Download presentation
Presentation is loading. Please wait.

1
面向知识图谱的搜索技术 张坤 搜狗搜索

2
网页搜索的技术发展 自然语言文本表示 索引 自然语言查询 排序 网页结果 检索
普通 音频 图片 视频 索引 自然语言查询 排序 网页结果 检索 那么,在讲下一代搜索技术之前,我们先简单回顾一下传统的网页搜索技术。

3
向量模型

4
互联网的图分析:Anchor和Pagerank

5
互联网的商业价值和社会价值

6
排序函数的构造(Learning to Rank)
")
7
搜索结构的变化 自然语言文本表示 索引 自然语言查询 排序 网页结果 检索 自然语言文本表示 自然语言查询 丰富展现 查询翻译 结果翻译
普通 音频 图片 视频 索引 自然语言查询 排序 网页结果 检索 自然语言文本表示 网页 普通 音频 图片 视频 自然语言查询 丰富展现 查询翻译 结果翻译 推理 预测 统计 推荐 复杂查询 信息翻译 知识库 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。 用户 获取信息更精准 激发用户获取进一步信息 系统 时间换空间(计算代替索引) 数据 信息的挑选与加工 优质信息转化为机器理解的知识,使得这些知识和机器发挥更大作
 数据. 信息的挑选与加工. 优质信息转化为机器理解的知识,使得这些知识和机器发挥更大作.")
8
整体架构图 展现 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成
Query SPARQL查询语句 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成 本体库 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。 知立方数据 结构化数据 推理补充数据 重要度计算 半结构化信息抽取 半结构化数据 异构数据整合 文本数据 实体抽取属性抽取 实体对齐 属性值决策 关系建立

9
知立方数据库构建 本体构建 各类型实体挖掘、属性名称挖掘 编辑系统 实例构建 纯文本属性、实体抽取 半结构化数据抽取 异构数据整合
实体对齐、属性值决策、关系建立 实体重要度计算 推理完善数据 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。

10
国际上流行的知识库 Wolframalpha 计算知识引擎,而不是搜索引擎 10万亿条的信息 Freebase 6800万实体 10亿的关系 DBpedia Wikipedia 结构化 364万个条目(本体) Yago 6.4亿条数据 1. Wolframalpha,一个计算知识引擎,而不是搜索引擎。其真正的创新之处,在于能够马上理解问题,并给出答案,在被问到“珠穆朗玛峰有多高”之类的问题时,WolframAlpha不仅能告诉你海拔高度,还能告诉你这座世界第一高峰的地理位置、附近有什么城镇,以及一系列图表。 2. Freebase,6800w实体,10y的关系。Google号称扩展到5y实体和25y的关系。所有内容都由用户添加,采用创意共用许可证,可以自由引用。 3. DBpedia,wikipedia基金会的一个子项目,处于萌芽阶段。DBpedia是一个在线关联数据知识库项目。它从维基百科的词条中抽取结构化数据,以提供更准确和直接的维基百科搜索,并在其他数据集和维基百科之间创建连接,并进一步将这些数据以关联数据的形式发布到互联网上,提供给需要这些关联数据的在线网络应用、社交网站或者其他在线关联数据知识库。 4.
 Yago. 6.4亿条数据. 1. Wolframalpha,一个计算知识引擎,而不是搜索引擎。其真正的创新之处,在于能够马上理解问题,并给出答案,在被问到 珠穆朗玛峰有多高 之类的问题时,WolframAlpha不仅能告诉你海拔高度,还能告诉你这座世界第一高峰的地理位置、附近有什么城镇,以及一系列图表。 2. Freebase,6800w实体,10y的关系。Google号称扩展到5y实体和25y的关系。所有内容都由用户添加,采用创意共用许可证,可以自由引用。 3. DBpedia,wikipedia基金会的一个子项目,处于萌芽阶段。DBpedia是一个在线关联数据知识库项目。它从维基百科的词条中抽取结构化数据,以提供更准确和直接的维基百科搜索,并在其他数据集和维基百科之间创建连接,并进一步将这些数据以关联数据的形式发布到互联网上,提供给需要这些关联数据的在线网络应用、社交网站或者其他在线关联数据知识库。 4.")
11
本体建立 —— 实体、属性抽取 半结构化网页 属性名计算和聚类 属性+属性值(候选) 实体+属性 查询日志 各类型实体抽取:利用用户搜索记录。该记录保存了用户的标识符、以及用户的查询条目、查询时间、搜索引擎返回的结果以及用户筛选后点击的链接。该数据集从一定程度上反映了人们对搜索结果的态度,是用户对网络资源的一种人工标识。根据用户搜索记录的数据特点,可用二部图表示该数据,其中qi表示用户的查询条目,uj表示用户点击过的链接,wij表示qi和uj之间的权重,一般是通过用户点击次数进行衡量。采用随机游走(Random Walk)对用户搜索记录进行聚类,并选出每个类中具有高置信度的链接作为数据来源,同时抽取对应实体,并将置信度较高的实体加入种子实体中,进行下一次迭代。 属性抽取 a)半结构化网站,利用Tag path和Text node标识网页,对属性聚类 b) 从查询日志中识别实体+属性名 查询日志分析 张学友年龄 刘德华年龄 ($人) 年龄
对用户搜索记录进行聚类,并选出每个类中具有高置信度的链接作为数据来源,同时抽取对应实体,并将置信度较高的实体加入种子实体中,进行下一次迭代。 属性抽取. a)半结构化网站,利用Tag path和Text node标识网页,对属性聚类. b) 从查询日志中识别实体+属性名. 查询日志分析. 张学友年龄. 刘德华年龄. ($人) 年龄.")
12
本体建立 —— 本体编辑 属性值范围包括 数值型,如年龄 枚举型,如民族、星座 短文本,如出生地 长文本,如简介

13
信息抽取系统建立 提一下客户端环境可以获得多角度的更加全面的用户行为。 在这部分,我们选择基于机器学习的排序模型技术。
基于多角度全面的海量的用户行为为基础,建立机器学习排序模型。使得搜索结果得到一个更加细致化、全面的效果优化。

14
信息抽取系统建立 数据管理和自动抽样系统 可视化UI系统 模板监控系统 结构化数据 模板库 网页库 抓取器
提一下客户端环境可以获得多角度的更加全面的用户行为。 在这部分,我们选择基于机器学习的排序模型技术。 基于多角度全面的海量的用户行为为基础,建立机器学习排序模型。使得搜索结果得到一个更加细致化、全面的效果优化。 网页库 抓取器

15
文本挖掘 步步惊心 新西游记 主题曲 电视剧 插曲 歌曲 歌手 片尾曲

16
不同数据源的整合 为什么要对齐? 没有任何一个网站有所有的信息,甚至是在一个领域里。为了获取到更加全面的知识,需要整合。

17
实体对齐实例

18
对齐过程 agglomerative (AGNES) a a b b a b c d e c c d e d d e e divisive
Step 0 Step 1 Step 2 Step 3 Step 4 b d c e a a b d e c d e a b c d e agglomerative (AGNES) divisive (DIANA)
 divisive. (DIANA)")
19
属性值决策与关系建立 属性值的决策: 关系建立与补齐 出生日期 身高

20
实体的重要性 实体搜索 按重要度排序 Entity-rank vs Page-rank 实体名称 知立方实体库 李娜 0.9 0.8 0.7
0.6 1,初始化:根据实体的属性及实体间关系初始化实体的重要度 2,迭代:重要度在实体关系图中传递 Entity-rank vs Page-rank 实体名称 知立方实体库

21
推理补充数据与验证 人物关系 电影演员 从原始三元组数据,推理生成新的数据,建立更多的实体间的链接关系,增加知识图的边的密度,例如:
<triple> <entity id=“1” name=“莫言”></entity> <property><![CDATA[作品]]></property> <entity id=“2” name=“红高粱家族”></entity> </triple> <entity id=“3” name=“生死疲劳”></entity> <property><![CDATA[作者]]></property> <entity id=“1” name=“莫言”</entity> <entity id=“4” name=“白棉花”></entity> • 推理 作者=>作品 莫言的作品: 红高粱家族 生死疲劳 白棉花 人物关系 配偶+男性=>丈夫,配偶+女性=>妻子; 电影演员 电影的主演=>演员出演了这部电影

22
整体架构图 展现 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成
Query SPARQL查询语句 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成 本体库 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。 知立方数据 结构化数据 推理补充数据 重要度计算 半结构化信息抽取 半结构化数据 异构数据整合 文本数据 实体抽取属性抽取 实体对齐 属性值决策 关系建立

23
查询语义理解 通用 词典 知识库 实体别名 属性模式 QO的架构及模块组成。 用户输入查询词 预处理 语义分析 查询语句生成 查询纠错 分词
基于CFG的句法分析 基于词典和CRF的分词和实体识别 基于模式挖掘的属性识别 实体别名 属性模式 QO的架构及模块组成。 基于模版匹配的SPARQL生成 基于需求重要度的SPARQL排序

24
乔阿吉姆·罗恩尼<PERSON>
实体的识别和归一 美国 罗恩尼 女抢匪 罗恩尼<PERSON> 女抢匪<MOVIE> 美国<LOC> 乔阿吉姆·罗恩尼<PERSON> 侠盗魅影<MOVIE> 自然语言查询 基于字典的序列标注模型CRF 实体标记 实体归一 网页对齐 知识库 实体 基于规则的挖掘策略 百科 实体 别名 Sogou点击日志 Query中的实体识别和归一

25
属性的模式挖掘 无间道<E>主演<P>刘德华<V>
知识库 互联网问题答案库 1.无间道谁演的? 刘德华 2.谁是无间道的主演? 刘德华 3.让子弹飞谁演的? 葛优 标记实体和属性值 打上标记后的问题答案 1.<MOVIE>谁演的?<PERSON> 2.谁是<MOVIE>的主演?<PERSON> 3.<MOVIE>谁演的?<PERSON> 由于表达方式的多样性,对同一属性,不同人有不同的说法。 我们通过挖掘百度知道,来获取属性的各种各样的描述方式。 去噪 频繁模式挖掘 主演的Pattern 1.<MOVIE>谁演的 2.谁是<MOVIE>的主演 属性的表达模式

26
基于CFG的句法分析 基于上下文无关文法的句法分析。 关键在于文法中规则的定义。 好的规则有助于很好的解决歧义问题。

27
实体推荐技术 LDA

28
实体过滤

30
整体架构图 展现 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成
Query SPARQL查询语句 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成 本体库 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。 知立方数据 结构化数据 推理补充数据 重要度计算 半结构化信息抽取 半结构化数据 异构数据整合 文本数据 实体抽取属性抽取 实体对齐 属性值决策 关系建立

31
后台检索系统 图检索系统 推理 正排 索引 推荐 倒排 预测 统计 本体 排序 计算层 展现层 索引层 检索层 按属性筛选 知立方数据
SPARQL解析 正排 索引 推理 展现层 倒排 SPARQL支持 按属性筛选 索引层 检索层 计算层 推荐 预测 统计 排序 知立方数据 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。 本体

32
整体架构图 展现 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成
Query SPARQL查询语句 推理 推荐 统计 实体识别 Pattern挖掘 标签消岐 检索系统 排序 检索系统 本体 生成系统 索引生成 索引生成 本体库 这种和互联网上的各种服务的无缝对接,是建立在对于用户查询输入在类别上、和查询中不同类型的精细化参数的精准理解基础之上的。 知立方数据 结构化数据 推理补充数据 重要度计算 半结构化信息抽取 半结构化数据 异构数据整合 文本数据 实体抽取属性抽取 实体对齐 属性值决策 关系建立

33
知立方信息展现 提供知识库信息的展示载体 将知识库中的信息转化为用户可消费的内容 提供更加丰富的富文本信息
提供文本之外的图片、列表、动画等更加丰富的展现形式 提供更友好的用户交互体验 更多的交互元素,如图片浏览,点击试听等 能够引导用户在更短的时间获取更多的信息 将知识库中的信息转化为用户可以理解的展现内容, 2. 能够提供更多用户可以直接消费的富文本信息(不局限于文字,增添图片,表格等) 3. 增加更多的用户交互元素,提升用户体验
 3. 增加更多的用户交互元素,提升用户体验.")
34
单实体展现及交互 Case: 刘德华 分别点击上方基本信息,点击歌曲,点击属性标签,点击具体的电影

35
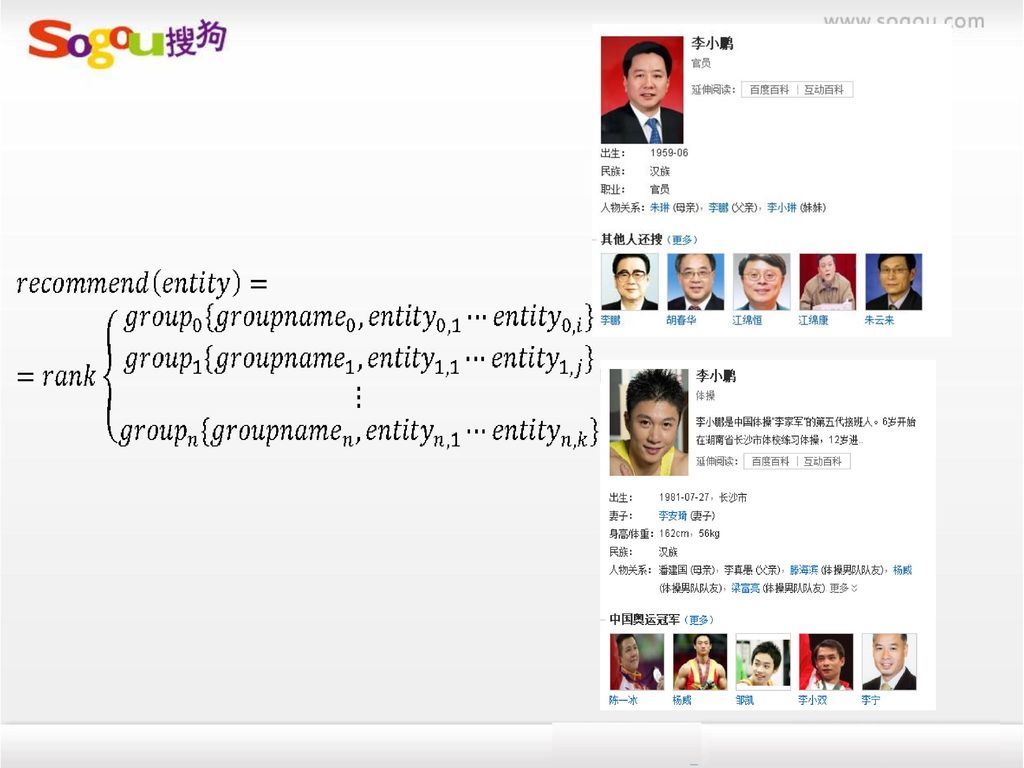
重名、系列实体展现及交互 Case1: 李娜 点击其他的同名人物 Case2:十大元帅 点击某个具体的人物

36
问答展现样式 康熙的年龄 梁启超儿子的太太

37
增加筛选条件

38
谢谢!

Similar presentations














班 顾韬 景琰杰 指导教师:张成鹏>")




