Download presentation
Presentation is loading. Please wait.

1
编 译 原 理 指导教师:杨建国 二零一零年三月

2
第四章 词法分析 第一节 词法分析程序的设计 第二节 单词的描述工具 第三节 有穷自动机 第四节 正规式和有穷自动机的等价性
第四章 词法分析 第一节 词法分析程序的设计 第二节 单词的描述工具 第三节 有穷自动机 第四节 正规式和有穷自动机的等价性 第五节 正规文法和有穷自动机的等价性 第六节 词法分析程序的自动构造工具 第七节 典型例题及解答

3
知识结构

4
知识结构 ⑤ ③ 正规文法 有穷自动机(NFA DFA) ② 寻找特殊方法和工具 ④ 描述 正规式 识别 {正规集} ① ⑥ 词法分析
自动构造工具LEX

5
第四章 词法分析 4.1 词法分析程序的设计 源程序 词法分析程序 语法分析程序 Token get token ….
4.1 词法分析程序的设计 源程序 词法分析程序 语法分析程序 Token get token …. 主要任务:读源程序,产生单词符号 其他任务: 滤掉空格,跳过注释、换行符 追踪换行标志,复制出错源程序, 宏展开,……

6
一.词法分析程序与语法分析程序的接口方式 词法分析工作可以是独立的一遍,把字符流的源程序 变为单词序列,输出在一个中间文件上,这个文件作 为语法分析程序的输入而继续编译过程

7
更通常情况,常将词法分析程序设计成一个子程序,
每当语法分析程序需要一个单词时,则调用该子程序。 词法分析程序每得到一次调用,便从源程序文件中读 入一些字符,直到识别出一个单词,或说直到下一单 词的第一个字符为止

8
二.词法分析程序的输出 1.单词符号一般可分为下列五种: 基本字(关键字):begin、end、if、while、var 标识符:常量名、变量名、过程名 常数(量):25、3.1415、true、“ABC” 运算符:+、-、*、<= 界符:逗点、分号、括号

9
2.输出表示: (单词种别,单词自身的值) 单词种别:语法分析需要的信息 单词自身的值:编译其他阶段需要的信息 例如:const i=25,yes=1;
 单词种别:语法分析需要的信息 单词自身的值:编译其他阶段需要的信息 例如:const i=25,yes=1;")
10
(标识符,指向该标识符所在符号表中位置的指针)
const i=25,yes=1;对单词i和yes的表示为: (标识符,指向i的表项的指针) (标识符,指向yes的表项的指针) 单词的种别可以用整数编码表示,假如标识符编码为1 ,常数为2,关键字为3,运算符为4,界符为5
 (标识符,指向yes的表项的指针) 单词的种别可以用整数编码表示,假如标识符编码为1. ,常数为2,关键字为3,运算符为4,界符为5.")
11
if i=5 then x:=y 关键字 if (3, ‘ if’) 标识符 i (1,指向i的符号表入口) 等号 = (4, ‘= ’) 常数 5 ( 2, ‘5’ ) 关键字 then ( 3, ‘then ’ ) 标识符 x ( 1,指向x的符号表入口) 赋值号:= ( 4, ‘:= ’ ) 标识符y ( 1, 指向y的符号表入口 ) 分号; ( 5, ‘; ’ )
 赋值号:= ( 4, ‘:= ’ ) 标识符y ( 1, 指向y的符号表入口 ) 分号; ( 5, ‘; ’ )")
12
三.将词法分析工作分离的考虑 1.使整个编译程序的结构更简洁、清晰和条理化: 2.编译程序的效率会改进: 3.增强编译程序的可移植性:

13
4.2 单词的描述工具 一.正规文法 什么是正规文法? 正规文法所描述的是VT上的正规集

14
程序设计语言中的几类单词可用下述规则描述:
<标识符> l|l<字母数字> <字母数字> l|d|l<字母数字>|d<字母数字> <无符号整数> d|d<无符号整数> <运算符> +|-|*|/|=|<<等号|><等号>…… <等号> = <界符> ,|;|(|)| …… 其中l表示a~z中的任何一个英文字母,d表示0~9中 的任何一个数字
| …… 其中l表示a~z中的任何一个英文字母,d表示0~9中. 的任何一个数字.")
15
关键字也是一种单词,一般关键字都是由字母构成,它
的描述也极容易,实际上,关键字集合是标识符集合的 子集 最复杂的一类单词要属无符号实数,如25.55e+5和2.1, 它们可以由例4.1的规则描述

16
例4.1: <无符号数> d<余留无符号数>|.<十进小数>e<指数部分> <余留无符号数> d<余留无符号数>|.<十进小数>e<指数 部分>| <十进小数> d<余留十进小数> <余留十进小数> e<指数部分>| d<余留十进小数> | <指数部分> d<余留整指数> |s<整指数> <整指数> d<余留整指数> <余留整指数> d<余留整指数> | 其中,s表示正或负号(+,-)
")
17
二.正规式(正则表达式) 表示正规集的工具 描述单词符号的工具
 表示正规集的工具 描述单词符号的工具")
18
正规式和它所表示的正规集的递归定义: 设字母表为,辅助字母表`={,,,,,,} (1)和都是上的正规式,它们所表示的正规集分别为 {}和{ } (2)任何a ,a是上的一个正规式,它所表示的正规集 为{a}

19
(3)假定e1和e2都是上的正规式,它们所表示的正规集分别
为L(e1)和L(e2),那么,(e1), e1 e2, e1e2, e1也都是正规 式,它们所表示的正规集分别为L(e1), L(e1)L(e2), L(e1)L(e2)和(L(e1)) 仅由有限次使用上述三步骤而定义的表达式才是上的正规 式,仅由这些正规式所表示的字集才是上的正规集
和L(e2),那么,(e1), e1 e2, e1e2, e1也都是正规. 式,它们所表示的正规集分别为L(e1), L(e1)L(e2), L(e1)L(e2)和(L(e1)) 仅由有限次使用上述三步骤而定义的表达式才是上的正规. 式,仅由这些正规式所表示的字集才是上的正规集.")
20
其中的“”读为“或”(也有使用“+”代替 “” 的
);“ ”读为“连接”;“”读为“闭包”(即,任 意有限次的自重复连接)。在不致混淆时,括号可省去, 但规定算符的优先顺序为“”、“”、“”、“ ”、 “” 。连接符“ ”一般可省略不写。“”、“ ”和 “” 都是左结合的
; 读为 连接 ; 读为 闭包 (即,任. 意有限次的自重复连接)。在不致混淆时,括号可省去, 但规定算符的优先顺序为 、 、 、 、 。连接符 一般可省略不写。 、 和. 都是左结合的.")
21
例4.2 令={a,b}, 上的正规式和相应的正规集的例子有:
正规式 正规集 a {a} ab {a,b} ab {ab} (ab)(ab) {aa,ab,ba,bb} a { ,a,a, ……任意个a的串} (ab) { ,a,b,aa,ab ……所有由a和b组成的串} (ab)(aabb)(ab) {上所有含有两个相继的a或两个 相继的b组成的串}
(ab) {aa,ab,ba,bb} a { ,a,a, ……任意个a的串} (ab) { ,a,b,aa,ab ……所有由a和b组成的串} (ab)(aabb)(ab) {上所有含有两个相继的a或两个. 相继的b组成的串}")
22
例4.3 ={d,,e,+,-},则上的正规式
d(dd )(e(+- )dd ) 其中d为0~9的数字 表示的是: 无符号数的集合
(e(+- )dd ) 其中d为0~9的数字. 表示的是: 无符号数的集合.")
23
例题:词法分析器的输入是什么?(10分) 例题:令={a,b},则上所有以a开头,后跟0个或许多个的 ab的字的全体对应的正规式是什么?(5分) 例题:请写出表示标识符的正规式e1=(l|_)(l|d|_)*所对应的 正规集。(5分) 例题:有一台饮料自动售货机,接收1元或2元硬币,出售3 元钱一瓶的饮料。顾客每次向机器中投放等于或大于3元的 硬币,便可得到一瓶饮料(注意:多投不找钱)。写出对 应饮料自动售货机售货过程的正规式。画出与该正规式的 最小DFA。(10分)
 例题:有一台饮料自动售货机,接收1元或2元硬币,出售3. 元钱一瓶的饮料。顾客每次向机器中投放等于或大于3元的. 硬币,便可得到一瓶饮料(注意:多投不找钱)。写出对. 应饮料自动售货机售货过程的正规式。画出与该正规式的. 最小DFA。(10分)")
24
答案:源程序(的字符流) 答案:a(ab)* 答案:{l,_,ll,ld,l_,_l,_ _,-d,……}或者{以1或_打头l,_,d组成 的字符串} 答案:设a=1,b=2,则a (b | a( a| b) ) | b (a |b) 或者:21|22|12|111|112

25
若两个正规式e1和e2所表示的正规集相同,则说e1和e2等价,写
例如: e1= (ab), e2 = ba 又如: e1= b(ab) , e2 =(ba)b e1= (ab) , e2 =(ab)
, e2 = ba. 又如: e1= b(ab) , e2 =(ba)b e1= (ab) , e2 =(ab)")
26
设r,s,t为正规式,正规式服从的代数规律有:
rs=sr “或”服从交换律 r(st)=(rs)t “或”的可结合律 (rs)t=r(st) “连接”的可结合律 r(st)=rsrt (st)r=srtr 分配律 r=r r=r 是“连接”的恒等元素(零一律) rr=r r=rrr… “或”的抽取律
=(rs)t 或 的可结合律. (rs)t=r(st) 连接 的可结合律. r(st)=rsrt. (st)r=srtr 分配律. r=r. r=r 是 连接 的恒等元素(零一律) rr=r. r=rrr… 或 的抽取律.")
27
三.正规文法和正规式的等价性 1.将上的一个正规式r转换成文法G=(VN,VT,P,S): 令VT=∑,确定产生式和VN的元素用如下办法:
: 令VT=∑,确定产生式和VN的元素用如下办法:")
28
A→xB,A →y A →xA,B →y A →xA,A →y 选择一个非终结符S生成产生式S r,并将S定为G的 识别符号。若x和y都是正规式 , BVN ,则: (R1) 对形如 A xy的正规产生式,重写为: A xB,B y (R2)对形如A x*y的正规产生式,重写为: A xB,A y,B xB,B y (R3)对形如A xy的正规产生式,重写为: A x,A y 不断应用R做变换,直到每个产生式右端只含一个VN
对形如A x*y的正规产生式,重写为: A xB,A y,B xB,B y (R3)对形如A xy的正规产生式,重写为: A x,A y. 不断应用R做变换,直到每个产生式右端只含一个VN.")
29
例4.4 将 r=a(a|d)*转换成相应的正规文法
令S是文法的开始符号,形成S a(a|d)*: R1 S aA A (a|d)* R2 S aA A (a|d)B A B (a|d)B B R3 S aA A A aB A dB B aB B dB B
*: R1 S aA A (a|d)* R2 S aA. A (a|d)B A B (a|d)B B R3 S aA A A aB A dB. B aB B dB. B ")
30
2.将正规文法转换成正规式: 基本上是上述过程的逆过程,最后只剩下一个开始符 号定义的正规式,其转换规则如表4.1所示:

31
例4.5 G[s]: S aA S a A aA A dA A a A d ①S aA|a A aA|a|dA|d (a|d)A|(a|d) (a|d)*(a|d) ②s=a(a|d)*(a|d)|a=a((a|d)*(a|d)|ε)=a((a|d)*|ε) ③r=a(a|d)*
![例4.5 G[s]: S aA S a A aA. A dA A a A d. ①S aA|a. A aA|a|dA|d (a|d)A|(a|d)](http://slidesplayer.com/slide/11583537/62/images/31/%E4%BE%8B4.5+G%5Bs%5D%3A+S+aA+S+a+A+aA.+A+dA+A+a+A+d.+%E2%91%A0S+aA%7Ca.+A+aA%7Ca%7CdA%7Cd+%28a%7Cd%29A%7C%28a%7Cd%29.jpg "(a|d)*(a|d) ②s=a(a|d)*(a|d)|a=a((a|d)*(a|d)|ε)=a((a|d)*|ε) ③r=a(a|d)*")
32
4.3 有穷自动机 一.确定的有穷自动机(DFA)(有限自动机) DFA:能准确地识别正规集 一个确定的DFA:M=(K,Σ,f,S,Z)
4.3 有穷自动机 一.确定的有穷自动机(DFA)(有限自动机) DFA:能准确地识别正规集 一个确定的DFA:M=(K,Σ,f,S,Z) K是一个有穷集,它的每个元素称为一个状态 Σ是一个有穷字母表,它的每个元素称为一个输入符 号,所以也称Σ为输入符号字母表
(有限自动机) DFA:能准确地识别正规集. 一个确定的DFA:M=(K,Σ,f,S,Z) K是一个有穷集,它的每个元素称为一个状态. Σ是一个有穷字母表,它的每个元素称为一个输入符. 号,所以也称Σ为输入符号字母表.")
33
f是转换函数,是在K×Σ→K上的映射,即,如
f(ki,a)=kj,(ki∈K,kj∈K)就意味着,当前状 态为ki,输入符为a时,将转换为下一个状态kj,我们 把kj称作ki的一个后继状态 S∈K是唯一的一个初态 Z K是一个终态集,终态也称可接受状态或结束状态
=kj,(ki∈K,kj∈K)就意味着,当前状. 态为ki,输入符为a时,将转换为下一个状态kj,我们. 把kj称作ki的一个后继状态. S∈K是唯一的一个初态. Z K是一个终态集,终态也称可接受状态或结束状态.")
34
例4.6:DFA M=({S,U,V,Q},{a,b},f,S,{Q})
f(S,a)=U f(V,a)=U f(S,b)=V f(v,b)=Q f(U,a)=Q f(Q,a)=Q f(U,b)=V f(Q,b)=Q
=U f(V,a)=U. f(S,b)=V f(v,b)=Q. f(U,a)=Q f(Q,a)=Q. f(U,b)=V f(Q,b)=Q.")
35
一个DFA可以表示成一个状态图(状态转换图)
假定DFA M含有m个状态,n个输入符号,那么这个 状态图含有m个结点,每个结点最多有n个弧射出,整 个图含有唯一一个初态结点( 、-)和若干个终态结 点(双圈、+),若f(ki,a)=kj,则从状态结点ki到状态结点 kj画标记为a的弧
和若干个终态结. 点(双圈、+),若f(ki,a)=kj,则从状态结点ki到状态结点. kj画标记为a的弧.")
36
例4.6中的DFA的状态图表示如图4.1所示: 图4.1 状态图表示

37
一个DFA可以表示成一个矩阵表示,该矩阵的行表示状
态,列表示输入符号,矩阵元素表示相应状态和输入符 号将转换成的新状态,即k行a列为f(k,a)的值。用 标明初态;否则第一行即是初态,相应终态行在表的右 端标以1,非终态标以0
的值。用 标明初态;否则第一行即是初态,相应终态行在表的右. 端标以1,非终态标以0.")
38
例4.5中的DFA的矩阵表示如图4.2所示: 图4.2 矩阵表示

39
若t ∑*,f(S,t)=P,其中S为 M的开始状态,P Z,
Z为终态集,则称t为DFA M所接受(识别) 设Q∈K,函数f(Q,ε)=Q,一个输入符号串t(t1tx,t1 ∈∑,tx ∈∑*),在DFA M上运行的定义为: f(Q,t1tx)=f(f(Q,t1),tx)
 设Q∈K,函数f(Q,ε)=Q,一个输入符号串t(t1tx,t1. ∈∑,tx ∈∑*),在DFA M上运行的定义为: f(Q,t1tx)=f(f(Q,t1),tx)")
40
例如,证明t=baab被例4.6的DFA所接受
f(S,baab)=f(f(S,b),aab)=f(V,aab)=f(f (V,a),ab)=f(U,ab)=f(f(U,a),b)=f( Q,b)=Q Q属于终态 得证
=f(f(S,b),aab)=f(V,aab)=f(f. (V,a),ab)=f(U,ab)=f(f(U,a),b)=f( Q,b)=Q. Q属于终态. 得证.")
41
DFA M所能接受的符号串的全体记为L(M)
结论:上一个符号串集V是正规的,当且仅当存 在一个上的确定有穷自动机M,使得V=L(M) DFA的确定性表现在转换函数f:K×∑→K是一个单值 函数,也就是说,对任何状态k∈K和输入符号a ∈∑, f(k,a)唯一地确定了下一个状态
 DFA的确定性表现在转换函数f:K×∑→K是一个单值. 函数,也就是说,对任何状态k∈K和输入符号a ∈∑, f(k,a)唯一地确定了下一个状态.")
42
提示:NFA与DFA的第三个区别是,前者可以空移:t(q, ε)={某些状态的集合}
一个NFA:M=(K,,f,S,Z) K是一个有穷集,它的每个元素称为一个状态 是一个有穷字母表,它的每个元素称为一个输入符号 f是一个从K * 到K的子集的映像,即:K* * →2 K (多值映射) SK是一个非空初态集 ZK是一个终态集 提示:NFA与DFA的第三个区别是,前者可以空移:t(q, ε)={某些状态的集合}
 K是一个有穷集,它的每个元素称为一个状态. 是一个有穷字母表,它的每个元素称为一个输入符号. f是一个从K * 到K的子集的映像,即:K* * →2 K. (多值映射) SK是一个非空初态集. ZK是一个终态集. 提示:NFA与DFA的第三个区别是,前者可以空移:t(q, ε)={某些状态的集合}")
43
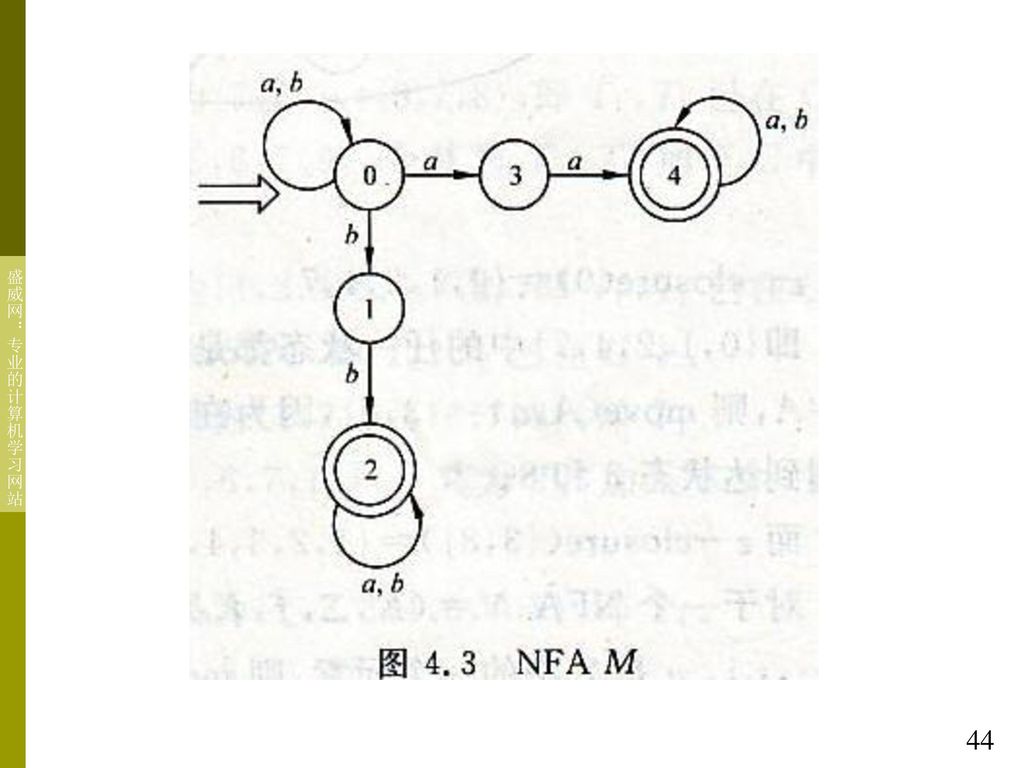
例4.7:一个NFA M=({0,1,2,3,4},{a,b},f,
{0},{2,4})其中 f(0,a)={0,3} f(2,b)={2} f(0,b)={0,1} f(3,a)={4} f(1,b)={2} f(4,a)={4} f(2,a)={2} f(4,b)={4} 它的状态图表示如图4.3所示:
其中. f(0,a)={0,3} f(2,b)={2} f(0,b)={0,1} f(3,a)={4} f(1,b)={2} f(4,a)={4} f(2,a)={2} f(4,b)={4} 它的状态图表示如图4.3所示:")
45
一个NFA也可以用一个矩阵表示... ∑*上的符号串t在NFA N上运行... ∑*上的符号串t被NFA N识别(读出、接受)... DFA是NFA的特例 对每个NFA N存在一个DFA M ,使得L(M)=L(N) 对于任何两个有穷自动机M和N,如果L(M)=L(N),则称 M与N是等价的
=L(N),则称. M与N是等价的.")
46
三.NFA转换为等价的DFA 定理:设L为一个由不确定的有穷自动机接受的集合,则 存在一个接受L的确定的有穷自动机 将NFA转换成接受同样语言的DFA,这种算法称为子集法

47
定义对状态集合I的两个运算: 1.I的-闭包,表示为-closure(I),是I中的任何状态S经任 意条弧而能到达的状态的集合。I的任何状态S都属于 -closure(I) 2.I的a弧转换,表示为move(I,a)=J,其中J是所有那些可 从I的某一状态经过一条a弧而到达的状态的全体

48
使用图4.4的NFA N的状态集合来理解上述两个运算:
-closure(0)= {0,1,2,4,7}=I1 move(I1,a)= {3,8} move(I1,b) = {5} -closure({3,8})= {1,2,3,4,6,7,8}=I2 -closure({5})= {1,2,4,5,6,7}=I3
= {0,1,2,4,7}=I1. move(I1,a)= {3,8} move(I1,b) = {5} -closure({3,8})= {1,2,3,4,6,7,8}=I2. -closure({5})= {1,2,4,5,6,7}=I3.")
49
对于一个NFA N=(K,,f,K0,Kt)来说,若I是K
的一个子集,设I={s1,s2,…,sj},a是∑中的一个元素,则 move(I,a)=f(s1,a) ∪f(s2,a) ∪…∪f(sj,a)
=f(s1,a) ∪f(s2,a) ∪…∪f(sj,a)")
50
假设NFA N=(K, ,f,K0,Kt)按如下办法构造一个DFA
M=(S, ,d,S0,St),使得L(M)=L(N): 1. M的状态集S由K的一些子集组成。用[S1 S2... Sj]表示S 的元素,其中S1, S2,,... Sj是K的状态。并且约定,状态S1, S2,,... Sj是按某种规则排列的,即对于子集{S1, S2}={ S2, S1,}来说,S的状态就是[S1 S2] 2.M和N的输入字母表是相同的,即是 3.转换函数是这样定义的: D([S1 S2,... Sj],a)= [R1R2... Ri] 其中 {R1,R2,... , Ri} = -closure(move({S1, S2,,... Sj},a))
,使得L(M)=L(N): 1. M的状态集S由K的一些子集组成。用[S1 S2... Sj]表示S. 的元素,其中S1, S2,,... Sj是K的状态。并且约定,状态S1, S2,,... Sj是按某种规则排列的,即对于子集{S1, S2}={ S2, S1,}来说,S的状态就是[S1 S2] 2.M和N的输入字母表是相同的,即是 3.转换函数是这样定义的: D([S1 S2,... Sj],a)= [R1R2... Ri] 其中. {R1,R2,... , Ri} = -closure(move({S1, S2,,... Sj},a))")
51
4.S0=-closure(K0)为M的开始状态
5.St={[Sj Sk... Se],其中[Sj Sk... Se]S且{Sj , Sk,,... Se} ∩KtØ}

52
构造NFA N的状态K的子集的算法,见图4.5:
假定所构造的子集族为C,即C= (T1, T2,,... Ti),其中T1, T2,,... Ti为状态K的子集
,其中T1, T2,,... Ti为状态K的子集.")
53
例4.8 应用图4.5的算法对图4.4的NFA N构造子集 步骤如下: 1.首先计算-closure(0):令T0=-closure(0)={0,1,2,4,7},T0未 被标记,它现在是子集族C的唯一成员 2.标记T0:令T1=-closure(move(T0,a))={1,2,3,4,6,7,8},将T1 加入C中,T1未被标记。令T2=-closure(move(T0,b)) ={1,2,4,5,6,7},将T2加入C中,T2未被标记 3.标记T1:-closure(move(T1,a))={1,2,3,4,6,7,8},即T1,T1已 在C中。T3=-closure(move(T1,b))={1,2,4,5,6,7,9},将T3加 入C中,T3未被标记
)={1,2,3,4,6,7,8},将T1. 加入C中,T1未被标记。令T2=-closure(move(T0,b)) ={1,2,4,5,6,7},将T2加入C中,T2未被标记. 3.标记T1:-closure(move(T1,a))={1,2,3,4,6,7,8},即T1,T1已. 在C中。T3=-closure(move(T1,b))={1,2,4,5,6,7,9},将T3加. 入C中,T3未被标记.")
54
4.标记T2:-closure(move(T2,a))={1,2,3,4,6,7,8},即T1,T1已
在C中。-closure(move(T2,b))={1,2,4,5,6,7},即T2,T2已在 C中 5.标记T3:-closure(move(T3,a))={1,2,3,4,6,7,8},即T1。- closure(move(T3,b))={1,2,4,5,6,7,10},令其为T4,在入C中, T4未被标记 6.标记T4:-closure(move(T4,a))={1,2,3,4,6,7,8},即T1。 -closure(move(T4,b))={1,2,4,5,6,7},即T2
)={1,2,4,5,6,7},即T2,T2已在. C中. 5.标记T3:-closure(move(T3,a))={1,2,3,4,6,7,8},即T1。- closure(move(T3,b))={1,2,4,5,6,7,10},令其为T4,在入C中, T4未被标记. 6.标记T4:-closure(move(T4,a))={1,2,3,4,6,7,8},即T1。 -closure(move(T4,b))={1,2,4,5,6,7},即T2.")
55
a b 01247 T0=01247 38 5 38 5 124567 T1= 38 59 59 T2=124567 38 5 T3= 38 5 10 5 10 T4= 38 5

56
至此,算法终止共构造了5个子集: T0={0,1,2,4,7} T1={1,2,3,4,6,7,8} T2={1,2,4,5,6,7} T3={1,2,4,5,6,7,9} T4={1,2,4,5,6,7,10} 那么图4.4的NFA N构造的DFA M为: 1.S={ [T0], [T1], [T2], [T3], [T4] } 2. ∑={a,b}

57
3. D([T0],a)=[T1] D([T3],a)=[T1]
D([T0],b)=[T2] D([T3],b)=[T4] D([T1],a)=[T1] D([T4],a)=[T1] D([T1],b)=[T3] D([T4],b)=[T2] D([T2],a)=[T1] D([T2],b)=[T2] 4.S0=[T0] 5.St=[T4] 为便于书写,将[T0]、 [T1]、 [T2]、 [T3]、 [T4]重新命名为 A、B、C、D、E或用0、1、2、3、4分别表示,若采用后 者,该DFA M的状态转换图如图4.6所示:
![3. D([T0],a)=[T1] D([T3],a)=[T1]](http://slidesplayer.com/slide/11583537/62/images/57/3.+D%28%5BT0%5D%2Ca%29%3D%5BT1%5D+D%28%5BT3%5D%2Ca%29%3D%5BT1%5D.jpg "D([T0],b)=[T2] D([T3],b)=[T4] D([T1],a)=[T1] D([T4],a)=[T1] D([T1],b)=[T3] D([T4],b)=[T2] D([T2],a)=[T1] D([T2],b)=[T2] 4.S0=[T0] 5.St=[T4] 为便于书写,将[T0]、 [T1]、 [T2]、 [T3]、 [T4]重新命名为. A、B、C、D、E或用0、1、2、3、4分别表示,若采用后. 者,该DFA M的状态转换图如图4.6所示:")
58
图4.6 DFA M

59
四. DFA的化简 最小状态DFA: 没有多余状态(死状态) 没有两个状态是互相等价(不可区别) 一个有穷自动机可以通过消除无用状态和合并等价状态 而转换成一个最小的与之等价的有穷自动机 有穷自动机的无用状态:从该自动机的开始状态出发, 任何输入串也不能到达的那个状态或者从这个状态没有 通路到达终态

60
例如图4.7的有穷自动机M: s4是不可到达,S6和S8不可到达 图4.7 消除多余状态

61
在有穷自动机中,两个状态s和t等价的条件是:
一致性条件——必须同是为可接受状态或不可接受状态 蔓延性条件——对于所有输入符号,必须转换到等价的 状态里 分割法:把一个DFA(不含多余状态)的状态分成一些 不相交的子集,使得任何不同的两子集的状态都是可区 别的,而同一子集中的任何两个状态都是等价的
的状态分成一些. 不相交的子集,使得任何不同的两子集的状态都是可区. 别的,而同一子集中的任何两个状态都是等价的.")
62
DFA M最小化方法: 先分成终态集合和非终态集合 对每个集合中的符号分别用输出字母去查看它们到达状 态的集合是否在同一个集合中 如果不在同一个集合,将它们划分在不同的集合中 直到不能再划分为止

63
例4.9 将图4.8中的DFA M最小化 P0=({1,2,3,4},{5,6,7}) a P1=({1,2},{3,4},{5,6,7}) a P2=({1,2},{3},{4},{5,6,7}) a P3=({1,2},{3},{4},{5},{6,7}) b 令1代表{1,2}消去2,令6代表{6,7},消去7,得到图4.8(b) 的DFA M`,它是4.8(a)的DFA M的最小化
 b. 令1代表{1,2}消去2,令6代表{6,7},消去7,得到图4.8(b) 的DFA M`,它是4.8(a)的DFA M的最小化.")
64
图4.8 DFA M和DFA M`

65
4.4 正规式和有穷自动机的等价性 对于∑上的一个NFA M,可以构造一个∑上的正规式 R,使得L(R)=L(M)
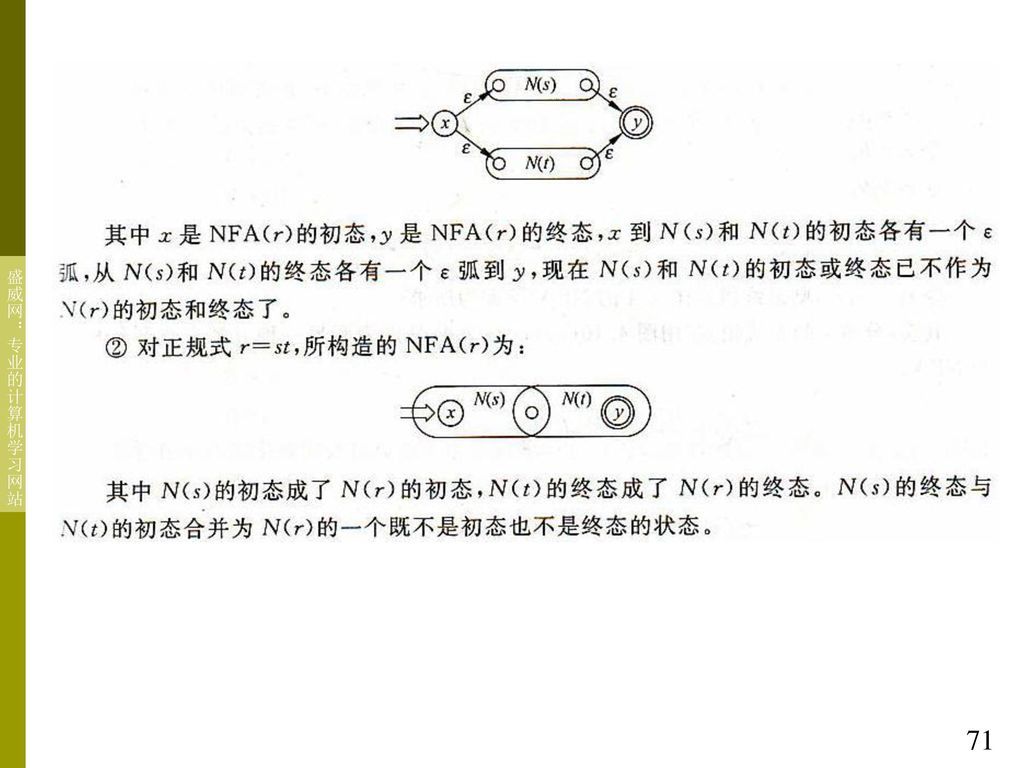
4.4 正规式和有穷自动机的等价性 对于∑上的一个NFA M,可以构造一个∑上的正规式 R,使得L(R)=L(M) 第一步,在M的状态转换图上加进两个结,一个为x结 点,一个为y结点。从x结点用弧连接到M的所有初始 结点,从M的所有终态结点用弧连接到y结点。形成 一个与M等价的M`, M`只有一个初态x和一个终态y 第二步,逐步消去M`中的所有结点,直至只剩下x和y 结点。在消结过程中,逐步用正规式来标记弧
=L(M) 第一步,在M的状态转换图上加进两个结,一个为x结. 点,一个为y结点。从x结点用弧连接到M的所有初始. 结点,从M的所有终态结点用弧连接到y结点。形成. 一个与M等价的M`, M`只有一个初态x和一个终态y. 第二步,逐步消去M`中的所有结点,直至只剩下x和y. 结点。在消结过程中,逐步用正规式来标记弧.")
66
其消结的规则如下: 最后x和y结点间的弧上的标记则为所求的正规式r

67
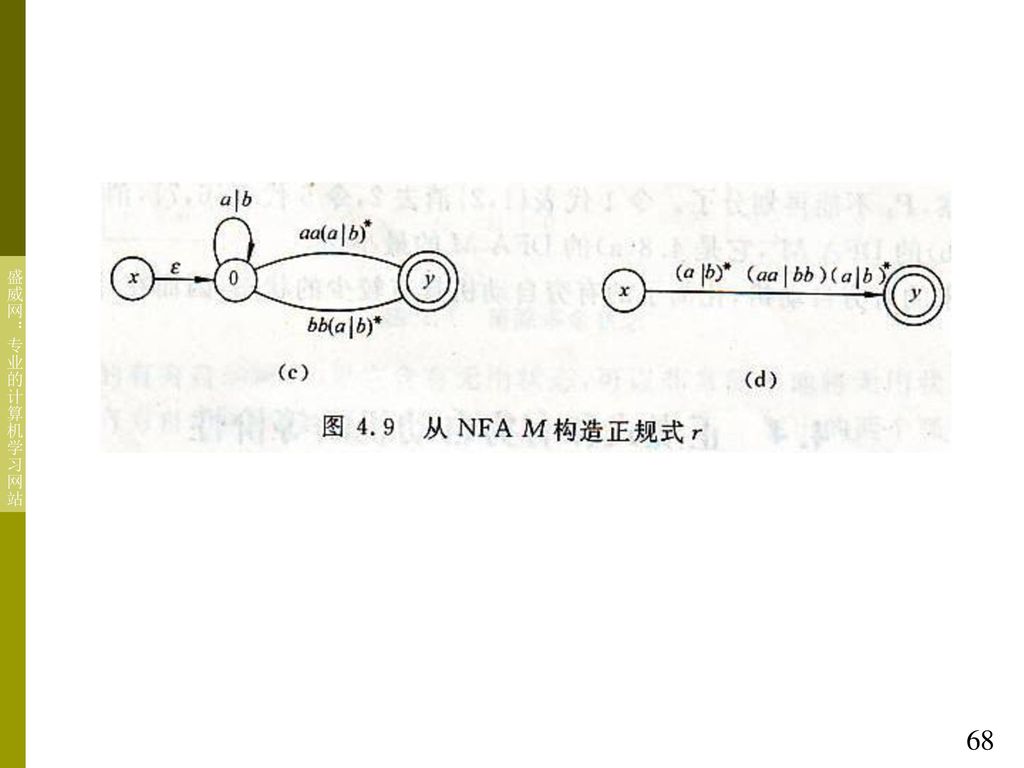
例4.10 以例4.7的NFA M为例,M的状态图在图4.3,求
正规式r,使L(r)=L(M)
=L(M)")
69
对于∑上的一个正规式R,可以构造一个∑上的NFA
M,似的L(M)=L(R) 语法制导方法:按正规式的语法结构指引构造过程,首先 将正规式分解成一系列子表达式,然后使用下面规则为r 构造NFA,对r的各种语法结构的构造规则具体描述如下: 1. ①对于正规式Ø,所构造的NFA为:
=L(R) 语法制导方法:按正规式的语法结构指引构造过程,首先. 将正规式分解成一系列子表达式,然后使用下面规则为r. 构造NFA,对r的各种语法结构的构造规则具体描述如下: 1. ①对于正规式Ø,所构造的NFA为:")
73
例4.11 为r=(a|b)*abb构造NFA N,使得L(N)=L(r)
从左到右分解r,令r1=a,第1个a,则有 令r2=b,则有 令r3=r1|r2,则有 令r4=r3*,则有:

74
令r5=a, 令r6=b, 令r7=b, 令r8=r5r6, 令r9=r8r7,则有: 令r10=r4r9,
则最终得到的NFA N:

75
其实,分解r的方式很多,用图4.10(a)(b)(c)(d)分别表明另一种分解方式和所构造的NFA。
图4.10 从正规式r构造NFA

76
思考:如果不用怎么分解 r=(a|b)*abb ?
1 2 3 a b 思考:如何把上面的NFA变成DFA? a b 01 02 03

77
1 2 3 a b

78
4.5 正规文法和有穷自动机的等价性 采用下面的规则可以从正规文法G直接构造一个有穷 自动机NFA M;使得L(M)=L(G):
4.5 正规文法和有穷自动机的等价性 采用下面的规则可以从正规文法G直接构造一个有穷 自动机NFA M;使得L(M)=L(G): M的字母表与G的终结符集相同 为G中的每个非终结符生成M的一个状态,G的开始符S 是开始状态S
=L(G): M的字母表与G的终结符集相同. 为G中的每个非终结符生成M的一个状态,G的开始符S. 是开始状态S.")
79
增加一个新状态Z,作为NFA的终态 对G中的形如A tB的规则(其中t为终结符或ℇ,A和B为 非终结符的产生式),构造M的一个转换函数f(A,t)=B 对G中形如A t的产生式,构造M的一个转换函数 f(A,t)=Z
=Z.")
80
例4.12:与文法G[S]等价的NFA M如图4.11 G[S]: S a A S bB S ε A aB A bA B aS B bA B ε
![例4.12:与文法G[S]等价的NFA M如图4.11 G[S]: S a A S bB S ε A aB A bA B aS B bA B ε](http://slidesplayer.com/slide/11583537/62/images/80/%E4%BE%8B4.12%EF%BC%9A%E4%B8%8E%E6%96%87%E6%B3%95G%EF%BC%BBS%EF%BC%BD%E7%AD%89%E4%BB%B7%E7%9A%84NFA+M%E5%A6%82%E5%9B%BE4.11+G%5BS%5D%3A+S+a+A+S+bB+S+%CE%B5+A+aB+A+bA+B+aS+B+bA+B+%CE%B5.jpg "例4.12:与文法G[S]等价的NFA M如图4.11 G[S]: S a A S bB S ε A aB A bA B aS B bA B ε")
81
有穷自动机转换成等价的正规文法: 对转换函数f(A,t)=B,可写一产生式:A tB 对可接受状态Z,增加一产生式:Z ε 有穷自动机的初态对应文法开始符 有穷自动机的字母表为文法的终结符集
=B,可写一产生式:A tB 对可接受状态Z,增加一产生式:Z ε 有穷自动机的初态对应文法开始符 有穷自动机的字母表为文法的终结符集")
82
例4.13:给出与图4.12的NFA等价的正规文法G G=({A,B,C,D},{a,b},P,A),其中P为: A a B C ε A bD D aB B bC D bD C aA D ε C bD

83
4.6 词法分析程序的自动构造工具 以LEX为例介绍如何从正规式产生识别该正规式所描述的 单词的词法分析程序
4.6 词法分析程序的自动构造工具 以LEX为例介绍如何从正规式产生识别该正规式所描述的 单词的词法分析程序 LEX是一个广泛使用的工具,UNIX系统中使用lex命令调 用。它用于构造各种各样语言的词法分析程序 图 4.13LEX编译系统的作用

84
图 4.14 使用LEX生成词法分析器

85
LEX程序由三部分组成: 说明部分:变量说明、常量说明、正规定义 %% 转换规则:Pn {action n} 辅助过程:容纳的是action所需要的辅助过程

86
图4.15给出一个识别PL/O单词的LEX程序片断: IDENT[a-zA-Z] [a-zA-Z0-9]*
NUMBER[0-9] [0-9]* %( #include 〈stdio.h〉 #include "code.h“ #include "symbol.h“ #include "y.tab.h“ extern int level; int cc=0; %) %% "" { cc++;} "\t" { tablize(); } /*adjustcc to tabposition*/ "\n" { cc=0; line-copy(); } /*copy a line of input file*/ "<" { cc++; return LT;} ">" { cc++; return GT;} "=" { cc++; return EQ;}
![图4.15给出一个识别PL/O单词的LEX程序片断: IDENT[a-zA-Z] [a-zA-Z0-9]*](http://slidesplayer.com/slide/11583537/62/images/86/%E5%9B%BE4.15%E7%BB%99%E5%87%BA%E4%B8%80%E4%B8%AA%E8%AF%86%E5%88%ABPL%2FO%E5%8D%95%E8%AF%8D%E7%9A%84LEX%E7%A8%8B%E5%BA%8F%E7%89%87%E6%96%AD%EF%BC%9A+IDENT%5Ba-zA-Z%5D+%5Ba-zA-Z0-9%5D%2A.jpg "NUMBER[0-9] [0-9]* %( #include 〈stdio.h〉 #include code.h #include symbol.h #include y.tab.h extern int level; int cc=0; %) %% { cc++;} \t { tablize(); } /*adjustcc to tabposition*/ \n { cc=0; line-copy(); } /*copy a line of input file*/ < { cc++; return LT;} > { cc++; return GT;} = { cc++; return EQ;}")
87
"#" { cc++; return NE;} "," { cc++; return colon; } "." { cc++; return Period;} "(" { cc++; return Lparen;} ")" { cc++; return Rparen;} "<=" { cc++;cc++;return LE;} ">=" { cc++;cc++;return GE;} "∶=" { cc++; cc++;return ASGN;} ";" { cc++; return Semicolon;} {NUMBER} { intn; cc += yyleng; sscanf(yytext,"%d", &n); yylval.number=n; return NUMBER; }
 { cc++; return Rparen;} <= { cc++;cc++;return LE;} >= { cc++;cc++;return GE;} ∶= { cc++; cc++;return ASGN;} ; { cc++; return Semicolon;} {NUMBER} { intn; cc += yyleng; sscanf(yytext, %d , &n); yylval.number=n; return NUMBER; }")
88
图 4.15 LEX程序例子--识别PL/0单词的LEX程序
{IDENT} { Symbol *s; cc += yyleng; if((s=lookup(yytext))==0) /*new identifier*/ s=install(yytext,VARIABLE,level,0); /* install symbol*/ if (s→type==C) yylval.number=s-〉adr; else /*it's a VARIABLE or PROC*/ yylval.sym=s; return s-〉type; } %% yywrap( ) { }; 图 4.15 LEX程序例子--识别PL/0单词的LEX程序
)==0) /*new identifier*/ s=install(yytext,VARIABLE,level,0); /* install symbol*/ if (s→type==C) yylval.number=s-〉adr; else /*it s a VARIABLE or PROC*/ yylval.sym=s; return s-〉type; } %% yywrap( ) { }; 图 4.15 LEX程序例子--识别PL/0单词的LEX程序.")
89
4.7 典型例题及解答 1.构造正规式1(0|1)*101相应的DFA
*101相应的DFA")
90
2.将图4.18所示的DFA最小化

91
【本章小结】 词法分析程序是编译第一阶段的工作,它读入字符流的源程序,按照词法规则识别单词,交由语法分析程序接下去。
词法分析程序是编译第一阶段的工作,它读入字符流的源程序,按照词法规则识别单词,交由语法分析程序接下去。 本章讲述了词法分析程序设计原则,并介绍了正规式和有穷动机分别作为正规集描述和识别机制。在此基础上给出了词法分析程序自动构造工具如LEX的原理。 词法分析程序的设计技术可应用于其它领域,比如查询语言以及信息检索系统等,这种应用领域的程序设计特点是,通过字符串模式的匹配来引发动作,回想LEX,说明词法分析程序的语言,可以看成是一个模式动作语言。 词法分析程序的自动构造工具也广泛应用于许多方面,如用以生成一个程序,可识别印刷电路板中的缺陷,又如开关线路设计和文本编辑的自动生成等。

92
第4章 作业题 P72: 1.(2)(3) 2. 4. 6. 7. 9.
(3)")
Similar presentations



招生对象:初中毕业生 (二)学制:五年 (三)办学层次:专科.>")



 单位 常用单位:摄氏度(℃) 原理: 根据液体热胀冷缩的性质制成的。>")





 櫃 公 司 僑外資持股情形申報作業.>")




 词法分析与有穷自动机.>")
分析法和算符优先分析法对文法的限制要少得多,对大多数用无二义的上下文无关文法描述的语言都可以用LR分析器予以识别,而且速度快,并能准确、及时地指出输入串的任何语法错误及出错位置。LR分析法的一个主要缺点是,若用手工构造分析器则工作量相当大,因此必须求助于自动产生LR分析器的产生器。>")

