Download presentation
Presentation is loading. Please wait.

1
第九章 时间序列计量经济学模型 时间序列的平稳性及其检验 随机时间序列分析模型 协整分析与误差修正模型

2
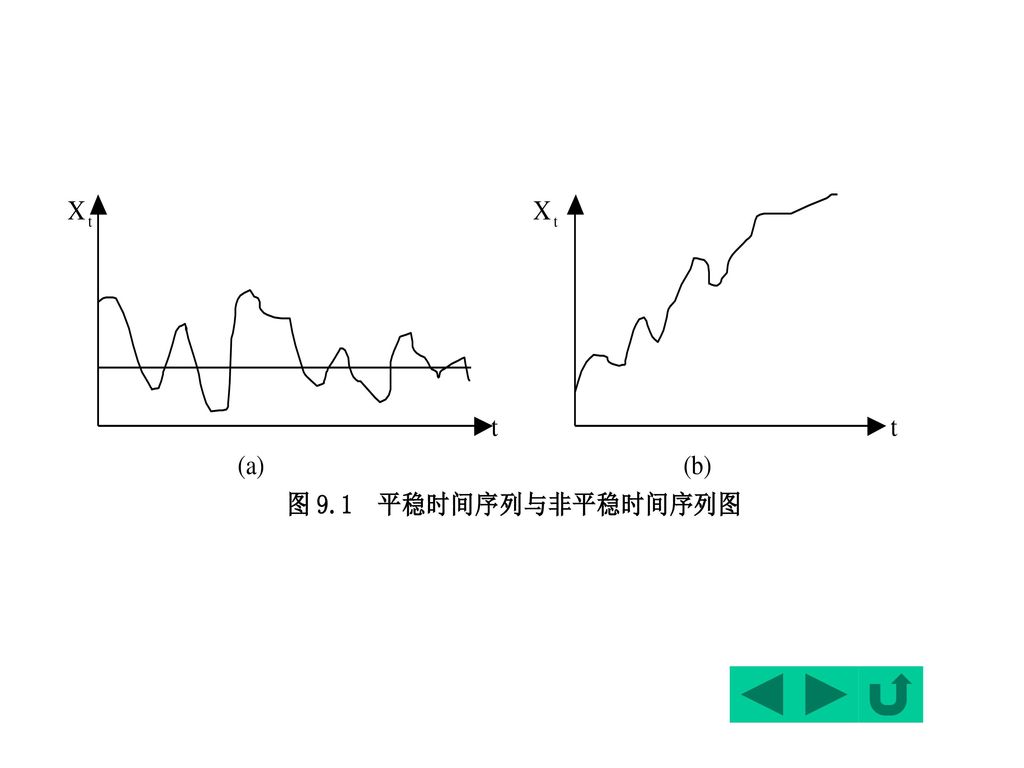
§9.1 时间序列的平稳性及其检验 一、问题的引出:非平稳变量与经典回归模型 二、时间序列数据的平稳性 三、平稳性的图示判断
四、平稳性的单位根检验 五、单整、趋势平稳与差分平稳随机过程

3
一、问题的引出:非平稳变量与经典回归模型

4
⒈常见的数据类型 到目前为止,经典计量经济模型常用到的数据有: 时间序列数据(time-series data)
截面数据(cross-sectional data) 平行/面板数据(panel data/time-series cross-section data) ★时间序列数据是最常见,也是最常用到的数据
 平行/面板数据(panel data/time-series cross-section data) ★时间序列数据是最常见,也是最常用到的数据.")
5
⒉经典回归模型与数据的平稳性 经典回归分析暗含着一个重要假设:数据是平稳的。
数据非平稳,大样本下的统计推断基础——“一致性”要求——被破怀。 经典回归分析的假设之一:解释变量X是非随机变量

6
第(2)条是为了满足统计推断中大样本下的“一致性”特性:
放宽该假设:X是随机变量,则需进一步要求: (1)X与随机扰动项 不相关∶Cov(X,)=0 (2) 依概率收敛: 第(1)条是OLS估计的需要 第(2)条是为了满足统计推断中大样本下的“一致性”特性:
X与随机扰动项 不相关∶Cov(X,)=0. (2) 依概率收敛: 第(1)条是OLS估计的需要. 第(2)条是为了满足统计推断中大样本下的 一致性 特性:")
7
注意:在双变量模型中: 因此: ▲如果X是非平稳数据(如表现出向上的趋势),则(2)不成立,回归估计量不满足“一致性”,基于大样本的统计推断也就遇到麻烦。
,则(2)不成立,回归估计量不满足 一致性 ,基于大样本的统计推断也就遇到麻烦。")
8
⒊ 数据非平稳,往往导致出现“虚假回归”问题
表现在:两个本来没有任何因果关系的变量,却有很高的相关性(有较高的R2)。例如:如果有两列时间序列数据表现出一致的变化趋势(非平稳的),即使它们没有任何有意义的关系,但进行回归也可表现出较高的可决系数。
。例如:如果有两列时间序列数据表现出一致的变化趋势(非平稳的),即使它们没有任何有意义的关系,但进行回归也可表现出较高的可决系数。")
9
在现实经济生活中,实际的时间序列数据往往是非平稳的,而且主要的经济变量如消费、收入、价格往往表现为一致的上升或下降。这样,仍然通过经典的因果关系模型进行分析,一般不会得到有意义的结果。

10
时间序列分析模型方法就是在这样的情况下,以通过揭示时间序列自身的变化规律为主线而发展起来的全新的计量经济学方法论。
时间序列分析已组成现代计量经济学的重要内容,并广泛应用于经济分析与预测当中。

11
二、时间序列数据的平稳性

12
1)均值E(Xt)=是与时间t 无关的常数; 2)方差Var(Xt)=2是与时间t 无关的常数;
定义: 假定某个时间序列是由某一随机过程(stochastic process)生成的,即假定时间序列{Xt}(t=1, 2, …)的每一个数值都是从一个概率分布中随机得到, 如果满足下列条件: 1)均值E(Xt)=是与时间t 无关的常数; 2)方差Var(Xt)=2是与时间t 无关的常数;
生成的,即假定时间序列{Xt}(t=1, 2, …)的每一个数值都是从一个概率分布中随机得到, 如果满足下列条件: 1)均值E(Xt)=是与时间t 无关的常数; 2)方差Var(Xt)=2是与时间t 无关的常数;")
13
3)协方差Cov(Xt,Xt+k)=k 是只与时期间隔k有关,与时间t 无关的常数;
则称该随机时间序列是平稳的(stationary),而该随机过程是一平稳随机过程(stationary stochastic process)。 小结:平稳的定义是用三个与时间无关的特征统计量来刻画的 介绍两种基本的随机过程:
,而该随机过程是一平稳随机过程(stationary stochastic process)。 小结:平稳的定义是用三个与时间无关的特征统计量来刻画的. 介绍两种基本的随机过程:")
14
例9.1.1.一个最简单的随机时间序列是一具有零均值同方差的独立分布序列:
Xt=t , t~N(0,2) 该序列常被称为是一个白噪声(white noise)。 由于Xt具有相同的均值与方差,且协方差为零,由定义,一个白噪声序列是平稳的。
 该序列常被称为是一个白噪声(white noise)。 由于Xt具有相同的均值与方差,且协方差为零,由定义,一个白噪声序列是平稳的。")
15
例9.1.2.另一个简单的随机时间列序被称为随机游走(random walk),该序列由如下随机过程生成:
X t=Xt-1+t 这里, t是一个白噪声。 容易知道该序列有相同的均值:E(Xt)=E(Xt-1) 为了检验该序列是否具有相同的方差,可假设Xt的初值为X0,则易知:
=E(Xt-1) 为了检验该序列是否具有相同的方差,可假设Xt的初值为X0,则易知:")
16
由于X0为常数,t是一个白噪声,因此: Var(Xt)=t2
X1=X0+1 X2=X1+2=X0+1+2 … … Xt=X0+1+2+…+t 由于X0为常数,t是一个白噪声,因此: Var(Xt)=t2 即Xt的方差与时间t有关而非常数,它是一非平稳序列。
=t2. 即Xt的方差与时间t有关而非常数,它是一非平稳序列。")
17
然而,对X取一阶差分(first difference):
Xt=Xt-Xt-1=t 由于t是一个白噪声,则序列{Xt}是平稳的。 后面将会看到:如果一个时间序列是非平稳的,它常常可通过取差分的方法而形成平稳序列。

18
事实上,随机游走过程是下面我们称之为1阶自回归AR(1)过程的特例:
Xt=Xt-1+t 不难验证: 1)||>1时,该随机过程生成的时间序列是发散的,表现为持续上升(>1)或持续下降(<-1),因此是非平稳的; 2)=1时,是一个随机游走过程,也是非平稳的。
||>1时,该随机过程生成的时间序列是发散的,表现为持续上升(>1)或持续下降(<-1),因此是非平稳的; 2)=1时,是一个随机游走过程,也是非平稳的。")
19
1阶自回归过程AR(1)又是如下k阶自回归AR(K)过程的特例: Xt= 1Xt-1+2Xt-2…+kXt-k
§9.2中将证明:只有当-1<<1时,该随机过程才是平稳的。 1阶自回归过程AR(1)又是如下k阶自回归AR(K)过程的特例: Xt= 1Xt-1+2Xt-2…+kXt-k 该随机过程平稳性条件将在第二节中介绍。
又是如下k阶自回归AR(K)过程的特例: Xt= 1Xt-1+2Xt-2…+kXt-k. 该随机过程平稳性条件将在第二节中介绍。")
20
三、平稳性检验的图示判断

21
给出一个随机时间序列,首先可通过该序列的时间路径图来粗略地判断它是否是平稳的。
一个平稳的时间序列在图形上往往表现出一种围绕其均值不断波动的过程。 而非平稳序列则往往表现出在不同的时间段具有不同的均值(如持续上升或持续下降)。
。")
23
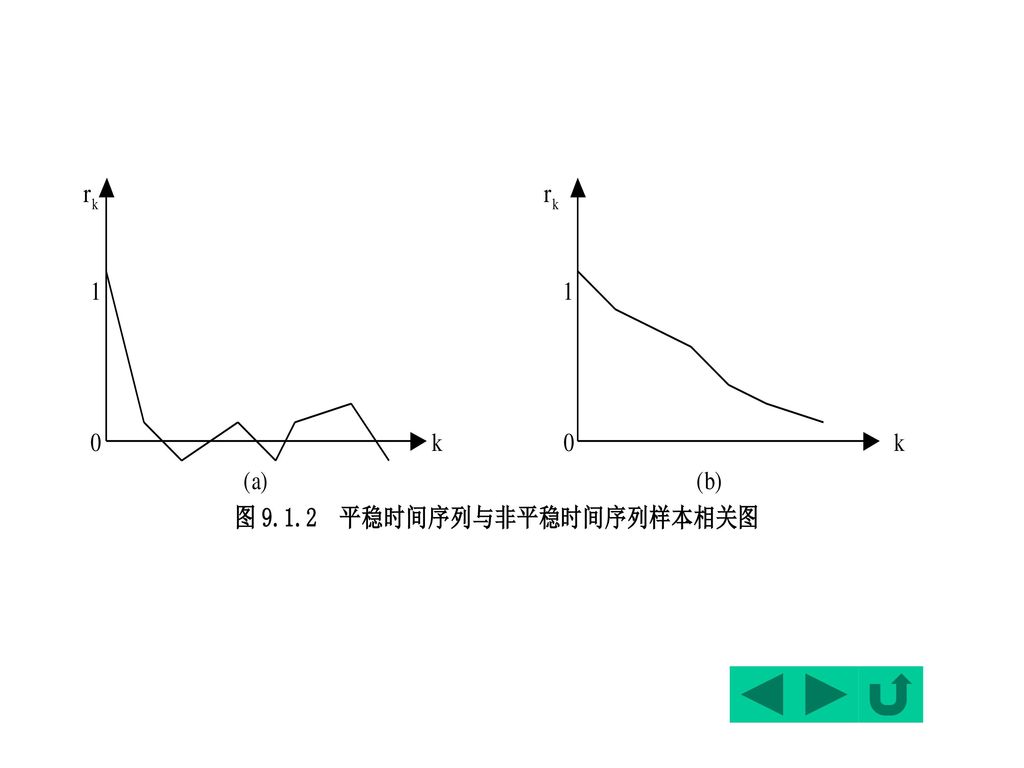
进一步的判断:检验样本自相关函数及其图形
定义随机时间序列的自相关函数(autocorrelation function, ACF)如下: k=k/0 其中:k=Cov(Xt, Xt+k), 0 =Var(Xt) 自相关函数是关于滞后期k的递减函数(Why?)。 实际上,对一个随机过程只有一个实现(样本),因此,只能计算样本自相关函数(Sample autocorrelation function)。
如下: k=k/0. 其中:k=Cov(Xt, Xt+k), 0 =Var(Xt) 自相关函数是关于滞后期k的递减函数(Why )。 实际上,对一个随机过程只有一个实现(样本),因此,只能计算样本自相关函数(Sample autocorrelation function)。")
24
一个时间序列的样本自相关函数定义为: 检验法则:rk 很快趋于0,即落入随机区间---平稳

26
注意: 确定样本自相关函数rk某一数值是否足够接近于0是非常有用的,因为它可检验对应的自相关函数k的真值是否为0的假设。 Bartlett曾证明:如果时间序列由白噪声过程生成,则对所有的k>0,样本自相关系数近似地服从以0为均值,1/n 为方差的正态分布,其中n为样本数。

27
也可检验对所有k>0,自相关系数都为0的联合假设,这可通过如下QLB统计量进行:

28
该统计量近似地服从自由度为m的2分布(m为滞后长度)。
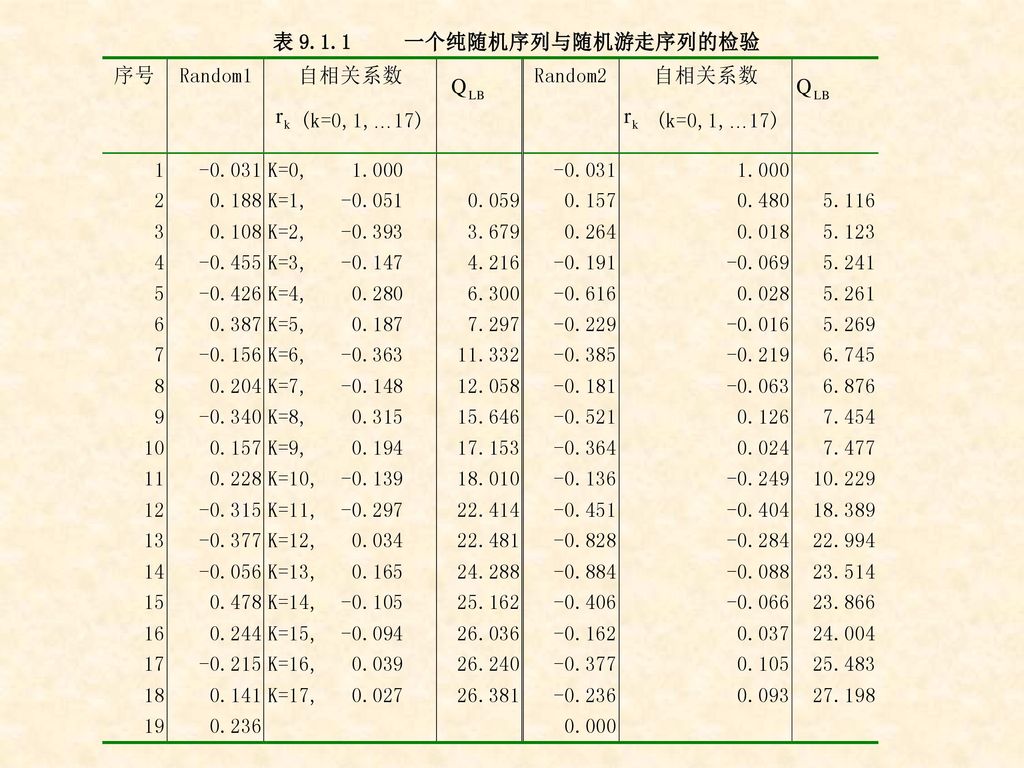
因此:如果计算的Q值大于显著性水平为的临界值,则有1-的把握拒绝所有k(k>0)同时为0的假设。 例9.1.3: 表9.1.1序列Random1是通过一随机过程(随机函数)生成的有19个样本的随机时间序列。
同时为0的假设。 例9.1.3: 表9.1.1序列Random1是通过一随机过程(随机函数)生成的有19个样本的随机时间序列。")
30
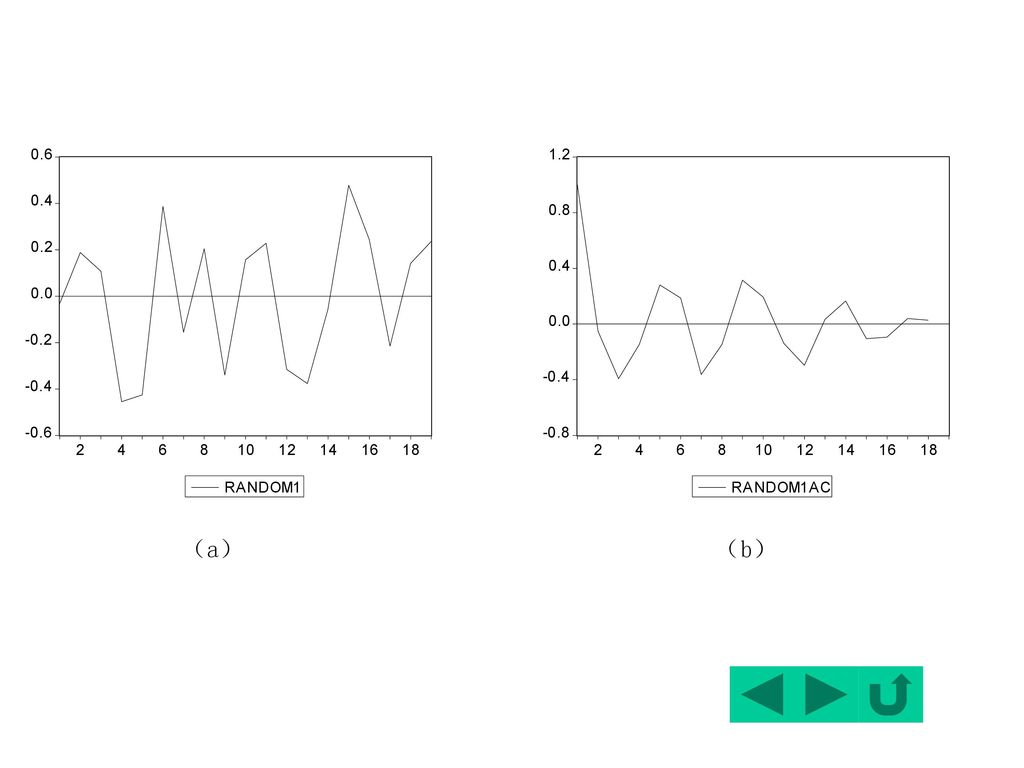
容易验证:该样本序列的均值为0,方差为0.0789。 从图形看:它在其样本均值0附近上下波动,且样本自相关系数迅速下降到0,随后在0附近波动且逐渐收敛于0。

32
由于该序列由一随机过程生成,可以认为不存在序列相关性,因此该序列为一白噪声。
根据Bartlett的理论:k~N(0,1/19),因此任一rk(k>0)的95%的置信区间都将是:
,因此任一rk(k>0)的95%的置信区间都将是:")
33
可以看出:k>0时,rk的值确实落在了该区间内,因此可以接受 k(k>0)为0的假设。
同样地,从QLB统计量的计算值看,滞后17期的计算值为26.38,未超过5%显著性水平的临界值27.58,因此,可以接受所有的自相关系数k(k>0)都为0的假设。 因此,该随机过程是一个平稳过程。
都为0的假设。 因此,该随机过程是一个平稳过程。")
34
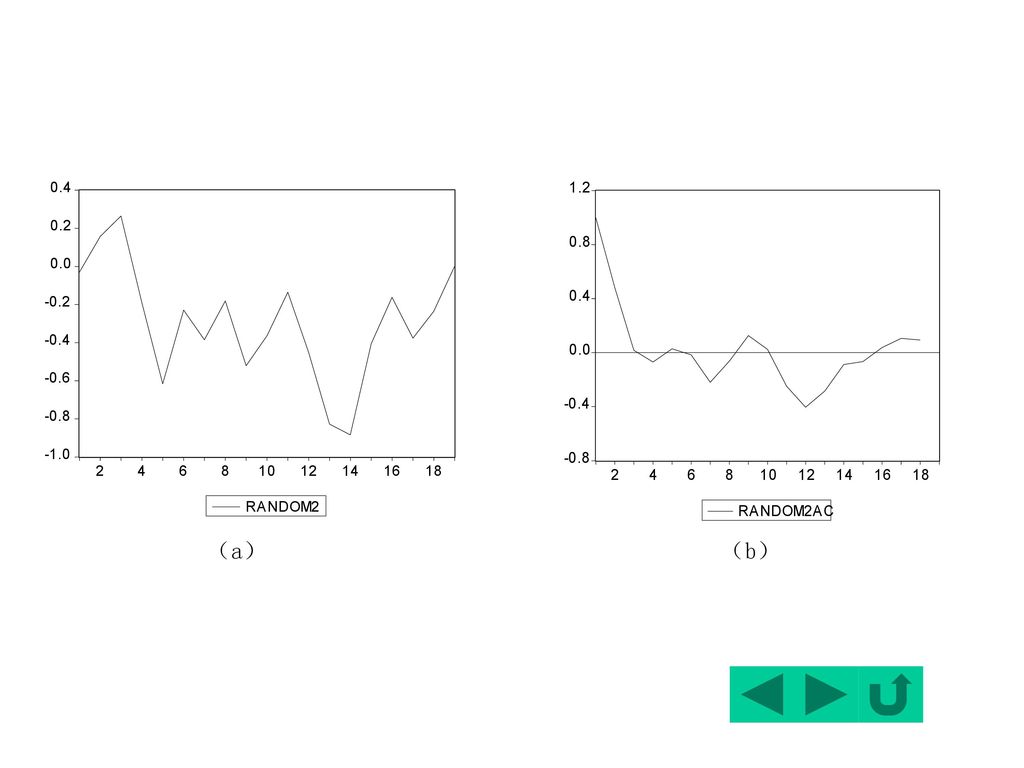
序列Random2是由一随机游走过程 Xt=Xt-1+t
生成的一随机游走时间序列样本。其中,第0项取值为0, t是由Random1表示的白噪声。

36
图形表示出:该序列具有相同的均值,但从样本自相关图看,虽然自相关系数迅速下降到0,但随着时间的推移,则在0附近波动且呈发散趋势。
样本自相关系数显示:r1=0.48,落在了区间[ , ]之外,因此在5%的显著性水平上拒绝1的真值为0的假设。 该随机游走序列是非平稳的。

37
例9.1.4 检验中国支出法GDP时间序列的平稳性。

39
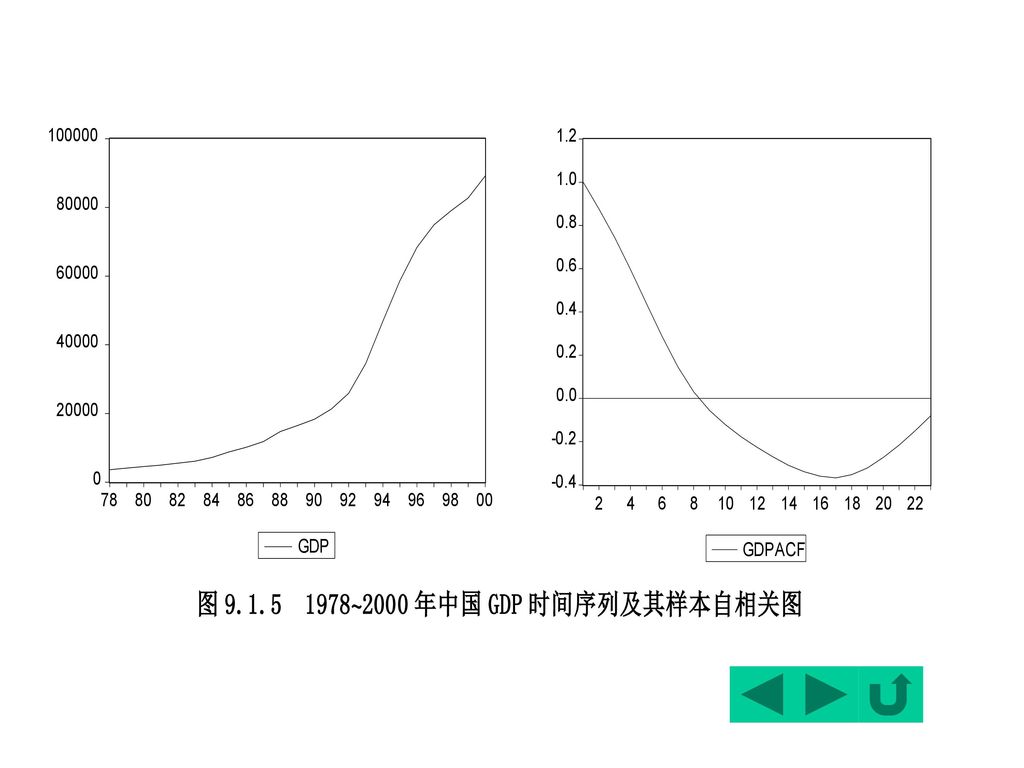
图形:表现出了一个持续上升的过程,可初步判断是非平稳的。
样本自相关系数:缓慢下降,再次表明它的非平稳性。

40
从滞后18期的QLB统计量看: QLB(18)=57.18>28.86=20.05
拒绝:该时间序列的自相关系数在滞后1期之后的值全部为0的假设。 结论: 1978—2000年间中国GDP时间序列是非平稳序列。

41
例9.1.5 检验§2.10中关于人均居民消费与人均国内生产总值这两时间序列的平稳性。
原图 样本自相关图

42
从图形上看:人均居民消费(CPC)与人均国内生产总值(GDPPC)是非平稳的。
从滞后14期的QLB统计量看:CPC与GDPPC序列的统计量计算值均为57.18,超过了显著性水平为5%时的临界值23.68。再次表明它们的非平稳性。

43
就此来说,运用传统的回归方法建立它们的回归方程是无实际意义的。
不过,§9.3中将看到,如果两个非平稳时间序列是协整的,则传统的回归结果却是有意义的,而这两时间序列恰是协整的。

44
四、平稳性的单位根检验 (unit root test)
")
45
1、DF检验 随机游走序列: Xt=Xt-1+t 是非平稳的,其中t是白噪声。而该序列可看成是随机模型: Xt=Xt-1+t
中参数=1时的情形。

46
对式: Xt=Xt-1+t (*) 进行回归,如果确实发现=1,就说随机变量Xt有一个单位根。
(*)式可变形式成差分形式: Xt=(1-)Xt-1+ t =Xt-1+ t (**) 检验(*)式是否存在单位根=1,也可通过(**)式判断是否有 =0。
式可变形式成差分形式: Xt=(1-)Xt-1+ t. =Xt-1+ t (**) 检验(*)式是否存在单位根=1,也可通过(**)式判断是否有 =0。")
47
一般地: 检验一个时间序列Xt的平稳性,可通过检验带有截距项的一阶自回归模型: Xt=+Xt-1+t (*) 中的参数是否小于1。 或者:检验其等价变形式: Xt=+Xt-1+t (**) 中的参数是否小于0 。
 中的参数是否小于0 。")
48
在第二节中将证明,(*)式中的参数>1或=1时,时间序列是非平稳的; 对应于(**)式,则是>0或 =0。
因此,针对式: Xt=+Xt-1+t 我们关心的检验为:零假设 H0:=0。 备择假设 H1:<0

49
上述检验可通过OLS法下的t检验完成。 然而,在零假设(序列非平稳)下,即使在大样本下t统计量也是有偏误的(向下偏倚),通常的t 检验无法使用。 Dicky和Fuller于1976年提出了这一情形下t统计量服从的分布(这时的t统计量称为统计量),即DF分布(见表9.1.3)。 由于t统计量的向下偏倚性,它呈现围绕小于零值的偏态分布。

50
因此,可通过OLS法估计: Xt=+Xt-1+t 并计算t统计量的值,与DF分布表中给定显著性水平下的临界值比较:

51
如果:t<临界值,则拒绝零假设H0: =0,
认为时间序列不存在单位根,是平稳的。 注意:在不同的教科书上有不同的描述,但是结果是相同的。 例如:“如果计算得到的t统计量的绝对值大于临界值的绝对值,则拒绝ρ=0”的假设,原序列不存在单位根,为平稳序列。

52
在利用Xt=+Xt-1+t对时间序列进行平稳性检验中,实际上假定了时间序列是由具有白噪声随机误差项的一阶自回归过程AR(1)生成的。
2、ADF检验 问题的提出: 在利用Xt=+Xt-1+t对时间序列进行平稳性检验中,实际上假定了时间序列是由具有白噪声随机误差项的一阶自回归过程AR(1)生成的。 但在实际检验中,时间序列可能由更高阶的自回归过程生成的,或者随机误差项并非是白噪声,这样用OLS法进行估计均会表现出随机误差项出现自相关(autocorrelation),导致DF检验无效。
生成的。 但在实际检验中,时间序列可能由更高阶的自回归过程生成的,或者随机误差项并非是白噪声,这样用OLS法进行估计均会表现出随机误差项出现自相关(autocorrelation),导致DF检验无效。")
53
另外,如果时间序列包含有明显的随时间变化的某种趋势(如上升或下降),则也容易导致上述检验中的自相关随机误差项问题。
为了保证DF检验中随机误差项的白噪声特性,Dicky和Fuller对DF检验进行了扩充,形成了ADF(Augment Dickey-Fuller )检验。
检验。")
54
ADF检验是通过下面三个模型完成的:

55
模型3 中的t是时间变量,代表了时间序列随时间变化的某种趋势(如果有的话)。模型1与另两模型的差别在于是否包含有常数项和趋势项。
检验的假设都是:针对H1: <0,检验 H0:=0,即存在一单位根。

56
实际检验时从模型3开始,然后模型2、模型1。 何时检验拒绝零假设,即原序列不存在单位根,为平稳序列,何时检验停止。否则,就要继续检验,直到检验完模型1为止。 检验原理与DF检验相同,只是对模型1、2、3进行检验时,有各自相应的临界值。 表9.1.4给出了三个模型所使用的ADF分布临界值表。

57
t t t 1 2 表:9.1.4 不同模型使用的ADF分布临界值表 模型 统计量 样本容量 0.01 0.025 0.05 0.10 25
50 100 250 500 〉500 -2.66 -2.62 -2.60 -2.58 -2.26 -2.25 -2.24 -2.23 -1.95 -1.60 -1.61 t s 2 25 50 100 250 500 〉500 -3.75 -3.58 -3.51 -3.46 -3.44 -3.43 -3.33 -3.22 -3.17 -3.14 -3.13 -3.12 -3.00 -2.93 -2.89 -2.88 -2.87 -2.86 -2.62 -2.60 -2.58 -2.57 t s 25 50 100 250 500 〉500 3.41 3.28 3.22 3.19 3.18 2.97 2.89 2.86 2.84 2.83 2.61 2.56 2.54 2.53 2.52 2.20 2.18 2.17 2.16 t a

58
t t t 3 续表:9.1.4 不同模型使用的ADF分布临界值表 模型 统计量 样本容量 0.01 0.025 0.05 0.10 s a
50 100 250 500 〉500 -4.38 -4.15 -4.04 -3.99 -3.98 -3.96 -3.95 -3.80 -3.73 -3.69 -3.68 -3.66 -3.60 3.50 -3.45 -3.43 -3.42 -3.41 -3.24 -3.18 -3.15 -3.13 -3.12 t s 25 50 100 250 500 〉500 4.05 3.87 3.78 3.74 3.72 3.71 3.59 3.42 3.39 3.38 3.20 3.14 3.11 3.09 3.08 2.77 2.75 2.73 2.72 t a 25 50 100 250 500 〉500 3.74 3.60 3.53 3.49 3.48 3.46 3.25 3.18 3.14 3.12 3.11 2.85 2.81 2.79 2.78 2.39 2.38 t b

59
同时估计出上述三个模型的适当形式,然后通过ADF临界值表检验零假设H0:=0。
一个简单的检验过程: 同时估计出上述三个模型的适当形式,然后通过ADF临界值表检验零假设H0:=0。 1)只要其中有一个模型的检验结果拒绝了零假设,就可以认为时间序列是平稳的;
只要其中有一个模型的检验结果拒绝了零假设,就可以认为时间序列是平稳的;")
60
2)当三个模型的检验结果都不能拒绝零假设时,则认为时间序列是非平稳的。
这里所谓模型适当的形式就是在每个模型中选取适当的滞后差分项,以使模型的残差项是一个白噪声(主要保证不存在自相关)。
。")
61
Eviews: Quick----Serie Statistic-----Unit Root Test 或者:
打开序列窗口--View--- Unit Root Test

62
例9.1.6 检验1978~2000年间中国支出法GDP序列的平稳性。
1)经过偿试,模型3取了2阶滞后: 通过拉格朗日乘数检验(Lagrange multiplier test)对随机误差项的自相关性进行检验: LM(1)=0.92, LM(2)=4.16,
经过偿试,模型3取了2阶滞后: 通过拉格朗日乘数检验(Lagrange multiplier test)对随机误差项的自相关性进行检验: LM(1)=0.92, LM(2)=4.16,")
63
小于5%显著性水平下自由度分别为1与2的2分布的临界值,可见不存在自相关性,因此该模型的设定是正确的。
从的系数看,t>临界值,不能拒绝存在单位根的零假设。 时间T的t统计量小于ADF分布表中的临界值,因此不能拒绝不存在趋势项的零假设。需进一步检验模型2 。

64
2)经试验,模型2中滞后项取2阶: LM检验表明模型残差不存在自相关性,因此该模型的设定是正确的。
经试验,模型2中滞后项取2阶: LM检验表明模型残差不存在自相关性,因此该模型的设定是正确的。")
65
从GDPt-1的参数值看,其t统计量为正值,大于临界值,不能拒绝存在单位根的零假设。
常数项的t统计量小于AFD分布表中的临界值,不能拒绝不存常数项的零假设。需进一步检验模型1。

66
3)经试验,模型1中滞后项取2阶:
经试验,模型1中滞后项取2阶:")
67
LM检验表明模型残差项不存在自相关性,因此模型的设定是正确的。
从GDPt-1的参数值看,其t统计量为正值,大于临界值,不能拒绝存在单位根的零假设。 可断定中国支出法GDP时间序列是非平稳的。

68
例9.1.7 检验§2.10中关于人均居民消费与人均国内生产总值这两时间序列的平稳性。
1) 对中国人均国内生产总值GDPPC来说,经过偿试,三个模型的适当形式分别为:
 对中国人均国内生产总值GDPPC来说,经过偿试,三个模型的适当形式分别为:")
70
三个模型中参数的估计值的t统计量均大于各自的临界值,因此不能拒绝存在单位根的零假设。
结论:人均国内生产总值(GDPPC)是非平稳的。
是非平稳的。")
71
2)对于人均居民消费CPC时间序列来说,三个模型的适当形式为 :
对于人均居民消费CPC时间序列来说,三个模型的适当形式为 :")
73
三个模型中参数CPCt-1的t统计量的值均比ADF临界值表中各自的临界值大,不能拒绝该时间序列存在单位根的假设,

74
五、单整、趋势平稳与差分平稳随机过程

75
随机游走序列Xt=Xt-1+t经差分后等价地变形为 Xt=t, 由于t是一个白噪声,因此差分后的序列{Xt}是平稳的。
⒈单整 随机游走序列Xt=Xt-1+t经差分后等价地变形为 Xt=t, 由于t是一个白噪声,因此差分后的序列{Xt}是平稳的。 如果一个时间序列经过一次差分变成平稳的,就称原序列是一阶单整(integrated of 1)序列,记为I(1)。
序列,记为I(1)。")
76
一般地,如果一个时间序列经过d次差分后变成平稳序列,则称原序列是d 阶单整(integrated of d)序列,记为I(d)。
现实经济生活中: 1)只有少数经济指标的时间序列表现为平稳的,如利率等;
只有少数经济指标的时间序列表现为平稳的,如利率等;")
77
2)大多数指标的时间序列是非平稳的,如一些价格指数常常是2阶单整的,以不变价格表示的消费额、收入等常表现为1阶单整。
大多数非平稳的时间序列一般可通过一次或多次差分的形式变为平稳的。 但也有一些时间序列,无论经过多少次差分,都不能变为平稳的。这种序列被称为非单整的(non-integrated)。
。")
78
例9.1.8 中国支出法GDP的单整性。 经过试算,发现中国支出法GDP是1阶单整的,适当的检验模型为:

79
例9.1.9 中国人均居民消费与人均国内生产总值的单整性。
经过试算,发现中国人均国内生产总值GDPPC是2阶单整的,适当的检验模型为:

80
同样地,CPC也是2阶单整的,适当的检验模型为:

81
⒉ 趋势平稳与差分平稳随机过程 前文已指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联关系,这时对这些数据进行回归,尽管有较高的R2,但其结果是没有任何实际意义的。这种现象我们称之为虚假回归或伪回归(spurious regression)。
。")
82
如:用中国的劳动力时间序列数据与美国GDP时间序列作回归,会得到较高的R2 ,但不能认为两者有直接的关联关系,而只不过它们有共同的趋势罢了,这种回归结果我们认为是虚假的。
为了避免这种虚假回归的产生,通常的做法是引入作为趋势变量的时间,这样包含有时间趋势变量的回归,可以消除这种趋势性的影响。

83
换言之,如果一个包含有某种确定性趋势的非平稳时间序列,可以通过引入表示这一确定性趋势的趋势变量,而将确定性趋势分离出来。
然而这种做法,只有当趋势性变量是确定性的(deterministic)而非随机性的(stochastic),才会是有效的。 换言之,如果一个包含有某种确定性趋势的非平稳时间序列,可以通过引入表示这一确定性趋势的趋势变量,而将确定性趋势分离出来。
而非随机性的(stochastic),才会是有效的。 换言之,如果一个包含有某种确定性趋势的非平稳时间序列,可以通过引入表示这一确定性趋势的趋势变量,而将确定性趋势分离出来。")
84
1)如果=1,=0,则(*)式成为一带位移的随机游走过程:
考虑如下的含有一阶自回归的随机过程: Xt=+t+Xt-1+t (*) 其中:t是一白噪声,t为一时间趋势。 1)如果=1,=0,则(*)式成为一带位移的随机游走过程: Xt=+Xt-1+t (**) 根据的正负,Xt表现出明显的上升或下降趋势。这种趋势称为随机性趋势(stochastic trend)。
 其中:t是一白噪声,t为一时间趋势。 1)如果=1,=0,则(*)式成为一带位移的随机游走过程: Xt=+Xt-1+t (**) 根据的正负,Xt表现出明显的上升或下降趋势。这种趋势称为随机性趋势(stochastic trend)。")
85
2)如果=0,0,则(*)式成为一带时间趋势的随机变化过程:
Xt=+t+t (***) 根据的正负,Xt表现出明显的上升或下降趋势。这种趋势称为确定性趋势(deterministic trend)。
 根据的正负,Xt表现出明显的上升或下降趋势。这种趋势称为确定性趋势(deterministic trend)。")
86
3) 如果=1,0,则Xt包含有确定性与随机性两种趋势。
判断一个非平稳的时间序列,它的趋势是随机性的还是确定性的,可通过ADF检验中所用的第3个模型进行。 该模型中已引入了表示确定性趋势的时间变量t,即分离出了确定性趋势的影响。

87
因此: (1)如果检验结果表明所给时间序列有单位根,且时间变量前的参数显著为零,则该序列显示出随机性趋势; (2)如果没有单位根,且时间变量前的参数显著地异于零,则该序列显示出确定性趋势。
如果检验结果表明所给时间序列有单位根,且时间变量前的参数显著为零,则该序列显示出随机性趋势; (2)如果没有单位根,且时间变量前的参数显著地异于零,则该序列显示出确定性趋势。")
88
随机性趋势可通过差分的方法消除 例如:对式: Xt=+Xt-1+t 可通过差分变换为: Xt= +t
例如:对式: Xt=+Xt-1+t 可通过差分变换为: Xt= +t 该时间序列称为差分平稳过程(difference stationary process);
;")
89
确定性趋势无法通过差分的方法消除,而只能通过除去趋势项消除
确定性趋势无法通过差分的方法消除,而只能通过除去趋势项消除 例如:对式: Xt=+t+t 可通过除去t变换为: Xt -t =+t 该时间序列是平稳的,因此称为趋势平稳过程(trend stationary process)。
。")
90
最后需要说明的是,趋势平稳过程代表了一个时间序列长期稳定的变化过程,因而用于进行长期预测则是更为可靠的。

91
§9.2 随机时间序列分析模型 一、时间序列模型的基本概念及其适用性 二、随机时间序列模型的平稳性条件 三、随机时间序列模型的识别
四、随机时间序列模型的估计 五、随机时间序列模型的检验

92
说明 经典计量经济学模型与时间序列模型 确定性时间序列模型与随机性时间序列模型

93
一、时间序列模型的基本概念及其适用性

94
1、时间序列模型的基本概念 随机时间序列模型(time series modeling)是指仅用它的过去值及随机扰动项所建立起来的模型,其一般形式为: Xt=F(Xt-1, Xt-2, …, t) 建立具体的时间序列模型,需解决如下三个问题: (1)模型的具体形式
模型的具体形式.")
95
(2)时序变量的滞后期 (3)随机扰动项的结构 例如,取线性方程、一期滞后以及白噪声随机扰动项( t =t),模型将是一个1阶自回归过程AR(1): Xt=Xt-1+ t,这里, t特指一白噪声。
,模型将是一个1阶自回归过程AR(1): Xt=Xt-1+ t,这里, t特指一白噪声。 .")
96
一般的p阶自回归过程AR(p)是 Xt=1Xt-1+ 2Xt-2 + … + pXt-p + t (*) (1)如果随机扰动项是一个白噪声(t=t),则称(*)式为一纯AR(p)过程(pure AR(p) process),记为: Xt=1Xt-1+ 2Xt-2 + … + pXt-p +t

97
(2)如果t不是一个白噪声,通常认为它是一个q阶的移动平均(moving average)过程MA(q):
t=t - 1t-1 - 2t-2 - - qt-q 该式给出了一个纯MA(q)过程(pure MA(p) process)。
过程(pure MA(p) process)。")
98
(1)一个随机时间序列可以通过一个自回归移动平均过程生成,即该序列可以由其自身的过去或滞后值以及随机扰动项来解释。
将纯AR(p)与纯MA(q)结合,得到一个一般的自回归移动平均(autoregressive moving average)过程ARMA(p,q): Xt=1Xt-1+ 2Xt-2 + … + pXt-p + t - 1t-1 - 2t-2 - - qt-q 该式表明: (1)一个随机时间序列可以通过一个自回归移动平均过程生成,即该序列可以由其自身的过去或滞后值以及随机扰动项来解释。
与纯MA(q)结合,得到一个一般的自回归移动平均(autoregressive moving average)过程ARMA(p,q): Xt=1Xt-1+ 2Xt-2 + … + pXt-p + t - 1t-1 - 2t-2 - - qt-q. 该式表明: (1)一个随机时间序列可以通过一个自回归移动平均过程生成,即该序列可以由其自身的过去或滞后值以及随机扰动项来解释。")
99
(2)如果该序列是平稳的,即它的行为并不会随着时间的推移而变化,那么我们就可以通过该序列过去的行为来预测未来。
这也正是随机时间序列分析模型的优势所在。

100
2、时间序列分析模型的适用性 经典回归模型的问题:
迄今为止,对一个时间序列Xt的变动进行解释或预测,是通过某个单方程回归模型或联立方程回归模型进行的,由于它们以因果关系为基础,且具有一定的模型结构,因此也常称为结构式模型(structural model)。
。")
101
然而,如果Xt波动的主要原因可能是我们无法解释的因素,如气候、消费者偏好的变化等,则利用结构式模型来解释Xt的变动就比较困难或不可能,因为要取得相应的量化数据,并建立令人满意的回归模型是很困难的。

102
有时,即使能估计出一个较为满意的因果关系回归方程,但由于对某些解释变量未来值的预测本身就非常困难,甚至比预测被解释变量的未来值更困难,这时因果关系的回归模型及其预测技术就不适用了。

103
例如,时间序列过去是否有明显的增长趋势,如果增长趋势在过去的行为中占主导地位,能否认为它也会在未来的行为里占主导地位呢?
另一条预测途径:通过时间序列的历史数据,得出关于其过去行为的有关结论,进而对时间序列未来行为进行推断。 例如,时间序列过去是否有明显的增长趋势,如果增长趋势在过去的行为中占主导地位,能否认为它也会在未来的行为里占主导地位呢? 或者时间序列显示出循环周期性行为,我们能否利用过去的这种行为来外推它的未来走向?

104
随机时间序列分析模型,就是要通过序列过去的变化特征来预测未来的变化趋势。
使用时间序列分析模型的另一个原因在于:如果经济理论正确地阐释了现实经济结构,则这一结构可以写成类似于ARMA(p,q)式的时间序列分析模型的形式。
式的时间序列分析模型的形式。")
105
Ct与Yt作为内生变量,它们的运动是由作为外生变量的投资It的运动及随机扰动项t的变化决定的。
例如,对于如下最简单的宏观经济模型: 这里,Ct、It、Yt分别表示消费、投资与国民收入。 Ct与Yt作为内生变量,它们的运动是由作为外生变量的投资It的运动及随机扰动项t的变化决定的。

106
两个方程等式右边除去第一项外的剩余部分可看成一个综合性的随机扰动项,其特征依赖于投资项It的行为。
上述模型可作变形如下: 两个方程等式右边除去第一项外的剩余部分可看成一个综合性的随机扰动项,其特征依赖于投资项It的行为。

107
如果It是一个白噪声,则消费序列Ct就成为一个1阶自回归过程AR(1),而收入序列Yt就成为一个(1,1)阶的自回归移动平均过程ARMA(1,1)。
,而收入序列Yt就成为一个(1,1)阶的自回归移动平均过程ARMA(1,1)。")
108
二、随机时间序列模型的平稳性条件

109
关于这几类模型的研究,是时间序列分析的重点内容:主要包括模型的平稳性分析、模型的识别和模型的估计。
1、AR(p)模型的平稳性条件 自回归移动平均模型(ARMA)是随机时间序列分析模型的普遍形式,自回归模型(AR)和移动平均模型(MA)是它的特殊情况。 关于这几类模型的研究,是时间序列分析的重点内容:主要包括模型的平稳性分析、模型的识别和模型的估计。
模型的平稳性条件. 自回归移动平均模型(ARMA)是随机时间序列分析模型的普遍形式,自回归模型(AR)和移动平均模型(MA)是它的特殊情况。 关于这几类模型的研究,是时间序列分析的重点内容:主要包括模型的平稳性分析、模型的识别和模型的估计。")
110
随机时间序列模型的平稳性,可通过它所生成的随机时间序列的平稳性来判断。如果一个p阶自回归模型AR(p)生成的时间序列是平稳的,就说该AR(p)模型是平稳的。
生成的时间序列是平稳的,就说该AR(p)模型是平稳的。")
111
考虑p阶自回归模型AR(p) Xt=1Xt-1+ 2Xt-2 + … + pXt-p +t (*)
引入滞后算子(lag operator )L: LXt=Xt-1, L2Xt=Xt-2, …, LpXt=Xt-p (*)式变换为: (1-1L- 2L2-…-pLp)Xt=t
L: LXt=Xt-1, L2Xt=Xt-2, …, LpXt=Xt-p. (*)式变换为: (1-1L- 2L2-…-pLp)Xt=t.")
112
记(L)= (1-1L- 2L2-…-pLp),则称多项式方程:
(z)= (1-1z- 2z2-…-pzp)=0 为AR(p)的特征方程(characteristic equation)。 可以证明,如果该特征方程的所有根在单位圆外(根的模大于1),则AR(p)模型是平稳的。
= (1-1z- 2z2-…-pzp)=0. 为AR(p)的特征方程(characteristic equation)。 可以证明,如果该特征方程的所有根在单位圆外(根的模大于1),则AR(p)模型是平稳的。")
113
例9.2.1 AR(1)模型的平稳性条件。 对1阶自回归模型AR(1) 方程两边平方再求数学期望,得到Xt的方差:
由于Xt仅与t相关,因此,E(Xt-1t)=0。如果该模型稳定,则有E(Xt2)=E(Xt-12),从而上式可变换为:
=0。如果该模型稳定,则有E(Xt2)=E(Xt-12),从而上式可变换为:")
114
在稳定条件下,该方差是一非负的常数,从而有 ||<1。
而AR(1)的特征方程: 的根为: z=1/ AR(1)稳定,即 || <1,意味着特征根大于1。
的特征方程: 的根为: z=1/ AR(1)稳定,即 || <1,意味着特征根大于1。")
115
例9.2.2 AR(2)模型的平稳性。 对AR(2)模型: 方程两边同乘以Xt,再取期望得: 又由于:
模型的平稳性。 对AR(2)模型: 方程两边同乘以Xt,再取期望得: 又由于:")
116
于是: 同样地,由原式还可得到: 于是方差为 :

117
由平稳性的定义,该方差必须是一不变的正数,于是有 1+2<1, 2-1<1, |2|<1
这就是AR(2)的平稳性条件,或称为平稳域。它是一顶点分别为(-2,-1),(2,-1),(0,1)的三角形。
的平稳性条件,或称为平稳域。它是一顶点分别为(-2,-1),(2,-1),(0,1)的三角形。")
118
AR(2)模型: 对应的特征方程1-1z-2z2=0 的两个根z1、z2满足: z1z2=-1/2 , z1+z2 =-1/2 解出1,2:
模型: 对应的特征方程1-1z-2z2=0 的两个根z1、z2满足: z1z2=-1/2 , z1+z2 =-1/2 解出1,2:")
119
由AR(2)的平稳性,|2|=1/|z1||z2|<1 ,则至少有一个根的模大于1,不妨设|z1|>1,有:
的平稳性,|2|=1/|z1||z2|<1 ,则至少有一个根的模大于1,不妨设|z1|>1,有:")
120
对高阶自回模型AR(p)来说,多数情况下没有必要直接计算其特征方程的特征根,但有一些有用的规则可用来检验高阶自回归模型的稳定性:
(2)由于i(i=1,2,p)可正可负,AR(p)模型稳定的充分条件是: |1|+|2|++|p|<1
由于i(i=1,2,p)可正可负,AR(p)模型稳定的充分条件是: |1|+|2|++|p|<1.")
121
2、MA(q)模型的平稳性 对于移动平均模型MR(q): Xt=t - 1t-1 - 2t-2 - - qt-q 其中t是一个白噪声,于是:
模型的平稳性 对于移动平均模型MR(q): Xt=t - 1t-1 - 2t-2 - - qt-q 其中t是一个白噪声,于是:")
122
当滞后期大于q时,Xt的自协方差系数为0。
因此:有限阶移动平均模型总是平稳的。

123
Xt=1Xt-1+ 2Xt-2 + … + pXt-p + t - 1t-1 - 2t-2 - - qt-q
3、ARMA(p,q)模型的平稳性 由于ARMA (p,q)模型是AR(p)模型与MA(q)模型的组合: Xt=1Xt-1+ 2Xt-2 + … + pXt-p + t - 1t-1 - 2t-2 - - qt-q 而MA(q)模型总是平稳的,因此ARMA (p,q)模型的平稳性取决于AR(p)部分的平稳性。 当AR(p)部分平稳时,则该ARMA(p,q)模型是平稳的,否则,不是平稳的。
模型的平稳性. 由于ARMA (p,q)模型是AR(p)模型与MA(q)模型的组合: Xt=1Xt-1+ 2Xt-2 + … + pXt-p + t - 1t-1 - 2t-2 - - qt-q. 而MA(q)模型总是平稳的,因此ARMA (p,q)模型的平稳性取决于AR(p)部分的平稳性。 当AR(p)部分平稳时,则该ARMA(p,q)模型是平稳的,否则,不是平稳的。")
124
4、总结 (1)一个平稳的时间序列总可以找到生成它的平稳的随机过程或模型; (2)一个非平稳的随机时间序列通常可以通过差分的方法将它变换为平稳的,对差分后平稳的时间序列也可找出对应的平稳随机过程或模型。
一个平稳的时间序列总可以找到生成它的平稳的随机过程或模型; (2)一个非平稳的随机时间序列通常可以通过差分的方法将它变换为平稳的,对差分后平稳的时间序列也可找出对应的平稳随机过程或模型。")
125
因此,如果我们将一个非平稳时间序列通过d次差分,将它变为平稳的,然后用一个平稳的ARMA(p,q)模型作为它的生成模型,则我们就说该原始时间序列是一个自回归单整移动平均(autoregressive integrated moving average)时间序列,记为ARIMA(p,d,q)。
模型作为它的生成模型,则我们就说该原始时间序列是一个自回归单整移动平均(autoregressive integrated moving average)时间序列,记为ARIMA(p,d,q)。")
126
例如,一个ARIMA(2,1,2)时间序列在它成为平稳序列之前先得差分一次,然后用一个ARMA(2,2)模型作为它的生成模型的。
当然,一个ARIMA(p,0,0)过程表示了一个纯AR(p)平稳过程;一个ARIMA(0,0,q)表示一个纯MA(q)平稳过程。
过程表示了一个纯AR(p)平稳过程;一个ARIMA(0,0,q)表示一个纯MA(q)平稳过程。")
127
三、随机时间序列模型的识别

128
所谓随机时间序列模型的识别,就是对于一 个平稳的随机时间序列,找出生成它的合适的随 机过程或模型,即判断该时间序列是遵循一纯 AR过程、还是遵循一纯MA过程或ARMA过程。
所使用的工具主要是时间序列的自相关函 数(autocorrelation function,ACF)及偏自相 关函数(partial autocorrelation function, PACF )。
及偏自相 关函数(partial autocorrelation function, PACF )。")
129
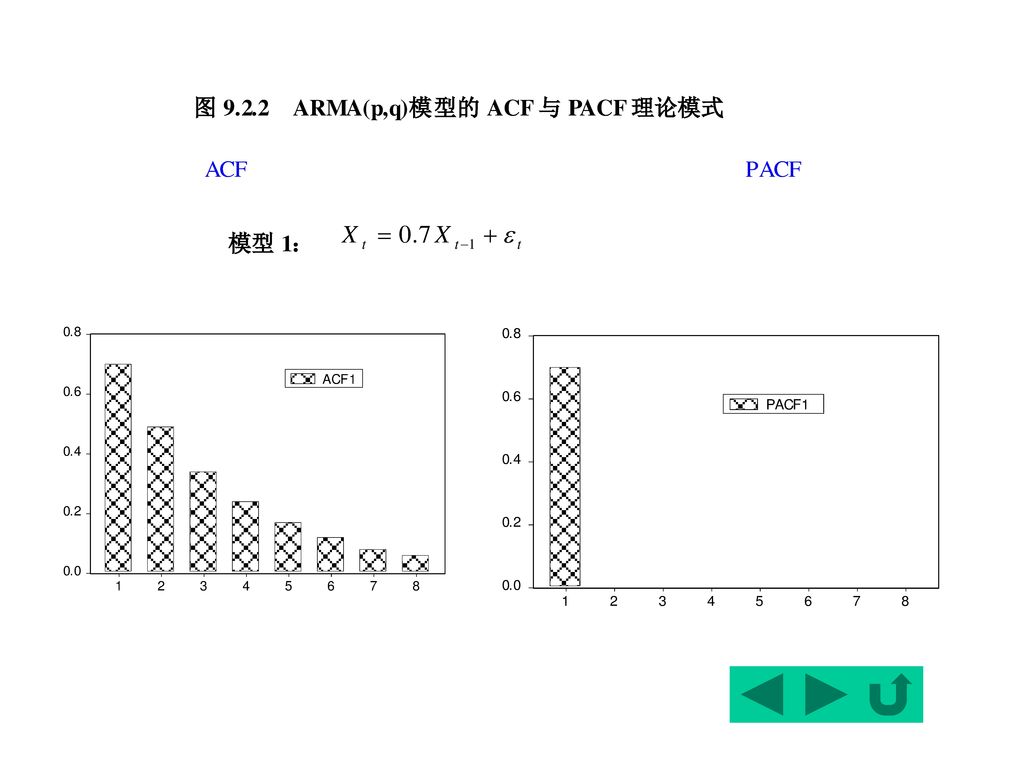
1、AR(p)过程 (1)自相关函数ACF 1阶自回归模型AR(1): Xt=Xt-1+ t 的k阶滞后自协方差为: =1,2,…
过程 (1)自相关函数ACF 1阶自回归模型AR(1): Xt=Xt-1+ t 的k阶滞后自协方差为: =1,2,…")
130
因此,AR(1)模型的自相关函数为: 注意, <0时,呈振荡衰减状。 =1,2,…
由AR(1)的稳定性知||<1,因此,k时,呈指数形衰减,直到零。这种现象称为拖尾或称AR(1)有无穷记忆(infinite memory)。 注意, <0时,呈振荡衰减状。
的稳定性知||<1,因此,k时,呈指数形衰减,直到零。这种现象称为拖尾或称AR(1)有无穷记忆(infinite memory)。 注意, <0时,呈振荡衰减状。")
131
该模型的方差0以及滞后1期与2期的自协方差1, 2分别为:
2阶自回归模型AR(2) Xt=1Xt-1+ 2Xt-2 + t 该模型的方差0以及滞后1期与2期的自协方差1, 2分别为: 类似地,可写出一般的k期滞后自协方差: (K=2,3,…)
 Xt=1Xt-1+ 2Xt-2 + t. 该模型的方差0以及滞后1期与2期的自协方差1, 2分别为: 类似地,可写出一般的k期滞后自协方差: (K=2,3,…)")
132
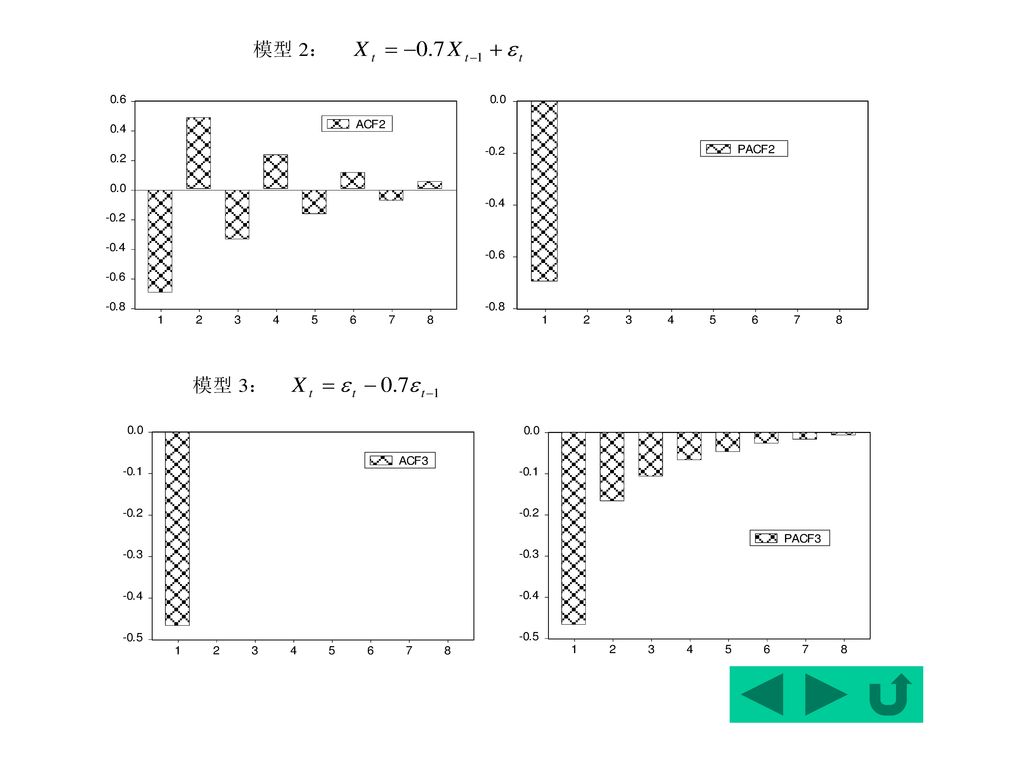
如果AR(2)稳定,则由1+2<1知|k|衰减趋于零,呈拖尾状。
其中 :1=1/(1-2), 0=1 如果AR(2)稳定,则由1+2<1知|k|衰减趋于零,呈拖尾状。 至于衰减的形式,要看AR(2)特征根的实虚性,若为实根,则呈单调或振荡型衰减,若为虚根,则呈正弦波型衰减。
, 0=1. 如果AR(2)稳定,则由1+2<1知|k|衰减趋于零,呈拖尾状。 至于衰减的形式,要看AR(2)特征根的实虚性,若为实根,则呈单调或振荡型衰减,若为虚根,则呈正弦波型衰减。")
133
一般地,p阶自回归模型AR(p): Xt=1Xt-1+ 2Xt-2 +… pXt-p + t k期滞后协方差为:
从而有自相关函数 :

134
如果AR(p)是稳定的,则|k|递减且趋于零。
可见,无论k有多大, k的计算均与其1到p阶滞后的自相关函数有关,因此呈拖尾状。 如果AR(p)是稳定的,则|k|递减且趋于零。 事实上,自相关函数: 是一p阶差分方程,其通解为:
是稳定的,则|k|递减且趋于零。 事实上,自相关函数: 是一p阶差分方程,其通解为:")
135
当1/zi均为实数根时,k呈几何型衰减(单调或振荡);
其中:1/zi是AR(p)特征方程(z)=0的特征根,由AR(p)平稳的条件知,|zi|<1; 因此, 当1/zi均为实数根时,k呈几何型衰减(单调或振荡); 当存在虚数根时,则一对共扼复根构成通解中的一个阻尼正弦波项, k呈正弦波衰减。
特征方程(z)=0的特征根,由AR(p)平稳的条件知,|zi|<1; 因此, 当1/zi均为实数根时,k呈几何型衰减(单调或振荡); 当存在虚数根时,则一对共扼复根构成通解中的一个阻尼正弦波项, k呈正弦波衰减。")
136
例如,在AR(1)随机过程中,Xt与Xt-2间有相关性可能主要是由于它们各自与Xt-1间的相关性带来的:
(2)偏自相关函数 自相关函数ACF(k)给出了Xt与Xt-1的总体相关性,但总体相关性可能掩盖了变量间完全不同的隐含关系。 例如,在AR(1)随机过程中,Xt与Xt-2间有相关性可能主要是由于它们各自与Xt-1间的相关性带来的:
偏自相关函数. 自相关函数ACF(k)给出了Xt与Xt-1的总体相关性,但总体相关性可能掩盖了变量间完全不同的隐含关系。 例如,在AR(1)随机过程中,Xt与Xt-2间有相关性可能主要是由于它们各自与Xt-1间的相关性带来的:")
137
即自相关函数中包含了这种所有的“间接”相关。
与之相反,Xt与Xt-k间的偏自相关函数(partial autocorrelation,简记为PACF)则是消除了中间变量Xt-1,…,Xt-k+1 带来的间接相关后的直接相关性,它是在已知序列值Xt-1,…,Xt-k+1的条件下,Xt与Xt-k间关系的度量。
则是消除了中间变量Xt-1,…,Xt-k+1 带来的间接相关后的直接相关性,它是在已知序列值Xt-1,…,Xt-k+1的条件下,Xt与Xt-k间关系的度量。")
138
在AR(1)中, 从Xt中去掉Xt-1的影响,则只剩下随机扰动项t,显然它与Xt-2无关,因此我们说Xt与Xt-2的偏自相关系数为零,记为:
中, 从Xt中去掉Xt-1的影响,则只剩下随机扰动项t,显然它与Xt-2无关,因此我们说Xt与Xt-2的偏自相关系数为零,记为:")
139
同样地,在AR(p)过程中,对所有的k>p,Xt与Xt-k间的偏自相关系数为零。
AR(p)的一个主要特征是:k>p时,k*=Corr(Xt,Xt-k)=0 即k*在p以后是截尾的。 一随机时间序列的识别原则: 若Xt的偏自相关函数在p以后截尾,即k>p时,k*=0,而它的自相关函数k是拖尾的,则此序列是自回归AR(p)序列。
的一个主要特征是:k>p时,k*=Corr(Xt,Xt-k)=0. 即k*在p以后是截尾的。 一随机时间序列的识别原则: 若Xt的偏自相关函数在p以后截尾,即k>p时,k*=0,而它的自相关函数k是拖尾的,则此序列是自回归AR(p)序列。")
140
需指出的是, rk*~N(0,1/n) 式中n表示样本容量。
在实际识别时,由于样本偏自相关函数rk*是总体偏自相关函数k*的一个估计,由于样本的随机性,当k>p时,rk*不会全为0,而是在0的上下波动。但可以证明,当k>p时,rk*服从如下渐近正态分布: rk*~N(0,1/n) 式中n表示样本容量。
 式中n表示样本容量。")
141
因此,如果计算的rk*满足: 我们就有95.5%的把握判断原时间序列在p之后截尾。

142
2、MA(q)过程 对MA(1)过程: 可容易地写出它的自协方差系数: 于是,MA(1)过程的自相关函数为:
过程 对MA(1)过程: 可容易地写出它的自协方差系数: 于是,MA(1)过程的自相关函数为:")
143
可见,当k>1时,k>0,即Xt与Xt-k不相关,MA(1)自相关函数是截尾的。
MA(1)过程可以等价地写成t关于无穷序列Xt,Xt-1,…的线性组合的形式: 或: (*) (*)是一个AR()过程,它的偏自相关函数非截尾但却趋于零,因此MA(1)的偏自相关函数是非截尾但却趋于零的。
过程可以等价地写成t关于无穷序列Xt,Xt-1,…的线性组合的形式: 或: (*) (*)是一个AR()过程,它的偏自相关函数非截尾但却趋于零,因此MA(1)的偏自相关函数是非截尾但却趋于零的。")
144
(*)式只有当||<1时才有意义,否则意味着距Xt越远的X值,对Xt的影响越大,显然不符合常理。
注意: (*)式只有当||<1时才有意义,否则意味着距Xt越远的X值,对Xt的影响越大,显然不符合常理。 因此,我们把||<1称为MA(1)的可逆性条件(invertibility condition)或可逆域。
式只有当||<1时才有意义,否则意味着距Xt越远的X值,对Xt的影响越大,显然不符合常理。 因此,我们把||<1称为MA(1)的可逆性条件(invertibility condition)或可逆域。")
145
一般地,q阶移动平均过程MA(q) 其自协方差系数为: 相应的自相关函数为:
 其自协方差系数为: 相应的自相关函数为:")
146
于是:可以根据自相关系数是否从某一点开始一直为0来判断MA(q)模型的阶。
可见,当k>q时, Xt与Xt-k不相关,即存在截尾现象,因此,当k>q时, k=0是MA(q)的一个特征。 于是:可以根据自相关系数是否从某一点开始一直为0来判断MA(q)模型的阶。 与MA(1)相仿,可以验证MA(q)过程的偏自相关函数是非截尾但趋于零的。
的一个特征。 于是:可以根据自相关系数是否从某一点开始一直为0来判断MA(q)模型的阶。 与MA(1)相仿,可以验证MA(q)过程的偏自相关函数是非截尾但趋于零的。")
147
MA(q)模型的识别规则:若随机序列的自相关函数截尾,即自q以后,k=0( k>q);而它的偏自相关函数是拖尾的,则此序列是滑动平均MA(q)序列。
同样需要注意的是:在实际识别时,由于样本自相关函数rk是总体自相关函数k的一个估计,由于样本的随机性,当k>q时,rk不会全为0,而是在0的上下波动。但可以证明,当k>q时,rk服从如下渐近正态分布:

148
rk~N(0,1/n) 式中n表示样本容量。 因此,如果计算的rk满足: 我们就有95.5%的把握判断原时间序列在q之后截尾。
 式中n表示样本容量。 因此,如果计算的rk满足: 我们就有95.5%的把握判断原时间序列在q之后截尾。")
149
3、ARMA(p, q)过程 当p=0时,它具有截尾性质; 当q=0时,它具有拖尾性质; 当p、q都不为0时,它具有拖尾性质
ARMA(p,q)的自相关函数,可以看作MA(q)的自相关函数和AR(p)的自相关函数的混合物。 当p=0时,它具有截尾性质; 当q=0时,它具有拖尾性质; 当p、q都不为0时,它具有拖尾性质
的自相关函数,可以看作MA(q)的自相关函数和AR(p)的自相关函数的混合物。 当p=0时,它具有截尾性质; 当q=0时,它具有拖尾性质; 当p、q都不为0时,它具有拖尾性质.")
150
从识别上看,通常: ARMA(p,q)过程的偏自相关函数(PACF)可能在p阶滞后前有几项明显的尖柱(spikes),但从p阶滞后项开始逐渐趋向于零; 而它的自相关函数(ACF)则是在q阶滞后前有几项明显的尖柱,从q阶滞后项开始逐渐趋向于零。
过程的偏自相关函数(PACF)可能在p阶滞后前有几项明显的尖柱(spikes),但从p阶滞后项开始逐渐趋向于零; 而它的自相关函数(ACF)则是在q阶滞后前有几项明显的尖柱,从q阶滞后项开始逐渐趋向于零。")
155
四、随机时间序列模型的估计

156
AR(p)、MA(q)、ARMA(p,q)模型的估计方 法较多,大体上分为3类: (1)最小二乘估计; (2)矩估计;
结构 阶数 模型 识别 确定 估计 参数 AR(p)、MA(q)、ARMA(p,q)模型的估计方 法较多,大体上分为3类: (1)最小二乘估计; (2)矩估计; (3)利用自相关函数的直接估计。 下面有选择地加以介绍。
、MA(q)、ARMA(p,q)模型的估计方 法较多,大体上分为3类: (1)最小二乘估计; (2)矩估计; (3)利用自相关函数的直接估计。 下面有选择地加以介绍。")
157
⒈ AR(p)模型的Yule Walker方程估计
利用k=-k,得到如下方程组:

158
利用实际时间序列提供的信息,首先求得自相关函数的估计值:
此方程组被称为Yule Walker方程组。该方程组建立了AR(p)模型的模型参数1,2,,p与自相关函数1,2,,p的关系, 利用实际时间序列提供的信息,首先求得自相关函数的估计值: 然后利用Yule Walker方程组,求解模型参数的估计值:
模型的模型参数1,2,,p与自相关函数1,2,,p的关系, 利用实际时间序列提供的信息,首先求得自相关函数的估计值: 然后利用Yule Walker方程组,求解模型参数的估计值:")
159
由于: 于是, 从而可得2的估计值 在具体计算时, 可用样本自相关函数rk替代。

160
⒉ MA(q)模型的矩估计 将MA(q)模型的自协方差函数中的各个量用估计量代替,得到: (*)
模型的矩估计 将MA(q)模型的自协方差函数中的各个量用估计量代替,得到: (*)")
161
的非线性方程组,可以用直接法或迭代法求解。
首先求得自协方差函数的估计值,(*)是一个包含(q+1)个待估参数 的非线性方程组,可以用直接法或迭代法求解。 常用的迭代方法有线性迭代法和Newton-Raphsan迭代法。
是一个包含(q+1)个待估参数. 的非线性方程组,可以用直接法或迭代法求解。 常用的迭代方法有线性迭代法和Newton-Raphsan迭代法。")
162
(1)MA(1)模型的直接算法 对于MA(1)模型,(*)式相应地写成: 于是: 有: 或:
MA(1)模型的直接算法 对于MA(1)模型,(*)式相应地写成: 于是: 有: 或:")
163
于是有解: 由于参数估计有两组解,可根据可逆性条件|1|<1来判断选取一组。

164
(2)MA(q)模型的迭代算法 对于q>1的MA(q)模型,一般用迭代算法估计参数: 由(*)式得 (**)
MA(q)模型的迭代算法 对于q>1的MA(q)模型,一般用迭代算法估计参数: 由(*)式得 (**)")
165
第一步,给出 的一组初值,比如, 代入(**)式,计算出第一次迭代值 ,
式,计算出第一次迭代值 ,")
166
第二步,将第一次迭代值代入(**)式,计算出第二次迭代值
按此反复迭代下去,直到第m步的迭代值与第m-1步的迭代值相差不大时(满足一定的精度),便停止迭代,并用第m步的迭代结果作为(**)的近似解。
,便停止迭代,并用第m步的迭代结果作为(**)的近似解。")
167
⒊ ARMA(p,q)模型的矩估计 第一步,估计1,2,,p
在ARMA(p,q)中共有(p+q+1)个待估参数1,2,,p与1,2,,q以及2,其估计量计算步骤及公式如下: 第一步,估计1,2,,p
中共有(p+q+1)个待估参数1,2,,p与1,2,,q以及2,其估计量计算步骤及公式如下: 第一步,估计1,2,,p.")
168
是总体自相关函数的估计值,可用样本自相关函数rk代替。
第二步,改写模型,求1,2,,q以及2的估计值 将模型:

169
改写为: (*) 令, 于是(*)可以写成: 构成一个MA模型。按照估计MA模型参数的方法,可以得到1,2,,q以及2的估计值。
 令, 于是(*)可以写成: 构成一个MA模型。按照估计MA模型参数的方法,可以得到1,2,,q以及2的估计值。")
170
⒋ AR(p)的最小二乘估计 假设模型AR(p)的参数估计值已经得到,即有, 残差的平方和为: (*)
的最小二乘估计 假设模型AR(p)的参数估计值已经得到,即有, 残差的平方和为: (*)")
171
根据最小二乘原理,所要求的参数估计值是下列方程组的解:
即 , j=1,2,…,p (**) 解该方程组,就可得到待估参数的估计值。
 解该方程组,就可得到待估参数的估计值。")
172
由自协方差函数的定义,并用自协方差函数的估计值 。
为了与AR(p)模型的Yule Walker方程估计进行比较,将(**)改写成: j=1,2,…,p 由自协方差函数的定义,并用自协方差函数的估计值 。
模型的Yule Walker方程估计进行比较,将(**)改写成: j=1,2,…,p. 由自协方差函数的定义,并用自协方差函数的估计值 。")
173
代入,上式表示的方程组即为: j=1,2,…,p 或 , j=1,2,…,p

174
解该方程组,得到: 即为参数的最小二乘估计。 Yule Walker方程组的解:

175
比较发现,当n足够大时,二者是相似的。 2的估计值为:
需要说明的是,在上述模型的平稳性、识别与估计的讨论中,ARMA(p,q)模型中均未包含常数项。 如果包含常数项,该常数项并不影响模型的原有性质,因为通过适当的变形,可将包含常数项的模型转换为不含常数项的模型。
模型中均未包含常数项。 如果包含常数项,该常数项并不影响模型的原有性质,因为通过适当的变形,可将包含常数项的模型转换为不含常数项的模型。")
176
方程两边同减/(1-1--p),则可得到:
下面以一般的ARMA(p,q)模型为例说明。 对含有常数项的模型 : 方程两边同减/(1-1--p),则可得到: 其中,
模型为例说明。 对含有常数项的模型 : 方程两边同减/(1-1--p),则可得到: 其中,")
177
五、模型的检验

178
如果通过所估计的模型计算的样本残差不代表一白噪声,则说明模型的识别与估计有误,需重新识别与估计。
1、残差项的白噪声检验 由于ARMA(p,q)模型的识别与估计是在假设随机扰动项是一白噪声的基础上进行的,因此,如果估计的模型确认正确的话,残差应代表一白噪声序列。 如果通过所估计的模型计算的样本残差不代表一白噪声,则说明模型的识别与估计有误,需重新识别与估计。 在实际检验时,主要检验残差序列是否存在自相关。
模型的识别与估计是在假设随机扰动项是一白噪声的基础上进行的,因此,如果估计的模型确认正确的话,残差应代表一白噪声序列。 如果通过所估计的模型计算的样本残差不代表一白噪声,则说明模型的识别与估计有误,需重新识别与估计。 在实际检验时,主要检验残差序列是否存在自相关。")
179
若大于相应临界值,则应拒绝所估计的模型,需重新识别与估计。
可用QLB的统计量进行2检验:在给定显著性水平下,可计算不同滞后期的QLB值,通过与2分布表中的相应临界值比较,来检验是否拒绝残差序列为白噪声的假设。 若大于相应临界值,则应拒绝所估计的模型,需重新识别与估计。

180
2、AIC与SBC模型选择标准 另外一个遇到的问题是,在实际识别ARMA(p,q)模型时,需多次反复偿试,有可能存在不止一组(p,q)值都能通过识别检验。 显然,增加p与q的阶数,可增加拟合优度,但却同时降低了自由度。 因此,对可能的适当的模型,存在着模型的“简洁性”与模型的拟合优度的权衡选择问题。

181
常用的模型选择的判别标准有:赤池信息法(Akaike information criterion,简记为AIC)与施瓦兹贝叶斯法(Schwartz Bayesian criterion,简记为SBC): 其中,n为待估参数个数(p+q+可能存在的 常数项),T为可使用的观测值,RSS为残差平 方和(Residual sum of squares)。
,T为可使用的观测值,RSS为残差平 方和(Residual sum of squares)。")
182
在选择可能的模型时,AIC与SBC越小越好
显然,如果添加的滞后项没有解释能力,则对RSS值的减小没有多大帮助,却增加待估参数的个数,因此使得AIC或SBC的值增加。 需注意的是:在不同模型间进行比较时,必须选取相同的时间段。

183
可以对经过一阶差分后的GDP建立适当的 ARMA(p,q)模型。
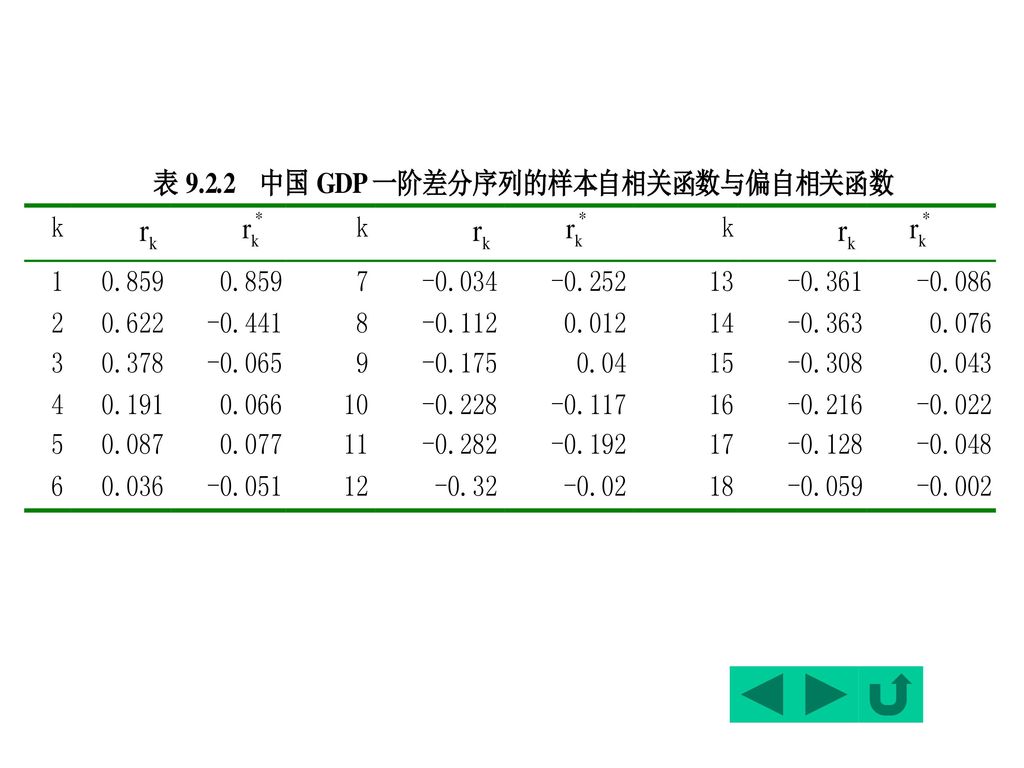
由第一节知:中国支出法GDP是非平稳的, 但它的一阶差分是平稳的,即支出法GDP是I(1) 时间序列。 可以对经过一阶差分后的GDP建立适当的 ARMA(p,q)模型。 记GDP经一阶差分后的新序列为GDPD1, 该新序列的样本自相关函数图与偏自相关函数 图如下:
 时间序列。 可以对经过一阶差分后的GDP建立适当的 ARMA(p,q)模型。 记GDP经一阶差分后的新序列为GDPD1, 该新序列的样本自相关函数图与偏自相关函数 图如下:")
184
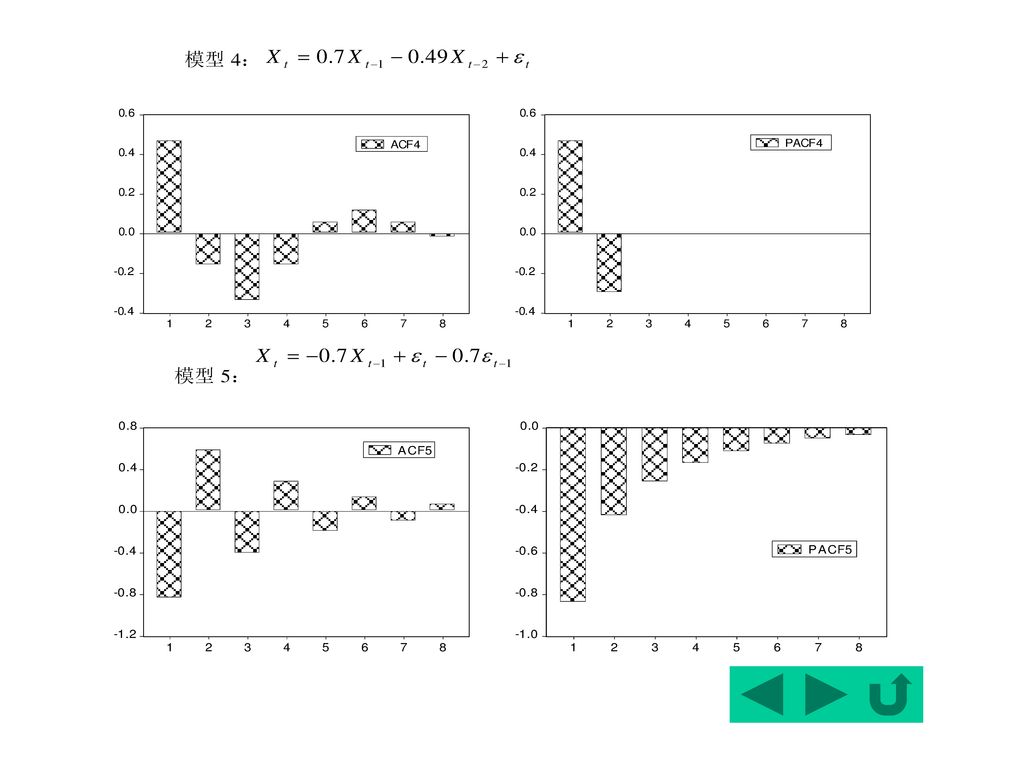
图形:样本自相关函数图形呈正弦线型衰 减波,而偏自相关函数图形则在滞后两期后迅速 趋于0。因此可初步判断该序列满足2阶自回归过 程AR(2)。
。")
185
可认为:偏自相关函数是截尾的。再次验证了一阶差分后的GDP满足AR(2)随机过程。
自相关函数与偏自相关函数的函数值: 相关函数具有明显的拖尾性; 偏自相关函数值在k>2以后, 可认为:偏自相关函数是截尾的。再次验证了一阶差分后的GDP满足AR(2)随机过程。
随机过程。")
187
设序列GDPD1的模型形式为: 有如下Yule Walker 方程: 解为:

188
有时,在用回归法时,也可加入常数项。 用OLS法回归的结果为: 本例中加入常数项的回归为: (7.91) (-3.60)
(7.91) (-3.60) r2= R2= DW=1.15 有时,在用回归法时,也可加入常数项。 本例中加入常数项的回归为: (1.99) (7.74) (-3.58) r2 = R2 = DW.=1.22
 (-3.60) r2= R2= DW=1.15. 有时,在用回归法时,也可加入常数项。 本例中加入常数项的回归为: (1.99) (7.74) (-3.58) r2 = R2 = DW.=1.22.")
189
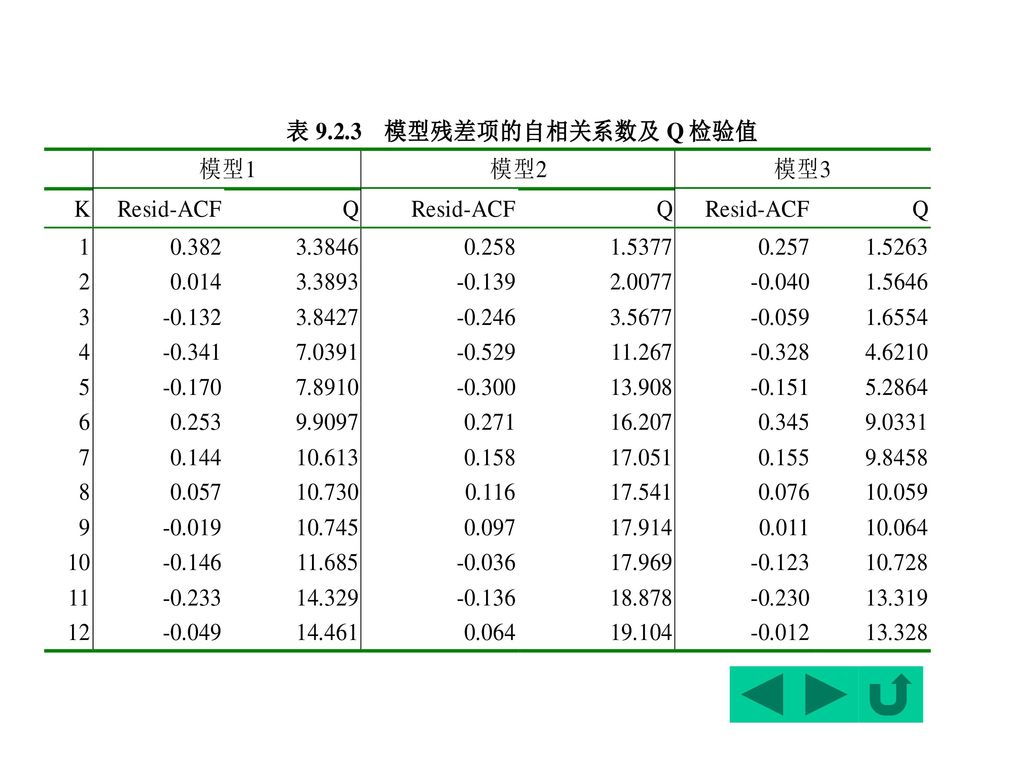
模型1与3可作为描述中国支出法GDP一阶差分序列的随机生成过程。
模型检验 下表列出三模型的残差项的自相关系数及QLB检验值。 模型1与模型3的残差项接近于一白噪声,但模型2存在4阶滞后相关问题,Q统计量的检验也得出模型2拒绝所有自相关系数为零的假设。因此: 模型1与3可作为描述中国支出法GDP一阶差分序列的随机生成过程。

191
用建立的AR(2)模型对中国支出法GDP进行外推预测。
模型1可作如下展开: 于是,当已知t-1、t-2、t-3期的GDP时,就可对第t期的GDP作出外推预测。

192
对2001年中国支出法GDP的预测结果(亿元) 模型3的预测式与此相类似,只不过多出一项常数项。 预测值 实际值 误差
预测值 实际值 误差 模型 % 模型 %

193
但它们都是I(2)时间序列,因此可以建立 它们的ARIMA(p,d,q)模型。
例9.2.4 中国人均居民消费的ARMA(p,q)模型 由于中国人均居民消费(CPC)与人均国内 生产总值(GDPPC)这两时间序列是非平稳的, 因此不宜直接建立它们的因果关系回归方程。 但它们都是I(2)时间序列,因此可以建立 它们的ARIMA(p,d,q)模型。
模型. 由于中国人均居民消费(CPC)与人均国内 生产总值(GDPPC)这两时间序列是非平稳的, 因此不宜直接建立它们的因果关系回归方程。 但它们都是I(2)时间序列,因此可以建立 它们的ARIMA(p,d,q)模型。")
194
下面只建立中国人均居民消费(CPC)的随机时间序列模型。
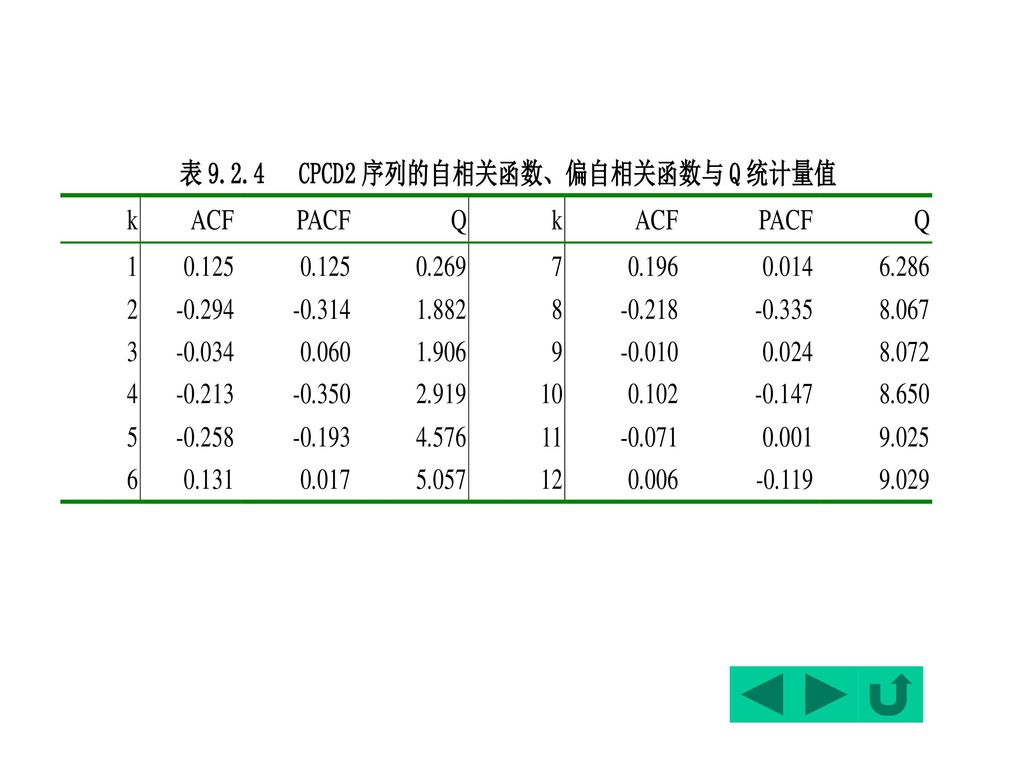
中国人均居民消费(CPC)经过二次差分后的新序列记为CPCD2,其自相关函数、偏自相关函数及Q统计量的值列于下表:
经过二次差分后的新序列记为CPCD2,其自相关函数、偏自相关函数及Q统计量的值列于下表:")
196
因此,也可考虑采用下面的MA模型: 在5%的显著性水平下,通过Q统计量容易验证该序列本身就接近于一白噪声,因此可考虑采用零阶MA(0)模型:
由于k=2时,|r2|=|-0.29|> 因此,也可考虑采用下面的MA模型:

197
当然,还可观察到自相关函数在滞后4、5、8时有大于0
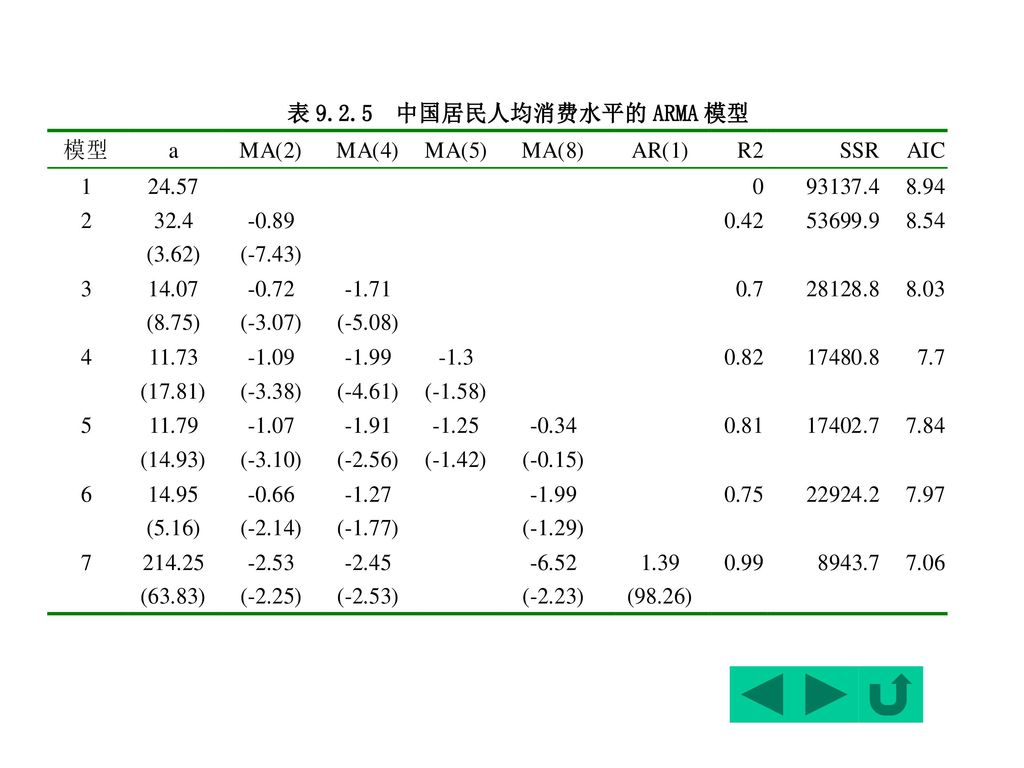
当然,还可观察到自相关函数在滞后4、5、8时有大于0.2的函数值,因此,可考虑在模型中增加MA(4)、MA(5)、MA(8)。不同模型的回归结果列于表9.2.5。 可以看出:在纯MA模型中,模型4具有较好的性质,但由于MA(5)的t检验偏小,因此可选取模型3。
、MA(5)、MA(8)。不同模型的回归结果列于表9.2.5。 可以看出:在纯MA模型中,模型4具有较好的性质,但由于MA(5)的t检验偏小,因此可选取模型3。")
199
最后,给出通过模型3的外推预测。 模型3的展开式为: 即 ,

200
为模型3中滞后2期与滞后4期的相应残差项的估计值。
由于t表示预测期的随机扰动项,它未知,可假设为0,于是t期的预测式为: 为模型3中滞后2期与滞后4期的相应残差项的估计值。

201
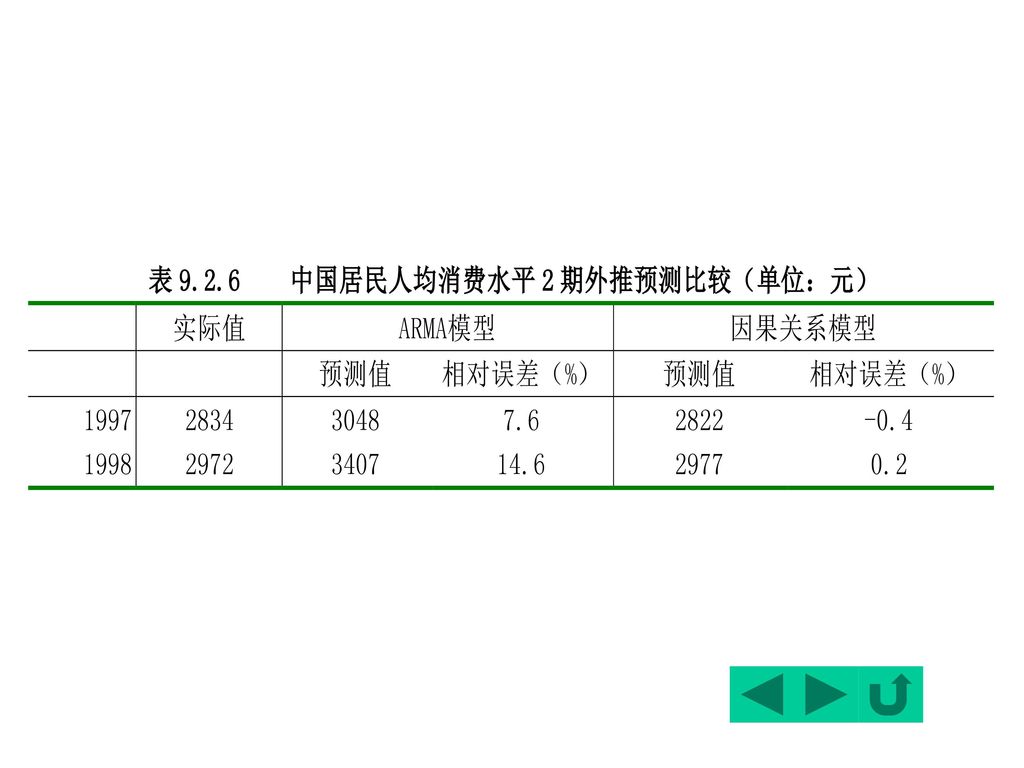
表9.2.6列出了采用模型3对中国居民人均居民消费水平的2期外推预测。
为了对照,表中也同时列出了采用§2.10的模型的预测结果。

203
§9.3 协整与误差修正模型 一、长期均衡关系与协整 二、协整检验 三、误差修正模型

204
一、长期均衡关系与协整

205
1. 问题的提出 经典回归模型(classical regression model)是建立在稳定数据变量基础上的,对于非稳定变量,不能使用经典回归模型,否则会出现虚假回归等诸多问题。 由于许多经济变量是非稳定的,这就给经典的回归分析方法带来了很大限制。
是建立在稳定数据变量基础上的,对于非稳定变量,不能使用经典回归模型,否则会出现虚假回归等诸多问题。 由于许多经济变量是非稳定的,这就给经典的回归分析方法带来了很大限制。 .")
206
但是,如果变量之间有着长期的稳定关系,即它们之间是协整的(cointegration),则是可以使用经典回归模型方法建立回归模型的。
例如,中国居民人均消费水平与人均GDP变量的例子中, 因果关系回归模型要比ARMA模型有更好的预测功能,其原因在于,从经济理论上说,人均GDP决定着居民人均消费水平,而且它们之间有着长期的稳定关系,即它们之间是协整的。

207
2. 长期均衡 经济理论指出,某些经济变量间确实存在着长期均衡关系,这种均衡关系意味着经济系统不存在破坏均衡的内在机制,如果变量在某时期受到干扰后偏离其长期均衡点,则均衡机制将会在下一期进行调整以使其重新回到均衡状态。 假设X与Y间的长期“均衡关系”由式描述:

208
式中:t是随机扰动项。 该均衡关系意味着:给定X的一个值,Y相应的均衡值也随之确定为0+1X。 在t-1期末,存在下述三种情形之一:

209
(2)Y小于它的均衡值:Yt-1< 0+1Xt ; (3)Y大于它的均衡值:Yt-1> 0+1Xt ;
在时期t,假设X有一个变化量Xt,如果变量X与Y在时期t与t-1末期仍满足它们间的长期均衡关系,则Y的相应变化量由式给出: 式中,vt=t-t-1。

210
实际情况往往并非如此 如果t-1期末,发生了上述第二种情况,即Y的值小于其均衡值,则Y的变化往往会比第一种情形下Y的变化Yt大一些; 反之,如果Y的值大于其均衡值,则Y的变化往往会小于第一种情形下的Yt 。

211
可见,如果Yt=0+1Xt+t正确地提示了X与Y间的长期稳定的“均衡关系”,则意味着Y对其均衡点的偏离从本质上说是“临时性”的。
显然,如果t有随机性趋势(上升或下降),则会导致Y对其均衡点的任何偏离都会被长期累积下来而不能被消除。
,则会导致Y对其均衡点的任何偏离都会被长期累积下来而不能被消除。")
212
式Yt=0+1Xt+t中的随机扰动项也被称为非均衡误差(disequilibrium error),它是变量X与Y的一个线性组合:
(*) 因此,如果Yt=0+1Xt+t式所示的X与Y间的长期均衡关系正确的话,(*)式表述的非均衡误差应是一平稳时间序列,并且具有零期望值,即是具有0均值的I(0)序列。
 因此,如果Yt=0+1Xt+t式所示的X与Y间的长期均衡关系正确的话,(*)式表述的非均衡误差应是一平稳时间序列,并且具有零期望值,即是具有0均值的I(0)序列。")
213
从这里已看到,非稳定的时间序列,它们的线性组合也可能成为平稳的。
假设Yt=0+1Xt+t式中的X与Y是I(1)序列,如果该式所表述的它们间的长期均衡关系成立的话,则意味着由非均衡误差(*)式给出的线性组合是I(0)序列。这时我们称变量X与Y是协整的(cointegrated)。
序列,如果该式所表述的它们间的长期均衡关系成立的话,则意味着由非均衡误差(*)式给出的线性组合是I(0)序列。这时我们称变量X与Y是协整的(cointegrated)。")
214
3.协整 如果序列{X1t,X2t,…,Xkt}都是d阶单整,存在向量: =(1,2,…,k),使得: Zt= XT ~ I(d-b) 其中,b>0,X=(X1t,X2t,…,Xkt)T,则认为序列{X1t,X2t,…,Xkt}是(d,b)阶协整,记为Xt~CI(d,b),为协整向量(cointegrated vector)。
T,则认为序列{X1t,X2t,…,Xkt}是(d,b)阶协整,记为Xt~CI(d,b),为协整向量(cointegrated vector)。")
215
由此可见:如果两个变量都是单整变量,只有当它们的单整阶数相同时,才可能协整;如果它们的单整阶数不相同,就不可能协整。
在中国居民人均消费与人均GDP的例中,该两序列都是2阶单整序列,而且可以证明它们有一个线性组合构成的新序列为0阶单整序列,于是认为该两序列是(2,2)阶协整。 由此可见:如果两个变量都是单整变量,只有当它们的单整阶数相同时,才可能协整;如果它们的单整阶数不相同,就不可能协整。
阶协整。 由此可见:如果两个变量都是单整变量,只有当它们的单整阶数相同时,才可能协整;如果它们的单整阶数不相同,就不可能协整。")
216
三个以上的变量,如果具有不同的单整阶数,有可能经过线性组合构成低阶单整变量。
例如,如果存在: 并且, 那么认为:

217
从协整的定义可以看出: (d,d)阶协整是一类非常重要的协整关系,它的经济意义在于:两个变量,虽然它们具有各自的长期波动规律,但是如果它们是(d,d)阶协整的,则它们之间存在着一个长期稳定的比例关系。 例如:前面提到的中国CPC和GDPPC,它们各自都是2阶单整,并且将会看到,它们是(2,2)阶协整,说明它们之间存在着一个长期稳定的比例关系,从计量经济学模型的意义上讲,建立如下居民人均消费函数模型:
阶协整,说明它们之间存在着一个长期稳定的比例关系,从计量经济学模型的意义上讲,建立如下居民人均消费函数模型:")
218
变量选择是合理的,随机误差项一定是“白噪声”(即均值为0,方差不变的稳定随机序列),模型参数有合理的经济解释。
这也解释了尽管这两时间序列是非稳定的,但却可以用经典的回归分析方法建立回归模型的原因。

219
从这里,我们已经初步认识到:检验变量之间的协整关系,在建立计量经济学模型中是非常重要的。
而且,从变量之间是否具有协整关系出发选择模型的变量,其数据基础是牢固的,其统计性质是优良的。

220
二、协整检验

221
第一步,用OLS方法估计方程: Yt=0+1Xt+t
1.两变量的Engle-Granger检验 为了检验两变量Yt,Xt是否为协整,Engle和Granger于1987年提出两步检验法,也称为EG检验。 第一步,用OLS方法估计方程: Yt=0+1Xt+t 并计算非均衡误差,得到:

222
的单整性的检验方法仍然是DF检验或者ADF检验。
称为协整回归(cointegrating)或静态回归(static regression)。 的单整性的检验方法仍然是DF检验或者ADF检验。 由于协整回归中已含有截距项,则检验模型中无需再用截距项。如使用模型1
或静态回归(static regression)。 的单整性的检验方法仍然是DF检验或者ADF检验。 由于协整回归中已含有截距项,则检验模型中无需再用截距项。如使用模型1.")
223
进行检验时,拒绝零假设H0:=0,意味着误差项et是平稳序列,从而说明X与Y间是协整的。
需要注意是,这里的DF或ADF检验是针对协整回归计算出的误差项,而非真正的非均衡误差t进行的。

224
于是对et平稳性检验的DF与ADF临界值应该比正常的DF与ADF临界值还要小。
而OLS法采用了残差最小平方和原理,因此估计量是向下偏倚的,这样将导致拒绝零假设的机会比实际情形大。 于是对et平稳性检验的DF与ADF临界值应该比正常的DF与ADF临界值还要小。

225
MacKinnon(1991)通过模拟试验给出了协整检验的临界值,表9.3.1是双变量情形下不同样本容量的临界值。
通过模拟试验给出了协整检验的临界值,表9.3.1是双变量情形下不同样本容量的临界值。")
226
例9.3.1 检验中国居民人均消费水平CPC与人均国内生产总值GDPPC的协整关系。
在前文已知CPC与GDPPC都是I(2)序列,而§2.10中已给出了它们的回归式: R2=0.9981 通过对该式计算的残差序列作ADF检验,得适当检验模型
序列,而§2.10中已给出了它们的回归式: R2= 通过对该式计算的残差序列作ADF检验,得适当检验模型.")
227
(-4.47) (3.93) (3.05) LM(1)= LM(2)=0.00 t=-4.47<-3.75=ADF0.05,拒绝存在单位根的假设,残差项是稳定的,因此中国居民人均消费水平与人均GDP是(2,2)阶协整的,说明了该两变量间存在长期稳定的“均衡”关系。
阶协整的,说明了该两变量间存在长期稳定的 均衡 关系。")
228
2.多变量协整关系的检验—扩展的E-G检验 假设有4个I(1)变量Z、X、Y、W,它们有如下的长期均衡关系:
多变量协整关系的检验要比双变量复杂一些,主要在于协整变量间可能存在多种稳定的线性组合。 假设有4个I(1)变量Z、X、Y、W,它们有如下的长期均衡关系: (*) 其中,非均衡误差项t应是I(0)序列: (**)
变量Z、X、Y、W,它们有如下的长期均衡关系: (*) 其中,非均衡误差项t应是I(0)序列: (**)")
229
一定是I(0)序列。 然而,如果Z与W,X与Y间分别存在长期均衡关系:
则非均衡误差项v1t、v2t一定是稳定序列I(0)。于是它们的任意线性组合也是稳定的。例如: (***) 一定是I(0)序列。
。于是它们的任意线性组合也是稳定的。例如: (***) 一定是I(0)序列。")
230
由于vt象(**)式中的t一样,也是Z、X、Y、W四个变量的线性组合,由此(***)式也成为该四变量的另一稳定线性组合。
(1, -0,-1,-2,-3)是对应于(**)式的协整向量,(1,-0-0,-1,1,-1)是对应于(***)式的协整向量。
是对应于(**)式的协整向量,(1,-0-0,-1,1,-1)是对应于(***)式的协整向量。")
231
在检验是否存在稳定的线性组合时,需通过设置一个变量为被解释变量,其他变量为解释变量,进行OLS估计并检验残差序列是否平稳。
检验程序: 对于多变量的协整检验过程,基本与双变量情形相同,即需检验变量是否具有同阶单整性,以及是否存在稳定的线性组合。 在检验是否存在稳定的线性组合时,需通过设置一个变量为被解释变量,其他变量为解释变量,进行OLS估计并检验残差序列是否平稳。

232
同样地,检验残差项是否平稳的DF与ADF检验临界值要比通常的DF与ADF检验临界值小,而且该临界值还受到所检验的变量个数的影响。
如果不平稳,则需更换被解释变量,进行同样的OLS估计及相应的残差项检验。 当所有的变量都被作为被解释变量检验之后,仍不能得到平稳的残差项序列,则认为这些变量间不存在(d,d)阶协整。 同样地,检验残差项是否平稳的DF与ADF检验临界值要比通常的DF与ADF检验临界值小,而且该临界值还受到所检验的变量个数的影响。
阶协整。 同样地,检验残差项是否平稳的DF与ADF检验临界值要比通常的DF与ADF检验临界值小,而且该临界值还受到所检验的变量个数的影响。")
233
表9.3.2给出了MacKinnon(1991)通过模拟试验得到的不同变量协整检验的临界值。
通过模拟试验得到的不同变量协整检验的临界值。")
234
3、多变量协整关系的检验—JJ检验 Johansen于1988年,以及与Juselius于1990年提出了一种用极大或然法进行检验的方法,通常称为JJ检验。 《高等计量经济学》(清华大学出版社,2000年9月)P E-views中有JJ检验的功能。

235
三、误差修正模型

236
前文已经提到,对于非稳定时间序列,可通过差分的方法将其化为稳定序列,然后才可建立经典的回归分析模型。
1、误差修正模型 前文已经提到,对于非稳定时间序列,可通过差分的方法将其化为稳定序列,然后才可建立经典的回归分析模型。 例如:建立人均消费水平(Y)与人均可支配收入(X)之间的回归模型:
与人均可支配收入(X)之间的回归模型:")
237
式中, vt= t- t-1 然而,这种做法会引起两个问题: 如果Y与X 具有共同的 向上或向下 的变化趋势 X,Y 成为 平稳 序列
差分 建立差分回归模型 式中, vt= t- t-1 然而,这种做法会引起两个问题:

238
(1)如果X与Y间存在着长期稳定的均衡关系:
Yt=0+1Xt+t 且误差项t不存在序列相关,则差分式: Yt=1Xt+t 中的t是一个一阶移动平均时间序列,因而是序列相关的;

239
因为,从长期均衡的观点看,Y在第t期的变化不仅取决于X本身的变化,还取决于X与Y在t-1期末的状态,尤其是X与Y在t-1期的不平衡程度。

240
例如,使用Yt=1Xt+t回归时,很少出现截距项显著为零的情况,即我们常常会得到如下形式的方程:
(*) 在X保持不变时,如果模型存在静态均衡(static equilibrium),Y也会保持它的长期均衡值不变。
 在X保持不变时,如果模型存在静态均衡(static equilibrium),Y也会保持它的长期均衡值不变。")
241
但如果使用(*)式,即使X保持不变,Y也会处于长期上升或下降的过程中(Why?),这意味着X与Y间不存在静态均衡。
这与大多数具有静态均衡的经济理论假说不相符。 可见,简单差分不一定能解决非平稳时间序列所遇到的全部问题,因此,误差修正模型便应运而生。

242
假设两变量X与Y的长期均衡关系为: Yt=0+1Xt+t 通过一个具体的模型来介绍它的结构。
误差修正模型(Error Correction Model,简记为ECM)是一种具有特定形式的计量经济学模型,它的主要形式是由Davidson、 Hendry、Srba和Yeo于1978年提出的,称为DHSY模型。 通过一个具体的模型来介绍它的结构。 假设两变量X与Y的长期均衡关系为: Yt=0+1Xt+t
是一种具有特定形式的计量经济学模型,它的主要形式是由Davidson、 Hendry、Srba和Yeo于1978年提出的,称为DHSY模型。 通过一个具体的模型来介绍它的结构。 假设两变量X与Y的长期均衡关系为: Yt=0+1Xt+t.")
243
由于现实经济中X与Y很少处在均衡点上,因此实际观测到的只是X与Y间的短期的或非均衡的关系,假设具有如下(1,1)阶分布滞后形式:
该模型显示出第t期的Y值,不仅与X的变化有关,而且与t-1期X与Y的状态值有关。

244
由于变量可能是非平稳的,因此不能直接运用OLS法。对上述分布滞后模型适当变形得:
或, (**) 式中,
 式中,")
245
如果将(**)中的参数,与Yt=0+1Xt+t中的相应参数视为相等,则(**)式中括号内的项就是t-1期的非均衡误差项。
(**)式表明:Y的变化决定于X的变化以及前一时期的非均衡程度。同时,(**)式也弥补了简单差分模型Yt=1Xt+t的不足,因为该式含有用X、Y水平值表示的前期非均衡程度。因此,Y的值已对前期的非均衡程度作出了修正。
式表明:Y的变化决定于X的变化以及前一时期的非均衡程度。同时,(**)式也弥补了简单差分模型Yt=1Xt+t的不足,因为该式含有用X、Y水平值表示的前期非均衡程度。因此,Y的值已对前期的非均衡程度作出了修正。")
246
称为一阶误差修正模型(first-order error correction model)。
(**) 称为一阶误差修正模型(first-order error correction model)。 (**)式可以写成: (***) 其中:ecm表示误差修正项。由分布滞后模型:
 称为一阶误差修正模型(first-order error correction model)。 (**)式可以写成: (***) 其中:ecm表示误差修正项。由分布滞后模型:")
247
知,一般情况下||<1 ,由关系式=1-得:0<<1。可以据此分析ecm的修正作用:
(1)若(t-1)时刻Y大于其长期均衡解0+1X,ecm为正,则(-ecm)为负,使得Yt减少; (2)若(t-1)时刻Y小于其长期均衡解0+1X ,ecm为负,则(-ecm)为正,使得Yt增大。 (***)体现了长期非均衡误差对的控制。
若(t-1)时刻Y大于其长期均衡解0+1X,ecm为正,则(-ecm)为负,使得Yt减少; (2)若(t-1)时刻Y小于其长期均衡解0+1X ,ecm为负,则(-ecm)为正,使得Yt增大。 (***)体现了长期非均衡误差对的控制。")
248
其主要原因在于变量对数的差分近似地等于该变量的变化率,而经济变量的变化率常常是稳定序列,因此适合于包含在经典回归方程中。
需要注意的是:在实际分析中,变量常以对数的形式出现。 其主要原因在于变量对数的差分近似地等于该变量的变化率,而经济变量的变化率常常是稳定序列,因此适合于包含在经典回归方程中。

249
中的1可视为Y关于X的长期弹性(long-run elasticity)
于是: (1)长期均衡模型 Yt=0+1Xt+t 中的1可视为Y关于X的长期弹性(long-run elasticity) (2)短期非均衡模型 Yt=0+1Xt+2Xt-1+Yt-1+t 中的1可视为Y关于X的短期弹性(short-run elasticity)。
长期均衡模型. Yt=0+1Xt+t. 中的1可视为Y关于X的长期弹性(long-run elasticity) (2)短期非均衡模型. Yt=0+1Xt+2Xt-1+Yt-1+t. 中的1可视为Y关于X的短期弹性(short-run elasticity)。")
250
Yt=0+1Xt+2Xt-1+Yt-1+t 中引入更多的滞后项。
更复杂的误差修正模型可依照一阶误差修正模型类似地建立。 如具有季度数据的变量,可在短期非均衡模型: Yt=0+1Xt+2Xt-1+Yt-1+t 中引入更多的滞后项。 引入二阶滞后的模型为:

251
经过适当的衡等变形,可得如下二阶误差修正模型:
(*) 引入三阶滞后项的误差修正模型与(*)式相仿,只不过模型中多出差分滞后项Yt-2,Xt-2,。
 引入三阶滞后项的误差修正模型与(*)式相仿,只不过模型中多出差分滞后项Yt-2,Xt-2,。")
252
多变量的误差修正模型也可类似地建立。 如三个变量如果存在如下长期均衡关系: 则其一阶非均衡关系可写成: 于是它的一个误差修正模型为:

253
(1)Granger 表述定理 2、误差修正模型的建立 误差修正模型有许多明显的优点:如:
b)一阶差分项的使用也消除模型可能存在的多重共线性问题;
一阶差分项的使用也消除模型可能存在的多重共线性问题;")
254
c)误差修正项的引入保证了变量水平值的信息没有被忽视;
d)由于误差修正项本身的平稳性,使得该模型可以用经典的回归方法进行估计,尤其是模型中差分项可以使用通常的t检验与F检验来进行选取;等等。 因此,一个重要的问题就是:是否变量间的关系都可以通过误差修正模型来表述?
由于误差修正项本身的平稳性,使得该模型可以用经典的回归方法进行估计,尤其是模型中差分项可以使用通常的t检验与F检验来进行选取;等等。 因此,一个重要的问题就是:是否变量间的关系都可以通过误差修正模型来表述?")
255
式中,t-1是非均衡误差项或者说成是长期均衡偏差项, 是短期调整参数。
Engle 与 Granger 1987年提出了著名的Grange表述定理(Granger representaion theorem): 如果变量X与Y是协整的,则它们间的短期非均衡关系总能由一个误差修正模型表述: 0<<1 (*) 式中,t-1是非均衡误差项或者说成是长期均衡偏差项, 是短期调整参数。
: 如果变量X与Y是协整的,则它们间的短期非均衡关系总能由一个误差修正模型表述: 0<<1. (*) 式中,t-1是非均衡误差项或者说成是长期均衡偏差项, 是短期调整参数。")
256
的左边Yt ~I(0) ,右边的Xt ~I(0) ,因此,只有Y与X协整,才能保证右边也是I(0)。
对于(1,1)阶自回归分布滞后模型: Yt=0+1Xt+2Xt-1+Yt-1+t 如果 Yt~I(1), Xt~I(1) ; 那么, 的左边Yt ~I(0) ,右边的Xt ~I(0) ,因此,只有Y与X协整,才能保证右边也是I(0)。
阶自回归分布滞后模型: Yt=0+1Xt+2Xt-1+Yt-1+t. 如果 Yt~I(1), Xt~I(1) ; 那么, 的左边Yt ~I(0) ,右边的Xt ~I(0) ,因此,只有Y与X协整,才能保证右边也是I(0)。")
257
然后建立短期模型,将误差修正项看作一个解释变量,连同其他反映短期波动的解释变量一起,建立短期模型,即误差修正模型。
因此,建立误差修正模型,需要: 首先对变量进行协整分析,以发现变量之间的协整关系,即长期均衡关系,并以这种关系构成误差修正项。 然后建立短期模型,将误差修正项看作一个解释变量,连同其他反映短期波动的解释变量一起,建立短期模型,即误差修正模型。

258
Y=lagged(Y, X)+ t-1 +t 0<<1
注意,由于, Y=lagged(Y, X)+ t-1 +t <<1 中没有明确指出Y与X的滞后项数,因此,可以是多个;同时,由于一阶差分项是I(0)变量,因此模型中也允许使用X的非滞后差分项Xt 。 Granger表述定理可类似地推广到多个变量的情形中去。
+ t-1 +t 0<<1. 中没有明确指出Y与X的滞后项数,因此,可以是多个;同时,由于一阶差分项是I(0)变量,因此模型中也允许使用X的非滞后差分项Xt 。 Granger表述定理可类似地推广到多个变量的情形中去。")
259
由协整与误差修正模型的的关系,可以得到误差修正模型建立的E-G两步法:
(2)Engle-Granger两步法 由协整与误差修正模型的的关系,可以得到误差修正模型建立的E-G两步法: 第一步,进行协整回归(OLS法),检验变量间的协整关系,估计协整向量(长期均衡关系参数); 第二步,若协整性存在,则以第一步求到的残差作为非均衡误差项加入到误差修正模型中,并用OLS法估计相应参数。
Engle-Granger两步法. 由协整与误差修正模型的的关系,可以得到误差修正模型建立的E-G两步法: 第一步,进行协整回归(OLS法),检验变量间的协整关系,估计协整向量(长期均衡关系参数); 第二步,若协整性存在,则以第一步求到的残差作为非均衡误差项加入到误差修正模型中,并用OLS法估计相应参数。")
260
需要注意的是:在进行变量间的协整检验时,如有必要可在协整回归式中加入趋势项,这时,对残差项的稳定性检验就无须再设趋势项。
另外,第二步中变量差分滞后项的多少,可以残差项序列是否存在自相关性来判断,如果存在自相关,则应加入变量差分的滞后项。

261
但仍需事先对变量间的协整关系进行检验。如对双变量误差修正模型:
(3)直接估计法 也可以采用打开误差修整模型中非均衡误差项括号的方法直接用OLS法估计模型。 但仍需事先对变量间的协整关系进行检验。如对双变量误差修正模型:
直接估计法. 也可以采用打开误差修整模型中非均衡误差项括号的方法直接用OLS法估计模型。 但仍需事先对变量间的协整关系进行检验。如对双变量误差修正模型:")
262
可打开非均衡误差项的括号直接估计下式: 这时短期弹性与长期弹性可一并获得。 需注意的是,用不同方法建立的误差修正模型结果也往往不一样。

263
以中国国民核算中的居民消费支出经过居民消费价格指数缩减得到中国居民实际消费支出时间序列(C);
例 中国居民消费的误差修正模型 经济理论指出,居民消费支出是其实际收入的函数。 以中国国民核算中的居民消费支出经过居民消费价格指数缩减得到中国居民实际消费支出时间序列(C); 以支出法GDP对居民消费价格指数缩减近似地代表国民收入时间序列(GDP)。 时间段为1978—2000(表9.3.3)
; 以支出法GDP对居民消费价格指数缩减近似地代表国民收入时间序列(GDP)。 时间段为1978—2000(表9.3.3)")
265
(1)对数据lnC与lnGDP进行单整检验
(3.81)(-4.01) (2.66) (2.26) (2.54) LM(1)= LM(2)= LM(3)= LM(4)=2.46
(-4.01) (2.66) (2.26) (2.54) LM(1)=0.38 LM(2)=0.67 LM(3)=2.34 LM(4)=2.46.")
266
发现有残关项有较强的一阶自相关性。考虑加入适当的滞后项,得lnC与lnGDP的分布滞后模型:
(0.30) (57.48) R2= DW=0.744 发现有残关项有较强的一阶自相关性。考虑加入适当的滞后项,得lnC与lnGDP的分布滞后模型:
 (57.48) R2=0.994 DW= 发现有残关项有较强的一阶自相关性。考虑加入适当的滞后项,得lnC与lnGDP的分布滞后模型:")
267
自相关性消除,因此可初步认为是lnC与lnGDP的长期稳定关系。
(*) (1.63) (6.62) (4.92) (-2.17) R2= DW= LM(1)= LM(2)=2.31 自相关性消除,因此可初步认为是lnC与lnGDP的长期稳定关系。
 (1.63) (6.62) (4.92) (-2.17) R2=0.994 DW=1.92 LM(1)=0.00 LM(2)=2.31. 自相关性消除,因此可初步认为是lnC与lnGDP的长期稳定关系。")
268
说明lnC与lnGDP是(1,1)阶协整的,(*)式即为它们长期稳定的均衡关系:
残差项的稳定性检验: (-4.32) R2= DW= LM(1)= LM(2)=1.34 t=-4.32<-3.64=ADF0.05 说明lnC与lnGDP是(1,1)阶协整的,(*)式即为它们长期稳定的均衡关系: (*)
 R2=0.994 DW=2.01 LM(1)=0.04 LM(2)=1.34. t=-4.32<-3.64=ADF0.05. 说明lnC与lnGDP是(1,1)阶协整的,(*)式即为它们长期稳定的均衡关系: (*)")
269
做为误差修正项,可建立 以稳定的时间序列 误差修正模型: (3)建立误差修正模型 如下:
(**) (6.96) (2.96) (-1.91) (-3.15) R2= DW= LM(1)= LM(2)=2.04
 (6.96) (2.96) (-1.91) (-3.15) R2=0.994 DW=2.06 LM(1)=0.70 LM(2)=2.04.")
270
用打开误差修正项括号的方法直接估计误差修正模型,适当估计式为:
由(*)式: 可得lnC关于lnGDP的长期弹性: ( )/( )=0.892; 由(**)式可得lnC关于lnGDP的短期弹性:0.686 用打开误差修正项括号的方法直接估计误差修正模型,适当估计式为:
式: 可得lnC关于lnGDP的长期弹性: ( )/( )=0.892; 由(**)式可得lnC关于lnGDP的短期弹性: 用打开误差修正项括号的方法直接估计误差修正模型,适当估计式为:")
271
(1.63) (6.62) (-2.99) (2.88) 写成误差修正模型的形式如下: 可见两种方法的结果非常接近。
(1.63) (6.62) (-2.99) (2.88) R2= = DW= LM(2)=2.31 LM(3)=2.78 写成误差修正模型的形式如下: (***) 由(***)式知,lnC关于lnGDP的短期弹性为0.698,长期弹性为0.892。 可见两种方法的结果非常接近。
 (6.62) (-2.99) (2.88) R2=0.791 = DW=1.93 LM(2)=2.31 LM(3)=2.78. 写成误差修正模型的形式如下: (***) 由(***)式知,lnC关于lnGDP的短期弹性为0.698,长期弹性为0.892。 可见两种方法的结果非常接近。")
272
由(*)式: 给出1998年关于长期均衡点的偏差: (4)预测
=ln(18230) ln(39008)-0.662ln(17072) +0.361ln(36684)=
 ln(39008)-0.662ln(17072) ln(36684)=")
273
由(**)式: 预测1999年的短期波动: lnC99=0.686(ln(41400)-ln(39008))+0.784(ln(18230)-ln(17072))-0.484(ln(39008)-ln(36684))-1.163×0.0125= 0.048
式: 预测1999年的短期波动: lnC99=0.686(ln(41400)-ln(39008))+0.784(ln(18230)-ln(17072))-0.484(ln(39008)-ln(36684))-1.163×0.0125=")
274
于是: 按照(*** )式: 预测的结果为: lnC99=0.698(ln(41400)-ln(39008))-0.378(ln(18230) ln(39008))=0.051
式: 预测的结果为: lnC99=0.698(ln(41400)-ln(39008))-0.378(ln(18230) ln(39008))=")
275
于是: 以当年价计的1999年实际居民消费支出为39334亿元,用居民消费价格指数(1990=100)紧缩后约为19697亿元,两个预测结果的相对误差分别为2.9%与2.6%。
紧缩后约为19697亿元,两个预测结果的相对误差分别为2.9%与2.6%。")
Similar presentations





















,又译成经济计量学,是1926年挪威经济学家R. Frish仿照生物计量学(Biometrics)一词首先提出来的,它的提出标志着计量经济学的诞生。 但是,人们一般认为,1930年12月29日世界计量经济学会成立和由它创办的学术刊物Econometrica于1933年正式出版,才标志着计量经济学作为一个独立的学科正式诞生了。>")
 选择单变量时间序列的原因>")
>")