Download presentation
1
主講人 陳陸輝 副研究員 政治大學 選舉研究中心
統計分析方法概論 主講人 陳陸輝 副研究員 政治大學 選舉研究中心

2
統計分析方法概論 一、常用資料分析策略 二、次數分配表 三、中央趨勢與離散程度 四、卡方獨立性檢定與各種關連性檢定 五、區間估計與假設檢定
六、變異數分析 七、迴歸模型 八、類別資料分析 九、各種常用的統計軟體

3
一、常用資料分析策略

4
二、次數分配表(p.19) 1.研究類型 單次(表5-1)/跨時(範例表一) 2.分佈情況 (1)常態分佈—統獨 (2)J型分佈—一國兩制
(3)U型分佈—兩極對立
U型分佈—兩極對立.")
5
表5-1 請問您認為「發展台灣與大陸的交流」與「發展台灣與其他國家的外 交關係」,哪一項應該比較(台:卡)優先?(p.19)
次 數 百分比 發展台灣與大陸的交流 385 35.8% 發展台灣與其他國家的外交關係 346 32.2% 兩者並重 148 13.8% 其他及無反應* 196 18.2% 合 計 1076 100.0% *其他及無反應包括:很難說、無意見、不知道、拒答。 資料來源:政治大選選舉研究中心,民國90年12月台灣地區電話訪問。

6
表5-2 民眾對民進黨過去一年來表現的評價(未合併資料)
")
7
表5-3 民眾對民進黨過去一年來表現評價的三分類(合併資料) (p.20)
 (p.20)")
8
表九~5「台灣人/中國人」自我認定(p.21)
")
9
用圖形呈現資料 除了我們用次數分配表來呈現資料之外,我們可以用圖形來加以表現。一般而言,我們可以使用圓餅圖(pie chart)、長條圖(bar chart)來呈現名目資料,也可以用直方圖(histogram)來表現包括等距資料以及等比資料的數字資料。
、長條圖(bar chart)來呈現名目資料,也可以用直方圖(histogram)來表現包括等距資料以及等比資料的數字資料。")
10
圖3-1 2000年總統選舉不同省籍背景選民支持對象長條圖
圖3-1 2000年總統選舉不同省籍背景選民支持對象長條圖

11
圖3-2 2000年總統大選三位主要候選人得票百分比的圓餅圖(p.152)
")
12
圖3-3 民眾對發展與「大陸關係」以及「外交關係」 何者優先看法的長條圖 (p.153)
35.8 32.2 13.8 18.2 5 10 15 20 25 30 35 40 大陸交流 外交關係 兩者並重 無反應

13
三、中央趨勢與離散程度(p.22-p.26)
")
14
當觀察值為常態分佈時,在平均數 正負一個標準差的區間之內,涵蓋了68%的所有觀察值 正負兩個標準差的區間之內,包括了95%的所有觀察值, 正負三個標準差的區間之內,包括了99.7%的所有觀察值。

15
四、卡方獨立性檢定與關聯性檢定(p.27) (一)卡方獨立性檢定 (二)關聯性檢定
 (一)卡方獨立性檢定 (二)關聯性檢定")
16
(一)、卡方獨立性檢定 在一般民意調查或是社會科學中, 最常使用的統計方法。
、卡方獨立性檢定 在一般民意調查或是社會科學中, 最常使用的統計方法。")
17
卡方獨立性檢定的基本原則與程序 基本原則是檢視觀察值與期望值之間的差異,是否達到統計上的顯著程度。
基本原則是檢視觀察值與期望值之間的差異,是否達到統計上的顯著程度。 如果具有顯著差異,則再進一步解釋差異的來源。

18
「南人食米、北人食麥」的卡方獨立性檢定 我們就以「南人食米、北人食麥」為例 按步就班分解卡方獨立性檢定
我們統計上的虛無假設是(研究假設與對立假設): 居住地區與飲食習慣之間是互相獨立的,沒有任何關聯。 參考第49頁有關假設檢定的說明
: 居住地區與飲食習慣之間是互相獨立的,沒有任何關聯。 參考第49頁有關假設檢定的說明.")
19
1.先列出兩個變數的次數(或是百分比)分配
分配")
20
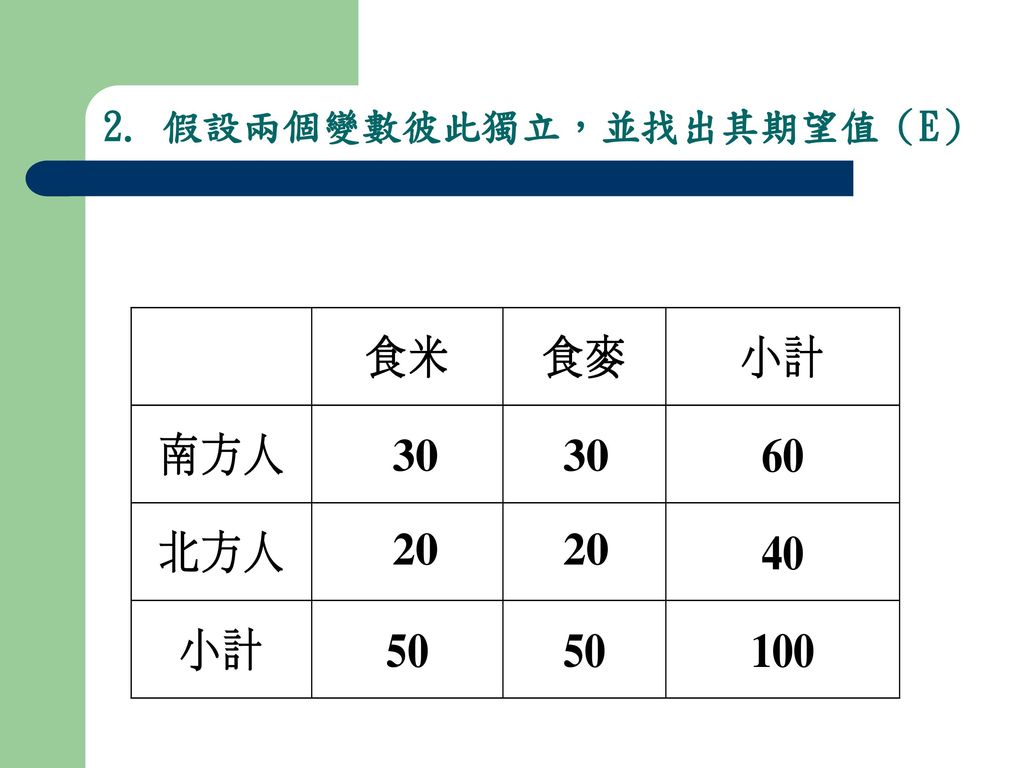
2. 假設兩個變數彼此獨立,並找出其期望值(E)
30 30 20 20
21
3. 觀察值的實際分佈(O) 45 15 5 35
")
22
4. 計算觀察值與期望值之間的差異(O-E) +15 -15 -15 +15
")
23
5. 計算每一個格子的卡方值(p.28) 225/30 225/30 225/20 225/20
 225/30 225/30 225/20 225/20")
24
6. 加總所有格子內的卡方值 加總所有卡方值,我們得到=37.5

25
7. 自由度的計算方式: r = row 橫列的數目 c = column 直行的數目
d.f. = (c-1) (r-1)=(2-1)*(2-1)=1 r = row 橫列的數目 c = column 直行的數目
 (r-1)=(2-1)*(2-1)=1. r = row 橫列的數目. c = column 直行的數目.")
26
8. 查表(p.279) 查卡方檢定表:自由度為1,卡方植為37.5 得到p<0.001,所以拒絕虛無假設。 一般統計表達方式 *: p<0.05 **: p<0.01 ***: p<0.001
 查卡方檢定表:自由度為1,卡方植為37.5 得到p<0.001,所以拒絕虛無假設。 一般統計表達方式 *: p<0.05 **: p<0.01 ***: p<0.001")
27
調整後餘值 / 殘差的運用與解釋(p.31) 卡方獨立性檢定只是對針對統計的虛無假設做出決策。我們若想瞭解各細格內的分佈是否「突出」,可藉助「調整後餘值」。 調整後餘值的分布是接近標準常態分配,平均數為0而標準差為1。 通常絕對值大於等於1.96時,表示該格子與其他觀察值之間具有顯著差異,其正負值則表示該格子出現的頻率偏高或是偏低。 若是其值落在正負1.96之間時,則表示該格子出現的頻率並不顯著地高或是低。

28
範例表三 2000年總統大選省籍與投票對象的卡方獨立性檢定(p.33)
")
29
表九~6 階級與政黨認同的交叉列表

30
表九~6 階級與政黨認同的調整後殘差

31
卡方獨立性檢定的程序 1.做卡方檢定,確定變數之間的關係是否獨立。 2.以調整後餘值,觀察特定細格是否顯著偏高或是偏低。
3.具體解釋表格內的百分比。

32
(二)、關聯性統計 1.類別/名目資料的關聯性統計 2.順序/等第變數間的關聯性統計 3.等距變數間的關聯性統計
、關聯性統計 1.類別/名目資料的關聯性統計 2.順序/等第變數間的關聯性統計 3.等距變數間的關聯性統計")
33
1 名目變數間的關聯性分析 一種常用的相關性測量為 Goodman and Kruskal’s Lambda 測量。 這是屬於一種誤差降低率
1 名目變數間的關聯性分析 一種常用的相關性測量為 Goodman and Kruskal’s Lambda 測量。 這是屬於一種誤差降低率 (proportional reduction of error,或是 PRE) 的相關性測量。其值的分布從0到1。 基本概念是: 當知道一個變數之後, 可以減低我們預測另外一個變數所犯錯誤的比例。
 的相關性測量。其值的分布從0到1。 基本概念是: 當知道一個變數之後, 可以減低我們預測另外一個變數所犯錯誤的比例。")
34
表4-5 2000年總統大選不同省籍選民投票的交叉列表
表4-5 2000年總統大選不同省籍選民投票的交叉列表 省籍 背景 _ X 次數分配小計 大陸各省_C Y 支持對象 宋楚瑜_1 連戰_2 陳水扁_3 47 33 183 224 98 29 369 245 38 383 22 443 118 790 149 1 ,057 本省客家_A 本省閩南_B

35
Lambda 相關性測量實例 如果沒有選民省籍背景的資料(變數X)的相關資訊的話,X,我們預測選民的投票傾向(Y)的最佳方法是運用眾數,使我們的誤差減低到最小,所以,其誤差為=0.581。這是我們預測所有選民都投給陳水扁時,所得到的誤差比例。 當我們運用選民的省籍來預測選民的投票對象時,其誤差降為0.501,減低了原錯誤約14個百分點。

36
2 順序變數間的關聯性分析 在進行分析之前, 要先將變數重新編碼, 讓兩個變數的數值愈大者,代表同一個方向。

37
表4-5 民眾政治效能感的交叉分析

38
兩個變數數值間的四種關係 P = 變數高低順序的方向一致的情況﹔ Q = 變數高低順序的方向不一致的情況﹔
=X順序相同,但是Y順序不相同的情況﹔ = Y順序相同,但是X順序不相同的情況。

39
上述四種情況的計算方式如下: P: 表格中的數字,乘以該數字右下角(東南方)的數字並將以加總,而不管同一直行或是同一橫欄的數字。
Q: 表格中的數字,乘以該數字左下角(西南方)的數字並將以加總,而不管同一直行或是同一橫欄的數字。
的數字並將以加總,而不管同一直行或是同一橫欄的數字。")
40
:每一格數字乘以 同一橫列右方的數字並加總。 同一直欄下方的數字並加總。

41
表4-6 各種等第變數間關聯性測量的方法 名稱 計算公式 計算結果 Kendall’s 0.248 0.360 0.331 0.495 Somer’s d ,Y是依變數 0.372 , X是依變數 0.350

42
3.等距變數間的關聯性分析 我們最常用的是皮爾森積差相關 (Pearson’s Product-moment correlation,
簡稱Pearson’s r)。
。")
43
皮爾森積差相關係數的分佈 皮爾森積差相關的係數值會落在-1與+1之間,這個值告訴我們兩個變數之間的關係的方向性以及關聯程度的強弱。
當係數為正時,表示兩個變數之間的關係是正向關係,也就是當一個變數增加的時候,另外一個變數也一樣增加。 當係數為負時,代表兩個變數之間的關係是負向關係,也就是當一個變數的值增加時,另外一個變數的值會減少。 當係數值為0,這表示兩個變數完全獨立,沒有任何關聯性。 皮爾森積差相關係數的絕對值愈大,代表兩個變數之間的關聯程度愈密切。

44
皮爾森積差相關的係數的解釋 絕對值在0.25以下時,變數之間的關聯性是非常地弱。
絕對值在0.26到0.50之間,變數間的關係可以算是中等的關係。 絕對值落在0.51到0.75之間,則變數之間的關聯程度就算是不錯的程度。 絕對值大於0.75時,變數之間的關聯程度就是相當不錯或是極佳的關係。 對社會科學而言,由於測量工具的不夠精確,社會科學認為當兩個變數之間的相關係數達到0.30時,就算是具有重要實質的相關性。

45
皮爾森積差相關係數的計算與解釋實例 經過計算之後,我們發現民眾對李登輝先生的評價與對國民黨的評價之間的關聯程度是0.63。表示民眾對李登輝的評價與對國民黨的評價之間的關聯方向是正向關係,也就是當民眾對李登輝先生的評價愈高,對國民黨的評價就傾向愈高。係數值為0.63,表示兩個變數之間具有不錯的關聯程度。

46
五、區間估計與假設檢定 1.單一樣本的區間估計(p.43) 2.獨立樣本間平均數差異的區間估計
 2.獨立樣本間平均數差異的區間估計")
47
3.配對樣本平均數差異的區間估計

48
4.假設檢定 (1)虛無假設(null hypothesis)
(2)對立假設(alternative hypothesis) 通常用HA來表示,也有用來H1表示的。這其實是我們研究中想驗證的假設。
對立假設(alternative hypothesis) 通常用HA來表示,也有用來H1表示的。這其實是我們研究中想驗證的假設。")
49
表九~12 統計檢定的兩種錯誤類型

50
六、變異數分析

51
七、迴歸分析模型 1.我們要看迴歸方程式中,單一解釋變數,是否顯著,則用t檢定。所以,該變數的估計係數與該估計係數的標準誤,決定t檢定的結果。 2.如果我們要考慮加入一個或是一組新變數,對於模型的解釋力有沒有「顯著」提升,此時,可以用F檢定。 3.如果要同時考慮好幾個變數,則個別變數顯著與否,可以參考t檢定,整組變數(整個模型)是某顯著,則可參考F檢定。
是某顯著,則可參考F檢定。")
52
八、類別資料分析(66) 1.勝算對數模型 2.等第勝算對數模型 3.多項勝算對數模型
 1.勝算對數模型 2.等第勝算對數模型 3.多項勝算對數模型")
53
九、各種常見的統計軟體 一般常用軟體 MINITAB SPSS—目前社會科學最常用的統計軟體 STATISTICA—與SPSS類似,功能相近
SAS—商學院較常使用的統計軟體 Stata—美國目前社會科學常用的統計軟體,類別資料分析的功能記強

54
特殊用途軟體 Limdep—也是一個針對類別資料分析運用MLE統計分析方法的軟體。
Gauss—要自己寫語法,是類別資料分析最強的軟體。不過,也相當不友善。 E-Views—時間序列使用軟體 RATS--時間序列使用軟體

55
該起床了 p(*O*)q
q")

 求积公式.>")
 吸 收發 表 口頭語言聽說 書面語言讀寫作 肢體語言看比.>")
. 一、数据库简介 “ 国泰安研究服务中心 ” ( www.gtarsc.com )是 中国经济、金融、会计研究的门户网站,主要从事 股票市场、上市公司、基金市场、期货市场、债券 市场、货币市场等经济数据的采集和研究服务。 国泰安研究服务中心由数据服务、研究服务与学者.>")










.>")




開發計畫>")
