Download presentation
Presentation is loading. Please wait.

1
数据结构 (DATA STRUCTURE)
")
2
第8章 查 找

3
本章目标 8.1 查找的基本概念 8.2 线性表的查找 8.3 树表的查找 8.4 散列表的查找

4
8.1 查找的基本概念

5
集合的定义和表示 前面几章中我们已经学习了3种数据结构——线性结构、树、图 从本章起,我们学习最后一种数据结构——集合结构

6
集合的定义和表示 集合(collection)是由同一类型的数据元素(或纪录)组成的群集
由于集合中的数据元素之间存在着松散的关系(松耦合关系),因此集合是一种灵活的数据结构 线性结构中的数据元素是一对一的关系 树中的数据元素是一对多的关系 图中的数据元素是多对多的关系 集合中的数据元素仅存在着“同属一个集合”的关系
,因此集合是一种灵活的数据结构. 线性结构中的数据元素是一对一的关系. 树中的数据元素是一对多的关系. 图中的数据元素是多对多的关系. 集合中的数据元素仅存在着 同属一个集合 的关系.")
7
集合的表示 集合在数学中常用右图表示, 其中的每个圆点代表一个数据元素。这里的数据元素可以是一个简单的数据类型,
如int、char等,但更经常的是复杂数据类型,如class、struct等。 在实际应用中,数据元素通常是数据库中的纪录(records),而集合则是这些记录的集合,即数据库中的表(tables)。
,而集合则是这些记录的集合,即数据库中的表(tables)。")
8
集合的表示 学号 姓名 性别 籍贯 电 话 通 讯 地 址 01 张三 男 长沙 麓山南路 327 号 02 李四 北京 学院路 435 03 王五 女 广州 天河路 478 04 赵六 上海 8 南京路 1563 05 钱七 南京 南京大学 06 刘八 武汉 6 武汉大学 07 朱九 昆明 云南大学 08 孙十 杭州 西湖路 35 一个数据元素可由若干个数据项(data items)组成。数据项是数据的不可分割的最小单位。例如,每个学生纪录由若干列(columns)组成,列就是学生纪录的数据项,每一列描述了学生某一方面的特征或属性
组成。数据项是数据的不可分割的最小单位。例如,每个学生纪录由若干列(columns)组成,列就是学生纪录的数据项,每一列描述了学生某一方面的特征或属性.")
9
集合的存储结构 集合这种数据结构在计算机中如何表示?它采用什么样的存储结构?
由于计算机中数据的存储结构只有两种:顺序存储结构和链式存储结构。因此集合的存储结构也不外乎这两种 我们已经学习了顺序表,线性链表(如单链表),树的二叉链表等存储结构。应该说这些存储结构都可以作为集合来存放数据元素。所以,我们没有必要再寻求一种新的存储结构存放集合中的元素 换句话说,顺序表、线性链表、二叉链表等存储结构从广义上讲都是集合,其中每个元素或结点代表一条纪录
,树的二叉链表等存储结构。应该说这些存储结构都可以作为集合来存放数据元素。所以,我们没有必要再寻求一种新的存储结构存放集合中的元素. 换句话说,顺序表、线性链表、二叉链表等存储结构从广义上讲都是集合,其中每个元素或结点代表一条纪录.")
10
关键字与查找 查找是按关键字进行的 所谓关键字(key)是数据元素(或记录)中的某个数据项或某些数据项的组合,用它可以唯一标识一个数据元素(或纪录) 任意两个数据元素的关键字都不能相同 例如一条学生记录包含学号、姓名、性别、籍贯、电话、通讯地址等数据项。有些数据项不能唯一标识一个数据元素,而有的则可以。例如,姓名就不能唯一标识一条纪录(因有同名的人),而学号则可以唯一标识一条纪录(每个学生学号是唯一的,不能相同)
,而学号则可以唯一标识一条纪录(每个学生学号是唯一的,不能相同)")
11
查找的定义 查找(find),也称为检索(retrieve)或搜索(search),就是根据给定值k,在一个集合(或表)中查找出其关键字等于k的数据元素(或纪录),若集合中有这样的元素,则查找成功,并返回整个数据元素(或纪录)或指出该元素在表中的位置;若表中不存在这样的记录,则称查找失败,并作相应处理 动态集合(dynamic collection) 在对集合中的元素进行查找时,若集合中不存在给定值k,那么我们就要将它插入集合中;也可以执行删除元素的操作,这样的集合叫动态集合 静态集合(static collection) 对集合只能做查找,不能做插入或删除元素的操作,只返回查找成功还是失败的结果,这样的集合叫静态集合
,也称为检索(retrieve)或搜索(search),就是根据给定值k,在一个集合(或表)中查找出其关键字等于k的数据元素(或纪录),若集合中有这样的元素,则查找成功,并返回整个数据元素(或纪录)或指出该元素在表中的位置;若表中不存在这样的记录,则称查找失败,并作相应处理. 动态集合(dynamic collection) 在对集合中的元素进行查找时,若集合中不存在给定值k,那么我们就要将它插入集合中;也可以执行删除元素的操作,这样的集合叫动态集合. 静态集合(static collection) 对集合只能做查找,不能做插入或删除元素的操作,只返回查找成功还是失败的结果,这样的集合叫静态集合.")
12
平均查找长度(ASL) 查找运算的基本操作是关键字的比较,所以,通常把查找过程中对关键字执行的平均比较次数(也称为平均查找长度 —— average search length)作为衡量一个查找算法效率优劣的标准 对于一个含有n个元素的集合(或表),查找成功时的平均查找长度可表示为 = n i c p ASL 1 其中pi为查找第i个元素的概率,且 =1。一般情形下我们认为查找每个元素的概率相等,即p1= p2=…= pn= , ci为查找到第i个元素所用的比较次数
,查找成功时的平均查找长度可表示为. = n. i. c. p. ASL. 1. 其中pi为查找第i个元素的概率,且 =1。一般情形下我们认为查找每个元素的概率相等,即p1= p2=…= pn= , ci为查找到第i个元素所用的比较次数.")
13
8.2 线性表的查找

14
8.2.1 无序表的查找——顺序查找 静态集合中的元素在初次建表时建立,不再改变
无序表的查找——顺序查找 静态集合中的元素在初次建表时建立,不再改变 顺序查找是最基本的查找方法之一。所谓顺序查找,又称线性查找,主要用于在线性结构中进行查找 顺序查找的基本思想是:从表的一端开始,顺序扫描线性表,依次将扫描到的元素的关键字和待找的值k作比较,若相等,则查找成功;若整个表扫描完毕,仍未找到其关键字等于k的元素,则查找失败 以顺序表或线性链表表示的静态集合可以采用顺序查找 顺序查找的表中的元素可以是无序的

15
顺序查找的算法实现 若返回值为0表示查找不成功,否则查找成功。函数中查找的范围从record[n]到record[1](即从后向前),record[0]作为监视哨,保存要找的值,查找时若遇到它,表示查找不成功 typedef struct { KeyType key; OtherType other; } ElemType; int search_seq(ElemType record[], KeyType k) { record[0].key=k; for (int i=n; record[i].key!=k; --i); return i; }
![顺序查找的算法实现 若返回值为0表示查找不成功,否则查找成功。函数中查找的范围从record[n]到record[1](即从后向前),record[0]作为监视哨,保存要找的值,查找时若遇到它,表示查找不成功.](http://slidesplayer.com/slide/11606843/62/images/15/%E9%A1%BA%E5%BA%8F%E6%9F%A5%E6%89%BE%E7%9A%84%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0+%E8%8B%A5%E8%BF%94%E5%9B%9E%E5%80%BC%E4%B8%BA0%E8%A1%A8%E7%A4%BA%E6%9F%A5%E6%89%BE%E4%B8%8D%E6%88%90%E5%8A%9F%EF%BC%8C%E5%90%A6%E5%88%99%E6%9F%A5%E6%89%BE%E6%88%90%E5%8A%9F%E3%80%82%E5%87%BD%E6%95%B0%E4%B8%AD%E6%9F%A5%E6%89%BE%E7%9A%84%E8%8C%83%E5%9B%B4%E4%BB%8Erecord%5Bn%5D%E5%88%B0record%5B1%5D%EF%BC%88%E5%8D%B3%E4%BB%8E%E5%90%8E%E5%90%91%E5%89%8D%EF%BC%89%EF%BC%8Crecord%5B0%5D%E4%BD%9C%E4%B8%BA%E7%9B%91%E8%A7%86%E5%93%A8%EF%BC%8C%E4%BF%9D%E5%AD%98%E8%A6%81%E6%89%BE%E7%9A%84%E5%80%BC%EF%BC%8C%E6%9F%A5%E6%89%BE%E6%97%B6%E8%8B%A5%E9%81%87%E5%88%B0%E5%AE%83%EF%BC%8C%E8%A1%A8%E7%A4%BA%E6%9F%A5%E6%89%BE%E4%B8%8D%E6%88%90%E5%8A%9F..jpg "typedef struct { KeyType key; OtherType other; } ElemType; int search_seq(ElemType record[], KeyType k) { record[0].key=k; for (int i=n; record[i].key!=k; --i); return i; }")
16
顺序查找的性能分析 c p ASL (n-i+1)
假设在每个位置查找的概率相等,即pi= ,由于查找是从后往前扫描,则有每个位置的查找比较次数cn=1, … ,c2= n-1,c1=n ,于是,查找成功的平均搜索长度为 = n i c p ASL 1 (n-i+1) 即它的时间复杂度为O(n)。 这就是说,查找成功的平均比较次数约为表长的一半。从ASL可知,当n较大时,ASL值较大,查找的效率较低 有时,表中各结点的查找概率并不相等。因此若事先知道表中各结点查找概率的分布情况,则可将表中结点按查找概率从小到大排列,即p1≤p2≤…≤pn,以便提高顺序查找的效率
 即它的时间复杂度为O(n)。 这就是说,查找成功的平均比较次数约为表长的一半。从ASL可知,当n较大时,ASL值较大,查找的效率较低. 有时,表中各结点的查找概率并不相等。因此若事先知道表中各结点查找概率的分布情况,则可将表中结点按查找概率从小到大排列,即p1≤p2≤…≤pn,以便提高顺序查找的效率.")
17
顺序查找的优缺点 优点:算法简单,对表结构无任何要求,无论是用数组还是用线性链表来存放数据元素,也无论元素之间是否按关键字有序或无序,它都同样适用。而且对于线性链表,只能顺序查找 缺点:查找效率低,当n较大时,不宜采用顺序查找,而必须寻求更好的查找方法

18
8.2.2 有序表的查找——折半查找 折半查找(或二分法搜索,binary search)是一种高效的查找方法 折半查找有两个条件限制
有序表的查找——折半查找 折半查找(或二分法搜索,binary search)是一种高效的查找方法 折半查找有两个条件限制 要求表必须采用顺序存储结构,即顺序表 表中元素必须按关键字有序(升序或降序)排列
是一种高效的查找方法. 折半查找有两个条件限制. 要求表必须采用顺序存储结构,即顺序表. 表中元素必须按关键字有序(升序或降序)排列.")
19
折半查找举例 给定有序表中关键字为8, 17, 25, 44, 68, 77, 98, 100, 115, 125,查找k=17的情况
[ ] low high (a) 初始情形 [ ] low high mid (b) 经过一次比较后的情形
 初始情形. [ ] low. high mid. (b) 经过一次比较后的情形.")
20
折半查找举例 查找k=20的情况 low mid high low high
[ ] (c) 经过二次比较后的情形(record[mid].key=17) low mid high [ ] low high (a) 初始情形
 经过二次比较后的情形(record[mid].key=17) low mid. high. [ ] low. high. (a) 初始情形.")
21
折半查找举例 low high mid mid low high [ 8 17 25 44 ] 68 44 98 100 115 125
[ ] low high mid (b) 经过一次比较后的情形 [ ] (c) 经过二次比较后的情形 mid low high
![折半查找举例 low high mid mid low high [ ]](http://slidesplayer.com/slide/11606843/62/images/21/%E6%8A%98%E5%8D%8A%E6%9F%A5%E6%89%BE%E4%B8%BE%E4%BE%8B+low+high+mid+mid+low+high+%5B+%5D.jpg "[ ] low. high mid. (b) 经过一次比较后的情形 [ ] (c) 经过二次比较后的情形. mid low. high.")
22
折半查找的算法实现 (d) 经过三次比较后的情形 mid low high int binarysearch(ElemType record[ ], KeyType k) { int low=1, high=n; while (low<=high) { mid=(low+high)/2; //取区间中点 if (record[mid].key==k) return mid; //查找成功 else if (k<record[mid].key) high=mid-1; //在左子区间中查找 else low=mid+1; //在右子区间中查找 } return 0; //查找失败
![折半查找的算法实现 (d) 经过三次比较后的情形. mid low. high. int binarysearch(ElemType record[ ], KeyType k) {](http://slidesplayer.com/slide/11606843/62/images/22/%E6%8A%98%E5%8D%8A%E6%9F%A5%E6%89%BE%E7%9A%84%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0+%28d%29+%E7%BB%8F%E8%BF%87%E4%B8%89%E6%AC%A1%E6%AF%94%E8%BE%83%E5%90%8E%E7%9A%84%E6%83%85%E5%BD%A2.+mid+low.+high.+int+binarysearch%28ElemType+record%5B+%5D%2C+KeyType+k%29+%7B.jpg "int low=1, high=n; while (low<=high) { mid=(low+high)/2; //取区间中点. if (record[mid].key==k) return mid; //查找成功. else if (k<record[mid].key) high=mid-1; //在左子区间中查找. else low=mid+1; //在右子区间中查找. } return 0; //查找失败.")
23
折半查找描述 我们不妨假设表中元素为升序排列。折半查找的基本思想是:首先将待查值k与有序表record[1]到record[n]的中点mid上的关键字record[mid].key进行比较,若相等,则查找成功;若k<record[mid]. key,则在record[1]到record[mid-1]中继续查找;若k>record [mid].key,则在record[mid+1]到record[n]中继续查找。每通过一次比较,区间的长度就缩小一半,如此不断进行下去,直至找到关键字为k的元素或查找失败

24
折半查找的性能分析 为了分析折半查找的性能,可以用二叉判定树来描述折半查找过程
把当前查找区间的中点作为根结点,左子区间和右子区间分别作为根的左子树和右子树,左子区间和右子区间再按类似的方法,由此得到的二叉树称为折半查找的二叉判定树。例如,上例给定的关键字序列8, 17, 25, 44, 68, 77, 98, 100, 115, 125的二叉判定树见下图 44 8 25 17 98 77 68 100 115 125 具有10个元素的折半二叉判定树

25
折半查找的性能分析 从上图可知,查找根结点68需一次查找;查找17和100各需二次查找;查找8、25、77、115各需三次查找;查找44、98、125各需四次查找。于是,可以得到结论:二叉树第k层结点的查找次数为k次(根结点为第1层),即要查找第k层的某个元素所需进行的比较次数为k次。而具有n个结点的二叉判定树的高度为log2n+1。所以,折半查找在查找成功时的比较次数至多为log2n+1次 二叉判定树不是完全二叉树,但它的叶结点在最大两层上,这样,n个结点的二叉判定树的高度和n个结点的完全二叉树的高度相同, 都是 log2n+1或 log2(n+1)
,即要查找第k层的某个元素所需进行的比较次数为k次。而具有n个结点的二叉判定树的高度为log2n+1。所以,折半查找在查找成功时的比较次数至多为log2n+1次. 二叉判定树不是完全二叉树,但它的叶结点在最大两层上,这样,n个结点的二叉判定树的高度和n个结点的完全二叉树的高度相同, 都是 log2n+1或 log2(n+1)")
26
折半查找的性能分析 下面我们计算一下折半查找成功时的ASL(假设每个结点的查找概率相等)
ASL= = ≤ (1 + 22 + 322 + … + h2h-1), h= log2(n+1),下面求不等式的右边: 设s= =20+221+322+…+(h-1)2h-2+h2h-1 则2s=21+222+…+(h-2)2h-2+(h-1)2h-1+h2h s=2s-s=h2h-( …+2h-2+2h-1) =h2h-(2h-1) =(h-1)2h+1 = (log2(n+1)-1)(n+1) +1=(n+1)log2(n+1)-n 不等式的右边为
, h= log2(n+1),下面求不等式的右边: 设s= =20+221+322+…+(h-1)2h-2+h2h-1. 则2s=21+222+…+(h-2)2h-2+(h-1)2h-1+h2h s=2s-s=h2h-( …+2h-2+2h-1) =h2h-(2h-1) =(h-1)2h+1. = (log2(n+1)-1)(n+1) +1=(n+1)log2(n+1)-n. 不等式的右边为 -1.")
27
折半查找的性能分析 当n很大时,ASLlog2(n+1)-1,可作为折半查找成功时的平均搜索长度,因此折半查找的平均时间复杂度为O(log2n) 可见 ,折半查找的效率比顺序查找高,但它要求被查找序列事先按关键字排好序,而排序本身是一种很费时的运算;另外,折半查找只适用于有序表,且限于顺序存储结构,对线性链表无法有效进行折半查找

28
分块查找 见上图,设一个数据表中的纪录分布在外存的4个页块中。块内的纪录可以按关键字有序,也可以无序(比如这个例子)排列。但块与块之间是按关键字有序的,即一个块中的所有关键字均大于另一个块,例如块4>块3>块2>块1。我们将这种有序叫做按块有序 地 址 块 1 块 2 块 3 块 4

29
稀疏索引(索引有序结构) 这时,我们可以建立一张索引表,表中的每个索引项对应一个页块,关键字域存放这个页块中最大的关键字,叫max_key,地址域存放该页块(而稠密索引则是记录)在磁盘中的地址(形式为柱面号:盘片号:块号) 这样,数据表占几个页块,索引表中就有几个索引项,所以索引项的数目远远小于实际的纪录数,这种线性索引结构叫做稀疏索引。又由于纪录按块有序,所以这种索引也叫索引有序结构(或索引顺序结构)
")
30
性能分析 下面我们仅讨论在内存中查找所消耗的时间代价
从前面的性能分析可知:内存中的查找包括(2)和(4)两步,即在索引表中顺序查找或折半查找和在页块中顺序查找。因此,总的ASL=Lb+Lw,其Lb为索引表的平均搜索长度, Lw为在页块中查找指定纪录的平均搜索长度 若对索引表顺序查找ASL=Lb+Lw= = ,b为数据文件在磁盘中占用的块数,也就是索引表中索引项的个数。s为每个页块中所能容纳的纪录数。因此,b= ,ASL=Lb+Lw= ( +s)+1。当s= 时,ASL取最小值 ,即时间复杂度为O(n ) 若对索引表折半查找ASL=Lb+Lw= log2( +1) +
和(4)两步,即在索引表中顺序查找或折半查找和在页块中顺序查找。因此,总的ASL=Lb+Lw,其Lb为索引表的平均搜索长度, Lw为在页块中查找指定纪录的平均搜索长度. 若对索引表顺序查找ASL=Lb+Lw= + = +1,b为数据文件在磁盘中占用的块数,也就是索引表中索引项的个数。s为每个页块中所能容纳的纪录数。因此,b= ,ASL=Lb+Lw= ( +s)+1。当s= 时,ASL取最小值 +1,即时间复杂度为O(n ) 若对索引表折半查找ASL=Lb+Lw= + log2( +1) +")
31
8.3 树表的查找

32
动态集合的特点 动态集合的特点是:集合结构本身在查找过程中动态生成,即对于给定值k,若集合中存在关键字等于k的纪录,则查找成功返回;否则插入关键字为k的新纪录

33
8.3.1 二叉排序树(BST) 二叉排序树(binary sorting tree—BST),又叫二叉查找树或二叉搜索树
它或者是一棵空树,或者是一棵具有如下特征的非空二叉树 若它的左子树非空,则左子树上所有结点的关键字均小于根结点的关键字 若它的右子树非空,则右子树上所有结点的关键字均大于根结点的关键字 左、右子树也分别为二叉排序树 通常采用二叉链表作为二叉排序树的存储结构 二叉排序树示例见图9.7

34
二叉排序树的插入和建立 二叉排序树是一种动态树型集合或动态树表。其特点是树的结构通常不是一次生成的,而是在查找过程中动态建立的:当树中不存在关键字值与给定值k相等的结点时,将k插入 基本思想是:若二叉排序树为空,则作为根结点插入;否则,若待插入的值k小于当前结点,则作为左孩子插入,若k大于当前结点,作为右孩子插入。若k等于当前结点,则不插入 新插入的结点一定是叶结点,并且是查找失败时查找路径上访问的最后一个叶结点的左孩子或右孩子

35
二叉排序树的插入和建立示例 例:给定关键字集合{79,62,68,90,88,89,17,5, 100,120}按顺序生成二叉排序树。其过程如下图所示(二叉排序树的形状与关键字的输入顺序有关,输入顺序不一样,得到的二叉排序树也不一样) 79 62 68 90 88 (a) (b) (c) (d) (e)
 (b) (c) (d) (e)")
36
二叉排序树的插入和建立示例 88 68 62 79 90 (f) 89 (g) 17 (h) 5 (i) 100 (j) 120
 89 (g) 17 (h) 5 (i) 100 (j) 120")
37
二叉排序树的插入——递归算法 插入算法通常有递归和非递归(迭代)两个版本 递归算法
void insert(BiTree &T, KeyType k) { if (T==NULL) { T=new BiTNode; Tdata=k; Tlchild=Trchild=NULL; } else if(k<Tdata) insert(Tlchild, k); else if(k>Tdata) insert(Trchild, k);
 { if (T==NULL) { T=new BiTNode; Tdata=k; Tlchild=Trchild=NULL; } else if(k<Tdata) insert(Tlchild, k); else if(k>Tdata) insert(Trchild, k);")
38
二叉排序树的插入——迭代算法 迭代算法 void insert(BiTree &T, KeyType k) {
BiTree p=T, prev=NULL; if (T==NULL) { T=new BiTNode; Tdata=k; Tlchild=Trchild=NULL; return; } while (p!=NULL) { prev=p; if (k<pdata) p=plchild; else if (k>pdata) p=prchild; else break; } //prev指向查找失败时查找路径上访问的最后一个叶结点 if (k<prevdata) { p=new BiTNode; pdata=k; plchild=prchild=NULL; prevlchild=p; return; } else if (k>prevdata) { plchild=prchild=NULL; prevrchild=p; return; } //当k==prevdata时,直接返回
 { T=new BiTNode; Tdata=k; Tlchild=Trchild=NULL; return; } while (p!=NULL) { prev=p; if (k<pdata) p=plchild; else if (k>pdata) p=prchild; else break; } //prev指向查找失败时查找路径上访问的最后一个叶结点. if (k<prevdata) { p=new BiTNode; pdata=k; plchild=prchild=NULL; prevlchild=p; return; } else if (k>prevdata) { plchild=prchild=NULL; prevrchild=p; return; } //当k==prevdata时,直接返回.")
39
二叉排序树的建立算法 只要反复调用二叉排序树的插入算法,即可建立二叉排序树
void createBST(BiTree &T, int n) { BiTree T=NULL; KeyType k; for (int i=1; i<=n; ++i) { cin>>k; //输入关键字序列 insert(T, k); }
 { BiTree T=NULL; KeyType k; for (int i=1; i<=n; ++i) { cin>>k; //输入关键字序列. insert(T, k); }")
40
二叉排序树插入小结 容易看出,中序遍历二叉排序树可以得到按关键字递增的有序序列。这就是说,一个原本无序的集合可通过构造一棵二叉排序树而变成有序集合,构造树的过程即为对无序集合进行排序的过程。不仅如此,每次插入的新结点都是叶结点,即在插入过程中,不必移动其他结点。这就相当于在一个有序集合上插入一个元素而不需移动其他元素。 因此,二叉排序树既拥有类似折半查找的性能,又采用了链式存储结构(而折半查找只适用于顺序存储结构),因此是一种优越的动态集合
,因此是一种优越的动态集合.")
41
二叉排序树的删除 删除是指在二叉排序树中删除一个与给定值key相等的结点,并保持二叉排序树的特性 从二叉排序树中删除一个结点共有3种情况
要删除的结点是一个叶结点。这是最简单的情况。只需将其父结点指向它的指针清零,再释放它即可。如图所示 15 4 1 20 16 p 删除p 释放

42
二叉排序树的删除 要删除的结点只有一个孩子。这种情况也不复杂。如果被删除的结点只有左子树,则父结点指向它的指针改为指向它的左孩子,再释放它;如果被删除的结点只有右子树,则父结点指向它的指针改为指向它的右孩子,再释放它。如图所示 15 4 1 20 16 删除p 释放 p 要删除的结点有两个孩子。在这种情况下没有一步到位的方法。下面讨论一种解决方法

43
复制删除法 Hibbard和Knuth提出了复制删除法。如果结点有两个孩子,可以用结点的直接前驱结点代替该结点,然后再删除这个前驱结点,而前驱结点只能是下面两种情况之一:如果前驱结点是叶结点,应用第一种情况;如果它有一个孩子,应用第二种情况

44
复制删除法 s p q s p q 将s的值复制给p s p q p q

45
复制删除法的算法实现 void deleteByCopying(BiTree &T, KeyType k) {
if (T==NULL) return; else { if (Tdata==k) delete(T); else if (k<Tdata) deleteByCopying(Tlchild, k); else deleteByCopying(Trchild, k); } } //deleteByCopying void delete(BiTree &p) { if (prchild==NULL) {q=p; p=plchild; free(q);} //只有左 //子树 else if (plchild==NULL) {q=p; p=prchild; free(q);} //只有右子树 else { //p既有左子树,又有右子树 q=p; s=plchild; while (srchild) {q=s; s=srchild;} //s为p的左子树的最 //右结点,即直接前驱,q为s的父结点 pdata=sdata; //用s替换p的关键字 To Be Continued
 return; else { if (Tdata==k) delete(T); else if (k<Tdata) deleteByCopying(Tlchild, k); else deleteByCopying(Trchild, k); } } //deleteByCopying. void delete(BiTree &p) { if (prchild==NULL) {q=p; p=plchild; free(q);} //只有左. //子树. else if (plchild==NULL) {q=p; p=prchild; free(q);} //只有右子树. else { //p既有左子树,又有右子树. q=p; s=plchild; while (srchild) {q=s; s=srchild;} //s为p的左子树的最. //右结点,即直接前驱,q为s的父结点. pdata=sdata; //用s替换p的关键字 To Be Continued.")
46
复制删除法的算法实现 if (q!=p) qrchild=slchild; else qlchild=slchild; free(s); } //else } //delete 这个算法是不对称的:它总是删除直接前驱结点,如果进行多次删除,就会减少左子树的高度而不影响右子树。进行多次删除后,整个树变得向右侧偏,右子树比左子树大得多 为了解决这个问题,可以对算法的对称性作一个简单改进:交替地从左子树删除前驱、从右子树删除后继,这叫做“对称删除法”

47
二叉排序树的查找 基本思想:若二叉排树为空,则查找失败,否则,先拿根结点与待查值k进行比较。若相等,则查找成功;若k小于根结点,则进入左子树重复此步骤;否则,进入右子树重复此步骤,若在查找过程中遇到二叉排序树的叶子结点时还没有找到与k相等的结点,则查找失败 递归算法 BiTree Find(BiTree T, KeyType k){ if (T==NULL) return NULL; //查找失败 else if (Tdata==k) return T; //查找成功 else if (k<Tdata) return Find(Tlchild, k); else return Find(Trchild, k); }
{ if (T==NULL) return NULL; //查找失败. else if (Tdata==k) return T; //查找成功. else if (k<Tdata) return Find(Tlchild, k); else return Find(Trchild, k); }")
48
二叉排序树的查找 非递归算法 BiTree Find(BiTree T, KeyType k) { BiTree p=T;
while (p!=NULL) { if (pdata==k) return p; else if (k<pdata) p=plchild; else p=prchild; } return NULL;
 { if (pdata==k) return p; else if (k<pdata) p=plchild; else p=prchild; } return NULL;")
49
二叉排序树查找的分析 在二叉排序树查找中,成功的查找次数不会超过二叉树的深度
而具有n个纪录的二叉排序树的深度,最佳为log2n+1(叶结点几乎都在最大两层上),最差为n(此时二叉排序树是一棵左(右)单枝树,蜕变为线性链表,其ASL=(n+1)/2 ) 因此,二叉排序树查找的最佳时间复杂度为O(log2n),最坏时间复杂度为O(n),一般情形下,其时间复杂度大致可看成O(log2n),比顺序查找要好 随机情况下,二叉排序树的ASL和log2n等数量级。然而,在某些情况下(有人统计约占50%),二叉排序树失去平衡,向某一侧偏斜,这时需要在构造二叉排序树的过程中进行“平衡化”处理,使其成为平衡二叉树
,最差为n(此时二叉排序树是一棵左(右)单枝树,蜕变为线性链表,其ASL=(n+1)/2 ) 因此,二叉排序树查找的最佳时间复杂度为O(log2n),最坏时间复杂度为O(n),一般情形下,其时间复杂度大致可看成O(log2n),比顺序查找要好. 随机情况下,二叉排序树的ASL和log2n等数量级。然而,在某些情况下(有人统计约占50%),二叉排序树失去平衡,向某一侧偏斜,这时需要在构造二叉排序树的过程中进行 平衡化 处理,使其成为平衡二叉树.")
50
8.3.2 AVL树 若一棵二叉排序树中每个结点的左、右子树的深度之差的绝对值不超过1,则称这样的二叉树为平衡二叉树或高度平衡树
将该结点的左子树深度减去右子树深度,称为该结点的平衡因子(balance factor,) 也就是说,一棵二叉排序树中,所有结点的平衡因子=0、1或-1时,该二叉排序树就是平衡二叉树,否则就不是平衡二叉树 B D K M P R 平衡二叉树 非平衡二叉树
 也就是说,一棵二叉排序树中,所有结点的平衡因子=0、1或-1时,该二叉排序树就是平衡二叉树,否则就不是平衡二叉树. B. D. K. M. P. R. 平衡二叉树. 非平衡二叉树.")
51
AVL树 例如:如果一棵平衡二叉树中存储了10,000条纪录,那么树的高度是log210,000+1=14。在实际情况中,这意味着如果在一棵平衡二叉树中存放10,000条纪录,查找一条纪录时最多需要测试14个结点。这和线性链表最多需要10,000次测试有着巨大的差别。所以,建造一棵平衡树或将一棵树改造成平衡树是值得的 总之,建造平衡二叉树的目的就是尽可能降低树的高度,减少树的平均搜索长度 下面我们介绍建立平衡二叉树的方法

52
AVL树 Adelson-Velskii和Landis提出了一个经典的方法将一棵二叉排序树转换为平衡二叉树,为纪念他们,人们将用该方法得到的平衡二叉树叫做AVL树 AVL树的结点结构为 typedef struct BSTNode { ElemType data; int bf; //平衡因子 struct BSTNode *lchild, *rchild; } BSTNode, *BSTree;

53
非平衡二叉树的平衡化处理 若一棵二叉排序树是平衡二叉树,插入某个结点后,可能会变成非平衡二叉树,这时,就可以对该二叉树进行平衡化处理,使其变成一棵平衡二叉树 处理的原则是:从插入位置沿通向根的路径回溯,检查各结点左右子树的高度差。如果在某一结点发现高度不平衡,停止回溯。从发生不平衡的结点起,沿刚才回溯的路径取下两层的结点 如果3个结点处于一条直线上,则用单旋转进行平衡化 如果3个结点处于一条折线上,则用双旋转进行平衡化 下面分四种情况讨论平衡化处理 平衡化旋转 单旋转 双旋转 左单旋 右单旋 先左后右(先左单旋、后右单旋) 先右后左(先右单旋、后左单旋)
 先右后左(先右单旋、后左单旋)")
54
左单旋(RR型) 如下图所示,在平衡二叉树结点A的右孩子B的右子树中插入一个结点,使A的平衡因子由-1变为-2,成为不平衡的二叉排序树。这时的平衡化处理为:将A逆时针旋转,成为B的左孩子,而原来B的左子树成为A的右子树 初始平衡二叉树 A B -1 h h+2 RR型 -2 h+1 插入结点失去平衡 平衡化恢复平衡

55
左单旋(RR型) void rotate_left(BSTree &p) { BSTree rightchild=prchild;
由此可见,这个以结点A为根的二叉排序树在插入结点前和平衡化处理后的高度都是h+2,因此对于以这棵二叉树为子树的结点(即A的祖先结点)来说,处理前和处理后的平衡因子是不变的,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树 void rotate_left(BSTree &p) { BSTree rightchild=prchild; prchild=rightchildlchild; rightchildlchild=p; p=rightchild; }
来说,处理前和处理后的平衡因子是不变的,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树. void rotate_left(BSTree &p) { BSTree rightchild=prchild; prchild=rightchildlchild; rightchildlchild=p; p=rightchild; }")
56
右单旋(LL型) 如下图所示,在平衡二叉树结点A的左孩子B的左子树中插入一个结点,使A的平衡因子由1变为2,成为不平衡的二叉排序树。这时的平衡化处理为:将A顺时针旋转,成为B的右孩子,而原来B的右子树成为A的左子树 A 2 1 h h+1 B 初始平衡二叉树 h+2 LL型 插入结点失去平衡 平衡化恢复平衡

57
右单旋(LL型) void rotate_right(BSTree &p) { BSTree leftchild=plchild;
右单旋是左单旋的镜像。以结点A为根的二叉排序树在插入结点前和平衡化处理后的高度都是h+2,因此对于以这棵二叉树为子树的结点(即A的祖先结点)来说,处理前后的平衡因子不变,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树 void rotate_right(BSTree &p) { BSTree leftchild=plchild; plchild=leftchildrchild; leftchildrchild=p; p=leftchild; }
来说,处理前后的平衡因子不变,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树. void rotate_right(BSTree &p) { BSTree leftchild=plchild; plchild=leftchildrchild; leftchildrchild=p; p=leftchild; }")
58
先左后右(LR型) 如下图所示,在平衡二叉树结点A的左孩子B的右子树中插入一个结点,使A的平衡因子由1变为2,成为不平衡的二叉排序树。此时平衡化处理为:先将C绕B做左单旋,使之成为LL型,而后将C绕A做右单旋 A 2 -1 h h+1 B 初始平衡二叉树 h+2 1 LR型 插入结点失去平衡 细化B的右子树 C h-1

59
先左后右(LR型) h-1 C绕B左单旋 h+2 C绕A右单旋恢复平衡 A 2 1 h B C
由此可见,这个以结点A为根的二叉排序树在插入结点前和平衡化处理后的高度都是h+2,因此对于以这棵二叉树为子树的结点(即A的祖先结点)来说,处理前和处理后的平衡因子是不变的,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树
来说,处理前和处理后的平衡因子是不变的,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树.")
60
先左后右(LR型) 可见,我们做了两步操作 先对以B为根的子树做左单旋,再对以A为根的子树做右单旋
算法为 rotate_left(Tlchild); rotate_right(T);
; rotate_right(T);")
61
先右后左(RL型) 如下图所示,在平衡二叉树结点A的右孩子B的左子树中插入一个结点,使A的平衡因子由-1变为-2,成为不平衡二叉排序树。此时平衡化处理为:先将C绕B做右单旋,使之成为RR型,而后将C绕A做左单旋 初始平衡二叉树 h+2 A B -1 h 插入结点失去平衡 细化B的左子树 -2 1 h+1 RL型 C h-1

62
先右后左(RL型) h-1 C绕B右单旋 h+2 C绕A左单旋恢复平衡 A -2 -1 h B C
先右后左是先左后右的镜像。以结点A为根的二叉排序树在插入结点前和平衡处理后的高度都是h+2,因此对于以这棵二叉树为子树的结点(即A的祖先结点)来说,处理前后的平衡因子不变,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树
来说,处理前后的平衡因子不变,高度始终保持平衡。平衡的丢失只影响到了A,没有扩散到A上层的结点。因此只需对以A为根的子树进行局部平衡化处理,而无需扩展到整个二叉排序树.")
63
先右后左(RL型) 可见,我们做了两步操作 先对以B为根的子树做右单旋,再对以A为根的子树做左单旋
算法为 rotate_right(Trchild); rotate_left(T);
; rotate_left(T);")
64
AVL树的建立举例 给定一个关键字序列{4, 5, 7, 2, 1, 3},生成一棵平衡二叉树 左单旋 先左后右 右单旋 -1 - 1 2
插入 4 (b) 5 (c) 7 - 1 2 左单旋 ( d ) e 右单旋 -1 3 f 先左后右
 5. (c) 左单旋. ( d. ) e. 右单旋 f. 先左后右.")
65
AVL树的删除 从AVL树中删除一个结点时,不像插入那样:平衡前后以A为根的子树高度都是h+2
删除时,平衡后有的情况是h+2,而有的情况是h+1 这样,即使找到第一个不平衡的结点并恢复平衡后,也不能像插入那样立即停止对树的平衡过程 这也意味着在最坏情况下,从被删除的结点到根结点的每一个结点都有可能需要重新平衡 具体情况略

66
AVL树的性能分析 这时,访问结点的ASL比纯AVL树(||≤1)多将近一倍,但插入或删除时的重新平衡化操作却能以10倍递减
但由于它是高度平衡树,因此它的高度与完全二叉树类似 它的查找性能优于一般的二叉排序树,不像二叉排序树,会出现最坏的时间复杂度O(n),它的时间复杂度与二叉排序树的最佳时间复杂相同,为O(log2n) 此外,实验表明78%的删除完全不需要平衡化,而只有53%的插入不需要平衡化 最后还应指出,可以将AVL树的高度差放大,当然此时AVL树的高度也会相应增加,从而使查找效率降低。例如 1.81log2n – ||≤ h = log2n – ||≤3 这时,访问结点的ASL比纯AVL树(||≤1)多将近一倍,但插入或删除时的重新平衡化操作却能以10倍递减
,它的时间复杂度与二叉排序树的最佳时间复杂相同,为O(log2n) 此外,实验表明78%的删除完全不需要平衡化,而只有53%的插入不需要平衡化. 最后还应指出,可以将AVL树的高度差放大,当然此时AVL树的高度也会相应增加,从而使查找效率降低。例如. 1.81log2n – 0.71 ||≤2 h = 2.15log2n – 1.13 ||≤3. 这时,访问结点的ASL比纯AVL树(||≤1)多将近一倍,但插入或删除时的重新平衡化操作却能以10倍递减.")
67
小结 小 结 平衡二叉树是组织纪录的常用方法。查找的时间代价与O(log2n)等数量级,适合于组织在内存中的规模较小的集合。
小 结 平衡二叉树是组织纪录的常用方法。查找的时间代价与O(log2n)等数量级,适合于组织在内存中的规模较小的集合。 对于存储在外存(如磁盘)上的大型文件系统和数据库管理系统,由于其中存放的是海量数据,所以log2n仍然很大,对外存进行log2n次访问还是很耗时,因此在外存中存储大量纪录时,我们通常采用索引(index)结构。
等数量级,适合于组织在内存中的规模较小的集合。 对于存储在外存(如磁盘)上的大型文件系统和数据库管理系统,由于其中存放的是海量数据,所以log2n仍然很大,对外存进行log2n次访问还是很耗时,因此在外存中存储大量纪录时,我们通常采用索引(index)结构。")
68
B_树与B+树 我们学过AVL树,知道它适合于组织在内存中的纪录集。对于存放在外存中的较大的文件系统和数据库管理系统(DBMS),用AVL树来组织就不太合适了。因为这样一来,找到某个特定关键字需对外存进行log2n次访问,当n很大时,这仍是很费时的 因此在文件系统和大型数据库管理系统中大量采用“B_树”索引来存储数据记录

69
B_树的定义 B_树是一种高度平衡的动态m叉查找树 其定义为 树中所有结点至多有m 棵子树(至多全满) 根结点至少有2棵子树
所有结点具有如下结构n , P0 , (K1, A1, P1) , (K2, A2, P2),…, (Kn, An, Pn)。其中, Ki是关键字,且必须Ki<Ki+1(1≤i≤ n);Pi(0≤i≤n≤m)是指向子结点的指针(实际上是子结点在磁盘中的地址);Ai是指向包含关键字Ki的纪录的指针(实际上是纪录在磁盘中的地址) 在子结点Pi中所有的关键字都大于Ki而小于Ki+1。在子结点P0中的所有关键字都小于K1,而子结点Pn中所有的关键字都大于Kn 所有叶结点都在同一层上(=0, 高度平衡)
 , (K2, A2, P2),…, (Kn, An, Pn)。其中, Ki是关键字,且必须Ki<Ki+1(1≤i≤ n);Pi(0≤i≤n≤m)是指向子结点的指针(实际上是子结点在磁盘中的地址);Ai是指向包含关键字Ki的纪录的指针(实际上是纪录在磁盘中的地址) 在子结点Pi中所有的关键字都大于Ki而小于Ki+1。在子结点P0中的所有关键字都小于K1,而子结点Pn中所有的关键字都大于Kn. 所有叶结点都在同一层上(=0, 高度平衡)")
70
B_树的定义 5叉B_树示意图 60 10 20 40 70 80 81 89 95 73 77 62 66 45 50 55 58 25 30 12 16 18 6 8 1 3 2 由定义可知,B_树的每个结点其实就是一个索引表,称为索引结点。其关键字域按升序排列,Ai指针域指向包含该关键字的纪录在外存中的地址。每个索引结点对应于磁盘中的一个块,因此也叫索引块。对索引结点的访问等价于从磁盘读取相应的索引块

71
B_树的性质 AVL树近似于二叉B_树,B_树是AVL树的推广,且高度平衡
已知m叉B_树的度为m,它的高度为h,则B_树的最大结点数为:(mh-1)/(m-1)。由于每个结点最多可容纳m-1个关键字,因此最多关键字数为mh-1,也就是说,以这棵B_树作为纪录集的索引结构,最多可索引到mh-1条纪录 包含N个关键字的m叉B_树的高度 h≤log ( )+1
/(m-1)。由于每个结点最多可容纳m-1个关键字,因此最多关键字数为mh-1,也就是说,以这棵B_树作为纪录集的索引结构,最多可索引到mh-1条纪录. 包含N个关键字的m叉B_树的高度 h≤log ( )+1.")
72
B_树的性质 证明:第一层至少有1个关键字。由于除根之外的每个结点至少有q= -1个关键字,因此第二层至少有2q个关键字;第三层至少有2q(q+1)个;第四层至少有2q(q+1)2个,……,第h层至少有2q(q+1)h-2。 因此,N≥1+2q(1+(q+1)+(q+1)2+…+(q+1)h-2),即 N≥2(q+1)h-1-1= 2 h-1-1, 因此,h≤log ( )+1。这便是具有N个关键字的B_树的最大高度。 这意味着即使B_树存储的关键字很多,对于很大的度m,高度仍非常小。如当m=200,N=2,000,000时,h≤4,这就是说,最坏情况下,在B_树中查找一个关键字只需从磁盘读4次索引块。
+(q+1)2+…+(q+1)h-2),即. N≥2(q+1)h-1-1= 2 h-1-1, 因此,h≤log ( )+1。这便是具有N个关键字的B_树的最大高度。 这意味着即使B_树存储的关键字很多,对于很大的度m,高度仍非常小。如当m=200,N=2,000,000时,h≤4,这就是说,最坏情况下,在B_树中查找一个关键字只需从磁盘读4次索引块。")
73
B_树的性质 若提高B_树的度m,可以减少树的高度,从而减少读磁盘的次数。但m不能无限增加,它受到我们在程序中开辟的内存工作区(working space)大小的限制。同时,m的增加也会增加块内查找的时间。因此应合理地选择m的值,使总的时间开销最小
大小的限制。同时,m的增加也会增加块内查找的时间。因此应合理地选择m的值,使总的时间开销最小.")
74
B_树的查找 设B_树的度为m,则B_树的存储结构为 typedef struct BTNode { int n; //结点中关键字的个数
BTNode *parent; //指向父结点的指针 KeyType key[m]; //关键字数组,0号单元不用 struct BTNode *p[m]; //指向子结点的指针数组 Record *recptr[m]; //纪录指针数组,0号单元不用 } BTNode, *BTree; typedef struct { //该结构体类型代表查找结果 BTNode *p; //指向找到的结点 int i; //结点中的关键字序号 int tag; //tag=1表示查找成功;tag=0表示查找失败 } Result; //若查找成功,则tag=1,指针p所指结点的 //第i个关键字等于给定值k;否则tag=0,k插 //入p所指结点的第i和第i+1个关键字之间

75
B_树的查找 B_树结点示意图 B_树的查找操作为 key[0] n parent p[0] recptr[0] key[1] p[1]
… key[m-1] p[m-1] recptr[m-1] B_树的查找操作为
![B_树的查找 B_树结点示意图 B_树的查找操作为 key[0] n parent p[0] recptr[0] key[1] p[1]](http://slidesplayer.com/slide/11606843/62/images/75/B_%E6%A0%91%E7%9A%84%E6%9F%A5%E6%89%BE+B_%E6%A0%91%E7%BB%93%E7%82%B9%E7%A4%BA%E6%84%8F%E5%9B%BE+B_%E6%A0%91%E7%9A%84%E6%9F%A5%E6%89%BE%E6%93%8D%E4%BD%9C%E4%B8%BA+key%5B0%5D+n+parent+p%5B0%5D+recptr%5B0%5D+key%5B1%5D+p%5B1%5D.jpg "… key[m-1] p[m-1] recptr[m-1] B_树的查找操作为.")
76
B_树的查找 Result search(BTree T, KeyType k) { Result r; int i;
ReadNode(T); //从磁盘读取T指向的索引块 Btree p=T, q=NULL; while (p!=NULL) { i=0; pkey[pn+1]=INFINITY; while (pkey[i+1]<k) i++; if (pkey[i+1]==k) { r=(p, i+1, 1); //找到k,是pkey[i+1] return r; } else { //pkey[i+1]>k q=p; p=pp[i]; ReadNode(p); //读取下一层结点 } //while r=(q, i, 0); return r; //未找到k,k应插入到qkey[i]之后
; //从磁盘读取T指向的索引块. Btree p=T, q=NULL; while (p!=NULL) { i=0; pkey[pn+1]=INFINITY; while (pkey[i+1]<k) i++; if (pkey[i+1]==k) { r=(p, i+1, 1); //找到k,是pkey[i+1] return r; } else { //pkey[i+1]>k. q=p; p=pp[i]; ReadNode(p); //读取下一层结点. } //while. r=(q, i, 0); return r; //未找到k,k应插入到qkey[i]之后.")
77
B_树查找分析 从该算法可见,B_树的查找过程蕴含着交替进行的两种基本操作 (1) 在B_树中沿指针向下找索引结点(索引块)
(2) 在索引结点中找关键字 由于B_树存储在磁盘上,则操作(1)是读磁盘的过程,操作(2)是在内存中进行的,即先将磁盘中的索引块读入内存,然后再利用顺序查找或折半查找在内存中查询等于k的关键字 显然,读取磁盘比在内存中进行查找耗费的时间多得多,因此,读取磁盘的次数,即关键字k所属索引结点在B_树中的层数是决定B_树查找效率的首要因素 在B_树上进行查找,查找成功所需的时间取决于关键字所在层数;查找不成功所需的时间取决于B_树的高度
 在索引结点中找关键字. 由于B_树存储在磁盘上,则操作(1)是读磁盘的过程,操作(2)是在内存中进行的,即先将磁盘中的索引块读入内存,然后再利用顺序查找或折半查找在内存中查询等于k的关键字. 显然,读取磁盘比在内存中进行查找耗费的时间多得多,因此,读取磁盘的次数,即关键字k所属索引结点在B_树中的层数是决定B_树查找效率的首要因素. 在B_树上进行查找,查找成功所需的时间取决于关键字所在层数;查找不成功所需的时间取决于B_树的高度.")
78
B_树的插入 B_树是从空树起,逐个插入关键字而动态生成的。当从根走到叶结点没有找到k,就在当前叶结点中的适当位置插入k。因此,插入总是从某个叶结点开始的。但在插入k时,如果结点中关键字的个数超过上界m-1,则结点要发生“分裂”;否则就直接插入 结点“分裂”的原则是 设结点p已经有m-1个关键字,当再插入一个关键字后结点中的状态为 m, P0 , (K1, P1) , (K2, P2) , … ,(Km-1, Pm-1), (Km, Pm) 这时必须把结点p分成p和q,它们包含的信息分别为 结点p: -1, P0 , (K1, P1) , (K2, P2) , …, (K -1, P -1) 结点q: m - , P , (K +1, P +1) , …, (Km, Pm) 位于中间的关键字K 与指向新结点q的指针形成(K , q),插入到这两个结点的父结点中
 , (K2, P2) , … ,(Km-1, Pm-1), (Km, Pm) 这时必须把结点p分成p和q,它们包含的信息分别为 结点p: -1, P0 , (K1, P1) , (K2, P2) , …, (K -1, P -1) 结点q: m - , P , (K +1, P +1) , …, (Km, Pm) 位于中间的关键字K 与指向新结点q的指针形成(K , q),插入到这两个结点的父结点中.")
79
B_树的插入 我们看一个3叉B_树(又叫2-3树)的插入过程 插入算法*: rootn=1; rootparent=NULL;
53 75 139 插入53 53 插入75 53 75 插入139 53 75 139 插入49,145 49 75 139 53 145 36 插入36 49 75 139 53 145 36 49 139 75 145 53 插入算法*: void insert(BTree T, KeyType key) { Result r=search(T, key); //查找key if (r.tag==1) return; //查找成功 BTree p=r.p; BTree q=par=NULL; BTree ap=NULL; //(k, ap) KeyType k=key; int i=r.i; while (1) { //结点不分裂 if (pn<=m-2) { insertKey(p, i, k, ap); //(k, ap)插入结点p的i和i+1之间 WriteNode(p); return; //将结点p写回磁盘并返回 } //结点分裂 int s=(m+1)/2; //s为分裂位置m/2 insertKey(p, i, k, ap); //先插入,结点中pn=m q=new BTree(); //建立新结点q move(p, q, s, m); //将p的key[s+1..m]和p[s..m]移到q的key[1..s-1]和p[0..s-1],pn改为s-1,qn改为m-s k=pkey[s]; ap=q; //形成向父结点插入的(k, ap) //分裂的结点不是根结点 if (pparent!=NULL) { //p不是根结点 par=pparent; ReadNode(par); //读结点p的父结点给par i=0; parkey[parn+1]=INFINITY; while (parkey[i+1]<k) ++i; qparent=pparent; WriteNode(p); WriteNode(q); //写回结点p和q到磁盘 p=par; //分裂的结点是根结点 else { //p是根结点 BTree root=new BTree(); //创建根结点root rootn=1; rootparent=NULL; rootkey[1]=k; rootp[0]=p; rootp[1]=ap; pparent=qparent=root; WriteNode(p); WriteNode(q); WriteNode(root); return; } //else } //while 139 145 49 75 101 36 53 101 插入101 36 49 139 75 145 53 145 49 75 101 36 139 53
 { Result r=search(T, key); //查找key. if (r.tag==1) return; //查找成功. BTree p=r.p; BTree q=par=NULL; BTree ap=NULL; //(k, ap) KeyType k=key; int i=r.i; while (1) { //结点不分裂. if (pn<=m-2) { insertKey(p, i, k, ap); //(k, ap)插入结点p的i和i+1之间. WriteNode(p); return; //将结点p写回磁盘并返回. } //结点分裂. int s=(m+1)/2; //s为分裂位置m/2 insertKey(p, i, k, ap); //先插入,结点中pn=m. q=new BTree(); //建立新结点q. move(p, q, s, m); //将p的key[s+1..m]和p[s..m]移到q的key[1..s-1]和p[0..s-1],pn改为s-1,qn改为m-s. k=pkey[s]; ap=q; //形成向父结点插入的(k, ap) //分裂的结点不是根结点. if (pparent!=NULL) { //p不是根结点. par=pparent; ReadNode(par); //读结点p的父结点给par. i=0; parkey[parn+1]=INFINITY; while (parkey[i+1]<k) ++i; qparent=pparent; WriteNode(p); WriteNode(q); //写回结点p和q到磁盘. p=par; //分裂的结点是根结点. else { //p是根结点. BTree root=new BTree(); //创建根结点root. rootn=1; rootparent=NULL; rootkey[1]=k; rootp[0]=p; rootp[1]=ap; pparent=qparent=root; WriteNode(p); WriteNode(q); WriteNode(root); return; } //else. } //while 插入")
80
B_树的删除 B_树中的所有非根结点至少有m/2个子结点(至少半满),即至少含有m/2-1个关键字。若从一个结点删除某个关键字后,该结点低于半满,则要发生结点的“合并”。否则直接删除 结点“合并”的原则是 1、若从叶结点删除k 1.1、在删除k后,叶结点中关键字数≥ m/2 -1 (至少半满),只需将k后面的关键字左移填补空位 1.2、在删除k后,叶结点中关键字数< m/2-1,导致下溢。这时, 1.2.1、如果该叶结点有关键字数 > m/2-1的左兄弟或右兄弟,则将父结点中的分隔键移到这个叶结点中,然后从这个兄弟中移一个关键字到父结点中
,只需将k后面的关键字左移填补空位. 1.2、在删除k后,叶结点中关键字数< m/2-1,导致下溢。这时, 1.2.1、如果该叶结点有关键字数 > m/2-1的左兄弟或右兄弟,则将父结点中的分隔键移到这个叶结点中,然后从这个兄弟中移一个关键字到父结点中.")
81
B_树的删除 1.2.2、如果该叶结点的左右兄弟的关键字数都 = m/2-1,则将这个叶结点和它的一个兄弟合并:该叶结点的关键字、它的兄弟的关键字以及父结点的分隔键全部放到该叶结点中,然后删除它的这个兄弟结点。 由于父结点中的分隔键被移走后出现一个空位,有可能导致父结点下溢,这时可把父结点看作叶结点,重复1直到可以执行1.2.1或者到达树的根结点结束 2、若从一个非叶结点删除k 将要删除的关键字用它的直接后继(也可以用直接前驱)替换,这只能从一个叶结点中找到。然后将这个后继值从叶结点中删除,这就回到了第1种情况
替换,这只能从一个叶结点中找到。然后将这个后继值从叶结点中删除,这就回到了第1种情况.")
82
B_树的删除 我们看一个5叉B_树的删除过程 (a) 初始B_树 删除6,情况1.1 (b) 删除6后的B_树 16 3 8 22 25 1
7 13 14 15 18 20 23 24 27 37 删除6,情况1.1 (b) 删除6后的B_树 16 3 8 22 25 1 2 5 7 13 14 15 18 20 23 24 27 37
 删除6后的B_树")
83
B_树的删除 再删除7,情况1.2.1 (c) 删除7后的B_树 再删除8,情况1.2.2,结点合并 (d) 删除8后的B_树(未完) 16
3 13 22 25 1 2 5 8 14 15 18 20 23 24 27 37 再删除8,情况1.2.2,结点合并 (d) 删除8后的B_树(未完) 16 3 22 25 1 2 5 13 14 15 18 20 23 24 27 37
 删除8后的B_树(未完)")
84
B_树的删除 继续,情况1.2.2 结点合并 (e) 删除8后的B_树 再删除16,情况2+ 1.1,用前驱替换
3 16 22 25 1 2 5 13 14 15 18 20 23 24 27 37 (e) 删除8后的B_树 再删除16,情况2+ 1.1,用前驱替换 3 15 22 25 1 2 5 13 14 18 20 23 24 27 37 (f-1) 删除16后的B_树 (f-2) 删除16后的B_树 或用直接后继替换情况 删除算法*: void delete(BTree T, KeyType k) { Result r=search(T, k); //查找k if (r.tag=0) return; //没找到k BTree p=r.p, q=s=NULL; int j=r.i; //p是k所在结点,j是k在p中的位置 if (pp[j]!=NULL) { //p非叶结点,情况2,要用叶结点中的直接后继替代 s=pp[j]; ReadNode(s); q=p; while (s!=NULL) {q=s; s=sp[0];} //q是包含后继的叶结点 pkey[j]=qkey[1]; //qkey[1]是后继,替代k(pkey[j]) compress(q, 1); p=q; //删除这个直接后继,p指向该叶结点 } else compress(p, j); //p是叶结点,将k从p中删除 int d=(m+1)/2; //d为m/2 while (1) { if (pn>=d-1) break; //情况1.1,不需要处理 else { //情况1.2,叶结点p不足半满 j=0; q=pparent; ReadNode(q); //q是p的父结点 while (j<qn && qp[j]!=p) j++; if (j==0) RightAdjust(p, q, d, 1); //p是q的最左孩子,与右兄弟和父结点一起作调整 else LeftAdjust(p, q, d, j); //p非q的最左孩子,与左兄弟和父结点一起作调整 p=q; //p继续指向父结点,对父结点继续作调整 if (p==T) break; } //while(1) if (Tn==0) { p=Tp[0]; delete T; T=p; Tparent=NULL; void RightAdjust(BTree p, BTree q, int d, int j) { BTree p1=qp[j]; //p1是p的右兄弟 if (p1n>d-1) { //情况1.2.1,在3个结点中重新调整关键字 pn++; pkey[pn]=qkey[j]; //将父结点q的key[1]下移至p qkey[j]=p1key[1]; //将右兄弟p1的key[1]上移至q的 pp[pn]=p1p[0]; p1p[0]=p1p[1]; compress(p1, 1); else RightMerge(p, q, p1, j); //情况1.2.2,p与p1合并 void LeftAdjust(BTree p, BTree q, int d, int j) {……} //略 void compress(BTree p, int j) { //将结点p的第j个关键字删除,后面的关键字和指针前移 for (int i=j; i<pn; i++) { pkey[i]=pkey[i+1]; pp[i]=pp[i+1]; pn--; void RightMerge(BTree p, BTree q, BTree p1, int j) { //将结点p和p1合并为p,删除p1。q是它们的父结点。 pkey[pn+1]=qkey[j]; pp[pn+1]=p1p[0]; for (int i=1; i<=p1n; ++i) { pkey[pn+i+1]=p1key[i]; pp[pn+i+1]=p1p[i]; compress(q, j); pn=pn+p1n+1; delete p1; void LeftMerge(BTree p, BTree q, BTree p1, int j) {……} //略
 删除8后的B_树. 再删除16,情况2+ 1.1,用前驱替换 (f-1) 删除16后的B_树. (f-2) 删除16后的B_树. 或用直接后继替换情况 删除算法*: void delete(BTree T, KeyType k) { Result r=search(T, k); //查找k. if (r.tag=0) return; //没找到k. BTree p=r.p, q=s=NULL; int j=r.i; //p是k所在结点,j是k在p中的位置. if (pp[j]!=NULL) { //p非叶结点,情况2,要用叶结点中的直接后继替代. s=pp[j]; ReadNode(s); q=p; while (s!=NULL) {q=s; s=sp[0];} //q是包含后继的叶结点. pkey[j]=qkey[1]; //qkey[1]是后继,替代k(pkey[j]) compress(q, 1); p=q; //删除这个直接后继,p指向该叶结点. } else compress(p, j); //p是叶结点,将k从p中删除. int d=(m+1)/2; //d为m/2 while (1) { if (pn>=d-1) break; //情况1.1,不需要处理. else { //情况1.2,叶结点p不足半满. j=0; q=pparent; ReadNode(q); //q是p的父结点. while (j<qn && qp[j]!=p) j++; if (j==0) RightAdjust(p, q, d, 1); //p是q的最左孩子,与右兄弟和父结点一起作调整. else LeftAdjust(p, q, d, j); //p非q的最左孩子,与左兄弟和父结点一起作调整. p=q; //p继续指向父结点,对父结点继续作调整. if (p==T) break; } //while(1) if (Tn==0) { p=Tp[0]; delete T; T=p; Tparent=NULL; void RightAdjust(BTree p, BTree q, int d, int j) { BTree p1=qp[j]; //p1是p的右兄弟. if (p1n>d-1) { //情况1.2.1,在3个结点中重新调整关键字. pn++; pkey[pn]=qkey[j]; //将父结点q的key[1]下移至p. qkey[j]=p1key[1]; //将右兄弟p1的key[1]上移至q的. pp[pn]=p1p[0]; p1p[0]=p1p[1]; compress(p1, 1); else RightMerge(p, q, p1, j); //情况1.2.2,p与p1合并. void LeftAdjust(BTree p, BTree q, int d, int j) {……} //略. void compress(BTree p, int j) { //将结点p的第j个关键字删除,后面的关键字和指针前移. for (int i=j; i<pn; i++) { pkey[i]=pkey[i+1]; pp[i]=pp[i+1]; pn--; void RightMerge(BTree p, BTree q, BTree p1, int j) { //将结点p和p1合并为p,删除p1。q是它们的父结点。 pkey[pn+1]=qkey[j]; pp[pn+1]=p1p[0]; for (int i=1; i<=p1n; ++i) { pkey[pn+i+1]=p1key[i]; pp[pn+i+1]=p1p[i]; compress(q, j); pn=pn+p1n+1; delete p1; void LeftMerge(BTree p, BTree q, BTree p1, int j) {……} //略.")
85
B_树的分析 根据B_树的定义,每个索引块必须保证至少半满,因此整个索引树可能会有50%的空间被浪费。实验表明,B_树的平均利用率是69%(即31%的磁盘空间被浪费了) 因此,Knuth等人在B_树的基础上又提出了B*树 在B*树中,除根以外的所有结点都至少2/3满而不是半满。更准确说,对m叉B*树索引结点中的关键字数n,有 ≤n ≤m-1。当结点分裂时,两个结点分裂成三个,而不是一分为二,即当两个互为兄弟的结点都满时,分裂成三个结点,原来两个结点中的所有关键字在三个结点中平均分配,使每个结点至少2/3满。实验表明,B*树的平均利用率是81%,比B_树要好。而且通过延迟结点的分裂降低了结点分裂发生的频率,提高了操作效率 类似地,索引结点至少3/4满的B_树叫B**树。至少 满的B_树叫Bn *树

86
B+树 B+树可以看成B_树的一种变型,在实现大型文件系统和数据库管理系统的索引结构方面比B_树使用的更广泛
在B+树中包含了B_树。除叶结点所在的最底下一层以外实际上是一棵正规的B_树,只不过这棵B_树的每个结点中并不像一般的B_树那样包含指向关键字所属纪录的指针(即在BTNode中没有Record *recptr[m]域)。实际上,这个指针数组被放到了叶结点中
。实际上,这个指针数组被放到了叶结点中.")
87
B+树的定义 树中每个非叶结点至多有m个子结点(至多全满) 根结点至少有2个子结点,其他非叶结点至少有 个子结点(至少半满)
根结点至少有2个子结点,其他非叶结点至少有 个子结点(至少半满) 所有非叶结点只是快速访问数据的索引,可以看成索引部分,具有如下结构:n , P0 , (K1, P1) , (K2, P2) , …, (Kn, Pn),其中,Ki是关键字,且必须Ki<Ki+1(1≤i≤n);Pi(0≤i≤n≤m)是指向子结点的指针(实际上是子结点在磁盘中的地址)。结点格式同B_树 在子结点Pi中所有的关键字都大于等于Ki而小于Ki+1。在子结点P0中的所有关键字都小于K1,而子结点Pn中所有的关键字都大于等于Kn 所有叶结点都在同一层上。按关键字从小到大排列。与B+树的其他结点可以有着不同的结构: struct LeafNode { KeyType key[m1]; // m1可以不同于B_树的m Record *recptr[m1]; // 指向包含相应关键字的纪录 LeafNode *next; }; 叶结点中关键字的个数介于 和m1之间,即半满和全满之间
 所有非叶结点只是快速访问数据的索引,可以看成索引部分,具有如下结构:n , P0 , (K1, P1) , (K2, P2) , …, (Kn, Pn),其中,Ki是关键字,且必须Ki<Ki+1(1≤i≤n);Pi(0≤i≤n≤m)是指向子结点的指针(实际上是子结点在磁盘中的地址)。结点格式同B_树. 在子结点Pi中所有的关键字都大于等于Ki而小于Ki+1。在子结点P0中的所有关键字都小于K1,而子结点Pn中所有的关键字都大于等于Kn. 所有叶结点都在同一层上。按关键字从小到大排列。与B+树的其他结点可以有着不同的结构: struct LeafNode { KeyType key[m1]; // m1可以不同于B_树的m. Record *recptr[m1]; // 指向包含相应关键字的纪录. LeafNode *next; }; 叶结点中关键字的个数介于 和m1之间,即半满和全满之间.")
88
B+树的定义 B+树示意图 索引集 23 18 33 48 50 52 45 47 30 31 19 20 21 10 12 15 ^ 22

89
B+树的查找 通常在B+树中有两个头指针:一个指向B+树的根结点,另一个指向关键字最小的结点

90
B+树的插入 B+树的插入仅在叶结点上进行。向一个还有空间的叶结点上插入关键字需要将它按顺序放在这个叶子上。索引集没有变化

91
B+树的删除 B+树的删除同样仅在叶结点上进行
当在叶结点上删除一个关键字后,结点中的关键字数< (低于半满),必须做调整或合并操作
,必须做调整或合并操作.")
92
8.4 散列表的查找

93
8.4.1 散列技术 散列(hash),也称哈希、杂凑
散列技术 散列(hash),也称哈希、杂凑 它既是一种查找方法,又是一种存储方法,称为散列存储。基于散列技术的存储结构称为散列表或哈希表(hash table)。它是一种动态索引技术 散列查找,与前面介绍的查找方法完全不同,前面介绍的所有查找都是基于待查关键字与集合中的元素进行比较而实现的 那么有没有一种方法根据待查关键字本身的特点就能直接获得记录的存储地址呢? 答案是肯定的,这就是散列技术。理想情况下它能使我们只读一次磁盘便能把记录读入内存,获得O(1)阶的查找效率
,也称哈希、杂凑. 它既是一种查找方法,又是一种存储方法,称为散列存储。基于散列技术的存储结构称为散列表或哈希表(hash table)。它是一种动态索引技术. 散列查找,与前面介绍的查找方法完全不同,前面介绍的所有查找都是基于待查关键字与集合中的元素进行比较而实现的. 那么有没有一种方法根据待查关键字本身的特点就能直接获得记录的存储地址呢? 答案是肯定的,这就是散列技术。理想情况下它能使我们只读一次磁盘便能把记录读入内存,获得O(1)阶的查找效率.")
94
散列查找 散列查找是一种通过构造散列函数得到待查关键字的地址的查找方法
它的基本思想是:以记录的关键字k为自变量,通过一个确定的函数关系,计算出对应的函数值H(k),把这个值作为记录的内存或外存的地址 查找时也是根据这个函数计算存储位置 通常散列存储区是一块连续的内存空间,可以用一个一维数组表示,散列地址便是数组的下标
,把这个值作为记录的内存或外存的地址. 查找时也是根据这个函数计算存储位置. 通常散列存储区是一块连续的内存空间,可以用一个一维数组表示,散列地址便是数组的下标.")
95
散列查找 下面举个例子 假设有一个关键字序列为{ 18, 75, 60, 43, 54, 90, 46 },给定散列函数H(k)=k%13,存贮区的大小为16,则可以得到每个关键字的散列地址为: H(18)=18%13=5, H(75)=75%13=10, H(60)=60%13=8, H(43)=43%13=4, H(54)=54%13=2, H(90)=90%13=12, H(46)=46%13=7 根据散列地址,可以将上述7个关键字序列存储到一维数组HT(代表散列表)中,具体表示为: HT
=k%13,存贮区的大小为16,则可以得到每个关键字的散列地址为: H(18)=18%13=5, H(75)=75%13=10, H(60)=60%13=8, H(43)=43%13=4, H(54)=54%13=2, H(90)=90%13=12, H(46)=46%13=7. 根据散列地址,可以将上述7个关键字序列存储到一维数组HT(代表散列表)中,具体表示为: HT.")
96
散列查找 HT就是散列存储的表,称为散列表。 从散列表中查找一个元素相当方便。例如,要找75,只需计算散列函数H(75)=75%13=10,则可以在HT[10]中找到75 上面讨论的散列表是一种理想的情形,即每一个关键字对应一个唯一的地址。但是有可能出现这样的情形,两个不同的关键字有可能对应同一地址,即k1 k2,而f (k1)=f (k2),这样将导致后放的关键字无法存储,我们把这种现象叫做冲突(collision) 在散列存储中,冲突是很难避免的,特别是当存储空间小而待存记录多时。散列函数选得越差,发生冲突的可能性就越大。我们把相互冲突的关键字称为同义词(synonym)
![散列查找 HT就是散列存储的表,称为散列表。 从散列表中查找一个元素相当方便。例如,要找75,只需计算散列函数H(75)=75%13=10,则可以在HT[10]中找到75.](http://slidesplayer.com/slide/11606843/62/images/96/%E6%95%A3%E5%88%97%E6%9F%A5%E6%89%BE+HT%E5%B0%B1%E6%98%AF%E6%95%A3%E5%88%97%E5%AD%98%E5%82%A8%E7%9A%84%E8%A1%A8%EF%BC%8C%E7%A7%B0%E4%B8%BA%E6%95%A3%E5%88%97%E8%A1%A8%E3%80%82+%E4%BB%8E%E6%95%A3%E5%88%97%E8%A1%A8%E4%B8%AD%E6%9F%A5%E6%89%BE%E4%B8%80%E4%B8%AA%E5%85%83%E7%B4%A0%E7%9B%B8%E5%BD%93%E6%96%B9%E4%BE%BF%E3%80%82%E4%BE%8B%E5%A6%82%EF%BC%8C%E8%A6%81%E6%89%BE75%EF%BC%8C%E5%8F%AA%E9%9C%80%E8%AE%A1%E7%AE%97%E6%95%A3%E5%88%97%E5%87%BD%E6%95%B0H%2875%29%3D75%2513%3D10%EF%BC%8C%E5%88%99%E5%8F%AF%E4%BB%A5%E5%9C%A8HT%5B10%5D%E4%B8%AD%E6%89%BE%E5%88%B075..jpg "上面讨论的散列表是一种理想的情形,即每一个关键字对应一个唯一的地址。但是有可能出现这样的情形,两个不同的关键字有可能对应同一地址,即k1 k2,而f (k1)=f (k2),这样将导致后放的关键字无法存储,我们把这种现象叫做冲突(collision) 在散列存储中,冲突是很难避免的,特别是当存储空间小而待存记录多时。散列函数选得越差,发生冲突的可能性就越大。我们把相互冲突的关键字称为同义词(synonym)")
97
散列查找 一般情况下,冲突只能尽可能地减少而不能完全避免。因为散列函数是从关键字集合到地址集合的映像。通常,关键字集合比较大,它的元素包括所有可能的关键字,而地址集合比较小,它的元素仅为散列表中的地址值。因此,在一般情况下,散列函数是一个压缩映像,这就不可避免产生冲突 因此,对于散列技术需要讨论两个问题 对于一个给定的关键字集合,选择一个计算简单且地址分布比较均匀的散列函数,避免或尽量减少冲突 确定一个解决冲突的方法,即寻找一种方法存储产生冲突的同义词

98
8.4.2 散列函数 构造散列函数时应注意以下几个问题 下面我们介绍几种常见的构造方法
散列函数 构造散列函数时应注意以下几个问题 如果散列表允许有m个地址,则散列函数的值域应该在0~m-1之间 散列函数计算出来的地址应能均匀地分布在整个地址空间中 散列函数应简单,不要过于复杂,导致运算量过大 下面我们介绍几种常见的构造方法

99
1、直接定址法 此类方法取关键字的某个线形函数值作为散列地址:H(key)=a×key + b {其中a,b为常数}
这类散列函数是一对一的映射,一般不会产生冲突。但是,它要求散列地址空间与关键字集合的大小相同,这种要求一般很难实现,因此实际中很少用这种方法 例:有一组关键字:{ , , , , , , },散列函数为H(key)=key-940000,则 H(942148)= H(941269)= H(940527)= H(941630)= H(941805)= H(941558)= H(942047)= H(940001)=1 可以按计算出的地址存放记录
=key-940000,则 H(942148)=2148 H(941269)=1269 H(940527)=527 H(941630)=1630 H(941805)=1805 H(941558)=1558 H(942047)=2047 H(940001)=1. 可以按计算出的地址存放记录.")
100
2、数字分析法 设有n个d位符号组成的关键字,每一位中可能有r 种不同的符号
可根据散列表的大小,选取其中各种符号分布均匀的若干位作为散列地址。计算第k位符号分布均匀度 k的公式为 其中, 表示第i 种符号在第k 位上出现的次数 。计算出的 k值越小,表明在第k 位上各种符号分布得越均匀

101
2、数字分析法 例:有n = 8个关键字,r = 10(共10个符号)
")
102
2、数字分析法 这样,可以取关键字的后3位作记录的散列地址 散列地址 关键字
1 4 8 2 6 9 5 2 7 6 3 0 8 0 5 5 5 8 0 4 7 0 0 1 散列地址 关键字 采用数字分析法必须事先明确知道可能出现的关键字,它完全依赖于关键字集合。如果换一个关键字集合,选择哪几位要重新决定

103
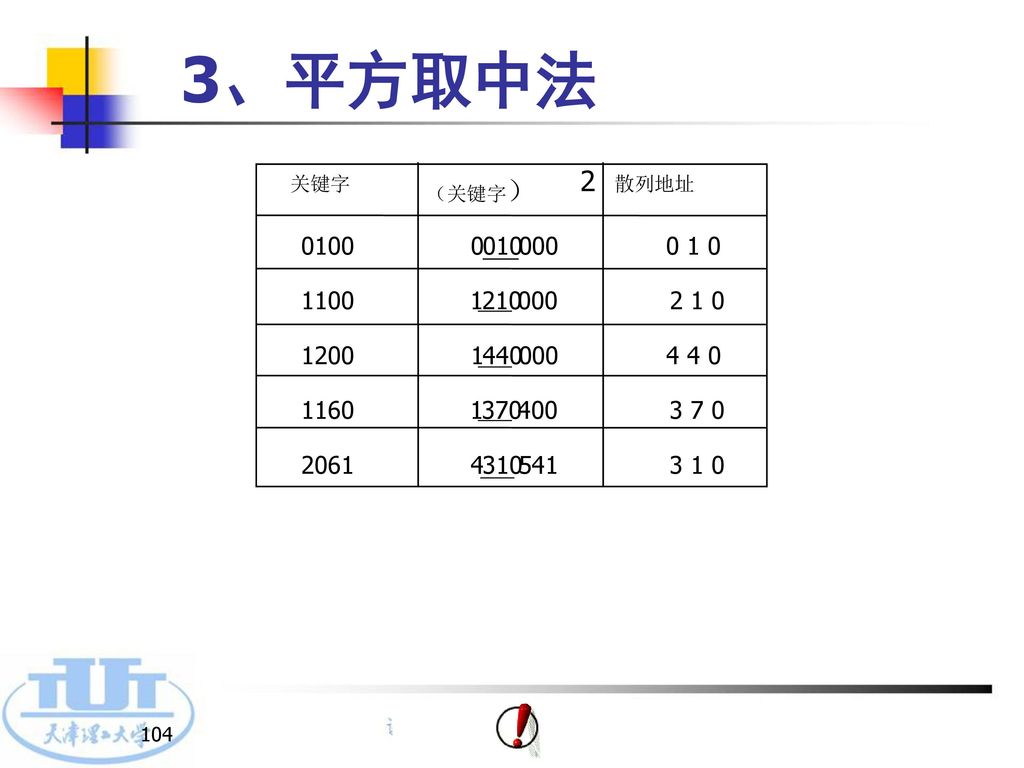
3、平方取中法 通常,要选定散列函数时不一定知道关键字的全部信息,预先估计关键字的数字分布并不容易,要找数字均匀分布的位更难
而一个数平方后的中间几位数和这个数的每一位都相关,此时可采用平方取中法:先求关键字的平方,再取中间的几位作为散列地址。因为平方后的中间几位一般由关键字的所有位决定 取几位由散列表的表长决定。在平方取中法中,若取散列表长m=2r,则对平方数取中间的r位

104
3、平方取中法 关键字 (关键字) 2 散列地址 0100 010 000 0 1 0 1100 1 210 2 1 0 1200 440 4 4 0 1160 370 400 3 7 0 2061 4 310 541 3 1 0
105
4、折叠法 若关键字位数较多,可将关键字分割成位数相同的几段(最后一段的位数可以短一些),然后将各段的迭加和(舍去进位)作为散列地址
有两种叠加方法 移位法 —— 把各段的最后一位对齐相加 分界法 —— 沿各段的分界象折扇一样来回折叠,然后对齐相加

106
4、折叠法 例如,对于key= 582 423 241 [1]315 H(key)=315 移位法 324 [1]243 H(key)=243 分界法 一般当关键字的位数很多,而且关键字每一位上字符的分布比较均匀时,可以用这种方法得到散列地址
![4、折叠法 例如,对于key= [1]315. H(key)=315. 移位法](http://slidesplayer.com/slide/11606843/62/images/106/4%E3%80%81%E6%8A%98%E5%8F%A0%E6%B3%95+%E4%BE%8B%E5%A6%82%EF%BC%8C%E5%AF%B9%E4%BA%8Ekey%3D+%5B1%5D315.+H%28key%29%3D315.+%E7%A7%BB%E4%BD%8D%E6%B3%95.jpg "[1]243. H(key)=243. 分界法. 一般当关键字的位数很多,而且关键字每一位上字符的分布比较均匀时,可以用这种方法得到散列地址.")
107
5、除余法 设散列表长为m,取一个不大于m,但最接近或等于m的素数p。散列函数为: H(key) = key%p (p≤m)
这个方法的关键是选取适当的p。选择p最好不要是偶数或合数。一般选p为小于或等于散列表长度m的最大素数比较好。例如: 当m = 8,16,32,64,128,256,512, p = 7,13,31,61,127,251,503,1019 不仅如此,我们经常是直接将表长m取为素数,并让p=m

108
5、除余法 那么,为什么p取≤m的最大素数呢?
首先,用上面的散列函数计算出来的地址范围是0到p-1,因此从p到m-1的散列地址实际上是不可能用散列函数计算出来的。不是最大素数自然就降低了散列地址的可取范围,这当然不是我们所乐见的 此外,p是素数,求模后的余数相等的可能性小,这是我们取素数的原因 除余法的地址计算公式简单,而且在很多情况下效果较好,因此是一种常用的构造散列函数的方法

109
由于散列存储中选取的散列函数不是线性函数,故不可避免地会产生冲突,下面给出常见的解决冲突的方法
解决冲突的方法 由于散列存储中选取的散列函数不是线性函数,故不可避免地会产生冲突,下面给出常见的解决冲突的方法

110
1、闭散列法(closed hash) 又叫开放定址法
就是从发生冲突的那个单元开始,使用某种方法在散列表中进行探查,从散列表中找出一个空闲的存储单元,把发生冲突的关键字存储到该单元中,从而解决冲突。如果表未被装满,则在允许的范围内必定有新的位置 探查的方法主要有2种

111
线性探查法(linear probing)
若地址为d (即H(k) =d)的单元发生冲突,则依次探查下列地址单元:d+1, d+2, ...…, m-1, 0, 1, ...…, d –1。直至找到第一个空单元或找到关键字为k的单元为止: 若是空单元就插入k 若找到关键字为k的单元则表示查找成功 若沿着该探查序列查找一遍之后,又回到了地址d,则说明散列表已满且无关键字k,则查找失败 求下一个地址的公式为:Hi=(H0+i)%m或Hi+1=(Hi+1)%m,i=1, 2, 3, …, m-1。H0为散列函数。m最好是一个素数 例:给定关键字序列为{ 19,14,23,1,68,20,84,27,55,11,10,79,25 },散列函数H(k)=k%13,散列表为HT[13],用线性探查法构造散列表并计算等概率下查找成功的ASLsucc
 =d)的单元发生冲突,则依次探查下列地址单元:d+1, d+2, ...…, m-1, 0, 1, ...…, d –1。直至找到第一个空单元或找到关键字为k的单元为止: 若是空单元就插入k. 若找到关键字为k的单元则表示查找成功. 若沿着该探查序列查找一遍之后,又回到了地址d,则说明散列表已满且无关键字k,则查找失败. 求下一个地址的公式为:Hi=(H0+i)%m或Hi+1=(Hi+1)%m,i=1, 2, 3, …, m-1。H0为散列函数。m最好是一个素数. 例:给定关键字序列为{ 19,14,23,1,68,20,84,27,55,11,10,79,25 },散列函数H(k)=k%13,散列表为HT[13],用线性探查法构造散列表并计算等概率下查找成功的ASLsucc.")
112
线性探查法(linear probing)
【解】19%13=6,14%13=1,23%13=10,1%13=1,68%13=3,20%13=7,84%13=6,27%13=1,55%13=3, 11%13=11,10%13=10,79%13=1,25%13=12 19 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12

113
线性探查法(linear probing)
1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12 1 2 3 4 9 10 7 8 5 6 11 12
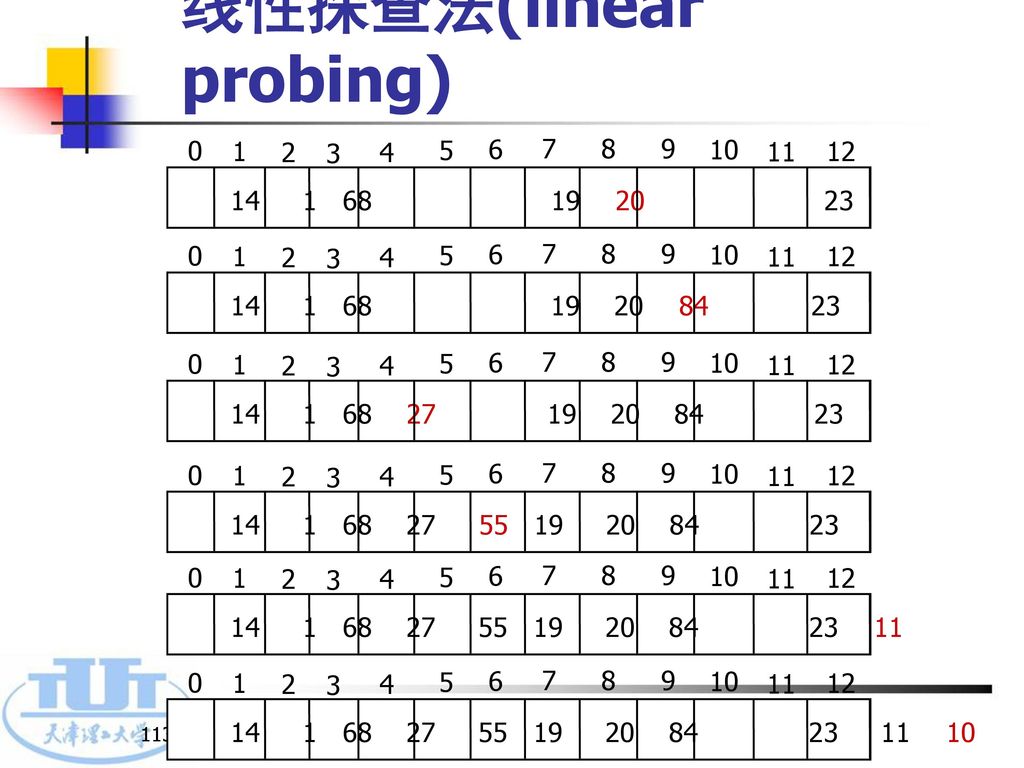
114
线性探查法(linear probing)
1 2 3 4 9 10 7 8 5 6 11 12 线性探查法容易产生聚集(clusters)问题,即一旦发生冲突,就要向后一位一位的寻找,直至找到第一个空单元为止。随着关键字的插入,就会在散列表的某个部位形成大量元素的聚集,进而降低后面关键字的查找和插入效率。例如在插入79之前,由于从HT[1]到HT[8]形成了聚集,导致79被放入HT[9],即比较了9次,才找到空单元,离它本身应在的地址已经很远了。这势必会造成日后查找效率的降低 1 2 3 4 9 10 7 8 5 6 11 12 ASLsucc= ( ) =
问题,即一旦发生冲突,就要向后一位一位的寻找,直至找到第一个空单元为止。随着关键字的插入,就会在散列表的某个部位形成大量元素的聚集,进而降低后面关键字的查找和插入效率。例如在插入79之前,由于从HT[1]到HT[8]形成了聚集,导致79被放入HT[9],即比较了9次,才找到空单元,离它本身应在的地址已经很远了。这势必会造成日后查找效率的降低 ASLsucc= ( ) =")
115
二次探查法(quadratic probing)
为了避免聚集现象的发生,可以选择其他的探查方法 二次探查法的探查序列依次为:+12, -12, +22, -22, … , +( )2, -( )2 等,也就是说,发生冲突时,将同义词来回在冲突地址的两端进行散列。求下一个地址的公式为:Hi=(H0±i2)%m,i =1,2,3,…,H0为散列函数 当H0-i2<0时,(H0-i2)%m也是负数,实际算式可改为 if ((j=(H0-i2)%m)<0) j+=m。m最好是一个素数 散列表长m一般是形如4j+3的素数(j是某一正整数),这才能保证探查序列包含整个表空间 尽管使用二次探查得到的结果在搜索性能上比线性探查好得多,但仍不能避免聚集的发生,因为对于发生冲突的key,使用的探查序列相同,后面仍有发生冲突的可能,而且随着插入的关键字越来越多,聚集将成为搜索效率降低的主要因素,这种聚集叫二次聚集,它比线性聚集的危害要小
2, -( )2 等,也就是说,发生冲突时,将同义词来回在冲突地址的两端进行散列。求下一个地址的公式为:Hi=(H0±i2)%m,i =1,2,3,…,H0为散列函数. 当H0-i2<0时,(H0-i2)%m也是负数,实际算式可改为 if ((j=(H0-i2)%m)<0) j+=m。m最好是一个素数. 散列表长m一般是形如4j+3的素数(j是某一正整数),这才能保证探查序列包含整个表空间. 尽管使用二次探查得到的结果在搜索性能上比线性探查好得多,但仍不能避免聚集的发生,因为对于发生冲突的key,使用的探查序列相同,后面仍有发生冲突的可能,而且随着插入的关键字越来越多,聚集将成为搜索效率降低的主要因素,这种聚集叫二次聚集,它比线性聚集的危害要小.")
116
双散列法(rehash) 聚集的问题可以用双散列法解决
这个方法用两个散列函数。一个计算散列地址,另一个解决冲突。其探查序列可以写成:Hi= (H0+i×RH(key))%m或Hi+1= (Hi+RH(key))%m,i=1, 2, 3, m-1。H0为散列函数,RH(key)为再散列函数 如果谨慎地选取RH函数就可以避免聚集,因为即使两个关键字冲突,它们的RH函数值相等的可能性很小。定义RH函数的方法较多,但无论采用什么方法,都必须使其和m互素,才能使发生冲突的同义词地址均匀地分布在整个散列表中,否则可能造成同义词地址的循环计算
)%m或Hi+1= (Hi+RH(key))%m,i=1, 2, 3, m-1。H0为散列函数,RH(key)为再散列函数. 如果谨慎地选取RH函数就可以避免聚集,因为即使两个关键字冲突,它们的RH函数值相等的可能性很小。定义RH函数的方法较多,但无论采用什么方法,都必须使其和m互素,才能使发生冲突的同义词地址均匀地分布在整个散列表中,否则可能造成同义词地址的循环计算.")
117
2、开散列法(open hash) 闭散列法利用求模运算得到散列表中的另一地址,地址单元脱离不开散列表,所以叫闭散列法
开散列法则是将所有同义词链接到一个单链表中,形成同义词链表,因此这种方法又叫链地址法 链地址法的思想是:将所有同义词结点链接在同一个单链表中。可以将散列表定义为一个由m个头指针组成的指针数组HT[m],凡是散列地址为i的结点,均插入到以HT[i]为头指针的单链表中

118
链地址法 若一组关键字为{ 26,36,41,38,44,15,68,12,6,51,25 },散列函数定义为:H(key)=key %13。用链地址法建立的散列表为: 1 2 3 4 5 6 7 8 9 10 11 12 26 41 68 15 44 36 38 51 25 ^

119
链地址法 与闭散列法相比,链地址法有以下几个优点
链地址法不会产生聚集现象,因而平均查找长度较小 结点空间是动态分配的,故更适合于无法确定表长的情况 删除结点的操作易于实现 用链地址法处理冲突需要增设指针,似乎增加了存储开销。但事实上,由于闭散列法必须保持大量的空间以确保搜索效率,而这种空间不仅要存储关键字,还要存储含有该关键字的记录在磁盘中的地址,其实比指针大得多,所以使用链地址法反而比闭散列法节省存储空间

120
8.4.4 散列表的查找及其分析 散列表的查找过程和建表过程类似
散列表的查找及其分析 散列表的查找过程和建表过程类似 假设给定的值为k, 根据建表时设定的散列函数H,计算出散列地址H(k),若表中该地址对应的空间未被占用,则查找失败,把k插入该空单元中;否则将该地址中的值与k比较,若相等则查找成功,若不相等,则按事先设定的处理冲突的方法找下一个地址。如此重复下去,直至某个地址空间未被占用(查找失败,把k插入该空单元)或关键字比较相等(查找成功)为止 在散列表查找过程中进行比较的次数通常取决于下列3个因素 散列函数 处理冲突的方法 散列表的装满程度
,若表中该地址对应的空间未被占用,则查找失败,把k插入该空单元中;否则将该地址中的值与k比较,若相等则查找成功,若不相等,则按事先设定的处理冲突的方法找下一个地址。如此重复下去,直至某个地址空间未被占用(查找失败,把k插入该空单元)或关键字比较相等(查找成功)为止. 在散列表查找过程中进行比较的次数通常取决于下列3个因素. 散列函数. 处理冲突的方法. 散列表的装满程度.")
121
8.4.4 散列表的查找及其分析 前面已经谈过散列函数和处理冲突的方法,这里不再赘述
散列表的查找及其分析 前面已经谈过散列函数和处理冲突的方法,这里不再赘述 下面我们着重讨论一下散列表的装满程度是如何影响散列表的查找效率的 一般情况下,散列函数和处理冲突的方法相同的散列表,其平均查找长度(ASL)依赖于散列表的装载因子 装载因子的定义是散列表中己存入的元素个数n与散列表的表长m的比值,即=n/m 标志散列表的装满程度。直观地看,越小,空闲空间越多,发生冲突的可能性越小;反之,越大,表中已填入的记录越多,再填记录时,发生冲突的可能性就越大 可以证明,散列表的ASL是(=n/m)的函数,不直接依赖于n或m本身。由此,不管记录个数n多大,我们总可以通过扩充散列表的长度m,将装载因子降低到一个合适的程度,以便将ASL限制在一个合理的范围内
依赖于散列表的装载因子. 装载因子的定义是散列表中己存入的元素个数n与散列表的表长m的比值,即=n/m. 标志散列表的装满程度。直观地看,越小,空闲空间越多,发生冲突的可能性越小;反之,越大,表中已填入的记录越多,再填记录时,发生冲突的可能性就越大. 可以证明,散列表的ASL是(=n/m)的函数,不直接依赖于n或m本身。由此,不管记录个数n多大,我们总可以通过扩充散列表的长度m,将装载因子降低到一个合适的程度,以便将ASL限制在一个合理的范围内.")
122
The End

Similar presentations
,如果甲数 能被乙数整除,我们就说甲数是乙数的 倍数,乙数是甲数的因数。 如: 12÷4=3 4 就是 12 的因数 2 、回顾一下,我们认识的自然数可以分 成几类? 3 、其实自然数还有一种新的分类方法, 你知道吗?这就是我们今天这节课的学.>")


: 写出 5 的倍数( 6 个) 2 , 4 , 6 , 8 , 10 , 12 , 14 , 16 , 18 , 20 5 , 10 , 15 , 20 , 25 , 30.>")





.>")
>")



.>")
 一、曲线积分与路径无关的定义 二、曲线积分与路径无关的条件 三、二元函数的全微分的求积 四、小结.>")



