Download presentation
1
第三章 存储系统 现代计算机系统都以存储器为中心 在计算机运行过程中,存储器是各 种信息存储和交换的中心。

2
第三章 存储系统 存储系统原理 虚拟存储器 高速缓冲存储器 三级存储器

3
3.1 存储系统原理 存储系统的定义 存储器的层次结构 存储器的频带平衡 并行存储器 什么是存储系统(存储体系、存储器层次)?
为什么研究存储系统? 存储系统的性能指标如何表示? 如何构成存储系统? 存储系统的定义 存储器的层次结构 存储器的频带平衡 并行存储器

4
存储系统的定义 在一台计算机中,通常有多种存储器 种类:主存储器、Cache、通用寄存器、先行缓冲存储器、磁盘存储器、磁带存储器、光盘存储器等 材料工艺:ECL、TTL、MOS、磁表面、激光,SRAM,DRAM 访问方式:直接译码、先进先出、随机访问、相联访问、块传送、文件组

5
存储器的主要性能:速度、容量、价格 速度用存储器的访问周期、读出时间、频带宽度等表示 容量用字节B、千字节KB、兆字节MB和千兆字节GB等单位表示 价格用单位容量的价格表示,如$/bit
存储系统的关键是如何组织好速度、容量和价格均不相同的存储器,使这个存储器的速度接近速度最快的那个存储器,存储容量与容量最大的那个存储器相等,单位容量的价格接近最便宜的那个存储器。

6
1、存储系统(存储体系、存储层次)的定义 两个或两个以上速度、容量和价格各不相同的存储器用硬件、软件、或软件与硬件相结合的方法连接起来成为一个存储系统。这个系统对应用程序员透明,并且,从应用程序员看,它是一个存储器,这个存储器的速度接近速度最快的那个存储器,存储容量与容量最大的那个存储器相等,单位容量的价格接近最便宜的那个存储器。

7
从外部看: M1 (T1,S1, C1) M2 (T2, S2, C2) Mn (Tn, Sn, Cn) 从外部看 T≈min(T1, T2, …, Tn), 用存储周期表示 S = max(S1, S2, …, Sn), 用MB或GB表示 C≈min(C1, C2, …, Cn), 用每位的价格表示
, 用存储周期表示 S = max(S1, S2, …, Sn), 用MB或GB表示 C≈min(C1, C2, …, Cn), 用每位的价格表示.")
8
速度接近Cache的速度 存储容量是主存的容量 每位价格接近主存储器 Cache
从系统程序员的角度看, 速度接近Cache的速度 存储容量是主存的容量 每位价格接近主存储器 Cache 主存储器

9
虚拟存储系统 从应用程序员的角度看, 速度接近主存储器的速度 主存储器 存储容量是虚拟地址空间 每位价格接近磁盘存储器 磁盘存储器
2、存储系统的容量 要求: 存储系统的容量等于M2存储器的容量 提供尽可能大、能随机访问的地址空间

10
3、存储系统的单位容量平均价格 M1 (S1, C1 , T1) M2 (S2, C2 , T2)
方法有两种: 只对M2存储器进行编址,M1存储器只在内部编址 另外设计一个容量很大的逻辑地址空间 3、存储系统的单位容量平均价格 计算公式: M1 (S1, C1 , T1) S2>>S1时, C≈C2, 但 S2与S1不能相差太大 M2 (S2, C2 , T2)
 S2>>S1时, C≈C2, 但. S2与S1不能相差太大. M2. (S2, C2 , T2)")
11
4、存储系统的速度 命中率定义:在M1存储器中访问到的概率 N1: M1的访问次数 N2: M2的访问次数 访问周期与命中率的关系:
表示方法:访问周期、存取周期、存储周期、存取时间、读出时间等 命中率定义:在M1存储器中访问到的概率 N1: M1的访问次数 N2: M2的访问次数 访问周期与命中率的关系: T=HT1+(1-H)T2 当命中率H→1时,T→T1
T2. 当命中率H→1时,T→T1.")
12
存储系统的访问效率: 当H=0.99时, e2=1/(0.99+5(10.99))=0.96
存储系统的访问效率主要与命中率和两级存储器的速度之比有关。 例3.1:假设T2=5T1,在命中率H为0.9和0.99两种情况下,分别计算存储系统的访问效率。 解: 当H=0.9时, e1=1/(0.9+5(10.9))=0.72 当H=0.99时, e2=1/(0.99+5(10.99))=0.96
)=0.72. 当H=0.99时, e2=1/(0.99+5(10.99))=0.96.")
13
提高存储系统速度的两条途径: 一是提高命中率H 二是两个存储器的速度不要相差太大 其中第二条有时做不到(如虚拟存储器),主要依靠提高命中率
例3.2:在虚拟存储系统中,两级存储器的速度相差特别悬殊T2=105T1。如果要使访问效率e=0.9,问需要有多高的命中率?

14
0.9H+90000(1H)=1 89999.1H=89999 解 采用预取技术提高命中率
方法:不命中时,把M2存储器中相邻几个单元组成的一个数据块都取出来送入M1存储器中。 计算公式: 其中:H’是采用预取技术后的命中率;H是原来的命中率;n为数据块大小与数据重复使用次数的乘积。

15
证明:采用预取技术之后,不命中率降低n倍:
也可以采用另外一种证明方法:在原有命中率计算公式中,把访问次数扩大到n倍,这时,由于采用了预取技术,命中次数为:nN1+(n1)N2 ,不命中次数仍为N2,因此新的命中率为:
N2 ,不命中次数仍为N2,因此新的命中率为:")
16
Cache块为1个字大时, H=0.8, 访问效率为: Cache块为4个字大时, H=0.99, 访问效率为:
例3.3:在一个Cache存储系统中,当Cache的块大小为一个字时,命中率H=0.8;假设数据的重复利用率为5,计算块大小为4个字时,Cache存储系统的命中率是多少?假设T2=5T1,分别计算访问效率。 解:n=45=20, 采用预取技术后, 命中率提高到: Cache块为1个字大时, H=0.8, 访问效率为: Cache块为4个字大时, H=0.99, 访问效率为:

17
例3.4:在一个虚拟存储系统中,T2=105 T1,原来的命中率只有0.8,如果访问磁盘存储器的数据块大小为4K字,并要求访问效率不低于0.9,计算数据在主存储器中的重复利用率至少为多少?
解:假设数据在主存储器中的重复利用率为m,根据前面的给出关系: 解方程组得m=44,即数据在主存储器中的重复利用率至少为44次。

18
存储器的层次结构 多个层次的存储器: Register Files Buffers(Lookahead) Cache Main Memory Online Storage Off-line Storage 如下页图所示,如果用I表示层数,则有: 工作速度:Ti<Ti+1 存储容量:Si<Si+1 单位价格:Ci>Ci+1

19
通用寄存器堆 指令和数据缓冲 Cache (SRAM) 主存储器(DRAM) 联机外部存储器 脱机外部存储器 CPU 内部 每位的价格越来越便宜 存储容量越来越大 访问速度越来越快
 主存储器(DRAM) 联机外部存储器 脱机外部存储器 CPU 内部 每位的价格越来越便宜 存储容量越来越大 访问速度越来越快")
20
各级存储器的主要性能特性 存储器层次 通用寄存器 缓冲栈 Cache 存储周期 < 10ns < 10ns ns 存储容量 < 512B < 512B 8K-2MB 价格$c/KB 1200 80 3.2 访问方式 直接译码 先进先出 相联访问 材料工艺 ECL ECL SRAM 分配管理 编译器分配 硬件调度 硬件调度 带宽 (待续)
")
21
各级存储器的主要性能特性(续) 存储器层次 主存储器 磁盘存储器 脱机存储器 存储周期 60-300ns ms min 存储容量 32M-1GB 1G-1TB 5G-10TB 价格$c/KB 0.36 0.01 0.0001 访问方式 随机访问 块访问 文件组 材料工艺 DRAM 磁表面 磁、光等 分配管理 操作系统 系统/用户 系统/用户 带宽 80-160 10-100

22
CPU与主存储器的速度差距越来越大 1955年,第一台大型机IBM704,CPU和主存储器的工作周期均为12微秒,目前,CPU的工作速度提高了4个数量级以上,主存储器的工作速度仅提高两个数量级。
研究存储系统的目的就是要找出解决这一问题的办法。

23
频带平衡 计算机中各级存储器频带应该达到平衡 例如: 一台速度为500MIPS的计算机系统, 主存储器的各种访问源的频带宽度如下: CPU取指令: 500MW/s CPU取操作数和保存运算结果:1000MW/s 各种输入输出设备访问存储器:50MW/s 三项相加,要求存储器的频带宽度不低于1550MW/s, 访问周期不大于0.64ns, 实际上目前主存储器的工作周期为100ns左右, 两者相差150多倍。

24
解决存储器频带平衡方法 (1) 多个存储器并行工作(本节) (2) 设置各种缓冲存储器(第五章) (3) 采用存储系统(本章下两节)
并行存储器 主要内容: 并行访问存储器 交叉访问存储器(两种)
")
25
1、并行访问存储器 方法:把m字w位的存储器改变成为m/n字n×w位的存储器
逻辑实现: 把地址码分成两个部分,一部分作为存储器的地址,另一部分负责选择数据 主要缺点:访问冲突大 (1) 取指令冲突 (2) 读操作数冲突 (3) 写数据冲突 (4) 读写冲突
 取指令冲突 (2) 读操作数冲突 (3) 写数据冲突. (4) 读写冲突.")
26
多路选择器 MBR …… 存储体(m/n字nw位) MAR 并行访问存储器 数据寄存器 MBR 存储体 (m字w位) 地址寄存器 MAR 一般存储器
 MAR 并行访问存储器 数据寄存器 MBR 存储体 (m字w位) 地址寄存器 MAR 一般存储器")
27
2、高位交叉访问存储器 主要目的:扩大存储器容量 实现方法:用地址码的高位区分存储体号
参数计算方法: m:每个存储体的容量 n:总共的存储体个数 j:存储体的体内地址,j=0, 1, 2, …, m-1 k:存储体的体号,k=0, 1, 2, …, n-1 存储器的地址:A=m×k+j 存储器的体内地址:Aj=A mod m 存储器的体号: Ak=向下取整(A/m)
")
28
MBR 存储体0 MAR 存储体n-1 存储体1 …… 译码器 (高位) 存储器地址寄存器(低位)
 存储器地址寄存器(低位)")
29
3、低位交叉访问存储器 主要目的:提高存储器访问速度 实现方法:用地址码的低位区分存储体号
参数计算方法: 存储器地址A的计算公式为:A=nj+k 存储器的体内地址:Aj=向下取整(A/n) 存储器的体号:Ak=A mod n 地址是编码方法: 由8个存储体构成的主存储器的低位交叉编址方式
 存储器的体号:Ak=A mod n. 地址是编码方法: 由8个存储体构成的主存储器的低位交叉编址方式.")
30
MBR 存储体0 MAR 存储体n-1 存储体1 …… 存储器地址寄存器(高位) 译码器 (低位)
 译码器 (低位)")
31
8 9 10 11 12 13 14 15 1 2 3 4 5 6 7 24 … 31 16 19 23 32 39 40 47 48 55 56 63 主存储器数据寄存器 体内地址(3位) 模块地址(3位)
 模块地址(3位)")
32
n个存储体分时启动 实际上是一种采用流水线方式工作的并行存储器 理论上,存储器的速度可望提高n倍 每存储体的启动间隔t为: 其中:n为存储体个数 Tm为每个存储体的访问周期
#0 #1 #2 …… #n-1 t Tm

33
3.2 虚拟存储器 1961年英国曼彻斯特大学Kilbrn等人提出 70年代广泛地应用于大中型计算机系统中 目前许多微型机也开始使用虚拟存储器 虚拟存储器工作原理 地址的映象和变换方法 加快内部地址变换速度的方法 页面替换算法及其实现方法 提高主存命中率的方法

34
虚拟存储器工作原理 把主存储器、磁盘存储器和虚拟存储器都划分成固定大小的页,主存储器的页称为实页,虚拟存储器中的页称为虚页。 一个主存地址A由两部分组成,实页号p和页内偏移d 一个虚地址Av由三部分组成,用户号U、虚页号P和页内偏移D。

35
用户号U 虚页号P 页内偏移D 多用户虚拟地址Av的组成 实页号p 页内偏移d 主存地址A的组成 内部地址变换: 多用户虚拟地址Av变换成主存实地址A 多用户虚拟地址中的页内偏移D直接作为主存实地址中的页内偏移d 主存实页号p与它的页内偏移d直接拼接起来就得到主存实地址A

36
外部地址变换: 首先查外页表得到磁盘存储器实地址 把磁盘存储器实地址和主存储器实页号送入输入输出处理机 把要访问数据所在的一整页都从磁盘存储器调入到主存储器

37
地址的映象与变换 三种地址空间:虚拟地址空间,主存储器地址空间,辅存地址空间 地址映象: 把虚拟地址空间映象到主存地址空间

39
地址变换:在程序运行时,把虚地址变换成主存实地址
因地址映象和变换方法不同,有三种虚拟存储器:页式虚拟存储器、段式虚拟存储器、段页式虚拟存储器 1、段式虚拟存储器 地址映象方法:每个程序段都从0地址开始编址,长度可长可短,可以在程序执行过程中动态改变程序段的长度。

40
主程序 (0段) 1k 1段 2段 3段 500 200 段号 段长 起址 8k 1 16k 2 9k 3 30k 程序 空间 主存储器
 1k 1段 2段 3段 段号 段长 起址 8k 1 16k 2 9k 3 30k 程序 空间 主存储器")
41
地址变换方法: 由用户号找到基址寄存器 从基址寄存器中读出段表的起始地址 把起始地址与多用户虚地址中段号相加得到段表地址 把段表中给出的起始地址与段内偏移D相加就能得到主存实地址

42
段表 长度 段表 基址 6 As 段名 起始 地址 装入 位 段长 访问 方式 用户号U 段号S 段内偏移D 多用户 虚地址 主存实地址 4 3 2 1 n-1 段表基址寄存器 一个用户(一道作业)的段表
的段表.")
43
段式虚拟存储器的主要优点: (1) 程序的模块化性能好 (2) 便于程序和数据的共享 (3) 程序的动态链接和调度比较容易 (4) 便于实现信息保护
段式虚拟存储器的主要缺点: (1) 地址变换所花费的时间比较长,做两次加法运算 (2) 主存储器的利用率往往比较低 (3) 对辅存(磁盘存储器)的管理比较困难
 地址变换所花费的时间比较长,做两次加法运算 (2) 主存储器的利用率往往比较低 (3) 对辅存(磁盘存储器)的管理比较困难.")
44
2、页式虚拟存储器 页式虚拟存储器把虚拟地址空间划分成一个个固定大小的块,每块称为一页,把主存储器的地址空间也按虚拟地址空间同样的大小划分为页。页是一种逻辑上的划分,它可以由系统软件任意指定。 虚拟地址空间中的页称为虚页,主存地址空间中的页称为实页。 每个用户使用一个基址寄存器(在CPU内),通过用户号U可以直接找到与这个用户程序相对应的基址寄存器,从这个基址寄存器中读出页表起始地址。访问这个页表地址,把得到的主存页号p与虚地址中的页内偏移直接拼接起来得到主存实地址。如图所示:
,通过用户号U可以直接找到与这个用户程序相对应的基址寄存器,从这个基址寄存器中读出页表起始地址。访问这个页表地址,把得到的主存页号p与虚地址中的页内偏移直接拼接起来得到主存实地址。如图所示:")
45
0页 1页 2页 3页 页号 主存页号 1 2 3 用户程序 主存储器 页表 页式虚拟存储器的地址映象

46
Pa 装入 修改 主存页号 标志 用户号U 虚页号P 页内偏移D 页内偏移d 2 p 页表基址 页表 实页号p

47
主要优点: (1) 主存储器的利用率比较高 (2) 页表相对比较简单 (3) 地址变换的速度比较快 (4) 对磁盘的管理比较容易
主要缺点: (1) 程序的模块化性能不好 (2) 页表很长,需要占用很大的存储空间。例如:虚拟存储空间4GB,页大小1KB,则页表的容量为4M字,16MB
 程序的模块化性能不好 (2) 页表很长,需要占用很大的存储空间。例如:虚拟存储空间4GB,页大小1KB,则页表的容量为4M字,16MB.")
48
3、段页式虚拟存储器 用户按照程序段来编写程序,每个程序段分成几个固定大小的页。 地址变换方法: (1) 先查段表,得到该程序段的页表起始地址和页表长度, (2) 再查页表找到要访问的主存实页号, (3) 最后把实页号p与页内偏移d拼接得到主存的实地址。
 先查段表,得到该程序段的页表起始地址和页表长度, (2) 再查页表找到要访问的主存实页号, (3) 最后把实页号p与页内偏移d拼接得到主存的实地址。")
50
装入 修改 实页号 标志 用户号U 段号S 页内偏移 0/1 1 p A 实页号p 虚页号P As 页表 地址 Ap

51
4、外部地址变换 在操作系统中,把页面失效当作一种异常故障来处理。 每个用户程序都有一张外页表,虚拟地址空间中的每一页或每个程序段,在外页表中都有对应的一个存储字。 每一个存储字除了磁盘存储器的地址之外,至少还包括一个装入位。

52
装入 磁盘实地址 用户号 页内偏移 1 虚页号 外部地址 变换(软 件实现) 磁盘号 柱面号 磁头号 块号 多用户 虚地址 外页表
 磁盘号 柱面号 磁头号 块号 多用户 虚地址 外页表")
53
加快内部地址变换的方法 造成虚拟存储器速度降低的主要原因: (1) 要访问主存储器须先查段表或页表 (2) 可能需要多级页表
页表级数的计算公式: 其中: Np为页面的大小 Nv为虚拟存储空间大小 Nd为一个页表存储字的大小 例如:虚拟存储空间大小Nv=4GB,页的大小Np=1KB,每个页表存储字占用4个字节。计算得到页表的级数:

54
25625664=4M字 通常把1级页表驻留在主存储器中,2、3级页表只驻留一小部分在主存。 1、目录表 基本思想:用一个小容量高速存储器存放页表。

55
地址变换过程:把多用户虚地址中U与P拼接起来,相联访问目录表。读出主存实页号p,把p与多用户虚地址中的D拼接得到主存实地址。如果相联访问失败,发出页面失效请求。
主要优点:与页表放在主存中相比,查表速度快。 主要缺点:可扩展性比较差。 主存储器容量增加时,目录表的造价高,速度降低。

56
实页号 其它标志 用户号U 页内偏移D p 虚页号P 多用户 虚地址 目录表(按内容访问的相联存储器) 页内偏移d 实页号p 多用户虚页号 U, P 修改 0/1 主存实地址 相联访问
 页内偏移d 实页号p 多用户虚页号 U, P 修改 0/1 主存实地址 相联访问")
57
2、快慢表 快表TLB(Translation Lookaside Buffer): 小容量(几~几十个字),高速硬件实现,采用相联方式访问 慢表:当快表中查不到时,从存放在主存储器中的慢表中查找 按地址访问,用软件实现。 快表与慢表也构成了一个两级存储系统。

58
实页号 用户号U 页内偏移D p 虚页号P 多用户 虚地址 快表(按内容相联访问) 页内偏移d 实页号p 多用户虚页号 U, P 主存实地址 装入 1 慢表
 页内偏移d 实页号p 多用户虚页号 U, P 主存实地址 装入 1 慢表")
59
3、散列函数 目的:把相联访问变成按地址访问,从而加大快表容量 散列(Hashing)函数:Ah=H(Pv), 20位左右 5~8位 采用散列变换实现快表按地址访问 避免散列冲突:采用相等比较器 地址变换过程:相等比较与访问存储器同时进行

60
实页号 用户号U 页内偏移D p 虚页号P 多用户 虚地址 按地址访问的快表 页内偏移d 实页号p 多用户虚页号 Pv 主存实地址 散列变 换(硬 件实现) 相等比较 查慢表 快表地址 Ah 快表 命中

61
采用了两项新的措施: 一是采用两个相等比较器 二是用相联寄存器组把24位用户号U压缩成3位
5、虚拟存储器举例 例3.7: I BM370/168计算机的虚拟存储器快表结构及地址变换过程。虚拟地址长36位,页面大小为4KB,每个用户最多占用4K个页面,最多允许16G个用户,但同时上机的用户数一般不超过6个。 采用了两项新的措施: 一是采用两个相等比较器 二是用相联寄存器组把24位用户号U压缩成3位

63
页面替换算法及其实现方法 页面替换发生时间: 当发生页面失效时,要从磁盘中调入一页到主存。如果主存所有页面都已经被占用,必须从主存储器中淘汰掉一个不常使用的页面,以便腾出主存空间来存放新调入的页面。 评价页面替换算法好坏的标准: 一是命中率要高 二是算法要容易实现

64
页面替换算法的使用场合: (1) 虚拟存储器中,主存页面的替换,一般用软件实现 (2) Cache块替换一般用硬件实现 (3) 虚拟存储器的快慢表中,快表存储字的替换,用硬件实现 (4) 虚拟存储器中,用户基地址寄存器的替换,用硬件实现 (5) 在有些虚拟存储器中目录表的替换 1、页面替换算法 (1) 随机算法(RAND Random algorithm):
 随机算法(RAND Random algorithm):")
65
算法简单,容易实现; 没有利用历史信息,没有反映程序的局部性,命中率低。
(2) 先进先出算法 (FIFO First-In First-Out algorithm): 比较容易实现,利用了历史信息,没有反映程序的局部性。 最先调入主存的页面,很可能也是经常要使用的页面。 (3) 近期最少使用算法 (LFU Least Frequently Used algorithm):
 先进先出算法 (FIFO First-In First-Out algorithm): 比较容易实现,利用了历史信息,没有反映程序的局部性。 最先调入主存的页面,很可能也是经常要使用的页面。 (3) 近期最少使用算法 (LFU Least Frequently Used algorithm):")
66
既充分利用了历史信息,又反映了程序的局部性,实现起来非常困难。
(4) 最久没有使用算法 (LRU Least Recently Used algorithm): 把LRU算法中的“多”与“少”简化成“有”与“无”,实现起来比较容易。 (5) 最优替换算法 (OPT OPTimal replacemant algorithm): 是一种理想化的算法。用来作为评价其它页面替换算法好坏的标准。 在虚拟存储器中,实际上有可能采用只有FIFO和LRU两种算法。
 最久没有使用算法 (LRU Least Recently Used algorithm): 把LRU算法中的 多 与 少 简化成 有 与 无 ,实现起来比较容易。 (5) 最优替换算法 (OPT OPTimal replacemant algorithm): 是一种理想化的算法。用来作为评价其它页面替换算法好坏的标准。 在虚拟存储器中,实际上有可能采用只有FIFO和LRU两种算法。")
67
例3. 8: 一个程序共有5个页面组成,程序执行过程中的页地址流如下:
例3.8: 一个程序共有5个页面组成,程序执行过程中的页地址流如下: P1, P2, P1, P5, P5, P1, P3, P4, P3, P4 假设分配给这个程序的主存储器共有3个页面。给出FIFO、LRU、OPT 三种页面替换算法对这3页主存的使用情况,包括调入、替换和命中等。

69
例3.9: 一个循环程序,依次使用P1,P2,P3,P4四个页面,分配给这个程序的主存页面数为3个。FIFO、LRU和OPT三种页面替换算法对主存页面的调度情况如下图所示。在FIFO和LRU算法中,总是发生下次就要使用的页面本次被替换出去的情况,这就是“颠簸”现象。

71
2、堆栈型替换算法 定义: 对任意一个程序的页地址流作两次主存页面数分配,分别分配m个主存页面和n个主存页面,并且有m≤n。如果在任何时刻t,主存页面数集合Bt都满足关系:Bt(m) Bt(n),则这类算法称为堆栈型替换算法。 堆栈型算法的基本特点: 随着分配给程序的主存页面数增加,主存的命中率也提高,至少不下降。

72
提高主存命中率的方法 影响主存命中率的主要因素: (1) 程序执行过程中的页地址流分布情况 (2) 所采用的页面替换算法 (3) 页面大小 (4) 主存储器的容量 (5) 所采用的页面调度算法 以下,对后三个因素进行分析
 程序执行过程中的页地址流分布情况 (2) 所采用的页面替换算法 (3) 页面大小 (4) 主存储器的容量 (5) 所采用的页面调度算法 以下,对后三个因素进行分析.")
73
1、页面大小与命中率的关系 页面大小为某个值时,命中率达到最大。 页面大小与命中率关系的解释: 假设At和At+1是相邻两次访问主存的逻辑地址,d=|At-At+1|。 如果d<Sp,随着Sp的增大,At和At+1在同一页面的可能性增加,即H随着Sp的增大而提高。 如果d>Sp,At和At+1一定不在同一个页面内。随着Sp的增大,主存页面数减少,页面替换将更加频繁。H随着Sp的增大而降低。

74
当Sp比较小的时候,前一种情况是主要的,H随着Sp的增大而提高。 当Sp达到某一个最大值之后,后一种情况成为主要的,H随着Sp的增大而降低。 当页面大小增大时,造成的浪费也要增加。 当页面大小 减小时,页表和 页面表在主存储 器中所占的比例 将增加。 页面大小 SP 命中率 H 1 S 2S

75
2、主存容量与命中率的关系 1.0 命中率 H 主存容量S 主存命中率H随着分配给该程序的主存容量S的增加而单调上升。
在S比较小的时候, H提高得非常快。 随着S的逐渐增 加,H提高的速 度逐渐降低。当 S增加到某一个 值之后,H几乎 不再提高。 命中率 H 主存容量S 1.0

76
3、页面调度方式与命中率的关系 请求式: 当使用到的时候,再调入主存
预取式: 在程序重新开始运行之前,把上次停止运行前一段时间内用到的页面先调入到主存储器,然后才开始运行程序。 可以避免在程序开始运行时,频繁发生页面失效的情况。 如果调入的页面用不上,浪费了调入的时间,占用了主存资源。

77
3.3 高速缓冲存储器(Cache) 基本工作原理 地址映象与变换方法 Cache替换算法及其实现 Cache的一致性问题
 基本工作原理 地址映象与变换方法 Cache替换算法及其实现 Cache的一致性问题")
78
为什么要使用cache? CPU速度与主存速度相差很大(例如,一般的DRAM的工作速度比CPU慢100倍以上。 Cache工作速度很高,可以将其集成到CPU内。高性能CPU通常用两级Cache,一级在CPU内,其容量比较小,速度很快,第二级在主板上,容量比较大,速度比第一级低5倍左右。 Chache全部用硬件调度对所有程序员都是透明的。 Cache与主存储器之间以块为单位进行数据交换。块的大小通常以在主存储器的一个存储周期内可以访问到的数据长度为限。

79
存储系统 两级存储器速度比 Cache 虚拟存储器 要达到的目标 提高速度 扩大容量 实现方法 全部硬件 软件为主 硬件为辅 3~10倍 105倍 页(块)大小 1~16字 1KB~16KB 等效存储容量 主存储器 透明性 对系统和 应用程序员 仅对应用 程序员 不命中时处理方式 等待主存储器 任务切换 Cache存储系统与虚拟存储系统比较

80
基本工作原理 块号B 块内地址W 主存/Cache 地址变换 块号b 块内地址w Cache Cache替 换策略 储器 主存 替换块 装入块 已满 未满 未命中 命中 数据送 CPU 主存地址 来自CPU

81
地址映象与变换方法 地址映象: 把存放在主存中的程序按照某种规则装入到Cache中,并建立主存地址与Cache地址之间的对应关系
在选取地址映象方法要考虑的主要因素: 地址变换的硬件容易实现;地址变换的速度要快;主存空间利用率要高;发生块冲突的概率要小

82
1、全相联映象及其变换 映象规则:主存中的任意一块都可以映象到Cache中的任意一块。 如果Cache的块数为Cb,主存的块数为Mb,映象关系共有:Cb×Mb种。 用硬件实现非常复杂 在虚拟存储器中,全部用软件实现

83
块0 Cache 块1 …… 块Cb-1 块i 块Mb-1 主存储器 全相联映象方式

84
有效位 块号B 块内地址 主存地址 目录表(由相联存储器组成,共Cb个字) 主存块号B B 块号b 块内地址w Cache块号b b 相联比较 命中 Cache地址
 主存块号B B 块号b 块内地址w Cache块号b b 相联比较 命中 Cache地址")
85
2、直接映象及其变换 映象规则:主存中一块只能映象到Cache的一个特定的块中。 计算公式:b=B mod Cb,其中: b为Cache的块号, B是主存的块号, Cb是Cache的块数。 整个Cache地址与主存地址的低位部分完全相同。

86
块0 Cache 块1 …… 块Cb-1 主存 储器 直接相联映象方式 块Cb 块2Cb-1 块Mb-Cb 块Mb-1 区0 区1 区Me-1

87
地址变换过程: 用主存地址中的块号B去访问区号存储器 把读出来的区号与主存地址中的区号E进行比较 比较结果相等, 且有效位为1, 则Cache命中 比较结果相等, 有效位为0, 表示Cache中的这一块已经作废 比较结果不相等, 有效位为0, 表示Cache中的这一块是空的 比较结果不相等, 有效位为1, 表示原来在Cache中的这一块是有用的

88
有效位 区号E 块内地址w 1 主存 地址 区表存储器 区号E (按地址访问) E 块号b 命中 Cache地址 块号B 相等比较 块失效 比较相等且 有效位为1, 访问Cache
 E 块号b 命中 Cache地址 块号B 相等比较 块失效 比较相等且 有效位为1, 访问Cache")
89
提高Cache速度的一种方法: 把区号存储器与Cache合并成一个存储器
直接映象方法的主要优点: 硬件实现很简单, 不需要相联访问存储器 访问速度也比较快, 实际上不做地址变换 直接映象方式的主要缺点: 块的冲突率较高

90
有效位 区号E 块内地址w 1 按地址访问的Cache 区号 E 块号b 相等 块号B 相等比较 访主存 数据0 D0 数据1 D1 …… 数据w-1 Dw-1 1/w … 送CPU

92
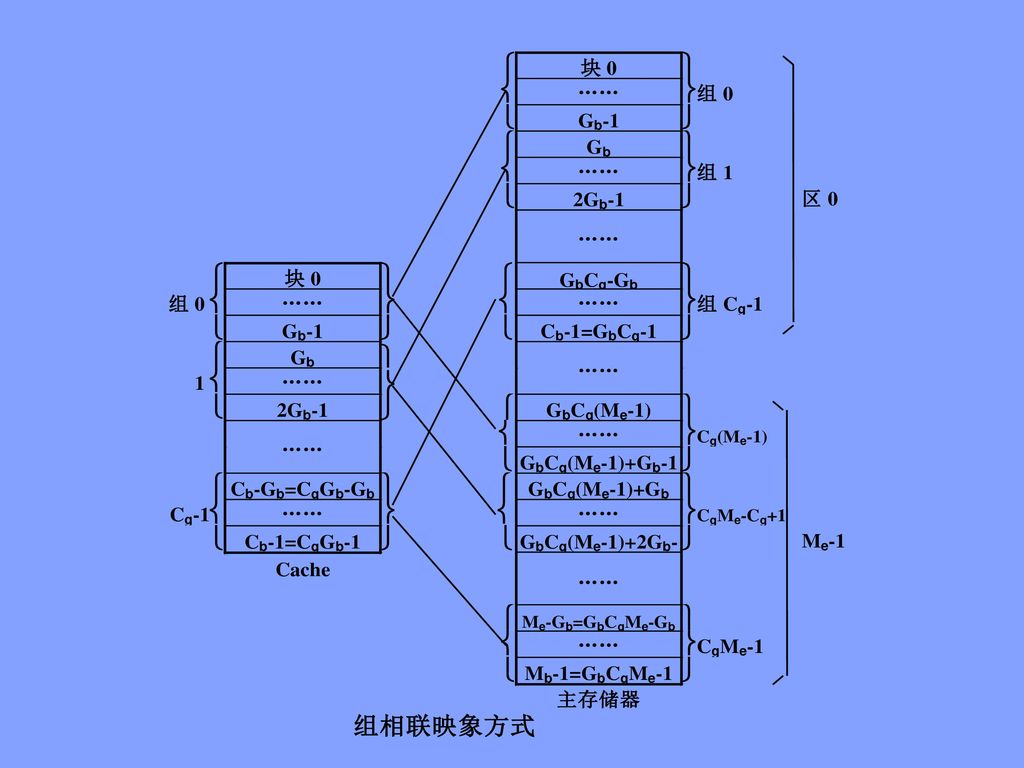
3、组相联映象及其变换 映象规则: 主存和Cache按同样大小划分成块,还按同样大小划分成组 从主存的组到Cache的组之间采用直接映象方式 在两个对应的组内部采用全相联映象方式

93
组相联映象方式的优点: 块的冲突概率比较低 块的利用率大幅度提高 块失效率明显降低
组相联映象方式的缺点: 实现难度和造价要比直接映象方式高 地址变换过程: 用主存地址的组号G按地址访问块表存储器

94
把读出来的一组区号和块号与主存地址中的区号和块号进行相联比较 如果有相等的,表示Cache命中 如果没有相等的,表示Cache没有命中

95
Cache替换算法及其实现 Cache替换算法使用的时间: 发生块失效,且可以装入新调入块的几个Cache块都已经被装满时 直接映象方式实际上不需要替换算法 全相联映象方式的替换算法最复杂

96
组内块号b 区号E 块内地址W 主存 地址 块表 E区号,组内块号B 相联比较 (Gb个块) 块内地址w 相等 Cache地址 组内块号B 相联比较 不等 组号G 组号g
 块内地址w 相等 Cache地址 组内块号B 相联比较 不等 组号G 组号g")
97
Cache替换算法要解决的问题: 1、记录每次访问Cache的块号 2、管理好所记录的Cache块号,为找出被替换的块号提供方便 3、根据记录和管理的结果,找出被替换的块号

98
Cache的一致性问题 本节讨论的内容仅限于单处理机、单存储器
造成Cache与主存的不一致的原因: (1) 由于CPU写Cache,没有立即写主存 (2) 由于IO处理机或IO设备写主存 Cache的更新算法 (1) 写直达法(写通过法), Write-through CPU在执行写操作时,把数据同时写入Cache和主存。 (2) 写回法 (抵触修改法)Write-Back CPU数据只写入Cache,不写入主存
 由于CPU写Cache,没有立即写主存 (2) 由于IO处理机或IO设备写主存. Cache的更新算法 (1) 写直达法(写通过法), Write-through. CPU在执行写操作时,把数据同时写入Cache和主存。 (2) 写回法 (抵触修改法)Write-Back CPU数据只写入Cache,不写入主存.")
99
CPU X’ I/O X Cache 主存储器 (a) CPU写Cache (b) I/O写主存 Cache与主存不一致的两种情况
 CPU写Cache (b) I/O写主存 Cache与主存不一致的两种情况")
100
仅当替换时,才把修改过的Cache块写回到主存
写回法与写直达法的优缺点比较: (1) 可靠性,写直达法优于写回法 (2) 与主存的通信量, WB少于WT 例如:写操作占总访存次数的20%, Cache命中率为99%, 每块4个字。当Cache发生块替换时, 有30%块需要写回主存, 其余的因未被修改过而不必写回主存。则对于WT法, 写主存次数占总访存次数的20%。而WB法为(199%) 30%4=1.2%。因此, WB法与主存的通信量要比WT法少10多倍。
 可靠性,写直达法优于写回法 (2) 与主存的通信量, WB少于WT 例如:写操作占总访存次数的20%, Cache命中率为99%, 每块4个字。当Cache发生块替换时, 有30%块需要写回主存, 其余的因未被修改过而不必写回主存。则对于WT法, 写主存次数占总访存次数的20%。而WB法为(199%) 30%4=1.2%。因此, WB法与主存的通信量要比WT法少10多倍。")
101
(3) 控制的复杂性, 写直达法比写回法简单 (4) 硬件实现的代价, 写回法要比写直达法好
写Cache的两种方法: (1) 不按写分配法:在写Cache不命中时,只把所要写的字写入主存。 (2) 按写分配法:在写Cache不命中时,还把一个块从主存读入Cache。 目前,在写回法中采用按写分配法,在写直达法中采用不按写分配法。
 不按写分配法:在写Cache不命中时,只把所要写的字写入主存。 (2) 按写分配法:在写Cache不命中时,还把一个块从主存读入Cache。 目前,在写回法中采用按写分配法,在写直达法中采用不按写分配法。")
102
Cache的预取算法 预取算法有如下几种: (1) 按需取:在出现Cache不命中时,把一个块取到Cache中来 (2) 恒预取:无论Cache是否命中,都把下一块取到Cache中 (3) 不命中预取:当Cache不命中,把本块和下一块取到Cache中 主要考虑因素: 命中率的提高 Cache与主存之间通信量的增加

103
从模拟实验的结果看: 采用恒预取能使Cache的不命中率降低75~85% 采用不命中预取能使Cache的不命中率降低30~40%

104
3.4 三级存储系统 速度接近Cache 的速度,存储容 量是主存的容量 每位价格接近主 存储器 主存储器 Cache 系统程序员看
3.4 三级存储系统 在大部分计算机系统中,既有虚拟存储器,也有Cache存储系统。 存储系统可以有多种构成方法 不同的构成只是实现技术不同 Cache 系统程序员看 主存储器 速度接近Cache 的速度,存储容 量是主存的容量 每位价格接近主 存储器 Cache存储系统

105
主存 储器 应用程序员看 磁盘 存储器 速度接近主存储 器的速度,存储 容量是虚拟地址 空间,每位价格 接近磁盘存储器 虚拟存储系统 Cache 主存储器 磁盘存储器 一种三级存储系统 一种新的二级存储系统

106
存储系统的几种组织方式: CPU 虚拟 地址 MMU Cache 主存 储器 物理 地址 数据或指令 物理地址

107
物理 地址 虚拟地址 MMU CPU 主存 储器 数据 或指令 Cache 数据或指令
2、一个存储系统组织方式:虚拟地址Cache存储系统;如Intel公司的i860等处理机采用这种组织方式。 CPU 虚拟地址 MMU Cache 主存 储器 数据或指令 物理 地址 数据 或指令 3、全Cache系统。没有主存储器,Cache-磁盘存储系统。

108
本 章 重 点 1、存储系统的定义及主要性能 2、并行存储器和无冲突访问存储器的工作原理 3、虚拟存储系统的工作原理
4、虚拟存储器中加快地址变换的方法 5、虚拟存储系统的页面替换算法

109
6、Cache存储系统地址映象及变换方法 7、Cache存储系统的块替换算法 8、Cache存储系统的一致性问题 练习题:










 *** 20**年**月**日.>")





 4-3 ROM(只读存储器) 4-4 高速缓冲存储器(Cache)>")









