Download presentation
Presentation is loading. Please wait.

1
Chapter 7 Search

2
所谓搜索,就是在数据集合中寻找满足某种条件的数据对象
1.搜索成功 即找到满足条件的数据 对象这时, 作为结果, 可报告该对 象在结构中的位置, 还可给出该对 象中的具体信息 2.搜索不成功 或搜索失败。作为结 果, 应报告一些信息, 如失败标 志、位置等

3
通常称用于搜索的数据集合为搜索结构,它是由同一数据类型的对象(或记录)组成
在每个对象中有若干属性,其中有一个属性,其值可唯一地标识这个对象。称为关键码。使用基于关键码的搜索,搜索结果应是唯一的。但在实际应用时,搜索条件是多方面的,可以使用基于属性的搜索方法,但搜索结果可能不唯一

4
实施搜索时有两种不同的环境 静态环境 搜索结构不用插入和删除操作 静态搜索表
静态环境 搜索结构不用插入和删除操作 静态搜索表 动态环境 为保持较高的搜索效率, 搜索结构在执行插入和删除等操作的前后将自动进行调整,结构可能发生变化 动态搜索表

5
查找算法的评价指标 查找成功:最少比较次数 最多比较次数 平均比较次数 查找失败:最少比较次数

6
顺序查找 以顺序表或线性链表表示静态查找表

7
顺序查找过程 k k ST.elem 假设给定值 e=64, 要求 ST.elem[k] = e, 问: k = ?
![顺序查找过程 k k ST.elem 假设给定值 e=64, 要求 ST.elem[k] = e, 问: k =](http://slidesplayer.com/slide/14116192/86/images/7/%E9%A1%BA%E5%BA%8F%E6%9F%A5%E6%89%BE%E8%BF%87%E7%A8%8B+k+k+ST.elem+%E5%81%87%E8%AE%BE%E7%BB%99%E5%AE%9A%E5%80%BC+e%3D64%2C+%E8%A6%81%E6%B1%82+ST.elem%5Bk%5D+%3D+e%2C+%E9%97%AE%3A+k+%3D.jpg "顺序查找过程 k k ST.elem 假设给定值 e=64, 要求 ST.elem[k] = e, 问: k =")
8
i i ST.elem 64 key=64 i i ST.elem 60 key=60

9
int Search_Seq( TB ST, TYPE key )
{ ST.elem[0].key = key; // “哨兵” for (i=ST.length; ST.elem[i].key!=key; --i); // 从后往前找 return i; // 找不到时,i为0 }
; // 从后往前找. return i; // 找不到时,i为0. }")
10
分析顺序查找的 时间性能

11
(Average Search Length)
查找算法的平均查找长度 (Average Search Length) 为确定记录在查找表中的位置,需 和给定值进行比较的关键字个数的期望 值
 为确定记录在查找表中的位置,需. 和给定值进行比较的关键字个数的期望. 值.")
12
其中: n 为表长,Pi 为查找表中第i个记录的概率,且 , Ci为找到该记录时,曾和给定值比较过的关键字的个数

13
在等概率情形 pi = 1/n, i = 1, 2, , n 在搜索不成功情形,ASLunsucc = n+1

14
查找成功:最少比较次数 1 最多比较次数 n 平均比较次数 (n+1)/2 查找失败:最少比较次数 n+1 最多比较次数 n+1 平均比较次数 n+1
/2 查找失败:最少比较次数 n+1 最多比较次数 n+1 平均比较次数 n+1")
15
Key Denition in C++ To select existing types as records and keys, a client could use type denition statements such as: typedef int Key; typedef int Record; A client can design new classes that display appropriate behavior based on the following skeletons:

16
// Definition of a Key class:
class Key{ public: // Add any constructors and methods for key data. private: // Add declaration of key data members here. }; // Declare overloaded comparison operators for keys. bool operator ==(const Key &x, const Key &y); bool operator > (const Key &x, const Key &y); bool operator < (const Key &x, const Key &y); bool operator >=(const Key &x, const Key &y); bool operator <=(const Key &x, const Key &y); bool operator !=(const Key &x, const Key &y); // Definition of a Record class: class Record{ Key Key(); // implicit conversion from Record to Key. // Add any constructors and methods for Record objects. // Add data components.
; bool operator > (const Key &x, const Key &y); bool operator < (const Key &x, const Key &y); bool operator >=(const Key &x, const Key &y); bool operator <=(const Key &x, const Key &y); bool operator !=(const Key &x, const Key &y); // Definition of a Record class: class Record{ Key Key(); // implicit conversion from Record to Key. // Add any constructors and methods for Record objects. // Add data components.")
17
Sequential Search and Analysis
Begin at one end of the list and scan down it until the desired key is found or the other end is reached: Error_code sequential_search(const List<Record> &the_list, const Key &target, int &position) /* Post: If an entry in the_list has key equal to target, then return success and the output parameter position locates such an entry within the list. Otherwise return not_present and position becomes invalid. */ { int s = the_list.size(); for (position = 0; position < s; position++) { Record data; the_list.retrieve(position, data); if (data == target) return success; } return not_present;
 /* Post: If an entry in the_list has key equal to target, then return. success and the output parameter position locates such an entry. within the list. Otherwise return not_present and position becomes invalid. */ { int s = the_list.size(); for (position = 0; position < s; position++) { Record data; the_list.retrieve(position, data); if (data == target) return success; } return not_present;")
18
折半查找 若以有序表表示静态查找表, 适用于表长较大的查找表 则查找过程可以基于“折半”进行
上述顺序查找表的查找算法简单,但平均查找长度较大,特别不 适用于表长较大的查找表 若以有序表表示静态查找表, 则查找过程可以基于“折半”进行

19
基于有序顺序表的折半搜索 设n个对象存放在一个有序顺序表中,并按其关键码从小到大排好了序
折半搜索时, 先求位于搜索区间正中的对象的下标mid,用其关键码与给定值x比较

20
1.Element[mid].key==x 搜索成功
如果搜索区间已缩小到一个对象,仍未找到想要搜索的对象,则搜索失败
![1.Element[mid].key==x 搜索成功](http://slidesplayer.com/slide/14116192/86/images/20/1.Element%5Bmid%5D.key%3D%3Dx+%E6%90%9C%E7%B4%A2%E6%88%90%E5%8A%9F.jpg "如果搜索区间已缩小到一个对象,仍未找到想要搜索的对象,则搜索失败.")
21
例如: key=64 的查找过程如下 mid = (low+high)/2 Low 指示查找区间的下界 high 指示查找区间的上界
ST.length ST.elem low low high high mid mid mid mid = (low+high)/2 Low 指示查找区间的下界 high 指示查找区间的上界
/2. Low 指示查找区间的下界. high 指示查找区间的上界.")
22
搜索成功的例子 6 搜索 low mid high 5

23
搜索失败的例子 5 搜索 low mid high 6

24
int Search_Bin(TB ST, TYPE key)
{ low = 1; high = ST.length; while(low<=high) { mid=(low+high)/2; if(key==ST.elem[mid].key)return mid; if(key<ST.elem[mid].key)high=mid-1; if(key>ST.elem[mid].key)low=mid+1; } return 0;
 { mid=(low+high)/2; if(key==ST.elem[mid].key)return mid; if(key<ST.elem[mid].key)high=mid-1; if(key>ST.elem[mid].key)low=mid+1; } return 0;")
25
有序顺序表的折半搜索的判定树 ( 10, 20, 30, 40, 50, 60 ) 10 50 = 30 < > 20 40
 = 30 < > 20 40")
26
索引顺序查找 1)由索引确定记录所在区间 2)在顺序表的某个区间内进行查找 可见: 索引顺序查找的过程也是一个 “缩小区间”的查找过程
注意:索引可以根据查找表的特点来构造

27
索引顺序查找的平均查找长度 = 查找“索引”的平均查找长度 + 查找“顺序表”的平均查找长度 对于按顺序索引表的平均查找长度:

33
二叉排序树 (二叉查找树)
")
34
二叉排序树或者是一棵空树;或者 是具有如下特性的二叉树 (1)若它的左子树不空,则左子树上 所有结点的值均小于根结点的值
(2)若它的右子树不空,则右子树上 所有结点的值均大于根结点的值 (3)它的左、右子树也都分别是二叉 排序树
若它的右子树不空,则右子树上. 所有结点的值均大于根结点的值. (3)它的左、右子树也都分别是二叉. 排序树.")
35
50 30 80 20 40 90 10 25 35 85 66 23 88 不 是二叉排序树

36
二叉排序树的 查找算法

37
若二叉排序树为空,则查找不成功 否则: 1)若给定值等于根结点的关键字, 则查找成功 2)若给定值小于根结点的关键字, 则继续在左子树上进行查找 3)若给定值大于根结点的关键字, 则继续在右子树上进行查找
若给定值大于根结点的关键字, 则继续在右子树上进行查找.")
38
50 50 50 50 50 50 30 30 80 80 20 40 40 90 90 35 35 85 32 88 查找关键字 == 50 , 35 , 90 , 95

39
n 个结点的二叉搜索树的数目 3 个结点的二叉搜索树 {123} {132} {213} {312} {321} 1 2 3

40
如果对一棵二叉搜索树进行中序遍历,可以按从小到大的顺序,将各结点关键码排列起来,所以也称二叉搜索树为二叉排序树

41
在查找过程中,生成了一条查找路径 ——查找成功 或者 ——查找不成功 从根结点出发,沿着左分支或右分支逐层向下直至关键字等于给定值的结点
从根结点出发,沿着左分支或右分支逐层向下直至指针指向空树为止 ——查找不成功

42
f f T key = 48 22 f T f f T f T p 30 T 20 40 T f 10 25 35 p T f 23 T

43
搜索28 搜索失败 搜索45 搜索成功 35 15 45 10 25 40 50 20 30

47
查找性能的分析 均可按照平均查找长度的定义来求它 的 ASL 值,显然,由值相同的 n个关 键字,构造所得的不同形态的各棵二
对于每一棵特定的二叉排序树, 均可按照平均查找长度的定义来求它 的 ASL 值,显然,由值相同的 n个关 键字,构造所得的不同形态的各棵二 叉排序树的平均查找长 度的值不同, 甚至可能差别很大

48
由关键字序列 1,2,3,4,5构造而得的二叉排序树
ASL =( )/ 5 = 3 3 4 5 由关键字序列 3,1,2,5,4构造而得的二叉排序树 3 ASL =( )/ 5 = 2.2 1 5 2 4
/ 5 = 由关键字序列 3,1,2,5,4构造而得的二叉排序树. 3. ASL =( )/ 5 =")
49
输入数据,建立二叉搜索树的过程 输入数据 { 53, 78, 65, 17, 87, 09, 81, 15 } 53 78 65 17 87

51
如果输入序列选得不好,会建立起一棵单支树,使得二叉搜索树的高度达到最大
同样 3 个数据{ 1, 2, 3 },输入顺序不同,建立起来的二叉搜索树的形态也不同。这直接影响到二叉搜索树的搜索性能 如果输入序列选得不好,会建立起一棵单支树,使得二叉搜索树的高度达到最大

52
{1,2,3} {1,3,2} {2,1,3} {3,1,2} {3,2,1} 1 2 3

53
二叉平衡树 (AVL树)
")
54
一棵AVL树或者是空树,或者是具有下列性质的二叉搜索树:它的左子树和右子树都是AVL树,且左子树和右子树的高度之差的绝对值不超过1
不平衡 平衡 A C B A D C B E D E

55
结点的平衡因子 (balance factor)
每个结点附加一个数字, 给出该结点左子树的高度减去右子树的高度所得的高度差, 这个数字即为结点的平衡因子 AVL树任一结点平衡因子只能取 -1, 0, 1

56
如果一个结点的平衡因子的绝对值大于1, 则这棵二叉搜索树就失去了平衡, 不再是AVL树
如果一棵二叉搜索树是平衡的, 且有 n个结点,其高度可保持在 O(log2n),平均搜索长度也可保持在O(log2n)
,平均搜索长度也可保持在O(log2n)")
57
5 5 4 8 4 8 2 2 是平衡树 不是平衡树 1

58
平衡化旋转 如果在一棵平衡的二叉搜索树中插入一个新结点,造成了不平衡。此时必须调整树的结构,使之平衡化 平衡化旋转有两类:
单旋转 (左旋和右旋) 双旋转 (左旋加右旋和右旋加左旋)
 双旋转 (左旋加右旋和右旋加左旋)")
59
右单旋转 LL型 左单旋转 RR型

60
左右双旋转 LR型 右左双旋转 RL型

61
构造二叉平衡(查找)树的方法 在插入过程中,采用平衡旋转技术 依次插入的关键字为5, 4, 2, 8, 6, 9
向右旋转 一次 先向右旋转 再向左旋转 6

62
向左旋转一次 4 2 6 5 8 6 9 4 8 继续插入关键字 9 2 9 5

63
B - 树

64
B-树是一种 平衡 的 多路 查找 树

65
n 个关键字 Ki(1≤ i≤n) n<m n 个指向记录的指针 Di(1≤i≤n) n+1 个指向子树的指针 Ai(0≤i≤n)
在 m 阶的B-树上,每个非终端结点可能含有: n 个关键字 Ki(1≤ i≤n) n<m n 个指向记录的指针 Di(1≤i≤n) n+1 个指向子树的指针 Ai(0≤i≤n) 多叉树的特性
 n<m. n 个指向记录的指针 Di(1≤i≤n) n+1 个指向子树的指针 Ai(0≤i≤n) 多叉树的特性.")
66
非叶结点中的多个关键字均自小至大有序排列,即:K1< K2 < … < Kn
Ai-1 所指子树上所有关键字均小于Ki Ai 所指子树上所有关键字均大于Ki 查找树的特性

67
树中所有叶子结点均不带信息,且在树中的同一层次上
根结点或为叶子结点,或至少含有两棵子树 其余所有非叶结点均至少含有m/2棵子树,至多含有 m 棵子树 平衡树的特性

68
查找过程 从根结点出发,沿指针搜索结点和在结点内进行顺序(或折半)查找 两个过程交叉进行
查找 两个过程交叉进行")
69
若查找成功,则返回指向被查关键字所在结点的指针和关键字在结点中的位置
若查找不成功,则返回插入位置

70
B+树 是B-树的一种变型

71
※ 每个叶子结点中含有 n 个关键字和 n 个指向记录的指针;并且,所有叶子结点彼此相链接构成一个有序链表,其头指针指向含最小关键字的结点

72
※ 每个非叶结点中的关键字 Ki 即为其相应指针 Ai 所指子树中关键字的最大值
※ 所有叶子结点都处在同一层次上,每个叶子结点中关键字的个数均介于 m/2和 m 之间

73
查找过程 ※ 在 B+ 树上,既可以进行缩小范围的查找,也可以进行顺序查找
※ 在进行缩小范围的查找时,不管成功与否,都必须查到叶子结点才能结束 ※若在结点内查找时, Ki-1 <给定值≤Ki,则应继续在 Ai 所指子树中进行查找

74
root sq
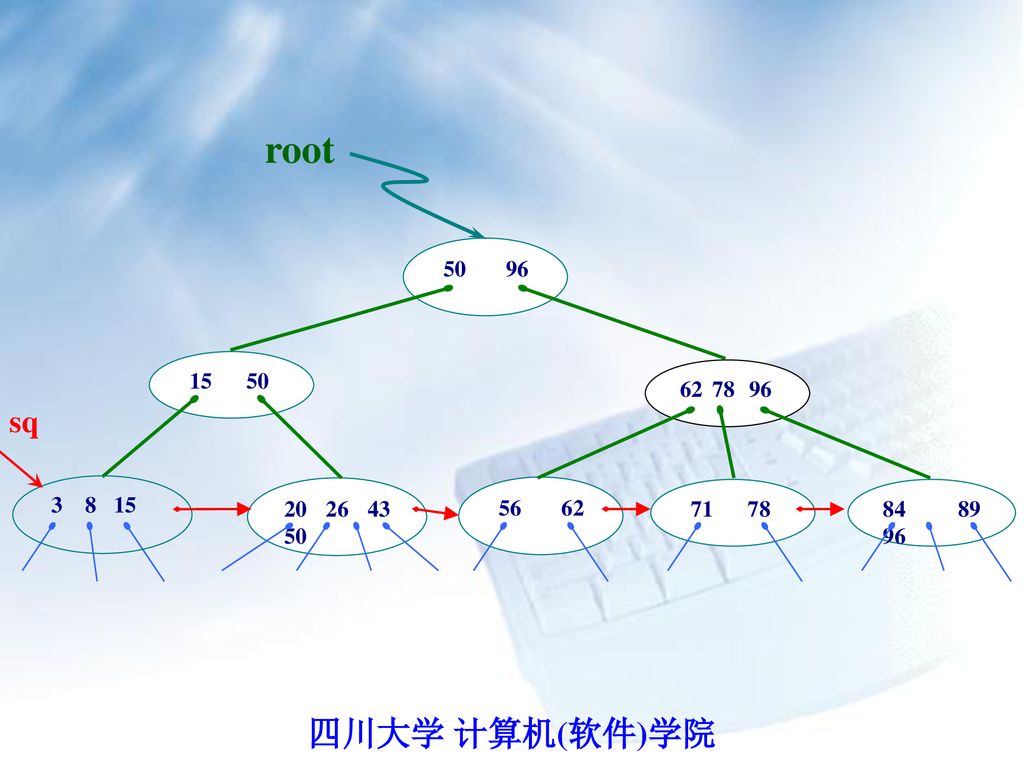
75
哈 希 查 找 (Hash)
")
76
以上讨论的表示查找表的各种结构的共同特点:记录在表中的位置和它的关键字之间不存在一个确定的关系

77
查找的过程为给定值依次和关 键字集合中各个关键字进行比较 查找的效率取决于和给定值进行比较的关键字个数

78
用这类方法表示的查找表,其平均查找长度都不为零
不同的表示方法,其差别仅在于: 关键字和给定值进行比较的顺序不同

79
对于频繁使用的查找表,希望 ASL = 0 只有一个办法:预先知道所查关键字在表中的位置 即,要求:记录在表中位置和其关键字之间存在一种确定的关系

80
在一般情况下,需在关键字与记录在表中的存储位置之间建立一个函数关系,以 H(key) 作为关键字为 key 的记录在表中的位置,通常称这个函数 H(key) 为哈希函数
 作为关键字为 key 的记录在表中的位置,通常称这个函数 H(key) 为哈希函数")
81
※哈希函数是一个映象,即:将关键 字的集合映射到某个地址集合上,它 的设置很灵活,只要这个地址集合的 大小不超出允许范围即可

82
※由于哈希函数是一个压缩映象,因 此,在一般情况下,很容易产生 “ 冲 突 ” 现象,即: key1 key2,而 H(key1) = H(key2)
 = H(key2)")
83
※很难找到一个不产生冲突的哈希函数。一般情况下,只能选择恰当的哈希函数,使冲突尽可能少地产生

84
因此,在构造这种特殊的“查 找表”时,除了需要选择一个好” ( 尽可能少产生冲突 )的哈希函数 之外;还需要找到一种“处理冲突” 的方法
的哈希函数 之外;还需要找到一种 处理冲突 的方法")
85
哈希表的定义 根据设定的哈希函数 H( key ) 和所选处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 ( 区间) 上,并以关键字在地址集中的“映象”作为相应记录在表中的存储位置,如此构造所得的查找表称为“哈希表”
 和所选处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集 ( 区间) 上,并以关键字在地址集中的 映象 作为相应记录在表中的存储位置,如此构造所得的查找表称为 哈希表")
86
构造哈希函数的方法 对数字的关键字可有下列构造方法 数字分析法 直接定址法 平方取中法 除留余数法 折叠法 随机数法
若是非数字关键字,则需先对其进行数字化处理

87
数字分析法

88
此方法适合于: 能预先估计出全体关键字的每一位 上各种数字出现的频度
假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为地址 此方法适合于: 能预先估计出全体关键字的每一位 上各种数字出现的频度
,分析关键字集中的全体, 并从中提取分布均匀的若干位或它们的组合作为地址. 此方法适合于: 能预先估计出全体关键字的每一位. 上各种数字出现的频度.")
89
平方取中法

90
以关键字的平方值的中间几位作为存储地址。求“关键字的平方值” 的目的是“扩大差别” ,同时平方值的中间各位又能受到整个关键字中各位的影响
此方法适合于: 关键字中的每一位都有某些数字重 复出现频度很高的现象

91
折叠法

92
将关键字分割成若干部分,然后取它们的叠加和为哈希地址。有两种叠加处理的方法:移位叠加和间界叠加
此方法适合于: 关键字的数字位数特别多

93
直接定址法

94
哈希函数为关键字的线性函数 H(key) = key 或者 H(key) = a key + b 此法适合于: 地址集合的大小 = = 关键字集合的大小
 = key 或者 H(key) = a key + b 此法适合于: 地址集合的大小 = = 关键字集合的大小")
95
除留余数法

96
H(key) = key MOD p 其中, p≤m (表长) 并且 p 应为不大于 m 的素数 或是 不含 20 以下的质因子
设定哈希函数为: H(key) = key MOD p 其中, p≤m (表长) 并且 p 应为不大于 m 的素数 或是 不含 20 以下的质因子
 = key MOD p. 其中, p≤m (表长) 并且. p 应为不大于 m 的素数. 或是. 不含 20 以下的质因子.")
97
随机数法

98
设定哈希函数为: H(key) = Random(key) 其中,Random 为伪随机函数 的关键字构造哈希函数
通常,此方法用于对长度不等 的关键字构造哈希函数

99
实际造表时,采用何种构造哈希函数的方法取决于建表的关键字集合的情况(包括关键字的范围和形态),总的原则是使产生冲突的可能性降到尽可能地小
,总的原则是使产生冲突的可能性降到尽可能地小")
100
处理冲突的方法 “处理冲突” 的实际含义是 为产生冲突的地址寻找下一个哈希地址 1. 开放定址法 2. 链地址法

101
开放定址法(闭域法) 为产生冲突的地址 H(key) 求得一个地址序列: H0, H1, H2, …, Hs 1≤ s≤m-1
其中:H0 = H(key) Hi = ( H(key) + di ) MOD m i=1, 2, …, s
 Hi = ( H(key) + di ) MOD m. i=1, 2, …, s.")
102
增量 di 的三种取法

103
1)线性探测再散列 di = c i 最简单的情况 c=1
di=i×H2(key) (又称双散列函数探测)
 (又称双散列函数探测)")
104
{ 19, 01, 23, 14, 55, 68, 11, 82, 36 } H(key) = key MOD 11 采用线性探测再散列处理冲突 55 01 23 14 68 11 82 36 19

105
链地址法(开域法) 将所有哈希地址相同的记录都链接在同一链表中
 将所有哈希地址相同的记录都链接在同一链表中")
106
{ 19, 01, 23, 14, 55, 68, 11, 82, 36 } H(key) = key MOD 7 1 2 3 4 5 6 14 01 36 23 11 19 68 82 55

107
哈希表的查找

108
对于给定值 K, 计算哈希地址 i = H(K) 若 r[i] = NULL 则查找不成功 若 r[i].key = K 则查找成功
查找过程和造表过程一致。假设采用开放定址处理冲突,则查找过程为: 对于给定值 K, 计算哈希地址 i = H(K) 若 r[i] = NULL 则查找不成功 若 r[i].key = K 则查找成功 否则 “求下一地址 Hi” ,直至 r[Hi] = NULL (查找不成功) 或 r[Hi].key = K (查找成功) 为止
![对于给定值 K, 计算哈希地址 i = H(K) 若 r[i] = NULL 则查找不成功 若 r[i].key = K 则查找成功](http://slidesplayer.com/slide/14116192/86/images/108/%E5%AF%B9%E4%BA%8E%E7%BB%99%E5%AE%9A%E5%80%BC+K%EF%BC%8C+%E8%AE%A1%E7%AE%97%E5%93%88%E5%B8%8C%E5%9C%B0%E5%9D%80+i+%3D+H%28K%29+%E8%8B%A5+r%5Bi%5D+%3D+NULL+%E5%88%99%E6%9F%A5%E6%89%BE%E4%B8%8D%E6%88%90%E5%8A%9F+%E8%8B%A5+r%5Bi%5D.key+%3D+K+%E5%88%99%E6%9F%A5%E6%89%BE%E6%88%90%E5%8A%9F.jpg "查找过程和造表过程一致。假设采用开放定址处理冲突,则查找过程为: 对于给定值 K, 计算哈希地址 i = H(K) 若 r[i] = NULL 则查找不成功. 若 r[i].key = K 则查找成功. 否则 求下一地址 Hi ,直至. r[Hi] = NULL (查找不成功) 或 r[Hi].key = K (查找成功) 为止.")
109
//--- 开放定址哈希表的存储结构 ---
Template <class ElemType > class HashTable{ public: Error_Code SearchHash (KeyType K,int &p, int &c); //其它公有函数成员 private: ElemType *elem; int count; // 当前数据元素个数 //如下加函数函数成员 };
; //其它公有函数成员. private: ElemType *elem; int count; // 当前数据元素个数. //如下加函数函数成员. };")
110
while (elem[p].key != NULLKEY && !EQ(K, elem[p].key))
Template <class ElemType > Status HashTable ::SearchHash (KeyType K, int &p, int &c) { // 在开放定址哈希表H中查找关键码为K的记录 } p = Hash(K); // 求得哈希地址 while (elem[p].key != NULLKEY && !EQ(K, elem[p].key)) collision(p, ++c); // 求得下一探查地址 p if (EQ(K, elem[p].key)) return SUCCESS; // 查找成功,返回待查数据元素位置 p else return UNSUCCESS; // 查找不成功
![while (elem[p].key != NULLKEY && !EQ(K, elem[p].key))](http://slidesplayer.com/slide/14116192/86/images/110/while+%28elem%5Bp%5D.key+%21%3D+NULLKEY+%26%26+%21EQ%28K%2C+elem%5Bp%5D.key%29%EF%BC%89.jpg "Template <class ElemType > Status HashTable ::SearchHash (KeyType K, int &p, int &c) { // 在开放定址哈希表H中查找关键码为K的记录. } p = Hash(K); // 求得哈希地址. while (elem[p].key != NULLKEY && !EQ(K, elem[p].key)) collision(p, ++c); // 求得下一探查地址 p. if (EQ(K, elem[p].key)) return SUCCESS; // 查找成功,返回待查数据元素位置 p. else return UNSUCCESS; // 查找不成功.")
111
哈希表查找的分析 从查找过程得知,哈希表查找的平均查找长度实际上并不等于零

112
决定哈希表查找的ASL的因素 1) 选用的哈希函数; 2) 选用的处理冲突的方法;
1) 选用的哈希函数; 2) 选用的处理冲突的方法; 3) 哈希表饱和的程度,装载因子 α=n/m 值的大小(n—记录数, m—表的长度)
 选用的哈希函数; 2) 选用的处理冲突的方法; 3) 哈希表饱和的程度,装载因子 α=n/m 值的大小(n—记录数, m—表的长度)")
113
一般情况下,可以认为选用的哈希函数是“均匀”的,则在讨论ASL时,可以不考虑它的因素

114
可以证明:查找成功时平均查找长度有下列结果:
线性探测再散列 随机探测再散列 链地址法

115
从以上结果可见: —— 这是哈希表所特有的特点 哈希表的平均查找长度是 的函数,而不是 n 的函数
这说明,用哈希表构造查找表时,可以选择一个适当的装填因子 ,使得平均查找长度限定在某个范围内 —— 这是哈希表所特有的特点

116
哈希表也可以用来构造静态查找表 并且,对静态查找表,有时可以找到不发生冲突的哈希函数。即,此时的哈希表的 ASL=0, 称此类哈希函数为理想(perfect)的哈希函数
的哈希函数")
Similar presentations











 課程名稱:資料結構 授課老師:_____________.>")







.>")








