Download presentation
1
一种基于Hadoop的视频大数据分布式解码方法 冯强
iiec.cqu.edu.cn

2
目录 项目简介 研究现状 解码方案描述 实验结果分析 总结

3
Hadoop + Computer Vision 项目任务
项目简介 项目名称:HadoopCV Hadoop + Computer Vision 项目任务 存储海量视频数据; 基于Hadoop处理视频数据; 视频大数据 + 分布式解码

4
项目简介 HadoopCV处理流程 常规处理流程 视频数据 视频数据 Mapper OpenCV IplImage IplImage
算法处理 算法处理 Reducer

5
项目简介 系统边界

6
目录 项目简介 研究现状 解码方案描述 实验结果分析 总结

7
研究现状 单机解码 分布式解码(转码) 使用单一计算节点进行解码,数据存储和解码都在本地完成,目前流行的视频播放软件均采用这种模式
优点:架构简单,无需提供额外的视频管理机制,即用即解; 缺点:解码效率受节点配置影响,拓展性较差,数据安全性也较差,对大数据的处理能力不足。 分布式解码(转码) 利用分布式系统进行解码,视频数据先分割成适合分块处理的大小,然后上传到分布式文件系统上。需要进行解码的时候,再将数据下载到本地,通过第三方解码库的调用进行解码,处理完成之后重新上传。这种解码模式数据存储在分布式文件系统上,但解码的时候需要数据的下载和上传。 优点:利用了分布式计算框架,通过并行处理提高了解码效率; 缺点:没有充分利用分布式文件系统存储的优点,数据上传和下载的过程增加了系统开销,另外数据需要进行分割之后上传,需要提供相应的管理机制。
 利用分布式系统进行解码,视频数据先分割成适合分块处理的大小,然后上传到分布式文件系统上。需要进行解码的时候,再将数据下载到本地,通过第三方解码库的调用进行解码,处理完成之后重新上传。这种解码模式数据存储在分布式文件系统上,但解码的时候需要数据的下载和上传。 优点:利用了分布式计算框架,通过并行处理提高了解码效率; 缺点:没有充分利用分布式文件系统存储的优点,数据上传和下载的过程增加了系统开销,另外数据需要进行分割之后上传,需要提供相应的管理机制。")
8
基于Hadoop的视频大数据分布式解码方法:
研究现状 基于Hadoop的视频大数据分布式解码方法: 架构简单,无需提供额外的视频管理机制; 利用了分布式计算框架,通过并行处理提高解码效率;

9
研究现状 视频压缩原理 原始帧 GOP 解码需要: 头数据; 关键帧; 关键帧

10
研究现状 Hadoop直接处理视频数据 问题一:帧不完整 问题二:分割后缺少关键帧 问题三:分割后缺少头数据
其中,标号为2、9、16的帧将会被分割到两个Block中;Block2中2、3、4、5帧由于缺少关键帧信息,将无法解码出正确的图像,Block3中的第10帧以及Block4中所有的帧均存在同样的问题;Block2、Block3、Block4中由于缺少视频头数据,将无法进行解码。

11
目录 项目简介 研究现状 解码方案描述 实验结果分析 总结

12
解码方案描述 数据预处理: HDFS设计之初是为了处理文本大数据,但只要被写入的数据很少被改动,并且对数据的操作主要是大规模的流式读取和小规模的随机读取,原则上HDFS就可以存储任何类型的数据,因此,视频数据可以不加任何处理的上传到HDFS之上。 数据物理分割: 视频文件在上传到HDFS之后,根据用户设定的Block大小,默认顺序分割成64M大小的数据块,分布式的存储于集群中的DataNode之上,此时,所有大于64M的文件都被物理分割。NameNode通过维护文件系统的元数据(metadata)对文件进行管理,而HDFS面向用户的接口又是一个完整连续的文件,HDFS对用户隐藏了分割的细节。
对文件进行管理,而HDFS面向用户的接口又是一个完整连续的文件,HDFS对用户隐藏了分割的细节。")
13
解码方案描述 数据逻辑分割: Block:物理分割数据块; Split:逻辑分割数据块;
Hadoop在根据用户的指定运行一个作业(job)的时候,会根据Block在工作机的位置分配计算任务,每个单独运行的任务称之为一个Map,每个Map对应一个Split,Split作为文件的一个逻辑分割为Map提供计算数据源,默认的Split按照自己位置分割,起始位置跟工作机的Block相同。
的时候,会根据Block在工作机的位置分配计算任务,每个单独运行的任务称之为一个Map,每个Map对应一个Split,Split作为文件的一个逻辑分割为Map提供计算数据源,默认的Split按照自己位置分割,起始位置跟工作机的Block相同。")
14
解码方案描述 Hadoop直接处理视频数据 问题原因: 问题一:帧不完整 问题二:分割后缺少关键帧 问题三:分割后缺少头数据
按字节分割,不是按照帧的位置进行分割; 解决问题关键: 如何进行按照帧的位置进行分割 Block是按照字节位置对文件进行分割,而不是按照帧的边界位置进行分割,而压缩过的帧由于编码的存在无法计算字节位置,另外编码过的帧大小不一,这也导致无法通过按照帧的边界位置重新划定大小统一的Split进行分割,因此才会导致4.2.2中问题一、问题二(下文简称问题一、问题二和问题三)的产生。为了解决这两个问题,我们重新定义Split的分割位置,由原来的字节位置分割修改为按帧位置进行分割,
的产生。为了解决这两个问题,我们重新定义Split的分割位置,由原来的字节位置分割修改为按帧位置进行分割,")
15
解码方案描述 数据逻辑分割: Split定义: Split读取规则: 依然按照Block起止位置进行定义,数据大小同Block大小;
向前读取; 丢弃第一个关键帧之前数据,确定Split的真正起始帧位置; Split的终止帧位置设定在Block结束字节位置附近,定义在结束字节位置之后的第一个I帧;

16
解码方案描述 数据逻辑分割: 问题一:帧不完整 问题二:分割后缺少关键帧
Split的定义仍然是根据HDFS的Block位置,但是在数据读取策略上,根据关键帧的位置,重新定义Split,这样就可以保证所有的Split中都有必要的I帧信息,同一个GOP中不会出现缺少I帧而无法解码的问题。至此,问题一、问题二解决。

17
解码方案描述 分布式解码: FFmepg: FFmpeg是一个开源免费跨平台的视频和音频流方案,可以运行在windows和linux上,包括一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。 Fuse-dfs: fuse-dfs是hadoop项目自带的一个功能模块。主要实现把dfs上的数据映射至本地指定mount点。由于现存的软件无法直接使用hdfs上的数据,所以此时可以借助fuse来实现本地文件系统的映射。

18
解码方案描述 分布式解码: FFmpeg解码: Fuse-dfs挂载HDFS: Split确定数据边界;
RecorderReader循环读取; 解码数据; FFmpeg解码: 支持本地文件接口; 不兼容HDFS; Fuse-dfs挂载HDFS: 虚拟本地文件接口,提高兼容性; 隐藏网络传输细节,通过网络传输 视频头数据; 在确定好了Split划分边界之后,需要提供相应的数据读取策略,Hadoop中称之为RecordReader(RR),RecordReader为相应的Map提供计算数据,体现到视频数据上就是解码,这里我们采用开源解决方案FFmpeg做解码工作 在使用FFmpeg做解码工作的时候,由于面向的是HDFS,虽然HDFS提供了文件的读取接口,但与FFmpeg支持的本地文件接口不兼容,这就导致了FFmpeg无法读取HDFS上的数据;同时,为解决问题三,我们需要提供一种策略,把视频文件的头数据通过网络传输给每个Split。 这里我们采用的Fuse-dfs解决如上问题,Fuse-dfs可以将HDFS挂载到本地文件系统,这样FFmpeg就可以像解码本地文件一样解码HDFS上的视频数据,不仅可以隐藏网络传输细节,同时还可以提高系统的兼容性。
,RecordReader为相应的Map提供计算数据,体现到视频数据上就是解码,这里我们采用开源解决方案FFmpeg做解码工作. 在使用FFmpeg做解码工作的时候,由于面向的是HDFS,虽然HDFS提供了文件的读取接口,但与FFmpeg支持的本地文件接口不兼容,这就导致了FFmpeg无法读取HDFS上的数据;同时,为解决问题三,我们需要提供一种策略,把视频文件的头数据通过网络传输给每个Split。 这里我们采用的Fuse-dfs解决如上问题,Fuse-dfs可以将HDFS挂载到本地文件系统,这样FFmpeg就可以像解码本地文件一样解码HDFS上的视频数据,不仅可以隐藏网络传输细节,同时还可以提高系统的兼容性。")
19
解码方案描述 分布式解码: 问题三:分割后缺少头数据

20
解码方案描述 输入/输出:

21
解码方案描述 输入/输出: FrameNumWritable:标识帧位于视频帧序列的播放位置,以及帧对于的视频文件路径;
ImageWritable: 标识帧的图像数据; Text:图像数据Hash过后的文本数据; VideoMapper: 负责将解码过后的图像Hash成文本数据; VideoReducer: 负责将图像文本数据写入文件;

22
解码方案描述 解码方案整体架构

23
目录 项目简介 研究现状 解码方案描述 实验结果分析 总结

24
实验结果分析 实验集群概述: Hadoop集群由15台PC机组成,每台PC机CPU为Intel(R) Pentium(R) 4 CPU 2.80GHz,内存为1.5G,硬盘为80G。其中1台作为集群Master,14台作为集群Slaves。 运行环境: 操作系统:Ubuntu Hadoop版本:1.0.3 JDK版本:1.7.0_07 OpenCV版本:2.4.2 ffmpeg版本:1.0

25
实验结果分析 分布式/单机解码效率对比: 从图中可以看出,当视频小于60M,单机解码时间小于分布式解码,大于60M,分布式解码所需时间小于单机解码;同时,随着视频逐渐增大,分布式解码时间远远小于单机解码时间。

26
实验结果分析 分布式/单机解码效率对比:

27
把单机解码的视频作为样本视频记录E,分布式解码的视频为实际视频记录A。
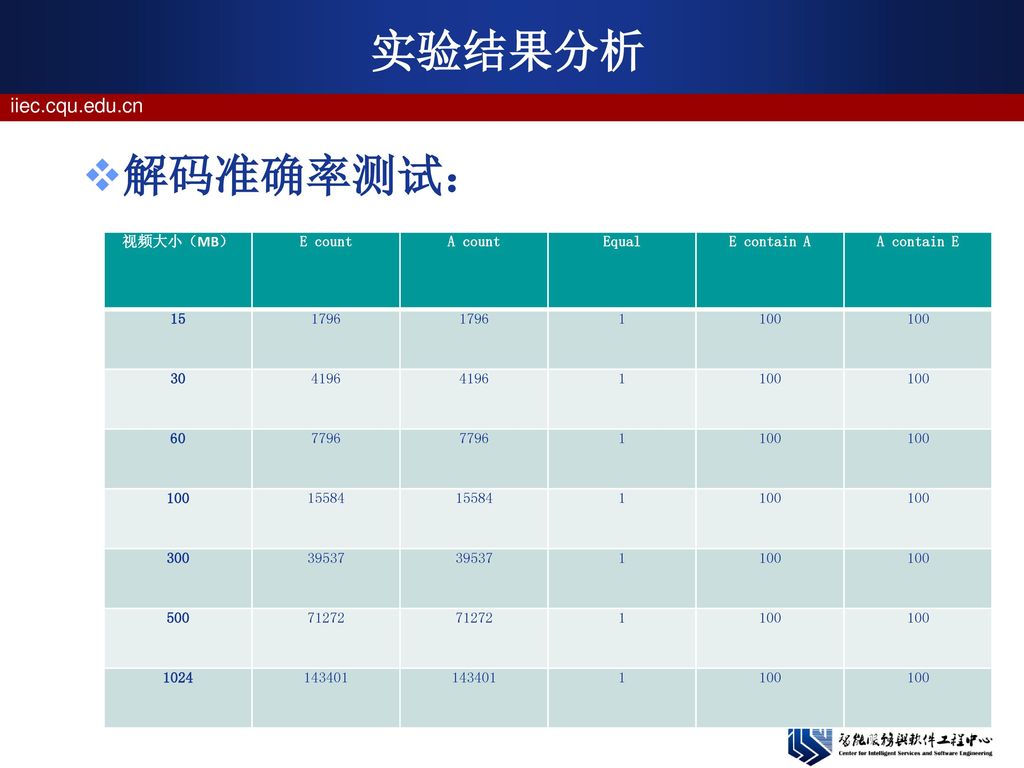
实验结果分析 解码准确率测试: 把单机解码的视频作为样本视频记录E,分布式解码的视频为实际视频记录A。 帧数对比:比较A与E的视频帧数是否相同; 严格对比:将每一帧图像Hash成只包含头信息(图像长、宽、大小、通道数、深度)、图像数据的hash码。对比两条记录的这些信息来确定两帧图像是否相等。 计算包含百分比:如果帧数相同且严格对比结果匹配,A与E完全相同;如果帧数相同但是严格对比结果不匹配,计算实际记录A与样本记录E中相互包含帧的百分比。
、图像数据的hash码。对比两条记录的这些信息来确定两帧图像是否相等。 计算包含百分比:如果帧数相同且严格对比结果匹配,A与E完全相同;如果帧数相同但是严格对比结果不匹配,计算实际记录A与样本记录E中相互包含帧的百分比。")
28
实验结果分析 解码准确率测试: 视频大小(MB) E count A count Equal E contain A A contain E
15 1796 1 100 30 4196 60 7796 15584 300 39537 500 71272 1024 143401
29
实验结果分析 分割大小对解码效率的影响: 24G视频做测试样本,标准的h.264压缩标准,标清视频704x576分辨率,24h数据量约为24G。

30
实验结果分析 集群配置对解码效率的影响: BlockSize
视频小于6G时,块的增大增加了分布式解码的运行时间;但随着视频的增大,块的增大减少了分布式解码的运行时间,特别在24G视频时效果最为显著。当块大小为256M时,对小视频解码效率有较小影响,对大视频解码效率有较大提高,因此,本实验的集群用于分布式解码时,集群块大小设置为256M较为合适。

31
实验结果分析 集群配置对解码效率的影响: 节点数量

32
目录 项目简介 研究现状 解码方案描述 实验结果分析 总结

33
总结 方案概述: 基于Hadoop的视频大数据分布式解码方法,是一种分布式解码方法;
原始视频可以不用提前将分割即可直接上传到HDFS,由Hadoop进行物理分割; 逻辑分割Split的边界根据帧的位置进行界定,从而解决了按字节分割导致的帧分裂,以及同一个GOP内缺少关键帧的问题。 使用Fuse-dfs,FFmpeg等第三方库解决不同Split缺少视频头数据的问题。

34
总结 优点: 缺点: 视频不需要进行预处理,节省了计算时间; 利用分布式计算,提高了解码效率; 解码准确率高;
Split在进行逻辑划分数据的时候,有少量的数据需要跨工作机传输,增加了集群的网络负责,降低了解码效率。

35
Thank You ! iiec.cqu.edu.cn















 教育部 101年12月12日 1 1.>")



班 第二组 蔡聿桐.>")

