Download presentation
Presentation is loading. Please wait.

1
三星統計公司調查與研究方法認證推廣專業顧問 徐茂洲 副教授
與結構方程模型共舞 論文寫作SEM不求人 三星統計公司調查與研究方法認證推廣專業顧問 徐茂洲 副教授

4
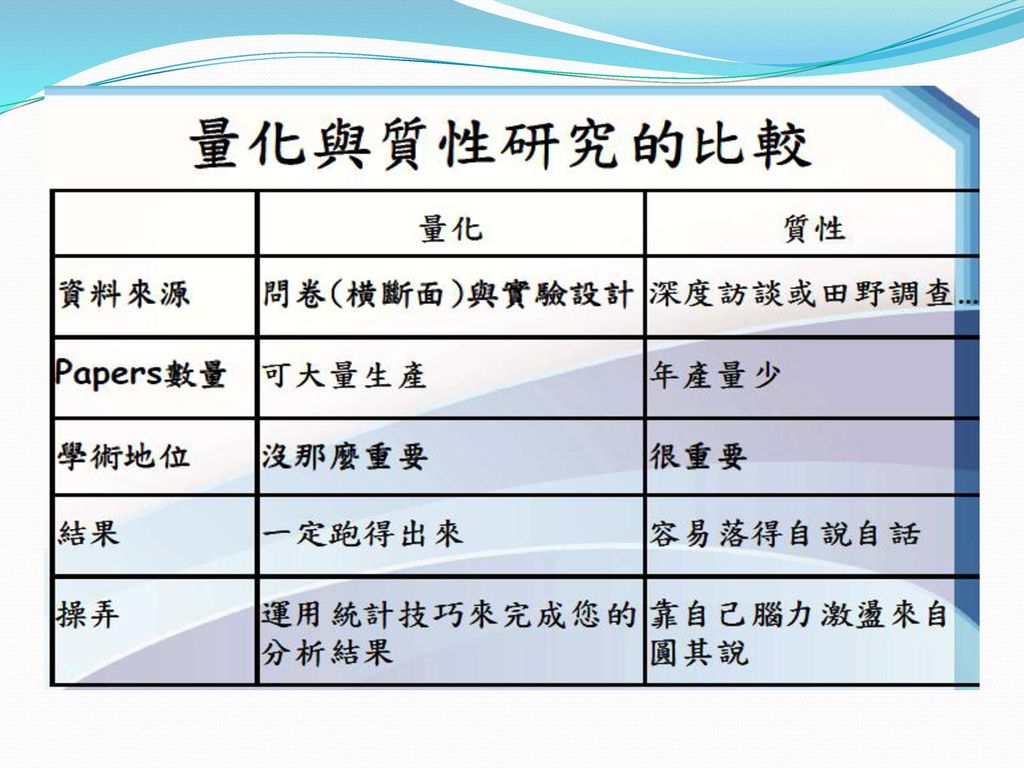
SEM論文

10
估計 Lisrel 與Amos分析結果的比較

11
SEM是近期成長快速的統計技術 (Herhberger, 2003)
Herhberger, S, L.(2003). The Growth of Structural Equation Modeling: Structural equation modeling, 10(1),
. The Growth of Structural Equation Modeling: Structural equation modeling, 10(1),")
12
SEM發表的期刊論文有比較好嗎? (Babin, Hair, Boles, 2008)
ˇ ㄨ 不用SEM的PAPERS是否比較容易被拒絕? 使用SEM的PAPERS是否評價比較高? 使用SEM是否對reviewers較有影響力? 軟體使用Amos是否比Lisrel容易被拒絕? 模型配適度好壞是否會影響reviewers評價? 美國人使用SEM是否比其它國家的學者多? 美國人用SEM投稿是否比其它國家的人有優勢? Babin, B.J., Hair, J.F., Boles, J.S. (2008). Publishing research in marketing journals using structural equation modeling. Journal of Marketing Theory and Practice, 16,
. Publishing research in marketing journals using structural equation modeling. Journal of Marketing Theory and Practice, 16,")
25
實務上SEM分析對資料結構 有何要求?

26
SEM實務上基本要求 模型中潛在因素最好兩個(Bollen,1989) 量表七點尺度為佳(Bollen,1989)
問卷引用知名學者,盡量不要自己創造 理論架構根據學者提出理論修正 模型主構面維持五個以內不要超出七個 Bollen, K.A., (1989).Structural Equations with Latent Variables, Wiley, New York
.Structural Equations with Latent Variables, Wiley, New York.")
27
Kline (2011)、Schreiber (2008)、McDonald and Ho (2002) 等相關文獻整理出SEM 分析流程。
、Schreiber (2008)、McDonald and Ho (2002) 等相關文獻整理出SEM 分析流程。")
31
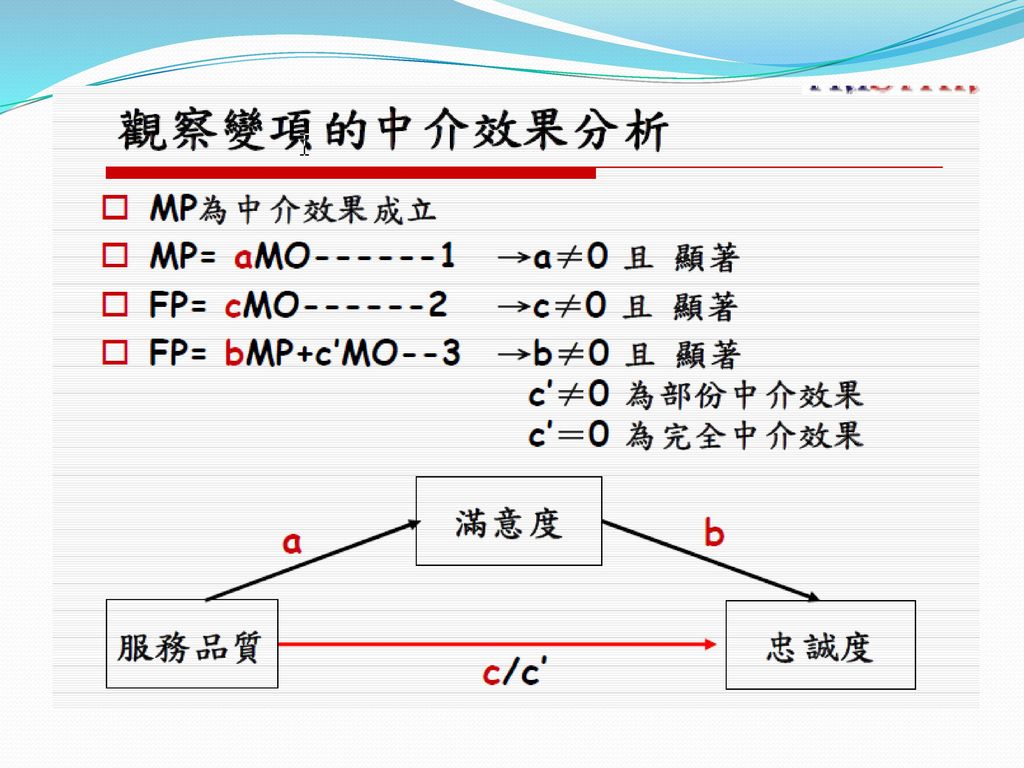
研究假設 陳順宇(2007)SEM是應用變數間共變異數矩陣驗證變數關係,所得之θ模式共變異數矩陣與樣本共變異數矩陣間差異愈小愈好。
兩個矩陣的差異越小表示模型有較好的適配度(Maruyama,1998) Chin(1998)SEM之模式配適度不能過差,配適度不佳代表模型與樣本間差異過大,模型設定錯誤,形成後續研究結果之謬誤。因此本研究首先針對模式配適度提出假設,S-Σ(θ)=0,S為樣本共變異數矩陣,Σ(θ)為模型期望共變異數矩陣
 Chin(1998)SEM之模式配適度不能過差,配適度不佳代表模型與樣本間差異過大,模型設定錯誤,形成後續研究結果之謬誤。因此本研究首先針對模式配適度提出假設,S-Σ(θ)=0,S為樣本共變異數矩陣,Σ(θ)為模型期望共變異數矩陣.")
35
驗證式因素分析(CFA)與探索式 因素分析(EFA)究竟有何不同?
與探索式 因素分析(EFA)究竟有何不同?")
43
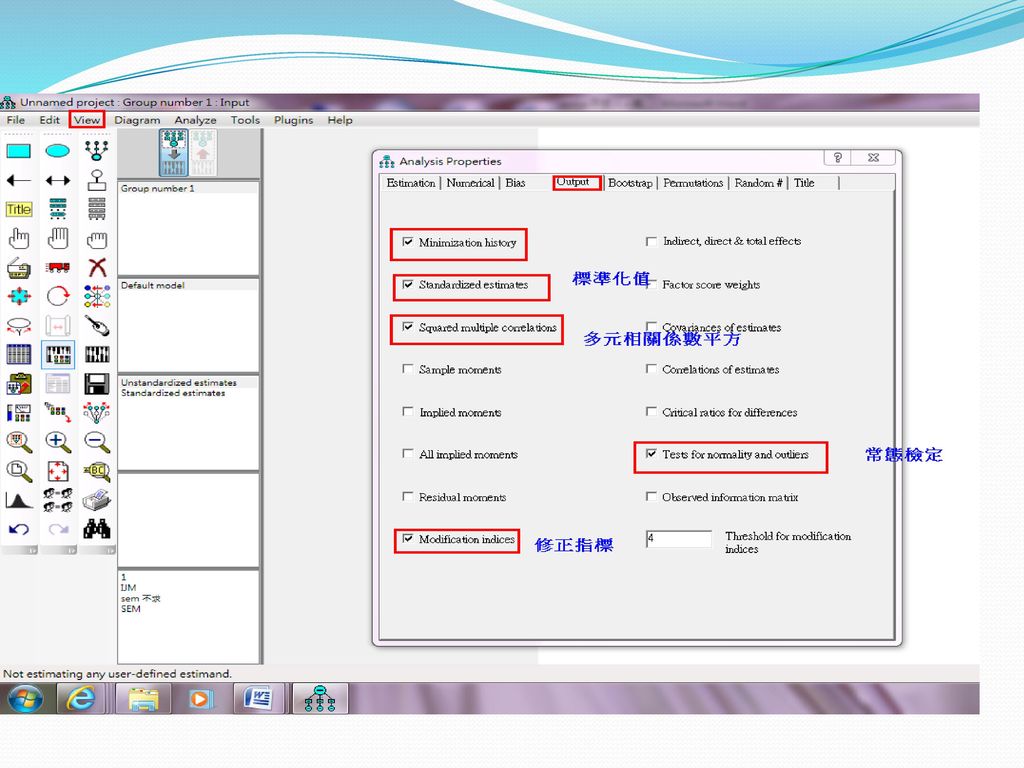
如何在SEM分析中執行常態及極端值的檢定?

44
常態及極端值檢定

46
極端值檢定

47
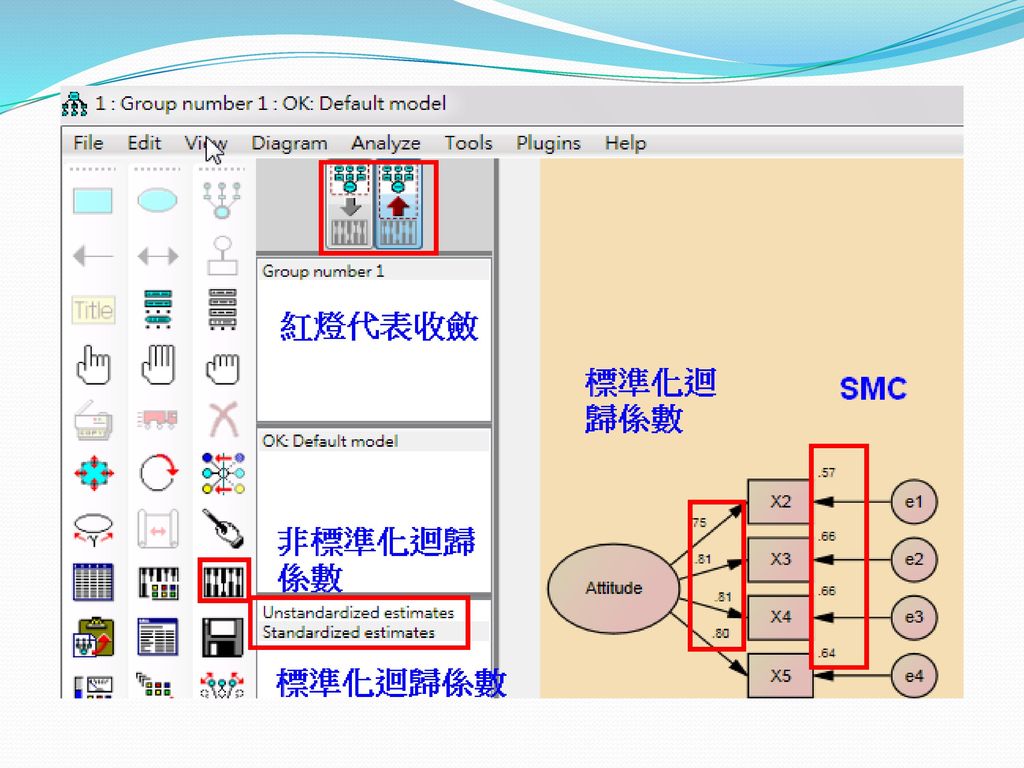
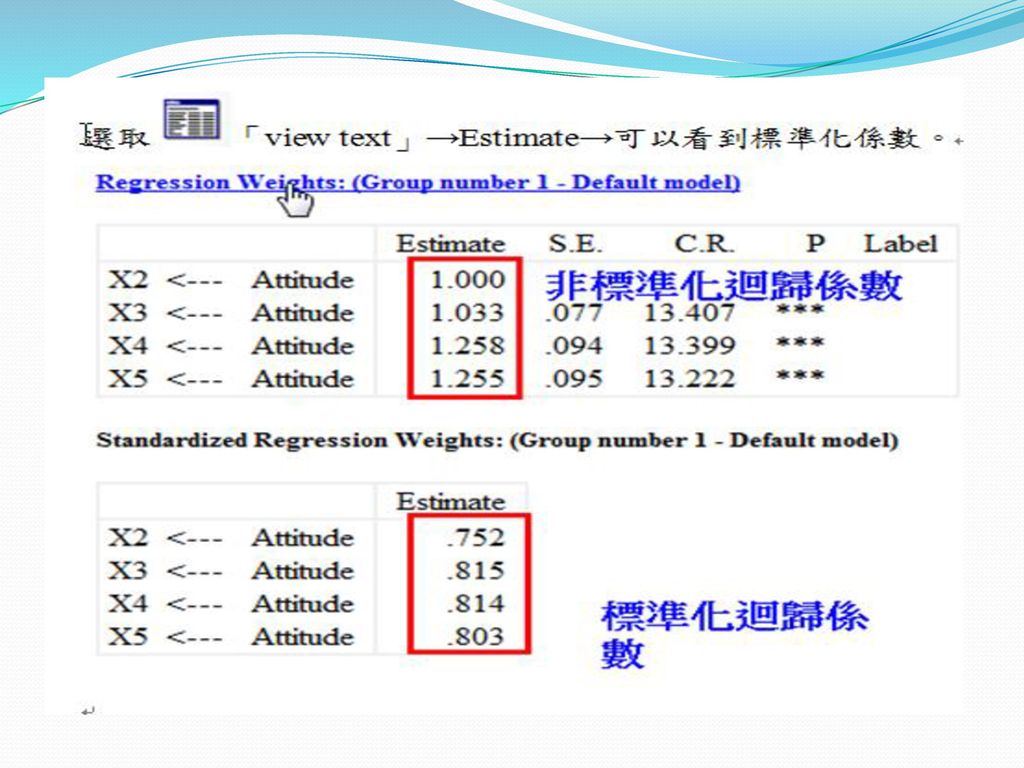
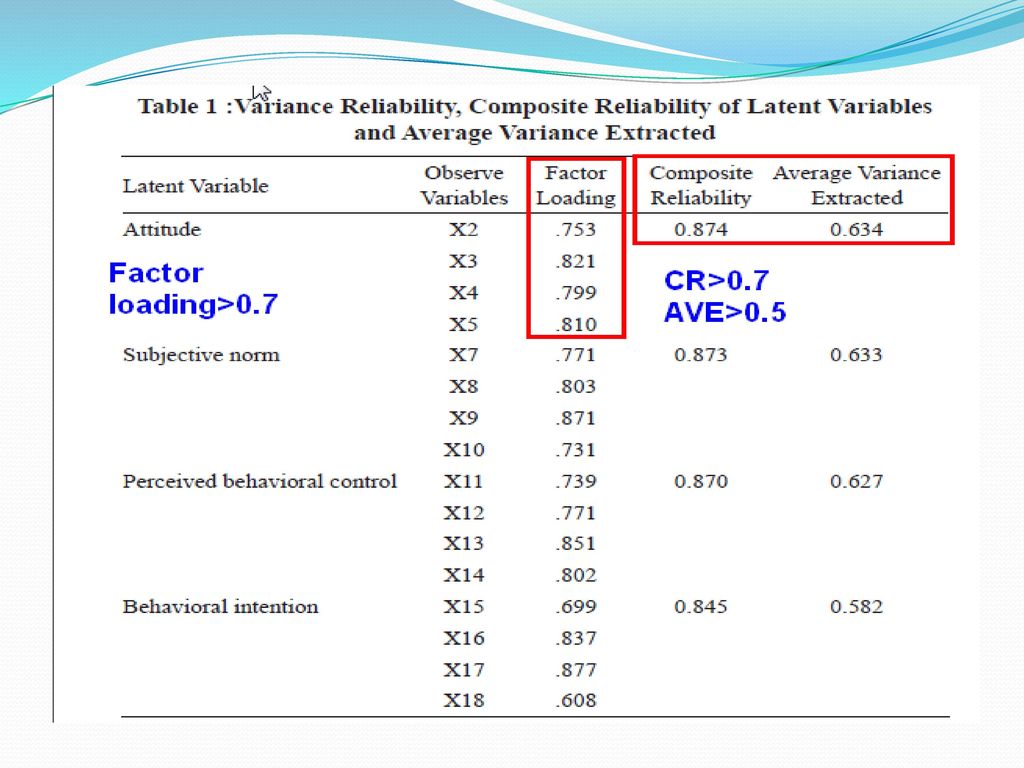
驗證式因素分析 一階驗證性因素分析 二階驗證性因素分析 組成信度 (CR)與變異數萃取量 (AVE)
與變異數萃取量 (AVE)")
49
變異抽取量 (variance extracted,VE)
VE是計算潛在變項之各測量變數對該潛在變項的變異解釋力,若VE愈高,則表示潛在變項有愈高的信度與收斂效度。Fornell and Larcker(1981)建議其標準值須大於0.5。 計算公式 AVE=Σ(因素負荷量2)/((Σ因素負荷量)2+ (Σ各測量變項的測量誤差)) (Joreskog and Sorbom , 1996)
建議其標準值須大於0.5。 計算公式. AVE=Σ(因素負荷量2)/((Σ因素負荷量)2+ (Σ各測量變項的測量誤差)) (Joreskog and Sorbom , 1996)")
53
計算組成信度與變異數萃取量

55
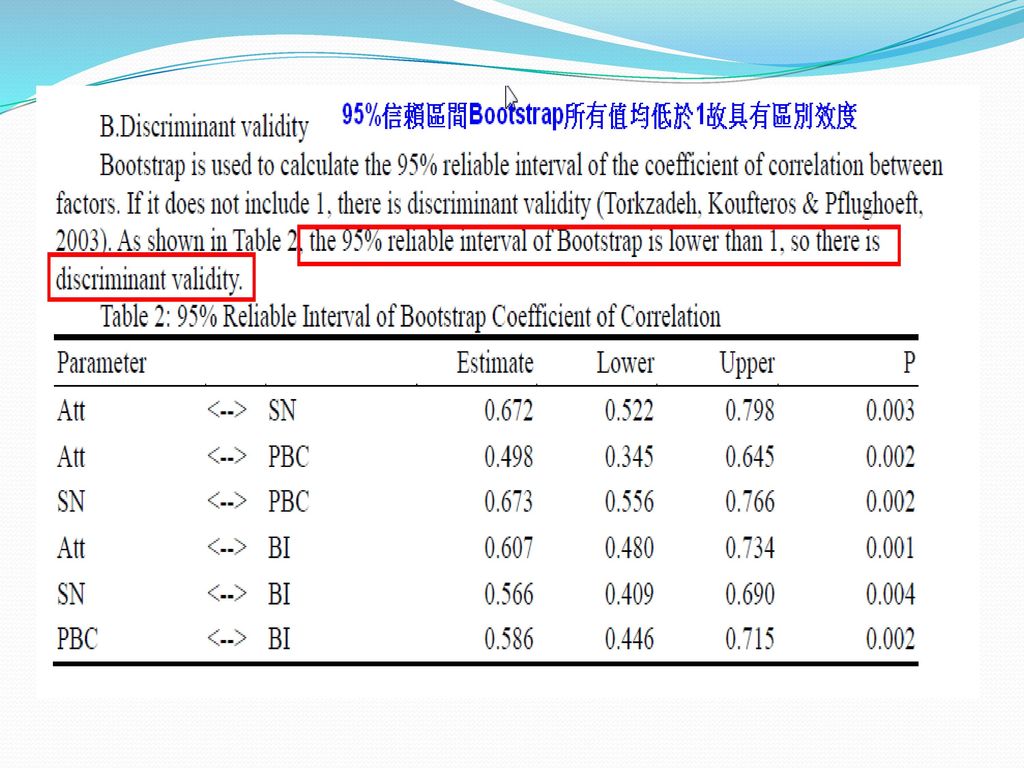
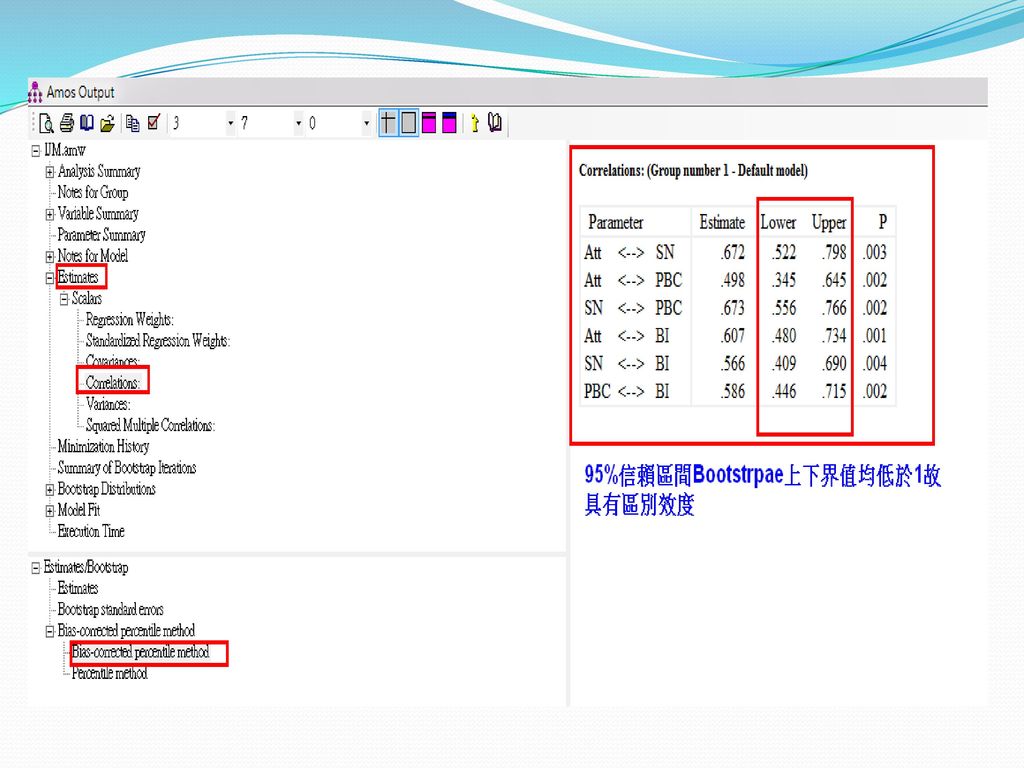
區別效度的檢定 1. 直接檢查構面的相關係數,一般以0.85為標準(較不嚴謹) 。
2. 利用bootstrap計算構面之間的相關係數95%信賴區間,若沒包含1,則有區別效度(Torkzadeh, Koufteros, pflughoeft , 2003)。 3. SEM檢定構面之間的相關係數設為1,如果reject則表示有區別效度(巢型結構)(Anderson and Gerbing,1988, Bogozzi et al., 1991) 。 4. AVE法,每個構面的AVE要大於構面相關係數的平方(Fornell and Larcker, 1981) 。 5. ECVI,AIC指標配適法(非巢型結構)(Kline, 2005, p151)
。 3. SEM檢定構面之間的相關係數設為1,如果reject則表示有區別效度(巢型結構)(Anderson and Gerbing,1988, Bogozzi et al., 1991) 。 4. AVE法,每個構面的AVE要大於構面相關係數的平方(Fornell and Larcker, 1981) 。 5. ECVI,AIC指標配適法(非巢型結構)(Kline, 2005, p151)")
56
區別效度的檢定

57
信賴區間法

60
係數檢定法 卡方值增加3.84 ;△CFI高於0.01

61
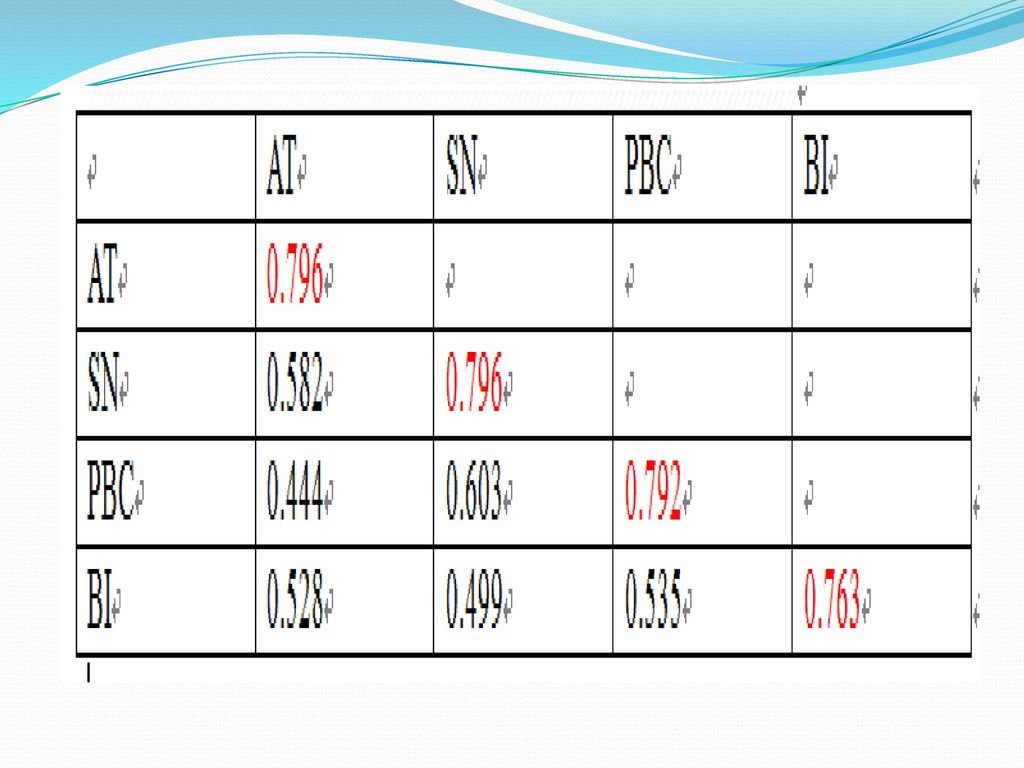
AVE Fornell and Lacker(1981)每個構面AVE開根號需大於各成對變項的相關係數,表示構面之間具有區別效度。對角線為各構面AVE開根號均大於對角線外的標準化相關係數
每個構面AVE開根號需大於各成對變項的相關係數,表示構面之間具有區別效度。對角線為各構面AVE開根號均大於對角線外的標準化相關係數")
63
ECVI 、AIC指標適配法(Mallard and Lance,1998)
將不同構面題目縮減成比較構面,模型配適度會變差,因此可將模型因素適當合併到其他構面,重新用Sem分析,檢查ECVI與AIC值的變化, 這兩個值越小越好。 構面縮減後ECVI與AIC值的高於縮減前,模型在縮減後比較差,因此不適合縮減,也就是具有區別效度。

64
四個模型均優於三個模型因此具有區別效度

65
違犯估計(offending estimates)
“所估計的參數違反統計所能接受的範圍” 1. 負的誤差變異數 2. 標準化迴歸係數接近或超過於1 (以0.95為門檻,Heir et. Al. 1998) 3. 有太大的標準誤
 3. 有太大的標準誤.")
69
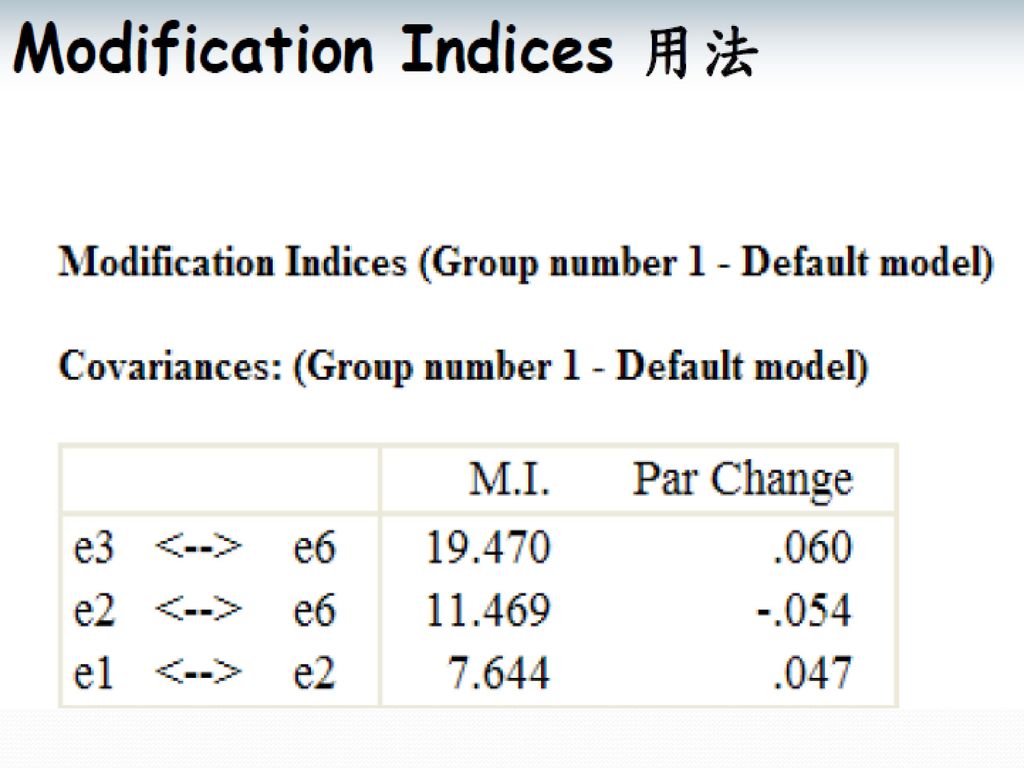
模型修正指標(Modification Index)
MI代表當假設模型的某特定參數被設定自由估計後其整體卡方值大概會降低的量。 MI多少才算大呢? 並無一定的標準,然而根據rule of thumb,在SEM模型下,100以上一定要處理,50以上要考慮,50以下看情形。修正時一次只能處理一個參數。

71
殘差相關爭議

72
共同方法變異檢定 彭臺光(2006) 被引用119次。 單因子CFA CMV檢定
CMV事後偵測,可採用SEM來處理。將不同構面所有的變數,以單因子CFA模型分析;若有CMV的存在,表示構面之間應有顯著相關,且具有不錯的模型適配度 (Korsgaard & Roberson, 1995; Monssholder, Bennett, Kemery & Wesolowski, 1998) 。
 。")
73
共同方法變異

74
模型配適度判斷準則 模型配適度可分成三大評估準則 估計出的配適度>0.5表示愈接近1愈好,0.9以上為理想值,0.8以上為可接受
估計出的配適度<0.5表示愈接近0愈好,0.05以下為理想值,0.08以下為可接受 估計出的配適度不在0~1之間,表示值愈低愈好

75
配適度良好是SEM估計的必要條件 模型配適度愈差,表示模型愈有可能設定錯誤,路徑的估計就愈有可能偏誤,評估結果的目的就愈不可靠。
模型中的變數是模型整體不可分割的一部份,poor model中有可能變數相關的重要性與方向與well model是不一樣的。

76
配適度指標的限制(Kline,2011,P192~193) 配適度指標的值只是模型的整體配適度或平均值而已,因此在模型的某些題目仍會有較大的差異。 SEM沒有萬用的指標 每一個配適度指標,僅表示資料某一面向的訊息,因此某一指標良好,不表示模型配適良好 配適度指標的值與模型是否設定是否正確沒太大的相關 如模型有4個構面,而且配適度好,並不代表你的模型是對的,僅能告訴大家模型與樣本資料的配適良好。

77
配適度指標的限制(Kline,2011,P192~193) 良好的配適度不代表有良好的統計檢定力及解釋能力,變數之間相關愈低,愈容易得到良好的模型配適度。 配適度指標不能用來解釋成理論是具有意義的如某一迴歸估計值的符號方向與理論值相反,即使配適度良好,也不能說是正確的,須要有良好的解釋。
 良好的配適度不代表有良好的統計檢定力及解釋能力,變數之間相關愈低,愈容易得到良好的模型配適度。 配適度指標不能用來解釋成理論是具有意義的如某一迴歸估計值的符號方向與理論值相反,即使配適度良好,也不能說是正確的,須要有良好的解釋。")
78
SRMR的求法 模型的繪圖區,按 “Plugins”選“Standardized RMR” ,圖區會出現如左的表框,千萬不要關閉,直接按 “ ” ,即可得到SRMR的估計值。

79
Jackson, Gillaspy, & PurcStephenson (2009).
發表於Psychological methods 期刊中論文Reporting practices in confirmatory factor analysis: An overview and some recommendations.整理 應用CFA相關文獻 研究結果顯示194篇論文中出現最多的主要期刊有psychological Assessment(n=69), Journal of Applied psychology(n=19), Journal of counseling psychology(n=14), Journal of personality and social psychology(n=13)。194篇論文中報告配適度指標出現最多的分別為Chi-square (n=173;佔89.2%)、Degree of freedom(n=173;佔89.2%)、CFI(n=152;佔78.4%)、RMSEA(n=126;64.9%)、TLI(n=90;佔46.4%)、GFI(n=66;佔34.0%)、NFI(n=46;佔23.7%)、SRMR(n=45;佔23.2%)、χ2/df(n=42;佔21.6%)、AGFI(n=39;佔20.1%)。本研究參考配適度指標應用最廣泛的十種配適度指標報告此篇論文。本研究模式適配度均符合標準。
, Journal of Applied psychology(n=19), Journal of counseling psychology(n=14), Journal of personality and social psychology(n=13)。194篇論文中報告配適度指標出現最多的分別為Chi-square (n=173;佔89.2%)、Degree of freedom(n=173;佔89.2%)、CFI(n=152;佔78.4%)、RMSEA(n=126;64.9%)、TLI(n=90;佔46.4%)、GFI(n=66;佔34.0%)、NFI(n=46;佔23.7%)、SRMR(n=45;佔23.2%)、χ2/df(n=42;佔21.6%)、AGFI(n=39;佔20.1%)。本研究參考配適度指標應用最廣泛的十種配適度指標報告此篇論文。本研究模式適配度均符合標準。")
80
模型配適度 Model Fit Summary 模型配適度摘要 CMIN:卡方差異值 (愈小愈好) DF:自由度 (愈大表示模型愈精簡)
 DF:自由度 (愈大表示模型愈精簡)")
81
模型配適度 IFI, TLI(NNFI),CFI為最常報告的配適度指標,理想值為>0.9甚至於>0.95
精簡配適度指標>0.5表示模型不太複雜,但在配適度指標中不常出現

82
模型配適度 IFI, TLI(NNFI),CFI為最常報告的配適度指標,理想值為>0.9甚至於>0.95
精簡配適度指標>0.5表示模型不太複雜,但在配適度指標中不常出現

83
模型配適度 愈小愈好,沒有一定標準,因此只有在競爭模型(兩個以上的模型)才會用到
卡方最小差異值: (N-1)FMIN為卡CMIN,因此樣本數愈大,CMIN愈大
FMIN為卡CMIN,因此樣本數愈大,CMIN愈大.")
84
模型配適度 愈小愈好,沒有一定標準,因此只有在競爭模型(兩個以上的模型)才會用到 在95%信心水準下>200表示樣本是足夠的
小於75表示樣本嚴重的不足

85
P值顯著的爭議 實務上卡方值不是個很實用的配適度指標
P值在200個樣本以上,幾乎所有的研究都是顯著的,因此佐以其它的配適度指標協助判斷Tanaka (1993), Maruyama (1998) 。
, Maruyama (1998) 。")
89
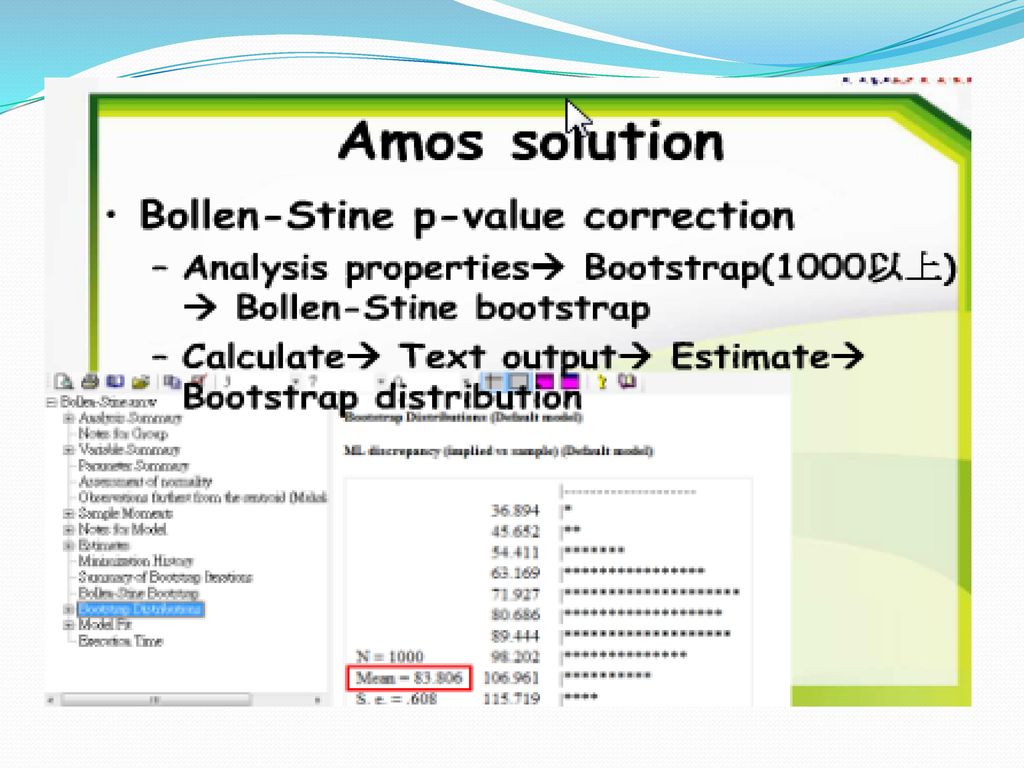
Bollen-Stine test(1993) 利用Bollen-Stine 校正P-Value評估整體適配度。
 利用Bollen-Stine 校正P-Value評估整體適配度。")
92
配適度指標 chi-square=\cmin degree of freedom=\df χ2 /df=\cmindf
GFI=\gfi AGFI=\agfi CFI=\cfi RMSEA=\rmsea PCFI=\pcfi

94
利用SPSS中產生共變異數矩陣 點選“分析” →“相關” →“雙變數” → “選入變數” →“貼上語法”加入紅色這幾行字
“執行”,即可產生共變異數矩陣的新檔。 CORRELATIONS varlist /MATRIX=OUT(*). MCONVERT.
. MCONVERT.")
95
模型配適的額外資訊 統計檢定力 在社會及行為科學研究中,有些研究人員會宣稱其分析樣本夠大足以達到研究目的代表性。
SEM的統計檢定力是模型樣本大小的函數 低的POWER會導致顯著的卡方值及模型配適度不佳時,無法拒絕模型。 交叉效度 可檢定模型本身是否具模型穩定性。

96
交叉效度 實務上顯著

109
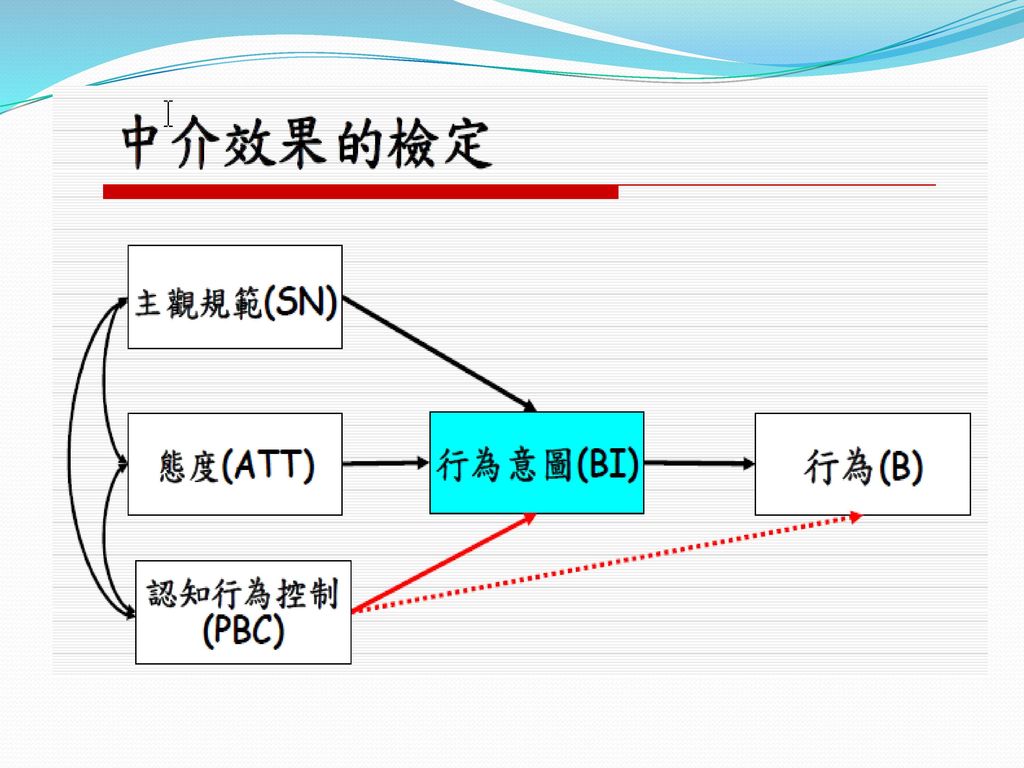
中介論文 蹼泳運動賽會參與者行為傾向模式之研究-中介效果驗證

111
群組比較paper Cross-Cultural Journal of Sport & Exercise Psychology 測驗學刊

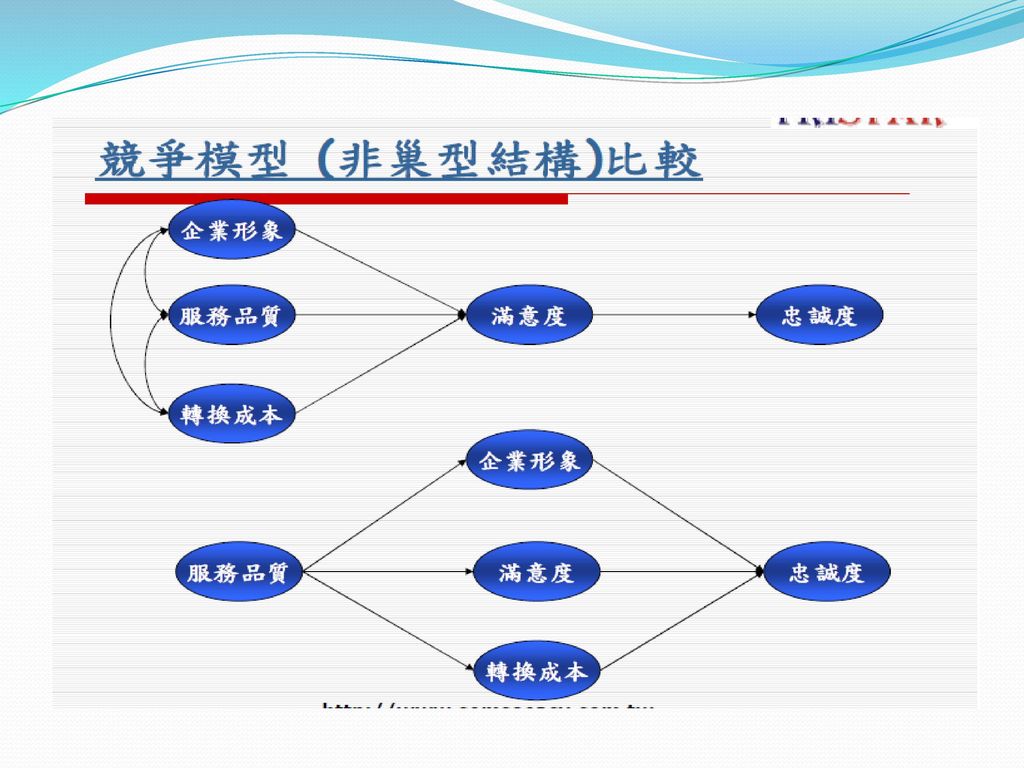
116
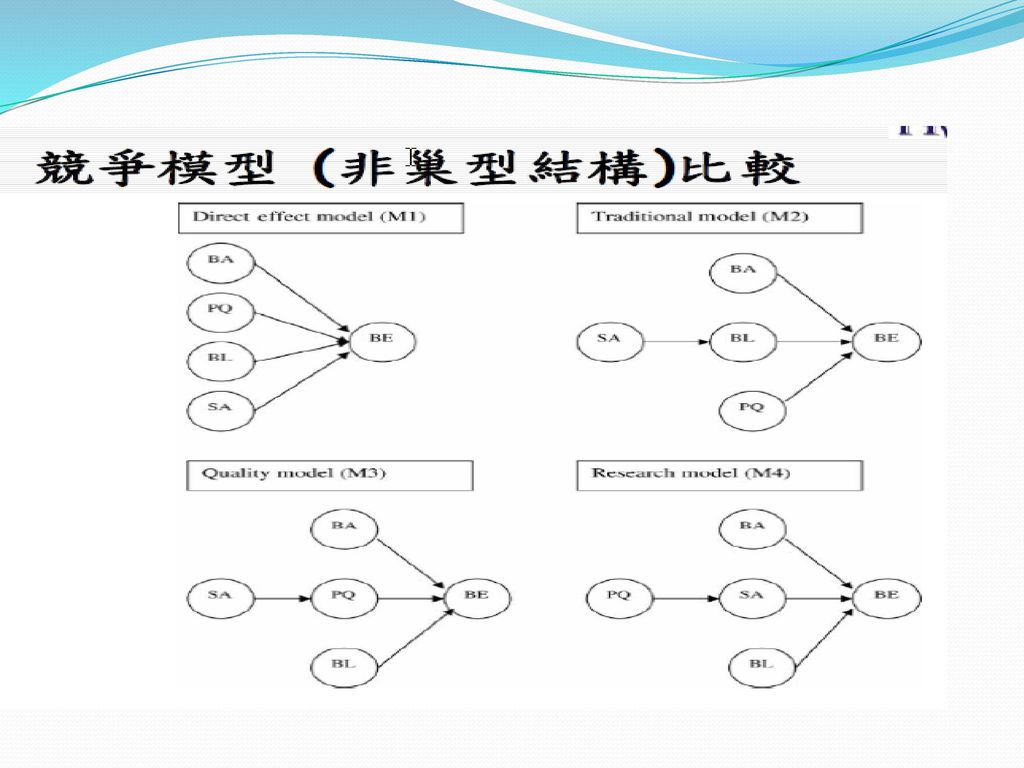
競爭模式 旅遊行為意圖模型選擇與比較

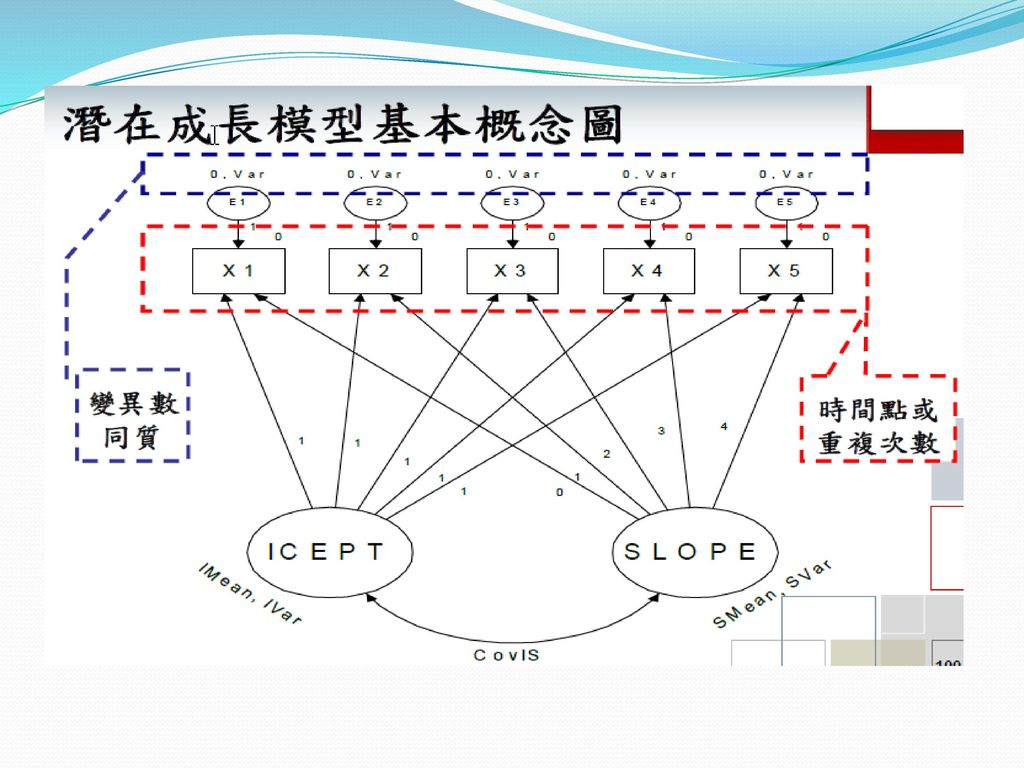
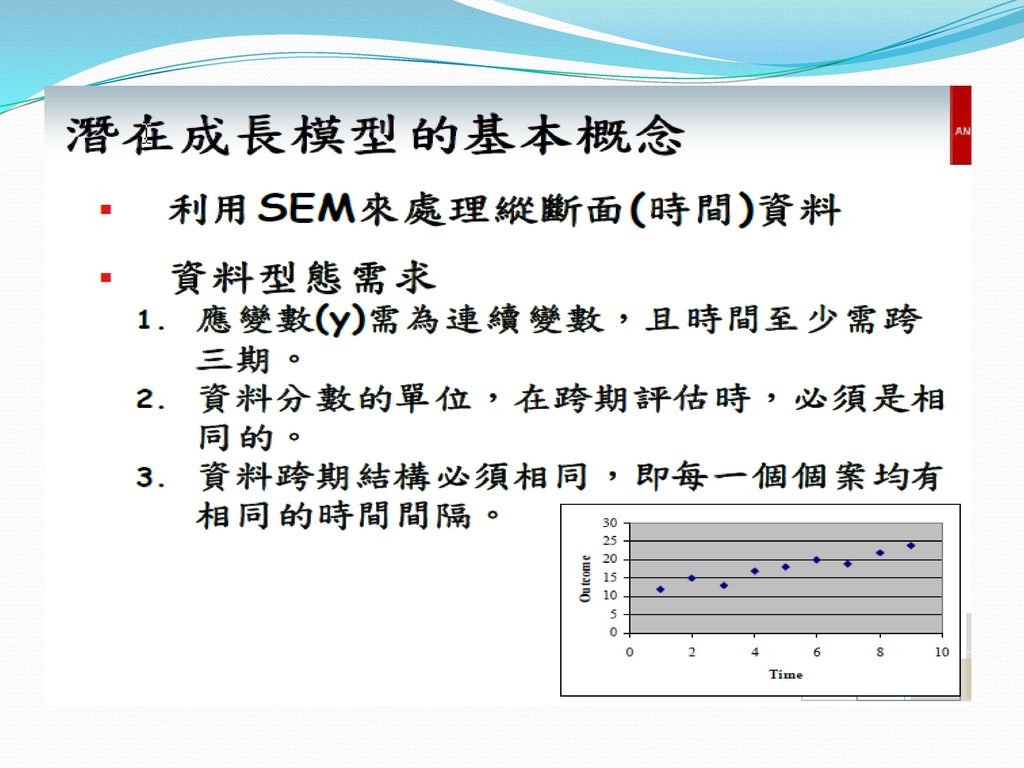
120
LGM paper PE 婚姻品質與憂鬱傾向

126
Item parceling 二階構面降為一階構面 多個題目合併成較少的題目 類別變數轉連續變數

127
Prerequisite of Item parceling
足夠的收斂效度 – Cronbabchs’ α > 0.7 – Composite Reliability > 0.7 – Average Variance Extracted > 0.5

Similar presentations





























































>")




 Wonnacott and Wonnacott. Introductory>")






