Download presentation
1
資料探勘 (Data Mining) 蔡懷寬
 蔡懷寬")
2
Please tell me Why you are here? Make a definition of Data Mining

3
? Input Output

4
道 Input Output

5
Input ?

6
Linear System Input

7
Input ?

8
Nonlinear System Input

9
Input ?

10
Chaotic System Input

11
Introduction What is data mining? Why data mining?
How to do data mining? Data Mining: On what kind of data? Data preprocessing Association rules Clustering Classification

12
DATA?

13
“Data Structure” Wisdom Knowledge Information Data

14
“Data Structure” 資料(Data) 未經處理的資訊 資訊(Information) 經某人組織,展現的資料
知識(Knowledge) 資訊經過讀,看,聽後理解而得到了知識 智慧(Wisdom) 知識經過精煉,整合後萃取出的精華
 資訊經過讀,看,聽後理解而得到了知識. 智慧(Wisdom) 知識經過精煉,整合後萃取出的精華.")
15
有哪些資料 ? 文字 書籍, 期刊, WWW, 備忘錄, … 刊載/參考 膠捲 照片, 其它影像 廣播, 電視 電話通訊 資料庫

16
資料量:以美國國會圖書館為例 國會圖書館藏書量 (1999) 總計: 約3 petabytes (3000 terabytes)
書: 約 20 Terabytes(1012 bytes) 20M books 1 MB per book 其他資料 13M 影像照片, 1MB each = 13 TB 4M 地圖, say 200 TB 500K 檔案, 1GB each = 500 TB 3.5M 有聲資料, ~2000 TB 總計: 約3 petabytes (3000 terabytes)
 20M books. 1 MB per book. 其他資料. 13M 影像照片, 1MB each = 13 TB. 4M 地圖, say 200 TB. 500K 檔案, 1GB each = 500 TB. 3.5M 有聲資料, ~2000 TB. 總計: 約3 petabytes (3000 terabytes)")
17
網路世界... 在1999年有約 800 Million Web Page在網際網路上
Faulker’s Cyberscape Digest 08/06/99 網路的交通流量是每 100 天成長二倍 – 估計有 62 Million 美國人已經在使用網際網路 (US Commerce Dept 1998) 廣播節目花了 38 年才得到五千萬聽眾, 電視節目花了 13 年, 而網際網路才花了 4 年...
 廣播節目花了 38 年才得到五千萬聽眾, 電視節目花了 13 年, 而網際網路才花了 4 年...")
18
資訊生命週期(Information Life Cycle)
Creation Utilization Searching Active Inactive Semi-Active Retention/ Mining Disposition Discard Using Creating Authoring Modifying Organizing Indexing Storing Retrieval Distribution Networking Accessing Filtering

19
資訊產生的問題 資訊儲存 資訊擷取 如何且在哪裡儲存資訊 ? 如何從儲存的資料還原成資訊 如何找到所需要的資訊
如何和 存取(Accessing)/過濾(Filtering)的方法連結
/過濾(Filtering)的方法連結.")
20
Key Issues Creation Utilization Searching Active Retention/ Mining
Inactive Semi-Active Retention/ Mining Disposition Discard Using Creating Authoring Modifying Organizing Indexing Storing Retrieval Distribution Networking Accessing Filtering

21
Data Mining ?

22
DEFINITION DATA MINING 就是從資料中裡,將隱含的、潛在性有用的及不清楚的資料,挖掘、淬取出來的過程。也就是說從資料中挖掘以前不知道的知識。 相關名詞 : 知識淬取(knowledge extraction) 資料打撈(data dredging) 資料考古學(data archaeology)
 資料打撈(data dredging) 資料考古學(data archaeology)")
23
遠古至今即存在Data Mining 月暈知風 礎潤知雨 晚上起霧第二天晴天 看到媽媽拿鞭子落跑 這些在我們的傳統用法稱之為:
經驗法則

24
Data Mining 之演進過程 Data Mining ~1995 Statistics ~1800?
Expert Systems ~1970 Pattern Recognition ~1970 Rule induction Machine learning ~1980 Relational Databases, Triggers ~1980 Knowledge Discovery for Databases (KDD) ~1990 MIS decision support ~1990 Data Mining ~1995
 ~1990. MIS decision support. ~1990. Data Mining. ~1995.")
25
Why Data Mining Necessity is the Mother of Invention!

28
Data Mining 為何興起? 商品條碼之廣泛使用 企業界之電腦化 數以百萬計之資料庫正在使用 多年來累積了大量企業交易資料
Data Knowledge

29
Data Mining 之同義詞 Knowledge Discovery in Databases (KDD)
Knowledge Extraction Data archaeology Data Patten Analysis

30
主要功用 從資料庫中挖掘知識 了解使用者行為 幫助企業作決策 增進商機 Too much!!!

31
Data Mining 應用例子(1) 樂透
 樂透")
32
Data Mining 應用例子(2) 超級市場 牛奶與白麵包 啤酒與香菸 啤酒與尿布
 超級市場 牛奶與白麵包 啤酒與香菸 啤酒與尿布")
33
Data Mining 應用例子(3) NBA 美國職籃 1996, 紐約尼克隊 總教練 Pat Riley 運用Data Mining
發現: 出戰芝加哥公牛隊,尼克中鋒尤恩被包夾時,得分率偏低

34
一般被包夾防守時,有一人空出來,可輕鬆投籃得分

35
Data Mining 應用例子(4) 搜尋網站 GOOGLE
 搜尋網站 GOOGLE")
36
Data Mining 應用例子(5) 公司對客戶的市場分析,例如: 消費習慣、客戶分群、消費預測 例子: 超級市場、錄影帶出租店、信用卡…
 公司對客戶的市場分析,例如: 消費習慣、客戶分群、消費預測 例子: 超級市場、錄影帶出租店、信用卡…")
37
Data Mining 應用例子(7) 大宇宙的預測: 天氣預測 地震預測 土石流預測 慧星撞地球 …
 大宇宙的預測: 天氣預測 地震預測 土石流預測 慧星撞地球 …")
38
Data Mining 應用例子(8) 小宇宙的預測 疾病預測 基因功能預測 結構預測 …
 小宇宙的預測 疾病預測 基因功能預測 結構預測 …")
39
How to Do Data Mining? First of all, you have to learn
How to put your data Database Then, you have to do data preprocessing Finally, you should have some weapons : Data mining techniques

40
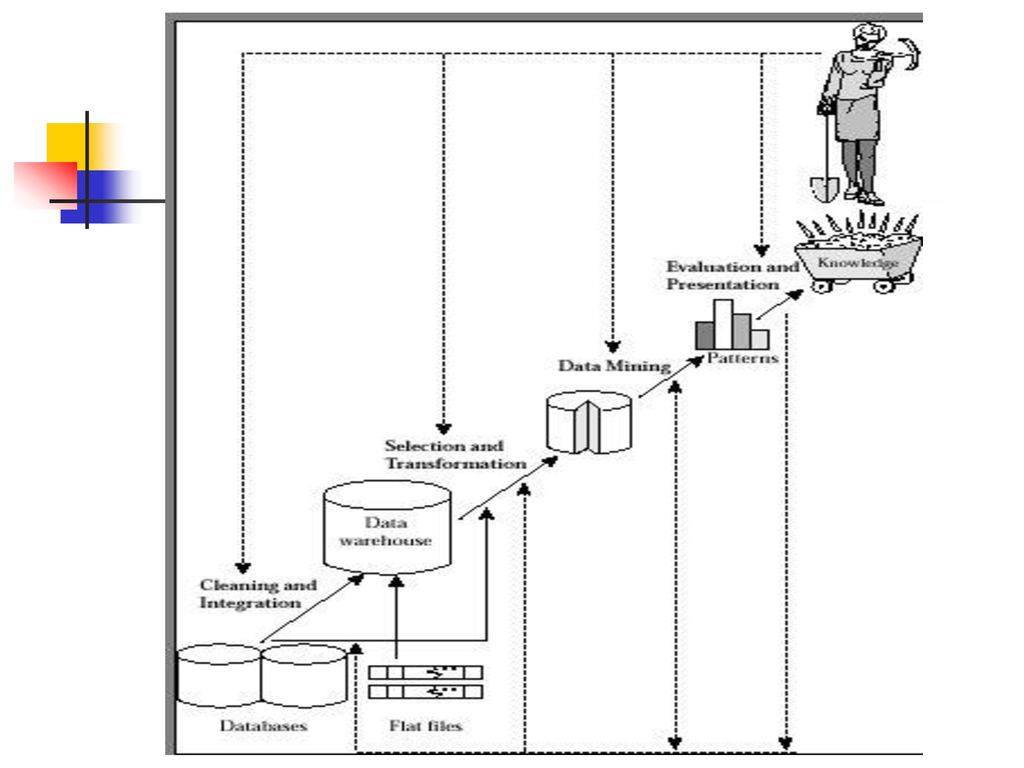
Typical Data Mining System

41
Data Warehouse

42
Why Data Preprocessing?
Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data noisy: containing errors or outliers inconsistent: containing discrepancies in codes or names No quality data, no quality mining results! Quality decisions must be based on quality data Data warehouse needs consistent integration of quality data

43
Major Tasks in Data Preprocessing
Data cleaning Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies Data integration Integration of multiple databases, data cubes, or files Data transformation Normalization and aggregation Data reduction Obtains reduced representation in volume but produces the same or similar analytical results Data discretization Part of data reduction but with particular importance, especially for numerical data

44
Data Mining 主要方法介紹 關聯規則 (Association rule)
屬性導向歸納法(Attribute Oriented Induction) 資料分類 (Classification) 資料分群 (Data Clustering) 模式導向相似性搜尋(Pattern-Based Similarity Search) 資料方塊法 (Data Cube) Sequence Pattern Mining
 資料分類 (Classification) 資料分群 (Data Clustering) 模式導向相似性搜尋(Pattern-Based Similarity Search) 資料方塊法 (Data Cube) Sequence Pattern Mining.")
45
關聯規則 Association Rule 同一個交易中,一個item出現也會引起另一個item的出現 Association rule例子
若顧客購買麵包,則他很可能也會購買牛奶 Association rule: 麵包 => 牛奶 P(牛奶|麵包) 的機率值高
 的機率值高.")
46
關聯規則之 可信度 (confidence)
關聯規則 A => B 可信度為: 在A出現之條件下出現B之機率 例子: 資料庫中的交易紀錄如下: t1: (…,麵包,…,牛奶,…) t2: (…,麵包,…………..) t3: (…,麵包,…,牛奶,…) t4: (……………………) 請問 麵包 => 牛奶 之可信度為多少?
 t2: (…,麵包,…………..) t3: (…,麵包,…,牛奶,…) t4: (……………………) 請問 麵包 => 牛奶 之可信度為多少")
47
關聯規則之 可信度 (Confidence)
資料庫中的交易紀錄 t1: (…,麵包,…,牛奶,…) t2: (…,麵包,…………..) t3: (…,麵包,…,牛奶,…) t4: (……………………) 可信度= P(B|A) = P(A,B)/P(A) P(牛奶|麵包) = P(麵包 ,牛奶) N(麵包 ,牛奶) = P(麵包) N(麵包)
 t2: (…,麵包,…………..) t3: (…,麵包,…,牛奶,…) t4: (……………………) 可信度= P(B|A) = P(A,B)/P(A) P(牛奶|麵包) = P(麵包 ,牛奶) N(麵包 ,牛奶) = P(麵包) N(麵包)")
48
關聯規則之 支持度 (Support) 關聯規則 A => B 支持度為: A與B同時出現之機率 P(A, B)
例子: 資料庫中的交易紀錄如下: t1: (…,麵包,…,牛奶,…) t2: (…,麵包,…………..) t3: (…,麵包,…,牛奶,…) t4: (……………………) 請問 麵包 => 牛奶 之支持度為多少?
 t2: (…,麵包,…………..) t3: (…,麵包,…,牛奶,…) t4: (……………………) 請問 麵包 => 牛奶 之支持度為多少")
49
練習 交易編號 購買產品 T1 (K, A, D, B) T2 (D, A, C, E, B) T3 (C, A, B, E)
交易編號 購買產品 T1 (K, A, D, B) T2 (D, A, C, E, B) T3 (C, A, B, E) T4 (B, A, D) 關聯規則 A=> D 之 可信度 為多少? 關聯規則 A=> D 之 支持度 為多少?
 T2 (D, A, C, E, B) T3 (C, A, B, E) T4 (B, A, D) 關聯規則 A=> D 之 可信度 為多少 關聯規則 A=> D 之 支持度 為多少")
50
練習 交易編號 購買產品 T1 (K, A, D, B) T2 (D, A, C, E, B) T3 (C, A, B, E)
交易編號 購買產品 T1 (K, A, D, B) T2 (D, A, C, E, B) T3 (C, A, B, E) T4 (B, A, D) 請找出可信度 >= 60% 支持度 >= 50%之關聯規則
 T2 (D, A, C, E, B) T3 (C, A, B, E) T4 (B, A, D) 請找出可信度 >= 60% 支持度 >= 50%之關聯規則.")
51
Interestingness of Association Rules
調查學生早餐: 打棒球: 60% 吃麥片: 75% 打棒球且吃麥片: 40% P(吃麥片|打棒球)=P(吃麥片∩打棒球) / P(打棒球) = 40% / 60% = 0.66 打棒球 => 吃麥片 (66%) P(吃麥片) = 75%
=P(吃麥片∩打棒球) / P(打棒球) = 40% / 60% = 打棒球 => 吃麥片 (66%) P(吃麥片) = 75%")
52
Attribute Oriented Induction屬性導向歸納法
Concept Tree : general to specific

53
加拿大 某大學資料庫 Name Status Major Birth_Place GPA Anderson M.A. history
Vancouver 3.5 Bach Junior math Calgary 3.7 Carlton liberal art Edmonton 2.6 Fraser M.S. physics Ottawa 3.9 Gupta Ph.D. Bombay 3.3 Hart Sophomore chemistry Richmond 2.7 Jackson Senior computing Victoria Liu biology Shanghai 3.4 … Meyer music Burnaby 3.0 Monk 3.8 Wang statistics Nanjing 3.2 Wise Freshman literature Toronto

54
出生地之 Concept Tree ANY Canada foreign B.C Ontario … China India ……
Vancouver … Victoria … … Beijing … Bombay …

55
{Bumaby, …..,Vancouver,Victoria} British Columbia
{Calgary, …..Edmonton,Lethbridge} Alberta {Hamilton, Toronto,Waterloo} Ontario {Bombay, …..,New Delhi} India {Beijing,Nanjing,…..,Shanghai} China {India,China} foreign { British Columbia,Alberta,…..,Ontario} Canada {foreign,Canada} ANY(place)
")
56
{biology,chemistry,computing,…..,physics} science
{literature,music,…..,painting} art {science, art } ANY(major) {freshman,sophomore,junior,senior} undergraduate {M.S.,M.A.,Ph.D.} graduate {undergraduate,graduate} ANY(status) { } poor { } average { } good { } excellent {poor,average,good,excellent} ANY(grade)
 {freshman,sophomore,junior,senior} undergraduate. {M.S.,M.A.,Ph.D.} graduate. {undergraduate,graduate} ANY(status) { } poor. { } average. { } good. { } excellent. {poor,average,good,excellent} ANY(grade)")
57
年級與學位之 Concept Tree undergraduate graduate
ANY undergraduate graduate freshman sophomore junior senior M.S. M.A. Ph.D

58
問題: 請找出研究生的特性法則 (characteristic rule)
Initial Relation: 將研究生資料過濾出來 Names Major Birth_Place GPA Vote Anderson history Vancouver 3.5 1 Fraser physics Ottawa 3.9 Gupta math Bombay 3.3 Liu biology Shanghai 3.4 … Monk computing Victoria 3.8 Wang staistics Nanjing 3.2

59
策略1:屬性移除(Attribute Removal)
Names這個屬性中有許多不同的屬性值,且沒有較高的概念層級可以表示它,所以Names屬性就被移除 Major Birth_Place GPA Vote history Vancouver 3.5 1 physics Ottawa 3.9 math Bombay 3.3 biology Shanghai 3.4 … computing Victoria 3.8 staistics Nanjing 3.2

60
策略2:概念樹的爬升 (concept-tree climbing)
假如某一屬性在概念階層中存在著一個更高層級的概念,則該屬性值就以其更高層級的值來取代 ”history”、”physics”、”math”、”biology”會由”science”取代 ”literature”、”music”、”painting”會由”art”取代

61
策略3:資料數的傳播 (vote propagation)
屬性值向上爬升後,若產生相同的tuple,則將相同的tuple合併為一筆一般化tuple,並將vote值累加到歸納後的tuple中

62
Major Birth_Place GPA Vote art B.C excellent 35 science Ontario 10 30 India good China 15

63
策略4:門檻控制 (Threshold Control)
屬性的門檻值 設定『屬性的門檻值<5』 Records的門檻值 設定『歸納後Records的門檻值<4』

64
Major Birth_Place GPA Vote Art Canada excellent 35 Science 40 Foreign good 25 Major Birth_Place GPA Vote {art,science} Canada Excellent 75 Science Foreign good 25

65
策略5:法則轉換(rule transformation)
將最終表格的tuple,轉換成法則 一個研究生(有75%的機率)是加拿大人,得到極佳的GPA或(有25%的機率)是外國學生,得到不錯的GPA
是加拿大人,得到極佳的GPA或(有25%的機率)是外國學生,得到不錯的GPA.")
66
練習 (屬性導向歸納法) 請問: 研究生與大學生之國籍狀況? 註:屬性的門檻值<=2 Hint:1. 先挑出需要的屬性
2. 畫出Concept Tree

67
Data Classification In a data classification problem, each object is described by a set of attribute values and each object belongs to one of the predefined classes. The goal is to derive a set of rules that predicts which class a new object should belong to, based on a given set of training samples. Data classification is also called supervised learning.

68
Alternative Data Classification Algorithms
Decision tree (Q4.5 and Q5.0); Instance-based learning(KNN); Naïve Bayesian classifier; Support vector machine (SVM); Artificial Neural Networks (ANN); Some novel approaches.
; Instance-based learning(KNN); Naïve Bayesian classifier; Support vector machine (SVM); Artificial Neural Networks (ANN); Some novel approaches.")
69
Decision Tree

70
Decision Tree 之意義 If We have much money
AND We are buying a gift for an adult THEN Buy a car AND We re buying a gift for a child THEN Buy a computer

71
選擇最重要的屬性 選擇最重要的決策屬性 (Chooses most important issue first) 做為測試點
 做為測試點")
72
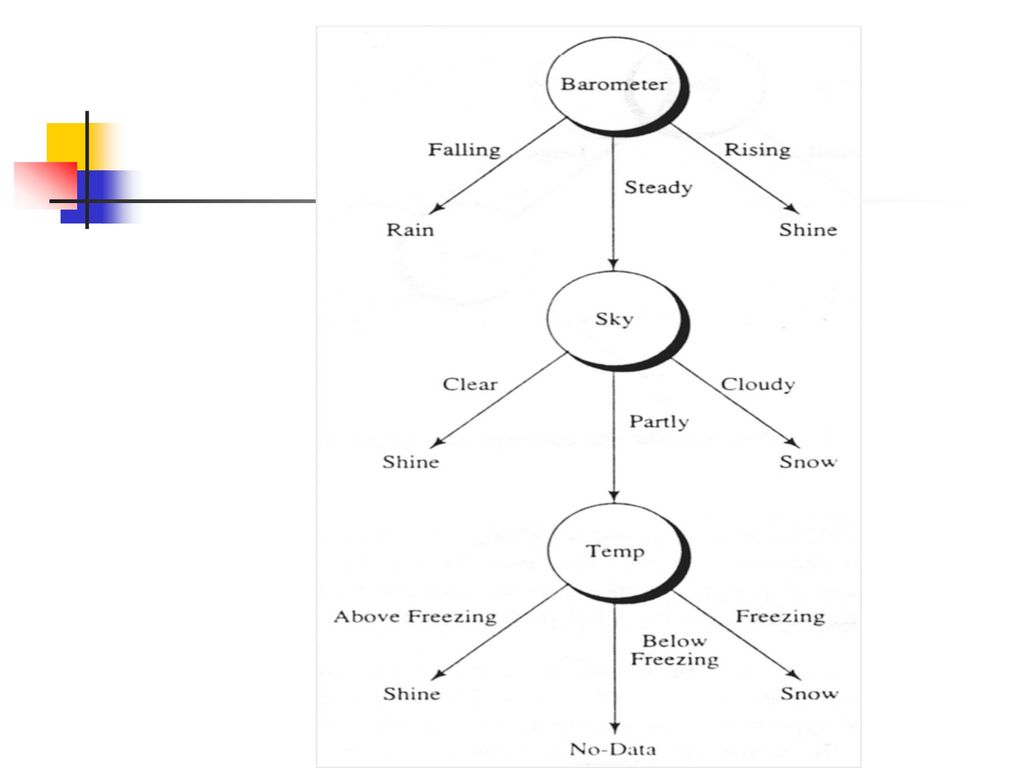
天氣預測的決策表 Decision Factors Result WIND SKY Above freezing West Cloudy
Decision Factors Result TEMPERATURE WIND SKY BAROMETER PREDICTION Above freezing West Cloudy Falling Rain Below freezing * Steady Snow East Rising Shine Partly Clear South Freezing North

74
資料分群 (Data Clustering)
把資料庫中的資料分類成群 讓群組內的資料相似度最高,讓群組跟群組間的資料相似度最低

75
Alternative Data Clustering Algorithms
Partitioning Methods Hierarchical Methods Density-Based Methods Grid-Based Methods Model-Based Clustering Methods Some novel approaches.

76
有一個資料庫的資料 姓名 身高 體重 性別 Peter 170 60 M John 70 25 Mary 150 58 F …

77
把這些資料分成兒童、少年人和成年人三個不同的群組
老人 年青人

78
如何算重心點 ? A(X1, Y1) C(X3,Y3) B(X2, Y2)
 C(X3,Y3) B(X2, Y2)")
79
(Step 1)隨意選三個種子點 (Step 2)利用三個種子點將所有點分群
圖6-2

80
(Step 3) : 找新重心點
 : 找新重心點")
81
(Step 4)利用新重心點將所有點分群 圖6-4
利用新重心點將所有點分群 圖6-4")
82
Data Classification 與 Data Clustering之比較
是根據資料的屬性和一些預先建立的規則(Rule)來將資料分類 事前必先對資料的結構有一定的了解才能實行 Data Clustering 它不需要了解資料庫中的資料特色和結構,就能把資料分類
來將資料分類. 事前必先對資料的結構有一定的了解才能實行. Data Clustering. 它不需要了解資料庫中的資料特色和結構,就能把資料分類.")
83
Related Challenging Issues
Two challenging issues associated with data clustering and classification: feature selection; outlier detection.

84
模式導向相似性搜尋 (Pattern-Based Similarity Search)
Mary為目標物件,希望可以找出跟Mary相似的記錄 姓名 身高 體重 性別 Mary 168 45 F 身高 體重 +2 +3 允許的差異度 :

85
從資料庫中找出的結果 姓名 身高 體重 性別 Kate 167 43 F John 169 45 M Rose 168 44

86
搜尋過程如下 : 設定目標物件 設定允許的差異度 模式導向相似性搜法 DB 搜尋結果

87
歐幾里得距離法 (Euclidean distance)
尋找與目標物件(target sequence)向量距離越短越好的物件
向量距離越短越好的物件.")
88
Data Cube 資料方塊法 Model Year Color Units Chevy 1994 Black 50 White 40
ALL 90 1995 85 115 200 290

89
Data Cube 資料方塊法 依廠牌、年度、顏色來累計 Model Year Color Chevy 1994 black 50
Sales By Model by Year by Color by Model by Year Chevy 1994 black 50 White 40 90 1995 85 white 115 200 290

90
Data Cube 資料方塊法 資料方塊法的一般概念為具體化一些經常被要求的高成本計算
尤其是計數(count)、總計(sum)、求平均數(average)、取最大值(max)等函數 將具體化後的景觀儲存在一個資料方塊,可供決策支援、知識發現及其他應用做參考
、總計(sum)、求平均數(average)、取最大值(max)等函數. 將具體化後的景觀儲存在一個資料方塊,可供決策支援、知識發現及其他應用做參考.")
91
3D Cube Ford 1990 Chevy 1991 Red White Blue Black

92
2D Cube 1990 1991 Ford Chevy

93
1D Cube Ford Chevy Roll-Up方式 與 Drill-Down方式

94
7. Sequence Pattern Mining
顧客通常在購買某類商品後,經過一段時間,會再購買另一類商品 例如: 租過黃飛鴻第一集,經過一段時間,通常會再租黃飛鴻第二集,之後再租黃飛鴻第三集 例如: 買過“綿被、枕頭、床單”之後,經過一段時間 ,通常會再購買“紙尿褲、奶粉”

95
請找出至少發生兩次的 Sequence Patten
顧客代號 交易時間 購買物品代號 1 90/7/25 90/7/30 30 60, 90 2 90/7/10 90/7/15 90/7/20 10, 20 40, 60, 70 3 30, 50, 70 4 90/8/25 40, 70 90 5 90/7/12 例如: 先買20 再買30 再買60, 70 20 30 60, 70

96
7. Mining Sequential Pattern
顧客編號 交易時間 購買物品 1 89/1/1 89/2/1 30 60, 90 2 89/4/10 89/5/20 10, 20 40,60,70

97
7. Mining Sequential Pattern
顧客編號 購買序列 1 (30) (60 90) 2 (10 20) (30) ( ) 3 ( ) 4 (30) (40 70) (90) 5 (90)
 (60 90) 2. (10 20) (30) ( ) 3. ( ) 4. (30) (40 70) (90) 5. (90)")
98
7. Mining Sequential Pattern
(30) (90) (30) (40 70)
 (90) (30) (40 70)")
99
思考: Association Rule 與 Sequential Pattern有何不同 ?

100
思考: Association Rule 與 Sequential Pattern有何不同 ?
若顧客購買麵包,則他同一時間也會購買牛奶 Sequential Pattern 關心不同時間的交易 租過黃飛鴻第一集,經過一段時間,通常會再租黃飛鴻第二集

101
week Date Topic 1 Moon festival 2 Introduction to Data mining 3 Market basis analysis 4 Memory-based reasoning 5 Data Preprocessing 6 Classification I: Decision tree 7 Classification II: Support Vector Machine 8 Classification III: Applications 9 Midterm 10 Data Clustering I: Hierarchical clustering 11 Data Clustering II: Partitioned clustering 12 Data Clustering III: Applications 13 Advanced algorithm: Neural Network and Genetic Algorithm 14 Information retrieval 15 Text mining 16 92.1.4 Student project report 17 Final term



. Articles( 冠词 ) The Indefinite Article( 不 定冠词): a/an 泛指 The definite article( 定 冠词): the 特指 Exercise 零冠词即不用冠词.>")
 資料探勘與生醫資訊相關研究 ( 研究方向、成果與計畫 )>")

/ 應用系統(ERP, SCM, CRM)>")




>")


及其應用之介紹>")


 What did I do?>")
.>")


