Download presentation
1
ArchSummit 全球架构师峰会深 圳站 2015

2
移动大数据平台架构实践 阎志涛

3
关于 TalkingData TalkingData( 北京腾云天下科技有限公司 ) 成立于 2011 年 9 月, 2013 年完成千万美元 A 轮融资 ( 北极光 领投 ) , 2014 年完成数千万美元的 B 轮融资 (MileStone 和软银领投 ) ,总部位于北京,在美国硅谷、 日本东京、上海都设有分公司; 经过近四年的高速发展, TalkingData 逐步打造了由开发者服务平台、数据服务平台、数据商业化平 台为中心的数据生态体系,覆盖超过 15 亿独立智能设备,服务超过 8 万款移动应用,以及 6 万多应用 开发者; 公司服务的客户既有如:腾讯、百度、网易、搜狐、 360 、 Google 、 Yahoo 、 Zynga 、宝开、聚 美、唯品会、嘀嘀打车等知名互联网企业,又有中国银联、招商银行、兴业银行、中信银行、平安 集团、国信证券、海通证券、 Orchirly 、碧桂园、亨得利、全城热恋等传统行业巨头; 我们在移动互联网发展过程中创造数据价值,并帮助传统行业积极拥抱未来。
 成立于 2011 年 9 月, 2013 年完成千万美元 A 轮融资 ( 北极光 领投 ) , 2014 年完成数千万美元的 B 轮融资 (MileStone 和软银领投 ) ,总部位于北京,在美国硅谷、 日本东京、上海都设有分公司; 经过近四年的高速发展, TalkingData 逐步打造了由开发者服务平台、数据服务平台、数据商业化平 台为中心的数据生态体系,覆盖超过 15 亿独立智能设备,服务超过 8 万款移动应用,以及 6 万多应用 开发者; 公司服务的客户既有如:腾讯、百度、网易、搜狐、 360 、 Google 、 Yahoo 、 Zynga 、宝开、聚 美、唯品会、嘀嘀打车等知名互联网企业,又有中国银联、招商银行、兴业银行、中信银行、平安 集团、国信证券、海通证券、 Orchirly 、碧桂园、亨得利、全城热恋等传统行业巨头; 我们在移动互联网发展过程中创造数据价值,并帮助传统行业积极拥抱未来。")
4
App AnalyticsGame AnalyticsMobile Ad TrackingMobile DMP 游戏运营分析 移动广告监测 移动数据管理平台 移动应用统计分析 40000+ 应用款数 10 亿 + 累计覆盖 40% 覆盖 Top 盈收游戏 9亿+9亿+ 玩家累计覆盖 190+ 家 网盟对接 40% 覆盖 行业广告主 5 亿+点击 月监测点 腾讯、阿里、谷歌、 Inmobi 等数十家 DSP 在和我们合作

5
关于 TalkingData 15 亿 + 6.5 万 + 2万+2万+ 190+ 全球覆盖设备应用开发者 游戏开发者 对接广告平台

6
移动互联网大数据特点 移动互联网大数据的 4V –Volume 随时随地都在产生数据,数据量更大 –Variety 随时随地联网的特性,使得移动互联网的数据更具有多样性。在移动侧可以有更 为精准的位置数据,各种传感器数据。 –Velocity 对速度处理的要求性更高,很多的业务场景需要更实时的数据处理才能使得数据 产生价值。 –Value 更多高价值的数据产生 万物皆可联网,数据方便人的生活 –IOT 逐渐成为现实,万物都在贡献数据 – 各种智能硬件逐渐普及

7
我们每天处理的原始数据量

8
数据相关产品 2011 年 – App Analytics 2012 年 – AdTracking 2013 年 – Game Analytics 2014 年 – Data Center, Mobile DMP, Mobile Insight 2015 年 – DataSync ……

9
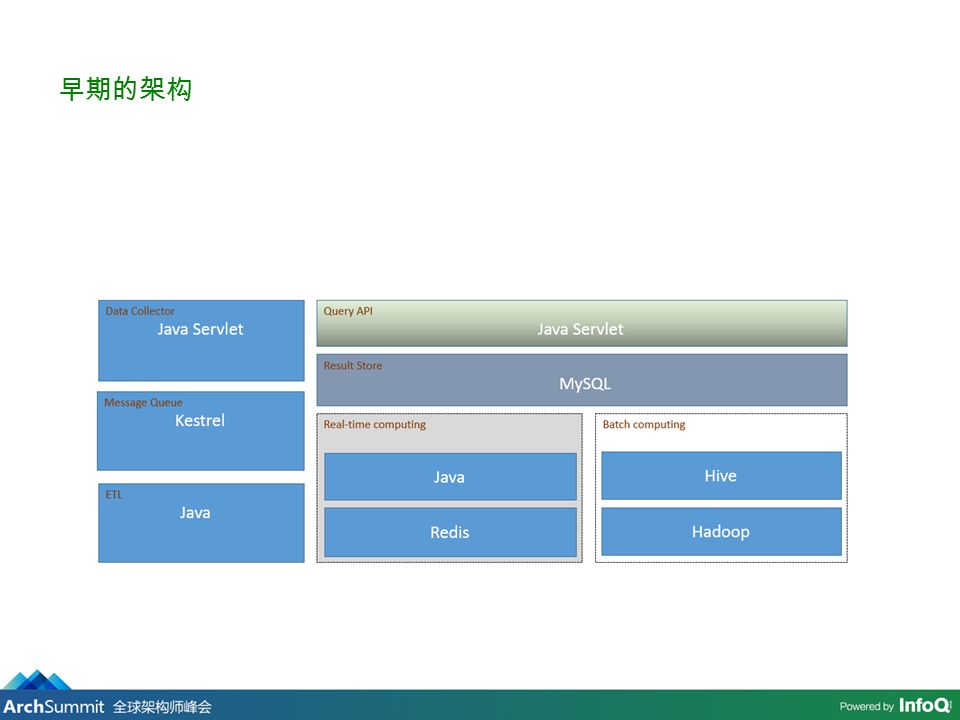
早期的架构

11
面临的挑战 研发团队完全按照业务线组织,多个竖井 很多能力没有服务化,重复建设 App Analytics SDK Collector Data Store Compute Service Game Analytics SDK Collector Data Store Compute Service AdTracking SDK Collector Data Store Compute Service DMP Data Store Compute Service Insight Data Store Compute Service

12
面临的挑战 整个架构为统计分析业务而生 未来更多的数据业务 – 纯粹竖井模式很难支持新业务的开展 更多的数据价值探索的需求 – 纯粹竖井模式很难深入了解技术 更多的数据( Bigger than Bigger) – 纯粹竖井模式不利于资源的合理利用 没有统一的数据视图
 – 纯粹竖井模式不利于资源的合理利用 没有统一的数据视图")
13
架构升级 - TD 移动大数据管理平台( π 系统) 整合多产品线的基础服务 – 统一存储 – 统一计算 – 统一数据总线 – 统一数据挖掘 – 统一视觉呈现 – 统一数据收集 – 统一 SDK – 统一监控和管理 更好的水平扩展能力 提供更灵活高效的技术支撑 – 产品能迭代速度更快 – 研究成果加速流动
 整合多产品线的基础服务 – 统一存储 – 统一计算 – 统一数据总线 – 统一数据挖掘 – 统一视觉呈现 – 统一数据收集 – 统一 SDK – 统一监控和管理 更好的水平扩展能力 提供更灵活高效的技术支撑 – 产品能迭代速度更快 – 研究成果加速流动")
14
π 系统架构

15
统一 SDK – 新的统一的数据收取框架 – 业务层和基础层分离 – 非阻塞模式 – 处理各种异常 – 高效存储格式

16
统一数据收集 统一数据收集系统 – 利用 C++,Node.js, 基于 lmdb 的内存队列 – 支持分布式部署 – 数据收集系统支持存储转发 – 分布式收集节点和中心节点数据传输高压缩比

17
统一数据收集

18
统一的数据总线 统一数据总线 – 基于 Kafka 的数据总线 – 规范不同业务线的 topic 命名规则 – 统一的管理

19
统一存储 统一的分布式存储 (HDFS) – 数据域管理,多业务系统可以共享存储资源 – 数据文件按照时间进行切片 – 数据文件时效管理,中间数据可以自动删除 – 数据自动归档 –Parquet 列式存储格式,方便数据计算 – 计划支持数据 EC(Erasure Coding) – 分布式缓存 Tachyon
 – 数据域管理,多业务系统可以共享存储资源 – 数据文件按照时间进行切片 – 数据文件时效管理,中间数据可以自动删除 – 数据自动归档 –Parquet 列式存储格式,方便数据计算 – 计划支持数据 EC(Erasure Coding) – 分布式缓存 Tachyon")
20
统一存储 NoSQL 数据库 – 开发 Bitmap 存储, bitmap 基本运算下沉到存储层,底 层基于 RocksDB –MongoDB 3.0(WiredTiger 引擎),基于 SSD –Redis
,基于 SSD –Redis")
21
统一存储 关系型存储 –MySQL Cluster(MariaDB,TokuDB) –WebScaleSQL
 –WebScaleSQL")
22
统一存储 元数据管理 – 基于 Hcatalog 进行二次开发 – 支持不同数据源 – 支持 json,protobuffer 等数据格式 – 支持版本

23
统一计算 统一的计算框架和接口 – 基于 Yarn 进行计算资源调度(调研 Mesos) – 基于 Spark 的并行计算框架 – 基于预先生成 Bitmap 的 OLAP 解决方案 – 利用 Spark Streaming 进行流式计算 – 自行开发的任务调度系统 – 统一的计算查询接口
 – 基于 Spark 的并行计算框架 – 基于预先生成 Bitmap 的 OLAP 解决方案 – 利用 Spark Streaming 进行流式计算 – 自行开发的任务调度系统 – 统一的计算查询接口")
24
统一的数据挖掘 数据挖掘服务化 – 基于统一计算框架 – 针对 Spark, 自行实现了 LR,DT 等数据挖掘算法 库 – 将数据挖掘服务化,变成统一计算的一种能力

25
统一的视觉呈现 – 视觉呈现组件化 – 支持各种自定义报表 – 支持各种数据可视化效果

26
统一监控 – 基于 Zabbix 开发 – 支持 CPU 、内存、硬盘、网络以及进程运行状 态等等的监控 – 支持短信、邮件、微信报警

27
看上去很美好,但是,罗马不是一天建成的 上线统一 Collector 后,出现雪崩 – 接收请求的 Collector 机器只有两个 –Nginx upstream 配置 fall=1 统一 Kafka 数据总先后,数据压力大后,各业务系 统相互影响 – 对 Kafka 了解不足 – 对压力预估不足 Spark 新版本对 Yarn-alpha 不再支持 – 新版本 Spark 不能使用

28
带来的好处 更方便的增加新的数据业务 术业有专攻,工程师可以更深入的了解技术 资源可以更合理的进行配备




 輻射與核能發電. 媽!這是我上班的 地方-核電廠。 地方好寬闊喔! 聽說日本原子彈爆炸死好幾 萬人,阿榮啊!你在這裡上 班,安全嗎?>")

















