Download presentation
Presentation is loading. Please wait.

1
浅谈现代分析化学的基础理论教学

3
分析化学的起源可以追朔到古代的炼金术。当时的分析手段主要是依靠人类的感官和双手进行分析和判断。
16世纪出现了第一个使用天平的试金实验室,使分析化学开始赋有科学的内涵。

4
直到19世纪中期,德国的分析化学富里西尼乌斯(C
直到19世纪中期,德国的分析化学富里西尼乌斯(C.R Fresenius 1818—1897)出版了两部分析化学书《定性分析化学导论》和《定量分析导论》,使化学分析方法基本上开始形成一套较完整的体系。1862年,富里西尼乌斯又创办了《分析化学学报》为分析化学的发展打下了良好的基础。当时全世界本来只有专载全面的各类化学论文的几种期刊,而《分析化学学报》却是最早的专载化学一个分支学科论文的期刊,该刊至今还在定期出版,而且是国际负有盛名的科学刊物。
出版了两部分析化学书《定性分析化学导论》和《定量分析导论》,使化学分析方法基本上开始形成一套较完整的体系。1862年,富里西尼乌斯又创办了《分析化学学报》为分析化学的发展打下了良好的基础。当时全世界本来只有专载全面的各类化学论文的几种期刊,而《分析化学学报》却是最早的专载化学一个分支学科论文的期刊,该刊至今还在定期出版,而且是国际负有盛名的科学刊物。")
5
进入20世纪.由于现代科学的发展.相邻学科之间的相互渗透,使分析化学发生了巨大的变革,并发展成为一门学科。众所周知,其发展经历了 3 次巨大的变革.

6
分析化学发展历史 第一次变革:20~30年代 溶液四大平衡理论的建立,分析化学 由 技术 → 科学 第二次变革:40~60年代 经典分析化学(化学分析)→ 现代分析化学(仪器分析为主) 第三次变革:由70年代末至今 提供组成、结构、含量、分布、形态、化学模式识别等全面信息,成为当代最富活力的学科之一

7
1 现代分析化学---已成为 一门重要的信息科学
提供组成、结构、含量、分布、形态、模式识别等全面信息,成为当代最富活力的学科之一

8
2 现代分析化学的基础理论(理论体系) 现行的经典科学理论依靠理性的数学工具进行了较严密的推导,用数学论述了经典科学的各种研究论题的内在规律。
 现行的经典科学理论依靠理性的数学工具进行了较严密的推导,用数学论述了经典科学的各种研究论题的内在规律。")
9
数学给科学注入了生命,科学才在现代成为具有强大生命力的理论,发挥着巨大的威力。所以,数学是现代科学的密不可分的重要内容,可以说,没有数学就没有现代经典自然科学。

10
化学计量学 chemometrics 数学、统计学、计算机科学与化学结合而形成的化学分支学科。它应用数学、统计学和其他方法和手段(包括计算机)选择最优试验设计和测量方法,并通过对测量数据的处理和解析,最大限度地获取有关物质系统的成分、结构及其他相关信息。
选择最优试验设计和测量方法,并通过对测量数据的处理和解析,最大限度地获取有关物质系统的成分、结构及其他相关信息。")
11
化学计量学是瑞典S. 沃尔德在1971年首先提出来的。1974年美国B. R

12
从八十年代起,在国内,俞汝勤院士以化学计量学的教学与研究为基础,致力于分析化学学科基础理论的研究与探索。以研究生学计量学教学为基础,出版了“现代分析化学信息理论基础”(1987年)及“化学计量学导论”(1991年)。受国家教委委托,他主持了高校青年教师化学计量学讲习班。为新加坡国立大学及国家标准机构主讲了2期化学计量学讲习班(1993、1994)。主持了2项化学计量学国家自然科学基金重点项目,开展了较系统的分析化学计量学基础研究工作,包括稳健多元校正与滤波、基于形态分析概念的多元校正,以及运用模拟退火算法的多续元校正、人工神经网络的稳健化及其在分析校正与化学定量构效关系方面的应用等。
及 化学计量学导论 (1991年)。受国家教委委托,他主持了高校青年教师化学计量学讲习班。为新加坡国立大学及国家标准机构主讲了2期化学计量学讲习班(1993、1994)。主持了2项化学计量学国家自然科学基金重点项目,开展了较系统的分析化学计量学基础研究工作,包括稳健多元校正与滤波、基于形态分析概念的多元校正,以及运用模拟退火算法的多续元校正、人工神经网络的稳健化及其在分析校正与化学定量构效关系方面的应用等。")
13
1-3 化学计量学的研究内容 化学计量学的研究对象是有关化学测量的基础理论和方法学。它所研究的内容包括:统计学和统计方法;分析信息理论;采样;试验设计与优化;分析校正理论;分析信号检测和处理;化学模式识别;图像分析;构效关系研究;人工智能和专家系统;人工神经元网络与自适应化学模式识别;库检索等。

14
分析化学作为化学学科中的测量科学之一,始终是围绕着“量”做学问,并将它作为其核心的研究内容。
很长时间以来,化学其他学科的同行们总是把分析化学仅仅看成是方法的发现和收集。

15
化学计量学为化学测量提供的理论和方法,也正是围绕着“量”这一核心的。

16
分析化学系统 采样理论– 研究如何获取物质量的代表样 样品的物理-化学处理-- 量从样品到试样的转移
分析试验设计—研究最佳的分析量的程序和方法 信号的检测、识别和处理 –准确运用量产生的信号 校正理论--建立量和信号的定量关系 数据的处理--测量结果的科学的统计处理 信息的提取—提供以量为核心的多维信息

17
现代分析化学的基础理论—化学计量学 采样理论 分析试验设计及优化理论 信号的检测理论(现今基础课的内容之一)
校正理论(现今基础课的内容之一) 测量数据的统计处理(现今基础课的内容之一) 化学模式识别理论与化学定量构效关系 信息理论 另:1.样品的物理-化学处理 (现今基础课的内容) 2.定量分析的原理和方法(现今基础课的主要内容)
 测量数据的统计处理(现今基础课的内容之一) 化学模式识别理论与化学定量构效关系. 信息理论. 另:1.样品的物理-化学处理 (现今基础课的内容) 2.定量分析的原理和方法(现今基础课的主要内容)")
18
化学计量学不仅为分析化学测量提供理论和方法,还为各类波谱及化学测量数据的解析,为化学化工过程的机理研究和优化提供新途径,它涵盖了化学测量的全过程,已是一门内涵相当丰富的化学学科分支。
化学计量学的发展为化学各分支学科、其中特别是分析化学、环境化学、药物化学、有机化学、化学工程等,提供了不少解决问题的新思路、新途径和新方法。

19
数理统计学 是化学计量学理论的主要的数学基础之一。 这是因为化学测量存在着可变性、不确定性、模糊性三大特性。

20
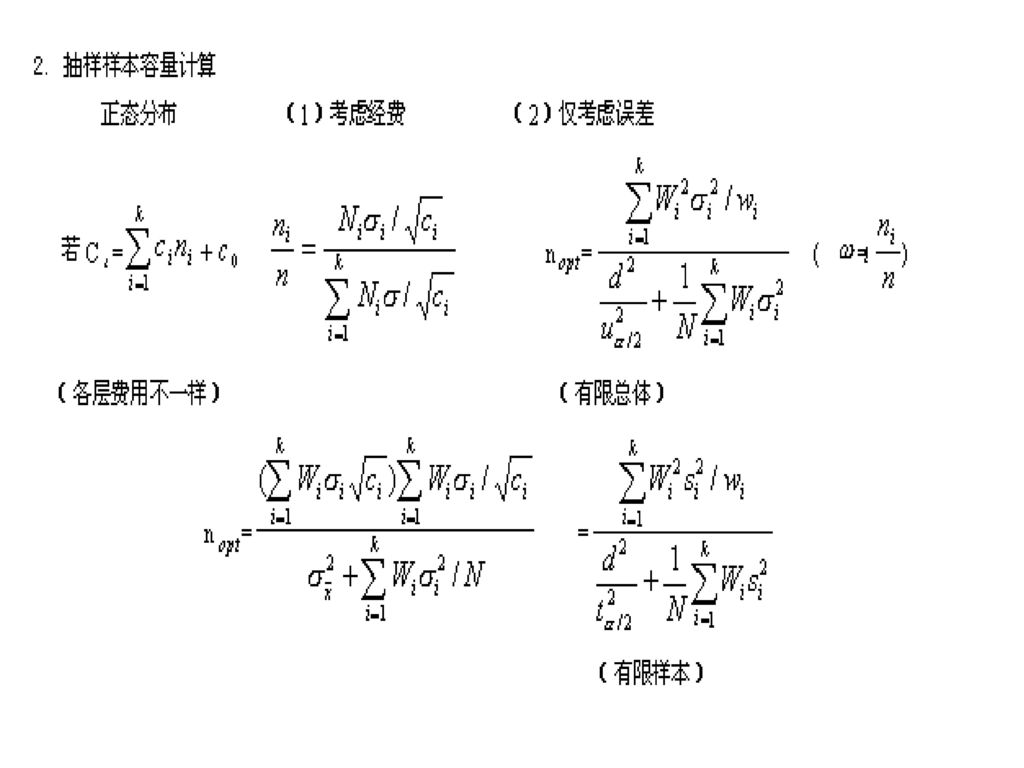
第一部分 采样理论(抽样理论)
")
21
抽样(又叫采样)是人们对客观世界的认识,生活的体验,真理的追求乃至科学实验、社会调查中常用的一种方法,其目的就是要通过局部来了解总体。
特别是那些工作量大而没有条件进行全部调查、分析、试验的,或者数据的测定是破坏性的试验,此时要想对被研究物质进行整体研究是不可能的,而只能采取抽样来进行。

22
抽样的问题既有采样的技术性问题;也有应用数理统计学的方法学的问题。后者是采样理论的核心问题。

23
一、正确的采样是分析测试的第一步。 如仅从分析采样的技术来考虑:这里就有着采集、储存、制备的过程。

24
1. 气体的采样 气体的性质受温度、压力的影响,因密度不一样会产生分层现象,难以储存、运输,这些都表明气休样品采集后应该马上进行分析. 气体样品可以通过抽吸、液体置换或扩散到真空接受器中吸取.气体采样装置一般是由玻璃制成,并带有适宜的旋塞,应采用不需涂油就能保证气体密封的金属旋塞.采样装置中应配有能阻挡固体颗粒的过滤器,能阻挡烟雾的薄膜,能吸收各种气体组分的溶液。

25
2.液体的采样 液体的采样方法有流动法、吸移法和虹吸法等. 如果液体因不相溶或密度不同而分层,在采样前应摇动使之均匀. 具有不混溶而分层的液体应从各分层中吸取与层厚度成一定比例的体积,对各层样品分别进行分析,或者将它们重新混合配成一个具有代表性的样品.

26
3.固体的采样 与气休和液体物质不同,固体物质还受颗粒大小的影响.大多数固体物质是由不同大小的颗粒组成,明显不均.另外,也许感兴趣的物种仅存在于某一形式的颗粒中(细的、粗的或离散的纯颗粒)或分散于整个物料之中.各种颗粒、团粒、块团,其形式也是不尽相同的.所以这些因素就使得代表性固体物质的采样十分困难。
或分散于整个物料之中.各种颗粒、团粒、块团,其形式也是不尽相同的.所以这些因素就使得代表性固体物质的采样十分困难。")
27
二.取样应遵循的基本原则 1.抽样得到的样本必须具有代表性 要考虑时间、温度、空间的变化 必要时须用统计方法来检验 2.抽样时所取的样本数必须具有合理性

28
三.取样的统计学要求 1.样本均值应能提供总体均值的无偏估计 2.样本方差应能提供总体方差的无偏估计
3.在给定的时间和人力消耗下,应给出尽可能的精密的总体估计。

29
从理论上讲,抽检的样品越多,研究结果就越接近被研究物质的“真实情况”,但这又是不经济的,因此必须要进行抽样方式和抽样量的研究,从而达到以少量样品反映物质真实情况的目的。当然样品量也不能太小,太小的话也达不到能提供准确信息的目的,因为抽样中的误差是受样本的大小所左右的。

30
四.抽样方法的研究 1.简单随机抽样和机械抽样 当对被测对象了解甚少时,应采取随机抽样,而且数量应尽可能多一些。 采用简单随机抽样方法,一个最简便易行又符合随机原则的方式就是使用随机数字表。随机数字表可以通过计算机来产生。因为随机数字表中的每个数码出现的几率相等,所以构成总体的每个样品被抽取的几率也相等。

31
利用excel软件也可以进行随机抽样,其方法是:打开excel,点击“工具”按钮,选中“数据分析”,再选中“抽样”,即可进行。先将全部样品编号并输入,给出抽样数,选择“随机”,就可在输出区域中得到被随机抽中的样品的编号。随机抽样.doc

32
2 多级抽样 对于大总体,往往要采取分阶段抽样的方法,这种方法就称为多级抽样。其办法是先按简单随机抽样方法或机械抽样方法抽取总体中n个一级单位(总体中的样本容量为N个)然后再在这n个一级单位中(每个一级单位中各含M个样本)分别抽取m个二级单位,如此,直到抽得最基础单位(最小单位)。
然后再在这n个一级单位中(每个一级单位中各含M个样本)分别抽取m个二级单位,如此,直到抽得最基础单位(最小单位)。")
33
3.分层抽样 随机抽样依赖于机遇,无须事先对样品的物理、化学、生物属性以及环境条件 加以区别和掌握,这样反而浪费了一些重要的信息。
分层抽样是将抽样总体按其固有属性、特点或某种原因划分为若干层,然后在各层中用随机取样或机械抽样抽取适当的抽样单位以组成样本。

44
第二部分 分析试验设计和最优化理论

45
一.分析试验设计 试验设计即是试验方案的设计,它的基本任务就是:合理地安排实验,分析实验结果与影响因素之间的关系,确定影响因素的主次,从而寻找出最佳的试验条件。

46
我国一些学者自20世纪50年代就开始研究试验优化,在理论研究设计方法与应用技巧方面都有新的创见,构造了许多新的正交表,提出了行之有效的正交忧化数据分析方法,提出了直接性和稳健性择优相结合的方法,提出了参数设计中多种减少外表设计试验点的新方法,还构造了系列的均匀设计表,创建了均匀设计法,这就形成了一套有中国特色的试验设计法。

47
一.试验分组设计 要合理地安排试验,首先会而且是经常会碰到的问题是。如何将试验的对象进行分组,因为通常总希望除了要考察的因素之外,还希望其它条件能力求一致,这样试验之间就有可比性,但有时限于客观条件而不可能做到一致,那就必须进行正确的分组设计。例如在医学的药品试验中,就常常要把试验的对象(人或动物)分成试验组和对照组。
分成试验组和对照组。")
49
二.简单比较和正交拉丁方 在分析试验设计中,当影响的因素较多时,就无法对各个因素的每个水平进行全面的搭配实验,这就需要寻找试验次数少而又能获得可靠结果的试验方法。 通常,全面的因素试验只有在因素不多的情况下才可能进行,如果是6个因素,每个因素是5个水平,全面试验就是56 =15625次,这显然是行不通的。因此,常采取的简化试验次数的办法有:

50
1.简单比较法 例如某合成反应,需要寻找最适宜的酸度(A)、试剂浓度(B)、温度(C),每个因素分三个水平,一般常用的简单做法是单因素条件试验,即首先人为地固定A和B的量,来变化C。
、试剂浓度(B)、温度(C),每个因素分三个水平,一般常用的简单做法是单因素条件试验,即首先人为地固定A和B的量,来变化C。")
52
但是这种方法有不少缺点: ①看起来好象是做了9次试验,但实际上只 是7 次,因为其中有两个各做了两次。 ②各因素,各水平出现的机会不等。 ③一开始只知道C2是在A1B1条件下最好, 但其他条件下是否好,未做试验,因此 是不是最佳,并不确定。 ④当因素间交互作用影响比较大时,就不一 定是各种条件因素的最好的搭配组合。 ⑤用这种方法安排试验,如不重复做试验, 是给不出误差估计的,因此,同样的试验 次数,提供信息不多。

53
2. 拉丁方试验设计 均衡分布思想,虽然远在古代就有,但只是在近代才与生产科研实际相结合,产生了拉丁方、正交表,显示出它的巨大威力。

54
在我国很早就有均衡分布思想。据在后周(公元10世纪)时期撰写的“洛书”记载传说夏禹治水时,洛水浮现的大乌龟背上有个隐图,其形为“九宫者,载九履一,左三右七,二四为肩;六八为足,五居中央。”如表实际上这是世界上最早的三阶纵横图。表中,无论是行、列,还是对角线,所有数字之和都等于15,这比拉丁方的均衡性更强。
时期撰写的 洛书 记载传说夏禹治水时,洛水浮现的大乌龟背上有个隐图,其形为 九宫者,载九履一,左三右七,二四为肩;六八为足,五居中央。 如表实际上这是世界上最早的三阶纵横图。表中,无论是行、列,还是对角线,所有数字之和都等于15,这比拉丁方的均衡性更强。")
56
正交拉丁方法 正交试验法就是在正交拉丁方法的基础上发展起来的。正交拉丁方是指由拉丁字母组成的正方形中,其每一行,每一列内都没有重复的字母。例如下面两个就是44拉丁方。 A B C D A B C D B A D C B C D A C D B A C D A B D C A B D A B C

57
拉丁方也可用其它形式表示,例如因素C的33拉丁方,可写成
C1 C2 C3 C2 C3 C1 C3 C1 C2 利用上述拉丁方就可以把试验安排得很均衡。

59
三.正交设计 在多因素试验设计中,已被广泛使用的正交设计法(orthogonal design),是一种既能减少试验次数,又能获得可靠结果的多因素的优选方法。 正交设计是利用一套规格化的表格来安排试验。这种表就叫正交表(orthogonal layout)。正交的含义是指两列向量的数量积等于零,它有着搭配均衡的特性。在正交表中,任意两列的搭配都是均衡的。
。正交的含义是指两列向量的数量积等于零,它有着搭配均衡的特性。在正交表中,任意两列的搭配都是均衡的。")
64
为什么正交试验法能大大减小试验工作量呢?三因素三水平如要做全面试验共需做27次,而正交试验只要做9次就可以了呢?

66
图中9次试验点在整个试验空间中分布均衡,而且因素变化很有规律性,这样就使得各因素之间的比较和试验结果的统计处理变得十分简便。正交试验法实际上是一种在多维空间中寻优的试验法,其办法就是让试验点分布均衡,通过比较实验结果而最终找出最优试验点的范围。

67
[例] 研究一新的光度分析体系,试验的因素有酸度(稀盐酸,mol/L),温度(T ℃),反应时间(min)以及显色剂浓度(%)等条件的影响,试验的水平如下:
![[例] 研究一新的光度分析体系,试验的因素有酸度(稀盐酸,mol/L),温度(T ℃),反应时间(min)以及显色剂浓度(%)等条件的影响,试验的水平如下:](http://slidesplayer.com/slide/11537765/62/images/67/%5B%E4%BE%8B%5D+%E7%A0%94%E7%A9%B6%E4%B8%80%E6%96%B0%E7%9A%84%E5%85%89%E5%BA%A6%E5%88%86%E6%9E%90%E4%BD%93%E7%B3%BB%EF%BC%8C%E8%AF%95%E9%AA%8C%E7%9A%84%E5%9B%A0%E7%B4%A0%E6%9C%89%E9%85%B8%E5%BA%A6%EF%BC%88%E7%A8%80%E7%9B%90%E9%85%B8%EF%BC%8Cmol%2FL%EF%BC%89%EF%BC%8C%E6%B8%A9%E5%BA%A6%EF%BC%88T+%E2%84%83%EF%BC%89%EF%BC%8C%E5%8F%8D%E5%BA%94%E6%97%B6%E9%97%B4%28min%29%E4%BB%A5%E5%8F%8A%E6%98%BE%E8%89%B2%E5%89%82%E6%B5%93%E5%BA%A6%28%25%29%E7%AD%89%E6%9D%A1%E4%BB%B6%E7%9A%84%E5%BD%B1%E5%93%8D%EF%BC%8C%E8%AF%95%E9%AA%8C%E7%9A%84%E6%B0%B4%E5%B9%B3%E5%A6%82%E4%B8%8B%EF%BC%9A.jpg "[例] 研究一新的光度分析体系,试验的因素有酸度(稀盐酸,mol/L),温度(T ℃),反应时间(min)以及显色剂浓度(%)等条件的影响,试验的水平如下:")
70
根据试验的结果,由极差值可知,显色时间和AB的交互作用是最主要的,其次是显色剂浓度(显色剂的试验浓度都是过量的),再次是酸度和温度,而AC影响最小,可不必考虑,
,再次是酸度和温度,而AC影响最小,可不必考虑,")
72
四 均匀试验设计 正交设计是利用正交表的均衡分散性和整齐可比性,以较少的实验次数获得基本上能反映全面情况的试验结果的一种优化试验设计方法.为了保证整齐可比和搭配均衡的特点,简化数据处理,实验点应在试验范围内充分地均衡分散,因此试验点不能过少.当欲考察的因素较多,特别是因素水平数较多时,需要的试验次数仍然很多,例如要考察9个水平试验,用正交表安排试验,至少要进行92次试验.

73
为此,寻找一种适用于多因素、多水平而试验次数更少的试验设计方法是有意义的,我国数学家方开泰和王元等利用数论方法构造了均匀试验设计(uniform design)表.
如果不考察试验数据的整齐可比性,而让试验点在试验范围内充分地均衡分散,则可以从全面试验中挑选比正交试验设计更少的实验点作为代表进行试验,这种着眼于实验点充分地均衡分散的试验 方法,称为均匀试验设计方法.

74
和正交试验设计需要正交表一样,均匀试验设计也需要用规格化的表格来安排实验,这种表格称均匀设计表,简称U表(uniform),如果水平数相等,则均匀表可记为Un(tq),其中U指均匀设计表,n指试验次数,t为因素的水平数,q为最多可安排的因素数.
,如果水平数相等,则均匀表可记为Un(tq),其中U指均匀设计表,n指试验次数,t为因素的水平数,q为最多可安排的因素数.")
75
试验安排的特点使试验数据失去了整齐可比性,所以数据一般应采用回归分析法进行分析.由于实验次数较少,试验精度较差,为了提高其精度,可采用试验次数较多的均匀设计表来重新安排因素各水平的试验.

76
例. :阿魏酸的制备 阿魏酸是某些药品的主要成分,为了在制备过程中能增加其产量。 经过分析研究,挑选出因素和试验区域,为
原料配比: 吡啶总量: 反应时间: 确定了每个因素相应的水平数为7。

77
第1步: 将试验因素的水平列成下表: 77

78
第2步: 应用选择的 UD-表, 做出试验安排。 1. 将 x1, x2和 x3放入列1,2和3. x x x3 2.用x1的7个水平替代第一列的1到 7. 1.0 1.4 1.8 2.2 2.6 3.0 3.4 3. 对第二列,第三列做同样 的替代. 4. 完成该设计对应的试验,得到7个结果,将其放入最后一列. 78

79
第 3步: 用回归模型匹配数据

80
然后,尝试用二次回归模型来匹配这些数据:
使用‘向前’的变量选择法,发现适宜的模型: 表 1.1.6: 方差分析(ANOVA) 表
 表.")
82
x1=[ ]; x2=[ ]; x3=[ ]; x4=[ ]; y=[ ]'; >> X=[ones(12,1) x1' x2' x3' x4' (x1.^2)' (x2.^2)' (x3.^2)' (x4.^2)']; [b,bint,r,rint,stats]=regress(y,X); >> b,stats
![x1=[ ]; x2=[ ];](http://slidesplayer.com/slide/11537765/62/images/82/x1%3D%5B+%5D%3B+x2%3D%5B+%5D%3B.jpg "x3=[ ]; x4=[ ]; y=[ ] ; >> X=[ones(12,1) x1 x2 x3 x4 (x1.^2) (x2.^2) (x3.^2) (x4.^2) ]; [b,bint,r,rint,stats]=regress(y,X); >> b,stats.")
83
b =

84
stats = >> 置信概率

85
将计算得的b阵代入可算得最优条件为 TC=140℃、tc=41s、Ta=1790 ℃,ta=7s

86
五 单纯形试验法(simplex) 单纯形优化法最初由Erns引入化学研究,它是一种按黑箱方式工作的试验设计方法。前面已经介绍过,正交设计试验是通过在多维空间中均衡地布置试验点,并比较它们的优劣来寻优的,而单纯形试验法是基于在多维空间中的几何图形的变换来寻找试验点,并逐一比较试验结果后逐步搜索寻优的。

87
这里所说的图形是指的在n维空间中,具有n+1个顶点的图形,例如,两维空间使用三角形,三维空间使用有四个顶点的多面体。这些图形的顶点即是试验所安排的试验点,通过比较各试验点的结果并丢弃最差点而代之以新点,从而再构成新的单纯形,这样就可逐步逼近最优试验点。

88
1、两因素试验 两因素试验(n=2),可以看成是在两维空间中进行的,即在平面上寻优的过程。假定试验从初始点X0开始,在平面中X0的坐标为(a1,a2),例如a1可以是pH值,a2可以是试剂的浓度值。从X0开始,如果构造一个正三角形,另两个顶点为X1和X2,则它们可以分别取如下值:X1(a1+p,a2+q),X2(a1+q,a2+p)。
,可以看成是在两维空间中进行的,即在平面上寻优的过程。假定试验从初始点X0开始,在平面中X0的坐标为(a1,a2),例如a1可以是pH值,a2可以是试剂的浓度值。从X0开始,如果构造一个正三角形,另两个顶点为X1和X2,则它们可以分别取如下值:X1(a1+p,a2+q),X2(a1+q,a2+p)。")
89
对每一个因素,应选择一个步长,也即该因素对于起始水平变化的幅度。在图形中,步长即是两点间的距离。如果各因素的步长都是相同的数值a,那么试验的初始单纯形就是以X0为顶点,各棱长均为a的正规单纯形,(亦即正三角形或正多面体),各点的p值, q值,可根据公式来计算 。
,各点的p值, q值,可根据公式来计算 。")
90
在确定了初始单纯形的试验点后,即可根据这些试验点的因素水平做试验,得到n+1个目标(试验结果)值,再根据它们的优劣,舍去最差的点,按照单纯形试验法,逐一算出新的试验点,这样最终就达到了优化的目标。
值,再根据它们的优劣,舍去最差的点,按照单纯形试验法,逐一算出新的试验点,这样最终就达到了优化的目标。")
91
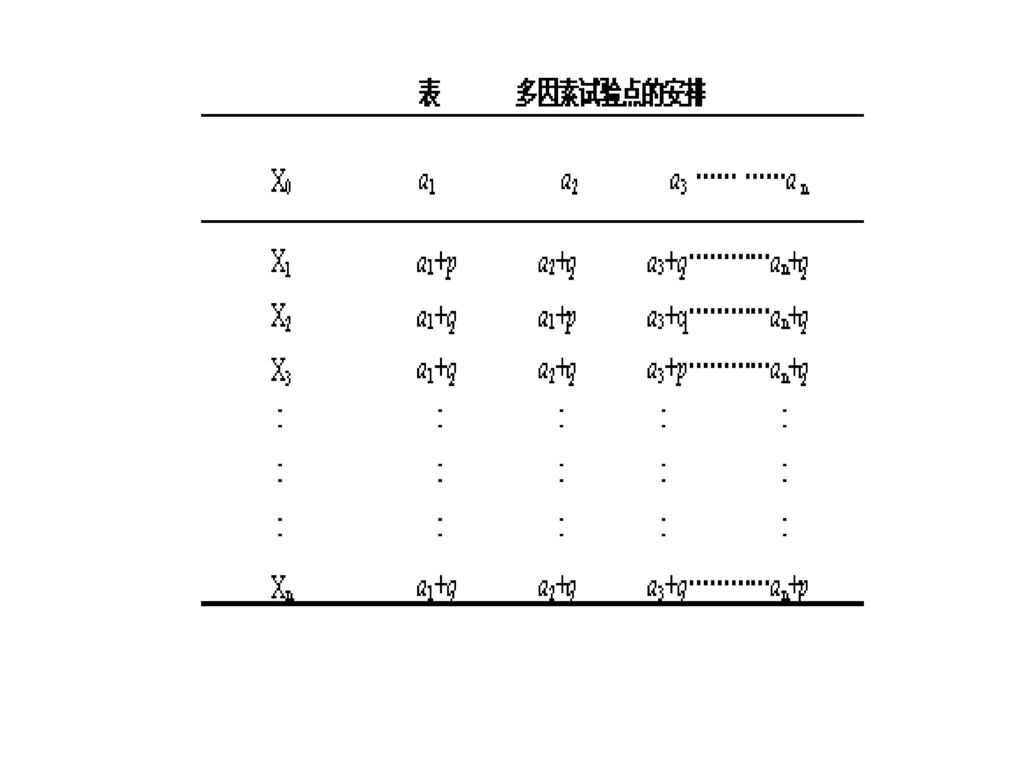
2、多因素试验点的安排 对于n个因素来说,各个试验点的安排可以用一个矩阵来表示。如初始试验点为X0(a1,a2……an),那么其余各点可以安排见表。
,那么其余各点可以安排见表。")
93
3、单纯形移动的计算规则 在基本单纯形法中,步长是不作改变的,称之为正规单纯形,因此在试验中最优点附近的收敛速度就显得不快,而且收敛精度也较差。在此基础上,又出现了改良形的单纯形法,即增加了步长可变的寻优步骤,使得寻优的收敛速度和精度都得到了改善。

94
(1)试验者先根据化学知识和经验选取初始试验点X0和步长a,并计算出其余各试验点的试验水平,构成初始单纯形。
试验者先根据化学知识和经验选取初始试验点X0和步长a,并计算出其余各试验点的试验水平,构成初始单纯形。")
95
(3)求重心X(e):去掉最坏点X(b),计算出其余各点的重心X(e),计算公式为
求重心X(e):去掉最坏点X(b),计算出其余各点的重心X(e),计算公式为")
96
(4)求出反射点X(r):计算公式为 X(r) = X(e) + (X(e) - X(b))
求出反射点X(r):计算公式为 X(r) = X(e) + (X(e) - X(b))")
98
(5)进一步试验的结果可以有三种情况: ①延伸:如实验结果f(X(r)) f(X(g)) f(X(t)), 则X(r)是当前最佳点,则在这方向上继续延伸至X(k),计算公式为 X(k) =X(e) +(X(r) X(e))
 =X(e) +(X(r) X(e)) .")
99
此时延伸系数可取比1大的数,如=2,这样就又形成新单纯形,X(g) X(t) X(k),再继续寻优。
 X(t) X(k),再继续寻优。")
100
②改变方向:如试验结果是f(X(g)) f(X(r)) f(X(t)),则X(r)为次佳点,则弃去f(X(t)),改变试验方向,计算X(g)和X(r)的重心和X(t)的放射点,组成新单纯形,继续调优。 ③收缩:如实验结果是f(X(g)) f(X(t)) f(X(r)),则应舍去X(r),进行收缩。收缩又分两种情况:
) f(X(t)) f(X(r)),则应舍去X(r),进行收缩。收缩又分两种情况:")
103
(6)如收缩失败,则需压缩,即缩小单纯形。如可压缩至一半,其如图。压缩后的X(t)=(X(g)) X(t))/2 + X(t), X(b)=(X(g)) X(b))/2 + X(b)。
如收缩失败,则需压缩,即缩小单纯形。如可压缩至一半,其如图。压缩后的X(t)=(X(g)) X(t))/2 + X(t), X(b)=(X(g)) X(b))/2 + X(b)。")
105
8)单纯形调优的结束,可用 来加以判断,此时,f(X(g))为当前最优点,f(X(b)) 为当前最佳点的试验值, 为预先给定的允许误差,若满足时,试验即可结束。 对于多因素的调优,通常可根据单纯形法的算法流程用计算机来进行处理。
单纯形调优的结束,可用 来加以判断,此时,f(X(g))为当前最优点,f(X(b)) 为当前最佳点的试验值, 为预先给定的允许误差,若满足时,试验即可结束。 对于多因素的调优,通常可根据单纯形法的算法流程用计算机来进行处理。")
106
[例] long对应用蔷薇苯胺测定SO2的条件进行优化,用分光光度法进行吸光度测定,以甲醛和盐酸二因素单纯形法调优,试验调优采用作图法,见图。图中数值为吸光度值,⑴~⒂为试验次数。
![[例] long对应用蔷薇苯胺测定SO2的条件进行优化,用分光光度法进行吸光度测定,以甲醛和盐酸二因素单纯形法调优,试验调优采用作图法,见图。图中数值为吸光度值,⑴~⒂为试验次数。](http://slidesplayer.com/slide/11537765/62/images/106/%5B%E4%BE%8B%5D+long%E5%AF%B9%E5%BA%94%E7%94%A8%E8%94%B7%E8%96%87%E8%8B%AF%E8%83%BA%E6%B5%8B%E5%AE%9ASO2%E7%9A%84%E6%9D%A1%E4%BB%B6%E8%BF%9B%E8%A1%8C%E4%BC%98%E5%8C%96%EF%BC%8C%E7%94%A8%E5%88%86%E5%85%89%E5%85%89%E5%BA%A6%E6%B3%95%E8%BF%9B%E8%A1%8C%E5%90%B8%E5%85%89%E5%BA%A6%E6%B5%8B%E5%AE%9A%EF%BC%8C%E4%BB%A5%E7%94%B2%E9%86%9B%E5%92%8C%E7%9B%90%E9%85%B8%E4%BA%8C%E5%9B%A0%E7%B4%A0%E5%8D%95%E7%BA%AF%E5%BD%A2%E6%B3%95%E8%B0%83%E4%BC%98%EF%BC%8C%E8%AF%95%E9%AA%8C%E8%B0%83%E4%BC%98%E9%87%87%E7%94%A8%E4%BD%9C%E5%9B%BE%E6%B3%95%EF%BC%8C%E8%A7%81%E5%9B%BE%E3%80%82%E5%9B%BE%E4%B8%AD%E6%95%B0%E5%80%BC%E4%B8%BA%E5%90%B8%E5%85%89%E5%BA%A6%E5%80%BC%EF%BC%8C%E2%91%B4%EF%BD%9E%E2%92%82%E4%B8%BA%E8%AF%95%E9%AA%8C%E6%AC%A1%E6%95%B0%E3%80%82.jpg "[例] long对应用蔷薇苯胺测定SO2的条件进行优化,用分光光度法进行吸光度测定,以甲醛和盐酸二因素单纯形法调优,试验调优采用作图法,见图。图中数值为吸光度值,⑴~⒂为试验次数。")
108
液相色谱分离的优化

113
平均水平的单纯形法寻优

114
[例]示波极谱法测定痕量Cu,Pb,Cd,用单纯形试验法选择支持电解质的试剂盐酸、盐酸羟胺、氯化钠的配比,以体积相同,重量百分比浓度不同的水平作试验,所取的试验水平列在下表
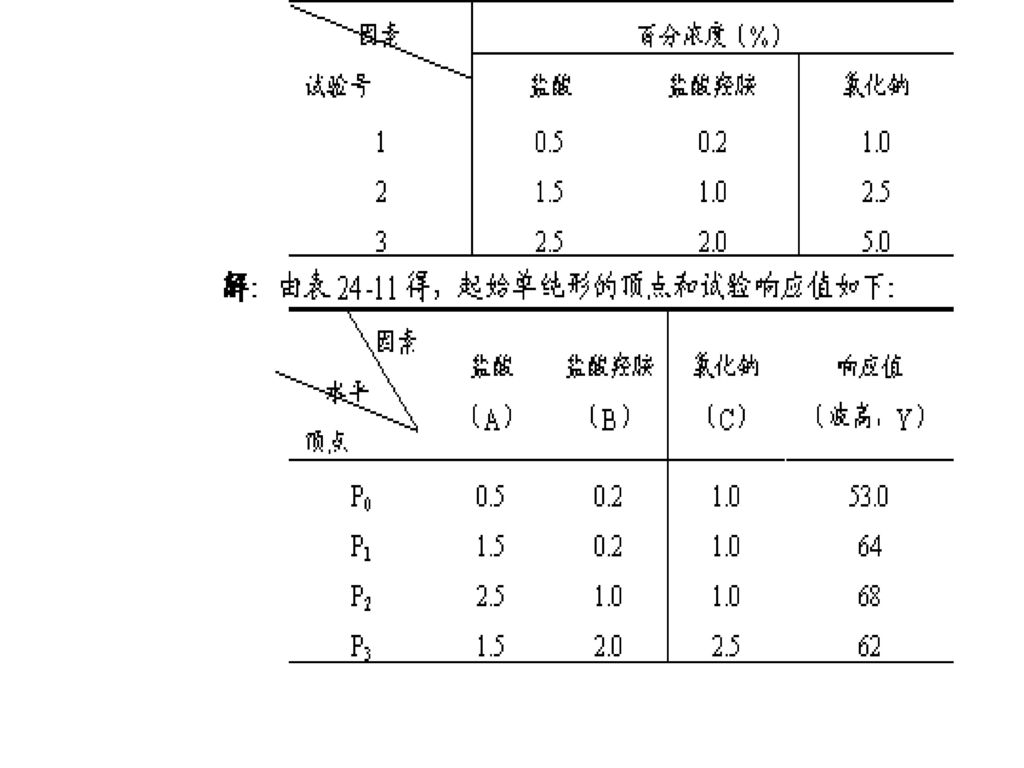
![[例]示波极谱法测定痕量Cu,Pb,Cd,用单纯形试验法选择支持电解质的试剂盐酸、盐酸羟胺、氯化钠的配比,以体积相同,重量百分比浓度不同的水平作试验,所取的试验水平列在下表](http://slidesplayer.com/slide/11537765/62/images/114/%5B%E4%BE%8B%5D%E7%A4%BA%E6%B3%A2%E6%9E%81%E8%B0%B1%E6%B3%95%E6%B5%8B%E5%AE%9A%E7%97%95%E9%87%8FCu%EF%BC%8CPb%EF%BC%8CCd%EF%BC%8C%E7%94%A8%E5%8D%95%E7%BA%AF%E5%BD%A2%E8%AF%95%E9%AA%8C%E6%B3%95%E9%80%89%E6%8B%A9%E6%94%AF%E6%8C%81%E7%94%B5%E8%A7%A3%E8%B4%A8%E7%9A%84%E8%AF%95%E5%89%82%E7%9B%90%E9%85%B8%E3%80%81%E7%9B%90%E9%85%B8%E7%BE%9F%E8%83%BA%E3%80%81%E6%B0%AF%E5%8C%96%E9%92%A0%E7%9A%84%E9%85%8D%E6%AF%94%EF%BC%8C%E4%BB%A5%E4%BD%93%E7%A7%AF%E7%9B%B8%E5%90%8C%EF%BC%8C%E9%87%8D%E9%87%8F%E7%99%BE%E5%88%86%E6%AF%94%E6%B5%93%E5%BA%A6%E4%B8%8D%E5%90%8C%E7%9A%84%E6%B0%B4%E5%B9%B3%E4%BD%9C%E8%AF%95%E9%AA%8C%EF%BC%8C%E6%89%80%E5%8F%96%E7%9A%84%E8%AF%95%E9%AA%8C%E6%B0%B4%E5%B9%B3%E5%88%97%E5%9C%A8%E4%B8%8B%E8%A1%A8.jpg "[例]示波极谱法测定痕量Cu,Pb,Cd,用单纯形试验法选择支持电解质的试剂盐酸、盐酸羟胺、氯化钠的配比,以体积相同,重量百分比浓度不同的水平作试验,所取的试验水平列在下表")
116
可见,起始单纯形的顶点很容易确定,不需计算。从表中可知,P0应舍弃,舍弃后的重心计算如下:

117
反射点计算如下: P — A = 2 Pe P0 = 21.80.5 = 3.1 (=1) P — B = 21.10.2 = 2.0 P — C = 21.51.0 = 2.0 于是求得P4(3.1,2.0,2.0),此时P1 P2 P3 P4形成新单纯形,试验得P4的响应值,即可进行比较,再丢掉最坏点,就可实现单纯形连续推移,直到找到最佳点为止。
,此时P1 P2 P3 P4形成新单纯形,试验得P4的响应值,即可进行比较,再丢掉最坏点,就可实现单纯形连续推移,直到找到最佳点为止。")
118
怎么来分析各因素影响的大小呢,可以根据以下表来计算各因素的效应。

119
由此可得 1A = 11 2A+0.8B = 15 1A+1.8B+1.5C = 9 解得 A = B = C = 9.16 因此,可知主要因素为A、C,而B为次要因素。

120
最优化方法简介 1.单目标优化和多目标优化 在试验设计中,有时用来衡量试验效果的目标只有一个,寻求这一目标最优值的试验设计就称为单目标优化。有时需要同时用几个目标来衡量试验效果,如在分析方法研究中,常常要同时用灵敏度、选择性、准确度作为目标,去寻求获得高灵敏度、高选择性、高准确度的实验条件,这就是多目标优化。

121
2. 同时试验与序贯试验 在试验设计中,根据试验方案和计划的安排不同,可分为同时试验法和序贯试验法两种方法。所谓同时试验法,就是对与目标有关的因素及因素水平进行预先的规划,根据规划的方案同时对各因素及因素水平进行试验,然后对试验得到的结果进行分析比较,找出最佳条件。如正交试验法就是一种同时试验的方法。所谓序贯试验法,则是先进行一次或少数几次试验,分析这少数几次试验的结果,根据这些结果的优劣,作出下一次试验的计划,这样逐步试验以寻得最优的实验条件。单纯形试验优化法就是典型的序贯试验。

122
3、试验最优化和解析最优化 在多因素试验设计中,当各因素之间的函数关系为已知时,寻求目标y的最优值的试验设计和优化,可以用数学上求函数极值的方法得到,这就是解析最优化方法。在绝大多数的化学试验设计中,y与各因素xi之间的关系并没有解析表达式,在这种情况下,则要通过大量的实验得到目标y与因素之间关系的信息,以获得最佳的实验条件。这就是试验最优化

123
试验最优化方法 单因素试验 1)0.618法 菲波那奇数列 …… Lim(Fn/Fn+1)=(√5-1)/2=0.618 世界上公认的人体比的标准值 古希腊建筑(巴特农神殿)、雕塑(维纳斯)、绘画等都遵循之
、雕塑(维纳斯)、绘画等都遵循之.")
124
2)抛物线法 设 x1,x3,x3的试验结果y1,y2,y3,过三点可作抛物线:
抛物线法 设 x1,x3,x3的试验结果y1,y2,y3,过三点可作抛物线:")
125
用Y近似目标函数f(x),求Y的最大值点:
即下一试验点,并与相近的两个点构成新的抛物线。 若新点与旧点相同,可取中间点或附近点安排试验。

126
多因素试验 1)爬山法 朝陡度高的方向爬 如A1(x1,y1),A2(x2,y2)的试验结果为f1,f2, 若f1>f2,则由A2上升到A1的陡度为
爬山法 朝陡度高的方向爬 如A1(x1,y1),A2(x2,y2)的试验结果为f1,f2, 若f1>f2,则由A2上升到A1的陡度为")
127
在试验区间取一点A ,在其上下左右取4个点做试验,计算所有方向上 的陡度,即A1A2,A3A4……并在陡度最大的方向上用0
2)坐标轮换法
坐标轮换法.")
128
解析最优化方法 1.最小二乘法 2.线性规划法 3.牛顿迭代法 4.梯度法

129
六. 色谱窗口图解优化技术

130
为了选择最佳分离条件,气一液色谱固定相中的固定液设计由二元混合物组成,它们分别为A、B。在A、B混合体系中无限稀释的溶液在固定液(A+B)和气相之间的分配系数K为:
KR=VAKA0+VBKB0 式中KA0、KB0分别表示为纯的固定液A和B所对应的分配系数。VA、VB分别表示A和B的体积分数。 分配系数K=CL/CG是指被分离组分在固定相和载气之间浓度之比

131
例 固定液是邻苯二甲酸二正壬酯和角鲨烷。有一个15个组分组成的混合体系待测,它们在纯邻苯二甲酸二正壬酯和纯角鲨烷单一固定相中的分配系数如表所示。

133
将这15种组分的 KRi~VA分段作图,其情形如下图所示。从图中可以看到KRi~VA直线相互有不少交点,因而采用单一的固定相是不可能同时分离这15个组分的。实际的色谱图也说明了这种情况。

136
这15个组分的全部窗口如下图所示,其中VA=0

139
由于A+B混合固定液的保留特征是各固定液特征的体积分数之和。那么,“A十担体”与“B十担体”的机械混合是否可以与“A与B的混合液十担体”有同等的效果呢?色谱的测试结果表示是具有同等效果的。也就是说.可以将A和B分别涂在担体上,然后进行简单地机械混和、装柱即可。

140
遗传算法 神经网络算法 小波转换

141
第三部分 1.信号的检测理论 重复性 复现性 灵敏度 检出限 定量检出限 信号的处理 平滑 滤波

142
2.校正理论 一元线性回归(LR) 多元线性回归(MLR) K矩阵 P矩阵 通用标准加入法(GSAM) 主成分分析法(PCA)卡尔曼滤波(KF)主成分回归法 (PCR) 偏最小二乘法(PLS)目标转换因子分析法(TTFA)
 多元线性回归(MLR) K矩阵 P矩阵 通用标准加入法(GSAM) 主成分分析法(PCA)卡尔曼滤波(KF)主成分回归法 (PCR) 偏最小二乘法(PLS)目标转换因子分析法(TTFA)")
143
重复性即是指测量结果的重复性,其定义为:在相同条件下,对同一被测量进行多次连续测量所得结果之间的一致性。所说的相同条件指的是测量程序、测量条件、人员、仪器、地点等均相同,并应是短期内的重复。

144
重复性可以用测量结果的分散性来表示,这个分散性就是标准偏差S ,称之为重复性标准偏差,用来表示,要求重复的次数应充分大,例如:n≥20 。
重复性限r的定义是:在重复性条件下的两次测量结果之差的绝对值,以95%的概率不致被超出的值。 r= S

145
复现性也即是指测量结果的复现性,又称“再现性”,其定义为:在改变了的测量条件下,对同一被测量进行多次连续测量所得结果之间的一致性。所说的改变了的测量条件指的就是测量程序、测量条件、人员、仪器、地点等均不相同或不完全相同。

146
检出限,也有叫检测下限的,是指能产生一个可靠地被检出的分析信号所必需的被测物质的最低浓度或含量。根据这个定义,检出限是与被分析样品、分析的方法和测量的仪器有关的。因此,针对不同对象就有不同的检出限的规定。

147
检出限的意义主要是定性的检出,而定量的检出限又称检定限。它是定量分析方法对某组分实际可能测定的下限,既与测量噪声有关,也与背景空白有关
IUPAC将检定限定义为10倍的空白浓度的标准偏差。

148
校正理论 最小二乘法………… 以卡尔曼滤波为例

149
三个未知样本(三组分)试样的吸收光谱
试样的吸收光谱")
150
然后,即可按迭代计算步骤进行计算。本题最终的计算结果见表25-6

151
如果将例各组分滤波过程所得的浓度随波长的变化作图的话,可见到浓度的变化在起初时起伏较大,以后逐渐平稳,并趋近于模拟的实际浓度。表25-7及图25-3示出了在计算到第十二步时已开始趋向实际浓度值。

152
MATLAB编程 function [cc,c,v]=kalmfil(x,y); x=[0.280,0.062,0.003;0.466,0.118,0.007;0.584,0.204,0.016;0.590,0.318,0.040;0.466,0.449,0.09;0.28,0.58,0.142;0.153,0.660,0.23;0.068,0.71,0.386;0.03,0.665,0.54;0.008,0.575,0.68;0.002,0.46,0.794;0.001,0.475,0.84;0,0.48,0.8;0,0.47,0.695;0,0.3,0.544;0,0.25,0.386;0,0.2,0.237;0,0.13,0.144;0,0.08,0.07] [n,p]=size(x); y=[0.159,0.27,0.385,0.398,0.386,0.342,0.319,0.324,0.323,0.313,0.298,0.311,0.304,0.28,0.199,0.152,0.107,0.068,0.038] [n1,collhs]=size(y);
![MATLAB编程 function [cc,c,v]=kalmfil(x,y);](http://slidesplayer.com/slide/11537765/62/images/152/MATLAB%E7%BC%96%E7%A8%8B+function+%5Bcc%2Cc%2Cv%5D%3Dkalmfil%28x%2Cy%29%3B.jpg "x=[0.280,0.062,0.003;0.466,0.118,0.007;0.584,0.204,0.016;0.590,0.318,0.040;0.466,0.449,0.09;0.28,0.58,0.142;0.153,0.660,0.23;0.068,0.71,0.386;0.03,0.665,0.54;0.008,0.575,0.68;0.002,0.46,0.794;0.001,0.475,0.84;0,0.48,0.8;0,0.47,0.695;0,0.3,0.544;0,0.25,0.386;0,0.2,0.237;0,0.13,0.144;0,0.08,0.07] [n,p]=size(x); y=[0.159,0.27,0.385,0.398,0.386,0.342,0.319,0.324,0.323,0.313,0.298,0.311,0.304,0.28,0.199,0.152,0.107,0.068,0.038] [n1,collhs]=size(y);")
154
3.测量数据的统计处理

155
1 ) 位置参数 决定总体分布位置的参数: 平均值、中位值 2 ) 离差的量度 决定总体分布形状(离散的程度)的参数: 相对平均标准差、均值标准差、极差、 四分位数
 位置参数 决定总体分布位置的参数: 平均值、中位值 2 ) 离差的量度 决定总体分布形状(离散的程度)的参数: 相对平均标准差、均值标准差、极差、 四分位数")
156
3.)置信区间的概念 ①置信区间 ②置信概率P ③置信界限 ④置信度(置信水平) ⑤显著性水平α
置信区间的概念 ①置信区间 ②置信概率P ③置信界限 ④置信度(置信水平) ⑤显著性水平α")
157
4) 总体均值的区间估计 t =
 总体均值的区间估计 t =")
158
(1)正态总体µ的置信区间(σ已知)
正态总体µ的置信区间(σ已知)")
160
(2) 正态总体µ的置信区间(σ未知)
 正态总体µ的置信区间(σ未知)")
161
5) 统计检验
 统计检验")
162
假设检验:先对总体参数提出一个假设,然后利用样本信息检验这个假设是否成立。

163
利用显著性水平根据检验统计量的值建立拒绝原假设的规则

164
2.2.2.1 均值和真值的比较---一个正态总体的参数检验
在总体均值已知的情况下,常会遇到样本平均值与总体均值比较的问题。例如利用已知标准试样来检验某分析系统是否有显著性差异(又称偏倚)的问题。(分析系统通常指:试剂、仪器设备、人员操作、环境等)。
的问题。(分析系统通常指:试剂、仪器设备、人员操作、环境等)。")
167
例 用原子发射光谱摄谱法检查高纯材料中微量硼,六次测定,黑度值分别为13. 0、7. 0、8. 0、8. 0、11. 0、12
例 用原子发射光谱摄谱法检查高纯材料中微量硼,六次测定,黑度值分别为13.0、7.0、8.0、8.0、11.0、12.0,平均值为9.8。炭电极的空白测定值为4.0、5.0、12.0、8.0、6.0,平均值为7.0。试问该材料中是否能确定有硼? 解: n1=6 , =9.8, s1= n2=5 , =7.0, s2=3.2 本题可以有两种解法。

169
异常值检验 在对同一个量进行重复性的测量数据中,常会发现有个别数值与其它数据相差比较大,但又找不到偏离的原因,这样的值就称为异常值。对于异常值的处理应该慎重,它很可能是引起系统误差的不明原因所造成的,此时应立即查明原因,予以剔除;也有可能是由于随机误差引起的极端波动的测定值,此时就应对其进行检验后再来决定是否应予舍去。 根据统计的原理,异常值的检验通常有以下一些方法: Grubbs法;Dixon法

170
国家标准推荐:检验一个可疑值以Grubbs法为准;一个以上可疑值,以Dixon检验法为准,一般α应取小一些,如α=0.01较好。

171
第四部分 化学模式识别理论与化学定量构效关系

Similar presentations










































。 2、发酵工程在医药工业和食品工业中的 应用(A:知道)。>")









、B(19周岁)两人来到中国,欲向C服装公司订购一批服装到本国销售。其中,A来自甲国,该国法律规定,具有完全民事行为能力的成年人的年龄标准为16周岁;而B来自乙国,乙国法律规定,具有完全民事行为能力的成年人的年龄标准为20周岁。中国法律规定的具有完全民事行为能力的人的年龄标准为18周岁(不考虑16至18周岁的特殊情况)。>")






