Download presentation
1
Some Knowledge of Machine Learning(1)
Speaker: Zhi-qiang You

2
Outline Apriori+FP-Growth Meanshift Decision Tree Max Entropy

3
Association Rule Apriori (Rakesh Agrawal & Ramakrishnan Srikant 94year proposed) 背景介绍 Apriori算法是一种频繁项集挖掘算法。算法的名字是因为算法基于先验知识(prior knowledge).根据前一次找到的频繁项来生成本次的频繁项。关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物蓝分析 (market basket analysis)。例如,购买佳能的顾客,有70%的可能也会买在一个月之类买HP打印机。这其中最有名的例子就是”尿布和啤酒“的故事了。 Agrawal R, Srikant R. Fast algorithms for mining association rules[C]//Proc. 20th int. conf. very large data bases, VLDB. 1994, 1215:
.根据前一次找到的频繁项来生成本次的频繁项。关联规则的目的在于在一个数据集中找出项之间的关系,也称之为购物蓝分析 (market basket analysis)。例如,购买佳能的顾客,有70%的可能也会买在一个月之类买HP打印机。这其中最有名的例子就是 尿布和啤酒 的故事了。 Agrawal R, Srikant R. Fast algorithms for mining association rules[C]//Proc. 20th int. conf. very large data bases, VLDB. 1994, 1215:")
4
X U Y = {{a,b},{a,c}}={a,b,c}
支持度与置信度 关联规则A->B的支持度support=P(AB),指的是事件A和事件B同时发生的概率。置信度confidence=P(B|A)=P(AB)/P(A),指的是发生事件A的基础上发生事件B的概率。比如说在规则Computer => antivirus_software , 其中 support=2%, confidence=60%中,就表示的意思是所有的商品交易中有2%的顾客同时买了电脑和杀毒软件,并且购买电脑的顾客中有60%也购买了杀毒软件。 如果事件A中包含k个元素,那么称这个事件A为k项集,并且事件A满足最小支持度阈值的事件称为频繁k项集。 X U Y = {{a,b},{a,c}}={a,b,c}
,指的是事件A和事件B同时发生的概率。置信度confidence=P(B|A)=P(AB)/P(A),指的是发生事件A的基础上发生事件B的概率。比如说在规则Computer => antivirus_software , 其中 support=2%, confidence=60%中,就表示的意思是所有的商品交易中有2%的顾客同时买了电脑和杀毒软件,并且购买电脑的顾客中有60%也购买了杀毒软件。 如果事件A中包含k个元素,那么称这个事件A为k项集,并且事件A满足最小支持度阈值的事件称为频繁k项集。 X U Y = {{a,b},{a,c}}={a,b,c}")
5
Apriori算法的基本思想 过程分为两个步骤:第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;第二步利用频繁项集构造出满足用户最小信任度的规则。具体做法就是:首先找出频繁1-项集,记为L1;然后利用L1来产生候选项集C2,对C2中的项进行判定挖掘出L2,即频繁2-项集;不断如此循环下去直到无法发现更多的频繁k-项集为止。每挖掘一层Lk就需要扫描整个数据库一遍。算法利用了一个性质:Apriori 性质:任一频繁项集的所有非空子集也必须是频繁的。意思就是说,生成一个k-itemset的候选项时,如果这个候选项有子集不在(k-1)-itemset(已经确定是frequent的)中时,那么这个候选项就不用拿去和支持度判断了,直接删除。具体而言:
-itemset(已经确定是frequent的)中时,那么这个候选项就不用拿去和支持度判断了,直接删除。具体而言:")
6
Apriori事例

7
FP-Growth FP-Growth算法由数据挖掘界大牛Han Jiawei教授于SIGMOD 00‘大会提出,提出根据事物数据库构建FP-Tree,然后基于FP-Tree生成频繁模式集。

10
FP-Tree构建 FP-Tree算法第一步:扫描事务数据库,每项商品按频数递减排序,并删除频数小于最小支持度MinSup的商品。(第一次扫描数据库) 薯片:7鸡蛋:7面包:7牛奶:6啤酒:4 (这里我们令MinSup=3) 以上结果就是频繁1项集,记为F1。
 以上结果就是频繁1项集,记为F1。")
11
第二步:对于每一条购买记录,按照F1中的顺序重新排序。(第二次也是最后一次扫描数据库)
")
12
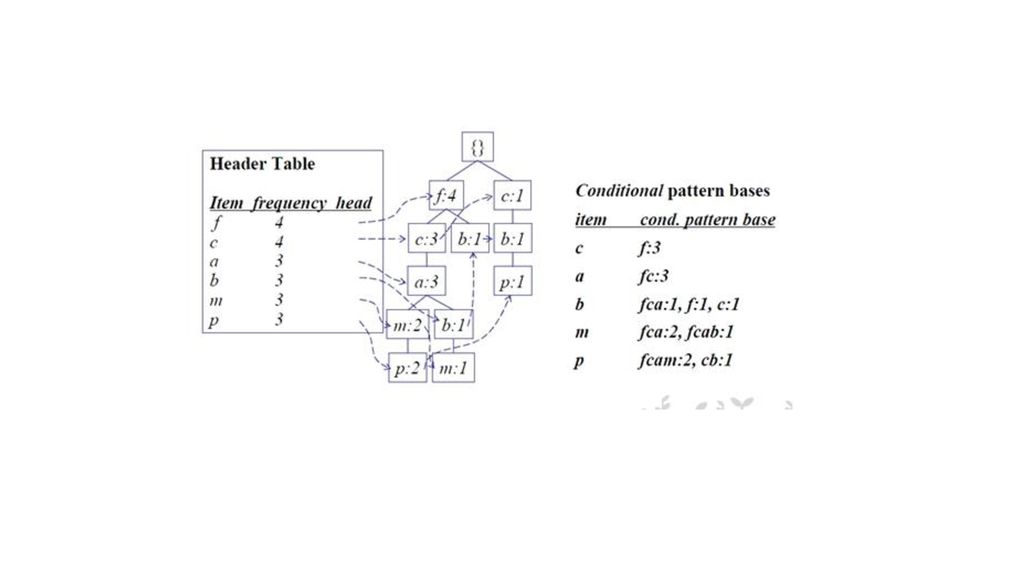
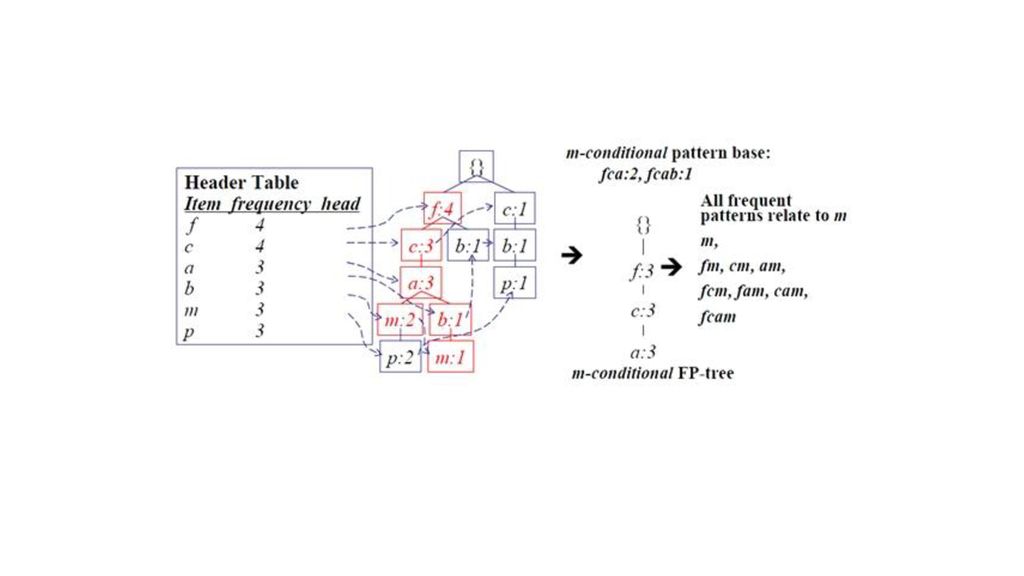
第三步:把第二步得到的各条记录插入到FP-Tree中。刚开始时后缀模式为空。
插入第一条(薯片,鸡蛋,面包,牛奶)之后 插入第三条记录(面包,牛奶,啤酒) 插入第二条记录(薯片,鸡蛋,啤酒)
之后. 插入第三条记录(面包,牛奶,啤酒) 插入第二条记录(薯片,鸡蛋,啤酒)")
13
输入 输出 图中左边的那一叫做表头项,树中相同名称的节点要链接起来,链表的第一个元素就是表头项里的元素。 如果FP-Tree为空(只含一个虚的root节点),则FP-Growth函数返回。
,则FP-Growth函数返回。")
14
Meanshift

17
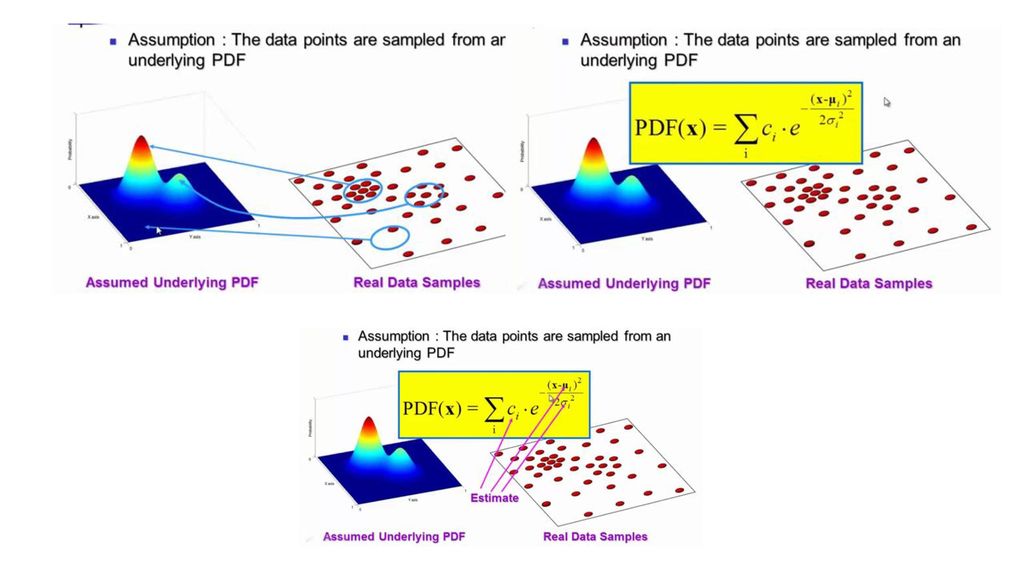
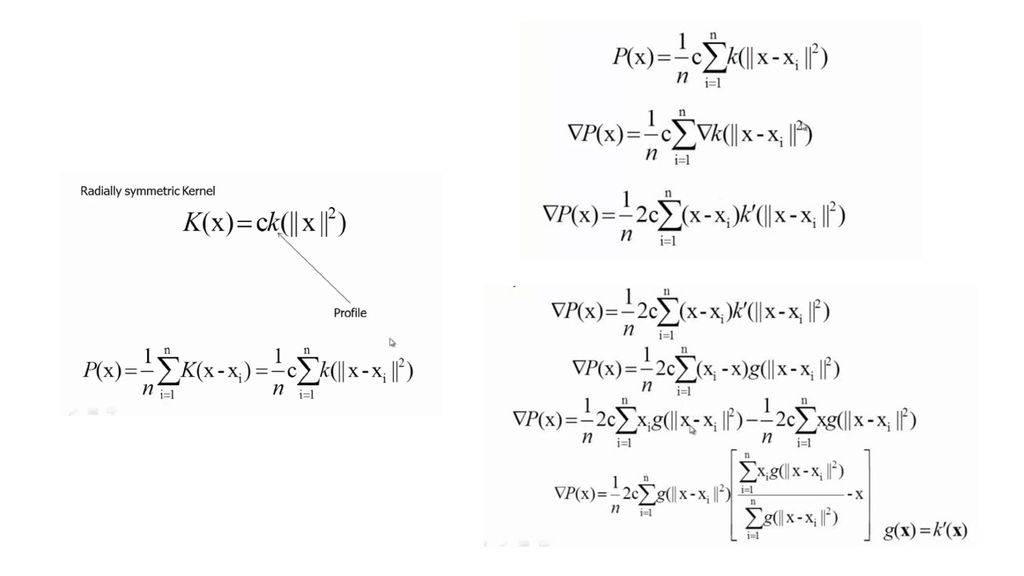
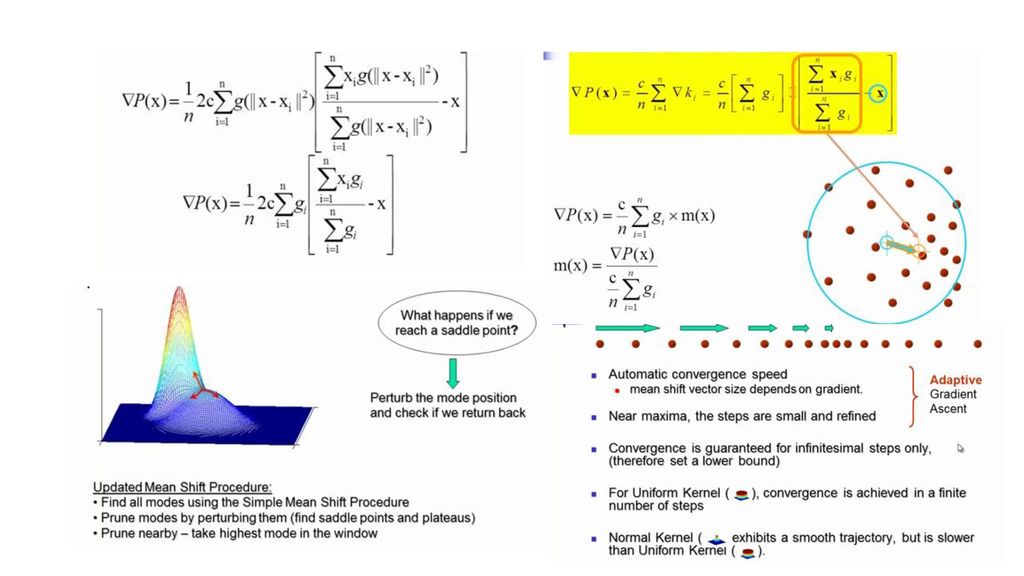
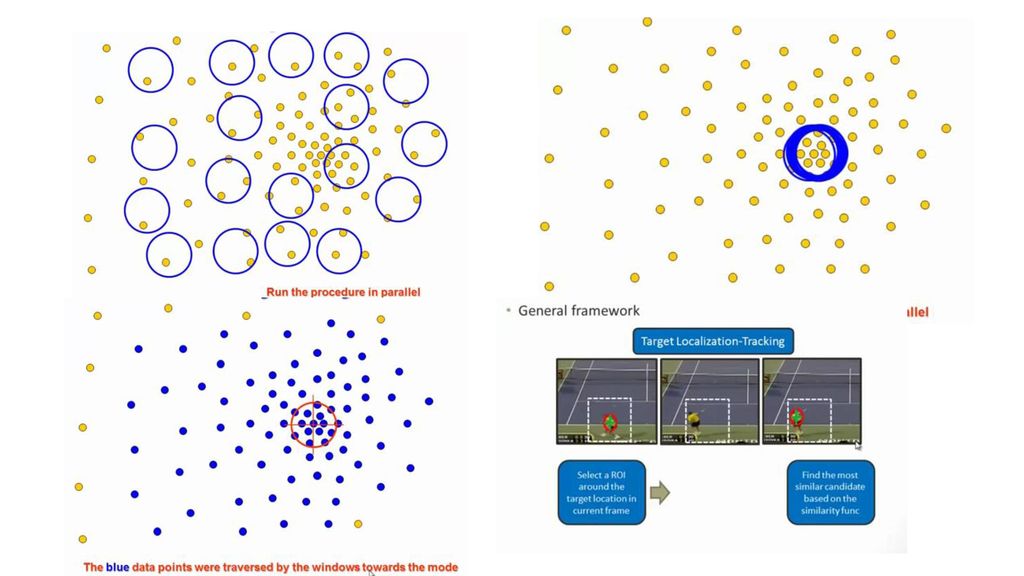
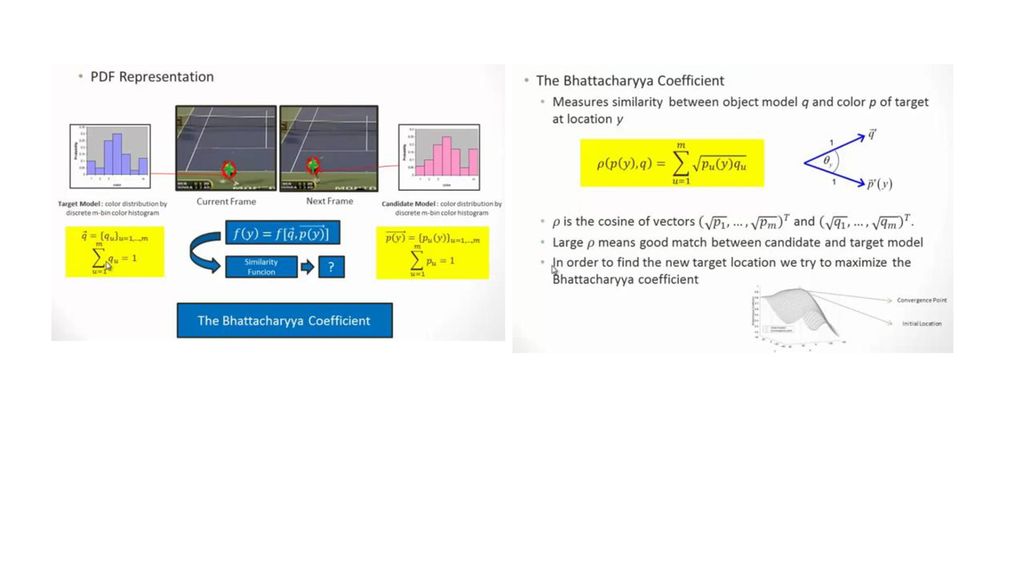
Pdf形式

22
Decision Tree 决策树是一种分类器,可以看成一个if-then规则的集合,其学习本质上是从训练数据集中归纳出一组分类规则,其学习过程使用到的损失函数通常为正则化的极大似然函数,学习的策略是以损失函数为目标函数的最小化。 一个女孩的母亲要给这个女孩介绍男朋友 女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。

23
常用的决策树学习算法 构建一棵决策树主要涉及特征的选取(树的生成),剪枝(提高分类器泛化能力)
1、ID3(使用信息增益准则进行特征选取,只涉及到树的生成,该类算法容易造成过拟合) 2、C4.5(对ID3算法进行了改进,使用信息增益比来进行特征选择) 3、CART(分类与回归树(Classification and Regression tree),既可以用于分类也可以用于回归,应用广泛的决策树学习方法,使用基尼指数进行特征选取)
 2、C4.5(对ID3算法进行了改进,使用信息增益比来进行特征选择) 3、CART(分类与回归树(Classification and Regression tree),既可以用于分类也可以用于回归,应用广泛的决策树学习方法,使用基尼指数进行特征选取)")
24
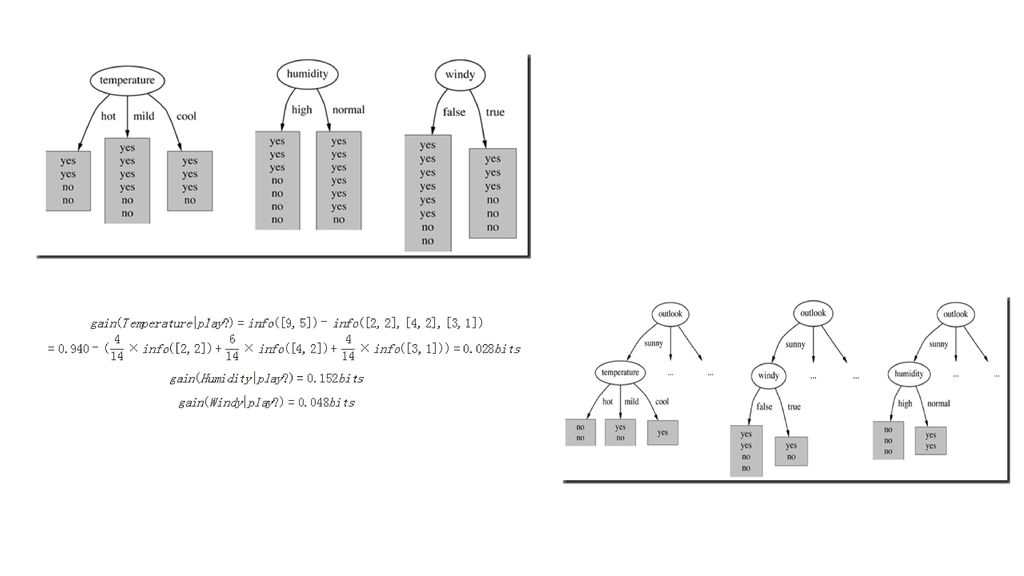
信息增益、信息增益比、基尼系数 可以简单的理解为“熵”描述了用来预测的信息位数 共14个实例,9个正例(yes),5个负例(no)。
Given a probability distribution, the info required to predict an event is the distribution’s entropy. Entropy gives the information required in bits (this can involve fractions of bits!) 可以简单的理解为“熵”描述了用来预测的信息位数 entropy(p1,p2,…,pn)=–p1log2(p1)–p2log2(p2)–…–pnlog2(pn) 共14个实例,9个正例(yes),5个负例(no)。 这样当前数据的信息量(原始状态)用熵来计算就是: info(play?)=info([9,5])=entropy(914,514)=–914log2(914)–514log2(514)= =0.940 有了上面计算熵(信息)的基础,接下来看信息增益了。
 可以简单的理解为 熵 描述了用来预测的信息位数. entropy(p1,p2,…,pn)=–p1log2(p1)–p2log2(p2)–…–pnlog2(pn) 共14个实例,9个正例(yes),5个负例(no)。 这样当前数据的信息量(原始状态)用熵来计算就是: info(play )=info([9,5])=entropy(914,514)=–914log2(914)–514log2(514)= = 有了上面计算熵(信息)的基础,接下来看信息增益了。")
25
信息增益 信息增益,按名称来理解的话,就是前后信息的差值,在决策树分类问题中,即就是
决策树在进行属性选择划分前和划分后的信息差值,即可以写成: gain()=infobeforeSplit()–infoafterSplit() 在划分后,可以看到数据被分成三份,则各分支的信息计算如下: info([2,3])=−2/5log2(2/5)–3/5log2(3/5)=0.971bits info([4,0])=−4/4log2(4/4)–0/4log2(0/4)=0bits info([3,2])=−3/5log2(3/5)–2/5log2(2/5)=0.971bits 因此,划分后的信息总量应为: info([2,3],[4,0],[3,2])=5/14× /14×0+5/14×0.971=0.693bits gain(outlook|play?)=infobeforeSplit()–infoafterSplit()=info(play?)–info([3,2],[4,0],[3,2])=0.940–0.694=0.246bits
=infobeforeSplit()–infoafterSplit() 在划分后,可以看到数据被分成三份,则各分支的信息计算如下: info([2,3])=−2/5log2(2/5)–3/5log2(3/5)=0.971bits. info([4,0])=−4/4log2(4/4)–0/4log2(0/4)=0bits. info([3,2])=−3/5log2(3/5)–2/5log2(2/5)=0.971bits. 因此,划分后的信息总量应为: info([2,3],[4,0],[3,2])=5/14× /14×0+5/14×0.971=0.693bits. gain(outlook|play )=infobeforeSplit()–infoafterSplit()=info(play )–info([3,2],[4,0],[3,2])=0.940–0.694=0.246bits.")
27
信息增益率 那么下面来看信息增益存在的一个问题:假设某个属性存在大量的不同值,如ID编号(在上面例子中加一列为ID,编号为a~n),在划分时将每个值成为一个结点,这样就形成了下面的图:
,在划分时将每个值成为一个结点,这样就形成了下面的图:")
28
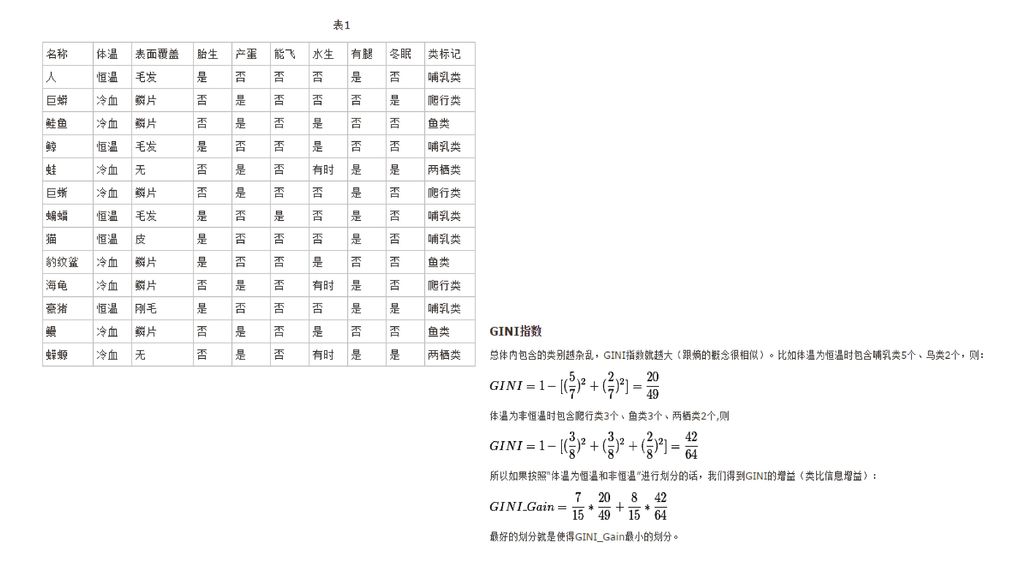
GINI系数

30
剪枝 当分类回归树划分得太细时,会对噪声数据产生过拟合作用。因此我们要通过剪枝来解决。剪枝又分为前剪枝和后剪枝:前剪枝是指在构造树的过程中就知道哪些节点可以剪掉,于是干脆不对这些节点进行分裂,在N皇后问题和背包问题中用的都是前剪枝,上面的χ2方法也可以认为是一种前剪枝;后剪枝是指构造出完整的决策树之后再来考查哪些子树可以剪掉。 在分类回归树中可以使用的后剪枝方法有多种,比如:代价复杂性剪枝、最小误差剪枝、悲观误差剪枝等等。这里我们只介绍代价复杂性剪枝法。 对于分类回归树中的每一个非叶子节点计算它的表面误差率增益值α。

31
最大熵模型 几个例子: 1、不要把所有的鸡蛋放在一个篮子里,这样可以降低风险。
2、假如输入的拼音是“wang-xiao-bo”,利用语言模型,根据有限的上下文(比如前两个词),我们能给出两个最 常见的名字“王小波”和“王晓波”。至于要唯一确定是哪个名字就难了。 3、色子(普通的和处理过的) 最大熵原理指出,当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。(不做主观假设这点很重要。)在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以人们称这种模型叫"最大熵模型"。当我们遇到不确定性时,就要保留各种可能性。
,我们能给出两个最 常见的名字 王小波 和 王晓波 。至于要唯一确定是哪个名字就难了。 3、色子(普通的和处理过的) 最大熵原理指出,当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。(不做主观假设这点很重要。)在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以人们称这种模型叫 最大熵模型 。当我们遇到不确定性时,就要保留各种可能性。")
32
小概率事件发生时携带的信息量比大 概率事件发生时携带的信息量多
如果事件 发生的概率为1,在这种情况下,事件 发生就没有什么“惊奇”了,并且不传达任何“信息”, 因为我们已经知道这“信息”是什么,没有任何的“不确定”;反之,如果事件 发生的概率很小,这就有 更大的“惊奇”和有“信息”了。这里,“不确定”、“惊奇”和“信息”是相关的,信息量与事件发生的概率成反比。 举个例子,一个快餐店提供3种食品:汉堡(B)、鸡肉(C)、鱼(F)。价格分别是1元、2元、3元。已知人们在这家店的平均消费是1.75元,求顾客购买这3种食品的概率。
、鸡肉(C)、鱼(F)。价格分别是1元、2元、3元。已知人们在这家店的平均消费是1.75元,求顾客购买这3种食品的概率。")
33
如果你假设一半人买鱼另一半人买鸡肉,那么根据熵公式,这不确定性就是1位(熵等于1)。但是这个假设很不合适。
以及关于对概率分布的不确定性度量,熵: 对前两个约束,两个未知概率可以由第三个量来表示,可以得到:

37
Thank you!
















/ 應用系統(ERP, SCM, CRM)>")





 教育部 101年12月12日 1 1.>")


