Download presentation
Presentation is loading. Please wait.

1
多元迴歸 Multiple Regression
量化研究法二 統計原理與分析技術 第16章 多元迴歸 Multiple Regression

2
簡單迴歸與多元迴歸 Simple and Multiple regression
基本定義 簡單迴歸:以單一自變項去解釋(預測)依變項的迴歸分析 多元迴歸:同時以多個自變項去解釋(預測)依變項的迴歸分析 各變項均為連續性變項,或是可虛擬為連續性變項者 方程式 簡單迴歸:Y=b1x1+a 多元迴歸:Y=b1x1+b2x2+b3x3+……+bnxn+a 多元迴歸的特性: 對於依變項的解釋與預測,可以據以建立一個完整的模型。 各自變項之間概念上具有獨立性,但是數學上可能是非直交(具有相關) 自變項間的相關對於迴歸結果具有關鍵性的影響。
依變項的迴歸分析. 多元迴歸:同時以多個自變項去解釋(預測)依變項的迴歸分析. 各變項均為連續性變項,或是可虛擬為連續性變項者. 方程式. 簡單迴歸:Y=b1x1+a. 多元迴歸:Y=b1x1+b2x2+b3x3+……+bnxn+a. 多元迴歸的特性: 對於依變項的解釋與預測,可以據以建立一個完整的模型。 各自變項之間概念上具有獨立性,但是數學上可能是非直交(具有相關) 自變項間的相關對於迴歸結果具有關鍵性的影響。")
3
預測與解釋 預測型迴歸 解釋型迴歸 主要目的在實際問題的解決或實務上的應用
從一組獨變項中,找出最關鍵與最佳組合的迴歸方程式,產生最理想的預測分數 獨變項的選擇所考慮的是要件為是否具有最大的實務價值,而非基於理論上的適切性 最常用的變項選擇方法是逐步迴歸法(stepwise regression) 解釋型迴歸 主要目的則在瞭解現象的本質與理論關係,也就是探討獨變項與依變項的關係 檢驗變項的解釋力與變項關係,對於依變項的變異提出一套具有最合理解釋的迴歸模型 理論的重要性不僅在於決定獨變項的選擇與安排,也影響研究結果的解釋 最常用的變項選擇方法是為同時迴歸法(simultaneous regression)或階層迴歸法(hierarchical regression)
 解釋型迴歸. 主要目的則在瞭解現象的本質與理論關係,也就是探討獨變項與依變項的關係. 檢驗變項的解釋力與變項關係,對於依變項的變異提出一套具有最合理解釋的迴歸模型. 理論的重要性不僅在於決定獨變項的選擇與安排,也影響研究結果的解釋. 最常用的變項選擇方法是為同時迴歸法(simultaneous regression)或階層迴歸法(hierarchical regression)")
4
多元迴歸的資料結構

5
多元相關 R:多元相關(multiple correlation) R2:多元相關平方 依變項的迴歸預測值(Y’)與實際觀測值(Y)的相關
表示Y被X解釋的百分比,是一種機率的概念 簡單迴歸中,僅有一個獨變項,R=r, R2 =r2 多元迴歸中,有多個獨變項,R≠r, R為多個獨變項的線性整合分數與依變項的相關

6
多元迴歸方程式 迴歸模型:對於依變項的迴歸方程式

7
迴歸變異量拆解與F考驗 依變項的變異可拆解成迴歸效果與誤差效果 殘差為估計變異誤,開方即得估計標準誤
分子為迴歸解釋變異數(SSreg/dfreg),分母為誤差變異數(SSres/dfres),相除得到F值。
,分母為誤差變異數(SSres/dfres),相除得到F值。")
8
多元迴歸的參數檢定 迴歸分析的檢定 整體考驗 事後考驗 對於R2的F考驗 對於個別解釋變數的顯著性考驗:t test

9
係數 標準化迴歸係數 b係數去除單位效果(乘以自變項標準差,除以依變項標準差) 表示其他解釋變數被控制後的淨解釋力(邊際解釋力)
 表示其他解釋變數被控制後的淨解釋力(邊際解釋力)")
10
迴歸的基本假設 基本假設一:固定自變項假設(fixed variable)
我們關心的是依變項,是否能夠找到重要的自 變項來對依變項加以闡釋,因此我們假設可以 找到這些變項的重要數據。

11
基本假設二 : 線性關係假設(linear relationship)
-當X們與Y的關係被納入研究之後,迴歸分析必須 建立在Y與X變項們之間具有線性關係的假設上。 -非線性的變項關係,需將數據進行數學轉換才能 視同線性關係來進行迴歸分析(非線性迴歸),而類 別自變項則需以虛擬變項的方式,將單一的類別 自變項依各水準分成多個二分的自變項,以視同 連續變項的形式來進行(虛擬回歸)。 -回歸係數是線性。
,而類 別自變項則需以虛擬變項的方式,將單一的類別 自變項依各水準分成多個二分的自變項,以視同 連續變項的形式來進行(虛擬回歸)。 -回歸係數是線性。")
12
基本假設三:常態性假設(normality)
-常態性的假設係指迴歸分析中的所有觀察值Y 被迴歸方程式解釋剩下的殘差是一個常態分配, 即Y來自於一個呈常態分配的母群體。因此經 由迴歸方程式所分離的誤差項e,即由特定ㄧ 群Xi特定值所預測得到預測值的與實際Yi之間 的差距,也應呈常態分配。 -誤差項e的平均數為0是ㄧ個假設。 -此假設是為了迴歸係數的檢定。

13
基本假設四: 誤差獨立性假設(independence)
誤差項除了應呈隨機化的常態分配外,不同特 定值X所產生預測值的誤差之間應相互獨立,無 相關存在,也就是無自我相關(non-autocorrelation), 而誤差項也需與自變項X們相互獨立。當誤差項 出現自我相關,無法獲得有效的參數估計值(有 效:估計參數的變異數),降低統計檢定力,易得 到不顯著的結果。
, 而誤差項也需與自變項X們相互獨立。當誤差項 出現自我相關,無法獲得有效的參數估計值(有 效:估計參數的變異數),降低統計檢定力,易得 到不顯著的結果。")
14
基本假設五:誤差等分散性假設或稱同質性(homoscedasticity)
誤差等分散性(a)與誤差變異歧異性(b)圖示
與誤差變異歧異性(b)圖示.")
15
基本假設六:無多重共線性假設 -在多元迴歸分析,若自變項間相關程度過高,不但自變項之間的概念區隔模糊,難以解釋之外,在數學上會因為自變項間共變過高,造成自變項標準誤膨脹的扭曲現象,這種自變項間過度高相關稱為多重共線性(multi-collinearnality),迴歸分析應避免多重共線性的存在。 -多重共線性若明顯的情況下,迴歸所計算出的參數值,變異量嚴重膨脹,使得參數估計的變異數(標準差)過大,進一步造成推論上的問題,如信賴區間擴大,導致第一類型錯誤,或是迴歸係數檢定不容易顯著。
過大,進一步造成推論上的問題,如信賴區間擴大,導致第一類型錯誤,或是迴歸係數檢定不容易顯著。")
16
多元共線性(mulitlinearility)
獨變項間的多重相互關係

17
多元共線性的檢驗 對於某一個自變項共線性的檢驗,可以使用容忍值(tolerance)或變異數膨脹因素(variance inflation factor, VIF)來評估。 Ri2為某一個自變項被其他自變項當作依變項來預測時,該自變項可以被解釋的比例,1- Ri2(容忍值)為該自變項被其他自變項無法解釋的殘差比 Ri2比例越高,容忍值越小,代表預測變項不可解釋殘差比低,VIF越大,即預測變項迴歸係數的變異數增加,共變性越明顯。 整體迴歸模式的共線性診斷可以透過特徵值(eigenvalue)與條件指數(conditional index; CI)來判斷。 各變量相對的變異數比例(variance proportions),可看出自變項之間多元共線性的結構特性。當任兩變項在同一個特徵值上的變異數比例接近1時,表示存在共線性組合。
為該自變項被其他自變項無法解釋的殘差比. Ri2比例越高,容忍值越小,代表預測變項不可解釋殘差比低,VIF越大,即預測變項迴歸係數的變異數增加,共變性越明顯。 整體迴歸模式的共線性診斷可以透過特徵值(eigenvalue)與條件指數(conditional index; CI)來判斷。 各變量相對的變異數比例(variance proportions),可看出自變項之間多元共線性的結構特性。當任兩變項在同一個特徵值上的變異數比例接近1時,表示存在共線性組合。")
18
解釋型迴歸分析 目的 程序 利用多元迴歸程序來進行變項間關係的釐清與相對比較的迴歸應用
變數選擇多利用同時進入法,稱為同時迴歸(simultaneous regression) 程序 選擇自變數與依變數 報告變數的描述統計量與相關矩陣 檢驗自變數的多元共線性與其他假設 報告迴歸模型解釋力(R2)與顯著性考驗(整體考驗) 進行個別自變數的顯著性考驗(事後考驗) 個別變數解釋力(beta係數)的報告與比較
 程序. 選擇自變數與依變數. 報告變數的描述統計量與相關矩陣. 檢驗自變數的多元共線性與其他假設. 報告迴歸模型解釋力(R2)與顯著性考驗(整體考驗) 進行個別自變數的顯著性考驗(事後考驗) 個別變數解釋力(beta係數)的報告與比較.")
19
範例 表16.5 六十位科學競賽活動參賽者背景資料與各種測量數據

20
分析結果 表16.6 科學競賽資料的同時迴歸法估計結果與模式摘要

21
預測型迴歸分析 目的 程序 藉由迴歸模型的建立,研究者或實務工作者得以發展出一套對於依變項的預測系統
透過有效的變項選擇程序,以確立迴歸方程式 預測誤差的評估與計算,以及預測分數如何反應誤差的影響 迴歸模型的推論效力問題 變數選擇多利用逐步進入法,稱為逐步迴歸(stepwise regression) 程序 決定自變數與依變數 報告變數的描述統計量與相關矩陣 排除無效變數,保留有效變數,建立多元迴歸方程式 向前法:各自變項與依變項相關高低逐一被選入 向後法:自變項全部進入模型,再將沒有解釋力的變數淘汰 逐步法:合併向前法與向後法,逐一納入自變數,同時也淘汰沒有解釋力的變數 報告迴歸模型解釋力(R2)與顯著性考驗(整體考驗) 進行分數預測與區間估計
 程序. 決定自變數與依變數. 報告變數的描述統計量與相關矩陣. 排除無效變數,保留有效變數,建立多元迴歸方程式. 向前法:各自變項與依變項相關高低逐一被選入. 向後法:自變項全部進入模型,再將沒有解釋力的變數淘汰. 逐步法:合併向前法與向後法,逐一納入自變數,同時也淘汰沒有解釋力的變數. 報告迴歸模型解釋力(R2)與顯著性考驗(整體考驗) 進行分數預測與區間估計.")
22
逐步迴歸分析結果(向前法 )
")
23
逐步迴歸分析結果(向後法 )
")
24
範例小結 以向前法、向後法、逐步法,得到的結果都相同
最佳方程式包含有X2、X6、X1三個獨變項,可以解釋依變項變異的82.6%(R2=.826) 多元迴歸方程式:
 多元迴歸方程式:")
25
逐步法與同時法比較 逐步分析法較同時進入法可以找到最有預測力的變項,同時也可以避免共線性的影響,適合做探索性的研究使用。
逐步法適合用以預測性研究,協助建立最佳預測模型 逐步法是以統計程序處理變項重要性,在理論解釋性研究缺乏基礎 同時法的優點則是可以從整體效果模式中看到所有自變項的效果,每一個自變項的解釋力皆被考慮與呈現。

26
分數的預測 依變項平均數估計標準誤(standard error of mean predicted score)
個別觀察值估計標準誤(standard error of individual score)
")
27
範例 科學實作能力(X)對於參賽成績(Y)的簡單迴歸 X=50,Y’=38.126 X的平均數(71.545),Y預測值為54.10
對於參賽成績(Y)的簡單迴歸 X=50,Y’= X的平均數(71.545),Y預測值為54.10")
28
複核效化 複核效化(cross-validation) Shrinkage(縮動) 樣本數
指測量或分析的結果具有跨樣本或跨情境的有效性。迴歸模型的類化能力 樣本依賴性:迴歸模型僅能應用於建立迴歸模型的該樣本所代表的母體 複核效化是將在某一個樣本上所得到迴歸模型參數,以另一個樣本的觀察資料來重新檢驗模型的解釋力 Shrinkage(縮動) 某一個迴歸模型從當初建立的樣本,應用到另一個樣本時,模型解釋力通常會降低 以原來迴歸建立時的解釋力數據去套用到新樣本時,會產生高估現象。 當獨變項越多,樣本數越少的情況下(也就是變項/樣本比越大時),高估現象越嚴重 樣本數 變數與樣本數比:1:15到1:30之間,類化能力較為穩定 一個獨變項要有15到30個樣本,10個獨變項的迴歸模型,應有150到300個受測者,類化能力較為穩定
 某一個迴歸模型從當初建立的樣本,應用到另一個樣本時,模型解釋力通常會降低. 以原來迴歸建立時的解釋力數據去套用到新樣本時,會產生高估現象。 當獨變項越多,樣本數越少的情況下(也就是變項/樣本比越大時),高估現象越嚴重. 樣本數. 變數與樣本數比:1:15到1:30之間,類化能力較為穩定. 一個獨變項要有15到30個樣本,10個獨變項的迴歸模型,應有150到300個受測者,類化能力較為穩定.")
29
複核效化的程序 Stevens, 1996建議程序 操作程序
將樣本隨機分成兩個樣本,先利用其中一個樣本進行模型發展,另一個樣本作為檢查樣本,重新評估模型的解釋力 檢核樣本(screening sample) 建立模型的樣本 測定樣本(calibration sample)或效度樣本(validation sample) 檢驗類化能力的樣本 操作程序 由檢核樣本所得到迴歸方程式,然後以該方程式帶入測定樣本的預測變數值,得到依變項預測值Y’ 複核效度指標:測定樣本的依變項觀察值(Y)與預測值(Y’)的相關係數 亦可直接比較兩個樣本的解釋力的差異(ΔR2) 複核效化解釋力係數Pedhazur(1997)
 建立模型的樣本. 測定樣本(calibration sample)或效度樣本(validation sample) 檢驗類化能力的樣本. 操作程序. 由檢核樣本所得到迴歸方程式,然後以該方程式帶入測定樣本的預測變數值,得到依變項預測值Y’ 複核效度指標:測定樣本的依變項觀察值(Y)與預測值(Y’)的相關係數. 亦可直接比較兩個樣本的解釋力的差異(ΔR2) 複核效化解釋力係數Pedhazur(1997)")
30
階層迴歸分析 目的 自變數的分組,依照研究者的需要或理論上的概念區分成不同的區組(block),然後依照特定的次序投入模型中 操作方法
將獨變項以分層來處理,所進行的多步驟多元迴歸分析 一種整合性的多層次分析策略,兼具統計決定與理論決定的變項選擇程序 自變數的分組,依照研究者的需要或理論上的概念區分成不同的區組(block),然後依照特定的次序投入模型中 理論組合(theoretical sets) 各區組的決定,是以理論的觀點進行組合 功能組合(functional sets) 各區組的決定,是以自變數的功能與性質進行組合 例如人口變項的組合、社經地位的指標的組合 時間序列組合(time-series sets) 各區組的決定,是以研究設計的觀點,越早進入者,表示是影響他人的「因」,較晚者則為被影響的「果」 結構組合(structural sets) 指獨變項的組合是基於變項間的組成關係 例如類別變項的虛擬化處理 操作方法 各區組內可以僅有一個獨變項或多個變項 多變項的區組內,各變項進入方程式方法則可為同時法或逐步法
,然後依照特定的次序投入模型中. 理論組合(theoretical sets) 各區組的決定,是以理論的觀點進行組合. 功能組合(functional sets) 各區組的決定,是以自變數的功能與性質進行組合. 例如人口變項的組合、社經地位的指標的組合. 時間序列組合(time-series sets) 各區組的決定,是以研究設計的觀點,越早進入者,表示是影響他人的「因」,較晚者則為被影響的「果」 結構組合(structural sets) 指獨變項的組合是基於變項間的組成關係. 例如類別變項的虛擬化處理. 操作方法. 各區組內可以僅有一個獨變項或多個變項. 多變項的區組內,各變項進入方程式方法則可為同時法或逐步法.")
31
表16.10 階層迴歸分析各區組模型摘要與參數估計值

32
Basic assumptions to regression
Assumptions for residuals (error scores) Zero Mean Homoscedastic Independence with predictors Normality Assumptions for specification errors Linear relationship All relevant predictors must be included No irrelevant predictors can be included Assumptions for measurement errors Relevant measurement procedures and variable selections Providence of the goodness index of measurement
 Zero Mean. Homoscedastic. Independence with predictors. Normality. Assumptions for specification errors. Linear relationship. All relevant predictors must be included. No irrelevant predictors can be included. Assumptions for measurement errors. Relevant measurement procedures and variable selections. Providence of the goodness index of measurement.")
33
Issues in Regression Multicollinearity
Theoretical issues Analytic or Technical issues Measurement issues Categorical variable as predictors Effect coding Dummy coding Type of regression analysis Determination of selection procedures of predictors Simultaneous regression Stepwise regression Hierarchical regression Controlling for Type I and II error Less is more Theoretical consideration Measurement consideration

34
Misusage and threaten factors for correlation coefficient
Conclusion of causal effects Restricting or Irrelevant range of variables Underestimation due to limited variance of variable Spurious correlation Correlation due to common cause Influences of Nuisance variables Confounding effects due to the third variables Suppressor variable: Irrelevant variance can be Suppressed Skewness to normality Influences of extreme scores Poor measurement attributes Low reliability Poor validity Irrelevant criterion variables Violation of assumption of linear relationship Misuse of non-continuous variables

35
線性關係分析:路徑分析 Path Analysis

36
路徑分析基本原理 一種用以探討多重變項之間因果結構模式的統計技術 最初由遺傳學家Wright於1921年所提出,至1960年代才廣泛受到重視
路徑分析由一系列的迴歸分析所組成,除了借用迴歸方程式的原理,並透過假設性的架構,將不同的方程式加以組合,形成結構化的模式

37
路徑分析的基本概念 結構方程式(structural equation) 外衍變項(exogenous variable)
構成路徑模型的數學方程式,外衍與內衍變項之間的關係係數bi,稱為路徑係數(path coefficient)。 外衍變項(exogenous variable) 模型中作為影響或解釋其他變項的變異量的變項。其變異量由不屬於路徑模型的其他變項所決定。 內衍變項(endogenous variable) 模型中被他人所影響或解釋的變項。其變異量由外衍變項及殘差(干擾)變異量兩部分。 干擾變異(disturbances) 內衍變項無法被外衍變項解釋的部分
。 外衍變項(exogenous variable) 模型中作為影響或解釋其他變項的變異量的變項。其變異量由不屬於路徑模型的其他變項所決定。 內衍變項(endogenous variable) 模型中被他人所影響或解釋的變項。其變異量由外衍變項及殘差(干擾)變異量兩部分。 干擾變異(disturbances) 內衍變項無法被外衍變項解釋的部分.")
38
中介作用(Mediation) Mediation(indirect effect)
Occur when the causal effect of an independent variable(X) on a dependent variable (Y) is TRANSMITTED by a mediator (M). Mediator accounts for the relationship b/w two other variables (Baron & Kenny, 1986) sab is given by Aroian (1944), Mood, Graybill, & Boes (1974), Sobel(1982)
 on a dependent variable (Y) is TRANSMITTED by a mediator (M). Mediator accounts for the relationship b/w two other variables (Baron & Kenny, 1986) sab is given by Aroian (1944), Mood, Graybill, & Boes (1974), Sobel(1982)")
39
故事一:多拉A夢追星族

40
誰是多啦A夢的粉絲族? Y=b1X1+b2X2+b3X3+b4X4+a 喜歡小叮噹的程度 性別 年齡 成績 童心

41
任意門的鑰匙 *範例一. Data list free /id like gender age gpa child. Begin data.
End data. Variable labels like "喜歡程度" gender "性別" age "年齡" gpa "成績表現" child "童心". Value labels gender 0 "女" 1 "男" /gpa 1 "前段" 2 "中段" 3 "後段". desc var=all. Correlation variables like gender age gpa child. REGRESSION /DEPENDENT like /METHOD=ENTER gender age gpa child . Exe.

42
誰是多啦A夢的粉絲族?

43
誰是多啦A夢的粉絲族?

44
This is a … Regression Model
這是最好的模型嗎? 性別 .022 年齡 .064 喜歡小叮噹 成績 .000 .982 童心

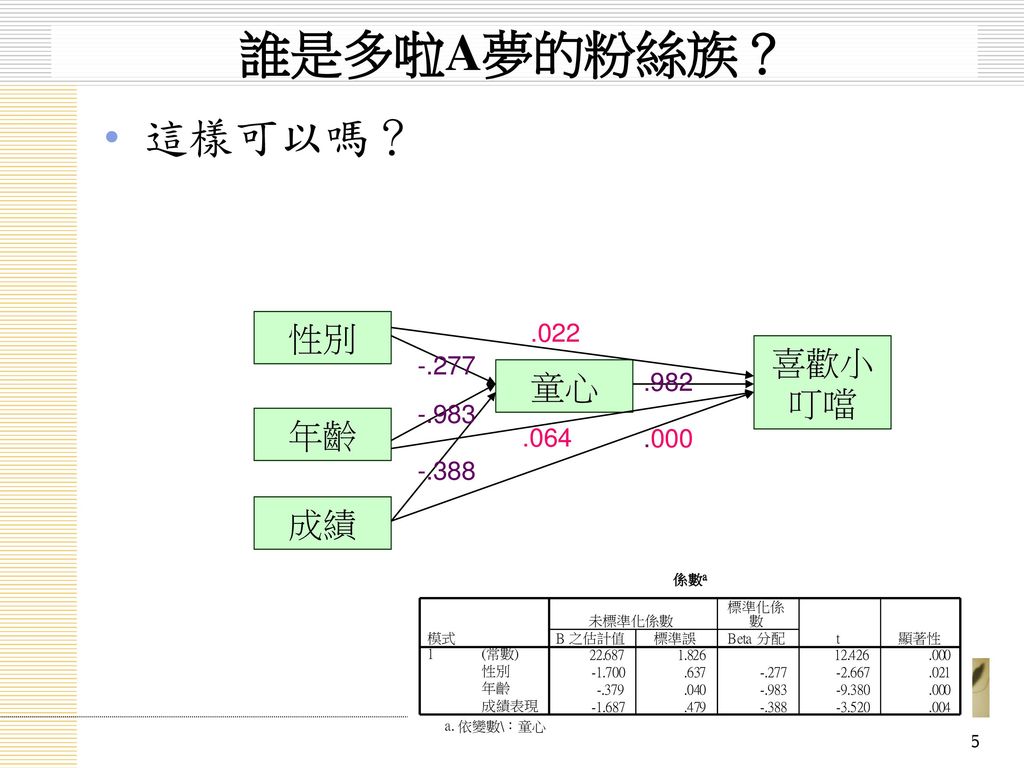
45
誰是多啦A夢的粉絲族? 這樣可以嗎? 性別 喜歡小叮噹 童心 年齡 成績 .022 -.277 .982 -.983 .064 .000
-.388 -.983 -.277
46
誰是多啦A夢的粉絲族? 這是我們的最終解答嗎? 還有什麼別的嗎? 性別 喜歡小叮噹 童心 年齡 成績 -.277 .982 -.983
-.388 成績

47
中介效果的成立與檢定 中介效果基本條件 童心 年齡 喜歡小叮噹 C1: X→Y significant (-.714)
(Judd & Kenny, 1981; Baron & Kenny, 1986; Muller, Judd, & Yzerbyt, 2005) C1: X→Y significant (-.714) C2: X →Me significant (-.788) C3: Me →Y significant (.926) C4: Add a Me, X →Y non-sigificant (-.714 →.043) 童心 -.788* .926** .959** -.714* 年齡 喜歡小叮噹 .043 間接效果=-.788×(-.959)=-.76 =-.76=(-.788)*(-.959)
 C1: X→Y significant (-.714) C2: X →Me significant (-.788) C3: Me →Y significant (.926) C4: Add a Me, X →Y non-sigificant (-.714 →.043) 童心 * .926** .959** -.714* 年齡. 喜歡小叮噹 間接效果=-.788×(-.959)= =-.76=(-.788)*(-.959)")
48
誰是多啦A夢的粉絲族? 這個怎麼樣? Estimate S.E. C.R. P 標準化 CHILD <--- GENDER AGE
-1.700 .834 -2.037 .042 -.28 AGE -.379 .053 -7.164 *** -.98 GPA -1.687 .628 -2.688 .007 -.39 LIKE .825 .127 6.482 .93

49
路徑分析的程序 建立假設模型 參數估計 估計各種效果 模型修飾(trimming a model) 變項的選擇 變項關係的決定 模型的安排
計算殘差變異數 估計各種效果 直接、間接與整體效果 模型衍生相關的計算與運用 擬似相關的計算 模型修飾(trimming a model)
")
50
路徑分析圖

51
路徑分析的各種變項關係

52
遞迴模型與非遞迴模型 迴歸(非遞迴)模型(nonrecursive model):因果關係是單一方向性,且殘差項是彼此獨立的殘差模型。
非迴歸(遞迴)模型 (nonrecursive model):允許相關的殘差(correlated-disturbance),或是變項間具有回溯關係殘差。
模型 (nonrecursive model):允許相關的殘差(correlated-disturbance),或是變項間具有回溯關係殘差。")
53
殘差變異數 每一個內衍變項所不能被外衍變項解釋的部份
以1減去R2乘以內衍變項的變異數,得到非標準化的殘差變異數(若不乘以內衍變項變異數則是標準化的變異數)
")
54
路徑分析效果估計 直接效果(direct effect) 間接效果(indirect effect) 整體效果(total effect)
顯著的外衍與內衍變項解釋關係,直接由迴歸係數表示 間接效果(indirect effect) 顯著的外衍與內衍變項解釋關係之間具有一個或多個中介變項(mediated variable)的作用 內衍與外衍變項之間的直接效果均為顯著,若有任何一個直接效果不顯著,間接效果無法成立 整體效果(total effect) 間接與直接效果的加總
 顯著的外衍與內衍變項解釋關係之間具有一個或多個中介變項(mediated variable)的作用. 內衍與外衍變項之間的直接效果均為顯著,若有任何一個直接效果不顯著,間接效果無法成立. 整體效果(total effect) 間接與直接效果的加總.")
55
路徑係數的估計

56
路徑分析各項效果分解說明

57
模型衍生相關 (model-implied or predicated correlation)
定義 由模型推導出兩個變項的相關強度 功能 比較個別參數的優劣性:兩變項之間以理論假設求出的參數與實際觀測值的差距 檢驗整體模型的契合度(加總模型中所有理論與實際觀測差距值) 內容: 自變項對於內衍變項的整體效果的迴歸係數數值 非因果性關係的係數值(如相關係數) 計算的原理:軌跡法則(tracing rule)
 內容: 自變項對於內衍變項的整體效果的迴歸係數數值. 非因果性關係的係數值(如相關係數) 計算的原理:軌跡法則(tracing rule)")
58
模型衍生相關範例 自我效能與學業表現的衍生相關的軌跡: 自我效能感對於學業成績的模型衍生相關: .29+.13+.02+.00=.44
直接效果:自我效能→學業表現=.29 間接效果:自我效能→成就動機→學業表現=.13 相關間接效果I:自我效能社會期待→學業表現=.13×.16=.02 相關間接效果II:自我效能社會期待→成就動機→學業表現=.13×.02×.21=.00 自我效能感對於學業成績的模型衍生相關: =.44 將.44與原始的Pearson相關相比較

Similar presentations


















 湖南师范大学外国语学院 邓 杰 教授.>")
