Download presentation
1
机器翻译研究现状 史晓东 mandel@xmu.edu.cn http://210.34.19.214 12 July 2004 于 复旦大学

2
大纲 从 863 评测谈起 机器翻译:流行的和过时的 统计机器翻译及其趋势 机器翻译和机助翻译 厦门大学统计机器翻译讨论班

3
从 863 评测谈起 去年的机器翻译评测结果:(英译汉) 单位国防科大 / 厦大 哈工大 机译 华建中软 对话 5.92015.08986.72515.4604 篇章 5.78974.90346.65586.1942
 单位国防科大 / 厦大 哈工大 机译 华建中软 对话 篇章")
4
去年的机器翻译评测结果: (汉译英) 单位 CCID 国防科大 / 厦大 哈工大 机译 华建中软 对话 5.94895.46945.55677.77226.0575 篇章 5.34014.84624.64746.31135.5097
 单位 CCID 国防科大 / 厦大 哈工大 机译 华建中软 对话 篇章")
5
JHU Chinese-English MT score:

6
我的简单评测:采用 NIST mt- eval version 10 的简单数据 nist sample tst: 4.0011 neon 汉英 (a piece of shit) : 2.8849 华建译通英汉双向超智能版( 2002 ): 3.1963
 : 华建译通英汉双向超智能版( 2002 ):")
8
评测驱动系统:不容置疑 自动评测让我们知道什么是最好的系统 但是,目前( 863 也好, NIST 也好),国 内外所有的评测数据(至少是汉英)都 不完全公开。 难以在一个公正的平台上来重现评测结 果,从而更快地促进技术进步 仅仅是钱的问题? 系统甚至迎合评测进行训练 (Och 2003)
,国 内外所有的评测数据(至少是汉英)都 不完全公开。 难以在一个公正的平台上来重现评测结 果,从而更快地促进技术进步 仅仅是钱的问题? 系统甚至迎合评测进行训练 (Och 2003)")
9
不是结论 就汉英系统而言,国外的已经超过国内 的。 USC, CMU, JHU, RWTH Aachen, IBM ,哪一个都是响当当的名字 国内,华建?,自动化所?哈工大?, 中软?东北大学?计算所?北大 ? 清华? 华建在产业化方面取得了很大的成功。 国内的通病是研究气氛不太活跃。

10
机器翻译:流行的和过时的 Data-driven MT, esp. SMT is now in Vogue 传统的基于规则的系统,在学术会议上 不再有人提起 商业化 MT: 虽然规则系统仍在中流地位, 但 SMT 打着旗号咆哮崛起

11
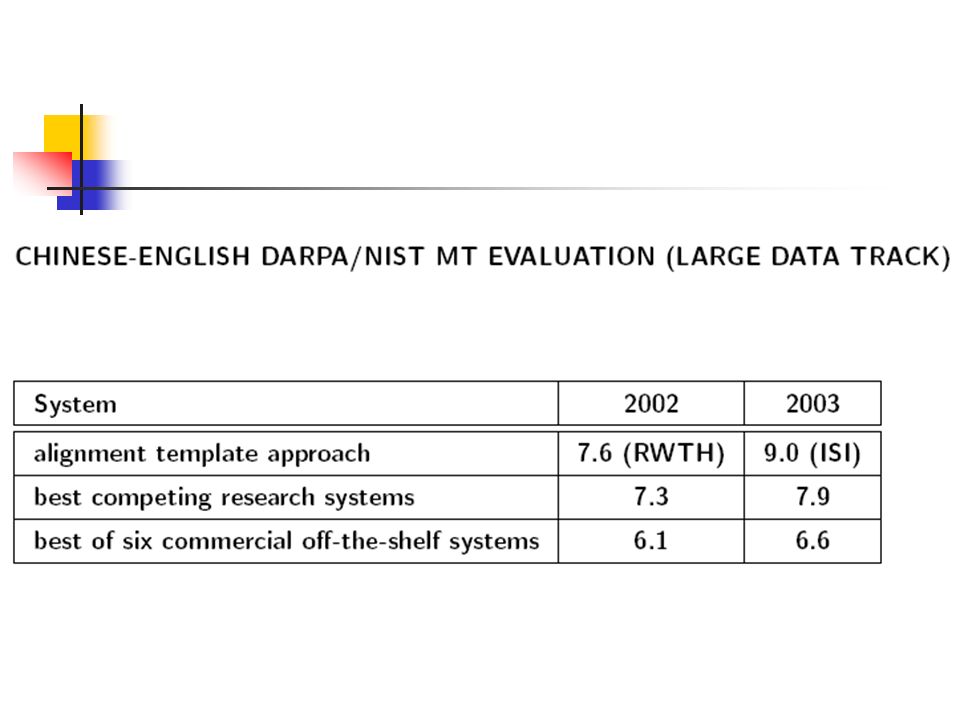
SMT 的雄心(摘自 Language Weaver 公司)
")
12
显然,事情往往不是那么简单 SMT 从 40 年代末 Weaver 就提出。 1990 年 IBM 的 Brown 等人才精确描述并加以实现。 1996 年 IBM 突然放弃。 1999 年 JHU 讨论 班以后渐渐中兴。现在则如日中天。但 是, SMT 并不能解决一切问题。 螺旋式上升是一切事物发展的规律,新 事物的成长总是伴随着对旧事物的矫枉 过正

13
SMT 的优缺点 优点 无需人工干预,利用语料库直接训练得到机器翻译 系统。可以利用海量语料库; 系统开发周期短; 由于采用语言模型,译文质量机器味少; 缺点 时空开销相对大; 需要较大的语料库,翻译结果受语料库影响很大, 对训练语料库中未出现的语言现象处理不好; 缺乏深层次理解,解决深层或长距离相关性比较困 难

14
经典的统计机器翻译 基于信源信道思想的 IBM 模型 IBM 的 Peter Brown 等人首先提出 目前影响最大 几乎成为统计机器翻译的同义词

15
IBM 统计机器翻译基本方程式 设从源语言 S 翻译为目标语言 T ,给定 s ,求 t P.Brown 称上式为统计机器翻译基本方程式 语言模型: P(t) 翻译模型: P(s|t) 语言模型反映流利度 (fluency ,达 ) 翻译模型反映忠实度 (adequacy ,信 ) 从可能的译文中求出最佳译文,称为 decoding
 翻译模型: P(s|t) 语言模型反映流利度 (fluency ,达 ) 翻译模型反映忠实度 (adequacy ,信 ) 从可能的译文中求出最佳译文,称为 decoding")
16
两个模型好于单用翻译模型 如果直接采用翻译模型,就需要根据上 下文建立复杂的上下文条件概率模型, 条件变量包括翻译、词序变化等 如果采用两个模型,翻译模型可以相对 简单: 如翻译模型:可以不考虑上下文而只考虑单 词之间的翻译概率 语言模型:一般采用 n 元模型, 也可采用 PCFG 等

17
引入隐含变量:对齐 a 翻译模型与对齐 对齐:建立源语言句子和目标语言句子的 翻译单位之间的对应关系,以便与计算 翻译概率。 IBM 模型中,建立的是 word for word 的翻译模型

18
IBM 提出了 5 个翻译模型 Model 1 仅考虑 word for word 的互译概 率 Model 2 加入了词的位置变化的概率 Model 3 加入了一个词翻译成多个词的 概率 Model 4 :位置变化依赖于前一位置以 及对应的译词 Model 5 : nondeficient version of Model 4

19
IBM Model 3

20
IBM 翻译模型的参数训练 GiZA++ , Och 所写 可以免费下载

21
SMT decoding 经典的算法: stack decoder, 借自语音识 别。改进: A* 搜索 贪心搜索:从一个可能性较大的翻译进 行改进 转化为邮递员问题( TSP ),用动态规划 求解, Beam 搜索
,用动态规划 求解, Beam 搜索")
22
IBM 方法的问题 词对词的翻译:翻译三角形的最低层次 没有短语的概念,没有词法( taken , took , take 都是不同的词汇),非对称性 (只能一对多,不能多对一), n 元语言 模型太简单(无法描述非局部限 制),......
,非对称性 (只能一对多,不能多对一), n 元语言 模型太简单(无法描述非局部限 制),......")
23
统计机器翻译趋势: 翻译三角形: Vauquois pyramid IBM model 1-5

24
王野翊的改进 背景:德英口语翻译系统 语法结构差异较大 数据稀疏(训练数据有限) 改进:两个层次的对齐模型 粗对齐:短语之间的对齐 短语识别 细对齐:短语内词的对齐 词语聚类:基于互信息的方法 A* 搜索 结果 机器翻译的正确率提高:错误率降低了 11% 提高了整个系统的效率:搜索空间更小,速度更快
 改进:两个层次的对齐模型 粗对齐:短语之间的对齐 短语识别 细对齐:短语内词的对齐 词语聚类:基于互信息的方法 A* 搜索 结果 机器翻译的正确率提高:错误率降低了 11% 提高了整个系统的效率:搜索空间更小,速度更快")
25
Och 等人的改进 背景: VerbMobil 的一个模块 改进 语言模型:基于类的五元语法,回退法平滑 基于类的模型:词语自动聚类(解决数据稀疏) 翻译模型:基于对齐模板( Alignment Template ) 的方法 模板 : 类的序列 短语对齐:模板对齐 + 词汇选择 用双向 HMM 对齐模型得到对齐模板
 翻译模型:基于对齐模板( Alignment Template ) 的方法 模板 : 类的序列 短语对齐:模板对齐 + 词汇选择 用双向 HMM 对齐模型得到对齐模板")
26
Yamada 和 Knight 的改进 基于语法的翻译模型( Syntax-based TM ) : 输入是源语言句法树,输出是目标语言句子 翻译的过程: reorder,insert,translate 每个内部结点的子结点随机地重新排列 在每一个结点的左边或右边随机插入一个单词 左、右插入和不插入的位置取决于父结点和当前结点标记 插入哪个词的概率只与被插入词有关,与位置无关 对于每一个叶结点进行翻译:词对词的翻译概率 输出译文句子
 : 输入是源语言句法树,输出是目标语言句子 翻译的过程: reorder,insert,translate 每个内部结点的子结点随机地重新排列 在每一个结点的左边或右边随机插入一个单词 左、右插入和不插入的位置取决于父结点和当前结点标记 插入哪个词的概率只与被插入词有关,与位置无关 对于每一个叶结点进行翻译:词对词的翻译概率 输出译文句子")
27
Direct Maximum Entropy Translation Model 基于最大熵的统计机器翻译模型 源于基于特征的自然语言理解( IBM 的 Papineni ) RWTH Aachen 的 Och 提出 也称为 log-linear models
 RWTH Aachen 的 Och 提出 也称为 log-linear models")
28
Direct Maximum Entropy Translation Model(2) 假设从句子 f 翻译成 e , h 1 (e,f), …, h M (e,f) 分 别是 e 、 f 上的 M 个特征函数, λ 1, …,λ M 是与 这些特征分别对应的 M 个参数, 那么直接翻译概率可以用以下公式给出:
 假设从句子 f 翻译成 e , h 1 (e,f), …, h M (e,f) 分 别是 e 、 f 上的 M 个特征函数, λ 1, …,λ M 是与 这些特征分别对应的 M 个参数, 那么直接翻译概率可以用以下公式给出:")
29
Direct Maximum Entropy Translation Model(3) 对于给定的 f ,其最佳译文 e 可以用以下公 式表示:
 对于给定的 f ,其最佳译文 e 可以用以下公 式表示:")
30
Direct Maximum Entropy Translation Model(4) 取以下特征和参数时等价于 IBM 信源信道 模型: 仅使用两个特征: h 1 (e,f)=p(e) h 2 (e,f)=p(f|e) λ 1 = λ 2 = 1
 取以下特征和参数时等价于 IBM 信源信道 模型: 仅使用两个特征: h 1 (e,f)=p(e) h 2 (e,f)=p(f|e) λ 1 = λ 2 = 1")
31
Direct Maximum Entropy Translation Model(5) 参数训练 最优化后验概率准则:这个判断准则是凸的, 存在全局最优(但存在 over-fitting 风险) 考虑多个参考译文:
 参数训练 最优化后验概率准则:这个判断准则是凸的, 存在全局最优(但存在 over-fitting 风险) 考虑多个参考译文:")
32
Direct Maximum Entropy Translation Model(6) Och 采用的一些特征函数: Pr(e),Pr(f|e),Pr(e|f) ; 句子长度:对于产生的每一个目标语言单词进行惩 罚 ( 注意 IBM 模型给予短句子更多的概率 ) ; 其他语言模型:如一个基于类的语言模型; 词典特征:计算给定的输入输出句子中有多少词典 中存在的共现词对。 动词短语个数是否相符....( 其他语法、语义、语用特征 )
 Och 采用的一些特征函数: Pr(e),Pr(f|e),Pr(e|f) ; 句子长度:对于产生的每一个目标语言单词进行惩 罚 ( 注意 IBM 模型给予短句子更多的概率 ) ; 其他语言模型:如一个基于类的语言模型; 词典特征:计算给定的输入输出句子中有多少词典 中存在的共现词对。 动词短语个数是否相符....( 其他语法、语义、语用特征 )")
33
Direct Maximum Entropy Translation Model(7) 经典的信源信道模型只有在理想的情况 下才能达到最优,对于简化的语言模型 和翻译模型,取不同的参数值实际效果 更好; 最大熵方法扩充了统计机器翻译的思路: 允许选择有区别性的语言和翻译特征函 数。
 经典的信源信道模型只有在理想的情况 下才能达到最优,对于简化的语言模型 和翻译模型,取不同的参数值实际效果 更好; 最大熵方法扩充了统计机器翻译的思路: 允许选择有区别性的语言和翻译特征函 数。")
34
最大熵方法和短语对齐成了 SMT 系统的两大基本特征 CMU 的机器翻译系统 (Vogel) JHU 的机器翻译系统 (Byrne) MIT 的机器翻译系统 (Koehn)
 JHU 的机器翻译系统 (Byrne) MIT 的机器翻译系统 (Koehn)")
35
趋势预测 SMT 的成功很大程度上来自记忆短语翻 译,但是如何处理新的未出现的短语呢? 建立更多的数据相关性模型:如上下文 依赖关系(句内和句间)特征函数的引 入 一句话:箭尾渐渐向翻译三角形的顶端 移动,或综合不同路径
特征函数的引 入 一句话:箭尾渐渐向翻译三角形的顶端 移动,或综合不同路径")
36
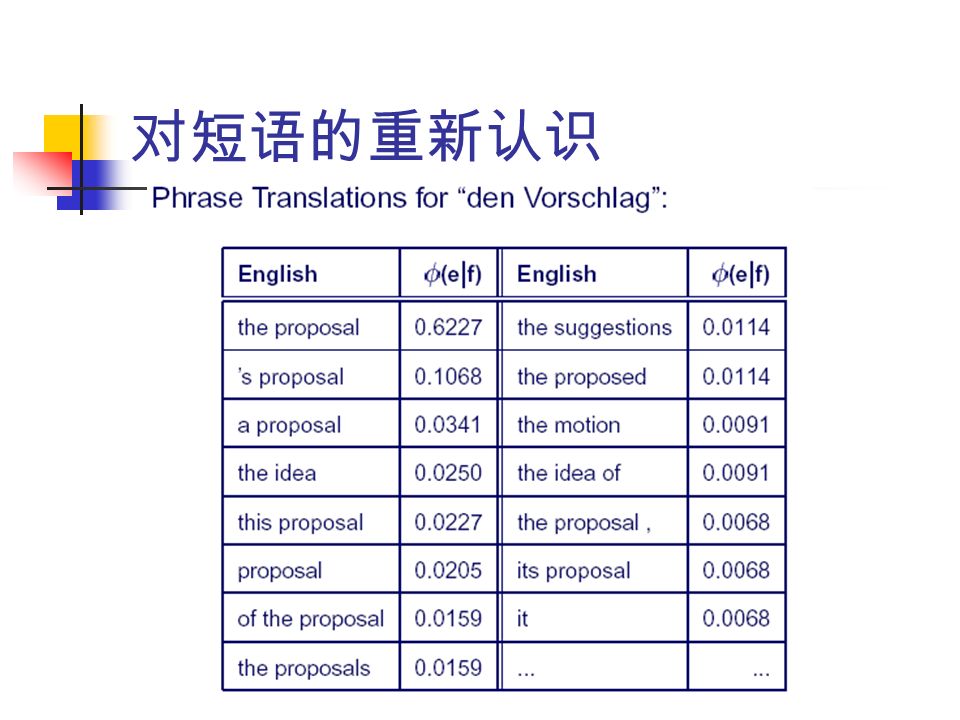
我的一些想法 对短语的重新认识

38
我的一些想法( 2 ) 分解 + 合成: 把不同的特征分层次处理:如时态的处 理,可以从 SMT 中独立出来。 不同的语言特征应该采用不同的(概率 或非概率)模型来解释,而不是采用一 个混沌的一体化模型 (holistic model)
 分解 + 合成: 把不同的特征分层次处理:如时态的处 理,可以从 SMT 中独立出来。 不同的语言特征应该采用不同的(概率 或非概率)模型来解释,而不是采用一 个混沌的一体化模型 (holistic model)")
39
我的一些想法( 3 ) A practical MT system is (Prof Sinha): RBMT (x%) + EBMT(y%) +KBMT(z%) +SMT(w%)=> HMT (Hybrid MT) || => MEMT 我认为不是组合,而是融合
 A practical MT system is (Prof Sinha): RBMT (x%) + EBMT(y%) +KBMT(z%) +SMT(w%)=> HMT (Hybrid MT) || => MEMT 我认为不是组合,而是融合")
40
机器翻译与机助翻译 虽然 SMT 近期取得了很大成功,但是显 然 MT 还有很长的路要走 MAT 对于专业翻译人员来说,更加实用, 如 TRADOS 公司的 Translator ’ s workbench 在本地化行业中大名鼎鼎 但是,没有充分利用 Internet

41
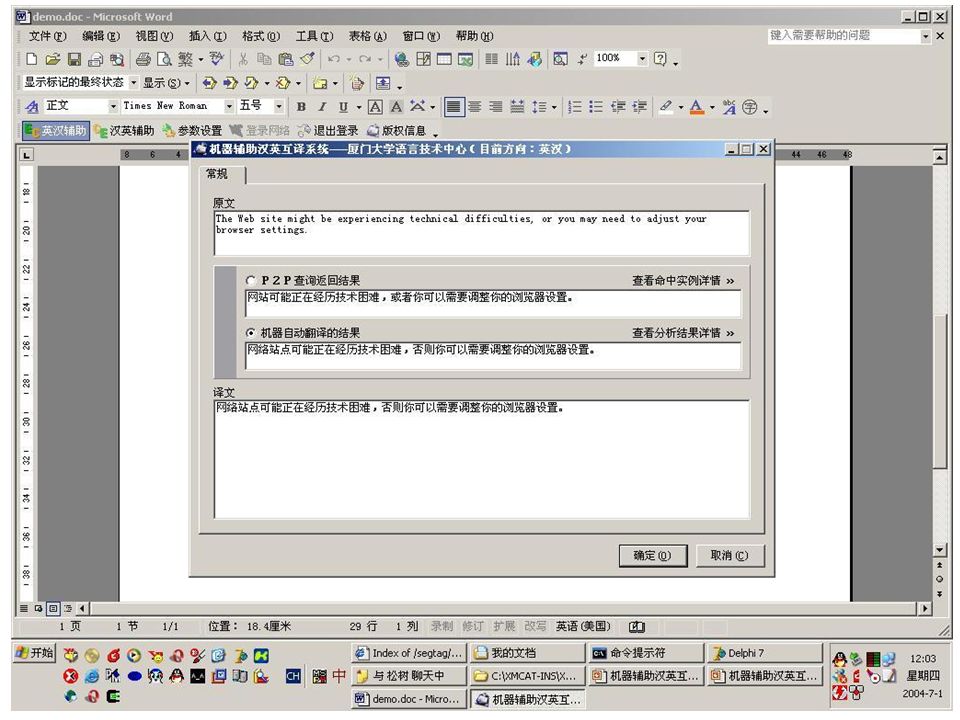
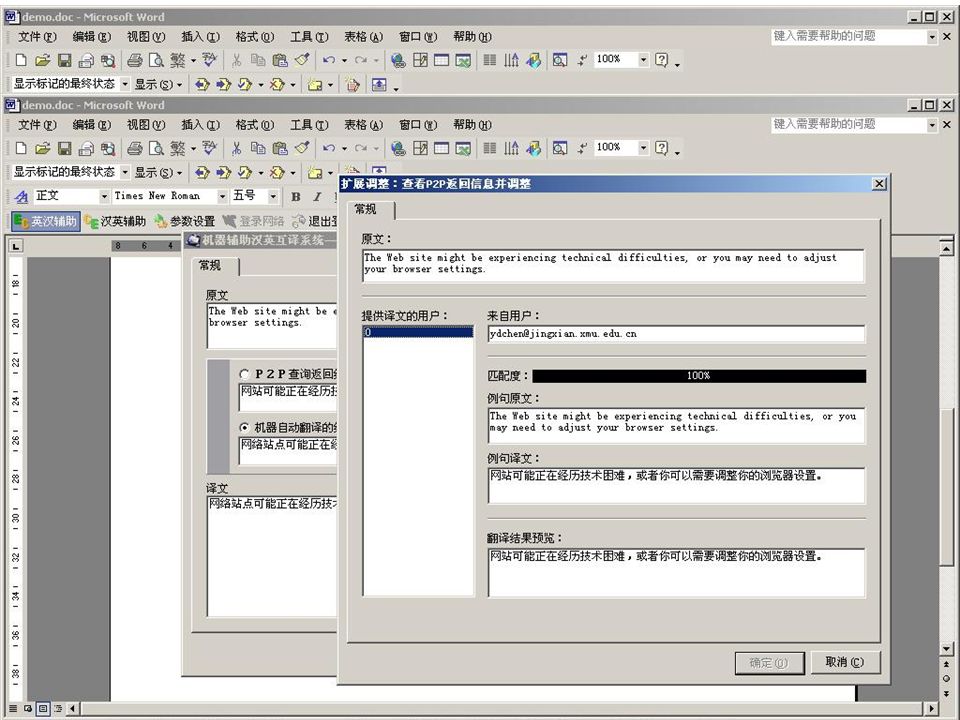
我们目前完成了一个新的辅助 翻译系统 多引擎 MT 提供参考译文 通过对等网络在联机翻译用户之间共享 翻译库,效率随着翻译用户的数量增多 而提高 目前版本可以免费下载: http://210.34.19.214/xmcat.rar

44
厦门大学统计机器翻译讨论班 目的: 在国内造成研究统计机器翻译的气氛 目前虽然 GIZA++ 公开了训练的源代码,但 是只能运行在 linux 平台上 世界上没有人公开 decoder 的源代码 因此,我们想做一个在 windows 平台上的公 开一切源代码的 SMT 工具箱

45
主要内容 系统地研究 SMT 的国内外文献 在 Windows 平台上实现所有的主要算法, 包括训练和解码,在适当的时候进行源 代码公开( GPL ),促进 SMT 的发展 建立一个集评测工具和评测数据的平台, 使得大家可以共享和比较 目标:向开发最好的汉英系统前进
,促进 SMT 的发展 建立一个集评测工具和评测数据的平台, 使得大家可以共享和比较 目标:向开发最好的汉英系统前进")
46
任务艰巨 但是,我们的实力和 JHU 的 1999 年 SMT 讨论班相差太大,显然与 JHU2003 讨论 班也不可同日而语,因为我们都是新手 我们唯一的优点是没有任何包袱。 希望我们能努力工作、取得成功,为促 进 SMT 在国内的研究作出微薄贡献

47
主要参考文献: 刘群:统计机器翻译综述,中文信息学报, 2003 姚天顺:机器翻译的过去和我们的再努力, 2002 JHU 2003 Worshop 的文献 http://www.clsp.jhu.edu/ws03/groups/translate/biblio.shtml http://www.clsp.jhu.edu/ws03/groups/translate/biblio.shtml MT Summit IX 文献 http://www.amtaweb.org/summit/MTSummit/papers. html http://www.amtaweb.org/summit/MTSummit/papers. html 我的网站: http://210.34.19.214

48
谢谢大家 !




专业技术资格社会化认证体系建.>")
















