Download presentation
Presentation is loading. Please wait.

1
統計調查管理研習班 統計調查抽樣設計 鄭宇庭 國立政治大學統計學系

2
統計調查管理研習班 統計調查抽樣設計 抽樣基本概念

3
ex. 多少比率贊成統圖獨、公投、行政首長下台
抽樣問題的基本要素 母體太大 樣本 推論 推論 mean ex. 台灣平均家中小孩、收入 total τ ex. 多少瀕臨絕種動物、多少人抗議遊行 proportion p ex. 多少比率贊成統圖獨、公投、行政首長下台

4
每個樣本包含一些訊息( , τ, p),每一個樣本需要經費。
決策者決定要花多少錢來買訊息。 每個人都希望花最少的錢獲得最多訊息。 所以抽樣計劃可以告訴你花多錢 (sample size) 可以得到多精確的結果。
 可以得到多精確的結果。")
5
在一個社區探討民眾對於社區建設的支持率(贊成率):
elements(基本單元): 有投票權的社區民眾 measurement(測量): 意見---贊成(1),反對(0) population(總體): 在這個社區有投票權的民眾的集合 target , survey sampling units(抽樣單位): 一個民眾、一個家 frame(底冊;抽樣單位的名單): 個人---戶政事務所 家庭---電話簿 sample---(抽樣樣本): 在底冊中若被抽樣選中的抽樣單 位所形成的集合
: 有投票權的社區民眾. measurement(測量): 意見---贊成(1),反對(0) population(總體): 在這個社區有投票權的民眾的集合. target , survey. sampling units(抽樣單位): 一個民眾、一個家. frame(底冊;抽樣單位的名單): 個人---戶政事務所. 家庭---電話簿. sample---(抽樣樣本): 在底冊中若被抽樣選中的抽樣單. 位所形成的集合.")
6
如何選擇樣本數 :母體參數, :估計 B:精準度 ( , α = 5% ) 希望控制在B之下,那種抽樣方法可以達到 B,而且花費最少 。
 希望控制在B之下,那種抽樣方法可以達到 B,而且花費最少 。")
7
統計調查管理研習班 統計調查抽樣設計 抽樣方法

8
I. 非機率抽樣 Quota Sampling (配額抽樣) (分層抽樣- 隨機選取 ;配額抽樣-隨意選取) (ex.1948年前蓋洛普民調) Convenience Sampling (便利抽樣) (ex.街頭面訪) Judgment Sampling (判斷抽樣) (ex.主計處編製物價指數) Snowball Sampling (雪球抽樣) (ex.單親家庭,特殊疾病)
 Judgment Sampling (判斷抽樣) (ex.主計處編製物價指數) Snowball Sampling (雪球抽樣) (ex.單親家庭,特殊疾病)")
9
II. 機率抽樣 Simple Random Sampling (簡單隨機抽樣) (缺點:母體不能太大,花費太大) Systematic Sampling (等距抽樣) (ex.電話簿抽樣) Stratified Sampling (分層抽樣) (ex. 大四、大三、大二、大一) Cluster Sampling (群集抽樣) (ex. 一班) Multistage Sampling 多段抽樣
 Cluster Sampling (群集抽樣) (ex. 一班) Multistage Sampling 多段抽樣.")
10
簡單隨機抽樣方法 Simple Random Sampling

11
各種隨機抽樣方法,一般可分為五個步驟 (1) 決定採用何種抽樣方法 (2) 選擇估計數 (3) 求估計數的標準誤
(4) 計算母體參數的信賴區間 (5) 決定樣本大小
 計算母體參數的信賴區間. (5) 決定樣本大小.")
12
定義 簡單隨機抽樣法 (Simple Random Sampling)(SRS)
我們從母體 N 抽出樣本 n 的隨機樣本,其每一組可能的樣本均有相等被抽出的機會。這種抽樣程序即稱為簡單隨機抽樣法。其所抽出的樣本稱為簡單隨機樣本。

13
隨機樣本的抽出 隨機數字表 (Random Number Table) 隨機數字表的使用 隨機選取起始點,連續取用數字
隨機選取起始點,抽出個、十、百位數字

14
母體平均數的估計 平均數 (µ) Bound on the error of estimation
 Bound on the error of estimation")
15
(II) 總和 (τ) Bound on the error of estimation
 總和 (τ) Bound on the error of estimation")
16
Bound on the error of estimation
(III) 比例 (P) y=0, 1 Bound on the error of estimation
 比例 (P) y=0, 1. Bound on the error of estimation.")
17
樣本數的選擇 如何代入S ? (1) 分兩階段取樣 (2)Pilot Survey 平均數 (µ)
(3)Prior Information (4) range = 4S
Prior Information (4) range = 4S.")
18
(II) 總和 (τ) 如何代入S ? (1) 分兩階段取樣 (2)Pilot Survey (3)Prior Information (4) range = 4S
 總和 (τ) 如何代入S (1) 分兩階段取樣 (2)Pilot Survey (3)Prior Information (4) range = 4S")
19
(III) 比例 (P) 如何代入S ? (1) 分兩階段取樣 (2)Pilot Survey (3)Prior Information (4)p=q = 1/2
 比例 (P) 如何代入S (1) 分兩階段取樣 (2)Pilot Survey (3)Prior Information (4)p=q = 1/2")
20
簡單隨機抽樣使用時機 (1) 母體小 (2) 令人滿意的母體名冊 (3) 單位訪問成本不受地點遠近之影響
簡單隨機抽樣使用時機 (1) 母體小 (2) 令人滿意的母體名冊 (3) 單位訪問成本不受地點遠近之影響 (4) 母體名冊是有關母體資訊的唯一來源
 母體小. (2) 令人滿意的母體名冊. (3) 單位訪問成本不受地點遠近之影響. (4) 母體名冊是有關母體資訊的唯一來源.")
21
分層隨機抽樣方法 Stratified Random Sampling

22
定義 分層隨機抽樣法 (Stratified Random Sampling)
將母體按某種標準分為若干副母體,這些副母體舊稱為層(strata)。各層中所包含的個體互不重疊。其次各層中以簡單隨機抽樣抽出各層的簡單隨機樣本,然後將各層隨機樣本合併起來即成一組分層隨機樣本。這種抽樣程序即稱為分層隨機抽樣法。
。各層中所包含的個體互不重疊。其次各層中以簡單隨機抽樣抽出各層的簡單隨機樣本,然後將各層隨機樣本合併起來即成一組分層隨機樣本。這種抽樣程序即稱為分層隨機抽樣法。")
23
分層的功用 縮小樣本的誤差 降低成本 管理方便 副母體特性

24
分層的準則 空間(地點)的標準: 北部,中部,南部,東部 種類的標準: 產業的類別 等級的標準: 產品優劣,喜好差異
數量的標準: 人數,所得 組織的標準:學院,縣市鄉鎮鄰里

25
分層的先決條件 去分層? 分層抽樣的一個先決問題是如何去分層,應依哪一種性質或標準
抽樣調查必有一定的目的,應針對這個目的分層,或說哪一種分層法最有助於抽樣目的之達成,即採用那一種 抽樣必用某方法去實行,哪一種方法最便於實行,即採用那一種 分層需憑藉已有的全體的某些資料,這些資料是否完整,應就最完整可靠的資料去分層 抽樣調查所費不貲,而各種分層法所用的費用多少並不相同,應採用最少的一種去分層

26
母體平均數、總和及比例的估計 (I) 平均數 (µ) Bound on the error of estimation
 平均數 (µ) Bound on the error of estimation")
27
(II) 總和 (τ) Bound on the error of estimation
 總和 (τ) Bound on the error of estimation")
28
Bound on the error of estimation
(III) 比例 (P) Bound on the error of estimation
 比例 (P) Bound on the error of estimation.")
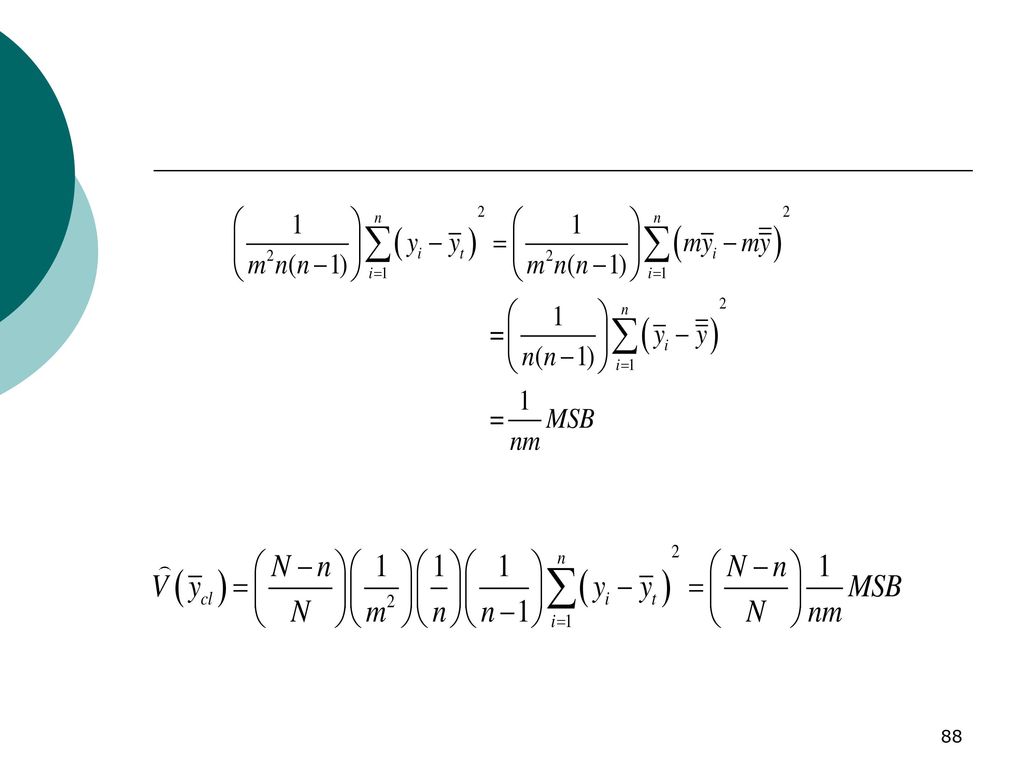
29
樣本數的選擇 (I) 平均數 (µ)
 平均數 (µ)")
30
(II) 總和 (τ)
 總和 (τ)")
31
(III) 比例 (P)
 比例 (P)")
32
配置樣本 分層隨機抽樣方法中,若 n 表示總樣本大小而 表示各層的樣本, 則 n 和 會滿足:
由上式可知 表示每層樣本大小 和總樣本大小 n 的比例,稱之為樣本配置(allocation) 。
 。")
33
當考慮分層隨機抽樣每一層樣本大小 的配置時,應注意下列三項事情: 每層母體的大小 每層變數的變異數 每層選取樣本的成本

34
其中 表示固定成本,而 表示每層每單位的調查費用。在本節中,我們將探討 (1)在抽樣調查總費用 C 固定的條件下,如何計算每層配置的權數
設 C 表示抽樣調查的總費用,且 C 滿足 其中 表示固定成本,而 表示每層每單位的調查費用。在本節中,我們將探討 (1)在抽樣調查總費用 C 固定的條件下,如何計算每層配置的權數 以使得樣本統計量的變異數 V 有最小值;(2)在準確度固定的條件下,如何計算每層配置的權數 以使得調查總費用 C 有最小值。
在抽樣調查總費用 C 固定的條件下,如何計算每層配置的權數. 以使得樣本統計量的變異數 V 有最小值;(2)在準確度固定的條件下,如何計算每層配置的權數. 以使得調查總費用 C 有最小值。")
35
不論是限制總成本而使變異數為最小,或固定準確度而使總成本為最小,理論可得
代入 n 之公式可得

36
同理

37
若每層的樣本大小滿足上述的等式,則此種樣本配置稱為Deming’s配置或最優配置。
如何代入σ ? (1) Prior Information (2) Range = 4σ (3) p = q = 1/2
 Prior Information. (2) Range = 4σ. (3) p = q = 1/2.")
38
Neyman’s Allocation 若我們不考慮每層樣本的成本 或假設 則每層樣本大小 為

39
Proportional Allocation
若我們不考慮每層的母體變異數 和樣本的成本 或假設 ; 則每層樣本大小 為

40
分層抽樣和簡單抽樣的比較 Neyman分層估計量的準確度較Proportional分層估計量的準確度高,即
若我們以取出不放回的方式取樣或有限校正因子fpc 趨近於1,則Proportional分層估計量較簡單隨機估計量準確,即

41
事後分層 我們在前面討論的分層抽樣是事先分層好,然後在每個分好的層內分別抽樣。事後分層式在抽到樣本之後,再依樣本的資料(例如:性別,年齡等)將樣本分層。假設首先抽取到 n 個隨機樣本,而將樣本資料分層後在第 i 層得到 個樣本。此時層樣本數 是隨機變數,且 滿足多項式分配。這個結果和事前分層然後抽樣不相同,在後者情況下, 是固定數不是隨機變數 。
將樣本分層。假設首先抽取到 n 個隨機樣本,而將樣本資料分層後在第 i 層得到 個樣本。此時層樣本數 是隨機變數,且 滿足多項式分配。這個結果和事前分層然後抽樣不相同,在後者情況下, 是固定數不是隨機變數 。")
42
如果 是固定的,則 但是,如果 是隨機則在計算 需將 以其期 望值代入

43
可得 右式第一項為Proportional分層估計量的變異數,第二 項之數值恆為正數。此增加的變異量是因為在事後才 分層所造成的額外可能的差異。

44
雙重抽樣法 (Double Sampling)
在分層隨機抽樣法中, 各層母體大小為已知。在本節中我們將討論各層母體大小未知時,如何利用樣本資料來估計母體參數。 在雙重抽樣法中,我們將分兩個階段來估計各個階段的母體參數。首先,我們自母體中以簡單隨機抽樣法抽出 個樣本,做為第一重樣本以估計各層母體大小 ; 其次,再從第一重 個樣本中以簡單隨機抽樣法,從每一層中隨機抽出 個樣本做為第二重樣本以估計母體參數。

45
系統抽樣方法 Systematic Sampling

46
定義 系統抽樣法 (Systematic Sampling)
將含有N單位的群體依序從 1 至 N 加以編號,並將之分為若干 k 個單位。其抽取方法,普通係由第一 k 個單位中隨機抽取一個單位,假定其為第 j 號,然後由第 j 號開始,每隔 k 個單位取一個單位,直到取遍了整個群體為止。此種樣本稱為系統樣本(Systematic Sample), 或稱 k 取 1 系統樣本(1-in-k systematic sample)。
, 或稱 k 取 1 系統樣本(1-in-k systematic sample)。")
47
系統抽樣法的主要任務在於 達到真正的隨機性 抽樣操作的簡單化 解決隨機表不敷應用的困擾

48
系統抽樣法的優點 抽樣工作簡捷無誤 解決隨機表不敷應用的困擾 統計效率等於或大於簡單隨機抽樣的統計效率 選擇偏誤(或者訪員偏誤)減少
減少")
49
如何選取系統樣本 系統樣本中 k 值的大小通常是由 N 及 n 值決定,即若母體大小 N 已知,則可得 k≦ N/n 。例如 : 若 N=15,000且我們想從抽樣名冊中抽取 n=100個單位做為一個樣本,則 k 值必須小於等於 150。 若 k=150,則我們可得100個樣本 ; 若 k < 150,則我們可得100個以上的樣本,而我們只需選取前100個樣本即可。 但若母體大小 N 未知,則我們便無法精確的選擇 k 值,此時我們必須先決定樣本大小 n,然後再猜測 k 值以得到 n 個抽樣樣本。

50
在此節中,我們假設母體呈現隨機性 (random)。
母體平均數、總和及比例的估計 若母體資料呈現隨機性次序(random order),則稱此母體資料具有隨機性(random) 。 在此節中,我們假設母體呈現隨機性 (random)。
,則稱此母體資料具有隨機性(random) 。 在此節中,我們假設母體呈現隨機性 (random)。")
51
(I) 平均數 (µ) Bound on the error of estimation
 平均數 (µ) Bound on the error of estimation")
52
(II) 總和 (τ) Bound on the error of estimation
 總和 (τ) Bound on the error of estimation")
53
Bound on the error of estimation
(III) 比例 (P) Bound on the error of estimation
 比例 (P) Bound on the error of estimation.")
54
樣本數的選擇 (I) 平均數 (µ)
 平均數 (µ)")
55
(II) 總和 (τ)
 總和 (τ)")
56
(III) 比例 (P)
 比例 (P)")
57
重複系統抽樣法(Repeated Systematic Sampling)
由於我們無法利用一個系統樣本來估計 ,故本節介紹如何利用重複系統抽樣法來估計系統樣本平均數的變異數。 重複系統抽樣法是指在一個母體中同時抽出許多系統樣本,而由這許多系統樣本組成一個系統樣本的設計。

58
例如 :在系統抽樣法中,設母體大小 N=500,若我們隨機在此母體中抽出一個“5取1”的系統樣本,則可得依樣本大小n =100的系統樣本。 同理,若我們以重複系統抽樣法在此母體中抽出十個“50取1”的系統樣本,則可得十個樣本大小 n=10 的系統樣本。我們則可以利用重複系統抽樣法所得的十個系統樣本來估計系統樣本平均數的變異數。

59
在上述的重複系統抽樣法, k = 5 , , 則母體平均數和總和的估計量為

60
系統抽樣和簡單抽樣準確度的比較 在本節中,我們將討論母體系統資料之間的相關性對母體平均數系統估計量 的變異數 的影響,也將比較母體平均數簡單隨機樣本平均數 的變異數 和系統估計量 的變異數 的大小關係。

61
N = kn 系統樣本 1 … 2 ︰ i k

62
系統樣本平均數的變異數 可以表示成組間變異SSB:

63
令 則在系統抽樣法中,母體平均數的系統估計量 的變異數可表示 故可得

64
故 及 的大小完全由 MSW 及 的大小決定 : 若 , 則 系統估計量較簡單估計量的準確度低。 若 , 則 系統估計量較簡單估計量的準確度相同。 系統估計量較簡單估計量的準確度高。

65
此式說明 可以分成兩個部分,第一部份為母體總變異數 ,第二部份為系統樣本內的總變異SSW。可知系統樣本內的總變異愈大,即 SSW 愈
大,則系統樣本平均數的變異數愈小 ; 也就是說, 系統樣本內的資料差異愈大,則系統樣本平均數的變異數愈小 。

66
最後,我們將討論那一種母體系統變數資料會使得系統樣本內變數資料的差異很大或很小
最後,我們將討論那一種母體系統變數資料會使得系統樣本內變數資料的差異很大或很小 ? 或那一種母體系統變數資料會使得 k 個系統樣本內變量之間的相關係數為正值,為負值或為 0 ? 為回答這個問題,我們必須考慮下面三種母體變數資料的型態 : 隨機性母體 (randomness population) 次序性母體 (ordered population) 週期性母體 (periodic population)
 次序性母體 (ordered population) 週期性母體 (periodic population)")
67
若母體系統變數資料呈現隨機性次序 (random order),則稱此母體系統變數資料具有隨機性 (randomness) 。則我們會預期所取的系統樣本內變量之間的相關係數會趨近於 0 。
若母體系統變數資料呈現直線趨勢 (linear trend),則稱此母體系統變數資料具有次序性 (ordered) 。則我們會預期所取的系統樣本內變量之間的相關係數會小於 0 。 若母體系統變數資料呈現週期變動 (cyclical variation),則稱此母體系統變數資料具有週期性 (periodic) 。則我們會預期所取的系統樣本內變量之間的相關係數會大於 0 。
,則稱此母體系統變數資料具有次序性 (ordered) 。則我們會預期所取的系統樣本內變量之間的相關係數會小於 0 。 若母體系統變數資料呈現週期變動 (cyclical variation),則稱此母體系統變數資料具有週期性 (periodic) 。則我們會預期所取的系統樣本內變量之間的相關係數會大於 0 。")
68
群集抽樣方法 Cluster Sampling

69
群集抽樣法的意義 不論採用簡單隨機抽樣法,分層隨機 抽樣法或系統抽樣法作抽樣調查,都 必須有抽樣底冊方可進行。在沒有抽 樣底冊或在經費短絀情況下,要作抽 樣調查,就得採用其他抽樣方法,例 如群集抽樣法。

70
定義 群集隨機抽樣法 (Cluster Sampling)
")
71
群集隨機抽樣法的意義 劃分群集的標準,大體而言,與劃分層的標準完全相反,分層著重層內各元素的齊一,而群集則加強各群集內元素間的分化,也就是要做到各群集內的元素能是其母體的縮型,才算合乎劃分群集的標準。因為如此,從這些群集中抽取若干群集為一樣本,則其代表性就高。

72
群集和分層隨機抽樣法的差別 以抽樣單位區分:群集隨機抽樣法的抽樣單位為群集而分層隨機抽樣法的抽樣單位為母體元素。
以劃分目的區分:群集隨機抽樣法希望群與群之間的差異愈小愈好而分層隨機抽樣法則希望每層之內的差異愈小愈好。

73
集體抽樣法的功能 母體名冊不容易獲得或者非常昂貴 成本考量 減少行政管理困難

74
群集樣本 n 個群集 1 … 2 ︰ i N

75
假設 母體: N 個群集 樣本: n 個群集

76
一般 母體: N 個群集 樣本: n 個群集

77
假設 (conti) 樣本: n 個群集
 樣本: n 個群集")
78
母體平均數、總和及比例的估計 (I) 平均數 (µ) Bound on the error of estimation
 平均數 (µ) Bound on the error of estimation")
79
(II) 總和 (τ) : M 已知 Bound on the error of estimation
 總和 (τ) : M 已知 Bound on the error of estimation")
80
(II-1) 總和 (τ) : M 未知 Bound on the error of estimation
 總和 (τ) : M 未知 Bound on the error of estimation")
81
Bound on the error of estimation
(III) 比例 (P) Bound on the error of estimation
 比例 (P) Bound on the error of estimation.")
82
樣本數的選擇 (I) 平均數 (µ) 如何代入 ? (1)Pilot Survey (2)Prior Information
 平均數 (µ) 如何代入 (1)Pilot Survey (2)Prior Information")
83
(II) 總和 (τ) : M 已知 如何代入 ? (1)Pilot Survey (2)Prior Information
 總和 (τ) : M 已知 如何代入 (1)Pilot Survey (2)Prior Information")
84
(II-1) 總和 (τ) : M 未知 如何代入 ? (1)Pilot Survey (2)Prior Information
 總和 (τ) : M 未知 如何代入 (1)Pilot Survey (2)Prior Information")
85
(III) 比例 (P) 如何代入 ? (1)Pilot Survey (2)Prior Information
 比例 (P) 如何代入 (1)Pilot Survey (2)Prior Information")
86
群集抽樣和簡單抽樣準確度之比較 在此節,我們只討論各個群集大小都相等時,群集估計量和簡單平均估計量準確度的比較。

87
群集樣本平均數的變異數 可以表示成組間變異
群集樣本平均數的變異數 可以表示成組間變異 SSB:

92
故 及 的大小完全由 的正負號決定 : 若 , 則 群集估計量較簡單估計量的準確度低。 群集估計量較簡單估計量的準確度相同。 群集估計量較簡單估計量的準確度高。

93
當 時, 有最大值。又 表示各群集之內沒有變異,各群集之間有很大的變異, 此時群集隨機抽樣法較簡單隨機抽樣法的準確度低。

94
當 時, 有最小值。又 表示各群集之間沒有變異,各群集之內有很大的變異, 此時群集隨機抽樣法較簡單隨機抽樣法的準確度高。

95
比例機率抽樣法 (Probabilities Proportional to Size) (pps)
在群集抽樣法中,若每一群集的母體大小差異不大時或母體變異數差異不大時,我們會以均等機率(equal probability),即一般的簡單隨機抽樣法進行抽樣。但若每一群集的母體大小差異很大時或母體變異數差異很大時,則各個群集單位對母體參數所提供的訊息就可能不一樣。若能對母體每一群集,給予一個對應的抽取機率 ,i=1,2, …, N 。則
,即一般的簡單隨機抽樣法進行抽樣。但若每一群集的母體大小差異很大時或母體變異數差異很大時,則各個群集單位對母體參數所提供的訊息就可能不一樣。若能對母體每一群集,給予一個對應的抽取機率 ,i=1,2, …, N 。則.")
96
若可選取

97
在可是在抽樣之前是不可能知道各個群集的總數(yi),因此我們通常就以每一群集的母體大小做為每一群集對母體參數所提供的訊息比重,如下所示 :
,因此我們通常就以每一群集的母體大小做為每一群集對母體參數所提供的訊息比重,如下所示 :")
98
母體總和及平均數的比例機率估計

99
多階段抽樣方法 Multi-Stage Sampling

100
在本節,我們將簡單隨機抽樣法,分層隨機抽樣法及群集抽樣法,這三種抽樣法結合在一起。
這三種隨機抽樣法,各有其優點也有其缺點。簡單隨機抽樣法不須考慮任何抽樣因素故簡單實用;分層隨機抽樣法雖然較簡單隨機抽樣法精確,但其前提是各層之內變數資料的變異要小;群集隨機抽樣法兼具經濟與準確雙重好處,但前提是各個群集之間變數資料的變異要小。

101
當抽樣母體很大時,執行簡單隨機抽樣法,其抽出率f 相對的會很小,所以母體参數估計的準確度相對的也會變小。
執行分層隨機抽樣法時,為了將類似的元素放在同一層級中,則層級個數勢必也相對的變大,如此一來便失去分層的意義。 執行群集抽樣法時,為了將相異的元素放在同一群集中,則每個群集的群集大小勢必也相對的會變大,如此一來群集抽樣便失去了同時到達經濟與準確的目的。

102
多階段抽樣法 將母體分割成N個抽樣單位,稱為第一階段並在其中以 簡單隨機抽樣法抽出n個抽樣單位稱為第一抽樣單位
(primary sampling units),以psu表示; 其次,將第一階段 中的每一個抽樣單位分割成Mi(i=1,2, …,N)個抽樣單位, 稱為第二階段,並在第一抽樣單位中以簡單隨機抽樣 法抽出mi個(i=1,2, …,n)抽樣單位稱為第二抽樣單位 (secondary sampling units),以ssu表示; 然後,再將第二 階段中的每一個抽樣單位分割成Kij (i=1,2, …,N; j=1,2,…, Mi)個抽樣單位,稱為第三階段,並在第二抽 樣單位中以簡單隨機抽樣法抽出kij個(i=1,2, …,n; j=1,2,…, mi)抽樣單位稱為第三抽樣單位(third sampling units),以tsu表示。
,以psu表示; 其次,將第一階段. 中的每一個抽樣單位分割成Mi(i=1,2, …,N)個抽樣單位, 稱為第二階段,並在第一抽樣單位中以簡單隨機抽樣. 法抽出mi個(i=1,2, …,n)抽樣單位稱為第二抽樣單位. (secondary sampling units),以ssu表示; 然後,再將第二. 階段中的每一個抽樣單位分割成Kij (i=1,2, …,N; j=1,2,…, Mi)個抽樣單位,稱為第三階段,並在第二抽. 樣單位中以簡單隨機抽樣法抽出kij個(i=1,2, …,n; j=1,2,…, mi)抽樣單位稱為第三抽樣單位(third sampling. units),以tsu表示。")
103
一般而言,多段抽樣法,大多只進行到第三段為止,最多進行至第四段,鮮有進行至第五段以上者。
由多階段抽樣法的定義可知,簡單隨機抽樣法即為一階段抽樣法; 分層隨機抽樣法即為 n = N 的兩階段抽樣法; 群集隨機抽樣法即為 的兩階段抽樣法。因此分層隨機抽樣法及群集隨機抽樣法只是兩階段抽樣法的特例。

104
兩段抽樣法樣本結構 欲瞭解多段抽樣法,須先從兩段抽樣法開始。所謂兩段抽樣法係先將母體按某種標準分為若干類,用簡單隨機抽樣方式從其中抽取若干類,為第一階段操作; 再由被抽得的類別中進行抽樣調查,為第二階段操作。 兩段抽樣法為群集抽樣法及分層抽樣法的折衷辦法。其第一階段為群集抽樣法,即先由所有群集中抽出若干群集;其第二階段為分層抽樣法,即對所抽得的群集再舉行分層抽樣調查。

105
母體總和、平均數及比例的估計 將母體分割成N個抽樣單位為第一階段; 其次將第一階段中的每
一個抽樣單位分割成Mi(i=1,2, …,N)個抽樣單位為第二階段。 第一階段抽樣單位 第二階段抽樣單位 母體資料 1 M1 y11, y12, ..., y1M1 2 M2 y21,y22, ..., y2M2 N MN yN1,yN2, ..., yNMN
個抽樣單位為第二階段。 第一階段抽樣單位. 第二階段抽樣單位. 母體資料. 1. M1. y11, y12, ..., y1M1. 2. M2. y21,y22, ..., y2M2. N. MN. yN1,yN2, ..., yNMN.")
106
從第一階段的抽樣母體以簡單隨機抽樣法抽出n個抽樣單位; 其次再從第一階段第i 個抽樣單位中以簡單隨機抽樣法抽出
mi(i=1,2, …,n)個為第二抽樣單位。 第一抽樣單位 樣本資料 1 m1 y11, y12, , y1m1 2 m2 y21,y22, , y2m2 n mn yn1,yn2, , ynmn
個為第二抽樣單位。 第一抽樣單位. 樣本資料. 1. m1. y11, y12, , y1m1. 2. m2. y21,y22, , y2m2. n. mn. yn1,yn2, , ynmn.")
107
在兩階段抽樣法中,將會使用到下列公式: 寫成 在期望值及變異數的下方加註一個2表示我們在執行第二階段的抽樣分析;在下方加註一個1表示我們在執行第一階段的抽樣分析。

108
母體總和、平均數及比例的估計 先考慮第二階段: 母體 樣本

109
母體總和、平均數及比例的估計 再考慮第一階段: 母體 樣本

110
母體總和、平均數及比例的估計 計量,故 再由上式可得下列統計量為第一階段第i個抽樣單位母體總 數和的不偏估計量,
由簡單隨機抽樣法可知樣本平均數為母體平均數的不偏估 計量,故 再由上式可得下列統計量為第一階段第i個抽樣單位母體總 數和的不偏估計量, 同理,我們在第一階段以簡單隨機抽樣法取出n 個抽樣單 位,則

113
母體總和、平均數及比例的估計 (I) 平均數 (µ) M 已知
 平均數 (µ) M 已知")
114
若M未知,則用下列式子來估計M

115
(I-1) 平均數 (µ) M未知
 平均數 (µ) M未知")
116
(II) 總和 (τ)
 總和 (τ)")
117
(III) 比例 (P) M已知
 比例 (P) M已知")
118
(III-1) 比例 (P) M未知
 比例 (P) M未知")
119
單位大小相等的兩階段估計 當第一階段的抽樣單位大小都相等且第二階段的抽樣單位大小都相等時,此種兩階段抽樣法稱為單位大小相等的兩階段抽樣法,即

120
又

121
則

122
(1) 當N很大時, 僅跟群集的平均數有關。 (2) , , 兩階段抽樣法就成了群集抽樣法。 (3 ) n = N, , 兩階段抽樣法就成了分層抽樣法。 (4) 當 時,兩階段抽樣法就比較像群集抽樣法。 (5) 當 時,兩階段抽樣法就比較像分層抽樣法。 (6) 當在兩階段抽樣法中,如果各個分類中是異質,選擇(4) 。 (7) 當在兩階段抽樣法中,如果各個分類中是同質,選擇(5) 。
 當 時,兩階段抽樣法就比較像群集抽樣法。 (5) 當 時,兩階段抽樣法就比較像分層抽樣法。 (6) 當在兩階段抽樣法中,如果各個分類中是異質,選擇(4) 。 (7) 當在兩階段抽樣法中,如果各個分類中是同質,選擇(5) 。")
123
樣本數的選擇 即第一階段的抽出單位 n 及第二單位 m 的大小應該 如何配置。假設調查的固定成本經費為C0,第一階
在單位大小相等的兩階段抽樣法,如何配置樣本? 即第一階段的抽出單位 n 及第二單位 m 的大小應該 如何配置。假設調查的固定成本經費為C0,第一階 段抽出單位的費用為C1 ,第二階段抽出單位的費用 為C2 ,因此總成本的費用為 C = C0 + nC1 + nmC2 。 我們將探討 (1)在抽樣調查總費用 C 固定的條件下, 如何計算 n 及 m 的配置,以使得樣本統計量的變異數 V 有最小值;(2)在準確度固定的條件下,如何計算 n 及 m 的配置,以使得調查總費用 C 有最小值。
在抽樣調查總費用 C 固定的條件下, 如何計算 n 及 m 的配置,以使得樣本統計量的變異數. V 有最小值;(2)在準確度固定的條件下,如何計算 n 及. m 的配置,以使得調查總費用 C 有最小值。")
124
不論是限制總成本而使變異數為最小,或固定準確度而使總成本為最小,理論可得
解出 m 值後,再代入總成本或變異數,即可得 n

125
從上式可知,當 增加時,m 增加 ; 當 增加時,m 減少。 當 C1 增加時,m 增加 ; 當 C2 增加時,m 減少。

126
比例機率抽樣法 (Probabilities Proportional to Size)(pps)
前面數節的兩階段抽樣法稱為均等機率兩階段抽樣法,在本節中則是注重於比例機率之兩階段抽樣法。比例機率之兩階段抽樣法的比例部分只用於第一階段。在群集的比例機率抽樣法中,母體總和的比率機率估計量為 : 在兩階段抽樣法中,第i 個群集總數和 未知,故我們將母體總和的比率機率估計量修正為:

127
如同群集抽樣法中,我們通常以每一抽出單位中的母體大小做為每一抽出單位的比重,即
故可得母體總和的比率機率估計量為:

128
母體總和及平均數的比例機率估計

129
統計調查管理研習班 統計調查抽樣設計 調查應用實例

130
抽樣調查設計 調查目的 調查對象及區域範圍 調查底冊 抽樣方法 調查方法 調查工具---問卷 試驗調查(問卷測試) 人員訓練
實施調查期間與進度 資料收集---coding, key in, checking 資料分析

131
調查中誤差之來源 調查是由一連串的步驟共同形成的測量過程。若要評估根據調查所做的推估的品質好壞,調查過程中的每一個環節都應該要考慮到:
1. 抽樣方面的誤差 2. 問卷方面的誤差 3. 訪員方面的誤差 4. 資料整理的誤差

132
抽樣方面的誤差 A. 當從母體抽樣出來的抽樣底冊或名單並沒有包 括所有母體所描述的特性時,那麼就會有某一 些類別的人被排除在樣本之外;
B. 因為抽樣所依循的樣本比例(機率)並沒有充 分地反應母體比例; C. 當有一些樣本拒絕參與調查、不肯提供答案, 或對某些敏感性問題拒答。
並沒有充. 分地反應母體比例; C. 當有一些樣本拒絕參與調查、不肯提供答案, 或對某些敏感性問題拒答。")
133
問卷方面的誤差 A. 當問題被誤解; B. 當問題本身並不能表達出自己真正想 得到的資訊; C. 當受訪者並不願正確地回答題目。

134
訪員方面的誤差 A. 當訪員並沒有逐字地唸出題目; B. 當訪員做引導式的追問(probe); C. 當訪員對受訪者的答案加入自己的偏見;
D. 訪員記錄不正確。

135
資料整理的誤差 A. 當過錄員使用不一致的過錄原則, 或對所該適用的過錄碼判斷錯誤; B. 當資料在鍵入電腦時鍵入錯誤。

136
世上並無抽樣調查的『專家』, 有的只是有『經驗』。 只有一種方法可以學到經驗: 做實際的問題。 有人問馬克吐溫怎麼寫小說?答曰: 「坐下來把紙攤開來寫」。 怎麼應用抽樣調查?其答案也相差不遠。

137
抽樣調查的方法及技巧, 猶如中國武俠小說中的劍招, 而實戰經驗,因為現場狀況太多, 無法在課堂上,課本上教出來。 所以,你可以學到劍法招式, 可是衝鋒肉搏仍然是你自己家的事。 惟有勇於接受問題,了解問題,進而解決問題, 才能從獨孤求敗蛻變成獨孤不敗。

Similar presentations



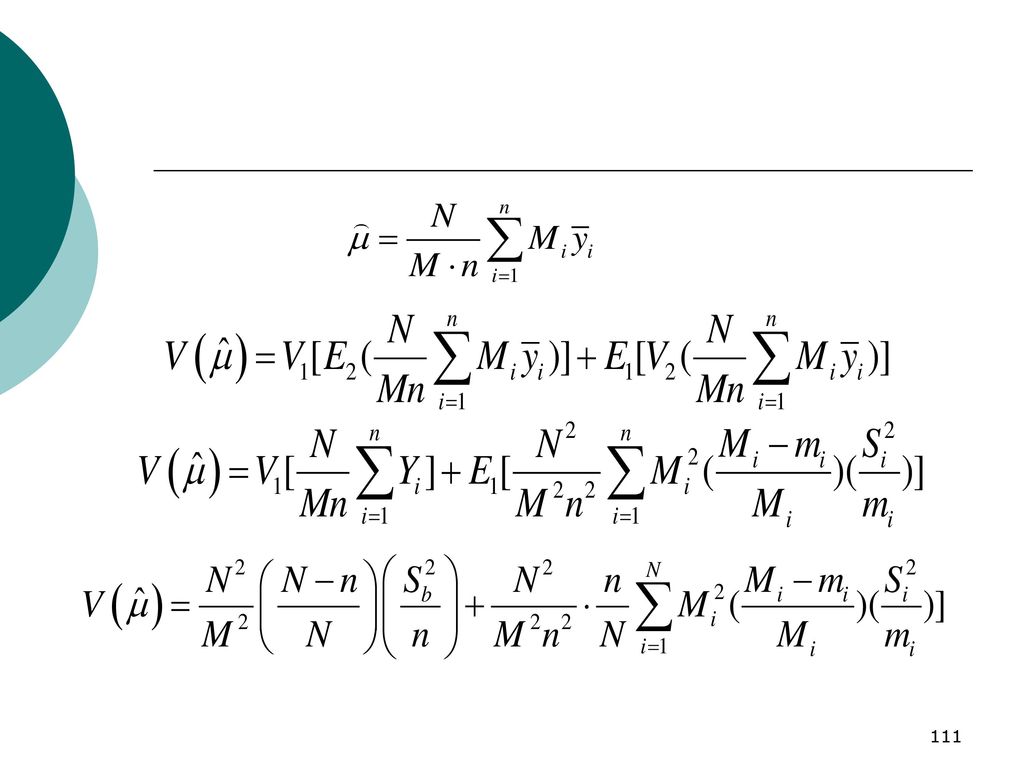
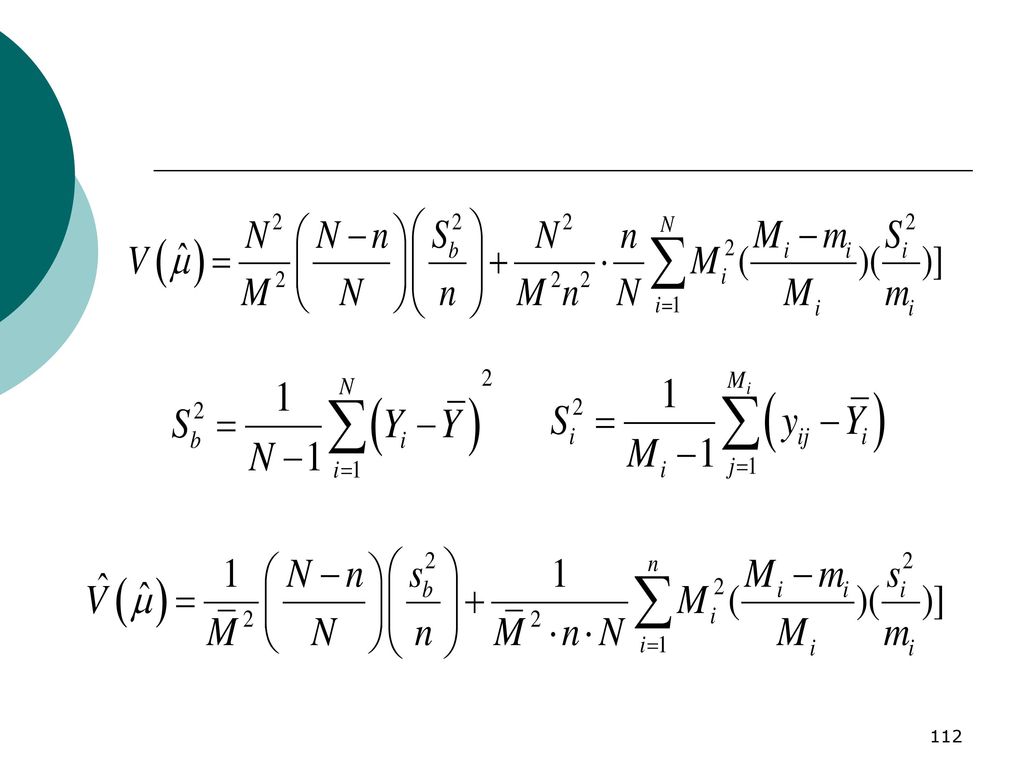






>")








>")
>")


