Download presentation
Presentation is loading. Please wait.

1
第六章 短时记忆

2
本章基本内容 第一节 短时记忆的概念 第二节 短时记忆的容量 第三节 短时记忆的信息代码 第四节 短时记忆的信息提取
第一节 短时记忆的概念 第二节 短时记忆的容量 第三节 短时记忆的信息代码 第四节 短时记忆的信息提取 第五节 短时记忆中的遗忘

3
第一节:短时记忆的概念 短时记忆的概念 瞬时记忆:信息保持1秒 短时记忆:信息保持15~30秒 长时记忆:信息保持很长

4
第一节:短时记忆的概念 一、短时记忆与工作记忆 Baddeley和Hitch提出短时贮存这一概念应该被工作记忆所替代。 包括三个组成部分:
中枢执行系统 语音回路 视空图像处理器

5
语音回路的作用 对语言理解的作用 原理:语音回路与人的语言理解的认知活动有密切的关系。如果强制被试大声音重复,如阅读句子无关的语音(the,the,the)时,这个语音会进入语音存储系统,从而导致发音控制加工失去作用,并影响阅读理解成绩。
时,这个语音会进入语音存储系统,从而导致发音控制加工失去作用,并影响阅读理解成绩。 .")
6
二、短时记忆存在的证据 两种记忆系统说 人物:James,1890提出。 研究范式: 自由回忆范式

7
两种记忆说的内容 记忆不是一个单一的东西,存在着短时记忆和长时记忆两种不同的记忆,它们彼此独立而又互相联系,形成一个统一的记忆系统。
长时记忆(LTM)是一个信息库,可以长期贮存大量信息,又称永久记忆。 外部信息经过感觉通道进入短时记忆(STM),STM是信息进入长时记忆的一个容量有限的缓冲器和加工器。
是一个信息库,可以长期贮存大量信息,又称永久记忆。 外部信息经过感觉通道进入短时记忆(STM),STM是信息进入长时记忆的一个容量有限的缓冲器和加工器。")
8
两种记忆系统的模型 Waugh & Norman(1965)最早提出的模型 初级记忆 次级记忆 遗忘 刺激 复 述
最早提出的模型 初级记忆 次级记忆 遗忘 刺激 复 述")
9
自由回忆实验范式 (1)先给被试按一定顺序相继呈现若干个音节、字词或其他项目。
(2)要求被试尽量回忆出已学习过的东西,但不必按照原先呈现的顺序来回忆。 (3)将自由回忆的结果与原先呈现的顺序加以对照,就可发现在原来的刺激系列中,不同位置上刺激的记忆效果。 (4)据此作图,可得到系列位置曲线。
要求被试尽量回忆出已学习过的东西,但不必按照原先呈现的顺序来回忆。 (3)将自由回忆的结果与原先呈现的顺序加以对照,就可发现在原来的刺激系列中,不同位置上刺激的记忆效果。 (4)据此作图,可得到系列位置曲线。")
10
短时记忆存在的证据 研究者:Deese(1957) 方法:自由回忆 任务:让被试听一个由10个常用词组成的词表,每次呈现一个词,每次1s。
要求:听完后进行自由回忆。 因变量:正确回忆率

11
沙 漠

12
数 学

13
灯 泡

14
深 刻

15
网 络

16
成 就

17
情 感

18
电 梯

19
日 记

20
天 空

21
结果(系列位置曲线)
")
22
传统心理学对系列位置效应的解释 (1)近因效应和首因效应
词表中间部分的字词回忆成绩较差,而起始部分和结尾部分的字词回忆成绩较优(首因效应、近因效应),并均高于中间部分。 (2)前摄抑制和倒摄抑制解释。
,并均高于中间部分。 (2)前摄抑制和倒摄抑制解释。")
23
Murdock将这种理论分析在系列位置曲线图上表示出来。
现代认知心理学的解释 将系列位置曲线反映两种记忆: 结尾反映短时记忆 起始和中间反映长时记忆 Murdock将这种理论分析在系列位置曲线图上表示出来。

24
系列位置的两种记忆

25
验证两种记忆说对系列位置曲线的解释 根据两种记忆说所做的两种预测:
若增加每个刺激的呈现时间,就会增加复述的时间,使更多信息进入长时记忆,但不会对短时记忆产生影响 若进行延缓回忆并防止复述,将损害短时记忆,但不会影响长时记忆。

26
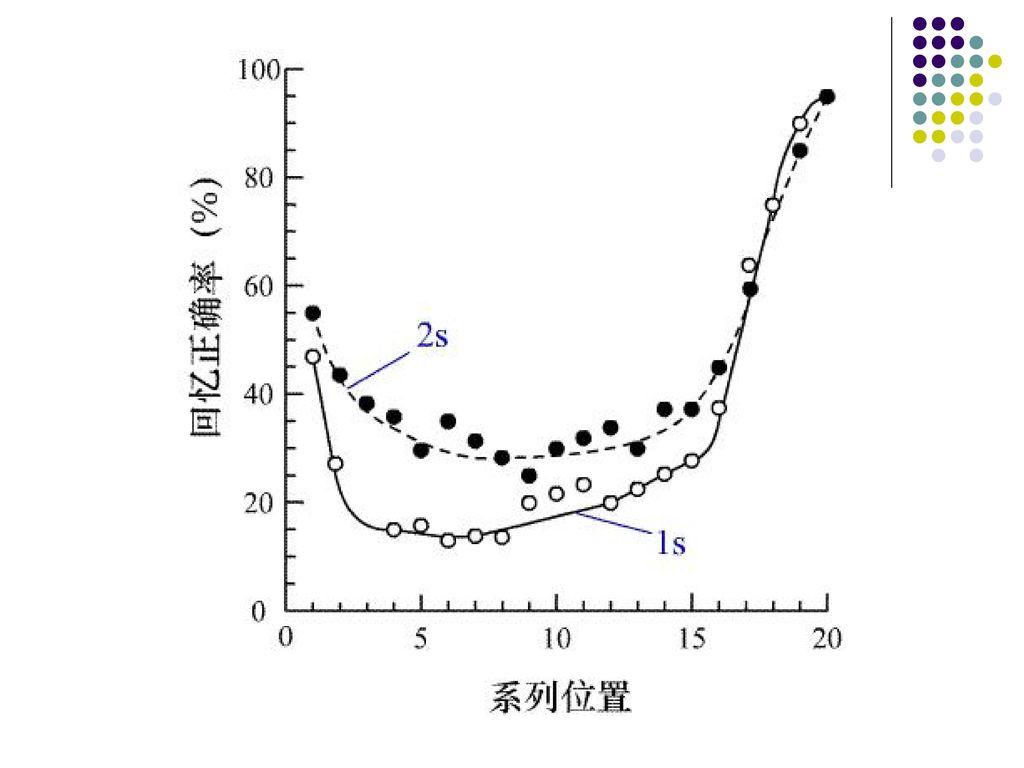
Murdock对预测(1)的实验 被试:成人 材料:字词 呈现时间:分为1s和2s两种。
的实验 被试:成人 材料:字词 呈现时间:分为1s和2s两种。")
28
增加刺激呈现时间有利于长时记忆,而不影响短时记忆。
结果: (1)呈现时间为2s的在系列起始部分和中间部分的回忆成绩要优于呈现时间为1s的; (2)在结尾部分两种呈现时间条件下没有什么差别。 结论: 增加刺激呈现时间有利于长时记忆,而不影响短时记忆。
呈现时间为2s的在系列起始部分和中间部分的回忆成绩要优于呈现时间为1s的; (2)在结尾部分两种呈现时间条件下没有什么差别。 结论: 增加刺激呈现时间有利于长时记忆,而不影响短时记忆。")
29
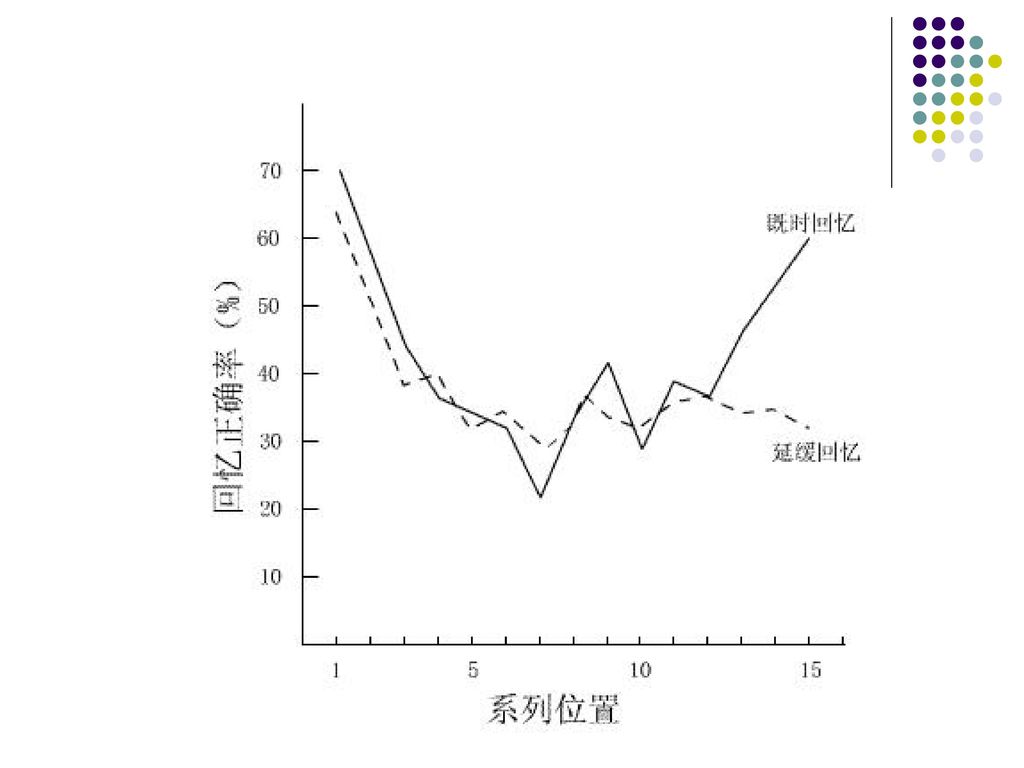
Glanzer等人对预测(2)的实验 被试:成人 方法:自由回忆方法 结果: 即时回忆:在刺激系列(词表)呈现完毕后立即回忆;
延缓回忆:在刺激系列呈现完毕后,立即进行心算作业30s,再回忆词表。 结果: 延缓回忆损害了刺激系列结尾部分即短时记忆,对长时记忆没有影响。

31
三、记忆的模型 (一)记忆的信息加工模型 (二)记忆的加工水平模型(p164) (三)记忆的神经网络模型(p166)
记忆的信息加工模型 (二)记忆的加工水平模型(p164) (三)记忆的神经网络模型(p166)")
32
记忆的信息加工模型 人物:Atkinson & Shiffrin(1968) 刺激 瞬时记忆 短时记忆 长时记忆 注意 复述 消退 遗忘
三个记忆系统模式图

33
记忆的加工水平模型 人物:Craik & Lockhart(1972) 加工水平模型——记忆的单一储存模式
从瞬时记忆——短时记忆——长时记忆是加工由浅到深的过程。 记忆实质上是信息加工的副产品。只要注意或思考某种信息,就可以自动达到记忆的目的。

34
记忆的加工水平模型的实验 范式:学习单词——自由回忆单词 材料:学习时:24张单词表,词/2s;自由回忆 被试:
一组:有意学习(要回忆),自由回忆 二组:偶然学习(判断是否愉快),自由回忆 三组:找出字母E,自由回忆 四组:计算字母数,自由回忆 因变量:单词回忆百分率
,自由回忆. 二组:偶然学习(判断是否愉快),自由回忆. 三组:找出字母E,自由回忆. 四组:计算字母数,自由回忆. 因变量:单词回忆百分率.")
35
记忆的加工水平模型的实验 实验结果 P164 结构分析是浅层分析 语义分析是深层分析

36
记忆的加工水平模型的拓展 人物:Craik & Lockhart(1973) 复述分:
维持性复述(maintenance rehearsal) 精细性复述(elaborative rehearsal) 维持性复述不能增强记忆。
 精细性复述(elaborative rehearsal) 维持性复述不能增强记忆。")
37
维持性复述不能增强记忆的实验 实验范式:偶然记忆 (incidental memory) 材料:一系列单词
….mother, oil, giraffe, grader, football, table, chair, grain …. 要求:学习一系列单词,记住某个特定字母G开头的最后一个单词,学完后自由回忆。 因变量:各个单词回忆正确率 实验假设:giraffe, grader; grain 复述数

38
维持性复述不能增强记忆的实验 结果:复述次数与记忆成绩无影响 推论:实验中的复述是一种简单的复述。 加工水平模型的评价:
目前用于内隐记忆与外显记忆的解释。

39
记忆的神经网络模型 人物:Martindale,1991提出。 信息加工模型的不足: 结构和控制是分开的,控制过程是一种执行加工器。
神经网络模型: 短时记忆分析器中被高度激活的结点的持续;长时记忆是结点之间联系的强度。联系由弱变强由短时记忆转化为长时记忆。 工作记忆的模型就是神经网络模型的拓展。

40
Working Memory model Central executive Phonological loop
Attentional control system with limited resources Responsible for transferring information from short-term memory to long-term memory Phonological loop Temporary storage and processing of verbal information Phonological store and articulatory loop Visuo-spatial sketchpad Temporary retention and manipulation of visuo-spatial informaiton

41
Working-Memory Model

42
Memory sensory short term long term working iconic echoic declarative
phonol. loop v-s sketch pad Central Exec phon. store rehearsal declarative (explicit) non-decl. (implicit) facts events skills habits priming class. cond. ...
 non-decl. (implicit) facts. events. skills. habits. priming. class. cond. ...")
43
工作记忆模型的解释 中央执行系统是工作记忆的关键成分,虽容量有限,可参与任何认知活动。语音环和视空图像处理器从属于中央执行系统并为特定目的服务。 每一成分均是能量有限,且相对独立于其他任一成分而工作。 该模型能解释某些脑损伤患者表现出的选择性障碍。

44
工作记忆的测量方法 数字工作记忆测量 言语工作记忆测量 空间工作记忆测量

45
数字工作记忆测量 12+( )=19 18- ( )=11 6+ ( )=13 8 + ( )=12
= ( )=11 6+ ( )= ( )=12")
46
言语工作记忆测量 八 ( )玲珑 威 ( )凛凛 吹 ( )求疵 炎 ( )子孙
玲珑 威 ( )凛凛 吹 ( )求疵 炎 ( )子孙")
47
一、记忆的广度 二、短时记忆的容量和激活之间关系
第二节 STM的容量 一、记忆的广度 二、短时记忆的容量和激活之间关系

48
一、短时记忆容量(记忆的广度) 记忆广度法 分散注意作业法 探测作业法
 记忆广度法 分散注意作业法 探测作业法")
49
记忆广度法 提出者:Jacobs 目的:在一次单独的呈现之后有多少项目被试能立刻按其正确的顺序重复出来。 材料:数字、字母、单词等
种类:顺背广度和倒背广度

50
顺背广度:要求被试按呈现的顺序重复出来 倒背广度:要求被试按呈现的相反顺利重复出来。 下面尝试一下:

51
科学

52
刺激

53
处理

54
执行

55
请按顺序回忆

56
倒背广度法

57
漫步

58
生活

59
现代

60
石子

61
城市

62
节奏

63
请按倒序回忆

64
结果计算方法 第一种:假设每种长度刺激项目包含三个系列,则正确再现一个系列得1/3分,三个系列全部正确再现者得1分。以得1分的最长刺激项目的长度为基础,再加上从其它长度刺激项目所得的分数,就是所求的记忆广度。 得1分的最长项目为6,以此为基础。长度7通过两个,计2/3分,长度8没有通过,计为0;长度9通过1个,计为1/3,长度10没有通过。则6+2/3+0+1/3=7

65
第二种方法 用内插法找出能够立刻正确重复出50%的刺激系列的长度。该长度为短时记忆的广度

66
短时记忆的容量 一、有限容量:7±2 二、容量有限的性质

67
Short Term Memory

68
短时记忆容量7±2 首次提出了短时记忆容量有限的观点。
Miller在1956年发表了“神奇的数字:7加减2,我们加工信息能力的某些限制”论文(The magical number seven,plus or minus two: some limits on our capacity for processing information,Psychological Review, 1956,63,81-87)。 首次提出了短时记忆容量有限的观点。
。 首次提出了短时记忆容量有限的观点。")
69
组块的含义 组块(chunk) 指将若干小单位联合成较大的单位的信息加工。
 指将若干小单位联合成较大的单位的信息加工。")
70
第一,短时记忆中的信息不是以材料所含信息量的多少(即bit)为单位,而是以组块为单位。
第二,短时记忆容量的有限性是就组块数而言的,即7±2个组块。 第三,不同组块中所包含的信息量不同的。例如,一个字母可以是一个组块,许多字母组成的单词也可以是一个组块。

71
组块的实验研究 张武田(1986)的实验 材料:中文单字词、四字词 方法:顺背广度法 并与英文材料的短时记忆容量相比较。
的实验 材料:中文单字词、四字词 方法:顺背广度法 并与英文材料的短时记忆容量相比较。")
72
表1 汉字词和英文的短时记忆容量比较 认定的组块单位 单个字为单位 两个字为单位 单字词 双字词 四字词 7 6 5 12 20 3.5
表1 汉字词和英文的短时记忆容量比较 认定的组块单位 单个字为单位 两个字为单位 单字词 双字词 四字词 7 6 5 12 20 3.5 10 英一音节词 英双音节词 双字词组 八字词组 4 3 7(音节) 14 22 26 ——(英文) 9
 ——(英文) 9.")
73
组块的实验研究 喻柏林(1989)的实验研究 材料:汉字单词、双字词、四字成语、七字句 方法:顺背广度法 目的:不同的语言单位的STM容量
拟合直线为: YSTM容量= X单位 即语言单位越大,包含的信息密度越高,STM容量却随之减少。

74
短时记忆的容量和激活之间关系 人物:Esterbrook,1959年提出。 内容:
短时记忆的容量随着激活的增加而降低,这是因为更多的激活引起了已经具有很高激活的认知单元的增加,从而导致对其他认知单元的更大的抑制。 P169图

75
第三节 STM编码 一、听觉码 二、视觉码 三、语义码

76
一、听觉码 短时记忆中占支配地位的代码: 听觉码(声码) 人物:Conrad,1964年首次提出。
 人物:Conrad,1964年首次提出。")
77
Conrad的实验 材料:10个字母组成的一个字母序列,其中有些字母的发音相似,如:C,V;M,N;S,F等。 呈现时间:0.75秒/字母
方法:顺背广度 条件:(1)视觉呈现刺激 (2)在白噪音背景上,听觉呈现刺激 任务: 刺激呈现完毕后要求被试立即进行顺序回忆。
视觉呈现刺激. (2)在白噪音背景上,听觉呈现刺激. 任务: 刺激呈现完毕后要求被试立即进行顺序回忆。")
80
结果 被试回忆出现错误最高的是发音相似的字母上 STM的信息代码是听觉编码

81
二、视觉码 Posner证实短时记忆存在视觉码 材料:Aa AA AB ab 任务:判断两个字母是否相同 假设:

83
结果:Aa的时间长于AA。 表明:字母的视觉代码至少存在于短时记忆保持过程的初期,然后才出现字母的听觉代码。 对于大量的非语言材料来说,视觉代码更为重要,因为视觉信息转换为声音,就会丢失一些信息。

84
语音转录假说 人物: Conrad等 内容: 词的认知有两个阶段,一是利用字母与音素对应的关系,把一群字母转换为一群音素;二是寻求与这种音素形式相匹配的心理词汇的词条 另,有研究发现另一条通路(视觉通路): 在词的认知时,通过词形表征达到心理词汇的词条,且视觉通路加工不语音通路快。

85
刘爱伦的研究(汉语与英语的不同) 材料:汉字 方法:顺背广度 条件:视觉呈现、听觉呈现 假设:
H1 如果汉字编码中,形占优势,则视觉呈现条件下的成绩好 H0 如果汉字编码中,音占优势,则听觉呈现条件下的成绩好

86
结果: 视觉呈现方式下的回忆成绩明显优于听觉呈现方式下的成绩 汉语与英语的差异: 形合语言 意合语言

87
三、语义码 语义码是一种与意义有关的抽象代码。 实验表明,短时记忆中也存在语义代码。

88
Wichens的实验研究之一 方法:采用前摄抑制方法 目的:STM中是否存在语义代码。 程序:连续4次试验。
试验1:给实验组和控制组的被试呈现同样的3个字母,然后进行分心作业(减3)20秒,以防止复述。之后被试努力回忆那三个字母。 试验2、试验3:同试验1 试验4:控制组仍呈现3个字母,实验组呈现却是3个数字。
20秒,以防止复述。之后被试努力回忆那三个字母。 试验2、试验3:同试验1. 试验4:控制组仍呈现3个字母,实验组呈现却是3个数字。")
89
实验结果

90
结果:前3个试验都表现出前摄抑制,即短时记忆成绩下降。在第4次试验中,控制组的成绩仍受前摄抑制的作用而继续下降,而实验组的成绩却急剧上升。
短时记忆存在着某种语义编码。使得若前后识记材料有意义联系时(字母-字母),表现出前摄抑制的作用,而在前后识记材料失去意义联系时(字母-数字),则出现前摄抑制的解除。
,表现出前摄抑制的作用,而在前后识记材料失去意义联系时(字母-数字),则出现前摄抑制的解除。")
91
Wichens的实验研究之二 P174 实验材料:水果名称 实验程序:同研究一 实验结果:同研究一

92
第四节 STM信息的提取 本节的主要内容 一、 Sternberg的系列搜索 Sternberg的经典研究 Sternberg经典实验的验证
二、马丁代尔的平行搜索

93
STM信息的提取 将短时记忆中的项目回忆出来,或者当该项目再度呈现时能够再认,都是短时记忆的信息提取。

94
(一)Sternberg的经典研究 Sternberg(1966,1969)最早研究了短时记忆信息提取问题。被称为著名的“短时记忆信息提取实验”。 这个实验解决了两个重要问题,即短时记忆信息提取是系列扫描的,并且是从头至尾扫描的。
Sternberg的经典研究 Sternberg(1966,1969)最早研究了短时记忆信息提取问题。被称为著名的 短时记忆信息提取实验 。 这个实验解决了两个重要问题,即短时记忆信息提取是系列扫描的,并且是从头至尾扫描的。")
95
一、Sternberg的经典研究 实验目的: 短时记忆的信息提取过程是系列扫描 系列扫描: 平行扫描:

96
(一) Sternberg的经典研究 实验范式 探测法 (Probe method) 探测范式的程序: (1)学习项目 (2)探测项目
实验设想:探测呈现-比较阶段-反应阶段 学习项目的多少影响反应时

97
(一) Sternberg的经典研究 实验方法: 被试:大学生 材料: 学习项目:记忆集(1-6个数字) (数字均是0-9)
探测项目:一个数字

98
(一) Sternberg的经典研究 实验程序:
探测阶段:呈现一个数字(测试项目)并同时开始计时。要被试判定该测试数字是否是刚才识记过的,作出“是”、“否”反应,按键后计时也随之停止。
并同时开始计时。要被试判定该测试数字是否是刚才识记过的,作出 是 、 否 反应,按键后计时也随之停止。")
99
实验指导语: 这个实验研究短时记忆信息的提取。随着一个较长的提示音,在屏幕中央会出现一个原形窗口。随后在这个窗口会连续呈现几个数字,你要注意记住它们。之后,你会听到一个稍短的提示音,随之又出现一个数字,你要辨别这个数字是否是刚才记过的,并按键反应。如果是没有记过的,按‘(红色键);如果你觉得是记过的,按(绿色键)。 请注意要分辨的又快又准。这样一共要做很多次,请你尽量都能做的对。明白这段话的意思后,请按回车键开始实验。
;如果你觉得是记过的,按(绿色键)。 请注意要分辨的又快又准。这样一共要做很多次,请你尽量都能做的对。明白这段话的意思后,请按回车键开始实验。")
100
实验程序 5

101
8

102
3

103
7

104
测试

105
4

107
6

108
7

109
举例结束

110
从测试项目呈现到被试反应之间的时间即为被试做出反应的时间(RT)。
。")
111
平行扫描与系列扫描 Sternberg认为,从STM中提取信息来实现再认,需要将测试项目与当前记忆集中的项目进行比较,判定是否与之匹配。他提出两种假设。

112
(一) Sternberg的经典研究 实验假设: (1)短时记忆信息提取是系列扫描。 (2)短时记忆信息提取是平行扫描。
 Sternberg的经典研究 实验假设: (1)短时记忆信息提取是系列扫描。 (2)短时记忆信息提取是平行扫描。")
113
假设一 系列扫描(Serial Scanning):如果测试项目与记忆集中诸项目一个个地相继进行比较,那么被试的RT将随着识记项目增多或记忆集增大而增加。
:如果测试项目与记忆集中诸项目一个个地相继进行比较,那么被试的RT将随着识记项目增多或记忆集增大而增加。")
114
假设一

115
假设二 平行扫描:如果测试项目与记忆集中全部项目同时进行比较,那么被试的RT不会随识记项目的数量或记忆集的大小而发生变化。

116
假设二

117
Sternberg的实验结果

118
(一) Sternberg的经典研究 实验结论: (1)STM的信息提取是逐个进行比较的,即进行系列扫描。 实验进一步推论:
这种系列扫描是从头至尾的? 还是自动停止的?

119
系列扫描的方式 从头至尾的系列扫描:对记忆集中的全部项目按顺序检查一遍,然后才判定测试项目是否与记忆集中一个项目相匹配。
自动停止的系列扫描:记忆集中检查出所要的项目后即停止比较。

120
预测 (1)两种扫描在“否”反应中的RT相同,在“是”反应中不同;
(2)从头至尾扫描中,两种反应的RT相近,斜率相同;自我停止扫描中,RT“是” = 1/2RT”否”
从头至尾扫描中,两种反应的RT相近,斜率相同;自我停止扫描中,RT 是 = 1/2RT 否")
121
两种系列扫描模型

122
Sternberg的实验结果

123
结果及解释 结果:RT“是” = RT”否” STM的信息提取以从头至尾的系列扫描进行。
解释:符合“认知经济”的原则。 比较过程和反应过程是分开的,且比较过程非常迅速,反应过程需时较多,为求工作效率,与其在每次比较之后都要作一次判断,不如在全部比较之后作一次判定更为省时。 解释模型(p178)
")
124
(二) Sternberg的实验的验证 Sternberg还用一些项目(颜色、单词、随机图形、无意义音节)结果发现相似的结果。
1969年Chase等进行了有关识记和再认的感觉道的变化对再认反应时间影响的实验; 一些研究者以不同被试研究了人脸图形、字母、数字、音节、颜色等材料短时记忆信息提取。

125
(三)对Sternberg模型的批评 Carballis观点:
实验中识记项目数量太小(≤6个),容易得到被试RT和识记项目数量的线性关系。 当应用较长的一列识记项目,可出现系列位置效应; Morin认为,实验中刺激呈现的速度太慢。当识记项目快速呈现并立即进行测试,出现首因效应和近因效应。
,容易得到被试RT和识记项目数量的线性关系。 当应用较长的一列识记项目,可出现系列位置效应; Morin认为,实验中刺激呈现的速度太慢。当识记项目快速呈现并立即进行测试,出现首因效应和近因效应。")
126
Townsend从加工能量有限的观点出发,对实验结果作出完全相反的解释。
他认为,测试项目与记忆集中的项目是同时进行比较的,出现RT随识记项目的增多而呈线性增加是由于加工能量分配不同造成的。 Martindale的批评——神经网络观

127
Martindale的神经网络观 解释斯腾伯格的实验 短时记忆是认知单元的激活 学习项目呈现的多,结点被激活的少
测试项目是学习项目,收到双重激活, 激活量大就做“是”反应。 学习项目越多,辨别较高水平的激活越难。 反应时与学习项目成正比。

128
思考题: sternberg的短时记忆提取实验是相加因素法的具体的实验之一,运用相加因素法法,描述短时记忆信息提取的阶段。

129
STM信息提取的模型 对测试项目的编码,假设用时e(ms)
把已编码的测试项目和记忆集中的项目依次比较,并确定它们是否一致。假设每次比较用时C(ms),如果记忆集中有N个项目,则全部比较完用时CN(ms)。 基于比较的结果是否一致,做出“有”或“无”的决定,假设用时d(ms)。 被试的(RT=e+CN+d),即RT=CN+(e+d). RT是由斜率为C,截矩为(e+d)所决定的关于N的线性函数。
,如果记忆集中有N个项目,则全部比较完用时CN(ms)。 基于比较的结果是否一致,做出 有 或 无 的决定,假设用时d(ms)。 被试的(RT=e+CN+d),即RT=CN+(e+d). RT是由斜率为C,截矩为(e+d)所决定的关于N的线性函数。")
130
相加因素法 sternberg的短时记忆提取实验,确定了4个对提取过程有独立作用的因素以及4个独立的加工阶段: e ms cN ms
d ms RT=CN+(e+d)
")
131
一、消退理论 二、干扰理论 三、消退理论和干扰理论的进一步验证 四、前摄抑制和倒射抑制
第五节 短时记忆的遗忘 一、消退理论 二、干扰理论 三、消退理论和干扰理论的进一步验证 四、前摄抑制和倒射抑制

132
一、消退理论 STM的遗忘主要受复述的影响。复述可以减慢或阻止遗忘的进程。
STM的容量有限,保持时间也较短,如果不进行复述,则信息在STM中一般能维持15-30秒。如果得到复述,则保持时间较长。

133
STM信息进入LTM的途径——复述 长时记忆 短时记忆 瞬时记忆 复述 记忆的三级加工模型

134
消退理论的验证性实验 人物:Peterson,1959 实验范式:自由回忆 材料:辅音字母(3个) 程序:字母呈现——分心任务——回忆
操作变量:字母呈现到回忆的间隔时间 因变量:正确回忆率

135
实验结果

136
二、干扰理论 遗忘是资料不能提取—干扰的作用 三个假设: 记忆表征会在头脑永久中储存 遗忘是其他表征影响了目标表征
容量有限,多个表征相互作用,扭曲变形。 复述是防止新表征的登录

137
三、消退理论和干扰理论的进一步验证 Reitman的分心作业实验 分心作业:在噪音中分辨纯音信号,难分辨
特点:防止复述;15s后回忆防止干扰 结果:无遗忘现象 支持:干扰理论 进一步的实验,提纯无复述的被试,有遗忘,但是遗忘程度大 结论:遗忘主要是干扰,次要是消退。

138
四、前摄抑制和后射抑制 Peterson的干扰理论实验的质疑 遗忘是前面字母的干扰引起的,还是干扰任务引起的。 实验结果p186,
结论:遗忘是前面的字母干扰的。

139
本章总结 第一节 短时记忆的概念 第二节 短时记忆的容量 第三节 短时记忆的信息代码 第四节 短时记忆的信息提取 第五节 短时记忆中的遗忘

140
谢谢各位! 本章结束

Similar presentations











 在百数表上依次将 2 的倍数找出 并用红色的彩笔涂上颜色。>")




 安徽财经大学会计学院.>")





.>")
 , 单位毫秒 暂停程序执行使用Sleep函数 Sleep(持续时间), 单位毫秒 引用这两个函数时,必须包含头文件>")