Download presentation
1
多變量分析 Multivariant Analysis
量化研究與統計分析 多變量分析 Multivariant Analysis 謝寶煖 台灣大學圖書資訊學系

2
多變量分析 主成分分析 Principal Component Analysis 因素分析 Factor Analysis
判別分析法 Discriminant Analysis 集群分析法 Cluster Analysis 典型相關分析 Canonical Correlation Analysis 結構方程式(SEM)
")
3
謝寶煖 台灣大學圖書資訊學系 pnhsieh@ntu.edu.tw
量化研究與統計分析 因素分析 項目分析與信度估計 謝寶煖 台灣大學圖書資訊學系

4
項目分析 預試分析 遺漏值分析 描述性統計評估法 題目適切性評估 信度分析 拒絕或難以回答某一個題目 遺漏值過多時,該題不宜採用
題目平均數評估法:極端平均數代表不良試題 題目變異數評估法:變異數太小,表示受試者填答的情形趨於一致,代表題目沒有鑑別力,是不良的題目

5
項目分析 遺漏值檢驗 描述性統計檢測 平均數 標準差 偏態係數 分析>報表>觀察值摘要 極端組比較 同質性檢驗 相關係數 因素負荷量

7
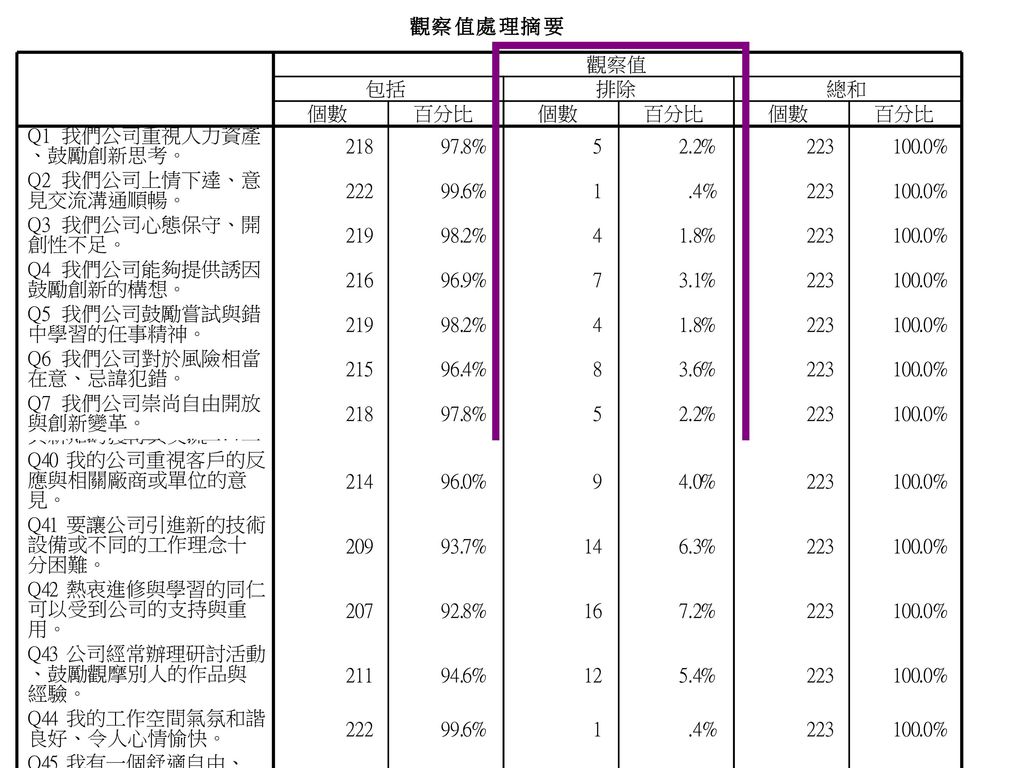
項目分析 遺漏值檢驗 由觀察值處理摘要表中,觀察值「排除」之個數和百分比,可得知高遺漏值題目 遺漏值超過5%的題目 優先刪除之題目
高遺漏值題目是否有集中趨勢,有,表示受試者在填答遭遇困難時,前後題的填答會受到影響

9
項目分析 描述性統計檢測 平均數:過高或過低 標準差:較小 偏態:嚴重 有上述三種現象,表示題目之鑑別度不足

10
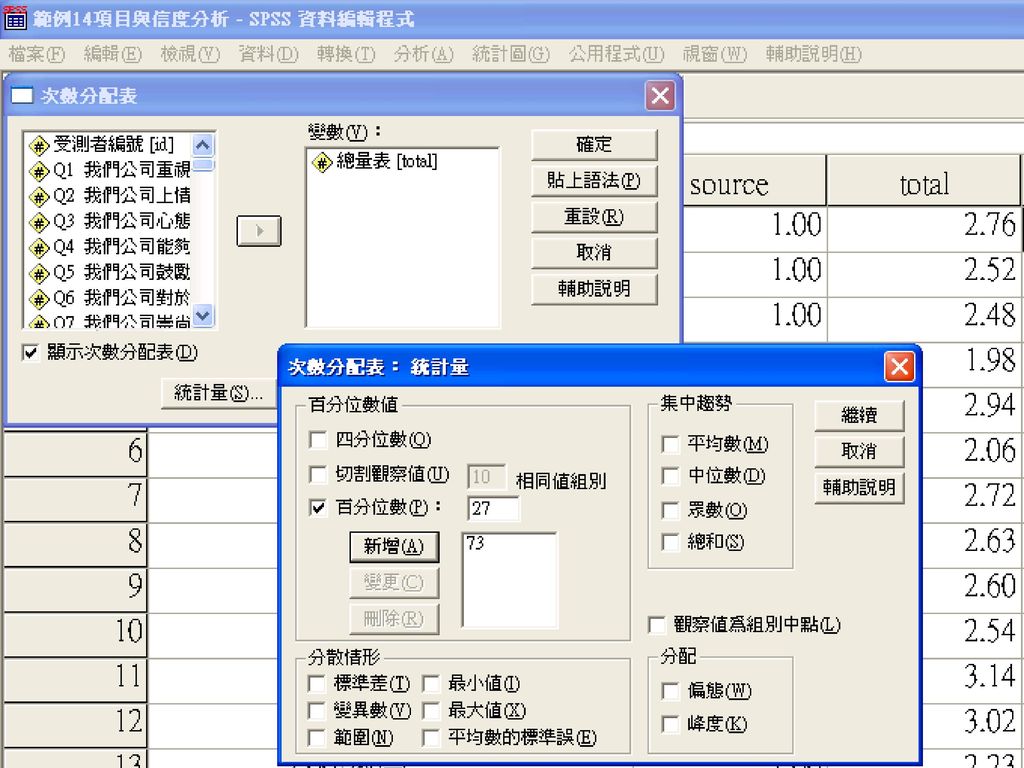
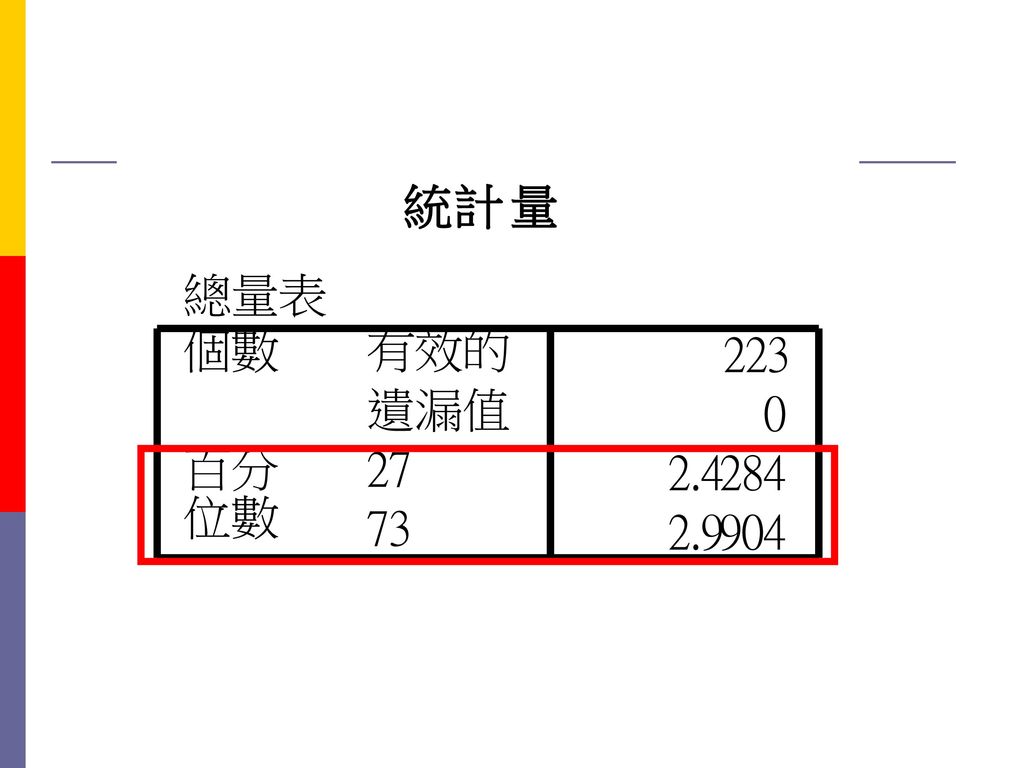
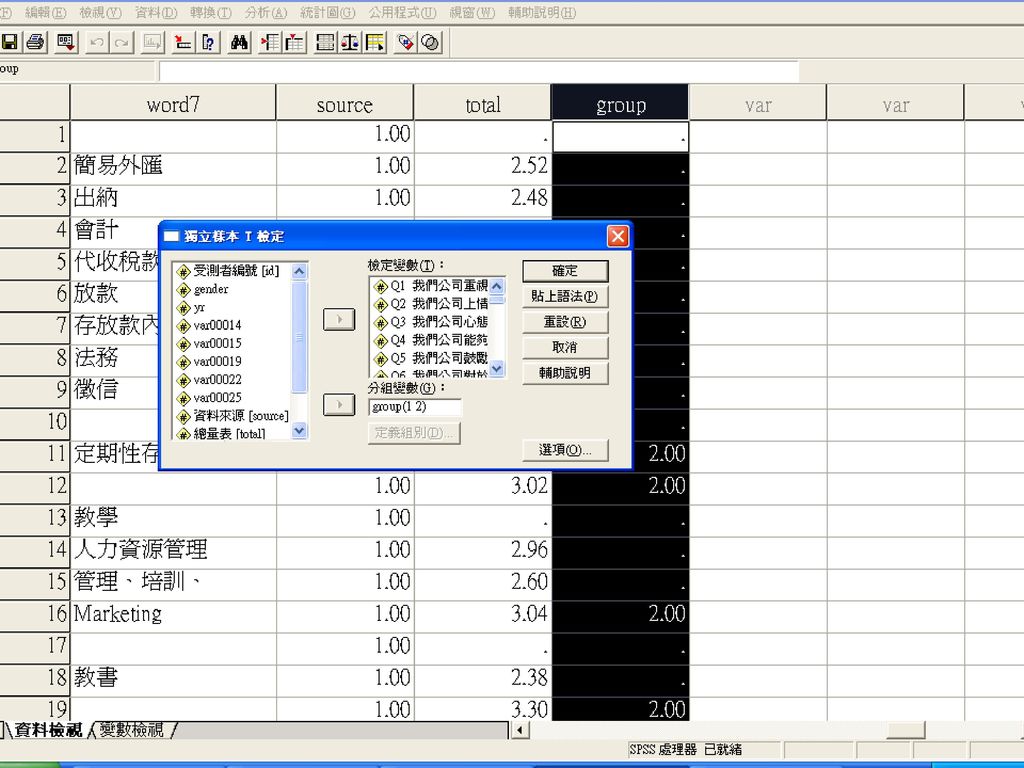
項目分析 極端組比較 將所有受試者中,全量表總體得分最高與最低的兩極端者予以歸類分組,再以t 檢定或F檢定來檢驗顯著差異,以反應題目的鑑別度。 取全量表總分最高的27%與最低的27%,為極端組,進行平均數差異檢定。 轉換>計算 增加新變項total ,以SUM函數計算量表總分、總平均 分析>描述性統計>次數分配表,分析量表總分 統計量,勾選百分位數,新增73與27(27%受試者的分割點)
")
13
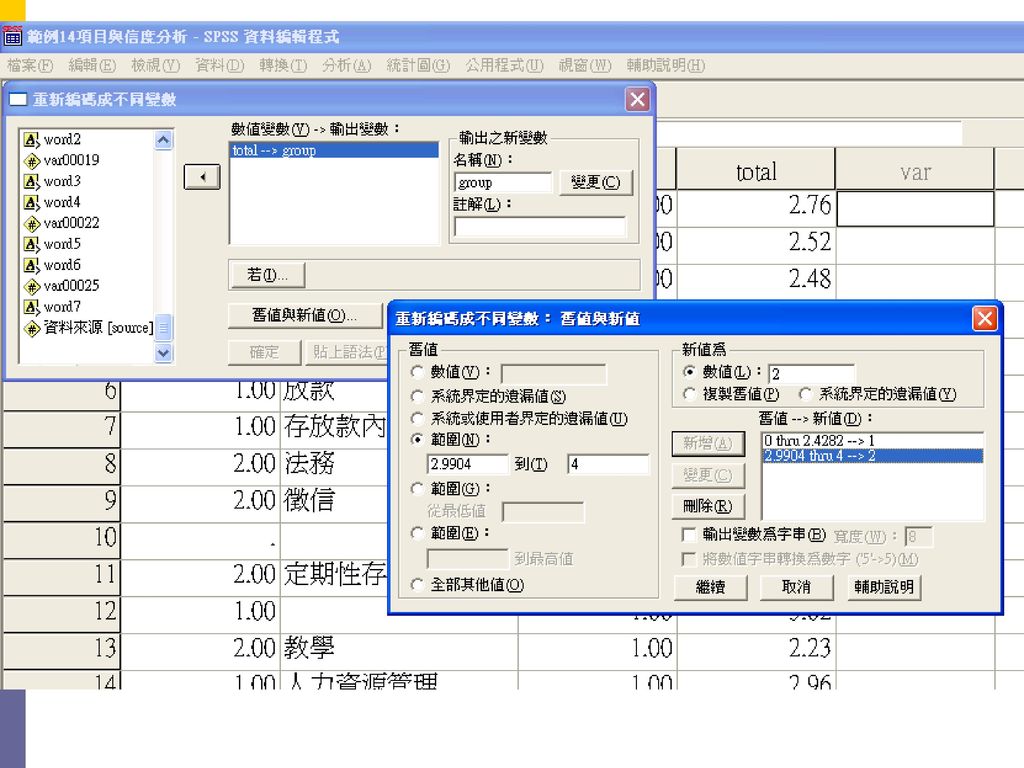
分組 T檢定 轉換>重新編碼>成不同變數 分析>比較平均數法>獨立樣本t檢定 未達0.5顯著水準者,表示該題目明顯地無法鑑別高低分姐。
未達0.1顯著水準,表示題目的鑑別度稍差

17
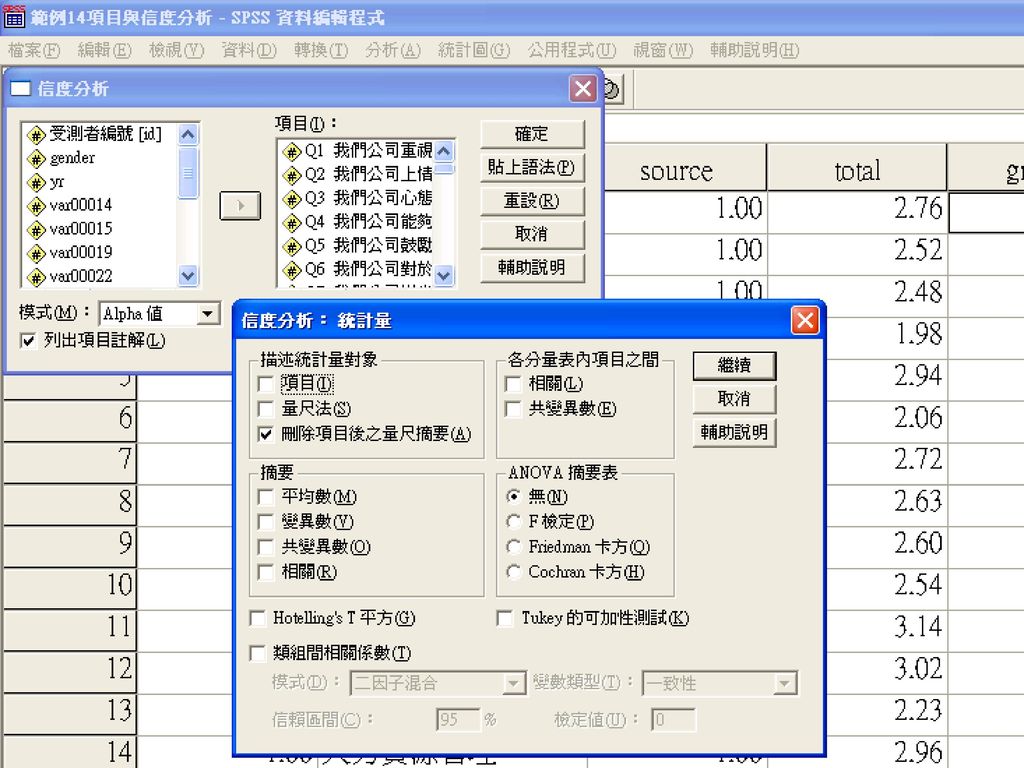
同質性檢定 同一題本的試題,係測量同一種屬性,彼此間應該高度相關 試題的內部一致性或同質性 分析>量尺法>信度分析
統計量>刪除題項後之量尺摘要

19
此欄之alpha值大於報表末之整份量表alpha值時,考慮刪除
相關係數較低的題目,列入刪除之考慮 此欄之alpha值大於報表末之整份量表alpha值時,考慮刪除

20
整份量表的信度係數

21
信度與效度

22
信度與效度 判斷測量(問卷)品質的好壞與否,最常用的方法是估計測量的信度(reliability)與效度(validity)
信度:是指量測結果的穩定程度,亦即針對同一事物進行兩次或兩次以上的測量,其結果的相似程度。相似程度愈高,代表信度愈高,測量的結果也就愈可靠。 效度:是指測量結果的有效程度,亦即測量過程是否測量真正想要測量的事物屬性。

23
信度 信度是測量的可靠性(trustworthiness),測量結果的一致性(consistency)或穩定性(stability)
如果我們以一個量表測量學生對學校的滿意度,測驗分數的信度表示測驗內部問題間是否相互符合,或是不同的測驗時點下,測驗分數前後一致的程度。 信度的高低是一種相對的概念,並非全有或全無的特質。任何一種測量,或多或少都會有誤差,誤差由機率因素所支配,就是一種隨機誤差(random error)。誤差愈小,信度愈高;誤差愈大,信度愈低。因此,信度也可以看做是測驗結果受機率影響的程度。
。誤差愈小,信度愈高;誤差愈大,信度愈低。因此,信度也可以看做是測驗結果受機率影響的程度。")
24
測量信度的原理 測量信度的原理,建立在測驗分數的變異理論上。對於某個變項的測量,分數係落在一定範圍內,因些可以獲得一個該變項的離散量數,變異數。這些分數的變異,主要由兩個因素造成,一是真實的分數本身即存在的變異,以及因為隨機誤差所產生的波動。即 變項總變異量=真實分數的變異+隨機誤差的變異

25
為信度係數,代表一個測量分數是否具有信度的指標。信度係數介於0與+1之間,數值越大,信度越高

26
信度的類型 測量的信度通常是以相關係數表示,在計算過程中,由於總變異量的獲得方法與來源不同,故有下列各種信度係數的計算方法
再測信度(test-retest reliability) 複本信度(alternate-form reliability) 折半信度(split-half reliability) 內部一致性信度(internal consistency) 評分者間信度(inter-rater reliability)
 複本信度(alternate-form reliability) 折半信度(split-half reliability) 內部一致性信度(internal consistency) 評分者間信度(inter-rater reliability)")
27
信度的類型 再測信度(test-retest reliability)
係指同一種測量工具,對同一群受測者,前後測驗兩次,並以受試者在兩次測驗分數的相關係數作為再測信度的指標。 總變異來源是受試者在兩次測量上的得分差距的變異。得分差距代表的是因為時閜所造成的誤差,信度係數反映的是測量分數的穩定性,又稱為穩定係數(coefficient of stability). 一般而言,相隔時間愈長,穩定係數愈低。
. 一般而言,相隔時間愈長,穩定係數愈低。")
28
信度的類型 複本信度(alternate-form reliability)
當一套測量工具有兩種以上的複本時,可以交替使用,根據一群受試者接受兩種複本測驗的分數來計算相關係數,即得複本信度。 複本信度的變異來源是受試者在兩種不同版本工具得分的差異的變異量,差異的存在是因為問題內容的差異,而非時間的因素,因此反映的時測驗分數的可信賴度或內部穩定性。

29
信度的類型 折半信度(split-half reliability)
當測量工具沒有複本且只能實施一次的情況下,研究者可以將測驗題目依題目的單雙數或其他方法分成兩半,根據受測者在兩半測驗上的分數,求取相關係數而得到折半信度。 由於此一相關係數只是半個測驗的相關程度,測驗題目少了一半,故必須使用史布公式(Spearman-Brown formula)加以校正。
加以校正。")
30
信度的類型 內部一致性信度(internal consistency) 庫李信度與係數是一種直接分析題目間的一致性或相關程度的信度指標。
庫李信度是Kuder和Richardson在1937年所提出,是將測驗中每題答對與答錯的百分比乘積之總和除總變異。適用於二分變數的測量;但是在社會科學的研究中,多數的測量並非對錯的二分測量,而是以量尺作為測量工具,因此1951年Cronbach加以修正,得到係數。 Cronbach 所求得的是問卷題目間的相關程度。

31
信度的類型 內部一致性信度(internal consistency)
Cronbach 所求得的是問卷題目間的相關程度。所反映的是測量工具的內部同質性、一致性或穩定性。同質性愈高,代表問卷題目是在測量相同的特質或屬性。 一般而言,Cronbach 是各種信度中較為嚴謹的,也是目前採行最廣的一種信度指標。 一般而言,信度係數大於0.7即為適當

32
信度的類型 評分者間信度(inter-rater reliability)
當測量的進行使用的工具是人,而不是量表時,不同的評量者可能打出不同的分數,分數變異來源是評分者間的差異,若計算兩個評分者間的分數的相關,即是評分者間信度。 若將兩個評分者視為兩個版本的複本,評分者間信度亦是一種內部一致性係數,反映測量分數在同一個時間點下分數變化。

33
信度分析

34
信度分析 可研究測量量尺的性質,以及組成他們的項目
信度分析程序會計算一些常用的量尺法信度量數,同時也會提供有關量尺中個別項目之間關係的資訊。 類組間相關係數可用來計算 interrater 信度估計值。

35
信度分析 範例 我的問卷是以有用的方式來測量消費者滿意度嗎?
使用信度分析,就可以確定問卷中項目彼此有關的程度,可以得到信度的概要指標或量尺的內部一致性,還可以識別應排除於該量尺之外的問題項目。

36
信度分析 統計量 計有每個變數與量尺的描述性統計量、所有項目的摘要統計量、各分量表內項目之間相關與共變異數、信度估計值、ANOVA
表、類組間相關係數、Hotelling's T 平方及 Tukey 的可加性測試。

37
信度分析 模式 Alpha (Cronbach) 值:此為各分量表內項目之間平均相關的內部一致性模式
折半信度:本模式會將量尺分開為兩部分,並檢查部分之間的相關 Guttman 值:此模式會計算真實信度的 Guttman 值下限 平行模式檢定:此模式在所有複製過程,會假設所有項目均有相等的變異數及相等的誤差變異數 嚴密平行模式:此模式會做出平行模式之假設,並假設所有項目均有相等的平均數。

38
信度分析 SPSS統計分析程序 分析> 量尺法>信度分析... 選取當作可加性量尺法可能元件的二或多個變數
分析> 量尺法>信度分析... 選取當作可加性量尺法可能元件的二或多個變數 從「模式」下拉式清單中選擇一種模式。

40
Alpha if item deleted > .9331
宜刪除項目

41
效度 效度是測量的正確性,指問卷確能測得其所欲測量的特質或屬性的程度。

42
效度的類型 內容效度(content validity) 效標關聯效度(criterion-related validity )
建構效度(construct validity )
")
43
效度的類型 內容效度(content validity)
問卷內容的適切程度,是針對問卷的目標和內容,以系統的邏輯方法來詳細分析,又稱邏輯效度(logical validity)。 強調問卷內容的廣度、涵蓋性、和豐富性,以作為外在推論的主要依據 表面效度(face validity),指問卷在外顯形式上的有效程度,是一群評定者主觀上對於測量工具外觀上有效程度的評估。
。 強調問卷內容的廣度、涵蓋性、和豐富性,以作為外在推論的主要依據. 表面效度(face validity),指問卷在外顯形式上的有效程度,是一群評定者主觀上對於測量工具外觀上有效程度的評估。")
44
效度的類型 效標關聯效度 (criterion-related validity )
又稱為實證效度(empirical validity)或統計效度(statistical validity)。 係以測量分數和特定效標(validity criterion)之間的相關係數,表示問卷有效性的高低
或統計效度(statistical validity)。 係以測量分數和特定效標(validity criterion)之間的相關係數,表示問卷有效性的高低.")
45
效度的類型 建構效度( construct validity ) 係指問卷能測得一個抽象概念或特質的程度。
其檢驗,是建立在特定的理論基礎上,透過理論的澄清,引導出各項關於潛在特質或行為表現的基本假設,並以實徵方法,查核測量結果是否符合理論假設的內涵。

46
因素分析 Factor Analysis

47
因素分析之意義 因素分析起源於心理學(約在1904年),因為在心理學研究領域經常遇到一些如智力、道德、操守等不能直接測量的因素,希望經由可測量的變數來定義出這些因素。 因素分析也是研究一份測驗建構效度(Construct Validity)最有效的方法之一,藉由因素的發現可確定心理學上一些特質觀念的結構成份,更可因此而得知測驗中有效的測量因素是那些。 因素分析是想將為眾多的變數濃縮成為少數幾個有意義因素,而又能保存住原有資料結構所提供的大部分資訊。 因素分析是想以少數幾個因素來解釋一群相互之間有關係存在的變數之數學模式。
最有效的方法之一,藉由因素的發現可確定心理學上一些特質觀念的結構成份,更可因此而得知測驗中有效的測量因素是那些。 因素分析是想將為眾多的變數濃縮成為少數幾個有意義因素,而又能保存住原有資料結構所提供的大部分資訊。 因素分析是想以少數幾個因素來解釋一群相互之間有關係存在的變數之數學模式。")
48
因素分析之類型 探索性因素分析(Exploratory factor analysis)
用來試探、描述、分類和分析正在研究中的社會及行為科學現象。 通常研究者對其所編製的測驗或量表到底能夠測出那幾個因素仍不清楚,沒有預先提出它們可測出幾個共同因素之研究假設。 驗証性因素分析(Confirmatory factor analysis) 在觀察變數(X1,,X2,,…, Xp)與所萃取之潛在因素(Y1,Y2,…,Yq)有一定理論架構之前提下,為驗證理論架構與實際資料之相容性,所進行之因素分析。
 在觀察變數(X1,,X2,,…, Xp)與所萃取之潛在因素(Y1,Y2,…,Yq)有一定理論架構之前提下,為驗證理論架構與實際資料之相容性,所進行之因素分析。")
49
探索性因素分析 v.s. 驗証性因素分析 由三個變數x1, x2, x3找到2個共同因素f1, f2,則其路徑圖如下
其中表可觀測的, 表不可觀測的。 Note: 在驗證性因素分析路徑圖中並非每個因素 fi 皆與變數 xi 間有連線(即路徑) 一般使用LISREL分析方法
 一般使用LISREL分析方法.")
50
因素分析之主要的功能 發掘多變量資料中各變數間複雜的組合型式。 進行探索性的研究,以找出潛在的共同特徵,供未來實驗之用。
發展變數間的實證類型。 減少多變量資料的維度。 將預測變數加以轉換,使其結構單純化後,再應用某些技術加以處理。 將知覺與偏好資料尺度化,並展現在一維空間。

51
因素分析 構面縮減 協助研究者簡化測量的內容,將複雜的共變結構予以簡化,使得許多相似概念的變項,透過數學關係的轉換,簡化成幾個特定的同質性類別。研究者可以根據每一個因素的主要概念,選用最具有代表性的題目來測量特質,以最少的題項,進行最直接最適切的測量,減少受試者的作答時間,減少疲勞效果與填答抗拒。

52
因素分析的條件 變項必須是連續變項,符合線性關係的假設 樣本的過程必須具有隨機性,並具有一定的規模
Comrey建議,樣本數在100以下不宜進行因素分析,樣本數宜大於300 如果研究的母群體具有相當的同質性(如學生樣本),且變項數目不多,樣本數可以介於100到200之間 Gorsuch建議樣本數至少要有變數個數的5倍,且大於100,最適者為一比十的比例。 變數之間需具有一定程度的相關,一群相關太高或太低的變項,皆會造成執行因素分析的困難。相關性太低難以抽取一組穩定的因素,通常相關係數絕對值低於0.3時,不建議進行因素分析;相關性太高的變項,多重共線性明顯,有區辨效度不足的疑慮,所獲得的因素結構價值不高。可透過球形檢定與KMO檢定來檢驗
,且變項數目不多,樣本數可以介於100到200之間. Gorsuch建議樣本數至少要有變數個數的5倍,且大於100,最適者為一比十的比例。 變數之間需具有一定程度的相關,一群相關太高或太低的變項,皆會造成執行因素分析的困難。相關性太低難以抽取一組穩定的因素,通常相關係數絕對值低於0.3時,不建議進行因素分析;相關性太高的變項,多重共線性明顯,有區辨效度不足的疑慮,所獲得的因素結構價值不高。可透過球形檢定與KMO檢定來檢驗.")
53
因素分析之假設 樣本單位在某一變數上的分數,由共同因素(common factor,Fi)與獨特因素(unique factor,Ui)所組成。 共同因素:各變數共有的成份。 獨特因素:每個變數所獨有的成份。 獨特因素有二個假設 所有獨特因素彼此沒有相關 所有獨特因素和所有共同因素間也沒有相關

54
理論架構 --數學模式 Zjn=aj1F1n+aj2F2n+…+ajqFqn+djUjn, j=1,2,…,p, n=1,2,…,N 其中
Zjn:第n個樣本單位在第j個觀察變數的分數 Fin:第n個樣本單位在第i個共同因素之分數 Ujn:第n單位在第j個觀察變數的獨特因素之分數 aji:為因素權重(factor weight) ,用以表示第i 個共同因素對第j個觀察變數之權重,又稱為 組型負荷量(pattern loading) dj:第j個觀察變數之獨特因素的權重 且假設 Z、F、U均為已標準化之分數
 ,用以表示第i. 個共同因素對第j個觀察變數之權重,又稱為. 組型負荷量(pattern loading) dj:第j個觀察變數之獨特因素的權重. 且假設 Z、F、U均為已標準化之分數.")
55
理論架構—共同性和獨特性 σj2 = 1 = hj2 + dj2 = 其中 σj2:第 j 個觀察變數之變異數
hj2:觀察變數 j 之共同性 (所有共同因素解釋變 數 j 之變異的能力) dj2:觀察變數 j 的獨特性(變數j的獨特因素所解 釋的變異數部份) 若共同因素之間沒有相關存在,則共同性(hj2)為 hj2=aj12+aj22+…+ajq2
 dj2:觀察變數 j 的獨特性(變數j的獨特因素所解. 釋的變異數部份) 若共同因素之間沒有相關存在,則共同性(hj2)為. hj2=aj12+aj22+…+ajq2.")
56
理論架構--結構負荷量 結構負荷量:各因素和變數間之相關係數, 即 ∑ ZjiFpi rZjFp= i n

57
樣本大小的原則 一般原則是要求樣本數目 至少要有變數個數的5倍 (>100) 最適者為一比十的比例
 最適者為一比十的比例")
58
探索性因素分析的步驟 決定是否適合進行因素分析以縮減構面 萃取共同因素 決定需要抽取之共同因素的數目 因素轉軸
解釋共同因素代表的意義或分析結果

59
1.決定是否適合做因素分析 在進行因素分析尋求較少之因素來代表較多之變數之前,應先確定各變數分數間具有共同變異之存在,如此才值得作因素分析。

60
1.決定是否適合做因素分析 檢驗相關係數是否適當的方法 1. KMO取樣適當性量數
(Kaiser-Meyer-Olkin measure of sampling adequacy) KMO值愈大時,表示變數間的共同因素愈多,愈適合進行因素分析,其準則如下: 2.Bartlett’s球形考驗(Bartlett’s test of sphericity ) Bartlett 球形考驗,若顯著,表示母體相關矩陣間有共同因素存在,適合進行因素分析。 KMO值 0.9以上 0.8以上 0.7以上 0.6以上 0.5以上 0.5以下 FA適合性 極適合 適合 尚可 勉強可 不適合 非常不適合
 KMO值愈大時,表示變數間的共同因素愈多,愈適合進行因素分析,其準則如下: 2.Bartlett’s球形考驗(Bartlett’s test of sphericity ) Bartlett 球形考驗,若顯著,表示母體相關矩陣間有共同因素存在,適合進行因素分析。 KMO值. 0.9以上. 0.8以上. 0.7以上. 0.6以上. 0.5以上. 0.5以下. FA適合性. 極適合. 適合. 尚可. 勉強可. 不適合. 非常不適合.")
61
2.萃取共同因素之方法 主軸法/主成份法 (method of principal)
是以共同因素對總共同性之貢獻極大化為萃取原則 重心法(centroid method of factoring) 在電腦普及以前,常以重心法估計組型負荷量 重心法是根據觀察變數之相關係數矩陣計算組型負荷量 最大概似法(maximum likelihood analysis) 需先假設共同因素之個數及服從常態分配,然後依此假定推導因素及共同性 缺點計算過程相當繁複且不一定得到收斂的結果 較適用於驗證性因素分析
 在電腦普及以前,常以重心法估計組型負荷量. 重心法是根據觀察變數之相關係數矩陣計算組型負荷量. 最大概似法(maximum likelihood analysis) 需先假設共同因素之個數及服從常態分配,然後依此假定推導因素及共同性. 缺點計算過程相當繁複且不一定得到收斂的結果. 較適用於驗證性因素分析.")
62
2.萃取共同因素之方法 主成分法(Principal components)
假設各共同因素間彼此均無關聯,即相關係數為零,也不考慮變數分數中的獨特因素 目的在使每一個成分能夠代表最大的觀察變異量 第一個主成分為觀察變項的線性整合,能夠反應最大的變異量,依序發展各主成分 可以得到最大的解釋變異量 優點:所得之共同因素彼此無相關 缺點:忽略獨特性,故共同性有高估的危險 主要因素法(principal factors) 以共同性為分析的對象 因素的抽取以疊代程序來進行,起始值為SMC(squared multiple correlations),反覆帶入共同性直到無改善 能夠產生最理想的重製矩陣
 以共同性為分析的對象. 因素的抽取以疊代程序來進行,起始值為SMC(squared multiple correlations),反覆帶入共同性直到無改善. 能夠產生最理想的重製矩陣.")
63
2.萃取共同因素之方法 映像因素萃取(image factor extraction)
各觀察變項的變異量為其他變項的投射。每一個變項的映像分數係以多元迴歸的方法來計算,映像分數的共變矩陣被進行PCA(主成份分析) 類似PCA,能夠產生單一的數學解,對角線與FA相同,為共同性 因素負荷量不是相關係數,而是變項與因素的共變 最大概似因素萃取(maximum likelihood factor extraction) 以因素負荷量的母數估計數為主要目的 計算樣本求得之觀察矩陣能夠反應母體的最大機率之負荷量 因素可進行顯著性考驗,適用於驗證性分析 也即是求取變項與因素間的最大典型相關
 類似PCA,能夠產生單一的數學解,對角線與FA相同,為共同性. 因素負荷量不是相關係數,而是變項與因素的共變. 最大概似因素萃取(maximum likelihood factor extraction) 以因素負荷量的母數估計數為主要目的. 計算樣本求得之觀察矩陣能夠反應母體的最大機率之負荷量. 因素可進行顯著性考驗,適用於驗證性分析. 也即是求取變項與因素間的最大典型相關.")
64
2.萃取共同因素之方法 無加權最小平方法(unweighted least squares factoring)
求取觀察與重製矩陣的殘差的最小平方值 只有非對角線上的數據被納入分析 共同性是分析完成之後才進行計算 一般加權最小平方法(generalized weighted least squares factoring) 在無加權平方法下,增加權數的考量(以共同性加權) 有較大的共同變異的變項被較大的加權 Alpha法(alpha factoring) 處理共同因素的信度,提高因素的類化性(generalizability) 共同性的估計是在使因素的alpha信度達到最大
 在無加權平方法下,增加權數的考量(以共同性加權) 有較大的共同變異的變項被較大的加權. Alpha法(alpha factoring) 處理共同因素的信度,提高因素的類化性(generalizability) 共同性的估計是在使因素的alpha信度達到最大.")
65
3.決定共同素之數目—原則 原則 解釋變異量 萃取的因素愈少愈好,而萃取出之因素能解釋各變數之變異數則愈大愈好 研究上的考量
因素越多,解釋變異量越大 因素越多,簡效性越低(模式越複雜) 原則 萃取的因素愈少愈好,而萃取出之因素能解釋各變數之變異數則愈大愈好 研究上的考量 參考理論架構及過去有關文獻來決定抽取共同因素之數目 探索性的目的,想要瞭解因素的結構時,邊緣強度的因素可以保留,以瞭解其性質 當研究者需要穩定的因素進行研究時,保留信度高的因素即可
 原則. 萃取的因素愈少愈好,而萃取出之因素能解釋各變數之變異數則愈大愈好. 研究上的考量. 參考理論架構及過去有關文獻來決定抽取共同因素之數目. 探索性的目的,想要瞭解因素的結構時,邊緣強度的因素可以保留,以瞭解其性質. 當研究者需要穩定的因素進行研究時,保留信度高的因素即可.")
66
因素數目判斷原則 因素之特徵值(eigenvalue) 利用因素陡坡圖檢驗(scree test)
大於1(表示大於1.00的原始觀察變異量) 因素數目合理範圍為變項數除以3至除以5之間 所謂特徵值,是指每一行因素負荷量平方加總後之總和,表示該因素能解釋全體變異的能力。因每一變數之變異數均為1,若所抽取之因素所能解釋的變異數小於1,則其解釋變數之變異數的效力便不如單一變數。 (H. Kaiser) 缺點:變數少於20之研究中取出的因素偏少,而變數多於50之研究中取出之因素卻偏多 利用因素陡坡圖檢驗(scree test) 特徵值明顯出現變化時為合理數目 當特徵值開始很平滑下降時就不取。 (R. Cattell,1966) 。
 因素數目合理範圍為變項數除以3至除以5之間. 所謂特徵值,是指每一行因素負荷量平方加總後之總和,表示該因素能解釋全體變異的能力。因每一變數之變異數均為1,若所抽取之因素所能解釋的變異數小於1,則其解釋變數之變異數的效力便不如單一變數。 (H. Kaiser) 缺點:變數少於20之研究中取出的因素偏少,而變數多於50之研究中取出之因素卻偏多. 利用因素陡坡圖檢驗(scree test) 特徵值明顯出現變化時為合理數目. 當特徵值開始很平滑下降時就不取。 (R. Cattell,1966) 。")
67
因素數目判斷原則 殘差分析 因素負荷量檢驗 殘差類似於各變項間的相關在移除了因素的影響後的淨相關
檢驗不同因素數目下,殘差矩陣中的數值,高於.05或.10以上者過多,表示可能存在其他因素 因素負荷量檢驗 單一觀察變項的因素並不恰當 二個觀察變項的因素在兩變項相關高(r>.7),與其他變項相關低時,為合理。
,與其他變項相關低時,為合理。")
68
3.決定共同素之數目—方法 兩因素負荷量的差大於0.3者
在75%之變異數已能被抽取出之因素加以解釋後繼續抽取之因素對變異數之解釋如少於5%則不予選取。

69
問卷調查範例 此問卷想要測量什麼? 非常 非常 同意 同意 無意見 不同意 不意 1. 大體來說,我對我自己十分滿意
非常 非常 同意 同意 無意見 不同意 不意 1. 大體來說,我對我自己十分滿意 2. 有時我會覺得自己一無是處 3. 我覺得自己有許多優點 4. 我自信我可以和別人表現得一樣好 5. 我時常覺得自己沒有什麼好驕傲的 6. 有時候我的確感到自己沒有什麼用處 7. 我覺得自己和別人一樣有價值 8. 我十分地看重自己 9. 我常會覺得自己是一個失敗者 10. 我對我自己抱持積極的態度 此問卷想要測量什麼?

70
範例—「自尊」的評量Rosenberg(1965)
研究構面 操作變項 變數代號 衡量尺度 自尊量表 1. 大體來說,我對我自己十分滿意 I51 五點量表 2.有時我會覺得自己一無是處 I52 3.我覺得自己有許多優點 I53 4.我自信我可以和別人表現得一樣好 I54 5.我時常覺得自己沒有什麼好驕傲的 I55 6.有時候我的確感到自己沒有什麼用處 I56 7.我覺得自己和別人一樣有價值 I57 8.我十分地看重自己 I58 9.我常會覺得自己是一個失敗者 I59 10.我對我自己抱持積極的態度 I60

71
範例—因素分析後之因素負荷量矩陣 變數名稱 因素命名 正面肯定 負面評價 7.我覺得自己和別人一樣有價值 8.我十分地看重自己
4.我自信我可以和別人表現得一樣好 1. 大體來說,我對我自己十分滿意 3.我覺得自己有許多優點 10.我對我自己抱持積極的態度 6.有時候我的確感到自己沒有什麼用處 負面評價 2.有時我會覺得自己一無是處 5.我時常覺得自己沒有什麼好驕傲的 9.我常會覺得自己是一個失敗者

72
正面肯定 圖 潛伏結構 負面評價 自尊因素 組型負荷量 自尊變數 獨特性 獨特因素 0.780 0.756 0.680 0.679
自尊因素 組型負荷量 自尊變數 獨特性 獨特因素 圖 潛伏結構 負面評價 正面肯定 我覺得自己和別人一樣有價值,I57 我十分地看重自己,I58 我自信我可以和別人表現得一樣好,I54 大體來說我對我自己十分滿意,I51 我覺得自己有許多優點,I53 我對我自己抱持積極的態度,I60 有時候我的確感到自己沒有什麼用處,I56 有時我會覺得自己一無是處,I52 我時常覺得自己沒有什麼好驕傲的,I55 我常會覺得自己是一個失敗者,I59 0.780 0.756 0.680 0.679 0.625 0.821 0.762 0.666 0.641 e1 e5 e6 e7 e8 e2 e10 e9 e4 e3 0.368 0.395 0.429 0.501 0.266 0.582 0.467 0.45 0.555 0.364

73
範例—未轉軸因素分析報表

74
範例—未轉軸因素分析報表

75
4.因素轉軸 目的 轉軸的時機 使各因素解更為清晰明瞭,以提供較充份的資訊 依目的:得到最佳的結構,或保留因素的原始面貌
利用因素散佈圖協助判斷 觀察變項應在各軸上:接近各軸,遠離原點,形成群落

76
轉軸的方法 直交轉軸法(orthogonal rotation) 斜交轉軸法(oblique rotation)
兩軸維持著90度的旋轉,旋轉至最大解釋量之點。 問題:各因素間通常存有某種關係,若硬性規定它們之間的關係是直角難免有與事實不符情事。 斜交轉軸法(oblique rotation) 兩軸非維持90度的旋轉。 問題:無法作不同研究間之比較。
 兩軸非維持90度的旋轉。 問題:無法作不同研究間之比較。")
77
轉軸前後原理圖示

78
直交轉軸法與斜交轉軸法之差異 直交解的因素組型即為其因素結構。 因素組型 因素結構 指變數以因素的線性結合表示時各因素之係數所組成之矩陣
係由變數與因素間之相關係數所組成之矩陣

79
直交轉軸法 Orthogonal rotation(直交轉軸) Varimax:使負荷量的變異數在因素內最大( Г =1)
Quartimax :使負荷量的變異數在變項內最大( Г =0) Equamax :綜合前兩者,使負荷量的變異數在因素內與變項內同時最大( Г =.5) Г(gamma)指標:表示簡化的程度:0表變項最簡化,1表因素最簡化,.5表兩者各半
 Equamax :綜合前兩者,使負荷量的變異數在因素內與變項內同時最大( Г =.5) Г(gamma)指標:表示簡化的程度:0表變項最簡化,1表因素最簡化,.5表兩者各半.")
80
直交轉軸法 Max S = ∑ (aji-ai) 變異數最大法(Varimax)(Kaiser,1958) 1 m
與四方最大法相反,其要使因素矩陣同一直行(因素) 結構簡單化。為達到其目的,此法係先將因素矩陣中的各負荷量予以平方,再使同一因素上各平方值的變異數為最大。 此法轉軸後所得之因素結構較為簡單,且容易解釋,故使用最廣。 Max S 2 ai = 1 m ∑ J=1 k (aji-ai)
 結構簡單化。為達到其目的,此法係先將因素矩陣中的各負荷量予以平方,再使同一因素上各平方值的變異數為最大。 此法轉軸後所得之因素結構較為簡單,且容易解釋,故使用最廣。 Max. S. 2. ai. = 1. m. ∑ J=1. k. (aji-ai)")
81
直交轉軸法 Max S = ∑ (aji-aj) 四方最大法(Quartimax) 1 k
使因素負荷矩陣同一橫列(變數)上高負荷量和低負荷量的數目儘量多,而中等負荷量的數目儘量減少,以符合簡單結構的原則。為達到其目的,此法係先將因素負荷矩陣中的各負荷量予以平方,再使同一變數上這些平方值的變異數為最大。 Max S 2 aj = 1 k ∑ i=1 (aji-aj)
上高負荷量和低負荷量的數目儘量多,而中等負荷量的數目儘量減少,以符合簡單結構的原則。為達到其目的,此法係先將因素負荷矩陣中的各負荷量予以平方,再使同一變數上這些平方值的變異數為最大。 Max. S. 2. aj. = 1. k. ∑ i=1. (aji-aj)")
82
斜交轉軸法 Oblique rotation(斜交轉軸) 允許因素間具有相關之轉軸
因素間最大的相關由δ(delta)決定, 負的δ越小,表示愈接近直交, δ=-4為直交, δ接近1時,因素間的相關可能最高 Direct oblimin:使因素負荷量的差積(cross-products)最小化 Direct quartimin:使型態矩陣中的負荷量平方的差積(cross-products)最小化 Orthoblique:使用quartimax算式將因素負荷量重新量尺化(rescaled)以產生直交的結果,因此最後的結果保有斜交的性質 Promax:將直交轉軸(varimax)的結果再進行有相關的斜交轉軸。因素負荷量取2,4,6次方以產生接近0但不為零的值,藉以找出因素間的相關,但仍保有最簡化因素的特性
決定, 負的δ越小,表示愈接近直交, δ=-4為直交, δ接近1時,因素間的相關可能最高. Direct oblimin:使因素負荷量的差積(cross-products)最小化. Direct quartimin:使型態矩陣中的負荷量平方的差積(cross-products)最小化. Orthoblique:使用quartimax算式將因素負荷量重新量尺化(rescaled)以產生直交的結果,因此最後的結果保有斜交的性質. Promax:將直交轉軸(varimax)的結果再進行有相關的斜交轉軸。因素負荷量取2,4,6次方以產生接近0但不為零的值,藉以找出因素間的相關,但仍保有最簡化因素的特性.")
83
需做斜交轉軸 有另一個因素存在 不適合做因素分析 簡單結構 直交轉軸

84
5. 因素命名準則 以負荷值最大的作為優先命名。 例如,問題之因素一可命名為「正面肯定」, 因素二 可命名為「負面評價」。

85
因素的解釋與命名 因素負荷量的判斷 不同轉軸法下的考量 .71(50%)優秀 .63(40%)非常好 .55(30%)好
.45(20%)普通 .32(10%)不好 .32以下:不及格 不同轉軸法下的考量 直交轉軸使用轉軸後矩陣 斜交轉軸使用型態矩陣,以獲悉因素的意義(結構矩陣中的係數被因素間的相關擴張,導致高估)
普通. .32(10%)不好. .32以下:不及格. 不同轉軸法下的考量. 直交轉軸使用轉軸後矩陣. 斜交轉軸使用型態矩陣,以獲悉因素的意義(結構矩陣中的係數被因素間的相關擴張,導致高估)")
86
範例—操作步驟1

87
問題—操作步驟2

88
問題—操作步驟3

89
問題—操作步驟4

90
問題—操作步驟5

91
問題—操作步驟6

92
問題—操作步驟7

93
範例—報表解析1 KMO值為0.879,表示變數的共同因素多,適合作因素分析。
由於p-value=0.000,小於α=0.05,因此顯著,表示母體相關矩陣間有共同因素存在,可進一步進行因素分析。

94
範例—報表解析2 我們以特徵值大於1為萃取因素的標準,共萃取出兩個因素。轉軸後第一個因素的特徵值為3.322,第二個因素的特徵值為2.302,其解釋變異量分別為33.215﹪與23.024﹪,合計共解釋了56.239﹪的變異量。

95
範例—報表解析3 由陡坡圖決定因素個數,在此選取兩個因素。

96
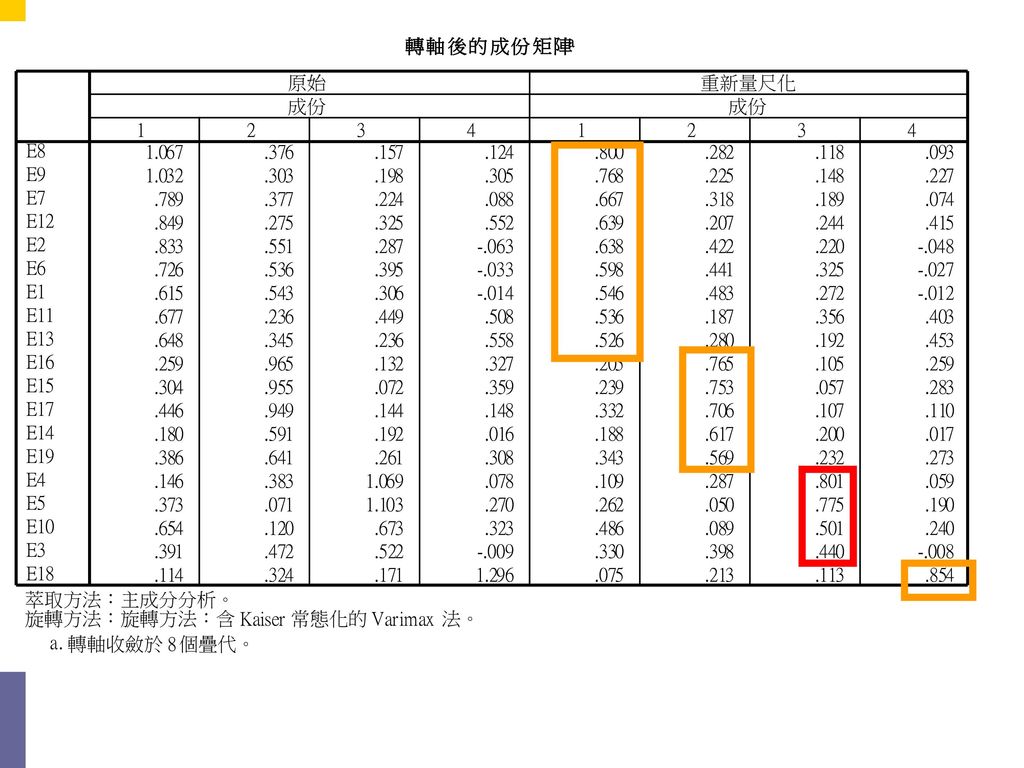
範例—報表解析4 在此成分矩陣中,由於有模糊地帶,無法將10個變數分別歸至兩個因素中,因此以轉軸後的成分矩陣進行歸類。

97
範例—報表解析5 因素一命名為正面肯定 因素二命名為負面評價

98
範例—報表解析6 ei2 0.501 0.364 0.467 0.429 0.555 0.266 0.368 0.395 0.45 0.582 1 - hi2 = ei2 獨特性

99
正面肯定 圖 潛伏結構 負面評價 自尊因素 組型負荷量 自尊變數 獨特性 獨特因素 0.780 0.756 0.680 0.679
自尊因素 組型負荷量 自尊變數 獨特性 獨特因素 圖 潛伏結構 負面評價 正面肯定 我覺得自己和別人一樣有價值,I57 我十分地看重自己,I58 我自信我可以和別人表現得一樣好,I54 大體來說我對我自己十分滿意,I51 我覺得自己有許多優點,I53 我對我自己抱持積極的態度,I60 有時候我的確感到自己沒有什麼用處,I56 有時我會覺得自己一無是處,I52 我時常覺得自己沒有什麼好驕傲的,I55 我常會覺得自己是一個失敗者,I59 0.780 0.756 0.680 0.679 0.625 0.821 0.762 0.666 0.641 e1 e5 e6 e7 e8 e2 e10 e9 e4 e3 0.368 0.395 0.429 0.501 0.266 0.582 0.467 0.45 0.555 0.364

100
範例—報表解析7 F正面肯定 = × I57 + × I58 + × I54 + × I51 + × I53 + × I60 F負面評價 = × I56 + × I52 + × I55 + × I59

102
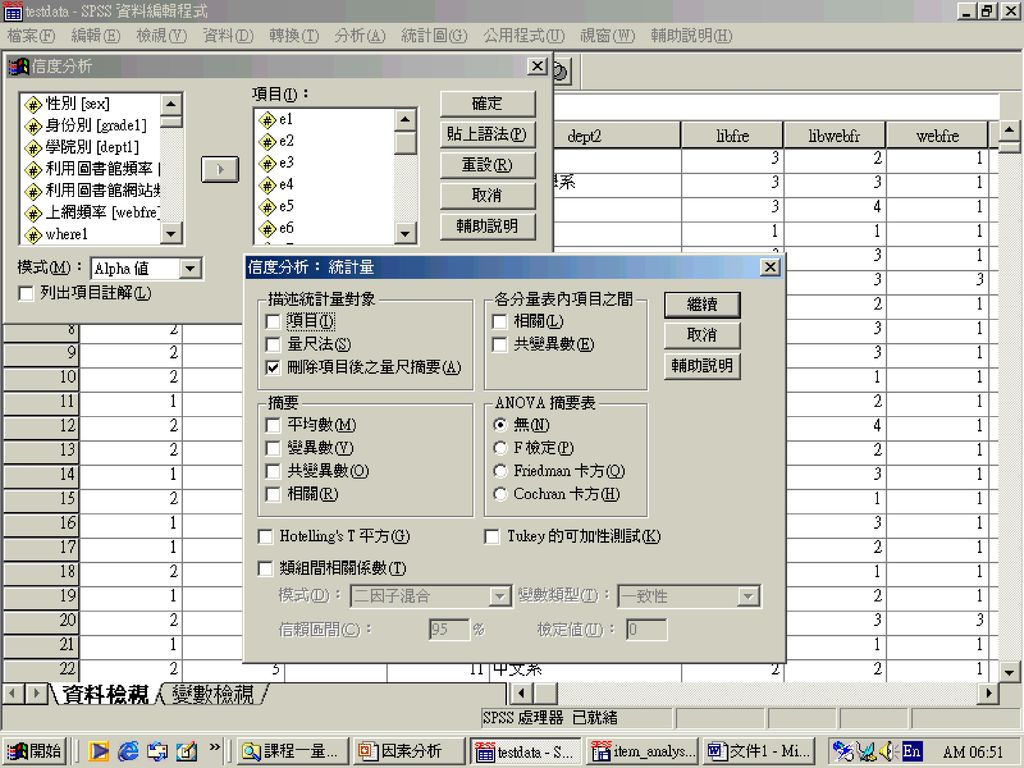
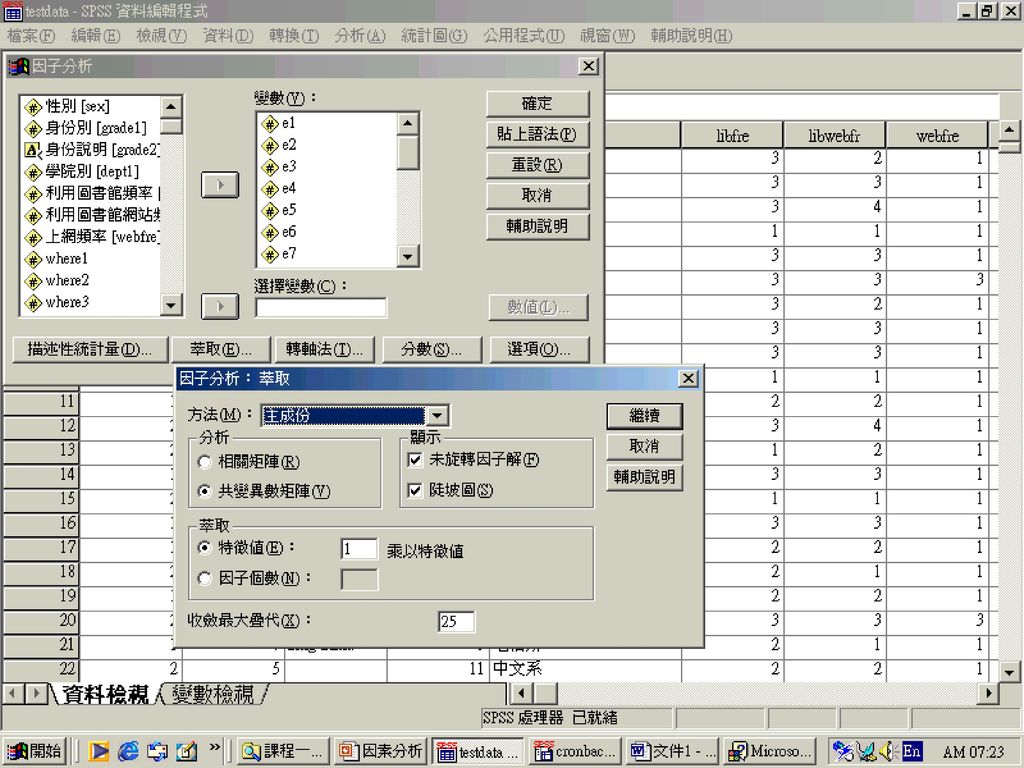
因素分析 統計分析程序 分析 > 資料縮減 > 因子 描述統計量:單變項描述統計、未轉軸統計量、相關矩陣(KMO球形檢定)
粹取:因素抽取方法(主成份)、陡坡圖、特徵值(1) 轉軸法:最大變異法、轉軸後的解 選項:因素負荷量的排列方式
、陡坡圖、特徵值(1) 轉軸法:最大變異法、轉軸後的解. 選項:因素負荷量的排列方式.")
105
因素分析 相關性檢定 相關係數必須顯著地高於0;某一群題目兩兩之間有高相關,表示可能存有一個因素 相關矩陣
KMO與Bartlett球形檢定(Bartlett’s test of sphericity) KMO取樣適切量數,化表興該變項有關的所有相關係數與淨相關係數的比較值,係數愈大,表示相關情形良好 KMO統計量0.90以上, 因素分析適合性極佳 KMO統計量0.80以上, 因素分析適合性良好 KMO統計量0.70以上, 因素分析適合性中度 KMO統計量0.60以上, 因素分析適合性平庸 KMO統計量0.50以上, 因素分析適合性可悲 KMO統計量0.50以下, 因素分析適合性無法接受
 KMO取樣適切量數,化表興該變項有關的所有相關係數與淨相關係數的比較值,係數愈大,表示相關情形良好. KMO統計量0.90以上, 因素分析適合性極佳. KMO統計量0.80以上, 因素分析適合性良好. KMO統計量0.70以上, 因素分析適合性中度. KMO統計量0.60以上, 因素分析適合性平庸. KMO統計量0.50以上, 因素分析適合性可悲. KMO統計量0.50以下, 因素分析適合性無法接受.")
106
相關矩陣 如果觀察矩陣中相關係數均小於.3,抽取因素能力低,可能需放棄使用因素分析

107
KMO統計量為0. 941,顯示因素分析適合性極佳。Bartlett球形檢定之卡方值為18672

108
表示各變項的變異量被共同因素解釋的比例。
重新量尺化的萃取後共同性愈高,表示該變項與其他變項可測量的共同特質愈多,也就是愈有影響力。此問卷以E18、E8最有影響力。

109
以特徵值為1進行萃取,得到四個主要因素,分別可以解釋46%、7%6.7%5.3%的變異量,解釋總變異量為65%。

110
當線形趨於平緩時,表示沒有特殊因素值得抽取

112
第一項因素主要與圖書館網站所提供資訊的正確性、完整性、即時性的有關,故命名為「網站資訊」,可解釋46%的變異。
第二項因素主要與………….

113
圖書館網站滿意度量表經由因素分析之主成份分析法,由19個問項中粹取出四個主要因素,分別命名為「資訊」、「忠誠」、「使用」、「人性」,合計可解釋65%的變異量。

114
Q & A






 推行「服務表現監察制度」 有部份院舍採用其他服務質素評核制度, 例如 ISO 認證或「五常法」>")




 2008 作者 贾俊平 统计学.>")












