Download presentation
Presentation is loading. Please wait.

1
變異數分析 (Analysis-of-Variance簡稱ANOVA)
藉著分析樣本的變異數,來比較三個或三個以上不同母體平均數差異的統計方法。 過去所學的t檢定可以讓我們檢查兩個獨立母體的平均數是否有差異。 而變異數分析則可讓我們檢查更多母體之間的平均數差異是否顯著。

2
名詞解釋 實驗 (experiment) 任何觀察或蒐集具有變異性或隨機性資料的行動都可稱為實驗。
例如:若我們想要比較三個不同廣告對影響力,則分析者必須隨機抽取適當人數的消費者,前來觀看這些廣告,並且紀錄他們的反應數據或評價。這整個過程就可以稱為一個「實驗」,而最後所得到的消費者評價數據(實驗測量值),稱為這個實驗的反應值(responses)
,稱為這個實驗的反應值(responses)")
3
因子 (factor) 水準 (level) 引起資料發生差異的原因稱為因子,亦稱獨立變數、自變數、實驗變數
在人文社會類的研究通常架構因果關係時的「因」 如:探討不同家庭背景是否導致統計學成績有差異,家庭背景就是因子 水準 (level) 每一個因子會有不同的分類或測量值,稱為該因子的「水準」,也有人稱為處方或配方。 如:家庭背景 若區分成雙親、單親、他人撫養等三種
 每一個因子會有不同的分類或測量值,稱為該因子的「水準」,也有人稱為處方或配方。 如:家庭背景 若區分成雙親、單親、他人撫養等三種.")
4
「處理」是實驗中想要加以比較的不同特性、不同組合或不同分類等。
處理(treatment) 「處理」是實驗中想要加以比較的不同特性、不同組合或不同分類等。 例如:若想調查性別對收入的影響。則男性與女性是我們想比較的不同分類,稱為此實驗的2個「處理」。 若再加上國籍因子的考量,則共有4個處理:本國男性、本國女性、外國男性與外國女性。 實驗單位 (experimental unit) 「實驗單位」則是實驗中被處理所影響的最基本單位。在此例中,一個實驗單位是一個「人」。
 「處理」是實驗中想要加以比較的不同特性、不同組合或不同分類等。 例如:若想調查性別對收入的影響。則男性與女性是我們想比較的不同分類,稱為此實驗的2個「處理」。 若再加上國籍因子的考量,則共有4個處理:本國男性、本國女性、外國男性與外國女性。 實驗單位 (experimental unit) 「實驗單位」則是實驗中被處理所影響的最基本單位。在此例中,一個實驗單位是一個「人」。")
5
反應值(responses)又稱為依變數(dependent variable)
研究者欲觀察的反應值通常為研究架構中的「果」 「反應值」是某個處理對實驗單位所產生的影響力大小。若想要測量這樣的影響力,端視實驗當時所使用的測量工具或測量機制來決定影響力的單位是什麼。 如:不同的教學法對學生學習成績是否有差異,成績就是反應值

6
例如:若某實驗是研究日光燈擺放位置 (左上方、正 上方、右上方、後上方) 對近視度數的影響。
單因子實驗: 因子: 1個→燈的位置 水準 : 4個→左上方、正上方、右上方、後上方 處理: 4個→左上方、正上方、右上方、後上方 實驗單位:學生 反應值:某個處理讓某 1 個學生增加的近視度數

7
例如:若想調查性別(男女)及國籍(本國外國) 對收入的影響
雙因子實驗: 因子: 2個→性別、國籍 水準(性別):2個→男、女 水準(國籍):2個→本國、外國 處理: 4個→本國男、本國女、外國男、外國女 實驗單位:就業人士 反應值:某個處理之就業人士的年收入
:2個→男、女. 水準(國籍):2個→本國、外國. 處理: 4個→本國男、本國女、外國男、外國女. 實驗單位:就業人士. 反應值:某個處理之就業人士的年收入.")
8
與「變異」有關的名詞 離差(deviation):任一觀察值與其平均數的差 變異(variation):離差的平方
平方和SS(sum of square) :變異的加總 均方MS(mean square):平方和除以自由度, 又稱為變異數 12-8
 :變異的加總. 均方MS(mean square):平方和除以自由度, 又稱為變異數")
9
樣本反應值的總變異分解 總變異(total variation) 代表不同的反應值之間差異性或變異性的總和指標,通常以 來表示總變異的大小。
在比較 k 個處理所造成的反應值差異時,總變異可以分解為 (1) 組間變異 (between-group variation) (2) 組內變異 (within-group variation)
 組間變異 (between-group variation) (2) 組內變異 (within-group variation)")
10
組間變異 所謂「組間變異」,是指總變異之中,由於不同處理的影響力所造成的反應值變異或差異。 例如: 某汽車廠商準備相同款式的 40 輛汽車,想要比較4種不同廠牌汽油的行駛里程數 每10輛汽車分配同一廠牌的汽油1公升 實驗結束後,我們會得到40輛汽車的里程數反應值 這40 個里程數值之間一定或多或少有所不同 其中一個理由,正是因為4種不同廠牌汽油的影響力是不一樣的。 這裡,不同廠牌之間所造成的里程數差異,就稱為「組間變異」。

11
組內變異 在上例中 造成實驗中40輛汽車里程數不同的原因,除4種不同廠牌汽油的影響之外 還因為每一輛相同款式的汽車車體,也各有其差異性
假設其中10輛汽車都使用A廠牌的汽油(也就是被分配給同一個處理,或被分到同一組),他們各自的耗油量也會有所不同。 這是因為,不管實驗單位是工業產品、人或動物,個體之間都存在一些細微的差異性, 而這樣的差異性就會造成同一組的實驗單位得到不同的反應值 因此,因為同組的實驗單位之間的差異性所造成的反應值差異,就稱為「組內變異」。
,他們各自的耗油量也會有所不同。 這是因為,不管實驗單位是工業產品、人或動物,個體之間都存在一些細微的差異性, 而這樣的差異性就會造成同一組的實驗單位得到不同的反應值. 因此,因為同組的實驗單位之間的差異性所造成的反應值差異,就稱為「組內變異」。")
12
消除干擾因素的影響 在比較4種不同廠牌汽油的耗油量實驗中,我們有興趣的是不同廠牌的汽油的平均耗油量是否有顯著差異。
但是,實驗中每一輛汽車的駕駛、車胎、品質等因素,也往往會造成最後里程數測量值的不同。 若要真正判別出汽油廠牌差異所造成的影響,同時也避免上述次要因子的干擾,我們必須藉由實驗的重複性(replication)與隨機性(randomization)來達到這個目的。
與隨機性(randomization)來達到這個目的。")
13
觀察性資料與實驗性資料 範例:吃蛋糕是否容易導致肥胖? 觀察性資料: 訪問 100 位體重過重者,並記錄這些人之中經常吃蛋糕的人數。
實驗性資料: 徵求 100 位體重正常的人,隨機分成兩組,其中一組每天吃蛋糕。過一個月後,測量所有人的體重。 重點:從觀察性資料無法直接得到因果推論

14
單因子完全隨機設計 單因子完全隨機設計是用來檢定某一個因子中,各個水準的影響力是否會造成反應值之間的顯著差異。在此,因子的一個水準相當於一個處理。 假設實驗中的主要因子有 k 個水準,並且隨機指派 ni 個實驗單位給第 i 個處理 i = 1, 2, …, k, 而且 n = n1+ n2 +…+ nk

15
(群體)處理 1 2 … k 各組樣本和 樣本總和 各組樣本數 樣本總數 各組樣本平方和 樣本平方總和
統計學導論 Chapter 12 變異數分析 12-15

16
母體模式 母體模式以一個方程式來代表所有反應值的 產生方式 或寫成 這個模式代表了所有 n 個反應值的可能產生原因,與主要因子的影響方式。也就是說,每一個反應值 Yij 是由實驗之前未受處理影響的平均值 ,加上第 i 個處理的影響效果 i (代表組間變異),再加上同組實驗單位之間的隨機差異εij (代表組內變異),共三個值相加而得最後的測量值。
,再加上同組實驗單位之間的隨機差異εij (代表組內變異),共三個值相加而得最後的測量值。")
17
在上述假設下,進行檢定各群體(處理效果)平均值是否有顯著差異。 H0:μ1=μ2=…=μk(所有平均數都相等) H1:至少有兩個平均數不相等
變異數分析模式 基本假設 1.每個反應變數的母體均為常態分配。 2.每個母體的變異數均相等。 3.抽自各母體的各組隨機樣本互為獨立。 在上述假設下,進行檢定各群體(處理效果)平均值是否有顯著差異。 H0:μ1=μ2=…=μk(所有平均數都相等) H1:至少有兩個平均數不相等 統計學導論 Chapter 12 變異數分析 12-17
平均值是否有顯著差異。 H0:μ1=μ2=…=μk(所有平均數都相等) H1:至少有兩個平均數不相等. 統計學導論 Chapter 12 變異數分析")
18
顯著的標準決定於各組變異數的大小,當各組的均值差異相對於各組內的變異很大時,各群體平均值的差異變得很明顯。

19
變異數分解 相對於母體模式 反應值也可用樣本平均數表示成 這個式子可改寫成 從此式中,統計學家已經證明 總差異=組間差異+組內差異
總平方和 = 組間平方和 + 組內平方和

20
統計學導論 Chapter 12 變異數分析 12-20

21
速算公式 統計學導論 Chapter 12 變異數分析 12-21

22
(群體)處理 1 2 … k Σ SSB= SST= 2 2 2 各組樣本和 樣本總和 各組樣本數 樣本總數 各組樣本平方和 樣本平方總和
統計學導論 Chapter 12 變異數分析 12-22

23
變異數分析表則將變異數分析模式中的總變異,分解成組間變異和組內變異,並求出統計量F值,以具體檢定組間的差異是否顯著。
變異數分析表(ANOVA Table) 變異來源 平方和(SS) 自由度(DF) 均方(MS) F統計量 組間 SSB k-1 MSB=SSB/k-1 F=MSB/MSE 組內 SSE n-k MSE=SSE/n-k 總和 SST n-1 若F>Fα(k-1,n-k) 則拒絕H0 統計學導論 Chapter 12 變異數分析 12-23
 變異來源. 平方和(SS) 自由度(DF) 均方(MS) F統計量. 組間. SSB. k-1. MSB=SSB/k-1. F=MSB/MSE. 組內. SSE. n-k. MSE=SSE/n-k. 總和. SST. n-1. 若F>Fα(k-1,n-k) 則拒絕H0. 統計學導論 Chapter 12 變異數分析")
24
範例1:某工廠欲瞭解4部機器的性能,由於4部機器分別由不同的人操作,以及其他無法測知的因素,致使每一部機器之每小時平均產量可能有所不同。下表列出每一部機器在某段期間所測得的每小時之產量,請檢定4部機器的性能(平均產量)是否有顯著的差異? 機器 1 2 3 4 樣本 10 14 17 12 15 18 16 8 21 統計學導論 Chapter 12 變異數分析 12-24

25
機器 1 2 3 4 總和 樣本 10 14 17 12 15 18 16 8 21 樣本和 60 68 112 90 330 樣本數 5 7 6 22 樣本平方和 758 1186 1804 1364 5112

26
ANOVA 變異來源 平方和(SS) 自由度(DF) 均方(MS) F統計量 組間 68 3 68/3=22.67 4.34 組內 94
18 94/18=5.22 總和 162 21 (4部機器的平均產量沒有差異) 拒絕域R:F>F0.05(3,18)=3.16 故4部機器的平均產量有顯著的差異 統計學導論 Chapter 12 變異數分析 12-26
 拒絕域R:F>F0.05(3,18)=3.16. 故4部機器的平均產量有顯著的差異. 統計學導論 Chapter 12 變異數分析")
27
全民英檢近年來漸受到重視,現今想探知北、中、南部的大專院校之大學生,是否在英文程度上有所差異?已知隨機抽取三地區之大學生,進行20題英文測驗,得下列資料:
12-27
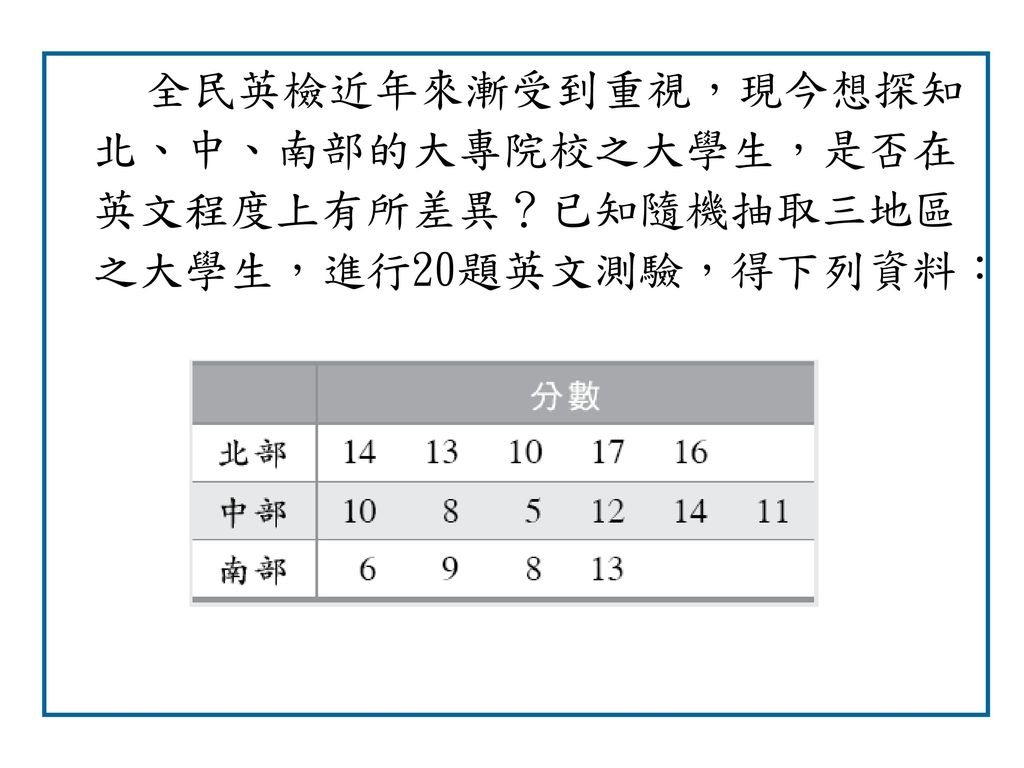
28
解: 樣本 樣本和 樣本數 平方和 北部 70 5 1010 中部 60 6 650 南部 36 4 350 總和 166 15 2010
14 13 10 17 16 70 5 1010 中部 8 12 11 60 6 650 南部 9 36 4 350 總和 166 15 2010 解: ANOVA 變異來源 平方和(SS) 自由度(DF) 均方(MS) F統計量 組間 66.93 2 66.93/2=33.47 3.79 組內 106 12 106/12=8.83 總和 172.93 14 拒絕域R:F>F0.05(2,12)=3.89 故三地區的英文程度沒有顯著差異 12-28
 自由度(DF) 均方(MS) F統計量. 組間 /2= 組內 /12=8.83. 總和 拒絕域R:F>F0.05(2,12)=3.89. 故三地區的英文程度沒有顯著差異")
29
多重比較 在上一節的F檢定中,如果我們拒絕了H0,表示至少有兩個處理(或水準)的效果有明顯差異。
若我們要知道哪幾個處理平均數造成這些差異性。 有幾種方法來決定哪些母體平均數是不同的: Fisher的最小顯著差異法(LSD) Bonferroni的多重比較方法 Tukey的多重比較方法 Scheffe的多重比較方法 …
 Bonferroni的多重比較方法. Tukey的多重比較方法. Scheffe的多重比較方法. …")
30
Fisher的最小顯著差異法(LSD) 若兩個樣本平均數間的差異大於一個臨界值,則兩個母體平均數被認為是不同的。
我們定義最小顯著差異(least significant difference, LSD) 決定每一對母體平均數間是否存在著差異的簡單辦法,是將兩樣本平均數間差異的絕對值與LSD 做比較: 如果所有k 個樣本大小皆相等,則LSD 對所有成對的平均數都是相同的。如果有一些樣本大小不同,對每一個組合都必須計算LSD。
 決定每一對母體平均數間是否存在著差異的簡單辦法,是將兩樣本平均數間差異的絕對值與LSD 做比較: 如果所有k 個樣本大小皆相等,則LSD 對所有成對的平均數都是相同的。如果有一些樣本大小不同,對每一個組合都必須計算LSD。")
31
Bonferroni的多重比較方法 Bonferroni法修正了臨界值 如果所有k 個樣本大小皆相等,則C對所有成對的
平均數都是相同的。如果有一些樣本大小不同, 對每一個組合都必須計算C。

32
範例1 樣本 檢定結論:4部機器的平均產量有顯著的差異 機器 1 2 3 4 樣本和 60 68 112 90 樣本數 5 7 6
10 14 17 12 15 18 16 8 21 樣本和 60 68 112 90 樣本數 5 7 6 樣本平均數 變異來源 平方和(SS) 自由度(DF) 均方(MS) F統計量 組間 68 3 68/3=22.67 4.34 組內 94 18 94/18=5.22 總和 162 21 檢定結論:4部機器的平均產量有顯著的差異
 自由度(DF) 均方(MS) F統計量. 組間 /3= 組內 /18=5.22. 總和 檢定結論:4部機器的平均產量有顯著的差異.")
33
利用LSD法進行母體平均數的比較 檢定結論:機器1的平均產量與機器2,3,4有顯著差異 機器2,3,4彼此間的平均產量沒有顯著差異

34
利用Bonferroni法進行母體平均數的比較
檢定結論:機器1,2,3,4彼此間的平均產量沒有顯著差異

35
雙因子變異數分析 雙因子變異數分析 雙因子變異數分析的種類
指探討兩個分類性的解釋變數對依變數之間的關係,檢定A因子或B因子的衡量水準對依變數是否會造成顯著的差異 雙因子變異數分析的種類 未重複試驗 抽樣時每個因子配對的衡量水準下只抽取一個樣本 重複試驗 每個配對的樣本數超過2(含)個以上,而每個配對樣本數則稱為重複次數
個以上,而每個配對樣本數則稱為重複次數.")
36
未重複試驗 之雙因子變異數分析 資料格式

37
未重複試驗 雙因子變異數分析的兩個假設 A因子的假設 B因子的假設

38
變異的分解 總變異=A因子引起的變異+B因子引起的變異+隨機變異 SST=SSA+SSB+SSE

39
變異數分析表 檢定A因子是否有影響 若 拒絕 H0 檢定B因子是否有影響

41
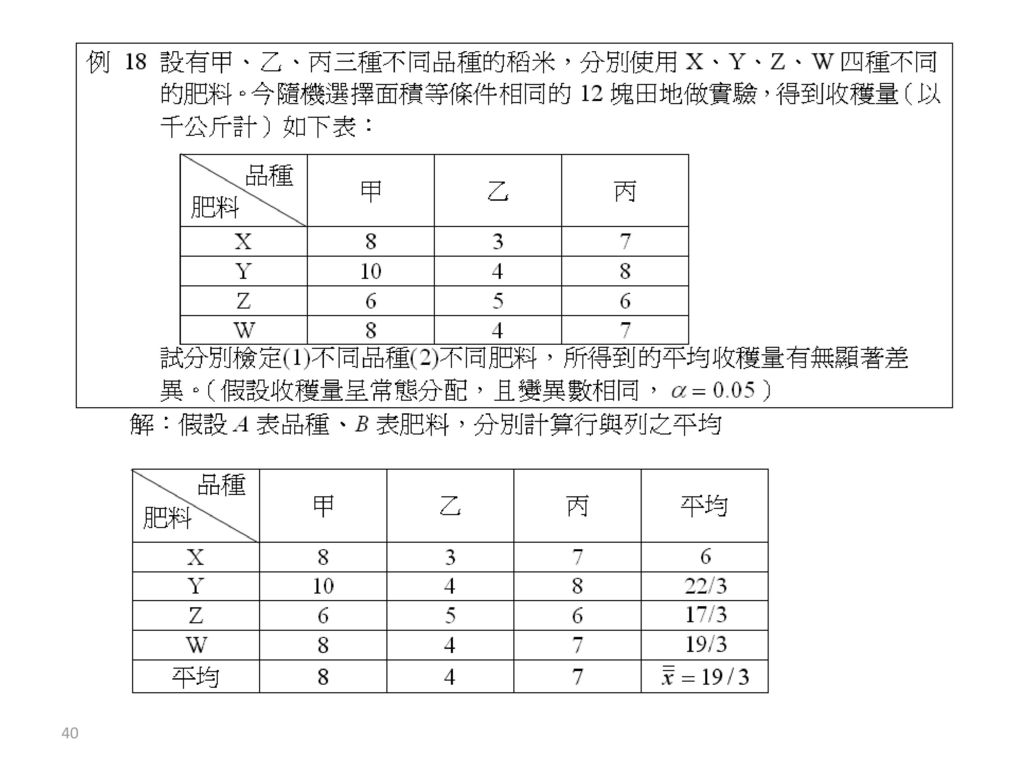
甲 乙 丙 和 樣本數 X 8 3 7 18 Y 10 4 22 Z 6 5 17 W 19 32 16 28 76 12 平方和 264 66 198 528

42
變異 平方和SS 自由度df 均方MS F值 品種(A因子) 2 14.18 肥料(B因子) 4.6667 3 1.5556 1.27 組內變異 7.3333 6 1.2222 總變異 11

Similar presentations







 冷战时期美苏关系的演变.>")





 雙變項統計分析(一)>")





