Download presentation
Presentation is loading. Please wait.

1
数据仓库与数据挖掘 复习

2
数据仓库 数据仓库基本原理、OLAP基本原理 数据仓库的模型设计和OLAP建模 数据仓库的规划和开发
SQL Server 2005与数据仓库的实现

3
数据挖掘 数据挖掘概念 数据挖掘基础 数据挖掘支柱: 数据、技术、模型 数据挖掘的应用

4
概念 W.H.Inmon对数据仓库所下的定义:数据仓库是面向主题的、集成的、稳定的、随时间变化的数据集合,用以支持管理决策的过程。
数据挖掘:企业角度 指从数据库的大量数据中提取隐含、目前未知、潜在有用和最终可理解的模式(如知识规则、限制条件和规律等)的非平凡过程。 非平凡:具有智能性和自动性,是传统数据分析方法的提升和延伸。
的非平凡过程。 非平凡:具有智能性和自动性,是传统数据分析方法的提升和延伸。")
5
概念 数据挖掘:商业角度 是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其它模型化处理,从中提取辅助商业决策的关键性数据。 模式 定义:模式是一个用语言L表示的表达式E,它可用来描述数据集F中的数据的特征,E所描述的数据是集合F的一个子集FE。

6
概念 “清洗”就是将错误的、不一致的数据在进入数据仓库之前予以更正或删除,以免影响DSS决策的正确性。
元数据:是用来描述数据的数据。它描述和定位数据组件、它们的起源及它们在数据仓库进程中的活动;关于数据和操作的相关描述(输入、计算和输出)。元数据可用文件存在元数据库中。
。元数据可用文件存在元数据库中。")
7
概念 OLAP:粒度就是对数据仓库中数据综合程度的一个度量。它既影响数据仓库中的数据量的多少,也影响数据仓库所能回答询问的种类。
DM:粒度的第二种形式是指抽样率,即以一定的抽样率对数据仓库中的数据进行抽样后得到一个样本数据库,数据挖掘将在这个样本数据库上进行。

8
概念 维代表了用户观察数据的特定视角,如时间维、地区维、产品维等。
度量是数据的实际意义,描述数据“是什么”,即一个数值的测量指标,如人数、单价、销售量等。 数据切片、切块、上卷、下钻、转轴 数据钻取就是从较高的维度层次下降到较低的维度层次上来观察多维数据。

9
概念:数据挖掘 相关属性 概念分层:定义一个映射序列,将低层概念映射到更一般的高层概念。 Schema hierarchy模式分层
挖掘过程中要考虑的感兴趣的属性 模式模板:给定挖掘任务,除说明要挖掘的知识类型,可进一步说明和提供所发现模式匹配的元模式、元规则、元查询:————可以用于指导发现过程 概念分层:定义一个映射序列,将低层概念映射到更一般的高层概念。 Schema hierarchy模式分层 Set-grouping hierarchy集合分组分层 Operation-derived hierarchy操作导出的分层 Rule-based hierarchy基于规则的分层

10
概念:数据挖掘 强关联规则(strong association rule) 同时满足用户定义的最小置信度阈值和最小支持度阈值的关联规则。
 同时满足用户定义的最小置信度阈值和最小支持度阈值的关联规则。")
11
数据仓库部分 要解决“蜘蛛网”问题,必须将用于事务处理的数据环境和用于数据分析的环境分离。 这样,数据处理被分为两大类:
操作型处理(事务型处理) 操作型处理以传统的数据库为中心进行企业的日常业务处理。 分析型处理 分析型处理以数据仓库为中心分析数据背后的关联和规律,为企业决策提供可靠有效的依据。
 操作型处理以传统的数据库为中心进行企业的日常业务处理。 分析型处理. 分析型处理以数据仓库为中心分析数据背后的关联和规律,为企业决策提供可靠有效的依据。")
12
数据仓库体系结构

13
数据仓库的数据组织结构 不同于一般的数据库系统,需要将从原有的业务数据库中获得的基本数据和综合数据分成一些不同的级别。在数据仓库中,采用分级的方式进行组织。

14
星型结构和雪花型结构 星型结构 通过将事实表和维表进行连接,我们就可以得到“星型结构”(Star-Scheme)。
。")
15
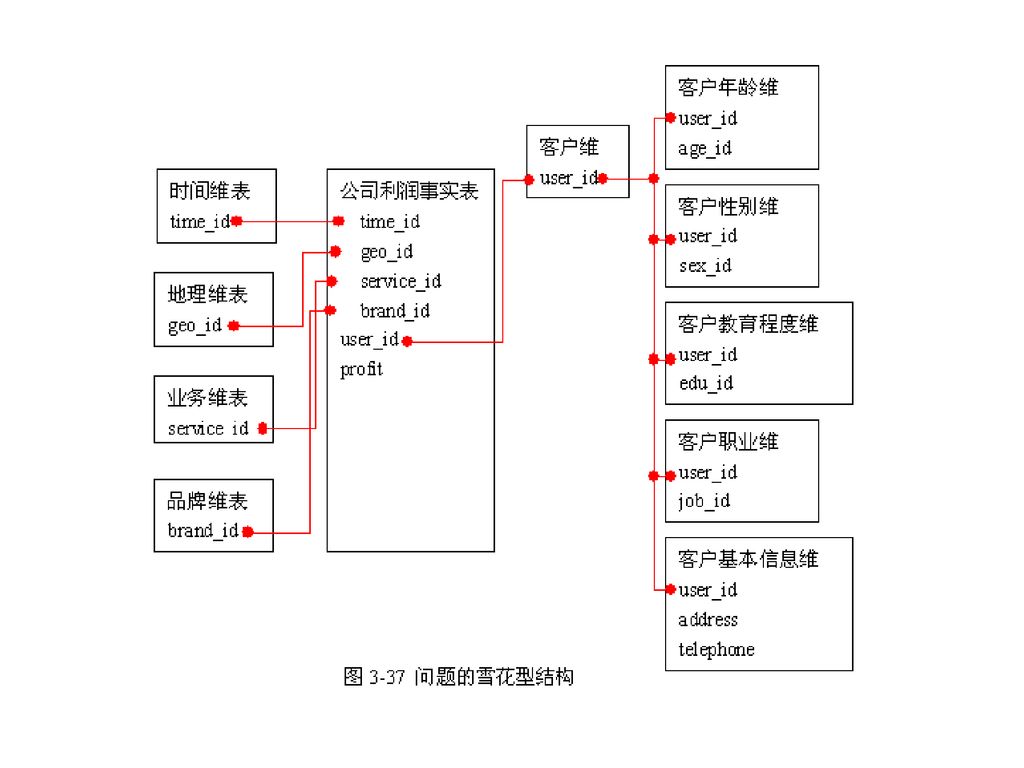
雪花型结构 实际应用需求并不像标准星型结构描述的那么简单,当问题涉及的维度很多时,事实表中的条目数将迅速增长。 假定原来的事实表条目数为m,增加一个具有n个条目的维表,通常,事实表的条目数将变成mn条,这样事实表所占用的存储空间将迅速增大。 在这种情况下,可以考虑使用“雪花型”的结构。

17
总的来讲,ROLAP在大数据量的存储上有绝对的优势,因此拥有巨型数据量的系统可以选择ROLAP。
MOLAP在响应速度、预运算和多维计算方面具有优势,中小型系统可以考虑使用MOLAP。 但是ROLAP和MOLAP之间的技术差异不是绝对的。现在MOLAP和ROLAP厂商正在相互借鉴,相互学习对方的技术优势。 HOLAP就是对MOLAP和ROLAP的良好折中。

18
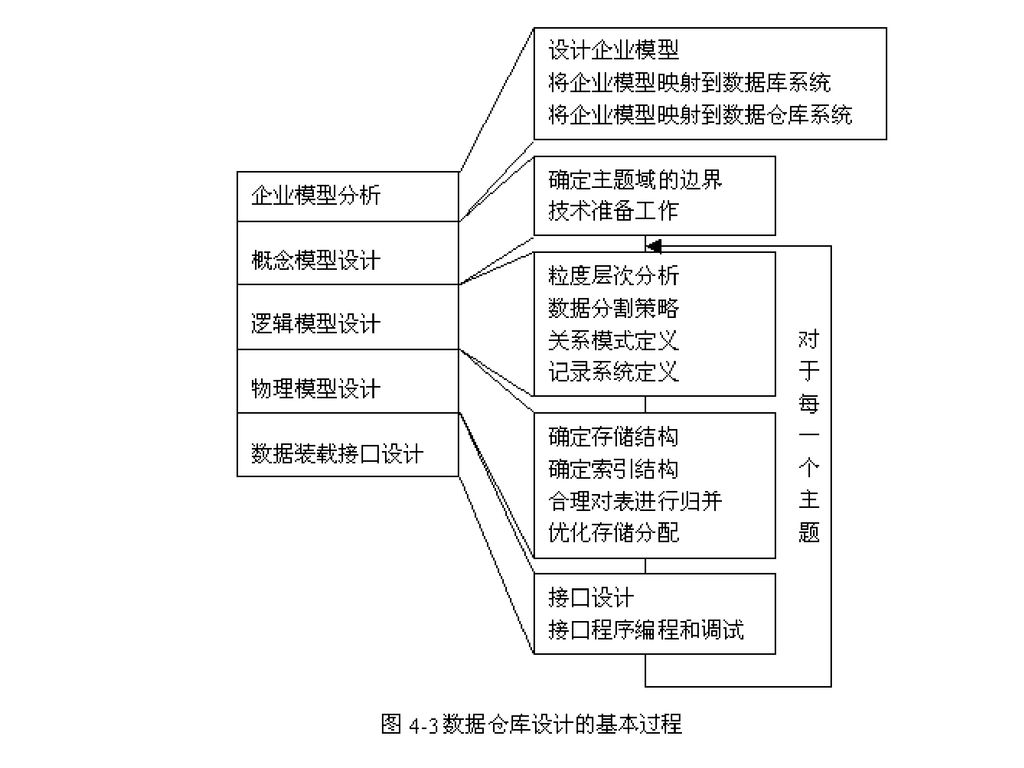
数据仓库设计的基本过程: 建立企业模型; 概念模型设计; 逻辑模型设计; 物理模型设计以及数据装载接口的设计。

20
应用A 应用B 外部 数据 DB DB 收集应用需求 数据仓库建模 分析应用需求 数据获取与集成 DW DB 构建数据库 构建数据仓库 应用编程 DSS应用编程 系统测试 系统测试 理解需求 系统实施 SDLC方法 CLDS方法

21
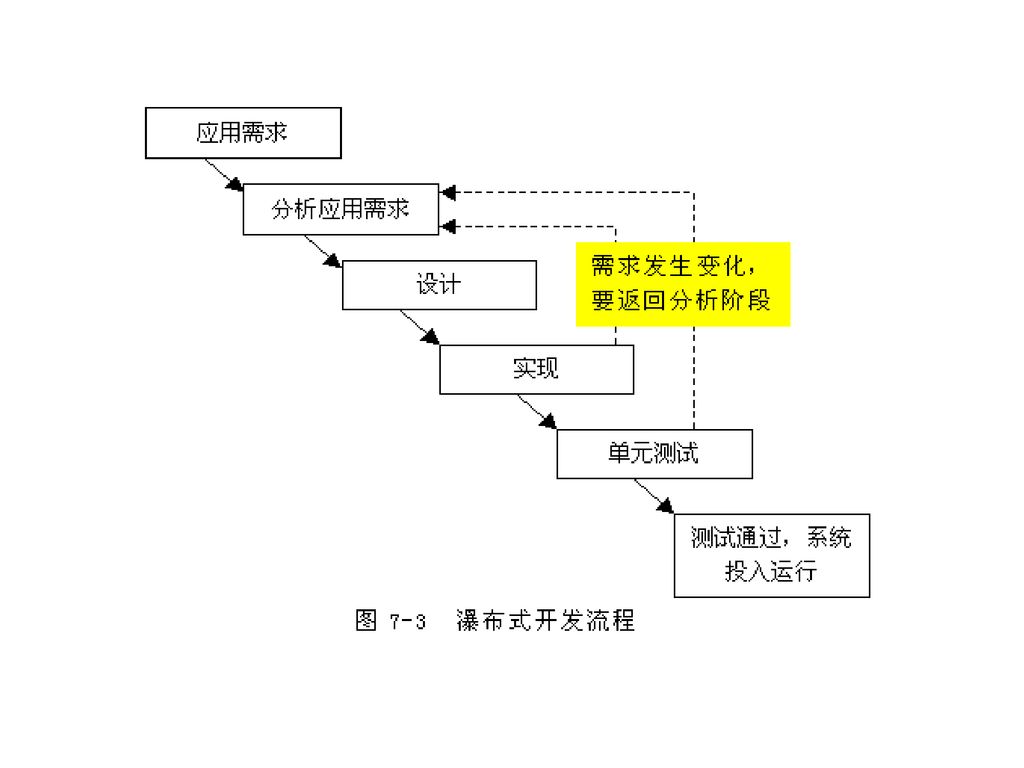
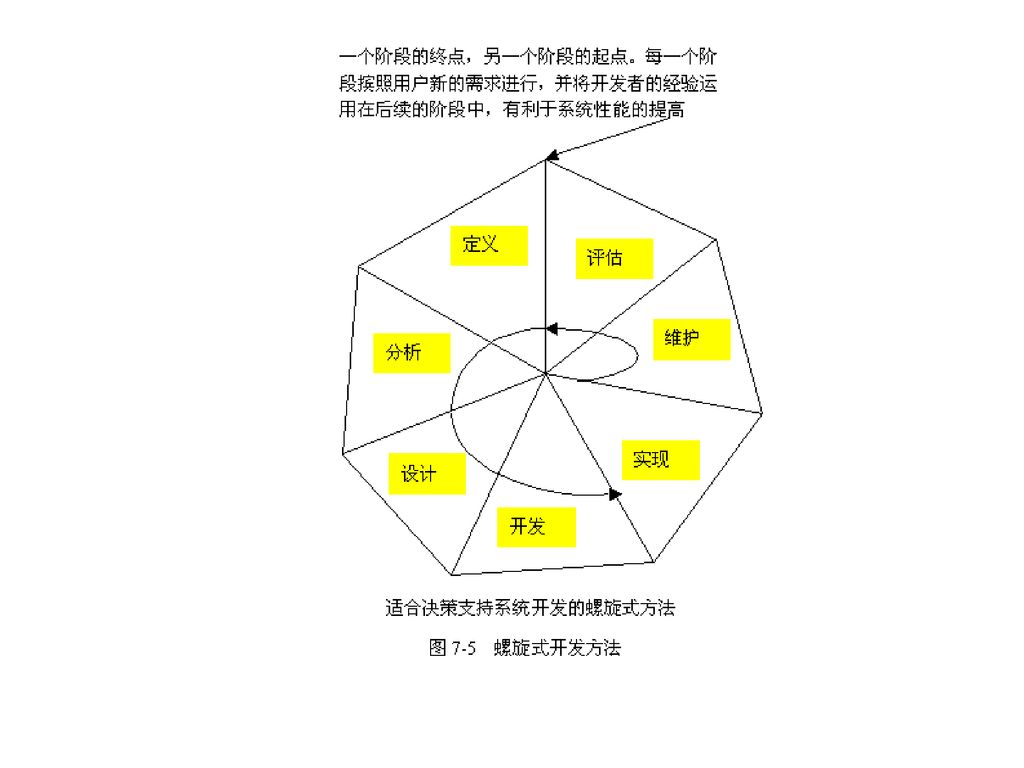
数据仓库的开发方法 瀑布式开发 螺旋式开发

24
数据仓库 应用 OLAP DM

25
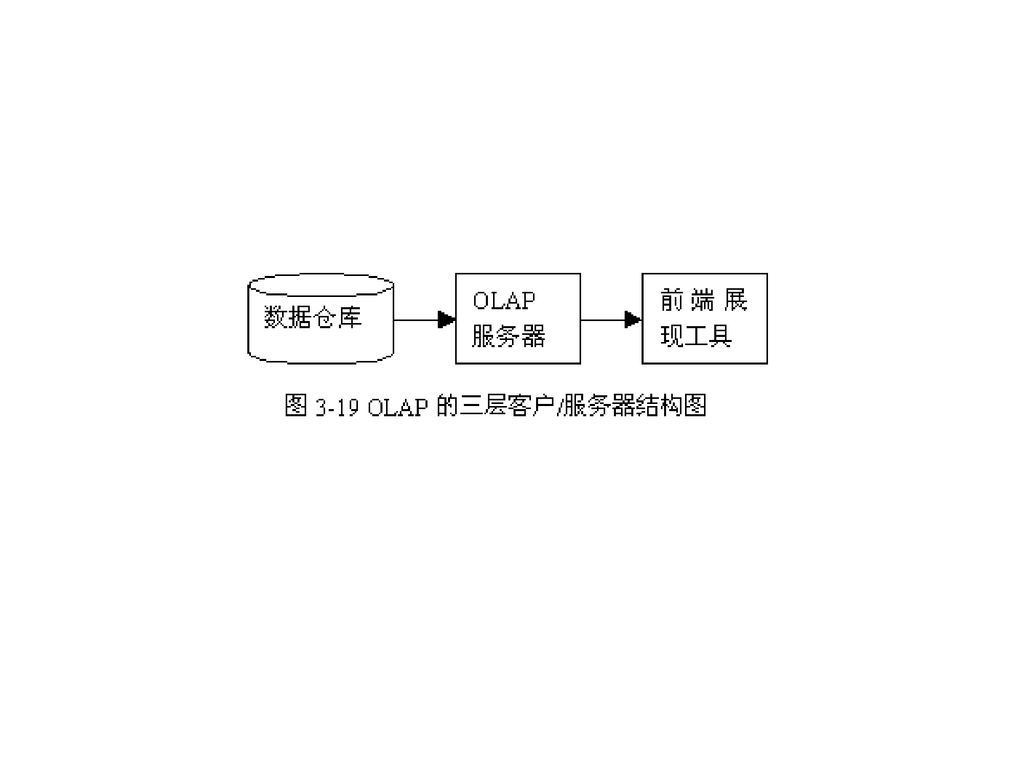
OLAP

27
DM 在何种数据上进行数据挖掘 Relational database 关系数据库 Data warehouse 数据仓库
Transactional database 事务数据库 Advanced database and information repository Object-relational database 对象关系数据库 Spatial and temporal data 空间和时间数据 Time-series data 时间系列数据 Stream data 流数据 Multimedia database 多媒体数据库 Heterogeneous and legacy database 异类和遗留数据库 Text databases & WWW 文本数据库和WWW

28
数据挖掘功能 Concept description概念描述: Characterization and discrimination特征化和区分 Generalize归纳, summarize汇总, and contrast data characteristics, e.g., dry vs. wet regions Association关联 (correlation and causality相关性和因果关系) Diaper à Beer [0.5%, 75%] Classification and Prediction 分类和预测 分类:找出描述或区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。 E.g., classify countries based on climate, or classify cars based on gas mileage英里里程 Presentation: decision-tree, classification rule, neural network Predict some unknown or missing numerical values
 Diaper à Beer [0.5%, 75%] Classification and Prediction 分类和预测. 分类:找出描述或区分数据类或概念的模型(或函数),以便能够使用模型预测类标记未知的对象类。 E.g., classify countries based on climate, or classify cars based on gas mileage英里里程. Presentation: decision-tree, classification rule, neural network. Predict some unknown or missing numerical values.")
29
Outlier analysis孤立点分析
Cluster analysis 聚类分析 Class label类标记 is unknown: Group data to form new classes, e.g., cluster houses to find distribution patterns Maximizing intra-class类内 similarity & minimizing interclass类间 similarity Outlier analysis孤立点分析 孤立点: 与数据的一般行为或模型不一致的数据对象。 Noise or exception? 噪声或例外 No! useful in fraud detection, rare events analysis Trend and evolution analysis趋势和演变分析 Trend and deviation: regression analysis Sequential pattern mining, periodicity analysis Similarity-based analysis Other pattern-directed or statistical analyses

30
分类 General functionality 一般功能性
Predictive data mining 预测式 Descriptive data mining 描述式 Different views, different classifications Kinds of data to be mined 挖掘的数据类型 Kinds of knowledge to be discovered 发现的知识类型 Kinds of techniques utilized 根据使用的技术 Kinds of applications adapted 根据应用

31
数据挖掘实施控制self 挖掘环境得以成功的要素 五个要素: 由一人来专职负责——建立团队 团队由各个学科的人员组成
分成技术的和商业的 范围广:企业用户到数据所有者,从统计人员到经理 各个事业单位一开始就参与进来 数据挖掘的目的,是将结果发布给各事业单位去执行,一开始参与进来,可以从商业角度推动这项工作。 信息技术部门一开始也要参与进来 数据挖掘是一项技术,与组织内的其它技术应协调、一致,因为用于挖掘的数据可能来自任何其它不同的系统。 示范项目可以展现数据挖掘的能力 示范项目的成功,推动数据挖掘的开展。 此项目需要数据挖掘团队精心挑选,并与软件供应商和拥有丰富经验的顾问门亲密合作。

32
数据挖掘过程 数据挖掘的互动循环过程将数据挖掘定位于企业的需求。包括下面几个阶段: Michael J.A. Berry的四阶段过程
数据挖掘人员广泛听取业内专家意见,确定关键业务问题,明确所需数据。另一方面,业内专家意见需要通过数据验证。 B.将数据转换成可执行的结果 构建模型是一个反复循环的过程,需要知道结果被如何使用。 C.结果实施过程 挖掘目的是将生成的决策付诸行动。存在不同的表现方式:如有的结果帮助企业深入了解自己;有的结果只能使用一次;有的需要保存,放进数据仓库 D.评价结果的实施 评测结果将给数据挖掘互动循环系统提出新的问题和新的数据,同时,指出数据挖掘的努力方向。

33
数据挖掘过程——B.将数据转换成可执行的结果
明确所需的数据 获得数据 生成有效数据 探索、清洁数据 转换数据 添加衍生变量 创建建模数据集 选择建模方法 训练模型 检查模型的执行效果 选择最好的模型 数据不太准确 得不到数据 数据不准确 添加新的衍生变量可以改变执行效果 新的数据分割或重抽样可以改进模型的效果 另一方法或参数可改进效果

34
Data Mining: A KDD Process
Knowledge Data mining—core of knowledge discovery process Pattern Evaluation Data Mining Task-relevant Data Selection Data Warehouse Data Cleaning Data Integration Databases A5

35
预处理:对数据列的基本处理 对于数据挖掘十分重要的一些特例的分布情况: 只有一种值的列 几乎只含一种值的列 列的值各不相同
缺乏任何信息内容,忽略。 例如:1. null,no,0 2. 如建立一个模型预测新泽西州的汽车客户损失率,关于州 名将都是“NJ”,忽略这个字段 几乎只含一种值的列 一般规则:如果某一列中95% —99%的值相同,这一列很可能没用 列的值各不相同 ——无法进行预测 如:客户身份证号码 忽略与目标同义的列 某一列与目标列相关度很高时,可能意味着这一列是目标列的同义列。 如:判断是否流失,非空的流失日期 与 已经流失 同义

36
数据预处理的主要任务 Data cleaning数据清洗 Data integration 数据集成
Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies 填充空缺值,平滑噪声数据,识别或移走孤立点,解决不一致 Data integration 数据集成 Integration of multiple databases, data cubes, or files 集成到多个数据库、数据立方体或文件 Data transformation数据变换 Normalization and aggregation 规范化和聚集 Data reduction 数据规约 Obtains reduced representation in volume but produces the same or similar analytical results 获得数据集的压缩表示,产生同样的或几乎同样的分析结果 Data discretization数据离散化 Part of data reduction but with particular importance, especially for numerical data (减少数据,特别是数值数据。如:概念分层)
")
37
挖掘方法:概念描述 重点学习方法: 1.面向属性的归纳(泛化方法);
;")
38
特征化 :面向属性归纳方法。 比较 类特征化(解析特征化):用到面向属性归纳和属性相关分析方法。 类比较(解析比较) 一般概念描述 分类概念描述 概念描述 特征化/类特征化(解析特征化):t-权的量化特征规则。 比较/类比较(解析比较): d-权的量化区分规则。 量化描述规则
: d-权的量化区分规则。 量化描述规则.")
39
Attribute-Oriented Induction——通过概化实现一般性概念描述
How it is done? (基本思想) ①使用关系数据库查询收集任务相关的数据 (initial relation) ②考察任务相关的数据中每个属性的不同值的个数,进行泛化。通过属性删除或属性泛化进行。 ③通过合并相等的广义元组,并累计它们对应的计数值进行聚集。 压缩泛化后的数据集合 ④ 结果的广义关系可以映射到不同形式。如图表、规则
 ①使用关系数据库查询收集任务相关的数据 (initial relation) ②考察任务相关的数据中每个属性的不同值的个数,进行泛化。通过属性删除或属性泛化进行。 ③通过合并相等的广义元组,并累计它们对应的计数值进行聚集。 压缩泛化后的数据集合. ④ 结果的广义关系可以映射到不同形式。如图表、规则.")
40
关联规则挖掘 重点:在事务数据库中挖掘单维布尔关联规则
mining of single-dimensional Boolean association rules in transactional databases

41
1.找出所有频繁项集 使用候选项集找频繁项集(由Apriori算法实现) 2.由频繁项集产生强关联规则
 2.由频繁项集产生强关联规则")
42
单维布尔关联规则挖掘(Association rule mining)过程——1
1.使用候选项集找出所有频繁项集,由 Apriori算法实现 Apriori算法基本思想: 使用逐层搜索的迭代方法。k-项集用于搜索(k+1)-项集。 过程: DC1 L1 C2 L2 C3 L3 … Ck Lk … Cm-1 Lm-1 如此下去,直到不能找到频繁m-项集。 其中: Ck :候选k-项集的集合(k=1…m-1), 由Lk-1产生。 Lk:频繁k-项集的集合(k=1…m-1), Lk满足最小支持度,即 最小事务支持计数 。 D:待挖掘的事务数据库。 找每个Lk需要扫描整个数据库D 。 关键: Lk-1 Ck (连接步、剪枝步 ) A152
-项集。 过程: DC1 L1 C2 L2 C3 L3 … Ck Lk … Cm-1 Lm-1. 如此下去,直到不能找到频繁m-项集。 其中: Ck :候选k-项集的集合(k=1…m-1), 由Lk-1产生。 Lk:频繁k-项集的集合(k=1…m-1), Lk满足最小支持度,即 最小事务支持计数 。 D:待挖掘的事务数据库。 找每个Lk需要扫描整个数据库D 。 关键: Lk-1 Ck (连接步、剪枝步 ) A152.")
43
Apriori: A Candidate Generation-and-test Approach
Any subset of a frequent itemset must be frequent 任何频繁项集的非空子集都是频繁的。 if {beer, diaper, nuts} is frequent, so is {beer, diaper} Every transaction having {beer, diaper, nuts} also contains {beer, diaper} 即:子集不是频繁的,其超集也不是频繁的。 如果{A} 不是频繁集,则超集 {A,B}不是频繁集 超集:{A,B} 包含A How to apply in the Apriori algorithm? A152

44
单维布尔关联规则挖掘(Association rule mining)过程——2
2.由频繁项集产生关联规则 规则XY在事务集中的置信度(confidence)是指包含X和Y的事务数与包含X的事务数之比,即项集的支持度计数表示。记为confidence(XY),即 confidence(XY)=|{T: XYT,TD}|/|{T:XT,TD}| =n(XY)/ n(X) 根据该式,关联规则可以如下产生: 对于每个频繁项集L,产生L的所有非空子集。 对于L的每个非空子集s,如果 则输出规则“s (L-s)”。其中,min_conf是最小置信度阈值。 support_count(L) support_count(s) ≥ min_conf A156
是指包含X和Y的事务数与包含X的事务数之比,即项集的支持度计数表示。记为confidence(XY),即. confidence(XY)=|{T: XYT,TD}|/|{T:XT,TD}| =n(XY)/ n(X) 根据该式,关联规则可以如下产生: 对于每个频繁项集L,产生L的所有非空子集。 对于L的每个非空子集s,如果. 则输出规则 s (L-s) 。其中,min_conf是最小置信度阈值。 support_count(L) support_count(s) ≥ min_conf. A156.")
45
The Apriori Algorithm—An Example
Database TDB Itemset sup {A} 2 {B} 3 {C} {D} 1 {E} Tid Items 10 A, C, D 20 B, C, E 30 A, B, C, E 40 B, E C1 Itemset sup {A} 2 {B} 3 {C} {E} L1 1st scan 联接 C2 Itemset sup {A, C} 2 {B, C} {B, E} 3 {C, E} C2 Itemset sup {A, B} 1 {A, C} 2 {A, E} {B, C} {B, E} 3 {C, E} Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} L2 2nd scan 剪枝 联接 3rd scan 剪枝 C3 L3 Itemset {B, C, E} Itemset sup {B, C, E} 2 用性质 A153

46
由频繁项集产生关联规则_实例 L3 例如: L3:频繁3-项集的集合。包含项集L={B,C,E},可以由L产生那些关联规则?
Database TDB 例如: L3:频繁3-项集的集合。包含项集L={B,C,E},可以由L产生那些关联规则? L的非空子集s有{B,C} , {B,E} , {C,E} , {B} , {C} , {E} 。 输出关联规则结果“s (L-s )” 如下: 如果最小置信度阈值为70% ,则只有1、3规则可以输出。因为1、3为产生的强规则。 support_count(L) support_count(s) ≥ min_conf Tid Items 10 A, C, D 20 B, C, E 30 A, B, C, E 40 B, E L3 Itemset sup {B, C, E} 2
 如下: 如果最小置信度阈值为70% ,则只有1、3规则可以输出。因为1、3为产生的强规则。 support_count(L) support_count(s) ≥ min_conf. Tid. Items. 10. A, C, D. 20. B, C, E. 30. A, B, C, E. 40. B, E. L3. Itemset. sup. {B, C, E} 2.")
47
Classification vs. Prediction
数据挖掘界广泛接受的观点: 分类:用预测法预测类标号(对离散数据的分类) 预测:用预测法预测连续值(对数值数据的分类) (如:回归方法) A186 B46
 预测:用预测法预测连续值(对数值数据的分类) (如:回归方法) A186 B46.")
48
Classification—A Two-Step Process
1.构造模型 Model construction: 描述一个预定的数据集或类集。describing a set of predetermined classes 2.使用模型 Model usage: for classifying future or unknown objects A185

49
Classification Process (2): Use the Model in Prediction
Classifier Testing Data Unseen Data (Jeff, Professor, 4) Tenured? A185
 Tenured A185.")
50
ID3算法 Quinlan’s ID3是国际上最有影响和最为典型的决策树学习方法。
获取信息时,将不肯定的内容转为肯定的内容,因此信息伴随着不肯定性。一般来讲,小概率事件比大概率事件信息量大,如果某事“闻所未闻”或“百年不遇”则肯定比“习以为常”的事更具有信息量。 如何度量信息量。根据Shannon于1948年提出的信息论理论。 选择信息量较多的属性。 B42

51
Classification by decision tree induction
基本思想: 利用信息论中的信息增益理论寻找数据集中具有最大信息量的字段,建立决策树的一个节点,再根据字段的不同取值建立树的分支,在每个分支子集中重复建树的下层节点和分支的过程,即可建立决策树。 判定树分类算法 训练集 决策树 input output B38

52
Rough Set Approach 粗糙集用于近似地或粗糙地定义等价类 给定类C 的粗糙集的两种情况: 下近似:肯定包含在类C中
每个矩形代表一个等价类 A210

53
Rough Set Approach 对于从数据库中发现分类规则,其基本思想:
将数据库中的属性分为条件和结论属性,对数据库中的元组根据各个属性的不同属性值分成相应的子集,然后基于条件属性划分的子集与结论属性划分的子集间的上下近似关系生成关联规则。 E129

54
聚类 基本思想:物以类聚

55
What Is Good Clustering?
A good clustering method will produce high quality clusters with 类内高度相似 类间低度相似

56
Type of data in clustering analysis
Interval-scaled variables:区间标度变量 Binary variables二元变量: Nominal标称, ordinal序数, and ratio variables比例标度变量: Variables of mixed types混合类型的变量 相异度计算 A226

57
Partitioning Algorithms: Basic Concept
Global optimal: exhaustively enumerate all partitions Heuristic methods: k-means and k-medoids algorithms k-means (MacQueen’67): Each cluster is represented by the center(means ) of the cluster k-medoids or PAM (Partition around medoids) (Kaufman & Rousseeuw’87): Each cluster is represented by one of the objects in the cluster A231
: Each cluster is represented by the center(means ) of the cluster. k-medoids or PAM (Partition around medoids) (Kaufman & Rousseeuw’87): Each cluster is represented by one of the objects in the cluster. A231.")
58
The K-Means Clustering Method
Example 1 2 3 4 5 6 7 8 9 10 10 9 8 7 6 5 Update the cluster means 4 Assign each objects to most similar center 3 2 1 1 2 3 4 5 6 7 8 9 10 reassign reassign K=2 Arbitrarily choose K object as initial cluster center Update the cluster means

Similar presentations
 資料探勘與生醫資訊相關研究 ( 研究方向、成果與計畫 )>")
/ 應用系統(ERP, SCM, CRM)>")



>")


 电 话:>")

及其應用之介紹>")




 蔡懷寬 D7526010@csie.ntu.edu.tw.>")
 朝陽科技大學 資訊管理系 李麗華 教授.>")

 刘雷 上海生物信息技术研究中心 2013.3.15.>")
