Download presentation
Presentation is loading. Please wait.

1
引入树 线性表、堆栈和队列都是线性结构,它们的共同特点:一对一; 计算机对弈中的一个格局可能有多个后继格局,用线性结构难以描述。
树是一种非线性结构,以分支关系定义层次结构,适宜描述一对多的嵌套性数据。

2
第9章 树

3
主要内容 树和二叉树的基本概念 二叉树和树的存储结构 二叉树的抽象类 二叉树的遍历和树的遍历 二叉排序树 赫夫曼树及其应用

4
树和二叉树的基本概念 树的定义、术语及基本操作 二叉树的定义及其性质

5
树的定义 树是n(n>=0)个结点的有限集合; 如果n=0,称为空树; 如果n>0,即在一棵非空树中:
(1)有且仅有一个特定的结点称为根,它只有直接后继,但是没有直接前驱;
有且仅有一个特定的结点称为根,它只有直接后继,但是没有直接前驱;")
6
树的定义 (2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集合T1,T2,...,Tm,其中每一个集合本身又是一棵树,并且称之为根的子树。每棵子树的根结点有且仅有一个直接前驱,但可以有0个或多个直接后继。 可见,树的定义是一个递归的定义,即树的定义中又用到树的概念,此即树的固有特性。

7
T ={ A,B,C,D,E,F,G,H,I,J } A是根,其余结点可以划分为3个互不相交的集合:
T1={ B,E,F } T2={ C,G } T3={ D,H,I,J } 这些集合中的每一集合都本身又是一棵树,它们是根 A 的子树。 对于T1,B是根,其余结点可以划分为两个互不相交的集合: T11={ E } T12={ F } T11,T12是B的子树。

8
4)除根外的其它结点,都存在唯一条从根到该结点的路径;
J I A C B D H G F E 从逻辑结构看: 1)树中只有根结点没有前趋; 2)除根外,其余结点都有且仅一个前趋; 3)树的结点,可以有零个或多个后继; 4)除根外的其它结点,都存在唯一条从根到该结点的路径; 5)树是一种分支结构(除了一个称为根的结点外)每个元素都有且仅有一个直接前趋,有且仅有零个或多个直接后继。
树中只有根结点没有前趋; 2)除根外,其余结点都有且仅一个前趋; 3)树的结点,可以有零个或多个后继; 4)除根外的其它结点,都存在唯一条从根到该结点的路径; 5)树是一种分支结构(除了一个称为根的结点外)每个元素都有且仅有一个直接前趋,有且仅有零个或多个直接后继。")
9
树的应用 C 文件夹1 文件夹n 文件1 文件2 文件夹21 文件夹22 文件21 文件22 常用的数据组织形式——计算机的文件系统。
不论是DOS文件系统还是window文件系统,所有的文件都是用树的形式进行组织。 文件夹1 文件夹n 文件1 文件2 文件夹21 文件夹22 文件21 文件22 C

10
树的术语 树的结点:包含一个 数据元素的内容及若 干指向子树的分支。 孩子结点:结点的子树的 根称为该结点的孩子;如E是B的孩子。
J I A C B D H G F E 树的结点:包含一个 数据元素的内容及若 干指向子树的分支。 孩子结点:结点的子树的 根称为该结点的孩子;如E是B的孩子。 双亲结点:B结点是A结点的孩子,则A结点是B结点的双亲;如B是E的双亲。 兄弟结点:同一双亲的孩子结点;如H、I、J互为兄弟。 堂兄结点:同一层上结点;如G与E、F、H、I、J互为堂兄。

11
树的术语 祖先结点:某一结点的 祖先是从根到该结点所 经分支上的所有结点;如H的祖先为A、D。
J I A C B D H G F E 祖先结点:某一结点的 祖先是从根到该结点所 经分支上的所有结点;如H的祖先为A、D。 子孙结点:以某结点为根的子树中的任一结点称为该结点的子孙;如A的子孙为B、C、D、E、F、G、H、I、J。 结点的度:结点子树的个数;如D的度为3。 叶子结点:也叫终端结点,是度为0的结点;如E、F、G、H、I、J。 分支结点:度不为0的结点;如A、B、C、D。

12
树的术语 结点层次: 根结点的层定义为0, 根的孩子为第1层结点,依此类推。 树的高度(深度):树中结点的最大层次;如图所示树的高度为2。
J I A C B D H G F E 结点层次: 根结点的层定义为0, 根的孩子为第1层结点,依此类推。 树的高度(深度):树中结点的最大层次;如图所示树的高度为2。 树的度:树中各结点的度的最大值;如图所示树的度为3。
:树中结点的最大层次;如图所示树的高度为2。 树的度:树中各结点的度的最大值;如图所示树的度为3。")
13
树的术语 森林: 是 m(m≥0)棵互不相交的树的集合。 任何一棵非空树是一个二元组 Tree = (root,F)
A 是 m(m≥0)棵互不相交的树的集合。 B E F K L C G D H I J M 任何一棵非空树是一个二元组 Tree = (root,F) 其中:root 称为根结点,F 称为子树森林。 有序树:子树之间存在明确的次序关系的树。 无序树:不考虑子树的顺序。
棵互不相交的树的集合。 B. E. F. K. L. C. G. D. H. I. J. M. 任何一棵非空树是一个二元组. Tree = (root,F) 其中:root 称为根结点,F 称为子树森林。 有序树:子树之间存在明确的次序关系的树。 无序树:不考虑子树的顺序。")
14
树的基本操作 初始化:即置T为空树; 求根结点:即求树T的根结点或是求结点x所在树的根结点; 求双亲结点:求树T中结点x的双亲结点;
求孩子结点:求树T中结点x的第i个孩子结点。

15
树的基本操作 求右兄弟:即求树T中结点x的右兄弟结点; 建立一棵树:即生成一棵以x为根,以森林F为子树的一棵树;
插入子树:即将以结点x为根的子树T'作为树T中结点y的第i棵子树。

16
树的基本操作 删除子树:即将以结点x为根的第i棵子树T‘从树T中删除; 遍历:即按某个顺序依次访问树中的各个结点,并使每个结点只被访问一次;

17
线性结构 VS 树型结构 根结点 第一个数据元素 (无前驱) (无前驱) 多个叶子结点 最后一个数据元素 (无后继) (无后继)
其他数据元素 (一个前驱、 多个后继) 其他数据元素 (一个前驱、 一个后继)
 其他数据元素. (一个前驱、 一个后继)")
18
二叉树的定义 二叉树是一种普遍使用的树形结构;
二叉树(Binary Tree)或为空树,或是由一个根结点及2棵不相交的左子树和右子树构成,并且左、右子树本身也是二叉树; 二叉树的子树有左右之分,属于有序树。
或为空树,或是由一个根结点及2棵不相交的左子树和右子树构成,并且左、右子树本身也是二叉树; 二叉树的子树有左右之分,属于有序树。")
19
二叉树的例子 右子树 根结点 A E B C F G D 左子树 H K 特点:1)每个结点的度≤2; 2)是有序树。
每个结点的度≤2; 2)是有序树。")
20
二叉树的五种基本形态: 只含根结点 空树 左右子树均不为空树 N 右子树为空树 左子树为空树 N N N L R L R

21
二叉树的性质1 : 用归纳法证明: 若二叉树的层次从0开始,则第 i 层上至多有2i 个结点(i≥0)。
2) 假设对所有的 j,1≤ j i,命题成立; 3) 二叉树上每个结点至多有两棵子树,则第 i 层的结点数是i-1层的2倍,即2i-1 2 = 2i 。
 假设对所有的 j,1≤ j i,命题成立; 3) 二叉树上每个结点至多有两棵子树,则第 i 层的结点数是i-1层的2倍,即2i-1 2 = 2i 。")
22
二叉树的性质2 : 证明: 基于上一条性质,深度为 k 的二叉树上的结点数至多为
高度为 k 的二叉树上至多含 2k+1-1 个结 点(k≥-1)。 证明: 基于上一条性质,深度为 k 的二叉树上的结点数至多为 +2k = 2k+1-1 。
。 证明: 基于上一条性质,深度为 k 的二叉树上的结点数至多为 +2k = 2k+1-1 。")
23
二叉树的性质3 : 对任何一棵二叉树,若它含有n0 个叶子结点、n2 个度为 2 的结点,则必存在关系式:n0 = n2+1。
证明: 设,二叉树上结点总数 n = n0 + n1 + n2 又,二叉树上进入结点的分支总数b: b = n1+2n2 (度为1的结点产生一条分支,度为2的结点产生两条分支) b = n-1 (一个根结点的二叉树无分支,增加一个结点产生一条分支) b= n0 + n1 + n2 - 1 由此, n0 = n2 + 1 。
 b = n-1 (一个根结点的二叉树无分支,增加一个结点产生一条分支) b= n0 + n1 + n 由此, n0 = n2 + 1 。")
24
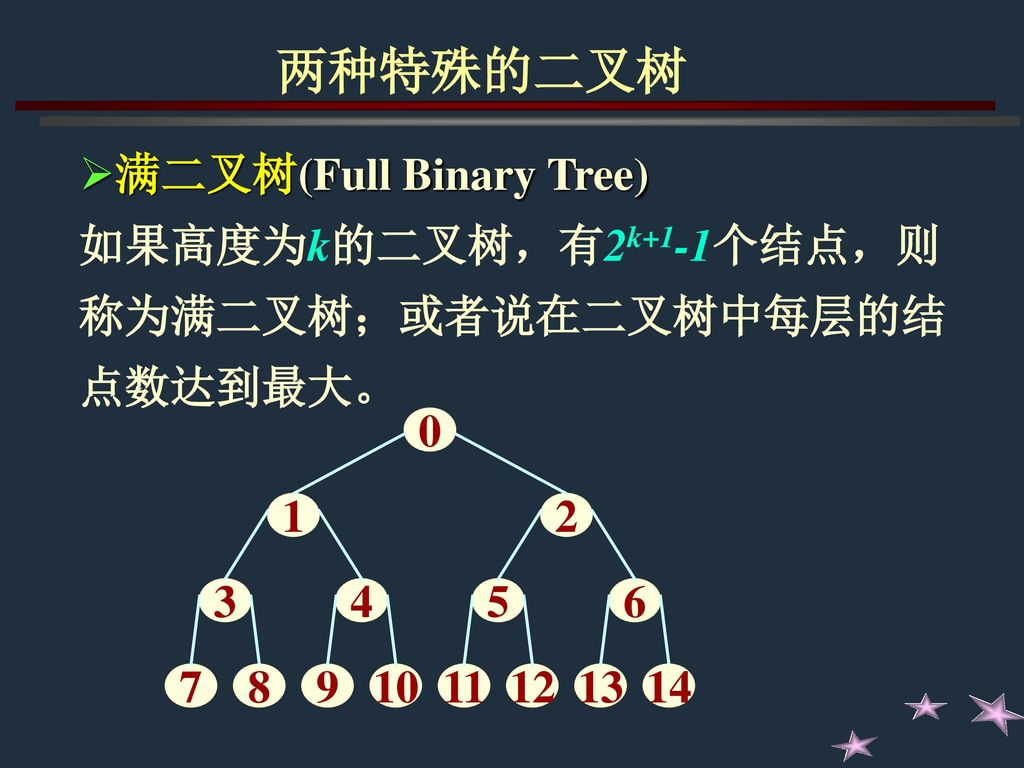
两种特殊的二叉树 满二叉树(Full Binary Tree) 如果高度为k的二叉树,有2k+1-1个结点,则称为满二叉树;或者说在二叉树中每层的结点数达到最大。 1 2 3 4 5 6 7 8 9 10 11 12 13 14
25
完全二叉树 (Complete Binary Tree) 1、树中所含的 n 个结点和满二叉树中编号为 1 至 n 的结点一一对应;
两种特殊的二叉树 完全二叉树 (Complete Binary Tree) 1、树中所含的 n 个结点和满二叉树中编号为 1 至 n 的结点一一对应; 2、一棵二叉树,只有最下一层结点数未达到最大,且最下层结点都集中在该层的最左端。 a a b c c b d e f g d e h i j
 1、树中所含的 n 个结点和满二叉树中编号为 1 至 n 的结点一一对应; 2、一棵二叉树,只有最下一层结点数未达到最大,且最下层结点都集中在该层的最左端。 a. a. b. c. c. b. d. e. f. g. d. e. h. i. j.")
26
完全二叉树的特点是: 叶子结点只可能在层次最大的两层上出现; 对任何一个结点,若其右子树的高度为h,则其左子树的高度只能是h或h+1。

27
二叉树的性质4 : 具有 n 个结点的完全二叉树的高度为:
log2(n+1)-1 。 证明: 设完全二叉树的高度为 k ,结点数为n, 则据第二条性质得2k-1 < n ≤ 2k+1-1 2k < n +1≤ 2k k < log2 (n+1) ≤ k+1 因为 k 只能是整数, k =log2(n+1) - 1 。
-1 。 证明: 设完全二叉树的高度为 k ,结点数为n, 则据第二条性质得2k-1 < n ≤ 2k k < n +1≤ 2k+1 k < log2 (n+1) ≤ k+1. 因为 k 只能是整数, k =log2(n+1) - 1 。")
28
二叉树的性质5 若对含 n 个结点的完全二叉树从上到下、从左至右进行 0 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点: (1) 若 i=0,则该结点是二叉树的根,无双亲, 否则,编号为 (i-1)/2 的结点为其双亲结点。 (2) 若 2i+1>n ,则该结点无左孩子; 若2i+1≤n ,编号为 2i +1的结点为其左孩子结点。 (3) 若 2i+2>n,则该结点无右孩子; 若2i+2≤n,编号为2i+2 的结点为其右孩子结点。
/2 的结点为其双亲结点。 (2) 若 2i+1>n ,则该结点无左孩子; 若2i+1≤n ,编号为 2i +1的结点为其左孩子结点。 (3) 若 2i+2>n,则该结点无右孩子; 若2i+2≤n,编号为2i+2 的结点为其右孩子结点。")
29
性质5举例 1 2 3 4 5 6 7 8 9 若 i=0,该结点是二叉树的根, 无双亲; 若 i≠0,编号为 (i-1)/2
的结点为其双亲。 若2i+1>n ,该结点无左孩子 (i=6,7); 若2i+1≤n,编号为 2i+1 的 结点为其左孩子(i=4,5)。 若 2i+2>n,该结点无右孩子(i= 5,6,7); 若2i+2≤n,编号为2i+2 的结点为其右孩子(i=2,3)。 1 2 3 4 5 6 7 8 9
; 若2i+1≤n,编号为 2i+1 的. 结点为其左孩子(i=4,5)。 若 2i+2>n,该结点无右孩子(i= 5,6,7); 若2i+2≤n,编号为2i+2. 的结点为其右孩子(i=2,3)。")
30
小 结 树的定义 树的有关术语 树的基本操作 二叉树的定义 二叉树的性质

31
二叉树的存储结构 顺序存储结构:数组表示 链式存储结构:二叉链表 三叉链表

32
二叉树的顺序存储 对于完全二叉树,采用一组连续的内存单元,按编号顺序依次存储完全二叉树的结点。 0 1 2 3 4 5 6 A F E D
C B 1 2 3 4 5 A B C D E F

33
二叉树的顺序存储 对于一棵一般的二叉树,如果补齐构成完全二叉树所缺少的那些结点,便可以对二叉树的结点进行编号。 A F G E D C B
5 6 1 3 4 2 7 8 A F G E D C B 9

34
二叉树的顺序存储 0 1 2 3 4 5 6 7 8 9 将二叉树原有的结点按编号存储到内存单元“相应”的位置上。 5 6 1 3 4 2
5 6 1 3 4 2 7 8 A F G E D C B 9 A B C D E 0 F G

35
顺序存储结构的缺点 一般的二叉树会比完全二叉树少很多结点,造成空间浪费,例如单支树就是一个极端情况。

36
二叉树的链式存储 1、二叉链表 2、三叉链表

37
1. 二叉链表 Parent A D B Data E C LChild RChild F 结点结构: lchild data rchild

38
二叉链表图示 root A D B A E C B D F C E F

39
二叉链表的结点 结点结构: lchild data rchild struct BintreeNode{ //结点结构
Type data; //结点的数据域 BintreeNode * Lchild; //左孩子指针 BintreeNode * Rchild; //右孩子指针 }; 在建立其抽象类时,整个二叉树链表需要一个表头指针,它指向二叉树的根结点。

40
2.三叉链表 root 结点结构: A B D C E F
parent lchild data rchild A B D C E F

41
三叉链表的结点 结点结构: parent lchild data rchild struct BintreeNode{
Type data; //结点的数据域 BintreeNode * Lchild; //左孩子指针 BintreeNode * Rchild; //右孩子指针 BintreeNode * Parent ; //双亲结点指针 };

42
小 结 顺序存储结构:数组表示 链式存储结构:二叉链表 三叉链表

43
9.3 树的存储结构与转换 树的存储结构 树、森林与二叉树的转换

44
树的存储结构 顺序存储结构:双亲表示法 孩子(双亲)表示法:(顺序+链式) 孩子-兄弟表示法:链式
表示法:(顺序+链式) 孩子-兄弟表示法:链式")
45
双亲表示法 结点结构: data parent 假设以一组连续空间存储树的各结点,每个结点又设有两个域,结点类型如下:
struct TreeNode{ Type data; //结点的数据域 TreeNode *Parent; //结点双亲指针 }; data域记录数据信息,Parent为指针,它指向其双亲结点。 结点结构: data parent

46
树的双亲表示法 A B D C E F G H 0 A -1 1 B 0 2 C 0 3 D 0 4 E 1 5 F 2 6 G 2
data parent 数组下标 0 A 1 B 2 C 3 D 4 E 5 F 6 G 2 7 H 2 B D C E F G H 双亲结点在数组中的位置,-1表示无双亲 特点: 找双亲方便,找孩子难

47
树的链式存储 通过保存树中每个结点的孩子结点的位置,表示树中结点之间的结构关系。 多重链表 单链表

48
多重链表(类似于二叉链表) 两种方式:定长结点 和 不定长结点 定长结点:优点是结点结构一致,便于实现树的操作。缺点是浪费一些内存空间。
data child1 child2 ...... childd 不定长结点:优点是节省内存空间。缺点是不定长的结点会使一些操作实现变复杂。 data degree child1 child2 ...... childd

49
单链表表示法 线性表 + 单链表 将每个结点的孩子结点排列起来,构成一个单链表,称为孩子链表;
n个结点共有n个孩子链表(叶子结点的孩子链表为空表); n个结点的孩子链表头指针又组成一个顺序表。
; n个结点的孩子链表头指针又组成一个顺序表。")
50
孩子链表表示法 此时,单链表中各结点由两个域构成:struct TreeNode{ // 结点定义 Type data;
TreeNode *next }; TreeNode *vertex[n]; //顺序表是一个指针数组,数组元素是指向孩子链表的头指针,n个结点n个指针。

51
孩子链表存储表示 A B C D E F G 0 A 1 B 2 C 3 D 4 F 5 E 6 G data firstchild
同一结点的 孩子构成链表 6

52
孩子双亲表示法 孩子表示法便于实现涉及孩子的操作,却不适用于涉及双亲的操作。 将双亲指针加入可以同时方便有关孩子和双亲的操作。

53
孩子-兄弟表示法 结点结构: firstchild data nextsibling 孩子-兄弟表示法又称二叉树表示法,或二叉链表表示法;
链表中结点的两个指针域分别指向该结点的第一个孩子结点和下一个兄弟结点,分别命名为FirstChild和NextSibling域。 结点结构: firstchild data nextsibling

54
孩子-兄弟表示法 struct TreeNode{ //结点结构 Type data;
TreeNode * FirstChild; //第一个孩子指针 TreeNode * NextSibling; //下一个兄弟指针 }; //sibling:兄弟, 姐妹 如下图所示:

55
孩子兄弟表示法图示 A B C E D F G root A B C D E F G C的第一个孩子结点E E的紧邻的 右兄弟结点

56
孩子-兄弟表示法优点 便于实现各种树的操作。
易于查找结点的孩子结点。例如要访问结点x的第i个孩子,则只要先从FirstChild域找到第一个孩子结点,然后沿着孩子结点的NextSibling 域连续走i-1步,便可找到x的第i个孩子结点。 如果为每个结点增设一个Parent域,则同样能方便地实现求双亲结点的操作。

57
树、森林与二叉树的转换 树与二叉树之间的转换 森林与二叉树之间的转换

58
孩子兄弟表示法图示 A B C E D F G root A B C D E F A B C E D F G G

59
树和森林的表示方法 树的孩子兄弟链表结构与二叉树的二叉链表结构,都以二叉链表作为存储结构,它们的物理结构完全相同;
在树和二叉树之间必然存在一一对应关系; 如果把森林中第二棵树的根结点看成是第一棵树根结点的兄弟,同样可导出森林与二叉树的对应关系。

60
树与二叉树的转换 F I A B D H G C E I A C B D H G F E 树 根 结点X的第一个孩子 结点X紧邻的右兄弟

61
森林与二叉树的转换 森林:树的集合 将森林中树的根看成兄弟,用树与二叉树的转换方法,可进行森林与二叉树转换。 A B C D E F G H
森林:树的集合 将森林中树的根看成兄弟,用树与二叉树的转换方法,可进行森林与二叉树转换。 A B C D E F G H I J A B C D E F G H I J A B C D E F G H I J

62
小 结 树的存储结构 树、森林与二叉树的转换 顺序存储结构:双亲表示法 孩子(双亲)表示法:(顺序+链式) 孩子-兄弟表示法:链式
树与二叉树之间的转换 森林与二叉树之间的转换

63
9.4 二叉树的抽象类 二叉树结点的抽象类 二叉树的抽象类

64
结点类的定义: template <class T> class BinaryTree; //类的提前引用声明:二叉排序树类
//类的提前引用声明:二叉树类 template <class T> class BinaryTree; //类的提前引用声明:二叉排序树类 template <class T> class BST; template <class T> class BinTreeNode { //将BinaryTree类声明为BinaryTreeNode类的友元类 friend class BinaryTree<T>; //将BST类声明为BinaryTreeNode类的友元类 friend class BST<T>;

65
const的含义:该成员函数的算法不修改该类的成员变量的值
public: BinTreeNode( ); //构造函数 BinTreeNode(T & value); //传结点数据构造函数 BinTreeNode(T & value, BinTreeNode<T>*left, BinTreeNode<T>*right); //分支结点构造函数 void release( ); //删除当前结点的左右子树 T &GetData( )const {return data; } BinaryTreeNode<T> GetLeft( )const {return Lchild; } BinaryTreeNode<T> GetRight( )const {return Rchild; } void SetData(T & value) {data=value;} //修改结点数据值 void SetLeft(BinTreeNode<T> *L);//修改结点左孩子指针 void SetRight(BinTreeNode<T> *R);//修改结点右孩子指针 private: T data; //数据域 BinTreeNode<T> *Lchild; //左孩子指针 BinTreeNode<T> *Rchild; //右孩子指针 };
; //构造函数. BinTreeNode(T & value); //传结点数据构造函数. BinTreeNode(T & value, BinTreeNode<T>*left, BinTreeNode<T>*right); //分支结点构造函数. void release( ); //删除当前结点的左右子树. T &GetData( )const {return data; } BinaryTreeNode<T> GetLeft( )const {return Lchild; } BinaryTreeNode<T> GetRight( )const {return Rchild; } void SetData(T & value) {data=value;} //修改结点数据值. void SetLeft(BinTreeNode<T> *L);//修改结点左孩子指针. void SetRight(BinTreeNode<T> *R);//修改结点右孩子指针. private: T data; //数据域. BinTreeNode<T> *Lchild; //左孩子指针. BinTreeNode<T> *Rchild; //右孩子指针. };")
66
传结点数据的构造函数:构造有值结点,无左右子树
无参构造函数:构造无值结点,无左右子树 template<class T> BinTreeNode<T>::BinTreeNode( ):Lchild(NULL), Rchild(NULL) //参数初始化表 { } 传结点数据的构造函数:构造有值结点,无左右子树 BinTreeNode<T>::BinTreeNode(T & value) { data=value; Lchild=Rchild=NULL; } 带子树的结点构造函数:构造有值、有左右子树的结点 BinTreeNode<T>::BinTreeNode(T & value, BinTreeNode<T>*left, BinTreeNode<T>*right) Lchild=left; Rchild=right; }
:Lchild(NULL), Rchild(NULL) //参数初始化表. { } 传结点数据的构造函数:构造有值结点,无左右子树. BinTreeNode<T>::BinTreeNode(T & value) { data=value; Lchild=Rchild=NULL; } 带子树的结点构造函数:构造有值、有左右子树的结点. BinTreeNode<T>::BinTreeNode(T & value, BinTreeNode<T>*left, BinTreeNode<T>*right) Lchild=left; Rchild=right; }")
67
释放子树空间:释放以某结点为根的子树中所有结点的存储空间,但不释放根结点所占的存储空间。
template<class T> void BinTreeNode<T>::release( ) { if(Lchild!=NULL) { Lchild->release( ); //递归调用释放左子树 delete Lchild; Lchild=NULL: } if(Rchild!=NULL) { Rchild->release( ); //递归调用释放右子树 delete Rchild; Rchild=NULL:
 { if(Lchild!=NULL) { Lchild->release( ); //递归调用释放左子树. delete Lchild; Lchild=NULL: } if(Rchild!=NULL) { Rchild->release( ); //递归调用释放右子树. delete Rchild; Rchild=NULL:")
68
设置新的左子树:在给一个左子树或右子树重新赋值之前,必须先释放掉该指针原来所指向的子树的所有结点。
template<class T> void BinTreeNode<T>::SetLeft(BinTreeNode<T> *L) { Lchild->release( ); //释放原来的左子树 delete Lchild; //释放左子树的根结点 Lchild=L; } //修改左指针 设置新的右子树 void BinTreeNode<T>::SetRight(BinTreeNode<T> *R) { Rchild->release( ); //释放原来的右子树 delete Rchild; //释放右子树的根结点 Rchild=R; } //修改右指针
 { Lchild->release( ); //释放原来的左子树. delete Lchild; //释放左子树的根结点. Lchild=L; } //修改左指针. 设置新的右子树. void BinTreeNode<T>::SetRight(BinTreeNode<T> *R) { Rchild->release( ); //释放原来的右子树. delete Rchild; //释放右子树的根结点. Rchild=R; } //修改右指针.")
69
const类型的形参:只用于赋给别的变量,它本身不能被修改
二叉树的抽象类 const类型的形参:只用于赋给别的变量,它本身不能被修改 template<class T> class BinaryTree { public: BinaryTree( ); //构造一棵空的二叉树 BinaryTree(const BinaryTree<T>&source);//复制二叉树 //以value为根,left和right为左右子树构造一棵二叉树 BinaryTree(T value, BinTreeNode<T>*left, BinTreeNode<T>*right); //析构函数,释放二叉树所有结点所占的存储空间 ~ BinaryTree( ); void DeleteAllValues( ); //清除操作,使树变为空树 //判二叉树空否,若二叉树为空,返回1,否则返回0 int IsEmpty( );
; //构造一棵空的二叉树. BinaryTree(const BinaryTree<T>&source);//复制二叉树. //以value为根,left和right为左右子树构造一棵二叉树. BinaryTree(T value, BinTreeNode<T>*left, BinTreeNode<T>*right); //析构函数,释放二叉树所有结点所占的存储空间. ~ BinaryTree( ); void DeleteAllValues( ); //清除操作,使树变为空树. //判二叉树空否,若二叉树为空,返回1,否则返回0. int IsEmpty( );")
70
//在以t为根的二叉树中查找,找到值等于value的结点
时,返回该结点地址,否则返回空指针 virtual BinaryTreeNode<T>*Find(BinaryTreeNode<T>*t, T &value)=0; //在当前二叉树中查找数据域值等于value的结点 virtual BinaryTreeNode<T>*Find(T &value)=0; //在以t为根的二叉树中,找到值等于value的结点,返回0;找不到值等于value的结点则插入该结点,并返回1 virtual int Insert(BinaryTreeNode<T>*t,T &value)=0; //在当前二叉树中插入新元素 virtual int Insert(const T&value)=0; //在以t为根的二叉树中,没有找到值等于value的结点,返回0;否则将此结点从该二叉树中删除,并返回1 virtual int Delete(BinaryTreeNode<T>*t,T &value)=0;
=0; //在当前二叉树中查找数据域值等于value的结点. virtual BinaryTreeNode<T>*Find(T &value)=0; //在以t为根的二叉树中,找到值等于value的结点,返回0;找不到值等于value的结点则插入该结点,并返回1. virtual int Insert(BinaryTreeNode<T>*t,T &value)=0; //在当前二叉树中插入新元素. virtual int Insert(const T&value)=0; //在以t为根的二叉树中,没有找到值等于value的结点,返回0;否则将此结点从该二叉树中删除,并返回1. virtual int Delete(BinaryTreeNode<T>*t,T &value)=0;")
71
//返回当前二叉树中删除的一个元素 virtual int Delete(const T &value)=0; BinaryTreeNode<T>*LeftChild(T &value);//返回左孩子 BinaryTreeNode<T>*RightChild(T &value);//返回右孩子 void Traver(BinaryTreeNode<T>*current);//current为根 void Traver( ); //遍历以root为根的二叉树 BinaryTreeNode<T>*GetRoot( ) const{return root;} //取根 //输入运算符重载 frind istream &operator>>(istream &in, BinaryTree<T> &Tree); //输出运算符重载 frind ostream &operator<<(istream &out, protected: BinaryTreeNode<T> *root; };
;//返回右孩子. void Traver(BinaryTreeNode<T>*current);//current为根. void Traver( ); //遍历以root为根的二叉树. BinaryTreeNode<T>*GetRoot( ) const{return root;} //取根. //输入运算符重载. frind istream &operator>>(istream &in, BinaryTree<T> &Tree); //输出运算符重载. frind ostream &operator<<(istream &out, protected: BinaryTreeNode<T> *root; };")
72
构造空树的函数 拷贝构造函数 template<class T>
BinaryTree<T>::BinaryTree( ) { root=NULL; } 拷贝构造函数 BinaryTree<T>::BinaryTree(const BinTree<T> &source) root = source.root->copy( );
 { root=NULL; } 拷贝构造函数. BinaryTree<T>::BinaryTree(const BinTree<T> &source) root = source.root->copy( );")
73
构造函数:新构造一个根结点,将已知两棵树分别作为左、右子树。调用结点类的带参构造函数
template<class T> BinaryTree<T>::BinaryTree(T value, BinaryTreeNode<T>*left, BinTreeNode<T>*right) { root=new BinaryTreeNode<T>(value, left, right); } 析构函数:使用结点类中的release函数, release函数只删除两个子树中的结点,因此最后需要删除根结点。 BinaryTree<T> :: ~ BinaryTree( ) { root->release( ); delete root; root=NULL;}
 { root=new BinaryTreeNode<T>(value, left, right); } 析构函数:使用结点类中的release函数, release函数只删除两个子树中的结点,因此最后需要删除根结点。 BinaryTree<T> :: ~ BinaryTree( ) { root->release( ); delete root; root=NULL;}")
74
删除整棵树中的所有结点:删除树中所有的结点,最后将根指针置空。
template<class T> void BinaryTree<T>::DeletAllValues( ) { root->release( ); delete root; root=NULL; } 判定二叉树是否为空:检查根指针是否为空。 int BinaryTree<T>::IsEmpty( ) { return root==NULL; } //root==NULL逻辑表达式
 { root->release( ); delete root; root=NULL; } 判定二叉树是否为空:检查根指针是否为空。 int BinaryTree<T>::IsEmpty( ) { return root==NULL; } //root==NULL逻辑表达式.")
75
返回左孩子地址 返回右孩子地址 template<class T>
BinaryTreeNode<T>*BinaryTree<T>::LeftChild(T &value) { BinaryTreeNode<T> *current=Find(value); if(current!=NULL) return current->GetLeft( ); else return NULL;} 返回右孩子地址 template <class T> BinaryTreeNode<T>*BinaryTree<T>::RightChild(T &value) { BinaryTreeNode<T>*current=Find(value); if(current!=NULL) return current->GetRight( );
 { BinaryTreeNode<T> *current=Find(value); if(current!=NULL) return current->GetLeft( ); else return NULL;} 返回右孩子地址. template <class T> BinaryTreeNode<T>*BinaryTree<T>::RightChild(T &value) { BinaryTreeNode<T>*current=Find(value); if(current!=NULL) return current->GetRight( );")
76
输入流运算符重载:输入并建立一棵二叉排序树,用重载运算符来实现。
template <class T> istream & operator>>(istream &in, BinaryTree<T> &Tree) { T item, Ref; //定义2个数据元素类型的变量 cout<<“Construct binary tree:\n”; cout<<“Input the value of the last null data:\n”; in>>Ref; //输入参考结点值 cout<<“Input data(end with”<<Ref<<”):”; in>>item; while(item!=Ref) //二叉排序树中不存在值相等的结点 { Tree.Insert(item); in>>item;} return in;}
 { T item, Ref; //定义2个数据元素类型的变量. cout<< Construct binary tree:\n ; cout<< Input the value of the last null data:\n ; in>>Ref; //输入参考结点值. cout<< Input data(end with <<Ref<< ): ; in>>item; while(item!=Ref) //二叉排序树中不存在值相等的结点. { Tree.Insert(item); in>>item;} return in;}")
77
输出流运算符重载:输出一棵二叉树,需要用到二叉树的遍历函数Traver,Traver函数的算法是:在遍历结点的同时输出所遍历到的结点值。
template <class T> ostream & operator<<(ostream &out, BinaryTree<T> &Tree) { cout<<“Traversal of binary tree:\n”; Tree.Traver(Tree.root); //Traver是二叉树的遍历函数 return out; }
 { cout<< Traversal of binary tree:\n ; Tree.Traver(Tree.root); //Traver是二叉树的遍历函数. return out; }")
78
小结 二叉树的结点类 二叉树的抽象类

79
9.5 二叉树的遍历 1、遍历的概念 2、二叉树的遍历 3、二叉树遍历的应用

80
1、遍历的基本概念 遍历:按某种搜索路径访问二叉树中的每个结点,而且每个结点仅被访问一次。
访问:含义很广,可以是对结点的各种处理,如修改结点数据、输出结点数据等。 遍历是各种数据结构最基本的操作,许多其它的操作可以在遍历基础上实现。 遍历对线性结构来说很容易解决,但是二叉树每个结点都可能有两棵子树,因而需要寻找一种规律,使得二叉树上的结点能排列成线性。

81
2、二叉树的遍历 二叉树由三部分组成:根结点、左子树、右子树; 若能依次遍历这三部分,就遍历完了整个二叉树。 L:遍历左子树
D:访问根结点 R:遍历右子树 先左后右: DLR、LDR、LRD 先右后左: DRL、RDL、RLD

82
先左后右的遍历算法 先(根)序遍历 中(根)序遍历 后(根)序遍历
序遍历 中(根)序遍历 后(根)序遍历")
83
先(根)序遍历 先序遍历DLR递归描述 基本项:若二叉树为空,结束 递归项: (1)访问根结点; (2)先序遍历左子树;
(3)先序遍历右子树。 A C B D E F G 先序遍历序列(DLR):A B D E G C F
先序遍历右子树。 A. C. B. D. E. F. G. 先序遍历序列(DLR):A B D E G C F.")
84
先序遍历算法如下: template<class T> void BinaryTree<T> ::PreOrder( ) { //先序遍历当前二叉树 PreOrder(root); }
 { //先序遍历当前二叉树 PreOrder(root); }")
85
//先序遍历以current为根的子树,递归函数
template<class T> void BinaryTree<T>::PreOrder(BinTreeNode<T> *current) {//current==NULL,即到达叶子结点是递归终止条件 if(current!=NULL) { cout<<current->data; //访问根结点,用输出语句暂代 PreOrder(current->leftChild); //先序遍历左子树 PreOrder(current->rightChild); //先序遍历右子树 }
 {//current==NULL,即到达叶子结点是递归终止条件. if(current!=NULL) { cout<<current->data; //访问根结点,用输出语句暂代. PreOrder(current->leftChild); //先序遍历左子树. PreOrder(current->rightChild); //先序遍历右子树. }")
86
中(根)序遍历 中序遍历序列(LDR):D B G E A F C 中序遍历递归描述 基本项:若二叉树为空,结束 递归项:
(1)中序遍历左子树; (2)访问根结点; (3)中序遍历右子树。 A C B D E F G 中序遍历序列(LDR):D B G E A F C
中序遍历左子树; (2)访问根结点; (3)中序遍历右子树。 A. C. B. D. E. F. G. 中序遍历序列(LDR):D B G E A F C.")
87
中序遍历算法如下: template<class T> void BinaryTree<T> ::InOrder( ) { //中序遍历当前二叉树 InOrder(root); }
 { //中序遍历当前二叉树 InOrder(root); }")
88
//中序遍历以current为根的子树,递归函数
template<class T> void BinaryTree<T>::InOrder(BinTreeNode<T> *current) { if(current!=NULL) //current==NULL为递归终止条件 { InOrder(current->LChild); //中序遍历左子树 cout<<current->data; //访问根结点,用输出语句暂代 InOrder(current->RChild); //中序遍历右子树 }
 { if(current!=NULL) //current==NULL为递归终止条件. { InOrder(current->LChild); //中序遍历左子树. cout<<current->data; //访问根结点,用输出语句暂代. InOrder(current->RChild); //中序遍历右子树. }")
89
后(根)序遍历 后序遍历序列(LRD):D G E B F C A 后序遍历递归描述 基本项:若二叉树为空,结束 递归项:
(1)后序遍历左子树; (2)后序遍历右子树; (3)访问根结点。 A C B D E F G 后序遍历序列(LRD):D G E B F C A
后序遍历左子树; (2)后序遍历右子树; (3)访问根结点。 A. C. B. D. E. F. G. 后序遍历序列(LRD):D G E B F C A.")
90
后序遍历算法如下: template<class T> void BinaryTree<T> ::PostOrder( ) {//后序遍历当前二叉树 PostOrder(root); }
 {//后序遍历当前二叉树 PostOrder(root); }")
91
//后序遍历以current为根的子树,递归函数
template<class T> void BinaryTree<T>::PostOrder(BinTreeNode<T> *current) { if(current!=NULL)//current==NULL是递归终止条件 PostOrder(current->leftChild); //后序遍历左子树 PostOrder(current->rightChild);//后序遍历右子树 cout<<current->data; //访问根结点, 用输出语句代 }
 { if(current!=NULL)//current==NULL是递归终止条件. PostOrder(current->leftChild); //后序遍历左子树. PostOrder(current->rightChild);//后序遍历右子树. cout<<current->data; //访问根结点, 用输出语句代. }")
92
3、二叉树遍历的应用 计算二叉树结点个数 计算二叉树的高度 判断两棵二叉树是否相等或等价

93
1)计算二叉树结点个数 利用二叉树的后序遍历规则,先遍历左子树和右子树,分别计算出左子树和右子树中的结点个数,然后把访问根结点加进去,就可以得到整个二叉树的结点个数。 template<class T> int BinaryTree<T>::Size(const BinTreeNode<T> *t)const { //计算以t为根的二叉树的结点个数 if(t==NULL) return 0; //递归结束条件为空树,结点个数为0 else return 1+Size(t->LChild)+Size(t->RChild); }
const. { //计算以t为根的二叉树的结点个数. if(t==NULL) return 0; //递归结束条件为空树,结点个数为0. else return 1+Size(t->LChild)+Size(t->RChild); }")
94
2)计算二叉树的高度 如果二叉树为空树,高度为-1;否则按后序遍历规则,先递归计算根结点的左子树和右子树的高度,再求出两者中较大者,并加1(要包括根结点,高度加1),就可以得到整个二叉树的高度。 template<class T> int BinaryTree<T>::Depth(const BinTreeNode<T> *t)const { //计算以t为根的二叉树的高度 if (t==NULL) return -1; //递归结束条件为空树,空树高度为-1 else return 1+Max(Depth(t->LChild),Depth(t->RChild)); } 其中Max函数是求两者中的较大者: int Max(int x,int y) { return(x>y ? x:y);}
const. { //计算以t为根的二叉树的高度. if (t==NULL) return -1; //递归结束条件为空树,空树高度为-1. else return 1+Max(Depth(t->LChild),Depth(t->RChild)); } 其中Max函数是求两者中的较大者: int Max(int x,int y) { return(x>y x:y);}")
95
3)判断两棵二叉树是否相等或等价 template<class T> //= =运算符重载
int operator==(const BinTreeNode<T> &a, const BinTreeNode<T> &b) { //判断两棵二叉树的等价性 return equal(a.root, b.root); } //如果a和b的子树不等同,则函数返回0,否则函数返回1 template<class T> int equal(BinTreeNode<T>&a, BinTreeNode<T>&b)//递归函数 { if(a==NULL && b==NULL) return 1; //两者都为NULL //a与b根结点的数据相同,且它们的左、右子树也相同 if(a!==NULL && b!==NULL && a->data==b->data && equal(a->Lchild, b->LChild) && equal(a->Rchild, b->RChild) ) return 1; return 0; }
 { //判断两棵二叉树的等价性. return equal(a.root, b.root); } //如果a和b的子树不等同,则函数返回0,否则函数返回1. template<class T> int equal(BinTreeNode<T>&a, BinTreeNode<T>&b)//递归函数. { if(a==NULL && b==NULL) return 1; //两者都为NULL. //a与b根结点的数据相同,且它们的左、右子树也相同. if(a!==NULL && b!==NULL && a->data==b->data && equal(a->Lchild, b->LChild) && equal(a->Rchild, b->RChild) ) return 1; return 0; }")
96
小结 二叉树的遍历 二叉树遍历的应用

97
9.6 树的遍历 深度优先遍历 先根次序遍历 后根次序遍历 广度优先遍历

98
先根次序遍历 第一步:访问树的根结点; 第二步:“先根次序”遍历根的第一棵子树;
深度优先遍历 先根次序遍历 第一步:访问树的根结点; 第二步:“先根次序”遍历根的第一棵子树; 第三步:“先根次序”遍历根的第二棵子树、第三棵子树,… , 直至遍历完整棵树。

99
后根次序遍历 第一步: “后根次序”遍历根的第一棵子树; 第二步:“后根次序”遍历根的第二棵子树、第三棵子树,…, 直至遍历根的所有子树;
第三步:访问根结点。

100
第二步,自左向右顺序访问层次为1的各个结点;
广度优先遍历 按层次进行访问遍历: 第一步,访问层次为0 的根结点; 第二步,自左向右顺序访问层次为1的各个结点; 第三步,自左向右顺序访问层次为2的各个结点; 直至所有的结点都访问完。

101
树的遍历实例 先序遍历: A B E F I G C D H J K L N O M 后序遍历: E I F G B C J K N O L
层次遍历: A B C D E F G H I J K L M N O

102
小结 树的遍历 深度优先遍历 先根次序遍历 后根次序遍历 广度优先遍历

103
二叉排序树 二叉排序树的定义 二叉排序树的查找过程 二叉排序树的插入、删除操作

104
1、定义 (3)它的左、右子树也都分别是二叉 二叉排序树或者是一棵空树;或者 是具有如下特性的二叉树: (1)若它的左子树不空,则左子树上
所有结点的值均小于根结点的值; (2)若它的右子树不空,则右子树上 所有结点的值均大于根结点的值; (3)它的左、右子树也都分别是二叉 排序树。
若它的右子树不空,则右子树上. 所有结点的值均大于根结点的值; (3)它的左、右子树也都分别是二叉. 排序树。")
105
例如: 50 30 80 20 40 90 10 25 35 85 66 23 88 不 是二叉排序树。

106
二叉排序树类的定义:它是BinaryTree类的派生类, BinTreeNode的友元类。 template<class T>
class BST: public BinaryTree<T> {public: //… 其他成员函数的声明与定义 //在以t为根的二叉树中找到值为value的结点时,返回其地址 BinTreeNode<T> *Find(BinTreeNode<T> *t,T&value); BinTreeNode<T> *Find(T&value); //在当前二叉树中查找 //在以t为根的二叉树找到值为value的结点时,则不插入,返回 0;否则将其插入到二叉树中,返回1 int Insert(BinTreeNode<T> *t,T&value); int Insert(T&value);//在当前二叉树中插入值为value的新结点 //在以t为根的二叉树中找不到值为value的结点时,返回0;否则 将其从二叉树中删除,返回1 int Delete(BinTreeNode<T> *t,T&value); int Delete(T&value); };//在当前二叉树中删除值为value的结点
; BinTreeNode<T> *Find(T&value); //在当前二叉树中查找. //在以t为根的二叉树找到值为value的结点时,则不插入,返回. 0;否则将其插入到二叉树中,返回1. int Insert(BinTreeNode<T> *t,T&value); int Insert(T&value);//在当前二叉树中插入值为value的新结点. //在以t为根的二叉树中找不到值为value的结点时,返回0;否则. 将其从二叉树中删除,返回1. int Delete(BinTreeNode<T> *t,T&value); int Delete(T&value); };//在当前二叉树中删除值为value的结点.")
107
2.二叉排序树的查找过程 关键字:二叉排序树建立时所依据的结点值,能唯一地表示该结点,且所有的关键字互不相同。
从根结点开始,若二叉排序树为空,则查找不成功;否则, 1)若给定值等于根结点的关键字,则查找成功; 2)若给定值小于根结点的关键字,则继续在左子树上进行递归查找; 3)若给定值大于根结点的关键字,则继续在右子树上进行递归查找。
若给定值等于根结点的关键字,则查找成功; 2)若给定值小于根结点的关键字,则继续在左子树上进行递归查找; 3)若给定值大于根结点的关键字,则继续在右子树上进行递归查找。")
108
例如: 二叉排序树 50 50 50 50 50 50 30 30 80 80 20 40 40 90 90 35 35 85 32 88 查找关键字 == 50 , 35 , 90 , 95 ,

109
从上述查找过程可见, 在查找过程中,生成了一条查找路径: 从根结点出发,沿着左分支或右分支逐层向下直至关键字等于给定值的结点; ——查找成功 或者 从根结点出发,沿着左分支或右分支逐层向下直至指针指向空树为止。 ——查找不成功

110
二叉排序树的查找算法 递归算法 迭代算法

111
递归算法:在以t为根的树中查找值为value的结点
template<class T> BinTreeNode<T>*BST<T>::Find(BinTreeNode<T> *t, T &value) { //空树或查找成功,返回 if (t==NULL || t->data==value) return t; else if(value < t->data) //否则,继续查找左子树 return (Find(t->Lchild, value)); //否则,继续查找右子树 else return (Find(t->Rchild, value)); }
 { //空树或查找成功,返回. if (t==NULL || t->data==value) return t; else if(value < t->data) //否则,继续查找左子树. return (Find(t->Lchild, value)); //否则,继续查找右子树. else return (Find(t->Rchild, value)); }")
112
迭代算法:在以t为根的树中查找值为value的结点
template<class T> BinTreeNode<T>*BST<T>::Find(BinTreeNode<T> *t, T &value) { if(t!=NULL) //树非空 { BinTreeNode<T> *s=t; //从根开始查找 while(s!=NULL) //等于NULL表示查找失败 { if (value == s->data) return s; //查找成功 if(value > s->data) s=s->GetRight( ); // 否则,继续查找 右子树 else s=s->GetLeft( ); // 否则,继续查找 左子树 } return NULL; } // 树空, 返回
 { if(t!=NULL) //树非空. { BinTreeNode<T> *s=t; //从根开始查找. while(s!=NULL) //等于NULL表示查找失败. { if (value == s->data) return s; //查找成功. if(value > s->data) s=s->GetRight( ); // 否则,继续查找 右子树. else. s=s->GetLeft( ); // 否则,继续查找 左子树. } return NULL; } // 树空, 返回.")
113
定义了上述Find函数,即可定义当前二叉排序树的查找函数:
template<class T> BinTreeNode<T>*BST<T>::Find(T&value) { if(root==NULL) //如果当前树为空树,直接返回NULL return NULL; else return Find(root, value); }
 { if(root==NULL) //如果当前树为空树,直接返回NULL. return NULL; else. return Find(root, value); }")
114
3、二叉排序树的插入 “插入”操作在查找不成功时才进行 二叉排序树是一种动态树表;
特点:树的结构通常不是一次生成的,而是在查找过程中,当树中不存在关键码等于给定值的结点,就进行插入; 插入的原则:若二叉排序树为空,则插入结点为树的新根结点,否则继续在左子树和右子树上查找,直至某个结点的左子树或右子树为空为止,则插入结点作为一个新的叶子结点。

115
插入算法 template<class T>
int BST<T>::Insert(BinTreeNode<T> *t,T&value) { //在以t为根的二叉排序树中插入值为value的结点 if(t==NULL) { t=new BinTreeNode<T>(value); if (t==NULL) { cout<<“Out of space”<<endl;exit(0); } return 1; } if(value < t->data) Insert(t->GetLeft( ), value); //左孩子指针 else if(value > t->data) Insert(t->GetRigth( ), value); //右孩子指针 else return 0; }
 { //在以t为根的二叉排序树中插入值为value的结点. if(t==NULL) { t=new BinTreeNode<T>(value); if (t==NULL) { cout<< Out of space <<endl;exit(0); } return 1; } if(value < t->data) Insert(t->GetLeft( ), value); //左孩子指针. else if(value > t->data) Insert(t->GetRigth( ), value); //右孩子指针. else return 0; }")
116
对二叉排序树进行中序遍历可以得到有序序列
例:利用插入算法建立二叉排序树 {53,68,55 , 17 ,82,10,45} 53 68 55 17 82 10 45 对二叉排序树进行中序遍历可以得到有序序列

117
4、二叉排序树的删除 和插入相反,删除在查找成功之后进行,并且要求在删除二叉排序树上某个结点之后,仍然保持二叉排序树的特性。 可分三种情况讨论: (1)被删除的结点是叶子; (2)被删除的结点只有左子树或者只有右子树; (3)被删除的结点既有左子树,也有右子树。
被删除的结点既有左子树,也有右子树。")
118
二叉排序树的删除 删除原则:保持二叉排序树的特性。 要删除二叉排序树中的P结点,分三种情况: P为叶子结点 P只有左子树或右子树
F P PR PL

119
二叉排序树的删除 P为叶子结点,只需修改 P 双亲的指针: F->lchild=NULL F->rchild=NULL F F
删除前 删除后

120
二叉排序树的删除 (1) (2) P只有左子树或右子树 P只有左子树,用P的左孩子代替P (1)(2) S P PL Q
中序遍历:PL P S Q 中序遍历:PL S Q (1) S Q PL P 中序遍历:Q S PL P 中序遍历:Q S PL (2)
 S. Q. PL. P. 中序遍历:Q S PL P. 中序遍历:Q S PL. (2)")
121
二叉排序树的删除 (3) (4) P只有左子树或右子树 P只有右子树,用P的右孩子代替P (3)(4) 中序遍历:P PR S Q S PR
中序遍历:Q S P PR S Q PR 中序遍历:Q S PR (4) P
 P.")
122
二叉排序树的删除 p左、右子树均非空 沿 P 左子树的根 C 的右子树分支找到 S,S的右子树为空,将 S 的左子树成为 S 的双亲Q 的右子树,用 S 取代 p (5) 中序遍历:CL C QL Q SL S P PR F F S C PR CL Q QL SL F P C PR CL Q QL S SL (5) 中序遍历:CL C QL Q SL S PR F
 中序遍历:CL C QL Q SL S PR F.")
123
二叉排序树的删除 (6) P左、右子树均非空 若 C 无右子树,用 C 取代 P (6) F P C PR CL F C PR CL
中序遍历:CL C P PR F 中序遍历:CL C PR F (6)
")
124
二叉排序树的删除 要删除二叉排序树中的p结点,分三种情况:
P为叶子结点,只需修改 P 双亲 F的指针: F->lchild=NULL F->rchild=NULL P只有左子树或右子树 P只有左子树,用P的左孩子代替P (1)(2) P只有右子树,用P的右孩子代替P (3)(4) p左、右子树均非空 沿 P 左子树的根 C 的右子树分支找到 S,S的右子树为空,将 S 的左子树成为 S 的双亲Q 的右子树,用 S 取代 P (5) 若 C 无右子树,用 C 取代 P (6)
(2) P只有右子树,用P的右孩子代替P (3)(4) p左、右子树均非空. 沿 P 左子树的根 C 的右子树分支找到 S,S的右子树为空,将 S 的左子树成为 S 的双亲Q 的右子树,用 S 取代 P (5) 若 C 无右子树,用 C 取代 P (6)")
125
小结 二叉排序树及其查找 二叉排序树的插入、删除操作

126
9.8 应用实例—赫夫曼树 最优二叉树的定义 如何构造最优二叉树 应用:赫夫曼编码

127
最优二叉树的定义 路径:从树中的一个结点到另一个结点之间的分支构成这两个结点间的路径; 路径长度:路径上的分支数目称为路径长度;
结点的权:给树中结点所赋的具有物理意义的值; 结点的带权路径长度:从根到该结点的路径长度与该结点权的乘积; 树的带权路径长度=树中所有叶子结点的带权路径之和;通常记作 WPL= wi Li。 赫夫曼树(最优二叉树):假设有n个权值(w1,w2, … , wn),构造有 n 个叶子结点的二叉树,每个叶子结点有一个 wi 作为它的权值,则带权路径长度最小的二叉树称为赫夫曼树。
:假设有n个权值(w1,w2, … , wn),构造有 n 个叶子结点的二叉树,每个叶子结点有一个 wi 作为它的权值,则带权路径长度最小的二叉树称为赫夫曼树。")
128
最优二叉树的定义 2 4 7 5 9 5 4 2 7 9 实例 WPL(T) = 74+94+53+42+21
WPL(T) = 72+52+23+43+92 =60 WPL(T) = 74+94+53+42+21 =89
 = 72+52+23+43+92. =60. WPL(T) = 74+94+53+42+21. =89.")
129
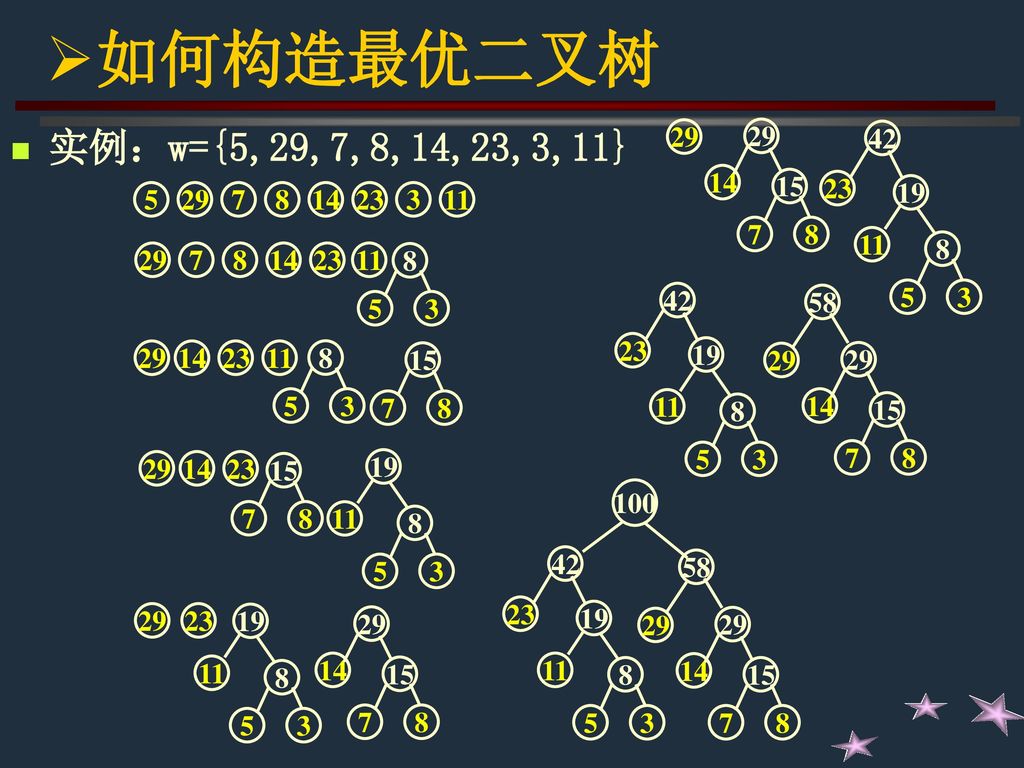
如何构造最优二叉树 赫夫曼树的构造步骤 根据给定的n个权值 {w1, w2, ……wn},构造n棵只有根结点的二叉树,令其权值为wj;
在森林中选取两棵根结点权值最小的树分别作为左右子树,构造一棵新的二叉树,置新二叉树根结点权值为其左右子树根结点权值之和; 在森林中删除这两棵树,同时将新得到的二叉树加入森林中; 重复上述两步,直到森林中只剩一棵树为止,这棵树即赫夫曼树。

130
如何构造最优二叉树 实例:w={5,29,7,8,14,23,3,11} 29 14 8 7 15 11 3 5 19 23 42 5 14 29 7 8 23 3 11 14 29 7 8 23 11 3 5 11 3 5 8 19 23 42 29 14 7 15 58 8 7 15 14 29 23 3 5 11 11 3 5 8 19 14 29 23 7 15 11 3 5 8 19 23 42 29 14 7 15 58 100 11 3 5 8 19 29 23 14 7 15
131
最优二叉树的应用——赫夫曼编码 赫夫曼编码(数据通信用的二进制编码)
用赫夫曼树可以构造一种不等长的二进制编码,并且构造所得的赫夫曼编码是一种最优前缀编码,即使得所传电文的总长度最短。 思想:根据字符出现频率进行编码,使电文总长最短。 编码:根据字符出现频率构造赫夫曼树,然后将树中结点引向其左孩子的分支标为“0”,引向其右孩子的分支标为“1”;每个字符的编码即为从根到每个叶子的路径上得到的0、1序列。

132
例: 最优二叉树的应用——赫夫曼编码 字母集{a, b, c, d, e}, 频率{ 5, 6, 2, 9, 7 }
频率{ 5, 6, 2, 9, 7 } 试为这5个字母设计不等长的赫夫曼编码,并给出该电文的总码数。

133
赫夫曼编码 5 6 2 9 7 6 9 7 7 5 2 9 5 2 7 13 6 7

134
赫夫曼编码 29 赫夫曼编码: a b 00 c d 10 e 01 1 13 16 1 1 6 7 9 5 2 7 1 00 01 10 b e d 110 111 电文总码数: 5*3+6*2+2*3+9*2+7*2=55 a c

135
小结 最优二叉树的定义 如何构造最优二叉树 赫夫曼编码

136
本章总结 树和二叉树的基本概念 二叉树 树的存储结构及其与二叉树的转换 二叉树的抽象类 二叉树的遍历 树的遍历 二叉排序树 赫夫曼树及其应用

Similar presentations

>")



 配套课件.>")

.>")



和二叉树 5.1 树的基本概念 5.2 二叉树 5.3 遍历二叉树和线索二叉树 5.4 树和森林>")







