Download presentation
1
基本概論 Basic concepts

2
學習目標 在學習本章之後,讀者們要能夠瞭解: 1.何謂資料結構 2.認識演算法和資料結構在資訊科學領城扮演的角色。
3.學習用程式語言來撰寫各種資料結構。 4.瞭解資料結構的實際應用。

3
資料、資訊 與 資料結構

4
資料(Data) 是用來表達一個觀念或一個事件的一群文 字、數字、符號或圖表
例如股票行情、火車時刻表及報章雜誌等上 的文字、數字及圖表 從計算機處理的觀點來看,所謂「資料」 就是指可以輸入到計算機中,並且被程式 處理的文字、數字、符號或圖表。 包括了數值資料、字串資料及多媒體資料 (影像、聲音及視訊)
")
5
資訊(information) 利用大量的資料,經過有系統的整理、分 析、篩選處理而提鍊出來
具有參考價格及提供決策依據的文字、數 字、符號或圖表 將有用資料作整理、歸納與分析。

6
資料結構(Data Structure) 資料元素不是獨立存在的,它們之間存在著某稱的邏輯關係 資料結構應包括兩部分:資料和結構
資料是指資料元素的有限集合 結構則是指資料元素間關係的集合 資料結構的目的主要有二 節省資料儲存的所需的空間 是加快資料處理的速度

7
資料、資訊與資料結構

8
資料結構 演算法 與程式

9
資料結構和演算法是有著密切關係的,選擇一個好的資料結構,有助於製造一個好的演算法,寫出一個好的程式。一個好的資料結構應便於有效地進行資料的追加、刪除和檢索,應能簡潔的表現複雜的結構
我們的目標在於將抽象的資料結構及演算法轉換成具體的電腦程式,用來解決問題。

10
資料、資訊與資料結構

11
資料結構(Data Structure)+ 演算法(Algorithms)=程式(Program)
資料結構、演算法可以說是一切程式設計的基礎。 只要有良好的資料結構和演算法,就可以設計出一個好的程式 資料結構研究的方向就是如何讓電腦能快速地從記憶體中,拿出我們所需的資料 資料結構和演算法對一個執行有效率的程式來說,扮演著非常重要的角色。

12
資料結構

13
常見的資料結構 集合 線性結構 樹狀結構 圖形結構

14
定義及特性 指相互之間存在一種或多種特定關係的資料 元素的集合,而根據資料元素之間關係的不 同特性
相關資料的組合,以某種方式組識而成,讓 我們能把這樣的組合對應到某種抽象的觀念 或是實際的事物。 資料結構可能非常單純,也可能非常的複雜

15
資料結構可定義成:『如何安排資料以配合 適當的演算法解決問題的學問』。 資料結構簡化了解決問題的程序
資料結構的定義分成兩部分來討論: 一是資料定義與組識的邏輯(logical)結構 另一個是和資料操作有關的實體(Physical)結構。 資料結構可定義成:『如何安排資料以配合 適當的演算法解決問題的學問』。 資料結構簡化了解決問題的程序
結構. 另一個是和資料操作有關的實體(Physical)結構。 資料結構可定義成:『如何安排資料以配合 適當的演算法解決問題的學問』。 資料結構簡化了解決問題的程序.")
16
基本結構 集合(Set): 即數學中的集合關係一樣,資料元素的關係 就是「一個集合」,它們之間沒有任何先後 次序的關係,並著重在資料是否存在或屬於 集合的問題。
: 即數學中的集合關係一樣,資料元素的關係 就是「一個集合」,它們之間沒有任何先後 次序的關係,並著重在資料是否存在或屬於 集合的問題。")
17
線性結構: 資料元素之間存在一對一的關係,我們稱之為有 序的集合(Ordered set) ,也就是資料與資料之間 是有先後次序的
例如陣列(Array)、串列(List)、堆疊(Stack)與佇 列(Queue)等 這樣的結構不僅要知道資料是否存資料集合中, 還要確定資料儲存的位置和前後資料之間的順序 Chapter2,3,4,5章
、串列(List)、堆疊(Stack)與佇 列(Queue)等. 這樣的結構不僅要知道資料是否存資料集合中, 還要確定資料儲存的位置和前後資料之間的順序. Chapter2,3,4,5章.")
18
樹狀結構: 結構中元素存在一對多的關係,如二元搜尋樹 (binary search tree)、累堆(heap)也就是說資料具 上下關係的階層化組織 第6,7章
、累堆(heap)也就是說資料具 上下關係的階層化組織 第6,7章")
19
圖形結構: 資料元素彼此間存在多對多關係,所謂的先後和上 下關係,在此類的資料結構中,變得更模糊了 第8章

20
演算法

21
定義 演算法描述解決問題的方法,而且是以程序式的描述為主,讓人一看就知道是怎麼一回事
可以用某種程式語言來撰寫演算法所代表的程序,並由電腦來執行這個程式 在演算法中,必須以適當的資料結構來描述問題中抽象或具體的事物,有時還得定義資料結構本身有那些操作。

22
演算法(Algorithm)代表一系列為達成某種目標而進行的工作,通常演算法裡的工作都是針對資料所做的某種處理
有很多日常生活或工作中的事務可以用演算法來描述 電腦科學中所談的演算法是比較嚴謹的

23
特性或條件(criteria) 輸入(Input): 輸出(Output):
演算法通常是接受一些輸入,加以處理或運算,而 產生一些輸出值。這些輸入必須有清楚的型別和個數描述。 輸出(Output): 結果的描述,至少輸出一個結果。
: 結果的描述,至少輸出一個結果。")
24
有限的(Finiteness): 有效的(Effectiveness):
演算法必須要能在有限的步驟內完成或終止,而且所使用的資料量也是有限的。我們不需要知道執行步驟的確實數目,但必須知道執行此演算法的步驟(或時間)不會超過某個上限。 有效的(Effectiveness): 清楚而不造成混淆,並且能讓使用者用紙筆來執行。
不會超過某個上限。 有效的(Effectiveness): 清楚而不造成混淆,並且能讓使用者用紙筆來執行。")
25
表示法 代數的表示法: 表格式的表示法: 利用像陣列或矩陣的結構也可以描述演算法
例如申報所得稅時所用的累進稅表,從表格中的資訊可計算出應該繳的所得稅。 假如用列表方式就能達到目的,其實並不需要複雜的表示法。

26
資料流程圖(DFD,Data flow diagram)
很多應用系統以資料的處理為核心,適合用資料流程圖(DFD,Data flow diagram)來表示系統的功能 DFD算是一種半正式的表示法,早在1970年代就被很多人所接受和採用。
來表示系統的功能 DFD算是一種半正式的表示法,早在1970年代就被很多人所接受和採用。")
27
控制流程圖: 資料流程(Data flow)和控制流程(Control flow)是演算法一體之兩面 資料流程說明各操作之間交換的資料
控制流程則強調各操作進行的順序,所以資料流程圖比較適合用來描述演算法的功能,而控制流程圖則說明各功能是如何達成的。 控制流程圖(CFD,Control-flow diagram)可採用圖的符號來表示,這些基本符號說明了操作除了能按順序進行外,也可以因某些條件成立與否而改變執行的順序。
可採用圖的符號來表示,這些基本符號說明了操作除了能按順序進行外,也可以因某些條件成立與否而改變執行的順序。")
28
CFD表示法所用的圖形符號

29
虛擬碼 虛擬碼兼具文字描述及流程圖的優點,虛擬碼的方 式是用文字加程式語言來描述演算法的過程。 下面即是描述如何進入學生選課系統的操作流程:
虛擬碼兼具文字描述及流程圖的優點,虛擬碼的方 式是用文字加程式語言來描述演算法的過程。 下面即是描述如何進入學生選課系統的操作流程: 進入選課系統 讀入學生輸入之選課代碼; if(選課代碼是錯誤的) 告知錯誤,並回到主程式; if(所選科目已經額滿) 告知額滿,並回到主程式; if(所選科目衝堂) 告知衝堂,並回到主程式; 將所選科目加入此學生的選課清單內;
 告知錯誤,並回到主程式; if(所選科目已經額滿) 告知額滿,並回到主程式; if(所選科目衝堂) 告知衝堂,並回到主程式; 將所選科目加入此學生的選課清單內;")
30
設計演算法的目標與條件 正確性(correctness): 可讀性(readability): 健全性:
根據輸入的資料內容,便能得到預期的資料輸出,也就是可以正確的執行,這是對演算法的基本要求。 可讀性(readability): 演算法的主要目的是為了讓使用者易於閱讀電腦程式處理的流程,如此才有助於程式日後的維護與修改。 健全性: 對於資料的錯誤輸入與輸出,演算法仍能適當的反應或處理,而不至於使程式或電腦當掉,這就是演算法的健全性。 效率性 (performance): 面對同樣的問題,不同的演算法所需的時間會有佷大的差別,故一個好的演算法,其執行時間效率必須控制在可以容忍範圍內。 記憶體需求低: 資料的處理會佔用記憶體資源,所佔用的空間則愈小愈好。
: 演算法的主要目的是為了讓使用者易於閱讀電腦程式處理的流程,如此才有助於程式日後的維護與修改。 健全性: 對於資料的錯誤輸入與輸出,演算法仍能適當的反應或處理,而不至於使程式或電腦當掉,這就是演算法的健全性。 效率性 (performance): 面對同樣的問題,不同的演算法所需的時間會有佷大的差別,故一個好的演算法,其執行時間效率必須控制在可以容忍範圍內。 記憶體需求低: 資料的處理會佔用記憶體資源,所佔用的空間則愈小愈好。")
31
程式語言

32
評估準則 正確性:是否完成所有的事項,並正確的解決問題。 可讀性:是否讓人容易了解程式之原意。
易維護性:是否具有程序、結構化與模組化的基礎。 清晰性:程式中的變數及程序等名稱是否具有意義。 文書性:是否有完備的程式說明文件。 效率性:是否簡單明暸直接表示程式的意圖,以最簡要的程式碼,最快的執行速度來完成。

33
程式的編寫原則: 程式要段落分明,並以有條不紊的階層式區塊排列; 識別字或變數的命名須有意義;
須簡單且直接表達程式的意義,儘可能使用內建函數; 撰寫結構化程式,引用基本的控制流程結構; 少用GOTO,避免不必要之分支。 多使用副程式以使程式單元化;因為副程式可以重複使用,且程式的測試工作亦容易多了。 善用物件導向程式繼承、封裝與多型等,將軟體IC化可以提昇軟體開發的生產力。 儘量將輸入與輸出、處理邏輯與資料儲存分開來設計。 不要將程式的效率性擺第一,先考慮程式的正確性、清晰性、易讀性及可維護性。 程式必須加上註解,以提升程式的可讀性。

34
Performance Measurement
演算法的效率 Performance Measurement

35
演算法的效率 演算法是否要具有某種結構? 在設計上有那些考量? 同一問題是不是可用多種演算法來提供解答? 我們要如何比較不同演算法的優劣?

36
分析方式 「空間複雜度」(Space complexity) 「時間複雜度」(Time complexity)兩方面來分析。
空間複雜度是指演算法使用的記憶體空間的大小,當電腦執行一個演算法時,其實就是在執行一個程式,這個程式所需要的空間包含了程式的指令,變數與常數等,假如占用的空間太大,程式在執行時的效率可能會受到很明顯的影響。 「時間複雜度」(Time complexity)兩方面來分析。 決定於演算法執行完成所用的時間。在程式設計中,決定某程式區段的步驟計數是程式設計師在控制整體程式系統時間的重要因素,不過要決定精確的次數卻也真是個困難的工作。由於並無法精確的預知一個程式的細部行為,只能以「漸近式(Asymptotic Notation) 」來討論其複雜度,再根據函數的成長率來判斷演算法的優劣。
兩方面來分析。 決定於演算法執行完成所用的時間。在程式設計中,決定某程式區段的步驟計數是程式設計師在控制整體程式系統時間的重要因素,不過要決定精確的次數卻也真是個困難的工作。由於並無法精確的預知一個程式的細部行為,只能以「漸近式(Asymptotic Notation) 」來討論其複雜度,再根據函數的成長率來判斷演算法的優劣。")
37
時間複雜度 Time Complexity

38
定義 在程式設計中,決定某程式區段的步驟計數是程式設計師在控制整體程式系統時間的重要因素
往往以一種「概量」的精神來做為衡量的準則,稱為「時間複雜度」(Time complexity)。
。")
39
對輸入量n而言,它的最大執行時間就是時間複雜度(Time complexity)的衡量標準。
定義一個T(n) 表示在一個完全理想狀態的計算機中程式所執行的實際指令次數。 時間複雜度是輸入量為n的一種函數 一個程式的執行時間並不完全和輸入量有關,演算法的好壞也會影響 對輸入量n而言,它的最大執行時間就是時間複雜度(Time complexity)的衡量標準。
 表示在一個完全理想狀態的計算機中程式所執行的實際指令次數。 時間複雜度是輸入量為n的一種函數. 一個程式的執行時間並不完全和輸入量有關,演算法的好壞也會影響. 對輸入量n而言,它的最大執行時間就是時間複雜度(Time complexity)的衡量標準。")
40
時間複雜度可包含程式的編譯時間與執行時間
一個程式只要編譯一次即可執行多次 通常我們會比較在意程式的執行時間 常用所謂的「漸近式表示法」(Asymptotic Notation)來簡化時間複雜度的表示法。
來簡化時間複雜度的表示法。")
41
O(1) <O(㏒n) < O(n) < O(n㏒n) < O(n2 ) < O(n3 ) <O(2 n )
常見的時間複雜度 按照複雜度排序 O(1) <O(㏒n) < O(n) < O(n㏒n) < O(n2 ) < O(n3 ) <O(2 n ) O(1):常數時間 O(n):線性時間 O(logn):次線性時間 O(nlogn):對數線性時間 O(n2):平方時間 O(n3):立方時間 O(2n):指數時間
 <O(㏒n) < O(n) < O(n㏒n) < O(n2 ) < O(n3 ) <O(2 n ) O(1):常數時間. O(n):線性時間. O(logn):次線性時間. O(nlogn):對數線性時間. O(n2):平方時間. O(n3):立方時間. O(2n):指數時間.")
42
程式執行的次數(Frequency count)
程式執行所花費的執行次數 有些程式並非每一次執行次數皆相同 當不同的輸入值而有不同的次數。 這樣的情況要將程式分為最佳狀況與最壞狀況 最佳狀況就是1次,最壞狀況是無窮次(n次)。
。")
43
分析模式 最佳狀況 平均狀況 最壞狀況

44
最佳狀況 平均狀況(Average-Case) 分析演算法對何種輸入資料,所需花費的時間最少。 程式最低的時間複雜度,稱為Omega(W)
也就是程式執行的次數一定相等或大於最佳狀況。 平均狀況(Average-Case) 分析演算法在所有可能的輸入組合下,平均所需要的時間。 程式平均的時間複雜度,稱為Theta(Q) 程式執行的次數介於最佳與最壞狀況之間。
 分析演算法在所有可能的輸入組合下,平均所需要的時間。 程式平均的時間複雜度,稱為Theta(Q) 程式執行的次數介於最佳與最壞狀況之間。")
45
較常以Big-Oh來表示演算法的執行效率。
最壞狀況(Worst-Case) 分析演算法在所有可能的輸入組合下,最多所需要的時間。 程式最高的時間複雜度,稱為Big-O 就是程式執行的次數一定相等或小於最壞狀況 較常以Big-Oh來表示演算法的執行效率。
 分析演算法在所有可能的輸入組合下,最多所需要的時間。 程式最高的時間複雜度,稱為Big-O. 就是程式執行的次數一定相等或小於最壞狀況. 較常以Big-Oh來表示演算法的執行效率。")
46
何謂Big-O 定義 f(n) = O(g(n))
若存在正的常數C和n0,則對所有n≥ n0,必使得得0≤f(n) ≤Cg(n)的條件成立。 實例說明 假設下列多項式各為某程式片斷或敘述的執行次數,請利用Big-Oh來表示時 間複雜度。 (a) 3n+2 (b) 10n2+5n+1 (c) 7*2n+n2+n 【解析】 (a) 3n+2=O(n),∵我們可找到c=4,n0=2,使得3n+2 ?4n (b) 10n2+5n+1=O(n2),∵我們可找到c=11,n0=6,使得10n2+5n+1 ?11n2 (c) 7*2n+n2+n=O(2n),∵我們可找到c=8,n0=4,使得7*2n+n2+n ?8*2n
 ≤Cg(n)的條件成立。 實例說明. 假設下列多項式各為某程式片斷或敘述的執行次數,請利用Big-Oh來表示時. 間複雜度。 (a) 3n+2 (b) 10n2+5n+1 (c) 7*2n+n2+n 【解析】 (a) 3n+2=O(n),∵我們可找到c=4,n0=2,使得3n+2 4n (b) 10n2+5n+1=O(n2),∵我們可找到c=11,n0=6,使得10n2+5n+1 11n2 (c) 7*2n+n2+n=O(2n),∵我們可找到c=8,n0=4,使得7*2n+n2+n 8*2n")
47
常見Big-Oh的幾種情形 1、 O(1)或O(c):常數時間 (constant time)
這表示演算法則的執行時間是一個常數倍,而忽略資料集合大小的變化。一個例子是在電腦中它存取RAM所花的時間,在記憶體中去讀取及寫入所用的時間是相同的,而不考慮整個記憶體的數量。如果有這樣的演算法則存在,則我們可以在任何大小的資料集合中自由的使用,而不需要擔心時間或運算的次數會一直成長或變得很高。 2、 O(n):稱為線性時間 (linear time) 它執行的時間會隨資料集合的大小而線性成長。我們可以找到一個例子是在一個沒有排列過的資料集中要找一個最大元素,且我們以簡單的方式去解釋其內容,直到我們將所有的資料都找過並且找到最大值為止。 3、 O(log2n):稱為次線性時間 (sub-linear time) 這一種函式的成長速度比線性的程序還慢,而此常數(它是不成長的)的情形還快。 4、 O(n2):稱為平方時間 (quadratic time) 演算法則執行時間會成二次方的成長,這種會變的不切實際,特別是當資料集合的大小變的很大時。 5、 O(n3):稱為立方時間 (cubic time) 演算法則執行時間會成三次方的成長,這種會變的不切實際,特別是當資料集合的大小變的很大時。 6、 O(2n):稱為指數時間 (exponential time) 7、 O(n1og2n):介於線性及三次方成長的中間之行為模式。
:稱為線性時間 (linear time) 它執行的時間會隨資料集合的大小而線性成長。我們可以找到一個例子是在一個沒有排列過的資料集中要找一個最大元素,且我們以簡單的方式去解釋其內容,直到我們將所有的資料都找過並且找到最大值為止。 3、 O(log2n):稱為次線性時間 (sub-linear time) 這一種函式的成長速度比線性的程序還慢,而此常數(它是不成長的)的情形還快。 4、 O(n2):稱為平方時間 (quadratic time) 演算法則執行時間會成二次方的成長,這種會變的不切實際,特別是當資料集合的大小變的很大時。 5、 O(n3):稱為立方時間 (cubic time) 演算法則執行時間會成三次方的成長,這種會變的不切實際,特別是當資料集合的大小變的很大時。 6、 O(2n):稱為指數時間 (exponential time) 7、 O(n1og2n):介於線性及三次方成長的中間之行為模式。")
48
何謂Ω(omega) 定義 f(n)=Ω(g(n)) 若存在正的常數C和n0,則對所有n≥ n0,必使得0≤Cg(n)≤f(n)的條件成立。
實例說明 假設下列多項式各為某程式片斷或敘述的執行次數,請利用Ω來 表示時間複雜度。 (a) 3n+2 (b) 200n2+4n+5 【解析】 (a) 3n+2=Ω(n),∵我們可找到c=3,n0=1,使得3n+2 ?3n (b) 200n2+4n+5=Ω(n2),∵我們可找到c=200,n0=1,使得200n2+4n+5 ?200n2
 3n+2 (b) 200n2+4n+5 【解析】 (a) 3n+2=Ω(n),∵我們可找到c=3,n0=1,使得3n+2 3n (b) 200n2+4n+5=Ω(n2),∵我們可找到c=200,n0=1,使得200n2+4n+5 200n2.")
49
何謂Θ(Theta) f(n)= Θ(g(n)) 定義
若存在正的常數C1,C2和n0,則對所有n≥ n0,必使得0≤C1g(n)≤f(n) ≤C2g(n)的條件成立
≤f(n) ≤C2g(n)的條件成立.")
50
結語 對於使用漸近式表示法來描述時間複雜度到底那一種是最佳的方法﹖在前面我們就指出了「big-oh」是對演算法的時間複雜度描述最常用的表示法。原因就是在漸近表示法中我們通常只關切其最大項目 (leading term) 的原因。
 的原因。")
51
C語言與資料結構

52
C語言與資料結構主要的特色 具備低階語言與高階語言的特性。 是一種結構化的語法且可以控制硬體設備。 可以在DOS及WINDOWS環境下執行。
具備低階語言與高階語言的特性。 是一種結構化的語法且可以控制硬體設備。 可以在DOS及WINDOWS環境下執行。 其使用方式一般可以使用純文字編輯器,如NotePad (記事本) 進行程式撰寫,再使用C語言編譯軟體,進行編譯及連結完成C語言;或者直接使用C語言編譯軟體來編寫C語言,並且進行編譯及連結。
 進行程式撰寫,再使用C語言編譯軟體,進行編譯及連結完成C語言;或者直接使用C語言編譯軟體來編寫C語言,並且進行編譯及連結。")
53
C語言的資料型別大致可分為 基本型別: 資料型別: 字元型、整數型、實數型。
字元型、整數型、實數型。 資料型別: 結構型......陣列、結構、記錄、等位 (Union)、指標型。
、指標型。")
54
典型的資料結構 表 (table) 堆疊 (stack) 佇列 (queue) 串列 (list) 樹 (tree) 圖 (graph)
 堆疊 (stack) 佇列 (queue) 串列 (list) 樹 (tree) 圖 (graph)")
55
淺談資料型態 當我們學一種程式語言時,通常會從了解其語法與語意開始,其實程式語言就像一般口語,是溝通的工具,只不過溝通的對象更進一步延伸到電腦。在程式語言中,資料以常數或變數 (Variable) 的型態出現,並利用型式 (type) 來將資料分門別類,因此有所謂的整數 (Integer)、浮點數 (floating-point numbers)、字串 (string) 等。另外將資料以各種不同的方式組合在一起。如C語言中的結構及指標等敘述,亦可形成更多的型式。
 的型態出現,並利用型式 (type) 來將資料分門別類,因此有所謂的整數 (Integer)、浮點數 (floating-point numbers)、字串 (string) 等。另外將資料以各種不同的方式組合在一起。如C語言中的結構及指標等敘述,亦可形成更多的型式。")
56
各種資料結構的關係

57
用程式語言描述資料結構 C語言程式主架構 void main( ) //主程式 { //中括號不可以省略 敘述式;//分號不可以省略 } //中括號不可以省略
 //主程式 { //中括號不可以省略 敘述式;//分號不可以省略 } //中括號不可以省略")
58
變數宣告 一個整數變數的宣告方式是: int iAmt 宣告字元及數值範圍如下表:

59
類別 位元長度 表示方法 數值範圍 整數 16 int -32768到32768 short 32 long 到 unsigned int 0到65535 unsigned short unsigned long 0到 浮點數 float 10的負38次方到10的正38次方 64 double 10的負308次方到10的正308次方 字元 8 char 0到225

60
陣列宣告 指標Pointer的宣告 陣列(Array)是資料結構中最常被使用到的資料格式之一;它的宣告方式如下: int iX[10]
假設我們要宣告一個變數ptr為指標變數: int *ptr; 表示ptr指向型態為整數的記憶體位址,但並不能直接引用或設定任何給定值。
![陣列宣告 指標Pointer的宣告 陣列(Array)是資料結構中最常被使用到的資料格式之一;它的宣告方式如下: int iX[10]](http://slidesplayer.com/slide/11221654/60/images/60/%E9%99%A3%E5%88%97%E5%AE%A3%E5%91%8A+%E6%8C%87%E6%A8%99Pointer%E7%9A%84%E5%AE%A3%E5%91%8A+%E9%99%A3%E5%88%97%28Array%29%E6%98%AF%E8%B3%87%E6%96%99%E7%B5%90%E6%A7%8B%E4%B8%AD%E6%9C%80%E5%B8%B8%E8%A2%AB%E4%BD%BF%E7%94%A8%E5%88%B0%E7%9A%84%E8%B3%87%E6%96%99%E6%A0%BC%E5%BC%8F%E4%B9%8B%E4%B8%80%EF%BC%9B%E5%AE%83%E7%9A%84%E5%AE%A3%E5%91%8A%E6%96%B9%E5%BC%8F%E5%A6%82%E4%B8%8B%EF%BC%9A+int+iX%5B10%5D.jpg "假設我們要宣告一個變數ptr為指標變數: int *ptr; 表示ptr指向型態為整數的記憶體位址,但並不能直接引用或設定任何給定值。")
61
動態記憶體的配罝 陣列的大小宣告,一定是在程式開發階段就得確定 指標最重要的意義在於資料量可以隨著需要而改變
宣告太小,程式執行可能發生錯誤, 宣告太大,則容易造成空間浪費 指標最重要的意義在於資料量可以隨著需要而改變

62
main ( ) { int n , *p ; scanf(“%d” , &n) ; p=( int *) malloc (sizeof (int) * n); } malloc ( )是系統提供的函數,它可以向系統要求配置指定大小的記憶體。
 { int n , *p ; scanf( %d , &n) ; p=( int *) malloc (sizeof (int) * n); } malloc ( )是系統提供的函數,它可以向系統要求配置指定大小的記憶體。")
63
結構Structure的宣告 C語言的基本資料型態 陣列和指標則限制變數的資料型態必須一致
有整數、字元、浮點數等 陣列和指標則限制變數的資料型態必須一致 真正在資料處理的實務上時,資料型態可能不同或需要更多的型態 此C語言提供了使用者自定型態的功能,即所謂的結構。

64
假設我們要宣告一個新結構gstudent:
struct gstudent { char Name [10] int Age float weight; long height; }

65
自訂資料型態typedef 有時會為了程式撰寫方便和增加可讀性,亦可在C語言中以typedef的方式來定義新的資料型態
以上述為例可以改寫成:

66
typedef struct_ gstudent
{ char Name [10] int Age float weight; long height; } gstudent ; //新的資料型態

67
資料結構理論與實務

68
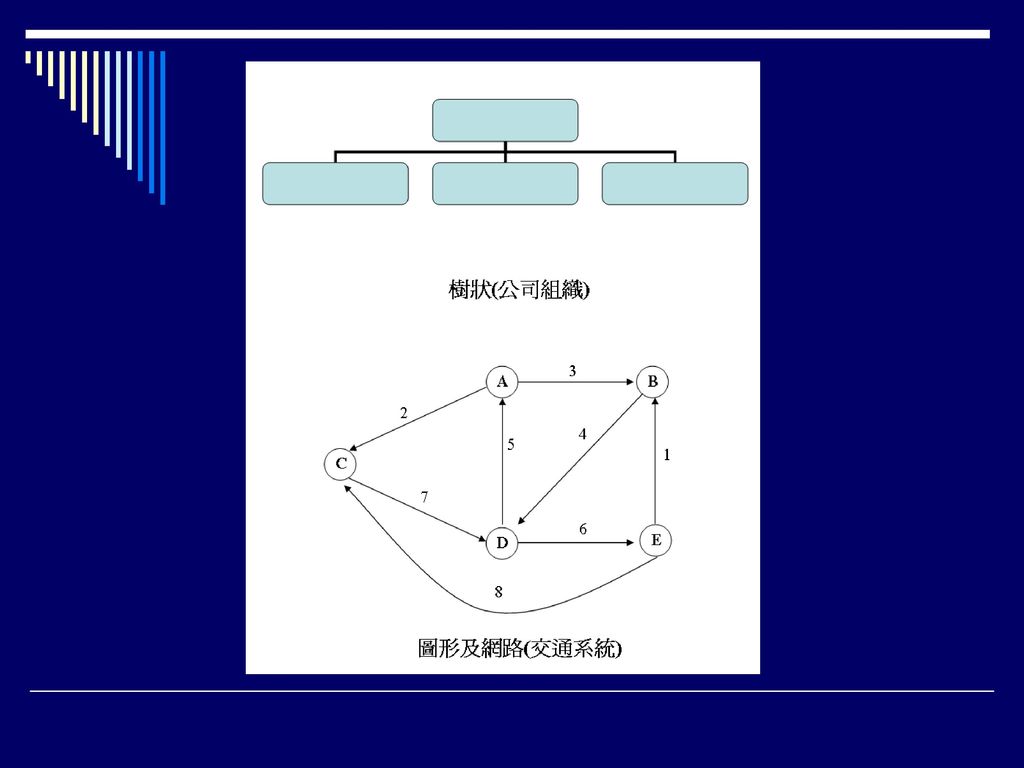
資料結構理論與實務 將蒐集到的資料有系統、組織地安排,建立資料與資料間的關係,仿照日常生活中的人、事、物常見的各式各樣結構,如陣列、鏈結串列、堆疊和佇列、樹狀結構、圖形和網路結構、排序、檔案結構等,將資料做最適當的安排、儲存,以方便資料的更新與存取,此為資料結構的最主要目的。由於好的資料結構不僅可以節省資料的儲存空間,增加資料的隱密性及安全性,又可以加速資料的更新及存取時間,故資料結構為資訊科學、工程及管理最重要的基本知識。 資料結構看似是一個學術理論的專有名詞,但卻與實際生活息息相關。如學生在操場上分班的排列結構,就如同一個個的『陣列』佇立著; 火車行駛時,其一節一節的車廂串連在一起,就如同『鏈結串列』;而倉庫堆放貨物時,都是一個接一個往上及往外疊,其結構類似『堆疊』;電影院外售票口的排隊人潮,即是井然有序的『佇列』。

72
資料結構主要探討主題 如何以最節省記憶空間的方式來表示儲存在記憶體中的資料。 各種不同的資料結構表示法和相關的演算法。
如何以最節省記憶空間的方式來表示儲存在記憶體中的資料。 各種不同的資料結構表示法和相關的演算法。 如何有效地改進演算法的效率,使程式的執行速度更快。 如何以最有利於使用者介面的方式來建構資料存取方法、資料儲存之結構和資料儲存之媒體。 資料處理的技巧,如排序、搜尋、合併、更新、分配等演算法之介紹和比較。 程式模組之單元化,以有效提升軟體開發之生產力。











 Data Structure>")





>")
>")




