Download presentation
1
普通心理學第六章 學習歷程

2
行為主義 行為主義(behaviorism)的創始人John Watson(華生),有一段膾炙人口的名言
只要給他一打可愛健康的嬰兒, 在他的規劃的環境中養育, 則不論這些孩子先天的才智、賦性、傾向、種族、 出身的家庭背景為何,他保證可以亂點鴛鴦譜,任意的將他們培育成各式各樣的「專家」 譬如:醫生、律師、乞丐、小偷

3
作為一個萌芽時代的心理學家,Watson這段話洋溢著一股「捏面人豪情」,彷彿人就像麵團一般,可以任由養育者肆意的揉捏,塑出你所能想到的任何造型
人充滿可塑性,每個人會成為怎樣的人,基本上決定於他的成長經驗。 他在他的環境中成長,從環境獲取經驗,並藉由經驗,建立他自己的行為模式 人出生時,除了與生俱來極少數的反射動作外,在心理上一無所有,沒有任何傾向,或發展藍圖。

4
「學習」的定義 學習(learning)意味著行為的改變。 我們所謂的「學習」顯然包含兩個要件: (1)行為的改變必須是基於經驗的影響
(2)行為的改變必須是相當持久而穩定的現象。
行為的改變必須是相當持久而穩定的現象。")
5
第一個要件要讓我們將疾病、腦傷、藥物的影響等生理變化所造成的行為改變,排除於學習之外
第二個要件讓我們能夠區分行為的短暫起伏與真正的學習。 事實上,有許多隨機因素會對行為造成影響 譬如,強烈的地震讓人產生恐慌的反應 但是除非這種反應持續相當長的一段時間,否則我們不能說其中有學習發生。

6
一歲左右開始學步,也開始牙牙學語,意思是說,走路與說話都是「學來的」
就某種程度來說,這樣講不能算錯 走路依靠骨骼與肌肉,也依賴腦部相關神經的指揮,這些器官尚未發展到足夠強大與精巧之前,走路是不可能的 更重要的是,開始走路似乎是十分順理成章的事。

7
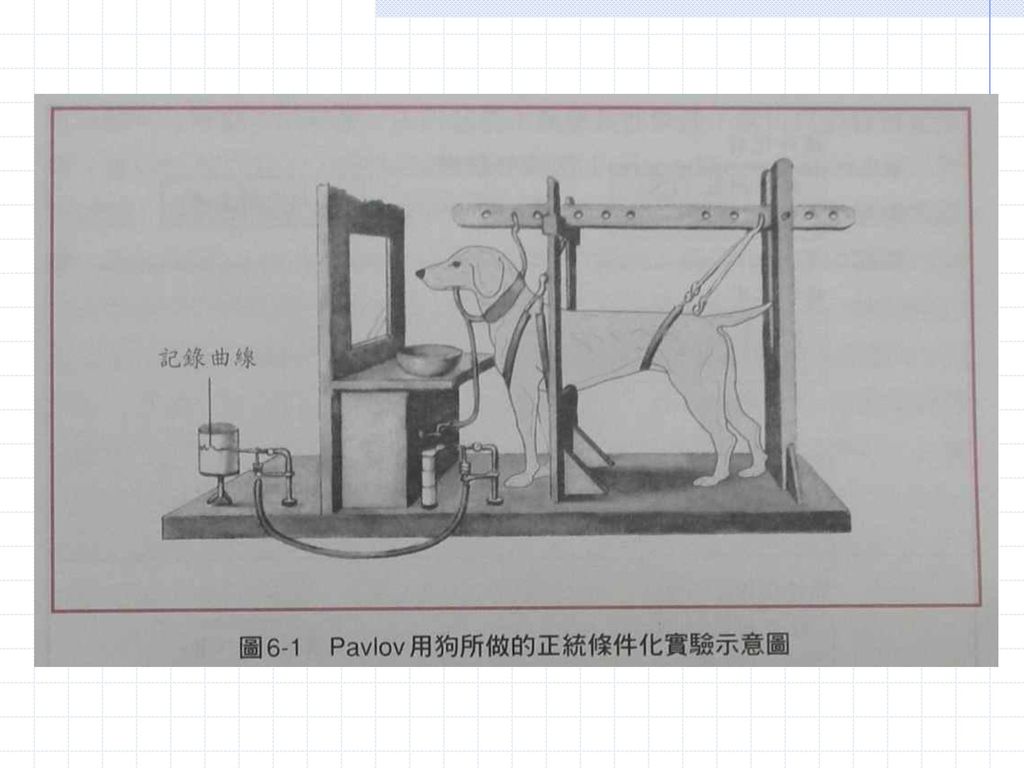
正統條件化 正統條件化(Classical conditioning,或譯為古典制約)。 作為生理學家,Pavlov研究的是消化系統。
為了對唾液在消化歷程中的角色做定量研究,他在狗的下巴打洞,裝上一條管子,以便將狗在進食時所分泌的唾液引到一個容器內,然後加以測量。

9
Pavlov的學理預設是:唾液分泌是動物口腔受食物刺激後的生理反射(reflex)
")
10
Pavlov當年在實驗室中觀察到的現象,其實不難想像。
剛開始的時候,只有當時物進入狗的嘴裡,狗的唾液分泌量才會明顯增加。 很快的,只要看到助理人員端著食物走進來,即使食物還沒到口,那條狗已經「垂涎欲滴」了 接著,連助理人員的腳步聲,也能引發大量的唾液分泌。

11
十分明顯的,助理人員的外表、腳步聲原本只是中性刺激
想想看,如果有人看到你的臉、聽到你的聲音,就「食指大動」,這個世界有多怪異? 但是在特定的實驗室條件下,他們變成了能夠引發唾液反應的刺激。 所謂「條件化」,指的正是這種在特定條件下引發的反應歷程。

13
這樣的實驗程序之所以被稱為學習歷程,是因為受試者原先不會對鈴聲做唾液反應
經過條件化程序後,他的行為已經產生了持久而穩定的改變 每次我們搖鈴,就可以看到他的唾液反應。 原先它不會對鈴聲做唾液反應,現在他「學會了」。

14
這樣一個簡單而「不自然」的學習,乍看之下似乎與人類的行為無關
「學會流口水」似乎不是什麼值得研究的現象,因此,這種研究看來只是吃飽了沒事幹的學者所做的無聊動物實驗。 Pavlov的研究其實是個大發現,和我們日常許許多多的行為表現息息相關,這點我們留待稍後再說明。 讓我們先看看,所謂的條件化歷程,應具備哪些要件?

15
首先,條件化歷程中,需要一個能引起特定反應的刺激。
譬如說,肉末能引起唾液反應、對眼睛噴氣能引起眨眼反應,這想種刺激都可以用來作為條件化實驗中的刺激。 由於他們不需要其他條件,就可以引發特定反應(流口水或眨眼),因此稱為無條件刺激(unconditioned stimulus,簡稱US)
,因此稱為無條件刺激(unconditioned stimulus,簡稱US)")
16
由無條件刺激所引發的反應,如流口水或眨眼,就稱為無條件反應(unconditioned response,簡稱UR)。
其次,條件化程序中需要一個可以控制的中性刺激,譬如說一段鈴聲、一只亮起來的燈泡,一陣加諸於受試者手指頭的震顫等等。 這些中性刺激必須與US配對數次(或數十次)之後,才能引發原先只有US才能引發的反應。
之後,才能引發原先只有US才能引發的反應。")
17
換句話說,只有在這個特定條件下,這些中性刺激才能引發它們原先不能引發的反應。
因此,這類刺激就稱為條件刺激(conditioned stimulus,簡稱CS)。 由CS所引發的反應,雖然跟UR是同類的,一般而言,在強度上卻比UR稍弱一點,因此另稱為條件反應(conditioned response,簡稱CR)
。 由CS所引發的反應,雖然跟UR是同類的,一般而言,在強度上卻比UR稍弱一點,因此另稱為條件反應(conditioned response,簡稱CR)")
18
摘要的說,所謂的「條件化」,是透過CS與US的配對,使得CS能引發CR的歷程。
有些心理學家喜歡用連結(association),這個字眼來指稱這個歷程。 他們認為,條件化的結果是使得CS與US在受試者腦中發生聯結。 基於這點,行為主義的學習觀點被稱為聯結論(associationism)。
,這個字眼來指稱這個歷程。 他們認為,條件化的結果是使得CS與US在受試者腦中發生聯結。 基於這點,行為主義的學習觀點被稱為聯結論(associationism)。")
19
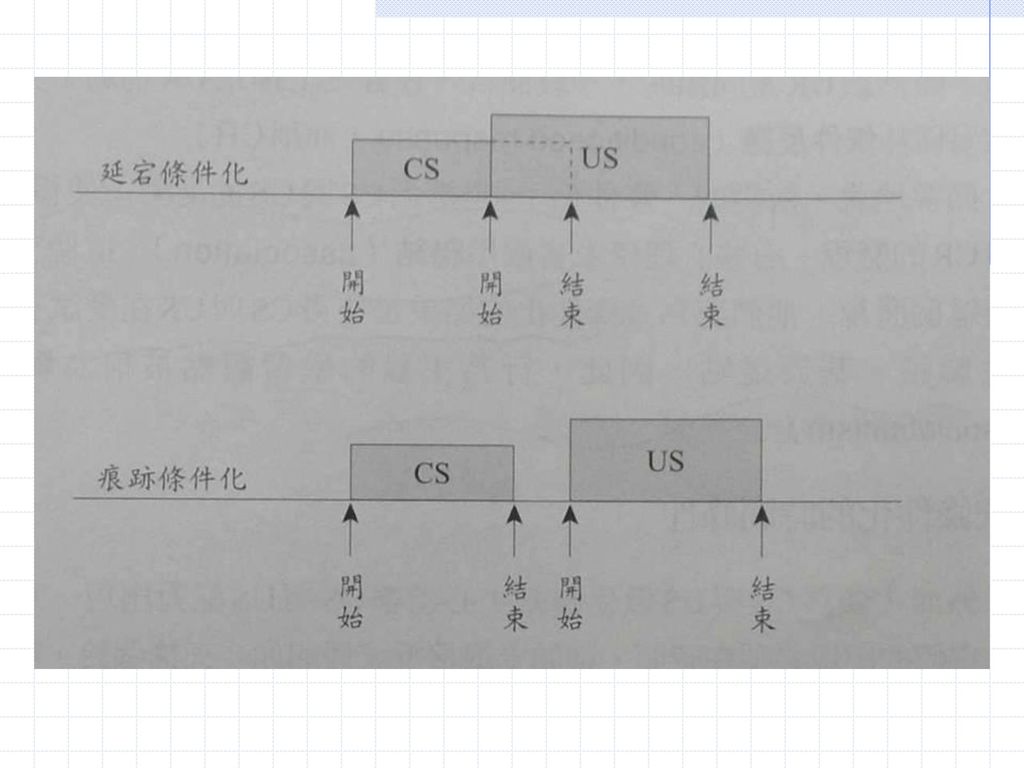
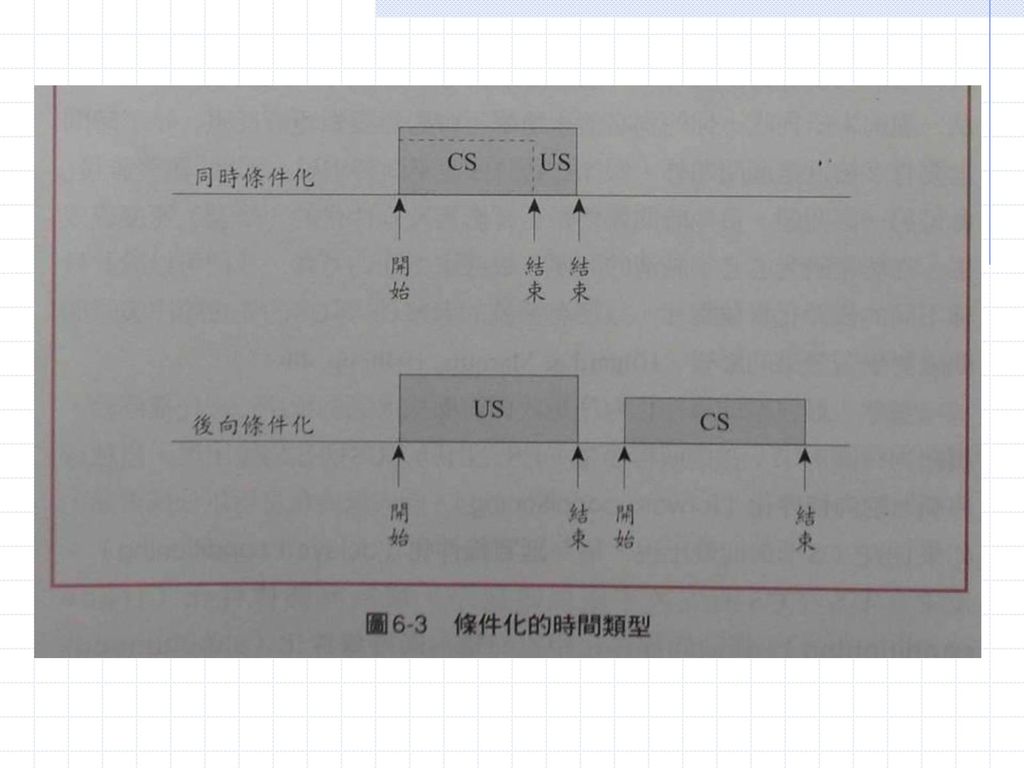
CS先出現,US則在稍後出現。 這種程序稱為前向條件化(forward conditioning)。 與前向條件化相對的,是同時條件化(simultaneous conditioning)與後向條件化(backward conditioning)。 顧名思義,同時條件化是CS與US同時出現的條件化程序。 同樣的後向條件化是US先於CS出現的條件化程序。

22
兩種前向條件化的學習效果,均優於同時條件化
後向條件化的學習效果則很差。

23
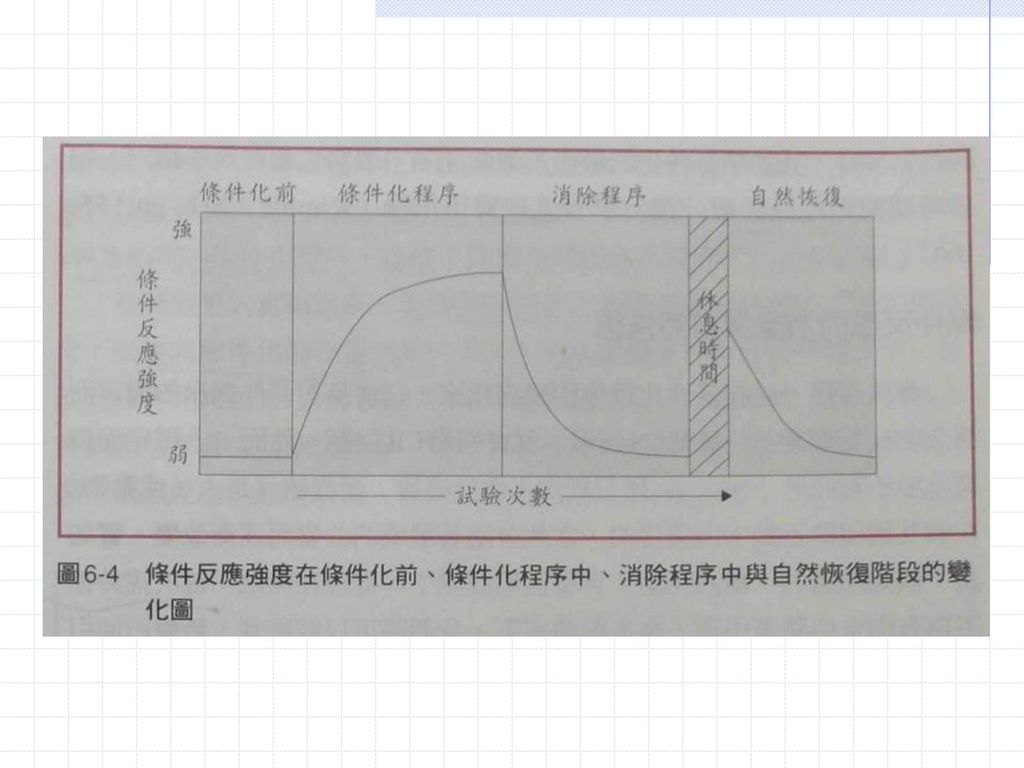
每次搖鈴都不再有肉末伴隨著出現,鈴聲所能引起的唾液分泌量越來越少,終至無異於平常沒有肉末時的分泌量。
這個除去條件反應的程序就叫做條件反應的消除(extinction)程序。 已被消除的條件反應,在休息一段時間後,反應會再度出現,只是比強度未消除前弱了一點,稱為自然恢復(spontaneous recovery)。
程序。 已被消除的條件反應,在休息一段時間後,反應會再度出現,只是比強度未消除前弱了一點,稱為自然恢復(spontaneous recovery)。")
25
一個嬰兒的母親每天都有些不同──她的髮型因為睡覺而變形了,她的聲音因情緒而有高低之分等等
但是嬰兒對母親的反應不能因此而有劇烈的改變,才能維繫一個穩定的母子互動模式 使得嬰兒得以在穩定的母子關係支持下成長。

26
根據這樣的分析,我們可以預測,經過條件化程序之後,不僅原先的條件刺激能引起條件反應,只要與條件刺激足夠類似的其他刺激,應該也都能夠引起條件反應。
這個預測的行為現象,確實在實驗室裡被觀察到了。 這種「由類似刺激引發條件反應」的現象,稱為刺激類化。 新刺激與原條件刺激的相似程度越高,所引發的條件反應就會越強,反之則越弱。

27
人類不但能將學得的反應類化到相似的刺激去,也能學會辨別類似的刺激,然後給予不同的反應。
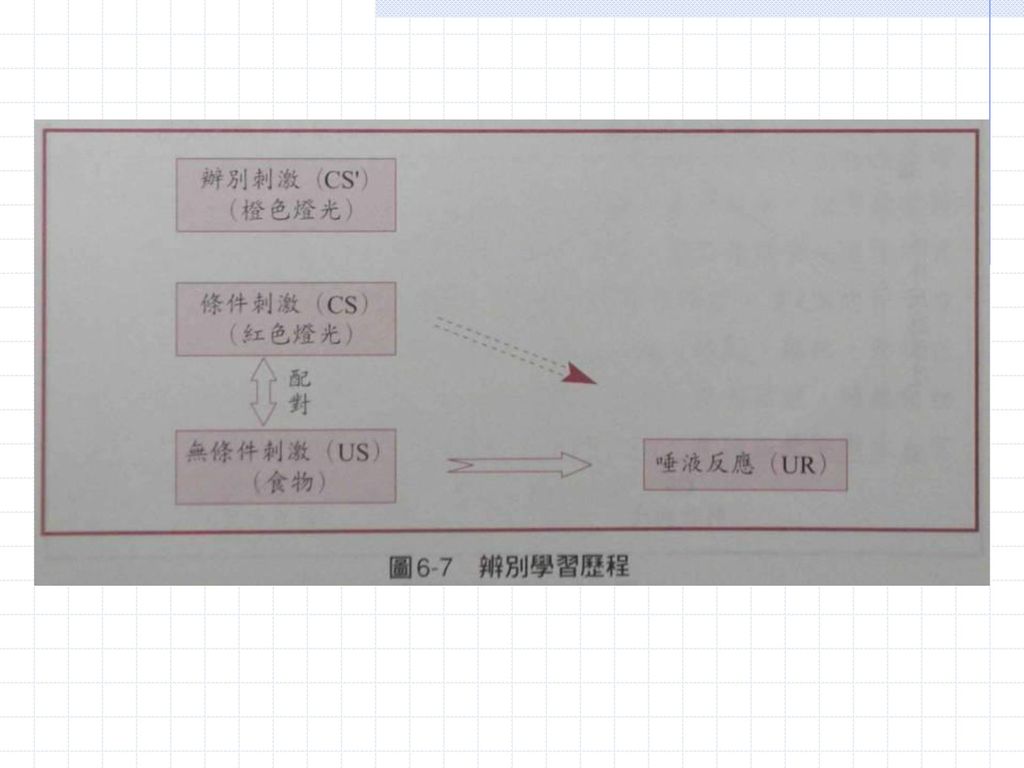
透過這種學習,不適當的類化反應得以被去除或抑制。 這種學習稱為辨別學習(discrimination learning)或刺激的辨別(stimulus discrimination)。 正統條件化中的辨別學習歷程可以用下圖來表示。
或刺激的辨別(stimulus discrimination)。 正統條件化中的辨別學習歷程可以用下圖來表示。")
29
從上圖可以看出,在辨別學習程序中,有兩個相似的刺激
受試者要學的是,對其中一個刺激(條件刺激,CS)產生條件反應,對另一個(類似於條件刺激的)(CS’)不反應(或產生其他的反應)。 在學習程序中,兩個刺激以隨機的順序輪流出現。 每當CS出現時,無條件刺激(US)就會伴隨出現。反之,CS’出現時,US不會伴隨出現。
產生條件反應,對另一個(類似於條件刺激的)(CS’)不反應(或產生其他的反應)。 在學習程序中,兩個刺激以隨機的順序輪流出現。 每當CS出現時,無條件刺激(US)就會伴隨出現。反之,CS’出現時,US不會伴隨出現。")
30
這樣的程序反覆進行下去,到最後,只要CS出現,就會引發CR反應
到了這個地步,顯然受試者已經學會對這兩個刺激做辨別反應

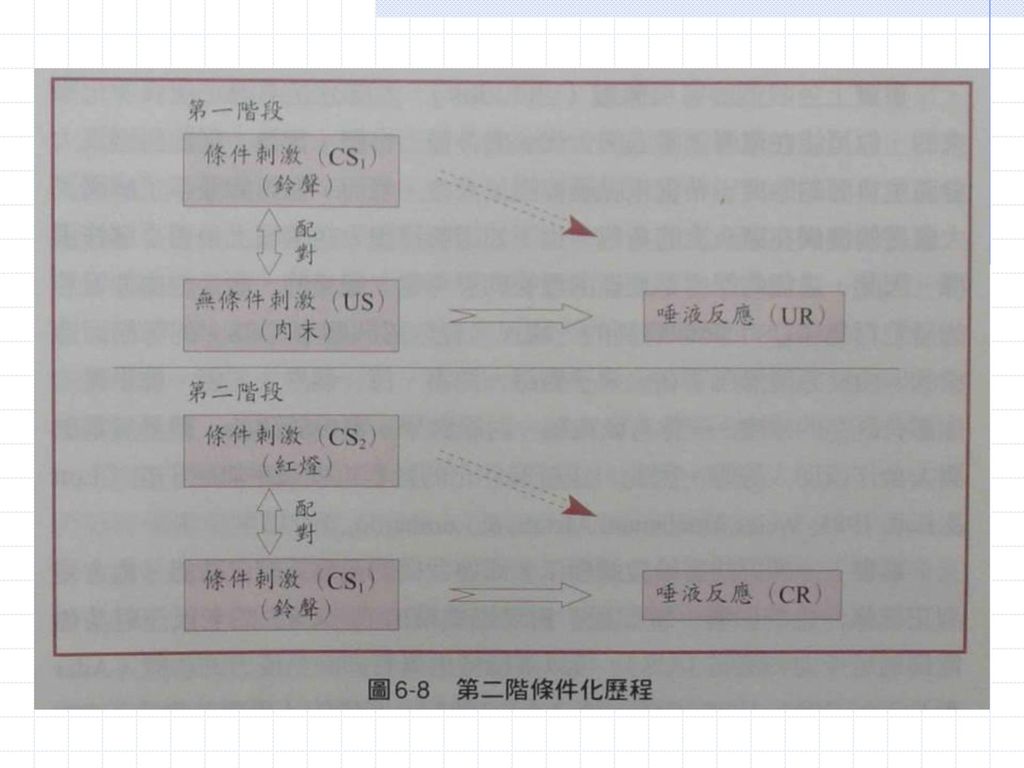
31
第二階段條件化 除了CS與US直接聯結(配對)外,條件化還有更微妙的形式。 試想如下的兩階段實驗。
第一階段實驗就像圖6-2所示典型的Pavlov氏實驗,先搖鈴(CS1),然後給狗一團肉末(US),結果當然是幾次嘗試之後,狗聽到鈴聲就會開始流口水 (CR)
,然後給狗一團肉末(US),結果當然是幾次嘗試之後,狗聽到鈴聲就會開始流口水 (CR)")
32
當第一階段條件化完成後,實驗程序變為,先亮起一個紅燈(CS2),然後搖鈴
在這個階段中,實驗者並不給狗肉末或其他食物。 然而,實驗結果卻顯示,第二階段進行幾次嘗試後,亮起紅燈就能引發狗的唾液反應。 這個實驗稱為第二階條件化(second-order conditioning),其實驗程序可用下頁圖來表示。
,其實驗程序可用下頁圖來表示。")
34
古典制約學習模式的不足之處 古典制約學習,是屬於聯結性學習的一種學習模式。
此種學習模式的特殊刺激的取代,由制約刺激取代非制約刺激,引起後者原來所引起個體的反應 從而建立制約刺激與制約反應之間的聯結關係。

35
此種刺激與反應間新關係建立的歷程,極為古典制約學習。
惟此種模式,只能解釋合於刺激取代的聯結式學習 不能解釋聯結式學習以外的其他事實。

36
操作條件化 日常生活中,學習通常包含許多動作,其中有不少是對環境的試探動作,這些動作常常造成環境相應的改變。
試想一個小孩子自己摸索著學習上網的狀況,你可以想見他怎樣拿著滑鼠,東試試西試試的樣子。 他會進入哪一個網站,會面臨怎樣的困擾或驚奇,決定於他從哪裡入手試探。

37
這樣的摸索繼續下去,沒幾天的功夫,你就會赫然發現,他已經能在網路上遨遊了。
在這樣的學習中,學習者的「反應」(這是行為主義者慣用的字眼)居於重要的地位。 通常學習者會先採取行動,然後根據行動的後果去校正他的行為。 在這類學習中,學習者學到的是一系列的行為模式,它可以達到目標或獲致某種後果。
居於重要的地位。 通常學習者會先採取行動,然後根據行動的後果去校正他的行為。 在這類學習中,學習者學到的是一系列的行為模式,它可以達到目標或獲致某種後果。")
38
這類學習被心理學家稱為工具性學習(instrumental learning)。
工具性學習的研究可以追溯到與Pavlov大約同時代的美國心理學家Edward Thorndike(1898)所做的先驅性研究 Thorndike設計一種叫做難題箱(puzzle box)的實驗儀器 實驗時,將一隻飢餓的貓關在裡頭,箱外則放著食物。 貓必須採下一個踏板,或抓連接踏板的繩子或扣環,才能打開箱門,吃到食物。
所做的先驅性研究. Thorndike設計一種叫做難題箱(puzzle box)的實驗儀器. 實驗時,將一隻飢餓的貓關在裡頭,箱外則放著食物。 貓必須採下一個踏板,或抓連接踏板的繩子或扣環,才能打開箱門,吃到食物。")
39
Thorndike描述說,剛開始的時候,貓抓遍了箱內每個地方,擠遍箱子的每一個縫隙。
偶爾,他會抓到繩子、扣環或踏板,誤打誤撞的打開了門。 這樣的嘗試一次接一次的進行下去,漸漸地,那些亂抓、亂擠的無效行為減少了,有效的開門動作越來越快出現 到最後只要一被放進箱子,他立刻就踩踏板或抓扣環,打開箱門出來

40
Thorndike從這些觀察結果中,歸納出有名的效果律(law of effect):
行為是否持續出現,決定於他的效果 更具體的說,Thorndike相信學習是個嘗試錯誤(trail-and-error)歷程 開始的時候,行為是任意的(或隨機的) 但是,有些行為會帶來好的結果,其他行為則否。
歷程. 開始的時候,行為是任意的(或隨機的) 但是,有些行為會帶來好的結果,其他行為則否。")
41
任何行為一旦帶來好結果,他再出現的機率就會上升,反之則下降
如此反覆進行下去,到最後,無效的行為完全消失,有效的行為則反覆出現 這種學習模式有如達爾文的演化歷程:物種隨機的變異,由環境來決定哪一種變異可以獲得繁衍的機會 行為也是隨機的變異,也由行為在環境中的效果,決定哪一種行為得以持續下去

42
桑代克(Thorndike)的學習理論有以下兩大要點:
(一)學習是經由嘗試錯誤的過程 在問題情境中,個體表現出一種嘗試性的反應,直到其中有一個正確反應出現,將問題解決為止。 多種嘗試性的反應,能有效解決問題,從而獲得滿足結果的反應,就是在該刺激情境中所欲學得的特定反應。
學習是經由嘗試錯誤的過程. 在問題情境中,個體表現出一種嘗試性的反應,直到其中有一個正確反應出現,將問題解決為止。 多種嘗試性的反應,能有效解決問題,從而獲得滿足結果的反應,就是在該刺激情境中所欲學得的特定反應。")
43
在某種刺激情境中學得某種特定反應之後,其他嘗試而無效的反應,即不再出現。
此種多種反應中選擇其一與特定刺激固定聯結的歷程,稱為嘗試錯誤學習(trail-and-error learning)
")
44
(二)效果律是嘗試錯誤學習能否建立的關鍵因素
在嘗試錯誤學習歷程中,某一反應之所以能夠與某一刺激發生聯結,原因是該反應能夠獲致令人滿意的效果。 這是嘗試錯誤學習能否建立的基本原則,桑代克稱此基本原則為效果律。 除了以效果律作為聯結性學習的基本原則外,桑代克又提出兩個附屬原則,用以解釋影響刺激與反應之間聯結強弱之條件

45
一為練習律(law of exercise),指刺激與反應間的聯結,隨練習次數的增多而加強
另一是準備律(law of readiness),指刺激與反應間的聯結,隨個體本身準備狀態而異 個體在準備反應的狀態下,聽其反應,則感滿足,有過滿足經驗,以後遇到同樣情境時,自會使個體繼續同樣反應。
,指刺激與反應間的聯結,隨個體本身準備狀態而異. 個體在準備反應的狀態下,聽其反應,則感滿足,有過滿足經驗,以後遇到同樣情境時,自會使個體繼續同樣反應。")
46
Skinner的實驗分析 Thorndike的觀點在大約四十年後,在B.F. Skinner(史基納)手上大放異彩。
Skinner設計一種有名的實驗儀器,叫Skinner箱(Skinner box),可以用來訓練鴿子或老鼠學會各種行為。
,可以用來訓練鴿子或老鼠學會各種行為。")
47
Skinner箱是個簡單的籠子,牆上有一個凸出的地方,放著一個食物盤,食物盤背後的牆上則有一個凹槽,連通一根輸送食物丸子的管子。
食物盤旁邊牆上突出一根可以壓下去的橫桿。 這根橫桿如果壓下去,就會啟動牆後輸送食物的裝置,讓一顆食物丸子掉到食物盤上。 實驗時,Skinner會將一隻飢餓的老鼠放進Skinner箱,任他自由活動。

48
正如Thorndike難題箱裡的貓,你可以想見,老鼠一被放進去,就會到處聞聞嗅嗅地探索。
這些探索行為可能包括抬起前腳立了起來,嗅一嗅牆壁的高處。 偶爾他正好在突出的按桿前豎起前腳,因此當他放下前腳時便可能壓到牆上突出的按桿,然後聽到卡答一響,一顆食物丸子掉進他身旁的碟子。 老鼠當然很快就會把食物丸子吃掉,然後繼續他的探索。

49
過一會兒,可能老故事重演,老鼠無意間壓桿,並獲得一小丸食物。
當實驗繼續進行下去,老鼠其他行為會越來越少,立起來壓桿的次數會愈來越快的增加 最後只看到他反覆的壓桿與進食的動作 至此,老鼠已經學會壓桿獲取食物的行為。 顯然,在這個實驗程序中,老鼠已經學到一種全新的行為習慣──壓桿獲取食物。

50
這種行為既不是老鼠在自然環境中常有的,也不是他被放進Skinner箱之前已有的
而且這是個穩定的行為習慣,因此,他是學來的。 Skinner的貢獻是,他對這種學習遠較Thorndike更深入的分析。 Skinner首先必須釐清的自然是:透過這個學習學到的行為,如何可以被去除?

51
這點其實可以根據常識推想而知:既然再壓桿可以獲取食物,只要壓桿動作不再讓老鼠獲得食物,壓桿行為應該可以被去除。
實驗結果完全符合這個常識性預測:在壓桿不再獲得食物的實驗情況下,老鼠每多壓一次桿,他下次再壓桿的時間間隔就會拉長一點,直到壓桿的行為完全消失。 與正統條件化的情況一樣,這個去除行為的歷程也叫做「消除」。

52
操作制約學習的學習歷程 亦即利用他們之間的因果關係,建立一個前所未有的新關係。對其經過歷程在補充說明以下三點: (一)本無關係 以史基納的實驗為例,實驗者計畫要個體學習者是S1->R的聯結;即希望白鼠學得見槓桿(S1)就按壓桿(R)的習慣。 但在實驗之初,刺激與反應之間本無關係。 雖然白鼠有壓桿反應,但那是偶然,不是由槓桿刺激所引起。

53
(二)已有關係 在操作制約學習歷程中,沒有像古典制約那樣在UCS與UCR之間已存在著必然的關係。 在操作制約學習歷程中,操作性反應(壓桿)是個體自發的,不是由某一刺激引起 但是這個反應之後如果帶出某種結果,我們也可以把他看程式以有關係。 不過在此一關係中,個體自發性反應(壓桿)為因,反應之後帶出的刺激(食物)為果
為因,反應之後帶出的刺激(食物)為果.")
54
只有個體先反應,而後才出現刺激。 所以這個關係事實上是屬於RS,而非SR。 如果個體不反應,該刺激就不會出現,自然也就無從產生學習。 (三)新建關係 在操作制約學習中,要個體學習者是由於偶然向某一刺激反應而變為向該刺激習慣的反應。 只是,此種刺激與反應間關係的建立,是靠個體偶然反應的結果所控制。

55
操作制約學習過程的重要現象 (一)類化與辨別 與古典制約學習相比,操作制約學習後學到的反應,也會產生刺激類化現象
以在史基納箱內的鴿子,學習到啄亮片而得到食物的實驗為例 如鴿子先學到的是啄黃色亮片而得到食物,以後見到紅色亮片也會表現啄擊反應,即為刺激類化現象。

56
如鴿子啄擊黃紅兩種亮片都能獲得食物,他將對兩種亮片繼續啄擊下去
如只選擇紅色亮片的啄擊作為要鴿子保留的反應,那就只要在啄擊紅色亮片後給予增強物,而啄擊黃色亮片則否 如此差別安排,在分別啄擊數次後,鴿子就只會啄擊紅色亮片,而放棄黃色亮片。此現象即為刺激辨別

57
(二)二層制約學習 在古典制約學習歷程中,原來的制約刺激,經制約練習(相伴出現)達到取代非制約刺激的作用之後,即可進一步將該制約刺激當作非制約刺激使用 與另一新的制約刺激配合,從而建立高一層次的制約學習,這叫二層制約學習。

58
在操作制約學習中,也可產生同樣現象。 當史基納箱內白鼠學到壓桿取食反應之後,如在食物出現之前,先由發聲器傳出一種聲音(CS),並繼續與食物(UCS)相伴出現多次 聲音本身即將變成引起白鼠壓桿反應的增強物 為在性質上,他屬於次級增強物。

59
(三)行為塑造(shaping) 如希望建立的行為比較複雜,其間包括許多個連續的反應,無法只靠在一連串反應之後的增強物發生作用 在此種情形下,只能採分解動作的方式,將構成形無的反應,依序各自施以操作制約學習式訓練 學到第一個反應,在學習第二個反應,依序進行,直到最後的反應

60
最後從頭到尾連貫起來,學到一連串的正確反應
訓練動物是如此,教人學習技能也是如此 此種行為塑造的學習方式,又稱為連續漸進法。

61
古典制約學習與操作制約學習 的不同 就原理的運用來說,兩者均為配對呈現兩種刺激,而使中性刺激具有引發互惠的學習,所以兩者在原則上是同類的
古典制約學習與操作制約學習 的不同 就原理的運用來說,兩者均為配對呈現兩種刺激,而使中性刺激具有引發互惠的學習,所以兩者在原則上是同類的 但就制約的過程及其實質內容而言又不盡相同。

62
(一)刺激呈現的次序不同 在古典制約的學習中,總是制約刺激(CS)與非制約刺激(UCS)在前,非制約反應(UCR)與制約反應在後(CR);而且後者乃係前者所引起 但在操作制約學習中,卻是制約反應(CR)在前,非制約刺激(UCS)在後 非制約刺激之後故也引起非制約反應(UCR),但非制約刺激的出現,卻是由制約反應的結果,而制約反應是個體自發的,非由任何外界固定刺激所引起。
,但非制約刺激的出現,卻是由制約反應的結果,而制約反應是個體自發的,非由任何外界固定刺激所引起。")
63
(二)反應的性質不同 在古典制約學習中,制約反應和非制約反應在性質上是相同的(如均唾液分泌) 但在操作制約學習中,兩者相異(如制約反應為壓桿,非制約反應為吃食物)
反應的性質不同 在古典制約學習中,制約反應和非制約反應在性質上是相同的(如均唾液分泌) 但在操作制約學習中,兩者相異(如制約反應為壓桿,非制約反應為吃食物)")
64
(三)學習的性質不同 古典制約學習乃是一種刺激代替的歷程,即制約刺激代替了非制約刺激,而引起非制約刺激所能引起的反應。但在操作制約學習歷程中並無刺激代替現象。
學習的性質不同 古典制約學習乃是一種刺激代替的歷程,即制約刺激代替了非制約刺激,而引起非制約刺激所能引起的反應。但在操作制約學習歷程中並無刺激代替現象。")
65
(四)行為發生的原因不同 在古典制約學習中,個體的反應是被誘發的行為,其反應常是被動的,即所謂反應性行為。 但在操作制約學習中,個體的反應是自發行為,是主動的參與,即所謂操作性行為。 (五)根據的學習理論不同 兩種制約學習歷程的建立,係受不同原則之支配:古典制約學習主要受接近律的支配;操作制約學習則主要受效果律的支配。

66
正增強(物)與負增強(物) 謂增強物(reinforcer),是指在學習情境中出現之任何事件(人、事、物等),而有助於某刺激與某反應間之聯結者 (一)正增強(物) 凡是個體反應後所出現的刺激物,能強化該反應者,該種刺激物即稱為正增強物(positive reinforcer)。
正增強(物) 凡是個體反應後所出現的刺激物,能強化該反應者,該種刺激物即稱為正增強物(positive reinforcer)。 .")
67
因為正增強物的出現,能對個體的反應產生強化作用,此種作用就稱為正增強(作用)(positive reinforcement)
一種刺激物之所以對個體的反應產發生增強作用,主要是它能夠適合或滿足個體的需要。 例如:食物具有酬賞或獎勵的性質。 向食物之類用為增強的刺激物,稱為正增強刺激或正增強物。

68
(二)負增強(物) 凡是個體反應後能使厭惡性刺激物停止,因而強化了該反應者,該種刺激物即稱為負增強物(negative reinforcer) 因為負增強物的消失,能對個體的反應產生強化作用,此種作用就稱為負增強(作用)(negative reinforcement) 在一般動物實驗中,電擊即為常用的負增強物。

69
談負增強物或負增強作用時,有兩點須加注意
其一,雖稱其為「負」,但對個體行為而言,仍然是具有強化作用 其二,在性質上,負增強物雖使個體厭惡,但其在學習上的功能作與懲罰不同。

70
(三)從增強物出現的頻率安排來看 從增強物出現的頻率安排來看,可分連續增強與部分增強兩種情形 1.連續增強(continuous reinforcement):是指每當個體在學習中有正確或適當的反應時,均給予增強的方式。 2.部分增強(partial reinforcement):是指每隔一段時間,或在個體有了幾次正確或適當反應之後,才給予增強的方式,這種方式又稱間歇增強(intemittent reinforcement)
:是指每隔一段時間,或在個體有了幾次正確或適當反應之後,才給予增強的方式,這種方式又稱間歇增強(intemittent reinforcement)")
71
部分增強又可分成如下四種形式: (1)固定時距式(fixed interval;Fl):即每隔一段固定時間,才給予增強一次 例如:史基納箱裡的老鼠每個五分鐘,操作槓桿就獲食一次。 (2)固定比率式(fixed ratio;FR):即在固定的幾次反應之後,才給予增強一次 例如白鼠在史基納箱中,每壓桿三次,才給予食物一次。

72
(3)變異時距式(variable interval;VI):即以不固定的時間間隔實施增強
例如:在史基納箱裡的白鼠,有時間隔三分鐘,有時五分鐘,有時甚至七分鐘,才給予食物一次 (4)變異比率式(variable ratio;VR):即不按一定的反應比率實施增強 例如:在史基納箱裡的白鼠,有時壓桿三次,有時五次,有時甚至七次,才給予食物一次。上述四種不同的增強方式,對個體的反應效果不一
變異比率式(variable ratio;VR):即不按一定的反應比率實施增強. 例如:在史基納箱裡的白鼠,有時壓桿三次,有時五次,有時甚至七次,才給予食物一次。上述四種不同的增強方式,對個體的反應效果不一.")
73
一般而言,變異式較固定式效果為優;變異式中又以變異比率式較變異時距式為佳。

74
原級增強、次級增強和高級 (層次)增強 (一)原級增強(primary reinforcement)
原級增強、次級增強和高級 (層次)增強 (一)原級增強(primary reinforcement) 是指原級增強物所引起的增強效應而言。凡增強刺激其本身具有引發反應的效用,都屬於此類增強物(如食物、飲料等)。
增強. (一)原級增強(primary reinforcement) 是指原級增強物所引起的增強效應而言。凡增強刺激其本身具有引發反應的效用,都屬於此類增強物(如食物、飲料等)。")
75
例如:在巴夫洛夫的實驗中,食物都不必經由訓練,就可以引起狗流口水的反應。
像這種因食物而產生的增強作用,就可以叫做原級增強(作用) (二)次級增強(secondary reinforcement) 由次級增強物所引起的增強效應,即為次級增強 次級增強物係指與原級增強物配對制約後,具有引發原級增強物所能引發的反應者
 (二)次級增強(secondary reinforcement) 由次級增強物所引起的增強效應,即為次級增強. 次級增強物係指與原級增強物配對制約後,具有引發原級增強物所能引發的反應者.")
76
此種刺激不能直接滿足生理需求,但可引發反應。
例如巴夫洛夫的實驗中,與食物配對出現後的鈴聲,即具有使狗流口水的效應 像這種因鈴聲而產生的增強作用,就可以叫做次級增強(作用)
")
77
(三)高級(層次)增強(higher-order reinforcenment)
以次級增強物為基礎,另以其他刺激為制約的刺激所形成的增強效應,稱為高級增強,也叫高層次增強 具有高級增強效應的刺激物,即為高級增強物 例如,在巴夫洛夫的實驗中,鈴聲為次級增強物,再以燈光與之配對,終能引發狗流口水反應 像這種因燈光而產生的增強作用,就可以叫做高級增強(作用)。
。")
78
負增強與懲罰的區別 所謂負增強,是指撤除個體所厭惡的負增強物為誘因,企圖使個體表現出良好的行為,或使已表現的良好行為得到強化。
負增強與懲罰的區別,可以歸納為下列三點: (一)實施方向不同 懲罰是「給予」個體負增強物,負增強是「撤除」已加諸個體的負增強物。
實施方向不同. 懲罰是「給予」個體負增強物,負增強是「撤除」已加諸個體的負增強物。")
79
(二)出現時機不同 懲罰是在個體表現不良行為之後為之,負增強則在個體表現良好行為後為之。 而且負增強是在個體接受懲罰後,若表現良好的行為,才撤除加諸其身的負增強物。 換言之,懲罰在先,負增強在後。
出現時機不同 懲罰是在個體表現不良行為之後為之,負增強則在個體表現良好行為後為之。 而且負增強是在個體接受懲罰後,若表現良好的行為,才撤除加諸其身的負增強物。 換言之,懲罰在先,負增強在後。")
80
(三)使用目的不同 懲罰的基本使用目的,是在抑制或遏止不良的行為 負增強的基本使用目的,是在誘發並強化良好的行為
使用目的不同 懲罰的基本使用目的,是在抑制或遏止不良的行為 負增強的基本使用目的,是在誘發並強化良好的行為")
81
反應隨因 老鼠在Skinner箱中的行為顯然遵循Thorndike的效果律。 然而Skinner的實驗與Thorndike的實驗有點不同。

82
然而在Skinner的實驗中,老鼠在吃到食物後,實驗並未暫時中斷,等著開始另一次嘗試。
Skinner把這樣的學習情境稱為自由學習(free learning)。 在自由學習的實驗情境中,實驗會怎樣進行,或快或慢,基本上,決定於受試者的行為。
。 在自由學習的實驗情境中,實驗會怎樣進行,或快或慢,基本上,決定於受試者的行為。")
83
受試者的動作決定他的環境會不會出現 這樣的實驗情境有如受試者在操作(operate)它的環境,是以Skinner稱這種學習為操作的條件化(operant conditioning),而不稱為工具性學習。
它的環境,是以Skinner稱這種學習為操作的條件化(operant conditioning),而不稱為工具性學習。")
84
學習的先決條件是:「行為與其後果之間有穩定的關係」。
這個條件稱為反應隨因(response contingency)──伴隨著反應的出現(譬如:壓下按桿),會有某個後續狀況跟著發生(譬如,一小丸食物會掉進盤子裡去) 反過來說,如果反應並未發生(沒有壓下按桿),該後續狀況就不會出現 根據這樣的觀點,既然反應隨因是學習的先決條件,那麼,任何行為的後果如果是隨機的,或是不斷改變的,學習就不可能發生。
──伴隨著反應的出現(譬如:壓下按桿),會有某個後續狀況跟著發生(譬如,一小丸食物會掉進盤子裡去) 反過來說,如果反應並未發生(沒有壓下按桿),該後續狀況就不會出現. 根據這樣的觀點,既然反應隨因是學習的先決條件,那麼,任何行為的後果如果是隨機的,或是不斷改變的,學習就不可能發生。")
85
Skinner在他的實驗中所闡明的學習法則,最重要的就是這個反應隨因原則
在這些實驗中,只要反應隨因條件確立,學習就會發生,否則就不可能有任何學習 因此,只要能弄清楚學習情境中存在著怎樣的反應隨因關係,就可以充分說明人或動物為什麼會有這樣或那樣的行為

86
完全不需要去揣測行為者有怎樣的想法、觀念、目標或意圖,也不必去問壓一根按桿和獲得食物之間,會有什麼心理上的關聯。
因此,從行為主義的角度來看,了解人的想法是多餘的,不但無助於我們了解人的行為,反而有礙於我們探索真正的行為成因。

87
我們可以用如下的觀點去看老鼠在Skinner箱裡的行為,而絲毫不減少我們對老鼠行為的了解與預測能力
促成老鼠不斷壓桿的,不是他心裡的任何想法,而是伴隨著壓桿動作而來的食物丸子 這樣看來,食物在操作的條件化中,對行為具有強化(reinforcement)的功能
的功能.")
88
而學習歷程不多不少,正是行為被強化的歷程。
在這個歷程中,諸如食物、糖水之類的東西,由於擁有強化行為的功能,就被稱為強化物(reinforcer)。
。")
89
黑猩猩的「頓悟」 一九二O年代,德國心理學家Wolfgang Köhler對黑猩猩的問題解決行為所做的一系列研究
成了今天心理學教科書裡最被廣為引用為的文獻之一。 在這些研究中,Köhler所觀察到黑猩猩的行為,看起來和Thorndike的難題箱中貓的行為,或Skinner箱中老鼠的行為,顯然大異其趣。

90
譬如說,在其中一個實驗中,Köhler將一串香蕉吊在黑猩猩蘇丹的籠子天花板上,懸掛的高度恰好讓黑猩猩身手搆不到。
除此之外,在籠子的一個角落裡,還放著一個大箱子 開始的時候,蘇丹試著跳起來抓香蕉,當這個辦法證明無效後,蘇丹開始在籠子內踱步 一會兒,他停在箱子前,接著,彎下腰來,將箱子推到香蕉下面,然後站上去拿到香蕉。

91
在隨後的實驗中,Köhler把香蕉懸掛的更高,這次蘇丹採用的辦法是將幾個箱子疊了起來,然後爬上去拿香蕉
另有一次,籠子裡沒有箱子,結果蘇丹拉著Köhler的手,走到香蕉下面,然後爬到Köhler的頭上取得香蕉 蘇丹的這些行為和 Thorndike的貓或Skinner箱中的老鼠,最大的不同在於,它的行為似乎不是盲目的嘗試錯誤。

92
譬如說,他在一度失敗後,在籠子裡踱步,好像已經放棄吃香蕉的意圖
接著突然表現出有效的解決問題行為,而且從此之後它都能用相同或類似的辦法解決問題 這種行為的突然改變,顯然不是經由操作條件化歷程 從外表看來,蘇丹似乎曾在腦中盤算解決問題的辦法,才在行為上突然表現出來

93
在想出解決辦法之前,他在行為上沒有任何徵兆,直到想到辦法,才在行為上突然表現出來
由於這種行為上的特色,Köhler稱這種行為的改變為頓悟(insight)。 「頓悟」也許是個過度誇張或太容易引人遐思的字眼。
。 「頓悟」也許是個過度誇張或太容易引人遐思的字眼。")
94
然而,Köhler的研究顯示,行為不一定要一次又一次表現出來,以便一次又一次的獲得強化,才能建立新的行為習慣
假如我們不能用外在行為去解釋蘇丹的學習,那麼剩下的唯一解釋便只能歸諸於心理的認知活動 Köhler用黑猩猩當受試者,自然是有道理的 因為,黑猩猩是僅次於人類的聰明靈長類,因此比較可能有類似於人的高級心智活動。

95
然而,新近的證據顯示,類似於蘇丹的頓悟行為,在適當的實驗條件下,也會出現於鴿子身上。
無論如何,這些實驗證據所表明的,對行為而言,大腦高層次的活動不是無關的。

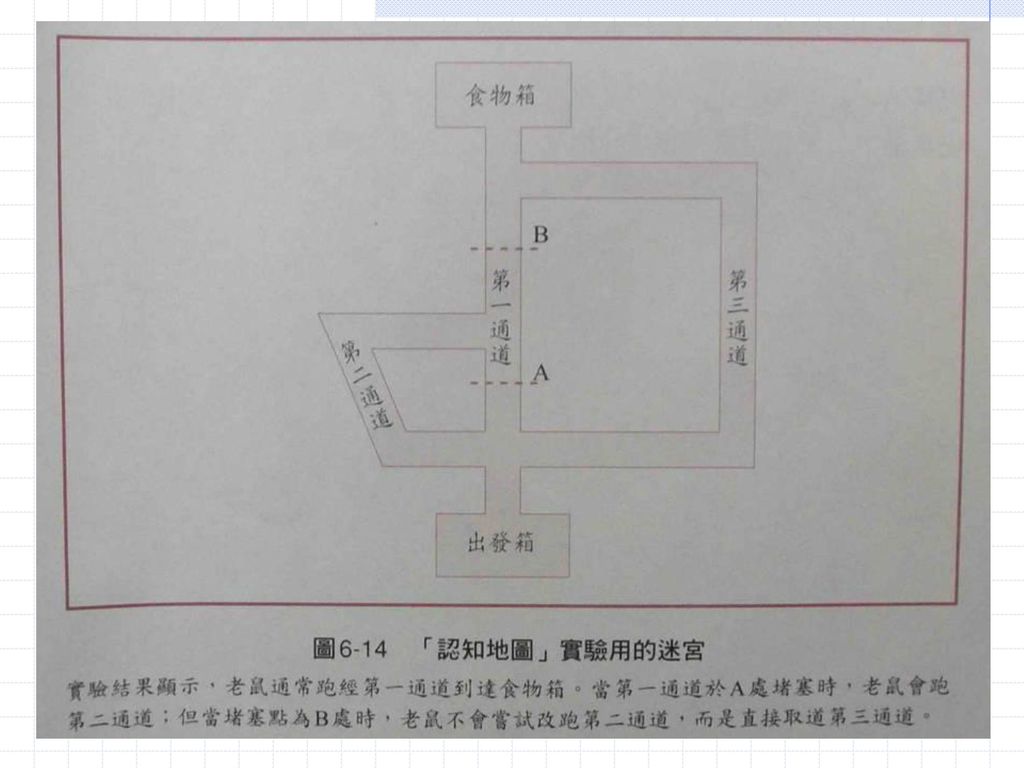
96
認知地圖 與認知因素有關的實驗,適用迷宮做的實驗。Tolman和Honzik用下圖所示的迷宮做了一個有名的實驗。

98
無論老鼠腦中是否真的有一張認知地圖,Tolman和Honzik的實驗,以及前面引述的感覺前條件化實驗,阻斷實驗、Köhler關於「頓悟」的實驗
實驗結果闡明的顯然是,認知因素應該在學習中佔有重要的地位 刻意的將人的心理活動──如認知活動──排除於心理學研究之外,顯然不是適當的做法

99
因此,心理學家於1960年左右,開始關心認知歷程,從而引發了心理學的「認知革命」
我們將從下一章開始,陸續介紹這方面的研究結果。



 也称精神治疗,是以医学心理 学的各种理论为指导,以心理和生理相互作用的机理 为依据,应用各种心理学技术或手段包括言语、表情、 行动或通过某些仪器及一定的训练方式,改善病人的.>")



数学学习与“尝试错误” 一.桑代克的迷箱实验 1.解决数学问题的思路探索 二. 学习的本质 过程:>")

>")
.>")








>")


