Download presentation
Presentation is loading. Please wait.

1
人群健康研究的统计方法 预防医学系 指导教师:方亚 电话:

2
统计学 计 量 资 料 的 统 推 断 计 数 资 料 的 统 描 述 计 数 资 料 的 统 推 断 相 关 与 回 归 计 量 资 料
医 学 统 计 的 基 本 概 念 和 步 骤 计 量 资 料 的 统 推 断 计 数 资 料 的 统 描 述 计 数 资 料 的 统 推 断 相 关 与 回 归 计 量 资 料 的 统 描 述

3
医学统计学简介

4
一、医学统计学的定义 统计学是一门研究数据的科学。它指导人们在科学实践中如何有效地获取数据、正确地分析数据以及合理地解释所得到的结果。
医学统计学是统计学的一个分支。它是把概率论和数理统计学的基本原理和方法应用于医学科学领域,涉及医学研究设计、数据搜集、数据整理和数据分析的一门应用性学科。

5
医学研究的对象是人,而人既具有生物属性,又具有社会属性,其变异性大,影响因素错综复杂。例如:
1)同样是健康人,即使年龄和性别相同,其身高、体重、血压等数值有所不同; 2)同一个人,即使在同一天中,其不同时间段的血压等数值有所不同; 3)采用同样方案治疗某病,即使年龄、性别、病情、病程均相同,其治疗效果有所不同;
同样是健康人,即使年龄和性别相同,其身高、体重、血压等数值有所不同; 2)同一个人,即使在同一天中,其不同时间段的血压等数值有所不同; 3)采用同样方案治疗某病,即使年龄、性别、病情、病程均相同,其治疗效果有所不同;")
6
上述几例都是由于个体存在变异的结果。变异是人群的特征,医学统计学研究的对象就是来自人群的、具有变异特征的数据资料。
合理的 偶然现象 客观规律性 统计分析

7
如:1948年,链霉素治疗结核病的对照研究 临床试验 随机化原则 将病人分别分配到链霉素疗效观察组与对照组(不用链霉素)。 6个月治疗后 观察组 55名结核病人 死亡4人 对照组 52名结核病人 死亡14人 X光检查,观察组病人的病情比对照组有更大的改善

8
又如:孕期补充维生素(叶酸)与婴儿神经管缺陷
80年代初,有文章报道孕期补充维生素(叶酸)可以减少生育神经管缺陷婴儿的危险。 据报道,先服用维生素后怀孕的妇女比怀孕后才开始服用维生素的妇女和拒绝参加试验的怀孕妇女所生的婴儿神经管缺陷的发生率要低。
可以减少生育神经管缺陷婴儿的危险。 据报道,先服用维生素后怀孕的妇女比怀孕后才开始服用维生素的妇女和拒绝参加试验的怀孕妇女所生的婴儿神经管缺陷的发生率要低。")
9
参加服用维生素试验和拒绝试验的孕妇之间存在某些生理特征上的系统差别,致使在解释试验结果时发生困难。这不能不认为是因实验设计缺乏周密考虑所造成的经验教训。
补救 随机化分配受试者 叶酸补充组 安慰剂组 样本人数过少 无法作出肯定的科学结论

10
叶酸补充组 592名 6名 1991年 大样本的随机化试验 获得了肯定的科学结论 怀孕妇女 新生儿神经管缺陷 安慰剂组 602名 21名
1991年 大样本的随机化试验 获得了肯定的科学结论 怀孕妇女 新生儿神经管缺陷 安慰剂组 名 名 叶酸补充组 592名 名 统计学分析证实,叶酸对预防新生儿神经管缺陷确有明显的效果 学习医学统计学的重要性 医学统计学在医学领域里具有不可低估的重要性, 是医学科学工作者不可缺少的知识和技能。

11
第一章 医学统计学的基本概念和步骤 第一节 统计学中的几个基本概念

12
一、总体和样本 总体(population) 根据研究目的确定的同质的全部研究对象。 ⊙ 有限总体:总体中个体的总数是有限的。
⊙ 无限总体:总体的时间、空间未加以限制,总体中的个 体数可无限增加。 如研究糖尿病人的血压测定值; 由于无时间和空间的限制,全部糖尿病人的血压测定值 为无限总体。

13
样本(sample) 根据随机化的原则从总体中抽出有代表性的一部分观察单位。 ⊙抽样:抽取样本的过程。 ⊙统计推断:对样本进行观察,用样本的特征推断总体的 特征。是研究人群健康经常用到的方法。
 根据随机化的原则从总体中抽出有代表性的一部分观察单位。 ⊙抽样:抽取样本的过程。 ⊙统计推断:对样本进行观察,用样本的特征推断总体的 特征。是研究人群健康经常用到的方法。")
14
二、同质和变异 同质(homogeneity) 指被研究指标的非实验因素相同. 被研究指标:儿童身高
影响较大、易控制的因素:性别、年龄、民族、地区(相同) 变异(variation) 指在同质的基础上各观察单位(或个体)之间的差异。 同性别、同年龄、同地区、同体重儿童的某项指标有高有低,称为某项指标的变异。
 变异(variation) 指在同质的基础上各观察单位(或个体)之间的差异。 同性别、同年龄、同地区、同体重儿童的某项指标有高有低,称为某项指标的变异。")
15
三、参数和统计量 参数(parameter ) 描述总体的统计指标。
如研究中国12岁以上男性的吸烟率,观察12岁以上的全部中国男性,登记他们的目前吸烟情况,计算出的吸烟率即为参数。 统计量(statistic) 描述样本的统计指标。 用随机的方法从总体中抽出一部分12岁的男性,计算的吸烟率称作统计量。
 描述样本的统计指标。 用随机的方法从总体中抽出一部分12岁的男性,计算的吸烟率称作统计量。")
16
四、误差 误差(error):观察值与实际值之差 。 主要有3种:系统误差,随机测量误差,抽样误差 1. 系统误差
在资料的搜集过程中,因试剂未标定、仪器未校正、标 准未统一等而导致测量结果有倾向性的误差。应严格控 制,它影响结果的准确度。

17
偶然因素的影响,导致同一研究对象在多次测定中结果 不一致的情况。应控制在允许范围内。
2. 随机测量误差 在试剂、仪器已校正,操作方法已统一的情况下,由于 偶然因素的影响,导致同一研究对象在多次测定中结果 不一致的情况。应控制在允许范围内。 3.抽样误差 由于抽样而使某变量值的统计量与总体参数不相同。 抽样误差不可避免,但它可以用统计学方法处理。

18
五、概率 概率(probability) 描述随机事件发生可能性大小的数值,常用P表示。 小数或百分数。 P值的范围:介于0和1之间。
 描述随机事件发生可能性大小的数值,常用P表示。 小数或百分数。 P值的范围:介于0和1之间。")
19
在医学统计学中,主要是处理大概率和小概率的问题。大小概率的分界点为0. 05(5%)。习惯上称P0
统计分析中的很多结论都是带有概率性的。

20
六、变量及变量值 变量(variable):观察对象的特征或指标 如,性别,年龄,体重
变量值(value of variable):测量的结果 如,性别—男、女 年龄—数值,体重—测量值
:测量的结果. 如,性别—男、女. 年龄—数值,体重—测量值.")
21
第二节 统计资料的类型 计量资料 measurement data 用定量的方法对观察单位进行测量取得的资料。如身高、体重、血压等。
第二节 统计资料的类型 计量资料 measurement data 用定量的方法对观察单位进行测量取得的资料。如身高、体重、血压等。 计数资料 enumeration data 用定性的方法取得的资料。如性别,职业等 定 量 等级资料 rank data 将观察对象按照某种属性分为几个等级的资料。如将贫血分为轻、中、重3个等级,治疗效果分为显效、好转、有效和无效4个等级等。

22
资料类型不同,选择的统计分析方法也不同 较常见的是计量资料和计数资料,区分方法: 计量资料: (1)可以是任意数,如整数、小数、正数、负数; (2)有明确的计量单位,如 kg, cm。 计数资料: (1)只能是正整数; (2)无计量单位。
只能是正整数; (2)无计量单位。")
23
资料间的相互转化: 血红蛋白 (等级资料) (计数资料) 血红蛋白含量(g/L)(计量资料) 含量多少 正常否
重度贫血,中度贫血,轻度贫血,正常,血红蛋白增高 (等级资料) 血红蛋白 正常与异常 (计数资料)
 血红蛋白. 正常与异常. (计数资料)")
24
第三节 统计工作的基本步骤 1.设计 2.搜集资料 3.整理资料 4.分析资料 四个步骤相互联系

25
科学、周密、严谨的设计是搜集准确可靠资料的保证;
准确、完整、及时地搜集资料、恰当地整理资料是统计分析的基础; 选择正确的方法分析资料和表达资料可获得科学的结论。

26
一、设计(design) 调查设计 实验设计 专业设计 统计设计 三个原则 对照 资料搜集 资料整理 资料分析 随机 重复
 调查设计 实验设计 专业设计 统计设计 三个原则 对照 资料搜集 资料整理 资料分析 随机 重复")
27
二、资料搜集 (data collection) 资料来源:
1. 统计报表 –医院工作报表、疫情报表 2. 报告卡—传染病、职业病、肿瘤、出生、死亡 3. 日常医疗卫生工作记录—门诊及住院病历 4. 专题调查或实验 要求:及时、完整、准确 参与搜集资料人员的选择是关键。 高素质、有相关专业基础、以往曾有类似研究经历 严格培训和管理

28
三、资料整理(data sorting) 目的:将搜集到的原始资料系统化、条理化,便于进一步计算统计指标和深入分析。
整理前:要对资料再次检查与核对,发现缺项或错项较多的调查表,须补查或剔除。 审查无误后,设计分组 分组方式常用的有两种:

29
1. 质量分组 将观察单位按属性和类别分组,如按性别、职业、病种等分组。 2. 数量分组 将观察单位按数值大小分组,如划分年龄组、身高组等。
手工汇总或计算机汇总

30
根据研究设计的目的、要求、资料的类型和分布特征选择正确的统计方法进行统计分析:
四、资料分析(data analysis) 根据研究设计的目的、要求、资料的类型和分布特征选择正确的统计方法进行统计分析: 统计描述 统计推断
 根据研究设计的目的、要求、资料的类型和分布特征选择正确的统计方法进行统计分析: 统计描述. 统计推断.")
31
第四节 医学统计学的应用 一、拓宽医学研究思路 二、医学科研设计科学合理 三、资料准确可靠 四、选择合适分析方法及正确解释结果

32
小结 SUMMARY

33
一、医学统计学定义 二、几个基本概念 运用概率论和数理统计的基本原理和方法,结合医学实际,研究数据收集、整理和分析的一门应用性科学。
1.总体和样本 总体:同质的全部研究对象。有限总体,无限总体 样本:总体中有代表性的一部分 2.同质和变异 同质:被研究指标的非实验因素相同 变异:在同质的基础上各观察单位之间的差异

34
3.参数和统计量 参数:总体 统计量:样本 4.误差 观察值 —实际值 主要有3种:系统误差,随机测量误差,抽样误差

35
5. 概率 可能性大小,常用P表示。 P值的范围:0--1 分界点为0.05(5%)。P0.05为小概率事件。 6. 变量及变量值 变量:指标 变量值:观察值
。P0.05为小概率事件。 6. 变量及变量值 变量:指标 变量值:观察值")
36
计量资料、计数资料、等级资料 三、统计资料类型 四、统计工作的基本步骤 五、医学统计学的应用 1.设计:专业、统计
2.搜集资料:准确、完整、及时 3.整理资料:质量分组,数量分组 4.分析资料:统计描述,统计推断 五、医学统计学的应用 返回 目录

37
第二章 计量资料的统计描述

39
第一节 计量资料的频数分布 例 某农村地区2001年14岁女孩的身高资料如下,请编制频数表和观察频数分布情况。
第一节 计量资料的频数分布 例 某农村地区2001年14岁女孩的身高资料如下,请编制频数表和观察频数分布情况。 表 某农村地区2001年14岁女孩的身高资料(cm)
")
40
1.计算极差或全距(range) 常用R表示
一、频数分布表及其制作 1.计算极差或全距(range) 常用R表示 R=最大值-最小值 即R= =36.7(cm) 2.决定组段和组距 组段:10个左右 下限,上限 组距(class interval):相邻两组段下限值之差。 等距,“极差/组段数”的整数值
 常用R表示. R=最大值-最小值. 即R= =36.7(cm) 2.决定组段和组距. 组段:10个左右 下限,上限. 组距(class interval):相邻两组段下限值之差。 等距, 极差/组段数 的整数值.")
41
第一个组段的下限应略小于最小值,即取124cm
本例:分10个组段 组距=极差/组段数=36.7/10=3.67(cm) 取整为4cm 第一个组段的下限应略小于最小值,即取124cm 最末组上限要略大于最大值,即取164cm。 3.列表划记
 取整为4cm. 第一个组段的下限应略小于最小值,即取124cm. 最末组上限要略大于最大值,即取164cm。 3.列表划记.")
42
某农村地区2001年14岁女孩的身高资料(cm)
")
43
频数分布图

44
集中趋势(central tendency)
两个重要的特征 集中趋势(central tendency) 身高的测量值虽然高低不等,但向中间集中,中等身材 ( cm)的人数最多 离散趋势 (tendency of dispersion) 随着身高测量值逐渐变大或变小,人数越来越少, 向两端分散
 身高的测量值虽然高低不等,但向中间集中,中等身材. ( cm)的人数最多. 离散趋势 (tendency of dispersion) 随着身高测量值逐渐变大或变小,人数越来越少, 向两端分散.")
45
第二节 集中趋势指标 作用:描述数值变量资料的平均水平 常用指标:算术均数、几何均数、中位数 一、均数(mean)---算术均数
第二节 集中趋势指标 作用:描述数值变量资料的平均水平 常用指标:算术均数、几何均数、中位数 一、均数(mean)---算术均数 描述一组计量资料集中趋势(或平均水平)的指标。 总体均数:(读作mu) 样本均数: 适用条件:资料呈正态或近似正态分布。
---算术均数. 描述一组计量资料集中趋势(或平均水平)的指标。 总体均数:(读作mu) 样本均数: 适用条件:资料呈正态或近似正态分布。")
46
1. 直接法 观察例数不多(如样本含量n小于30) 公式: :求和,读作sigma, xi:各观察值, n:总例数
 公式: :求和,读作sigma, xi:各观察值, n:总例数")
47
例 有8名正常人的空腹血糖测定值(mmol/L)为6.2,5.4,5.7,5.3,6.1,6.0,5.8,5.9,求其均数。
为6.2,5.4,5.7,5.3,6.1,6.0,5.8,5.9,求其均数。")
48
2. 加权法 观察例数很多,先编制频数表,再计算 fi 每组的频数 xi 组中值-- (下限+上限)/2 (自 学)
/2 (自 学)")
49
二、几何均数(geometric mean) 表示法:G
适用条件: 1.资料呈偏态分布,但经对数变换后呈正态分布; 2.观察值间呈倍数关系或近似倍数关系的资料。 如抗体的平均滴度、药物的平均效价等。

50
计算方法: 1.直接法 : 观察例数不多(如样本含量n<30)
")
51
例 有8份血清的抗体效价分别为 1:5, 1:10, 1:20, 1:40, 1:80, 1:160, 1:320, 1:640, 求平均抗体效价。
将各抗体效价的倒数代入公式,得: =lg-1( )=57 即血清的抗体平均效价为1:57
=57. 即血清的抗体平均效价为1:57.")
52
2. 加权法:观察例数很多时采用 (自 学)
")
53
三、中位数和百分位数 (一)中位数(median) 定义:一组由小到大排列的观察值中位置居中的数值
中位数是一个位置指标,以中位数为界,将观察值 分为左右两半。 表示法:M 适用条件:资料呈明显的偏态分布;开口资料; 资料分布不清楚

54
计算方法: 1. 直接法 (n较小时) (1)将观察值按大小顺序排列; (2)n为奇数 n为偶数
 (1)将观察值按大小顺序排列; (2)n为奇数 n为偶数")
55
(1)M=127 (mmHg) (2)M=(125+127)/2=126(mmHg)
120,123,125,127,128,130,132, 求中位数。 (2)若又观察了一个人的血压值为118(mmHg), (1)M=127 (mmHg) (2)M=( )/2=126(mmHg)
若又观察了一个人的血压值为118(mmHg), (1)M=127 (mmHg) (2)M=( )/2=126(mmHg)")
56
2. 频数表法(n较大时) 参见百分位数计算公式
 参见百分位数计算公式")
57
把一组数据从小到大排列,分成100等份,各等份含1%的观察值,分割界限上的值就是百分位数。它是一个位置指标。 Px
(二)百分位数(percentile) 把一组数据从小到大排列,分成100等份,各等份含1%的观察值,分割界限上的值就是百分位数。它是一个位置指标。 Px 中位数是第50百分位数,用P50表示。 第25,第75,第95百分位数记为P25, P75, P95是统计学上常用的指标。
百分位数(percentile) 把一组数据从小到大排列,分成100等份,各等份含1%的观察值,分割界限上的值就是百分位数。它是一个位置指标。 Px. 中位数是第50百分位数,用P50表示。 第25,第75,第95百分位数记为P25, P75, P95是统计学上常用的指标。")
58
计算: (1)将观察值编制成频数表; (2)按所分组段由小到大计算累计频数和累计频率; (3)找出百分位数所在组(如P95所在组为累计频率为
95%的所在组) L:Px 所在组段下限 i:组距 n:总例数 f:Px所在组段频数 fL:小于L的各组段累计频数
 L:Px 所在组段下限. i:组距 n:总例数. f:Px所在组段频数. fL:小于L的各组段累计频数.")
59
例 某传染性疾病的潜伏期(天)见下表, 求潜伏期的第95百分位数P95 某传染性疾病的潜伏期(天)的百分位数计算表 18.4(天)
见下表, 求潜伏期的第95百分位数P95 某传染性疾病的潜伏期(天)的百分位数计算表 18.4(天)")
60
10.33(天) 求平均潜伏期M。 对于任何分布的资料都可以用中位数反映平均水平。
中位数不受个别特大或特小值的影响,只受位置居中的观察值波动的影响。 若资料呈对称或正态分布,中位数=均数 百分位数用于描述一组资料在某百分位置上的水平,常常用于正常值范围的估计。

61
第三节 离散趋势指标 三组同龄男孩体重(kg)如下: 甲组 26 28 30 32 34 均数=30 (kg)
第三节 离散趋势指标 三组同龄男孩体重(kg)如下: 甲组 均数=30 (kg) 乙组 均数=30 (kg) 丙组 均数=30 (kg) 平均水平指标仅描述一组数据的集中趋势,可作为总体均数的一个估计值。由于变异的客观存在,需要一类指标描述资料的离散趋势。 常用指标: 全距,四分位数间距,方差,标准差,变异系数
如下: 甲组 均数=30 (kg) 乙组 均数=30 (kg) 丙组 均数=30 (kg) 平均水平指标仅描述一组数据的集中趋势,可作为总体均数的一个估计值。由于变异的客观存在,需要一类指标描述资料的离散趋势。 常用指标: 全距,四分位数间距,方差,标准差,变异系数.")
62
一、全距(range) 定义:一组资料中最大值与最小值之差。 表示法:R R=最大值-最小值 意义:反映个体变异范围的大小。
缺点:仅考虑两端数据的差异,未考虑其它数据的变异 情况,不能全面反映一组资料的离散程度,且不稳 定,易受极端值的影响。

63
二、四分位数间距(quartile interval)
定义:上四分位数QU(P75)与下四分位数QL(P25)之差, 即包括了全部观察值中间的一半。 表示法: Q 意义: Q值越大,说明变异程度越大。常用于描述偏态 分布资料的离散程度。 缺点:该指标比全距稍稳定,但仍未考虑每个观察值。
与下四分位数QL(P25)之差, 即包括了全部观察值中间的一半。 表示法: Q. 意义: Q值越大,说明变异程度越大。常用于描述偏态. 分布资料的离散程度。 缺点:该指标比全距稍稳定,但仍未考虑每个观察值。")
64
某传染性疾病的潜伏期(天) QL(P25)所在组在潜伏期为8~组,L=8, fx=48,i=4, fL=26; QU(P75)所在组为12~组,L=12,fx=25,i=4,fL=74, 分别代入公式得
 QL(P25)所在组在潜伏期为8~组,L=8, fx=48,i=4, fL=26; QU(P75)所在组为12~组,L=12,fx=25,i=4,fL=74, 分别代入公式得.")
65
三、方差(variance)和 标准差(standard deviation)
克服极差和四分位数间距不能反映每个观察值之间的离散情况这一缺点 离均差总和=总体中每个观察值xi与总体均数之差的 总和 =( xi - )=0 离均差平方和=( xi - )2 受观察单位数的影响 取离均差平方和的均数:方差
=0. 离均差平方和=( xi - )2. 受观察单位数的影响. 取离均差平方和的均数:方差.")
66
方差(variance):离均差平方和的均数
总体方差用2表示,公式 样本方差用S2表示,公式

67
标准差(standard deviation):方差开平方,取平方
根的正值。(恢复原度量单位) 总体标准差、样本标准差的公式分别为:
 总体标准差、样本标准差的公式分别为:")
68
S甲=3.16(kg); S乙=4.74(kg); S丙=2.92 (kg)
(n-1)和(fi-1)为自由度(degree of freedom) 适用条件:对称分布,特别是正态或近似正态分布资料 意义:说明资料的变异程度,其值越大,说明变异程度越大 S甲=3.16(kg); S乙=4.74(kg); S丙=2.92 (kg)
和(fi-1)为自由度(degree of freedom) 适用条件:对称分布,特别是正态或近似正态分布资料. 意义:说明资料的变异程度,其值越大,说明变异程度越大. S甲=3.16(kg); S乙=4.74(kg); S丙=2.92 (kg)")
69
标准差的应用: 1.表示观察值的变异程度。 标准差愈小,说明观察值的离散程度愈小,从而也反映了用平均数反映平均水平,其代表性愈好。 2. 估计医学参考值范围。 标准差在科技论文报告中经常与算术均数一起使用。 3. 计算标准误。 4. 计算变异系数。

70
四、变异系数(coefficient of variation) 表示法:CV
适用条件:比较度量单位不同或均数相差悬殊的两组 (或多组)资料的变异程度。 公式:
资料的变异程度。 公式:")
71
例 某地调查110名20岁男大学生,其身高均数为 172.73cm,标准差为4.09cm;其体重均数为 55.04kg, 标准差为4.10kg,试比较两者变异度。 身高 CV=(4.09/172.73)100%=2.37% 体重 CV=(4.10/55.04) 100%=7.45% 该地20岁男大学生体重的变异度大于身高的变异度
 100%=7.45% 该地20岁男大学生体重的变异度大于身高的变异度.")
72
第四节 正态分布和医学参考值范围

73
高峰位于中央(均数所在处)、两侧逐渐降低且左右对称、不与横轴相交的光滑曲线。正态分布是一种重要的连续型分布。
一、正态分布 正态分布(normal distribution) 高峰位于中央(均数所在处)、两侧逐渐降低且左右对称、不与横轴相交的光滑曲线。正态分布是一种重要的连续型分布。
 高峰位于中央(均数所在处)、两侧逐渐降低且左右对称、不与横轴相交的光滑曲线。正态分布是一种重要的连续型分布。")
74
正态分布和标准正态分布的概率密度函数 (probability density function)
正态分布的概率密度函数为: 标准正态分布的概率密度函数为:

75
u=(X- )/ 标准正态分布 正态分布
/ 标准正态分布 正态分布")
76
二、正态分布的特征 ①正态曲线(normal curve)在横轴上方均数处最高; ②正态分布以均数为中心,左右对称;
数有关,形状与标准差有关。标准差大,离散程度大, 正态分布曲线则“胖”,反之,则“瘦”; ④正态分布的面积分布有一定的规律性。

77
三、正态曲线下面积的分布规律

78
四、医学参考值范围 (一)参考值(reference ranges)的意义 医学参考值:正常人指标测定值的波动范围。
(二)制定参考值的基本步骤 1.从正常人总体中抽样 按随机化原则和方法进行抽样研究 抽取样本含量要足够大,最好在100例以上
制定参考值的基本步骤. 1.从正常人总体中抽样. 按随机化原则和方法进行抽样研究. 抽取样本含量要足够大,最好在100例以上.")
79
2.决定取单侧还是双侧 3. 选定合适的百分界限 参考值范围是指绝大多数正常人的测定值应该所在的范围。 习惯上指80%、90%、95%或99% 4.选定适当的方法进行参考值范围的估计

80
(三) 参考值范围的估计方法
 参考值范围的估计方法")
81
=(130.18~155.98)(cm) 利用某农村地区2001年14岁女孩的身高资料(cm)求95%的参考值范围。
从图可以看出该资料基本服从正态分布,因此采用正态分布法公式。本例的,S=6.58,双侧95%的参考值范围为: =(130.18~155.98)(cm)
(cm)")
82
总 结 一、集中趋势指标(说明一组同质资料的平均水平) 均数,几何均数,中位数 二、离散趋势指标(说明一组同质资料的离散度大小)
总 结 一、集中趋势指标(说明一组同质资料的平均水平) 均数,几何均数,中位数 二、离散趋势指标(说明一组同质资料的离散度大小) 全距,四分位数间距,方差,标准差,变异系数 三、正态分布和医学参考值范围 1.正态分布 图形,特征,面积分布规律 N(,2),N(0,1) 2.参考值范围
 均数,几何均数,中位数. 二、离散趋势指标(说明一组同质资料的离散度大小) 全距,四分位数间距,方差,标准差,变异系数. 三、正态分布和医学参考值范围. 1.正态分布 图形,特征,面积分布规律. N(,2),N(0,1) 2.参考值范围.")
84
参考值范围的估计方法 百分范围 (%) 单 侧 双 侧 95 99 返回目录
 单 侧 双 侧 返回目录")
85
第三章 计量资料的统计推断

86
用统计指标、统计表和统计图来描述资料的分析规律及其数量特征
统计描述 统计分析 总体参数估计 统计推断 假设检验

87
统计推断(statistical inference)
通过样本统计量信息推断相应总体参数的方法。 包括对总体参数的置信推断及参数间差异的假设检验。

88
第一节 均数的抽样误差和总体均数的估计 一、均数的抽样误差和标准误 1. 均数的抽样误差( sampling error of mean )
由抽样而造成的样本均数与总体均数的差异或各样本均数的差异。 2.标准误 standard error( SE, SEM ) 样本均数的标准差。反映均数抽样误差大小的指标。
 样本均数的标准差。反映均数抽样误差大小的指标。")
89
计算公式 意义 用途 σ: 总体标准差 n:样本含量 S : 样本标准差 标准误越小,说明样本均数与总体均数越接近,样本均数的代表性越好
(1)衡量抽样误差大小 (2)估计总体均数的置信区间 (3)用于假设检验 用途
衡量抽样误差大小. (2)估计总体均数的置信区间. (3)用于假设检验. 用途.")
90
例:对某地成年男性红细胞数的抽样调查中,随机抽取了100名成年男性,调查得到其均数是5. 38×1012/L,标准差为0
例:对某地成年男性红细胞数的抽样调查中,随机抽取了100名成年男性,调查得到其均数是5.38×1012/L,标准差为0.44×1012/L,求其标准误。 n=100 s=0.44×1012/L (1012/L)
")
91
二、 t 分布(t-distribution)
X1,X2,X3,…, ~N ( , 2 ) X1,X2,X3,…, ~N ( , 2x ) Sx ~N (0,1 ) ~N (0,1 ) Sx u 分布 t 分布 x
 X1,X2,X3,…, ~N ( , 2x ) Sx. ~N (0,1 ) ~N (0,1 ) Sx. u 分布. t 分布. x.")
92
(nu) t分布形状 =n-1 n:样本含量 N(0,1)
 t分布形状 =n-1 n:样本含量 N(0,1)")
93
表示法:双侧 单侧 用 途:1. 总体均数置信区间的估计 2. 用于t检验 自由度相同时,P值 , t值 P值相同时,自由度 , t值 自由度 时, t值=u值

94
三、总体均数置信区间的估计 1、总体均数的点值估计 (point estimation) 2、总体均数的区间估计 (interval estimation) 置信度( confidence level):估计正确的概率(1-) 95%,99% :错误概率,0.05,0.01 置信区间 confidence interval(CI): 按一定的置信度估计 总体均数所在的区间 按一定的置信度估计得到的区间
: 按一定的置信度估计. 总体均数所在的区间. 按一定的置信度估计得到的区间.")
95
n 较大时,总体均数的95%可信区间 n 较小时,总体均数的95%可信区间

96
例 从某年某地20岁健康男大学生中抽得110名的一个样本, 求得身高的均数为172. 73cm, 标准差为4
例 从某年某地20岁健康男大学生中抽得110名的一个样本, 求得身高的均数为172.73cm, 标准差为4.09cm, 试估计该地20岁健康男大学生身高均数的95%置信区间。 (172.73-1.96×0.39 , +1.96×0.39) =(171.97, ) cm 该地20岁健康男大学生身高均数的95%置信区间为 (171.97, ) cm
 =(171.97, ) cm. 该地20岁健康男大学生身高均数的95%置信区间为. (171.97, ) cm.")
97
例 从某年某地20岁健康男大学生中抽得11名的一个样本, 求得身高的均数为172. 25cm, 标准差为3
例 从某年某地20岁健康男大学生中抽得11名的一个样本, 求得身高的均数为172.25cm, 标准差为3.31cm, 试估计该地20岁健康男大学生身高均数的95%置信区间。 =11-1=10,查附表9-1得t0.05/2(10)=2.228 (172.25-2.228×0.996, +2.228×0.996) =(170.03, ) 该地20岁健康男大学生身高均数的95%置信区间为 (170.03, ) cm
= (172.25-2.228×0.996, +2.228×0.996) =(170.03, ) 该地20岁健康男大学生身高均数的95%置信区间为. (170.03, ) cm.")
98
总体均数的95%置信区间 100次抽样,可得到100个置信区间,平均有95个置信区间包括客观存在的总体均数,只有5个置信区间未包括总体均数

99
第二节 假设检验的基本思想和基本步骤 例 根据大量调查,已知健康成年男子脉搏均数为72次/分。某医生在山区随机抽查25名健康成年男子,获得其脉搏均数为74.2次/分,标准差为6.5次/分,问该山区成年男子的脉搏是否不同于一般?

100
一、假设检验的基本思想 引起两个样本均数不相等的原因有两种可能 : 1、来自相同的总体,由于抽样误差所致;
2、来自不相同的总体,由于本质差异所致。 假设检验就是在这两者中作出决策的过程。

101
二、假设检验的基本步骤 1、建立检验假设,确定检验水准 (1)两种假设
H0: 无效假设(null hypothesis) 差异由抽样误差所致 H1: 备择假设(alternative hypothesis) (2)两侧检验:单侧,双侧 (3)检验水准(显著性水平) =0.05 双侧检验: H0: H1: =0.05 单侧检验: H0: H1: (或 ) =0.05
 差异由抽样误差所致. H1: 备择假设(alternative hypothesis) (2)两侧检验:单侧,双侧. (3)检验水准(显著性水平) =0.05. 双侧检验: H0: H1: =0.05. 单侧检验: H0: H1: (或 ) =0.05.")
102
2、计算统计量 3、确定P值,作出统计推断结论 u 值 p值 结论 < > 不拒绝 H0,差异无统计学意义 (1.645) 拒绝 H0,差异有统计学意义
 1.96 0.05 拒绝 H0,差异有统计学意义.")
103
第三节 t检验和u检验 t检验 u检验 适用条件:正态分布,总体方差齐同 单样本t检验:样本均数与总体均数的比较

104
一、样本均数与总体均数的比较 总体均数:大量观侧得到的稳定值或理论值。0
例 根据大量调查,已知健康成年男子脉搏均数为72次/分。某医生在山区随机抽查25名健康成年男子,获得其脉搏均数为74.2次/分,标准差为6.5次/分,问该山区成年男子的脉搏是否不同于一般?

105
=n-1=25-1=24,查t界值表:t0.05/2(24)=2.064 1、建立检验假设,确定检验水准 2、计算检验统计量t
3、确定概率 =n-1=25-1=24,查t界值表:t0.05/2(24)=2.064 ∵t=1.692< 则P>0.05 4、判断结果 按=0.05水准,不拒绝H0,尚不能认为该山区成年男 子的脉搏不同于一般。
= ∵t=1.692<2.064 则P> 、判断结果. 按=0.05水准,不拒绝H0,尚不能认为该山区成年男. 子的脉搏不同于一般。")
106
=n-1=25-1=24,查t界值表:t0.05(24)=1.711 该山区成年男子的脉搏是否高于一般? 1、建立检验假设,确定检验水准
3、确定概率 =n-1=25-1=24,查t界值表:t0.05(24)=1.711 ∵t=1.692< 则P>0.05 4、判断结果 按=0.05水准,不拒绝H0,尚不能认为该山区成年男 子的脉搏高于一般。
= ∵t=1.692<1.711 则P> 、判断结果. 按=0.05水准,不拒绝H0,尚不能认为该山区成年男. 子的脉搏高于一般。")
107
二、配对资料的比较 差数的均数 差数的标准差 差数均数的标准误 n 对子数

108
【例】某医院用某中药治疗高血压病人10名,治疗前后舒张压的变化情况如下,试问此药有无降压作用?
患者号 舒 张 压 差值 d2 治疗前 治疗后 1 115 116 -1 2 110 90 20 400 3 129 108 21 441 4 109 89 22 484 5 92 18 324 6 26 676 7 36 8 120 -4 16 9 88 32 1024 10 104 96 64 148 3466

109
1.建立检验假设,确定检验水准 H0: H1: 2.计算统计量t值 已知 则

110
3.确定P值 由t界值表得 t0.05/2,9 = 2.262, t0.01/2,9 = 3.250 ∵本例t=3.936> t0.01/2,9 ∴ P<0.01 4.判断结果 在 概率水平下拒绝H0,可以认为该中草药有降血压的作用。

111
三、两个样本均数的比较 的标准误 合并方差

112
【例】用两组小白鼠分别给以高蛋白和低蛋白饲料,实验期间自出生后28天至84天共8周,观察各鼠所增体重(mg),结果如下。问两组膳食对小白鼠增加体重有无不同?
高蛋白组 低蛋白组

113
1、建立假设,确定检验水准 2、计算统计量t值 已知 则

114
3、确定概率 ∵t=1.891< , ∴ 4、判断结果 在 的概率水平下不拒绝H0;即尚不能认为两组膳食对增加小白鼠体重的影响的差异有显著性意义。

115
u检验—正态近似检验 n1>50 and n2>50
例:某地抽样调查了部分健康成人的红细胞数,其中男性360人,均数为4.661012/L,标准差为0.5751012/L;女性255人,均数为4.1781012/L,标准差为0.2911012/L,试问该地男、女红细胞数的均数有无差别?

116
第四节 方差分析 (Analysis of variance,ANOVA)
用途:两个或两个以上样本均数的比较 使用条件:1.样本来自正态总体 2.样本相互独立 3.总体方差齐同

117
正常组 冠心病组 脂肪肝组 t-test ANOVA
例:随机抽取50-59岁男性正常者、冠心病人、脂肪肝患者各11人,测定空腹血糖值(见下表),试推断这三类人群总体均值是否相同? 正常组 冠心病组 脂肪肝组 ANOVA t-test
,试推断这三类人群总体均值是否相同 正常组 冠心病组 脂肪肝组 ANOVA. t-test.")
118
单因素方差分析(one-factor ANOVA) 单方向方差分析(one-way ANOVA)
一、单因素方差分析 单因素方差分析(one-factor ANOVA) 单方向方差分析(one-way ANOVA)
 单方向方差分析(one-way ANOVA)")
119
总= 组内+ 组间 SS总= SS组内+ SS组间 变异 SS 与自由度 (1)总变异 SS总= 总=N-1 (N:总例数)
全部观察值与总均数差异的平方和 (2)组内变异 SS组内= 组内=N-k (k:组数) 全部组内观察值与组均数差异的平方和 (3)组间变异 SS组间= 组间= k-1 各组均数与总均数差异的平方和 总= 组内+ 组间 SS总= SS组内+ SS组间
组内变异 SS组内= 组内=N-k (k:组数) 全部组内观察值与组均数差异的平方和. (3)组间变异 SS组间= 组间= k-1. 各组均数与总均数差异的平方和. 总= 组内+ 组间. SS总= SS组内+ SS组间.")
120
2. 均方 MS (1)组内均方 MS组内= SS组内/ 组内 (2)组间均方 MS组间= SS组间/ 组间 3. F 值 F = MS组间/ MS组内
组内均方 MS组内= SS组内/ 组内 (2)组间均方 MS组间= SS组间/ 组间 3. F 值 F = MS组间/ MS组内")
121
单因素方差分析步骤 (1)计算各部分离均差平方和: 1. 建立检验假设,确定检验水准
1. 建立检验假设,确定检验水准 H0: μ1=μ2 =…= μa H1: μi ≠μj , α=0.05 2. 计算统计量F (1)计算各部分离均差平方和: SS总= = SS组间= = SS组内= SS总-SS组间
计算各部分离均差平方和: SS总= = SS组间= = SS组内= SS总-SS组间.")
122
(2)计算自由度: 总=N-1 组间= k 组内=N-k (3)计算均方: MS组间= SS组间/ 组间 MS组内= SS组内/ 组内 (4)计算统计量F: F = MS组间/ MS组内

123
4. 列方差分析表 单因素分析的方差分析表 3. 确定概率,判断结果 查F表,得到F0.05,(组间, 组内) 的临界值,
如果F>F0.05,(组间, 组内) ,则p<0.05,拒绝H0。 4. 列方差分析表 单因素分析的方差分析表 变异来源 SS MS F P 组间 组内 总
 ,则p<0.05,拒绝H0。 4. 列方差分析表. 单因素分析的方差分析表. 变异来源. SS. MS. F. P. 组间. 组内. 总.")
124
正常组 冠心病组 脂肪肝组 ( ) ni ( N ) ( ) ( )
 ni ( N ) ( ) ( )")
125
1. 建立检验假设,确定检验水准 H0: μ1=μ2 =μ3 , H1: μ1、μ2、μ3不等或不全相等 α=0.05 2. 计算统计量F (1) 计算离均差平方和 SS总= = =12.33 SS组间= SS组内= SS总-SS组间= =5.63

126
(2) 计算自由度 总=N-1=33-1=32 组间= k-1 =3-1= 组内=N-k=33-3=30 (3)计算均方 MS组间= SS组间/ 组间=6.70/2=3.35 MS组内= SS组内/ 组内=5.63/30=0.19 (4)计算统计量F F= MS组间/ MS组内=3.35/0.19=17.63
计算统计量F. F= MS组间/ MS组内=3.35/0.19=")
127
3. 确定概率,判断结果 4. 列方差分析表 方差分析表 查F表得到:F0.05(2,30)=3.32, F0.01(2,30)=5.39
F=17.63>5.39,则 p<0.01,拒绝H0 可认为三组人群的空腹血糖有显著性差异 4. 列方差分析表 方差分析表 变异来源 SS MS F P 组间 <0.01 组内 总

128
二、多个样本均数间的两两比较 q-检验 MS误差:误差均方 (单因素:MS组内) 样本均数排序,编秩次
ν: 残差离均差的自由度 ν= n-k a: 组间跨度, a= j – i +1 查q值表,如果 | q | > 则P< ,拒绝H0。

129
2. 计算统计量q: Group 脂肪肝组 冠心病组 正常组 Mean 5.71 69.30 4.61 Rank (1) (2) (3)
1. 建立检验假设,确定检验水准 H0: μA=μB H1: μA μB , α=0.05 2. 计算统计量q: 3. 确定概率,判断结果 a=3,ν组内 =30,q 0.01(30,3)=4.45<8.46, p<0.01,拒绝H0。
=4.45<8.46, p<0.01,拒绝H0。")
130
结论: 在0.05水平上,三组均数差别都有显著性差异, 脂肪肝组和冠心病组均高于正常组,脂肪肝组高 于冠心病组。
两两比较计算用表 q(30,a)临界值 比较组 组间跨度a 统计量 q P值 =0.05 =0.01 (1) (2) (3) (4) (5) (6) (1)与(3) 3 8.46 <0.01 (1)与(2) 2 5.00 <0.01 (2)与(3) 2 3.46 <0.05 结论: 在0.05水平上,三组均数差别都有显著性差异, 脂肪肝组和冠心病组均高于正常组,脂肪肝组高 于冠心病组。
临界值. 比较组. 组间跨度a. 统计量 q. P值. =0.05. =0.01. (1) (2) (3) (4) (5) (6) (1)与(3) <0.01. (1)与(2) <0.01. (2)与(3) <0.05. 结论: 在0.05水平上,三组均数差别都有显著性差异, 脂肪肝组和冠心病组均高于正常组,脂肪肝组高. 于冠心病组。")
131
第五节 假设检验中的二类错误及注意事项 一、两类错误 第Ⅰ类错误 (type Ⅰ error) 拒绝了实际上成立H0。“弃真”(α)
第五节 假设检验中的二类错误及注意事项 一、两类错误 第Ⅰ类错误 (type Ⅰ error) 拒绝了实际上成立H0。“弃真”(α) 第Ⅱ类错误 (type Ⅱ error) 接受了实际上不成立的H0。“存伪”(β) (1- β):检验效能(power of test) 当两个总体确实存在差异时,所使用的统计检验能够发现该差异的能力。
 拒绝了实际上成立H0。 弃真 (α) 第Ⅱ类错误 (type Ⅱ error) 接受了实际上不成立的H0。 存伪 (β) (1- β):检验效能(power of test) 当两个总体确实存在差异时,所使用的统计检验能够发现该差异的能力。")
132
二、注意事项 资料必须合乎随机化原则 选用的假设检验方法应符合其应用条件 实际差别大小与统计学意义的区别 判断不能绝对化 单双侧检验的选择

133
总 结 一、均数的抽样误差及总体均数的估计 二、假设检验的基本思想和基本步骤 标准误 三、t检验和u检验 四、方差分析
总 结 一、均数的抽样误差及总体均数的估计 二、假设检验的基本思想和基本步骤 三、t检验和u检验 四、方差分析 五、假设检验中的两类错误及注意事项 标准误 返回 目录

134
第四章 计数资料的统计描述 例: 1. 某地某年为了解该地区居民饮用含氟过高水人 群氟斑牙情况,调查了甲区560人,乙区1200人。 其中,甲区患病人数为106人,乙区为122人。 甲乙两地农村蛲虫感染情况调查,甲地蛲虫感染156人,乙地蛲虫感染101人。 计数资料:绝对数

135
在调查研究中所获得的某种性质类别一系列原始
一、相对数的概念 1. 绝对数 在调查研究中所获得的某种性质类别一系列原始 计数数据。反映事物的绝对水平或实际水平。 仅由绝对数还不能进行更深入的分析比较。 例1 患病情况 乙区比甲区多( )=16人 能否说乙区比甲区患病情况严重? 例2 蛲虫感染人数 甲地比乙地多( )=55人 能否肯定甲地比乙地人群蛲虫感染程度更为严重?
=16人. 能否说乙区比甲区患病情况严重? 例2 蛲虫感染人数 甲地比乙地多( )=55人. 能否肯定甲地比乙地人群蛲虫感染程度更为严重?")
136
例1 甲区患病率=(106/560)100%=18.93% 乙区患病率=(122/1200)100%=10.17% 甲区患病情况比乙区严重。 例2 已知甲地调查244人,乙地调查158人 甲地感染率=156/244 × 100%=63.9% 乙地感染率=101/158 × 100%=63.9% 两地人群蛲虫感染的严重程度是一样的。

137
2. 相对数 两个有关联的数据之比。用以说明事物的相对关系, 便于对比分析。 相对数与绝对数的关系:互相补充

138
二、常用相对数 1. 构成比 proportion: 公式: 事物内部某一构成部分的观察单位数 A+B+C+……
作用:表示事物内部某一构成部分在全部构成中所占的比例 公式: 事物内部某一构成部分的观察单位数 构成比= ×100% 事物各构成部分观察单位数的总和 A = ×100% A+B+C+……

139
说明: (1)构成比的特点是各部分的数值总和为100%。 (2)构成比中某一部分所占比重的增减,相应 会影响其他部分的比重。
(3)构成比只能说明比重大小,不能反映事物 发生的频率或严重程度。(率与构成比的区别)
构成比只能说明比重大小,不能反映事物. 发生的频率或严重程度。(率与构成比的区别)")
140
举例: 某地区5种急性传染病的死亡情况 1990年 1998年 病 名 死亡人数 构成(%) 死亡人数 构成(%)
1990年 年 病 名 死亡人数 构成(%) 死亡人数 构成(%) 伤寒-副伤寒 流 脑 痢 疾 白 喉 百日咳 合 计
 死亡人数 构成(%) 伤寒-副伤寒 流 脑 痢 疾 白 喉 百日咳 合 计")
141
2. 率 rate 该现象的总数之比 作用:说明某现象发生的强度或频率 率= ×比例基数 可能发生该现象的总例数
定义:一定时间内,某现象实际发生数与可能发生 该现象的总数之比 作用:说明某现象发生的强度或频率 公式: 某现象实际发生的例数 率= ×比例基数 可能发生该现象的总例数 比例基数 %,‰,1/万,1/十万

142
某地某时期某病新发病例总数 发病率= ×K 该地同期平均人口数 某地某时期死亡总数 死亡率= ×K 该地同期平均人口数

143
注意: (1)比例基数可根据习惯用法确定,算得的率保留一、 二位整数,如死亡率,自然增长率等用%,肿瘤死 亡率用 1/十万。
(2)计算率时,分母不宜太小。 (3)率不能直接相加。
计算率时,分母不宜太小。 (3)率不能直接相加。")
144
举例: 某县某年恶性肿瘤死亡统计 年 龄 人口数 死亡数 死亡专率(1/10万) 0~ 356980 11 3.08
年 龄 人口数 死亡数 死亡专率(1/10万) 0~ 15~ 30~ 50~ ≥ 合 计
 0~ ~ ~ ~ ≥ 合 计")
145
3、相对比 relative ratio 作用:反映两者的对比水平。 公式: 定义:两个有关指标之比 通常以倍数或百分数(%)表示。
相对比=甲指标/乙指标(或 × 100%) 举例:某年某地出生婴儿中,男性婴儿数为316人, 女性婴儿数为303人, 则出生婴儿性别比例 316/303=1.04
 举例:某年某地出生婴儿中,男性婴儿数为316人, 女性婴儿数为303人, 则出生婴儿性别比例. 316/303=1.04.")
146
4、动态数列( dynamic series )
定义:一系列按时间顺序排列的统计指标(包括绝对数、 相对数和平均数)。 作用:说明事物在时间上的变化和发展趋势 常用指标:绝对增长量,发展速度与增长速度, 平均发展速度与平均增长速度
。 作用:说明事物在时间上的变化和发展趋势. 常用指标:绝对增长量,发展速度与增长速度, 平均发展速度与平均增长速度.")
147
(1)绝对增长量 事物在一定时期内所增加的绝对数量。 1) 累计增长量=报告期指标-基期指标 2) 逐年增长量=报告期指标-前一期指标 (2)发展速度与增长速度 事物在一定时期的速度变化。相对比。 1) 定基发展速度=(报告期指标/基期指标)×100% 2) 环比发展速度=(报告期指标/前一期指标)×100%
 定基发展速度=(报告期指标/基期指标)×100% 2) 环比发展速度=(报告期指标/前一期指标)×100%")
148
1) 定基增长速度=定基发展速度-1 2) 环比增长速度=环比发展速度-1 定基比 —统一用某个时期的指标作基数,以各时期 的指标与之相比。(报告期指标/基期指标) 环 比 —用一个时期的指标作基数(非固定的), 以相邻的后一个时期的指标与之相比。 (报告期指标/前一期指标)
")
149
某医院1991~2000年平均每日门诊量变化 平均日门 绝对增长量 发展速度 增长速度 年份 诊人次 逐期 累计 定基 环比 定基 环比 (1) (2) (3) (4) (5) (6) (7) (8)
 (2) (3) (4) (5) (6) (7) (8)")
150
发展速度说明报告期指标为基期指标的若干倍
发展速度与增长速度的区别: 发展速度说明报告期指标为基期指标的若干倍 (或发展到若干倍),增长速度只说明增加或减少 了若干倍。
,增长速度只说明增加或减少. 了若干倍。")
151
三、应用相对数的注意事项 2. 构成比不能代替率 3. 正确计算平均率 1. 分母不宜太小 5. 样本率(比)的比较应进 行假设检验
4.注意资料的可比性 (1)观察对象同质,观察时间相等,研究方法一致 (2)内部构成相同 (3)对比不同时期资料应注意客观条件是否相同 发病率“升高”
观察对象同质,观察时间相等,研究方法一致. (2)内部构成相同. (3)对比不同时期资料应注意客观条件是否相同. 发病率 升高")
152
甲乙两院的治愈率 甲 院 乙 院 科 别 出院数 治愈数 治愈率(%) 出院数 治愈数 治愈率(%) 内 科 外 科 五官科 合 计

155
四、 标准化法 甲乙两种疗法治疗某病的治愈率比较 甲 疗 法 乙 疗 法 病 型 病人数 治愈数 治愈率(%) 病人数 治愈数 治愈率(%)
四、 标准化法 甲乙两种疗法治疗某病的治愈率比较 甲 疗 法 乙 疗 法 病 型 病人数 治愈数 治愈率(%) 病人数 治愈数 治愈率(%) 普通型 重 型 合 计
 病人数 治愈数 治愈率(%) 普通型 重 型 合 计")
156
为消除内部构成不同的影响,采用统一标准,分别计算标准化率后再进行比较的方法。
(一)基本思想 为消除内部构成不同的影响,采用统一标准,分别计算标准化率后再进行比较的方法。 (二)标准化率的计算 1. 选定标准 2. 计算标准化率
基本思想. 为消除内部构成不同的影响,采用统一标准,分别计算标准化率后再进行比较的方法。 (二)标准化率的计算. 1. 选定标准. 2. 计算标准化率.")
157
直接法标准化治愈率(%)计算表 甲 疗 法 乙 疗 法 病 型 标准治 原治 预 期 原治 预期 疗人数 愈率 治愈数 愈率 治愈数 (1) (2) (3) (4)=(2)×(3) (5) (6)=(2)×(5) 普通型 重 型 合 计 甲疗法标准化治愈率=380/800 × 100%=47.5% 乙疗法标准化治愈率=427/800× 100%=53.4%
 (2) (3) (4)=(2)×(3) (5) (6)=(2)×(5) 普通型 重 型 合 计 甲疗法标准化治愈率=380/800 × 100%=47.5% 乙疗法标准化治愈率=427/800× 100%=53.4%")
158
甲疗法标准化治愈率=47.5% 直接法标准化治愈率(%)计算表 甲 疗 法 乙 疗 法 病 型 标准人 原治 分 配 原治 分 配
甲 疗 法 乙 疗 法 病 型 标准人 原治 分 配 原治 分 配 口构成 愈率 治愈率 愈率 治愈率 (1) (2) (3) (4)=(2)×(3) (5) (6)=(2)×(5) 普通型 重 型 合 计 甲疗法标准化治愈率=47.5% 乙疗法标准化治愈率=53.4%
 (2) (3) (4)=(2)×(3) (5) (6)=(2)×(5) 普通型 重 型 合 计 甲疗法标准化治愈率=47.5% 乙疗法标准化治愈率=53.4%")
159
(三)应用标准化时的注意事项 1. 标准化法只适用于某因素两组内部构成不同,并有可能影响两组总率比较的情况。
2. 选择的标准不同,计算出的标准化率也不同。 3. 标准化率只是表示相互比较的资料间的相对水平。 4. 两样本标准化率是样本值,存在抽样误差。样本含量较小时,应做假设检验。

160
SUMMARY 一、相对数的概念 二、常用相对数 1. 构成比 定义,作用 2. 率 公式,注意 3. 比 举例 4. 动态数列

161
四、标准化法standardization 基本思想
三、应用相对数的注意事项 1. 计算相对数时,分母不宜太小 2.不能以构成比代替率 3. 正确计算平均率 4. 注意资料的可比性 5. 样本率(比)的比较应进行假设检验 四、标准化法standardization 基本思想 返回 目录
的比较应进行假设检验. 四、标准化法standardization. 基本思想. 返回. 目录.")
162
第五章 计数资料的统计推断

163
第一节 率的抽样误差和总体率的估计 σp =√π(1-π)/n 一、率的抽样误差与标准误 意义:率的标准误小,说明抽样误差较小,
第一节 率的抽样误差和总体率的估计 一、率的抽样误差与标准误 σp =√π(1-π)/n σp 率的标准误, π 总体率, n 样本例数。 总体率π由样本率p来估计: sp =√p(1-p)/n 意义:率的标准误小,说明抽样误差较小, 表示样本率与总体率较接近,即用样本率 代表总体率的可靠性大。
/n σp 率的标准误, π 总体率, n 样本例数。 总体率π由样本率p来估计: sp =√p(1-p)/n 意义:率的标准误小,说明抽样误差较小, 表示样本率与总体率较接近,即用样本率. 代表总体率的可靠性大。")
164
二、总体率的估计 已知 P=8.81% n=329 1. 查表法 当n较小时
2. 正态近似法 当n足够大, 且np和n(1-p)均大于5时,可按下式计算总体率的置信区间: 例: 在某地随机抽取329人, 作HBsAg检验, 得阳性率为 8.81%,求阳性率的95%置信区间。 已知 P=8.81% n=329 Sp=√P(1-P)/n=√0.0881( )/329 =0.0156=1.56% 阳性率的95%置信区间为(8.81±1.96×1.56) 即: 5.75%~11.87%
均大于5时,可按下式计算总体率的置信区间: 例: 在某地随机抽取329人, 作HBsAg检验, 得阳性率为. 8.81%,求阳性率的95%置信区间。 已知 P=8.81% n=329. Sp=√P(1-P)/n=√0.0881( )/329. =0.0156=1.56% 阳性率的95%置信区间为(8.81±1.96×1.56) 即: 5.75%~11.87%")
165
第二节 率的u检验 np和n(1-p)均>5 一、样本率与总体率的比较
均>5 一、样本率与总体率的比较")
166
例:已知某地一般人群高血压患病率为13.26%,某医师在农村随机抽取460人进行观察,有43 人确诊为高血压,问该人群高血压患病率是否低于一般人群?
1. H0:π= H1:π< α=0.05(单侧) 2.P=43/460=0.0935 3. u>u P< 拒绝H0 可认为该人群高血压患病率低于一般人群。
 2.P=43/460= u>u0.01 P<0.01 拒绝H0. 可认为该人群高血压患病率低于一般人群。")
167
二、两样本率的比较 例 为研究某职业人群颈椎病发病的性别差异,今随机抽查了该职业人群男性120人和女性110人,发现男性中有36人患有颈椎病,女性中有22人患有颈椎病。试作统计推断。 1. H0:π1= π H1:π1≠π2 α=0.05 2. Sp1-p2= u=1.745 3. u=1.745<1.96, p>0.05 尚不能认为该职业人群颈椎病发病有性别差异。

168
第三节 χ2 检 验 1. 检验两个或多个样本率(或构成比)之间差异是否有显著性 2. 说明两种属性或现象之间是否存在相关关系
第三节 χ2 检 验 1. 检验两个或多个样本率(或构成比)之间差异是否有显著性 2. 说明两种属性或现象之间是否存在相关关系 3. 拟合优度检验
之间差异是否有显著性. 2. 说明两种属性或现象之间是否存在相关关系. 3. 拟合优度检验.")
169
一、四格表资料的χ2 检验 例:为了解某中草药预防流脑的效果,将410名观察者随机分为两组,观察结果如表, 问两组流感发病率是否有差别?
两组人群流感发病率比较 分组 例数 发病人数 未发病人数 发病率(%) 服药组 (50.49) (179.51) 对照组 (39.51) (140.49) 合 计
 服药组 (50.49) 190(179.51) 对照组 (39.51) 130(140.49) 合 计")
170
nR nC (一)χ2 检验的基本思想 (实际频数-理论频数)2 (A-T)2 χ2 =Σ = Σ──── 理论频数 T TRC = ───
χ2 =Σ = Σ──── 理论频数 T nR nC TRC = ─── n υ=(行数-1)(列数-1)=(R-1)(C-1)
(列数-1)=(R-1)(C-1)")
171
(二)χ2 检验的基本步骤 3 1. 建立检验假设,确定检验水准 H0:π1=π2 H1:π1≠π2 α=0.05 2. 计算统计量χ2值
1. 建立检验假设,确定检验水准 H0:π1=π2 H1:π1≠π2 α=0.05 2. 计算统计量χ2值 (A-T) nR nC χ2=Σ──── TRC = ─── T n 3. 确定P值,判断结果 υ=(R-1)(C-1) 3
2 nR nC. χ2=Σ──── TRC = ─── T n. 3. 确定P值,判断结果. υ=(R-1)(C-1) 3.")
172
χ2 检验结果判断 χ20.05(1)=3.84 P=0.05 χ20.01(1)=6.63 P=0.01 χ2 值 P 差别 H0
χ2 检验结果判断 χ2 值 P 差别 H0 <χ2 0.05(υ) > 无统计学意义 不拒绝 ≥χ2 0.05(υ) ≤ 有统计学意义 拒绝 ≥χ2 0.01(υ) ≤ 有统计学意义 拒绝 χ20.05(1)= P=0.05 χ20.01(1)= P=0.01
 >0.05 无统计学意义 不拒绝. ≥χ2 0.05(υ) ≤0.05 有统计学意义 拒绝. ≥χ2 0.01(υ) ≤0.01 有统计学意义 拒绝. χ20.05(1)=3.84 P=0.05. χ20.01(1)=6.63 P=0.01.")
173
两组人群流感发病率比较 分组 例数 发病人数 未发病人数 发病率(%) 服药组 (50.49) (179.51) 对照组 (39.51) (140.49) 合 计
 130(140.49) 合 计")
174
υ=(2-1)(2-1)=1;χ2 =6.36>3.84, P<0.05;
基本公式法 (n>40, 且T>5) 1. 建立检验假设,确定检验水准 H0 : л1 =л2 H1 : л1 ≠л2 α=0.05 2. 计算χ2 值 (1)T (2)χ2 =公式=6.36 3. 确定概率, 判断结果 υ=(2-1)(2-1)=1;χ2 =6.36>3.84, P<0.05; 两组发病率差异有统计学意义, 服药组的流感发病率低于对照组。
 1. 建立检验假设,确定检验水准. H0 : л1 =л2 H1 : л1 ≠л2 α= 计算χ2 值. (1)T. (2)χ2 =公式= 确定概率, 判断结果. υ=(2-1)(2-1)=1;χ2 =6.36>3.84, P<0.05; 两组发病率差异有统计学意义, 服药组的流感发病率低于对照组。")
175
专用公式 (n>40, 且T>5) ───────────── 某情况 分组 ──── 合 计 是 否 甲 a b a+b
四格表形式 ───────────── 某情况 分组 ──── 合 计 是 否 甲 a b a+b 乙 c d c+d 合计 a+c b+d n (ad-bc)2 n χ2 =──────────── (a+b)(c+d)(a+c)(b+d)
2 n. χ2 =──────────── (a+b)(c+d)(a+c)(b+d)")
176
四格表资料χ2 值计算表 ─────────────────────── 发病数 未发病数 合 计 服药组 (a) (b) (a+b) 对照组 (c) (d) (c+d) ─────────────────────── 合 计 (a+c) (b+d) (n) (40 × ×50)2 × 410 χ2 =─────────────=6.36 230 × 180 × 90 × 320
 130(d) 180(c+d) ─────────────────────── 合 计 90(a+c) 320(b+d) 410(n) (40 × ×50)2 × 410. χ2 =─────────────= × 180 × 90 × 320.")
177
校正公式 (n>40, 且1<T<5 )
(│A-T│-0.5)2 χ2 =Σ─────── T (│ad-bc│-n/2 )2 n 或 χ2 =───────── (a+b)(c+d)(a+c)(b+d)
2. χ2 =Σ─────── T. (│ad-bc│-n/2 )2 n. 或 χ2 =───────── (a+b)(c+d)(a+c)(b+d)")
178
例:甲乙两种药物治疗某病, 疗效如下表, 问两药的有效率差别有无显著意义?
甲乙两药治疗某病的效果比较 有 效 无效 合计 % 甲 3(6.5) 31(27.5) 乙 7(3.5) 11(14.5) 合计
 31(27.5) 乙 7(3.5) 11(14.5) 合计")
179
1. 检验假设: 假设两种药物的疗效相同 H0 : л1 =л2 H1 : л1 ≠л2 α=0.05 2. 计算χ2 值: (│3 × × 7│-52/2)2 × 52 χ2 =─────────────=5.050 34 × 18 × 10 × 42 3. 确定P值, 判断结果 χ2 =5.050>χ2 0.05(1) , 故P<0.05, 拒绝无效假设H0 , 认为甲乙两种药物治疗某病的疗效不同, 乙药的有效率 高于甲药。
 , 故P<0.05, 拒绝无效假设H0 , 认为甲乙两种药物治疗某病的疗效不同, 乙药的有效率. 高于甲药。")
180
Fisher确切概率法 应用条件: T<1 或 n40

181
二、配对资料的χ2 检验 配对四格表形式 ─────────────── 乙 合 计 + - ──────────────
乙 合 计 + - ────────────── + a b a+b 甲 - c d c+d ────────────── 合计 a+c b+d n

182
例: 甲乙两名医师对120张X线片子的矽肺诊断结果如下表, 试分析两名医师诊断结果的差别有无显著意义。
乙 医 师 合 计 + - 甲 + 医 师 - 合 计

183
(b-c)2 χ2 =──── b+c>40 b+c 或 (│b-c│-1)2 χ2=───── b+c≤40 b+c υ=1
2 χ2 =──── b+c>40 b+c 或 (│b-c│-1)2 χ2=───── b+c≤40 b+c υ=1")
184
1. 建立检验假设,确定检验水准 H0 : 两医师诊断结果相同,b=c H1 : 两医师诊断结果不同, b≠c α=0.05 2. 计算χ2值: 因b+c=14<40, 故 (│12-2│-1)2 χ2 =───────=5.786 12+2 3. 确定P值,判断结果 χ2 =5.786χ2 0.05(1),则0.01<P<0.05,按α=0.05水准, 拒绝H0 , 接受H1 , 认为两医生诊断矽肺的结果不同, 甲医师诊断阳性率高于乙医师。
,则0.01<P<0.05,按α=0.05水准, 拒绝H0 , 接受H1 , 认为两医生诊断矽肺的结果不同, 甲医师诊断阳性率高于乙医师。")
185
χ2 =n (∑─── -1) υ=(R-1)(C-1) nR nc nR 行合计数 nC 列合计数
适用:多个样本率(或构成比)比较 A2 χ2 =n (∑─── -1) υ=(R-1)(C-1) nR nc nR 行合计数 nC 列合计数 n 总例数 A 实际观察数
比较. A2. χ2 =n (∑─── -1) υ=(R-1)(C-1) nR nc nR 行合计数 nC 列合计数. n 总例数 A 实际观察数.")
186
某年3个地区婚检检出疾病构成 例:某年3个地区婚检检出疾病分类如下表, 试分 析3个地区婚检检出疾病的构成比有无差别?
生殖S病 遗传病 传染病 内科病 合计 甲 乙 丙 合 计

187
1. 建立检验假设,确定检验水准 H0 : 3个地区婚检疾病构成比相同 H1 : 3个地区婚检疾病构成比不同或不全相同 α=0.05 2. 计算χ2值 χ2 = 3. 确定P值,判断结果 υ=(4-1) × (3-1)=6 查附表, χ2 0.05(6) =12.59, χ2 0.01(6) =16.81, 故P<0.05, 按α=0.05水准拒绝H0 , 接受H1 , 可认为3个地区婚检检出疾病的构成比不同, 有地区差异。
 × (3-1)=6. 查附表, χ2 0.05(6) =12.59, χ2 0.01(6) =16.81, 故P<0.05, 按α=0.05水准拒绝H0 , 接受H1 , 可认为3个地区婚检检出疾病的构成比不同, 有地区差异。")
188
应用R × C表χ2 检验的注意事项 1.T不宜太小,否则导致分析偏性。 一般不宜有1/5以上格子的T<5, 或有一个T<1。
(1)增加样本含量; (2)将理论数太小的行或列与相邻的行或列的观察值合并,但应注意合并的合理性; (3)删除理论数太小的行或列。 2.当检验结论为拒绝H0时只能认为所比较的各组间总的差异有显著意义(或至少有两组之间差异有显著意义),但不能确定哪两组之间的差异,或彼此间的差异有显著意义。
增加样本含量; (2)将理论数太小的行或列与相邻的行或列的观察值合并,但应注意合并的合理性; (3)删除理论数太小的行或列。 2.当检验结论为拒绝H0时只能认为所比较的各组间总的差异有显著意义(或至少有两组之间差异有显著意义),但不能确定哪两组之间的差异,或彼此间的差异有显著意义。")
189
SUMMARY 1.基本公式(n≥40, 且T≥5) 一、率的抽样误差和总体率的估计 二、率的u检验 三、χ2 检验
(一)四格表资料的χ2 检验 1.基本公式(n≥40, 且T≥5) 2.专用公式 (n≥40, 且T≥5) 3.校正公式 (n≥40, 且1≤T<5 ) χ20.05(1)= P=0.05 χ20.01(1)= P=0.01
四格表资料的χ2 检验. 1.基本公式(n≥40, 且T≥5) 2.专用公式 (n≥40, 且T≥5) 3.校正公式 (n≥40, 且1≤T<5 ) χ20.05(1)=3.84 P=0.05. χ20.01(1)=6.63 P=0.01.")
190
(b-c)2 (二)配对资料的χ2 检验 (三)R × C表资料的χ2 检验 χ2 =──── b+c>40 b+c
1.计算 注意事项

191
一、率的抽样误差和总体率的估计 二、χ2 检验的原理和基本步骤 χ20.05(1)=3.84 P=0.05
三、四格表资料的χ2 检验 (一)基本公式(n≥40, 且T≥5) (二)专用公式 (n≥40, 且T≥5) (三) 校正公式 (n≥40, 且1≤T<5 ) 返回 目录
基本公式(n≥40, 且T≥5) (二)专用公式 (n≥40, 且T≥5) (三) 校正公式 (n≥40, 且1≤T<5 ) 返回. 目录.")
192
第六章 相关与回归

193
年龄与血压,身高与体重,胰岛素与血糖水平,药物剂量与疗效,污染物浓度与污染源的距离,……
变量间的关系: 年龄与血压,身高与体重,胰岛素与血糖水平,药物剂量与疗效,污染物浓度与污染源的距离,…… 分析方法?

194
直线相关与直线回归

195
1. 研究变量间的相互关系及紧密程度 —相关分析 2. 研究变量间的数量依存关系 —回归分析 最简单的分析方法 —直线相关,直线回归 (1)只涉及两个变量 X,Y (2)X与Y之间呈直线关系
只涉及两个变量 X,Y (2)X与Y之间呈直线关系")
196
第一节 直 线 相 关 linear correlation

197
一、概 念 1.直线相关:两个变量之间的线性关系。 (1)正相关,完全正相关 (2)负相关,完全负相关 (3)零相关
一、概 念 1.直线相关:两个变量之间的线性关系。 (1)正相关,完全正相关 (2)负相关,完全负相关 (3)零相关 2. 判断:作散点图(scatter plot),是否呈直线。
正相关,完全正相关 (2)负相关,完全负相关 (3)零相关. 2. 判断:作散点图(scatter plot),是否呈直线。")
198
0<r<1 -1<r<0 r=0 r=1 r=-1 r=0

199
例 为了研究红细胞数与细胞体积是否有关系, 实验者从10只狗身上抽取血样本, 并分别测得其红细胞体积x(mm3)及对应的红细胞数y(×1012 /L), 各对观测值见下表。
及对应的红细胞数y(×1012 /L), 各对观测值见下表。")
200
10只狗的红细胞体积与红细胞数 编 号 红细胞体积 红细胞数 x (mm3) y (1012/L)
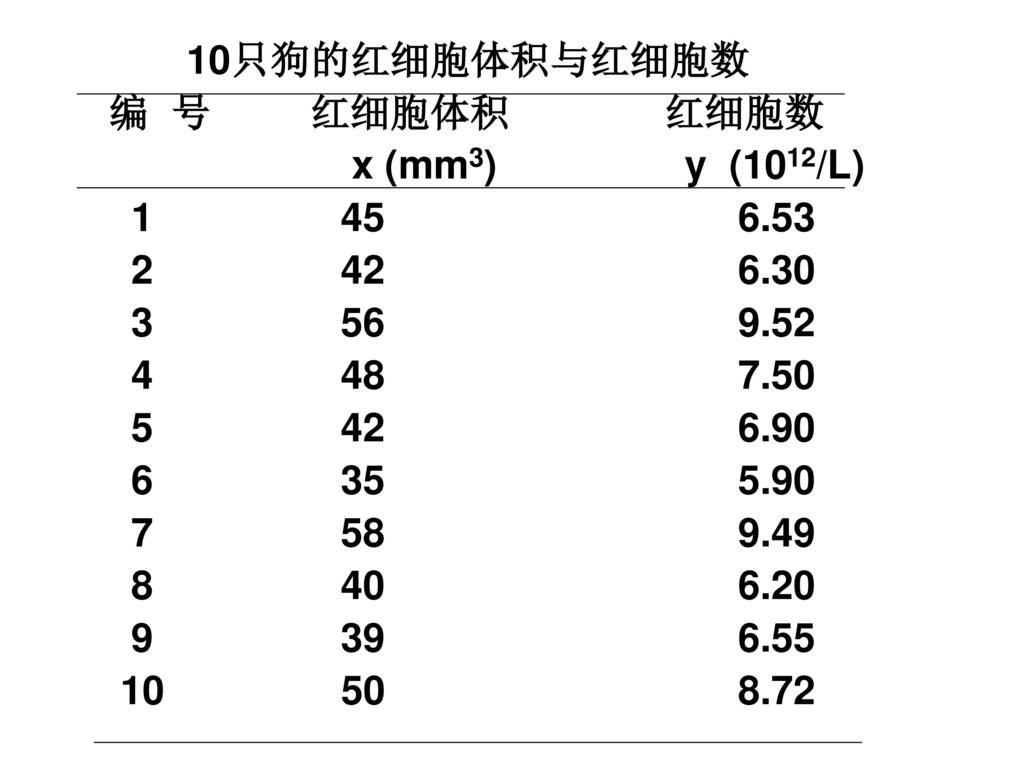
201
散点图显示: 10个点 (xi , yi ) 几乎散布在一直线上, 故可初步认为x与y之间存在线性关系。
 几乎散布在一直线上, 故可初步认为x与y之间存在线性关系。")
202
直线相关系数 linear correlation coefficient
二、相关系数的意义与计算 直线相关系数 linear correlation coefficient = 积差相关系数 correlation of product- moment coefficient = Pearson 相关系数

203
1. 意义:表示两个变量间直线关系的密切程度和相关方向的统计指标。
2. 表示符号:总体相关系数 ρ 样本相关系数 r 3. 说明(1) 无单位 (2) 取值范围 -1≤r≤1
 无单位. (2) 取值范围 -1≤r≤1.")
204
密切程度(强度)——r绝对值的大小 r : 直线相关关系愈密切; r : 直线相关关系愈不密切。 方向 —— r的符号 r>0 :正相关 r<0 :负相关
——r绝对值的大小 r 1: 直线相关关系愈密切; r 0: 直线相关关系愈不密切。 方向 —— r的符号 r>0 :正相关 r<0 :负相关")
205
0<r<1 : 正相关 r=1 : 完全正相关 –1<r<0 : 负相关 r=-1 : 完全负相关 注:r= 零相关 (无相关)
")
206
0<r<1 -1<r<0 r=0 r=1 r=-1 r=0

207
相关系数的计算 r=lxy /√lxx ·lyy 其中 lxx = x的离均差平方和 =Σx2 -(Σx)2 /n
lyy = Y的离均差平方和 =Σy2 -(Σy)2 /n lxy =x与y的离均差积和 =Σxy-[(Σx)(Σy)]/n
2 /n. lxy =x与y的离均差积和. =Σxy-[(Σx)(Σy)]/n.")
208
计算步骤: 1.编制相关系数计算表: 基本数据—Σx、Σy 、Σx2 、Σy2 、Σxy Σx= Σx2 =21203 Σy= Σy2 =560.32 Σxy=

209
简单相关系数计算表 红细胞体积 红细胞数 x2 y2 xy x×109 (fl) y×1012 (/L)
简单相关系数计算表 红细胞体积 红细胞数 x y xy x×109 (fl) y×1012 (/L) Σ
 y×1012 (/L) Σ")
210
2.计算离均差平方和及积和: lxx =Σx2 -(Σx)2 /n =21203-(455)2 /10=500.50 lyy =Σy2-(Σy)2 /n = (73.70)2 /10=17.15 lxy =Σxy-[(Σx)(Σy)]/n = [(455)(73.70)]/10 =88.17
(Σy)]/n. = [(455)(73.70)]/10. =")
211
3.计算相关系数: r=lxy /√lxx ·lyy =88.17/√500.50×17.15 =88.17/92.65 =0.952 结果表明, 红细胞体积与红细胞数之间存在一定的数量关系, 呈正相关。

212
三、相关系数的假设检验 1. t检验法: r -0 r t= = S r √(1-r2 )/(n-2) ~ t(n-2)
/(n-2) ~ t(n-2)")
213
(1)建立检验假设,确定检验水准 H0:ρ=0,x与y无直线相关关系 H1:ρ0,x与y有直线相关关系 =0.05 (2)计算统计量 t=(r√ n-2)/√1-r2 =(0.952√10-2)/√1-(0.952)2 =8.8 (3)确定P值,判断结果 =10-2=8,查表得 t 0.01(8) =3.355 因 t=8.8>t 0.01(8) , 故P<0.01, 表明红细胞体积与红细胞数之间的线性关系存在。
确定P值,判断结果. =10-2=8,查表得 t 0.01(8) = 因 t=8.8>t 0.01(8) , 故P<0.01, 表明红细胞体积与红细胞数之间的线性关系存在。")
214
2. 查表法: 附表13-1:相关系数r界值表 r P 对r的判断 <r0.05(υ) > 无统计学意义 ≥ r0.05(υ) ≤ 有统计学意义 ≥r0.01(υ) ≤ 有统计学意义
 ≤ 0.05 有统计学意义. ≥r0.01(υ) ≤ 0.01 有统计学意义.")
215
上例: 查附表, r0.01(8) =0.765, 本例r=0.952, r>r0.01(8) ,故P<0.01,
说明红细胞体积与红细胞数之间的线性关系具有统计学意义。

216
四、相关分析应用的注意问题 1. 实际意义。要求x与y都是来自正态分布的随机变量。 2. 先绘制散点图。
3. 小样本t检验只能推断两变量间有无直线关系,而不能推断其相关的密切程度。

217
第二节 直线回归 linear regression

218
一、概 念 分析两变量(X,Y)间线性依存关系的一种统计方法 x—自变量 independent variable
一、概 念 分析两变量(X,Y)间线性依存关系的一种统计方法 x—自变量 independent variable y—应变量 dependent variable 建立y回归于x的线性回归方程式, 可确定: 当x为某一定值时, y将会在什么范围内变动。
间线性依存关系的一种统计方法. x—自变量 independent variable. y—应变量 dependent variable. 建立y回归于x的线性回归方程式, 可确定: 当x为某一定值时, y将会在什么范围内变动。")
219
二、直线回归方程的建立 (一)线性回归方程式 =b0+bx — 由x推算y的估计值 b0 — x=0时的 值,即回归直线在y 轴上的
二、直线回归方程的建立 (一)线性回归方程式 =b0+bx — 由x推算y的估计值 b0 — x=0时的 值,即回归直线在y 轴上的 截距(intercept) : (1) b0 >0, 直线与纵轴的交点在原点的上方; (2) b0 =0, 直线通过原点; (3) b0 <0,直线与纵轴的交点在原点的下方
线性回归方程式. =b0+bx. — 由x推算y的估计值. b0 — x=0时的 值,即回归直线在y 轴上的. 截距(intercept) : (1) b0 >0, 直线与纵轴的交点在原点的上方; (2) b0 =0, 直线通过原点; (3) b0 <0,直线与纵轴的交点在原点的下方.")
220
b— 回归直线的斜率 ( slope),即回归系数 ( regression coefficient), 它表示当x每增加(或减少)一个单位时, 平均增加(或减少 )b个单位。
(1) b>0, 直线从左下方走向右上方,即Y随X的增大而增大; (2) b=0, 直线与X轴平行,即X与Y无线性关系; (3) b<0, 直线从左上方走向右下方,即Y随X的增大而减小
 b>0, 直线从左下方走向右上方,即Y随X的增大而增大; (2) b=0, 直线与X轴平行,即X与Y无线性关系; (3) b<0, 直线从左上方走向右下方,即Y随X的增大而减小.")
221
=Σ(x- )2=Σx2-(Σx)2/n 求最适合直线的最普通的方法 ——最小二乘法(least square method)
使得各实测点与直线的纵向距离平方和,即误差平方和 Σ(y- )2为最小的方法。 由此导出b,b0算式: b=lxy/lxx b0 = -b lxy=离均差积和 =Σ(x- )(y- )=Σxy-(Σx)(Σy)/n lxx=x的离均差平方和 =Σ(x- )2=Σx2-(Σx)2/n
2为最小的方法。 由此导出b,b0算式: b=lxy/lxx. b0 = -b. lxy=离均差积和. =Σ(x- )(y- )=Σxy-(Σx)(Σy)/n. lxx=x的离均差平方和. =Σ(x- )2=Σx2-(Σx)2/n.")
222
(二)直线回归方程的计算步骤 例 用分光光度计测物质含量, 其光密度读数与物质含量有关, 现有丙酮酸钠含量(μmol/L)与光密度读数, 要求标准曲线。
直线回归方程的计算步骤 例 用分光光度计测物质含量, 其光密度读数与物质含量有关, 现有丙酮酸钠含量(μmol/L)与光密度读数, 要求标准曲线。")
223
丙酮酸钠含量与光密度读数 ────────────────── 样品号 丙酮酸钠含量 光密度读数 1 1 1.0 2 2 2.1
样品号 丙酮酸钠含量 光密度读数 ────────────────────

224
1. 绘制散点图:以丙酮酸钠含量为横坐标, 光密度为纵坐标,散点呈直线趋势。 5 4 3 2 1

225
lxy=Σxy-(Σx)(Σy)/n=55.6-(15×15.3)/5 =9.70
2. 计算基本数据:Σx、Σx2、Σy、Σy2、Σxy、 ,lxx、lxy。 Σx= Σx2=55 Σy=15.3 Σy2= Σxy=55.6 =Σx/n=15/5=3 =Σy/n=15.3/5=3.06 lxx=Σx2-(Σx)2/n=55-(15)2/5=10.0 lxy=Σxy-(Σx)(Σy)/n=55.6-(15×15.3)/5 =9.70
2/n=55-(15)2/5=10.0. lxy=Σxy-(Σx)(Σy)/n=55.6-(15×15.3)/5. =9.70.")
226
3. 计算b、 b0 ,得回归方程: b=lxy/lxx=9.70/10=0.97 b0= -b =3.06-0.97×3=0.15 =0.15+0.97x 4. 画回归直线: 以x=1及x=5代入回归方程, 求相应的 。 x=1时, =1.12; x=5时, =5.0。 以(1, 1.12)、(5, 5.0)两点作直线即是所求的回归直线,
、(5, 5.0)两点作直线即是所求的回归直线,")
227
5 4 3 2 1

228
(三)回归系数的假设检验 1. lyy与的分解 应变量y的平方和的分解
回归系数的假设检验 1. lyy与的分解 应变量y的平方和的分解")
229
^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ y值的变异可用离均差平方和Σ(y-y)2来反映 y-y=(y - y )+(y -y)
y = b0+bx =(y - bx)+bx=y+b( x-x ) Σ( y-y ) ( y-y ) =Σ〔y-y- b(x-x)〕〔y+b(x-x)-y〕 =Σb(x-x)(y-y)-Σb2(x-x)2 =Σb2 (x-x)2-Σb2(x-x)2=0 ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^
+bx=y+b( x-x ) Σ( y-y ) ( y-y ) =Σ〔y-y- b(x-x)〕〔y+b(x-x)-y〕 =Σb(x-x)(y-y)-Σb2(x-x)2. =Σb2 (x-x)2-Σb2(x-x)2=0. ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^")
230
^ ^ ^ ^ SS总= SS回+ SS残 Σ(y-y )2:回归平方和, 用SS回表示。 回归值 y 与平均数 y 之差的平方和,
Σ( y-y )2=Σ( y-y )2+Σ(y –y )2 SS总= SS回+ SS残 Σ(y-y )2:回归平方和, 用SS回表示。 回归值 y 与平均数 y 之差的平方和, 反映了在y总的变异中由于x与y的线性 关系而引起y变化的部分。 SS回越大,说明回归效果越好。 ^ ^ ^ ^
2=Σ( y-y )2+Σ(y –y )2. SS总= SS回+ SS残. Σ(y-y )2:回归平方和, 用SS回表示。 回归值 y 与平均数 y 之差的平方和, 反映了在y总的变异中由于x与y的线性. 关系而引起y变化的部分。 SS回越大,说明回归效果越好。 ^ ^ ^ ^")
231
^ Σ( y-y )2:残差平方和,用SS残表示。 所有观察点距回归直线的剩余的平方和,是在总 平方和中无法用x解释的部分。
2:残差平方和,用SS残表示。 所有观察点距回归直线的剩余的平方和,是在总 平方和中无法用x解释的部分。")
232
Σ( y – y )2:总平方和,用SS总表示。 y的离均差平方和,说明未考虑x与y的回归 关系时y的变异。 三者之间的关系: SS总=SS回+SS残 υ总=υ回+υ残 υ总=N-1, υ回=1, υ残=N-2

233
2. 方差分析 (1) H0: β= H1:β =0.05 (2)计算统计量F值 F=Ms回/Ms残 Ms回=SS回/υ回 Ms残=SS残/υ残 (3)确定P值,判断结果 F 0.05(1,n-2), F 0.01(1,n-2)
, F 0.01(1,n-2)")
234
回归显著性检验方差分析表 变异来源 SS MS F P 回 归 残 差 总变异

235
^ 由前例资料建立回归方程 y=0.15+0.97x 已知 n=5, Σx=15, Σx2=55, Σy=15.3,
Σy2=56.33, b=0.97 SS总=Σ( y - y )2=Σy2 - (Σy)2/n =56.33-(15.3)2/5=9.512 SS回=b2Σ( x – x )2=b2〔Σx2 - (Σx)2/n〕 =(0.97)2〔55-(15)2/5〕=9.409 SS残=SS总-SS回=9.512-9.409 =0.103 ^
2=Σy2 - (Σy)2/n. =56.33-(15.3)2/5= SS回=b2Σ( x – x )2=b2〔Σx2 - (Σx)2/n〕 =(0.97)2〔55-(15)2/5〕= SS残=SS总-SS回=9.512- = ^")
236
F=Σ(y-y)2/[Σ(y-y)2/(n-2)] ^ ^
=9.409/[0.103/(5-2)] = ^ ^
![F=Σ(y-y)2/[Σ(y-y)2/(n-2)] ^ ^](http://slidesplayer.com/slide/11330093/61/images/236/F%EF%BC%9D%CE%A3%28y%EF%BC%8Dy%292%2F%5B%CE%A3%28y%EF%BC%8Dy%292%2F%28n-2%29%5D+%5E+%5E.jpg "=9.409/[0.103/(5-2)] = ^ ^")
237
回归显著性检验方差分析表 变异来源 SS MS F P 回 归 <0.01 残 差 总变异 回归方程有统计学意义

238
^ ^ 3. t检验 (1) H0: β=0, H1: β≠0,α=0.05 (2) 计算统计量 t值
tb=│b-0│/Sb=│b│/Sb υ=n-2 Sb=回归系数的标准误 =S y·x/√Σ( x-x )2 Sy·x:剩余标准差,标准估计误差,指当x对y的影响被扣除后, y仍有剩余变异的程度。 Sy·x=√Σ(y-y)2/(n-2) ^ ^
2. Sy·x:剩余标准差,标准估计误差,指当x对y的影响被扣除后, y仍有剩余变异的程度。 Sy·x=√Σ(y-y)2/(n-2) ^ ^")
239
(3)确定P值,判断结果 t 0.05(n-2) Sy·x=√0.1030/(5-2)=0.1853 Sb=Sy.x /√Σ(x-x)2 =0.1853/√10 =0.0586 tb=│b│/Sb=0.97/0.0586=16.553 υ=n-2=5-2=3 查表得 t 0.01(3)=5.841 ,则P<0.01, 说明回归系数有统计学意义,所求回归方程成立。
=5.841 ,则P<0.01, 说明回归系数有统计学意义,所求回归方程成立。")
240
说明: (1)t检验的结果与F检验的结果是一致的。 tb=√F 本例 F= , √F=16.554=tb (2)对于简单线性回归方程,回归方程的显著性检验 与回归系数的显著性检验及简单相关系数的显著 性检验是等价的。 tb= tr

241
三、直线回归的应用 1.描述两变量间依存变化的数量关系 2.预测预报

242
四、回归分析应用的注意问题 1. 实际意义。要求y来自正态分布的随机变量。 2. 先绘制散点图 3. 回归模型基本条件 4. 避免外延
5. 直线关系与因果关系 6. 决定系数r2:反映应变量总的变异中可用 回归关系解释的比例。 r2 越接近1, 说明回归效果越好。无负值, 0~1之间。

243
应用决定系数,可避免对相关系数表示的 相关程度作过分夸张的解释。
例如,当r=0.5时, 则r2=0.25, 表示回归平方和在总平方和中占25%,即指一变量的变异仅有25%的变异是由另一变量所引起的, 另外还有75%的变异并非是由另一变量的变异所引起。

244
SUMMARY 一、直 线 相 关 1. 相关系数的意义:密切程度,方向 2. 相关系数的计算 3. 相关系数的显著性检验—t, 查表法
4. 注意问题 二、直 线 回 归 1.线性回归方程的建立:最小二乘法 2.回归系数的意义,计算,显著性检验(t, F) 3.应用 4.注意问题
 3.应用. 4.注意问题.")
Similar presentations













>")





