Download presentation
1
数据库技术及应用 ——SQL Server 任课教师: 毕丛娣 电话: 2011年3月

2
第一章 数据库系统概述 1.1 信息、数据与数据处理 1.2 数据描述 1.3 数据模型 1.4 数据库系统

3
1.1 信息、数据与数据处理 一、 基本概念 1、信息(Information)
1.1 信息、数据与数据处理 一、 基本概念 1、信息(Information) 是客观事物属性和运动状态的描述。(信息是经过加工处理的、对人类客观行为产生影响的、通过各种方式传播的、可被感知的数据表现形式。) 2、数据(Data) 是能被计算机处理的符号,是数据库中存储的基本对象,是信息的具体表现形式,是信息的载体。 3、数据与信息 从信息处理角度看,任何事物的存在方式和运动状态都可以通过数据来表示。数据经过加工处理后,使其具有知识性并对人类活动产生作用,从而形成信息。
 是客观事物属性和运动状态的描述。(信息是经过加工处理的、对人类客观行为产生影响的、通过各种方式传播的、可被感知的数据表现形式。) 2、数据(Data) 是能被计算机处理的符号,是数据库中存储的基本对象,是信息的具体表现形式,是信息的载体。 3、数据与信息. 从信息处理角度看,任何事物的存在方式和运动状态都可以通过数据来表示。数据经过加工处理后,使其具有知识性并对人类活动产生作用,从而形成信息。")
4
用数据符号表示信息有多种表现形式: (1)对客观事物进行定量记录的符号,如:数量、年龄、成绩等。 (2)对客观事物进行定性记录的符号,如:姓名,单位、地址等。 (3)对客观事物进行形象特征和过程记录的符号,如:声音、图像、视频等。 总之:信息是有用的数据,数据是信息的表现形式。 4、数据处理 对大量的存储数据进行加工处理(它包括对数据的采集、整理、存储、分类、排序、检索、维护、加工、统计和传输等),从大量的原始数据中获取人们所需要的资料并提取有用的数据成分,作为行为和决策的依据。
,从大量的原始数据中获取人们所需要的资料并提取有用的数据成分,作为行为和决策的依据。")
5
1.1 信息、数据与数据处理 二、数据管理技术的发展过程 1、人工管理阶段(20世纪40年代中--50年代中)
1.1 信息、数据与数据处理 二、数据管理技术的发展过程 1、人工管理阶段(20世纪40年代中--50年代中) 2、文件系统阶段(20世纪50年代末--60年代中) 3、数据库系统阶段(20世纪60年代末--现在)
 2、文件系统阶段(20世纪50年代末--60年代中) 3、数据库系统阶段(20世纪60年代末--现在)")
6
1.1 信息、数据与数据处理 各发展过程的特点: 1、 人工管理阶段 (1)数据不保存。 (2)应用程序与数据之间缺少独立性。
1.1 信息、数据与数据处理 各发展过程的特点: 1、 人工管理阶段 (1)数据不保存。 (2)应用程序与数据之间缺少独立性。 (3)数据无共享、冗余度极大。 2、 文件系统阶段 (1)数据可长期保存。 (2)应用程序与数据之间有了一定的独立性。 (3)数据文件形式多样化,可以顺序或随机访问数据。 (4)数据文件不再只属于一个应用程序。 (5)共享性差、仍有一定的数据冗余。 (6)数据的不一致性。
数据不保存。 (2)应用程序与数据之间缺少独立性。 (3)数据无共享、冗余度极大。 2、 文件系统阶段. (1)数据可长期保存。 (2)应用程序与数据之间有了一定的独立性。 (3)数据文件形式多样化,可以顺序或随机访问数据。 (4)数据文件不再只属于一个应用程序。 (5)共享性差、仍有一定的数据冗余。 (6)数据的不一致性。")
7
人工管理阶段应用程序与数据之间的对应关系
1.1 信息、数据与数据处理 应用程序1 数据集1 应用程序2 数据集2 应用程序n 数据集n ...… 人工管理阶段应用程序与数据之间的对应关系

8
文件系统阶段应用程序与数据之间的对应关系
1.1 信息、数据与数据处理 应用程序1 文件1 应用程序2 文件2 应用程序n 文件n 文件管理系统 ...… 文件系统阶段应用程序与数据之间的对应关系

9
数据库系统阶段应用程序与数据之间的对应关系
1.1 信息、数据与数据处理 3、数据库系统阶段 DBMS 应用程序1 应用程序2 数据库 … 数据库系统阶段应用程序与数据之间的对应关系

10
1.1 信息、数据与数据处理 3、数据库系统阶段 (1)数据整体结构化。 (2)数据的共享性高。 (3)具有很高的数据独立性。
1.1 信息、数据与数据处理 3、数据库系统阶段 (1)数据整体结构化。 (2)数据的共享性高。 (3)具有很高的数据独立性。 (4)完备的数据控制功能。(安全性控制、完整性控制、并发性控制和故障恢复功能)
数据整体结构化。 (2)数据的共享性高。 (3)具有很高的数据独立性。 (4)完备的数据控制功能。(安全性控制、完整性控制、并发性控制和故障恢复功能)")
11
1.2 数据描述 数据描述:以“数据”符号的形式,从满足用户需求出发,对客观事物属性和运动状态进行描述。数据的描述既要符合客观现实,又要适应数据库原理与结构,同时也适应计算机原理与结构。 计算机世界 (数据模型) 信息世界 (概念模型) 现实世界 数据的转换过程
 信息世界. (概念模型) 现实世界. 数据的转换过程.")
12
1.2 数据描述 现实世界中客观对象的抽象过程 现实世界 概念模型 数据库设计人员完成 概念模型 逻辑模型 数据库设计人员完成
1.2 数据描述 现实世界 认识 抽象 现实世界 概念模型 数据库设计人员完成 概念模型 信息世界 概念模型 逻辑模型 数据库设计人员完成 DBMS支持的数据模型 逻辑模型 物理模型 由DBMS完成 机器世界 现实世界中客观对象的抽象过程

13
1.3 数据模型 模型:是对客观存在的事物及其相互间的联系的抽象与 模拟。可以分为实物模型与抽象模型。
1.3 数据模型 模型:是对客观存在的事物及其相互间的联系的抽象与 模拟。可以分为实物模型与抽象模型。 实物模型:是对客观存在的事物的外部特征和内部功能的模拟与刻画。如汽车模型、轮船模型。 抽象模型:是对客观存在的事物的某些规律性的、本质的特性进行模拟与刻画。如v=d/t。 数据模型:是一种抽象模型,是一组集成的概念,用于描述和操作组织内的数据、数据间的联系以及对数据的约束。包括数据结构、数据操作和完整性约束。

14
1.3 数据模型 一、 概念模型 概念模型:实体—联系模型(Entity- Relationship E-R)它是按用户的观点来对数据和信息建模,用于数据库设计。 1、基本概念 (1) 实体(Entity) 客观存在并可相互区别的事物称为实体。 (2) 属性(Attribute) 实体所具有的某一特性称为属性。一个实体可以由若干个属性来刻画。 (3) 码(Key) 唯一标识实体的属性集称为码。
 属性(Attribute) 实体所具有的某一特性称为属性。一个实体可以由若干个属性来刻画。 (3) 码(Key) 唯一标识实体的属性集称为码。")
15
1.3 数据模型 (4) 域(Domain) 属性的取值范围称为该属性的域。 (5) 实体型(Entity Type)
1.3 数据模型 (4) 域(Domain) 属性的取值范围称为该属性的域。 (5) 实体型(Entity Type) 用实体名及其属性名集合来抽象和刻画同类实体称为实体型。例如:学生(学号,姓名,性别,出生年月,籍贯,班级编号)。 (6) 实体集(Entity Set) 同一类型实体的集合称为实体集。 (7) 联系(Relationship) 是两个或两个以上的实体集之间的关联联系。
 域(Domain) 属性的取值范围称为该属性的域。 (5) 实体型(Entity Type) 用实体名及其属性名集合来抽象和刻画同类实体称为实体型。例如:学生(学号,姓名,性别,出生年月,籍贯,班级编号)。 (6) 实体集(Entity Set) 同一类型实体的集合称为实体集。 (7) 联系(Relationship) 是两个或两个以上的实体集之间的关联联系。")
16
1.3 数据模型 实体型A 联系名 实体型B 1 1:1联系 n 1:n联系 m m:n联系 两个实体型之间的联系 班级 班级 课程 班长
1.3 数据模型 实体型A 联系名 实体型B 1 1:1联系 n 1:n联系 m m:n联系 班级 班级 课程 班长 学生 学生 两个实体型之间的联系

17
2、 概念模型的一种表示方法:实体-联系方法(E-R方法)
1.3 数据模型 2、 概念模型的一种表示方法:实体-联系方法(E-R方法) 实体型 用矩形表示,矩形框内写明实体名。 属性 用椭圆形表示,并用无向边将其与相应的实体连接起来 联系 用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标上联系的类型(1:1、1:n或m:n) 学生 学号 年龄 性别 姓名
 实体型. 用矩形表示,矩形框内写明实体名。 属性. 用椭圆形表示,并用无向边将其与相应的实体连接起来. 联系. 用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标上联系的类型(1:1、1:n或m:n) 学生. 学号. 年龄. 性别. 姓名.")
18
1.3 数据模型 班级 班级-班长 班长 1 1:1联系 课程 选修 学生 m n m:n联系 组成 1:n联系 联系的表示方法示例

19
联系的属性 联系本身也是一种实体型,也可以有属性。如果一个联系具有属性,则这些属性也要用无向边与该联系连接起来 课程 m n 学生 选修
成绩

20
E-R图的一个实例 用E-R图表示某个工厂物资管理的概念模型 实体 仓库: 仓库号、面积、电话号码 零件 :零件号、名称、规格、单价、描述
供应商:供应商号、姓名、地址、电话号码、帐号 项目:项目号、预算、开工日期 职工:职工号、姓名、年龄、职称

21
实体之间的联系如下: (1)一个仓库可以存放多种零件,一种零件可以存放在多个仓库中。仓库和零件具有多对多的联系。用库存量来表示某种零件在某个仓库中的数量。 (2)一个仓库有多个职工当仓库保管员,一个职工只能在一个仓库工作,仓库和职工之间是一对多的联系。职工实体型中具有一对多的联系 (3)职工之间具有领导-被领导关系。即仓库主任领导若干保管员。 (4)供应商、项目和零件三者之间具有多对多的联系
职工之间具有领导-被领导关系。即仓库主任领导若干保管员。 (4)供应商、项目和零件三者之间具有多对多的联系.")
22
一个实例

23
1.3 数据模型 二、 数据模型(按计算机的观点建模) 1、主要有层次模型、网状模型和关系模型,面向对象模型等。
1.3 数据模型 二、 数据模型(按计算机的观点建模) 1、主要有层次模型、网状模型和关系模型,面向对象模型等。 关系模型采用二维表 表示事物及事物间的联系。 2、关系模型组成要素 数据结构:数据库的组成对象,以及对象之间的联系 数据操作 :查询、更新(包括插入、删除、修改) 完整性约束条件:实体完整性、参照完整性和用户自定义完 整性。
 1、主要有层次模型、网状模型和关系模型,面向对象模型等。 关系模型采用二维表 表示事物及事物间的联系。 2、关系模型组成要素. 数据结构:数据库的组成对象,以及对象之间的联系. 数据操作 :查询、更新(包括插入、删除、修改) 完整性约束条件:实体完整性、参照完整性和用户自定义完 整性。")
24
1.3 数据模型 3、关系数据模型的数据结构 关系模型中数据的逻辑结构是一张二维表,它由行和列组成。 学 号 姓 名 年 龄 性 别 系 名
1.3 数据模型 3、关系数据模型的数据结构 关系模型中数据的逻辑结构是一张二维表,它由行和列组成。 属性 学生登记表 元组 学 号 姓 名 年 龄 性 别 系 名 年 级 王小明 19 女 社会学 2005 黄大鹏 20 男 商品学 张文斌 18 法律 …

25
1.3 数据模型 关系(Relation):通常说的二维表 元组(Tuple):表中的一行即为一个元组 属性(Attribute)
1.3 数据模型 关系(Relation):通常说的二维表 元组(Tuple):表中的一行即为一个元组 属性(Attribute) 表中的一列即为一个属性,给每一个属性起一个名称即属性名 主码(Key) 表中的某个属性组,它可以唯一确定一个元组。
:通常说的二维表. 元组(Tuple):表中的一行即为一个元组. 属性(Attribute) 表中的一列即为一个属性,给每一个属性起一个名称即属性名. 主码(Key) 表中的某个属性组,它可以唯一确定一个元组。")
26
1.3 数据模型 外码(Web Key) 表中的某个属性组,它是另一个关系的主码。 域(Domain):属性的取值范围。
1.3 数据模型 外码(Web Key) 表中的某个属性组,它是另一个关系的主码。 域(Domain):属性的取值范围。 分量 :元组中的一个属性值。 关系模式 对关系的描述: 关系名(属性1,属性2,…,属性n) 学生(学号,姓名,年龄,性别,系,年级)
 表中的某个属性组,它是另一个关系的主码。 域(Domain):属性的取值范围。 分量 :元组中的一个属性值。 关系模式. 对关系的描述: 关系名(属性1,属性2,…,属性n) 学生(学号,姓名,年龄,性别,系,年级)")
27
1.3 数据模型 术语对比 关系术语 一般表格的术语 关系名 表名 关系模式 表头(表格的描述) 关系 (一张)二维表 元组 记录或行 属性
1.3 数据模型 术语对比 关系术语 一般表格的术语 关系名 表名 关系模式 表头(表格的描述) 关系 (一张)二维表 元组 记录或行 属性 列 属性名 列名 属性值 列值 分量 一条记录中的一个列值
 关系. (一张)二维表. 元组. 记录或行. 属性. 列. 属性名. 列名. 属性值. 列值. 分量. 一条记录中的一个列值.")
28
1.3 数据模型 例1 学生、系、系与学生之间的一对多联系: 例2 学生、课程、学生与课程之间的多对多联系:
1.3 数据模型 例1 学生、系、系与学生之间的一对多联系: 学生(学号,姓名,年龄,性别,系号,年级) 系 (系号,系名,办公地点) 例2 学生、课程、学生与课程之间的多对多联系: 课程(课程号,课程名,学分) 选修(学号,课程号,成绩)
 系 (系号,系名,办公地点) 例2. 学生、课程、学生与课程之间的多对多联系: 课程(课程号,课程名,学分) 选修(学号,课程号,成绩)")
29
1.3 数据模型 4、关系数据模型的操作与完整性约束 数据操作是集合操作,操作对象和操作结果都是关系,主要操作为查询、插入、删除、修改。
1.3 数据模型 4、关系数据模型的操作与完整性约束 数据操作是集合操作,操作对象和操作结果都是关系,主要操作为查询、插入、删除、修改。 关系的完整性约束条件 实体完整性(通过设置主键实现) 参照完整性(通过关系实现) 用户定义的完整性(删除约束、更新约束、插入约束)
 参照完整性(通过关系实现) 用户定义的完整性(删除约束、更新约束、插入约束)")
30
1.3 数据模型 5、关系模型的主要特点: (1)关系的每一个分量必须是一个不可分的数据项。 (2)行的顺序、列的顺序可更改。
1.3 数据模型 5、关系模型的主要特点: (1)关系的每一个分量必须是一个不可分的数据项。 (2)行的顺序、列的顺序可更改。 (3)不允许有重复的行或列。 职工号 姓名 职 称 工 资 扣 除 实 发 基 本 津 贴 职务 房 租 水 电 86051 陈 平 讲 师 1305 1200 50 160 112 2283
关系的每一个分量必须是一个不可分的数据项。 (2)行的顺序、列的顺序可更改。 (3)不允许有重复的行或列。 职工号. 姓名. 职 称. 工 资. 扣 除. 实 发. 基 本. 津 贴. 职务. 房 租. 水 电 陈 平. 讲 师")
31
1.4 数据库系统(DBS) 一、数据库系统的组成 1、硬件 2、软件 数据库管理系统(DBMS) 数据库应用系统(DBAS)
4、人员 数据库管理员(DBA) 用户(User)
 用户(User)")
32
用户 用户 用户 应用系统 应用开发工具 数据库管理系统 数据库管理员 操作系统 数据库 数据库系统

33
1.4 数据库系统(DBS) 1、数据库(DB) 数据库的定义(数据库系统的核心,是数据库系统的管理对象)
数据库(Database,简称DB)是长期储存在计算机内、有组织的、可共享的大量数据的集合。 数据库的基本特征 数据按一定的数据模型组织、描述和储存 可为各种用户共享 冗余度较小 数据独立性较高 易扩展,有安全性、并发性、完整性控制
是长期储存在计算机内、有组织的、可共享的大量数据的集合。 数据库的基本特征. 数据按一定的数据模型组织、描述和储存. 可为各种用户共享. 冗余度较小. 数据独立性较高. 易扩展,有安全性、并发性、完整性控制.")
34
1.4 数据库系统(DBS) 2、数据库管理系统(DBMS) (1)什么是DBMS(Database Management System)
位于用户与操作系统之间的一层数据管理软件。 是基础软件,是一个大型复杂的系统软件。 (2)DBMS的用途 科学地组织和存储数据、高效地获取和维护数据。
DBMS的用途. 科学地组织和存储数据、高效地获取和维护数据。")
35
(3)DBMS的主要功能 包括:数据定义、数据操作、数据库的运行管理、数据库的建立和维护。
1.4 数据库系统(DBS) (3)DBMS的主要功能 包括:数据定义、数据操作、数据库的运行管理、数据库的建立和维护。 数据定义语言 提供数据定义语言(DDL), 定义和修改数据库及其中的数据对象。 数据操作语言 提供数据操纵语言(DML),实现对数据库的基本操作 (查询、插入、删除和修改)。 数据控制语言 提供数据控制语言(DCL),实现对数据库的安全性与完整性控制,实现并发控制和故障恢复。
 (3)DBMS的主要功能 包括:数据定义、数据操作、数据库的运行管理、数据库的建立和维护。 数据定义语言. 提供数据定义语言(DDL), 定义和修改数据库及其中的数据对象。 数据操作语言. 提供数据操纵语言(DML),实现对数据库的基本操作. (查询、插入、删除和修改)。 数据控制语言. 提供数据控制语言(DCL),实现对数据库的安全性与完整性控制,实现并发控制和故障恢复。")
36
1.4 数据库系统(DBS) 3、人 员 数据库管理员 系统分析员和数据库设计人员 应用程序员 用户
 3、人 员 数据库管理员 系统分析员和数据库设计人员 应用程序员 用户")
37
1.4 数据库系统(DBS) 数据库管理员(DBA) 具体职责: 决定数据库中的信息内容和结构 决定数据库的存储结构和存取策略
定义数据的安全性要求和完整性约束条件 监控数据库的使用和运行 数据库的改进和重组

38
1.4 数据库系统(DBS) 系统分析员 负责应用系统的需求分析和规范说明 与用户及DBA协商,确定系统的硬软件配置
参与数据库系统的概要设计 数据库设计人员 参加用户需求调查和系统分析 确定数据库中的数据 设计数据库各级模式

39
二、 数据库系统的三级模式结构(体系结构)
1.4 数据库系统(DBS) 二、 数据库系统的三级模式结构(体系结构) 数据库系统的三级模式结构由外模式、模式、内模式组成。 图1-8所示: 1、外模式(External Schema) 又称用户模式或子模式,描述的是数据的局部逻辑结构 ,是某个或几个数据库用户所看到的数据库的数据视图。例如视图和基本表。 2、模式(Schema) 又称概念模式或逻辑模式,描述的是数据的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图。例如:全体表结构。
 二、 数据库系统的三级模式结构(体系结构) 数据库系统的三级模式结构由外模式、模式、内模式组成。 图1-8所示: 1、外模式(External Schema) 又称用户模式或子模式,描述的是数据的局部逻辑结构 ,是某个或几个数据库用户所看到的数据库的数据视图。例如视图和基本表。 2、模式(Schema) 又称概念模式或逻辑模式,描述的是数据的全局逻辑结构,是对数据库中全部数据的逻辑结构和特征的总体描述,是所有用户的公共数据视图。例如:全体表结构。")
40
3、内模式(Internal Schema)
又称存储模式或物理模式,是数据物理结构和存储方式的描述,是数据库中全体数据的内部表示。例如:数据库的存储文件和他们的索引文件。 外模式处于最外层,它反映了用户对数据库的实际要求;模式处于中层,它反映了设计者的数据全局的逻辑要求;内模式处于最内层,它反映数据的物理结构和存取方法。 4、三级模式的二级映象 外模式/模式映像(外模式不受模式变化影响) 模式/内模式映像 (模式不受内模式变化的影响)
 模式/内模式映像 (模式不受内模式变化的影响)")
41
1.4 数据库系统(DBS) 数据库系统的三级模式结构
 数据库系统的三级模式结构")
42
小结 数据库系统概述 数据库的基本概念 数据管理的发展过程 数据模型 数据描述的三个世界转换 概念模型( E-R 模型)
小结 数据库系统概述 数据库的基本概念 数据管理的发展过程 数据模型 数据描述的三个世界转换 概念模型( E-R 模型) 关系模型(概念、功能)
 关系模型(概念、功能)")
43
小结 数据库系统的组成 数据库系统的结构 数据库系统三级模式结构 数据库系统两层映像系统结构

44
1.5 数据库设计 1.5.1 数据库设计概述 1、 数据库设计 数据库设计是指对于一个给定的应用环境,构造(设计)优化的数据库逻辑模式和物理结构,并据此建立数据库及其应用系统,使之能够有效地存储和管理数据,满足各种用户的应用需求,包括信息管理要求和数据操作要求。 2、目标:为用户和各种应用系统提供一个信息基础设施和高效率的运行环境,最小的冗余,最高效的共享。

45
3、主要任务: 在外模式的需求的基础上,设计数据库系统的模式,为内模式的设计提供依据。.
3、主要任务: 在外模式的需求的基础上,设计数据库系统的模式,为内模式的设计提供依据。. 数据库设计的任务主要就是设计数据库模式。这一数据库模式要能够概括具体的数据库应用系统的数据库全局的数据结构,能够反映使用本系统所有用户的数据视图。一个良好的数据库模式应具有最小的数据冗余,在一定范围内实现数据共享特性。 数据库模式一经设计完成,通常情况下是不轻易改动的,它不仅作为应用程序存取数据、处理数据的数据结构参照,还要成为实现数据物理存储的数据结构定义的依据。

46
1.5.2 数据库设计的方法与步骤 1)数据库设计分6个阶段 需求分析 概念结构设计 逻辑结构设计 物理结构设计 数据库实施
数据库设计的方法与步骤 1)数据库设计分6个阶段 需求分析 概念结构设计 逻辑结构设计 物理结构设计 数据库实施 数据库运行和维护 2)需求分析和概念设计独立于任何数据库管理系统 3)逻辑设计和物理设计与选用的DBMS密切相关 设计一个完善的数据库应用系统往往是上述六个阶段的不断反复
数据库设计分6个阶段. 需求分析. 概念结构设计. 逻辑结构设计. 物理结构设计. 数据库实施. 数据库运行和维护. 2)需求分析和概念设计独立于任何数据库管理系统. 3)逻辑设计和物理设计与选用的DBMS密切相关. 设计一个完善的数据库应用系统往往是上述六个阶段的不断反复.")
47
一、 需求分析阶段(最困难、最耗费时间的一步)
1、需求分析的任务 详细调查现实世界要处理的对象(组织、部门、企业等) 充分了解原系统(手工系统或计算机系统) 明确用户的各种需求 确定新系统的功能 充分考虑今后可能的扩充和改变
 充分了解原系统(手工系统或计算机系统) 明确用户的各种需求. 确定新系统的功能. 充分考虑今后可能的扩充和改变.")
48
2、需求分析的重点 信息要求 处理要求 安全性与完整性要求 需求分析阶段是数据库设计的基础,是数据库设计的最初阶段。这一阶段要收集大量的支持系统目标实现的各类基础数据、用户需求信息和信息处理需求,并加以分析归类和初步规划,确定设计思路。需求分析做得好与坏,决定了后续设计的质量和速度,制约数据库应用系统设计的全过程。

49
3、需求分析具体做法: 调查数据库应用系统所涉及的用户的歌部门的组成情况、职责、业务及其流程。确定系统功能范围,明确哪些业务的工作有计算机完成,那些由人工完成。了解用户对数据库应用系统的各种要求,包括信息要求、处理要求。如:各个部门输入和使用什么数据,如何加工处理这些数据,处理后的数据的输出那荣、格式及发布的对象等。 结构化分析方法(Structured Analysis,简称SA方法) 从最上层的系统组织机构入手 自顶向下、逐层分解分析系统
 从最上层的系统组织机构入手. 自顶向下、逐层分解分析系统.")
50
形成系统数据流图(DFD)和数据字典(DD)
4、需求分析的目标 形成系统数据流图(DFD)和数据字典(DD) 数据字典:是系统中数据描述的集合,包括数据项、数据结构、数据流、数据存储、处理过程5个部分。
和数据字典(DD) 数据字典:是系统中数据描述的集合,包括数据项、数据结构、数据流、数据存储、处理过程5个部分。")
51
1) 数据项 数据项:是不可再分的数据单位。 对数据项的描述: 数据项={ 数据项名,数据项含义说明,别名,
数据类型,长度,取值范围,取值含义,与其他数据项的逻辑关系,数据项之间的联系 }

52
数据项举例: 例:学生学籍管理子系统的数据字典。 数据项(以“学号”为例) 数据项: 学号 含义说明:唯一标识每个学生 别名: 学生编号
数据项: 学号 含义说明:唯一标识每个学生 别名: 学生编号 类型: 字符型 长度: 8 取值范围: 至 取值含义:前两位标别该学生所在年级, 后六位按顺序编号 与其他数据项的逻辑关系:××××……

53
2) 数据结构 数据结构举例: 数据结构反映了数据之间的组合关系。 对数据结构的描述 数据结构描述={数据结构名,含义说明,
组成:{数据项或数据结构}} 数据结构举例: 数据结构(以“学生”为例) 数据结构: 学生 含义说明: 是学籍管理子系统的主体数据结构, 定义了一个学生的有关信息 组成: 学号,姓名,性别,年龄,所在系,年级
 数据结构: 学生. 含义说明: 是学籍管理子系统的主体数据结构, 定义了一个学生的有关信息. 组成: 学号,姓名,性别,年龄,所在系,年级.")
54
3) 数据流 数据流是数据结构在系统内传输的路径。 对数据流的描述: 数据流描述={ 数据流名,说明,数据流来 源,数据流去向,组成:{数
数据流描述={ 数据流名,说明,数据流来 源,数据流去向,组成:{数 据结构},平均流量,高峰 期流量}

55
数据流举例: 数据流,“体检结果”可如下描述: 数据流: 体检结果 说明: 学生参加体格检查的最终结果 数据流来源:体检 数据流去向:批准
数据流: 体检结果 说明: 学生参加体格检查的最终结果 数据流来源:体检 数据流去向:批准 组成: …… 平均流量: …… 高峰期流量:……

57
4)数据存储 数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一。 对数据存储的描述
数据存储描述={数据存储名,说明,编号,输入的数据 流 ,输出的数据流 ,组成:{数据结 构},数据量,存取频度,存取方式}

58
数据存储举例: 数据存储,“学生登记表”可如下描述: 数据存储: 学生登记表 说明: 记录学生的基本情况 流入数据流:…… 流出数据流:……
数据存储: 学生登记表 说明: 记录学生的基本情况 流入数据流:…… 流出数据流:…… 组成: …… 数据量: 每年3000张 存取方式: 随机存取

59
5) 处理过程 具体处理逻辑一般用判定表或判定树来描述 处理过程说明性信息的描述: 处理过程描述={处理过程名,说明,输入:{数据流},
处理过程描述={处理过程名,说明,输入:{数据流}, 输出:{数据流},处理:{简要说明}}

60
处理过程举例: 处理过程(“分配宿舍”可如下描述) 处理过程:分配宿舍 说明: 为所有新生分配学生宿舍 输入: 学生,宿舍 输出: 宿舍安排
处理过程:分配宿舍 说明: 为所有新生分配学生宿舍 输入: 学生,宿舍 输出: 宿舍安排 处理: 在新生报到后,为所有新生分配学生宿舍。 要求同一间宿舍只能安排同一性别的学生, 同一个学生只能安排在一个宿舍中。 每个学生的居住面积不小于3平方米。 安排新生宿舍其处理时间应不超过15分钟。

61
需求分析 概念结构设计 物理结构设计 二、概念结构设计阶段 将需求分析得到的用户需求抽象为信息结构即概念模型的过程就是概念结构设计。
概念结构设计是整个数据库设计的关键 描述概念模型的工具:E-R图(Entity-Relationship图) 现实世界 机器世界 信息世界 需求分析 概念结构设计 物理结构设计 常用策略 自顶向下地进行需求分析 自底向上地设计概念结构
 现实世界. 机器世界. 信息世界. 需求分析. 概念结构设计. 物理结构设计. 常用策略. 自顶向下地进行需求分析. 自底向上地设计概念结构.")
62
1、逐一设计分E-R图 1 m 职称作为一个实体

63
病房作为一个实体

64
仓库作为一个实体

65
2、集成局部视图,得到全局概念结构 略……

67
3. 验证整体概念结构 整体概念结构最终还应该提交给用户,征求用户和有关人员的意见,进行评审、修改和优化,然后把它确定下来,作为数据库的概念结构,作为进一步设计数据库的依据。

68
三、逻辑结构设计阶段 1、逻辑结构设计的任务 把概念结构设计阶段设计好的基本E-R图转换为与选用DBMS产品所支持的数据模型相符合的逻辑结构。 2、逻辑结构设计的步骤 1)将概念结构转化为一般的关系、网状、层次模型 2)对数据模型进行优化
对数据模型进行优化.")
69
3、E-R图向关系模型的转换方法 (1)一个实体转化为一个关系模式,实体的属性就是关系的属 性。
(2)若是1:1的联系,可在联系两端的实体中的任意一个关系的 属性中加入另一个关系的关键字。(例如:班级与班长。) (3)一个1:n联系,可在n段实体转化成的关系中加入1端实体 关系中的关键字。(例如:学生 与 班级) (3) 一个m:n联系转换为一个关系模式。 例如:学生 选修课程,“选修”联系是一个m:n联系,可以将它转换为如下关系模式,其中学号与课程号为关系的组合码: 选修(学号,课程号,成绩)
若是1:1的联系,可在联系两端的实体中的任意一个关系的. 属性中加入另一个关系的关键字。(例如:班级与班长。) (3)一个1:n联系,可在n段实体转化成的关系中加入1端实体. 关系中的关键字。(例如:学生 与 班级) (3) 一个m:n联系转换为一个关系模式。 例如:学生 选修课程, 选修 联系是一个m:n联系,可以将它转换为如下关系模式,其中学号与课程号为关系的组合码: 选修(学号,课程号,成绩)")
70
四、数据库物理设计阶段 数据库物理结构设计就是为设计好的逻辑数据模型选择最适合的应用环境。换句话说,就是能够在应用环境中的物理设备上,由全局逻辑数据模型产生一个能在特定的DBMS上实现的关系数据库模式。 数据库的物理结构设计主要分为两个方面: 1、确定数据库的物理结构 2、对物理结构进行评价

71
1、确定数据库的物理结构 在设计数据库的物理结构设计时,要面向特定的数据库管理系统,要了解数据库管理系统的功能,熟悉存储设备的性能。通常对关系型数据库的物理结构设计的内容主要包括: (1)为关系模式选择存取方法 (2)设计关系、索引等数据库文件的最佳文件组织方式。 (3)估计所需要的磁盘空间总量。 (4)设计安全机制
设计关系、索引等数据库文件的最佳文件组织方式。 (3)估计所需要的磁盘空间总量。 (4)设计安全机制.")
72
2、对物理结构进行评价 需要对时间效率、空间效率、维护代价和用户要求进 行权衡,设计方案可能有多种,数据库设计人员就要对 这些方案进行评价,如果能够满足逻辑数据要求,可进 入数据库实施阶段。

73
五、数据库实施阶段 数据库实施阶段是根据物理结构设计阶段的结果,建一 个具体的数据库,将原始数据载入到数据库中,并编写应用 系统程序,对数据库进行试运行操作。 根据逻辑设计和物理设计的结果 建立数据库 组织数据入库(分批入库,做好转储工作) 编制与调试应用程序 数据库进行试运行(功能测试与性能测试)
 编制与调试应用程序. 数据库进行试运行(功能测试与性能测试)")
74
六、数据库运行和维护阶段 在数据库运行阶段,对数据库经常性的维护工作主要是由DBA完成的,包括: 数据库的转储和恢复 数据库的安全性、完整性控制 数据库性能的监督、分析和改进 数据库的重组织和重构造 设计一个完善的数据库应用系统往往是上述六个阶段的不断反复

75
通过实际例子来进行数据库设计。 请设计一个学生在学校学习的数据库系统。通过接触了解,我们认为学生每学期按照事先安排的课程计划开始学习。每门课程由多名教师讲授;一个教师可以讲授多门课程;每名学生可以选修多门课程;学期结束后通过考试,教师登记每门课程、每名学生的成绩,并得到确认后存档;要求可以按照教师、学生、课程查询和统计成绩,了解课程授课的质量;能给出统计分析报表,供院主管部门参考。

76
需 求 分 析 学生 主管 部门 选修 授课 上课 考试 登记 成绩 统计 之 数 据 流 图 源点和终点:学生 教师 主管部门
需 求 分 析 之 数 据 流 图 源点和终点:学生 教师 主管部门 数据存储:课程表 点名表 教师情况 成绩统计表 成绩表 数据流:选课记录 课程 成绩表 学生名单 缺课记录 课名 课程表 学生 教师 主管 部门 课程信息 讲义 选修 授课 上课 考试 登记 成绩 学生基本信息 学生成绩 学生名单 学生名单 缺课记录 选课记录 成绩表 教师情况表 点名表 成绩表 统计 统计信息 统计信息 成绩统计表 统计信息

77
需 求 分 析 之 数 据 字 典 选择数据流“选课记录”为例,说明数据字典的作用 数据流名称:选课记录 数据流位置:从选课处理到点名表
需 求 分 析 之 数 据 字 典 选择数据流“选课记录”为例,说明数据字典的作用 数据流名称:选课记录 数据流位置:从选课处理到点名表 数据流的组成:学生学号+学生姓名+课程编号+课程名称+教师编号+学期编号 选择数据存储“成绩表”为例,说明数据字典的作用 数据存储名称:成绩表 数据存储的组成:学生学号+学生姓名+课程编号+课程名称+教师编号+学期编号+成绩+班级+系

78
概 念 设 计 之 分支 E-R图 编号 姓名 性别 职称 系别 自然情况 教 师 讲授 n m 课 程 编号 名称 学时 学期 性质

79
概 念 设 计 学 生 选修 课 程 之 分支 E-R图 n 成绩 m 编号 姓名 性别 班级 学生证号 自然情况 编号 名称 学时 学期
概 念 设 计 之 分支 E-R图 编号 姓名 性别 班级 学生证号 自然情况 学 生 选修 n m 成绩 课 程 编号 名称 学时 学期 性质

80
概 念 设 计 教 师 讲授 学 生 选修 课 程 之 总体 E-R图 n m 成绩 编号 姓名 性别 职称 系别 自然情况 名称 学时
概 念 设 计 之 总体 E-R图 教 师 课 程 编号 姓名 性别 职称 系别 自然情况 名称 学时 学期 性质 讲授 n m 学 生 班级 学生证号 选修 成绩

81
逻 辑 设 计 系统所涉及的基本表: Teacher(Tno,Tname,Tsex,Ttech,Depart,Nature)
逻 辑 设 计 系统所涉及的基本表: Teacher(Tno,Tname,Tsex,Ttech,Depart,Nature) Stu_BaseInfo(Sno,Sname,Ssex,Classroom,Certificate,Nature) Department(Dno,Dname) Course(Cno ,Cname,Period,Semester,Character) Classroom(CLno,,Clname,Depart) Grade(Sno,Cno,Grade) Teaching(Tno,Cno)
 Stu_BaseInfo(Sno,Sname,Ssex,Classroom,Certificate,Nature) Department(Dno,Dname) Course(Cno ,Cname,Period,Semester,Character) Classroom(CLno,,Clname,Depart) Grade(Sno,Cno,Grade) Teaching(Tno,Cno)")
82
小结 数据库的设计过程 需求分析 (DFD 、DD) 概念结构设计(E-R图) 逻辑结构设计 (形成数据库逻辑模式)
逻辑结构设计 (形成数据库逻辑模式) 物理设计(物理存储安排,设计索引,形成数据库内模式) 实施和维护
 物理设计(物理存储安排,设计索引,形成数据库内模式) 实施和维护.")
83
第二章 SQLServer系统概述 SQL server简介及性能 SQL server 2000的安装 SQL server 2000使用
介绍一些简单的基本操作

84
一、SQL server 2000简介 Microsoft SQL Server 2000是微软公司推出的产品
它是一款面向高端的分布式关系型数据库管理系统 采用单进程多线程的工作模式 具有C/S(客户端/服务器)体系结构,采用Transact-SQL 的结构化查询语言在客户端和服务器之间传递信息。
体系结构,采用Transact-SQL 的结构化查询语言在客户端和服务器之间传递信息。")
85
C/S(客户端/服务器)体系结构 服务器端 客户端 网络
体系结构 服务器端 客户端 网络")
86
1、发展历程 1988年微软公司和其它的一个公司共同开发了SQL server的第 一个版本(只适用于OS/2操作平台)。
。")
87
2、SQL server 2000的性能 数据库:32767个,最小为1MB,最大为1TB 表:每个数据库最多有20亿个表。 每列的最大字符数为8060 列:每表最多1024个列。 用户连接:32767个 打开的数据库:32767个

88
3、特点: 界面友好 体系结构合理(C/S) 丰富的编程接口(ADO、 URL、OLE DB、 ODBC) 服务器与客户机使用T_SQL语言进行交互
 丰富的编程接口(ADO、 URL、OLE DB、 ODBC) 服务器与客户机使用T_SQL语言进行交互")
89
4、SQL Server 2000的主要产品系列 企业版(Enterprise Edition):可作为大型站点、企业的数据库服务器。
标准版(Standard Edition):用于小型工作组或部门的数据库服务器。 个人版(Personal Edition):用于单机系统或客户端。 开发版(Developer Edition):用于程序员开发应用程序,不适合普通数据库用户。 此外,还包含企业评估版和Windows CE版。
:用于小型工作组或部门的数据库服务器。 个人版(Personal Edition):用于单机系统或客户端。 开发版(Developer Edition):用于程序员开发应用程序,不适合普通数据库用户。 此外,还包含企业评估版和Windows CE版。")
90
二、SQL server 2000的安装 1、硬件要求 处理器(CPU):主频不低于166MH
内存(RAM):最少64MB内存,建议使用更多的内存。 硬盘空间:SQL Server 数据库组件:95到270MB,一般为 250MB;Analysis Services :至少50MB,一般为130MB。 监视器:VGA或更高分辨率;SQL Server 图形工具要求 800×600或更高分辨率。 定位设备:Microsoft 鼠标或兼容设备
:最少64MB内存,建议使用更多的内存。 硬盘空间:SQL Server 数据库组件:95到270MB,一般为. 250MB;Analysis Services :至少50MB,一般为130MB。 监视器:VGA或更高分辨率;SQL Server 图形工具要求. 800×600或更高分辨率。 定位设备:Microsoft 鼠标或兼容设备.")
91
2、软件需求 企业版 标准版 个人版 Windows 2000 server 支持 支持 支持
企业版 标准版 个人版 Windows 2000 server 支持 支持 支持 Windows 2000 professional 暂缺 暂缺 支持 Windows NT 支持 支持 支持 Windows 暂缺 暂缺 支持

92
3、 安装SQL server 2000 采用本地计算机即作为服务器又作为客户机 其它安装步骤按提示进行

93
第1步 将SQL Server 2000安装盘放入光驱,运行光驱中的autorun.exe,出现安装界面,如图所示

94
仅客户端:若已有数据库服务器,只需安装客户端工具时选择此项。 服务器和客户端:用于安装数据库服务器和客户机工具。
第2步 选择“安装数据库服务器”选项,进入安装向导的欢迎窗口,按照安装向导提示的单击“下一步”,选择本地计算机/远程计算机。 第3步 进入SQL Server2000的安装选项窗口。选“创建新的SQL Server实例,或安装客户端工具(C)”,单击“下一步”。 第4步 系统显示对话框,用户输入姓名和公司名,单击“下一步”。 第5步 选择“创建新的SQL Server的服务器实例或安装客户端工具”,此时,安装向导将进一步给用户提供如图1.11所示的选择: 仅客户端:若已有数据库服务器,只需安装客户端工具时选择此项。 服务器和客户端:用于安装数据库服务器和客户机工具。 仅连接:用于应用程序开发时使用,只是安装连接工具。 第6步 选择安装服务器和客户端,并输入服务器实例名,则进入安装类型选择窗口。
 ,单击 下一步 。 第4步 系统显示对话框,用户输入姓名和公司名,单击 下一步 。 第5步 选择 创建新的SQL Server的服务器实例或安装客户端工具 ,此时,安装向导将进一步给用户提供如图1.11所示的选择: 仅客户端:若已有数据库服务器,只需安装客户端工具时选择此项。 服务器和客户端:用于安装数据库服务器和客户机工具。 仅连接:用于应用程序开发时使用,只是安装连接工具。 第6步 选择安装服务器和客户端,并输入服务器实例名,则进入安装类型选择窗口。")
97
第7步 选择启动“服务账户”,确定SQL Server服务和SQL Server代理服务是同一账户用户启动,还是由不同账户用户启动。

98
第8步 进入身份验证模式窗口,如图所示。建议选择”混合模式”

99
\…\MSSQL\Backup :这个目录最初为空。是创建磁盘备份文件的默认位置;
\…\MSSQL\Binn:放的是可执行文件。 \…\MSSQL\Data:数据文件和日志文件的位置 \…\MSSQL\LOG:所有提示信息、警告、错误信息的存储位置。只保留最新6个。 \…\MSSQL\Install:存放安装时使用的脚本和输出文件。 \…\MSSQL\jobs:临时作业的输出位置。退出时删除

100
三、SQL server 2000的使用 1、SQL群组各组件的功能简介: 企业管理器:
查询分析器: 用以交互的设计和测试Transact-SQL语句、脚本。 导入和导出数据: 引导用户逐步了解DTS的功能,如数据和对象的导入、导出等。 服务管理器: 用于启动、停止、暂停服务器上的SQL server 2000组件。

101
用于管理客户端的网络库<Net_Library>以及定义服务器的别名。 服务器网络使用工具:
事件探查器: 从服务器捕获SQL server 2000事件的工具,保存在一个跟踪文件中 客户端网络使用工具: 用于管理客户端的网络库<Net_Library>以及定义服务器的别名。 服务器网络使用工具: 用于管理服务器的网络库 <Net_Library> 。 联机丛书: SQL server在线帮助。

102
2、服务器的启动 选择“开始—程序—Microsoft SQL Server”程序组中的“服务器管理器”命令项,进入SQL Server服务器管理器窗口。 使用服务管理器启动与停止服务 使用企业管理器启动与停止服务 使用控制面板启动与停止服务 启动按钮 停止按钮

103
3、企业管理器 企业管理器是一个完善的数据库管理系统当中最主要的管理工具,其中绝大多数的数据库管理工作都可以在企业管理器中完成。
企业管理器以树型结构的形式来完成管理SQL server数据库服务器、数据库以及数据库中的对象,能够在单一的控制界面上来实现对位于同一企业网络结构中多个SQL server数据库服务器的有效管理。 打开企业管理器的方法: [开始] ---[程序] --- [Microsoft SQL Server 2000] --- [企业管理器]

104
企业管理器的主要功能如下: 注册服务器 配置本地服务器 配置远程服务器 配置多重服务器 设置登录安全性 对数据库、数据库对象进行管理和操作 创建警告 建立操作员 为独立的环境创建和安排作业 为多重服务器环境创建和安排作业 创建和管理复制方案 为企业管理器设置轮询间隔

105
企业管理器 菜单 树型管理结构 图形浏览界面 更改用户密码

106
2、连接、启动、暂停或停止SQL Server服务 3、创建和管理数据库; 4、创建和管理各种数据库对象; 5、备份数据库和事务日志;
企业管理器主要可以完成如下工作: 1、注册和管理SQL Server服务器 2、连接、启动、暂停或停止SQL Server服务 3、创建和管理数据库; 4、创建和管理各种数据库对象; 5、备份数据库和事务日志; 6、管理用户账户。

107
5、需要进行的几项操作: 1)如果在安装的时候采用的是Client/Server模式进行的,则在服务器端和客户端都安装成功后需要进行服务器端和客户端的连接工作。 2)当SQL安装完成之后超级用户sa的密码为空,需要修改sa的密码。
如果在安装的时候采用的是Client/Server模式进行的,则在服务器端和客户端都安装成功后需要进行服务器端和客户端的连接工作。 2)当SQL安装完成之后超级用户sa的密码为空,需要修改sa的密码。")
108
6、SQL server 2000的安全性 SQL server 2000使用两层安全机制来确认用户的有效性----即身份验证和权限验证两个阶段。 1)身份验证模式 (可以通过服务器属性更改) Windows认证: 用户对SQL server 访问的控制由Windows账号或用户组完成,当进行连接时,用户不需要提供SQL server 登陆账号。 SQL server认证: SQL server管理员必须建立SQL server 登陆账号和口令。当用户要连接到SQL server 时,必须同时提供SQL server 的登陆账号和口令。 混合认证模式:两种模式同时工作,用户即能使用Windows 2000认证模式又能使用SQL Server认证模式连接到SQL Server服务器。

109
2)权限验证 身份验证成功,连接到SQL Server数据库后,用户必须使用特定的用户账号才能对数据库进行访问。SQL Server采取三个步骤来确认权限。 1) 当用户执行一项操作时,例如用户执行了一条插入一条记录的指令,客户端将用户T-SQL 语句发给SQL Server。 2) 当SQL Server接收到该命令语句后,立即检查该用户是否有执行这条指令的权限。 3) 如果用户具备这个权限,SQL Server将完成相应的操作,如果用户没有这个权限,SQL Server系统将返回一个错误给用户。
 当SQL Server接收到该命令语句后,立即检查该用户是否有执行这条指令的权限。 3) 如果用户具备这个权限,SQL Server将完成相应的操作,如果用户没有这个权限,SQL Server系统将返回一个错误给用户。")
110
7、服务器注册 什么是服务器的注册 必须注册本地或远程服务器后,才能使用 SQL Server 企业管理器来管理这些服务器。在注册服务器时必须指定:服务器的名称、登录到服务器时使用的安全类型;如果需要,指定登录名和密码以及注册了服务器后想将该服务器列入其中的组的名称。即使服务器是本机也需要注册,只不过一般情况下,安装好数据库服务器后,系统自动完成了注册的过程。

111
服务器和客户机的连接 1)在企业管理器的树型目录中,SQL server上右击,选则“新建SQL server注册”项。如图
在企业管理器的树型目录中,SQL server上右击,选则 新建SQL server注册 项。如图")
112
2)打开注册向导,单击下一步出现如图所示界面。选中服务器单击添加按钮单击下一步。
打开注册向导,单击下一步出现如图所示界面。选中服务器单击添加按钮单击下一步。")
114
SQL Server 服务器注册向导选择服务器组的界面
利用账户sa成功注册到SQL Server服务器HU后的界面

115
8、查询分析器的使用 查询分析器的功能 1)在“查询”窗口中创建查询和其他SQL脚本执行它们,执行结果在结果窗格中以文本或表格形式显示,还允许用户将执行的结果保存到报表文件中或导出到指定文件中。 2)利用模板功能,可以借助预定义脚本来快速创建数据库和数据库对象等。 3)利用对象浏览器脚本功能,快速复制现有数据库对象。 4)调试存储过程。 5)调试查询性能问题,包括显示执行计划、显示服务器跟踪、显示客户统计、索引优化向导 6) 在“打开表”窗口中快速插入、更新或删除表中的行。
利用模板功能,可以借助预定义脚本来快速创建数据库和数据库对象等。 3)利用对象浏览器脚本功能,快速复制现有数据库对象。 4)调试存储过程。 5)调试查询性能问题,包括显示执行计划、显示服务器跟踪、显示客户统计、索引优化向导. 6) 在 打开表 窗口中快速插入、更新或删除表中的行。")
116
启动查询分析器 通过单击“开始”菜单,在“程序—SQL Server”组中选择“查询分析器”命令,就可启动“查询分析器”,并出现登录界面,如图所示。

117
查询分析器 当前数据库的选择 查询子窗口 对象浏览器子窗口 查询结果显示窗口 模板标签

118
9、 SQL server 2000简单的操作 1)在企业管理器中修改服务器的连接授权数量与认证模式 2)Sa超级用户的密码修改操作 3)通过查询分析器完成本地服务器和客户机的连接检验密码是否修改成功 4)分别在企业管理器和查询分析器中完成远程服务器和客户机的连接
分别在企业管理器和查询分析器中完成远程服务器和客户机的连接.")
119
作业 1、体会C/S体系结构总结 2、上机学会修改用户sa的密码 企业管理器来完成 查询分析器来完成
4~5人一组,构建Client/Server体系结构 2、上机学会修改用户sa的密码 企业管理器来完成 查询分析器来完成

120
3.SQL 包含哪些组件,其功能各是什么? 4.安装SQL Server前应作哪些规划? 5.SQL Server支持哪两种身份认证模式?各有何特点? 6.安装SQL Server,并练习企业管理器和查询分析器的使用。

121
3.1数据库类型 3.2数据库存储结构 3.3创建数据库 3.4维护数据库
第三章 数据库管理与使用 3.1数据库类型 3.2数据库存储结构 3.3创建数据库 3.4维护数据库

122
3.1数据库类型 一、系统数据库 存储SQL-server系统的系统及信息,如数据库信息、账户登录信息、数据库文件信息和数据库备份信息等。功能如表3-1所示。 二、用户数据库 由用户创建,用于存储用户信息的数据库。 功能如表3-2所示。

123
3.2数据库存储结构 一、数据库的逻辑结构 用来存储特定信息并支持特定功能的数据库对象。 数据库对象 说明 表
由行和列构成的集合,用来存储数据 数据类型 定义列或变量的数据类型,SQL Server提供了系统数据类型,并允许用户自定义数据类型 视图 由表或其他视图导出的虚拟表 索引 为数据快速检索提供支持且可以保证数据唯一性的辅助数据结构 约束 用于为表中的列定义完整性的规则 默认值 为列提供的缺省值 存储过程 存放于服务器的预先编译好的一组完成某一特定操作过程T-SQL语句 触发器 特殊的存储过程,当用户对表中数据进行维护时,该存储过程被自动执行

124
二、 物理存储结构 用来存储数据库对象的文件和文件组。 1、文件 SQL servser系统中有两种表现形式:数据文件和事务日志文件。
二、 物理存储结构 用来存储数据库对象的文件和文件组。 1、文件 SQL servser系统中有两种表现形式:数据文件和事务日志文件。 (1)主数据文件 主数据文件简称主文件,正如其名字所示,该文件是数据库的关键文件,包含了数据库的启动信息,并且存储数据。每个数据库必须有且仅能有一个主文件,其默认扩展名为.MDF。 (2)辅助数据文件 辅助数据文件简称辅(助)文件,用于存储未包括在主文件内的其他数据。一个数据库可以没有,也可有多个辅助文件,默认扩展名为.NDF。 (3)事务日志文件 事务日志文件用于存储数据库事务日志信息的文件,用来记录进行数据库恢复和数据库操作的操作信息。只要对数据库进行更新、插入和删除操作,相关信息就记录在事务日志文件中。每个数据库至少有一个日志文件,也可以有多个。日志文件的扩展名为.LDF。
主数据文件. 主数据文件简称主文件,正如其名字所示,该文件是数据库的关键文件,包含了数据库的启动信息,并且存储数据。每个数据库必须有且仅能有一个主文件,其默认扩展名为.MDF。 (2)辅助数据文件. 辅助数据文件简称辅(助)文件,用于存储未包括在主文件内的其他数据。一个数据库可以没有,也可有多个辅助文件,默认扩展名为.NDF。 (3)事务日志文件. 事务日志文件用于存储数据库事务日志信息的文件,用来记录进行数据库恢复和数据库操作的操作信息。只要对数据库进行更新、插入和删除操作,相关信息就记录在事务日志文件中。每个数据库至少有一个日志文件,也可以有多个。日志文件的扩展名为.LDF。")
125
(4)文件的存放位置 系统的主数据文件默认存储位置和文件如下: SQL Server 2000根目录\mssql\data\数据库名_Data.MDF 系统的主日志文件的默认存储位置和文件如下: SQL Server 2000根目录\mssql\data\数据库名_Log.LDF 选择“数据文件”和“事务日志”两个标签栏,显示系统的默认设置,用户可以更改这两个文件的存放位置和文件名。

126
5、事务与事务日志 事务:是一组T-SQL语句的集合,这组语句作为单个的工作与恢复的单元。事务作为一个整体来执行,对于其数据的修改,要么全都执行,要么全都不执行。 事务日志 :是数据库中已发生的所有修改和执行每次修改的事务的一连串记录。为了维护数据的一致性,并且便于进行数据库恢复,SQL server将各种类型的事务记录在事务日志中。 SQL server自动使用预写类型的事务日志,也就是说在进行任何操作之后,更 改数据库之前,先把相关的更改写进事务日志中。 随着数据库数据的不断变化,事务日志文件不断增大。因此,必须把它们备份出来,为更多的事务提供空间。备份时,事务日志文件会被截断。

127
事物日志工作流程: 写入日志 数据库修改操作 页调入内存 写入磁盘

128
3.3创建数据库 1、数据库的类型 系统数据库 用户数据库 2、数据库命名规则
字符长度最长不超过128个字符,可包含英文字母、数字和几个特殊字符:“_” (下划线) ”等。 首字符不能是数字。 名称内不允许有空格和其他特殊字符且不允许是SQL Server的保留字。 名称标识符不区分大小写。 3、数据库的建立方法 通过企业管理器建立数据库 使用创建数据库向导建立数据库 Transact-SQL语句建立数据库
 、 # 等。 首字符不能是数字。 名称内不允许有空格和其他特殊字符且不允许是SQL Server的保留字。 名称标识符不区分大小写。 3、数据库的建立方法. 通过企业管理器建立数据库. 使用创建数据库向导建立数据库. Transact-SQL语句建立数据库.")
129
一、 通过企业管理器创建数据库 第1步:在“SQL Server 企业管理器”窗口中展开Microsoft SQL Servers和SQL Server组,选择SQL Server服务器。在选择的SQL Server服务器上点击鼠标右键,选择“新建”“数据库…”

130
第2步:在“数据库属性”对话框“常规”选项卡“名称”文本框中输入创建的数据库名(本例中数据库名为XSCJ)。
。")
131
第3步 选择“数据文件”标签栏,在文件名为“XSCJ_DATA”这一行的“初始大小”列将系统缺省大小1改为5,设置是否允许数据库增长、增长方式以及最大文件大小。

132
第4步 选择“事务日志”标签栏,设置日志文件的初始大小、是否增长、增长方式及最大大小。

133
创建好的数据库XSCJ的界面。

134
二、 使用向导创建数据库(Create Database Wizard)
第1步 在SQL Server 企业管理器中选择SQL Server服务器,在“工具”菜单中选择“向导…”项

135
第2步 在出现的“选择向导”对话框中展开“数据库”,选择“创建数据库向导”,单击“确定”。进入“创建数据库向导”界面后根据提示设置数据库参数。

136
输入数据库名,输入或选择数据文件和日志文件的存放位置

137
指定各数据文件的名称及初始大小

138
定义数据库文件的增长

139
指定日志文件名和初始大小

140
定义事务日志文件的增长

141
三、 使用Create Database 语句创建数据库
CREATE DATABASE database_name [ ON ( [ PRIMARY ] [ NAME = logical_file_name , ] FILENAME = 'os_file_name' [ ,SIZE = size ] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ] ) [,...n ]) LOG ON (NAME = logical_file_name , FILENAME = 'os_file_name' [ ,SIZE = size ] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ] ) [,...n ]) [COLLATE collation_name]
 [,...n ]) LOG ON. (NAME = logical_file_name , FILENAME = os_file_name [ ,SIZE = size ] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ] ) [,...n ]) [COLLATE collation_name]")
142
其中:ldatabase_name:新数据库的名称。
lON:指定显式定义用来存储数据库数据部分的磁盘文件(数据文件)。 PRIMARY:在主文件中指定文件。主文件组包含所有数据库系统表。还包含所有未指派给用户文件组的对象。如果没有指定 PRIMARY,那么 CREATE DATABASE 语句中列出的第一个文件将成为主文件。 lLOG ON:指定建立数据库的事务日志的文件。如果没有指定 LOG ON,将自动创建一个日志文件,该文件使用系统生成的名称,大小为数据库中所有数据文件总大小的 25%。 NAME:指定数据或日志文件的名称。 FILENAME:指定文件的操作系统文件名称和路径。 SIZE:指定数据或日志文件的大小,默认单位是KB,也可以是MB,没指定默认是1MB. MAXSIZE:指定数据或日志文件能够增长到的最大长度,默认单位是KB,也可以是MB,没指定,文件可以一直增长到磁盘满为止。 FILEGROWTH:指定文件的增长量。默认10%。 COLLATE: 指定数据库的默认排序规则。
。 PRIMARY:在主文件中指定文件。主文件组包含所有数据库系统表。还包含所有未指派给用户文件组的对象。如果没有指定 PRIMARY,那么 CREATE DATABASE 语句中列出的第一个文件将成为主文件。 lLOG ON:指定建立数据库的事务日志的文件。如果没有指定 LOG ON,将自动创建一个日志文件,该文件使用系统生成的名称,大小为数据库中所有数据文件总大小的 25%。 NAME:指定数据或日志文件的名称。 FILENAME:指定文件的操作系统文件名称和路径。 SIZE:指定数据或日志文件的大小,默认单位是KB,也可以是MB,没指定默认是1MB. MAXSIZE:指定数据或日志文件能够增长到的最大长度,默认单位是KB,也可以是MB,没指定,文件可以一直增长到磁盘满为止。 FILEGROWTH:指定文件的增长量。默认10%。 COLLATE: 指定数据库的默认排序规则。")
143
例: Creat Database语句来创建Educational数据库,其主文件大小为10MB,最大为20MB,增长方式为10%;日志文件的大小为2MB,最大为6MB,增长方式为1MB。
CREATE DATABASE Educational ON PRIMARY (NAME=Educational_Data, FILENAME=‘C:\Program Files\Microsoft SQL Server\MSSQL\DATA\Educational_Data.mdf’, SIZE=10MB, MAXSIZE=20MB, FILEGROWTH=10%) LOG ON (NAME=Educational_Log, FILENAME=‘C:\Program Files\Microsoft SQL Server\MSSQL\DATA\Educational_Log.ldf’, SIZE=2MB, MAXSIZE=6MB, FILEGROWTH=1MB)
 LOG ON (NAME=Educational_Log, FILENAME=‘C:\Program Files\Microsoft SQL Server\MSSQL\DATA\Educational_Log.ldf’, SIZE=2MB, MAXSIZE=6MB, FILEGROWTH=1MB)")
144
二、 修改数据库 1、对已存在的数据库可以进行的修改: 增加或删除数据文件 改变数据文件的大小和增长方式 改变日志文件的大小和增长方式
增加或删除日志文件 增加或删除文件组 2、操作方法:在“企业管理器”中在需要修改的数据库名上右击,选择“属性”,如图所示。

145
3、 使用ALTER DATABASE语句修改数据库
[例]:修改数据库Educational日志文件的最大值由100MB改为现在的80MB。 ALTER DATABASE Educational MODIFY FILE(NAME= Educational _log, MAXSIZE=80MB) [例]:修改Educational _data数据文件的初始值由5MB改为10MB。 MODIFY FILE(NAME= Educational _data, SIZE=10MB)
 [例]:修改Educational _data数据文件的初始值由5MB改为10MB。 MODIFY FILE(NAME= Educational _data, SIZE=10MB)")
146
• old_name: 是数据库的当前名称; • new_name: 是数据库的新名称。
4、 数据库的更名 1)数据库的更名的命令语法形式: sp_renamedb old_name , new_name 其中: • old_name: 是数据库的当前名称; • new_name: 是数据库的新名称。 例如:将数据库文件educationl 的名字改为abcd。 sp_renamedb educational , abcd
数据库的更名的命令语法形式: sp_renamedb old_name , new_name. 其中: • old_name: 是数据库的当前名称; • new_name: 是数据库的新名称。 例如:将数据库文件educationl 的名字改为abcd。 sp_renamedb educational , abcd.")
147
3.4 维护数据库 一、查看和修改数据库信息 操作步骤: 1、启动企业管理器 2、右键单击要查看的数据库结点,打开快捷菜单。
3.4 维护数据库 一、查看和修改数据库信息 操作步骤: 1、启动企业管理器 2、右键单击要查看的数据库结点,打开快捷菜单。 3、在快捷菜单中选择“属性”菜单命令,进入相关属性对话框。 或者: 在快捷菜单中选择“查看”,再选择“任务版”菜单命令。

148
二、数据库的附加与分离 1、附加数据库 在数据库文件的移植过程中,copy的数据库物理文件需要经过附加才可以在企业管理器中查看与管理。

149
2、分离数据库 在数据库服务器工作中数据库的物理文件是不能被复制的,经过分离后,数据库将脱离企业管理器的控制,不被客户共享。

150
三、删除数据库 1.在SQL Server企业管理器中,在要删除的数据库上右击,选择“删除”菜单项 2.利用Drop语句删除数据库
Drop database database_name 说明:只有处于正常状态下的数据库,才能使用DROP语句删除。当数据库处于以下状态时不能被删除:数据库正在使用;数据库正在恢复;系统数据库master、tempdb、model、 msdb。

151
四、数据库的收缩 在数据库使用过程中,物理文件将会因删除和修改等操作产生间隙,收缩数据库可以减少间隙。
提示:利用agent服务,定时收缩数据库。

152
习 题 1. SQL Server 2000的数据库对象有哪些? 2. 简述SQL Server 2000物理数据库的结构。
习 题 1. SQL Server 2000的数据库对象有哪些? 2. 简述SQL Server 2000物理数据库的结构。 3. 写出创建产品销售数据库CPXS和表的T-SQL语句:数据库初始大小为10MB,最大大小100MB,数据库自动增长,增长方式是按10%比例增长;日志文件初始为2MB,最大可增长到5MB(默认为不限制),按1MB增长(默认是按10%比例增长);其余参数自定。 4. 将第3题中所创建的CPXS数据库的增长方式改为按5MB增长。
,按1MB增长(默认是按10%比例增长);其余参数自定。 4. 将第3题中所创建的CPXS数据库的增长方式改为按5MB增长。")
153
第四章 数据表管理与使用 数据类型 创建数据表 维护数据表 删除数据表

154
4.1 数据类型 一、字符型 字符型数据用于存储字符串,字符串中可包括字母、数字和其它特殊符号。字符型数据可由ASCII字符集和Unicode( “统一字符编码标准”,用于支持国际上非英语语种的字符数据的存储和处理)字符集组成。例如:’刘鹏’、‘北京’、‘abc’。 由ASCII字符集组成的字符型数据有定长字符型(Char(n))、变长字符型(Vachar(n))、和文本型(Text) 由Unicode字符组成的字符型数据有定长字符型(Nchar(n))、变长字符型(Nvachar(n))、和文本型(Ntext)。
)、变长字符型(Vachar(n))、和文本型(Text) 由Unicode字符组成的字符型数据有定长字符型(Nchar(n))、变长字符型(Nvachar(n))、和文本型(Ntext)。")
155
类 型 长 度 范 围 Char(n) n字符长 1~8000(实际长度不足n时,则在字符串尾部添加空格) Vachar(n) 实际字符长 1~8000(n是字符串可达到的最大长度) Text 1~231个字符 Nchar(n) n字符长两倍 1~4000 Nvachar(n) 实际字符长两倍 Ntext
 Text. 1~231个字符. Nchar(n) n字符长两倍. 1~4000. Nvachar(n) 实际字符长两倍. Ntext.")
156
二、数值型 精度:指数值数据中所存储的十进制数据的总位数。
小数位数:指数值数据中小数点右边可以有的数字位数的最大值。例如数值数据 的精度是7,小数位数是3。 长度:指存储数据所使用的字节数。 (1)整数型(用于存储整型数据) 包括长整型(bigint)、整型(int/integer)、短整型(smallint)和微短整型(tinyint)。 (2)精确数值型(用于存储带小数的完整的十进制数) numeric /decimal(p[,s]) p为精度,s为小数点位数。 精度为1~9时,存储字节长度为5; 精度为10~19时,存储字节长度为9; 精度为20~28时,存储字节长度为13; 精度为29~38时,存储字节长度为17。
整数型(用于存储整型数据) 包括长整型(bigint)、整型(int/integer)、短整型(smallint)和微短整型(tinyint)。 (2)精确数值型(用于存储带小数的完整的十进制数) numeric /decimal(p[,s]) p为精度,s为小数点位数。 精度为1~9时,存储字节长度为5; 精度为10~19时,存储字节长度为9; 精度为20~28时,存储字节长度为13; 精度为29~38时,存储字节长度为17。")
157
(3) 浮点型 (近似值型) 有Float和Real 两种类型。 (4) 货币型 专门处理货币的数据类型,在第一个数字前冠以一个货币符号($),整数位超过3个字符长,自动加分隔符,有Money和Smallmoney两种类型。 (5) 位型(bit) SQL Server中的位型数据相当于其他语言中的逻辑型数据,它只存储0和1,表示“真”和“假”。
 位型(bit) SQL Server中的位型数据相当于其他语言中的逻辑型数据,它只存储0和1,表示 真 和 假 。")
158
类 型 长 度 范 围 Bigint 8字节 ~92233…807 Int/Integer 4字节 ~ Smallint 2字节 -32768~32767 Tinyint 1字节 0~255 Numeric/Decimal(p[,s] 长度随精度而定 ~1038-1 Float(n) -3.4E+38~3.4E+38(1≤n≤24)之间 -1.79E+308~1.79E+308(25 ≤n≤53)之间 Real -3.4E+38~3.4E+38 Money Smallmoney Bit 0(真)或1(假),非零视为1
 -3.4E+38~3.4E+38(1≤n≤24)之间 E+308~1.79E+308(25 ≤n≤53)之间. Real. -3.4E+38~3.4E+38. Money. Smallmoney. Bit. 0(真)或1(假),非零视为1.")
159
有Datetime和Smalldatetime两种类型。 类 型 长 度 范 围 Datetime 8字节 4字节
三、日期时间类型(存储日期和时间) 有Datetime和Smalldatetime两种类型。 类 型 长 度 范 围 Datetime 8字节 1753年1月1日~9999年12月31日 Smalldatetime 4字节 1950年1月1日~2049年6月6日
 有Datetime和Smalldatetime两种类型。 类 型. 长 度. 范 围. Datetime. 8字节. 1753年1月1日~9999年12月31日. Smalldatetime. 4字节. 1950年1月1日~2049年6月6日.")
160
二进制数据类型常用于存储图像数据、有格式的文本数据(word、excel文件)、程序文件数据等。n取值范围为 1 到 8,000,缺省为1。
四、二进制数据类型 二进制数据类型常用于存储图像数据、有格式的文本数据(word、excel文件)、程序文件数据等。n取值范围为 1 到 8,000,缺省为1。 类 型 长 度 说 明 Binary(n) n+4字节 用于存储图像等二进制数据 Varbinary(n) 实际长度+4字节 存放8KB内可变长的二进制数据 Image 实际长度 存放大于8KB的可变长的二进制数据,如照片、表格、word文档
、程序文件数据等。n取值范围为 1 到 8,000,缺省为1。 类 型. 长 度. 说 明. Binary(n) n+4字节. 用于存储图像等二进制数据. Varbinary(n) 实际长度+4字节. 存放8KB内可变长的二进制数据. Image. 实际长度. 存放大于8KB的可变长的二进制数据,如照片、表格、word文档.")
161
五、其他数据类型 1、时间戳数据类型(Timestamp) 是一种自动记录时间的数据类型。长度是8字节。若创建表时定义一个列的数据类型为时间戳类型,那么每当对该表加入新行或修改已有行时,都由系统自动将一个计数器值加到该列,即将原来的时间戳值加上一个增量。 2、唯一标识符数据类型(Uniqueidentifier) 系统根据网络适配器地址和主机CPU的标识而生成的全局唯一标识符代码(GUID)。 3、游标数据类型(Curdor) 用于创建游标变量或定义存储过程的输出参数。游标数据是SELECT语句返回的结果。 4、变体数据类型(Sql_variant) 是可以存储Text、Ntext、Image、Timestamp以外的数据类型。
 系统根据网络适配器地址和主机CPU的标识而生成的全局唯一标识符代码(GUID)。 3、游标数据类型(Curdor) 用于创建游标变量或定义存储过程的输出参数。游标数据是SELECT语句返回的结果。 4、变体数据类型(Sql_variant) 是可以存储Text、Ntext、Image、Timestamp以外的数据类型。")
162
4.2创建数据表 数据表(简称表):满足关系模型的一组相关数据的集合,表是包含数据库中所有数据的数据库对象。
创建表的过程:就是定义表的列数、列名、列类型、列宽度、建立索引以及完整性定义等。 可以使用企业管理器和T-sql命令创建数据表。

163
在SQL Server系统中,一张二维表对应一个数据表,称为表文件(Table),一张二维表由表名、表头、表的内容三部分组成,一个表文件则由表文件名、表的结构、表的行三要素构成。
(1)表的文件名相当于二维表中的表名,它是表的主要标识。用户就是依靠表名在磁盘上存取、使用指定的表。 (2)表的结构相当于二维表的表头,二维表的每一列对应了表中的一个列,其属性是由列名、列类型和列长度而决定的。 (3)表的行是表中不可分割的基本项,即二维表的内容。
表的文件名相当于二维表中的表名,它是表的主要标识。用户就是依靠表名在磁盘上存取、使用指定的表。 (2)表的结构相当于二维表的表头,二维表的每一列对应了表中的一个列,其属性是由列名、列类型和列长度而决定的。 (3)表的行是表中不可分割的基本项,即二维表的内容。")
165
4.定义表的结构 定义表的结构,就是根据二维表的定义来确定表的组织形式,也即定义表的列个数、列名、列类型、列宽度及是否以该列建立索引等。

166
一、用企业管理器 操作步骤: 第1步:在SQL Server 企业管理器中,用鼠标右键单击选择数据库(这里是数据库XSCJ),在快捷菜单中选择“新建(N)”“表(T)…”。
,在快捷菜单中选择 新建(N) 表(T)… 。")
167
第2步 在编辑窗口中分别输入或选择各列的名称、数据类型、是否允许为空值等属性,在“学号”列上单击鼠标右键,选择“设置主键”菜单项,将学号列设置为主键,将“性别”列的缺省值设置为“男”。

168
第3步 在表的各列的属性均编辑完成后,单击“保存”图形按钮,出现 “选择表名”对话框。
第4步 在“选择表名”对话框中输入表名XS,单击“确定”,XS表就创建好了。

169
二、用SQL命令 格式: CREATE Table <表名>
([<列名1>[数据类型(长度)[默认值][列级约束][,<列名2>数据类型[默认值][列级约束]]…… [,UNIQUE (列名[,列名]……)] [,PRIMARY KEY (列名[,列名]……)] [,FOREIGE KEY (列名[,列名]……)] REFERENCES 表名(列名[,列名]……)] [CHECK (条件)])
[默认值][列级约束][,<列名2>数据类型[默认值][列级约束]]…… [,UNIQUE (列名[,列名]……)] [,PRIMARY KEY (列名[,列名]……)] [,FOREIGE KEY (列名[,列名]……)] REFERENCES 表名(列名[,列名]……)] [CHECK (条件)])")
170
例如:建立学生1的表 步骤如下: 1、进入查询分析器。 2、输入如下命令: CREATE Table 学生1(学号 CHAR(6),姓名 CHAR(6),性别 CHAR(2),出生日期 DATETIME,籍贯 VARCHAR(50),班级编号 CHAR(7),PRIMARY KEY (学号)) 3、执行命令。
,姓名 CHAR(6),性别 CHAR(2),出生日期 DATETIME,籍贯 VARCHAR(50),班级编号 CHAR(7),PRIMARY KEY (学号)) 3、执行命令。")
172
三、 修改表结构 1、在SQL Server企业管理器中展开需进行操作的表XS,在其上单击鼠标右键,在弹出的快捷菜单上选择“设计表”,如图.
2、使用SQL语言中的ALTER TABEL命令。

173
四、 更改表名 操作方法: 在SQL Server企业管理器中展开需更名的表,在其上单击鼠标右键,在弹出的快捷菜单上选择“重命名”.

174
4.3维护数据表 一、插入数据 向表中输入数据。步骤如下: 1、启动企业管理器
2、展开SQL server组→“数据库” →“展开表结点” →在右边窗格中右键单击“xscj”打开快捷菜单→“打开表” →“返回所有行” →“向表中添加数据”。

176
二、 修改表结构 在SQL Server企业管理器中展开需进行操作的表XS,在其上单击鼠标右键,在弹出的快捷菜单上选择“设计表”,如图.

177
3、修改数据 步骤:同添加数据。 4、删除数据 步骤: (1)同修改数据。 (2)右键单击要删除的行,选择删除。
同修改数据。 (2)右键单击要删除的行,选择删除。")
178
4.4 表的删除 在“企业管理器”中展开数据库XSCJ,再展开表,在表test上点击鼠标右键,在弹出的快捷菜单上选择“删除” 。

179
加快检索速度,保持数据唯一性,保持数据完整性
复习提问 使用索引的目的? 聚簇索引与非聚簇索引的区别? 填充因子的作用? 使用索引负面影响? 主键索引和唯一索引的区别? 加快检索速度,保持数据唯一性,保持数据完整性 是否更改数据的物理顺序 减少数据更新时对索引页面的影响 数据更新与插入时速度变慢 主键索引每个表只能建一个,唯一 索引可以建多个

180
第五章数据完整性及实现 数据完整性 数据完整性实现 约束 规则 默认

181
5.1数据完整性 一、数据完整性概述 数据完整性(Data Integrity)是指存储在数据库中的数据的一致性、准确性和可靠度。换言之,实施数据完整性的目的就是为了确保数据库中数据的质量。 数据完整性的设计是评估数据库设计好坏的一个重要指标。在SQL Server系统中,在设计数据库和设计表时,设计者就要确认每列对应哪些数据是正确的,使用什么方法可以不会有错误的数据存到列中。数据完整性为我们提供了这样的保障,其类型有4种。

182
二、数据完整性的分类 1.域完整性(Domain Integrity)要求存入表中指定列的数据一定有效。域完整性通常是用来检验某列的数据的有效性。 2.实体完整性(Entity Integrity)要求表中所有行有一个标识符(主键),其值不能空值(NULL),且能唯一地标识对应的行。 3.参照完整性(Referential Integrity)是指添加、修改或删除数据行时,两个表的主键和外键的数据的一致性。 4.用户自定义完整性(User-Defined Integrity)是用户自行定义的,不属于其它完整性的所有规则。
是指添加、修改或删除数据行时,两个表的主键和外键的数据的一致性。 4.用户自定义完整性(User-Defined Integrity)是用户自行定义的,不属于其它完整性的所有规则。")
183
数据完整性实施的方法 数据完整性 实施的方法 域完整性
DEFAULT 定义 、 FOREIGN KEY 约束、 CHECK 约束、NOT NULL定义 、 规则 实体完整性 索引、 PRIMARY KEY 约束、 UNIQUE 约束、 IDENTITY 属性(自动标识) 参照完整性 FOREIGN KEY 约束、CHECK 约束、存储过程、触发器 用户自定义 完整性 CREATE TABLE 命令语句中所有列与表级的约束、 存储过程、触发器
 参照完整性. FOREIGN KEY 约束、CHECK 约束、存储过程、触发器. 用户自定义. 完整性. CREATE TABLE 命令语句中所有列与表级的约束、 存储过程、触发器.")
184
关于约束的概述: 约束:是附加于表上用于限制数据完整性、实现数据完整性的最主要的方法。 约束的操作方式有两种:一种是在创建表结构时定义约束;另一种是修改表结构时,增加约束。 根据约束的应用范围分为两种:列级约束和表级约束。 根据约束的作用分为5种:PRIMARY KEY约束、UNIQUE约束、CHECK约束、DEFAULT约束、FOREIGN KEY约束。

185
5.2数据完整性实现 5.2.1域完整性的实现 域完整性是通过定义相应的CHECK约束、规则和默认值等 数据库对象实现的。
操作步骤如下: (1)启动SQL Server企业管理器。 (2)选择创建约束的表,单击鼠标右键,打开快捷菜单。 (3)选择“设计表”菜单命令。 (4)单击鼠标右键,打开快捷菜单。 (5)选择“CHECK 约束”菜单命令,进入“属性”窗口。 (6)选择“CHECK约束”选项卡,命名约束名,输入约束表达式。
启动SQL Server企业管理器。 (2)选择创建约束的表,单击鼠标右键,打开快捷菜单。 (3)选择 设计表 菜单命令。 (4)单击鼠标右键,打开快捷菜单。 (5)选择 CHECK 约束 菜单命令,进入 属性 窗口。 (6)选择 CHECK约束 选项卡,命名约束名,输入约束表达式。")
187
2、利用 CREATE 命令创建约束 SQL 命令的格式: CREATE TABLE table_name /*指定表名*/ (column_name datatype NOT NULL | NULL [DEFAULT constraint_expression] /*缺省值约束表达式*/ [[check_name ] CHECK ( logical_expression )] /*CHECK约束表达式*/ [,…n]) /* 定义列名、数据类型、标识列、是否空值及定义缺省值约束、CHECK 约束*/ 命令功能: 创建一个表,并定义数据完整性。
] /*CHECK约束表达式*/ [,…n]) /* 定义列名、数据类型、标识列、是否空值及定义缺省值约束、CHECK 约束*/ 命令功能: 创建一个表,并定义数据完整性。")
188
例:使用SQL命令为“学生”表中的“学号”列创建CHECK约束,约束为学号必须是06开头。
在“查询分析器”窗口输入如下的命令: CREATE TABLE 学生(学号 CHAR(6) CHECK (学号 LIKE ‘06%’),姓名 CHAR(6),性别 CHAR(2),出生年月 DATETIME,籍贯 VARCHAR(50),班级编号 CHAR(7))
 CHECK (学号 LIKE ‘06%’),姓名 CHAR(6),性别 CHAR(2),出生年月 DATETIME,籍贯 VARCHAR(50),班级编号 CHAR(7))")
189
3.利用SQL命令修改CHECK约束 SQL命令格式: ALTER TABLE < Table_name > ADD [CONSTRAINT Check_name] CHECK (Logical_expression) 命令功能:修改表结构,并可以定义数据完整性。 例如:为学生1表增加完整性:性别只能是男或女,约束 名为aaa。 ALTER TABLE 学生1 ADD CONSTRAINT aaa CHECK(性别='男'or 性别='女') 或 ADD CHECK(性别='男'or 性别='女')
![3.利用SQL命令修改CHECK约束 SQL命令格式: ALTER TABLE < Table_name > ADD [CONSTRAINT Check_name] CHECK (Logical_expression)](http://slidesplayer.com/slide/11418122/61/images/189/3.%E5%88%A9%E7%94%A8SQL%E5%91%BD%E4%BB%A4%E4%BF%AE%E6%94%B9CHECK%E7%BA%A6%E6%9D%9F+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+ALTER+TABLE+%3C+Table_name+%3E+ADD+%5BCONSTRAINT+Check_name%5D+CHECK+%28Logical_expression%29.jpg "命令功能:修改表结构,并可以定义数据完整性。 例如:为学生1表增加完整性:性别只能是男或女,约束. 名为aaa。 ALTER TABLE 学生1. ADD CONSTRAINT aaa CHECK(性别= 男 or 性别= 女 ) 或. ADD CHECK(性别= 男 or 性别= 女 )")
190
4.利用SQL语句删除CHECK约束 SQL命令格式: ALTER TABLE < Table_name > DROP CONSTRAINT Check_name 命令功能: 修改表结构,并可以删除数据完整性。 例如:删除学生1表中的约束aaa。 ALTER TABLE 学生1 DROP CONSTRAINT aaa

191
5.2.2 实体完整性的实现 实体完整性的实现是通过创建索引、PRIMARY KEY约束和UNIQUE约束实现的。
实体完整性的实现 实体完整性的实现是通过创建索引、PRIMARY KEY约束和UNIQUE约束实现的。 1.利用企业管理器创建PRIMARY KEY约束 操作步骤如下: (1)启动SQL Server企业管理器。 (2)展开“SQL Server组”,展开“数据库”,选择使用的数据库,再展开“表”。 (3)选择要创建约束的表,单击鼠标右键,打开快捷菜单。 (4)选择“设计表”菜单命令,进入“设计表”窗口。 (5)选择要创建约束的列(学号),单击鼠标右键,打开快捷菜单。 (6)选择“设置主键”菜单命令。
启动SQL Server企业管理器。 (2)展开 SQL Server组 ,展开 数据库 ,选择使用的数据库,再展开 表 。 (3)选择要创建约束的表,单击鼠标右键,打开快捷菜单。 (4)选择 设计表 菜单命令,进入 设计表 窗口。 (5)选择要创建约束的列(学号),单击鼠标右键,打开快捷菜单。 (6)选择 设置主键 菜单命令。")
192
2.利用企业管理器创建UNIQUE约束 操作步骤如下: (1)启动SQL Server企业管理器。 (2)展开“SQL Server组”,展开“数据库”,选择使用的数据库,再展开“表”。 (3)选择要创建约束的表,单击鼠标右键,打开快捷菜单。 (4)选择“设计表”菜单命令,进入“设计表”窗口。 (5)选择要创建约束的列,单击鼠标右键,打开快捷菜单。 (6)选择“索引/键”菜单命令,进入“属性”窗口。 (7)选择“索引/键”选项卡,首先,单击“新建”按钮,然后,命名索引名,选择索引列及索引顺序,选择索引文件组,选择创建UNIQUE前的复选框,最后,单击“关闭”按钮,返回“设计表”窗口。
选择 设计表 菜单命令,进入 设计表 窗口。 (5)选择要创建约束的列,单击鼠标右键,打开快捷菜单。 (6)选择 索引/键 菜单命令,进入 属性 窗口。 (7)选择 索引/键 选项卡,首先,单击 新建 按钮,然后,命名索引名,选择索引列及索引顺序,选择索引文件组,选择创建UNIQUE前的复选框,最后,单击 关闭 按钮,返回 设计表 窗口。")
193
3.利用企业管理器删除PRIMARY KEY约束、删除UNIQUE约束
操作步骤如下: (1)启动SQL Server企业管理器。 (2)展开“SQL Server组”,展开“数据库”,选择使用的数据库,再展开“表”。 (3)选择要删除约束的表,单击鼠标右键,打开快捷菜单。 (4)选择“设计表”菜单命令,进入“设计表”窗口。 (5)选择要删除约束的列,单击鼠标右键,打开快捷菜单。 (6)单击设置主键。 (7)选择“索引/键”菜单命令,进入“属性”窗口。 (8)首先,选择“索引/键”选项卡,然后,单击“删除”按钮,最后在单击“关闭”按钮,返回“设计表”窗口。
启动SQL Server企业管理器。 (2)展开 SQL Server组 ,展开 数据库 ,选择使用的数据库,再展开 表 。 (3)选择要删除约束的表,单击鼠标右键,打开快捷菜单。 (4)选择 设计表 菜单命令,进入 设计表 窗口。 (5)选择要删除约束的列,单击鼠标右键,打开快捷菜单。 (6)单击设置主键。 (7)选择 索引/键 菜单命令,进入 属性 窗口。 (8)首先,选择 索引/键 选项卡,然后,单击 删除 按钮,最后在单击 关闭 按钮,返回 设计表 窗口。")
194
4. 利用SQL语句删除PRIMARY KEY和UNIQUE约束
ALTER TABLE < Table_name > DROP CONSTRAINT Check_name 命令功能:修改表结构,并删除数据完整性。 例:使用SQL命令,删除“学生”表中的“学号”列UNIQUE约束。 ALTER TABLE 学生 DORP CONSTRAINT IX_学生

195
5. 利用SQL语句修改PRIMARY KEY约束
ALTER TABLE Table_name ADD [ CONSTRAINT constraint_name ] PRIMARY KEY CLUSTERED | NONCLUSTERED ( column [ ,...n ] ) 命令功能:修改表结构,并可增加数据完整性。
 命令功能:修改表结构,并可增加数据完整性。")
196
5.2.3 参照完整性的实现 1.利用企业管理器定义表间的参照完整性 操作步骤如下: (1)启动SQL Server企业管理器。
参照完整性的实现 1.利用企业管理器定义表间的参照完整性 操作步骤如下: (1)启动SQL Server企业管理器。 (2)在“控制台根目录”窗口,展开“SQL Server组”,展开“数据库”,选择使用的数据库,再展开“表”。 (3)在“控制台根目录”窗口,选择“表”,单击鼠标右键,打开快捷菜单。 (4)在快捷菜单中,选择“新建表”菜单命令,进入“设计表”窗口。 (5)在“设计表”窗口,设计表的结构。
启动SQL Server企业管理器。 (2)在 控制台根目录 窗口,展开 SQL Server组 ,展开 数据库 ,选择使用的数据库,再展开 表 。 (3)在 控制台根目录 窗口,选择 表 ,单击鼠标右键,打开快捷菜单。 (4)在快捷菜单中,选择 新建表 菜单命令,进入 设计表 窗口。 (5)在 设计表 窗口,设计表的结构。")
197
(6)重复(3)-(5)的操作,在“设计表”窗口,设计表的结构。
(7)在“控制台根目录”窗口,选择“关系图”,单击鼠标右键,打开快捷菜单。 (8)在快捷菜单中,选择“新建数据库关系图”菜单命令,进入“新关系图”窗口,并打开“创建数据库关系的向导”。 (9)在“创建数据库关系的向导”各窗口,依次添加要建立关系的表,返回“新关系图”窗口。 (10)在“新关系图”窗口,首先,选择外键列,将其拖到主键列处,进入“创建关系”窗口。 (11)在“创建关系”窗口,首先,确定“关系名”,然后,选择其它参数,最后,单击“确定”按钮,返回“新关系图”窗口,结束创建参照完整性的操作。
在 控制台根目录 窗口,选择 关系图 ,单击鼠标右键,打开快捷菜单。 (8)在快捷菜单中,选择 新建数据库关系图 菜单命令,进入 新关系图 窗口,并打开 创建数据库关系的向导 。 (9)在 创建数据库关系的向导 各窗口,依次添加要建立关系的表,返回 新关系图 窗口。 (10)在 新关系图 窗口,首先,选择外键列,将其拖到主键列处,进入 创建关系 窗口。 (11)在 创建关系 窗口,首先,确定 关系名 ,然后,选择其它参数,最后,单击 确定 按钮,返回 新关系图 窗口,结束创建参照完整性的操作。")
198
2.利用SQL语句创建参照完整性 SQL命令格式: CREATE TABLE < Table_name > ([<列名1>] 类型 (长度) [缺省值][列级约束] [,<列名2> 数据类型[缺省值][列级约束]]…. [,UNIQUE(列名[,列名]….)] [,PRIMARY KEY(列名[,列名]…)] [,FOREIGN KEY (列名[,列名]…) REFERENCES 表名(列名[,列名]…)] [,CKECK (条件)] ) 命令功能:创建表结构,并创建数据完整性。
![2.利用SQL语句创建参照完整性 SQL命令格式: CREATE TABLE < Table_name > ([<列名1>] 类型 (长度) [缺省值][列级约束] [,<列名2> 数据类型[缺省值][列级约束]]….](http://slidesplayer.com/slide/11418122/61/images/198/2.%E5%88%A9%E7%94%A8SQL%E8%AF%AD%E5%8F%A5%E5%88%9B%E5%BB%BA%E5%8F%82%E7%85%A7%E5%AE%8C%E6%95%B4%E6%80%A7+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+CREATE+TABLE+%3C+Table_name+%3E+%EF%BC%88%5B%3C%E5%88%97%E5%90%8D1%3E%5D+%E7%B1%BB%E5%9E%8B+%28%E9%95%BF%E5%BA%A6%29+%5B%E7%BC%BA%E7%9C%81%E5%80%BC%5D%5B%E5%88%97%E7%BA%A7%E7%BA%A6%E6%9D%9F%5D+%5B%EF%BC%8C%3C%E5%88%97%E5%90%8D2%3E+%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%5B%E7%BC%BA%E7%9C%81%E5%80%BC%5D%5B%E5%88%97%E7%BA%A7%E7%BA%A6%E6%9D%9F%5D%5D%E2%80%A6..jpg "[,UNIQUE(列名[,列名]….)] [,PRIMARY KEY(列名[,列名]…)] [,FOREIGN KEY (列名[,列名]…) REFERENCES 表名(列名[,列名]…)] [,CKECK (条件)] ) 命令功能:创建表结构,并创建数据完整性。")
199
例如:建立两个新表“教师_C”和“课程_C”,并在两个表之间创建参照完整性。步骤如下:
(1)CREATE TABLE 教师_C(教师编号 CHAR(7),姓名 CHAR(6), 性别 CHAR(2),职务 CHAR(8),教研室编号 CHAR(6),PRIMARY KEY(教师编号)) (2) CREATE TABLE 课程_C(课程编号 CHAR(5),课程名 CHAR(12),学时 SMALLINT,学分 SMALLINT,学期 CHAR(1),教师编号 CHAR(7),教室 CHAR(5), PRIMARY KEY(课程编号), FOREIGN KEY(教师编号) REFERENCES 教师_C(教师编号))
CREATE TABLE 教师_C(教师编号 CHAR(7),姓名 CHAR(6), 性别 CHAR(2),职务 CHAR(8),教研室编号 CHAR(6),PRIMARY KEY(教师编号)) (2) CREATE TABLE 课程_C(课程编号 CHAR(5),课程名 CHAR(12),学时 SMALLINT,学分 SMALLINT,学期 CHAR(1),教师编号 CHAR(7),教室 CHAR(5), PRIMARY KEY(课程编号), FOREIGN KEY(教师编号) REFERENCES 教师_C(教师编号))")
200
3.利用SQL语句修改参照完整性 SQL命令格式: ALTER TABLE < Table_name > ADD [ CONSTRAINT Constraint_name] [FOREIGN KEY] ( Column [ ,...n ] ) 命令功能:修改数据完整性。 4.利用企业管理器删除表间的参照关系 步骤如下: (1)在“控制台根目录”窗口右边窗格中,选择要删除的关系,单击右键打开快捷菜单。 (2)选择“删除”菜单命令。
![3.利用SQL语句修改参照完整性 SQL命令格式: ALTER TABLE < Table_name > ADD [ CONSTRAINT Constraint_name] [FOREIGN KEY] ( Column [ ,...n ] )](http://slidesplayer.com/slide/11418122/61/images/200/3.%E5%88%A9%E7%94%A8SQL%E8%AF%AD%E5%8F%A5%E4%BF%AE%E6%94%B9%E5%8F%82%E7%85%A7%E5%AE%8C%E6%95%B4%E6%80%A7+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+ALTER+TABLE+%3C+Table_name+%3E+ADD+%5B+CONSTRAINT+Constraint_name%5D+%5BFOREIGN+KEY%5D+%28+Column+%5B+%2C...n+%5D+%29.jpg "命令功能:修改数据完整性。 4.利用企业管理器删除表间的参照关系. 步骤如下: (1)在 控制台根目录 窗口右边窗格中,选择要删除的关系,单击右键打开快捷菜单。 (2)选择 删除 菜单命令。")
201
5.3 默认值及默认 一、默认值约束 1、使用企业管理器设置默认值 步骤(1)进入设计表窗口。 (2)选择相应的列,在窗口中进行设置。
进入设计表窗口。 (2)选择相应的列,在窗口中进行设置。")
202
2、使用SQL语句创建默认值约束 SQL命令格式: CREATE TABLE < Table_name > [ CONSTRAINT constraint_name ] [ DEFAULT constraint_expression ] 命令功能:创建表,并创建默认值约束。 例如:创建表“教师”,并为表中的列“性别”创建默认约束“男”。 CREATE TABLE 教师 (教师编号 CHAR(7),姓名 CHAR(6), 性别 CHAR(2) DEFAULT ‘男’, 职务 CHAR(8),教研室编号 CHAR(6),PRIMARY KEY(教师编号))
![2、使用SQL语句创建默认值约束 SQL命令格式: CREATE TABLE < Table_name > [ CONSTRAINT constraint_name ] [ DEFAULT constraint_expression ]](http://slidesplayer.com/slide/11418122/61/images/202/2%E3%80%81%E4%BD%BF%E7%94%A8SQL%E8%AF%AD%E5%8F%A5%E5%88%9B%E5%BB%BA%E9%BB%98%E8%AE%A4%E5%80%BC%E7%BA%A6%E6%9D%9F+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+CREATE+TABLE+%3C+Table_name+%3E+%5B+CONSTRAINT+constraint_name+%5D+%5B+DEFAULT+constraint_expression+%5D.jpg "命令功能:创建表,并创建默认值约束。 例如:创建表 教师 ,并为表中的列 性别 创建默认约束 男 。 CREATE TABLE 教师 (教师编号 CHAR(7),姓名 CHAR(6), 性别 CHAR(2) DEFAULT ‘男’, 职务 CHAR(8),教研室编号 CHAR(6),PRIMARY KEY(教师编号))")
203
3、修改默认值约束 SQL命令格式: ALTER TABLE < Table_name > ADD [ CONSTRAINT Constraint_name] [ DEFAULT constraint_expression ] 命令功能:修改表结构,并创建默认值约束。 例如:为学生表中的“学号”列添加一个默认值约束“0602”。 ALTER TABLE 学生 ADD DEFAULT ‘0602’ FOR 学号
![3、修改默认值约束 SQL命令格式: ALTER TABLE < Table_name > ADD [ CONSTRAINT Constraint_name] [ DEFAULT constraint_expression ]](http://slidesplayer.com/slide/11418122/61/images/203/3%E3%80%81%E4%BF%AE%E6%94%B9%E9%BB%98%E8%AE%A4%E5%80%BC%E7%BA%A6%E6%9D%9F+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+ALTER+TABLE+%3C+Table_name+%3E+ADD+%5B+CONSTRAINT+Constraint_name%5D+%5B+DEFAULT+constraint_expression+%5D.jpg "命令功能:修改表结构,并创建默认值约束。 例如:为学生表中的 学号 列添加一个默认值约束 0602 。 ALTER TABLE 学生 ADD DEFAULT ‘0602’ FOR 学号.")
204
二、关于默认对象的概述 默认:是一种数据库对象,它的作用类似于DEFAULT约束,记载表中插入数据行时,为没有指定数据的列提共实现定义的默认值。虽然默认对象和默认约束功能类似,但是使用方法不同,它们的区别表现为: (1)默认约束的定义属于表结构定义的一部分。默认约束是在CREATE TABLE或ALTER TABLE语句中定义的,删除表的时候默认约束随之删除。 (2)默认对象的定义是独立于表结构定义的。默认对象使用CREATE DEFAULT 语句定义,删除表的时候并不能删除默认对象。
默认约束的定义属于表结构定义的一部分。默认约束是在CREATE TABLE或ALTER TABLE语句中定义的,删除表的时候默认约束随之删除。 (2)默认对象的定义是独立于表结构定义的。默认对象使用CREATE DEFAULT 语句定义,删除表的时候并不能删除默认对象。")
205
三、创建默认对象 1、使用企业管理器创建默认对象 例如:使用企业管理器创建默认对象score,默认值为 60. 步骤如下: (1)展开数据库文件夹,选中默认结点,右击打开快捷菜单,选择“新建默认”命令,打开对话框。 (2)在“名称”文本框中输入SCORE,“值”文本框中输入60,单击确定。
在 名称 文本框中输入SCORE, 值 文本框中输入60,单击确定。")
206
2、使用SQL语句创建默认对象 语句格式: CREATE DEFAULT default_name AS default_expression 语句功能:创建默认对象。 例如:利用SQL语句创建上例中的默认对象。 CREATE DEFAULT score AS 60 3、使用默认对象 使用企业管理器将默认对象score绑定到成绩表的“成绩”上。 (1)在学生管理数据库文件夹里单击“默认”结点,然后在右侧窗格中选中“SCORE”默认对象,单击右键,在快捷菜单中选择“属性”命令,打开“默认属性”对话框。 (2)单击“绑定列”按钮,打开“默认值绑定到列”对话框。
在学生管理数据库文件夹里单击 默认 结点,然后在右侧窗格中选中 SCORE 默认对象,单击右键,在快捷菜单中选择 属性 命令,打开 默认属性 对话框。 (2)单击 绑定列 按钮,打开 默认值绑定到列 对话框。")
207
(3)在“表”下拉框中选择“成绩”,“未绑定列”列表中选中“成绩”,单击“添加”按钮,将其添加到“绑定列”列表中。 (4)单击“确定”按钮。
在 表 下拉框中选择 成绩 , 未绑定列 列表中选中 成绩 ,单击 添加 按钮,将其添加到 绑定列 列表中。 (4)单击 确定 按钮。")
208
5.4 规则 规则:是一种数据库对象,它的作用类似于CHECK约束,即在表中插入数据行时,检查数据的取值范围,规则对象和检查约束的区别类似于默认约束在使用上的区别。 规则的创建和使用方法与默认对象相似。

209
复习提问 SQL的中文意义? SQL的主要功能及其对应的命令动词? Where条件与having条件的区别?
Select 语句中的top的使用: select top 3 学号,姓名 from 学生

210
第6章 视图管理与使用 通过本章的学习,应该掌握以下内容: 创建和管理视图 利用视图简化查询操作 使用视图实现数据库的安全管理

211
第6章 视图管理与使用 6.1视图概述 视图是一种数据库对象,是从一个或多个表中按照查询规则抽取的数据组成的“表”,它与表不同的是,视图中的数据还是存储在原来的表中,所以视图只是逻辑存在的“虚表”。 视图是不能单独存在的,只有在打开与视图相关的数据库才能创建和使用视图。 当对视图中的数据进行修改时,对应的表的数据也会发生变化,同样,若表的数据发生变化,这种变化也会自动地反映到视图中。

212
第6章 视图管理与使用 1、视图的特点 只存放视图的定义,不存放视图对应的数据,不占用物理存储空间。
第6章 视图管理与使用 1、视图的特点 只存放视图的定义,不存放视图对应的数据,不占用物理存储空间。 视图是数据库管理系统提供给用户从多种角度观察数据库数据的重要机制,可以重新组织数据集,属于外模式,从表中派生出来,依赖于表,不能独立存在。 基表中的数据发生变化,从视图中查询出的数据也随之改变。 视图可以隐蔽数据结构的复杂性,使用户只专注于与自己有关的数据,从而简化用户的操作,提高操作的灵活性和方便性。

213
第6章 视图管理与使用 视图使多个用户能以多种角度看待同一数据集,也可以使多个用户从统一角度看待不同的数据集。
第6章 视图管理与使用 视图使多个用户能以多种角度看待同一数据集,也可以使多个用户从统一角度看待不同的数据集。 视图为机密数据提供了安全保障,在设计数据库应用系统时,对不同用户定义不同的视图,使机密数据不能出现在不应该看到这些数据的用户的视图上,可以提高数据的安全性。 视图可以定制不同用户对数据库的访问权限。 视图为数据库重构提供一定的逻辑独立性,如果只是通过 视图来存取数据库中的数据,数据库管理员可以有选择地改变构成视图的基本表,而不用考虑那些通过视图引用数据的应用程序的改动。

214
第6章 视图管理与使用 2、基于视图的操作 查询 删除 更新(插入、删除、修改) 定义基于该视图的新视图
 定义基于该视图的新视图")
215
第6章 视图管理与使用 6.2 创建视图 使用企业管理器创建视图 使用SQL命令创建视图

216
第6章 视图管理与使用 6.2.1 使用企业管理器创建视图 操作步骤如下: (1)启动SQL Server企业管理器。
第6章 视图管理与使用 使用企业管理器创建视图 操作步骤如下: (1)启动SQL Server企业管理器。 (2)在“控制台根目录”窗口,展开“SQL Server组”,展开“数据库”,选择使用的数据库再展开。 (3)在“控制台根目录”窗口,选择“视图”图标,单击鼠标右键,打开快捷菜单。 (4)在快捷菜单中,选择“新建视图”菜单命令,进入“新视图”窗口。 (5)在“新视图”窗口,单击鼠标右键,打开快捷菜单。 (6)在快捷菜单中,选择“添加表”菜单命令,进入“添加表”窗口。 (7)在“添加表”窗口,添加用于创建视图的表,单击“添加”按钮,返回“新视图”窗口。
启动SQL Server企业管理器。 (2)在 控制台根目录 窗口,展开 SQL Server组 ,展开 数据库 ,选择使用的数据库再展开。 (3)在 控制台根目录 窗口,选择 视图 图标,单击鼠标右键,打开快捷菜单。 (4)在快捷菜单中,选择 新建视图 菜单命令,进入 新视图 窗口。 (5)在 新视图 窗口,单击鼠标右键,打开快捷菜单。 (6)在快捷菜单中,选择 添加表 菜单命令,进入 添加表 窗口。 (7)在 添加表 窗口,添加用于创建视图的表,单击 添加 按钮,返回 新视图 窗口。")
217
第6章 视图管理与使用 6.2.1 使用企业管理器创建视图 (8)在“新视图”窗口,单击所要引用列前的复选框。
第6章 视图管理与使用 使用企业管理器创建视图 (8)在“新视图”窗口,单击所要引用列前的复选框。 (9)在“新视图”窗口,单击关闭按钮,进入“另存为”窗口。 (10)在“另存为”窗口,单击“确定”按钮,保存视图,结束创建视图的操作,返回“控制台根目录”窗口。 (11)在“控制台根目录”窗口,选择视图,单击鼠标右键,打开快捷菜单。 (12)在快捷菜单中,依次选择“打开视图”→“返回所有行”菜单命令,进入视图“浏览”窗口。 (13)在视图“浏览”窗口,单击 按钮,结束浏览视图的操作。
在 新视图 窗口,单击所要引用列前的复选框。 (9)在 新视图 窗口,单击关闭按钮,进入 另存为 窗口。 (10)在 另存为 窗口,单击 确定 按钮,保存视图,结束创建视图的操作,返回 控制台根目录 窗口。 (11)在 控制台根目录 窗口,选择视图,单击鼠标右键,打开快捷菜单。 (12)在快捷菜单中,依次选择 打开视图 → 返回所有行 菜单命令,进入视图 浏览 窗口。 (13)在视图 浏览 窗口,单击 按钮,结束浏览视图的操作。")
218
第6章 视图管理与使用 6.2.2 使用SQL命令创建视图 1、语句格式
第6章 视图管理与使用 使用SQL命令创建视图 1、语句格式 CREATE VIEW <视图名> [(<列名1>[,<列名2>]…)] AS <select 语句> [ WITH CHECK OPTION ] 功能:创建视图。
] AS <select 语句> [ WITH CHECK OPTION ] 功能:创建视图。")
219
第6章 视图管理与使用 [例1] 建立学生班级的视图。 CREATE VIEW 学生_班级 AS SELECT 学号,姓名,性别,班级编号
第6章 视图管理与使用 [例1] 建立学生班级的视图。 CREATE VIEW 学生_班级 AS SELECT 学号,姓名,性别,班级编号 FROM 学生
![第6章 视图管理与使用 [例1] 建立学生班级的视图。 CREATE VIEW 学生_班级 AS SELECT 学号,姓名,性别,班级编号](http://slidesplayer.com/slide/11418122/61/images/219/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%5B%E4%BE%8B1%5D+%E5%BB%BA%E7%AB%8B%E5%AD%A6%E7%94%9F%E7%8F%AD%E7%BA%A7%E7%9A%84%E8%A7%86%E5%9B%BE%E3%80%82+CREATE+VIEW+%E5%AD%A6%E7%94%9F_%E7%8F%AD%E7%BA%A7+AS+SELECT+%E5%AD%A6%E5%8F%B7%EF%BC%8C%E5%A7%93%E5%90%8D%EF%BC%8C%E6%80%A7%E5%88%AB%EF%BC%8C%E7%8F%AD%E7%BA%A7%E7%BC%96%E5%8F%B7.jpg "第6章 视图管理与使用. [例1] 建立学生班级的视图。 CREATE VIEW 学生_班级. AS. SELECT 学号,姓名,性别,班级编号. FROM 学生.")
220
第6章 视图管理与使用 RDBMS执行CREATE VIEW语句时只是把视图定义存入数据字典,并不执行其中的SELECT语句。
第6章 视图管理与使用 RDBMS执行CREATE VIEW语句时只是把视图定义存入数据字典,并不执行其中的SELECT语句。 在对视图查询时,按视图的定义从基本表中将数据查出。

221
第6章 视图管理与使用 [例2]建立女学生的视图,并要求进行修改和插入操作时仍需保证该视图只有女学生 。
第6章 视图管理与使用 [例2]建立女学生的视图,并要求进行修改和插入操作时仍需保证该视图只有女学生 。 CREATE VIEW G_Student1 AS SELECT 学号,姓名,性别,出生年月,籍贯 FROM 学生 WHERE 性别=’女’ WITH CHECK OPTION
![第6章 视图管理与使用 [例2]建立女学生的视图,并要求进行修改和插入操作时仍需保证该视图只有女学生 。](http://slidesplayer.com/slide/11418122/61/images/221/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%5B%E4%BE%8B2%5D%E5%BB%BA%E7%AB%8B%E5%A5%B3%E5%AD%A6%E7%94%9F%E7%9A%84%E8%A7%86%E5%9B%BE%EF%BC%8C%E5%B9%B6%E8%A6%81%E6%B1%82%E8%BF%9B%E8%A1%8C%E4%BF%AE%E6%94%B9%E5%92%8C%E6%8F%92%E5%85%A5%E6%93%8D%E4%BD%9C%E6%97%B6%E4%BB%8D%E9%9C%80%E4%BF%9D%E8%AF%81%E8%AF%A5%E8%A7%86%E5%9B%BE%E5%8F%AA%E6%9C%89%E5%A5%B3%E5%AD%A6%E7%94%9F+%E3%80%82.jpg "第6章 视图管理与使用. [例2]建立女学生的视图,并要求进行修改和插入操作时仍需保证该视图只有女学生 。 CREATE VIEW G_Student1. AS. SELECT 学号,姓名,性别,出生年月,籍贯. FROM 学生. WHERE 性别=’女’ WITH CHECK OPTION.")
222
2、WITH CHECK OPTION子句的作用
第6章 视图管理与使用 2、WITH CHECK OPTION子句的作用 对G_Student视图的更新操作: 修改操作:自动加上性别=’女’的条件 删除操作:自动加上性别=’女’的条件 插入操作:自动检查性别属性值是否为‘女' 如果不是,则拒绝该插入操作 如果没有提供性别属性值,则自动定义性别为‘女'

223
第6章 视图管理与使用 3、基于视图的视图 [例3] 建立籍贯是北京的女学生的视图。 CREATE VIEW G _Student2 AS
第6章 视图管理与使用 3、基于视图的视图 [例3] 建立籍贯是北京的女学生的视图。 CREATE VIEW G _Student2 AS SELECT 学号,姓名,性别,出生年月,籍贯 FROM G_student1 WHERE 籍贯=’北京’
![第6章 视图管理与使用 3、基于视图的视图 [例3] 建立籍贯是北京的女学生的视图。 CREATE VIEW G _Student2 AS](http://slidesplayer.com/slide/11418122/61/images/223/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%EF%BC%93%E3%80%81%E5%9F%BA%E4%BA%8E%E8%A7%86%E5%9B%BE%E7%9A%84%E8%A7%86%E5%9B%BE+%5B%E4%BE%8B%EF%BC%93%5D+%E5%BB%BA%E7%AB%8B%E7%B1%8D%E8%B4%AF%E6%98%AF%E5%8C%97%E4%BA%AC%E7%9A%84%E5%A5%B3%E5%AD%A6%E7%94%9F%E7%9A%84%E8%A7%86%E5%9B%BE%E3%80%82+CREATE+VIEW+G+_Student2+AS.jpg "第6章 视图管理与使用. 3、基于视图的视图. [例3] 建立籍贯是北京的女学生的视图。 CREATE VIEW G _Student2. AS. SELECT 学号,姓名,性别,出生年月,籍贯. FROM G_student1. WHERE 籍贯=’北京’")
224
第6章 视图管理与使用 4、带表达式的视图 [例4] 定义一个反映学生年龄的视图。
第6章 视图管理与使用 4、带表达式的视图 [例4] 定义一个反映学生年龄的视图。 CREATE VIEW age_Student (学号,姓名,年龄) AS SELECT 学号,姓名,2010-year(出生年月) FROM 学生
![第6章 视图管理与使用 4、带表达式的视图 [例4] 定义一个反映学生年龄的视图。](http://slidesplayer.com/slide/11418122/61/images/224/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%EF%BC%94%E3%80%81%E5%B8%A6%E8%A1%A8%E8%BE%BE%E5%BC%8F%E7%9A%84%E8%A7%86%E5%9B%BE+%5B%E4%BE%8B%EF%BC%94%5D+%E5%AE%9A%E4%B9%89%E4%B8%80%E4%B8%AA%E5%8F%8D%E6%98%A0%E5%AD%A6%E7%94%9F%E5%B9%B4%E9%BE%84%E7%9A%84%E8%A7%86%E5%9B%BE%E3%80%82.jpg "第6章 视图管理与使用. 4、带表达式的视图. [例4] 定义一个反映学生年龄的视图。 CREATE VIEW age_Student (学号,姓名,年龄) AS. SELECT 学号,姓名,2010-year(出生年月) FROM 学生.")
225
第6章 视图管理与使用 5、分组视图 [例6] 将学生的学号及他的平均成绩定义为一个视图 CREAT VIEW S_G(学号,平均成绩))
第6章 视图管理与使用 5、分组视图 [例6] 将学生的学号及他的平均成绩定义为一个视图 CREAT VIEW S_G(学号,平均成绩)) AS SELECT 学号,AVG(成绩) FROM 成绩 GROUP BY 学号
![第6章 视图管理与使用 5、分组视图 [例6] 将学生的学号及他的平均成绩定义为一个视图 CREAT VIEW S_G(学号,平均成绩))](http://slidesplayer.com/slide/11418122/61/images/225/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%EF%BC%95%E3%80%81%E5%88%86%E7%BB%84%E8%A7%86%E5%9B%BE+%5B%E4%BE%8B6%5D+%E5%B0%86%E5%AD%A6%E7%94%9F%E7%9A%84%E5%AD%A6%E5%8F%B7%E5%8F%8A%E4%BB%96%E7%9A%84%E5%B9%B3%E5%9D%87%E6%88%90%E7%BB%A9%E5%AE%9A%E4%B9%89%E4%B8%BA%E4%B8%80%E4%B8%AA%E8%A7%86%E5%9B%BE+CREAT+VIEW+S_G%28%E5%AD%A6%E5%8F%B7%EF%BC%8C%E5%B9%B3%E5%9D%87%E6%88%90%E7%BB%A9%EF%BC%89%29.jpg "第6章 视图管理与使用. 5、分组视图. [例6] 将学生的学号及他的平均成绩定义为一个视图. CREAT VIEW S_G(学号,平均成绩)) AS. SELECT 学号,AVG(成绩) FROM 成绩. GROUP BY 学号.")
226
ALTER VIEW <视图名> [(<列名1>[,<列名2>]…)]
第6章 视图管理与使用 使用SQL命令修改视图 SQL命令格式: ALTER VIEW <视图名> [(<列名1>[,<列名2>]…)] AS <select 语句> [ WITH CHECK OPTION ] 命令功能:修改视图。
![ALTER VIEW <视图名> [(<列名1>[,<列名2>]…)]](http://slidesplayer.com/slide/11418122/61/images/226/ALTER+VIEW+%3C%E8%A7%86%E5%9B%BE%E5%90%8D%3E+%5B%28%3C%E5%88%97%E5%90%8D1%3E%5B%2C%3C%E5%88%97%E5%90%8D2%3E%5D%E2%80%A6%29%5D.jpg "第6章 视图管理与使用 使用SQL命令修改视图. SQL命令格式: ALTER VIEW <视图名> [(<列名1>[,<列名2>]…)] AS <select 语句> [ WITH CHECK OPTION ] 命令功能:修改视图。")
227
第6章 视图管理与使用 6.4 删除视图 语句的格式: DROP VIEW <视图名>
第6章 视图管理与使用 6.4 删除视图 语句的格式: DROP VIEW <视图名> 如果该视图上还导出了其他视图,使用CASCADE级联删除语句,把该视图和由它导出的所有视图一起删除 删除基表时,由该基表导出的所有视图定义都必须显式地使用DROP VIEW 语句删除

228
第6章 视图管理与使用 级联删除: [例7] 删除视图G_Student2: DROP VIEW G_Student2
第6章 视图管理与使用 [例7] 删除视图G_Student2: DROP VIEW G_Student2 删除视图G_Student1: DROP VIEW G_Student1 级联删除: DROP VIEW G_Student1 CASCADE
![第6章 视图管理与使用 级联删除: [例7] 删除视图G_Student2: DROP VIEW G_Student2](http://slidesplayer.com/slide/11418122/61/images/228/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%E7%BA%A7%E8%81%94%E5%88%A0%E9%99%A4%EF%BC%9A+%EF%BC%BB%E4%BE%8B7%EF%BC%BD+%E5%88%A0%E9%99%A4%E8%A7%86%E5%9B%BEG_Student2%EF%BC%9A+DROP+VIEW+G_Student2.jpg "第6章 视图管理与使用. [例7] 删除视图G_Student2: DROP VIEW G_Student2. 删除视图G_Student1: DROP VIEW G_Student1. 级联删除: DROP VIEW G_Student1 CASCADE.")
229
第6章 视图管理与使用 6.5 使用视图 对视图数据的修改即是对基本表的修改,通过计算得到的新列不可修改。
第6章 视图管理与使用 6.5 使用视图 对视图数据的修改即是对基本表的修改,通过计算得到的新列不可修改。 创建视图时使用了WITH CHECK OPTION选项,对视图操作要满足定义视图时的条件。

230
第6章 视图管理与使用 1、向视图插入数据 [例] 向女学生视图中插入一个新的学生记录: ,赵新,男,1989年8月3日出生,南京人。 INSERT INTO G_Student1 VALUES(‘95029’,‘赵新’,’男’,’1989/8/3’,’南京’ ) 此命令是否可以执行? [例] CREATE VIEW G_Student AS SELECT 学号,姓名,性别,出生年月,籍贯 FROM 学生 WHERE 性别=’女’ WITH CHECK OPTION
![第6章 视图管理与使用 1、向视图插入数据. [例] 向女学生视图中插入一个新的学生记录: ,赵新,男,1989年8月3日出生,南京人。 INSERT. INTO G_Student1.](http://slidesplayer.com/slide/11418122/61/images/230/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%EF%BC%91%E3%80%81%E5%90%91%E8%A7%86%E5%9B%BE%E6%8F%92%E5%85%A5%E6%95%B0%E6%8D%AE.+%5B%E4%BE%8B%5D+%E5%90%91%E5%A5%B3%E5%AD%A6%E7%94%9F%E8%A7%86%E5%9B%BE%E4%B8%AD%E6%8F%92%E5%85%A5%E4%B8%80%E4%B8%AA%E6%96%B0%E7%9A%84%E5%AD%A6%E7%94%9F%E8%AE%B0%E5%BD%95%EF%BC%9A+%EF%BC%8C%E8%B5%B5%E6%96%B0%EF%BC%8C%E7%94%B7%EF%BC%8C1989%E5%B9%B48%E6%9C%883%E6%97%A5%E5%87%BA%E7%94%9F%EF%BC%8C%E5%8D%97%E4%BA%AC%E4%BA%BA%E3%80%82+INSERT.+INTO+G_Student1..jpg "VALUES(‘95029’,‘赵新’,’男’,’1989/8/3’,’南京’ ) 此命令是否可以执行? [例] CREATE VIEW G_Student1 AS. SELECT 学号,姓名,性别,出生年月,籍贯. FROM 学生. WHERE 性别=’女’ WITH CHECK OPTION.")
231
第6章 视图管理与使用 2、更新视图数据 [例] UPDATE G_student1 SET 籍贯=‘大连’ 等价于:
第6章 视图管理与使用 2、更新视图数据 [例] UPDATE G_student1 SET 籍贯=‘大连’ 等价于: UPDATE 学生 SET 籍贯= ‘大连’ WHERE 性别= ‘女’ CREATE VIEW G_Student AS SELECT 学号,姓名,性别,出生年月,籍贯 FROM 学生 WHERE 性别=’女’ WITH CHECK OPTION
![第6章 视图管理与使用 2、更新视图数据 [例] UPDATE G_student1 SET 籍贯=‘大连’ 等价于:](http://slidesplayer.com/slide/11418122/61/images/231/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+%EF%BC%92%E3%80%81%E6%9B%B4%E6%96%B0%E8%A7%86%E5%9B%BE%E6%95%B0%E6%8D%AE+%5B%E4%BE%8B%5D+UPDATE+G_student1+SET+%E7%B1%8D%E8%B4%AF%3D%E2%80%98%E5%A4%A7%E8%BF%9E%E2%80%99+%E7%AD%89%E4%BB%B7%E4%BA%8E%EF%BC%9A.jpg "第6章 视图管理与使用. 2、更新视图数据. [例] UPDATE G_student1 SET 籍贯=‘大连’ 等价于: UPDATE 学生 SET 籍贯= ‘大连’ WHERE 性别= ‘女’ CREATE VIEW G_Student1 AS. SELECT 学号,姓名,性别,出生年月,籍贯. FROM 学生. WHERE 性别=’女’ WITH CHECK OPTION.")
232
第6章 视图管理与使用 3、删除视图数据 [例] DELETE FROM G_student1 WHERE 籍贯=‘北京’
第6章 视图管理与使用 3、删除视图数据 [例] DELETE FROM G_student1 WHERE 籍贯=‘北京’ 等价于: DELETE FROM 学生 WHERE 籍贯= ‘北京’ AND 性别= ‘女’
![第6章 视图管理与使用 3、删除视图数据 [例] DELETE FROM G_student1 WHERE 籍贯=‘北京’](http://slidesplayer.com/slide/11418122/61/images/232/%E7%AC%AC6%E7%AB%A0+%E8%A7%86%E5%9B%BE%E7%AE%A1%E7%90%86%E4%B8%8E%E4%BD%BF%E7%94%A8+3%E3%80%81%E5%88%A0%E9%99%A4%E8%A7%86%E5%9B%BE%E6%95%B0%E6%8D%AE+%5B%E4%BE%8B%5D+DELETE+FROM+G_student1+WHERE+%E7%B1%8D%E8%B4%AF%3D%E2%80%98%E5%8C%97%E4%BA%AC%E2%80%99.jpg "第6章 视图管理与使用. 3、删除视图数据. [例] DELETE FROM G_student1. WHERE 籍贯=‘北京’ 等价于: DELETE FROM 学生. WHERE 籍贯= ‘北京’ AND 性别= ‘女’")
233
小结 视图的作用 1. 视图能够简化用户的操作 2. 视图使用户能以多种角度看待同一数据 3. 视图对重构数据库提供了一定程度的逻辑独立性
小结 视图的作用 1. 视图能够简化用户的操作 2. 视图使用户能以多种角度看待同一数据 3. 视图对重构数据库提供了一定程度的逻辑独立性 4. 视图能够对机密数据提供安全保护 5. 适当的利用视图可以更清晰的表达查询

234
复习提问: 数据的基本类型? 设计表结构的主要操作? 表结构与表记录的差别? 定义表结构时应定义哪些内容?

235
第7章 索引 索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。 索引是针对一个表而建立的,它是由数据页面以外的索引页面组成的。
第7章 索引 索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。 索引是针对一个表而建立的,它是由数据页面以外的索引页面组成的。 数据库中的索引是一个列表,在这个列表中包含了某个表中一列或者若干列值的集合,以及这些值的记录在数据表中的存储位置的物理地址。

236
当使用数据库数据表的索引来检索数据列时,SQL Server能很快地判断出数据储存的位置并且立即撷取该数据,特别是需要面对大量信息的时候,快速检索的效果更明显.
建立索引的目的:加快查询速度 ?谁可以建立索引:DBA 或 表的属主(即建立表的人)
")
237
一、表索引概述 1.创建索引的优缺点 (1)使用索引的优点 可以大大加快数据检索速度。 通过创建唯一索引,可以保证数据记录的唯一性。
在使用ORDER BY和GROUP BY子句进行检索数据时,可以显著减少查询中分组和排序的时间。 可以加速表与表之间的连接,这一点在实现数据的参照完整性方面有特别的意义。

238
(2)使用索引的缺点 ①创建索引要花费时间和占用存储空间。 创建索引需要占用存储空间,如创建聚簇索引需要占用的存储空间是数据库表占用空间的1.2倍。在建立索引时,数据被复制以便建立聚簇索引,索引建立后,再将旧的未加索引的表数据删除。创建索引也需要花费时间。 ② 建立索引加快了数据检索速度,却减慢了数据修改速度。

239
因为每当执行一次数据的插入、删除和更新操作,就要维护索引。修改的数据越多,涉及维护索引的开销也就越大。如果将一些数据行插入到一个已经放满行的数据页面上,还必须将这个数据页面中最后一些数据移到下一个页面中去,这样,还必须改变索引页中的内容,以保持数据顺序的正确性。这就是对索引的维护。由于修改数据时要动态维护其索引,所以,对建立了索引的表执行修改操作要比未建立索引的表执行修改操作所花的时间要长。因此,创建索引虽然可以加快数据查询的速度,但是却会减慢数据修改的速度。 结论: 大数据量的表、查询和排序操作频繁、更新和插入操作 较少的表适合使用索引。

240
2、索引分类 (1)聚簇索引、非聚簇索引 在聚集(簇)索引中,表中各记录的物理顺序与键值的逻辑(索引)顺序相同,由于一个表中的数据只能按照一种顺序来存储,所以在一个表中只能建立一个聚簇索引。 如果不是聚簇索引,表中各记录的物理顺序与键值的逻辑顺序不匹配。在检索记录的时候,聚簇索引比非聚簇索引有更快的数据访问速度。在添加或更新记录的时候,由于使用聚簇索引时需要先对记录排序,然后再存储到表中,所以使用聚簇索引要比非聚簇索引速度慢。在一个表中只能有一个聚簇索引,但允许有多个非聚簇索引。 结论: 最经常查询的列适合建立聚簇索引,经常更新的列 不适合建立聚簇索引。

241
(2)、主键索引、惟一索引和普通索引 主键索引:每个索引键的值必须是唯一的,每表1个。 惟一索引:每个索引键的值必须是唯一的,每表n个。
普通索引:允许索引键的值重复。

242
二、索引的创建与管理 1、创建索引 (1)操作方法
方法1:在SQL Server企业管理器中目标表名字上右击,选择“所有任务”/“管理索引” 方法2:在打开表设计器后,选择“管理索引/键”工具或在表设计器中右击选择“索引/键” 方法3:向导:在“工具菜单”中选择“向导”命令 (2)参数设置 点击“新建”按钮建立新索引 在“索引名称”对应的文本框中输入索引名称 UNIQUE确定索引类型是否惟一索引 “创建为clustered”项决定是否为聚簇索引 “填充因子”设定索引文件每页的填充比例
参数设置. 点击 新建 按钮建立新索引. 在 索引名称 对应的文本框中输入索引名称. UNIQUE确定索引类型是否惟一索引. 创建为clustered 项决定是否为聚簇索引. 填充因子 设定索引文件每页的填充比例.")
243
填充因子: 创建索引时,可以指定一个填充因子,以便在索引的每个页上留出额外的间隙和保留一定百分比的空间,供将来表的数据存储容量进行扩充和减少页拆分的可能性。填充因子的值是从 0 到 100 的百分比数值,指定在创建索引后对数据页的填充比例。值为 100 时表示页将填满,所留出的存储空间量最小。 提供填充因子选项是为了对性能进行微调,只有当不会对数据进行更改时(例如,在只读表中)才会使用此设置。值越小则数据页上的空闲空间越大,这样可以减少在索引增长过程中对数据页进行拆分的需要,但需要更多的存储空间。当表中数据会发生更改时,这种设置更为适当。
才会使用此设置。值越小则数据页上的空闲空间越大,这样可以减少在索引增长过程中对数据页进行拆分的需要,但需要更多的存储空间。当表中数据会发生更改时,这种设置更为适当。")
244
(3)命令建立索引 语句格式 CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…) [例]在Student表的Sname(姓名)列上建立一个聚簇索引 CREATE CLUSTERED INDEX Stusname ON Student(Sname)
![(3)命令建立索引 语句格式. CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…)](http://slidesplayer.com/slide/11418122/61/images/244/%EF%BC%88%EF%BC%93%EF%BC%89%E5%91%BD%E4%BB%A4%E5%BB%BA%E7%AB%8B%E7%B4%A2%E5%BC%95+%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F.+CREATE+%5BUNIQUE%5D+%5BCLUSTERED%7CNONCLUSTERED%5D+INDEX+%3C%E7%B4%A2%E5%BC%95%E5%90%8D%3E+ON+%3C%E8%A1%A8%E5%90%8D%3E%28%3C%E5%88%97%E5%90%8D%3E%5B%3C%E6%AC%A1%E5%BA%8F%3E%5D%5B%2C%3C%E5%88%97%E5%90%8D%3E%5B%3C%E6%AC%A1%E5%BA%8F%3E%5D+%5D%E2%80%A6%29.jpg "[例]在Student表的Sname(姓名)列上建立一个聚簇索引. CREATE CLUSTERED INDEX Stusname. ON Student(Sname)")
245
[例]为学生-课程数据库中的Student,Course,SC三个表建 立索引。
CREATE UNIQUE INDEX Stusno ON Student(Sno) CREATE UNIQUE INDEX Coucno ON Course(Cno) CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC) Student表按学号升序建唯一索引 Course表按课程号升序建唯一索引 SC表按学号升序和课程号降序建唯一索引
![[例]为学生-课程数据库中的Student,Course,SC三个表建 立索引。](http://slidesplayer.com/slide/11418122/61/images/245/%5B%E4%BE%8B%5D%E4%B8%BA%E5%AD%A6%E7%94%9F-%E8%AF%BE%E7%A8%8B%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%AD%E7%9A%84Student%EF%BC%8CCourse%EF%BC%8CSC%E4%B8%89%E4%B8%AA%E8%A1%A8%E5%BB%BA+%E7%AB%8B%E7%B4%A2%E5%BC%95%E3%80%82.jpg "CREATE UNIQUE INDEX Stusno ON Student(Sno) CREATE UNIQUE INDEX Coucno ON Course(Cno) CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC) Student表按学号升序建唯一索引. Course表按课程号升序建唯一索引. SC表按学号升序和课程号降序建唯一索引.")
246
[例] 在JWGL数据库的BOOK表上创建一个名为book_id_index的唯一性聚簇索引,索引关键字为book_id,升序,填充因子50%
USE jwgl GO CREATE UNIQUE CLUSTERED INDEX book_id_index ON book ( book_id ASC ) WITH FILLFACTOR = 50
![[例] 在JWGL数据库的BOOK表上创建一个名为book_id_index的唯一性聚簇索引,索引关键字为book_id,升序,填充因子50%](http://slidesplayer.com/slide/11418122/61/images/246/%5B%E4%BE%8B%5D+%E5%9C%A8JWGL%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84BOOK%E8%A1%A8%E4%B8%8A%E5%88%9B%E5%BB%BA%E4%B8%80%E4%B8%AA%E5%90%8D%E4%B8%BAbook_id_index%E7%9A%84%E5%94%AF%E4%B8%80%E6%80%A7%E8%81%9A%E7%B0%87%E7%B4%A2%E5%BC%95%EF%BC%8C%E7%B4%A2%E5%BC%95%E5%85%B3%E9%94%AE%E5%AD%97%E4%B8%BAbook_id%EF%BC%8C%E5%8D%87%E5%BA%8F%EF%BC%8C%E5%A1%AB%E5%85%85%E5%9B%A0%E5%AD%9050%25.jpg "USE jwgl. GO. CREATE UNIQUE CLUSTERED INDEX book_id_index. ON book ( book_id ASC ) WITH. FILLFACTOR = 50.")
247
2、查看索引 (1)使用企业管理器查看索引 步骤:①进入表结点,右键单击要查看的“表”。②选择“所有任务” →“管理索引”进入对话框。⑶关闭。
使用企业管理器查看索引 步骤:①进入表结点,右键单击要查看的 表 。②选择 所有任务 → 管理索引 进入对话框。⑶关闭。")
248
(2)使用SQL命令查看索引 命令格式: SP_helpindex <表名字> 例如:SP_HELPINDEX 学生
使用SQL命令查看索引 命令格式: SP_helpindex <表名字> 例如:SP_HELPINDEX 学生")
249
三、索引的修改与删除 (1)用企业管理器删除索引 在管理索引界面中选中要被删除的索引,然后点击“删除”按钮即可。
用企业管理器删除索引 在管理索引界面中选中要被删除的索引,然后点击 删除 按钮即可。")
250
2)命令删除索引 DROP INDEX <索引名> [例] 删除Student表的Stusname索引
DROP INDEX Stusname 注意:在系统表的索引上不能使用DROP INDEX。
![2)命令删除索引 DROP INDEX <索引名> [例] 删除Student表的Stusname索引](http://slidesplayer.com/slide/11418122/61/images/250/%EF%BC%92%EF%BC%89%E5%91%BD%E4%BB%A4%E5%88%A0%E9%99%A4%E7%B4%A2%E5%BC%95+DROP+INDEX+%3C%E7%B4%A2%E5%BC%95%E5%90%8D%3E+%5B%E4%BE%8B%5D+%E5%88%A0%E9%99%A4Student%E8%A1%A8%E7%9A%84Stusname%E7%B4%A2%E5%BC%95.jpg "DROP INDEX Stusname. 注意:在系统表的索引上不能使用DROP INDEX。")
251
四、表之间的关系 功能:保证数据的参照完整性 操作方法: 在表设计器中右击,选择“关系”; 或在工具栏中选择相关工具按钮。 参数设置:
选择主键表与外键表 选择两表的关联字段 选择INSERT 和 UPDATE的强制关系

252
小结 索引的功能 索引的分类 索引的创建与管理

253
作业: 教材课后习题 p127 -1,5,7,8

254
第 8 章 Transact-SQL语言 本章重点: T-SQL语言概述 数据定义 数据操作 数据查询

255
8.1 T-SQL语言概述 8.1.1 T-SQL语言的特点 1.语言功能的一体化
2.非过程化 在采用SQL语言进行数据操作时,只要提出“做什么”,无需指明“怎么做”,其他工作由系统完成。

256
3.采用面向集合的操作方式 用户只要使用一条操作命令,其操作对象和结果都可以是行的集合,无论是查询、插入、删除、更新操作的对象都采取面向行集合的操作方式。 4.一种语法结构两种使用方式 SQL语言既是自含式语言、又是嵌入式语言。自含式SQL能够独立地进行联机交互,用户只需在键盘上直接键入SQL命令就可以对数据库进行操作;嵌入式SQL能够嵌入到高级语言的程序中,如C++、VC、VB、ASP、JSP等程序中,用来实现对数据库的操作。

257
5.语言结构简捷 6.SQL语言支持关系数据库三级模式结构 只有九个语句,易学易用。
数据操作:select、insert、update、delete。 数据定义:create、alter、drop。 数据控制:grant、revoke。 6.SQL语言支持关系数据库三级模式结构 视图和部分基本表对应的是外模式;全体表结构对应的是模式;数据库的存储文件和它们的索引文件构成关系数据库的内模式。

258
8.1.2 T-SQL语言的功能 (1)数据定义语言(Data Dedinition Language,DDL)
用来定义数据库的模式、外模式和内模式,以实现对基本 表、视图以及索引文件的定义操作。 (2)数据操纵语言(Data Manipularion Language, DML) 数据查询:对数据库中的数据查询、统计、分组、排序。 数据维护:数据的插入、删除、更新。 (3)数据控制语言(Data Control Language,DCL) 包括对基本表和视图的授权,完整性规则的描述以及事务 控制语句。 (4)系统存储过程(System Stored Procedure) 用于用户方便的从系统表中查询信息或者完成与更新数据 库表相关的管理任务,或其他的管理任务。 (5)其它的语言元素
数据操纵语言(Data Manipularion Language, DML) 数据查询:对数据库中的数据查询、统计、分组、排序。 数据维护:数据的插入、删除、更新。 (3)数据控制语言(Data Control Language,DCL) 包括对基本表和视图的授权,完整性规则的描述以及事务 控制语句。 (4)系统存储过程(System Stored Procedure) 用于用户方便的从系统表中查询信息或者完成与更新数据 库表相关的管理任务,或其他的管理任务。 (5)其它的语言元素.")
259
数据定义语言(DDL)。用于执行数据库的任务,对数据库以及数据库中的各种对象进行创建、删除、修改等操作。 DDL包括的主要语句及功能如表8
说明 CREATE 创建数据库或数据库对象 不同数据库对象,其CREATE语句的语法形式不同 ALTER 对数据库或数据库对象进行修改 不同数据库对象,其ALTER语句的语法形式不同 DROP 删除数据库或数据库对象 不同数据库对象,其DROP语句的语法形式不同

260
(2) 数据操纵语言(DML)。用于操纵数据库中各种对象,检索和修改数据。DML包括的主要语句及功能如表8.2所示。
说明 SELECT 从表或视图中检索数据 是使用最频繁的SQL语句之一 INSERT 将数据插入到表或视图中 UPDATE 修改表或视图中的数据 既可修改表或视图的一行数据,也可修改一组或全部数据 DELETE 从表或视图中删除数据 可根据条件删除指定的数据

261
(3) 数据控制语言(DCL)。用于安全管理,确定哪些用户可以查看或修改数据库中的数据,DCL包括的主要语句及功能如表8.3所示。
说明 GRANT 授予权限 可把语句许可或对象许可的权限授予其他用户和角色 REVOKE 收回权限 与GRANT的功能相反,但不影响该用户或角色从其他角色中作为成员继承许可权限 DENY 收回权限,并禁止从其他角色继承许可权限 功能与REVOKE相似,不同之处:除收回权限外,还禁止从其他角色继承许可权限

262
(4)系统的存储过程(Store Procdure)
存储过程是存储在服务器上的一组为了完成特定功能的T-SQL语句集,它经编译后存储在数据库中,并作为一个单元进行处理。用于用户方便地从数据库中查询信息,或者完成与更新数据库表相关的管理任务,或其他的系统管理任务。 (5)其他的语言元素 T-SQL语言为了编写程序的需要,增加了一些其他的语言元素。
其他的语言元素. T-SQL语言为了编写程序的需要,增加了一些其他的语言元素。")
263
8.1.3 T-SQL语言的程序设计 一、 注释 1.行内注释 行内注释的语法格式为: – –注释文本 2.块注释 块注释的语法格式为:
一、 注释 1.行内注释 行内注释的语法格式为: – –注释文本 2.块注释 块注释的语法格式为: /*注释文本*/或: /* 注释文本 */

264
二、变量 变量(Variable)在程序运行中其值可以改变的存储单元,是程序中不可缺少的元素。 (1)全局变量 全局变量在整个SQL Server系统内使用,存储的通常是一些SQL Server的配置设定值和统计数据(参见附录二)。 使用全局变量时应该注意以下几点: ① 全局变量是在服务器级定义的。 ② 用户只能使用预先定义的全局变量。 ③ ④ 全局变量对普通用户来说是只读的。 例如:@@connections 服务器的已连接数 @@cpu_busy 服务器启动后系统处理的毫秒数 @@max_percision 服务器最大连接数

265
(2) 局部变量 局部变量用于保存单个数据值。例如,保存运算的中间结果、保存由存储过程返回的数据值、作为循环变量等,要先定义后使用。 ①局部变量的定义语句 : DECLARE Data_type}[,…n] char(6)
![(2) 局部变量 局部变量用于保存单个数据值。例如,保存运算的中间结果、保存由存储过程返回的数据值、作为循环变量等,要先定义后使用。 ①局部变量的定义语句 : DECLARE Data_type}[,…n]](http://slidesplayer.com/slide/11418122/61/images/265/%282%29+%E5%B1%80%E9%83%A8%E5%8F%98%E9%87%8F+%E5%B1%80%E9%83%A8%E5%8F%98%E9%87%8F%E7%94%A8%E4%BA%8E%E4%BF%9D%E5%AD%98%E5%8D%95%E4%B8%AA%E6%95%B0%E6%8D%AE%E5%80%BC%E3%80%82%E4%BE%8B%E5%A6%82%EF%BC%8C%E4%BF%9D%E5%AD%98%E8%BF%90%E7%AE%97%E7%9A%84%E4%B8%AD%E9%97%B4%E7%BB%93%E6%9E%9C%E3%80%81%E4%BF%9D%E5%AD%98%E7%94%B1%E5%AD%98%E5%82%A8%E8%BF%87%E7%A8%8B%E8%BF%94%E5%9B%9E%E7%9A%84%E6%95%B0%E6%8D%AE%E5%80%BC%E3%80%81%E4%BD%9C%E4%B8%BA%E5%BE%AA%E7%8E%AF%E5%8F%98%E9%87%8F%E7%AD%89%EF%BC%8C%E8%A6%81%E5%85%88%E5%AE%9A%E4%B9%89%E5%90%8E%E4%BD%BF%E7%94%A8%E3%80%82+%E2%91%A0%E5%B1%80%E9%83%A8%E5%8F%98%E9%87%8F%E7%9A%84%E5%AE%9A%E4%B9%89%E8%AF%AD%E5%8F%A5+%EF%BC%9A+DECLARE+Data_type%7D%5B%2C%E2%80%A6n%5D.jpg "char(6)")
266
②局部变量的赋值方法语句 : SET = Expression } [ ,...n ] 或 SELECT = Expression } [ ,...n ] FROM 学生 注意:局部变量的名称不能与全局变量的名称相同。
![②局部变量的赋值方法语句 : SET = Expression } [ ,...n ] 或. SELECT = Expression } [ ,...n ]](http://slidesplayer.com/slide/11418122/61/images/266/%E2%91%A1%E5%B1%80%E9%83%A8%E5%8F%98%E9%87%8F%E7%9A%84%E8%B5%8B%E5%80%BC%E6%96%B9%E6%B3%95%E8%AF%AD%E5%8F%A5+%EF%BC%9A+SET+%3D+Expression+%7D+%5B+%2C...n+%5D+%E6%88%96.+SELECT+%3D+Expression+%7D+%5B+%2C...n+%5D.jpg "FROM 学生. 注意:局部变量的名称不能与全局变量的名称相同。")
267
三、运算符 1.算术运算符 算术运算符有:+(加)、-(减)、*(乘)、/(除)和%(求模)五种运算。+ (加) 和–(减) 运算符也可用于对 datetime 及 smalldatetime 值进行算术运算。 2. 赋值运算符 “=”,用来完成赋值运算。 3.位运算符 位运算符在两个表达式之间执行位操作,这两个表达式的类型可为整型或与整型兼容的数据类型(如:字符型等,但不能为 image 类型),位运算符如表8.4所示。 运算符 运算规则 &(按位与) 两个位均为1时,结果为1,否则为0 |(按位或) 只要一个位为1,结果为1,否则为0 ^(按位异或) 两个位值不同时,结果为1,否则为0 ~(求反) 原来为1,则为0,原来为0,则为1
,位运算符如表8.4所示。 运算符. 运算规则. &(按位与) 两个位均为1时,结果为1,否则为0. |(按位或) 只要一个位为1,结果为1,否则为0. ^(按位异或) 两个位值不同时,结果为1,否则为0. ~(求反) 原来为1,则为0,原来为0,则为1.")
268
4. 比较运算符 比较运算符(又称关系运算符)如表8.5所示,用于测试两个表达式的值是否相同,其运算结果为逻辑值,可以为二种之一:TRUE、FALSE 。 运算符 含义 = 相等 > 大于 < 小于 >= 大于等于 <= 小于等于 <>、!= 不等于 !< 不小于 !> 不大于

269
例:查询指定学号的学生在XS表中的信息。
USE 学生管理 CHAR(6) = '060102' IF <> 0) SELECT * FROM 学生 WHERE 学号
 = IF <> 0) SELECT * FROM 学生. WHERE 学号")
270
逻辑运算符用于对某个条件进行测试,运算结果为 TRUE 或 FALSE。SQL Server提供的逻辑运算符如表8.6所示。
5. 逻辑运算符 逻辑运算符用于对某个条件进行测试,运算结果为 TRUE 或 FALSE。SQL Server提供的逻辑运算符如表8.6所示。 运算符 运算规则 AND 如果两个操作数值都为TRUE,运算结果为 TRUE。 OR 如果两个操作数中有一个为TRUE,运算结果为TRUE。 NOT 若一个操作数值为TRUE,运算结果为FALSE,否则为TRUE。 ALL 如果每个操作数值都为TRUE,运算结果为TRUE。 ANY 在一系列操作数中只要有一个为 TRUE,运算结果为TRUE。 BETWEEN 如果操作数在指定的范围内,运算结果为TRUE。 EXISTS 如果子查询包含一些行,运算结果为TRUE。 IN 如果操作数值等于表达式列表中的一个,运算结果为TRUE。 LIKE 如果操作数与一种模式相匹配,运算结果为TRUE。 SOME 如果在一系列操作数中,有些值为TRUE,运算结果为TRUE。

271
例如: 1、成绩必须在0~100之间。 成绩>=0 and 成绩<=100 2、性别为男或女。 性别 in (’男’,’女’)
")
272
6. 字符串联接运算符 通过运算符“+”实现两个字符串的联接运算。 例:多个字符串的联接。 ‘中华’+‘人民共和国’ 结果为:‘中华人民共和国’ 7. 运算符的优先顺序 当一个复杂的表达式有多个运算符时,运算符优先级决定执行运算的先后次序。执行的顺序会影响所得到的运算结果。 括号→算术运算符→字符串运算符→关系运算符→位运算符→逻辑运算符

273
四、函数 函数是在T-SQL语言为用户提供的标准过程。使用这些函数,可以使某些特定的操作更加简便(有关函数功能参见附录一)。 1. 数学函数
ABS、ACOS、ASIN、ATAN、CEILING、SIN、COS、TAN、EXP、FLOOR、LOG、 LOG10、PI、 POWER、RAND、ROUND、SIGN、SQRT 2. 字符串函数 字符串函数可以分为以下四大类: 基本字符串函数:UPPER、LOWER、SPACE、REPLICATE、STUFF、REVERSE、LTRIM、RTRIM。 字符串查找函数:CHARINDEX、PATINDEX。 字符串长度分析函数:DATALENGTH、SUBSTRING、RIGHT、LEFT。 字符串转换函数:ASCII、CHAR、STR、SOUNDEX、DIFFERENCE。

274
3. 转换函数 CAST( expression AS data_type ) 4. 日期与时间函数 YEAR、MONTH、DAY、GETDATE、DATEADD、DATEDIFF、DATENAME、DATEPART 5. 聚合函数 AVG()、COUNT()、MIN()、MAX()、SUM()
、COUNT()、MIN()、MAX()、SUM()")
275
五、程序流程控制语句 (1) PRINT 语句 语法格式如下: PRINT ‘一个字符串表达式’|局部变量
功能:将变量或表达式的值返回客户端。 (2)BEGIN…END语句 BEGIN { Sql_statement | Statement_block } END 功能:将多个T-SQL语句组合成一个语句块,并将其视为一个单元处理。
BEGIN…END语句. BEGIN. { Sql_statement | Statement_block } END. 功能:将多个T-SQL语句组合成一个语句块,并将其视为一个单元处理。")
276
(3).IF…ELSE 语句的语法格式如下: IF Boolean_expression { sql_statement1 | statement_block1 } [ ELSE { sql_statement 2| statement_block2 } ] 语句可以控制程序按条件执行。当IF关键字后的条件满足(布尔表达式返回TRUE 时),则执行IF关键字及其条件之后的T-SQL 语句。否则,就执行ELSE关键字后的T-SQL语句(若ELSE部分存在)。
![(3).IF…ELSE 语句的语法格式如下: IF Boolean_expression. { sql_statement1 | statement_block1 } [ ELSE. { sql_statement 2| statement_block2 } ]](http://slidesplayer.com/slide/11418122/61/images/276/%EF%BC%883%EF%BC%89.IF%E2%80%A6ELSE+%E8%AF%AD%E5%8F%A5%E7%9A%84%E8%AF%AD%E6%B3%95%E6%A0%BC%E5%BC%8F%E5%A6%82%E4%B8%8B%EF%BC%9A+IF+Boolean_expression.+%7B+sql_statement1+%7C+statement_block1+%7D+%5B+ELSE.+%7B+sql_statement+2%7C+statement_block2+%7D+%5D.jpg "语句可以控制程序按条件执行。当IF关键字后的条件满足(布尔表达式返回TRUE 时),则执行IF关键字及其条件之后的T-SQL 语句。否则,就执行ELSE关键字后的T-SQL语句(若ELSE部分存在)。")
277
例:如果“课程编号为01-01”的平均成绩高于75分,则显示平均成绩高于75分,否则显示低于75 。
USE 学生管理 char(20) ='平均成绩高于75.' IF ( SELECT AVG(成绩) FROM 成绩 WHERE 课程编号='01-01' ) <75 ELSE
 平均成绩低于75. = 平均成绩高于75. IF ( SELECT AVG(成绩) FROM 成绩. WHERE 课程编号= ) <75. ELSE.")
278
(4)CASE 语句 格式: CASE 测试表达式 WHEN 测试值1 THEN 结果表达式1 WHEN 测试值2 THEN 结果表达式2 ... [ELSE 结果表达式n] END 功能:根据多个条件,选择执行不同的语句。 例如: USE 学生管理 int from 成绩 where 学号='060102' WHEN @cj>60 and @cj<75 THEN print '及格' WHEN @cj>=75 and @cj<90 THEN print '良好' WHEN @cj>=90 THEN print '优秀'
![(4)CASE 语句 格式: CASE 测试表达式. WHEN 测试值1 THEN 结果表达式1. WHEN 测试值2 THEN 结果表达式 [ELSE 结果表达式n] END.](http://slidesplayer.com/slide/11418122/61/images/278/%EF%BC%884%EF%BC%89CASE+%E8%AF%AD%E5%8F%A5+%E6%A0%BC%E5%BC%8F%EF%BC%9A+CASE+%E6%B5%8B%E8%AF%95%E8%A1%A8%E8%BE%BE%E5%BC%8F.+WHEN+%E6%B5%8B%E8%AF%95%E5%80%BC1+THEN+%E7%BB%93%E6%9E%9C%E8%A1%A8%E8%BE%BE%E5%BC%8F1.+WHEN+%E6%B5%8B%E8%AF%95%E5%80%BC2+THEN+%E7%BB%93%E6%9E%9C%E8%A1%A8%E8%BE%BE%E5%BC%8F+%5BELSE+%E7%BB%93%E6%9E%9C%E8%A1%A8%E8%BE%BE%E5%BC%8Fn%5D+END..jpg "功能:根据多个条件,选择执行不同的语句。 例如: USE 学生管理. int. from 成绩 where 学号= THEN print 及格 THEN print 良好 THEN print 优秀")
279
(5)WHILE、BREAK和CONTINUE语句
格式如下: WHILE Boolean_expression { Sql_statement | Statement_block } [ BREAK ] [ CONTINUE ] 功能:通过循环条件控制重复执行一个或多个语句。

280
【例】 求1+2+3+…+n的累加和第一次超过1000时的n值。
INT = 1 = 0 WHILE <= 100 ) BEGIN +1 IF > 1000) BREAK END PRINT 'n='+ AS VARCHAR(5))+',Sum='+ AS VARCHAR(10))
 BEGIN IF > 1000) BREAK. END. PRINT n= + AS VARCHAR(5))+ ,Sum= + AS VARCHAR(10))")
281
(6)WAITFOR 语句 指定触发语句块、存储过程或事务执行的时刻、或需等待的时间间隔。 语法格式: WAITFOR { DELAY 'time' | TIME 'time' } 说明: DELAY 'time':用于指定SQL Server必须等待的时间,最长可达 24 小时,time可以用datetime 数据格式指定,用单引号括起来,但在值中不允许有日期部分,也可以用局部变量指定参数。

282
TIME 'time':指定SQL Server 等待到某一时刻, time值的指定同上。
执行 WAITFOR 语句后,在到达指定的时间之前将无法使用与 SQL Server 的连接。若要查看活动的进程和正在等待的进程,使用 sp_who。 【例】如下语句设定在早上八点执行存储过程‘Manager’。 BEGIN WAITFOR TIME '8:00' EXECUTE sp_addrole ‘Manager’ END

283
(7)GOTO语句 GOTO语句是无条件转移语句,语法格式为: GOTO 标号 …… 标号
GOTO语句 GOTO语句是无条件转移语句,语法格式为: GOTO 标号 …… 标号")
284
(8)RETURN语句 语法格式: RETURN [ integer_expression ]
功能:用于无条件终止一个查询、存储过程 或批处理。 integer_expression将整型表达式的值返回。 (9)GO 语句 格式:GO 功能:批处理结束标记。
![(8)RETURN语句 语法格式: RETURN [ integer_expression ]](http://slidesplayer.com/slide/11418122/61/images/284/%EF%BC%888%EF%BC%89RETURN%E8%AF%AD%E5%8F%A5+%E8%AF%AD%E6%B3%95%E6%A0%BC%E5%BC%8F%EF%BC%9A+RETURN+%5B+integer_expression+%5D.jpg "功能:用于无条件终止一个查询、存储过程 或批处理。 integer_expression将整型表达式的值返回。 (9)GO 语句. 格式:GO. 功能:批处理结束标记。")
285
8.2 数据定义 8.2.1 创建表 定义表可使用CREATE TABLE语句。 SQL语句格式: CREATE TABLE 表名
8.2 数据定义 创建表 定义表可使用CREATE TABLE语句。 SQL语句格式: CREATE TABLE 表名 (<列名> <数据类型>[ <列级完整性约束条件> ] [,<列名> <数据类型>[ <列级完整性约束条件>] ] … [,<表级完整性约束条件> ] ) 功能:创建表。
 功能:创建表。")
286
例如:创建学生表 CREATE TABLE Student (Sno CHAR(9) PRIMARY KEY,
Sname CHAR(8) NOT NULL, Ssex CHAR(2) constraint c1 CHECK (Ssex IN ('男','女') ) DEFAULT '男', Sage SMALLINT, Sdept CHAR(20) ) PRIMARY KEY (Sno)
 NOT NULL, Ssex CHAR(2) constraint c1 CHECK (Ssex IN ( 男 , 女 ) ) DEFAULT 男 , Sage SMALLINT, Sdept CHAR(20) ) PRIMARY KEY (Sno)")
287
[例] 在sc表中定义SC表与student表的参照完整性
CREATE TABLE SC (Sno CHAR(9) NOT NULL, Cno CHAR(4) NOT NULL, Grade NUMERIC(5,2), FOREIGN KEY (Sno) REFERENCES Student(Sno) )
![[例] 在sc表中定义SC表与student表的参照完整性](http://slidesplayer.com/slide/11418122/61/images/287/%EF%BC%BB%E4%BE%8B%EF%BC%BD+%E5%9C%A8sc%E8%A1%A8%E4%B8%AD%E5%AE%9A%E4%B9%89SC%E8%A1%A8%E4%B8%8Estudent%E8%A1%A8%E7%9A%84%E5%8F%82%E7%85%A7%E5%AE%8C%E6%95%B4%E6%80%A7.jpg "CREATE TABLE SC. (Sno CHAR(9) NOT NULL, Cno CHAR(4) NOT NULL, Grade NUMERIC(5,2), FOREIGN KEY (Sno) REFERENCES Student(Sno) )")
288
8.2.2 修改表结构 修改表结构可使用ALTER TABLE语句。 SQL语句格式: ALTER TABLE <表名>
修改表结构 修改表结构可使用ALTER TABLE语句。 SQL语句格式: ALTER TABLE <表名> [ ADD <新列名> <数据类型> [ 完整性约束 ] ] [ DROP <完整性约束名> ] [ ALTER COLUMN <列名> <数据类型> [ 完整性约束 ]] 功能:修改表结构。

289
例: ALTER TABLE student1 ADD CONSTRAINT c6 CHECK (ssex=‘男’ or ssex=‘女’) ALTER TABLE dept ADD CONSTRAINT b1 DEFAULT ‘xinxi’ FOR dname
 ALTER TABLE dept ADD CONSTRAINT b1 DEFAULT ‘xinxi’ FOR dname.")
290
8.2.3 删除表 删除表可使用DROP TABLE语句。 SQL语句格式: DROP TABLE <表名> 功能:删除表。
删除表 删除表可使用DROP TABLE语句。 SQL语句格式: DROP TABLE <表名> 功能:删除表。 例如:删除学生表。 DROP TABLE STUDENT

291
8.3 数据操纵 8.3.1 插入数据 插入单个行可使用INSERT语句。 SQL语句格式: INSERT
8.3 数据操纵 插入数据 插入单个行可使用INSERT语句。 SQL语句格式: INSERT INTO <表名> [(<列1>[,<列2 >…)] VALUES (<常量1> [,<常量2>] … …) 功能:插入单个行。 INTO子句 属性列的顺序可与表定义中的顺序不一致 没有指定属性列表示与原来表中列数量和顺序一致 可以指定部分属性列 VALUES子句 提供的值必须与INTO子句匹配(个数 类型 顺序)
] VALUES (<常量1> [,<常量2>] … …) 功能:插入单个行。 INTO子句. 属性列的顺序可与表定义中的顺序不一致. 没有指定属性列表示与原来表中列数量和顺序一致. 可以指定部分属性列. VALUES子句. 提供的值必须与INTO子句匹配(个数 类型 顺序)")
292
例如:为学生表插入新行(‘080001’,‘李四’,‘男’,20)
INSERT INTO 学生(学号,姓名,性别,年龄) VALUES (‘080001’,‘李四’,‘男’,20) 例: 将新生学号(090002,080003,080004)插入学生表中。 BEGIN INSERT INTO 学生(学号) VALUES (‘080002’) INSERT INTO 学生(学号) VALUES (‘080003’) INSERT INTO 学生(学号) VALUES (‘080004’) END
 VALUES (‘080001’,‘李四’,‘男’,20) 例: 将新生学号(090002,080003,080004)插入学生表中。 BEGIN. INSERT INTO 学生(学号) VALUES (‘080002’) INSERT INTO 学生(学号) VALUES (‘080003’) INSERT INTO 学生(学号) VALUES (‘080004’) END.")
293
8.3.2 更新数据 更新数据可使用UPDATE语句。 SQL语句格式: UPDATE <表名>
更新数据 更新数据可使用UPDATE语句。 SQL语句格式: UPDATE <表名> SET <列名>=<表达式>[,<列名>=<表达式>]… [WHERE <条件>] 功能:更新指定表中满足WHERE子句条件行的对应的数据。

294
SET 子句 指定修改方式 要修改的列 修改后取值 WHERE子句 指定要修改的元组 缺省表示要修改表中的所有元组 三种修改方式 1. 修改某一个元组的值 2. 修改多个元组的值 3. 带子查询的修改语句

295
1. 修改某一个元组的值 例:将学生‘200215121’的年龄改为22岁。 UPDATE Student SET Sage=22
WHERE Sno=' ' 练习: 将学生 的年龄改为22岁,所在系改为’CC’ UPDATE Student SET Sage=22 ,sdept=‘CC’ WHERE Sno=' '

296
2. 修改多个元组的值 例:将所有学生的年龄增加1岁。 UPDATE Student SET Sage= Sage+1

297
3. 带子查询的修改语句 例: 将计算机科学系全体学生的成绩置零。 UPDATE SC SET Grade=0 WHERE sno in
例: 将计算机科学系全体学生的成绩置零。 UPDATE SC SET Grade=0 WHERE sno in (SELCET sno FROM Student WHERE sdept= ‘计算机科学' )
")
298
8.3.3 删除数据 语句格式: DELETE FROM <表名> [WHERE <条件>] 功能:
删除数据 三种删除方式 1. 删除某一个元组的值。 2. 删除多个元组的值。 3. 带子查询的删除语句。 语句格式: DELETE FROM <表名> [WHERE <条件>] 功能: 删除指定表中满足WHERE子句条件的元组。 WHERE子句 指定要删除的元组。 缺省表示要删除表中的全部元组。
![8.3.3 删除数据 语句格式: DELETE FROM <表名> [WHERE <条件>] 功能:](http://slidesplayer.com/slide/11418122/61/images/298/8.3.3+%E5%88%A0%E9%99%A4%E6%95%B0%E6%8D%AE+%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F%EF%BC%9A+DELETE+FROM+%3C%E8%A1%A8%E5%90%8D%3E+%5BWHERE+%3C%E6%9D%A1%E4%BB%B6%3E%5D+%E5%8A%9F%E8%83%BD%EF%BC%9A.jpg "8.3.3 删除数据. 三种删除方式. 1. 删除某一个元组的值。 2. 删除多个元组的值。 3. 带子查询的删除语句。 语句格式: DELETE. FROM <表名> [WHERE <条件>] 功能: 删除指定表中满足WHERE子句条件的元组。 WHERE子句. 指定要删除的元组。 缺省表示要删除表中的全部元组。")
299
1. 删除某一个元组的值 例: 删除学号为200215128的学生记录。 DELETE FROM Student
例: 删除学号为 的学生记录。 DELETE FROM Student WHERE Sno=‘ '

300
2. 删除多个元组的值 例:删除学生表中,班级是‘0701’的行。 DELETE FROM 学生
WHERE LEFT(学号,4)=‘0701’ 例: 删除SC表中所有的学生记录。 DELETE FROM SC
=‘0701’ 例: 删除SC表中所有的学生记录。 DELETE. FROM SC.")
301
3. 带子查询的删除语句 例: 删除SC表中计算机科学系所有学生的记录。 DELETE FROM SC WHERE sno in
(SELECT sno FROM Student WHERE sdept=‘计算机科学’)
")
302
8.4 数据查询 语句格式: SELECT [ALL | DISTINCT] <目标列表达式>
[,<目标列表达式>] … FROM <表名或视图名> [, <表名或视图名> ] … [ WHERE <条件表达式> ] [ GROUP BY <列名1> [ HAVING <条件表达式> ] ] [ ORDER BY <列名2> [ ASC | DESC ] ] 功能:从指定的基本表或视图中,选择满足条件的行数据,并对它们进行分组、统计、排序和投影,形成查询结果集。
![8.4 数据查询 语句格式: SELECT [ALL | DISTINCT] <目标列表达式>](http://slidesplayer.com/slide/11418122/61/images/302/8.4+%E6%95%B0%E6%8D%AE%E6%9F%A5%E8%AF%A2+%E8%AF%AD%E5%8F%A5%E6%A0%BC%E5%BC%8F%EF%BC%9A+SELECT+%5BALL+%7C+DISTINCT%5D+%3C%E7%9B%AE%E6%A0%87%E5%88%97%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E.jpg "[,<目标列表达式>] … FROM <表名或视图名> [, <表名或视图名> ] … [ WHERE <条件表达式> ] [ GROUP BY <列名1> [ HAVING <条件表达式> ] ] [ ORDER BY <列名2> [ ASC | DESC ] ] 功能:从指定的基本表或视图中,选择满足条件的行数据,并对它们进行分组、统计、排序和投影,形成查询结果集。")
303
一、 选择表中的若干列 1. 查询指定列 [例1] 查询全体学生的学号与姓名。 SELECT 学号,姓名 FROM 学生
[例1] 查询全体学生的学号与姓名。 SELECT 学号,姓名 FROM 学生 [例2] 查询全体学生的姓名、性别、籍贯。 SELECT 姓名,性别,籍贯 FROM 学生
![一、 选择表中的若干列 1. 查询指定列 [例1] 查询全体学生的学号与姓名。 SELECT 学号,姓名 FROM 学生](http://slidesplayer.com/slide/11418122/61/images/303/%E4%B8%80%E3%80%81+%E9%80%89%E6%8B%A9%E8%A1%A8%E4%B8%AD%E7%9A%84%E8%8B%A5%E5%B9%B2%E5%88%97+1.+%E6%9F%A5%E8%AF%A2%E6%8C%87%E5%AE%9A%E5%88%97+%5B%E4%BE%8B1%5D+%E6%9F%A5%E8%AF%A2%E5%85%A8%E4%BD%93%E5%AD%A6%E7%94%9F%E7%9A%84%E5%AD%A6%E5%8F%B7%E4%B8%8E%E5%A7%93%E5%90%8D%E3%80%82+SELECT+%E5%AD%A6%E5%8F%B7%2C%E5%A7%93%E5%90%8D+FROM+%E5%AD%A6%E7%94%9F.jpg "[例1] 查询全体学生的学号与姓名。 SELECT 学号,姓名. FROM 学生 [例2] 查询全体学生的姓名、性别、籍贯。 SELECT 姓名,性别,籍贯. FROM 学生.")
304
2. 选出所有属性列: 将<目标列表达式>指定为 * [例3] 查询全体学生的详细记录。 SELECT 学号,姓名,性别,出生年月,籍贯,班级编号 FROM 学生 或 SELECT *
![2. 选出所有属性列: 将<目标列表达式>指定为 * [例3] 查询全体学生的详细记录。 SELECT 学号,姓名,性别,出生年月,籍贯,班级编号 FROM 学生 或 SELECT *](http://slidesplayer.com/slide/11418122/61/images/304/2.+%E9%80%89%E5%87%BA%E6%89%80%E6%9C%89%E5%B1%9E%E6%80%A7%E5%88%97%EF%BC%9A+%E5%B0%86%3C%E7%9B%AE%E6%A0%87%E5%88%97%E8%A1%A8%E8%BE%BE%E5%BC%8F%3E%E6%8C%87%E5%AE%9A%E4%B8%BA+%2A+%5B%E4%BE%8B3%5D+%E6%9F%A5%E8%AF%A2%E5%85%A8%E4%BD%93%E5%AD%A6%E7%94%9F%E7%9A%84%E8%AF%A6%E7%BB%86%E8%AE%B0%E5%BD%95%E3%80%82+SELECT+%E5%AD%A6%E5%8F%B7%2C%E5%A7%93%E5%90%8D%2C%E6%80%A7%E5%88%AB%2C%E5%87%BA%E7%94%9F%E5%B9%B4%E6%9C%88%2C%E7%B1%8D%E8%B4%AF%2C%E7%8F%AD%E7%BA%A7%E7%BC%96%E5%8F%B7+FROM+%E5%AD%A6%E7%94%9F+%E6%88%96+SELECT+%2A.jpg "2. 选出所有属性列: 将<目标列表达式>指定为 * [例3] 查询全体学生的详细记录。 SELECT 学号,姓名,性别,出生年月,籍贯,班级编号 FROM 学生 或 SELECT *")
305
3. 查询经过计算的值 SELECT子句的<目标列表达式>可以包括: 算术表达式 字符串常量 函数 列别名

306
[例4] 查全体学生的姓名及其年龄。 SELECT 姓名,year(getdate())-year(出生年月) FROM 学生 输出结果:
![[例4] 查全体学生的姓名及其年龄。 SELECT 姓名,year(getdate())-year(出生年月) FROM 学生 输出结果:](http://slidesplayer.com/slide/11418122/61/images/306/%5B%E4%BE%8B4%5D+%E6%9F%A5%E5%85%A8%E4%BD%93%E5%AD%A6%E7%94%9F%E7%9A%84%E5%A7%93%E5%90%8D%E5%8F%8A%E5%85%B6%E5%B9%B4%E9%BE%84%E3%80%82+SELECT+%E5%A7%93%E5%90%8D%2Cyear%28getdate%28%29%29-year%28%E5%87%BA%E7%94%9F%E5%B9%B4%E6%9C%88%29+FROM+%E5%AD%A6%E7%94%9F+%E8%BE%93%E5%87%BA%E7%BB%93%E6%9E%9C%EF%BC%9A.jpg "[例4] 查全体学生的姓名及其年龄。 SELECT 姓名,year(getdate())-year(出生年月) FROM 学生 输出结果:")
307
[例5] 查询全体学生的姓名、出生年份和班级编号,要求用小写字母表示班级编号.
SELECT 姓名,’Year of Birth: ‘, year(出生年月), LOWER(班级编号) FROM 学生
![[例5] 查询全体学生的姓名、出生年份和班级编号,要求用小写字母表示班级编号.](http://slidesplayer.com/slide/11418122/61/images/307/%5B%E4%BE%8B5%5D+%E6%9F%A5%E8%AF%A2%E5%85%A8%E4%BD%93%E5%AD%A6%E7%94%9F%E7%9A%84%E5%A7%93%E5%90%8D%E3%80%81%E5%87%BA%E7%94%9F%E5%B9%B4%E4%BB%BD%E5%92%8C%E7%8F%AD%E7%BA%A7%E7%BC%96%E5%8F%B7%EF%BC%8C%E8%A6%81%E6%B1%82%E7%94%A8%E5%B0%8F%E5%86%99%E5%AD%97%E6%AF%8D%E8%A1%A8%E7%A4%BA%E7%8F%AD%E7%BA%A7%E7%BC%96%E5%8F%B7..jpg "SELECT 姓名,’Year of Birth: ‘, year(出生年月), LOWER(班级编号) FROM 学生.")
308
使用列别名改变查询结果的列标题: SELECT 姓名,’Year of Birth: ‘ 出生年份, year(出生年月) 年份, LOWER(班级编号) 班级编号 FROM 学生
 年份, LOWER(班级编号) 班级编号 FROM 学生")
309
SELECT DISTINCT 学号 FROM 成绩
二、选择表中的若干元组 1. 消除取值重复的行 如果没有指定DISTINCT关键词,则缺省为ALL [例6] 查询选修了课程的学生学号。 SELECT 学号 FROM 成绩 等价于: SELECT ALL 学号 FROM 成绩 SELECT DISTINCT 学号 FROM 成绩

310
2.查询满足条件的元组 表8.1 常用的查询条件 查 询 条 件 谓 词 比 较
谓 词 比 较 =,>,<,>=,<=,!=,<>,!>,!<;NOT+上述比较运算符 确定范围 BETWEEN AND,NOT BETWEEN AND 确定集合 IN,NOT IN 字符匹配 LIKE,NOT LIKE 空 值 IS NULL,IS NOT NULL 多重条件(逻辑运算) AND,OR,NOT
 AND,OR,NOT.")
311
(1) 比较大小 [例7] 查询A1010601班全体学生的名单。 SELECT 姓名 FROM 学生
WHERE 班级编号=‘A ’ [例8] 查询所有年龄在20岁以上的学生姓名及其年龄。 SELECT 姓名,2011-year(出生年月) 年龄 FROM 学生 WHERE (2011-year(出生年月)) >20 [例9] 查询考试成绩有不及格的学生的学号。 SELECT DISTINCT 学号 FROM 成绩 WHERE 成绩<60
![(1) 比较大小 [例7] 查询A 班全体学生的名单。 SELECT 姓名 FROM 学生](http://slidesplayer.com/slide/11418122/61/images/311/%281%29+%E6%AF%94%E8%BE%83%E5%A4%A7%E5%B0%8F+%EF%BC%BB%E4%BE%8B7%EF%BC%BD+%E6%9F%A5%E8%AF%A2A+%E7%8F%AD%E5%85%A8%E4%BD%93%E5%AD%A6%E7%94%9F%E7%9A%84%E5%90%8D%E5%8D%95%E3%80%82+SELECT+%E5%A7%93%E5%90%8D+FROM+%E5%AD%A6%E7%94%9F.jpg "WHERE 班级编号=‘A ’ [例8] 查询所有年龄在20岁以上的学生姓名及其年龄。 SELECT 姓名,2011-year(出生年月) 年龄. FROM 学生. WHERE (2011-year(出生年月)) >20. [例9] 查询考试成绩有不及格的学生的学号。 SELECT DISTINCT 学号. FROM 成绩. WHERE 成绩<60.")
312
(2)确定范围 [例10] 查询年龄在20~23岁(包括20岁和23岁)之间的学生的 姓名、性别和年龄。
SELECT 姓名,性别,2011-year(出生年月) FROM 学生 WHERE year(出生年月) BETWEEN 20 AND 23 [例11] 查询年龄不在20~23岁之间的学生姓名、性别和年龄。 WHERE year(出生年月) NOT BETWEEN 20 AND 23
![(2)确定范围 [例10] 查询年龄在20~23岁(包括20岁和23岁)之间的学生的 姓名、性别和年龄。](http://slidesplayer.com/slide/11418122/61/images/312/%EF%BC%882%EF%BC%89%E7%A1%AE%E5%AE%9A%E8%8C%83%E5%9B%B4+%5B%E4%BE%8B10%5D+%E6%9F%A5%E8%AF%A2%E5%B9%B4%E9%BE%84%E5%9C%A820%7E23%E5%B2%81%EF%BC%88%E5%8C%85%E6%8B%AC20%E5%B2%81%E5%92%8C23%E5%B2%81%EF%BC%89%E4%B9%8B%E9%97%B4%E7%9A%84%E5%AD%A6%E7%94%9F%E7%9A%84+%E5%A7%93%E5%90%8D%E3%80%81%E6%80%A7%E5%88%AB%E5%92%8C%E5%B9%B4%E9%BE%84%E3%80%82.jpg "SELECT 姓名,性别,2011-year(出生年月) FROM 学生. WHERE 2011-year(出生年月) BETWEEN 20 AND 23. [例11] 查询年龄不在20~23岁之间的学生姓名、性别和年龄。 WHERE 2011-year(出生年月) NOT BETWEEN 20 AND 23.")
313
(3) 确定集合 [例12]查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。 SELECT 姓名,性别
FROM 学生 WHERE 系别 IN ( 'IS','MA','CS' ) [例13]查询既不是信息系、数学系,也不是计算机科学系的学生的姓名和性别。 WHERE 系别 NOT IN ( 'IS','MA','CS' )
![(3) 确定集合 [例12]查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。 SELECT 姓名,性别](http://slidesplayer.com/slide/11418122/61/images/313/%283%29+%E7%A1%AE%E5%AE%9A%E9%9B%86%E5%90%88+%5B%E4%BE%8B12%5D%E6%9F%A5%E8%AF%A2%E4%BF%A1%E6%81%AF%E7%B3%BB%EF%BC%88IS%EF%BC%89%E3%80%81%E6%95%B0%E5%AD%A6%E7%B3%BB%EF%BC%88MA%EF%BC%89%E5%92%8C%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6%E7%B3%BB%EF%BC%88CS%EF%BC%89%E5%AD%A6%E7%94%9F%E7%9A%84%E5%A7%93%E5%90%8D%E5%92%8C%E6%80%A7%E5%88%AB%E3%80%82+SELECT+%E5%A7%93%E5%90%8D%EF%BC%8C%E6%80%A7%E5%88%AB.jpg "FROM 学生. WHERE 系别 IN ( IS , MA , CS ) [例13]查询既不是信息系、数学系,也不是计算机科学系的学生的姓名和性别。 WHERE 系别 NOT IN ( IS , MA , CS )")
314
(4)字符匹配 [例14] 查询学号为060102的学生的详细情况。 SELECT * FROM 学生
[例14] 查询学号为060102的学生的详细情况。 SELECT * FROM 学生 WHERE 学号 LIKE ‘060102' 等价于: FROM 学号 WHERE Sno = ' '
![(4)字符匹配 [例14] 查询学号为060102的学生的详细情况。 SELECT * FROM 学生](http://slidesplayer.com/slide/11418122/61/images/314/%284%29%E5%AD%97%E7%AC%A6%E5%8C%B9%E9%85%8D+%5B%E4%BE%8B14%5D+%E6%9F%A5%E8%AF%A2%E5%AD%A6%E5%8F%B7%E4%B8%BA060102%E7%9A%84%E5%AD%A6%E7%94%9F%E7%9A%84%E8%AF%A6%E7%BB%86%E6%83%85%E5%86%B5%E3%80%82+SELECT+%2A+FROM+%E5%AD%A6%E7%94%9F.jpg "[例14] 查询学号为060102的学生的详细情况。 SELECT * FROM 学生. WHERE 学号 LIKE ‘ 等价于: FROM 学号. WHERE Sno =")
315
[例15] 查询所有姓刘学生的姓名、学号和性别。
SELECT 姓名,学号,性别 FROM 学生 WHERE 姓名 LIKE ‘刘%’ [例16] 查询姓"欧阳"且全名为三个汉字的学生的姓名。 SELECT 姓名 WHERE 姓名 LIKE '欧阳_ _'
![[例15] 查询所有姓刘学生的姓名、学号和性别。](http://slidesplayer.com/slide/11418122/61/images/315/%5B%E4%BE%8B15%5D+%E6%9F%A5%E8%AF%A2%E6%89%80%E6%9C%89%E5%A7%93%E5%88%98%E5%AD%A6%E7%94%9F%E7%9A%84%E5%A7%93%E5%90%8D%E3%80%81%E5%AD%A6%E5%8F%B7%E5%92%8C%E6%80%A7%E5%88%AB%E3%80%82.jpg "SELECT 姓名,学号,性别. FROM 学生. WHERE 姓名 LIKE ‘刘%’ [例16] 查询姓 欧阳 且全名为三个汉字的学生的姓名。 SELECT 姓名. WHERE 姓名 LIKE 欧阳_ _")
316
[例17] 查询名字中第2个字为"阳"字的学生的姓名和学号。
SELECT 姓名,学号 FROM 学生 WHERE 姓名 LIKE ‘_ _阳%’ [例18] 查询所有不姓刘的学生姓名。 SELECT 姓名,学号,性别 WHERE 姓名 NOT LIKE '刘%'
![[例17] 查询名字中第2个字为 阳 字的学生的姓名和学号。](http://slidesplayer.com/slide/11418122/61/images/316/%5B%E4%BE%8B17%5D+%E6%9F%A5%E8%AF%A2%E5%90%8D%E5%AD%97%E4%B8%AD%E7%AC%AC2%E4%B8%AA%E5%AD%97%E4%B8%BA+%E9%98%B3+%E5%AD%97%E7%9A%84%E5%AD%A6%E7%94%9F%E7%9A%84%E5%A7%93%E5%90%8D%E5%92%8C%E5%AD%A6%E5%8F%B7%E3%80%82.jpg "SELECT 姓名,学号. FROM 学生. WHERE 姓名 LIKE ‘_ _阳%’ [例18] 查询所有不姓刘的学生姓名。 SELECT 姓名,学号,性别. WHERE 姓名 NOT LIKE 刘%")
317
(5) 涉及空值的查询 谓词: IS NULL 或 IS NOT NULL
[例21] 某些学生选修课程后没有参加考试,所以有选课记录,但没有考试成绩。查询缺少成绩的学生的学号和相应的课程号。 SELECT 学号,课程编号 FROM 成绩 WHERE 成绩 IS NULL [例22] 查所有有成绩的学生学号和课程号。 WHERE 成绩 IS NOT NULL

318
6. 多重条件查询 [例23] 查询A1010601班女学生姓名。 SELECT 姓名 FROM 学生
WHERE 班级编号= ‘A ’ AND 性别=‘女’
![6. 多重条件查询 [例23] 查询A 班女学生姓名。 SELECT 姓名 FROM 学生](http://slidesplayer.com/slide/11418122/61/images/318/6.+%E5%A4%9A%E9%87%8D%E6%9D%A1%E4%BB%B6%E6%9F%A5%E8%AF%A2+%5B%E4%BE%8B23%5D+%E6%9F%A5%E8%AF%A2A+%E7%8F%AD%E5%A5%B3%E5%AD%A6%E7%94%9F%E5%A7%93%E5%90%8D%E3%80%82+SELECT+%E5%A7%93%E5%90%8D+FROM+%E5%AD%A6%E7%94%9F.jpg "WHERE 班级编号= ‘A ’ AND 性别=‘女’")
319
[例12] 查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。
SELECT 姓名,性别 FROM 学生 WHERE 系别 IN ( 'IS','MA','CS' ) 可改写为: FROM 学生 WHERE 系别= ‘ IS ’ OR 系别= ‘ MA’ OR 系别= ' CS '
![[例12] 查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。](http://slidesplayer.com/slide/11418122/61/images/319/%5B%E4%BE%8B12%5D+%E6%9F%A5%E8%AF%A2%E4%BF%A1%E6%81%AF%E7%B3%BB%EF%BC%88IS%EF%BC%89%E3%80%81%E6%95%B0%E5%AD%A6%E7%B3%BB%EF%BC%88MA%EF%BC%89%E5%92%8C%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6%E7%B3%BB%EF%BC%88CS%EF%BC%89%E5%AD%A6%E7%94%9F%E7%9A%84%E5%A7%93%E5%90%8D%E5%92%8C%E6%80%A7%E5%88%AB%E3%80%82.jpg "SELECT 姓名,性别. FROM 学生. WHERE 系别 IN ( IS , MA , CS ) 可改写为: FROM 学生. WHERE 系别= ‘ IS ’ OR 系别= ‘ MA’ OR 系别= CS")
320
三、ORDER BY 子句 可以按一个或多个属性列排序 升序:ASC;降序:DESC;缺省值为升序 当排序列含空值时,null值按最大计。

321
[例24] 查询选修了01-03号课程的学生的学号及其成绩,查询结果按分数降序排列。
SELECT 学号,成绩 FROM 成绩 WHERE 课程编号= ' ' ORDER BY 成绩 DESC [例25] 查询全体学生情况,查询结果按所在班级编号升序排列,同一班级中的学生按性别降序排列。 SELECT * FROM 学生 ORDER BY 编辑编号,性别 DESC
![[例24] 查询选修了01-03号课程的学生的学号及其成绩,查询结果按分数降序排列。](http://slidesplayer.com/slide/11418122/61/images/321/%5B%E4%BE%8B24%5D+%E6%9F%A5%E8%AF%A2%E9%80%89%E4%BF%AE%E4%BA%8601-03%E5%8F%B7%E8%AF%BE%E7%A8%8B%E7%9A%84%E5%AD%A6%E7%94%9F%E7%9A%84%E5%AD%A6%E5%8F%B7%E5%8F%8A%E5%85%B6%E6%88%90%E7%BB%A9%EF%BC%8C%E6%9F%A5%E8%AF%A2%E7%BB%93%E6%9E%9C%E6%8C%89%E5%88%86%E6%95%B0%E9%99%8D%E5%BA%8F%E6%8E%92%E5%88%97%E3%80%82.jpg "SELECT 学号,成绩. FROM 成绩. WHERE 课程编号= ORDER BY 成绩 DESC. [例25] 查询全体学生情况,查询结果按所在班级编号升序排列,同一班级中的学生按性别降序排列。 SELECT * FROM 学生. ORDER BY 编辑编号,性别 DESC.")
322
四、聚集函数 计数 COUNT([DISTINCT|ALL] *) COUNT([DISTINCT|ALL] <列名>)
计算总和 SUM([DISTINCT|ALL] <列名>) 计算平均值 AVG([DISTINCT|ALL] <列名>) 最大最小值 MAX([DISTINCT|ALL] <列名>) MIN([DISTINCT|ALL] <列名>)
![四、聚集函数 计数 COUNT([DISTINCT|ALL] *) COUNT([DISTINCT|ALL] <列名>)](http://slidesplayer.com/slide/11418122/61/images/322/%E5%9B%9B%E3%80%81%E8%81%9A%E9%9B%86%E5%87%BD%E6%95%B0+%E8%AE%A1%E6%95%B0+COUNT%EF%BC%88%5BDISTINCT%7CALL%5D+%2A%EF%BC%89+COUNT%EF%BC%88%5BDISTINCT%7CALL%5D+%3C%E5%88%97%E5%90%8D%3E%EF%BC%89.jpg "计算总和. SUM([DISTINCT|ALL] <列名>) 计算平均值. AVG([DISTINCT|ALL] <列名>) 最大最小值. MAX([DISTINCT|ALL] <列名>) MIN([DISTINCT|ALL] <列名>)")
323
聚集函数 (续) [例26] 查询学生总人数。 SELECT COUNT(*) FROM 学生 [例27] 查询选修了课程的学生人数。
[例26] 查询学生总人数。 SELECT COUNT(*) FROM 学生 [例27] 查询选修了课程的学生人数。 SELECT COUNT(DISTINCT 学号) FROM 成绩 [例28] 计算01-01号课程的学生平均成绩。 SELECT AVG(成绩) FROM 成绩 WHERE 课程编号= ' '
![聚集函数 (续) [例26] 查询学生总人数。 SELECT COUNT(*) FROM 学生 [例27] 查询选修了课程的学生人数。](http://slidesplayer.com/slide/11418122/61/images/323/%E8%81%9A%E9%9B%86%E5%87%BD%E6%95%B0+%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B26%5D+%E6%9F%A5%E8%AF%A2%E5%AD%A6%E7%94%9F%E6%80%BB%E4%BA%BA%E6%95%B0%E3%80%82+SELECT+COUNT%28%2A%29+FROM+%E5%AD%A6%E7%94%9F+%5B%E4%BE%8B27%5D+%E6%9F%A5%E8%AF%A2%E9%80%89%E4%BF%AE%E4%BA%86%E8%AF%BE%E7%A8%8B%E7%9A%84%E5%AD%A6%E7%94%9F%E4%BA%BA%E6%95%B0%E3%80%82.jpg "[例26] 查询学生总人数。 SELECT COUNT(*) FROM 学生 [例27] 查询选修了课程的学生人数。 SELECT COUNT(DISTINCT 学号) FROM 成绩. [例28] 计算01-01号课程的学生平均成绩。 SELECT AVG(成绩) FROM 成绩. WHERE 课程编号=")
324
聚集函数 (续) [例29] 查询选修01-01号课程的学生最高分数。 SELECT MAX(成绩) FROM 成绩
[例29] 查询选修01-01号课程的学生最高分数。 SELECT MAX(成绩) FROM 成绩 WHERE 课程编号= ’01-01 ‘ [例30]查询学生 选修课程的总学分数。 SELECT SUM(成绩) FROM 成绩 WHER 学号=' '
![聚集函数 (续) [例29] 查询选修01-01号课程的学生最高分数。 SELECT MAX(成绩) FROM 成绩](http://slidesplayer.com/slide/11418122/61/images/324/%E8%81%9A%E9%9B%86%E5%87%BD%E6%95%B0+%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B29%5D+%E6%9F%A5%E8%AF%A2%E9%80%89%E4%BF%AE01-01%E5%8F%B7%E8%AF%BE%E7%A8%8B%E7%9A%84%E5%AD%A6%E7%94%9F%E6%9C%80%E9%AB%98%E5%88%86%E6%95%B0%E3%80%82+SELECT+MAX%28%E6%88%90%E7%BB%A9%29+FROM+%E6%88%90%E7%BB%A9.jpg "[例29] 查询选修01-01号课程的学生最高分数。 SELECT MAX(成绩) FROM 成绩. WHERE 课程编号= ’01-01 ‘ [例30]查询学生 选修课程的总学分数。 SELECT SUM(成绩) FROM 成绩. WHER 学号=")
325
五、GROUP BY子句 GROUP BY子句分组: 涉及‘每个’、‘每种’字样时需要分组 条件表达式中用到聚集函数的,要先分组,然后将条件
表达式放在having子句中

326
[例31] 求每个课程号及相应的选课人数。 SELECT 课程编号,COUNT(学号) 人数 FROM 成绩 GROUP BY 课程编号 查询结果:
![[例31] 求每个课程号及相应的选课人数。 SELECT 课程编号,COUNT(学号) 人数 FROM 成绩 GROUP BY 课程编号 查询结果:](http://slidesplayer.com/slide/11418122/61/images/326/%5B%E4%BE%8B31%5D+%E6%B1%82%E6%AF%8F%E4%B8%AA%E8%AF%BE%E7%A8%8B%E5%8F%B7%E5%8F%8A%E7%9B%B8%E5%BA%94%E7%9A%84%E9%80%89%E8%AF%BE%E4%BA%BA%E6%95%B0%E3%80%82+SELECT+%E8%AF%BE%E7%A8%8B%E7%BC%96%E5%8F%B7%EF%BC%8CCOUNT%28%E5%AD%A6%E5%8F%B7%29+%E4%BA%BA%E6%95%B0+FROM+%E6%88%90%E7%BB%A9+GROUP+BY+%E8%AF%BE%E7%A8%8B%E7%BC%96%E5%8F%B7+%E6%9F%A5%E8%AF%A2%E7%BB%93%E6%9E%9C%EF%BC%9A.jpg "[例31] 求每个课程号及相应的选课人数。 SELECT 课程编号,COUNT(学号) 人数 FROM 成绩 GROUP BY 课程编号 查询结果:")
327
[例32] 查询选修了3门以上课程的学生学号。 SELECT 学号, COUNT(*) AS 课程门数 FROM 成绩 GROUP BY 学号 HAVING COUNT(*) > 思考:查询每个同学的学号与及格科目的数量。 SELECT 学号,COUNT(*) AS 及格数量 WHERE 成绩>=60
![[例32] 查询选修了3门以上课程的学生学号。 SELECT 学号, COUNT(*) AS 课程门数. FROM 成绩. GROUP BY 学号. HAVING COUNT(*) >3](http://slidesplayer.com/slide/11418122/61/images/327/%5B%E4%BE%8B32%5D+%E6%9F%A5%E8%AF%A2%E9%80%89%E4%BF%AE%E4%BA%863%E9%97%A8%E4%BB%A5%E4%B8%8A%E8%AF%BE%E7%A8%8B%E7%9A%84%E5%AD%A6%E7%94%9F%E5%AD%A6%E5%8F%B7%E3%80%82+SELECT+%E5%AD%A6%E5%8F%B7%EF%BC%8C+COUNT%28%2A%29+AS+%E8%AF%BE%E7%A8%8B%E9%97%A8%E6%95%B0.+FROM+%E6%88%90%E7%BB%A9.+GROUP+BY+%E5%AD%A6%E5%8F%B7.+HAVING+COUNT%28%2A%29+%3E3.jpg "思考:查询每个同学的学号与及格科目的数量。 SELECT 学号,COUNT(*) AS 及格数量. WHERE 成绩>=60.")
328
HAVING短语与WHERE子句的区别:
作用对象不同。 WHERE子句作用于表或视图,从中选择满足条件的元组。 HAVING短语作用于组,从分组后的结果中选择满足条件的组。 在一个查询语句中同时出现WHERE 条件和HAVING条件时,WHERE条件写在前面。

329
[例33]查询男生人数超过3人的班级的班级编号和男生人数
SELECT 班级编号,COUNT(*) AS 男生人数FROM 学生 WHERE 性别=‘男’ GROUP BY 班级编号 HAVING COUNT(*) >3
![[例33]查询男生人数超过3人的班级的班级编号和男生人数](http://slidesplayer.com/slide/11418122/61/images/329/%5B%E4%BE%8B33%5D%E6%9F%A5%E8%AF%A2%E7%94%B7%E7%94%9F%E4%BA%BA%E6%95%B0%E8%B6%85%E8%BF%87%EF%BC%93%E4%BA%BA%E7%9A%84%E7%8F%AD%E7%BA%A7%E7%9A%84%E7%8F%AD%E7%BA%A7%E7%BC%96%E5%8F%B7%E5%92%8C%E7%94%B7%E7%94%9F%E4%BA%BA%E6%95%B0.jpg "SELECT 班级编号,COUNT(*) AS 男生人数FROM 学生. WHERE 性别=‘男’ GROUP BY 班级编号. HAVING COUNT(*) >3.")
330
复 习: 1、视图是对一个或多个表的映射,视图是否是真正的表? 2、对视图数据的修改是否影响基本表数据? 3、使用视图的作用? 简化用户操作
复 习: 1、视图是对一个或多个表的映射,视图是否是真正的表? 2、对视图数据的修改是否影响基本表数据? 3、使用视图的作用? 简化用户操作 以多种角度看待数据 对机密数据安全保护 方便表达复杂查询

331
第 9 章 存储过程和触发器 本章重点: 什么是存储过程 创建存储过程 什么是触发器 创建触发器

332
9.1 存储过程 9.1.1 存储过程概述 9.1.2 创建用户存储过程 9.1.3 执行存储过程 9.1.4 修改存储过程
存储过程概述 创建用户存储过程 执行存储过程 修改存储过程 删除存储过程

333
9.1.1 存储过程概述 1.什么是存储过程(Stored Procedure)?
存储过程概述 1.什么是存储过程(Stored Procedure)? 存储过程是一种数据库对象,是为了实现某个特定任务,将一组预先编辑好的SQL语句以一个存储单元的形式存储在服务器上,供用户调用。 2.存储过程的分类 系统提供的存储过程 用户定义的存储过程(本地存储过程,临时存储过程,远程存储过程) 扩展存储过程
? 存储过程是一种数据库对象,是为了实现某个特定任务,将一组预先编辑好的SQL语句以一个存储单元的形式存储在服务器上,供用户调用。 2.存储过程的分类. 系统提供的存储过程. 用户定义的存储过程(本地存储过程,临时存储过程,远程存储过程) 扩展存储过程.")
334
1)系统存储过程 系统存储过程是指安装SQL Server时由系统创建的存储过程。存储在master数据库中,其前缀为sp_。系统存储过程主要用于从系统表中获取信息,也为系统管理员和有权限的用户提供更新系统表的途径。它们中的大部分可以在用户数据库中使用。 2)扩展存储过程 扩展存储过程是对动态链接库(DLL它是Dynamic Link Library 的缩写形式,是作为共享函数库的可执行文件。动态链接提供了一种方法,使进程可以调用不属于其可执行代码的函数。 )函数的调用。 是在sql-server环境之外执行的动态链接库,其前缀为xp_,使用时需要先加载到server系统中,并且按照使用系统存储过程的方法执行。 3)用户定义的存储过程 由用户为完成某一特定功能而编写的存储过程。
扩展存储过程. 扩展存储过程是对动态链接库(DLL它是Dynamic Link Library 的缩写形式,是作为共享函数库的可执行文件。动态链接提供了一种方法,使进程可以调用不属于其可执行代码的函数。 )函数的调用。 是在sql-server环境之外执行的动态链接库,其前缀为xp_,使用时需要先加载到server系统中,并且按照使用系统存储过程的方法执行。 3)用户定义的存储过程. 由用户为完成某一特定功能而编写的存储过程。")
335
3. 存储过程的优点 (1)提供了处理复杂任务的能力 通过传递参数和执行逻辑表达式,能够使用十分复杂的SQL语句处理复杂任务。
(2)增强代码的重用性和共享性 (3)减少网络数据流量 存储过程在服务器端运行,减少代码与数据的传递量。 (4)加强系统安全 使用存储过程可通过编程方式控制对数据库访问权限,提高数据库的安全性。 (5)加快系统运行速度 存储过程调用一次以后,其执行规则就驻留在高速缓冲存储器中,若再要执行,只需调用高速缓冲存储器中已编译好的代码便可执行,大大提高了系统性能。
增强代码的重用性和共享性. (3)减少网络数据流量. 存储过程在服务器端运行,减少代码与数据的传递量。 (4)加强系统安全. 使用存储过程可通过编程方式控制对数据库访问权限,提高数据库的安全性。 (5)加快系统运行速度. 存储过程调用一次以后,其执行规则就驻留在高速缓冲存储器中,若再要执行,只需调用高速缓冲存储器中已编译好的代码便可执行,大大提高了系统性能。")
336
9.1.2 创建用户存储过程 1.使用企业管理器创建用户存储过程 操作步骤如下: (1)启动SQL Server企业管理器。
创建用户存储过程 1.使用企业管理器创建用户存储过程 操作步骤如下: (1)启动SQL Server企业管理器。 (2)在“控制台根目录”窗口,展开“SQL Server组”,首先,选择“数据库”,然后,选择“存储过程”,单击鼠标右键,打开快捷菜单。 (3)在打开快捷菜单中,选择“新建存储过程”菜单命令,进入“存储过程属性”窗口。 (4)在“存储过程属性”窗口,在文本框中输入存储过程代码,单击“确定”,结束存储过程的创建。
启动SQL Server企业管理器。 (2)在 控制台根目录 窗口,展开 SQL Server组 ,首先,选择 数据库 ,然后,选择 存储过程 ,单击鼠标右键,打开快捷菜单。 (3)在打开快捷菜单中,选择 新建存储过程 菜单命令,进入 存储过程属性 窗口。 (4)在 存储过程属性 窗口,在文本框中输入存储过程代码,单击 确定 ,结束存储过程的创建。")
339
9.1.2 创建用户存储过程 2.使用T-SQL语句创建用户存储过程 SQL命令格式:
创建用户存储过程 2.使用T-SQL语句创建用户存储过程 SQL命令格式: CREATE PROC [ EDURE ] <Procedure_name> [ ; Number ] [ Data_type } [ VARYING ] [ = Default ] [ OUTPUT ] ] [ ,...n ] [ WITH { RECOMPILE | ENCRYPTION }] [ FOR REPLICATION ] AS sql_statements 功能:创建一个用户存储过程,并保存在数据库中。

340
procedure_name:存储过程的名字
number :用来对同名的过程分组,以便用一条语句将同组的过 程一起删除。 @parameter data_type:输入参数的名称与类型。 default: 参数默认值,必须是常量或null。 OUTPUT:参数是返回参数。 WITH RECOMPILE:该过程在运行时重新编译。 WITH ENCRYPTION:不可编辑过程中的语句文本选项。(可防 止别人看到自己的脚本,加密语句) sql_statements:存储过程中的任意数目和类型的T-SQL语句。
 sql_statements:存储过程中的任意数目和类型的T-SQL语句。")
341
例:查看90分以上的成绩信息 CREATE PROCEDURE grade_90 AS select * from 成绩 where 成绩>=90

342
9.1.3 执行存储过程 SQL命令格式: EXEC [ UTE ] [ @Return_status = ]
执行存储过程 SQL命令格式: EXEC [ UTE ] = ] { Procedure_name [ ;number ] } [ = ] { Value [ OUTPUT ] | [ DEFAULT ] } [ ,...n ] [ WITH RECOMPILE ] 功能: 调用存储过程。
![9.1.3 执行存储过程 SQL命令格式: EXEC [ UTE ] = ]](http://slidesplayer.com/slide/11418122/61/images/342/9.1.3+%E6%89%A7%E8%A1%8C%E5%AD%98%E5%82%A8%E8%BF%87%E7%A8%8B+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+EXEC+%5B+UTE+%5D+%3D+%5D.jpg "9.1.3 执行存储过程. SQL命令格式: EXEC [ UTE ] = ] { Procedure_name [ ;number ] } [ = ] { Value [ OUTPUT ] | [ DEFAULT ] } [ ,...n ] [ WITH RECOMPILE ] 功能: 调用存储过程。")
343
例:查看90分以上的成绩信息 CREATE PROCEDURE grade_90 AS select * from 成绩 where 成绩>=90 EXEC grade_90

344
例:按输入的学号查看学生信息 CREATE PROCEDURE GetStudent @no varchar(10) AS SELECT * FROM 学生 WHERE EXECUTE GetStudent ‘060101'

345
例:带默认值参数的存储过程 按输入的姓名查看学生信息 CREATE PROCEDURE GetStudentByName1 @name varchar(8) = ‘周康’ AS SELECT * FROM 学生 WHERE 姓名 EXECUTE GetStudentByName 返回所有周康的信息 或者 EXECUTE GetStudentByName1 ‘赵盘’; 返回赵盘的信息

346
例:带默认值参数的存储过程 CREATE PROCEDURE GetStudentByName @name varchar(10) = '%' AS SELECT * FROM 学生表 WHERE 姓名 like @name EXECUTE GetStudentByName --返回所有学生的信息 或者 EXECUTE GetStudentByName ‘赵盘’ 返回赵盘的信息

347
9.1.4 修改存储过程 SQL命令格式: ALTER PROC [ EDURE ] procedure_name [ ; number ]
修改存储过程 SQL命令格式: ALTER PROC [ EDURE ] procedure_name [ ; number ] [ data_type } [ VARYING ] [ 0= default ] [ OUTPUT ] ] [ ,...n ] [ WITH { RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION }] [ FOR REPLICATION ] AS sql_statements 功能: 修改存储过程。
![9.1.4 修改存储过程 SQL命令格式: ALTER PROC [ EDURE ] procedure_name [ ; number ]](http://slidesplayer.com/slide/11418122/61/images/347/9.1.4+%E4%BF%AE%E6%94%B9%E5%AD%98%E5%82%A8%E8%BF%87%E7%A8%8B+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+ALTER+PROC+%5B+EDURE+%5D+procedure_name+%5B+%3B+number+%5D.jpg "9.1.4 修改存储过程. SQL命令格式: ALTER PROC [ EDURE ] procedure_name [ ; number ] [ data_type } [ VARYING ] [ 0= default ] [ OUTPUT ] ] [ ,...n ] [ WITH { RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION }] [ FOR REPLICATION ] AS. sql_statements. 功能: 修改存储过程。")
348
例:按姓名查看学生信息 ALTER PROCEDURE GetStudent @name varchar(8) AS SELECT * FROM 学生 WHERE EXECUTE GetStudent ‘周康' 按学号查看学生信息 CREATE PROCEDURE GetStudent @no varchar(10) AS SELECT * FROM 学生 WHERE EXECUTE GetStudent ‘060101'
 AS. SELECT * FROM 学生. WHERE EXECUTE GetStudent ‘")
349
9.1.5 删除存储过程 例:DROP PROCEDURE GetStudent SQL命令格式:
删除存储过程 SQL命令格式: DROP PROCEDURE { procedure } [ ,...n ] 功能: 从当前数据库中删除一个或多个存储过程或存储过程组。 例:DROP PROCEDURE GetStudent

350
CREATE PROCEDURE sum1to10
As DECLARE @i int /* 循环条件 */ BEGIN SET set END PRINT @s /* 输出结果 */

351
9.2 触发器 触发器概述 创建触发器 修改触发器 删除触发器

352
触发器概述 1.什么是触发器 触发器(Trigger)是一种特殊类型的存储过程,触发器采用事件驱动机制,当某个触发事件发生时,定义在触发器中的功能将被DBMS自动执行。 触发器与表紧密相连,可以看作是表定义的一部分,不可能通过名称被直接调用,不允许参数,而是当用户对表中的数据进行修改时,自动执行。 2、SQL Server 中的常用的触发器: INSERT触发器 UPDATE触发器 DELETE触发器

353
9.2.1 触发器概述 3.触发器支持的功能 (1)触发器在触发事件执行之后被触发,方可完成事件本身的功能;
触发器概述 3.触发器支持的功能 (1)触发器在触发事件执行之后被触发,方可完成事件本身的功能; (2)触发器代码可以引用事件中对于行修改前后的值; (3)对于UPDATE事件可以定义对哪个表、或表中的哪一列被修改时,触发器被触发; (4)可以用WHEN子句来指定执行条件,当触发器被触发后,触发器功能代码只有在条件成立时才执行; (5)触发器有语句级触发器和行级触发器之分; (6)触发器可以完成一些复杂的数据检查,可以实现某些操作的前后处理等。
触发器在触发事件执行之后被触发,方可完成事件本身的功能; (2)触发器代码可以引用事件中对于行修改前后的值; (3)对于UPDATE事件可以定义对哪个表、或表中的哪一列被修改时,触发器被触发; (4)可以用WHEN子句来指定执行条件,当触发器被触发后,触发器功能代码只有在条件成立时才执行; (5)触发器有语句级触发器和行级触发器之分; (6)触发器可以完成一些复杂的数据检查,可以实现某些操作的前后处理等。")
354
9.2.1 触发器概述 3. 触发器的主要优点 (1)触发器能够实施比“外键约束”、“检查约束”和“规则”等对象更为复杂的数据完整性检验;
触发器概述 3. 触发器的主要优点 (1)触发器能够实施比“外键约束”、“检查约束”和“规则”等对象更为复杂的数据完整性检验; (2)和约束相比,触发器提供了更多的灵活性。约束将系统错误信息返回给用户,但这些错误并不是总能有帮助,而触发器则可以打印错误信息,调用其他存储过程,或根据需要纠正错误; (3)无论对表中的数据进行何种修改,增加、删除或更新,触发器都能被激活,对数据实施完整性检查; (4)触发器能够级联修改数据库中的表。
触发器能够实施比 外键约束 、 检查约束 和 规则 等对象更为复杂的数据完整性检验; (2)和约束相比,触发器提供了更多的灵活性。约束将系统错误信息返回给用户,但这些错误并不是总能有帮助,而触发器则可以打印错误信息,调用其他存储过程,或根据需要纠正错误; (3)无论对表中的数据进行何种修改,增加、删除或更新,触发器都能被激活,对数据实施完整性检查; (4)触发器能够级联修改数据库中的表。")
355
9.2.2 创建触发器 1. 使用企业管理器创建触发器 操作步骤如下: (1)启动SQL Server企业管理器。
创建触发器 1. 使用企业管理器创建触发器 操作步骤如下: (1)启动SQL Server企业管理器。 (2)在“控制台根目录”窗口,展开“SQL Server组”,首先,选择“数据库”,然后,选择要建触发器“表”,单击鼠标右键,打开快捷菜单。 (3)在打开快捷菜单中,依次选择“所有任务”→“管理触发器”菜单命令,进入“触发器属性”窗口。 (4)在“触发器属性”窗口,在文本框中输入触发器过程代码,单击“确定”,结束触发器的创建,返回“控制台根目录”窗口。 (5)在“控制台根目录”窗口,选择“表”,单击鼠标右键,打开快捷菜单。 (6)在打开快捷菜单中,依次选择“打开表”→“返回所有行”菜单命令,进入“表”窗口。 (7)在“表”窗口,向“表” 输入数据,当写入数据时,因有非法数据,将弹出一个对话框,提示用户写入数据不合法,触发器事件代码被触发。
启动SQL Server企业管理器。 (2)在 控制台根目录 窗口,展开 SQL Server组 ,首先,选择 数据库 ,然后,选择要建触发器 表 ,单击鼠标右键,打开快捷菜单。 (3)在打开快捷菜单中,依次选择 所有任务 → 管理触发器 菜单命令,进入 触发器属性 窗口。 (4)在 触发器属性 窗口,在文本框中输入触发器过程代码,单击 确定 ,结束触发器的创建,返回 控制台根目录 窗口。 (5)在 控制台根目录 窗口,选择 表 ,单击鼠标右键,打开快捷菜单。 (6)在打开快捷菜单中,依次选择 打开表 → 返回所有行 菜单命令,进入 表 窗口。 (7)在 表 窗口,向 表 输入数据,当写入数据时,因有非法数据,将弹出一个对话框,提示用户写入数据不合法,触发器事件代码被触发。")
356
2.使用SQL命令创建触发器 创建触发器可用CREATE TRIGGER语句。 SQL命令格式: CREATE TRIGGER trigger_name ON { table } [ WITH ENCRYPTION ] { FOR { [DELETE] [,] [INSERT] [,] [UPDATE] } [ NOT FOR REPLICATION ] AS { sql_statements [ ...n ] } |{ FOR { [,] [INSERT] [,] [UPDATE] } [ { IF UPDATE ( column ) [ { AND | OR } UPDATE ( column ) ] sql_statements [ ...n ] } 功能: 创建一个触发器。
![2.使用SQL命令创建触发器 创建触发器可用CREATE TRIGGER语句。 SQL命令格式: CREATE TRIGGER trigger_name ON { table } [ WITH ENCRYPTION ]](http://slidesplayer.com/slide/11418122/61/images/356/2.%E4%BD%BF%E7%94%A8SQL%E5%91%BD%E4%BB%A4%E5%88%9B%E5%BB%BA%E8%A7%A6%E5%8F%91%E5%99%A8+%E5%88%9B%E5%BB%BA%E8%A7%A6%E5%8F%91%E5%99%A8%E5%8F%AF%E7%94%A8CREATE+TRIGGER%E8%AF%AD%E5%8F%A5%E3%80%82+SQL%E5%91%BD%E4%BB%A4%E6%A0%BC%E5%BC%8F%EF%BC%9A+CREATE+TRIGGER+trigger_name+ON+%7B+table+%7D+%5B+WITH+ENCRYPTION+%5D.jpg "{ FOR { [DELETE] [,] [INSERT] [,] [UPDATE] } [ NOT FOR REPLICATION ] AS. { sql_statements [ ...n ] } |{ FOR { [,] [INSERT] [,] [UPDATE] } [ { IF UPDATE ( column ) [ { AND | OR } UPDATE ( column ) ] sql_statements [ ...n ] } 功能: 创建一个触发器。")
357
trigger_name:触发器名称。 WITH ENCRYPTION:对语句文本进行加密。 NOT FOR REPLICATION:当复制进程更改触发器所 涉及的表时,不执行该触发器。 IF UPDATE:指定对表中字段进行增加或修改内容 时起作用,不能用于删除操作。

358
9.2.3 修改触发器 1. 使用企业管理器修改触发器 修改触发器可以在“触发器属性”窗口进行,与创建触发器过程相同。
修改触发器 1. 使用企业管理器修改触发器 修改触发器可以在“触发器属性”窗口进行,与创建触发器过程相同。 2.使用SQL命令修改触发器 SQL命令格式: ALTER TRIGGER trigger_name ON ( table | view ) [ WITH ENCRYPTION ] { ( FOR | AFTER | INSTEAD OF ) { [ DELETE ] [ , ] [ INSERT ] [ , ] [ UPDATE ] } [ NOT FOR REPLICATION ] AS sql_statements } 功能: 修改触发器。
 [ WITH ENCRYPTION ] { ( FOR | AFTER | INSTEAD OF ) { [ DELETE ] [ , ] [ INSERT ] [ , ] [ UPDATE ] } [ NOT FOR REPLICATION ] AS sql_statements } 功能: 修改触发器。")
359
9.2.4 删除触发器 利用DROP TRIGGER可删除触发器。 SQL命令格式:
删除触发器 利用DROP TRIGGER可删除触发器。 SQL命令格式: DROP TRIGGER { trigger } [ ,...n ] 功能:从当前数据库中删除一个或多个触发器。

360
注意:此命令在查询设计器里输入 例1:为成绩表设置触发器:插入和更新规则要求成绩grade的值必须在0~100之间。
CREATE TRIGGER test1 ON 成绩 FOR INSERT ,update AS if EXISTS( select * from 成绩 where 成绩>100 or 成绩<0) begin raiserror('成绩必须在0到100之间',11,1) rollback transaction end 注意:此命令在查询设计器里输入
 begin. raiserror( 成绩必须在0到100之间 ,11,1) rollback transaction. end. 注意:此命令在查询设计器里输入.")
361
例:为学生表设置触发器:插入和更新规则要求性别的值只能是男或女。
CREATE TRIGGER t1 ON 学生 FOR INSERT, UPDATE AS if exists(select * from 学生 where 性别 not in('男','女')) begin raiserror('性别的值只能是男或女',11,1) rollback transaction end
) begin. raiserror( 性别的值只能是男或女 ,11,1) rollback transaction. end.")
362
事务(Transaction) 1、定义 一个数据库操作序列,一个不可分割的工作单元,这个执行单元要么成功完成所有操作,要么就是失败,并将所作的一切复原。 2、定义方式 BEGIN TRANSACTION SQL 语句1 。。。。。 ROLLBACK TRANSACTION SQL 语句2 。。。。。 COMMIT TRANSACTION

363
二、事务的特性(ACID特性) ⑴ 原子性 原子性是指事务内的操作要么都被执行,要么都不被执行。 ⑵ 一致性 一致性是指在事务开始前和结束后,所有的数据都必须处于一致性的状态。由事务引发的从一种状态到另一种状态的变化是一致的。 ⑶ 隔离性 隔离性是事务是独立的。它不与数据库的其他事务交互或冲突。 ⑷ 永久性 永久性指如果事务正常结束,则它对数据库所做的修改应是永久地保存。

364
例如,银行转账事务,这个事务把一笔金额从一个账户甲转给另一个账户乙。
BEGIN TRANSACTION 读账户甲的余额BALANCE BALANCE=BALANCE-AMOUNT (AMOUNT 为转账金额) 写回BALANCE IF(BALANCE < 0 ) THEN { RAISERROR(打印‘金额不足,不能转账’,11,1) ROLLBACK TRANSACTION (回滚语句,撤销刚才的修改,恢复事务) } ELSE 读账户乙的余额BALANCE1 BALANCE1=BALANCE1+AMOUNT 写回BALANCE1 COMMIT TRANSACTION (提交语句,使得自从事务开始以来所执行的所有数据修改成为数据库的永久部分,标志一个事物的结束)
 写回BALANCE. IF(BALANCE < 0 ) THEN. { RAISERROR(打印‘金额不足,不能转账’,11,1) ROLLBACK TRANSACTION (回滚语句,撤销刚才的修改,恢复事务) } ELSE. 读账户乙的余额BALANCE1. BALANCE1=BALANCE1+AMOUNT. 写回BALANCE1. COMMIT TRANSACTION (提交语句,使得自从事务开始以来所执行的所有数据修改成为数据库的永久部分,标志一个事物的结束)")
365
小 结 存储过程的优点? 创建存储过程和执行存储过程的方法? 触发器的作用? 如何定义和验证触发器? 事务的特点?

366
INSERT、 UPDATE 、 DELETE , 比check约束更细化
复习提问 创建存储过程的命令? 使用存储过程的优点? 触发器的类型?触发器与check约束的区别? 事务是一组不可分割的命令序列,该命令序列要么都执行,要么都不执行,体现了事务的什么特性? CREATE PROCEDURE 共享性 网络流量小 执行效率高 INSERT、 UPDATE 、 DELETE , 比check约束更细化 原子性

367
第10章 SQL Server的安全管理 数据库安全性 问题的提出 数据库的一大特点是数据可以共享 数据共享必然带来数据库的安全性问题
数据库系统中的数据共享不能是无条件的共享 例: 军事秘密、国家机密、新产品实验数据、 市场需求分析、市场营销策略、销售计划、 客户档案、医疗档案、银行储蓄数据 数据库安全性

368
10.1 SQL Server 的安全机制 在SQL Server系统中,主要安全保障措施有用户身份验证和用户权限管理两个方面。
(2)必须是该数据库用户,或是数据库某一角色成员; (3)在对数据库进行操作时,必须通过用户权限验证。
必须是该数据库用户,或是数据库某一角色成员; (3)在对数据库进行操作时,必须通过用户权限验证。")
369
10.2 安全认证模式 SQL Server系统的安全认证模式(身份认证)是系统确认用户的方式,系统用Windows 认证模式和SQL Server认证模式两种认证模式类型验证用户的身份。 不论是哪一种认证模式,在SQL Server系统有一个特殊的默认用户账号(sa:系统管理员),拥有这个用户账号的用户具有操作SQL Server服务器的一切权限。若想保证SQL Server服务器的安全,首先要保证sa账号的安全。
,拥有这个用户账号的用户具有操作SQL Server服务器的一切权限。若想保证SQL Server服务器的安全,首先要保证sa账号的安全。")
370
10.2.1 Windows 认证模式 用户登录Windows时进行身份认证,登录SQL Server时不再进行身份验证。
(1)必须将Windows NT网络账号加入到SQL Server中,才能采用Windows NT网络账号登录SQL Server; (2)如果使用Windows NT网络账号登录到另一个网络的SQL Server时,必须在Windows NT网络中设置彼此的托管权限。
必须将Windows NT网络账号加入到SQL Server中,才能采用Windows NT网络账号登录SQL Server; (2)如果使用Windows NT网络账号登录到另一个网络的SQL Server时,必须在Windows NT网络中设置彼此的托管权限。")
371
10.2.2 SQL Server认证模式 SQL Server认证模式是SQL Server服务器要对登录的用户进行身份验证。
对于Windows 9x系列的操作系统只能使用SQL Server认证模式,而当SQL Server在Windows NT或 Windows 2000上运行时,系统管理员可将用户登录认证模式类型设置为Windows 认证模式和混合模式。

372
例:使用企业管理器,创建SQL Server认证模式的登录账号。
1、以管理员的身份启动企业管理器,展开“服务器根目录”结点。 2、依次展开“安全性”、“登录”结点,单击鼠标右键,选择“新建登录”,进入“SQL server登录属性”对话框。 3、选择“常规”选项卡,选择“SQL Server身份验证”单选按钮,在“名称”文本框中输入用户名,在“密码”文本框中输入用户密码,“确定”。

373
身份验证 当用户登录账号创建完成后,用户便可以选择与所创建的身份认证模式相符的方式登录,一经系统验证是合法用户,便可进入SQL Server系统。

374
10.3 用户权限管理 SQL Server用户 服务器角色 数据库角色

375
10.3.1 SQL Server用户 用户访问数据库的操作权限如下:
(1) 在当前数据库中创建数据库对象及进行数据库备份的权限(如:创建表、视图、存储过程、规则、缺省值对象、函数的权限及备份数据库、日志文件等)。 操作:在数据库属性中设置 (2) 用户对数据库表的操作权限及执行存储过程的权限。 操作:在表属性中设置 (3) 用户对数据库中指定表列的操作权限。
 在当前数据库中创建数据库对象及进行数据库备份的权限(如:创建表、视图、存储过程、规则、缺省值对象、函数的权限及备份数据库、日志文件等)。 操作:在数据库属性中设置. (2) 用户对数据库表的操作权限及执行存储过程的权限。 操作:在表属性中设置. (3) 用户对数据库中指定表列的操作权限。")
376
10.3.2 服务器角色 SQL Server服务器有8种固定服务器角色(可多选): (1)Sysadmin (系统管理员)
(2)Dbcreator (数据库创建者) (3)Setupadmin (安装管理员) (4)Diskadmin (磁盘管理员) (5)Processadmin (进程管理员) (6)Securityadmin (安全管理员) (7)Serveradmin (服务器管理员) (8)Bulkadmin (块拷贝管理员)
Dbcreator (数据库创建者) (3)Setupadmin (安装管理员) (4)Diskadmin (磁盘管理员) (5)Processadmin (进程管理员) (6)Securityadmin (安全管理员) (7)Serveradmin (服务器管理员) (8)Bulkadmin (块拷贝管理员)")
377
10.3.3 数据库角色 数据库角色就是具有某项特定数据库操作权限的用户组,有固定数据库角色和用户数据库角色两种。
1.固定数据库角色,每个数据库中都存在的系统预定义用户组。提供了对数据库常用操作的权限,系统中固定数据库角色: 操作:在数据库中操作,向某一角色中添加用户。 (1)Public (2)db_owner (3)db_accessadmin (4)db_securityadmin (5)db_ddladmin (DDL管理员) (6)db_backupoperator (备份操作员) (7)db_datareader (8)db_datawriter (数据写入者) (9)db_denydatareader (10)db_denydatawriter p182
Public. (2)db_owner. (3)db_accessadmin. (4)db_securityadmin. (5)db_ddladmin (DDL管理员) (6)db_backupoperator (备份操作员) (7)db_datareader. (8)db_datawriter (数据写入者) (9)db_denydatareader. (10)db_denydatawriter. p182.")
378
10.3.3 数据库角色 2.用户数据库角色(在数据库中创建)
用户数据库角色与固定的数据库角色一样,具有一定的操作权限。因此,创建数据库角色,一是要创建角色,二是要定义角色的权限,从而用于管理同类角色成员使用数据库的权限。

379
10.4 数据库安全性控制概述 一、非法使用数据库的情况 编写合法程序绕过DBMS及其授权机制 直接或编写应用程序执行非授权操作
10.4 数据库安全性控制概述 一、非法使用数据库的情况 编写合法程序绕过DBMS及其授权机制 直接或编写应用程序执行非授权操作 通过多次合法查询数据库从中推导出一些保密数据

380
二、数据库安全性控制的常用方法 1、用户标识和鉴定(用户口令加密) 2、存取控制(定义用户和角色的权限、合法权限检查 ) 3、视图 4、审计:找出非法存取数据的人、时间和内容 (在企业管理器的本地服务器下的“管理”下的“SQL Server日志”中查看) 5、密码存储

381
三、操作练习 1、在企业管理器中建立新用户user1 ,密码为user1,数据库访问设置为‘学生管理”。(此时对表没有任何权限)
")
382
2、验证:在查询分析器中以user1身份连接数据库服务器。该用户无权访问的trainning数据库将看不到。
执行 select * from 学生 ,update 学生 set 班级编号=’1’ 和create table s1(no char(5))命令将被拒绝。
)命令将被拒绝。")
383
3、解决方法:到企业管理器中,将“学生管理”数据库的属性中的权限做修改。 将“学生”表的属性中的权限做修改。

384
4、设置学生表的属性的列权限,使user1用户只有对部分列的select权限,则以user1身份执行select * from 学生 将不成功。

385
5、以user1身份执行create database db1命令,将被拒绝。
解决方法:修改user1用户属性,将服务器角色设置为“database creators”

386
6、以user1身份执行select * from 成绩 会因没有权限被拒绝。
数据库角色设置:在企业管理器中找到“学生管理”数据库的“角色”,修改db_owner角色的属性,将user1添加到角色中。 验证:以user1身份执行select * from 成绩 ; drop table 系;等均成功。

387
7、 建立用户角色:在企业管理器中的学生管理数据库中建立新角色teacher,该角色对学生、教师、成绩等表有不同程度的访问权限。
(此时t1用户对任何表没有任何权限),将用户t1添加到teacher角色中,t1将自动得到teacher角色的全部授权。
,将用户t1添加到teacher角色中,t1将自动得到teacher角色的全部授权。")
388
8、建立视图score_01_01,可查看01-01号课程的信息。
视图授权:user1用户具有对该视图的全部权限。 验证:user1用户得到授权后,对score_01_01执行select,update,delete等命令均成功,但仍然没有对成绩表的任何权限,形成对01-01号课程以外数据的保护

389
四、存取控制的命令实现方法 通过 SQL 的 GRANT 语句和 REVOKE 语句实现
定义用户存取权限:定义用户可以在哪些数据库对象上进行哪些类型的操作

390
关系数据库系统中存取控制对象 对象类型 对象 操 作 类 型 数据库 模式 CREATE SCHEMA 基本表
CREATE TABLE,ALTER TABLE 视图 CREATE VIEW 索引 CREATE INDEX 数据 基本表和视图 SELECT,INSERT,UPDATE,DELETE,REFERENCES, ALL PRIVILEGES 属性列 SELECT,INSERT,UPDATE, REFERENCES

391
GRANT <权限>[,<权限>]... [ON <对象名>]
DBA 数据库对象创建者 (即属主Owner) 拥有该权限的用户 接受权限的用户 一个或多个具体用户 PUBLIC(全体用户) 1、GRANT 语法: GRANT <权限>[,<权限>]... [ON <对象名>] TO <用户>[,<用户>]... [WITH GRANT OPTION]; 语义:将对指定操作对象的指定操作权限授予指定的用户
![GRANT <权限>[,<权限>]... [ON <对象名>]](http://slidesplayer.com/slide/11418122/61/images/391/GRANT+%3C%E6%9D%83%E9%99%90%3E%5B%2C%3C%E6%9D%83%E9%99%90%3E%5D...+%5BON+%3C%E5%AF%B9%E8%B1%A1%E5%90%8D%3E%5D.jpg "DBA. 数据库对象创建者. (即属主Owner) 拥有该权限的用户. 接受权限的用户. 一个或多个具体用户. PUBLIC(全体用户) 1、GRANT. 语法: GRANT <权限>[,<权限>]... [ON <对象名>] TO <用户>[,<用户>]... [WITH GRANT OPTION]; 语义:将对指定操作对象的指定操作权限授予指定的用户.")
392
WITH GRANT OPTION子句 WITH GRANT OPTION子句: 指定:可以再授予 没有指定:不能传播 不允许循环授权

393
例题 [例1] 把查询tra_student表权限授给用户U1 GRANT SELECT ON tra_student TO U1
![例题 [例1] 把查询tra_student表权限授给用户U1 GRANT SELECT ON tra_student TO U1](http://slidesplayer.com/slide/11418122/61/images/393/%E4%BE%8B%E9%A2%98+%5B%E4%BE%8B1%5D+%E6%8A%8A%E6%9F%A5%E8%AF%A2tra_student%E8%A1%A8%E6%9D%83%E9%99%90%E6%8E%88%E7%BB%99%E7%94%A8%E6%88%B7U1+GRANT+SELECT+ON+tra_student+TO+U1.jpg "例题 [例1] 把查询tra_student表权限授给用户U1 GRANT SELECT ON tra_student TO U1")
394
例题(续) [例2] 把对tra_student表和tra_course表的全部权限授予用户U2和U3
GRANT ALL PRIVILEGES ON tra_student, tra_course TO U2, U3;
![例题(续) [例2] 把对tra_student表和tra_course表的全部权限授予用户U2和U3](http://slidesplayer.com/slide/11418122/61/images/394/%E4%BE%8B%E9%A2%98%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B2%5D+%E6%8A%8A%E5%AF%B9tra_student%E8%A1%A8%E5%92%8Ctra_course%E8%A1%A8%E7%9A%84%E5%85%A8%E9%83%A8%E6%9D%83%E9%99%90%E6%8E%88%E4%BA%88%E7%94%A8%E6%88%B7U2%E5%92%8CU3.jpg "GRANT ALL PRIVILEGES. ON tra_student, tra_course. TO U2, U3;")
395
例题(续) [例3] 把对表tra_chooseclass的查询权限授予所有用户 GRANT SELECT
ON tra_chooseclass TO PUBLIC
![例题(续) [例3] 把对表tra_chooseclass的查询权限授予所有用户 GRANT SELECT](http://slidesplayer.com/slide/11418122/61/images/395/%E4%BE%8B%E9%A2%98%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B3%5D+%E6%8A%8A%E5%AF%B9%E8%A1%A8tra_chooseclass%E7%9A%84%E6%9F%A5%E8%AF%A2%E6%9D%83%E9%99%90%E6%8E%88%E4%BA%88%E6%89%80%E6%9C%89%E7%94%A8%E6%88%B7+GRANT+SELECT.jpg "ON tra_chooseclass. TO PUBLIC.")
396
例题(续) [例4] 把查询tra_student表和修改学生学号的权限授给用户U4
GRANT UPDATE(stu_id), SELECT ON tra_student TO U4; 对属性列的授权时必须明确指出相应属性列名
![例题(续) [例4] 把查询tra_student表和修改学生学号的权限授给用户U4](http://slidesplayer.com/slide/11418122/61/images/396/%E4%BE%8B%E9%A2%98%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B4%5D+%E6%8A%8A%E6%9F%A5%E8%AF%A2tra_student%E8%A1%A8%E5%92%8C%E4%BF%AE%E6%94%B9%E5%AD%A6%E7%94%9F%E5%AD%A6%E5%8F%B7%E7%9A%84%E6%9D%83%E9%99%90%E6%8E%88%E7%BB%99%E7%94%A8%E6%88%B7U4.jpg "GRANT UPDATE(stu_id), SELECT. ON tra_student. TO U4; 对属性列的授权时必须明确指出相应属性列名.")
397
例题(续) [例5] 把对表tra_chooseclas的INSERT权限授予U5用户,并允许他再将此权限授予其他用户
GRANT INSERT ON tra_chooseclass TO U5 WITH GRANT OPTION
![例题(续) [例5] 把对表tra_chooseclas的INSERT权限授予U5用户,并允许他再将此权限授予其他用户](http://slidesplayer.com/slide/11418122/61/images/397/%E4%BE%8B%E9%A2%98%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B5%5D+%E6%8A%8A%E5%AF%B9%E8%A1%A8tra_chooseclas%E7%9A%84INSERT%E6%9D%83%E9%99%90%E6%8E%88%E4%BA%88U5%E7%94%A8%E6%88%B7%EF%BC%8C%E5%B9%B6%E5%85%81%E8%AE%B8%E4%BB%96%E5%86%8D%E5%B0%86%E6%AD%A4%E6%9D%83%E9%99%90%E6%8E%88%E4%BA%88%E5%85%B6%E4%BB%96%E7%94%A8%E6%88%B7.jpg "GRANT INSERT. ON tra_chooseclass. TO U5. WITH GRANT OPTION.")
398
传播权限 执行例5后,U5不仅拥有了对表tra_chooseclass的INSERT权限, 还可以传播此权限:
[例6] GRANT INSERT ON tra_chooseclass TO U6 WITH GRANT OPTION 同样,U6还可以将此权限授予U7: [例7] GRANT INSERT ON tra_chooseclass TO U7 但U7不能再传播此权限。

399
2、REVOKE 授予的权限可以由DBA或其他授权者用REVOKE语句收回 REVOKE语句的一般格式为:
[ON <对象名>] FROM <用户>[,<用户>]...;

400
[例8] 把用户U4修改学生学号的权限收回 REVOKE UPDATE(stu_id) ON tra_student FROM U4
![[例8] 把用户U4修改学生学号的权限收回 REVOKE UPDATE(stu_id) ON tra_student FROM U4](http://slidesplayer.com/slide/11418122/61/images/400/%5B%E4%BE%8B8%5D+%E6%8A%8A%E7%94%A8%E6%88%B7U4%E4%BF%AE%E6%94%B9%E5%AD%A6%E7%94%9F%E5%AD%A6%E5%8F%B7%E7%9A%84%E6%9D%83%E9%99%90%E6%94%B6%E5%9B%9E+REVOKE+UPDATE%28stu_id%29+ON+tra_student+FROM+U4.jpg "[例8] 把用户U4修改学生学号的权限收回 REVOKE UPDATE(stu_id) ON tra_student FROM U4")
401
REVOKE(续) [例9] 收回所有用户对表tra_chooseclass的查询权限 REVOKE SELECT
ON tra_chooseclass FROM PUBLIC
![REVOKE(续) [例9] 收回所有用户对表tra_chooseclass的查询权限 REVOKE SELECT](http://slidesplayer.com/slide/11418122/61/images/401/REVOKE%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B9%5D+%E6%94%B6%E5%9B%9E%E6%89%80%E6%9C%89%E7%94%A8%E6%88%B7%E5%AF%B9%E8%A1%A8tra_chooseclass%E7%9A%84%E6%9F%A5%E8%AF%A2%E6%9D%83%E9%99%90+REVOKE+SELECT.jpg "ON tra_chooseclass. FROM PUBLIC.")
402
REVOKE(续) [例10] 把用户U5对tra_chooseclas 表的INSERT权限收回 REVOKE INSERT
ON tra_chooseclas FROM U5 CASCADE 用户U5的INSERT权限收回的时候必须级联(CASCADE)收回 对于级联的用户,系统只收回他直接或间接从U5处获得的权限 .
![REVOKE(续) [例10] 把用户U5对tra_chooseclas 表的INSERT权限收回 REVOKE INSERT](http://slidesplayer.com/slide/11418122/61/images/402/REVOKE%EF%BC%88%E7%BB%AD%EF%BC%89+%5B%E4%BE%8B10%5D+%E6%8A%8A%E7%94%A8%E6%88%B7U5%E5%AF%B9tra_chooseclas+%E8%A1%A8%E7%9A%84INSERT%E6%9D%83%E9%99%90%E6%94%B6%E5%9B%9E+REVOKE+INSERT.jpg "ON tra_chooseclas. FROM U5 CASCADE. 用户U5的INSERT权限收回的时候必须级联(CASCADE)收回. 对于级联的用户,系统只收回他直接或间接从U5处获得的权限 .")
403
3、数据库角色管理 1)数据库角色的创建 CREATE ROLE <角色名> 2)给角色授权
GRANT <权限>[,<权限>]… ON <对象名 > TO <角色>[,<角色>]…

404
3)将一个角色授予其他的角色或用户 GRANT <角色1>[,<角色2>]… TO <角色3>[,<用户1>]… [WITH ADMIN OPTION] 4)角色权限的收回 REVOKE <权限>[,<权限>]… ON <对象名> FROM <角色>[,<角色>]…
![3)将一个角色授予其他的角色或用户 GRANT <角色1>[,<角色2>]… TO <角色3>[,<用户1>]… [WITH ADMIN OPTION] 4)角色权限的收回. REVOKE <权限>[,<权限>]…](http://slidesplayer.com/slide/11418122/61/images/404/3%EF%BC%89%E5%B0%86%E4%B8%80%E4%B8%AA%E8%A7%92%E8%89%B2%E6%8E%88%E4%BA%88%E5%85%B6%E4%BB%96%E7%9A%84%E8%A7%92%E8%89%B2%E6%88%96%E7%94%A8%E6%88%B7+GRANT+%3C%E8%A7%92%E8%89%B21%3E%EF%BC%BB%EF%BC%8C%3C%E8%A7%92%E8%89%B22%3E%EF%BC%BD%E2%80%A6+TO+%3C%E8%A7%92%E8%89%B23%3E%EF%BC%BB%EF%BC%8C%3C%E7%94%A8%E6%88%B71%3E%EF%BC%BD%E2%80%A6+%EF%BC%BBWITH+ADMIN+OPTION%EF%BC%BD+4%EF%BC%89%E8%A7%92%E8%89%B2%E6%9D%83%E9%99%90%E7%9A%84%E6%94%B6%E5%9B%9E.+REVOKE+%3C%E6%9D%83%E9%99%90%3E%EF%BC%BB%EF%BC%8C%3C%E6%9D%83%E9%99%90%3E%EF%BC%BD%E2%80%A6.jpg "ON <对象名> FROM <角色>[,<角色>]…")
405
[例11] 通过角色来实现将一组权限授予一个用户。
步骤如下: 1. 首先创建一个角色 R1 CREATE ROLE R1 2. 然后使用GRANT语句,使角色R1拥有Student表的SELECT、UPDATE、INSERT权限 GRANT SELECT,UPDATE,INSERT ON Student TO R1
![[例11] 通过角色来实现将一组权限授予一个用户。](http://slidesplayer.com/slide/11418122/61/images/405/%5B%E4%BE%8B11%5D+%E9%80%9A%E8%BF%87%E8%A7%92%E8%89%B2%E6%9D%A5%E5%AE%9E%E7%8E%B0%E5%B0%86%E4%B8%80%E7%BB%84%E6%9D%83%E9%99%90%E6%8E%88%E4%BA%88%E4%B8%80%E4%B8%AA%E7%94%A8%E6%88%B7%E3%80%82.jpg "步骤如下: 1. 首先创建一个角色 R1. CREATE ROLE R1. 2. 然后使用GRANT语句,使角色R1拥有Student表的SELECT、UPDATE、INSERT权限. GRANT SELECT,UPDATE,INSERT. ON Student. TO R1.")
406
3. 将这个角色授予王平,张明,赵玲。使他们具有角色R1所包含的全部权限
GRANT R1 TO 王平,张明,赵玲; 4. 可以一次性通过R1来回收王平的这3个权限 REVOKE R1 FROM 王平

407
[例12] 角色的权限修改 GRANT DELETE ON Student TO R1
![[例12] 角色的权限修改 GRANT DELETE ON Student TO R1](http://slidesplayer.com/slide/11418122/61/images/407/%5B%E4%BE%8B12%5D+%E8%A7%92%E8%89%B2%E7%9A%84%E6%9D%83%E9%99%90%E4%BF%AE%E6%94%B9+GRANT+DELETE+ON+Student+TO+R1.jpg "[例12] 角色的权限修改 GRANT DELETE ON Student TO R1")
408
[例13] REVOKE SELECT ON Student FROM R1
![[例13] REVOKE SELECT ON Student FROM R1](http://slidesplayer.com/slide/11418122/61/images/408/%5B%E4%BE%8B13%5D+REVOKE+SELECT+ON+Student+FROM+R1.jpg "[例13] REVOKE SELECT ON Student FROM R1")
409
小 结 数据的共享日益加强,数据的安全保密越来越重要 DBMS是管理数据的核心,因而其自身必须具有一整套完整 而有效的安全性机制
小 结 数据的共享日益加强,数据的安全保密越来越重要 DBMS是管理数据的核心,因而其自身必须具有一整套完整 而有效的安全性机制 实现数据库系统安全性的技术和方法 存取控制技术 视图技术 审计技术 自主存取控制功能 通过SQL 的GRANT语句和REVOKE语句实现 角色 使用角色来管理数据库权限可以简化授权过程

410
复习提问: 1、在SQL Server系统中主要安全保障措施有哪两个方面。 用户身份验证和用户权限管理
Windows 认证模式和SQL Server认证模式 3、数据库安全性控制的常用方法 用户标识和鉴定、存取控制、视图、审计、密码存储 4、 SQL 的授权与收回授权的命令是? GRANT 语句和 REVOKE 语句

411
问题的提出 在数据库系统运行时,可能会出现各种各样的问题,比如,磁盘损坏、电源故障、软件错误和恶意破坏等。在发生故障时,数据库中的数据很可能丢失或遭到破坏。SQL Server系统采取一系列措施保证在任何情况下保持事务的原子性和永久性,确保数据尽可能不丢失、不破坏。系统能把数据库从被破坏、不正确的状态恢复到最近一个正确的状态,DBMS的这种能力称为数据库的可恢复性(Recovery)。
。")
412
第 11 章 备份恢复与数据转换 本章重点: ·备份数据库 ·恢复备份 ·数据的导入导出

413
11.1 备份 11.1.1 备份概述 1.备份内容 2.备份介质(可以是远程介质) 3.备份频率(定时备份,不定时备份)
备份是防止数据丢失和被破坏一个较为理想的方法,在进行备份操作前要根据具体情况制定好数据备份方案,要考虑如下内容。 1.备份内容 2.备份介质(可以是远程介质) 3.备份频率(定时备份,不定时备份)
 3.备份频率(定时备份,不定时备份)")
414
4、备份方法: (1) 完全数据库备份:每次都备份整个数据库,也包括事务日志备份。 (2) 数据库事务日志备份:在两次数据库完全备份期间,进行事务日志备份,所备份的事务日志记录了两次数据库备份之间所有数据库活动记录。 (3) 差异备份:只备份上次数据库备份后发生更改的部分数据。 (4) 数据库文件或文件组备份:只备份特定的数据库文件或文件组,优点:可以分时多次完成备份。 注:第一次备份不能采用差异备份。
 差异备份:只备份上次数据库备份后发生更改的部分数据。 (4) 数据库文件或文件组备份:只备份特定的数据库文件或文件组,优点:可以分时多次完成备份。 注:第一次备份不能采用差异备份。")
415
11.1.2 备份数据库 操作步骤如下: (1)在“控制台根目录”窗口,展开“数据库”,单击鼠标右键,打开快捷菜单。
(2)在打开的快捷菜单中,依次选择“所有任务”→“备份数据库”菜单命令,进入“SQL Server备份”窗口。 (3)在“SQL Server备份”窗口,单击“添加”按钮,进入“选择备份目的”窗口 。 (4)在“选择备份目的”窗口,输入备份文件名(Backup)及其所在的路径(c:\),单击“确定”按钮,返回 “SQL Server备份”窗口。 (5)在“SQL Server备份”窗口,单击“确定”按钮,结束数据库完全备份的操作
在打开的快捷菜单中,依次选择 所有任务 → 备份数据库 菜单命令,进入 SQL Server备份 窗口。 (3)在 SQL Server备份 窗口,单击 添加 按钮,进入 选择备份目的 窗口 。 (4)在 选择备份目的 窗口,输入备份文件名(Backup)及其所在的路径(c:\),单击 确定 按钮,返回 SQL Server备份 窗口。 (5)在 SQL Server备份 窗口,单击 确定 按钮,结束数据库完全备份的操作.")
417
可延期定时执行

418
11.2 恢复备份 恢复概述 恢复能够及时还原和重建数据库,但不是所有的情况下都能够实现恢复操作。当系统发现出现了以下情况时,恢复操作是不能进行的。 (1)使用与被恢复的数据库名称不同的数据库名去恢复数据库; (2)服务器上数据库文件组与备份中的数据库文件组不一致; (3)需恢复的数据库名或文件名与备份的数据库名或文件名不同。
服务器上数据库文件组与备份中的数据库文件组不一致; (3)需恢复的数据库名或文件名与备份的数据库名或文件名不同。")
419
11.2.2 恢复数据库 操作步骤如下: (1)在“控制台根目录”窗口,展开“数据库”。
(2)在“控制台根目录”窗口,依次选择“工具”→“还原数据库”菜单命令,进入“还原数据库”窗口。 (3)在“还原数据库”窗口,首先,选择要恢复的“数据库”,然后,选择“从设备”,再选择“数据库-完全”,最后,单击“确定”按钮,进入“选择还原设备”窗口 。 (4)在“选择还原设备”窗口,选择设备(磁盘),单击“确定”按钮,进入 “选择还原目标”窗口。 (5)在“选择还原目标”窗口,选择还原要使用的文件名,单击“确定”按钮,结束数据库完全还原的操作。
在 控制台根目录 窗口,依次选择 工具 → 还原数据库 菜单命令,进入 还原数据库 窗口。 (3)在 还原数据库 窗口,首先,选择要恢复的 数据库 ,然后,选择 从设备 ,再选择 数据库-完全 ,最后,单击 确定 按钮,进入 选择还原设备 窗口 。 (4)在 选择还原设备 窗口,选择设备(磁盘),单击 确定 按钮,进入 选择还原目标 窗口。 (5)在 选择还原目标 窗口,选择还原要使用的文件名,单击 确定 按钮,结束数据库完全还原的操作。")
422
11.3 数据转换 为了解决数据转换问题,SQL Server系统提供了一个功能非常强大的组件,即数据转换服务
(DTS,Data Transformation Services)。 DTS是一组图形工具和可编程对象,包含DTS导入/导出向导和DTS设计器。 DTS提供了在SQL Server与OLE DB(通向不同的数据源的应用程序接口 )、开放式数据库(ODBC)的数据源、文本格式文件、或Excel工作表之间导入、导出和转换数据的功能。
。 DTS是一组图形工具和可编程对象,包含DTS导入/导出向导和DTS设计器。 DTS提供了在SQL Server与OLE DB(通向不同的数据源的应用程序接口 )、开放式数据库(ODBC)的数据源、文本格式文件、或Excel工作表之间导入、导出和转换数据的功能。")
423
OLE DB 是 一 种 技 术 标 准, 目 的 是 提 供 一 种 统 一 的 数 据 访 问 接 口, 这 里 所 说 的 数 据”, 除 了 标 准 的 关 系 型 数 据 库 中 的 数 据 之 外, 还 包 括 邮 件 数 据、Web 上 的 文 本 或 图 形、 目 录 服 务 (Directory Services), 以 及 主 机 系 统 中其他 数 据。OLE DB 标 准 的 核 心 内 容 就 是 要 求 以 上 这 些 各 种 各 样 的 数 据 存 储(Data Store) 都 提 供 一 种 相 同 的 访 问 接 口, 使 得 数 据 的 使 用 者 ( 应 用 程 序) 可 以 使 用 同 样 的 方 法 访 问 各 种 数 据, 而 不 用 考 虑 数 据 的 具 体 存 储 地 点
, 以 及 主 机 系 统 中其他 数 据。OLE DB 标 准 的 核 心 内 容 就 是 要 求 以 上 这 些 各 种 各 样 的 数 据 存 储(Data Store) 都 提 供 一 种 相 同 的 访 问 接 口, 使 得 数 据 的 使 用 者 ( 应 用 程 序) 可 以 使 用 同 样 的 方 法 访 问 各 种 数 据, 而 不 用 考 虑 数 据 的 具 体 存 储 地 点")
424
11.3.1 数据的导出 以下通过导出Excel 工作表实例,介绍使用DTS导出/导入操作的方法。 操作方法:
(1)在“控制台根目录”窗口,依次选择“工具”→“数据转换服务”→“导出数据” (2)在数据库名字上右击,使用快捷菜单。 操作步骤如下: (1)选择数据源 (2)选择目的数据源 (3)确定导出的文件路径 (4 )选择要导出的表和视图
在 控制台根目录 窗口,依次选择 工具 → 数据转换服务 → 导出数据 (2)在数据库名字上右击,使用快捷菜单。 操作步骤如下: (1)选择数据源. (2)选择目的数据源. (3)确定导出的文件路径. (4 )选择要导出的表和视图.")
425
数据的导入 操作方法和操作步骤与数据导出相似。……

426
例一、SQL Server数据导出到Excel

427
2、在“选择数据源”步骤中,选择被导出数据的驱动类型、
验证方式和数据库名称。

428
3、在‘选择目的’步骤中选择数据目标的驱动类型和
目标文件的位置与名称。

429
4、选择复制类型(直接复制或查询复制)
")
430
5、选择要被导出的数据表

432
转换的结果:

433
例二:将数据表在SQL Server中数据库之间复制。
操作要点: 数据源和目标数据的驱动类型都是‘用于SQL Server的Microsoft OLE DB提供程序’,身份验证都采用“SQL Server身份验证模式”。

434
小 结 数据备份与恢复 备份:数据库文件(第一次不能差异备份) 恢复:文件数据库 使用调度功能延期操作 DTS服务(数据转换服务)
小 结 数据备份与恢复 备份:数据库文件(第一次不能差异备份) 恢复:文件数据库 使用调度功能延期操作 DTS服务(数据转换服务) 数据导出,数据导入 SQLServerAccess SQLServerExcel SQLServerSQLServer
 恢复:文件数据库. 使用调度功能延期操作. DTS服务(数据转换服务) 数据导出,数据导入. SQLServerAccess. SQLServerExcel. SQLServerSQLServer.")

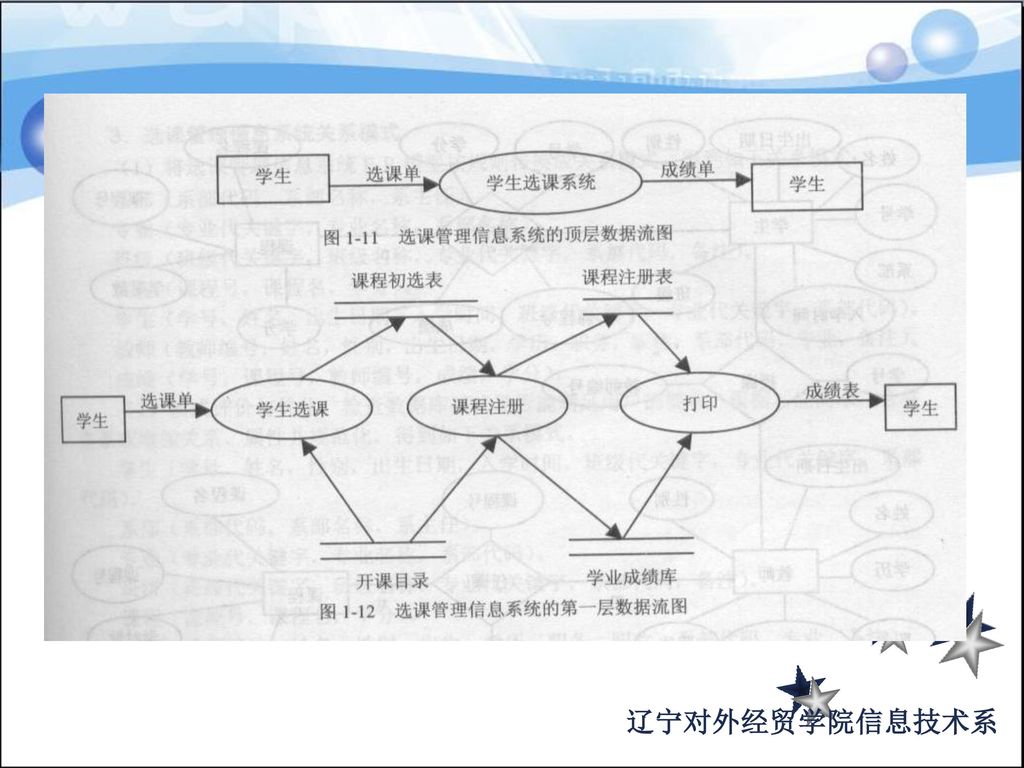
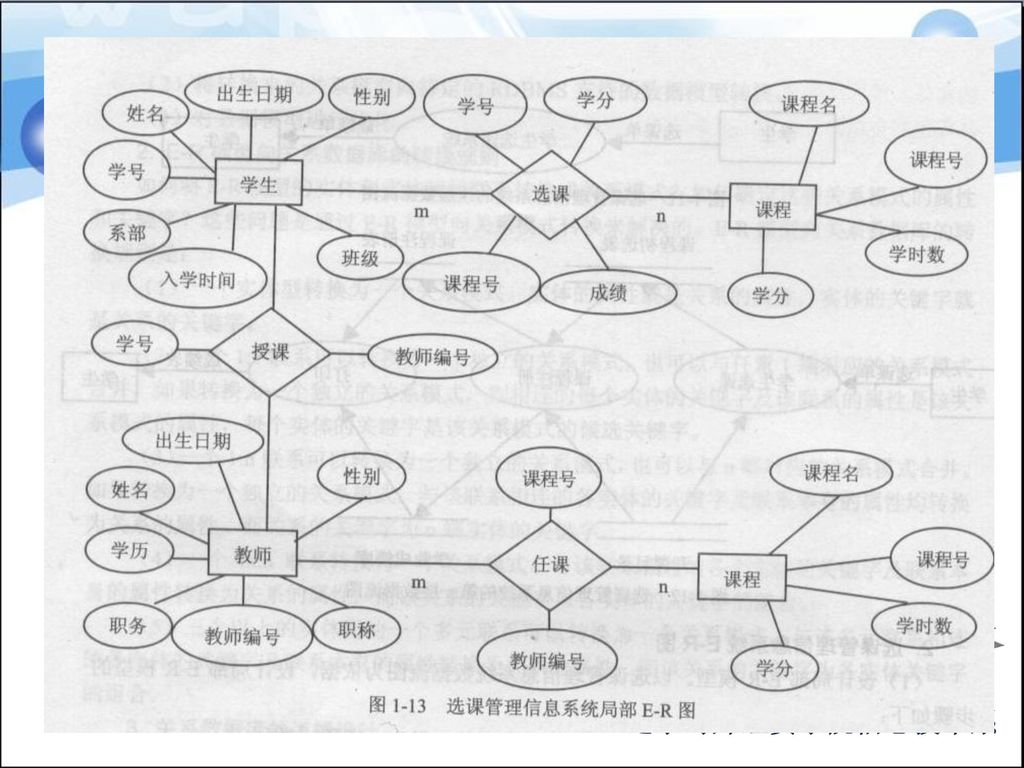
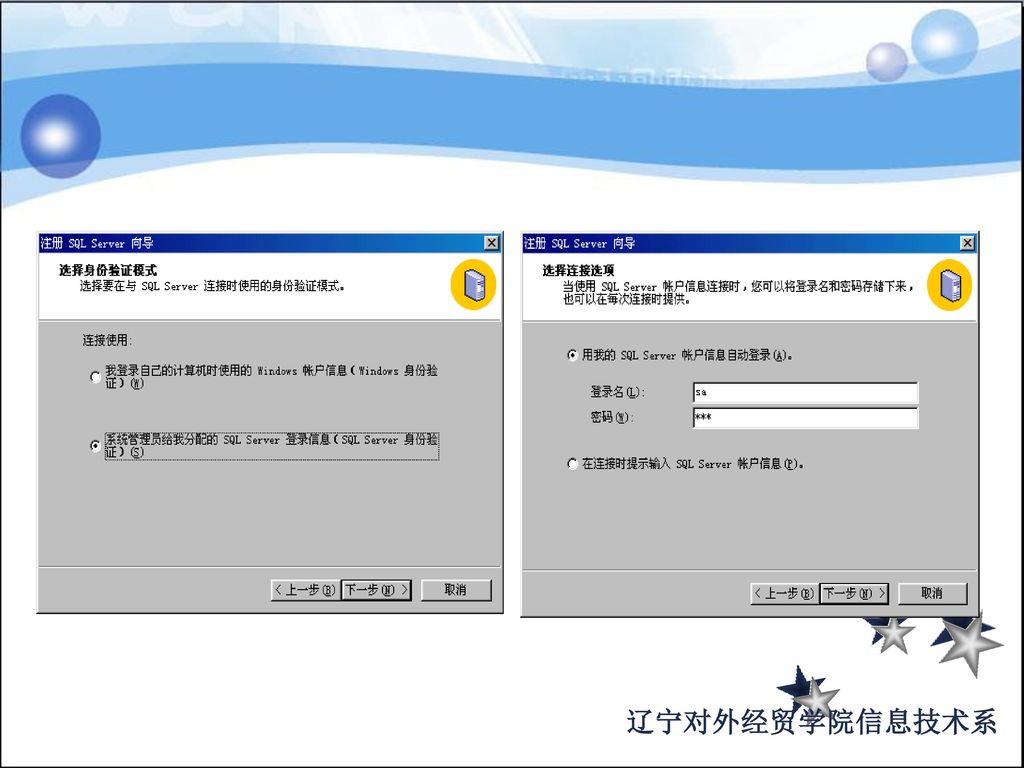
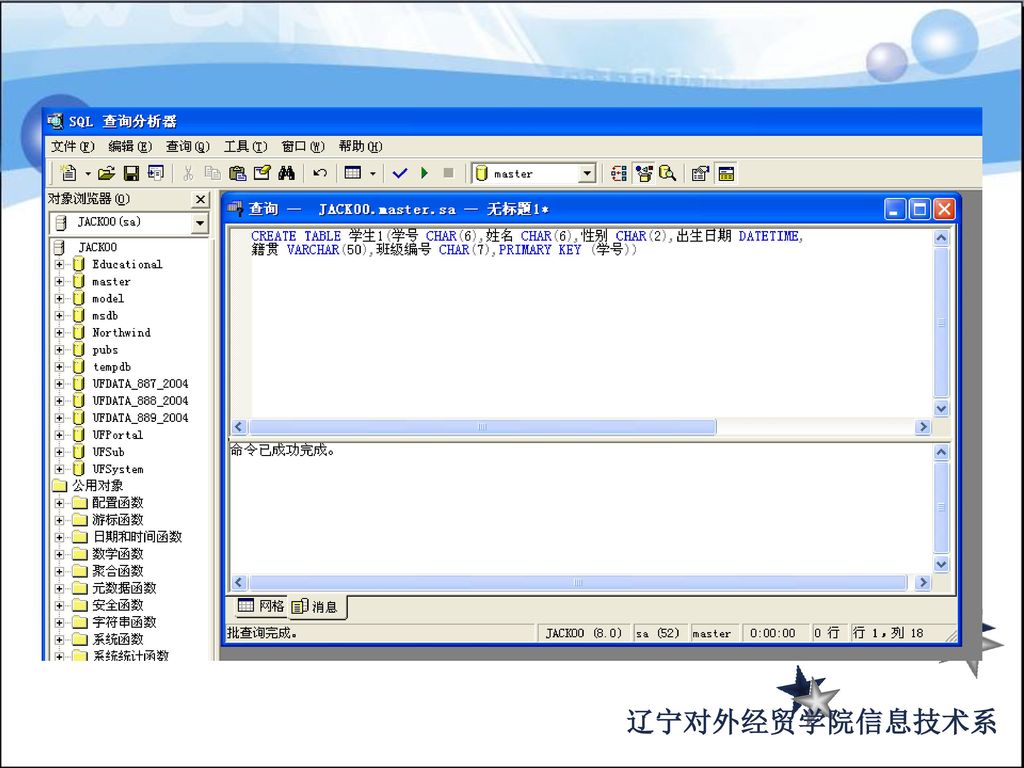
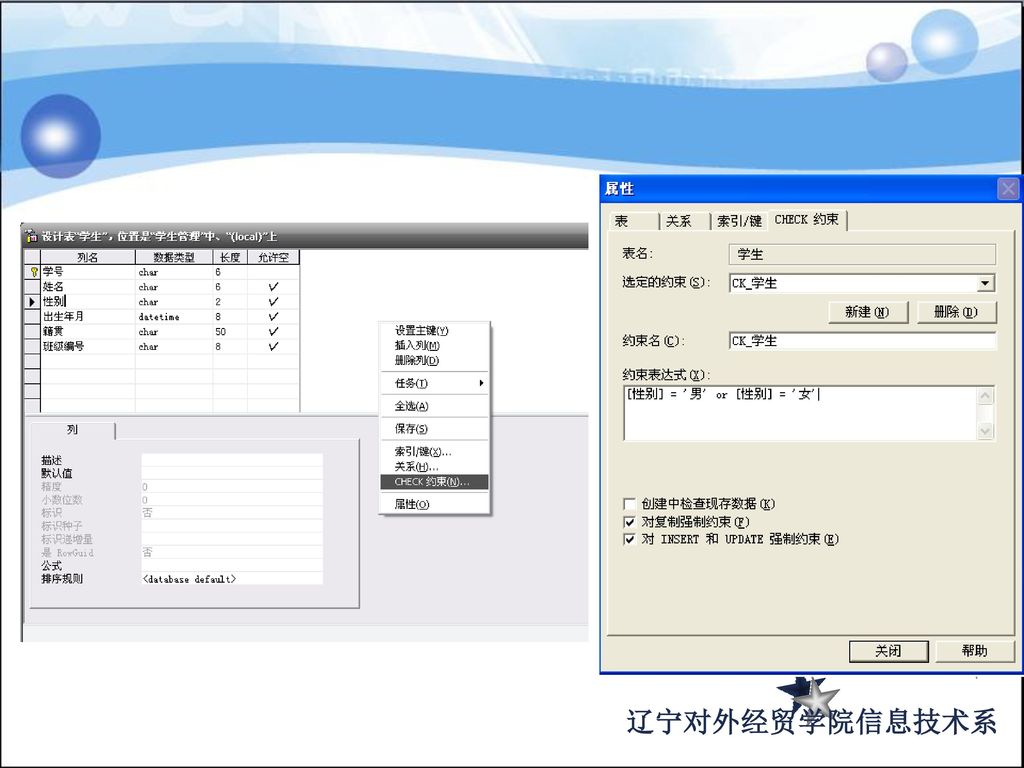
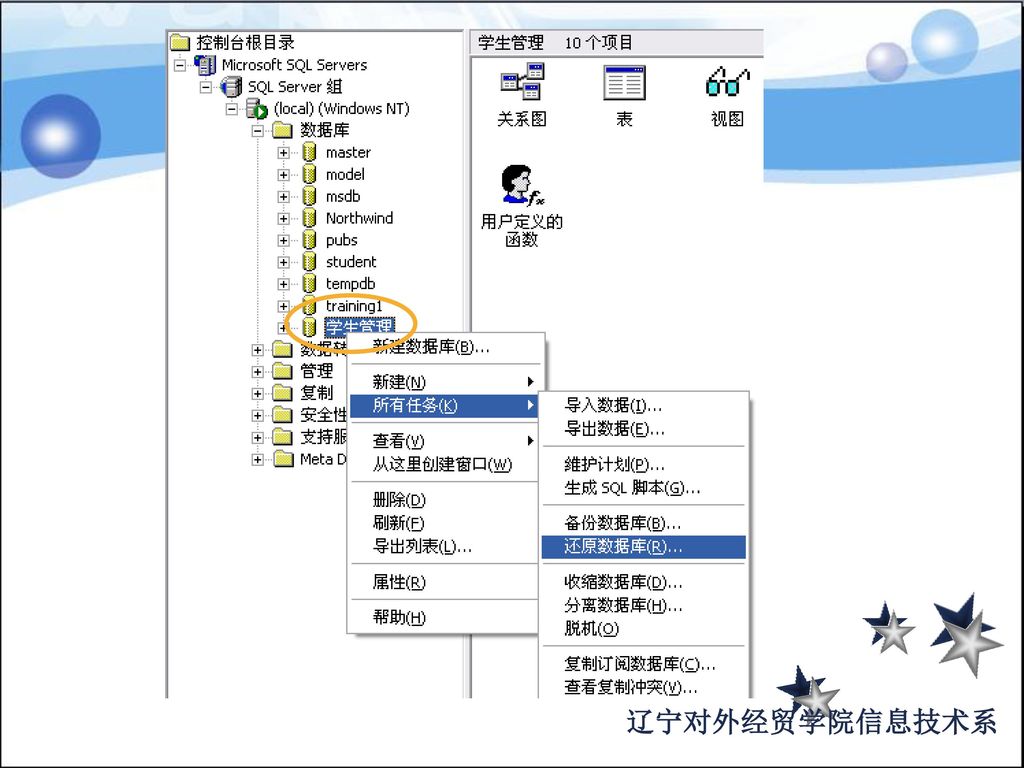
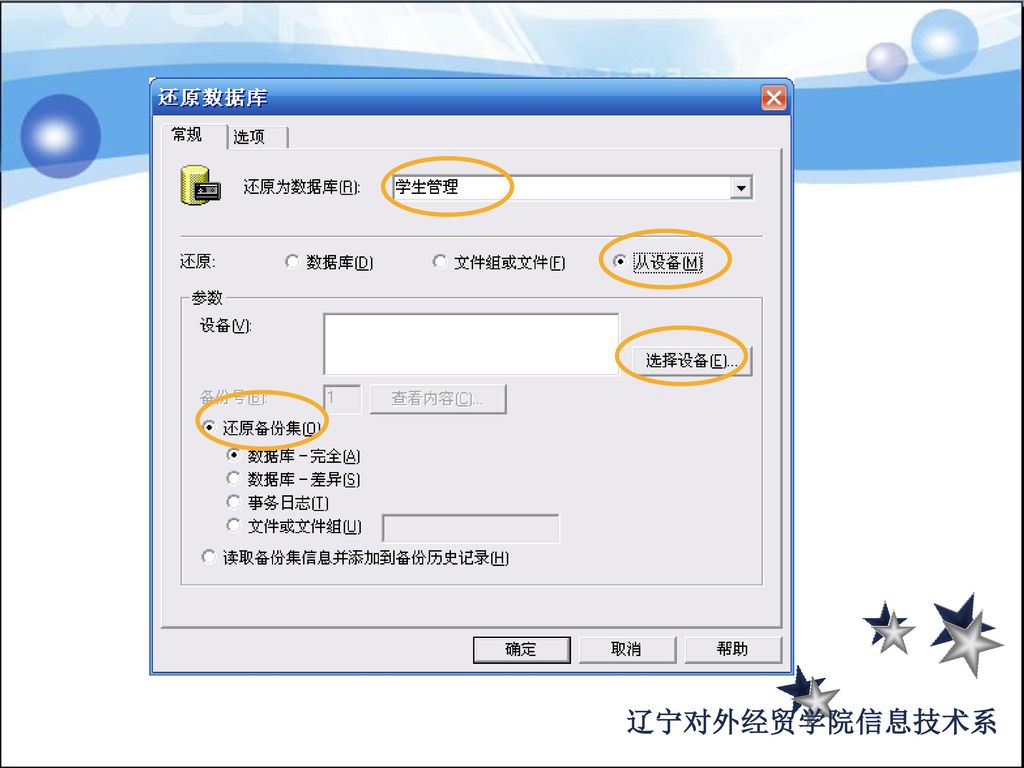


 西安交大 卫颜俊 2008 年 12 月 电子信箱: QQ: 610568018 网站 : 202.117.58.97/java.>")








 主编 贾铁军 科学出版社 编著 陈国秦 万程 邢一鸣>")
 任课教师:刘雅莉 E_mail:slxy_lyl@163.com 2014-9.>")






就是一个存储数据的仓库。为了方便数据的存储和管理,它将数据按照特定的规律存储在磁盘上。通过数据库管理系统,可以有效的组织和管理存储在数据库中的数据。如今,已经存在了Oracle、SQL Server、MySQL等诸多优秀的数据库。在这一章中将讲解的内容包括。>")