Download presentation
1
Chapter 10 搜尋(search)
")
2
何謂搜尋 從一些資料中找出一個特定的值 常用的資料搜尋方法 線性搜尋 二元搜尋 費氏搜尋 插補搜尋 雜湊搜尋 二元搜尋樹

3
線性搜尋可用在未經排序的資料搜尋 其他搜尋方法須先將資料排序完成才能進行搜尋工作

4
線性搜尋(Linear Search) 又稱循序式搜尋(Sequential Search)
從第一筆資料開始搜尋比對,如果找到則傳回該值或該位置,如果沒找到則往下一筆資料搜尋比對 例如,有一整數陣列的資料內容如下

5
如欲找出57,則: Step 1: 與陣列中第一筆資料比對,5713 Step 2: 與陣列中第一筆資料比對,5725

6
Best case時間複雜度為B(n)=1O(n),表示第一次就找到資料
Worst case時間複雜度為W(n)=nO(n),表示未找到資料或資料出現在最後一筆 Average case時間複雜度為A(n)=(1+2+…+n)/n=(n+1)/2O(n)
=nO(n),表示未找到資料或資料出現在最後一筆. Average case時間複雜度為A(n)=(1+2+…+n)/n=(n+1)/2O(n)")
7
二元搜尋(Binary Search) 適用於已排序完成資料之搜尋 欲搜尋值(Key Value)先與該資料的中位數(middle)比較
假設資料的內容為Data[0]到Data[n],則middle = n / 2,左邊界left = 0,右邊界right = n,其原理可歸納如下

8
若key Value小於Data[middle]
表示Key Value出現在Data[middle]之前,故搜尋Data[0]到Data[middle-1]之間的資料,此時left=left,right=middle-1,middle=(left+right)/2 若Key Value大於Data[middle] 表示Key Value出現在Data[middle]之後,故搜尋Data[middle+1]到Data[n]之間的資料,此時left=middle+1,right=right,middle=(left+right)/2
![若key Value小於Data[middle]](http://slidesplayer.com/slide/11244135/61/images/8/%E8%8B%A5key+Value%E5%B0%8F%E6%96%BCData%5Bmiddle%5D.jpg "表示Key Value出現在Data[middle]之前,故搜尋Data[0]到Data[middle-1]之間的資料,此時left=left,right=middle-1,middle=(left+right)/2. 若Key Value大於Data[middle] 表示Key Value出現在Data[middle]之後,故搜尋Data[middle+1]到Data[n]之間的資料,此時left=middle+1,right=right,middle=(left+right)/2.")
9
重複執行上述三步驟直到left=right或是找到欲搜尋資料為止 例如,有一個整數陣列的資料內容如下
若Key Value等於Data[middle] 表示已搜尋到資料 重複執行上述三步驟直到left=right或是找到欲搜尋資料為止 例如,有一個整數陣列的資料內容如下

10
如欲找出25,此時left = 0,right = 11,middle = 11 / 2 = 5 ,Key Value = 25:
Step 1: 25 < Data[5] = 37,left = 0,right = 4,middle = 2 Step 2: 25 > Data[3] = 12,left = 3,right = 4,middle = 3 Step 3: 25 = Data[3] = 25,表示找到資料

11
Best case時間複雜度為B(n)=1O(n),表示第一次即找到資料
Worst case時間複雜度為W(n)=log2n O(logn),表示未找到資料或資料出現在最後一次搜尋 Average case時間複雜度為O(logn)
=log2n O(logn),表示未找到資料或資料出現在最後一次搜尋. Average case時間複雜度為O(logn)")
12
費氏搜尋(Fibonacci Search)
二元搜尋法採用將資料範圍切半,運用到除法運算來減少搜尋範圍 費氏搜尋則利用加減運算來減少範圍 電腦處理加減運算的效率高於乘除運算,故費氏搜尋的效率會優於二元搜尋

13
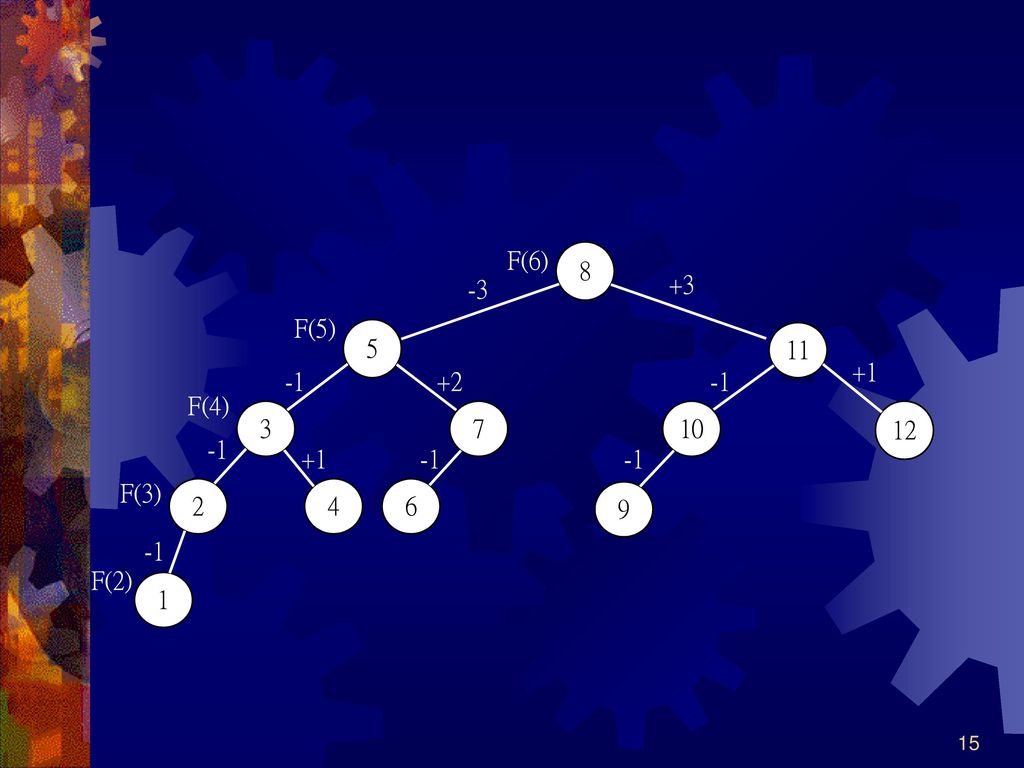
費氏搜尋就是利用費氏數列來切割資料範圍的搜尋方法
費氏數列: 第1項為1,第2項為1 ,第3項之後的規則為「第n項為第n-1項和第n-2項的和」,亦即F1=1,F2=1,Fn=Fn-1+Fn-2 產生之費氏數列:1、1、2、3、5、8、13、21、34、55… 費氏搜尋就是利用費氏數列來切割資料範圍的搜尋方法

14
費氏搜尋樹 以費氏級數的特性建造的二元樹。 任一費氏樹的節點數加1等於費氏樹 分成根節點、左子樹及右子樹三部分
左子樹的節點數為F(n-1)-1 右子樹的節點數為F(n-2)-1 各子樹仍為n-1級和n-2級的費氏樹 父節點與子節點之差為一個費氏數
-1. 右子樹的節點數為F(n-2)-1. 各子樹仍為n-1級和n-2級的費氏樹. 父節點與子節點之差為一個費氏數.")
16
設有n筆已排序好之資料,每次搜尋時必須先找出其費氏樹的樹根和差值,原則如下
先計算費氏級數F(a),使得F(a)n+1,如上圖若資料有12筆,則F(a) 12+1=13, 故a=6 第一次搜尋費氏樹的樹根r,即r=F(a-1),s=F(a-2),t=F(a-3)
,使得F(a)n+1,如上圖若資料有12筆,則F(a) 12+1=13, 故a=6. 第一次搜尋費氏樹的樹根r,即r=F(a-1),s=F(a-2),t=F(a-3)")
17
若搜尋值小於第F(a-1)筆資料的值 若搜尋值大於第F(a-1)筆資料的值
筆資料的值 若搜尋值大於第F(a-1)筆資料的值")
18
例如,有一個整數陣列的資料內容如下 若搜尋值等於第F(a-1)筆資料的值 重複直型上述三步驟直到找到欲搜尋資料或差值為0為止
筆資料的值 重複直型上述三步驟直到找到欲搜尋資料或差值為0為止")
19
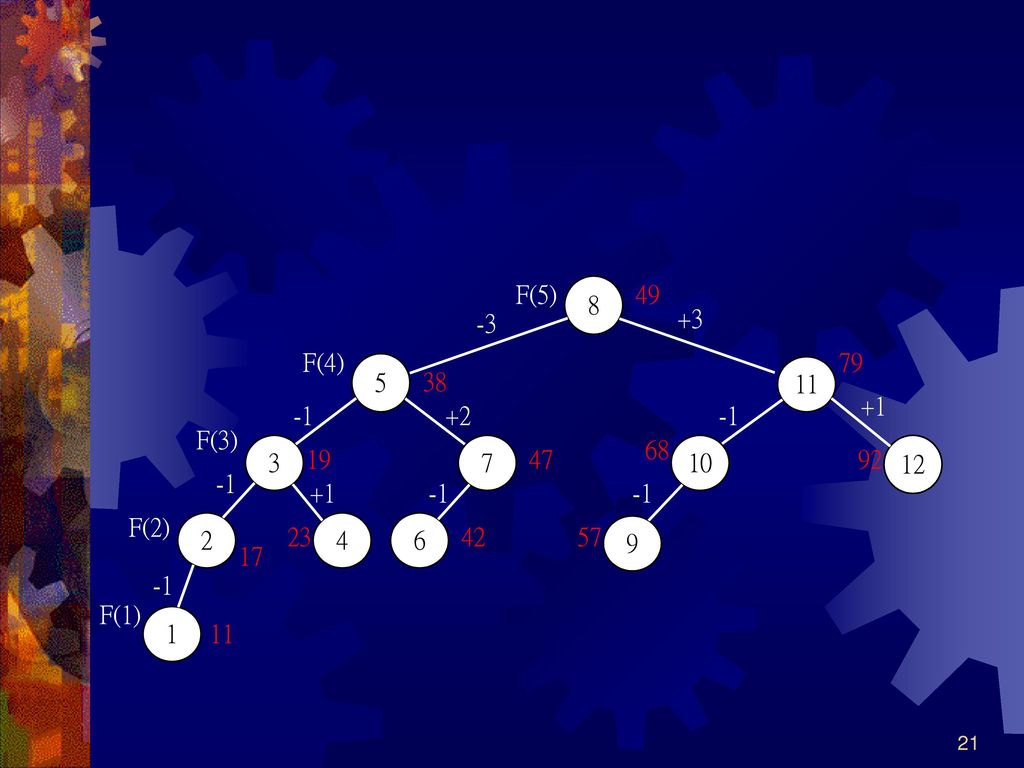
如欲搜尋42,此時資料有12筆,F(k)-1=12,所以k=7
第一次搜尋樹根r=F(k-1)=F(6)=8,s=5,t=3 搜尋值42<r的鍵值49 若t=0,令r=0 若t0,令r=r-t=5,temp=s=5,s=t=3,t=temp-t=2,此時r的鍵值為38
=F(6)=8,s=5,t=3. 搜尋值42<r的鍵值49. 若t=0,令r=0. 若t0,令r=r-t=5,temp=s=5,s=t=3,t=temp-t=2,此時r的鍵值為38.")
20
搜尋值42>r的鍵值 搜尋值42<r的鍵值 搜尋值42=r的鍵值,搜尋成功 若s=1,令r=0
若s1,令r=r+t=7,s=s-t=1,t=t-s=1,此時r的鍵值等於47 搜尋值42<r的鍵值 t0,令r=r-t=6,temp=s=1,s=t=1,t=temp-t=0,此時r的鍵值等於42 搜尋值42=r的鍵值,搜尋成功

22
差補搜尋(Interpolation Search)
採用『各個擊破法』(Divide and Conquer)的方式來搜尋資料位置 與欲搜尋資料比對的不是資料的中間項,而是以內插法按照比例所選出的一項 假設資料分佈如圖所示
的方式來搜尋資料位置. 與欲搜尋資料比對的不是資料的中間項,而是以內插法按照比例所選出的一項. 假設資料分佈如圖所示.")
23
Low為資料範圍的左邊邊界(下限) ,High為資料範圍的右邊邊界(上限) ,KeyValue為欲搜尋值,Data[High]為右邊邊界資料值,Data[Low]為左邊邊界資料值,Middle為與搜尋值比對的資料位置
![Low為資料範圍的左邊邊界(下限) ,High為資料範圍的右邊邊界(上限) ,KeyValue為欲搜尋值,Data[High]為右邊邊界資料值,Data[Low]為左邊邊界資料值,Middle為與搜尋值比對的資料位置](http://slidesplayer.com/slide/11244135/61/images/23/Low%E7%82%BA%E8%B3%87%E6%96%99%E7%AF%84%E5%9C%8D%E7%9A%84%E5%B7%A6%E9%82%8A%E9%82%8A%E7%95%8C%28%E4%B8%8B%E9%99%90%29+%EF%BC%8CHigh%E7%82%BA%E8%B3%87%E6%96%99%E7%AF%84%E5%9C%8D%E7%9A%84%E5%8F%B3%E9%82%8A%E9%82%8A%E7%95%8C%28%E4%B8%8A%E9%99%90%29+%EF%BC%8CKeyValue%E7%82%BA%E6%AC%B2%E6%90%9C%E5%B0%8B%E5%80%BC%EF%BC%8CData%5BHigh%5D%E7%82%BA%E5%8F%B3%E9%82%8A%E9%82%8A%E7%95%8C%E8%B3%87%E6%96%99%E5%80%BC%EF%BC%8CData%5BLow%5D%E7%82%BA%E5%B7%A6%E9%82%8A%E9%82%8A%E7%95%8C%E8%B3%87%E6%96%99%E5%80%BC%EF%BC%8CMiddle%E7%82%BA%E8%88%87%E6%90%9C%E5%B0%8B%E5%80%BC%E6%AF%94%E5%B0%8D%E7%9A%84%E8%B3%87%E6%96%99%E4%BD%8D%E7%BD%AE.jpg "Low為資料範圍的左邊邊界(下限) ,High為資料範圍的右邊邊界(上限) ,KeyValue為欲搜尋值,Data[High]為右邊邊界資料值,Data[Low]為左邊邊界資料值,Middle為與搜尋值比對的資料位置")
24
其公式為 首先先判斷算出來的Middle值是否小於Low,如果Middle小於Low,則令Middle等於Low;如果Middle大於High,則令Middle等於High

25
接著按下列規則運作 若搜尋值小於Data[Middle] 若搜尋值大於Data[Middle] 若左邊邊界Low小於右邊邊界High
表示資料在Data[Middle]之前,則須搜尋Data[Middle]之前的資料,High設為Middle-1 若搜尋值大於Data[Middle] 表示資料在Data[Middle]之後,則須搜尋Data[Middle]之後的資料,Low設為Middle+1 若左邊邊界Low小於右邊邊界High 表示未完成搜尋,重新計算Middle值;否則,Middle=Low
![接著按下列規則運作 若搜尋值小於Data[Middle] 若搜尋值大於Data[Middle] 若左邊邊界Low小於右邊邊界High](http://slidesplayer.com/slide/11244135/61/images/25/%E6%8E%A5%E8%91%97%E6%8C%89%E4%B8%8B%E5%88%97%E8%A6%8F%E5%89%87%E9%81%8B%E4%BD%9C+%E8%8B%A5%E6%90%9C%E5%B0%8B%E5%80%BC%E5%B0%8F%E6%96%BCData%5BMiddle%5D+%E8%8B%A5%E6%90%9C%E5%B0%8B%E5%80%BC%E5%A4%A7%E6%96%BCData%5BMiddle%5D+%E8%8B%A5%E5%B7%A6%E9%82%8A%E9%82%8A%E7%95%8CLow%E5%B0%8F%E6%96%BC%E5%8F%B3%E9%82%8A%E9%82%8A%E7%95%8CHigh.jpg "表示資料在Data[Middle]之前,則須搜尋Data[Middle]之前的資料,High設為Middle-1. 若搜尋值大於Data[Middle] 表示資料在Data[Middle]之後,則須搜尋Data[Middle]之後的資料,Low設為Middle+1. 若左邊邊界Low小於右邊邊界High. 表示未完成搜尋,重新計算Middle值;否則,Middle=Low.")
26
重複直型上述步驟直到找到欲搜尋資料或Low直大於High值為止
若Middle小於左邊邊界Low Middle=Low 若Middle大於右邊邊界High Middle=High 重複直型上述步驟直到找到欲搜尋資料或Low直大於High值為止

27
例如,有一個整數陣列的資料內容如下 現在想找出9,此時資料有12筆,Low=0,High=11,KeyValue=9,Data[Low]=1,Data[High]=33
![例如,有一個整數陣列的資料內容如下 現在想找出9,此時資料有12筆,Low=0,High=11,KeyValue=9,Data[Low]=1,Data[High]=33](http://slidesplayer.com/slide/11244135/61/images/27/%E4%BE%8B%E5%A6%82%EF%BC%8C%E6%9C%89%E4%B8%80%E5%80%8B%E6%95%B4%E6%95%B8%E9%99%A3%E5%88%97%E7%9A%84%E8%B3%87%E6%96%99%E5%85%A7%E5%AE%B9%E5%A6%82%E4%B8%8B+%E7%8F%BE%E5%9C%A8%E6%83%B3%E6%89%BE%E5%87%BA9%EF%BC%8C%E6%AD%A4%E6%99%82%E8%B3%87%E6%96%99%E6%9C%8912%E7%AD%86%EF%BC%8CLow%3D0%EF%BC%8CHigh%3D11%EF%BC%8CKeyValue%3D9%EF%BC%8CData%5BLow%5D%3D1%EF%BC%8CData%5BHigh%5D%3D33.jpg "例如,有一個整數陣列的資料內容如下 現在想找出9,此時資料有12筆,Low=0,High=11,KeyValue=9,Data[Low]=1,Data[High]=33")
29
Step 1: KeyValue=9>Data[Middle]=Data[2]=6 表示資料在Middle之後
所以Low=Middle+1=3
![Step 1: KeyValue=9>Data[Middle]=Data[2]=6 表示資料在Middle之後](http://slidesplayer.com/slide/11244135/61/images/29/Step+1%3A+KeyValue%3D9%3EData%5BMiddle%5D%3DData%5B2%5D%3D6+%E8%A1%A8%E7%A4%BA%E8%B3%87%E6%96%99%E5%9C%A8Middle%E4%B9%8B%E5%BE%8C.jpg "所以Low=Middle+1=3.")
30
Step 2: KeyValue=9>Data[Middle]=Data[3]=7 表示資料在Middle之後
所以Low=Middle+1=4
![Step 2: KeyValue=9>Data[Middle]=Data[3]=7 表示資料在Middle之後](http://slidesplayer.com/slide/11244135/61/images/30/Step+2%3A+KeyValue%3D9%3EData%5BMiddle%5D%3DData%5B3%5D%3D7+%E8%A1%A8%E7%A4%BA%E8%B3%87%E6%96%99%E5%9C%A8Middle%E4%B9%8B%E5%BE%8C.jpg "所以Low=Middle+1=4.")
31
如果想找出20,此時資料有12筆,Low=0,High=11,KeyValue=20,Data[Low]=1,Data[High]=33
Step 3: KeyValue=9=Data[Middle]=Data[4]=9 找到資料 如果想找出20,此時資料有12筆,Low=0,High=11,KeyValue=20,Data[Low]=1,Data[High]=33
![如果想找出20,此時資料有12筆,Low=0,High=11,KeyValue=20,Data[Low]=1,Data[High]=33](http://slidesplayer.com/slide/11244135/61/images/31/%E5%A6%82%E6%9E%9C%E6%83%B3%E6%89%BE%E5%87%BA20%EF%BC%8C%E6%AD%A4%E6%99%82%E8%B3%87%E6%96%99%E6%9C%8912%E7%AD%86%EF%BC%8CLow%3D0%EF%BC%8CHigh%3D11%EF%BC%8CKeyValue%3D20%EF%BC%8CData%5BLow%5D%3D1%EF%BC%8CData%5BHigh%5D%3D33.jpg "Step 3: KeyValue=9=Data[Middle]=Data[4]=9. 找到資料. 如果想找出20,此時資料有12筆,Low=0,High=11,KeyValue=20,Data[Low]=1,Data[High]=33.")
33
Step 1: KeyValue=20>Data[Middle]=Data[6]=15 表示資料在Middle之後
所以Low=Middle+1=7
![Step 1: KeyValue=20>Data[Middle]=Data[6]=15 表示資料在Middle之後](http://slidesplayer.com/slide/11244135/61/images/33/Step+1%3A+KeyValue%3D20%3EData%5BMiddle%5D%3DData%5B6%5D%3D15+%E8%A1%A8%E7%A4%BA%E8%B3%87%E6%96%99%E5%9C%A8Middle%E4%B9%8B%E5%BE%8C.jpg "所以Low=Middle+1=7.")
34
Step 2: KeyValue=20>Data[Middle]=Data[7]=18 表示資料在Middle之後
所以Low=Middle+1=8 此時Middle<Low,所以Middle=Low=8
![Step 2: KeyValue=20>Data[Middle]=Data[7]=18 表示資料在Middle之後](http://slidesplayer.com/slide/11244135/61/images/34/Step+2%3A+KeyValue%3D20%3EData%5BMiddle%5D%3DData%5B7%5D%3D18+%E8%A1%A8%E7%A4%BA%E8%B3%87%E6%96%99%E5%9C%A8Middle%E4%B9%8B%E5%BE%8C.jpg "所以Low=Middle+1=8. 此時Middle<Low,所以Middle=Low=8.")
35
Step 3: KeyValue=20<Data[Middle]=Data[8]=27 表示資料在Middle之前
所以High=Middle-1=7 因為此時High<Low,表示未能找到資料
![Step 3: KeyValue=20<Data[Middle]=Data[8]=27 表示資料在Middle之前](http://slidesplayer.com/slide/11244135/61/images/35/Step+3%3A+KeyValue%3D20%3CData%5BMiddle%5D%3DData%5B8%5D%3D27+%E8%A1%A8%E7%A4%BA%E8%B3%87%E6%96%99%E5%9C%A8Middle%E4%B9%8B%E5%89%8D.jpg "所以High=Middle-1=7. 因為此時High<Low,表示未能找到資料.")
36
插補搜尋法對於平均分佈的資料,其效率很高,其時間複雜度為O(log2log2n),比二元搜尋法好
對於分佈不平均的資料,其效率卻不好,worst case的時間複雜度為O(n)
")
37
加強型插補搜尋法 改良後的插補搜尋法,是取三數中的中間數做為Middle值

38
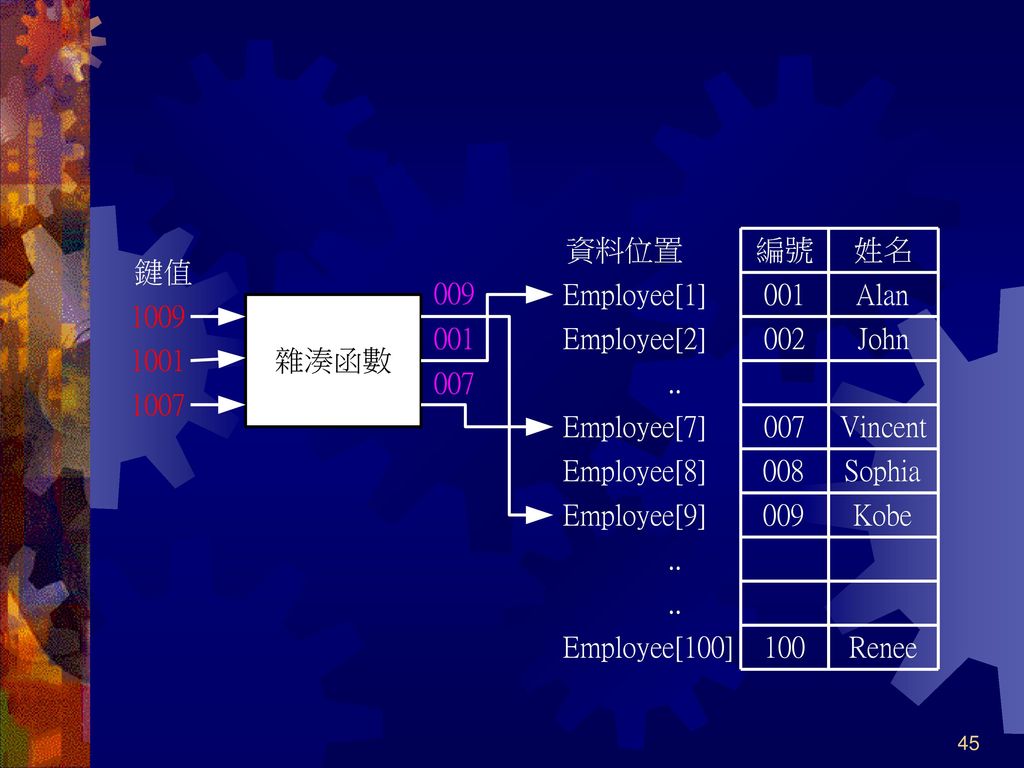
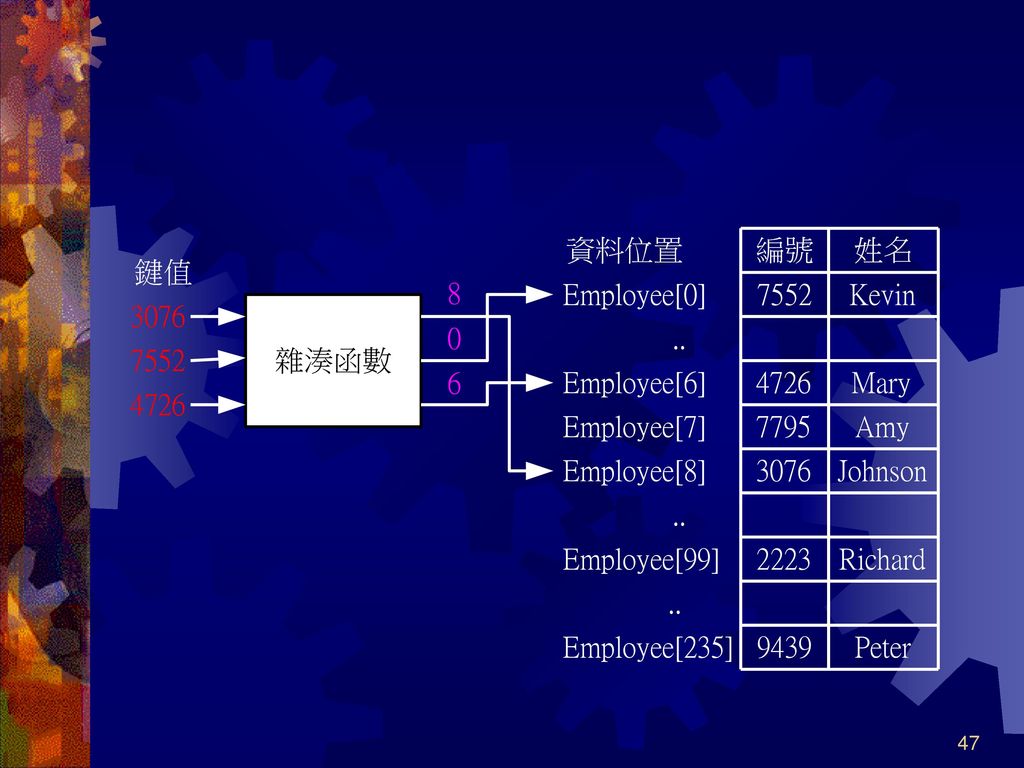
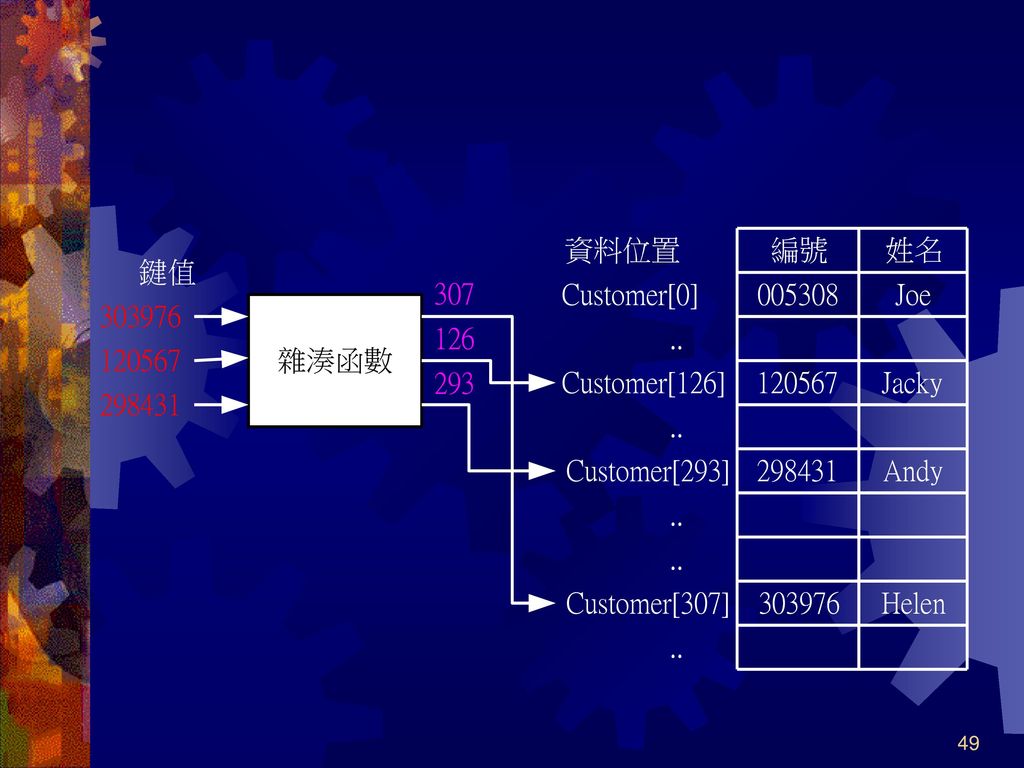
雜湊搜尋(Hash Search) 欲加速搜尋速度,減少資料比較次數是唯一方法 雜湊搜尋可將資料比較次數減少到每次搜尋只須一次
雜湊表中資料儲存位置是透過特定雜湊函數運算而來 進行雜湊搜尋時,只需將資料再透過雜湊函數的計算後,即可找到欲搜尋資料

39
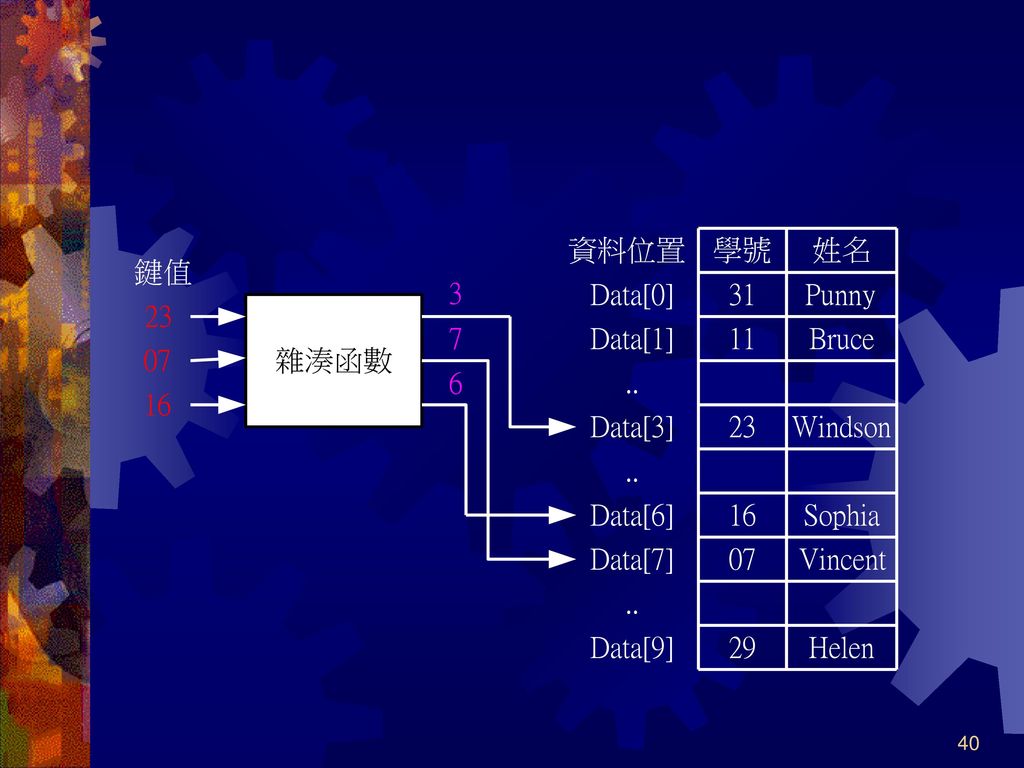
在雜湊結構中,我們稱輸入資料的值為鍵值(Key)
例如,利用雜湊表儲存學生資料,其中學生的學號即為雜湊表的鍵值,運作過程大致如下

41
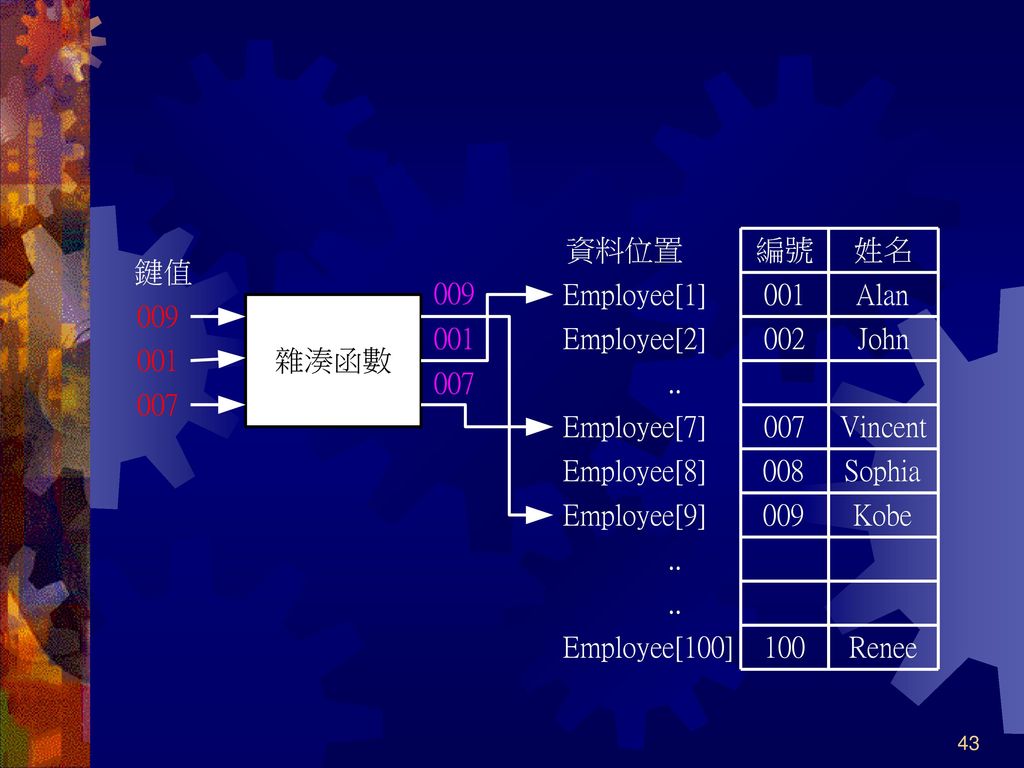
雜湊函數 直接法(Direct Method) 每一個鍵值對應一個儲存空間,而不經過任何數學運算動作
例如,公司有100個員工,員工編號介於1到100 ,直接法就是員工編號即為資料位置 直接法適用於鍵值較小的資料 例如,以身分證字號為鍵值,需要260億個儲存空間

42
雜湊法大部分是用在將數值範圍較大的鍵值,對映於少數的儲存空間,以加快搜尋速度,減少儲存空間的浪費

44
減去法(Subtraction Method)
資料鍵值減去一個特定的數值,以求得資料儲存的位置 例如,公司有100個員工,員工編號介於1001到1100 ,減去法就是員工編號減去1000即為資料儲存位置

46
餘數法(Modulo-Division Method)
將資料的鍵值除以陣列大小後,取其餘數做為資料儲存的位置 例如,公司有236個員工,而員工編號介於1000到9999 ,餘數法就是將員工編號除以資料個數減去236後,取餘數即為資料位置

48
數值抽出法(Digit-Extraction Method)
將資料的鍵值中的某幾位數取出後做為資料儲存的位置 例如,資料鍵值為一組六位數的號碼,假設以鍵值的第一位、第二位、第五位數做為資料位置的索引值

50
中間平方法(Midsquare Method)
將資料鍵值中的前幾位數取出後平方產生一新數值,再從新數值中取出中間某幾位數做為資料儲存位置 325*325= 056 213*213= 453 645*645= 277 215*215= 462

51
摺疊法(Folding Method) 將資料的鍵值分為多層,然後相加取其結果為資料儲存位置 移位摺疊法(Fold Shift)
各層資料直接相加,取其結果;例如鍵值為 ,則

52
邊界摺疊法(Fold Boundary) 各層資料在相加之前,每隔一部分進行一次反轉,相加後取其結果;例如鍵值123456789
321 (反轉) 456 + 987 (反轉) ━━━━━━ 1764
 (反轉) ━━━━━━")
53
旋轉法(Rotation Method) 將資料的鍵值進行旋轉,通常不直接做為雜湊函數,而是配合其他雜湊函數使用
 將資料的鍵值進行旋轉,通常不直接做為雜湊函數,而是配合其他雜湊函數使用")
54
偽亂數法(Pseudo-random Method)
將資料鍵值經由偽亂數法運算後的結果做為資料儲存位置 如鍵值為321547,陣列大小為107 ,取a=13、c=5 ,則

55
Y = (13 * ) % 107 = ( ) % 107 = % 107 = 54 取54做為資料儲存位置
 % 107 = ( ) % 107 = % 107 = 54 取54做為資料儲存位置")
56
雜湊碰撞解決法 利用雜湊函數產生資料位置時可能會發生資料位置已有一筆資料的情形,稱為雜湊碰撞(Hash Collision)
發生雜湊碰撞時,必須提供解決方法,讓資料有對映儲存位置,否則將造成資料流失或錯誤

57
線性開放定址法(Linear Open Addressing)
線性探索法(Linear Probe) 往下一筆資料位置尋找可用空間儲存資料 假設現有資料如下:654、638、214、357、376、854、652、392,採用數值抽出法,取出第二位,並將資料放入大小為10的雜湊表中
 往下一筆資料位置尋找可用空間儲存資料. 假設現有資料如下:654、638、214、357、376、854、652、392,採用數值抽出法,取出第二位,並將資料放入大小為10的雜湊表中.")
58
插入資料654,位置為5 插入資料638,位置為3

59
插入資料214,位置為1 插入資料357,位置為5,發生碰撞忘下一筆資料儲存空間尋找可用空間,位置為6

60
插入376,位置為7 插入854,位置為5,發生雜湊碰撞,往下一筆資料位置尋找可用空間,位置為8

61
插入資料662,位置為6,發生雜湊碰撞,往下一筆資料位置尋找可用空間,位置為9
插入資料392,位置為9,發生雜湊碰撞,往下一筆資料位置尋找可用空間,位置為0

62
二次方探索法(Quadratic Probe)
以現在的資料位址加上碰撞次數的平方數,當資料位址超出陣列大小時,則讓資料位址採循環方式處理(新資料位址對陣列大小取餘數) 假設第一次發生雜湊碰撞的位置在1,陣列大小為80,其運作方式如下
 假設第一次發生雜湊碰撞的位置在1,陣列大小為80,其運作方式如下.")
63
探索次數 雜湊碰撞位置 位置增加值 新資料位置 1 12=1 (1 + 1) % 80 = 2 2 22=4 (2 + 4) % 80 = 6 3 6 32=9 (6 + 9) % 80 = 15 4 15 42=16 ( ) % 80 = 31 5 31 52=25 ( ) % 80 = 56 56 62=36 ( ) % 80 = 12 7 12 72=49 ( ) % 80 = 61 8 61 82=64 ( ) % 80 = 17
 % 80 = =16. ( ) % 80 = =25. ( ) % 80 = =36. ( ) % 80 = =49. ( ) % 80 = =64. ( ) % 80 = 17.")
64
差值解決法(Offset Resolution)
以現在的資料位址加上一固定差值,當資料位址超出陣列大小時,讓位址以循環方式處理 假設現有資料如下:23、57、65、63、67、33,現採用餘數法,將資料放入大小為10的雜湊表,令差值為3

65
插入資料23,23%10=3,位置為3 插入資料57,57%10=7,位置為7

66
插入資料65,65%10=5,位置為5 插入63,位置為3,發生碰撞,新資料位置為3+3=6

67
插入67,位置為7,發生碰撞,新資料位置為7+3=1010%10=0
插入33,位置為3,發生碰撞,新資料位置為3+3=6,再發生碰撞,新位置為6+3=9

68
鏈結串列解決法 (Linked List Resolution)
以現在的資料位置再串連一個新的鏈結串列來儲存資料

69
分桶雜湊法(Bucket Hashing)
將資料分為幾大類,稱之為「桶」,每個大類可放置相同大類的資料多筆 經雜湊函數運算後屬同一大類的資料,即放在同一大類中,直到這一大類的資料全填滿才往下一大類儲存 Bucket的結構,可用多維陣列來製作

70
資料位置 分桶編號 資料編號 資料內容 Data[0] Bucket 0 880335 Alan Data[1] Bucket 1 871054 Jeff 881564 Kevin 831572 Poe Data[2] Bucket 2 872087 Peter 841098 Bob …… Data[9] Bucket 9 849035 Ketty
![資料位置 分桶編號. 資料編號. 資料內容. Data[0] Bucket Alan. Data[1] Bucket Jeff](http://slidesplayer.com/slide/11244135/61/images/70/%E8%B3%87%E6%96%99%E4%BD%8D%E7%BD%AE+%E5%88%86%E6%A1%B6%E7%B7%A8%E8%99%9F.+%E8%B3%87%E6%96%99%E7%B7%A8%E8%99%9F.+%E8%B3%87%E6%96%99%E5%85%A7%E5%AE%B9.+Data%5B0%5D+Bucket+Alan.+Data%5B1%5D+Bucket+Jeff.jpg "Kevin Poe. Data[2] Bucket Peter Bob. …… Data[9] Bucket Ketty.")
71
二元搜尋樹 二元搜尋樹的規則為左子節點的值小於或等於其父節點的值,而右子節點的值大於其父節點的值
基於二元搜尋樹的規則,欲搜尋某個數值時,只要先比較其根部父節點,如果搜尋值小於父節點值則往左子樹搜尋;反之則往右子樹搜尋














.>")



 課程名稱:資料結構 授課老師:_____________.>")




