Download presentation
Presentation is loading. Please wait.

1
一次数据库的查寻

2
数据库查询 分子生物学数据库的应用可以分为两个主要方面,即数据库查询(databaase query)和数据库搜索(database search)。数据库查询和数据库搜索是分子生物信息学中两个常用术语。
和数据库搜索(database search)。数据库查询和数据库搜索是分子生物信息学中两个常用术语。")
3
所谓数据库查询,是指对序列、结构以及各种二次数据库中的注释信息进行关键词匹配查找。
例如,对蛋白质序列数据库SwissProt输入关键词insulin(胰岛素),即可找出该数据库所有胰岛素或与胰岛素有关的序列条目(Entry)。数据库查询有时也称数据库检索,它和互联网上通过搜索引擎 (Search engine) 查找需要的信息是一个概念。
,即可找出该数据库所有胰岛素或与胰岛素有关的序列条目(Entry)。数据库查询有时也称数据库检索,它和互联网上通过搜索引擎 (Search engine) 查找需要的信息是一个概念。")
4
数据库查询、数据库检索和数据库搜索这三个词经常混用。其实,数据库搜索在分子生物信息学中有特定含义,它是指通过特定的序列相似性比对算法,找出核酸或蛋白质序列数据库中与检测序列具有一定程度相似性的序列。
例如,给定一个胰岛素序列,通过数据库搜索,可以在蛋白质序列数据库SwissProt中找出与该检测序列(query sequence)具有一定相似性的序列。
具有一定相似性的序列。")
5
在生物信息学中,数据库搜索是专门针对核酸和蛋白质序列数据库而言,其搜索的对象,不是数据库的注释信息,而是序列信息。
显然,数据库查询和数据库搜索在生物信息学中是两个完全不同的概念,它们所要解决的问题、所采用的方法和得到的结果均不相同

6
以SRS和Entrez为例, 介绍数据库查询的基本方法

7
随着分子生物信息数据库应用和开发的需求不断增长,SRS已经成为欧洲各国主要生物信息中心必备的数据库查询系统。
SRS是Sequence Retrieval System的缩写,由欧洲分子生物学实验室开发,最初是为核酸序列数据库EMBL和蛋白质序列数据库SwissProt的查询开发的。 随着分子生物信息数据库应用和开发的需求不断增长,SRS已经成为欧洲各国主要生物信息中心必备的数据库查询系统。 目前,SRS已经发展成商业软件,由英国剑桥的LION Bioscience公司继续开发,学术单位在签定协议后可以免费获得该软件的使用权,而非学术单位则需要购买使用权。

8
SRS系统 SRS是一个开放的数据库查询系统,即不同的SRS查询系统可以根据需要安装不同的数据库,目前共有300多个数据库安装在世界各地的SRS服务器上。 可以直接从LION公司的网页上查到这些数据库的名称,并知道它们分别安装在何处(

9
欧洲生物信息学研究所、英国的基因组测序中心Sanger Centre和英国基因组资源中心HGMP等大型生物信息中心安装了100多个数据库。
SRS系统 欧洲生物信息学研究所、英国的基因组测序中心Sanger Centre和英国基因组资源中心HGMP等大型生物信息中心安装了100多个数据库。 北京大学生物信息中心1997年开始安装SRS系统,目前共有70多个数据库,其中核酸序列数据库EMBL和蛋白质结构数据库PDB每日更新。国内微生物所、上海生命科学院等单位也于2000年开始安装SRS系统。下表列出国际上主要SRS数据库查询系统服务器系统的网址。

10
SRS系统 单 位 网 址 欧洲生物信息研究所 http://srs6.ebi.ac.uk/srs6/ 英国基因组资源中心
英国基因组测序中心 法国生物信息中心 荷兰生物信息中心 澳大利亚医学研究所 德国癌症研究所 加拿大生物信息资源中心

11
SRS系统使用方法 以北京生物信息中心SRS数据库查寻系统为例讲述SRS系统的使用方法,你可以打开网页

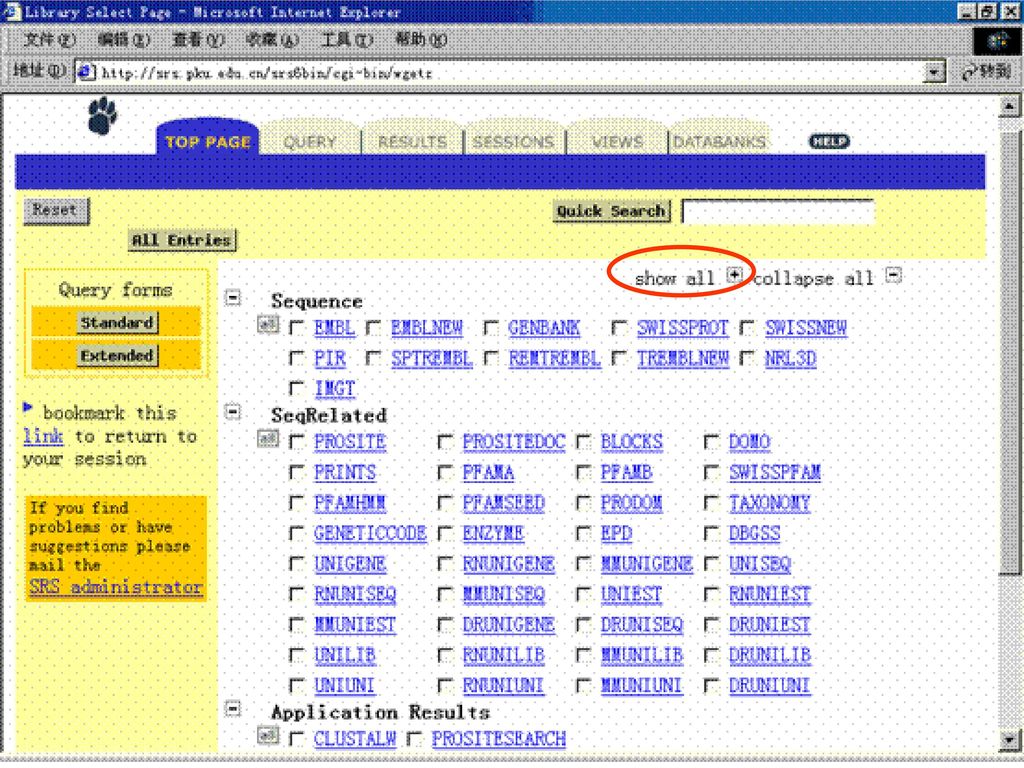
13
在SRS系统的主界面上可以看到北京大学生物信息中心SRS数据库系统安装的部分数据库种类和名称
1

14
点击页面右上方“Show all”右侧的”+”号按钮,即可显示所安装的所有数据库。用鼠标点击数据库名左侧的选择框以选中需要检索的数据库后,可以用三种方式进行查询。
检索可建立逻辑关系(and,or,not)进行
进行.")
16
1. 快速查询:在页面右上方的快速检索栏中填入关键词,按回车健或点击“Quick Search”按钮,即可得到查询结果。如选择蛋白质序列数据库SWISSPROT,输入钙离子通道“calcium channel”,按回车键或点击Quick Search按钮后即得到该数据库中与钙离子通道有关的蛋白质序列的条目及其它信息。 1

17
2. 标准查询:快速查询方式简单方便,但不便于由用户限定查询条件。
例如,上述查询结果中包含了部分钾离子通道序列条目,也包括了钙离子通道序列片段条目,因为在这些条目中,也出现了“calcium channel”关键词。选择标准查询方式,则可以由用户给出适当的查询条件,以缩小查询范围。

18
以蛋白质序列数据库SWISSPROT为例,选择该数据库后,点击 “Standard”按钮,则进入该数据库的标准查询页面。将页面左侧查询结合方式选择栏“combine search with”下的AND改为BUTNOT,再在查询表单中分别填入“calcium channel”、“potassium channel”和“fragment”,则可将钾离子通道和钙离子通道蛋白的序列片段滤除。同时,在序列条目显示方式栏“Use predefined view”中选择“proteinChart”(图2),
,")
19
图2 蛋白质序列数据库SwissProt标准查询页面

20
点击页面左上方的“Submit Query”按钮,则得到以Java图形表示的蛋白质序列疏水特性图。改变用于计算平均疏水值的残基数,可以得到不同的波形图(图3)。
。")
21
图3 蛋白质序列数据库SwissProt疏水特性图

22
3. 扩展查询:标准查询方式的功能比快速查询有所增加,但并没有体现SRS的全部查询功能。而利用扩展查询方式,则可充分利用SRS系统强大的查询功能。
例如,可以将输入关键词的查询范围限定在物种、说明、作者、文献等范围内,也可以限定日期和序列长度等。对EMBL数据库,还可以选择人、植物、EST等不同的子库进行检索(图4)。
。")
23
图4 核酸序列数据库EMBL扩展查询方式页面

24
例如,选择植物“Pln”,在物种“Organism”栏填入水稻的物种名“Oryza sativa”,在序列长度“>=”栏中填入400,并把“Display per page”的缺省值由30改为10000,点击“Submit Query”,则可得到EMBL数据库中长度大于400bp的所有水稻序列条目,并在屏幕上全部列出。 此外,还可以选择EMBL和SwissProt等数据库的序列特征表(feature table)中某些特殊内容,实现快速高效的检索。
中某些特殊内容,实现快速高效的检索。")
25
例如,选择蛋白质序列数据库SwissProt,进入开展查询页面,在“FtKey”栏中选择“disulfide”,不填入任何关键词而直接点击“Submit Query”,则可得到SWISSPROT中所有含二硫键的蛋白质序列条目。

26
上述SRS的使用方法,仅仅是其中一部分。SRS系统另有许多其它功能,它设有六个常用选择按钮:TOP PAGE、QUERY、RESULTS、SESSIONS、VIEWS、DATABANKS,点击这些按钮,则可随时进入其特定的页面

27
TOP PAGE:数据库选择页面,用来选择所需查询的数据库名称,用户可选择一个数据库进行查询,也可同时选择多个数据库查询
QUERY:标准查询方式页面,用来输入查询代码、编号、物种来源、说明、文献、作者、日期、关键词等查询项目,有的数据库可以选择全文搜索(All Text)选项,适用于对数据库内容不很熟悉、对所查信息不很确切的情况。
选项,适用于对数据库内容不很熟悉、对所查信息不很确切的情况。")
28
RESULTS:查询结果管理页面,用来对查询结果作组合、链接等处理,以得到进一步的筛选结果。
SESSIONS:查询过程存储页面,可以将某次查询过程以文件形式下载到用户本地计算机上保存起来,以供下次使用;也可把本地计算机上的存放的查询过程文件上载到服务器上。

29
VIEWS:显示管理页面,用户可以选择和定义查询结果的显示方式,包括文本方式、表格方式、图形方式、FASTA搜索结果方式等。
DATABANKS:系统安装的数据库清单,包括数据库名称、版本、类型、数据量、建立索引的日期等。 此外,SRS系统提供了详细的联机帮助信息,任何页面下点击右上方的Help按钮,即可启动联机帮助手册。仔细阅读该手册,可熟悉SRS系统的使用方法。

30
SRS系统的特点 SRS系统是一个功能强大的数据库查询功能,其主要特点作有以下几个方面 1. 统一的用户界面 SRS具有为统一的Web用户界面,用户只需安装Netscape等网络浏览器即可通过Internet查询世界各地SRS服务器上的300多个数据库。SRS支持以文本文件形式存放的各种数据库,包括序列数据库EMBL、SwissProt,结构数据库PDB,资料数据库AAIndex、Biocat、dbcat,文献数据库MedLine等

31
2. 高效的查询功能 生物信息数据库种类繁多,结构各异。如何快速、高效地对各种数据库进行查询,是数据库查询系统必须解决的问题。SRS系统采用了建立数据库索引文件的手段,较好地解决了这一问题。即使是含几百万个序列的EMBL数据库,只需几分钟即可实现整库查询,得到所需结果。此外,SRS系统具有查询结果相关处理功能,每次查询结果可作为进一步查询的子数据库,并可对其进行并、交等操作,对查询结果进行组合或筛选

32
3. 灵活的指针链接 通过超文本指针链接实现信息资源的有机联系,是目前Internet信息服务的主要趋势。许多生物信息数据库均包含与其它相关数据库的代码,如SwissProt数据库中的蛋白质序列包含了该序列在EMBL、PDB、Prosite、Medline等其它数据库的代码。利用超文本链接,可将这些相关数据库联系在一起。SRS采用实时方式,根据查询结果产生链接指针,而不是在原始数据库中增加超文本标记,既节省了存储空间,也便于数据库管理

33
4. 方便的程序接口 将序列分析等常用程序整合到基本查询系统中,是SRS的另一个重要特点。用户可以对查询结果直接进行进一步分析处理。例如,查询所得的蛋白质序列,可立即用BLAST和FASTA查询程序进行数据库搜索,找出其同源序列;也可以用PrositeSearch程序,寻找功能位点;用ClustalW程序进行多序列比较

34
5. 开放的管理模式 在管理模式上,SRS采用了开放的方式。无论是数据库还是应用程序,均可进行扩充和更新。用户可在本地机上安装自己的SRS系统,并将自己的数据库添加到SRS系统中,并可与其它数据库实现超文本链接。也可自行编写应用程序,整合到SRS系统中 6. 统一的开发平台 SRS系统中所有数据库均以文件系统方式存放,通过预先建立索引文件实现数据库查询。因此它不依赖于Oracle、Sybase等商业数据库管理软件,便于推广使用。为建立索引文件,特别是对EMBL这样大型数据库建立索引,系统的内存和CPU资源需要满足一定的要求

35
Entrez系统 Entrez由美国NCBI开发,用于对文献摘要、序列、结构和基因组等数据库进行关键词查询,找出相关的一个或几个数据库条目。该系统目前主要包括核酸序列数据库、蛋白质序列数据库、基因组数据库、蛋白质结构数据库、生物医学文献摘要数据库、系统分类数据库、人类遗传疾病和遗传缺失在线数据库,以及基因信息数据库、种群亲缘关系核酸序列比对数据库、表达序列标签数据库等。

36
Entrez 是由NCBI主持的一个数据库检索系统,它包括核酸,蛋白以及Medline文摘数据库,在这三个数据库中建立了非常完善的联系。
因此,可以从一个DNA序列查询到蛋白产物以及相关文献,而且,每个条目均有一个类邻(neighboring)信息,给出与查询条目接近的信息。
信息,给出与查询条目接近的信息。")
37
Entrez中的数据库包括: Entrez系统 Entrez中核酸数据库为:GenBank, EMBL, DDBJ
蛋白质数据库为:Swiss-Prot, PIR, PFR, PDB PubMed 基因组和染色体图谱资料

38
检索领域:(Search Fields) Entrez系统
在WWW Entrez检索系统中,检索内容被分为许多小的领域,每一个检索领域包含以下信息: 进入(Accession): 包含进入号 相关性(Affiliation): 包括该检索领域建立时的相关信息,原作者地址,有时亦有其他作者地址 作者姓名(Author Name): 包含文章作者清单 E.C号(E.C.Number): 是酶学委员会命名的酶的编号 特征词(Feature Key): 描述DNA特征的关键词 基因符号(Gene Symbol): 基因的标准名称 杂志名(Journal Title):为检索条目第一次发表时的杂志名,该杂志名是以缩写形式储存于数据 库中,如果不清楚杂志是如何缩写的可采用List Terms来查看 关键词(Keywords):可以使用较特定的索引条目来检索以上数据库。类似于医学光盘检索 Medline UID : 是Medline对每一个条目给出的唯一识别标记 MeSH主题词(MeSH Terms): 包括 MeSH的主题词,下级主题词 MeSH主要关键词 (MeSH Major Topic):为检索条目十分重要的MeSH词目
: 包含进入号. 相关性(Affiliation): 包括该检索领域建立时的相关信息,原作者地址,有时亦有其他作者地址. 作者姓名(Author Name): 包含文章作者清单. E.C号(E.C.Number): 是酶学委员会命名的酶的编号. 特征词(Feature Key): 描述DNA特征的关键词. 基因符号(Gene Symbol): 基因的标准名称. 杂志名(Journal Title):为检索条目第一次发表时的杂志名,该杂志名是以缩写形式储存于数据. 库中,如果不清楚杂志是如何缩写的可采用List Terms来查看. 关键词(Keywords):可以使用较特定的索引条目来检索以上数据库。类似于医学光盘检索. Medline UID : 是Medline对每一个条目给出的唯一识别标记. MeSH主题词(MeSH Terms): 包括 MeSH的主题词,下级主题词. MeSH主要关键词 (MeSH Major Topic):为检索条目十分重要的MeSH词目.")
39
修改日期(Modification Date): 包含该条目进入Entrez的日期, 与出版日期一
样,以年/月/日形式出现 页数(Page Number): 该文章所在杂志的页码 特性(Property): 一个或几个关键词,用来描述该序列的类型 出版日期(Publication Date):包含文章出版日期以及序列录入GenBank的日期 PubMed ID: PubMed对每一个条目给出的识别标记 物种(Organism): 包含与该蛋白或核酸序列相关物种的学名和俗名 蛋白质名称(Protein name): Seq Id: 与FASTA识别标记类似,为序列的一种识别标记 物质(Substance): 与该条目相关的化学物质名称
: 该文章所在杂志的页码. 特性(Property): 一个或几个关键词,用来描述该序列的类型. 出版日期(Publication Date):包含文章出版日期以及序列录入GenBank的日期. PubMed ID: PubMed对每一个条目给出的识别标记. 物种(Organism): 包含与该蛋白或核酸序列相关物种的学名和俗名. 蛋白质名称(Protein name): Seq Id: 与FASTA识别标记类似,为序列的一种识别标记. 物质(Substance): 与该条目相关的化学物质名称.")
40
Entrez系统 文字检索词(Text Words):包含文章中的所有词,其中: Medline词目:标题和文摘
蛋白质词目: 定义,评论,蛋白名称,蛋白描述 核酸条目: 定义,评论,基因名称,基因名称 标题检索词(Title Words): 在标题中出现的词,或在描述该条目时出现的词 卷(Volume): 刊登该文章杂志所在卷 使用Medline UID, PubMed ID和 Seq ID进行检索时,在栏目框中要输入数字。如要输入多个数字,中间要用空格或逗号隔开。并选择相对应的检索领域
: 在标题中出现的词,或在描述该条目时出现的词. 卷(Volume): 刊登该文章杂志所在卷. 使用Medline UID, PubMed ID和 Seq ID进行检索时,在栏目框中要输入数字。如要输入多个数字,中间要用空格或逗号隔开。并选择相对应的检索领域.")
41
检索模式(Search Modes) www Entrez可以采用几种不同途径的检索方式: Entrez系统
名词列表格式(list term):当输入一检索词后,Entrez将列出与此相关的该领域中所有标准的检索词名称, 此时,可选择一或多个标准名词去检索。 自动格式(automatic):当输入一个检索词后,即自动检索,如果输入的检索词超过一个,则Entrez会自动将之组合起来, 如果无结果,则可尝试将这多个检索词用“ ”括起来。
:当输入一检索词后,Entrez将列出与此相关的该领域中所有标准的检索词名称, 此时,可选择一或多个标准名词去检索。 自动格式(automatic):当输入一个检索词后,即自动检索,如果输入的检索词超过一个,则Entrez会自动将之组合起来, 如果无结果,则可尝试将这多个检索词用 括起来。")
42
阅读文献(Viewing Document)
Entrez系统 阅读文献(Viewing Document) 每一个文件都可以有数种阅读方式,目的各不相同。一般来说,“引文格式(citation)”最适合于阅读Medline形式的文件;“GenPept” 格式适用于阅读蛋白质文件;“GenBank”格式用来阅读核酸文件。
 每一个文件都可以有数种阅读方式,目的各不相同。一般来说, 引文格式(citation) 最适合于阅读Medline形式的文件; GenPept 格式适用于阅读蛋白质文件; GenBank 格式用来阅读核酸文件。")
43
阅读方式:可单一阅读,亦可成批阅读 Entrez系统 对于PubMed文章: 对于蛋白和核酸文件: 对于结构文件: 对于基因组文件:
引文(citation)格式:包含题目,文摘,MeSH主题词等 文摘格式:包含题目,文摘 ASN.1格式:文章以ASN.1格式出现 MEDLINE格式:文章以MEDLINE格式出现 对于蛋白和核酸文件: GenBank/GenPept格式: 标准的GenBank或GenPept格式 Report格式:GenBank格式 ASN.1格式 FASTA格式 图形格式(Graphic View) 对于结构文件: 结构总结格式:结构的基本信息,可以看三维结构 ASN.1格式: 对于基因组文件: 图形格式
格式:包含题目,文摘,MeSH主题词等. 文摘格式:包含题目,文摘. ASN.1格式:文章以ASN.1格式出现. MEDLINE格式:文章以MEDLINE格式出现. 对于蛋白和核酸文件: GenBank/GenPept格式: 标准的GenBank或GenPept格式. Report格式:GenBank格式. ASN.1格式. FASTA格式. 图形格式(Graphic View) 对于结构文件: 结构总结格式:结构的基本信息,可以看三维结构. ASN.1格式: 对于基因组文件: 图形格式.")
44
Entrez系统的使用方法 进入NCBI主页( toxin”,点击起始按钮“Go”,则可得到核酸序列数据库GenBank中和蜘蛛毒素相关的序列条目,一共17条。

45
图5 进入NCBI主页

46
GenBank和EMBL等核酸序列数据库中的大部分数据,是由生物学家通过计算机网络直接提交,或通过计算机程序直接从大规模序列测定所得结果送入数据库中,没有严格的标准。
在数据库查询时,经常会遇到“想找的找不到,找到的却不是”这样的问题。例如,上述“spider toxin”查询所得到的17个序列条目,有很大一部分是重复的;而我国特有蜘蛛“虎纹捕鸟蛛”的毒素(Huwentoxin)却没有检索到。这是因为作者在提交该序列时,使用了“Huwentoxin”,而没有使用“spider toxin”。因此,必须输入“Huwentoxin”,才能找到该序列条目(图6)。
却没有检索到。这是因为作者在提交该序列时,使用了 Huwentoxin ,而没有使用 spider toxin 。因此,必须输入 Huwentoxin ,才能找到该序列条目(图6)。")
48
GenBank核酸序列数据库中虎纹捕鸟蛛毒素Huwentoxin-I条目

49
尽管Entez系统使用方便,初次使用时,最好阅读一下联机帮助文件,按其提供的向导实例练习一遍,以便提高查询效率,很快找到需要的结果。点击中页面左侧的“About Enterz”按钮,即可进入其帮助页面(图6)。该页面的下方有一个说明各数据库之间相互关系的框图,点击图中的数据库名,即可进入该数据库的帮助页面。而点击右上方“More about”下的“Entrez”,则进入Entrez使用详解。点击“Try a tutorial”,则开始联机向导练习。该向导以查询结核杆菌基因组中编码青霉素结合蛋白(penicillin-binding)基因为例,边操作、边讲解,直到找到需要的结果
。该页面的下方有一个说明各数据库之间相互关系的框图,点击图中的数据库名,即可进入该数据库的帮助页面。而点击右上方 More about 下的 Entrez ,则进入Entrez使用详解。点击 Try a tutorial ,则开始联机向导练习。该向导以查询结核杆菌基因组中编码青霉素结合蛋白(penicillin-binding)基因为例,边操作、边讲解,直到找到需要的结果")
50
图6 Entrez数据库查询系统帮助页面

51
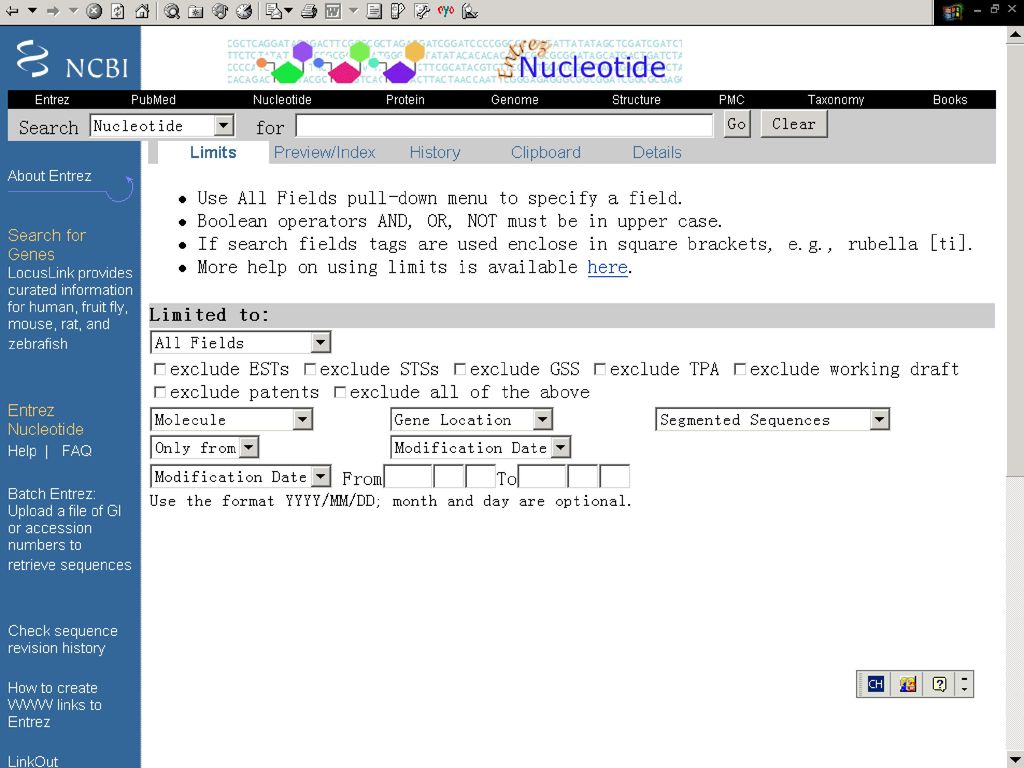
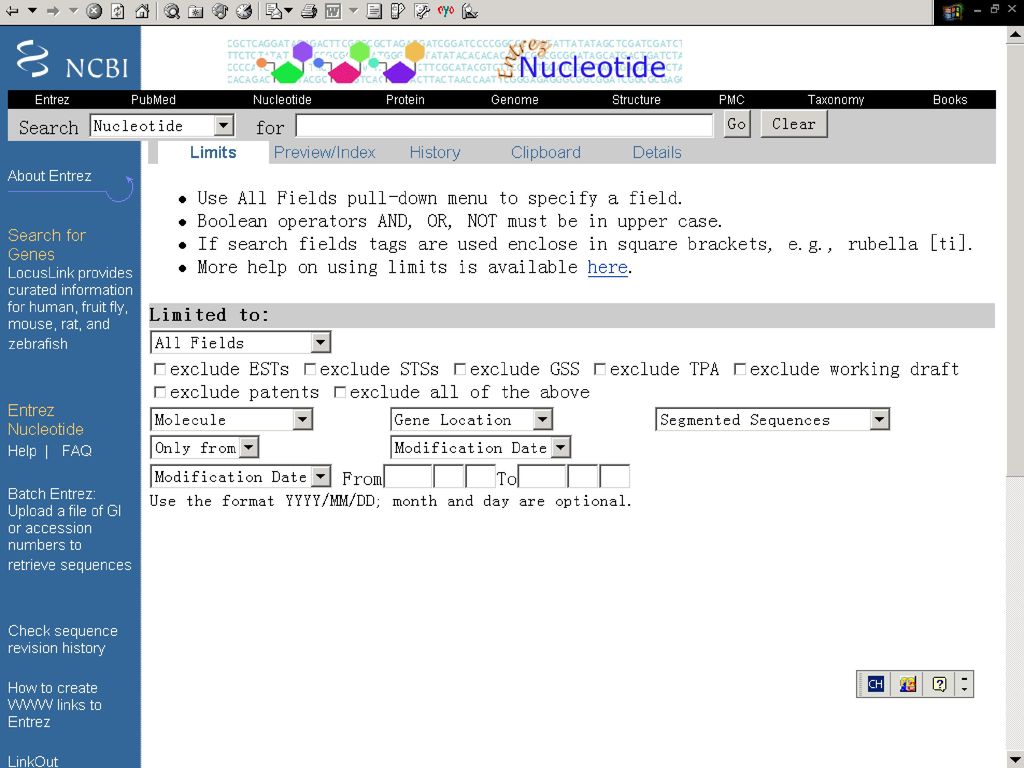
通过向导练习,可以熟悉Entrez系统的各种辅助功能,包括限定查询范围(Limits)、预览查询结果(Preview/Index)、查看查询记载(History)和操作剪贴板(Clipboard),提高查询效率。点击Limits按钮,即可进入限定查询范围页面,可以根据该数据库结构,将输入的关键词的查询范围限制在某个范围内,如编号、代码、提交日期等。
、预览查询结果(Preview/Index)、查看查询记载(History)和操作剪贴板(Clipboard),提高查询效率。点击Limits按钮,即可进入限定查询范围页面,可以根据该数据库结构,将输入的关键词的查询范围限制在某个范围内,如编号、代码、提交日期等。")
52
不同的数据库,其限定范围不同,如序列数据库可以限定序列长度,文献数据库则可以限定作者、题目、杂志名称等。
点击预览查询按钮(Preview/Index),检索栏中会增加一个“Preview”按钮,输入关键词后,若点击“Preview”按钮,则不列出具体查询结果,而只列出查询到的数据条目数。利用这一辅助功能,可以提高查询速度,并对查询结果有个初步了解,以便对查询结果作进一步处理,缩小查询范围。 点击“History”按钮,则可以查看查询过程的记录,对每次查询结果进行分析,并作进一步处理。
,检索栏中会增加一个 Preview 按钮,输入关键词后,若点击 Preview 按钮,则不列出具体查询结果,而只列出查询到的数据条目数。利用这一辅助功能,可以提高查询速度,并对查询结果有个初步了解,以便对查询结果作进一步处理,缩小查询范围。 点击 History 按钮,则可以查看查询过程的记录,对每次查询结果进行分析,并作进一步处理。")
53
例如,若需要检索与细胞凋亡有关的自噬基因“autophagy”的核酸序列,可以按下面步骤进行:
(1) 进入NCBI主页,点击Entrez按钮进入Entrez查询系统,点击“Nucleotide”按钮选择核酸序列数据库;
 进入NCBI主页,点击Entrez按钮进入Entrez查询系统,点击 Nucleotide 按钮选择核酸序列数据库;")
55
(2) 点击“Limits”按钮,在检索栏中填入“Autophagy”并在“Limited to”选择栏中选择“Title word”;点击“Preview/Index”按钮进入Preview页面,点击检索栏内的“Preview”按钮,得到核酸序列数据库的文献题目中与Autophagy有关的序列条目数以及该次查询结果的编号;
 点击 Limits 按钮,在检索栏中填入 Autophagy 并在 Limited to 选择栏中选择 Title word ;点击 Preview/Index 按钮进入Preview页面,点击检索栏内的 Preview 按钮,得到核酸序列数据库的文献题目中与Autophagy有关的序列条目数以及该次查询结果的编号;")
57
(3) 点击“Limits”按钮,在检索栏中填入“human”并在“Limited to”选择栏中选择“Organism”;点击“Preview/Index”按钮进入Preview页面,点击检索栏内的“Preview”按钮,得到核酸序列数据库中所有人类的序列条目数以及该次查询结果的编号;
 点击 Limits 按钮,在检索栏中填入 human 并在 Limited to 选择栏中选择 Organism ;点击 Preview/Index 按钮进入Preview页面,点击检索栏内的 Preview 按钮,得到核酸序列数据库中所有人类的序列条目数以及该次查询结果的编号;")
59
(4) 在检索栏中填入上述两次查询结果的编号,并用“AND”链接,如上述编号为#1和#2,则可在检索栏中输入“#1 AND #2”(注意AND必须用大写字母),点击“Go”按钮即可得到查询结果(图8)。
 在检索栏中填入上述两次查询结果的编号,并用 AND 链接,如上述编号为#1和#2,则可在检索栏中输入 #1 AND #2 (注意AND必须用大写字母),点击 Go 按钮即可得到查询结果(图8)。")
60
图8 利用Entrez系统检索人类自噬基因序列结果(注:核酸序列数据库在不断更新,实际搜索结果可能有所不同)
")
62
Entrez系统的特点

63
Entrez是面向生物学家的数据库查询系统,其特点之一是使用十分方便。它把序列、结构、文献、基因组、系统分类等不同类型的数据库有机地结合在一起,通过超文本链接,用户可以从一个数据库直接转入另一个数据库。例如,自噬基因检索结果中,列出了它们在蛋白质数据库中的链接,点击Protien即可得到该基因的蛋白质序列条目。 Entrez的另一个特点是把数据库和应用程序结合在一起。例如,通过“Related sequence”工具,可以直接找到与查询所得蛋白质序列同源的其它蛋白质。查询得到的蛋白质三维结构,可以通过在用户计算机上安装的Cn3D软件直接显示分子图形

64
Entrez系统的开发基于特殊的数据模型NCBI ANS
Entrez系统的开发基于特殊的数据模型NCBI ANS.1 (Abstract Syntax Notation),在对于文献摘要中的关键词查询时,不仅考虑了查询对象和数据库中单词的实际匹配,而且考虑了意义相近的匹配。在查询文献数据库摘要得到结果后,可以通过点击“Related Articles”继续查找相关文献
,在对于文献摘要中的关键词查询时,不仅考虑了查询对象和数据库中单词的实际匹配,而且考虑了意义相近的匹配。在查询文献数据库摘要得到结果后,可以通过点击 Related Articles 继续查找相关文献.")
Similar presentations

 意涵:研究學者(老人)與.>")



 全文数据库 iGroup 公司IEL部门>")














