Download presentation
Presentation is loading. Please wait.

1
工程数学 第17讲 本文件可从网址 上下载 (单击ppt讲义后选择'工程数学'子目录)
")
2
第七章 参数估计 §1 点估计

3
统计推断问题可以分为两大类, 一类是估计问题, 一类是假设检验问题. 本章讨论总体参数的点估计和区间估计
统计推断问题可以分为两大类, 一类是估计问题, 一类是假设检验问题. 本章讨论总体参数的点估计和区间估计. 设总体X的分布函数的形式为已知, 但它的一个或多个参数为未知, 借助于总体X的的一个样本来估计总体未知参数的值的问题称为参数的点估计问题.

4
例1 在某炸药厂, 一天中发生着火现象的次数X是一个随机变量, 假设它服从以l>0为参数的泊松分布, 参数l为未知, 现有以下样本值, 试估计参数l.

5
解 由于X~p(l), 故有l=E(X). 我们自然想到用样本均值来估计总体的均值E(X). 现由已知数据计算得到
得到E(X)=l的估计为1.22.
=l的估计为1.22.")
6
点估计的一般提法为: 设总体X的分布函数F(x;q)的形式为已知, q是待估参数. X1,X2,. ,Xn是X的一个样本, x1,x2,
点估计的一般提法为: 设总体X的分布函数F(x;q)的形式为已知, q是待估参数. X1,X2,...,Xn是X的一个样本, x1,x2,...,xn是相应的一个样本值. 点估计问题就是要构造一个
的形式为已知, q是待估参数. X1,X2,...,Xn是X的一个样本, x1,x2,...,xn是相应的一个样本值. 点估计问题就是要构造一个.")
7
两种常用的构造估计量的方法: 矩估计法 最大似然估计法
两种常用的构造估计量的方法: 矩估计法 最大似然估计法

8
(一)矩估计法 设X为连续型随机变量, 其概率密度为f(x;q1,q2,
(一)矩估计法 设X为连续型随机变量, 其概率密度为f(x;q1,q2,...,qk), 或X为离散型随机变量, 其分布律为P{X=x}=p(x;q1,q2,...,qk), 其中q1,q2,...,qk为待估参数, X1,X2,...,Xn是来自X的样本. 假设总体X的前k阶矩 (其中RX是x的可能取值的范围)存在, 一般来说, 它们是的q1,q2,...,qk函数.
矩估计法 设X为连续型随机变量, 其概率密度为f(x;q1,q2,...,qk), 或X为离散型随机变量, 其分布律为P{X=x}=p(x;q1,q2,...,qk), 其中q1,q2,...,qk为待估参数, X1,X2,...,Xn是来自X的样本. 假设总体X的前k阶矩. (其中RX是x的可能取值的范围)存在, 一般来说, 它们是的q1,q2,...,qk函数.")
9
因为样本矩 依概率收敛于相应的总体矩ml(l=1,2,...,k), 样本矩的连续函数依概率收敛于相应的总体矩的连续函数. 因此就用样本矩作为相应的总体矩的估计量. 这种估计方法称为矩估计法.
, 样本矩的连续函数依概率收敛于相应的总体矩的连续函数. 因此就用样本矩作为相应的总体矩的估计量. 这种估计方法称为矩估计法.")
10
矩估计法的具体做法为:设 这是一个包含k个未知参数q1,q2,...,qk的联立方程组. 一般可从中解出q1,q2,...,qk, 得到

11
以Ai分别代替上式中的mi, i=1,2,...,k, 就以 分别作为qi, i=1,2,...,k的估计量, 这种估计量称为矩估计量. 矩估计量的观察值称为矩估计值.

12
例2 设总体X~U(a,b), a,b未知. X1,X2,. ,Xn是来自总体X的样本, 试求a,b的矩估计量
例2 设总体X~U(a,b), a,b未知. X1,X2,...,Xn是来自总体X的样本, 试求a,b的矩估计量. 解 m1=E(X)=(a+b)/2 m2=E(X2)=D(X)+[E(X)]2 =(b-a)2/12+(a+b)2/4. 解得:
, a,b未知. X1,X2,...,Xn是来自总体X的样本, 试求a,b的矩估计量. 解 m1=E(X)=(a+b)/2 m2=E(X2)=D(X)+[E(X)]2 =(b-a)2/12+(a+b)2/4. 解得:")
13
分别以A1,A2代替m1,m2, 得到a,b的估计量分别为:

14
例3 设总体X的均值m及方差s2都存在, 且有s2>0, 但m,s2均为未知. 又设X1,X2,. ,Xn是来自X的样本
例3 设总体X的均值m及方差s2都存在, 且有s2>0, 但m,s2均为未知. 又设X1,X2,...,Xn是来自X的样本. 试求m,s2的矩估计量. 解 分别以A1,A2代替m1,m2, 得m和s2的矩估计量分别为

15
(二)最大似然估计法 若总体X属离散型, 其分布律P{X=x}=p(x;q), qQ的形式为已知, q为待估参数, Q是q的可能取值范围
(二)最大似然估计法 若总体X属离散型, 其分布律P{X=x}=p(x;q), qQ的形式为已知, q为待估参数, Q是q的可能取值范围. 设X1,X2,...,Xn是来自X的样本, 则X1,X2,...,Xn的联合分布律为 又设x1,x2,...,xn是相应的一个样本值. 则P{X1=x1,X2=x2,...,Xn=xn}的发生概率为
最大似然估计法 若总体X属离散型, 其分布律P{X=x}=p(x;q), qQ的形式为已知, q为待估参数, Q是q的可能取值范围. 设X1,X2,...,Xn是来自X的样本, 则X1,X2,...,Xn的联合分布律为. 又设x1,x2,...,xn是相应的一个样本值. 则P{X1=x1,X2=x2,...,Xn=xn}的发生概率为.")
16
这一概率随q的取值而变化, 它是q的函数, L(q)称为样本的似然函数(注意, 这里的x1,x2,. ,xn是已知的样本值, 它们都是常数)
这一概率随q的取值而变化, 它是q的函数, L(q)称为样本的似然函数(注意, 这里的x1,x2,...,xn是已知的样本值, 它们都是常数). 直观想法是: 现在已经取到样本值x1,x2,...,xn了, 这表明取到这一样本值的概率L(q)比较大 . 当然不会考虑那些不能使样本x1,x2,...,xn出现的qQ作为q的估计. 如果已知当q=q0Q时使L(q)取很大值而Q中的其它值使L(q)取很小值, 自然认为取q0为q的估计值较为合理.
称为样本的似然函数(注意, 这里的x1,x2,...,xn是已知的样本值, 它们都是常数). 直观想法是: 现在已经取到样本值x1,x2,...,xn了, 这表明取到这一样本值的概率L(q)比较大 . 当然不会考虑那些不能使样本x1,x2,...,xn出现的qQ作为q的估计. 如果已知当q=q0Q时使L(q)取很大值而Q中的其它值使L(q)取很小值, 自然认为取q0为q的估计值较为合理.")
18
若总体X属连续型, 其概率密度f(x;q),qQ的形式已知, q为待估函数, Q是q可能取值范围. 设X1,X2,
若总体X属连续型, 其概率密度f(x;q),qQ的形式已知, q为待估函数, Q是q可能取值范围. 设X1,X2,...,Xn是来自X的样本, 则其联合概率密度为 设x1,x2,...,xn是相应的一个样本值, 则随机点(X1,X2,...,Xn)落在点(x1,x2,...,xn)的邻域(边长分别为dx1,dx2,...,dxn的n维立方体)内的概率近似地为
,qQ的形式已知, q为待估函数, Q是q可能取值范围. 设X1,X2,...,Xn是来自X的样本, 则其联合概率密度为. 设x1,x2,...,xn是相应的一个样本值, 则随机点(X1,X2,...,Xn)落在点(x1,x2,...,xn)的邻域(边长分别为dx1,dx2,...,dxn的n维立方体)内的概率近似地为.")
20
在很多情形下, p(x;q)和f(x;q)关于q可微, 这时q常可从方程
解得. 又因L(q)与ln L(q)在同一q处取到极值, 因此, q的最大似然估计q也可以从方程 求得, 而从后一方程求解往往比较方便, (1.6)称为对数似然方程.
与ln L(q)在同一q处取到极值, 因此, q的最大似然估计q也可以从方程. 求得, 而从后一方程求解往往比较方便, (1.6)称为对数似然方程.")
21
例4 设X~b(1,p), X1,X2,. ,Xn是来自X的样本, 试求参数p的最大似然估计量. 解 设x1,x2,
例4 设X~b(1,p), X1,X2,...,Xn是来自X的样本, 试求参数p的最大似然估计量. 解 设x1,x2,...,xn是相应于样本X1,X2,...,Xn的一个样本值. X的分布律为 P{X=x}=px(1-p)1-x, x=0,1. 故似然函数为
, X1,X2,...,Xn是来自X的样本, 试求参数p的最大似然估计量. 解 设x1,x2,...,xn是相应于样本X1,X2,...,Xn的一个样本值. X的分布律为 P{X=x}=px(1-p)1-x, x=0,1. 故似然函数为.")
24
最大似然估计法也适用于分布中含多个未知参数q1,q2,...,qk的情况. 这时, 似然函数L是这些未知参数的函数. 分别令
解上述由k个方程组成的方程组, 即可得到各未知参数qi (i=1,2,...,k)的最大似然估计值 (1.7)称为 对数似然方程组.
的最大似然估计值 . (1.7)称为 对数似然方程组.")
25
例5 设X~N(m,s2), m, s2为未知参数, x1,x2,. ,xn是来自X的一个样本值. 求m, s2的最大似然估计值
例5 设X~N(m,s2), m, s2为未知参数, x1,x2,...,xn是来自X的一个样本值. 求m, s2的最大似然估计值. 解 X的概率密度为 似然函数为
, m, s2为未知参数, x1,x2,...,xn是来自X的一个样本值. 求m, s2的最大似然估计值. 解 X的概率密度为. 似然函数为.")
28
例6 设总体X在(a,b)上服从均匀分布, a,b未知, x1,x2,. ,xn是一个样本值. 试求a,b的最大似然估计量
例6 设总体X在(a,b)上服从均匀分布, a,b未知, x1,x2,...,xn是一个样本值. 试求a,b的最大似然估计量. 解 记x(1)=min(x1,x2,...,xn), x(n)=max(x1,x2,...,xn). X的概率密度是 由于ax1,x2,...,xnb等价于ax(1),x(n)b. 似然函数
上服从均匀分布, a,b未知, x1,x2,...,xn是一个样本值. 试求a,b的最大似然估计量. 解 记x(1)=min(x1,x2,...,xn), x(n)=max(x1,x2,...,xn). X的概率密度是. 由于ax1,x2,...,xnb等价于ax(1),x(n)b. 似然函数.")
29
于是对于满足条件ax(1), bx(n)的任意a,b有
即L(a,b)在a=x(1), b=x(n)时取到最大值 (x(n)-x(1))-1. 故a,b的最大似然估计值为 a,b的最大似然估计量为
在a=x(1), b=x(n)时取到最大值. (x(n)-x(1))-1. 故a,b的最大似然估计值为. a,b的最大似然估计量为.")
31
当总体分布中含有多个参数时, 也具有上述性质. 例如, 在例5中已得到s2的最大似然估计为

32
§2 基于截尾样本的最大似然估计

33
在研究产品可靠性时, 需要研究产品寿命T的各种特征. 产品寿命T是一个随机变量, 它的分布称为寿命分布
在研究产品可靠性时, 需要研究产品寿命T的各种特征. 产品寿命T是一个随机变量, 它的分布称为寿命分布. 为了对寿命分布进行统计推断, 就需要通过对产品的寿命试验, 以取得寿命数据. 一种典型的寿命试验是, 将随机抽取的n个产品在时间t=0时, 同时投入试验, 直到每个产品都失效. 记录每个产品的失效时间, 这样得到的样本(即由所有产品的失效时间0 t1 t2 ...tn所组成的样本)叫完全样本. 但产品的寿命往往较长, 我们不可能得到完全样本, 于是就考虑截尾寿命试验.
叫完全样本. 但产品的寿命往往较长, 我们不可能得到完全样本, 于是就考虑截尾寿命试验.")
34
截尾寿命试验常用的有两种: 一种是定时截尾寿命试验
截尾寿命试验常用的有两种: 一种是定时截尾寿命试验. 假设将随机抽取的n个产品在时间t=0时同时投入试验, 试验进行到事先规定的截尾时间t0停止. 如试验截止时共有m个产品失效, 它们的失效时间分别为 0t1t2...tmt0, 此时m是一个随机变量, 所得的样本 t1,t2,...,tm称为定时截尾样本.

35
另一种是定数截尾寿命试验. 假设将随机抽取的n个样本在时间t=0时同时投入试验, 试验进行到有m个(m是事先规定的, m<n)产品失效时停止. m个失效产品的失效时间分别为 0t1t2...tm, 这里tm是第m个产品的失效时间. 所得的样本t1,t2,...,tm称为定数截尾样本. 用截尾来进行统计推断是可靠性研究中常见的问题.

36
设产品的寿命分布是指数分布,其概率密度为 q>0未知. 设有n个产品投入定数截尾试验,截尾数为m, 得定数截尾样本0t1t2...tm, 现在要利用这一样本来估计未知参数q(即产品的平均寿命). 在时间区间[0,tm]有m个产品失效,而有n-m个产品在tm时尚未失效, 即有n-m个产品寿命超过tm.
. 在时间区间[0,tm]有m个产品失效,而有n-m个产品在tm时尚未失效, 即有n-m个产品寿命超过tm.")
37
用最大似然估计法估计q, 求上述观察结果的概率. 一个产品在[ti,ti+dti]失效的概率近似为
故上述观察结果出现的概率近似地为
![用最大似然估计法估计q, 求上述观察结果的概率. 一个产品在[ti,ti+dti]失效的概率近似为](http://slidesplayer.com/slide/11334794/61/images/37/%E7%94%A8%E6%9C%80%E5%A4%A7%E4%BC%BC%E7%84%B6%E4%BC%B0%E8%AE%A1%E6%B3%95%E4%BC%B0%E8%AE%A1q%2C+%E6%B1%82%E4%B8%8A%E8%BF%B0%E8%A7%82%E5%AF%9F%E7%BB%93%E6%9E%9C%E7%9A%84%E6%A6%82%E7%8E%87.+%E4%B8%80%E4%B8%AA%E4%BA%A7%E5%93%81%E5%9C%A8%5Bti%2Cti%2Bdti%5D%E5%A4%B1%E6%95%88%E7%9A%84%E6%A6%82%E7%8E%87%E8%BF%91%E4%BC%BC%E4%B8%BA.jpg "故上述观察结果出现的概率近似地为.")
38
其中dt1,...,dtm为常数. 因忽略一个常数因子不影响q的最大似然估计, 故可取似然函数为
对数似然函数为

39
于是得到q的最大似然估计为 其中s(tm)=t1+t2+...+tm+(n-m)tm称为总试验时间, 它表示直至时刻tm为止n个产品的试验时间总和
=t1+t2+...+tm+(n-m)tm称为总试验时间, 它表示直至时刻tm为止n个产品的试验时间总和")
40
对于定时截尾样本 0t1t2...tmt0 (其中t0是截尾时间), 与上面的讨论类似, 可得似然函数为
q的最大似然估计为 其中s(t0)=t1+t2+...+tm+(n-m)t0称为总试验时间, 它表示直至时刻t0为止n个产品的试验时间的总和.
=t1+t2+...+tm+(n-m)t0称为总试验时间, 它表示直至时刻t0为止n个产品的试验时间的总和.")
41
例 设电池的寿命服从指数分布, 其概率密度为 q>0未知. 随机地取50只电池投入寿命试验, 规定试验进行到其中有15只失效时结束试验, 测得失效时间(小时)为 115,119,131,138,142,147,148,155,158,159,163,166,167,170,172 试求电池的平均寿命估计.

42
解 n=50, m=15, s(t15)=115+119+...+172+(50-15)172=8270, 得q的最大似然估计为
= (50-15)172=8270, 得q的最大似然估计为")
43
§3 估计量的评选标准

44
1 无偏性

47
例2 设总体X服从指数分布, 其概率密度为 其中参数q>0为未知, 又设X1,X2,...,Xn是来自X

48
证 估计量. 而Z=min(X1,X2,...,Xn)具有概率密度
具有概率密度")
49
有效性 Xn)都是q 的无偏估计量, 若对于任意qQ, 有 且至少对某一个qQ上式中的不等式成立,
都是q 的无偏估计量, 若对于任意qQ, 有 且至少对某一个qQ上式中的不等式成立,")
50
例3(续例2) 试证当n>1时, q的无偏估计量
证 由于D(X)=q 2, 故有
=q 2, 故有.")
51
相合性 设 即, 若对于任意q都满足: 对于任意e>0, 有

52
作业 第七章习题 第207页 第1,2,5题 A组交作业

53
请提问

Similar presentations


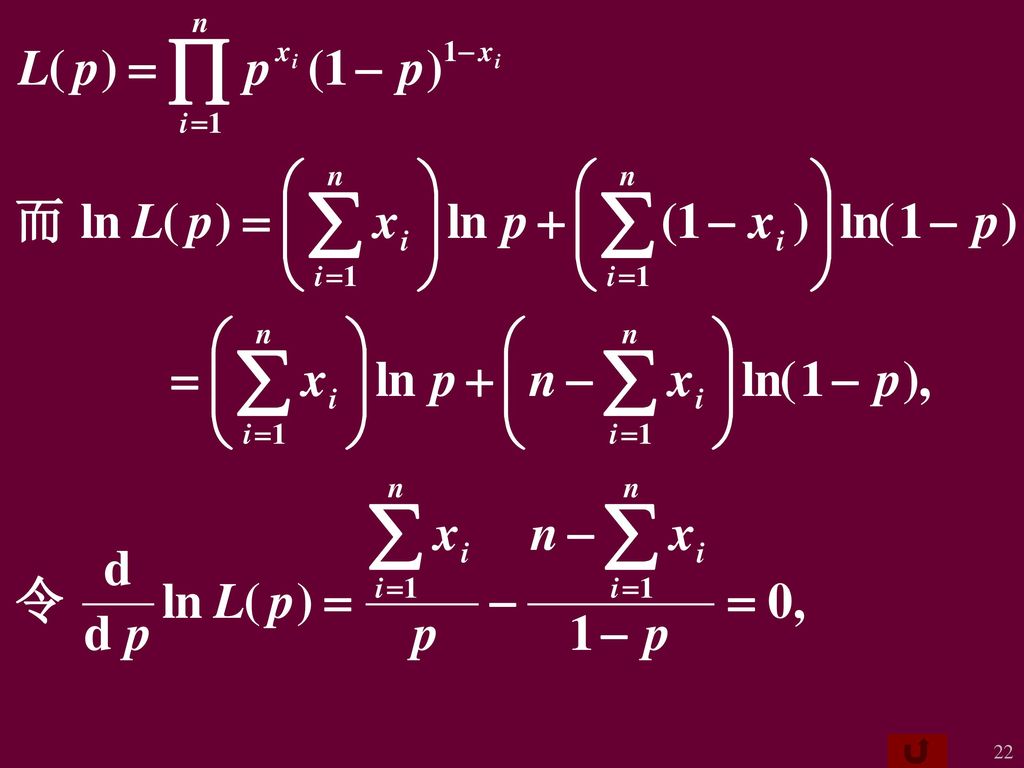


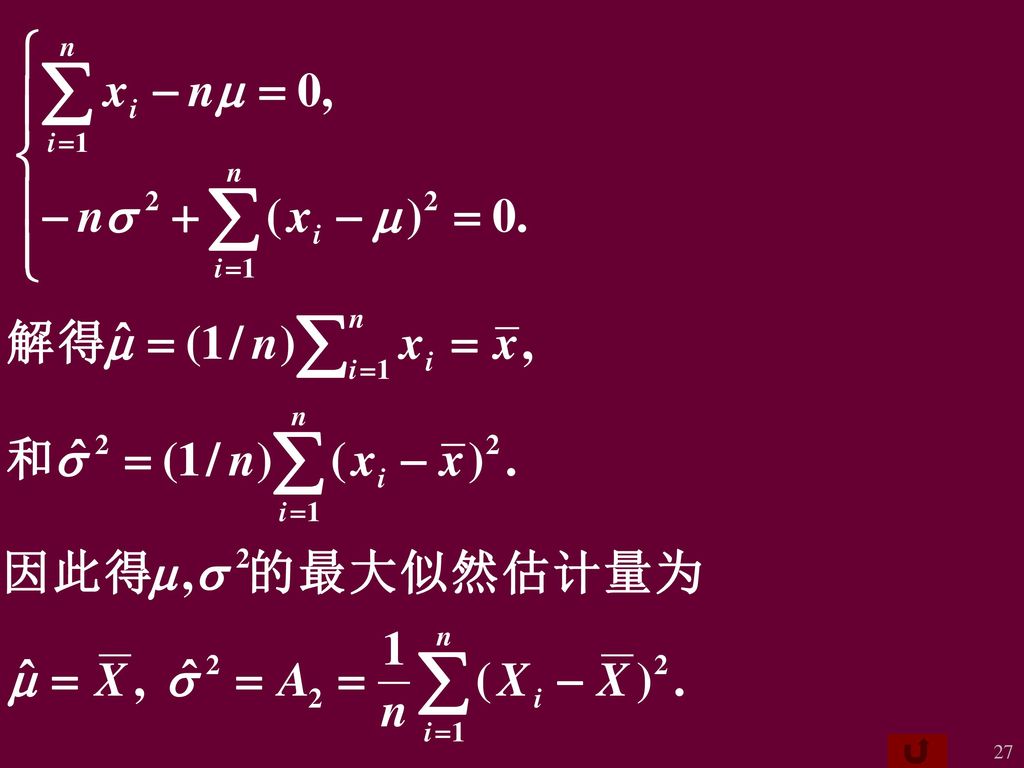







永久免费: 学校和老师使用校讯通平台发送短信 是免费的,并且通过使用平台,可获得部分购物卡补贴。 ( 2 )移动办公: 校讯通不受时间和空间的限制,只要 有一台可以上网的电脑,老师便可以通过互联网发送短信 给家长,能够实现移动办公,节省老师的工作时间。 ( 3 )简单易用:>")
 体检 ( 2015.12—2016.1 ) 网上申报 ( 2016.4 ) 实践能力测试 ( 2016.5 ) 专家评审 ( 2016.5 ) 领取证书.>")
 特色招生 術科考試 五專 免試入學 ( 每年六月 ) 特色招生 甄選入學 高中高職 免試入學 擇一報到 林園高中適性入學 入學管道流程 2.>")
 体育大街槐桉路-和平路 40 块 槐安路东二环-西三环 123.>")
 105 年 5 月 15 日(日) 08:20- 08:30 考試說明 08:20- 08:30 考試說明 08:30- 09:40 社 會 08:30- 09:40 自 然 09:40- 10:20 休息 09:40->")

.>")








