Download presentation
Presentation is loading. Please wait.

1
Memory Hierarchy Design
Chapter5 Memory Hierarchy Design Zheng Qinghua Computer Dept. of XJTU May, 2015

2
Outline Principle of Storage System
Principle and Technique of Cache System Management of Main Memory Principle of Virtual Memory

3
5.1 Overview of Hierarchy Memory System
Upper Level Capacity Access Time Cost Staging Xfer Unit faster CPU Registers 100s Bytes 1s ns Registers Instr. Operands prog./compiler 1-8 bytes Cache K Bytes 4 ns 1-0.1 cents/bit Cache cache cntl 8-128 bytes Blocks Main Memory M Bytes 100ns- 300ns $ cents /bit Memory OS 512-4K bytes Pages Disk G Bytes, 10 ms (10,000,000 ns) cents/bit Disk -5 -6 user/operator Mbytes Files Tape infinite sec-min 10 Larger CD /Tape Lower Level -8
 cents/bit. Disk user/operator. Mbytes. Files. Tape. infinite. sec-min. 10. Larger. CD /Tape. Lower Level. -8.")
4
Design principle of Hierarchy Memory System
Basic Principles: locality and cost/ performance of memory technology The principle of locality: Programs tend to reuse data and instructions they have used recently. A rule of thumb: a program spends 80% of its execution time in only 20% of the code.

5
Reason1: Locality An implication of locality is that we can predict with reasonable accuracy what instructions and data a program will use in the near future based on its accesses in the recent past. Temporal locality——Recently accessed items are likely to be accessed in the near future. Spatial locality——Items whose addresses are near one another tend to be referenced close together in time.

6
Desktop, Drawer, and File Cabinet Analogy
Once the “working set” is in the drawer, very few trips to the file cabinet are needed. Fig. Items on a desktop (register) or in a drawer (cache) are more readily accessible than those in a file cabinet (main memory).
 or in a drawer (cache) are more readily accessible than those in a file cabinet (main memory).")
7
Temporal and Spatial Localities
Addresses From Peter Denning’s CACM paper, July 2005 (Vol. 48, No. 7, pp ) Temporal: Accesses to the same address are typically clustered in time Spatial: When a location is accessed, nearby locations tend to be accessed also Time
 Temporal: Accesses to the same address are typically clustered in time. Spatial: When a location is accessed, nearby locations tend to be accessed also. Time.")
8
Typical Levels in a Hierarchical Memory
Design resolution The principle of locality + The smaller Memory is faster led to the hierarchy based on memories of different speeds and sizes. Typical Levels in a Hierarchical Memory

9
Reason2: Processor-DRAM Memory Gap (latency)
µProc 60%/yr. (2X/1.5yr) DRAM 9%/yr. (2X/10 yrs) 1 10 100 1000 1980 1981 1985 1986 1987 DRAM CPU 1982 Processor-Memory Performance Gap: (grows 50% / year) Performance “Moore’s Law” 2000
 DRAM 9%/yr. (2X/10 yrs) DRAM. CPU Processor-Memory. Performance Gap: (grows 50% / year) Performance. Moore’s Law")
10
The Need for a Memory Hierarchy
The widening speed gap between CPU and main memory Processor operations take of the order of 1 ns Memory access requires 10ns or even 100s of ns Memory bandwidth limits the instruction execution rate Each instruction executed involves at least one memory access Hence, a few to 100s of MIPS is the best that can be achieved A fast buffer memory can help bridge the CPU-memory gap The fastest memories are expensive and thus not very large A second even third intermediate cache level is thus often used

11
The Need for a Memory Hierarchy
The levels of the hierarchy usually subset one another; all data in one level is also found in the level below, and all data in that lower level is found in the one below it, and so on until we reach the bottom of the hierarchy. Each level maps addresses from a larger memory to a smaller but faster memory higher in the hierarchy. At the same time of address mapping, address checking and protection schemes for scrutinizing address are taken place too.

12
The Need for a Memory Hierarchy

13
5.1.2 Performance of Storage System ——Volume、Speed and Price
(T1 ,S1 ,C1 ) (T2 ,S2 ,C2 ) (T3 ,S3 ,C3 ) User’s viewpoint T = min (T1 ,T2 ,… Tn ) S= max ( S1,S2, …Sn ) C = max (C1,C2,…Cn) Average price C of all over storage system
 (T2 ,S2 ,C2 ) (T3 ,S3 ,C3 ) User’s viewpoint. T = min (T1 ,T2 ,… Tn ) S= max ( S1,S2, …Sn ) C = max (C1,C2,…Cn) Average price C of all over storage system.")
14
Access Time T Hit: data appears in some block in the upper level (example: Block X)
Hit Rate/H: the fraction of memory access found in the upper level Hit Time: Time to access the upper level which consists of RAM access time + Time to determine hit/miss Miss: data needs to be retrieved from a block in the lower level (Block Y) Miss Rate = 1 - (Hit Rate) Miss Penalty: Time to replace a block in the upper level + Time to deliver the block the processor Hit Time << Miss Penalty Lower Level Memory To Processor Upper Level Memory Blk X Blk Y From Processor
 Miss Rate = 1 - (Hit Rate) Miss Penalty: Time to replace a block in the upper level + Time to deliver the block the processor. Hit Time << Miss Penalty. Lower Level. Memory. To Processor. Upper Level. Memory. Blk X. Blk Y. From Processor.")
15
Access Time T T is close to Hit rate H
Access Time T T is close to Hit rate H. Hit rate H:the fraction of memory access found in upper level, H =N1/(N1+N2) , here, N1 is the number of hit times in upper memory(M1), N2 is the number of access times in next below block(M2) T(M1, M2) = H·T1 + (1-H)·T2 therefore, the efficiency of hierarchy memory system is:
 , here, N1 is the number of hit times in upper memory(M1), N2 is the number of access times in next below block(M2). T(M1, M2) = H·T1 + (1-H)·T2 therefore, the efficiency of hierarchy memory system is:")
16
本章要点 存储系统的概念及原理 高速缓存的概念及原理 主存的原理 虚拟存储器的概念及原理
外存、内存(RAM)—高速缓存(Cache)三级存储体系的原理
—高速缓存(Cache)三级存储体系的原理.")
17
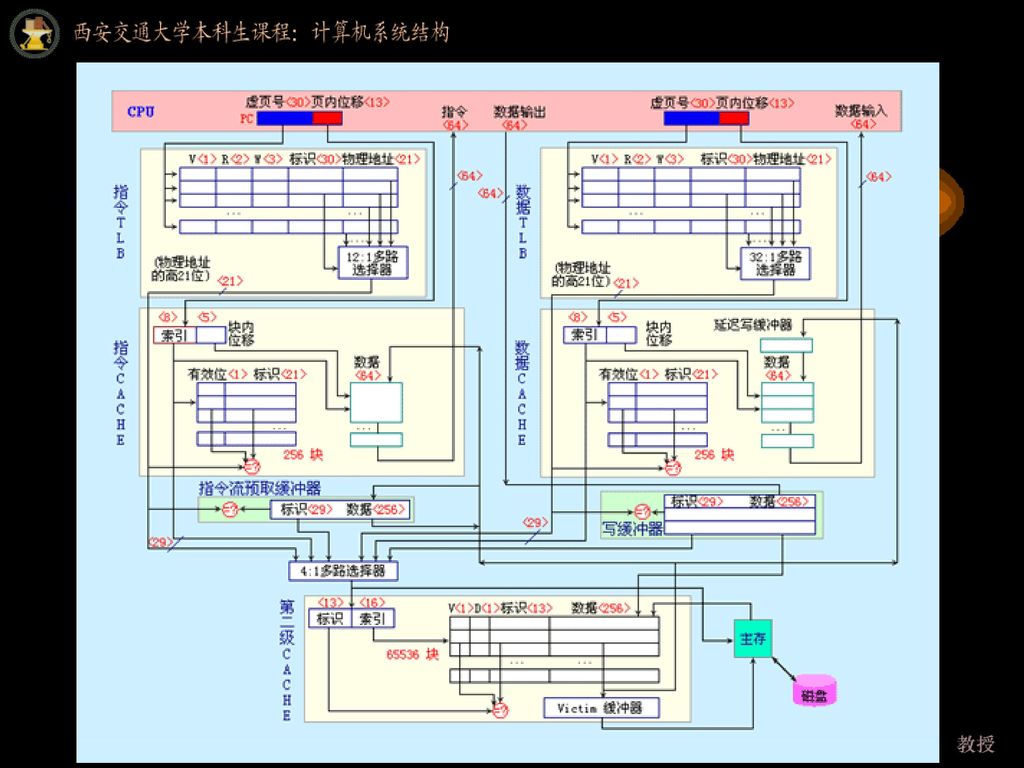
5.2 高速缓冲存储器Cache 5.2.1 Cache的基本工作原理
Cache和RAM间的数据交换单位:块,即一个存储周期内可以访问的字数或数据长度。 Cache的地址格式: 块 号 B 块内地址 W 块 号 b 块内地址 w

18
工作原理 CPU RAM 块 号 B 块内地址 W Cache 替换策略 块 号 b 块内地址w Cache 数据 CPU(一个字)
工作原理 CPU 块 号 B 块内地址 W RAM 主存 Cache 地址变换 Cache 替换策略 块 号 b 块内地址w Cache 数据 CPU(一个字)
")
19
Cache地址映射与变换中的核心问题 a.主存(B,W)—>(b, w) b.由于主存中的块和Cache中的块一样大小,因此, 两者具有同样的W; c.地址变换算法的考虑要点: 硬件实现是否容易 速度 冲突概率小 存储空间的利用率高

20
5.2.2 地址变换的几种方法 全相联映象及其变换 概念:指主存中的任意一块都可以映象到Cache中的任意一块。因此这种映射共有Cb×Mb种可能,其中Cb和Mb分别为Cache中的块数和主存中的块数。 Cache 地址目录表及其结构 该表存储主存块号和Cache块号间的对应关系 结构为 : 主存块号B Cache块号b 有效位 有关目录表结构

21
2) 主存的某一数据块可以装入缓存的任意一块的空间中。
全相联的地址映象规则: 1)主存与缓存分成相同大小的数据块。 2) 主存的某一数据块可以装入缓存的任意一块的空间中。 全相联映象方式: 块0 块1 : 块i 块M/B-1 B:每块大小 C:Cache容量 M:主存容量 块0 块1 : 块C/B-1 Cache 主存储器
主存与缓存分成相同大小的数据块。 2) 主存的某一数据块可以装入缓存的任意一块的空间中。 全相联映象方式: 块0. 块1. : 块i. 块M/B-1. B:每块大小. C:Cache容量. M:主存容量. 块0. 块1. : 块C/B-1. Cache. 主存储器.")
22
全相联映像(续) N = 区内块数,阴影区表示查找范围
 N = 区内块数,阴影区表示查找范围")
23
全相联映像的特点: 块的冲突概率最小 Cache的利用率也最高 但需要一个访问速度很快,容量为Cb的相联存储器,代价较高。 在虚拟存储系统中,一般都采用全相联映象方式。原因在于为了支持多任务调度时,CPU 可以快速切换到另一个任务之中。

24
全相联映像(续)
")
25
5.2.3 直接映象及其变换 Cache和RAM仍以块为单位,但在RAM中将空 间划分为大小和Cache完全一样的区,在RAM中, 将区再划分为若干块。 Cache中的块和RAM中的块形成一对多的映射 关系,如下: (B[A0],B[A1],…,B[An])—>b(Cache) 即满足:b =B Mod Cb其中,b为Cache中的块号, B为存储器块号,Cb为Cache中总块数。 Cache地址变换的实质: RAM 地址:(区号A,块号 B,块内地址W) Cache 地址:(Cache块号,块内地址)
—>b(Cache) 即满足:b =B Mod Cb其中,b为Cache中的块号, B为存储器块号,Cb为Cache中总块数。 Cache地址变换的实质: RAM 地址:(区号A,块号 B,块内地址W) Cache 地址:(Cache块号,块内地址)")
26
直 接 映 象

27
直 接 映 象(续)
")
28
如何将RAM地址转换成Cache地址? 有四种比较结果: Case1: 区号相等,且tag =1,则命中,即CPU从Cache中获取数据; Case2: 区号相等,但tag =0,则表示命中但数据无效,则: RAM读取—>Cache,tag :=1 —>CPU Case3:区号不等,且tag =0,则表示此块为空 Case4: 区号不等,但tag=1,则表示Cache中原来存放的那一块是有效的,为此,要先将此块写回RAM,然后再按Case2进行操作。

29
直接映象举例:Cache大小为8块 1 2 3 4 5 6 7

30
举例: 假设在某个计算机系统中Cache容量为64K字节,数据块大小是16个字节,主存容量是4M,地址映象为直接相联方式。
(1)主存地址多少位?格式如何? (2)Cache地址多少位?格式如何? (3)目录表的格式和容量? 解: 主存地址格式: 区号 区内块号 块内地址 Cache地址格式: 块 号 块内地址 目录表的格式: 主存区号 有效位 容量:应与缓存块数量相同即212=4096
主存地址多少位?格式如何? (2)Cache地址多少位?格式如何? (3)目录表的格式和容量? 解: 主存地址格式: 区号. 区内块号. 块内地址 Cache地址格式: 块 号. 块内地址 目录表的格式: 主存区号. 有效位 容量:应与缓存块数量相同即212=4096.")
31
5.2.4 组相联映象及其变换 提出背景: a.全相联方式速度较慢,且造价较高,但命中率最高 b.直接相联方式速度快,但命中率低。为此,提出
一种折中解决方案——组相联映像及其变换。 要 点: a.Cache和RAM的基本单位仍然是块; b.Cache和RAM被组织成为大小相等的若干个组; c.RAM的组—>Cache组间采用直接相联的方法, 而组内采用全相联技术。

32
组 相 联 映 像 n路组相联:组内有n块 要 点:组间直接,组内全相联

33
组相联映像(续) N = 区内块数,阴影区表示查找范围,根据组号在块表中寻找组,组内相联查找。
 N = 区内块数,阴影区表示查找范围,根据组号在块表中寻找组,组内相联查找。")
34
组相联映像(续) 例:设有8个块,分成2个组 1 2 3 4 5 6 7 第0组 第1组 注:Cache分为2个组,每个组的大小为4个块
 例:设有8个块,分成2个组 第0组 第1组 注:Cache分为2个组,每个组的大小为4个块")
35
举例:主存容量为1MB,缓存容量为32KB,每块为64个字节,缓存共分128组。
请写出: (1)主存与Cache的地址格式; (2)相关存储器的格式与容量 解: 缓存地址: 组号 块号 块内地址 主存地址: 区号 组号 块号 块内地址 区号Ei 块号Bi 缓存块号bi 装入位 相关存储器的格式: 相关存储器的容量,应与缓存的块数相同,即: 组数×组内块数=128×4=512
主存与Cache的地址格式; (2)相关存储器的格式与容量. 解: 缓存地址: 组号. 块号. 块内地址 主存地址: 区号. 组号. 块号. 块内地址 区号Ei. 块号Bi. 缓存块号bi. 装入位 相关存储器的格式: 相关存储器的容量,应与缓存的块数相同,即: 组数×组内块数=128×4=512.")
36
特点: Cache中块的利用率将大幅提高,命中率也将明显提高 ,组相联方式与全相联方式相比,实现起来更容易的多,但Cache的命中率与全相联映象方式很接近。因此,这种方式得到较广泛的应用。 当每组的块容量Gb为1时,就成了直接映象方式。即:1组=1块 当组数G=1时,为全相联方式 当Gb上升时,冲突概率和Cache的失效率就降低,但查表速度减慢。

37
5.2.5 Cache替换算法及其实现 提出的背景:当将主存块装入Cache时,有可能 Cache已满,此时要将Cache中的某块写回RAM, 然后再将RAM块装入至Cache中。 直接映象及变换算法,不需要采用替换算法。 替换算法概略 a.全相联映象及变换方式中,替换算法最复杂; b.组相联映象及变换,需要从Cache同一组内的几个块中选择一块替换。 c.Cache替换算法:随机算法,FIFO算法,LRU、LFU、OPT等几种方法,但常用的为LFU和FIFO算法两种。

38
这种方法通常应用于组相联映象及地址变换之中。 具体有以下两种实现方法:
方法1:轮换法 这种方法通常应用于组相联映象及地址变换之中。 具体有以下两种实现方法: a.每块一个计数器 块表的数据结构为:(区号E,块号B,Cache块号b,有效位e,计数器) 替换方法: ① 刚装入的块,其计数器清“0”,同组的其它块则+1。 ② 需要替换时,将同组中最大计数值的块作为替换对象。
 替换方法: ① 刚装入的块,其计数器清 0 ,同组的其它块则+1。 ② 需要替换时,将同组中最大计数值的块作为替换对象。")
39
特点: b.每组一个计数器 本质上,同组内的所有块是按顺序轮流替换的。因此,只要为每个组设置一个计数器即可。 计数器的值就是要被替换的块。
特点: ① 实现简单; ② 不符合程序的局部性原理

40
④ 方法2:LRU算法及其实现 基本思想:通过在块表中为每一Cache块设置一个计数器,记录其访问次数。然后根据计数器的值,确定被替换的对象。 计数器的使用及管理规则: ① 被装入的块,其对应的Counter为‘0’;而其它块的Counter + 1 ② 命中的块,其Counter<—0,同组中其它所有计数 器,分以下两种情况处理: Case1:All (Counter < 命中的Counter),则Counter+1 Case2:其余的Counter不变 ③ 需要替换时,选择max(counter)对应的块,作为替 换对象。
,则Counter+1 Case2:其余的Counter不变. ③ 需要替换时,选择max(counter)对应的块,作为替 换对象。")
41
5.2.6 Cache的一致性问题 问题的原因: a. CPU—>Cache,但没有写Memory。此时,若直接将Mem中的数据写入HD,就出问题。 b. HD—>I/O处理机—>RAM,但没有到Cache,在这种情况 下,若直接访问Cache中的数据也将出问题。 解决的方法 方法1:写直达法(Write-through) CPU—>数据—>(Cache, RAM),从而使两者一致 方法2:写回法 (Write-back) CPU—>数据—>Cache,当冲突发生时,一次写回RAM
 CPU—>数据—>(Cache, RAM),从而使两者一致. 方法2:写回法 (Write-back) CPU—>数据—>Cache,当冲突发生时,一次写回RAM.")
42
5.2.7 Cache的性能分析 主要分析: a. Cache系统的加速比及其影响参数 b. Cache 系统的数据一致性

43
Cache性能的主要影响参数分析 命中率和以下因素相关: H= f (地址流分布, 替换算法, Cache的容量, 分组的数目及组内块数, Cache的预取算法)
")
44
② Cache命中率与组数的关系 组数提升,组内块数就减少,导致H降低。 原因:组间采用直接相联方式,因此当分组数目提 升,主存中的某一块可以映象到 Cache 中的 块数就将减少,从而使H减少。

45
地址映象与命中率之间的关系

46
Cache的相联性与失效率 更新策略与命中率(定量分析公式)增加cache后的 CPU执行时间
增加cache后的 CPU执行时间")
47
例5.1 假设Cache的命中时间为1个时钟周期,失效开销为50个时钟周期,在混合Cache中一次load或store操作访问Cache的命中时间都要增加1个时钟周期(因为混合Cache只有一个端口,无法同时满足两个请求,会导致结构冲突),根据表5.4所列的失效率,试问指令Cache和数据Cache容量均为16 KB的分离Cache和容量为32 KB的混合Cache相比,哪种Cache的失效率更低?又假设采用写直达策略,且有一个写缓冲器,并且忽略写缓冲器引起的等待。请问上述两种情况下平均访存时间各是多少?
,根据表5.4所列的失效率,试问指令Cache和数据Cache容量均为16 KB的分离Cache和容量为32 KB的混合Cache相比,哪种Cache的失效率更低?又假设采用写直达策略,且有一个写缓冲器,并且忽略写缓冲器引起的等待。请问上述两种情况下平均访存时间各是多少?")
48
解: 如前所述,约75%的访存为取指令。 因此,分离Cache的总体失效率为: (75%×0.64%)+(25%×6.47%)=2.10% 根据表5.4,容量为32 KB的混合Cache的失效率略低一些,只有1.99%。 平均访存时间公式可以分为指令访问和数据访问两部分: 平均访存时间 = 指令所占的百分比×(指令命中时间+指令失效率×失效开销)+ 数据所占的百分比×(数据命中时间+数据失效率×失效开销)
+ 数据所占的百分比×(数据命中时间+数据失效率×失效开销)")
49
平均访存时间分离 =75%×(1+0.64%×50)+25%×(1+6.47%×50)
所以,两种结构的平均访存时间分别为: 平均访存时间分离 =75%×(1+0.64%×50)+25%×(1+6.47%×50) =(75%×1.32)+(25%×4.325) = =2.05 平均访存时间混合 = 75%×(1+1.99%×50)+25%×( %×50) =(75%×1.995)+(25%×2.995) = =2.24 因此,尽管分离Cache的实际失效率比混合Cache的高,但其平均访存时间反而较低。分离Cache提供了两个端口,消除了结构冲突。
+25%×(1+6.47%×50) =(75%×1.32)+(25%×4.325) = =2.05. 平均访存时间混合 = 75%×(1+1.99%×50)+25%×( %×50) =(75%×1.995)+(25%×2.995) = =2.24. 因此,尽管分离Cache的实际失效率比混合Cache的高,但其平均访存时间反而较低。分离Cache提供了两个端口,消除了结构冲突。")
50
程序执行时间 CPU时间=(CPU执行周期数+存储器停顿周期数)× 时钟周期时间 其中:
存储器停顿时钟周期数=“读”的次数×读失效率×读失效开销+“写”的次数×写失效率×写失效开销 存储器停顿时钟周期数=访存次数×失效率×失效开销

51
例5.2 我们用一个和Alpha AXP类似的机器作为第一个例子。假设Cache失效开销为50个时钟周期,当不考虑存储器停顿时,所有指令的执行时间都是2.0个时钟周期,访问Cache失效率为2%,平均每条指令访存1.33次。试分析Cache对性能的影响。 解 存储器停顿周期数 CPU 时间=IC×(CPIexe+──────── ) ×时钟周期时间 指令数 考虑Cache的失效后,性能为: CPU时间有cache=IC×(2.0+1.33×2 %×50)×时钟周期 =IC×3.33×时钟周期时间 实际CPI :3.33 3.33/2.0 = 1.67(倍) CPU时间也增加为原来的1.67倍。 但若不采用Cache,则:CPI=2.0+50×1.33=68.5
 ×时钟周期时间. 指令数. 考虑Cache的失效后,性能为: CPU时间有cache=IC×(2.0+1.33×2 %×50)×时钟周期. =IC×3.33×时钟周期时间. 实际CPI : /2.0 = 1.67(倍) CPU时间也增加为原来的1.67倍。 但若不采用Cache,则:CPI=2.0+50×1.33=68.5.")
52
Cache失效对于一个CPI较小而时钟频率较高的CPU来说,影响是双重的:
CPIexecution越低,固定周期数的Cache失效开销的相对影响就越大。 在计算CPI时,失效开销的单位是时钟周期数。因此,即使两台计算机的存储层次完全相同,时钟频率较高的CPU的失效开销较大,其CPI中存储器停顿这部分也就较大。 因此Cache对于低CPI、高时钟频率的CPU来说更加重要。

53
例5.3 考虑两种不同组织结构的Cache:直接映象Cache和2路组相联Cache,试问它们对CPU的性能有何影响?先求平均访存时间,然后再计算CPU性能。分析时用以下假设:
(1)理想Cache(命中率为100%)情况下的CPI为2.0,时钟周期为2ns,平均每条指令访存1.3次。 (2)两种Cache容量均为64KB,块大小都是32字节。 (3)图5.8说明,在组相联Cache中,必须增加一个多路选择器,用于根据标识匹配结果从相应组的块中选择所需的数据。因为CPU的速度直接与Cache命中的速度紧密相关,所以对于组相联Cache,由于多路选择器的存在而使CPU的时钟周期增加到原来的1.10倍。 (4) 这两种结构Cache的失效开销都是70 ns。 (5) 命中时间为1个时钟周期,64 KB直接映象Cache的失效率为1.4%,相同容量的2路组相联Cache的失效率为1.0%。
理想Cache(命中率为100%)情况下的CPI为2.0,时钟周期为2ns,平均每条指令访存1.3次。 (2)两种Cache容量均为64KB,块大小都是32字节。 (3)图5.8说明,在组相联Cache中,必须增加一个多路选择器,用于根据标识匹配结果从相应组的块中选择所需的数据。因为CPU的速度直接与Cache命中的速度紧密相关,所以对于组相联Cache,由于多路选择器的存在而使CPU的时钟周期增加到原来的1.10倍。 (4) 这两种结构Cache的失效开销都是70 ns。 (5) 命中时间为1个时钟周期,64 KB直接映象Cache的失效率为1.4%,相同容量的2路组相联Cache的失效率为1.0%。")
54
Alpha AXP 21064 CPU中Data Cache

55
解:平均访存时间=命中时间+失效率×失效开销 因此,两种结构的平均访存时间分别是:
平均访存时间1路=2.0+(0.014×70)=2.98 ns 平均访存时间2路=2.0×1.10+(0.010×70)=2.90 ns 2路组相联Cache的平均访存时间比较低。 CPU 时间=IC×(CPIexe+每条指令的平均存储器停顿周期数)×时钟周期 =IC ×(CPIexe×时钟周期时间+每条指令的平均存储器停顿时间) 因此:CPU时间1路 = IC×[2.0×2ns+(1.3×0.014×70ns)] = 5.27×IC CPU时间2路 = IC×[2.0×2ns×1.10+(1.3×0.010×70ns)] = 5.31×IC CPU时间2路 5.31×IC ───── = ───── =1.01 CPU时间1路 5.27×IC 直接映象Cache的平均性能好一些。
=2.98 ns. 平均访存时间2路=2.0×1.10+(0.010×70)=2.90 ns. 2路组相联Cache的平均访存时间比较低。 CPU 时间=IC×(CPIexe+每条指令的平均存储器停顿周期数)×时钟周期. =IC ×(CPIexe×时钟周期时间+每条指令的平均存储器停顿时间) 因此:CPU时间1路 = IC×[2.0×2ns+(1.3×0.014×70ns)] = 5.27×IC. CPU时间2路 = IC×[2.0×2ns×1.10+(1.3×0.010×70ns)] = 5.31×IC. CPU时间2路. 5.31×IC. ───── = ───── =1.01. CPU时间1路. 5.27×IC. 直接映象Cache的平均性能好一些。")
56
平均访存时间=命中时间+失效率×失效开销 可以从三个方面改进Cache的性能:
降低失效率 减少失效开销 减少Cache命中时间 17种Cache优化技术 8种用于降低失效率 5种用于减少失效开销 4种用于减少命中时间

57
5.3 降低Cache失效率的方法 三种失效(3C)
强制性失效(Compulsory miss):当第一次访问一个块时,该块不在Cache中,需从RAM中调入Cache,这就是强制性失效。 (冷启动失效,首次访问失效) 容量失效(Capacity miss ) :如果程序执行时所需的块不能全部调入Cache中,则当某些块被替换后,若又重新被访问,就会发生失效。这种失效称为容量失效。 冲突失效(Conflict miss):在组相联或直接映象Cache中,若太多的块映象到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。这就是发生了冲突失效。
:当第一次访问一个块时,该块不在Cache中,需从RAM中调入Cache,这就是强制性失效。 (冷启动失效,首次访问失效) 容量失效(Capacity miss ) :如果程序执行时所需的块不能全部调入Cache中,则当某些块被替换后,若又重新被访问,就会发生失效。这种失效称为容量失效。 冲突失效(Conflict miss):在组相联或直接映象Cache中,若太多的块映象到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。这就是发生了冲突失效。")
58
三种失效所占的比例

59
结论: 相联度越高,冲突失效就越少; 强制性失效和容量失效基本不受相联度的影响; 强制性失效不受Cache容量的影响,但容量失效却随着容量的增加而减少; 表5.5中的数据符合2:1的Cache经验规则,即大小为N的直接映象Cache的失效率约等于大小为N/2的2路组相联Cache的失效率。

60
5.3 降低Cache失效率的方法 减少三种失效的方法 强制性失效:增加块大小,预取 容量失效:增加容量 冲突失效:提高相联度
许多降低失效率的方法会增加命中时间或失效开销

61
另一方面,由于增加块大小会减少Cache中块的数目,所以有可能会增加冲突失效。
失效率与块大小的关系 对于给定的Cache容量,当块大小增加时,失效率开始是下降,后来反而上升了。 原因: 一方面它减少了强制性失效; 另一方面,由于增加块大小会减少Cache中块的数目,所以有可能会增加冲突失效。 Cache容量越大,使失效率达到最低的块大小就越大。

63
各种块大小情况下Cache的失效率 块大小 (字节) Cache容量(字节) 1K 4K 16K 64K 256K 16 15.05%
8.57% 3.94% 2.04% 1.09% 32 13.34% 7.24% 2.87% 1.35% 0.70% 64 13.76% 7.00% 2.64% 1.06% 0.51% 128 16.64% 7.78% 2.77% 1.02% 0.49% 256 22.01% 9.51% 3.29% 1.15%

64
各种块大小情况下Cache的平均访存时间
(字节) 失效开销 (时钟周期) Cache容量(字节) 1K 4K 16K 64K 256K 16 42 7.321 4.599 2.655 1.857 1.458 32 44 6.870 4.186 2.263 1.308 64 48 7.605 4.360 2.267 1.594 1.245 128 56 10.318 5.357 2.551 1.509 1.274 256 72 16.847 7.847 3.369 1.571 1.353
 失效开销. (时钟周期) Cache容量(字节) 1K. 4K. 16K. 64K. 256K")
65
容量为N的直接映象Cache的失效率和容量为N/2的2路组相联Cache的失效率差不多相同。
方法2: 提高相联度 采用相联度超过8的方案的实际意义不大。 2:1 Cache经验规则 容量为N的直接映象Cache的失效率和容量为N/2的2路组相联Cache的失效率差不多相同。 提高相联度是以增加命中时间为代价。例如: TTL或ECL板级Cache,2路组相联:增加10% 定制的CMOS Cache, 2路组相联:增加2%

66
例5.5 假定提高相联度会按下列比例增大处理器时钟周期:
时钟周期2路 =1.10×时钟周期1路 时钟周期4路 =1.12×时钟周期1路 时钟周期8路 =1.14×时钟周期1路 假定命中时间为一个时钟周期,直接映象情况下失效开销为50个时钟周期,而且假设不必将失效开销取整。使用表5.5中的失效率,试问当Cache为多大时,以下不等式成立? 平均访存时间8路 < 平均访存时间4路 平均访存时间4路 < 平均访存时间2路 平均访存时间2路 < 平均访存时间1路

67
解:在各种相联度的情况下,平均访存时间分别为:
平均访存时间8路 = 命中时间8路 + 失效率8路×失效开销8路 = 1.14+失效率8路×50 平均访存时间4路 = 1.12 +失效率4路×50 平均访存时间2路 = 1.10 +失效率2路×50 平均访存时间1路 = 1.00 +失效率1路×50 把相应的失效率代入上式,即可得平均访存时间。 例如,1 KB的直接映象Cache的平均访存时间为: 平均访存时间1路 = 1.00+0.133×50=7.65 128 KB的8路组相联Cache的平均访存时间为: 平均访存时间8路=1.14+0.006×50=1.44 失效率请查表5.5

68
在各种容量和相联度情况下Cache的平均访存时间
相联度(路) 1 2 4 8 7.65 6.60 6.22 5.44 5.90 4.90 4.62 4.09 4.60 3.95 3.57 3.19 3.30 3.00 2.87 2.59 16 2.45 2.20 2.12 2.04 32 2.00 1.80 1.77 1.79 64 1.70 1.60 1.57 1.59 128 1.50 1.45 1.42 1.44 当Cache容量不超过16 KB时,上述三个不等式成立。 从32 KB开始,对于平均访存时间有: 4路组相联的平均访存时间小于2路组相联的; 2路组相联的小于直接映象的;但8路组相联的却比4路组相联的大。
 当Cache容量不超过16 KB时,上述三个不等式成立。 从32 KB开始,对于平均访存时间有: 4路组相联的平均访存时间小于2路组相联的; 2路组相联的小于直接映象的;但8路组相联的却比4路组相联的大。")
69
方法3:增加Cache的容量 最直接的方法是增加Cache的容量 缺点: 增加成本 可能增加命中时间 这种方法在片外Cache中用得比较多

70
方法4:Victim Cache 一种能减少冲突失效次数而又不影响时钟频率的方法。
基本思想:在Cache和它从下一级存储器之间的通路中设置一个全相联的小Cache,用于存放被替换出去的块(称为Victim),以备重用。 作用 对减小冲突失效很有效,特别是对于小容量的直接映象数据Cache,作用尤其明显 例如:项数为4的Victim Cache: 能使4 KB Cache的冲突失效减少20%~90% Victim Cache在存储层次中的位置
,以备重用。 作用. 对减小冲突失效很有效,特别是对于小容量的直接映象数据Cache,作用尤其明显. 例如:项数为4的Victim Cache: 能使4 KB Cache的冲突失效减少20%~90% Victim Cache在存储层次中的位置.")
71
方法5:伪相联 Cache 多路组相联的低失效率和直接映象的命中速度 伪相联Cache的优点 命中时间小 失效率低 优 点 缺 点 直接映象
优 点 缺 点 直接映象 命中时间小 失效率高 组相联 失效率低 命中时间大

72
快速命中与慢速命中,要保证绝大多数命中都是快速命中。
基本思想及工作原理 在逻辑上把直接映象Cache的空间平分为上下两个区。对于任何一次访问,伪相联Cache先按直接映象Cache的方式去处理。若命中,则其访问过程与直接映象Cache的情况一样。若不命中,则再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。 快速命中与慢速命中,要保证绝大多数命中都是快速命中。

73
例5. 6 假设当在按直接映象找到的位置处没有发现匹配,而在另一个位置才找到数据(伪命中)需要2个额外的周期。仍用例5
例5.6 假设当在按直接映象找到的位置处没有发现匹配,而在另一个位置才找到数据(伪命中)需要2个额外的周期。仍用例5.5中的数据,问:当Cache容量分别为2 KB和128 KB时,直接映象、2路组相联和伪相联这三种组织结构中,哪一种速度最快? 【解】首先考虑标准的平均访存时间公式: 平均访存时间伪相联 = 命中时间伪相联+失效率伪相联×失效开销伪相联
需要2个额外的周期。仍用例5.5中的数据,问:当Cache容量分别为2 KB和128 KB时,直接映象、2路组相联和伪相联这三种组织结构中,哪一种速度最快? 【解】首先考虑标准的平均访存时间公式: 平均访存时间伪相联. = 命中时间伪相联+失效率伪相联×失效开销伪相联.")
74
由于:失效率伪相联=失效率2路 命中时间伪相联=命中时间1路+伪命中率伪相联×2 伪相联查找的命中率等于2路组相联Cache的命中率和直接映象Cache命中率之差。 伪命中率伪相联 =命中率2路-命中率1路 =(1-失效率2路)-(1-失效率1路) =失效率1路-失效率2路 综合上述分析,有: 平均访存时间伪相联=命中时间1路+(失效率1路-失效率2路) ×2+失效率2路×失效开销1路
-(1-失效率1路) =失效率1路-失效率2路. 综合上述分析,有: 平均访存时间伪相联=命中时间1路+(失效率1路-失效率2路) ×2+失效率2路×失效开销1路.")
75
将前面表中的数据代入上面的公式,得: 平均访存时间伪相联,2 KB =1+(0.098-0.076)×2+(0.076×50)=4.844 平均访存时间伪相联,128 KB =1+(0.010-0.007)×2+(0.007×50)=1.356 根据上一个例子中的表,对于2 KB Cache,可得: 平均访存时间1路 =5.90 个时钟 平均访存时间2路 =4.90 个时钟 对于128KB的Cache有,可得: 平均访存时间1路 =1.50 个时钟 平均访存时间2路 =1.45 个时钟 可见,对于这两种Cache容量,伪相联Cache都是速度最快。

76
方法6:硬件预取 指令和数据都可以预取 预取内容既可放入Cache,也可放在外缓冲器中。 指令预取通常由Cache之外的硬件完成
例如:指令流缓冲器 指令预取通常由Cache之外的硬件完成 预取效果,Joppi的研究结果 指令预取 (4 KB,直接映象Cache,块大小=16 B) 1个块的指令流缓冲器:捕获15%~25%的失效 4个块的指令流缓冲器: 捕获50%的失效 16个块的指令流缓冲器:捕获72%的失效 数据预取 (4 KB,直接映象Cache) 1个数据流缓冲器:捕获25%的失效 还可以采用多个数据流缓冲器
 1个块的指令流缓冲器:捕获15%~25%的失效. 4个块的指令流缓冲器: 捕获50%的失效. 16个块的指令流缓冲器:捕获72%的失效. 数据预取 (4 KB,直接映象Cache) 1个数据流缓冲器:捕获25%的失效. 还可以采用多个数据流缓冲器.")
77
Palacharla和Kessler的研究结果
流缓冲器:既能预取指令又能预取数据 对于两个64 KB四路组相联Cache来说: 8个流缓冲器能捕获50%~70%的失效 例5.7 Alpha AXP 21064采用指令预取技术,其实际失效率是多少?若不采用指令预取技术,Alpha AXP 21064的指令Cache必须为多大才能保持平均访存时间不变? 解:假设当指令不在指令Cache里,而在预取缓冲器中找到时,需要多花一个时钟周期。此时: 平均访存时间预取 =命中时间+失效率×预取命中率×1+ 失效率×(1-预取命中率)×失效开销
×失效开销.")
78
假设预取命中率为25%,命中时间为2个时钟周期,失效开销为50个时钟周期。查表5.4可知8 KB指令Cache的失效率为1.10%。则:
平均访存时间预取 =2+(1.10 %×25 %×1)+1.10 %×(1-25 %)×50 =2+ +0.413 =2.415 为了得到相同性能下的实际失效率,由原始公式得: 平均访存时间 =命中时间+失效率×失效开销 失效率 =(平均访存时间-命中时间)/失效开销 =(2.415-2)/50=0.83 % 该失效率介于普通8KBCache失效率1.10%和16KB Cache失效率0.64%之间。说明预取有效!
+1.10 %×(1-25 %)×50 =2+ +0.413 = 为了得到相同性能下的实际失效率,由原始公式得: 平均访存时间 =命中时间+失效率×失效开销. 失效率 =(平均访存时间-命中时间)/失效开销. =(2.415-2)/50=0.83 % 该失效率介于普通8KBCache失效率1.10%和16KB Cache失效率0.64%之间。说明预取有效!")
79
方法7: 编译器控制的预取 预取有以下几种类型: 在编译时加入预取指令,在数据被用到前发出预取请求。 寄存器预取:把数据取到寄存器中。
Cache预取:只将数据取到Cache中。 这两种预取又可分为故障性和非故障性: 故障性预取:在预取时,若出现虚地址故障或违反保护权限,就会发生异常。 非故障性预取:在遇到这种情况时则不会发生异常,因为这时它会放弃预取,转变为空操作。 这里假定Cache预取都是非故障性的,也称非绑定预取。

80
在预取数据的同时,处理器应能继续执行。只有这样,预取才有意义。称为“非阻塞Cache”或“非锁定Cache”
编译器控制预取的目的:使执行指令和读取数据能重叠执行。 循环是预取优化的主要对象 失效开销小时:循环体展开1~2次 失效开销大时:循环体展开许多次

81
例5.8 对于下面的程序,首先判断哪些访问可能会导致数据Cache失效。然后,加入预取指令以减少失效。最后,计算所执行的预取指令的条数以及通过预取避免的失效次数。
假定: (1) 我们用的是一个容量为8 KB、块大小为16 B的直接映象Cache,它采用写回法并且按写分配。 (2) a、b分别为3×100(3行100列)和101×3的双精度浮点数组,每个元素都是8 B。当程序开始执行时,这些数据都不在Cache内。 for ( i = 0 ; i < 3 ; i = i + 1 ) for ( j = 0 ; j < 100 ; j = j + 1 ) a [ i ][ j ] = a[ i ][ j ] + b[ j ][ 0 ] * b[ j+1 ][ 0 ];
 我们用的是一个容量为8 KB、块大小为16 B的直接映象Cache,它采用写回法并且按写分配。 (2) a、b分别为3×100(3行100列)和101×3的双精度浮点数组,每个元素都是8 B。当程序开始执行时,这些数据都不在Cache内。 for ( i = 0 ; i < 3 ; i = i + 1 ) for ( j = 0 ; j < 100 ; j = j + 1 ) a [ i ][ j ] = a[ i ][ j ] + b[ j ][ 0 ] * b[ j+1 ][ 0 ];")
82
假设失效开销很大,预取必须至少提前7次循环进行。
解 计算过程 失效情况 总的失效次数=251次 改进后的程序 假设失效开销很大,预取必须至少提前7次循环进行。

83
失效情况:总的失效次数=19次,但多执行了400次预取指令。
for ( j = 0; j < 100; j = j+1 ) { prefetch ( b[ j+7 ][ 0 ]); /* 预取7次循环后所需的b ( j , 0 ) */ prefetch ( a[ 0 ][ j+7 ]); /* 预取7次循环后所需的a (0 , j ) */ } for ( i = 1; i < 3; i = i+1 ) { for ( j = 0; j < 100; j = j+1 ) prefetch ( a [ i ][ j+7 ]); /* 预取7次循环后所需的a ( i , j ) */ a [ i ][ j ] = a [ i ][ j ] +b[ j ][ 0 ] * b[ j+1 ][ 0 ]; 失效情况:总的失效次数=19次,但多执行了400次预取指令。
 { prefetch ( b[ j+7 ][ 0 ]); /* 预取7次循环后所需的b ( j , 0 ) */ prefetch ( a[ 0 ][ j+7 ]); /* 预取7次循环后所需的a (0 , j ) */ } for ( i = 1; i < 3; i = i+1 ) { for ( j = 0; j < 100; j = j+1 ) prefetch ( a [ i ][ j+7 ]); /* 预取7次循环后所需的a ( i , j ) */ a [ i ][ j ] = a [ i ][ j ] +b[ j ][ 0 ] * b[ j+1 ][ 0 ]; 失效情况:总的失效次数=19次,但多执行了400次预取指令。")
84
5.4 减少Cache失效开销 平均访存时间=命中时间+失效率×失效开销 5.4.1 让读失效优先于写
例5.10 考虑以下指令序列: SW R3, 512(R0) ;M[512]←R3 (Cache索引为0) LW R1, 1024(R0) ;R1←M[1024] (Cache索引为0) LW R2, 512(R0) ;R2←M[512] (Cache索引为0) 请问寄存器R2的值总等于R3吗? 读失效的处理 写直达法:推迟读失效处理。缺点:读失效开销增加 写回法:先写缓冲器,再读存储器,最后写存储器。
 ;M[512]←R3 (Cache索引为0) LW R1, 1024(R0) ;R1←M[1024] (Cache索引为0) LW R2, 512(R0) ;R2←M[512] (Cache索引为0) 请问寄存器R2的值总等于R3吗? 读失效的处理. 写直达法:推迟读失效处理。缺点:读失效开销增加. 写回法:先写缓冲器,再读存储器,最后写存储器。")
85
5.4.2 写缓冲合并 目的:提高写缓冲器的效率 写直达Cache 依靠写缓冲来减少对下一级存储器写操作的时间。
写缓冲器为空:将数据和相应地址写入该缓冲器。从CPU的角度来看,该写操作就算完成了。 写缓冲器不为空:将本次写入地址与写缓冲中已有的所有地址比较,如有地址匹配而对应的位置又是空闲的,将本次数据与已有项合并,此即写缓冲合并。 写缓冲满且又没有能合并的项,就必须等待。 作用:提高了写缓冲器的空间利用率,而且还能减少因写缓冲器满而要进行的等待时间。

86
写缓冲合并效果示意图 写缓冲有4项,8Bbytes/项,V代表有效位。如不采用写合并,3/4空间浪费。采用写合并,只需占1项。

87
5.4.3 请求字处理技术 请求字(Requested Word): 从下一级存储器调入Cache的块中,只有一个字是CPU立即需要的。
尽早重启动:从块的起始位置开始读起。一旦请求字到达,就立即发送给CPU,让CPU继续执行。 请求字优先:调块时,从请求字所在的位置读起,然后再读取该块其余部分至Cache。 这种技术在以下情况下效果不大: Cache块较小 下一条指令正好访问同一Cache块的另一部分

88
5.4.4 非阻塞Cache技术(Nonblocking Cache)
非阻塞Cache:Cache失效时仍允许CPU进行其他的命中访问。即允许“失效下命中”(hit under miss)。 进一步提高性能: “多重失效下命中”( hit under multiple misses) “失效下失效”( miss under miss) (存储器必须能够处理多个失效) “多重失效下命中”将大大增加Cache复杂性,可能有多个访问同时进行。
。 进一步提高性能: 多重失效下命中 ( hit under multiple misses) 失效下失效 ( miss under miss) (存储器必须能够处理多个失效) 多重失效下命中 将大大增加Cache复杂性,可能有多个访问同时进行。")
89
问题:为什么浮点程序和定点程序的差异很大?

90
5.4.5 采用两级Cache 应把Cache做得更快?还是更大? 性能分析 平均访存时间 = 命中时间L1+失效率L1×失效开销L1
失效开销L1 = 命中时间L2+失效率L2×失效开销L2 平均访存时间 = 命中时间L1+失效率L1× (命中时间L2+失效率L2×失效开销L2)
")
91
局部失效率与全局失效率 局部失效率=该级Cache的失效次数/到达该级 Cache的访问次数
例如:上述式子中的失效率L2 全局失效率=该级Cache的失效次数/CPU发出的 访存的总次数 全局失效率L2=失效率L1×失效率L2 评价第二级Cache时,应使用全局失效率这个指标。它指出了在CPU发出的访存中,究竟有多大比例是穿过各级Cache,最终到达存储器的。

92
例5.12 假设在1000次访存中,第一级Cache失效40次, 第二级Cache失效20次。试问:在这种情况下,该Cache系统的局部失效率和全局失效率各是多少?

93
对于第二级Cache,我们有以下结论: 在第二级Cache比第一级 Cache大得多的情况下,两级Cache的全局失效率与第二级Cache相同的单级Cache的失效率非常接近。 局部失效率不是衡量第二级Cache的一个好指标,因此,在评价第二级Cache时,应采用全局失效率这个指标。 第二级Cache不会影响CPU的时钟频率,只影响一级Cache的失效开销,因此其设计有更大的考虑空间。两个问题: 它能否降低CPI中的平均访存时间部分? 它的成本是多少?

94
第二级Cache的参数 容量:第二级Cache的容量一般比第一级的大许多。至少为一级Cache的XX倍~XXX倍 相联度:第二级Cache可采用较高的相联度或伪相联方法。 例5.13 给出有关第二级Cache的以下数据: (1) 2路组相联使命中时间增加10%×CPU时钟周期 (2) 对于直接映象,命中时间L2 = 10个时钟周期 (3) 对于直接映象,局部失效率L2 = 25% (4) 对于2路组相联,局部失效率L2 = 20% (5) 失效开销L2 = 50个时钟周期 试问第二级Cache的相联度对失效开销的影响如何?
 2路组相联使命中时间增加10%×CPU时钟周期. (2) 对于直接映象,命中时间L2 = 10个时钟周期. (3) 对于直接映象,局部失效率L2 = 25% (4) 对于2路组相联,局部失效率L2 = 20% (5) 失效开销L2 = 50个时钟周期. 试问第二级Cache的相联度对失效开销的影响如何?")
95
解:对一个直接映象的第二级Cache来说,第一级Cache的失效开销为:
失效开销直接映象,L1 = 10+25%×50 = 22.5 个时钟周期 对于2路组相联第二级Cache来说,命中时间增加了10%(0.1)个时钟周期,故第一级Cache的失效开销为: 失效开销2路组相联,L1 = 10.1+20%×50 = 20.1 个时钟周期 把第二级Cache的命中时间取整,得11,则: 失效开销2路组相联,L1 = 11+20%×50 = 21.0 个时钟周期 故对于第二级Cache来说,2路组相联优于直接映象。
个时钟周期,故第一级Cache的失效开销为: 失效开销2路组相联,L1 = 10.1+20%×50 = 20.1 个时钟周期. 把第二级Cache的命中时间取整,得11,则: 失效开销2路组相联,L1 = 11+20%×50 = 21.0 个时钟周期. 故对于第二级Cache来说,2路组相联优于直接映象。")
96
块大小 第二级Cache可采用较大的块,如64 B、128 B、256 B 为减少平均访存时间,可以让容量较小的第一级Cache采用较小的块,而让容量较大的第二级Cache采用较大的块。 多级Cache间数据的一致性 需要考虑的另一个问题:第一级Cache中的数据是否总是同时存在于第二级Cache中。

97
5.5 减少命中时间 平均访存时间=命中时间+失效率×失效开销 5.5.1 容量小、结构简单的Cache
命中时间直接影响到处理器的时钟频率。在当今的许 多计算机中,往往是Cache的访问时间限制了处理器的时 钟频率。 5.5.1 容量小、结构简单的Cache 硬件越简单,速度就越快。 应使Cache足够小,以便可以与CPU一起放在同一块芯片上。某些设计采用了一种折中方案:把Cache的标识放在片内,而把Cache的数据存储器放在片外。

98
5.5.2 虚拟Cache 虚拟Cache:访问Cache的索引以及Cache中的标识都采用虚拟地址。
解决方法:在地址标识中增加PID字段(进程标识符) 三种情况下失效率的比较 单进程,PIDs,清空 PIDs与单进程相比:+0.3%~+0.6% PIDs与清空相比: -0.6%~-4.3% 同义(Synonym)和别名(Alias):两个虚拟地址对应同一个数据。 解决方法:反别名法、页着色(page coloring)
 三种情况下失效率的比较. 单进程,PIDs,清空. PIDs与单进程相比:+0.3%~+0.6% PIDs与清空相比: -0.6%~-4.3% 同义(Synonym)和别名(Alias):两个虚拟地址对应同一个数据。 解决方法:反别名法、页着色(page coloring)")
99
Purges是指允许进程切换但不使用PID

100
优点:兼得虚拟Cache和物理Cache的好处 局限性:Cache容量受到页内位移的限制
虚拟索引+物理标识 优点:兼得虚拟Cache和物理Cache的好处 局限性:Cache容量受到页内位移的限制 Cache容量≤页大小×相联度 举例:IBM 3033的Cache 页大小=4 KB 相联度=16 Cache容量=16×4 KB=64 KB 另一种方法:硬件散列变换 31 12 11 页地址 地址标识 页内位移 索 引 块内位移

101
5.5.3 Cache访问流水化 对第一级Cache的访问按流水方式组织 访问Cache需要多个时钟周期才可以完成 例如
Pentium访问指令Cache需要1个时钟周期 Pentium Pro到Pentium Ⅲ需要2个时钟周期 Pentium 4 则需要4个时钟周期 好处:提高时钟频率,提高CPU访问Cache的带宽,但不能减少Cache的命中时间

102
5.5.4 Trace Cache 开发指令级并行性所遇到的挑战:为了充分发挥指令处理流水线的并行性,要提供足够多条彼此互不相关的指令,这是很困难的。 解决方法:采用Trace Cache,存放CPU所执行的动态指令序列,而非静态指令。 包含了由分支预测展开的指令,该分支预测是否正确需要在取到该指令时进行确认。 实例:Intel Netburst,继P4之后 优缺点: 地址映象机制复杂。 提高指令Cache的空间利用率:只存储分支指令从转入位置到转出位置之间的指令,避免了无关指令的空间开销。

103
5.5.5 Cache优化技术总结 “+”号:表示改进了相应指标。 “-”号:表示它使该指标变差。 空格栏:表示它对该指标无影响。 复杂性:0表示最容易,3表示最复杂。

104
Cache优化技术总结 优化技术 失效 率 开销 命中 时间 硬件 复杂度 说 明 增加块大小 先+ 后-
实现容易;Pentium 4 的第二级Cache采用了128 B的块 增加Cache容量 + 被广泛采用,特别是第二级Cache 提高相联度 1 被广泛采用 Victim Cache 2 AMD Athlon采用了8个项的Victim Cache 伪相联Cache MIPS R10000的第二级Cache采用 硬件预取指令 和数据 2~3 许多机器预取指令,UltraSPARC Ⅲ预取数据

105
优化技术 失效 率 开销 命中 时间 硬件 复杂度 说 明 编译器控制 的预取 + 3 需同时采用非阻塞Cache;有几种微处理器提供了对这种预取的支持 用编译技术减少Cache失效次数 向软件提出了新要求;有些机器提供了编译器选项 使读失效 优先于写 1 在单处理机上实现容易,被广泛采用 写缓冲归并 与写直达合用,广泛应用,例如21164,UltraSPARC Ⅲ 尽早重启动 和关键字优先 2 被广泛采用 非阻塞Cache 在支持乱序执行的CPU中使用

106
优化技术 失效 率 开销 命中 时间 硬件 复杂度 说 明 两级Cache + 2 硬件代价大;两级Cache的块大小不同时实现困难;被广泛采用 容量小且结构简单的Cache 实现容易,被广泛采用 对Cache进行索引时不必进行地址变换 对于小容量Cache来说实现容易,已被Alpha 21164和UltraSPARC Ⅲ采用 流水化Cache 访问 1 被广泛采用 Trace Cache 3 Pentium 4 采用

107
本章要点 存储系统的概念及原理 高速缓存的概念及原理 主存及虚拟存储器的原理

108
5.6.1 如何提高存储器的访问效率 存储器体系中的频带平衡问题: a. CPU 访问存贮器的字长和速度;
如何提高存储器的访问效率 存储器体系中的频带平衡问题: a. CPU 访问存贮器的字长和速度; b. 各级存储器间的数据交换效率。 ① 问题的背景: 存储器访问的速度能否跟上系统的要求,是影响整个计算机系统性能极为重要的关键问题,也是系统结构设计者的主要问题。

109
② 举例说明: 设一台计算机的执行速度为200MIPs(2亿指令/秒), 则要求: CPU取指令:200MW/S(设每条指令长为一个字) CPU取/存操作数:400MW /S (平均每条指令访
问周期2 个操作数) 各种I/O设备访问存贮器:5MW /S ∴ 要求存贮器的总频宽为605MW /S 要求T≤16.5ns。这与目前的DRAM的访存周期是不符的,也就是说达不到这一要求的。
 各种I/O设备访问存贮器:5MW /S. ∴ 要求存贮器的总频宽为605MW /S 要求T≤16.5ns。这与目前的DRAM的访存周期是不符的,也就是说达不到这一要求的。")
110
5.6.1 如何提高存储器的访问效率 假设:在下面的讨论中,假设基本存储器结构的性能为: 送地址需要4个时钟周期
如何提高存储器的访问效率 假设:在下面的讨论中,假设基本存储器结构的性能为: 送地址需要4个时钟周期 每个字的访问时间为24个时钟周期 传送一个字(32位)的数据需4个时钟周期 如果Cache块大小为4个字,则: 失效开销为4×(4+24+4)=128个时钟周期
的数据需4个时钟周期. 如果Cache块大小为4个字,则: 失效开销为4×(4+24+4)=128个时钟周期.")
111
5.6.1 如何提高存储器的访问效率 方法1要点: 增加CPU和存储器之间连接通路的宽度 增加一个多路选择器 写入有可能变得复杂
如何提高存储器的访问效率 方法1要点: 增加CPU和存储器之间连接通路的宽度 增加一个多路选择器 写入有可能变得复杂 举例:DEC的Alpha Axp21064:256位宽

112
5.6.1 如何提高存储器的访问效率 方法2:采用简单的多体交叉存储器 在存储系统中采用多个DRAM,并利用它们潜在的并行性。
如何提高存储器的访问效率 方法2:采用简单的多体交叉存储器 在存储系统中采用多个DRAM,并利用它们潜在的并行性。 存储器的各个体一般是按字交叉的交叉存储器(interleaved memory) 通常是指存储器的各个体是按字交叉的 字交叉存储器非常适合于处理: Cache读失效,写回法Cache中的写回
 通常是指存储器的各个体是按字交叉的. 字交叉存储器非常适合于处理: Cache读失效,写回法Cache中的写回.")
113
如何提高存储器的访问效率

114
5.6.1 如何提高存储器的访问效率 假设四个存储体的地址是在字一级交叉的,即存储 体0中每个字的地址对4取模都是0,体1中每个字的地址
如何提高存储器的访问效率 假设四个存储体的地址是在字一级交叉的,即存储 体0中每个字的地址对4取模都是0,体1中每个字的地址 对4取模都是1,依此类推。 地址 体0 地址 体1 地址 体2 地址 体3 4 8 12 1 5 9 13 2 6 10 14 3 7 11 15

115
5.6.1 如何提高存储器的访问效率 例5.14 假设某台计算机的特性及其Cache的性能为: (1) 块大小为1个字;
如何提高存储器的访问效率 例5.14 假设某台计算机的特性及其Cache的性能为: (1) 块大小为1个字; (2) 存储器总线宽度为1个字; (3) Cache失效率为3%; (4) 平均每条指令访存1.2次; (5) Cache失效开销为32个时钟周期; (6)平均CPI(忽略Cache失效)为2。 试问多体交叉和增加存储器宽度对提高性能各有何作用? 如果当把Cache块大小变为2个字时,失效率降为2%;块大小变为4个字时,失效率降为1%。根据前面给出的访问时间,求在采用2路、4路多体交叉存取以及将存储器和总线宽度增加一倍时,性能分别提高多少?
 块大小为1个字; (2) 存储器总线宽度为1个字; (3) Cache失效率为3%; (4) 平均每条指令访存1.2次; (5) Cache失效开销为32个时钟周期; (6)平均CPI(忽略Cache失效)为2。 试问多体交叉和增加存储器宽度对提高性能各有何作用? 如果当把Cache块大小变为2个字时,失效率降为2%;块大小变为4个字时,失效率降为1%。根据前面给出的访问时间,求在采用2路、4路多体交叉存取以及将存储器和总线宽度增加一倍时,性能分别提高多少?")
116
5.6.1 如何提高存储器的访问效率 解:在改变前的计算机中,Cache块大小为一个字,
如何提高存储器的访问效率 解:在改变前的计算机中,Cache块大小为一个字, 其CPI为:2+(1.2×3%×32) = 3.15 当将块大小增加为2个字时,在下面三种情况下的CPI分别为: 32位总线和存储器,不采用多体交叉: 2+(1.2×2%×2×32) = 3.54 32位总线和存储器,采用多体交叉: 2+1.2×2%×(4+24+8)= 2.86 64位总线和存储器,不采用多体交叉: 2+(1.2×2%×1×32) = 2.77
 = 当将块大小增加为2个字时,在下面三种情况下的CPI分别为: 32位总线和存储器,不采用多体交叉: 2+(1.2×2%×2×32) = 位总线和存储器,采用多体交叉: 2+1.2×2%×(4+24+8)= 位总线和存储器,不采用多体交叉: 2+(1.2×2%×1×32) =")
117
将块大小增加到4个字,可以得到以下数据: 存储器中应该含有多少个体呢? 向量计算机采用以下衡量标准: 32位总线和存储器,不采用多体交叉:
2+(1.2×1%×4×32) = 3.54 32位总线和存储器,采用多体交叉: 2+1.2×1%×(4+24+16)= 2.53 64位总线和存储器,不采用多体交叉: 2+(1.2×1%×2×32) = 2.77 存储器中应该含有多少个体呢? 向量计算机采用以下衡量标准: 体的数目 ≥ 访问体中一个字所需的时钟周期数 存储系统的设计目标:对于顺序访问,每个时钟周期都能从一个存储体中送出一个数据。
 = 位总线和存储器,采用多体交叉: 2+1.2×1%×(4+24+16)= 位总线和存储器,不采用多体交叉: 2+(1.2×1%×2×32) = 存储器中应该含有多少个体呢? 向量计算机采用以下衡量标准: 体的数目 ≥ 访问体中一个字所需的时钟周期数. 存储系统的设计目标:对于顺序访问,每个时钟周期都能从一个存储体中送出一个数据。")
118
5.6.3 虚拟存储器 背景:1961年由英国曼彻斯特大学的Kitbrn等人提出的,其目的主要是解决主存容量不足的问题。
和操作系统中讲到“存储管理”不同的是,本课程主要阐述虚拟存储的原理。

119
1)Principle of Virtual Memory
Page:指RAM和外存之间数据交换的单位,其大 小为0.5k~16kB。 Real Page:主存中的页,将存储器分为若干实页 Virtual Page:虚拟存储器中的页。 实页号 页内偏移 d 用户号u ( 任务号 ) 虚 页 p 页内地址d
 虚 页 p. 页内地址d.")
120
1) Principle of Virtual Memory
虚空间:程序所能利用的空间。 实地址:主存物理空间的编址; 虚地址:编程序时程序员所用的地址,在编译程序中由处理机生成。 CPU 存储 管理 MMU 主 存 辅 外存地址 VA PA I或D Instruction, Data 虚拟存储器中CPU、MM、辅存间关系

121
1) Principle of Virtual Memory
地址变换:将虚拟存储空间中的虚地址—>主存地址 当发生缺页时,需要进行外部地址变换: 或:(Ui,Pv,d) —> (Head,Cylinder,Sector)
 —> (Head,Cylinder,Sector)")
122
… … … 磁盘地址(Head, Cyl., Sect) 外部地址变换 Uid Pv d 内部地址变换 主存页面表 Pm D 替换算法
0页 主 存 满 1页 Pm D … 替换算法 2p - 1 0页 0页 可用主存页号 1页 … … 2q - 1 0页 I/O处理器 I/O通道 … … 2ρ - 1

123
虚拟存储管理的几个基本问题 虚拟存储器的三种实现方法: 调页策略(Fetch Policy) 分配策略(Placement Policy)
① 段式虚拟存储器 ② 页式虚拟存储器 ③ 段页式虚拟存储器 虚拟存储管理的几个基本问题 调页策略(Fetch Policy) 分配策略(Placement Policy) 置换策略(Replacement Policy)
 分配策略(Placement Policy) 置换策略(Replacement Policy)")
124
调页策略 决定何时将页面载入内存 两种常用策略:
请求调页(On Demand Paging):只通过响应缺页中断调入需要的页面,也只调入发生缺页时所需的页面 预先调页(Prepaging):在发生缺页需要调入某页时,一次调入该页以及相邻的几个页 提高调页的I/O效率 效率不能保证:额外装入的页面可能没用
:只通过响应缺页中断调入需要的页面,也只调入发生缺页时所需的页面. 预先调页(Prepaging):在发生缺页需要调入某页时,一次调入该页以及相邻的几个页. 提高调页的I/O效率. 效率不能保证:额外装入的页面可能没用.")
125
分配策略 由操作系统决定进程各部分驻留在内存的哪个位置 常用方法: 最佳适配 首次适配 ……

126
置换策略 需要调入页面而内存已满时,决定置换(淘汰)内存中的哪个页面 常用方法:Rand,FIFO,LRU,LFU
不是所有内存中的页面都可以被置换: 有些帧给锁定(locked)了:OS内核、关键控制结构、I/O缓冲区等 常驻集策略决定了不同的置换范围:被置换的页面局限在本进程,或允许在其他进程
了:OS内核、关键控制结构、I/O缓冲区等. 常驻集策略决定了不同的置换范围:被置换的页面局限在本进程,或允许在其他进程.")
127
段页式虚拟存储器 目的:结合段和页式虚拟存储管理的优点 要点:虚拟地址的表示方式— ( 用户U,段号S,虚页号P ,页内偏移d ) 实页号 p 页内偏移 d 物理地址: 即实现:(用户U,段号S,虚页号p)—>(实页号P)
—>(实页号P) .")
128
缺点:要访问三次RAM才能得到相应的操作数,因此须提高页表的查找速度才能提高访存的速度。
段页式地址变换过程: 用户号 U 段号 S 虚页号 p 页内偏移 D MM + D P u M 主存地址 (段表地址) M 1 0/1 Ap + 1 P 0/1 装入 修改 标志 页表长 页表地址 装入位 实页号 修改位 标志 多用户段表 多用户页表 主存 缺点:要访问三次RAM才能得到相应的操作数,因此须提高页表的查找速度才能提高访存的速度。
 M. 1. 0/1. Ap P. 0/1. 装入. 修改. 标志. 页表长. 页表地址. 装入位. 实页号. 修改位. 标志. 多用户段表. 多用户页表. 主存. 缺点:要访问三次RAM才能得到相应的操作数,因此须提高页表的查找速度才能提高访存的速度。")
129
5.6.4 加快地址变换的方法 加快访问RAM的方法——快慢表
5.6.4 加快地址变换的方法 加快访问RAM的方法——快慢表 基本原理:采用程序局部性原理,可以大大缩小目录表的存储容量。例如:8-16个页目表项。而且这些目录项的访问速度与CPU的通用register 相当。称这个小容量的页目录表为快表。 快表和慢表间的关系:快表(TLB: Translation look aside buffer)只是慢表的一个副本,而且只存放了慢表中的一小部分。
只是慢表的一个副本,而且只存放了慢表中的一小部分。")
131
采用快慢表的内部地址变换的过程 要点: ① 快、慢表同时查找,前者以内容为索引,后者以地址为索引
② 当在快表中未找到时,在慢表中查找到的实页号P不仅送到地址register中,而且同时也送到快表之中。

132
进一步加快快表访问速度的方法 基本思想:单纯扩大快表的容量,虽然可以提高命中率,但却不能大幅度提高访存的速度,原因在于快表是采用基于内容的相联存储器方式实现的,容量大时会降低访问快表的速度。 解决方法:采用哈希(HASH) 算法,Ah=H(Pv) 要求此H采用硬件实现。例如:采用地址折叠法: 即:设Ah为6位,Pv为15位,则 b0=b0*b6*b12 b1=b1*b7*b13...
 算法,Ah=H(Pv) 要求此H采用硬件实现。例如:采用地址折叠法: 即:设Ah为6位,Pv为15位,则 b0=b0*b6*b12 b1=b1*b7*b13...")
133
哈希冲突的解决方法:将多用户虚页号也加入到快表中。
主存

134
5.6.5 页面替换算法及其实现 ① 目的:解决因缺页而引起的从外存装入页面信息 到内存的问题。
② 评价标准:一是命中率h,二是算法的实现难度。 ③ 典型的页面替换法: 方法一:随机算法RAND算法(random Algorithm) 要 点:通过随机算法(如随机数发生器)以确 定主存中要被替换的页面。 方法二:FIFO算法(first in first out Algorithm) 即队列算法:
 要 点:通过随机算法(如随机数发生器)以确 定主存中要被替换的页面。 方法二:FIFO算法(first in first out Algorithm) 即队列算法:")
135
方法3:近期最少使用算法(Least Recently Used)
要点:这种算法选择近期最少访问的页面作为被替换的页面。 难点:由于要为每个页面设置一个很长的计数器,并且要选定一个固定时长的计数器定时计数,实现较为困难。 方法4:最久没用使用的算法—LFU(Least Frequently Used Algorithm) 要点:这种算法把近期最久没有访问过的页面作为 被替换的页面。这样就把LRU中使用的多与少问题,转变成“有”与“无”的判断问题。
 要点:这种算法把近期最久没有访问过的页面作为 被替换的页面。这样就把LRU中使用的多与少问题,转变成 有 与 无 的判断问题。")
136
方法5:最优替换算法,即OPT算法(Optional Replacement algorithm)
要点: LRU和LFU都是以历史信息为依据,并假设将来的主存页面的使用情况和历史情况相同或类似。因此,这种情况不总是正确的。显然,最好的算法应该是选择将来最久不被访问的页面作为被替换的页面。这种替换算法的命中率一定是最高的。 缺点:这种方法是不实际的,因为将来是难以预测的,这只能作为一种理想的标准。

137
举例:某程序共用到4个页面,其中分配了3个主页面,总地址流为:
P1, P2, P1, P3, P4, P1, P2, P4, P3, P2, P3 试分析FIFO,LFU,OPT三种算法的性能。 地址流: P 1 P 2 P1 P3 P4 P1 P2 P4 P3 P2 P3 FIFO算法: 1 1 1 1 2 3 4 4 1 1 1 2 2 2 3 4 1 1 2 2 2 3 4 1 2 2 3 3 3 动作: 入 入 中 入 入 入 入 中 入 中 中

138
P1 P2 P1 P3 P4 P1 P2 P4 P3 P2 P3 LFU算法: 1 1 1 1 1* 1 1 1* 4 4 4 2 2* 3 3* 4* 4 2* 2 2 4 4 2 2 3 3 3 动作:入 入 中 入 入 中 入 中 入 中 中 OPT算法: 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 * 4 4 4 4* 3 3 3 动作:入 入 中 入 入 中 中 中 入 中 中

139
页面替换中的特殊现象: 在循环中出现的“颠簸”现象(thrashing):对一个循环程序,当分配的页面数小于程序实际用到的页数时,就有可能出现这种现象。 举例:当一个循环程序依次使用5个页面,而实际只分配给4个页面时,就会出现这种现象。
:对一个循环程序,当分配的页面数小于程序实际用到的页数时,就有可能出现这种现象。 举例:当一个循环程序依次使用5个页面,而实际只分配给4个页面时,就会出现这种现象。")
140
5.6.6 影响主存命中率的因素 存储系统的等效访问速度: T=H·T1+(1-H)·T2
其中:T1为访问主存的时间,T2为访问辅存的时间;而: T1= T[查表]+T[RAM] 一般地: T[RAM] > T[查表] 而T2>> T1 由此影响T的关键在于命中率H 影响命中率的5个主要因素: a.程序本身的页地址流 b.页面替换算法 c.页面的大小 d.主存容量 e:页面调度算法

141
本章小结 1、存储系统=(Cache-RAM) + (RAM-Disk) (Cache-RAM)的目标是提高速度,(RAM - Disk)的目标是扩充容量。 2、Cache—RAM之间的映射 全相联映射,直接相联地址映射,组相联 3、Cache替换算法:RAND, FIFO, LRU, LFU 4、Cache性能的影响因素:地址流分布, 替换算法, Cache容量, 分组数目及组内块数, 预取算法。 5、影响Cache的失效率、减少Cache开销、减少命中时间的方法,共17种方法 6、Cache的一致性问题

142
6、虚拟存储(RAM - Disk)的原理 内部地址映射:虚拟地址 转变成内部地址 3种存储管理方式:段式,页式,段页式 提高内部地址变换速度的方法:快表 + 慢表,采用Hash函数; 页面替换算法:Random, FIFO,LRU,OPT 命中率的影响因素:程序页地址流分布,页面替换算法;页面的大小;主存容量;页面调度算法 本章作业:1,2,3,4,5,7,8,9,10,11,12,13,14

Similar presentations

 l processing n The control of devices connneted to the computer is.>")







 4-3 ROM(只读存储器) 4-4 高速缓冲存储器(Cache)>")










