Download presentation
Presentation is loading. Please wait.

1
第2章 SQL语言初步 2.1 SQL的基本概念 2.2 基本表、索引的创建、删除和修改操作 2.3 SQL的查询语句——SELECT
2.4 含有子查询的数据更新 2.5 视图

2
2.1 SQL的基本概念 SQL支持数据库的三级模式结构,如图2―1所示。从图中可以看出,模式与基本表相对应,外模式与视图相对应,内模式对应于存储文件。基本表和视图都是关系。

3
图2―1 SQL支持的数据库模式

4
1.基本表(Base Table) 基本表是模式的基本内容。每个基本表都是一个实际存在的关系。 2.视图(View) 视图是外模式的基本单位,用户通过视图使用数据库中基于基本表的数据(基本表也可作为外模式使用)。一个视图虽然也是一个关系,但是它与基本表有着本质的区别。任何一个视图都是从已有的若干关系导出的关系,它只是逻辑上的定义,实际并不存在。在导出时,给出一个视图的定义(从哪几个关系中,
。一个视图虽然也是一个关系,但是它与基本表有着本质的区别。任何一个视图都是从已有的若干关系导出的关系,它只是逻辑上的定义,实际并不存在。在导出时,给出一个视图的定义(从哪几个关系中,")
5
根据什么标准选取数据,组成一个什么名称的关系等),此定义存放在数据库(数据字典)中,但没有真正执行此定义(并未真正生成此关系)。当使用某一视图查询时,将实时从数据字典中调出此视图的定义;根据此定义以及现场查询条件,从规定的若干关系中取出数据,组织成查询结果,展现给用户。 因此,视图是虚表,实际并不存在,只有定义存放在数据字典中。

6
当然,用户可在视图上再定义视图,就像在基本表上定义视图一样,因为视图也是关系。因而对于用户来说,使用一个视图和使用一个基本表的感觉是一样的。只是对视图进行修改时,有时会产生一些麻烦(将在具体介绍视图操作时讲述)。
。")
7
3.存储文件 存储文件是内模式的基本单位。每一个存储文件存储一个或多个基本表的内容。一个基本表可有若干索引,索引也存储在存储文件中。存储文件的存储结构对用户是透明的。 下面将介绍SQL的基本语句。各厂商的RDBMS实际使用的SQL语言,与标准SQL语言都有所差异及扩充。因此,具体使用时,应参阅实际系统的有关手册。

8
2.2 基本表、索引的创建、删除和修改操作 2.2.1 创建基本表——CREATETABLE 一、语句格式
[<,表级完整性约束>]) 其中,一对方括号内的内容为可选项。
 其中,一对方括号内的内容为可选项。")
9
二、说明 (1)<表名>:规定所创建的基本表的名称。在一个数据库中,不允许有两个基本表同名(应该更严格的说,任何两个关系都不能同名,这就把视图也包括了)。 (2)<列定义清单>:规定了该表中所有属性列的结构情况。每一列的内容有: <列名><类型>[<该列的完整性约束>] 两列内容之间用西文逗号隔开。

10
(3)<列名>:规定了该列(属性)的名称。一个表中不能有两列同名。
(4)<类型>:规定了该列的数据类型。各具体DBMS所提供的数据类型是不同的。但下面的数据类型几乎都是支持的: INT或INTEGER 全字长二进制整数 SMALLINT 半字长二进制整数 DEC(p[,q])或 压缩十进制数,共p位,其中小数点后有q位,
<类型>:规定了该列的数据类型。各具体DBMS所提供的数据类型是不同的。但下面的数据类型几乎都是支持的: INT或INTEGER 全字长二进制整数. SMALLINT 半字长二进制整数. DEC(p[,q])或. 压缩十进制数,共p位,其中小数点后有q位,")
11
DECIMAL(p[,q]) 0<=q<=p<=15,q=0时可省略
FLOAT 双字长的浮点数 CHAR(n)或CHARTER(n) 长度为n的定长字符串 VARCHAR(n) 最大长度为n的变长字符串 DATE 日期型,格式为YYYY―MM―DD TIME 时间型,格式为HH.MM.SS TIMESTAMP 日期加时间
![DECIMAL(p[,q]) 0<=q<=p<=15,q=0时可省略](http://slidesplayer.com/slide/11336135/61/images/11/DECIMAL%28p%EF%BC%BB%2Cq%EF%BC%BD%29+0%3C%3Dq%3C%3Dp%3C%3D15%EF%BC%8Cq%3D0%E6%97%B6%E5%8F%AF%E7%9C%81%E7%95%A5.jpg "FLOAT 双字长的浮点数. CHAR(n)或CHARTER(n) 长度为n的定长字符串. VARCHAR(n) 最大长度为n的变长字符串. DATE 日期型,格式为YYYY―MM―DD. TIME 时间型,格式为HH.MM.SS. TIMESTAMP 日期加时间.")
12
(5)<该列的完整性约束>:该列上数据必须符合的条件。最常见的有:
NOTNULL 该列值不能为空 NULL 该列值可以为空 UNIQUE 该列值不能有相同者 DEFAULT 该列上某值未定义时的默认值

13
(6)<表级完整性约束>:对整个表的一些约束条件,常见的有定义主码(外码),各列上数据必须符合的关联条件等。
SQL只要求语句的语法正确就可以,对格式不作特殊规定。一条语句可以放在多行上,字和符号间有一个或多个空格分隔。一般每个列定义单独占一行(或数行),每个列定义中相似的部分对齐(这不是必须的),从而增加可读性,一目了然。
,每个列定义中相似的部分对齐(这不是必须的),从而增加可读性,一目了然。")
14
例2.1 创建职工表。 CREATE TABLE Employee (Eno CHAR(4)NOTNULLUNIQUE Ename CHAR(8), Sex CHAR(2), Age INT, Marry CHAR(1), Title CHAR(6), Dno CHAR(2));
, Title CHAR(6), Dno CHAR(2));")
15
执行后,数据库中就新建立了一个名为Employee的表,此表尚无元组(即为空表)。此表的定义及各约束条件都自动存放进数据字典。
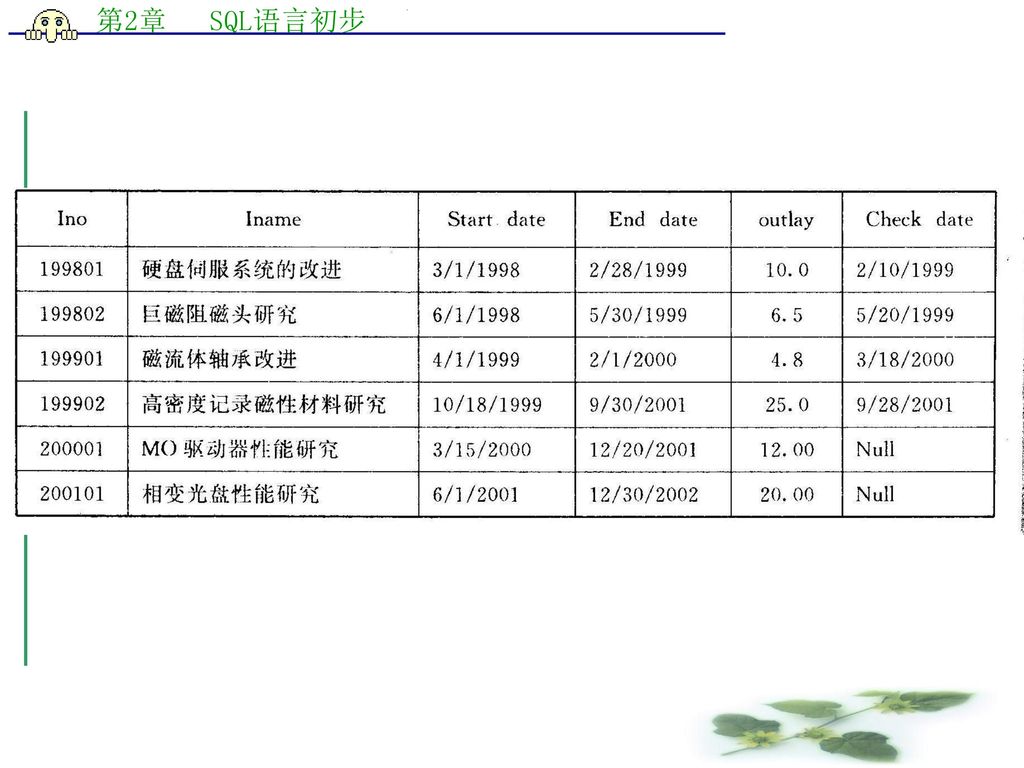
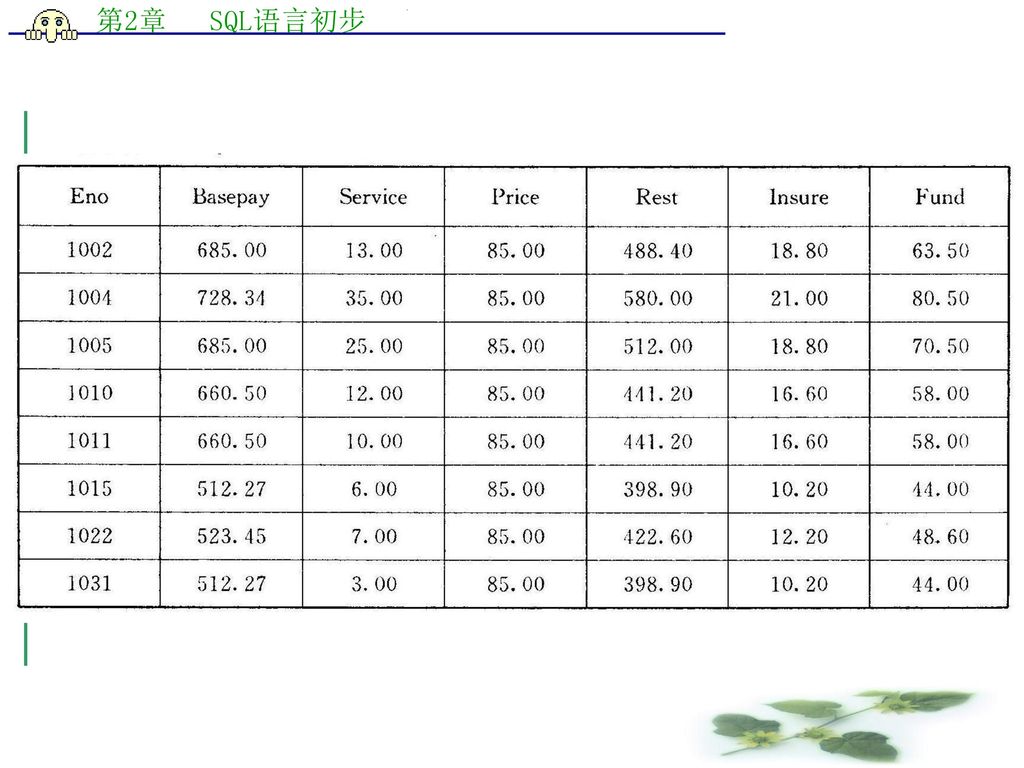
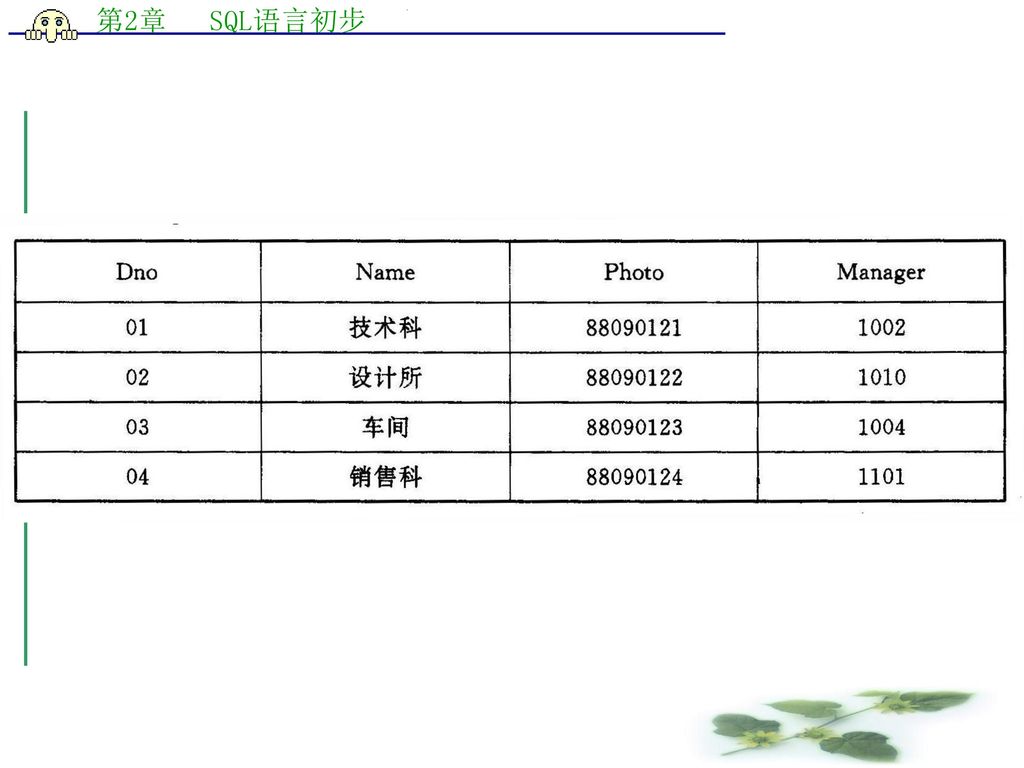
请学生自行建立表2―1所示的前三个表:Employee、Item、ItemEmp。表(四)及表(五)为该数据库中的另外两个表。
及表(五)为该数据库中的另外两个表。")
16
表2―1 数据库表

20
2.2.2 表结构的修改——ALTERTABLE 基本表的结构是可以随环境的变化而修改的,即根据需要增加、修改或删除其中一列(或完整性约束条件,增加或删除表级完整性约束等)。 一、语句格式 ALTERTABLE<表名> [ADD COLUMN<列名><数据类型>[完整性约束]] [DROP COLUMN<列名>]

21
[MODIFYCOLUMN<列名><数据类型>[完整性约束]]
[ADD CONSTRAINT<表级完整性约束>] [DROP CONSTRAINT<表级完整性约束>]
![[MODIFYCOLUMN<列名><数据类型>[完整性约束]]](http://slidesplayer.com/slide/11336135/61/images/21/%EF%BC%BBMODIFYCOLUMN%3C%E5%88%97%E5%90%8D%3E%3C%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%3E%EF%BC%BB%E5%AE%8C%E6%95%B4%E6%80%A7%E7%BA%A6%E6%9D%9F%EF%BC%BD%EF%BC%BD.jpg "[ADD CONSTRAINT<表级完整性约束>] [DROP CONSTRAINT<表级完整性约束>]")
22
二、说明 (1)ADDCOLUMN:为表增加一新列,具体规定与CREATETABLE的相当,但新列必须允许为空(除非有默认值)。 (2)DROP COLUMN:在表中删除一个原有的列。 (3)MODIFY COLUMN:修改表中原有列的定义。 (4)ADD CONSTRAINT:增加表级约束。 (5)DROP CONSTRAINT:删除原有的表级约束。
ADD CONSTRAINT:增加表级约束。 (5)DROP CONSTRAINT:删除原有的表级约束。")
23
例2.2 在Item-Emp表中增加一列REno(联系人)。
ALTER TABLE Item-Emp (ADD COLUMN Reno CHAR(8))
)")
24
2.2.3 表中增加元组的基本方法——INSERT INSERT语句和下面两小节介绍的UPDATE、DELETE都有很强的功能,这里仅介绍它们的基本功能。 INSERT语句既可以为表插入一条记录,也可一次插入一组纪录。这里介绍的是插入一条记录的语句格式。 一、语句格式 INSERTINTO<表名>[(<属性名清单>)] VALUES(<常量清单>); 本语句在指定表中插入一条新记录。
] VALUES(<常量清单>); 本语句在指定表中插入一条新记录。")
25
二、说明 (1)若有<属性名清单>,则<常量清单>中各常量为新记录中这些属性的对应值(根据语句中的位置一一对应)。但该表定义时,说明为NOTNULL、且无默认值的列必须在<属性名清单>中,否则将出错。 (2)如无<属性名清单>,则<常量清单>顺序为每个属性列赋值(每个属性列上都应有值)。
如无<属性名清单>,则<常量清单>顺序为每个属性列赋值(每个属性列上都应有值)。")
26
例2.3 在Employee表中插入一职工记录。
INSERT INTO Employee VALUES(′2002′,′胡一兵′,′男′,38,′1′,′工程师′,′01′);
;")
27
2.2.4 修改表中数据的基本方法——UPDATE 要修改表中已有记录的数据时,可用UPDATE语句。 一、语句格式 UPDATE<表名> SET<列名>=<表达式>[,<列名>=<表达式>]n [WHERE<条件>]; 本语句把指定<表名>内,符合<条件>记录中规定<列名>的值更新为该<列名>后<表达式>的值。
![2.2.4 修改表中数据的基本方法——UPDATE 要修改表中已有记录的数据时,可用UPDATE语句。 一、语句格式. UPDATE<表名> SET<列名>=<表达式>[,<列名>=<表达式>]n.](http://slidesplayer.com/slide/11336135/61/images/27/2.2.4+%E4%BF%AE%E6%94%B9%E8%A1%A8%E4%B8%AD%E6%95%B0%E6%8D%AE%E7%9A%84%E5%9F%BA%E6%9C%AC%E6%96%B9%E6%B3%95%E2%80%94%E2%80%94UPDATE+%E8%A6%81%E4%BF%AE%E6%94%B9%E8%A1%A8%E4%B8%AD%E5%B7%B2%E6%9C%89%E8%AE%B0%E5%BD%95%E7%9A%84%E6%95%B0%E6%8D%AE%E6%97%B6%EF%BC%8C%E5%8F%AF%E7%94%A8UPDATE%E8%AF%AD%E5%8F%A5%E3%80%82+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F.+UPDATE%3C%E8%A1%A8%E5%90%8D%3E+SET%3C%E5%88%97%E5%90%8D%3E%3D%3C%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%EF%BC%BB%2C%3C%E5%88%97%E5%90%8D%3E%3D%3C%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%EF%BC%BDn..jpg "[WHERE<条件>]; 本语句把指定<表名>内,符合<条件>记录中规定<列名>的值更新为该<列名>后<表达式>的值。")
28
二、说明 (1)[,<列名>=<表达式>]n的含义为最少0个的此类内容,也即本语句可修改符合 <条件>记录中一个或多个列的值。 (2)若无WHERE<条件>项,则修改全部记录。 例2.4 对工资表中,所有基本工资小于600的记录,基本工资都增加50。 UPDATE Salary SET Basepay=Basepay+50 WHERE Basepay<600;
![二、说明 (1)[,<列名>=<表达式>]n的含义为最少0个的此类内容,也即本语句可修改符合. <条件>记录中一个或多个列的值。 (2)若无WHERE<条件>项,则修改全部记录。 例2.4 对工资表中,所有基本工资小于600的记录,基本工资都增加50。](http://slidesplayer.com/slide/11336135/61/images/28/%E4%BA%8C%E3%80%81%E8%AF%B4%E6%98%8E+%281%29%EF%BC%BB%2C%3C%E5%88%97%E5%90%8D%3E%3D%3C%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%EF%BC%BD%EE%80%8B%EE%80%8Bn%E7%9A%84%E5%90%AB%E4%B9%89%E4%B8%BA%E6%9C%80%E5%B0%910%E4%B8%AA%E7%9A%84%E6%AD%A4%E7%B1%BB%E5%86%85%E5%AE%B9%EF%BC%8C%E4%B9%9F%E5%8D%B3%E6%9C%AC%E8%AF%AD%E5%8F%A5%E5%8F%AF%E4%BF%AE%E6%94%B9%E7%AC%A6%E5%90%88.+%3C%E6%9D%A1%E4%BB%B6%3E%E8%AE%B0%E5%BD%95%E4%B8%AD%E4%B8%80%E4%B8%AA%E6%88%96%E5%A4%9A%E4%B8%AA%E5%88%97%E7%9A%84%E5%80%BC%E3%80%82+%282%29%E8%8B%A5%E6%97%A0WHERE%3C%E6%9D%A1%E4%BB%B6%3E%E9%A1%B9%EF%BC%8C%E5%88%99%E4%BF%AE%E6%94%B9%E5%85%A8%E9%83%A8%E8%AE%B0%E5%BD%95%E3%80%82+%E4%BE%8B2.4+%E5%AF%B9%E5%B7%A5%E8%B5%84%E8%A1%A8%E4%B8%AD%EF%BC%8C%E6%89%80%E6%9C%89%E5%9F%BA%E6%9C%AC%E5%B7%A5%E8%B5%84%E5%B0%8F%E4%BA%8E600%E7%9A%84%E8%AE%B0%E5%BD%95%EF%BC%8C%E5%9F%BA%E6%9C%AC%E5%B7%A5%E8%B5%84%E9%83%BD%E5%A2%9E%E5%8A%A050%E3%80%82.jpg "UPDATE Salary. SET Basepay=Basepay+50. WHERE Basepay<600;")
29
2.2.5 删除记录——DELETE 有时需要删去一些记录,则可用DELETE语句。 一、语句格式 DELETE<表名> [WHERE<条件>] 本语句将在指定<表名>中删除所有符合<条件>的记录。
![2.2.5 删除记录——DELETE 有时需要删去一些记录,则可用DELETE语句。 一、语句格式 DELETE<表名> [WHERE<条件>] 本语句将在指定<表名>中删除所有符合<条件>的记录。](http://slidesplayer.com/slide/11336135/61/images/29/2.2.5+%E5%88%A0%E9%99%A4%E8%AE%B0%E5%BD%95%E2%80%94%E2%80%94DELETE+%E6%9C%89%E6%97%B6%E9%9C%80%E8%A6%81%E5%88%A0%E5%8E%BB%E4%B8%80%E4%BA%9B%E8%AE%B0%E5%BD%95%EF%BC%8C%E5%88%99%E5%8F%AF%E7%94%A8DELETE%E8%AF%AD%E5%8F%A5%E3%80%82+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F+DELETE%3C%E8%A1%A8%E5%90%8D%3E+%EF%BC%BBWHERE%3C%E6%9D%A1%E4%BB%B6%3E%EF%BC%BD+%E6%9C%AC%E8%AF%AD%E5%8F%A5%E5%B0%86%E5%9C%A8%E6%8C%87%E5%AE%9A%3C%E8%A1%A8%E5%90%8D%3E%E4%B8%AD%E5%88%A0%E9%99%A4%E6%89%80%E6%9C%89%E7%AC%A6%E5%90%88%3C%E6%9D%A1%E4%BB%B6%3E%E7%9A%84%E8%AE%B0%E5%BD%95%E3%80%82.jpg "2.2.5 删除记录——DELETE 有时需要删去一些记录,则可用DELETE语句。 一、语句格式 DELETE<表名> [WHERE<条件>] 本语句将在指定<表名>中删除所有符合<条件>的记录。")
30
二、说明 当无WHERE<条件>项时,将删除<表名>中的所有记录。但是,该表还在,只是没有了记录,是个空表而已。 例2.5 从职工表中删除Eno(职工号)为1003的记录。 DELETE FROM Employee WHERE Eno=′1003′;

31
更新操作与数据库的一致性 上述增删改语句一次只能对一个表进行操作。但有些操作必须在几个表中同时进行,否则就会产生数据的不一致性。例如,要修改项目(Item)中某记录的项目号(Ino),则其他项目表中所有原项目号相同的记录也必须同时修改为同一新项目号。但这只能用两条语句完成:
中某记录的项目号(Ino),则其他项目表中所有原项目号相同的记录也必须同时修改为同一新项目号。但这只能用两条语句完成:")
32
UPDATE Item SET Ino=′200102′ WHER ESno=′200001′; 以及: UPDATE Item-emp WHERE Ino=′200001′;

33
第一条语句执行后,第二条语句尚未完成前,数据库中数据处于不一致状态。若此时突然断电,第二条语句无法继续完成,则问题就严重了。为此,SQL中引入了事务概念,把这两条语句作为一个事务,要么全部都做,要么全部不做。有关事务的内容,将在第3章3.5节中介绍。

34
删除基本表——DROPTABLE 一、语句格式 DROPTABLE<表名> 二、说明 此语句一执行,指定的表即从数据库中删除(表被删除,表在数据字典中的定义也被删除),此表上建立的索引和视图也被自动删除(有些系统对建立在此表上的视图的定义并不删除,但也无法使用了)。 例2.6 删除职工表。 DROP TABLE Employee

35
2.2.8 建立索引——CREATEINDEX 在一个基本表上,可建立若干索引。有了索引,可以加快查询速度。索引的建立和删除工作由DBA或表的属主(建表人)负责。用户在查询时并不能选择索引,选择索引的工作由DBMS自动进行。 一、语句格式 CREATE[UNIQUE][CLUSTER]INDEX<索引名> ON<表名>(<列名清单>) 本语句为规定<表名>建立一索引,索引名为<索引名>。
 本语句为规定<表名>建立一索引,索引名为<索引名>。")
36
二、说明 (1)<列名清单>中,每个列名后都可指定ASC(升序)或DESC(降序)。若不指定,默认为升序。 (2)本语句建立索引的排列方式为:首先以<列名清单>中的第一个列的值排序;该列值相同的记录,按下一列名的值排序;以此类推。 (3)UNIQUE:规定索引的每一个索引值只对应于表中唯一的记录。
UNIQUE:规定索引的每一个索引值只对应于表中唯一的记录。")
37
(4)CLUSTER:规定此索引为聚簇索引。一个表最多只能有一个聚簇索引。有了聚簇索引后,表中记录的物理顺序将与聚簇索引中的一致。在最常查询的列上建立聚簇索引可以加快查询速度;在经常更新的列上建立聚簇索引,则DBMS维护索引的代价太大。 例2.7 为职工表建立一索引,首先以部门值排序,部门相同时,再以职工号降序排序。 CREATEINDEXIX-Emp1 ON Employee(Dno ASC,Eno DESC);
;")
38
2.2.9 删除索引——DROPINDEX 索引太多,索引的维护开销也将增大。因此,不必要的索引应及时删除。 一、语句格式 DROPINDEX<索引名> 二、说明 本语句将删除规定的索引。该索引在数据字典中的描述也将被删除。 例2.8 删除IX-Emp1索引。 DROPINDEXIX-Emp1;

39
2.3 SQL的查询语句——SELECT 查询是数据库应用的核心内容。SQL只提供一条查询语句——SELECT,但该语句功能丰富,使用方法灵活,可以满足用户的任何要求。使用SELECT语句时,用户不需指明被查询关系的路径,只需要指出关系名,查询什么,有何附加条件即可。

40
SELECT既可以在基本表关系上查询,也可以在视图关系上查询。因此,下面介绍语句中的关系既可以是基本表,也可以是视图。读者目前可把关系专指为基本表,到介绍视图操作时,再把它与视图联系起来。
一、语句格式 SELECT语句的基本格式为: SELECT[DISTINCT/ALL]<目标列表达式[别名]清单> FROM<关系名[别名]清单> [WHERE<查询条件表达式>];

41
本语句从<关系名清单>所规定的若干关系中首先找出符合WHERE子句中<查询条件表达式>的元组(无此子句时,查询出所有元组);再根据<目标列表达式清单>的规定,组合这些元组的属性值,形成一个新的查询结果关系;最后输出这个结果关系。
;再根据<目标列表达式清单>的规定,组合这些元组的属性值,形成一个新的查询结果关系;最后输出这个结果关系。")
42
二、说明 (1) DISTINCT/ALL。若从一关系中查询出符合条件的元组,但输出部分属性值,结果关系中就可能有重复元组存在。选择DISTINCT,则每组重复元组只输出一条元组;选择ALL,则所有重复元组全部输出。两个都不选,默认为ALL。 (2)<目标列表达式>。一般地,每个目标列表达式本身将作为结果关系列名,表达式的值作为结果关系中该列的值。一个目标列表达式的一般格式为:
<目标列表达式>。一般地,每个目标列表达式本身将作为结果关系列名,表达式的值作为结果关系中该列的值。一个目标列表达式的一般格式为:")
43
①[<关系名>. ]<属性名表达式>(如:Salary
①[<关系名>.]<属性名表达式>(如:Salary.Basepay+50)若被查询诸关系中,只有此关系有该属性,则关系名可省略,此例中,结果关系该列的列名即为此表达式,各元组在该列的分量即为原基本工资加50后的值。 ②[<关系名>.]*(如Employee.*) 若结果关系的各列正好是某被查询的关系的所有属性时,则可用此格式。本例的义是:结果关系各列正好是关系Employee的各列。若被查询关系只有一个,则上述关系名也可省略。
![①[<关系名>. ]<属性名表达式>(如:Salary](http://slidesplayer.com/slide/11336135/61/images/43/%E2%91%A0%EF%BC%BB%3C%E5%85%B3%E7%B3%BB%E5%90%8D%3E.+%EF%BC%BD%3C%E5%B1%9E%E6%80%A7%E5%90%8D%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%28%E5%A6%82%EF%BC%9ASalary.jpg "①[<关系名>.]<属性名表达式>(如:Salary.Basepay+50)若被查询诸关系中,只有此关系有该属性,则关系名可省略,此例中,结果关系该列的列名即为此表达式,各元组在该列的分量即为原基本工资加50后的值。 ②[<关系名>.]*(如Employee.*) 若结果关系的各列正好是某被查询的关系的所有属性时,则可用此格式。本例的义是:结果关系各列正好是关系Employee的各列。若被查询关系只有一个,则上述关系名也可省略。")
44
③不含有任何被查询关系中属性名的表达式。
最极端时,该表达式只由一个常量组成,则该列的列名和各元组的分量都为此常量。但是,这种情况一般都是在表达式中含有某个集函数。各实际RDBMS提供的集函数不尽相同,但一般都提供以下几个:

45
COUNT([DISTINCT/ALL]*)
统计结果中元组个数 COUNT([DISTINCT/ALL]<列名>) 统计一列上元组个数 MAX(<列名>) 给出一列上的最大值 MIN(<列名>) 给出一列上的最小值 SUM([DISTINCT/ALL]<列名>) 给出一列上值的总和(只对数值型) AVG([DISTINCT/ALL]<列名>) 给出一列上值的平均值(只对数值型)
![COUNT([DISTINCT/ALL]*)](http://slidesplayer.com/slide/11336135/61/images/45/COUNT%28%EF%BC%BBDISTINCT%2FALL%EF%BC%BD%2A%29.jpg "统计结果中元组个数. COUNT([DISTINCT/ALL]<列名>) 统计一列上元组个数. MAX(<列名>) 给出一列上的最大值. MIN(<列名>) 给出一列上的最小值. SUM([DISTINCT/ALL]<列名>) 给出一列上值的总和(只对数值型) AVG([DISTINCT/ALL]<列名>) 给出一列上值的平均值(只对数值型)")
46
例如: SELECTCOUNT(*) 求结果关系的元组总数 SELECTCOUNT(DISTINCT Basepay) 求结果关系中不同基本工资的个数 SELECTAVG(Basepay) 求结果关系中所有基本工资的平均值

47
(3)目标列表达式的[别名]。 没有此别名时,一个目标列表达式即为结果关系中此列的列名。当此目标列表达式是一个被查询关系的某列名时,这是没问题的。但当此目标列表达式是一个有着+,-,*,/符号的表达式时,此列名将会使列的含义含糊。特别地,当此目标列表达式包含有函数时,情况更是如此。为此,SQL提供了由用户另外为目标列表达式规定列名的手段,就是这里的[别名]。
![(3)目标列表达式的[别名]。](http://slidesplayer.com/slide/11336135/61/images/47/%283%29%E7%9B%AE%E6%A0%87%E5%88%97%E8%A1%A8%E8%BE%BE%E5%BC%8F%E7%9A%84%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E3%80%82.jpg "没有此别名时,一个目标列表达式即为结果关系中此列的列名。当此目标列表达式是一个被查询关系的某列名时,这是没问题的。但当此目标列表达式是一个有着+,-,*,/符号的表达式时,此列名将会使列的含义含糊。特别地,当此目标列表达式包含有函数时,情况更是如此。为此,SQL提供了由用户另外为目标列表达式规定列名的手段,就是这里的[别名]。")
48
当没有此[别名]时,目标列表达式即为结果关系中该列的列名;当给出一个[别名]时,结果关系中该列的列名即为此[别名](但结果关系中各元组在此列上的分量仍为该目标列表达式的值)。
![当没有此[别名]时,目标列表达式即为结果关系中该列的列名;当给出一个[别名]时,结果关系中该列的列名即为此[别名](但结果关系中各元组在此列上的分量仍为该目标列表达式的值)。](http://slidesplayer.com/slide/11336135/61/images/48/%E5%BD%93%E6%B2%A1%E6%9C%89%E6%AD%A4%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%97%B6%EF%BC%8C%E7%9B%AE%E6%A0%87%E5%88%97%E8%A1%A8%E8%BE%BE%E5%BC%8F%E5%8D%B3%E4%B8%BA%E7%BB%93%E6%9E%9C%E5%85%B3%E7%B3%BB%E4%B8%AD%E8%AF%A5%E5%88%97%E7%9A%84%E5%88%97%E5%90%8D%EF%BC%9B%E5%BD%93%E7%BB%99%E5%87%BA%E4%B8%80%E4%B8%AA%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%97%B6%EF%BC%8C%E7%BB%93%E6%9E%9C%E5%85%B3%E7%B3%BB%E4%B8%AD%E8%AF%A5%E5%88%97%E7%9A%84%E5%88%97%E5%90%8D%E5%8D%B3%E4%B8%BA%E6%AD%A4%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%28%E4%BD%86%E7%BB%93%E6%9E%9C%E5%85%B3%E7%B3%BB%E4%B8%AD%E5%90%84%E5%85%83%E7%BB%84%E5%9C%A8%E6%AD%A4%E5%88%97%E4%B8%8A%E7%9A%84%E5%88%86%E9%87%8F%E4%BB%8D%E4%B8%BA%E8%AF%A5%E7%9B%AE%E6%A0%87%E5%88%97%E8%A1%A8%E8%BE%BE%E5%BC%8F%E7%9A%84%E5%80%BC%29%E3%80%82.jpg "当没有此[别名]时,目标列表达式即为结果关系中该列的列名;当给出一个[别名]时,结果关系中该列的列名即为此[别名](但结果关系中各元组在此列上的分量仍为该目标列表达式的值)。")
49
(4)FROM<关系名[别名]清单>。
此子句指明了被查询的各关系的关系名。有时,一个关系会被两次查询,这时就需要把先后查询的同一关系区分开来。使用[别名]即可达到此目的。 例: FROM Item-Emp FIRST,Item-Emp SECOND 但此时,在SELECT子句和WHERE子句中出现的属性名,必须指明是FIRST关系的还是SECOND关系的。
![(4)FROM<关系名[别名]清单>。](http://slidesplayer.com/slide/11336135/61/images/49/%284%29FROM%3C%E5%85%B3%E7%B3%BB%E5%90%8D%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%B8%85%E5%8D%95%3E%E3%80%82.jpg "此子句指明了被查询的各关系的关系名。有时,一个关系会被两次查询,这时就需要把先后查询的同一关系区分开来。使用[别名]即可达到此目的。 例: FROM Item-Emp FIRST,Item-Emp SECOND. 但此时,在SELECT子句和WHERE子句中出现的属性名,必须指明是FIRST关系的还是SECOND关系的。")
50
(5)WHERE<查询条件表达式>。
本子句给出查询条件。其格式有以下几种: ①<属性名>θ<属性名>,<属性名>θ常量 其中θ为比较操作符=,<,>,<=,>=,<>等,如: WHERE姓名=′李勇′; WHERE Price=60;

51
②<属性名>[NOT]BETWEEN<常量1>AND
<常量2> 其中,<常量1>为下限,<常量2>为上限。 无[NOT]时,在<常量1>和<常量2>之间的值有效,否则无效;有[NOT]时,则相反。例如: WHEREOutlayBETWEEN10AND20 ③<属性名>[NOT]IN(<常量清单>) 无[NOT]时,<属性名>值在<常量清单>中有效,否则无效;有[NOT]时,则相反。例如: WHERE Eno NOT IN(1002,1010,1022)
![②<属性名>[NOT]BETWEEN<常量1>AND](http://slidesplayer.com/slide/11336135/61/images/51/%E2%91%A1%3C%E5%B1%9E%E6%80%A7%E5%90%8D%3E%EF%BC%BBNOT%EF%BC%BDBETWEEN%3C%E5%B8%B8%E9%87%8F1%3EAND.jpg "<常量2> 其中,<常量1>为下限,<常量2>为上限。 无[NOT]时,在<常量1>和<常量2>之间的值有效,否则无效;有[NOT]时,则相反。例如: WHEREOutlayBETWEEN10AND20. ③<属性名>[NOT]IN(<常量清单>) 无[NOT]时,<属性名>值在<常量清单>中有效,否则无效;有[NOT]时,则相反。例如: WHERE Eno NOT IN(1002,1010,1022)")
52
④<属性名>[NOT]LIKE<含有通配符的字符串>
通配符有“%”和“-”两种:“%”表示任意长度的字符串,“-”表示任意单个字符。无[NOT]时,值与该字符串匹配时有效,否则无效;有[NOT]时,则相反。例如: WHERE Ino LIKE"1998%" 若通配符本身就是字符串内容,则可增加短语ESCAPE解释之。如:WHERE Iname LIKE′C\-%′ESCAPE′\′,则紧跟在\后的-不是通配符,仅是一个字符而已。
![④<属性名>[NOT]LIKE<含有通配符的字符串>](http://slidesplayer.com/slide/11336135/61/images/52/%E2%91%A3%3C%E5%B1%9E%E6%80%A7%E5%90%8D%3E%EF%BC%BBNOT%EF%BC%BDLIKE%3C%E5%90%AB%E6%9C%89%E9%80%9A%E9%85%8D%E7%AC%A6%E7%9A%84%E5%AD%97%E7%AC%A6%E4%B8%B2%3E.jpg "通配符有 % 和 - 两种: % 表示任意长度的字符串, - 表示任意单个字符。无[NOT]时,值与该字符串匹配时有效,否则无效;有[NOT]时,则相反。例如: WHERE Ino LIKE 1998% 若通配符本身就是字符串内容,则可增加短语ESCAPE解释之。如:WHERE Iname LIKE′C\-%′ESCAPE′\′,则紧跟在\后的-不是通配符,仅是一个字符而已。")
53
⑤<属性名>IS[NOT]NULL
无[NOT]时,<属性名>值为NULL有效,否则无效;有[NOT]时,则相反。如: WHERE Chek-date IS NOT NULL ⑥<条件表达式>[AND|OR<条件表达式>]n 其中,各<条件表达式>本身为逻辑值(真或假),n的意义与2.2.4节中的n相同。如: WHERE Ino=′1998′AND Eno=′1016′ ⑦特别注意,WHERE子句中不能用集函数作为条件表达式。
![⑤<属性名>IS[NOT]NULL](http://slidesplayer.com/slide/11336135/61/images/53/%E2%91%A4%3C%E5%B1%9E%E6%80%A7%E5%90%8D%3EIS%EF%BC%BBNOT%EF%BC%BDNULL.jpg "无[NOT]时,<属性名>值为NULL有效,否则无效;有[NOT]时,则相反。如: WHERE Chek-date IS NOT NULL. ⑥<条件表达式>[AND|OR<条件表达式>]n. 其中,各<条件表达式>本身为逻辑值(真或假),n的意义与2.2.4节中的n相同。如: WHERE Ino=′1998′AND Eno=′1016′ ⑦特别注意,WHERE子句中不能用集函数作为条件表达式。")
54
三、举例 例2.9 SELECT DISTINCT Eno FROM Item-Emp WHERE Ino LIKE′1998%′ 从Item-Emp表中查找Ino的前4位为′1998′的元组,显示Eno列值(相同值只需显示一次)。 例 SELECT* FROM Salary WHERE Basepay BETWEEN 500 AND 700 从Salary表中查找Basepay在500和700间的元组,显示符合条件元组的所有属性。

55
例2.11 SELECT Employee.Eno, Ename,Ino
FROM Employee,Item-Emp WHER EEmployee.Eno=Item-Emp.Eno 查询参加项目职工的职工号、职工名和项目号。把职工表与参加表联接成一个新表,新表由两表各部分属性组成(见SELECT子句)。但只有职工表中Eno与参加表中Eno相等的元组连接。 注:如果没有WHERE子句的话,当Employee表有m条记录,Item-Emp表有n条记录时,输出关系有m*n条记录。
。但只有职工表中Eno与参加表中Eno相等的元组连接。 注:如果没有WHERE子句的话,当Employee表有m条记录,Item-Emp表有n条记录时,输出关系有m*n条记录。")
56
例2.12 SELECT FIRST.Eno,SECOND.REno
FROM Item-Emp FIRST,Item-Emp SECOND WHERE FIRST.REno=SECOND.Eno 这是一个自身连接的例子。根据Item-Emp,求出参加某项目者的间接联系人。 例 SELECT Salary.Eno,Ename,Basepay+ Service+Price+Rest-Insure-Fund WAGE FROM Salary,Employee WHERE Salary.Eno=Employee.Eno

57
例 SELECT* FROM Salary WHERE(BasepayBETWEEN600AND700)AND(ServiceIN(6.0,7.0,13.0,25.0))ANDEno LIKE′100-′ 从Salary中选取符合下列条件的元组: ①基本工资在600与700之间; ②工龄工资为6,7,13,25; ③职工号前三位为100(共有4位)。
。")
58
例 SELECT* FROM Item WHERE Check-date IS NULL 从项目表中选取鉴定日期是空值的记录

59
2.3.2 SELECT语句的高级使用格式 一、语句格式 SELECT语句的高级使用格式与基本格式相似,即 SELECT[DISTINCT/ALL] <目标列表达式[别名]清单> FROM<关系名[别名]清单> WHERE<查询条件表达式> 高级使用格式与基本使用格式的差别在于,高级使用格式的WHERE子句肯定存在,且<查询条件表达式>中嵌套有另外的查询。
![2.3.2 SELECT语句的高级使用格式 一、语句格式. SELECT语句的高级使用格式与基本格式相似,即. SELECT[DISTINCT/ALL] <目标列表达式[别名]清单> FROM<关系名[别名]清单>](http://slidesplayer.com/slide/11336135/61/images/59/2.3.2+SELECT%E8%AF%AD%E5%8F%A5%E7%9A%84%E9%AB%98%E7%BA%A7%E4%BD%BF%E7%94%A8%E6%A0%BC%E5%BC%8F+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F.+SELECT%E8%AF%AD%E5%8F%A5%E7%9A%84%E9%AB%98%E7%BA%A7%E4%BD%BF%E7%94%A8%E6%A0%BC%E5%BC%8F%E4%B8%8E%E5%9F%BA%E6%9C%AC%E6%A0%BC%E5%BC%8F%E7%9B%B8%E4%BC%BC%EF%BC%8C%E5%8D%B3.+SELECT%EF%BC%BBDISTINCT%2FALL%EF%BC%BD+%3C%E7%9B%AE%E6%A0%87%E5%88%97%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%B8%85%E5%8D%95%3E+FROM%3C%E5%85%B3%E7%B3%BB%E5%90%8D%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%B8%85%E5%8D%95%3E.jpg "WHERE<查询条件表达式> 高级使用格式与基本使用格式的差别在于,高级使用格式的WHERE子句肯定存在,且<查询条件表达式>中嵌套有另外的查询。")
60
二、说明 (1)一个SELECT―FROM―WHERE语句称为一个查询块,WHERE子句中的查询块称为嵌套查询。在此,外层的查询称为外层查询或父查询,内层的查询称为内层查询或子查询。 (2)一个查询还可以再嵌套子查询,这就是多层查询,层层嵌套,这就是结构化。 (3)求解嵌套查询的一般方法是由里向外,逐层处理。即,子查询在它的父查询处理前先求解,子查询的结果作为其父查询查找条件的一部分。
求解嵌套查询的一般方法是由里向外,逐层处理。即,子查询在它的父查询处理前先求解,子查询的结果作为其父查询查找条件的一部分。")
61
(4)有了嵌套查询后,SQL的查询功能就变得更丰富多采。复杂的查询可以用多个简单查询嵌套来解决,一些原来无法实现的查询也因有了多层嵌套查询而迎刃而解。嵌套查询时WHERE中<查询条件表达式>的格式有以下几种: ①<属性名>θ[ANY/ALL](SELECT语句) ANY只要与子查询中一个值符合即可,ALL要与子查询中所有值相符合。
 ANY只要与子查询中一个值符合即可,ALL要与子查询中所有值相符合。")
62
如: WHERE Dno=ANY (SELECT Dno FROM Employee WHERE Eno=′1002′OR Eno=′1003′) 职工表中,当职工号为1002或1003元组所在部门,与外层查询中的部门相同时,才符合查询条件,其他都不符合条件。
 职工表中,当职工号为1002或1003元组所在部门,与外层查询中的部门相同时,才符合查询条件,其他都不符合条件。 .")
63
为便于理解,将ANY和ALL的确切含义归纳如下:

64
>=ALL 必须大于等于所有结果 <=ANY 只要小于等于其中一个即可 <=ALL 必须小于等于所有的结果 =ANY 只要等于其中一个即可 <>ANY 只要与其中一个不等即可 <>ALL 必须与所有结果都不等

65
②<属性名>[NOT]IN(SELECT语句)
无[NOT]时,只要属性值在SELECT子查询结果中即可,否则无效;有[NOT]时,则相反。如: WHERE Eno IN (SELECT Eno FROM Item-Emp WHERE Ino LIKE′199%′) 凡是与某参加90年代项目职工的职工号相等即符合条件。
![②<属性名>[NOT]IN(SELECT语句)](http://slidesplayer.com/slide/11336135/61/images/65/%E2%91%A1%3C%E5%B1%9E%E6%80%A7%E5%90%8D%3E%EF%BC%BBNOT%EF%BC%BDIN%28SELECT%E8%AF%AD%E5%8F%A5%29.jpg "无[NOT]时,只要属性值在SELECT子查询结果中即可,否则无效;有[NOT]时,则相反。如: WHERE Eno IN. (SELECT Eno. FROM Item-Emp. WHERE Ino LIKE′199%′) 凡是与某参加90年代项目职工的职工号相等即符合条件。")
66
③[NOT]EXISTS(SELECT语句),如:
SELECT Eno,Ename FROM Employee WHEREEXISTS (SELECT* FROM Item-Emp WHERE Eno=Employee.Eno);
![③[NOT]EXISTS(SELECT语句),如:](http://slidesplayer.com/slide/11336135/61/images/66/%E2%91%A2%EF%BC%BBNOT%EF%BC%BDEXISTS%28SELECT%E8%AF%AD%E5%8F%A5%29%2C%E5%A6%82%EF%BC%9A.jpg "SELECT Eno,Ename. FROM Employee. WHEREEXISTS. (SELECT* FROM Item-Emp. WHERE Eno=Employee.Eno);")
67
EXISTS代表存在量词。在此格式中,子查询(SELECT语句)不返回任何数据,只产生逻辑值:无[NOT]时,子查询查到元组,返回值为真(TURE),否则为假;有[NOT]时,则相反。
此格式的子查询中,<目标列表达式清单>一般都用“*”号(是其他的属性名也可以,但无实际意义。因此,为了用户方便起见,一般用*)。
![EXISTS代表存在量词。在此格式中,子查询(SELECT语句)不返回任何数据,只产生逻辑值:无[NOT]时,子查询查到元组,返回值为真(TURE),否则为假;有[NOT]时,则相反。](http://slidesplayer.com/slide/11336135/61/images/67/EXISTS%E4%BB%A3%E8%A1%A8%E5%AD%98%E5%9C%A8%E9%87%8F%E8%AF%8D%E3%80%82%E5%9C%A8%E6%AD%A4%E6%A0%BC%E5%BC%8F%E4%B8%AD%EF%BC%8C%E5%AD%90%E6%9F%A5%E8%AF%A2%28SELECT%E8%AF%AD%E5%8F%A5%29%E4%B8%8D%E8%BF%94%E5%9B%9E%E4%BB%BB%E4%BD%95%E6%95%B0%E6%8D%AE%EF%BC%8C%E5%8F%AA%E4%BA%A7%E7%94%9F%E9%80%BB%E8%BE%91%E5%80%BC%EF%BC%9A%E6%97%A0%EF%BC%BBNOT%EF%BC%BD%E6%97%B6%EF%BC%8C%E5%AD%90%E6%9F%A5%E8%AF%A2%E6%9F%A5%E5%88%B0%E5%85%83%E7%BB%84%EF%BC%8C%E8%BF%94%E5%9B%9E%E5%80%BC%E4%B8%BA%E7%9C%9F%28TURE%29%2C%E5%90%A6%E5%88%99%E4%B8%BA%E5%81%87%EF%BC%9B%E6%9C%89%EF%BC%BBNOT%EF%BC%BD%E6%97%B6%EF%BC%8C%E5%88%99%E7%9B%B8%E5%8F%8D%E3%80%82.jpg "此格式的子查询中,<目标列表达式清单>一般都用 * 号(是其他的属性名也可以,但无实际意义。因此,为了用户方便起见,一般用*)。")
68
这类子查询的求解方式与前面是不同的(重复一遍,一般来说,子查询都在其父查询处理前求解)。在这里,子查询的查询条件往往依赖于其父查询的某属性值。这类查询称为相关子查询。这就是为什么本格式上述举例时,不能单独取出父查询的WHERE子句的缘故。 求执行相关子查询的过程为:从外查询的关系(Employee)中依次取一个元组,根据它的值在内查询进行检查,若WHERE子句为真,将此元组放入结果表(为假,则舍去)。这样反复处理,直至外查询关系的元组全部处理完为止。
中依次取一个元组,根据它的值在内查询进行检查,若WHERE子句为真,将此元组放入结果表(为假,则舍去)。这样反复处理,直至外查询关系的元组全部处理完为止。")
69
④[NOT]BETWEEN<上限>AND<下限>中的<下限>和<上限>也可以是子查询。这种情况下,子查询结果作为边界。
![④[NOT]BETWEEN<上限>AND<下限>中的<下限>和<上限>也可以是子查询。这种情况下,子查询结果作为边界。](http://slidesplayer.com/slide/11336135/61/images/69/%E2%91%A3%EF%BC%BBNOT%EF%BC%BDBETWEEN%3C%E4%B8%8A%E9%99%90%3EAND%3C%E4%B8%8B%E9%99%90%3E%E4%B8%AD%E7%9A%84%3C%E4%B8%8B%E9%99%90%3E%E5%92%8C%3C%E4%B8%8A%E9%99%90%3E%E4%B9%9F%E5%8F%AF%E4%BB%A5%E6%98%AF%E5%AD%90%E6%9F%A5%E8%AF%A2%E3%80%82%E8%BF%99%E7%A7%8D%E6%83%85%E5%86%B5%E4%B8%8B%EF%BC%8C%E5%AD%90%E6%9F%A5%E8%AF%A2%E7%BB%93%E6%9E%9C%E4%BD%9C%E4%B8%BA%E8%BE%B9%E7%95%8C%E3%80%82.jpg "④[NOT]BETWEEN<上限>AND<下限>中的<下限>和<上限>也可以是子查询。这种情况下,子查询结果作为边界。")
70
三、举例 例 SELECT* FROM Employee WHERE Eno=ANY (SELECT Eno FROM Item-Emp WHERE Ino=′2000%′); 在职工表中取出所有参加2000年度项目的职工。

71
例2.17 SELECT Eno,Ename,Dno,Title
FROM Employee WHER Eino IN (SELECT Ino FROMItem-Emp WHERE Eno=′1004′); 从Employee关系中取出所有与1004号职工共同参加项目的职工的元组。但仅输出属性职工号、姓名、部门和职称的值。
; 从Employee关系中取出所有与1004号职工共同参加项目的职工的元组。但仅输出属性职工号、姓名、部门和职称的值。")
72
例 SELECT Eno,Ename,Dno FROM Employee WHERE EXISTS (SELECT* FROM Item-Emp WHERE Eno=Employee.Eno AND Ino=′199801′); 从Employee关系中取出所有参加了199801项目的元组,只输出职工号,姓名,部门三属性值。

73
例 SELECT FIRST.Eno FROM Salary FIRST WHERE Basepay BETWEEN (SELECT Basepay FROM Salary SENCOND WHERE SENCORD.Eno=′1010′)AND800; 在工资表中,把基本工资介于职工号‘1010’工资和800元之间的职工号查询出来。
AND800; 在工资表中,把基本工资介于职工号‘1010’工资和800元之间的职工号查询出来。")
74
2.3.3 SELECT语句的完整使用格式 一、语句格式 SELECT[ALL/DISTINCT] <目标列清单[别名]清单> FROM<关系名[别名]清单> WHERE<查询条件表达式> [ORDERBY<列名[ASC/DESC]清单>] [GROUPBY<列名清单>[HAVING<条件表达式>]] SELECT语句的完整格式比前面的格式多了ORDERBY子句以及GROUPBY子句两个可选项。
![2.3.3 SELECT语句的完整使用格式 一、语句格式. SELECT[ALL/DISTINCT] <目标列清单[别名]清单> FROM<关系名[别名]清单> WHERE<查询条件表达式>](http://slidesplayer.com/slide/11336135/61/images/74/2.3.3+SELECT%E8%AF%AD%E5%8F%A5%E7%9A%84%E5%AE%8C%E6%95%B4%E4%BD%BF%E7%94%A8%E6%A0%BC%E5%BC%8F+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F.+SELECT%EF%BC%BBALL%2FDISTINCT%EF%BC%BD+%3C%E7%9B%AE%E6%A0%87%E5%88%97%E6%B8%85%E5%8D%95%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%B8%85%E5%8D%95%3E+FROM%3C%E5%85%B3%E7%B3%BB%E5%90%8D%EF%BC%BB%E5%88%AB%E5%90%8D%EF%BC%BD%E6%B8%85%E5%8D%95%3E+WHERE%3C%E6%9F%A5%E8%AF%A2%E6%9D%A1%E4%BB%B6%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E.jpg "[ORDERBY<列名[ASC/DESC]清单>] [GROUPBY<列名清单>[HAVING<条件表达式>]] SELECT语句的完整格式比前面的格式多了ORDERBY子句以及GROUPBY子句两个可选项。")
75
二、说明 (1) ORDERBY<列名[ASC/DESC]清单> 有了ORDER子句后,SELECT语句的查询结果表中各元组将排序输出:首先按第一个<列名>值排序;前一个<列名>值相同者,再按下一个<列名>值排序,以此类推。若某列名后有DESC,则以该列名值排序时为降序排列,否则,为升序排列。例如: ORDERBY Service,Basepay DESC 结果首先以工龄工资升序排序,工龄工资相等的元组再以基本工资降序排列。
![二、说明 (1) ORDERBY<列名[ASC/DESC]清单>](http://slidesplayer.com/slide/11336135/61/images/75/%E4%BA%8C%E3%80%81%E8%AF%B4%E6%98%8E+%281%29+ORDERBY%3C%E5%88%97%E5%90%8D%EF%BC%BBASC%2FDESC%EF%BC%BD%E6%B8%85%E5%8D%95%3E.jpg "有了ORDER子句后,SELECT语句的查询结果表中各元组将排序输出:首先按第一个<列名>值排序;前一个<列名>值相同者,再按下一个<列名>值排序,以此类推。若某列名后有DESC,则以该列名值排序时为降序排列,否则,为升序排列。例如: ORDERBY Service,Basepay DESC. 结果首先以工龄工资升序排序,工龄工资相等的元组再以基本工资降序排列。")
76
子查询的SELECT语句不能使用ORDERBY子句,此子句只能作用于最终查询结果。排序时,空值作为最大值处理。
(2)GROUPBY<列名清单>[HAVING<条件表达式>] 把查询所得元组根据GROUPBY中<列名清单>进行分组。在这些列上,对应值都相同的元组分在同一组;若无HAVING子句,则各组分别输出;若有HAVING子句,只有符合条件的组才输出。 一般地,当SELECT的<目标列表达式[别名]清单>中有集函数(COUNT、SUM等)时,才使用GROUP子句。
GROUPBY<列名清单>[HAVING<条件表达式>] 把查询所得元组根据GROUPBY中<列名清单>进行分组。在这些列上,对应值都相同的元组分在同一组;若无HAVING子句,则各组分别输出;若有HAVING子句,只有符合条件的组才输出。 一般地,当SELECT的<目标列表达式[别名]清单>中有集函数(COUNT、SUM等)时,才使用GROUP子句。")
77
例2.20 SELECT Dno,AVG(Age)Average-Age
FROM Employee GROUP BY Dno HAVING COUNT(*)>1; 把职工表中元组按部门分组,只有人数多于一人的组才输出;输出部门号和平均年龄两列。
>1; 把职工表中元组按部门分组,只有人数多于一人的组才输出;输出部门号和平均年龄两列。")
78
有了GROUPBY子句后,AVG函数对每一组求平均值,若无GROUPBY,AVG对整个输出求平均值。这一点,对所有的集函数都成立。
HAVING条件作用于结果组,选择满足条件的结果组。而WHERE条件作用于被查询的关系,从中选择满足条件的元组。

79
2.3.4 多个SELECT语句的集合操作 SQL提供了集合并操作手段UNION。 例 SELECT* FROM Item-Emp WHERE Ino=′19981′ UNION SELECT* WHERE Ino=′200001′;

80
本例把两条SELECT语句各自得到的结果集并为一个集(两集合中若有相同元组,只留一个)。
注意事项: 参加UNION的记录结果集必须有相同的列数,各对应项的数据类型也必须相同。SQL未直接提供集合交操作、集合差操作,但完全可用一般的SELECT语句代替之。请读者自行考虑。

81
2.4 含有子查询的数据更新 在2.2.3~2.2.6节中已介绍了INSERT、UPDATE和DELETE的基本使用方法及注意事项。本节介绍他们与子查询结合使用的方法。与子查询结合后,三语句的功能更强,使用手段也更加灵活。

82
INSERT与子查询的集合 一、语句格式 INSERTINTO<表名>[<属性名清单>] (子查询); 把子查询的结果插入指定的<表名>中。这样的一条INSERT语句,可以一次插入多条元组。
; 把子查询的结果插入指定的<表名>中。这样的一条INSERT语句,可以一次插入多条元组。 .")
83
二、举例 例2.22 假如部门号为‘01’的部门由于需要自己建立一个部门职工表,结构与Employee相同(表名为Employee-01)。则该表的元组可用一条INSERT语句一次全部插入如下: INSERT INTO Employee-01 SELECT* FROM Employee WHER EDno=′01′;

84
UPDATE与子查询的结合 一、语句格式 UPDATE<表名> SET<列名>=<表达式>[,<列名>=<表达式>]n [WHERE<带有子查询的条件表达式>] 本语句执行时,将修改使<带有子查询的条件表达式>为真的所有元组。n的意义与2.2.4节中的n相同。
![2.4.2 UPDATE与子查询的结合 一、语句格式. UPDATE<表名> SET<列名>=<表达式>[,<列名>=<表达式>]n.](http://slidesplayer.com/slide/11336135/61/images/84/2.4.2+UPDATE%E4%B8%8E%E5%AD%90%E6%9F%A5%E8%AF%A2%E7%9A%84%E7%BB%93%E5%90%88+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F.+UPDATE%3C%E8%A1%A8%E5%90%8D%3E+SET%3C%E5%88%97%E5%90%8D%3E%3D%3C%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%EF%BC%BB%EF%BC%8C%3C%E5%88%97%E5%90%8D%3E%3D%3C%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%EF%BC%BDn..jpg "[WHERE<带有子查询的条件表达式>] 本语句执行时,将修改使<带有子查询的条件表达式>为真的所有元组。n的意义与2.2.4节中的n相同。 .")
85
二、举例 例 UPDATE Salary SET Rest=Rest+200 WHERE Eno IN (SELECT Eno FROM Item-Emp WHEREIno=′199802′); 凡参加199802项目的职工,工资表中津贴的值都增加200。

86
DELETE与子查询的结合 一、语句格式 DELETE FROM<表名> [WHERE<带有子查询的条件表达式>] 本语句将删除使<带有子查询的条件表达式>为真的所有元组。
![2.4.3 DELETE与子查询的结合 一、语句格式 DELETE FROM<表名> [WHERE<带有子查询的条件表达式>] 本语句将删除使<带有子查询的条件表达式>为真的所有元组。](http://slidesplayer.com/slide/11336135/61/images/86/2.4.3+DELETE%E4%B8%8E%E5%AD%90%E6%9F%A5%E8%AF%A2%E7%9A%84%E7%BB%93%E5%90%88+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F+DELETE+FROM%3C%E8%A1%A8%E5%90%8D%3E+%EF%BC%BBWHERE%3C%E5%B8%A6%E6%9C%89%E5%AD%90%E6%9F%A5%E8%AF%A2%E7%9A%84%E6%9D%A1%E4%BB%B6%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%EF%BC%BD+%E6%9C%AC%E8%AF%AD%E5%8F%A5%E5%B0%86%E5%88%A0%E9%99%A4%E4%BD%BF%3C%E5%B8%A6%E6%9C%89%E5%AD%90%E6%9F%A5%E8%AF%A2%E7%9A%84%E6%9D%A1%E4%BB%B6%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%E4%B8%BA%E7%9C%9F%E7%9A%84%E6%89%80%E6%9C%89%E5%85%83%E7%BB%84%E3%80%82.jpg "2.4.3 DELETE与子查询的结合 一、语句格式 DELETE FROM<表名> [WHERE<带有子查询的条件表达式>] 本语句将删除使<带有子查询的条件表达式>为真的所有元组。")
87
二、举例 例 DELETE FROM Item-Emp WHERE Eno= (SELECT Eno FROM Employee WHERE姓名=′丁为国′); 从项目人员中,删除丁为国的所有元组。
; 从项目人员中,删除丁为国的所有元组。 .")
88
2.5 视 图 视图是数据库系统的一个重要机制。无论从方便用户的角度,还是从加强数据库安全的角度,视图都有着极其重要的作用。
2.5 视 图 视图是数据库系统的一个重要机制。无论从方便用户的角度,还是从加强数据库安全的角度,视图都有着极其重要的作用。 一个视图是从一个或多个关系(基本表或已有的视图)导出的关系。导出后,数据库中只存有此视图的定义(在数据字典中),但并没有实际生成此关系。因此视图是虚表。
导出的关系。导出后,数据库中只存有此视图的定义(在数据字典中),但并没有实际生成此关系。因此视图是虚表。")
89
用户使用视图时,其感觉与使用基本表是时相同的。但是
(1)由于视图是虚表,所以SQL对视图不提供建立索引的语句。 (2) SQL一般也不提供修改视图定义的语句(有此需要时,只要把原定义删除,重新定义一个新的即可,这样不影响任何数据)。 (3) 对视图中数据做更新时是有些限制的。
由于视图是虚表,所以SQL对视图不提供建立索引的语句。 (2) SQL一般也不提供修改视图定义的语句(有此需要时,只要把原定义删除,重新定义一个新的即可,这样不影响任何数据)。 (3) 对视图中数据做更新时是有些限制的。")
90
2.5.1 定义视图——CREATEVIEW 一、语句格式 CREATE VIEW<视图名>[<列名清单>] AS<子查询> [WITH CHECK OPTION]
![2.5.1 定义视图——CREATEVIEW 一、语句格式 CREATE VIEW<视图名>[<列名清单>] AS<子查询> [WITH CHECK OPTION]](http://slidesplayer.com/slide/11336135/61/images/90/2.5.1+%E5%AE%9A%E4%B9%89%E8%A7%86%E5%9B%BE%E2%80%94%E2%80%94CREATEVIEW+%E4%B8%80%E3%80%81%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F+CREATE+VIEW%3C%E8%A7%86%E5%9B%BE%E5%90%8D%3E%EF%BC%BB%3C%E5%88%97%E5%90%8D%E6%B8%85%E5%8D%95%3E%EF%BC%BD+AS%3C%E5%AD%90%E6%9F%A5%E8%AF%A2%3E+%EF%BC%BBWITH+CHECK+OPTION%EF%BC%BD.jpg "2.5.1 定义视图——CREATEVIEW 一、语句格式 CREATE VIEW<视图名>[<列名清单>] AS<子查询> [WITH CHECK OPTION]")
91
二、说明 (1)<视图名>给出所定义的视图的名称。 (2)若有<列名清单>,则此清单给出了此视图的全部属性的属性名;否则,此视图的所有属性名即为子查询中SELECT语句中的全部目标列。 (3)<子查询>为任一合法SELECT语句(但一般不含有ORDERBY,UNION等语法成分)。
<视图名>给出所定义的视图的名称。 (2)若有<列名清单>,则此清单给出了此视图的全部属性的属性名;否则,此视图的所有属性名即为子查询中SELECT语句中的全部目标列。 (3)<子查询>为任一合法SELECT语句(但一般不含有ORDERBY,UNION等语法成分)。")
92
(4)有[WITHCHECKOPTION]时,则今后对此视图进行INSERT、UPDATE和DELETE操作时,系统会自动检查视图是否符合原定义视图时子查询中的<条件表达式>。
本语句执行后,此视图的定义即进入数据字典,对语句中的<子查询>并未执行,也即视图并未真正生成。所以说,视图是虚表。
![(4)有[WITHCHECKOPTION]时,则今后对此视图进行INSERT、UPDATE和DELETE操作时,系统会自动检查视图是否符合原定义视图时子查询中的<条件表达式>。](http://slidesplayer.com/slide/11336135/61/images/92/%284%29%E6%9C%89%EF%BC%BBWITHCHECKOPTION%EF%BC%BD%E6%97%B6%EF%BC%8C%E5%88%99%E4%BB%8A%E5%90%8E%E5%AF%B9%E6%AD%A4%E8%A7%86%E5%9B%BE%E8%BF%9B%E8%A1%8CINSERT%E3%80%81UPDATE%E5%92%8CDELETE%E6%93%8D%E4%BD%9C%E6%97%B6%EF%BC%8C%E7%B3%BB%E7%BB%9F%E4%BC%9A%E8%87%AA%E5%8A%A8%E6%A3%80%E6%9F%A5%E8%A7%86%E5%9B%BE%E6%98%AF%E5%90%A6%E7%AC%A6%E5%90%88%E5%8E%9F%E5%AE%9A%E4%B9%89%E8%A7%86%E5%9B%BE%E6%97%B6%E5%AD%90%E6%9F%A5%E8%AF%A2%E4%B8%AD%E7%9A%84%3C%E6%9D%A1%E4%BB%B6%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%E3%80%82.jpg "本语句执行后,此视图的定义即进入数据字典,对语句中的<子查询>并未执行,也即视图并未真正生成。所以说,视图是虚表。")
93
三、举例 例 CREATE VIEW Employee-02 AS SELECT* FROM Employee WHERE Dno=′02′; 从职工表中取出部门为‘02’的元组组成一个视图。 视图可以从一个基本表或视图导出,也可以是从多个基本表或多个视图导出。

94
一个视图,如果只从单个基本表导出,且保留了原来的码,只是去掉了原基本表的某些行和非码属性,该视图称为 行列子集视图,如上述Employee-02视图。
定义视图时,若设置了一些派生属性(这些属性是原基本表没有的,其值是用一个表达式对原基本表的运算而得到的),则此视图称为带有表达式的视图,这些派生属性也称为虚拟列。 定义视图时,若使用了集函数和GROUPBY子句的查询,则此视图称为分组视图。
,则此视图称为带有表达式的视图,这些派生属性也称为虚拟列。 定义视图时,若使用了集函数和GROUPBY子句的查询,则此视图称为分组视图。")
95
2.5.2 删除视图——DROPVIEW 一、语句格式 DROPVIEW<视图名> 此语句将把指定视图的定义从数据字典中删除。 一个关系(基本表或视图)被删除后,所有由该关系导出的视图并不自动删除,它们仍在数据字典中,但已无法使用。删除视图必须用DROPVIEW语句。 二、举例 例2.26 DROP VIEW Employee-02 执行此语句后,Employee-02视图的定义就从数据字典中删除了。

96
2.5.3 视图的查询 一、用户的工作 对用户来说,对视图的查询与对基本表的查询是没有区别的,都使用SELECT语句对有关的关系进行查询工作。在查询时,用户不需区分是对基本表查询,还是对视图查询。SELECT语句中不需(也不可能)标明被查询的关系是基本表还是视图。如: SELECT* FROM Employee-02

97
二、DBMS对视图查询的处理 DBMS对某SELECT语句进行处理时,若发现被查询对象是视图,则DBMS将进行下述操作: (1)从数据字典中取出视图的定义。 (2)把视图定义的子查询和本SELECT的查询相结合,生成等价的对基本表的查询(此过程称为视图的消解)。 (3)执行对基本表的查询,把查询结果(作为本次对视图的查询结果)向用户显示。
执行对基本表的查询,把查询结果(作为本次对视图的查询结果)向用户显示。")
98
三、特殊情况的处理 一般情况下,对视图的查询是不会出现问题的。但有时,视图消解过程不能给出语法正确的查询条件。因此,对视图查询时,若出现语法错误,可能不是查询语句本身有语法错误,而是转换后出现的语法错误。此时,用户须自行把对视图的查询转化为对基本表的查询。

99
2.5.4 视图的更新 一、视图更新的含义及执行过程 视图是虚表,是没有数据的。所谓视图的更新,表面上是对视图执行INSERT、 UPDATE和DELE TE来更新视图的数据,其实质是由DBMS自动转化成对导出视图的基本表的更新,转化成对基本表的INSERT、UPDATE和DELETE语句(用户在感觉上确实是在对视图更新)。
。")
100
例 INSERT INTO Employee-02 VALUES(′1036′,′陈向东′,′男′,25,1,′工程师′,′02′); 将转化成对基本表Employee的插入: INSERT INTO Employee VALUES(′1036′,′陈向东′,′男′,25,1,′工程师′,′02′);
;")
101
例 UPDATE Employee-02 SET Ename=′程向东′ WHERE Eno=′1036′; 也将转化成对基本表Employee的更新: UPDATE Employee

102
例 DELETE FROM Employee-02 WHERE Eno=′1036′; 转化为: DELETE FROM Employee

103
二、定义视图时,WITHCHECKOPTION的作用
定义视图时,是根据AS<子查询>的条件定义的。但视图更新的语句INSERT、 UPDATE和DEL ETE却都不能保证被更新的元组必定符合原来AS<子查询>的条件。如果这样的话,那视图就没有多大的作用了。 在定义视图时,若加上子句WITHCHECKOPTION,则在对视图更新时,系统将自动检查原定义时的条件是否满足。若不满足,则拒绝执行。

104
三、视图的可更新性 不是所有的视图都是可更新的,因为有些视图的更新不能有意义的转化成相应基本表的更新。 例2.30 我们先定义一个视图如下: CREATE VIEW AVG AS SELECT Dno,Avg(Age) FROM Employee GROUP BY Dno

105
本语句从职工表导出一个视图AVG。该视图有两列:部门号,平均年龄。对此视图的任何更新都无法转换成对职工表的更新。可见,视图有可更新和不可更新之分。
(1)有些视图是各个已有的RDBMS都可更新的,这些视图就属于实际可更新的视图。如前面指出的行列子集视图就属于此类。 (2)有些视图在理论上就是不可更新的,如前面定义的AVG视图,称为不可更新的视图。
有些视图是各个已有的RDBMS都可更新的,这些视图就属于实际可更新的视图。如前面指出的行列子集视图就属于此类。 (2)有些视图在理论上就是不可更新的,如前面定义的AVG视图,称为不可更新的视图。")
106
(3)有些视图在理论上是可更新的,但特征较复杂,因此实际上还是不能更新。称为不允许更新的视图。一般的DBMS只允许对单个基本表导出的视图进行更新。并有下列限制:
①若视图的列由表达式或常数组成,则不允许执行INSERT和UPDATE,但可执行DELETE。 ②若视图的列由集函数组成,则不允许更新。

107
③若视图定义中有GROUPBY子句,则不允许更新。
④若视图定义中有DISTINCT选项,则不允许更新。 ⑤若视图定义中有嵌套查询,且内外层FROM子句中的表是同一个表,则不允许更新。 ⑥从不允许更新的视图导出的视图是不允许更新的。

108
视图的作用 视图是SQL语句支持的三级模式结构中外模式的成分。因此,视图是数据库中数据的物理独立性和逻辑独立性的重要支柱。这在讨论三级模式结构时就已强调了。除此之外,视图还有如下作用: 1.视图能方便用户操作 若用户所需数据来自多个基本表,则通过视图可使用户感到数据是来自一个关系的;若用户所需数据是对基本表中的数据通过某种运算才能得到的,

109
则通过视图可使用户感到数据是一个关系的基本数据。有了视图,用户就可对一个关系(一张虚表)进行较简单的查询就可完成工作。而这个关系究竟是基本表还是虚表,虚表又是如何定义的,用户都无需知道。
2.视图可对数据提供安全保护 有了视图以后,可使任何用户只能看到他有权看到的数据,用户对数据更新也由视图定义中的WITHCHECKOPTION而有所限制。因此,视图给数据提供了一定的安全保护。

110
3.视图能使不同用户都能用自己喜欢的方式看待同一数据同一数据,在不同用户的各个视图中,可以以不同的名称出现,可以以不同的角色出现(平均值,最大值……)。这给数据共享带来了很大的方便。视图的缺点在于:查询和更新时可能会出现问题。对这一点,用户也必须有所准备。
。这给数据共享带来了很大的方便。视图的缺点在于:查询和更新时可能会出现问题。对这一点,用户也必须有所准备。")
Similar presentations

 EXISTS,NOT EXISTS P409 Q,EXISTS 和 in 的区别( 1000 ,查询结果)>")
 西安交大 卫颜俊 2008 年 12 月 电子信箱: QQ: 610568018 网站 : 202.117.58.97/java.>")








 主编 贾铁军 科学出版社 编著 陈国秦 万程 邢一鸣>")

 任课教师:刘雅莉 E_mail:slxy_lyl@163.com 2014-9.>")





