
 //令LEN代表struct //student类型数据的长度. struct student. { long num; float score; struct student *next; };int n; //n为全局变量,本文件模块中各函数均可使用它.")
694
11.7 用指针处理链表 struct student *creat()
{struct student *head; struct student *p1,*p2; n=0; p1=p2=( struct student*) malloc(LEN); scanf("%ld,%f",&p1->num,&p1->score); head=NULL; while(p1->num!=0) { n=n+1; if(n==1)head=p1; else p2->next=p1; p2=p1; p1=(struct student*)malloc(LEN); } p2->next=NULL; return(head);}
 malloc(LEN); scanf( %ld,%f ,&p1->num,&p1->score); head=NULL; while(p1->num!=0) { n=n+1; if(n==1)head=p1; else p2->next=p1; p2=p1; p1=(struct student*)malloc(LEN); } p2->next=NULL; return(head);}")
695
11.7 用指针处理链表 11.7.5 输出链表 首先要知道链表第一个结点的地址,也就是 要知道head的值。然后设一个指针变量p,先指向
第一个结点,输出p所指的结点,然后使p后移 一个结点,再输出,直到链表的尾结点。 图11-17,11-18

696
11.7 用指针处理链表 例11.9 编写一个输出链表的函数print. void print(struct student *head)
{struct student *p; printf("\nNow,These %d records are:\n",n); p=head; if(head!=NULL) do {printf("%ld %5.1f\n",p->num,p->score); p=p->next; }while(p!=NULL); }
; p=head; if(head!=NULL) do. {printf( %ld %5.1f\n ,p->num,p->score); p=p->next; }while(p!=NULL); }")
697
11.7 用指针处理链表 11.7.6 对链表的删除操作 从一个动态链表中删去一个结点,并不是真 正从内存中把它抹掉,而是把它从链表中分离开
来,只要撤销原来的链接关系即可。 图11-19

698
11.7 用指针处理链表 例11.10写一函数以删除动态链表中指定的结点. 解题思路: 从p指向的第一个结点开始,检查该结点中的
num值是否等于输入的要求删除的那个学号。如果 相等就将该结点删除,如不相等,就将p后移一个 结点,再如此进行下去,直到遇到表尾为止。

699
11.7 用指针处理链表 可以设两个指针变量p1和p2,先使p1指向 第一个结点 。 如果要删除的不是第一个结点,则使p1后
移指向下一个结点(将p1->next赋给p1),在此 之前应将p1的值赋给p2 ,使p2指向刚才检查 过的那个结点 。
,在此. 之前应将p1的值赋给p2 ,使p2指向刚才检查. 过的那个结点 。")
700
11.7 用指针处理链表 注意: ①要删的是第一个结点(p1的值等于head的值,如图11-20(a)那样),则应将p1->next赋给head。这时head指向原来的第二个结点。第一个结点虽然仍存在,但它已与链表脱离,因为链表中没有一个结点或头指针指向它。虽然p1还指向它,它仍指向第二个结点,但仍无济于事,现在链表的第一个结点是原来的第二个结点,原来第一个结点已“丢失” ,即不再是链表中的一部分了。
那样),则应将p1->next赋给head。这时head指向原来的第二个结点。第一个结点虽然仍存在,但它已与链表脱离,因为链表中没有一个结点或头指针指向它。虽然p1还指向它,它仍指向第二个结点,但仍无济于事,现在链表的第一个结点是原来的第二个结点,原来第一个结点已 丢失 ,即不再是链表中的一部分了。")
701
11.7 用指针处理链表 注意: ②如果要删除的不是第一个结点,则将p1->next赋给p2->next,见图1120(d)。p2->next原来指向p1指向的结点(图中第二个结点),现在p2->next改为指向p1->next所指向的结点(图中第三个结点)。p1所指向的结点不再是链表的一部分。 还需要考虑链表是空表(无结点)和链表中找不到要删除的结点的情况。
。p2->next原来指向p1指向的结点(图中第二个结点),现在p2->next改为指向p1->next所指向的结点(图中第三个结点)。p1所指向的结点不再是链表的一部分。 还需要考虑链表是空表(无结点)和链表中找不到要删除的结点的情况。")
702
11.7 用指针处理链表 图11-20

703
11.7 用指针处理链表 算法: 图11-21

704
11.7 用指针处理链表 删除结点的函数del: struct student *del(struct student *head,long num) {struct student *p1,*p2; if (head==NULL){printf("\nlist null!\n");goto end;} p1=head; while(num!=p1->num && p1->next!=NULL) {p2=p1;p1=p1->next;} if(num==p1->num) {if(p1==head) head=p1->next; else p2->next=p1->next; printf("delete:%ld\n",num); n=n-1; } else printf("%ld not been found!\n",num); end;return(head);}
{printf( \nlist null!\n );goto end;} p1=head; while(num!=p1->num && p1->next!=NULL) {p2=p1;p1=p1->next;} if(num==p1->num) {if(p1==head) head=p1->next; else p2->next=p1->next; printf( delete:%ld\n ,num); n=n-1; } else printf( %ld not been found!\n ,num); end;return(head);}")
705
11.7 用指针处理链表 11.7.7对链表的插入操作 对链表的插入是指将一个结点插入到一个已有的链表中。
为了能做到正确插入,必须解决两个问题: ① 怎样找到插入的位置; ② 怎样实现插入。

706
11.7 用指针处理链表 先用指针变量p0指向待插入的结点,p1指向第 一个结点。
将p0->num与p1->num相比较,如果p0->num> p1-> num ,则待插入的结点不应插在p1所指的 结点之前。此时将p1后移,并使p2指向刚才p1 所指的结点。

707
11.7 用指针处理链表 再将p1->num与p0->num比,如果仍然是p0->num
大,则应使p1继续后移,直到p0->p1-> num为止。 这时将p0所指的结点插到p1所指结点之前。但是如 果p1所指的已是表尾结点,则p1就不应后移了。如 果p0-> num比所有结点的num都大,则应将p0所指 的结点插到链表末尾。 如果插入的位置既不在第一个结点之前,又不 在表尾结点之后,则将p0的值赋给p2->next,使 p2->next指向待插入的结点,然后将p1的值赋给 p0->next,使得p0->next指向p1指向的变量。

708
§ 11.7 用指针处理链表 如果插入位置为第一个结点之前(即p1等于 head时),则将p0赋给head,将p1赋给p0->next
图11-22 如果插入位置为第一个结点之前(即p1等于 head时),则将p0赋给head,将p1赋给p0->next 如果要插到表尾之后,应将p0赋给p1->next, NULL赋给p0->next
,则将p0赋给head,将p1赋给p0->next. 如果要插到表尾之后,应将p0赋给p1->next, NULL赋给p0->next.")
709
11.7 用指针处理链表 算法: 图11-23

710
11.7 用指针处理链表 例11.11插入结点的函数insert如下。
struct student *insert(struct student *head, struct student *stud) {struct student *p0,*p1,*p2; p1=head;p0=stud; if(head==NULL) {head=p0; p0->next=NULL;} else{while((p0->num>p1->num) && (p1->next!=NULL)) {p2=p1; p1=p1->next;} if(p0->num<=p1->num) {if(head==p1) head=p0; else p2->next=p0; p0->next=p1;} else {p1->next=p0; p0->next=NULL;}} n=n+1; return(head); }
 {struct student *p0,*p1,*p2; p1=head;p0=stud; if(head==NULL) {head=p0; p0->next=NULL;} else{while((p0->num>p1->num) && (p1->next!=NULL)) {p2=p1; p1=p1->next;} if(p0->num<=p1->num) {if(head==p1) head=p0; else p2->next=p0; p0->next=p1;} else {p1->next=p0; p0->next=NULL;}} n=n+1; return(head); }")
711
11.7 用指针处理链表 void main() { struct student *head,stu;long del_num; prinf(″intput records:\n″) ; head=creat();print(head);printf (″ \n intput the deleted number:\n″); scanf (″%ld″,&del_num) ;head=del(head,del_num); print(head); printf (″ \n intput the deleted number:\n″); scanf (″%ld″,&stu.num,&stu.score) ; head=insert(head,&stu); print(head); } 对链表的综合操作 将以上建立、输出、删除、插入的函数组织 在一个C程序中,用main函数作主调函数。
 { struct student *head,stu;long del_num; prinf(″intput records:\n″) ; head=creat();print(head);printf (″ \n intput the deleted number:\n″); scanf (″%ld″,&del_num) ;head=del(head,del_num); print(head); printf (″ \n intput the deleted number:\n″); scanf (″%ld″,&stu.num,&stu.score) ; head=insert(head,&stu); print(head); } 对链表的综合操作. 将以上建立、输出、删除、插入的函数组织. 在一个C程序中,用main函数作主调函数。")
712
11.7 用指针处理链表 此程序运行结果是正确的。它只删除一个结 点,插入一个结点。但如果想再插入一个结点,
重复写上程序最后4行,共插入两个结点,运行结 果却是错误的。 Input records: (建立链表) 10101,90↙ 10103,98↙ 10105,76↙ 0,0↙
 10101,90↙ 10103,98↙ 10105,76↙ 0,0↙")
713
11.7 用指针处理链表 intput the deleted number :10103(删除)
Now,these 3 records are: 1010190.0 1010398.0 1010576.0 intput the deleted number :10103(删除) delete:10103↙ Now,these 4 records are: 1010190.0 1010576.0
 delete:10103↙ Now,these 4 records are: 1010190.0. 1010576.0")
714
11.7 用指针处理链表 input the inserted record (插入第一个结点) 10102,90↙
Now,these 3 records are: 1010190.0 1010290.0 1010576.0 input the inserted record (插入第二个结点) 10104,99↙ Now,these 4 records are: 1010190.0 1010499.0
 10104,99↙ Now,these 4 records are: 1010190.0. 1010499.0.")
715
11.7 用指针处理链表 出现以上结果的原因是: stu是一个有固定地址的结构体变量。第一次把stu结点插入到链表中,第二次若再用它来插入第二个结点,就把第一次结点的数据冲掉了,实际上并没有开辟两个结点。为了解决这个问题,必须在每插入一个结点时新开辟一个内存区。我们修改main函数,使之能删除多个结点(直到输入要删的学号为0),能插入多个结点(直到输入要插入的学号为0)。
,能插入多个结点(直到输入要插入的学号为0)。")
716
11.7 用指针处理链表 main() {struct student *head,*stu; long del_num;printf("input records:\n"); head=creat(); print (head); printf("\ninput the deleted number:"); scanf("%ld",&del_num); while (del_num!=0){head=del(head,del_num); print (head);printf ("input the deleted number:"); scanf("%ld",&del_num);} printf("\ninput the inserted record:");stu=(struct student *) malloc(LEN); scanf("%ld,%f",&stu->num,&stu->score); while(stu->num!=0){head=insert(head,stu); printf("input the inserted record:");stu=(struct student *)malloc(LEN); scanf("%ld,%f",&stu->num,&stu->score); }}
 {struct student *head,*stu; long del_num;printf( input records:\n ); head=creat(); print (head); printf( \ninput the deleted number: ); scanf( %ld ,&del_num); while (del_num!=0){head=del(head,del_num); print (head);printf ( input the deleted number: ); scanf( %ld ,&del_num);} printf( \ninput the inserted record: );stu=(struct student *) malloc(LEN); scanf( %ld,%f ,&stu->num,&stu->score); while(stu->num!=0){head=insert(head,stu); printf( input the inserted record: );stu=(struct student *)malloc(LEN); scanf( %ld,%f ,&stu->num,&stu->score); }}")
717
11.7 用指针处理链表 stu定义为指针变量,在需要插入时先用 malloc函数开辟一个内存区,将其起始地址经强
的,每次指向一个新的struct student变量。在 调用insert函数时,实参为head和stu,将已建立 的链表起始地址传给insert函数的形参,将stu( 即新开辟的单元的地址)传给形参stud,返回的 函数值是经过插入之后的链表的头指针(地址)
传给形参stud,返回的. 函数值是经过插入之后的链表的头指针(地址)")
718
11.7 用指针处理链表 运行结果: input records: 10101,99 10103,87 10105,77 0,0
10101,99 10103,87 10105,77 0,0 Now,These 3 records are: 10101 99.0 10103 87.0 10105 77.0

719
11.7 用指针处理链表 intput the deleted number 10103(删除)
delete:10103↙ Now,these 4 records are 10101 99.0 10105 76.0 intput the deleted number 10103(删除) delete:10105↙ Now,these 4 records are 10101 99.0
 delete:10105↙ Now,these 4 records are. 10101 99.0.")
720
11.7 用指针处理链表 intput the deleted number:0 input the inserted record
10106,65↙ Now,these 3 records are intput the deleted number:0 input the inserted record 10104,87↙ Now,these 3 records are

721
11.8 共用体 11.8.1共用体的概念 使几个不同的变量共占同一段内存的结构称为 “共用体”类型的结构。 图11-24
定义共用体类型变量的一般形式为: union 共用体名 { 成员表列 }变量表列;

722
11.8 共用体 例如: union data union data { int i; { int i;
char ch; 或 char ch; float f; float f; }a,b,c; };union data a,b,c;

723
11.8 共用体 共用体和结构体的比较: 结构体变量所占内存长度是各成员占的内存长度之和。每个成员分别占有其自己的内存单元。
共用体变量所占的内存长度等于最长的成员的长度。 共用体和结构体的比较: 结构体变量所占内存长度是各成员占的内存长度之和。每个成员分别占有其自己的内存单元。 共用体变量所占的内存长度等于最长的成员的长度。 例如:上面定义的“共用体”变量a、b、c各占4 个字节(因为一个实型变量占4个字节),而不 是各占2+1+4=7个字节。
,而不. 是各占2+1+4=7个字节。")
724
11.8 共用体 例如:前面定义了a、b、c为共用体变量 11.8.2 共用体变量的引用方式 只有先定义了共用体变量才能引用它,而且不
能引用共用体变量,而只能引用共用体变量中的 成员。 例如:前面定义了a、b、c为共用体变量 a.i (引用共用体变量中的整型变量i) a.ch(引用共用体变量中的字符变量ch) a.f (引用共用体变量中的实型变量f)
 a.ch(引用共用体变量中的字符变量ch) a.f (引用共用体变量中的实型变量f)")
725
11.8 共用体 共用体类型数据的特点 (1)同一个内存段可以用来存放几种不同类型的成员,但在每一瞬时只能存放其中一种,而不是同时存放几种。 (2) 共用体变量中起作用的成员是最后一次存放的成员,在存入一个新的成员后原有的成员就失去作用。 (3) 共用体变量的地址和它的各成员的地址都是同一地址。
 共用体变量的地址和它的各成员的地址都是同一地址。")
726
11.8 共用体 (4) 不能对共用体变量名赋值,也不能企图引用变量名来得到一个值,又不能在定义共用体变量时对它初始化。
(5) 不能把共用体变量作为函数参数,也不能使函数带回共用体变量,但可以使用指向共用体变量的指针 (6) 共用体类型可以出现在结构体类型定义中,也可以定义共用体数组。反之,结构体也可以出现在共用体类型定义中,数组也可以作为共用体的成员。
 不能把共用体变量作为函数参数,也不能使函数带回共用体变量,但可以使用指向共用体变量的指针. (6) 共用体类型可以出现在结构体类型定义中,也可以定义共用体数组。反之,结构体也可以出现在共用体类型定义中,数组也可以作为共用体的成员。")
727
11.8 共用体 例11.12 设有若干个人员的数据,其中有学生和教师。学生的数据中包括:姓名、号码、性别、职业、班级。教师的数据包括:姓名、号码、性别、职业、职务。可以看出,学生和教师所包含的数据是不同的。现要求把它们放在同一表格中。 图11-25

728
11.7 用指针处理链表 算法: 图11-26

729
11.8 共用体 #include <stdio.h> struct { int num; char name[10];
char sex; char job; union int banji; char position[10]; }category; }person[2];/*先设人数为2*/
![11.8 共用体 #include <stdio.h> struct { int num; char name[10];](http://slidesplayer.com/slide/11113381/60/images/729/11.8+%E5%85%B1%E7%94%A8%E4%BD%93+%23include+%3Cstdio.h%3E+struct+%7B+int+num%3B+char+name%5B10%5D%3B.jpg "char sex; char job; union. int banji; char position[10]; }category; }person[2];/*先设人数为2*/")
730
11.8 共用体 void main() {int i; for(i=0;i<2;i++)
{scanf("%d %s %c %c", &person[i].num, &person[i].name, &person[i].sex, &person[i].job); if(person[i].job == 'S') scanf("%d", &person[i].category.banji); else if(person[i].job == 'T') scanf("%s", person[i].category.position); else printf(“Input error!”);} printf("\n"); printf("No. name sex job class/position\n"); {if (person[i].job == 'S') printf(“%-6d%-10s%-3c%-3c%-6d\n”,person[i].num, person[i].name, person[i].sex, person[i].job, person[i].category.banji); else printf(“%-6d%-10s%-3c%-3c%-6s\n”,person[i].num, person[i].name,person[i].sex, person[i].job, person[i].category.position);}} 11.8 共用体 运行情况如下: 101 Li f s 501 Wang m t professor No. Name sex jobclass/position 101 Li f s 501 102 Wang m t professor
; if(person[i].job == S ) scanf( %d , &person[i].category.banji); else if(person[i].job == T ) scanf( %s , person[i].category.position); else printf( Input error! );} printf( \n ); printf( No. name sex job class/position\n ); {if (person[i].job == S ) printf( %-6d%-10s%-3c%-3c%-6d\n ,person[i].num, person[i].name, person[i].sex, person[i].job, person[i].category.banji); else printf( %-6d%-10s%-3c%-3c%-6s\n ,person[i].num, person[i].name,person[i].sex, person[i].job, person[i].category.position);}} 11.8 共用体. 运行情况如下: 101 Li f s 501 Wang m t professor No. Name sex jobclass/position. 101 Li f s 501. 102 Wang m t professor.")
731
11.9 枚举类型 枚举:将变量的值一一列举出来,变量的值只限于列举 出来的值的范围内。 申明枚举类型用enum
enum weekday{sun,mon,tue,wed,thu,fri,sat}; 定义变量: enum weekday workday,week-day; enum{sun,mon,tue,wed,thu,fri,sat}workday; 变量值只能是sun到sat之一 。 枚举元素 枚举常量

732
11.9 枚举类型 说明: 在C编译中,对枚举元素按常量处理,故称枚举 常量。它们不是变量,不能对它们赋值。
(2) 枚举元素作为常量,它们是有值的,C语言编译 按定义时的顺序使它们的值为0,1,2… (3) 枚举值可以用来作判断比较。 (4) 一个整数不能直接赋给一个枚举变量。
 枚举元素作为常量,它们是有值的,C语言编译. 按定义时的顺序使它们的值为0,1,2… (3) 枚举值可以用来作判断比较。 (4) 一个整数不能直接赋给一个枚举变量。")
733
11.9 枚举类型 算法: 例11.13口袋中有红、黄、蓝、白、黑5种颜色的球若干 个。每次从口袋中先后取出3个球,问得到3种不同色的球
的可能取法,输出每种排列的情况。 算法: 图

734
§13.9 枚举类型 #include <stdio.h> main()
{enum color {red,yellow,blue,white,black}; enum color i,j,k,pri; int n,loop;n=0; for (i=red;i<=black;i++) for (j=red;j<=black;j++) if (i!=j) { for (k=red;k<=black;k++) if ((k!=i) && (k!=j)) {n=n+1; printf("%-4d",n); for (loop=1;loop<=3;loop++) { switch (loop) { case 1: pri=i;break; case 2: pri=j;break; case 3: pri=k;break; default:break; } §13.9 枚举类型
 for (j=red;j<=black;j++) if (i!=j) { for (k=red;k<=black;k++) if ((k!=i) && (k!=j)) {n=n+1; printf( %-4d ,n); for (loop=1;loop<=3;loop++) { switch (loop) { case 1: pri=i;break; case 2: pri=j;break; case 3: pri=k;break; default:break; } §13.9 枚举类型.")
735
§13.9 枚举类型 运行情况如下: 1redyellowblue2redyellowwhite3redyellowblack
switch (pri) { case red:printf("%-10s","red"); break; case yellow: printf("%-10s","yellow"); break; case blue: printf("%-10s","blue"); break; case white: printf("%-10s","white"); break; case black: printf("%-10s","black"); break; default :break; } printf("\n"); printf("\ntotal:%5d\n",n); §13.9 枚举类型 运行情况如下: 1redyellowblue2redyellowwhite3redyellowblack 58blackwhitered59blackwhiteyellow60blackwhiteblue total:60
 { case red:printf( %-10s , red ); break; case yellow: printf( %-10s , yellow ); break; case blue: printf( %-10s , blue ); break; case white: printf( %-10s , white ); break; case black: printf( %-10s , black ); break; default :break; } printf( \n ); printf( \ntotal:%5d\n ,n); §13.9 枚举类型. 运行情况如下: 1redyellowblue2redyellowwhite3redyellowblack 58blackwhitered59blackwhiteyellow60blackwhiteblue total:60.")
736
11.10 用typedef定义类型 用typedef声明新的类型名来代替已有的类型名。 声明INTEGER为整型
typedef int INTEGER 声明结构类型 Typedef struct{ int month; int day; int year;}DATE;

737
11.10 用typedef定义类型 声明NUM为整型数组类型 : typedef int NUM[100];
typedef int NUM[100]; 声明STRING为字符指针类型: typedef char *STRING; 声明POINTER为指向函数的指针类型,该函数返回 整型值 : typedef int (*POINTER)()
![11.10 用typedef定义类型 声明NUM为整型数组类型 : typedef int NUM[100];](http://slidesplayer.com/slide/11113381/60/images/737/11.10+%E7%94%A8typedef%E5%AE%9A%E4%B9%89%E7%B1%BB%E5%9E%8B+%E5%A3%B0%E6%98%8E%EF%BC%AE%EF%BC%B5%EF%BC%AD%E4%B8%BA%E6%95%B4%E5%9E%8B%E6%95%B0%E7%BB%84%E7%B1%BB%E5%9E%8B+%EF%BC%9A+%EF%BD%94%EF%BD%99%EF%BD%90%EF%BD%85%EF%BD%84%EF%BD%85%EF%BD%86+%EF%BD%89%EF%BD%8E%EF%BD%94+%EF%BC%AE%EF%BC%B5%EF%BC%AD%EF%BC%BB%EF%BC%91%EF%BC%90%EF%BC%90%EF%BC%BD%EF%BC%9B.jpg "typedef int NUM[100]; 声明STRING为字符指针类型: typedef char *STRING; 声明POINTER为指向函数的指针类型,该函数返回. 整型值 : typedef int (*POINTER)()")
738
11.10 用typedef定义类型 用typedef定义类型的方法: ① 先按定义变量的方法写出定义体(如:int i)。
② 将变量名换成新类型名(例如:将i换成COUNT)。 ③ 在最前面加typedef (例如:typedef int COUNT)。 ④ 然后可以用新类型名去定义变量。
。 ③ 在最前面加typedef. (例如:typedef int COUNT)。 ④ 然后可以用新类型名去定义变量。")
739
11.10 用typedef定义类型 用typedef定义类型的方法(举例): ① 先按定义数组变量形式书写:int n[100];
② 将变量名n换成自己指定的类型名: int NUM[100]; ③ 在前面加上typedef,得到 typedef int NUM[100]; ④ 用来定义变量:NUM n;
![11.10 用typedef定义类型 用typedef定义类型的方法(举例): ① 先按定义数组变量形式书写:int n[100];](http://slidesplayer.com/slide/11113381/60/images/739/11.10+%E7%94%A8typedef%E5%AE%9A%E4%B9%89%E7%B1%BB%E5%9E%8B+%E7%94%A8typedef%E5%AE%9A%E4%B9%89%E7%B1%BB%E5%9E%8B%E7%9A%84%E6%96%B9%E6%B3%95%EF%BC%88%E4%B8%BE%E4%BE%8B%EF%BC%89%EF%BC%9A+%E2%91%A0+%E5%85%88%E6%8C%89%E5%AE%9A%E4%B9%89%E6%95%B0%E7%BB%84%E5%8F%98%E9%87%8F%E5%BD%A2%E5%BC%8F%E4%B9%A6%E5%86%99%EF%BC%9Aint+n%5B100%5D%EF%BC%9B.jpg "② 将变量名n换成自己指定的类型名: int NUM[100]; ③ 在前面加上typedef,得到. typedef int NUM[100]; ④ 用来定义变量:NUM n;")
740
11.10 用typedef定义类型 说明: 用typedef可以声明各种类型名,但不能用 来定义变量。
而没有创造新的类型。 (3) 当不同源文件中用到同一类型数据时,常用 typedef声明一些数据类型,把它们单独放在一个文件 中,然后在需要用到它们的文件中用#include命令把 它们包含进来。 (4) 使用typedef有利于程序的通用与移植。
 当不同源文件中用到同一类型数据时,常用. typedef声明一些数据类型,把它们单独放在一个文件. 中,然后在需要用到它们的文件中用#include命令把. 它们包含进来。 (4) 使用typedef有利于程序的通用与移植。")
741
11.10 用typedef定义类型 说明: (5) typedef与#define有相似之处,例如:
typedef int COUNT;#define COUNT int的作用都是 用COUNT代表int。但事实上,它们二者是不同的。 #define是在预编译时处理的,它只能作简单的字符串 替换,而typedef是在编译时处理的。实际上它并不是 作简单的字符串替换,而是采用如同定义变量的方法 那样来声明一个类型。

742
第十二章 位运算

743
主要内容 12.1位运算符和位运算 12.2位运算举例 12.3位段

744
概念 位运算是指按二进制位进行的运算。因为在系统软件中,常要处理二进制位的问题。
例如:将一个存储单元中的各二进制位左移或右移一位,两个数按位相加等。 C语言提供位运算的功能,与其他高级语言(如PASCAL)相比,具有很大的优越性。
相比,具有很大的优越性。")
745
12.1 位运算符和位运算 C语言提供的位运算符有: 说明: 运算符 含义 运算符 含义 & 按位与 ~ 取反
运算符 含义 运算符 含义 & 按位与 ~ 取反 | 按位或 << 左移 ∧ 按位异或 >> 右移 说明: (1)位运算符中除~以外,均为二目(元)运算符,即要求两侧各有一个运算量。 (2)运算量只能是整型或字符型的数据,不能为实型数据。
位运算符中除~以外,均为二目(元)运算符,即要求两侧各有一个运算量。 (2)运算量只能是整型或字符型的数据,不能为实型数据。")
746
12.1.1“按位与”运算符(&) 例:3&5并不等于8,应该是按位与运算:
按位与是指:参加运算的两个数据,按二进制位进行“与”运算。如果两个相应的二进制位都为1,则该位的结果值为1;否则为0。即: 0&0=0,0&1=0,1&0=0,1&1=1 例:3&5并不等于8,应该是按位与运算: (3) & (5) (1) 注意:如果参加&运算的是负数(如-3&-5),则要以补码形式表示为二进制数,然后再按位进行“与”运算。 3&5的值得1
 & (5) (1) 注意:如果参加&运算的是负数(如-3&-5),则要以补码形式表示为二进制数,然后再按位进行 与 运算。 3&5的值得1.")
747
按位与的用途: (1) 清零。 若想对一个存储单元清零,即使其全部二进制位为0,只要找一个二进制数,其中各个位符合以下条件:原来的数中为1的位,新数中相应位为0。然后使二者进行&运算,即可达到清零目的。 例: 原有数为00101011,另找一个数,设它为10010100,这样在原数为1的位置上,该数的相应位值均为0。将这两个数进行&运算: &

748
如有一个整数a(2个字节),想要取其中的低字节,只需将a与8个1按位与即可。
(2) 取一个数中某些指定位。 如有一个整数a(2个字节),想要取其中的低字节,只需将a与8个1按位与即可。 a b c
 取一个数中某些指定位。 如有一个整数a(2个字节),想要取其中的低字节,只需将a与8个1按位与即可。 a. b. c")
749
(3)保留一位的方法:与一个数进行&运算,此数在该位取1。
例:有一数01010100,想把其中左面第3、4、5、7、8位保留下来,运算如下: (84) & (59) (16) 即:a=84,b=59 c=a&b=16
 & (59) (16) 即:a=84,b=59. c=a&b=16.")
750
12.1.2 “按位或”运算符(|) 两个相应的二进制位中只要有一个为1,该位的结果值为1。
即 0|0=0,0|1=1,1|0=1,1|1=1 例: 060|017,将八进制数60与八进制数17进行按位或运算。 |

751
应用:按位或运算常用来对一个数据的某些位定值为1。例如:如果想使一个数a的低4位改为1,只需将a与017进行按位或运算即可。
例: a是一个整数(16位), 有表达式:a | 0377 则低8位全置为1,高8位保留原样。
, 有表达式:a | 0377 则低8位全置为1,高8位保留原样。")
752
12.1.3“异或”运算符(∧) 即:0∧0=0,0∧1=1,1∧0=1, 1∧1=0 例: 即:071∧052=023 (八进制数)
异或运算符∧也称XOR运算符。它的规则是: 若参加运算的两个二进制位同号则结果为0(假) 异号则结果为1(真) 即:0∧0=0,0∧1=1,1∧0=1, 1∧1=0 例: ∧ 即:071∧052=023 (八进制数)
 异号则结果为1(真) 即:0∧0=0,0∧1=1,1∧0=1, 1∧1=0. 例: ∧ 即:071∧052=023 (八进制数)")
753
设有01111010,想使其低4位翻转,即1变为0,0变为1。可以将它与00001111进行∧运算,即:
∧运算符应用: (1) 使特定位翻转 设有01111010,想使其低4位翻转,即1变为0,0变为1。可以将它与00001111进行∧运算,即: 运算结果的低4位正好是原数低4位的翻转。可见,要使哪几位翻转就将与其进行∧运算的该几位置为1即可。 ∧
 使特定位翻转. 设有01111010,想使其低4位翻转,即1变为0,0变为1。可以将它与00001111进行∧运算,即: 运算结果的低4位正好是原数低4位的翻转。可见,要使哪几位翻转就将与其进行∧运算的该几位置为1即可。 ∧")
754
(2) 与0相∧,保留原值 例如:012∧00=012 00001010 因为原数中的1与0进行∧运算得1,0∧0得0,故保留原数。
∧ 因为原数中的1与0进行∧运算得1,0∧0得0,故保留原数。

755
(3) 交换两个值,不用临时变量 例如:a=3,b=4。 想将a和b的值互换,可以用以下赋值语句实现: a=a∧b; b=b∧a;
a=011 (∧)b=100 a=111(a∧b的结果,a已变成7) b=011(b∧a的结果,b已变成3) (∧)a=111 a=100(a∧b的结果,a已变成4)
b=100. a=111(a∧b的结果,a已变成7) b=011(b∧a的结果,b已变成3) (∧)a=111. a=100(a∧b的结果,a已变成4)")
756
即等效于以下两步: ① 执行前两个赋值语句:“a=a∧b;”和“b=b∧a;”相当于b=b∧(a∧b)。
② 再执行第三个赋值语句: a=a∧b。由于a的值等于(a∧b),b的值等于(b∧a∧b),因此,相当于a=a∧b∧b∧a∧b,即a的值等于a∧a∧b∧b∧b,等于b。 a得到b原来的值。
,b的值等于(b∧a∧b),因此,相当于a=a∧b∧b∧a∧b,即a的值等于a∧a∧b∧b∧b,等于b。 a得到b原来的值。")
757
“取反”运算符(~) ~是一个单目(元)运算符,用来对一个二进制数按位取反,即将0变1,将1变0。例如,~025是对八进制数25(即二进制数00010101)按位求反。 (~) (八进制数177752)
 (八进制数177752)")
758
左移运算符是用来将一个数的各二进制位全部左移若干位。
左移运算符(<<) 左移运算符是用来将一个数的各二进制位全部左移若干位。 例如:a=<<2 将a的二进制数左移2位,右补0。 若a=15,即二进制数00001111, 左移2位得00111100,(十进制数60) 高位左移后溢出,舍弃。
 左移运算符是用来将一个数的各二进制位全部左移若干位。 例如:a=<<2 将a的二进制数左移2位,右补0。 若a=15,即二进制数00001111, 左移2位得00111100,(十进制数60) 高位左移后溢出,舍弃。")
759
左移运算符(<<) 左移1位相当于该数乘以2,左移2位相当于该数乘以22=4,15<<2=60,即乘了4。但此结论只适用于该数左移时被溢出舍弃的高位中不包含1的情况。 假设以一个字节(8位)存一个整数,若a为无符号整型变量,则a=64时,左移一位时溢出的是0,而左移2位时,溢出的高位中包含1。
存一个整数,若a为无符号整型变量,则a=64时,左移一位时溢出的是0,而左移2位时,溢出的高位中包含1。")
760
右移运算符(>>) 右移运算符是a>>2表示将a的各二进制位右移2位,移到右端的低位被舍弃,对无符号数,高位补0。 例如:a=017时: a的值用二进制形式表示为 , 舍弃低2位11: a>>2= 右移一位相当于除以2 右移n位相当于除以2n。

761
在右移时,需要注意符号位问题: 对无符号数,右移时左边高位移入0;对于有符号的值,如果原来符号位为0(该数为正),则左边也是移入0。如果符号位原来为1(即负数),则左边移入0还是1,要取决于所用的计算机系统。有的系统移入0,有的系统移入1。移入0的称为“逻辑右移”,即简单右移;移入1的称为“算术右移”。
,则左边也是移入0。如果符号位原来为1(即负数),则左边移入0还是1,要取决于所用的计算机系统。有的系统移入0,有的系统移入1。移入0的称为 逻辑右移 ,即简单右移;移入1的称为 算术右移 。")
762
例: a的值是八进制数113755: a:1001011111101101 (用二进制形式表示)
在有些系统中,a>>1得八进制数045766,而在另一些系统上可能得到的是145766。Turbo C和其他一些C编译采用的是算术右移,即对有符号数右移时,如果符号位原来为1,左面移入高位的是1。

763
12.1.7 位运算赋值运算符 例如: &=, |=, >>=, <<=, ∧=
位运算赋值运算符 位运算符与赋值运算符可以组成复合赋值运算符。 例如: &=, |=, >>=, <<=, ∧= 例: a & = b相当于 a = a & b a << =2相当于a = a << 2

764
不同长度的数据进行位运算 如果两个数据长度不同(例如long型和int型),进行位运算时(如a & b,而a为long型,b为int型),系统会将二者按右端对齐。如果b为正数,则左侧16位补满0;若b为负数,左端应补满1;如果b为无符号整数型,则左侧添满0。
,进行位运算时(如a & b,而a为long型,b为int型),系统会将二者按右端对齐。如果b为正数,则左侧16位补满0;若b为负数,左端应补满1;如果b为无符号整数型,则左侧添满0。")
765
12.2 位运算举例 例12.1 取一个整数a从右端开始的4~7位 ① 先使a右移4位:a >> 4
目的是使要取出的那几位移到最右端 未右移时的情况 右移4位后的情况

766
(a >> 4) & ~ ( ~ 0 << 4 )
② 设置一个低4位全为1,其余全为0的数。 ~ ( ~ 0 << 4 ) ③ 将上面①、②进行&运算。 (a >> 4) & ~ ( ~ 0 << 4 ) 程序如下: #include <stdio.h> void main() { unsigned a,b,c,d; scanf(“%o”,&a); b=a>>4; c=~(~0<<4); d=b&c; printf(“%o,%d\n%o,%d\n”,a,a,d,d); 运行情况如下:331(输入) 331, 217 (a的值) 15, (d的值) 输入a的值为八进制数331, 其二进制形式为 经运算最后得到的d为 即八进制数15,十进制数13。
 ③ 将上面①、②进行&运算。 (a >> 4) & ~ ( ~ 0 << 4 ) 程序如下: #include <stdio.h> void main() { unsigned a,b,c,d; scanf( %o ,&a); b=a>>4; c=~(~0<<4); d=b&c; printf( %o,%d\n%o,%d\n ,a,a,d,d); 运行情况如下:331(输入) 331, 217 (a的值) 15, 13 (d的值) 输入a的值为八进制数331, 其二进制形式为 经运算最后得到的d为 即八进制数15,十进制数13。")
767
例12.2 循环移位。 要求将a进行右循环移位 将a右循环移n位,即将a中原来左面(16-n)位右移n位,原来右端n位移到最左面n位。
位右移n位,原来右端n位移到最左面n位。")
768
步骤: ① 将a的右端n位先放到b中的高n位中,实现语句:b=a<<(16-n); ② 将a右移n位,其左面高位n位补0, 实现语句:c=a>>n; ③ 将c与b进行按位或运算,即c=c|b;
; ② 将a右移n位,其左面高位n位补0, 实现语句:c=a>>n; ③ 将c与b进行按位或运算,即c=c|b;")
769
#include <stdio.h> void main() { unsigned a,b,c; int n;
程序如下: #include <stdio.h> void main() { unsigned a,b,c; int n; scanf(“a=%o,n=%d”,&a,&n); b=a<<(16-n); c=a>>n; c=c|b; printf(“%o\n%o”,a,c); } 运行情况如下: a=157653,n=3 15765 3 75765 运行开始时输入八进制数157653, 即二进制数 循环右移3位后得二进制数 即八进制数75765
 { unsigned a,b,c; int n; scanf( a=%o,n=%d ,&a,&n); b=a<<(16-n); c=a>>n; c=c|b; printf( %o\n%o ,a,c); } 运行情况如下: a=157653,n=3. 15765 3. 75765 运行开始时输入八进制数157653, 即二进制数 循环右移3位后得二进制数 即八进制数")
770
12.3 位段 信息的存取一般以字节为单位。实际上,有时存储一个信息不必用一个或多个字节,例如,“真”或“假”用0或1表示,只需1位即可。在计算机用于过程控制、参数检测或数据通信领域时,控制信息往往只占一个字节中的一个或几个二进制位,常常在一个字节中放几个信息。

771
怎样向一个字节中的一个或几个二进制位赋值和改变它的值呢?可以用以下两种方法:
可以人为地将一个整型变量data分为几部分。 但是用这种方法给一个字节中某几位赋值太麻烦。可以位段结构体的方法。 (2)位段 C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域” ( bit field) 。利用位段能够用较少的位数存储数据。
位段. C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为 位段 或称 位域 ( bit field) 。利用位段能够用较少的位数存储数据。")
772
程序如下: struct packed-data { unsigned a:2; unsigned b:6; unsigned c:4; unsigned d:4; int i; }data;

773
关于位段的定义和引用的说明: (1)位段成员的类型必须指定为unsigned或int类型。
(2) 若某一位段要从另一个字开始存放,可用以下形式定义: unsigned a:1; unsigned b:2;一个存储单元 unsigned:0; unsigned c:3;另一存储单元 a、b、c应连续存放在一个存储单元中,由于用了长度为0的位段,其作用是使下一个位段从下一个存储单元开始存放。因此,只将a、b存储在一个存储单元中,c另存在下一个单元(“存储单元”可能是一个字节,也可能是2个字节,视不同的编译系统而异)。
 若某一位段要从另一个字开始存放,可用以下形式定义: unsigned a:1; unsigned b:2;一个存储单元. unsigned:0; unsigned c:3;另一存储单元 a、b、c应连续存放在一个存储单元中,由于用了长度为0的位段,其作用是使下一个位段从下一个存储单元开始存放。因此,只将a、b存储在一个存储单元中,c另存在下一个单元( 存储单元 可能是一个字节,也可能是2个字节,视不同的编译系统而异)。")
774
关于位段的定义和引用的说明: (3) 一个位段必须存储在同一存储单元中,不能跨两个单元。如果第一个单元空间不能容纳下一个位段,则该空间不用,而从下一个单元起存放该位段。 (4) 可以定义无名位段。 (5) 位段的长度不能大于存储单元的长度,也不能定义位段数组。 (6) 位段可以用整型格式符输出。 (7) 位段可以在数值表达式中引用,它会被系统自动地转换成整型数。
 位段的长度不能大于存储单元的长度,也不能定义位段数组。 (6) 位段可以用整型格式符输出。 (7) 位段可以在数值表达式中引用,它会被系统自动地转换成整型数。")
775
第十三章 文件

776
文件的基本概念 文件的基本函数 文件的顺序读写 文件的随机读写 文件简单应用
本章要点 文件的基本概念 文件的基本函数 文件的顺序读写 文件的随机读写 文件简单应用

777
主要内容 13.1 C文件概述 13.2 文件类型指针 13.3 文件的打开与关闭 13.4 文件的读写 13.5 文件的定位
13.6 出错的检测 13.7 文件输入输出小结

778
13.1 C文件概述 文件:文件指存储在外部介质(如磁盘磁带)上 数据的集合。 操作系统是以文件为单位对数据进行管理的。 输出文件缓冲区
程序 数据区 输出文件缓冲区 输入文件缓冲区

779
13.1 C文件概述(续) 文件的分类 ●从用户观点: 特殊文件(标准输入输出文件或标准设备文件)。 普通文件(磁盘文件)。
●从操作系统的角度看,每一个与主机相连的输入 输出设备看作是一个文件。 例:输入文件:终端键盘 输出文件:显示屏和打印机

780
13.1 C文件概述(续) 文件的分类 ●按数据的组织形式: ASCII文件(文本文件):每一个字节放一个ASCII代码
二进制文件:把内存中的数据按其在内存中的存储形 式原样输出到磁盘上存放。 例:整数10000在内存中的存储形式以及分别按ASCII 码形式和二进制形式输出如下图所示:

781
13.1 C文件概述(续) 文件的分类 ASCII文件和二进制文件的比较: ASCII文件便于对字符进行逐个处理,也便于输出
字符。但一般占存储空间较多,而且要花费转换时 间。 二进制文件可以节省外存空间和转换时间,但一个 字节并不对应一个字符,不能直接输出字符形式。 一般中间结果数据需要暂时保存在外存上,以后又 需要输入内存的,常用二进制文件保存。

782
13.1 C文件概述(续) 文件的分类 C语言对文件的处理方法: 缓冲文件系统:系统自动地在内存区为每一个正
在使用的文件开辟一个缓冲区。用缓冲文件系统 进行的输入输出又称为高级磁盘输入输出。 非缓冲文件系统:系统不自动开辟确定大小的缓 冲区,而由程序为每个文件设定缓冲区。用非缓 冲文件系统进行的输入输出又称为低级输入输出 系统。

783
13.1 C文件概述(续) 说明: 在UNIX系统下,用缓冲文件系统来处理文本文件, 用非缓冲文件系统来处理二进制文件。
ANSI C 标准只采用缓冲文件系统来处理文本文 件和二进制文件。 C语言中对文件的读写都是用库函数来实现。

784
13.2 文件类型指针 Turbo C在stdio.h文件中有以下的文件类型声明: typedef struct
{ shortlevel; /*缓冲区“满”或“空”的程度*/ unsignedflags; /*文件状态标志*/ charfd; /*文件描述符*/ unsignedcharhold; /*如无缓冲区不读取字符*/ shortbsize; /*缓冲区的大小*/ unsignedchar*buffer;/*数据缓冲区的位置*/ unsignedar*curp;/*指针,当前的指向*/ unsignedistemp;/*临时文件,指示器*/ shorttoken;/*用于有效性检查*/}FILE; 在缓冲文件系统中,每个被使用的文件都要在内存中开辟一 FILE类型的区,存放文件的有关信息。

785
13.2 文件类型指针(续) FILE类型的数组: 文件型指针变量: FILE f[5];定义了一个结构体数组f,它有5个元素,
可以用来存放5个文件的信息。 文件型指针变量: FILE *fp;fp是一个指向FILE类型结构体的 指针变量。可以使fp指向某一个文件的结构体变量,从 而通过该结构体变量中的文件信息能够访问该文件。如果 有n个文件,一般应设n个指针变量,使它们分别指向n 个文件,以实现对文件的访问。
![13.2 文件类型指针(续) FILE类型的数组: 文件型指针变量: FILE f[5];定义了一个结构体数组f,它有5个元素,](http://slidesplayer.com/slide/11113381/60/images/785/13.2+%E6%96%87%E4%BB%B6%E7%B1%BB%E5%9E%8B%E6%8C%87%E9%92%88%28%E7%BB%AD%29+FILE%E7%B1%BB%E5%9E%8B%E7%9A%84%E6%95%B0%E7%BB%84%EF%BC%9A+%E6%96%87%E4%BB%B6%E5%9E%8B%E6%8C%87%E9%92%88%E5%8F%98%E9%87%8F%3A+FILE+f%EF%BC%BB5%EF%BC%BD%3B%E5%AE%9A%E4%B9%89%E4%BA%86%E4%B8%80%E4%B8%AA%E7%BB%93%E6%9E%84%E4%BD%93%E6%95%B0%E7%BB%84f%EF%BC%8C%E5%AE%83%E6%9C%895%E4%B8%AA%E5%85%83%E7%B4%A0%EF%BC%8C.jpg "可以用来存放5个文件的信息。 文件型指针变量: FILE *fp;fp是一个指向FILE类型结构体的. 指针变量。可以使fp指向某一个文件的结构体变量,从. 而通过该结构体变量中的文件信息能够访问该文件。如果. 有n个文件,一般应设n个指针变量,使它们分别指向n. 个文件,以实现对文件的访问。")
786
13.3 文件的打开与关闭 一.文件的打开(fopen函数) 函数调用: FILE *fp; fp=fopen(文件名,使用文件方式);
①需要打开的文件名,也就是准备访问的文件的名字; ②使用文件的方式(“读”还是“写”等); ③让哪一个指针变量指向被打开的文件。
; ③让哪一个指针变量指向被打开的文件。")
787
13.3 文件的打开与关闭(续) 文件使用方式 含 义 “r” (只读)为输入打开一个文本文件 “w” (只写)为输出打开一个文本文件
文件使用方式 含 义 “r” (只读)为输入打开一个文本文件 “w” (只写)为输出打开一个文本文件 “a” (追加)向文本文件尾增加数据 “rb” (只读)为输入打开一个二进制文件 “wb” (只写)为输出打开一个二进制文件 "ab“ (追加)向二进制文件尾增加数据 "r+“ (读写)为读/写打开一个文本文件 "w+” (读写)为读/写建立一个新的文本文件 "a+” (读写)为读/写打开一个文本文件 "rb+“ (读写)为读/写打开一个二进制文件 “wb+“ (读写)为读/写建立一个新的二进制文件 “ab+” (读写)为读/写打开一个二进制文件
为输入打开一个文本文件. w (只写)为输出打开一个文本文件. a (追加)向文本文件尾增加数据. rb (只读)为输入打开一个二进制文件. wb (只写)为输出打开一个二进制文件. ab (追加)向二进制文件尾增加数据. r+ (读写)为读/写打开一个文本文件. w+ (读写)为读/写建立一个新的文本文件. a+ (读写)为读/写打开一个文本文件. rb+ (读写)为读/写打开一个二进制文件. wb+ (读写)为读/写建立一个新的二进制文件. ab+ (读写)为读/写打开一个二进制文件.")
788
13.3 文件的打开与关闭(续) 二.文件的关闭(fclose函数) 函数调用: fclose(文件指针); 函数功能:
使文件指针变量不指向该文件,也就是文件指针变 量与文件“脱钩”,此后不能再通过该指针对原来与 其相联系的文件进行读写操作。 返回值: 关闭成功返回值为0;否则返回EOF(-1) 。
 。")
789
13.4 文件的读写 一、字符输入输出函数(fputs()和fgets()) fputs函数 函数调用: fputs ( ch,fp ) ;
函数功能: 将字符(ch的值)输出到fp所指向的文件中去。 返回值: 如果输出成功,则返回值就是输出的字符; 如果输出失败,则返回一个EOF。
输出到fp所指向的文件中去。 返回值: 如果输出成功,则返回值就是输出的字符; 如果输出失败,则返回一个EOF。")
790
13.4 文件的读写(续) fgets函数 函数调用: ch=fgets(fp); 函数功能: 从指定的文件读入一个字符,该文件必须是以读或
读写方式打开的。 返回值: 读取成功一个字符,赋给ch。 如果遇到文件结束符,返回一个文件结束标志 EOF 。

791
13.4 文件的读写(续) 常见的读取字符操作 从一个文本文件顺序读入字符并在屏幕上显示出来: ch = fgetc(fp);
while(ch!=EOF) { putchar(ch); } 注意:EOF不是可输出字符,因此不能在屏幕上显示。 由于字符的ASCII码不可能出现-1,因此EOF定义为 -1是合适的。当读入的字符值等于-1时,表示读入 的已不是正常的字符而是文件结束符。
 { putchar(ch); } 注意:EOF不是可输出字符,因此不能在屏幕上显示。 由于字符的ASCII码不可能出现-1,因此EOF定义为. -1是合适的。当读入的字符值等于-1时,表示读入. 的已不是正常的字符而是文件结束符。")
792
13.4 文件的读写(续) 常见的读取字符操作 从一个二进制文件顺序读入字符: while(!feof(fp)) {
{ ch = fgetc(fp); } 注意:ANSI C提供一个feof()函数来判断文件是否 真的结束。如果是文件结束,函数feof(fp)的值为1 (真);否则为0(假)。以上也适用于文本文件的读取。
; } 注意:ANSI C提供一个feof()函数来判断文件是否. 真的结束。如果是文件结束,函数feof(fp)的值为1. (真);否则为0(假)。以上也适用于文本文件的读取。")
793
§13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.1从键盘输入一些字符,逐个把它们送到
#include <stdlib.h> #include <stdio.h> void main(void) { FILE *fp; char ch,filename[10]; scanf("%s",filename); if((fp=fopen(filename,"w"))==NULL) { printf("cannot open file\n"); exit(0); /*终止程序*/} ch=getchar( ); /*接收执行scanf语句时最后输入的回车符 */ ch=getchar( ); /* 接收输入的第一个字符 */ while(ch!='#'{ fputc(ch,fp);putchar(ch); ch=getchar(); } fclose(fp); } §13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.1从键盘输入一些字符,逐个把它们送到 磁盘上去,直到输入一个“#”为止。 运行情况如下: file1.c (输入磁盘文件名) computer and c#(输入一个字符串) computer and c (输出一个字符串)
 { FILE *fp; char ch,filename[10]; scanf( %s ,filename); if((fp=fopen(filename, w ))==NULL) { printf( cannot open file\n ); exit(0); /*终止程序*/} ch=getchar( ); /*接收执行scanf语句时最后输入的回车符 */ ch=getchar( ); /* 接收输入的第一个字符 */ while(ch!= # { fputc(ch,fp);putchar(ch); ch=getchar(); } fclose(fp); } §13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.1从键盘输入一些字符,逐个把它们送到. 磁盘上去,直到输入一个 # 为止。 运行情况如下: file1.c (输入磁盘文件名) computer and c#(输入一个字符串) computer and c (输出一个字符串)")
794
§13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.2将一个磁盘文件中的信息复制到另一个磁 盘文件中 。
#include <stdlib.h> #include <stdio.h> main( ) {FILE *in,*out; char ch,infile[10],outfile[10]; printf("Enter the infile name:\n"); scanf("%s",infile); printf("Enter the outfile name:\n"); scanf("%s",outfile); if((in=fopen(infile,"r"))==NULL) { printf("cannot open infile\n"); exit(0);} if((out=fopen(outfile,"w"))==NULL) { printf("cannot open outfile\n"); while(!feof(in))fputc(fgetc(in),out); fclose(in); fclose(out);} §13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.2将一个磁盘文件中的信息复制到另一个磁 盘文件中 。 运行情况如下: Enter the infile name file1.c(输入原有磁盘文件名 Enter the outfile name: file2.c (输入新复制的磁盘文件名) 程序运行结果是将file1.c文件中的内容复制到 file2.c中去。
 {FILE *in,*out; char ch,infile[10],outfile[10]; printf( Enter the infile name:\n ); scanf( %s ,infile); printf( Enter the outfile name:\n ); scanf( %s ,outfile); if((in=fopen(infile, r ))==NULL) { printf( cannot open infile\n ); exit(0);} if((out=fopen(outfile, w ))==NULL) { printf( cannot open outfile\n ); while(!feof(in))fputc(fgetc(in),out); fclose(in); fclose(out);} §13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.2将一个磁盘文件中的信息复制到另一个磁. 盘文件中 。 运行情况如下: Enter the infile name. file1.c(输入原有磁盘文件名. Enter the outfile name: file2.c (输入新复制的磁盘文件名) 程序运行结果是将file1.c文件中的内容复制到. file2.c中去。")
795
§13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.2的改进:复制一个二进制文件,利用main
#include <stdlib.h> #include <stdio.h> main(int argc,char *argv[ ]) {FILE *in,*out; char ch; if (argc!=3) { printf("You forgot to enter a filename\n"); exit(0); } if((in=fopen(argv[1],"rb"))==NULL) { printf("cannot open infile\n"); exit(0);} if((out=fopen(argv[2],"wb"))==NULL) { printf("cannot open outfile\n"); while(!feof(in)) fputc(fgetc(in),out); fclose(in); fclose(out);} §13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.2的改进:复制一个二进制文件,利用main 参数,在输入命令行是将两个文件名输入。 运行方法: 设经编译连接后得到的可执行文件名为a.exe,则在DOS命令工 作方式下,可以输入以下的命令行: C>a file1.c file2.c file1.c和file2.c,分别输入到argv[1] 和argv[2]中,argv[0]的内容为a,argc的 值等于3 。
 {FILE *in,*out; char ch; if (argc!=3) { printf( You forgot to enter a filename\n ); exit(0); } if((in=fopen(argv[1], rb ))==NULL) { printf( cannot open infile\n ); exit(0);} if((out=fopen(argv[2], wb ))==NULL) { printf( cannot open outfile\n ); while(!feof(in)) fputc(fgetc(in),out); fclose(in); fclose(out);} §13.4 文件的读写(续) fputc和fgetc函数使用举例: 例13.2的改进:复制一个二进制文件,利用main. 参数,在输入命令行是将两个文件名输入。 运行方法: 设经编译连接后得到的可执行文件名为a.exe,则在DOS命令工. 作方式下,可以输入以下的命令行: C>a file1.c file2.c. file1.c和file2.c,分别输入到argv[1] 和argv[2]中,argv[0]的内容为a,argc的. 值等于3 。")
796
13.4 文件的读写(续) 二、数据块读写函数(fread()和fwrite()) 函数调用:
fread (buffer,size,count,fp); fwrite(buffer,size,count,fp); 参数说明: buffer:是一个指针。 对fread 来说,它是读入数据的存放地址。 对fwrite来说,是要输出数据的地址(均指起始地址)。 size: 要读写的字节数。 count: 要进行读写多少个size字节的数据项。 fp: 文件型指针。
; fwrite(buffer,size,count,fp); 参数说明: buffer:是一个指针。 对fread 来说,它是读入数据的存放地址。 对fwrite来说,是要输出数据的地址(均指起始地址)。 size: 要读写的字节数。 count: 要进行读写多少个size字节的数据项。 fp: 文件型指针。")
797
13.4 文件的读写(续) 使用举例: 若文件以二进制形式打开: fread(f,4,2,fp);
 使用举例: 若文件以二进制形式打开: fread(f,4,2,fp);")
798
13.4 文件的读写(续) 使用举例: 若有如下结构类型: struct student_type {char name[10];
int num; int age; char addr[30];}stud[40]; 可以用fread和fwrite来进行数据的操作: for(i=0;i<40;i++) fread(&stud[i],sizeof(struct student-type),1,fp); for(i=0;i<40,i++) fwrite(&stud[i],sizeof(struct student-type),1,fp);
![13.4 文件的读写(续) 使用举例: 若有如下结构类型: struct student_type {char name[10];](http://slidesplayer.com/slide/11113381/60/images/798/13.4+%E6%96%87%E4%BB%B6%E7%9A%84%E8%AF%BB%E5%86%99%28%E7%BB%AD%29+%E4%BD%BF%E7%94%A8%E4%B8%BE%E4%BE%8B%EF%BC%9A+%E8%8B%A5%E6%9C%89%E5%A6%82%E4%B8%8B%E7%BB%93%E6%9E%84%E7%B1%BB%E5%9E%8B%EF%BC%9A+struct+student_type+%7Bchar+name%5B10%5D%3B.jpg "int num; int age; char addr[30];}stud[40]; 可以用fread和fwrite来进行数据的操作: for(i=0;i<40;i++) fread(&stud[i],sizeof(struct student-type),1,fp); for(i=0;i<40,i++) fwrite(&stud[i],sizeof(struct student-type),1,fp);")
799
13.4 文件的读写(续) 使用举例: 例13.3从键盘输入4个学生的有关数据,然后把它们转存 到磁盘文件上去。
#include <stdio.h> #define SIZE 4 struct student_type { char name[10]; int num; int age; char addr[15]; }stud[SIZE]; /*定义结构*/

800
§13.4 文件的读写(续) void save( ) {FILE *fp; int i;
if((fp=fopen("stu-list","wb"))==NULL) { printf("cannot open file\n"); return;} for(i=0;i<SIZE;i++)/*二进制写*/ if(fwrite(&stud[i],sizeof(struct student_type),1,fp)!=1) printf(“file write error\n”);/*出错处理*/ fclose(fp); } /*关闭文件*/ main() {int i; for(i=0;i<SIZE;i++)/*从键盘读入学生信息*/ scanf("%s%d%d%s",stud[i].name,&stud[i].num, &stud[i].age,stud[i].addr); save( );}/*调用save()保存学生信息*/ 运行情况如下: 输入4个学生的姓名、学号、年龄和地址: Zhang 1001 19 room-101 Fun 1002 20 room-102 Tan 1003 21 room-103 Ling 1004 21 room-104
)==NULL) { printf( cannot open file\n ); return;} for(i=0;i<SIZE;i++)/*二进制写*/ if(fwrite(&stud[i],sizeof(struct student_type),1,fp)!=1) printf( file write error\n );/*出错处理*/ fclose(fp); } /*关闭文件*/ main() {int i; for(i=0;i<SIZE;i++)/*从键盘读入学生信息*/ scanf( %s%d%d%s ,stud[i].name,&stud[i].num, &stud[i].age,stud[i].addr); save( );}/*调用save()保存学生信息*/ 运行情况如下: 输入4个学生的姓名、学号、年龄和地址: Zhang 1001 19 room-101 Fun 1002 20 room-102 Tan 1003 21 room-103 Ling 1004 21 room-104")
801
§13.4 文件的读写(续) #include <stdio.h> #define SIZE 4
struct student_type { char name[10]; int num; int age; char addr[15]; }stud[SIZE]; main( ) { int i; FILE*fp; fp=fopen("stu-list","rb"); for(i=0;i<SIZE;i++) {fread(&stud[i],sizeof(struct student_type),1,fp); printf("%\-10s %4d %4d %\-15s\n",stud[i].name, stud[i].num,stud[i]. age,stud[i].addr); } fclose (fp);} §13.4 文件的读写(续) 验证在磁盘文件“stu-list”中是否已存在此数据, 用以下程序从“stu-list”文件中读入数据,然后在 屏幕上输出。 屏幕上显示出以下信息: Zhang 1001 19 room-101 Fun 1002 20 room-102 Tan 1003 21 room-103 Ling 1004 21 room-104
 { int i; FILE*fp; fp=fopen( stu-list , rb ); for(i=0;i<SIZE;i++) {fread(&stud[i],sizeof(struct student_type),1,fp); printf( %\-10s %4d %4d %\-15s\n ,stud[i].name, stud[i].num,stud[i]. age,stud[i].addr); } fclose (fp);} §13.4 文件的读写(续) 验证在磁盘文件 stu-list 中是否已存在此数据, 用以下程序从 stu-list 文件中读入数据,然后在. 屏幕上输出。 屏幕上显示出以下信息: Zhang 1001 19 room-101. Fun 1002 20 room-102. Tan 1003 21 room-103. Ling 1004 21 room-104")
802
13.4 文件的读写(续) 如果已有的数据已经以二进制形式存储在一个磁盘文件 “stu-dat”中,要求从其中读入数据并输出到
“stu-list”文件中,可以编写一个load函数, 从磁盘文件中读二进制数据。 void load( ) {FILE *fp;int i; if((fp=fopen("stu-dat","rb"))==NULL) { printf("cannot open infile\n"); return;} for(i=0;i<SIZE;i++) if(fread(&stud[i],sizeof(struct student_type),1,fp)!=1) {if(feof(fp)) {fclose(fp); return;} printf("file read error\n");} fclose (fp); }
 {FILE *fp;int i; if((fp=fopen( stu-dat , rb ))==NULL) { printf( cannot open infile\n ); return;} for(i=0;i<SIZE;i++) if(fread(&stud[i],sizeof(struct student_type),1,fp)!=1) {if(feof(fp)) {fclose(fp); return;} printf( file read error\n );} fclose (fp); }")
803
13.4 文件的读写(续) 三、格式化读写函数(fprintf()和fscanf()) 函数调用: 函数功能: 例:
从磁盘文件中读入或输出字符。 例: fprintf(fp,”%d,%6.2f”,i,t); Fscanf (fp,”%d,%f”,&i,&t); 注意: 用fprintf和fscanf函数对磁盘文件读写,使用方便,容易理解, 但由于在输入时要将ASCII码转换为二进制形式,在输出时又要 将二进制形式转换成字符,花费时间比较多。因此,在内存与磁 盘频繁交换数据的情况下,最好不用fprintf和fscanf函数,而 用fread和fwrite函数。
; Fscanf (fp, %d,%f ,&i,&t); 注意: 用fprintf和fscanf函数对磁盘文件读写,使用方便,容易理解, 但由于在输入时要将ASCII码转换为二进制形式,在输出时又要. 将二进制形式转换成字符,花费时间比较多。因此,在内存与磁. 盘频繁交换数据的情况下,最好不用fprintf和fscanf函数,而. 用fread和fwrite函数。")
804
13.4 文件的读写(续) 三、其他读写函数 putw()和getw() 函数调用: 函数功能: 例:
putw(int i,FILE * fp); int i = getw(FILE * fp); 函数功能: 对磁盘文件中读写一个字(整数)。 例: putw(10,fp); i = getw(fp); gutw函数定义如下: gutw(FILE *fp) { char s; s=char *&i; s[0] = getc(fp); s[1] = getc(fp); return i; } putw函数定义如下: putw(int I,FILE *fp) { char s; s=&I; putc(s[0],fp); putc(s[1],fp); return i; }
; int i = getw(FILE * fp); 函数功能: 对磁盘文件中读写一个字(整数)。 例: putw(10,fp); i = getw(fp); gutw函数定义如下: gutw(FILE *fp) { char s; s=char *&i; s[0] = getc(fp); s[1] = getc(fp); return i; } putw函数定义如下: putw(int I,FILE *fp) { char s; s=&I; putc(s[0],fp); putc(s[1],fp); return i; }")
805
13.4 文件的读写(续) 用户自定义读取其他类型数据的函数。 向磁盘文件写一个实数(用二进制方式)的函数putfloat :
putfloat(float num,FILE *fp) { char s; int count; s = (char*)# for(count = 0;count < 4;count++) putc(s[count],fp); }
 { char s; int count; s = (char*)# for(count = 0;count < 4;count++) putc(s[count],fp); }")
806
13.4 文件的读写(续) fgets函数 函数作用: 从指定文件读入一个字符串。 函数调用: fgets(str,n,fp);
从fp指向的文件输入n-1个字符,在最后加一个’\0’。 返回值: str的首地址。

807
13.4 文件的读写(续) fputs函数 函数作用: 向指定的文件输出一个字符串。 函数调用: fgets(“china”,fp);
第一个参数可以是字符串常量、字符数组名或字符型 指针。字符串末尾的′\0′不输出。 返回值: 输入成功,返回值为0; 输入失败,返回EOF。

808
13.5 文件的定位 #include<stdio.h> rewind函数 main() 函数作用:
{ FILE *fp1,*fp2; fp1=fopen("file1.c","r"); fp2=fopen("file2.c","w"); while(!feof(fp1)) putchar(getc(fp1)); rewind(fp1); while(!feof(fp1)) putc(getc(fp1),fp2); fclose(fp1);fclose(fp2); } rewind函数 函数作用: 使位置指针重新返回文件的开头,无返回值。 应用举例: 例13.4有一个磁盘文件,第一次将它的内容显示在屏幕 上,第二次把它复制到另一文件上。
; fp2=fopen( file2.c , w ); while(!feof(fp1)) putchar(getc(fp1)); rewind(fp1); while(!feof(fp1)) putc(getc(fp1),fp2); fclose(fp1);fclose(fp2); } rewind函数. 函数作用: 使位置指针重新返回文件的开头,无返回值。 应用举例: 例13.4有一个磁盘文件,第一次将它的内容显示在屏幕. 上,第二次把它复制到另一文件上。")
809
13.5 文件的定位 顺序读写和随机读写 顺序读写: 位置指针按字节位置顺序移动。 随机读写: 读写完上一个字符(字节)后,并不一定要读写其
后续的字符(字节),而可以读些文件中任意位置 上所需要的字符(字节)。
,而可以读些文件中任意位置. 上所需要的字符(字节)。")
810
13.5 文件的定位 fseek函数(一般用于二进制文件) 函数功能: 改变文件的位置指针。 函数调用形式:
起始点:文件开头 SEEK_SET 0 文件当前位置 SEEK_CUR 1 文件末尾 SEEK_END 2 位移量:以起始点为基点,向前移动的字节数。一般 要求为long型。

811
13.5 文件的定位 fseek函数应用举例 fseek(fp,100L,0); 将位置指针移到离文件头100个字节处。
将位置指针移到离当前位置50个字节处。 fseek(fp,50L, 2); 将位置指针从文件末尾处向后退10个字节。
; 将位置指针从文件末尾处向后退10个字节。")
812
§13.5 文件的定位 例13.5在磁盘文件上存有10个学生的数据。要求 将第1、3、5、7、9个学生数据输入计算机,并 在屏幕上显示出来。
#include <stdlib.h> #include<stdio.h> struct student_type { char name[10]; int num; int age; char sex; }stud[10]; main() { int i; FILE *fp; if((fp=fopen("stud-dat","rb"))==NULL) {printf("can not open file\n"); exit(0);} for(i=0;i<10;i+=2) {fseek(fp,i*sizeof(struct student_type),0); fread(&stud[i], sizeof(struct student_type),1,fp); printf(“%s %d %d %c\n”,stud[i].name, stud[i].num,stud[i].age,stud[i].sex);} fclose(fp)} §13.5 文件的定位 例13.5在磁盘文件上存有10个学生的数据。要求 将第1、3、5、7、9个学生数据输入计算机,并 在屏幕上显示出来。
 { int i; FILE *fp; if((fp=fopen( stud-dat , rb ))==NULL) {printf( can not open file\n ); exit(0);} for(i=0;i<10;i+=2) {fseek(fp,i*sizeof(struct student_type),0); fread(&stud[i], sizeof(struct student_type),1,fp); printf( %s %d %d %c\n ,stud[i].name, stud[i].num,stud[i].age,stud[i].sex);} fclose(fp)} §13.5 文件的定位. 例13.5在磁盘文件上存有10个学生的数据。要求. 将第1、3、5、7、9个学生数据输入计算机,并. 在屏幕上显示出来。")
813
13.5 文件的定位 ftell函数 函数作用: 得到流式文件中的当前位置,用相对于文件开头的位 移量来表示。 返回值:
应用举例: i = ftell(fp); if(i==-1L) printf(“error\n”);
; if(i==-1L) printf( error\n );")
814
13.6 出错的检测 ferror函数 调用形式: ferror(fp); 返回值: 返回0,表示未出错;返回非0,表示出错。
否则信息会丢失。在执行fopen函数时,ferror函数 的初始值自动置为0。

815
13.6 出错的检测 clearerr函数 调用形式: clearerr(fp); 函数作用: 使文件错误标志和文件结束标志置为0。
只要出现错误标志,就一直保留,直到对同一文件 调用clearerr函数或rewind函数,或任何其他一个输 入输出函数。

816
13.7 文件输入输出小结 分类 函数名 功能 打开文件 fopen() 打开文件 关闭文件 fclose() 关闭文件
分类 函数名 功能 打开文件 fopen() 打开文件 关闭文件 fclose() 关闭文件 文件定位 fseek() 改变文件位置指针的位置 Rewind() 使文件位置指针重新至于文件开头 Ftell() 返回文件位置指针的当前值 文件状态 feof() 若到文件末尾,函数值为真 Ferror() 若对文件操作出错,函数值为真 Clearerr() 使ferror和feof()函数值置零
 打开文件. 关闭文件 fclose() 关闭文件. 文件定位 fseek() 改变文件位置指针的位置. Rewind() 使文件位置指针重新至于文件开头. Ftell() 返回文件位置指针的当前值. 文件状态 feof() 若到文件末尾,函数值为真. Ferror() 若对文件操作出错,函数值为真. Clearerr() 使ferror和feof()函数值置零.")
817
13.7 文件输入输出小结 分类 函数名 功能 文件读写 fgetc(),getc()从指定文件取得一个字符
分类 函数名 功能 文件读写 fgetc(),getc()从指定文件取得一个字符 fputc(),putc()把字符输出到指定文件 fgets()从指定文件读取字符串 fputs()把字符串输出到指定文件 getw()从指定文件读取一个字(int型) putw()把一个字输出到指定文件 fread()从指定文件中读取数据项 fwrite()把数据项写到指定文件中 fscanf()从指定文件按格式输入数据 fprintf()按指定格式将数据写到指定文件中
,getc()从指定文件取得一个字符. fputc(),putc()把字符输出到指定文件. fgets()从指定文件读取字符串. fputs()把字符串输出到指定文件. getw()从指定文件读取一个字(int型) putw()把一个字输出到指定文件. fread()从指定文件中读取数据项. fwrite()把数据项写到指定文件中. fscanf()从指定文件按格式输入数据. fprintf()按指定格式将数据写到指定文件中.")
818
第十四章 常见错误和程序调试

819
主要内容 14.1 常见错误分析 14.2 程序调试

820
14.1常见错误分析 忘记定义变量。 输入输出的数据的类型与所用格式说明符不一致。 未注意int型数据的数值范围。
在输入语句scanf中忘记使用变量的地址符。 输入数据的形式与要求不符。 误把“=”作为“等于”运算符。 语句后面漏分号。 在不该加分号的地方加了分号。 对应该有花括号的复合语句,忘记加花括号。 括号不配对。

821
14.1常见错误分析 (11) 在用标识符时,忘记了大小写字母的区别。 (12) 引用数组元素时误用了圆括号。
(12) 引用数组元素时误用了圆括号。 (13) 在定义数组时,将定义的“元素个数”误认为是“可使用的最大下标值”。 (14) 对二维或多维数组的定义和引用的方法不对。 (15) 误以为数组名代表数组中全部元素。 (16) 混淆字符数组与字符指针的区别。 (17) 在引用指针变量之前没有对它赋予确定的值。 (18) switch语句的各分支中漏写break语句。 (19) 混淆字符和字符串的表示形式。 (20) 使用自加(++)和自减(--)运算符时出的错误。
 引用数组元素时误用了圆括号。 (13) 在定义数组时,将定义的 元素个数 误认为是 可使用的最大下标值 。 (14) 对二维或多维数组的定义和引用的方法不对。 (15) 误以为数组名代表数组中全部元素。 (16) 混淆字符数组与字符指针的区别。 (17) 在引用指针变量之前没有对它赋予确定的值。 (18) switch语句的各分支中漏写break语句。 (19) 混淆字符和字符串的表示形式。 (20) 使用自加(++)和自减(--)运算符时出的错误。")
822
14.1常见错误分析 (21) 所调用的函数在调用语句之后才定义,而又在调用前未声明。 (22) 对函数声明与函数定义不匹配。
(23) 在需要加头文件时没有用#include命令去包含头文件。 (24) 误认为形参值的改变会影响实参的值。 (25) 函数的实参和形参类型不一致。 (26) 不同类型的指针混用。 (27) 没有注意函数参数的求值顺序。 (28) 混淆数组名与指针变量的区别。 (29) 混淆结构体类型与结构体变量的区别,对一个结构体类型赋值。
 在需要加头文件时没有用#include命令去包含头文件。 (24) 误认为形参值的改变会影响实参的值。 (25) 函数的实参和形参类型不一致。 (26) 不同类型的指针混用。 (27) 没有注意函数参数的求值顺序。 (28) 混淆数组名与指针变量的区别。 (29) 混淆结构体类型与结构体变量的区别,对一个结构体类型赋值。")
823
14.1常见错误分析 (21) 所调用的函数在调用语句之后才定义,而又在调用前未声明。 (22) 对函数声明与函数定义不匹配。
(23) 在需要加头文件时没有用#include命令去包含头文件。 (24) 误认为形参值的改变会影响实参的值。 (25) 函数的实参和形参类型不一致。 (26) 不同类型的指针混用。 (27) 没有注意函数参数的求值顺序。 (28) 混淆数组名与指针变量的区别。 (29) 混淆结构体类型与结构体变量的区别,对一个结构体类型赋值。 (30) 使用文件时忘记打开,或打开方式与使用情况不匹配。
 在需要加头文件时没有用#include命令去包含头文件。 (24) 误认为形参值的改变会影响实参的值。 (25) 函数的实参和形参类型不一致。 (26) 不同类型的指针混用。 (27) 没有注意函数参数的求值顺序。 (28) 混淆数组名与指针变量的区别。 (29) 混淆结构体类型与结构体变量的区别,对一个结构体类型赋值。 (30) 使用文件时忘记打开,或打开方式与使用情况不匹配。")
824
14.1常见错误分析 程序出错有3种情况: ① 语法错误 ② 逻辑错误 ③ 运行错误

825
14.2 程序调试 所谓程序调试是指对程序的查错和排错。调试程序步骤: 先进行人工检查,即静态检查。 上机调试。
所谓程序调试是指对程序的查错和排错。调试程序步骤: 先进行人工检查,即静态检查。 上机调试。 在改正语法错误和“警告” 后,程序经过连接(link)就得到可执行的目标程序。运行程序,输入程序所需数据,就可得到运行结果。
就得到可执行的目标程序。运行程序,输入程序所需数据,就可得到运行结果。")
Similar presentations
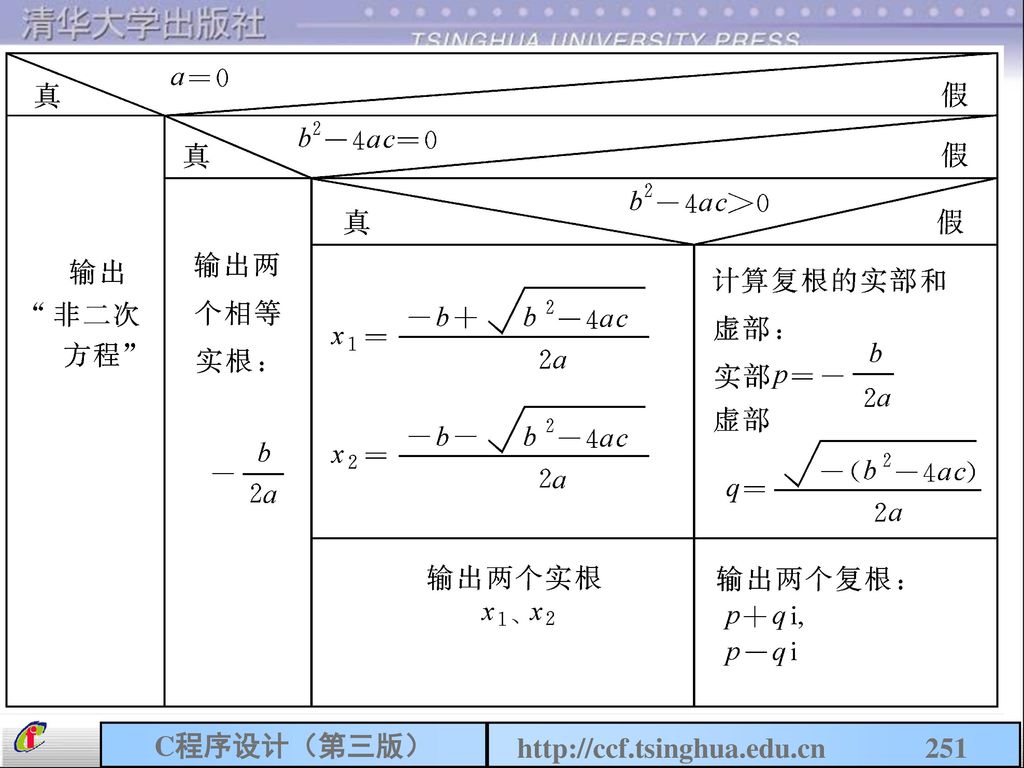






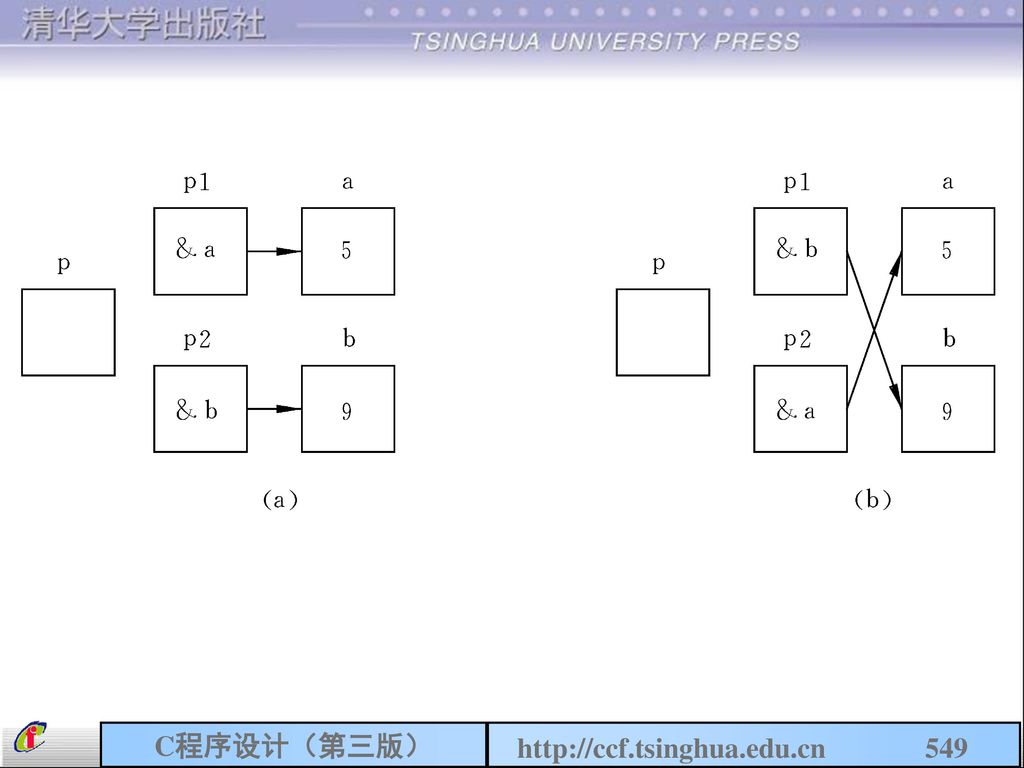

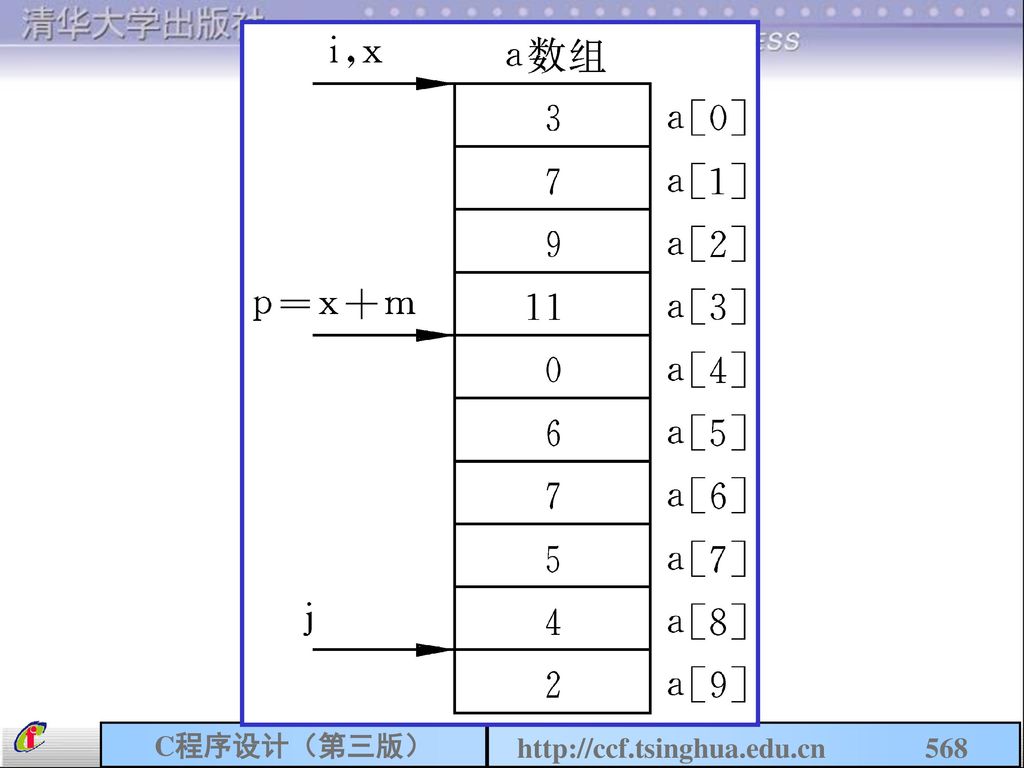




 適合重複性的計算或判斷.>")









 格式输入函数——scanf() 字符输出函数——putchar()>")








