Download presentation
Presentation is loading. Please wait.

1
第二章 经典单方程计量经济学模型: 一元线性回归模型
回归分析概述 一元线性回归模型的参数估计 一元线性回归模型检验 一元线性回归模型预测 实例

2
§2.1 回归分析概述 一、变量间的关系及回归分析的基本概念 二、总体回归函数(PRF) 三、随机扰动项 四、样本回归函数(SRF)
 三、随机扰动项 四、样本回归函数(SRF)")
3
一、变量间的关系及回归分析的基本概念 1. 变量间的关系 (1)确定性关系或函数关系:研究的是确定现象非随机变量间的关系。
(2)统计依赖或相关关系:研究的是非确定现象随机变量间的关系。
统计依赖或相关关系:研究的是非确定现象随机变量间的关系。")
4
对变量间统计依赖关系的考察主要是通过相关分析(correlation analysis)或回归分析(regression analysis)来完成的
或回归分析(regression analysis)来完成的")
5
注意 ①不线性相关并不意味着不相关。 ②有相关关系并不意味着一定有因果关系。 ③回归分析/相关分析研究一个变量对另一个(些)变量的统计依赖关系,但它们并不意味着一定有因果关系。 ④相关分析对称地对待任何(两个)变量,两个变量都被看作是随机的。回归分析对变量的处理方法存在不对称性,即区分应变量(被解释变量)和自变量(解释变量):前者是随机变量,后者不是。
变量,两个变量都被看作是随机的。回归分析对变量的处理方法存在不对称性,即区分应变量(被解释变量)和自变量(解释变量):前者是随机变量,后者不是。")
6
2. 回归分析的基本概念 回归分析(regression analysis)是研究一个变量关于另一个(些)变量的具体依赖关系的计算方法和理论。 其目的在于通过后者的已知或设定值,去估计和(或)预测前者的(总体)均值。 被解释变量(Explained Variable)或应变量(Dependent Variable)。 解释变量(Explanatory Variable)或自变量(Independent Variable)。
或应变量(Dependent Variable)。 解释变量(Explanatory Variable)或自变量(Independent Variable)。")
7
回归分析构成计量经济学的方法论基础,其主要内容包括:
(1)根据样本观察值对经济计量模型参数进行估计,求得回归方程; (2)对回归方程、参数估计值进行显著性检验; (3)利用回归方程进行分析、评价及预测。
根据样本观察值对经济计量模型参数进行估计,求得回归方程; (2)对回归方程、参数估计值进行显著性检验; (3)利用回归方程进行分析、评价及预测。")
8
二、总体回归函数 回归分析关心的是根据解释变量的已知或给定值,考察被解释变量的总体均值,即当解释变量取某个确定值时,与之统计相关的被解释变量所有可能出现的对应值的平均值。

9
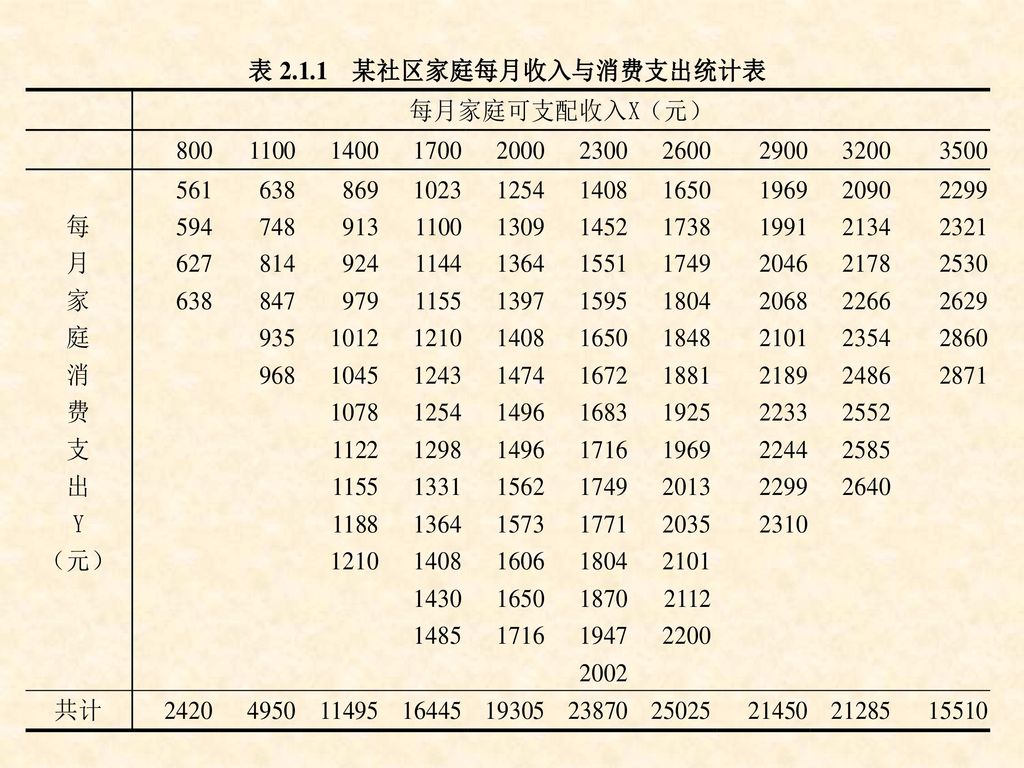
例2.1:一个假想的社区有100户家庭组成,要研究该社区每月家庭消费支出Y与每月家庭可支配收入X的关系。 即如果知道了家庭的月收入,能否预测该社区家庭的平均月消费支出水平。
为达到此目的,将该100户家庭划分为组内收入差不多的10组,以分析每一收入组的家庭消费支出。

11
由于不确定因素的影响,对同一收入水平X,不同家庭的消费支出不完全相同;
但由于调查的完备性,给定收入水平X的消费支出Y的分布是确定的,即以X的给定值为条件的Y的条件分布(Conditional distribution)是已知的,例如:P(Y=561|X=800)=1/4。
是已知的,例如:P(Y=561|X=800)=1/4。")
12
因此,给定收入X的值Xi,可得消费支出Y的条件均值(conditional mean)或条件期望(conditional expectation):E(Y|X=Xi)。
或条件期望(conditional expectation):E(Y|X=Xi)。")
13
500 1000 1500 2000 2500 3000 3500 4000 每月可支配收入X(元) 每 月 消 费 支 出 Y (元)
 每 月 消 费 支 出 Y (元)")
14
在给定解释变量Xi条件下被解释变量Yi的期望轨迹称为总体回归线(population regression line),或更一般地称为总体回归曲线(population regression curve)。 相应的函数: 称为(双变量)总体回归函数(population regression function, PRF)。
总体回归函数(population regression function, PRF)。")
15
函数形式:可以是线性或非线性的。 含义:回归函数(PRF)说明被解释变量Y的平均状态(总体条件期望)随解释变量X变化的规律。
例2.1中,将居民消费支出看成是其可支配收入的线性函数时: 为一线性函数。其中,0,1是未知参数,称为回归系数(regression coefficients)。
。")
16
三、随机扰动项 总体回归函数说明在给定的收入水平Xi下,该社区家庭平均的消费支出水平。
但对某一个别的家庭,其消费支出可能与该平均水平有偏差。 称为观察值围绕它的期望值的离差(deviation),是一个不可观测的随机变量,又称为随机干扰项(stochastic disturbance)或随机误差项(stochastic error)。
,是一个不可观测的随机变量,又称为随机干扰项(stochastic disturbance)或随机误差项(stochastic error)。")
17
例2.1中,给定收入水平Xi ,个别家庭的支出可表示为两部分之和:(1)该收入水平下所有家庭的平均消费支出E(Y|Xi),称为系统性(systematic)或确定性(deterministic)部分;(2)其他随机或非确定性(nonsystematic)部分i。
该收入水平下所有家庭的平均消费支出E(Y|Xi),称为系统性(systematic)或确定性(deterministic)部分;(2)其他随机或非确定性(nonsystematic)部分i。")
18
称为总体回归函数(PRF)的随机设定形式。表明被解释变量除了受解释变量的系统性影响外,还受其他因素的随机性影响。由于方程中引入了随机项,成为计量经济学模型,因此也称为总体回归模型。
的随机设定形式。表明被解释变量除了受解释变量的系统性影响外,还受其他因素的随机性影响。由于方程中引入了随机项,成为计量经济学模型,因此也称为总体回归模型。")
19
随机误差项主要包括下列因素: 在解释变量中被忽略的因素的影响; 变量观测值的观测误差的影响; 模型关系的设定误差的影响; 其他随机因素的影响。 产生并设计随机误差项的主要原因: 理论的含糊性; 数据的欠缺; 节省原则。

20
四、样本回归函数(SRF) 问题:能从一次抽样中获得总体的近似的信息吗?如果可以,如何从抽样中获得总体的近似信息?
例2.2:在例2.1的总体中有如下一个样本,能否从该样本估计总体回归函数PRF? 回答:能

21
该样本的散点图(scatter diagram):
画一条直线以尽好地拟合该散点图,由于样本取自总体,可以该直线近似地代表总体回归线。该直线称为样本回归线(sample regression lines)。
。")
22
记样本回归线的函数形式为: 称为样本回归函数(sample regression function,SRF)。
。")
23
注意:这里将样本回归线看成总体回归线的近似替代
则

24
同样地,样本回归函数也有如下的随机形式:
样本回归函数的随机形式/样本回归模型: 同样地,样本回归函数也有如下的随机形式: 由于方程中引入了随机项,成为计量经济模型,因此也称为样本回归模型(sample regression model)。
。")
25
▼回归分析的主要目的:根据样本回归函数SRF,估计总体回归函数PRF。
即,根据 估计

26
注意:这里PRF可能永远无法知道。

27
§2.2 一元线性回归模型的参数估计 一、一元线性回归模型的基本假设 二、参数的普通最小二乘估计(OLS) 三、参数估计的最大或然法(ML)
§2.2 一元线性回归模型的参数估计 一、一元线性回归模型的基本假设 二、参数的普通最小二乘估计(OLS) 三、参数估计的最大或然法(ML) 四、最小二乘估计量的性质 五、参数估计量的概率分布及随机干 扰项方差的估计
 三、参数估计的最大或然法(ML) 四、最小二乘估计量的性质. 五、参数估计量的概率分布及随机干. 扰项方差的估计.")
28
说 明 单方程计量经济学模型分为两大类:线性模型和非线性模型 线性模型中,变量之间的关系呈线性关系 非线性模型中,变量之间的关系呈非线性关系
说 明 单方程计量经济学模型分为两大类:线性模型和非线性模型 线性模型中,变量之间的关系呈线性关系 非线性模型中,变量之间的关系呈非线性关系 一元线性回归模型:只有一个解释变量 i=1,2,…,n Y为被解释变量,X为解释变量,0与1为待估参数, 为随机干扰项

29
回归分析的主要目的是要通过样本回归函数(模型)SRF尽可能准确地估计总体回归函数(模型)PRF。
估计方法有多种,其中最广泛使用的是普通最小二乘法(ordinary least squares, OLS)。 为保证参数估计量具有良好的性质,通常对模型提出若干基本假设。 实际这些假设与所采用的估计方法紧密相关。
。 为保证参数估计量具有良好的性质,通常对模型提出若干基本假设。 实际这些假设与所采用的估计方法紧密相关。")
30
假设1. 解释变量X是确定性变量,不是随机变量;
一、线性回归模型的基本假设 假设1. 解释变量X是确定性变量,不是随机变量; 假设2. 随机误差项具有零均值、同方差和不序列相关性: E(i)= i=1,2, …,n Var (i)= i=1,2, …,n Cov(i, j)= i≠j i,j= 1,2, …,n
=0 i=1,2, …,n. Var (i)=2 i=1,2, …,n. Cov(i, j)=0 i≠j i,j= 1,2, …,n.")
31
假设3. 随机误差项与解释变量X之间不相关:
Cov(Xi, i)= i=1,2, …,n 假设4. 服从零均值、同方差、零协方差的正态分布 i~N(0, 2 ) i=1,2, …,n
=0 i=1,2, …,n. 假设4. 服从零均值、同方差、零协方差的正态分布. i~N(0, 2 ) i=1,2, …,n.")
32
注意: 如果假设1、2满足,则假设3也满足; 如果假设4满足,则假设2也满足。
以上假设也称为线性回归模型的经典假设或高斯(Gauss)假设,满足该假设的线性回归模型,也称为经典线性回归模型(Classical Linear Regression Model, CLRM)。
假设,满足该假设的线性回归模型,也称为经典线性回归模型(Classical Linear Regression Model, CLRM)。")
33
假设6. 回归模型是正确设定的 另外,在进行模型回归时,还有两个暗含的假设:
假设5. 随着样本容量的无限增加,解释变量X的样本方差趋于一有限常数。即 假设6. 回归模型是正确设定的

34
假设5旨在排除时间序列数据出现持续上升或下降的变量作为解释变量,因为这类数据不仅使大样本统计推断变得无效,而且往往产生所谓的伪回归问题(spurious regression problem)。
假设6也被称为模型没有设定偏误(specification error)
")
35
给定一组样本观测值(Xi, Yi)(i=1,2,…n)要求样本回归函数尽可能好地拟合这组值.
二、参数的普通最小二乘估计(OLS) 给定一组样本观测值(Xi, Yi)(i=1,2,…n)要求样本回归函数尽可能好地拟合这组值. 普通最小二乘法(Ordinary least squares, OLS)给出的判断标准是:二者之差的平方和 最小。
 给定一组样本观测值(Xi, Yi)(i=1,2,…n)要求样本回归函数尽可能好地拟合这组值. 普通最小二乘法(Ordinary least squares, OLS)给出的判断标准是:二者之差的平方和. 最小。")
36
方程组(*)称为正规方程组(normal equations)。
称为正规方程组(normal equations)。")
37
记 上述参数估计量可以写成: 称为OLS估计量的离差形式(deviation form)。 由于参数的估计结果是通过最小二乘法得到 的,故称为普通最小二乘估计量(ordinary least squares estimators)。
。 由于参数的估计结果是通过最小二乘法得到 的,故称为普通最小二乘估计量(ordinary least squares estimators)。")
38
(**)式也称为样本回归函数的离差形式。 注意: 在计量经济学中,往往以小写字母表示对均值的离差。
顺便指出 ,记 则有 可得 (**) (**)式也称为样本回归函数的离差形式。 注意: 在计量经济学中,往往以小写字母表示对均值的离差。
 (**)式也称为样本回归函数的离差形式。 注意: 在计量经济学中,往往以小写字母表示对均值的离差。")
39
三、参数估计的最大或然法(ML) 最大或然法(Maximum Likelihood,简称ML),也称最大似然法,是不同于最小二乘法的另一种参数估计方法,是从最大或然原理出发发展起来的其他估计方法的基础。 基本原理: 对于最大或然法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。

40
在满足基本假设条件下,对一元线性回归模型:
随机抽取n组样本观测值(Xi, Yi)(i=1,2,…n)。 假如模型的参数估计量已经求得,为 那么Yi服从如下的正态分布: 于是,Y的概率函数为 (i=1,2,…n)
(i=1,2,…n)。 假如模型的参数估计量已经求得,为. 那么Yi服从如下的正态分布: 于是,Y的概率函数为. (i=1,2,…n)")
41
将该或然函数极大化,即可求得到模型参数的极大或然估计量。
因为Yi是相互独立的,所以的所有样本观测值的联合概率,也即或然函数(likelihood function)为: 将该或然函数极大化,即可求得到模型参数的极大或然估计量。
为: 将该或然函数极大化,即可求得到模型参数的极大或然估计量。")
42
由于或然函数的极大化与或然函数的对数的极大化是等价的,所以,取对数或然函数如下:

43
可见,在满足一系列基本假设的情况下,模型结构参数的最大或然估计量与普通最小二乘估计量是相同的。
解得模型的参数估计量为: 可见,在满足一系列基本假设的情况下,模型结构参数的最大或然估计量与普通最小二乘估计量是相同的。

44
例2.2.1:在上述家庭可支配收入-消费支出例中,对于所抽出的一组样本数,参数估计的计算可通过下面的表2.2.1进行。

45
因此,由该样本估计的回归方程为:

46
四、最小二乘估计量的性质 当模型参数估计出后,需考虑参数估计值的精度,即是否能代表总体参数的真值,或者说需考察参数估计量的统计性质。
一个用于考察总体的估计量,可从如下几个方面考察其优劣性: (1)线性性,即它是否是另一随机变量的线性函数;
线性性,即它是否是另一随机变量的线性函数;")
47
这三个准则也称作估计量的小样本性质。 (2)无偏性,即它的均值或期望值是否等于总体的真实值;
(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。 这三个准则也称作估计量的小样本性质。 拥有这类性质的估计量称为最佳线性无偏估计量(best liner unbiased estimator, BLUE)。
有效性,即它是否在所有线性无偏估计量中具有最小方差。 这三个准则也称作估计量的小样本性质。 拥有这类性质的估计量称为最佳线性无偏估计量(best liner unbiased estimator, BLUE)。")
48
(4)渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值;
当不满足小样本性质时,需进一步考察估计量的大样本或渐近性质: (4)渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值; (5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值; (6)渐近有效性,即样本容量趋于无穷大时,是否它在所有的一致估计量中具有最小的渐近方差。
渐近无偏性,即样本容量趋于无穷大时,是否它的均值序列趋于总体真值; (5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值; (6)渐近有效性,即样本容量趋于无穷大时,是否它在所有的一致估计量中具有最小的渐近方差。")
49
高斯—马尔可夫定理(Gauss-Markov theorem)
在给定经典线性回归的假定下,最小二乘估计量是具有最小方差的线性无偏估计量。

51
证: 易知 故 同样地,容易得出

53
(2)证明最小方差性 其中,ci=ki+di,di为不全为零的常数 则容易证明 普通最小二乘估计量(ordinary least Squares Estimators)称为最佳线性无偏估计量(best linear unbiased estimator, BLUE)
称为最佳线性无偏估计量(best linear unbiased estimator, BLUE) .")
54
由于最小二乘估计量拥有一个“好”的估计量所应具备的小样本特性,它自然也拥有大样本特性。

55
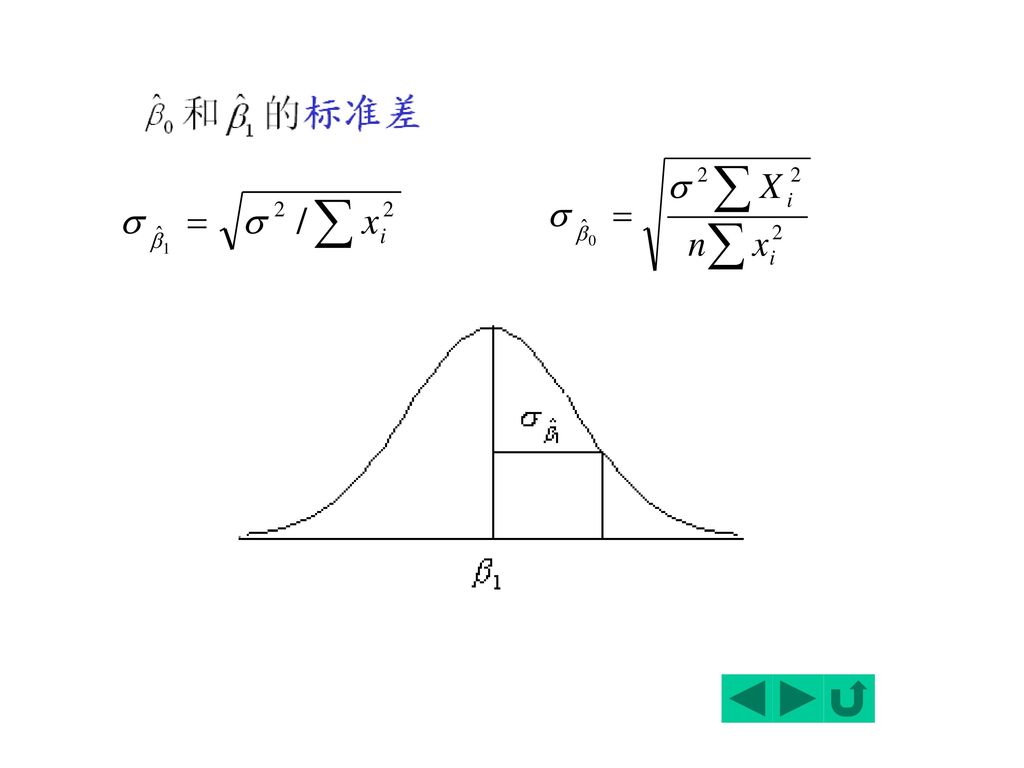
五、参数估计量的概率分布及随机干扰项方差的估计

57
2. 随机误差项的方差2的估计 2又称为总体方差。

58
由于随机项i不可观测,只能从i的估计——残差ei出发,对总体方差进行估计。 可以证明, 2的最小二乘估计量为
它是关于2的无偏估计量。

59
在最大或然估计法中, 因此, 2的最大或然估计量不具无偏性,但却具有一致性。

61
一、拟合优度检验 二、变量的显著性检验 三、参数的置信区间
§2.3 一元线性回归模型的统计检验 一、拟合优度检验 二、变量的显著性检验 三、参数的置信区间

62
说 明 回归分析是要通过样本所估计的参数来代替总体的真实参数,或者说是用样本回归线代替总体回归线。
说 明 回归分析是要通过样本所估计的参数来代替总体的真实参数,或者说是用样本回归线代替总体回归线。 尽管从统计性质上已知,如果有足够多的重复 抽样,参数的估计值的期望(均值)就等于其总体的参数真值,但在一次抽样中,估计值不一定就等于该真值。
就等于其总体的参数真值,但在一次抽样中,估计值不一定就等于该真值。")
63
那么,在一次抽样中,参数的估计值与真值的差异有多大,是否显著,这就需要进一步进行统计检验。
主要包括拟合优度检验、变量的显著性检验及参数的区间估计。

64
拟合优度检验:对样本回归直线与样本观测值之间拟合程度的检验。
一、拟合优度检验 拟合优度检验:对样本回归直线与样本观测值之间拟合程度的检验。 度量拟合优度的指标:判定系数(可决系数)R2 问题:采用普通最小二乘估计方法,已经保证了模型最好地拟合了样本观测值,为什么还要检验拟合程度?
R2. 问题:采用普通最小二乘估计方法,已经保证了模型最好地拟合了样本观测值,为什么还要检验拟合程度?")
65
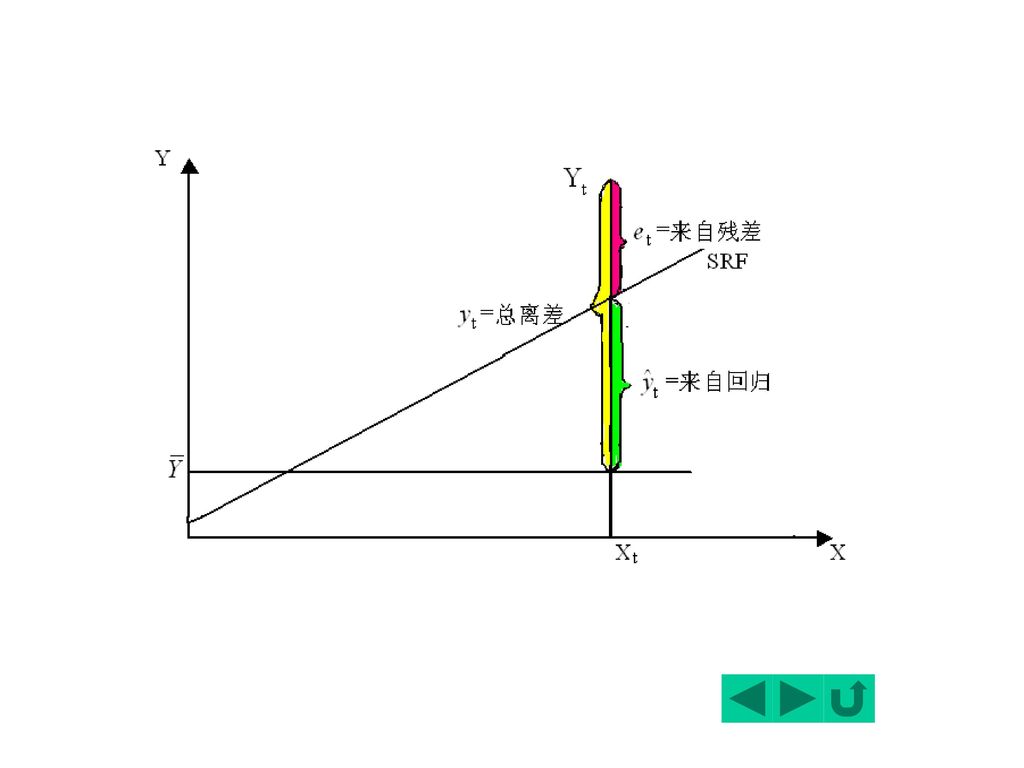
1、总离差平方和的分解 已知由一组样本观测值(Xi,Yi),i=1,2…,n得到如下样本回归直线
,i=1,2…,n得到如下样本回归直线")
67
如果Yi=Ŷi 即实际观测值落在样本回归“线”上,则拟合最好。 可认为,“离差”全部来自回归线,而与“残差”无关。

68
对于所有样本点,则需考虑这些点与样本均值离差的平方和,可以证明:

69
记 总体平方和(Total Sum of Squares) 回归平方和(Explained Sum of Squares) 残差平方和(Residual Sum of Squares ) TSS=ESS+RSS
 回归平方和(Explained Sum of Squares) 残差平方和(Residual Sum of Squares ) TSS=ESS+RSS.")
70
Y的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归线(ESS),另一部分则来自随机势力(RSS)。
在给定样本中,TSS不变, 如果实际观测点离样本回归线越近,则ESS在TSS中占的比重越大,因此 拟合优度=回归平方和ESS/总离差TSS

71
2、可决系数R2统计量 称 R2 为(样本)可决系数/判定系数(coefficient of determination)。
可决系数的取值范围:[0,1] R2越接近1,说明实际观测点离样本线越近,拟合优度越高。

72
在例2.1.1的收入-消费支出例中, 注:可决系数是一个非负的统计量。它也是随着抽样的不同而不同。为此,对可决系数的统计可靠性也应进行检验,这将在第3章中进行。

73
二、变量的显著性检验 回归分析是要判断解释变量X是否是被解释变量Y的一个显著性的影响因素。
变量的显著性检验所应用的方法是数理统计学中的假设检验。 计量经济学中,主要是针对变量的参数真值是否为零来进行显著性检验的。

74
1、假设检验 所谓假设检验,就是事先对总体参数或总体分布形式作出一个假设,然后利用样本信息来判断原假设是否合理,即判断样本信息与原假设是否有显著差异,从而决定是否接受或否定原假设。

75
假设检验采用的逻辑推理方法是反证法 先假定原假设正确,然后根据样本信息,观察由此假设而导致的结果是否合理,从而判断是否接受原假设。 判断结果合理与否,是基于“小概率事件不易发生”这一原理的

76
2、变量的显著性检验

77
检验步骤: H0: 1=0, H1:10 (2)以原假设H0构造t统计量,并由样本计算其值
(1)对总体参数提出假设 H0: 1=0, H1:10 (2)以原假设H0构造t统计量,并由样本计算其值 (3)给定显著性水平,查t分布表得临界值t /2(n-2)
对总体参数提出假设. H0: 1=0, H1:10. (2)以原假设H0构造t统计量,并由样本计算其值. (3)给定显著性水平,查t分布表得临界值t /2(n-2)")
78
若 |t|> t /2(n-2),则拒绝H0 ,接受H1 ; 若 |t| t /2(n-2),则拒绝H1 ,接受H0 ;
(4) 比较,判断 若 |t|> t /2(n-2),则拒绝H0 ,接受H1 ; 若 |t| t /2(n-2),则拒绝H1 ,接受H0 ; 对于一元线性回归方程中的0,可构造t统计量进行显著性检验:
 比较,判断. 若 |t|> t /2(n-2),则拒绝H0 ,接受H1 ; 若 |t| t /2(n-2),则拒绝H1 ,接受H0 ; 对于一元线性回归方程中的0,可构造t统计量进行显著性检验:")
79
在上述收入—消费支出例中,首先计算2的估计值

80
|t1|>2.306,说明家庭可支配收入在95%的置信度下显著,即是消费支出的主要解释变量;

81
三、参数的置信区间 假设检验可以通过一次抽样的结果检验总体参数可能的假设值的范围(如是否为零),但它并没有指出在一次抽样中样本参数值到底离总体参数的真值有多“近”。
,但它并没有指出在一次抽样中样本参数值到底离总体参数的真值有多 近 。")
82
要判断样本参数的估计值在多大程度上可以“近似”地替代总体参数的真值,往往需要通过构造一个以样本参数的估计值为中心的“区间”,来考察它以多大的可能性(概率)包含着真实的参数值。这种方法就是参数检验的置信区间估计。
包含着真实的参数值。这种方法就是参数检验的置信区间估计。")
83
如果存在这样一个区间,称之为置信区间(confidence interval); 1-称为置信系数(置信度)(confidence coefficient), 称为显著性水平(level of significance);置信区间的端点称为置信限(confidence limit)或临界值(critical values)。
; 1-称为置信系数(置信度)(confidence coefficient), 称为显著性水平(level of significance);置信区间的端点称为置信限(confidence limit)或临界值(critical values)。")
84
一元线性模型中,i (i=1,2)的置信区间:
在变量的显著性检验中已经知道: 意味着,如果给定置信度(1-),从分布表中查得自由度为(n-2)的临界值,那么t值处在(-t/2, t/2)的概率是(1- )。表示为: 即
,从分布表中查得自由度为(n-2)的临界值,那么t值处在(-t/2, t/2)的概率是(1- )。表示为: 即.")
85
于是得到:(1-)的置信度下, i的置信区间是
在上述收入-消费支出例中,如果给定 =0.01,查表得: 由于 于是,1、0的置信区间分别为: (0.6345,0.9195) ( ,226.98)
 ( ,226.98)")
86
由于置信区间一定程度地给出了样本参数估计值与总体参数真值的“接近”程度,因此置信区间越小越好。
要缩小置信区间,需要 (1)增大样本容量n。因为在同样的置信水平下,n越大,t分布表中的临界值越小;同时,增大样本容量,还可使样本参数估计量的标准差减小;
增大样本容量n。因为在同样的置信水平下,n越大,t分布表中的临界值越小;同时,增大样本容量,还可使样本参数估计量的标准差减小;")
87
(2)提高模型的拟合优度。因为样本参数估计量的标准差与残差平方和呈正比,模型拟合优度越高,残差平方和应越小。
由于置信区间一定程度地给出了样本参数估计值与总体参数真值的“接近”程度,因此置信区间越小越好。

88
要缩小置信区间,需 (1)增大样本容量n,因为在同样的置信水平下,n越大,t分布表中的临界值越小;同时,增大样本容量,还可使样本参数估计量的标准差减小; (2)提高模型的拟合优度,因为样本参数估计量的标准差与残差平方和呈正比,模型拟合优度越高,残差平方和应越小。
增大样本容量n,因为在同样的置信水平下,n越大,t分布表中的临界值越小;同时,增大样本容量,还可使样本参数估计量的标准差减小; (2)提高模型的拟合优度,因为样本参数估计量的标准差与残差平方和呈正比,模型拟合优度越高,残差平方和应越小。")
89
§2.4 一元线性回归分析的应用:预测问题 一、Ŷ0是条件均值E(Y|X=X0)或个值Y0的一个无偏估计
§2.4 一元线性回归分析的应用:预测问题 一、Ŷ0是条件均值E(Y|X=X0)或个值Y0的一个无偏估计 二、总体条件均值与个值预测值的置信区间
或个值Y0的一个无偏估计. 二、总体条件均值与个值预测值的置信区间.")
90
说 明 对于一元线性回归模型 给定样本以外的解释变量的观测值X0,可以得到被解释变量的预测值Ŷ0 ,可以此作为其条件均值E(Y|X=X0)或个别值Y0的一个近似估计。 严格地说,这只是被解释变量的预测值的估计值,而不是预测值。原因: (1)参数估计量不确定; (2)随机项的影响
参数估计量不确定; (2)随机项的影响.")
91
一、Ŷ0是条件均值E(Y|X=X0)或个值Y0的一个无偏估计
对总体回归函数E(Y|X=X0)=0+1X,X=X0时 E(Y|X=X0)=0+1X0 于是 可见,Ŷ0是条件均值E(Y|X=X0)的无偏估计。
=0+1X,X=X0时. E(Y|X=X0)=0+1X0. 于是. 可见,Ŷ0是条件均值E(Y|X=X0)的无偏估计。")
92
对总体回归模型Y=0+1X+,当X=X0时
于是

93
二、总体条件均值与个值预测值的置信区间 1、总体均值预测值的置信区间 由于 于是 可以证明

94
因此 故

95
其中 于是,在1-的置信度下,总体均值E(Y|X0)的置信区间为
的置信区间为")
96
2、总体个值预测值的预测区间 由 Y0=0+1X0+ 知: 于是 式中 : 从而在1-的置信度下, Y0的置信区间为

97
在上述收入—消费支出例中,得到的样本回归函数为:
则在 X0=1000处, Ŷ0 = – ×1000=673.84 而

98
因此,总体均值E(Y|X=1000)的95%的置信区间为:
或 (533.05, ) 同样地,对于Y在X=1000的个体值,其95%的置信区间为: 61.05<Yx=1000 < 61.05 或 (372.03, )
 同样地,对于Y在X=1000的个体值,其95%的置信区间为: 61.05<Yx=1000 < 或 (372.03, )")
99
总体回归函数的置信带(域)(confidence band)
个体的置信带(域)
")
100
对于Y的总体均值E(Y|X)与个体值的预测区间(置信区间):
(1)样本容量n越大,预测精度越高,反之预测精度越低; (2)样本容量一定时,置信带的宽度当在X均值处最小,其附近进行预测(插值预测)精度越大;X越远离其均值,置信带越宽,预测可信度下降。
样本容量n越大,预测精度越高,反之预测精度越低; (2)样本容量一定时,置信带的宽度当在X均值处最小,其附近进行预测(插值预测)精度越大;X越远离其均值,置信带越宽,预测可信度下降。")
101
§2.5 实例:时间序列问题 一、中国居民人均消费模型 二、时间序列问题

102
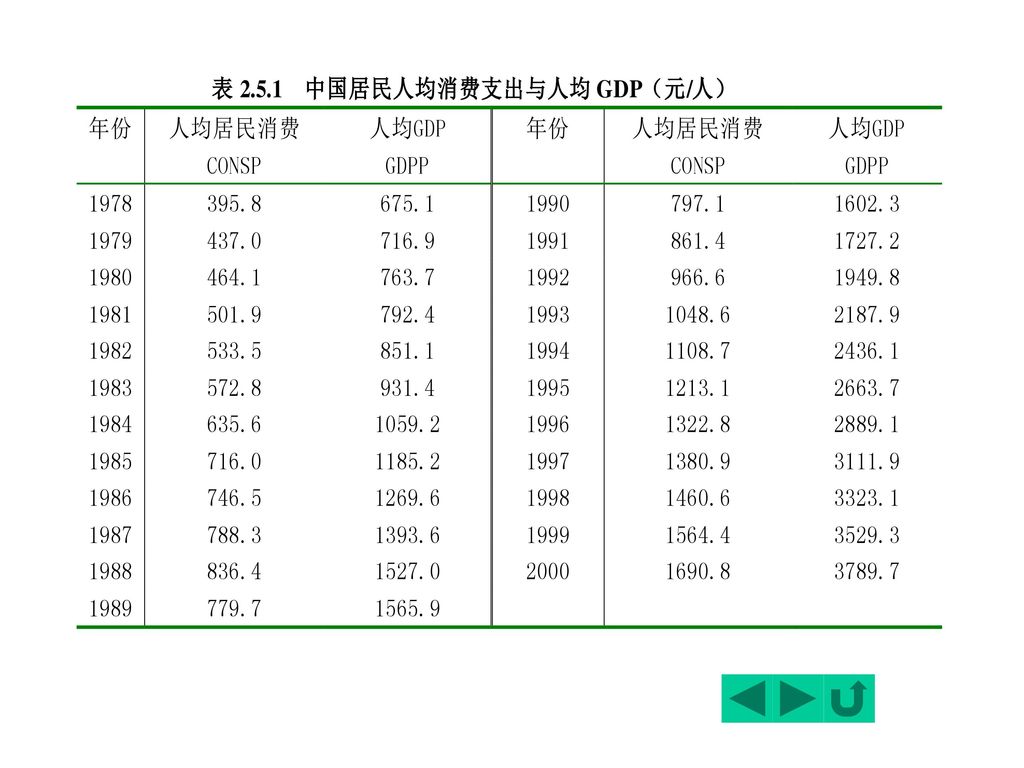
一、中国居民人均消费模型 例2.5.1 考察中国居民收入与消费支出的关系。 GDPP: 人均国内生产总值(1990年不变价) CONSP:人均居民消费(以居民消费价格指数(1990=100)缩减)。
 CONSP:人均居民消费(以居民消费价格指数(1990=100)缩减)。")
104
该两组数据是1978—2000年的时间序列数据(time series data);
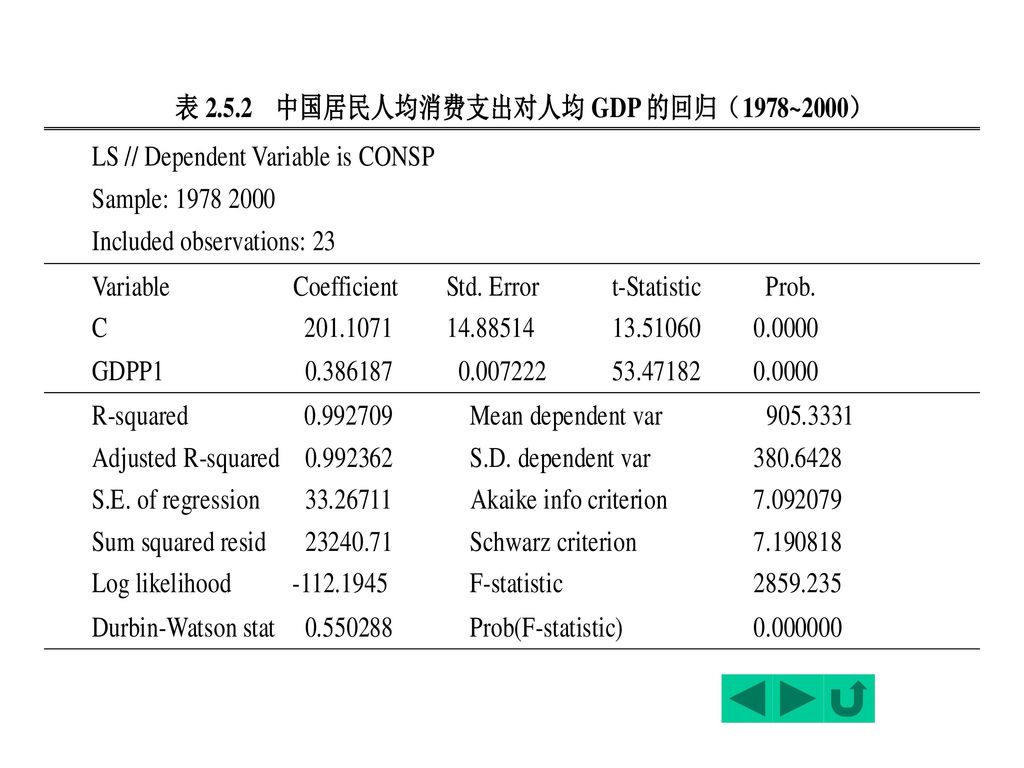
前述收入—消费支出例中的数据是截面数据(cross-sectional data)。 1. 建立模型 拟建立如下一元回归模型 采用Eviews软件进行回归分析的结果见下表
。 1. 建立模型. 拟建立如下一元回归模型. 采用Eviews软件进行回归分析的结果见下表.")
106
斜率项:0<0.3862<1,符合绝对收入假说
一般可写出如下回归分析结果: (13.51) (53.47) R2= F= DW=0.5503 2. 模型检验 R2=0.9927 T值:C:13.51, GDPP:53.47 临界值: t0.05/2(21)=2.08 斜率项:0<0.3862<1,符合绝对收入假说
 (53.47) R2= F= DW= 模型检验. R2= T值:C:13.51, GDPP: 临界值: t0.05/2(21)=2.08. 斜率项:0<0.3862<1,符合绝对收入假说.")
107
3. 预测 2001年:GDPP=4033.1(元)(1990年不变价) = 1758.7(元) 相对误差: -1.32%。
3. 预测 2001年:GDPP=4033.1(元)(1990年不变价) 点估计:CONSP2001= 4033.1 = (元) 2001年实测的CONSP(1990年价):1782.2元, 相对误差: -1.32%。
(1990年不变价) 点估计:CONSP2001= = (元) 2001年实测的CONSP(1990年价):1782.2元, 相对误差: -1.32%。")
108
在95%的置信度下,E(CONSP2001)的预测区间为:
2001年人均居民消费的预测区间 人均GDP的样本均值与样本方差: E(GDPP) =1823.5 Var(GDPP) = = 在95%的置信度下,E(CONSP2001)的预测区间为: =1758.740.13 或: (1718.6,1798.8)
 = Var(GDPP) = = 在95%的置信度下,E(CONSP2001)的预测区间为: =1758.7 或: (1718.6,1798.8)")
109
同样地,在95%的置信度下,CONSP2001的预测区间为:
=1758.786.57 或 (1672.1, )
")
110
二、时间序列问题 上述实例表明,时间序列完全可以进行类似于截面数据的回归分析。 然而,在时间序列回归分析中,有两个需注意的问题:
第一,关于抽样分布的理解问题。 能把表2.5.1中的数据理解为是从某个总体中抽出的一个样本吗?

111
第二,关于“伪回归问题”(spurious regression problem)。
可决系数R2,考察被解释变量Y的变化中可由解释变量X的变化“解释”的部分。 这里“解释”能否换为“引起”?

112
在现实经济问题中,对时间序列数据作回归,即使两个变量间没有任何的实际联系,也往往会得到较高的可决系数,尤其对于具有相同变化趋势(同时上升或下降)的变量,更是如此。这种现象被称为“伪回归”或“虚假回归”。
的变量,更是如此。这种现象被称为 伪回归 或 虚假回归 。")
Similar presentations











>")



 常数项级数的概念 袁安锋 2016.7.>")

 由未知数的系数组成的n阶行列式>")




