Download presentation
1
Artificial Neural Network 人工神经网络

2
目录 第1章 概述 1.1 人工神经网络研究与发展 1.2 生物神经元 1.3 人工神经网络的构成 第2章人工神经网络基本模型
第1章 概述 1.1 人工神经网络研究与发展 1.2 生物神经元 1.3 人工神经网络的构成 第2章人工神经网络基本模型 2.1 MP模型 2.2 感知器模型 2.3 自适应线性神经元 第3章 EBP网络(反向传播算法) 3.1 含隐层的前馈网络的学习规则 3.2 Sigmoid激发函数下的BP算法 3.3 BP网络的训练与测试 3.4 BP算法的改进 3.5 多层网络BP算法的程序设计 多层前向网络BP算法源程序 目录
 3.1 含隐层的前馈网络的学习规则. 3.2 Sigmoid激发函数下的BP算法. 3.3 BP网络的训练与测试. 3.4 BP算法的改进. 3.5 多层网络BP算法的程序设计. 多层前向网络BP算法源程序. 目录.")
3
目录 第4章 Hopfield网络模型 4.1 离散型Hopfield神经网络 4.2 连续型Hopfield神经网络
4.3 旅行商问题(TSP)的HNN求解 Hopfield模型求解TSP源程序 第5章 随机型神经网络 5.1 模拟退火算法 5.2 Boltzmann机 Boltzmann机模型源程序 5.3 Gaussian机 第6章自组织神经网络 6.1 竞争型学习 6.2 自适应共振理论(ART)模型 6.3 自组织特征映射(SOM)模型 6.4 CPN模型 目录
的HNN求解. Hopfield模型求解TSP源程序. 第5章 随机型神经网络. 5.1 模拟退火算法. 5.2 Boltzmann机. Boltzmann机模型源程序. 5.3 Gaussian机. 第6章自组织神经网络. 6.1 竞争型学习. 6.2 自适应共振理论(ART)模型. 6.3 自组织特征映射(SOM)模型. 6.4 CPN模型. 目录.")
4
目录 第7章 联想记忆神经网络 7.1 联想记忆基本特点 7.2 线性联想记忆LAM模型 7.3 双向联想记忆BAM模型
7.1 联想记忆基本特点 7.2 线性联想记忆LAM模型 7.3 双向联想记忆BAM模型 7.4 时间联想记忆TAM模型 Hopfield模型联想记忆源程序 第8章 CMAC模型 8.1 CMAC模型 8.2 CMAC映射算法 8.3 CMAC的输出计算 8.4 CMAC控制器模型 目录

5
神经网络研究与发展 40年代初,美国Mc Culloch和PiMs从信息处理的角度,研究神经细胞行为的数学模型表达.提出了二值神经元模型。MP模型的提出开始了对神经网络的研究进程。1949年心理学家Hebb提出著名的Hebb学习规则,即由神经元之间结合强度的改变来实现神经学习的方法。虽然Hebb学习规则在人们研究神经网络的初期就已提出,但是其基本思想至今在神经网络的研究中仍发挥着重要作用。

6
50年代末期,Rosenblatt提出感知机模型(Perceptron),首先从工程角度出发,研究了用于信息处理的神经网络模型
,首先从工程角度出发,研究了用于信息处理的神经网络模型")
7
在60年代末,美国著名人工智能专家Minsky和Papert对Rosenblatt的工作进行了深人研究,出版了有较大影响的(Perceptron)一书,指出感知机的功能和处理能力的局限性,甚至连XOR(异或)这样的问题也不能解决,同时也指出如果在感知器中引入隐含神经元,增加神经网络的层次,可以提高神经网络的处理能力,但是却无法给出相应的网络学习算法。因此Minsky的结论是悲观的。另一方面,由于60年代以来集成电路和微电子技术日新月异的发展,使得电子计算机的计算速度飞速提高,加上那时以功能模拟为目标、以知识信息处理为基础的知识工程等研究成果,给人工智能从实验室走向实用带来了希望,这些技术进步给人们造成这样的认识:以为串行信息处理及以它为基础的传统人工智能技术的潜力是无穷的,这就暂时掩盖了发展新型计算机和寻找新的人工智能途径的必要性和迫切性。另外,当时对大脑的计算原理、对神经网络计算的优点、缺点、可能性及其局限性等还很不清楚。总之,认识上的局限性使对神经网络的研究进入了低潮。
一书,指出感知机的功能和处理能力的局限性,甚至连XOR(异或)这样的问题也不能解决,同时也指出如果在感知器中引入隐含神经元,增加神经网络的层次,可以提高神经网络的处理能力,但是却无法给出相应的网络学习算法。因此Minsky的结论是悲观的。另一方面,由于60年代以来集成电路和微电子技术日新月异的发展,使得电子计算机的计算速度飞速提高,加上那时以功能模拟为目标、以知识信息处理为基础的知识工程等研究成果,给人工智能从实验室走向实用带来了希望,这些技术进步给人们造成这样的认识:以为串行信息处理及以它为基础的传统人工智能技术的潜力是无穷的,这就暂时掩盖了发展新型计算机和寻找新的人工智能途径的必要性和迫切性。另外,当时对大脑的计算原理、对神经网络计算的优点、缺点、可能性及其局限性等还很不清楚。总之,认识上的局限性使对神经网络的研究进入了低潮。")
8
在这一低潮时期,仍有一些学者扎扎实实地继续着神经网络模型和学习算法的基础理论研究,提出了许多有意义的理论和方法。其中,主要有自适应共振理论,自组织映射,认知机网络模型理论,BSB模型等等,为神经网络的发展奠定了理论基础。 进入80年代,首先是基于“知识库”的专家系统的研究和运用,在许多方面取得了较大成功。但在一段时间以后,实际情况表明专家系统并不像人们所希望的那样高明,特别是在处理视觉、听觉、形象思维、联想记忆以及运动控制等方面,传统的计算机和人工智能技术面临着重重困难。模拟人脑的智能信息处理过程,如果仅靠串行逻辑和符号处理等传统的方法来济决复杂的问题,会产生计算量的组合爆炸。因此,具有并行分布处理模式的神经网络理论又重新受到人们的重视。对神经网络的研究又开始复兴,掀起了第二次研究高潮。

9
1982年,美国加州理工学院物理学家J.J.Hopfield提出了一种新的神经网络HNN。他引入了“能量函数”的概念,使得网络稳定性研究有了明确的判据。HNN的电子电路物理实现为神经计算机的研究奠定了基础,并将其应用于目前电子计算机尚难解决的计算复杂度为NP完全型的问题,例如著名的“巡回推销员问”(TSP),取得很好的效果。从事并行分布处理研究的学者,于1985年对Hopfield模型引入随机机制,提出了Boltzmann机。1986年Rumelhart等人在多层神经网络模型的基础上,提出了多层神经网络模型的反向传播学习算法(BP算法),解决了多层前向神经网络的学习问题,证明了多层神经网络具有很强的学习能力,它可以完成许多学习任务,解决许多实际问题。
,取得很好的效果。从事并行分布处理研究的学者,于1985年对Hopfield模型引入随机机制,提出了Boltzmann机。1986年Rumelhart等人在多层神经网络模型的基础上,提出了多层神经网络模型的反向传播学习算法(BP算法),解决了多层前向神经网络的学习问题,证明了多层神经网络具有很强的学习能力,它可以完成许多学习任务,解决许多实际问题。")
10
近十几年来,许多具备不同信息处理能力的神经网络已被提出来并应用于许多信息处理领域,如模式识别、自动控制、信号处理、决策辅助、人工智能等方面。神经计算机的研究也为神经网络的理论研究提供了许多有利条件,各种神经网络模拟软件包、神经网络芯片以及电子神经计算机的出现,体现了神经网络领域的各项研究均取得了长足进展。同时,相应的神经网络学术会议和神经网络学术刊物的大量出现,给神经网络的研究者们提供了许多讨论交流的机会。

11
虽然人们已对神经网络在人工智能领域的研究达成了共识,对其巨大潜力也毋庸置疑,但是须知,人类对自身大脑的研究,尤其是对其中智能信息处理机制的了解,还十分肤浅。因而现有的研究成果仅仅处于起步阶段,还需许多有识之士长期的艰苦努力。 概括以上的简要介绍,可以看出,当前又处于神经网络理论的研究高潮,不仅给新一代智能计算机的研究带来巨大影响,而且将推动整个人工智能领域的发展。但另一方面,由于问题本身的复杂性,不论是神经网络原理自身,还是正在努力进行探索和研究的神经计算机,目前,都还处于起步发展阶段。 为了了解ANN,我们首先分析一下现行计算机所存在的问题。尽管冯·诺依曼型计算机在当今世界发挥着巨大的作用,但它在智能化信息处理过程中存在着许多局限性。我们简单分析一下冯·诺依曼型计算机求解某个问题所采用的方法。

12
(1)根据该问题的特点,建立合适的数学模型。
(2)根据所建立的数学模型的原始数据资料,生成适合于输入计算机的程序和数据。 (3)计算机的控制器命令输入器将计算步骤的初始数据记录到存贮器中。 (4) 控制器根据计算步骤的顺序,依次按存贮器地址读出第一个计算步骤,然后根据读出步骤的规定,控制运算器对相应数据执行规定的运算操作。 (5)反馈器从反馈信号中得知运算器操作完毕,把所得的中间结果记录到存贮器某个确定位置存贮好。 (6)反馈信号通知控制器再取第二个计算步骡,然后重复上述的执行过程。一直到整个运算完成后,控制器就命令输出器把存贮器中存放的最终结果用打印、显示或绘图等方式输出。
根据所建立的数学模型的原始数据资料,生成适合于输入计算机的程序和数据。 (3)计算机的控制器命令输入器将计算步骤的初始数据记录到存贮器中。 (4) 控制器根据计算步骤的顺序,依次按存贮器地址读出第一个计算步骤,然后根据读出步骤的规定,控制运算器对相应数据执行规定的运算操作。 (5)反馈器从反馈信号中得知运算器操作完毕,把所得的中间结果记录到存贮器某个确定位置存贮好。 (6)反馈信号通知控制器再取第二个计算步骡,然后重复上述的执行过程。一直到整个运算完成后,控制器就命令输出器把存贮器中存放的最终结果用打印、显示或绘图等方式输出。")
13
将以上整个计算过程概括起来,可以看出现行冯·诺依曼计算机有以下三个主要特点:
(1)它必须不折不如地按照人们已经编制好的程序步骤来进行相应的数值计算或逻辑运算,它没有主动学习的能力和自适应能力,因此它是被动的。 (2)所有的程序指令都要调入CPU一条接一条地顺序执行。因此.它的处理信息方式是集中的、串行的。 (3)存贮器的位置(即地址)和其中历存贮的具体内容无关。因此,在调用操作的指令或数据时,总是先找它所在存贮器的地址,然后再查出所存贮的内容。这就是说,存贮内容和存贮地址是不相关的。 由于现行计算机的上述特点,一方面它在像数值计算或逻辑运算这类属于顺序性(串行性)信息处理中,表现出远非人所能及的速度;另一方面,在涉及人类日常的信息活动,例如识别图形、听懂语言等,却又显得那样低能和笨拙。
它必须不折不如地按照人们已经编制好的程序步骤来进行相应的数值计算或逻辑运算,它没有主动学习的能力和自适应能力,因此它是被动的。 (2)所有的程序指令都要调入CPU一条接一条地顺序执行。因此.它的处理信息方式是集中的、串行的。 (3)存贮器的位置(即地址)和其中历存贮的具体内容无关。因此,在调用操作的指令或数据时,总是先找它所在存贮器的地址,然后再查出所存贮的内容。这就是说,存贮内容和存贮地址是不相关的。 由于现行计算机的上述特点,一方面它在像数值计算或逻辑运算这类属于顺序性(串行性)信息处理中,表现出远非人所能及的速度;另一方面,在涉及人类日常的信息活动,例如识别图形、听懂语言等,却又显得那样低能和笨拙。")
14
实际上.脑对外界世界时空客体的描述和识别,乃是认知的基础。认知问题离不开对低层次信息处理的研究和认识。虽然符号处理在脑的思维功能模拟等方面取得了很大进展,但它对诸如视觉、听觉、联想记忆和形象思维等问题的处理往往感到力不从心。所以符号处理不可能全面解决认知问题和机器智能化问题.它对高层次脑功能的宏观模拟很有效,而对一些低层次的模式处理则至今还有许多困难。

15
正是由于认识到传统的冯·诺依曼计算机在智能信息处理中的这种难以逾越的局限性.使得人们考虑到有必要进一步了解分析人脑神经系统信息处理和存贮的机理特征.以便寻求一条新的人工神经网络智能信息处理途径。
人工神经网络研究是采用自下而上的方法,从脑的神经系统结构出发来研究脑的功能,研究大量简单的神经元的集团信息处理能力及其动态行为。目前,神经网络的研究使得对多年来困扰计算机科学和符号处理的一些难题可以得到比较令人满意的解答,特别是对那些时空信息存贮及并行搜索、自组织联想记亿、时空数据统计描述的自组织以及从一些相互关联的活 动中自动获取知识等一般性问题的求解,更显示出独特的能力。由此引起了智能研究者们的广泛关注,并普遍认为神经网络方法适合于低层次的模式处理。

16
人脑信息处理机制 生物神经系统是一个有高度组织和相互作用的数量巨大的细胞组织群体。人类大脑的神经细胞大约在1011一1013个左右。神经细胞也称神经元,是神经系统的基本单元,它们按不同的结合方式构成了复杂的神经网络。通过神经元及其联接的可塑性,使得大脑具有学习、记忆和认知等各种智能。 人工神经网络的研究出发点是以生物神经元学说为基础的。生物神经元学说认为,神经细胞即神经元是神经系统中独立的营养和功能单元。生物神经系统.包括中枢神经系统和大脑,均是由各类神经元组成。其独立性是指每一个神经元均有自己的核和自己的分界线或原生质膜。

17
生物神经元之间的相互连接从而让信息传递的部位披称为突触(Synapse)。突触按其传递信息的不同机制,可分为化学突触和电突触、其中化学突触占大多数,其神经冲动传递借助于化学递质的作用。生物神经元的结构大致描述如下图所示。
。突触按其传递信息的不同机制,可分为化学突触和电突触、其中化学突触占大多数,其神经冲动传递借助于化学递质的作用。生物神经元的结构大致描述如下图所示。")
18
神经元由细胞体和延伸部分组成。延伸部分按功能分有两类,一种称为树突,占延伸部分的大多数,用来接受来自其他神经元的信息;另一种用来传递和输出信息,称为轴突。神经元对信息的接受和传递都是通过突触来进行的。单个神经元可以从别的细胞接受多达上千个的突触输入。这些输入可达到神经元的树突、胞体和轴突等不同部位,但其分布各不相同.对神经元的影响也不同。 人类大脑皮质的全部表面积约有20×104mm2,平均厚度约2.5mm,皮质的体积则约为50 × 104mm3。如果皮质中突触的平均密度是6 × l09/mm3左右,则可认为皮质中的全部突触数为3 × 1015个。如果再按上述人脑所含的全部神经元数目计算,则每个神经元平均的突触数目可能就有1.5—3.0万个左右。

19
神经元之间的联系主要依赖其突触的联接作用。这种突触的联接是可塑的,也就是说突触特性的变化是受到外界信息的影响或自身生长过程的影响。生理学的研究归纳有以下几个方面的变化:
(1)突触传递效率的变化。首先是突触的膨胀以及由此产生的突触后膜表面积扩大,从而突触所释放出的传递物质增多,使得突触的传递效率提高。其次是突触传递物质质量的变化,包括比例成分的变化所引起传递效率的变化。 (2)突触接触间隙的变化。在突触表面有许多形状各异的小凸芽,调节其形状变化可以改变接触间隙,并影响传递效率。 (3)突触的发芽。当某些神经纤维被破坏后,可能又会长出新芽,并重新产生附着于神经元上的突触.形成新的回路。由于新的回路的形成,使得结合模式发生变化,也会引起传递效率的变化。 (4)突触数目的增减。由于种种复杂环境条件的刺激等原因,或者由于动物本身的生长或衰老,神经系统的突触数目会发生变化,并影响神经元之间的传递效率。
突触传递效率的变化。首先是突触的膨胀以及由此产生的突触后膜表面积扩大,从而突触所释放出的传递物质增多,使得突触的传递效率提高。其次是突触传递物质质量的变化,包括比例成分的变化所引起传递效率的变化。 (2)突触接触间隙的变化。在突触表面有许多形状各异的小凸芽,调节其形状变化可以改变接触间隙,并影响传递效率。 (3)突触的发芽。当某些神经纤维被破坏后,可能又会长出新芽,并重新产生附着于神经元上的突触.形成新的回路。由于新的回路的形成,使得结合模式发生变化,也会引起传递效率的变化。 (4)突触数目的增减。由于种种复杂环境条件的刺激等原因,或者由于动物本身的生长或衰老,神经系统的突触数目会发生变化,并影响神经元之间的传递效率。")
20
神经元对信息的接受和传递都是通过突触来进行的。单个神经元可以从别的细胞接受多个输入。由于输入分布于不同的部位,对神经元影响的比例(权重)是不相同的。另外,各突触输入抵达神经元的先后时间也不一祥。因此,一个神经元接受的信息,在时间和空间上常呈现出一种复杂多变的形式,需要神经元对它们进行积累和整合加工,从而决定其输出的时机和强度。正是神经元这种整合作用,才使得亿万个神经元在神经系统中有条不紊、夜以继日地处理各种复杂的信息,执行着生物中枢神经系统的各种信息处理功能。 多个神经元以突触联接形成了一个神经网络。研究表明,生物神经网络的功能决不是单个神经元生理和信息处理功能的简单叠加,而是一个有层次的、多单元的动态信息处理系统。 它们有其独特的运行方式和控制机制,以接受生物内外环境的输入信息,加以综合分折处理,然后调节控制机体对环境作出适当的反应。

21
以上是从宏观上分析了人脑信息处理特点。从信息系统研究的观点出发,对于人脑这个智能信息处理系统,有如下一些固有特征:
(1)并行分布处理的工作模式。 实际上大脑中单个神经元的信息处理速度是很慢的,每次约1毫秒(ms),比通常的电子门电路要慢几个数量级。每个神经元的处理功能也很有限,估计不会比计算机的一条指令更复杂。 但是人脑对某一复杂过程的处理和反应却很快,一般只需几百毫秒。例如要判定人眼看到的两个图形是否一样,实际上约需400 ms,而在这个处理过程中,与脑神经系统的一些主要功能,如视觉、记亿、推理等有关。按照上述神经元的处理速度,如果采用串行工作模式,就必须在几百个串行步内完成,这实际上是不可能办到的。因此只能把它看成是一个由众多神经元所组成的超高密度的并行处理系统。例如在一张照片寻找一个熟人的面孔,对人脑而言,几秒钟便可完成,但如用计算机来处理,以现有的技术,是不可能在短时间内完成的。由此可见,大脑信息处理的并行速度已达到了极高的程度。
并行分布处理的工作模式。 实际上大脑中单个神经元的信息处理速度是很慢的,每次约1毫秒(ms),比通常的电子门电路要慢几个数量级。每个神经元的处理功能也很有限,估计不会比计算机的一条指令更复杂。 但是人脑对某一复杂过程的处理和反应却很快,一般只需几百毫秒。例如要判定人眼看到的两个图形是否一样,实际上约需400 ms,而在这个处理过程中,与脑神经系统的一些主要功能,如视觉、记亿、推理等有关。按照上述神经元的处理速度,如果采用串行工作模式,就必须在几百个串行步内完成,这实际上是不可能办到的。因此只能把它看成是一个由众多神经元所组成的超高密度的并行处理系统。例如在一张照片寻找一个熟人的面孔,对人脑而言,几秒钟便可完成,但如用计算机来处理,以现有的技术,是不可能在短时间内完成的。由此可见,大脑信息处理的并行速度已达到了极高的程度。")
22
(2)神经系统的可塑性和自组织性。 神经系统的可塑性和自组织性与人脑的生长发育过程有关。例如,人的幼年时期约在9岁左右,学习语言的能力十分强,说明在幼年时期,大脑的可塑性和柔软性特别良好。从生理学的角度看,它体现在突触的可塑性和联接状态的变化,同时还表现在神经系统的自组织特性上。例如在某一外界信息反复刺激下.接受该信息的神经细胞之间的突触结合强度会增强。这种可塑性反映出大脑功能既有先天的制约因素,也有可能通过后天的训练和学习而得到加强。神经网络的学习机制就是基于这种可塑性现象,并通过修正突触的结合强度来实现的。 (3)信息处理与信息存贮合二为一。 大脑中的信息处理与信息存贮是有机结合在一起的,而不像现行计算机那样.存贮地址和存贮内容是彼此分开的。由于大脑神经元兼有信息处理和存贮功能,所以在进行回亿时,不但不存在先找存贮地址而后再调出所存内容的问题,而且还可以由一部分内容恢复全部内容。 (4)信息处理的系统性 大脑是一个复杂的大规模信息处理系统,单个的元件“神经元”不能体现全体宏观系统的功能。实际上,可以将大脑的各个部位看成是一个大系统中的许多子系统。各个子系统之间具有很强的相互联系,一些子系统可以调节另一些子系统的行为。例如,视觉系统和运动系统就存在很强的系统联系,可以相互协调各种信息处理功能。 (5)能接受和处理模糊的、模拟的、随机的信息。 (6)求满意解而不是精确解。
信息处理与信息存贮合二为一。 大脑中的信息处理与信息存贮是有机结合在一起的,而不像现行计算机那样.存贮地址和存贮内容是彼此分开的。由于大脑神经元兼有信息处理和存贮功能,所以在进行回亿时,不但不存在先找存贮地址而后再调出所存内容的问题,而且还可以由一部分内容恢复全部内容。 (4)信息处理的系统性. 大脑是一个复杂的大规模信息处理系统,单个的元件 神经元 不能体现全体宏观系统的功能。实际上,可以将大脑的各个部位看成是一个大系统中的许多子系统。各个子系统之间具有很强的相互联系,一些子系统可以调节另一些子系统的行为。例如,视觉系统和运动系统就存在很强的系统联系,可以相互协调各种信息处理功能。 (5)能接受和处理模糊的、模拟的、随机的信息。 (6)求满意解而不是精确解。")
23
(7)系统的恰当退化和冗余备份(鲁棒性和容错性)。
人类处理日常行为时,往往都不是一定要按最优或最精确的方式去求解,而是以能解决问题为原则,即求得满意解就行了。 (7)系统的恰当退化和冗余备份(鲁棒性和容错性)。
系统的恰当退化和冗余备份(鲁棒性和容错性)。")
24
人工神经网络研究与应用的主要内容 人工种经网络的研究方兴末艾,很难准确地预测其发展方向。但就目前来看,人工神经网络的研究首先须解决全局稳定性、结构稳定性、可编程性等问题。现今的研究工作应包含以下的一些基本内容: (1)人工神经网络模型的研究。 神经网络原型研究,即大脑神经网络的生理结构、思维机制。 神经元的生物特性如时空特性、不应期、电化学性质等的人工模拟 易于实现的神经网络计算模型。 利用物理学的方法进行单元间相互作用理论的研究 如:联想记忆模型。 神经网络的学习算法与学习系统。
人工神经网络模型的研究。 神经网络原型研究,即大脑神经网络的生理结构、思维机制。 神经元的生物特性如时空特性、不应期、电化学性质等的人工模拟. 易于实现的神经网络计算模型。 利用物理学的方法进行单元间相互作用理论的研究. 如:联想记忆模型。 神经网络的学习算法与学习系统。")
25
(2)神经网络基本理论研究。 神经网络的非线性特性,包括自组织、自适应等作用。 神经网络的基本性能,包括稳定性、收敛性、容错性、鲁棒性、动力学复杂性。 神经网络的计算能力与信息存贮容量。 开展认知科学的研究。探索包括感知、思考、记忆和语言等的脑信息处理模型。采用诸如连接机制等方法,将认知信息处理过程模型化,并通过建立神经计算学来代替算法沦。

26
(3)神经网络智能信息处理系统的应用。 认知与人工智能.包括模式识别、计算机视觉与听觉、特征提取、语音识别语言翻译、联想记忆、逻辑推理、知识工程、专家系统、故障诊断、智能机器人等。 优化与控制,包括优化求解、决策与管理、系统辨识、鲁棒性控制、自适应控制、并行控制、分布控制、智能控制等。 信号处理;自适应信号处理(自适应滤波、时间序列预测、谱估计、消噪、检测、阵列处理)和非线性信号处理(非线性滤波、非线性预测、非线性谱估计、非线性编码、中值处理)。 传感器信息处理:模式预处理变换、信息集成、多传感器数据融合。
和非线性信号处理(非线性滤波、非线性预测、非线性谱估计、非线性编码、中值处理)。 传感器信息处理:模式预处理变换、信息集成、多传感器数据融合。")
27
(4)神经网络的软件模拟和硬件实现。 在通用计算机、专用计算机或者并行计算机上进行软件模拟,或由专用数字信号处理芯片 构成神经网络仿真器。 由模拟集成电路、数字集成电路或者光器件在硬件上实现神经芯片。软件模拟的优点是网络的规模可以较大,适合于用来验证新的模型和复杂的网络特性。硬件实现的优点是处理速度快,但由于受器件物理因素的限制,根据目前的工艺条件,网络规模不可能做得太大。仅几千个神经元。但代表了未来的发展方向,因此特别受到人们的重视。

28
计算机仿真系统。 专用神经网络并行计算机系统。 数字、模拟、数—模混合、光电互连等。 光学实现。 生物实现。
(5)神经网络计算机的实现。 计算机仿真系统。 专用神经网络并行计算机系统。 数字、模拟、数—模混合、光电互连等。 光学实现。 生物实现。 关于智能本质的研究是自然科学和哲学的重大课题之一,对于智能的模拟和机器再现肯定可以开发拓展出一代新兴产业。由于智能本质的复杂性,现代智能研究已超越传统的学科界限,成为脑生理学、神经科学、心理学、认知科学、信息科学、计算机科学、微电子学,乃至数理科学共同关心的“焦点”学科。人工神经网络的重大研究进展有可能使包括信息科学在内的其他学科产生重大突破和变革。展望人工神经网络的成功应用,人类智能有可能产生一次新的飞跃。
神经网络计算机的实现。 计算机仿真系统。 专用神经网络并行计算机系统。 数字、模拟、数—模混合、光电互连等。 光学实现。 生物实现。 关于智能本质的研究是自然科学和哲学的重大课题之一,对于智能的模拟和机器再现肯定可以开发拓展出一代新兴产业。由于智能本质的复杂性,现代智能研究已超越传统的学科界限,成为脑生理学、神经科学、心理学、认知科学、信息科学、计算机科学、微电子学,乃至数理科学共同关心的 焦点 学科。人工神经网络的重大研究进展有可能使包括信息科学在内的其他学科产生重大突破和变革。展望人工神经网络的成功应用,人类智能有可能产生一次新的飞跃。")
29
人工神经网络的信息处理能力 人工神经网络的信息处理能力 人工神经网络的信息处理能力包括两方面的内容:
一、神经网络信息存贮能力.即要解决这样的一个问题:在一个有N个神经元的神经网络中,可存贮多少值的信息? 二、神经网络的计算能力。需要解决的问题是:神经网络能够有效地计算哪些问题?在众多的文献中,人们都一致认为:存贮能力和计算能力是现代计算机科学中的两个基本问题,同样,它们也构成了人工神经网络研究中的基本问题。

30
前面提到在传统的冯.诺依曼型计算机中,其计算与存贮是完全独立的两个部分。这两个独立部分——存贮器与运算器之间的通道,就成为提高计算机计算能力的瓶颈,并且只要这两个部分是独立存在的,这个问题就始终存在。对不同的计算机而言,只是这一问题的严重程度不同而已。神经网络模型从本质上解决了传统计算机的这个问题。它将信息的存贮与信息的处理完善地结合在一起。这是因为神经网络的运行是从输入到输出的值传递过程,在信息传递的同时也就完成了信息的存贮与计算。

31
(1)神经网络的存贮能力。 神经网络的存贮能力因不同的网络而不相同。这里我们给出Hopfield的一些结论。 定义:一个存贮器的信息表达能力定义为其可分辨的信息类型的对数值。 在一个M×1的随机存贮器RAM中,有M位地址,一位数据,它可存贮2M位信息 这个RAM中,可以读/写长度为2M的信息串,而 M 长度为2M的信息串有 种, 所以,可以分辨上述这么多种信息串。按上面的定义, M×1的RAM的存贮能力为: C=2M(位)。
。")
32
[定理1.1] N个神经元的神经网络的信息表达能力上限为:
C< (位)。
![[定理1.1] N个神经元的神经网络的信息表达能力上限为:](http://slidesplayer.com/slide/11148879/60/images/32/%5B%E5%AE%9A%E7%90%861.1%5D+N%E4%B8%AA%E7%A5%9E%E7%BB%8F%E5%85%83%E7%9A%84%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E7%9A%84%E4%BF%A1%E6%81%AF%E8%A1%A8%E8%BE%BE%E8%83%BD%E5%8A%9B%E4%B8%8A%E9%99%90%E4%B8%BA%EF%BC%9A.jpg "C< (位)。")
33
[定理1.2] N个神经元的神经网络的信息表达能力下限为:
C (位)。 其中[N/2]指小于或等于N/2的最大整数。 [定理1.3] 神经网络可以存贮2N-1个信息,也可以区分2 N-1个不同的网络。
![[定理1.2] N个神经元的神经网络的信息表达能力下限为:](http://slidesplayer.com/slide/11148879/60/images/33/%5B%E5%AE%9A%E7%90%861%EF%BC%8E2%5D+N%E4%B8%AA%E7%A5%9E%E7%BB%8F%E5%85%83%E7%9A%84%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E7%9A%84%E4%BF%A1%E6%81%AF%E8%A1%A8%E8%BE%BE%E8%83%BD%E5%8A%9B%E4%B8%8B%E9%99%90%E4%B8%BA%EF%BC%9A.jpg "C (位)。 其中[N/2]指小于或等于N/2的最大整数。 [定理1.3] 神经网络可以存贮2N-1个信息,也可以区分2 N-1个不同的网络。")
34
神经网络的计算能力 ●数学的近似映射;识别和分类这些计算都可以抽象成一种近似的数学映射。如误差反播模型(BP)、对向传播网络模型(CPN)、小脑模型(CMAC)等都可以完成这种计算。 ●概率密度函数的估计:通过自组织的方式,开发寻找出一组等概率“锚点”,来响应在空间只“中按照一个确定概率密度函数选择到的一组矢量样本。自组织映射模型(SOM) 和CPN模型可以完成这样的计算。 ●从二进制数据基中提取相关的知识:这种计算是形成一种知识的聚类模型,这些知识 依照数据基的自组织在它们之间有某种统计上的共性,并依此来响应输入的数据基记录。脑中盒模型(BSB)有能力进行这种计算。 ●形成拓扑连续及统计意义上的同构映射:它是对固定概率密度函数选择的适应输入数据的一种自组织映射,其最终使得数据空间上的不同项有某种同构。SOM模型适合计算此类问题。
 和CPN模型可以完成这样的计算。 ●从二进制数据基中提取相关的知识:这种计算是形成一种知识的聚类模型,这些知识 依照数据基的自组织在它们之间有某种统计上的共性,并依此来响应输入的数据基记录。脑中盒模型(BSB)有能力进行这种计算。 ●形成拓扑连续及统计意义上的同构映射:它是对固定概率密度函数选择的适应输入数据的一种自组织映射,其最终使得数据空间上的不同项有某种同构。SOM模型适合计算此类问题。")
35
●最近相邻模式分类:通过比较大量的存贮数据来进行模式分类,但首先应通过学习样本模式进行分类。可用层次性的存贮模式来进行分类信息的表示。绝大多数的神经网络模型均能进行这种计算。如自适应共振理论模型(ART)、双向联想记亿模型 (BAM)、BP模型、玻尔兹曼机模型(BM)、BSB模型、CPN模型、Hopfield模型等等。 ●数据聚类:采用自组织的方法形成所选择的“颗粒”或模式的聚类,以此来响应输人数据。聚类是可变的.但要限制其鞍点的个数。对于任何新的目标,只要系统中没有对其提供聚类,都要形成新的聚类。很显然这种能力可直接应用于复杂的多目标跟踪。ART 模型最适合于这种计算。 ●最优化问题:用来求解局部甚至是全局最优解。Hopfield模型、玻尔兹曼机模型(BM)有能力进行这种计算。
有能力进行这种计算。")
36
自从80年代中期人工神经网络复苏以来,其发展速度及应用规模令人惊叹。技术发达国家和集团推行了一系列有关的重要研究计划、投资总额在数亿美元,出现了一批神经网络企业和在众多领域中的应用产品。有关神经网络的大型国际会议已召开了许多次,我国也召开了三次。在前几年的热浪过去之后,当前对于神经网络的研究正在转入稳定、但发展步伐依然是极其迅速的时期。这一时期的研究和发展有以下几个特点:

37
(1)神经网络研究工作者对于研究对象的性能和潜力有了更充分的认识.从而对研究和应用的领域有了更恰当的理解。在头脑冷静下来之后,可以看到,尽管神经网络所能做的事情比当初一些狂热鼓吹者所设想的要少,但肯定比那些悲观论者要多得多。现在普遍认识到神经网络比较适用于特征提取、模式分类、联想记忆、低层次感知、自适应控制等场合,在这些方面,严格的解析方法会遇到很大困难。当前对神经网络的研究目标,就是从理论上和实践上探讨一种规模上可控的系统,它的复杂程度虽然远比不上大脑,但又具有类似大脑的某些性质,这种性质如果用常规手段则难以实现。可以说,国际上关于人工神经网络研究的主要领域不是对神经网络建模的基础研究,而是一个工程或应用领域,即它从对脑的神经模型研究中受到启发和鼓舞,但试图解决的却是工程问题。虽然对脑工作机理的理解十分重要,但这种理解是一个相当长期的过程。而对于神经网络的应用需求则是大量的和迫切的。
神经网络研究工作者对于研究对象的性能和潜力有了更充分的认识.从而对研究和应用的领域有了更恰当的理解。在头脑冷静下来之后,可以看到,尽管神经网络所能做的事情比当初一些狂热鼓吹者所设想的要少,但肯定比那些悲观论者要多得多。现在普遍认识到神经网络比较适用于特征提取、模式分类、联想记忆、低层次感知、自适应控制等场合,在这些方面,严格的解析方法会遇到很大困难。当前对神经网络的研究目标,就是从理论上和实践上探讨一种规模上可控的系统,它的复杂程度虽然远比不上大脑,但又具有类似大脑的某些性质,这种性质如果用常规手段则难以实现。可以说,国际上关于人工神经网络研究的主要领域不是对神经网络建模的基础研究,而是一个工程或应用领域,即它从对脑的神经模型研究中受到启发和鼓舞,但试图解决的却是工程问题。虽然对脑工作机理的理解十分重要,但这种理解是一个相当长期的过程。而对于神经网络的应用需求则是大量的和迫切的。")
38
(2)神经网络的研究,不仅其本身正在向综合性发展,而且愈来愈与其他领域密切结合起来,发展出性能更强的结构。为了更好地把现有各种神经网络模型的特点综合起来,增强网络解决问题的能力,80年代末和90年代初出现了混合网络系统,如把多层感知器与自组织特征级联起来,在模式识别中可以取得比单一网络更好的结果。1991年美国ward System Group公司推出的软件产品Neuro windows(Brain—1)是这方面的典型代表。它可以产生128个交互作用的神经网络,每个网可是自组织网也可是多层感知器网,最多可达32层,每层可达32个节点,且可以与其他8层相联。据称这是近年来神经网络发展方面的一个跃进。它在微软公司的VB上运行,被认为是近些年来最重要的软件进展和最高水平的智能工具。
神经网络的研究,不仅其本身正在向综合性发展,而且愈来愈与其他领域密切结合起来,发展出性能更强的结构。为了更好地把现有各种神经网络模型的特点综合起来,增强网络解决问题的能力,80年代末和90年代初出现了混合网络系统,如把多层感知器与自组织特征级联起来,在模式识别中可以取得比单一网络更好的结果。1991年美国ward System Group公司推出的软件产品Neuro windows(Brain—1)是这方面的典型代表。它可以产生128个交互作用的神经网络,每个网可是自组织网也可是多层感知器网,最多可达32层,每层可达32个节点,且可以与其他8层相联。据称这是近年来神经网络发展方面的一个跃进。它在微软公司的VB上运行,被认为是近些年来最重要的软件进展和最高水平的智能工具。")
39
神经网络与传统人工智能方法相结合是近年来发展员快的一个方面。虽然在人工神经网络复苏之初有人喊过“人工智能已死,神经网络万岁”,虽然在传统的人工智能领域工作的许多人对于神经网络的发展抱有怀疑或否定态度.但这几年的发展日益证明,把这两者结合起来是一条最佳途径。采用综合方法可以取长补短,更好地发挥各自的特点。比如,神经网络的节点和连接可明确地与规定的目标和关系联系在一起,可把特定的推理规则作为目标节点之间的规定联接,节点数可以由所描写的规则所决定,可对节点的权及阈值加以选择以便描写所需的逻辑关系,利用组合规则解释节点的激活从而解释网络的行为,并按神经网络方式设计专家系统。最近所出现的把神经网络与人工智能系统结合起来的方式大体可分为两类,一类是把人工智能系统作为神经网络的前端,一类是把神经网络作为人工智能系统的前端。在前一类中,人工智能系统可以与使用者交互作用(如向使用者提出问题,了解使用者的需求),然后利用知识与神经网络准备数据。这方面的第一个商用系统是美国杜邦公司的LAM系统。它把人工智能系统、神经网络和文本检索系统结合起来,供建筑师、玻璃切割与装配工程师使用,使得对建筑物玻璃结构的设计、选配和施工更简单、灵活、省时,适应性更强。目前正在建筑行业大力推广。也可以利用人工智能系统作为信息流的控制器,利用教师机制和基于规则的指南,帮助使用者从大量选择项中选择正确的神经网络来解决某一专门问题。这种系统已在化工领域中得到应用,帮助用户由所需化合物的性质来确定化学公式,或由公式产生出相应的物理特性,或由性质产生出相应的化合物.等等。
,然后利用知识与神经网络准备数据。这方面的第一个商用系统是美国杜邦公司的LAM系统。它把人工智能系统、神经网络和文本检索系统结合起来,供建筑师、玻璃切割与装配工程师使用,使得对建筑物玻璃结构的设计、选配和施工更简单、灵活、省时,适应性更强。目前正在建筑行业大力推广。也可以利用人工智能系统作为信息流的控制器,利用教师机制和基于规则的指南,帮助使用者从大量选择项中选择正确的神经网络来解决某一专门问题。这种系统已在化工领域中得到应用,帮助用户由所需化合物的性质来确定化学公式,或由公式产生出相应的物理特性,或由性质产生出相应的化合物.等等。")
40
神经网络理论研究重大成果 1.Hornik等人证明了:仅有一个非线性隐层的前馈网络就能以任意精度逼近任意复杂度的函数 。
2.神经网络训练后,所表达的函数是“可以”求出的。 3.神经网络的几何意义。 4.神经网络集成。 5.自主的神经网络。

41
第2章 人工神经网络基本模型 一、MP模型 MP模型属于一种阈值元件模型,它是由美国Mc Culloch和Pitts提出的最早神经元模型
第2章 人工神经网络基本模型 一、MP模型 MP模型属于一种阈值元件模型,它是由美国Mc Culloch和Pitts提出的最早神经元模型 之一。MP模型是大多数神经网络模型的基础。

42
标准MP模型

43
wij ——代表神经元i与神经元j之间的连接强度(模拟生物神经元之间突触连接强度),称之为连接权;
ui——代表神经元i的活跃值,即神经元状态; vj——代表神经元j的输出,即是神经元i的一个输入; θi——代表神经元i的阈值。 函数f表达了神经元的输入输出特性。在MP模型中,f定义为阶跃函数:

44
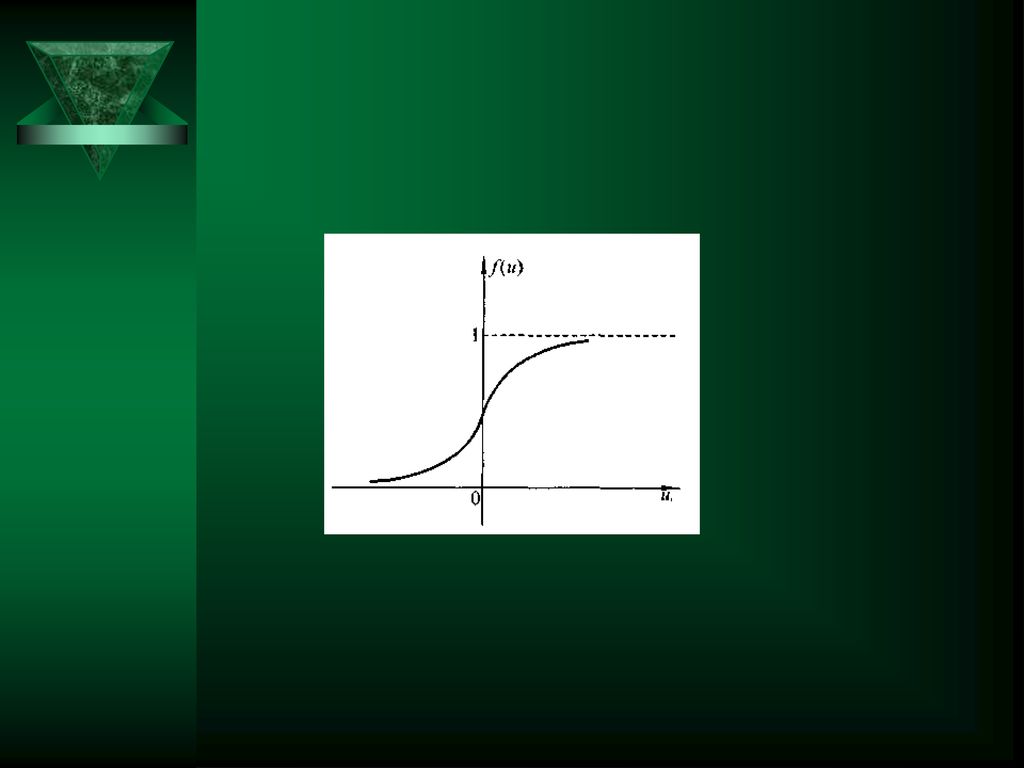
如果把阈值θi看作为一个特殊的权值,则可改写为:
其中,w0i=-θi,v0=1 为用连续型的函数表达神经元的非线性变换能力,常采用s型函数: 该函数的图像如下图所示

46
MP模型在发表时并没有给出一个学习算法来调整神经元之间的连接权。但是,我们可以根据需要,采用一些常见的算法来调整神经元连接权,以达到学习目的。下面介绍的Hebb学习规则就是一个常见学习算法。
Hebb学习规则 神经网络具有学习功能。对于人工神经网络而言,这种学习归结为神经元连接权的变化。调整wij的原则为:若第i和第j个神经元同时处于兴奋状态,则它们之间的连接应当加强,即: Δwij=αuivj 这一规则与“条件反射”学说一致,并已得到神经细胞学说的证实。 α是表示学习速率的比例常数。

47
2 感知器模型 感知器是一种早期的神经网络模型,由美国学者F.Rosenblatt于1957年提出.感知器中第一次引入了学习的概念,使人脑所具备的学习功能在基于符号处理的数学到了一定程度的模拟,所以引起了广泛的关注。 简单感知器 简单感知器模型实际上仍然是MP模型的结构,但是它通过采用监督学习来逐步增强模式划分的能力,达到所谓学习的目的。

48
其结构如下图所示 感知器处理单元对n个输入进行加权和操作v即: 其中,Wi为第i个输入到处理单元的连接权值θ为阈值。 f取阶跃函数.

49
感知器在形式上与MP模型差不多,它们之间的区别在于神经元间连接权的变化。感知器的连接权定义为可变的,这样感知器就被赋予了学习的特性。 利用简单感知器可以实现逻辑代数中的一些运算。
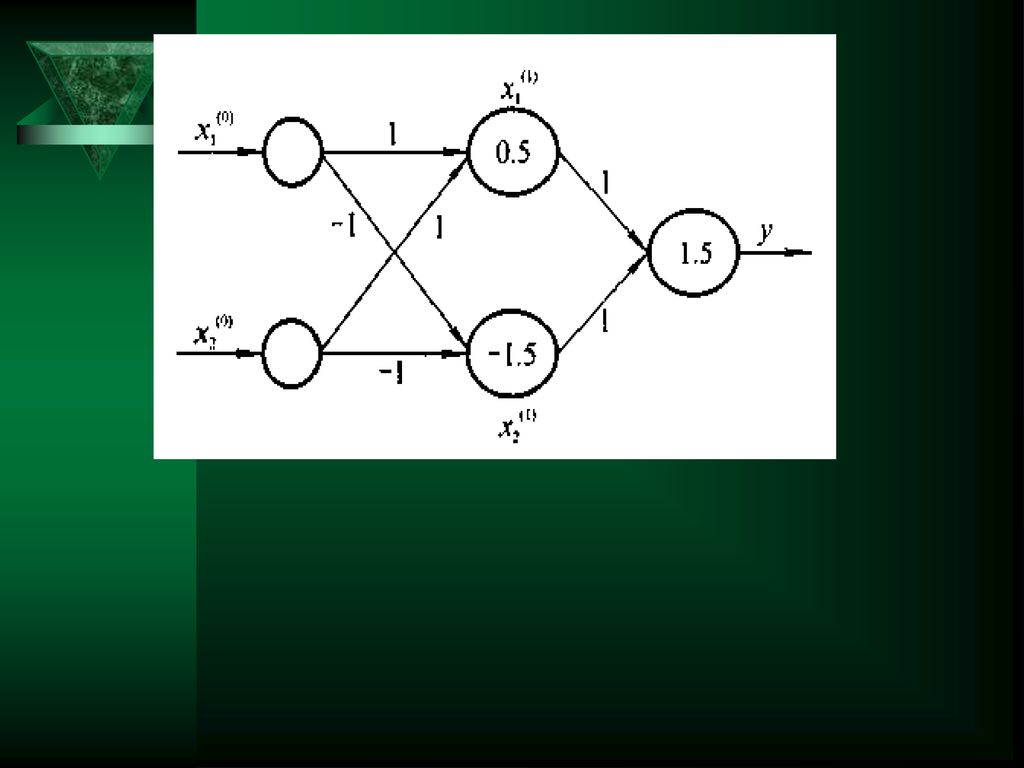
Y=f(w1x1+w2x2-θ) (1)“与”运算。当取w1=w2=1,θ=1.5时,上式完成逻辑“与”的运算。
 (1) 与 运算。当取w1=w2=1,θ=1.5时,上式完成逻辑 与 的运算。")
50
(2)“或”运算, 当取wl=w2=1, θ =0.5时,上式完成逻辑“或”的运算。 (3)“非”运算, 当取wl=-1,w2=0, θ =-1时.完成逻辑“非”的运算。
 或 运算, 当取wl=w2=1, θ =0.5时,上式完成逻辑 或 的运算。 (3) 非 运算, 当取wl=-1,w2=0, θ =-1时.完成逻辑 非 的运算。")
51
与许多代数方程一样,上式中不等式具有一定的几何意义。对于一个两输入的简单感知器,每个输入取值为0和1,如上面结出的逻辑运算,所有输入样本有四个,记为(x1,x2):(0,0),(0,1),(1,0),(1,1),构成了样本输入空间。例如,在二维平面上,对于“或”运算,各个样本的分布如下图所示。直线 1*x1+1*x2-0.5=0 将二维平面分为两部分,上部为激发区(y,=1,用★表示),下部为抑制区(y=0,用☆表示)。
,下部为抑制区(y=0,用☆表示)。")
52
简单感知器引入的学习算法称之为误差学习算法。该算法是神经网络学习中的一个重要算法,并已被广泛应用。现介绍如下:
误差型学习规则: (1)选择一组初始权值wi(0)。 (2)计算某一输入模式对应的实际输出与期 望输出的误差δ
选择一组初始权值wi(0)。 (2)计算某一输入模式对应的实际输出与期. 望输出的误差δ.")
53
(3)如果δ小于给定值,结束,否则继续。 (4)更新权值(阈值可视为输入恒为1的一个权值): Δwi(t+1)= wi(t+1)- wi(t) =η[d—y(t)]xi。 式中η为在区间(0,1)上的一个常数,称为学习步长,它的取值与训练速度和w收敛的稳定性有关;d、y为神经元的期望输出和实际输出;xi为神经元的第i个输入。 (5)返回(2),重复,直到对所有训练样本模式,网络输出均能满足要求。
![(3)如果δ小于给定值,结束,否则继续。 (4)更新权值(阈值可视为输入恒为1的一个权值): Δwi(t+1)= wi(t+1)- wi(t) =η[d—y(t)]xi。](http://slidesplayer.com/slide/11148879/60/images/53/%283%29%E5%A6%82%E6%9E%9C%CE%B4%E5%B0%8F%E4%BA%8E%E7%BB%99%E5%AE%9A%E5%80%BC%EF%BC%8C%E7%BB%93%E6%9D%9F%EF%BC%8C%E5%90%A6%E5%88%99%E7%BB%A7%E7%BB%AD%E3%80%82+%284%29%E6%9B%B4%E6%96%B0%E6%9D%83%E5%80%BC%28%E9%98%88%E5%80%BC%E5%8F%AF%E8%A7%86%E4%B8%BA%E8%BE%93%E5%85%A5%E6%81%92%E4%B8%BA1%E7%9A%84%E4%B8%80%E4%B8%AA%E6%9D%83%E5%80%BC%29%EF%BC%9A+%CE%94wi%EF%BC%88t%2B1%EF%BC%89%EF%BC%9D+wi%EF%BC%88t%2B1%EF%BC%89-+wi%EF%BC%88t%EF%BC%89+%EF%BC%9D%CE%B7%5Bd%E2%80%94y%28t%29%5Dxi%E3%80%82.jpg "式中η为在区间(0,1)上的一个常数,称为学习步长,它的取值与训练速度和w收敛的稳定性有关;d、y为神经元的期望输出和实际输出;xi为神经元的第i个输入。 (5)返回(2),重复,直到对所有训练样本模式,网络输出均能满足要求。")
55
对于学习步长V的取值一般是在(0,1)上的一个常数,但是为了改进收敛速度,也可以采用变步长的方法,这里介绍一个算法如下式:
式中,α为一个正的常量.这里取值为0.1。所以,对应于输入(0,0),修正权值(注意:θ=w0 , x0=-1) Δw0(1)=η[d—y]x0 =0.1(1—0)(—1)=—0.1, W0(1)=0.1+ Δw0(1)= =0.0 依次进行。
,修正权值(注意:θ=w0 , x0=-1) Δw0(1)=η[d—y]x0. =0.1(1—0)(—1)=—0.1, W0(1)=0.1+ Δw0(1)= =0.0. 依次进行。")
56
同样的方法,对其他输入样本都进行学习。整个学习过程就是某一超平面在样本空间中几何位置调整的过程 。
初值 w1(7)=—0.225. w2(7)=—0.0875, θ(7)=—0.1875。这样的一组网络参数满足计算要求。
=—0.225. w2(7)=—0.0875, θ(7)=—0.1875。这样的一组网络参数满足计算要求。")
58
感知器对线性不可分问题的局限性决定了它只有较差的归纳性,而且通常需要较长的离线学习才能达到收效。

59
多层感知器 如果在输入和输出层间加上一层或多层的神经元(隐层神经元),就可构成多层前向网络,这里称为多层感知器。 这里需指出的是:多层感知器只允许调节一层的连接权。这是因为按感知器的概念,无法给出一个有效的多层感知器学习算法。
,就可构成多层前向网络,这里称为多层感知器。 这里需指出的是:多层感知器只允许调节一层的连接权。这是因为按感知器的概念,无法给出一个有效的多层感知器学习算法。")
60
上述三层感知器中,有两层连接权,输入层与隐层单元间的权值是随机设置的固定值,不被调节;输出层与隐层间的连接权是可调节的。

61
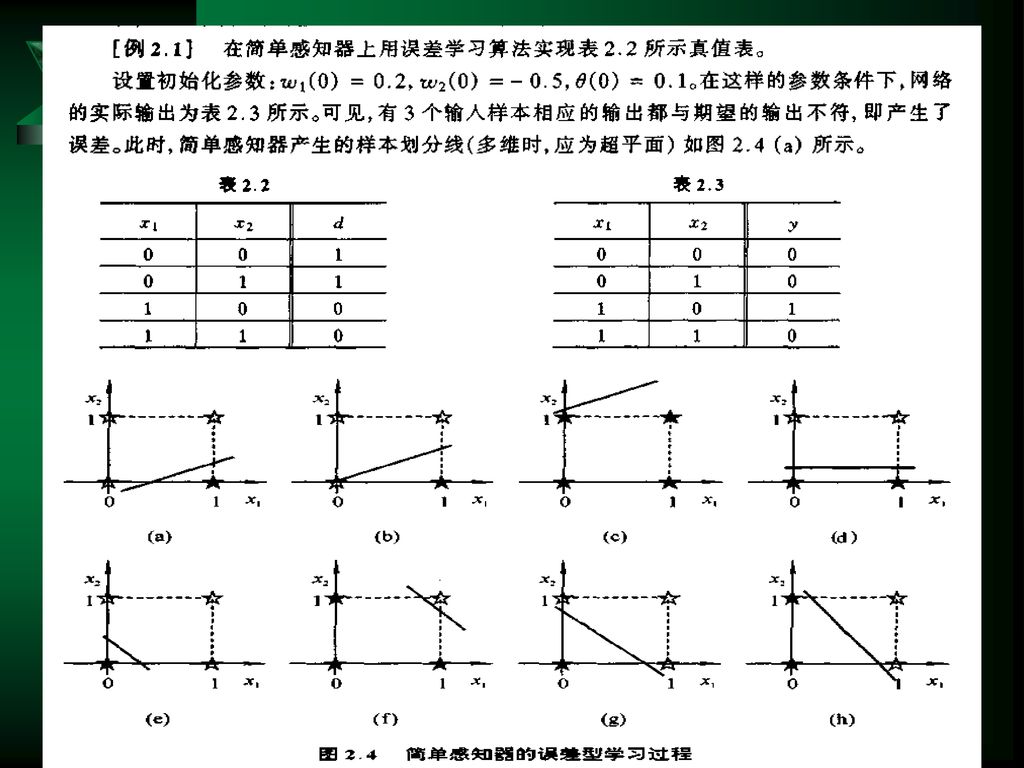
对于上面述及的异或问题,用一个简单的三层感知器就可得到解决
实际上,该三层感知器的输入层和隐层的连接,就是在模式空间中用两个超平面去划分样本,即用两条直线: x1+x2=0.5 x1十x 2=1.5。

64
可以证明,只要隐层和隐层单元数足够多,多层感知器网络可实现任何模式分类。但是,多层网络的权值如何确定,即网络如何进行学习,在感知器上没有得到解决:当年Minsky等人就是因为对于非线性空间的多层感知器学习算法未能得到解决,使其对神经网络的研究作出悲观的结论。

65
感知器收敛定理 对于一个N个输入的感知器,如果样本输入函数是线性可分的,那么对任意给定的一个输入样本x,要么属于某一区域F+,要么不属于这一区域,记为F—。F+,F—两类样本构成了整个线性可分样本空间。

66
[定理] 如果样本输入函数是线性可分的,那么下面的感知器学习算法经过有限次迭代后,可收敛到正确的权值或权向量。
假设样本空间F是单位长度样本输入向量的集合,若存在一个单位权向量w*。和一个较小的正数δ>0,使得w*·x>= δ对所有的样本输入x都成立,则权向量w按下述学习过程仅需有限步就可收敛。
![[定理] 如果样本输入函数是线性可分的,那么下面的感知器学习算法经过有限次迭代后,可收敛到正确的权值或权向量。](http://slidesplayer.com/slide/11148879/60/images/66/%5B%E5%AE%9A%E7%90%86%5D+%E5%A6%82%E6%9E%9C%E6%A0%B7%E6%9C%AC%E8%BE%93%E5%85%A5%E5%87%BD%E6%95%B0%E6%98%AF%E7%BA%BF%E6%80%A7%E5%8F%AF%E5%88%86%E7%9A%84%EF%BC%8C%E9%82%A3%E4%B9%88%E4%B8%8B%E9%9D%A2%E7%9A%84%E6%84%9F%E7%9F%A5%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E7%BB%8F%E8%BF%87%E6%9C%89%E9%99%90%E6%AC%A1%E8%BF%AD%E4%BB%A3%E5%90%8E%EF%BC%8C%E5%8F%AF%E6%94%B6%E6%95%9B%E5%88%B0%E6%AD%A3%E7%A1%AE%E7%9A%84%E6%9D%83%E5%80%BC%E6%88%96%E6%9D%83%E5%90%91%E9%87%8F%E3%80%82.jpg "假设样本空间F是单位长度样本输入向量的集合,若存在一个单位权向量w*。和一个较小的正数δ>0,使得w*·x>= δ对所有的样本输入x都成立,则权向量w按下述学习过程仅需有限步就可收敛。")
70
因此,感知器学习迭代次数是一有限数,经过有限次迭代,学习算法可收敛到正确的权向量w

71
[定理] 假定隐含层单元可以根据需要自由设置,那么用双隐层的感知器可以实现任意的二值逻辑函数(证明略)。
![[定理] 假定隐含层单元可以根据需要自由设置,那么用双隐层的感知器可以实现任意的二值逻辑函数(证明略)。](http://slidesplayer.com/slide/11148879/60/images/71/%5B%E5%AE%9A%E7%90%86%5D+%E5%81%87%E5%AE%9A%E9%9A%90%E5%90%AB%E5%B1%82%E5%8D%95%E5%85%83%E5%8F%AF%E4%BB%A5%E6%A0%B9%E6%8D%AE%E9%9C%80%E8%A6%81%E8%87%AA%E7%94%B1%E8%AE%BE%E7%BD%AE%EF%BC%8C%E9%82%A3%E4%B9%88%E7%94%A8%E5%8F%8C%E9%9A%90%E5%B1%82%E7%9A%84%E6%84%9F%E7%9F%A5%E5%99%A8%E5%8F%AF%E4%BB%A5%E5%AE%9E%E7%8E%B0%E4%BB%BB%E6%84%8F%E7%9A%84%E4%BA%8C%E5%80%BC%E9%80%BB%E8%BE%91%E5%87%BD%E6%95%B0%28%E8%AF%81%E6%98%8E%E7%95%A5%29%E3%80%82.jpg "[定理] 假定隐含层单元可以根据需要自由设置,那么用双隐层的感知器可以实现任意的二值逻辑函数(证明略)。")
72
下图给出了感知器的层数与模式划分区域的关系。









>")

 李 芮第 1 名 吕明洋第 2 名 王 越第 3 名 杨天宇第 4 名 张凯燕第 5 名 李 曦第 7 名 魏书静第 8 名 项春怡第 10 名 郑明明第.>")










班家长会.>")

班家长会.>")
