Download presentation
Presentation is loading. Please wait.

1
数据结构 Data Structure 主讲人:王国军,郑瑾 中南大学 中南大学信息院计科系 csgjwang@gmail.com
电话: 办公室:计算机楼406-B 版权申明:本PPT根据《数据结构》教材所附PPT改编,仅供计科09级/信安09级任课老师和学生使用。

2
串的定义 串也是一种线性结构 为什么要单独讲: (1)它的操作更复杂,例如查找、插入、删除都是字符串形式。
(2)非数值计算处理的对象大多是串
非数值计算处理的对象大多是串.")
3
提 纲 4.2.1 定长顺序存储表示 4.1 串类型的定义 4.2 串的表示和实现 4.2.2 块链存储表示 4.2.3 堆分配存储表示
4.1 串类型的定义 4.2 串的表示和实现 定长顺序存储表示 块链存储表示 堆分配存储表示 4.3 串的模式匹配算法 4.4 串操作应用举例

4
4.1 串类型的定义 一、串及基本概念 串(String) :由零个或多个字符组成的有限序列。一般记作:S=“a1a2a3…an”( n>=0) 串值 S 是串名 串长 如:S=“” 空串:若n=0,为空串。 空格串:仅含有空格字符的串。 如:S=“ ” 空串和空格串不同,例如“ ”和“”分别表示长度为1的空格串和长度为0的空串。

5
基本概念 子串:串中任意个连续的字符组成的子序列 如:S=“1234XYZ” S1=“34X” S1是S的子串 主串:包含子串的串
字串位置:字符在序列中的序号 i, 从1开始编号。 注意: 1、子串在主串中的位置,以子串的第一个字符在主串中的位置来表示。 2、空串是任意串的子串,任意串是其自身的子串。

6
基本概念 例1:a=“Bei” b=“Jing” c=“Bei Jing” 串名: a b c 串值: Bei Jing Bei Jing
串相等:两个串的长度相等且对应位置的字符都相等时,称这两个串相等。

7
二、串的抽象数据类型定义 串也是线性结构,它的逻辑结构与线性表相似。 区别: 1、串的数据对象约束为字符集。
2、在线性表的基本操作中,大多以单个元素为操作对象;而在串的基本操作中,通常以串的整体作 为操作对象。

8
串的抽象数据类型的定义 ADT String { D={ ai |ai∈CharacterSet, i=1,2,...,n, n≥0 }
串是有限长的字符序列,由一对双引号括起来,如: a string ADT String { D={ ai |ai∈CharacterSet, i=1,2,...,n, n≥0 } 数据对象: 数据关系: R1={ < ai-1, ai > | ai-1, ai ∈D, i=2,...,n } 基本操作: StrAssign (&T, chars) 初始条件:chars 是字符串常量。 操作结果:把 chars 赋为 T 的值。 StrCopy (&T, S) 初始条件:串 S 已存在。 操作结果:由串 S 复制得到串 T。
 初始条件:chars 是字符串常量。 操作结果:把 chars 赋为 T 的值。 StrCopy (&T, S) 初始条件:串 S 已存在。 操作结果:由串 S 复制得到串 T。")
9
StrEmpty (S) 初始条件:串S已存在。 操作结果:若 S 为空串,则返回 TRUE,否则返回 FALSE。
DestroyString (&S) 初始条件:串 S 已存在。 操作结果:串 S 被销毁。 StrEmpty (S) 初始条件:串S已存在。 操作结果:若 S 为空串,则返回 TRUE,否则返回 FALSE。 StrLength (S) 初始条件:串 S 已存在。 操作结果:返回 S 的元素个数,称为串的长度。
 初始条件:串 S 已存在。 操作结果:串 S 被销毁。 StrEmpty (S) 初始条件:串S已存在。 操作结果:若 S 为空串,则返回 TRUE,否则返回 FALSE。 StrLength (S) 初始条件:串 S 已存在。 操作结果:返回 S 的元素个数,称为串的长度。")
10
StrCompare (S, T) 初始条件:串 S 和 T 已存在。 操作结果:若S T,则返回值 0; 若S T,则返回值 0; 若S T,则返回值 0。
例如:StrCompare("data", "state") < 0 StrCompare("cat", "case") > 0
 < 0. StrCompare( cat , case ) > 0.")
11
Concat (&T, S1, S2) 初始条件:串 S1 和 S2 已存在。 操作结果:用 T 返回由 S1 和 S2 联接而成的新串。
例如: Concat (T, man, kind) 求得 T = mankind SubString (&Sub, S, pos, len) 初始条件: 串 S 已存在,1≤pos≤StrLength(S) 且 0≤len≤StrLength(S)-pos+1。 操作结果: Sub 返回串 S 的第 pos 个字符起长度为 len 的子串。
 求得 T = mankind SubString (&Sub, S, pos, len) 初始条件: 串 S 已存在,1≤pos≤StrLength(S) 且 0≤len≤StrLength(S)-pos+1。 操作结果: Sub 返回串 S 的第 pos 个字符起长度为 len 的子串。")
12
子串为“串”中的一个字符子序列 例如: SubString(sub, commander, 4, 3) 求得 sub = man SubString(sub, commander , 1, 9) 求得 sub = commander SubString(sub, commander, 9, 1) 求得 sub = r
 求得 sub = r ")
13
SubString(sub, commander, 4, 7)
SubString(sub, beijing, 7, 2) = ? sub = ? 起始位置和子串长度之间存在约束关系 SubString(student, 5, 0) = 长度为 0 的子串为“合法”串
 = sub = 起始位置和子串长度之间存在约束关系. SubString(student, 5, 0) = 长度为 0 的子串为 合法 串.")
14
Index (S, T, pos) 初始条件:串S和T已存在,T是非空串, ≤pos≤StrLength(S)。 操作结果: 若主串 S 中存在和串 T 值相同的子串, 则返回它在主串 S 中第pos个字符之后第一次出现的位置;否则函数值为0。 假设 S = abcaabcaaabc , T = bca Index(S, T, 3) = 6; Index(S, T, 1) = 2; Index(S, T, 8) = 0;
 = 6; Index(S, T, 1) = 2; Index(S, T, 8) = 0;")
15
Replace (&S, T, V) 初始条件:串S, T和 V 均已存在,且 T 是非空串。 操作结果:用 V 替换主串 S 中出现的所有与(模式串)T 相等的不重叠的子串。
假设 S = abcaabcaaabca, T = bca bca bca bca 若 V = x, 则经置换后得到 S = axaxaax 注意定义中"不重叠"三个字 若 V = bc, 则经置换后得到 S = abcabcaabc 而不是S = abcbcbc

16
StrInsert (&S, pos, T) 初始条件:串S和T已存在,
1≤pos≤StrLength(S)+1。 操作结果:在串S的第pos个字符之前插入串T。 例如:S = chater,T = rac, 则执行 StrInsert(S, 4, T) 之后得到 S = character
+1。 操作结果:在串S的第pos个字符之前插入串T。 例如:S = chater,T = rac, 则执行 StrInsert(S, 4, T) 之后得到 S = character")
17
ClearString (&S) 初始条件:串S已存在。 操作结果:将S清为空串。
StrDelete (&S, pos, len) 初始条件:串S已存在,1≤pos≤StrLength(S)-len+1。 操作结果:从串S中删除第pos个字符起长度为len的子串。 ClearString (&S) 初始条件:串S已存在。 操作结果:将S清为空串。 }ADT String
 初始条件:串S已存在,1≤pos≤StrLength(S)-len+1。 操作结果:从串S中删除第pos个字符起长度为len的子串。 ClearString (&S) 初始条件:串S已存在。 操作结果:将S清为空串。 }ADT String.")
18
对于串的基本操作集可以有不同的定义方法。在使用高级程序设计语言中的串类型时,应以该语言的参考手册为准。
例如:C语言函数库中提供下列串处理函数: gets(str) 输入一个串; puts(str) 输出一个串; strcat(str1, str2) 串联接函数; strcpy(str1, str2, k) 串复制函数; strcmp(str1, str2) 串比较函数; strlen(str) 求串长函数;
 输入一个串; puts(str) 输出一个串; strcat(str1, str2) 串联接函数; strcpy(str1, str2, k) 串复制函数; strcmp(str1, str2) 串比较函数; strlen(str) 求串长函数;")
19
在上述抽象数据类型定义的13种操作中, 串赋值StrAssign、串复制StrCopy、串比较StrCompare、求串长StrLength、串联接Concat 、以及求子串SubString等六种操作构成串类型的最小操作子集。 即:这些操作不可能利用其它串操作来实现, 反之,其它串操作(除串清除ClearString和串销毁 DestroyString外)可在这个最小操作子集上实现。
可在这个最小操作子集上实现。")
20
? 0 例如,可利用串比较、求串长和求子串等操作实现定位函数 Index( S, T, pos )。 i 算法的基本思想为:
? 0 StrCompare(SubString(S, i, StrLength(T)), T ) i S 串 pos n-m+1 T 串 T 串
), T ) i. S 串. pos. n-m+1. T 串. T 串.")
21
int Index (String S, String T, int pos)
{ // T为非空串。若主串S中第pos个字符之后存在与 T相等的子串, // 则返回第一个这样的子串在S中的位置,否则返回0 if (pos > 0) { } // if return 0; // S中不存在与T相等的子串 } // Index n = StrLength(S); m = StrLength(T); i = pos; while ( i <= n-m+1) { } // while SubString (sub, S, i, m); if (StrCompare(sub, T) != 0) ++i ; else return i ;
 { } // if. return 0; // S中不存在与T相等的子串. } // Index. n = StrLength(S); m = StrLength(T); i = pos; while ( i <= n-m+1) { } // while. SubString (sub, S, i, m); if (StrCompare(sub, T) != 0) ++i ; else return i ;")
22
又如串的替换函数: pos pos = i+m i pos S 串 sub n-pos+1 T 串 V 串 news 串 sub V 串

23
void Replace(String& S, String T, String V) {
} n=StrLength(S); m=StrLength(T); pos = 1; StrAssign(news, NullStr); i=1; while ( pos <= n-m+1 && i) { i=Index(S, T, pos); if (i!=0) { SubString(sub, S, pos, i-pos); // 不替换子串 Concat(news, news, sub); Concat(news, news, V); pos = i+m; }//if }//while SubString(sub, S, pos, n-pos+1); // 剩余串 Concat(S, news, sub);
; m=StrLength(T); pos = 1; StrAssign(news, NullStr); i=1; while ( pos <= n-m+1 && i) { i=Index(S, T, pos); if (i!=0) { SubString(sub, S, pos, i-pos); // 不替换子串. Concat(news, news, sub); Concat(news, news, V); pos = i+m; }//if. }//while. SubString(sub, S, pos, n-pos+1); // 剩余串. Concat(S, news, sub);")
24
4.2 串的表示和实现 在程序设计语言中,串只是作为输入或输出的常量出现,则只需存储此串的串值,即字符序列即可。但是,在多数非数值处理的程序中,串也以变量的形式出现。

25
内 容 定长顺序存储表示 4.2.1 块链存储表示 4.2.2 堆分配存储表示 4.2.3

26
4.2.1 定长顺序存储表示 也称为静态存储分配的顺序表。它是用一组连续的存储单元来存放串中的字符序列。所谓定长顺序存储结构,是直接使用定长的字符数组来定义,数组的上界预先给出: #define MAXSTRLEN 255 // 用户可在255以内定义最大串长 typedef unsigned char SString [MAXSTRLEN + 1]; // 0号单元存放串的长度

27
串的实际长度可在这个预定义长度的范围内随意设定,超过预定义长度的串值则被舍去,称之为“截断” 。
特 点 串的实际长度可在这个预定义长度的范围内随意设定,超过预定义长度的串值则被舍去,称之为“截断” 。 对串长有两种表示: 1. 以下标为0的数组分量存放串的长度,如:Pascal语言中的串类型。

28
按这种串的表示方法实现的串的运算时,其基本操作为 “字符序列的复制”。
2. 在串值后面加一个不记入串长的结束标记字符,如:C语言中规定了一个“串的结束标志 '\0'”(字符 '\0'称为空终结符)。 按这种串的表示方法实现的串的运算时,其基本操作为 “字符序列的复制”。
。 按这种串的表示方法实现的串的运算时,其基本操作为 字符序列的复制 。")
29
串的联接算法中需分三种情况处理 Concat(SString &T, SString S1, SString S2) T S1 S2
1、S1[0]+S2[0] ≤ MAXSTRLEN,得到的串T值是正确的结果 2、S1[0]< MAXSTRLEN,而S1[0]+S2[0] > MAXSTRLEN,串S2的一部分将“截断”。 串的实际长度可在预定义长度的范围内随意,超过预定义长度的值则截去 3、 S1[0]= MAXSTRLEN,得到的串值并非联接的结果,而和串S1相等。

30
串联接算法 Status Concat(SString &T, SString S1, SString S2)
{ // 用T返回由S1和S2联接而成的新串。若未截断,则返回TRUE,否则FALSE。 if (S1[0]+S2[0] <= MAXSTRLEN) { // 未截断 S1的串长 T[1..S1[0]] = S1[1..S1[0]]; T[S1[0]+1..S1[0]+S2[0]] = S2[1..S2[0]]; T[0] = S1[0]+S2[0]; uncut = TRUE; }
 { // 未截断. S1的串长. T[1..S1[0]] = S1[1..S1[0]]; T[S1[0]+1..S1[0]+S2[0]] = S2[1..S2[0]]; T[0] = S1[0]+S2[0]; uncut = TRUE; }")
31
else if (S1[0] <MAXSTRSIZE)
{ // 截断 T[1..S1[0]] = S1[1..S1[0]]; T[S1[0]+1..MAXSTRLEN] = S2[1..MAXSTRLEN-S1[0]]; T[0] = MAXSTRLEN; uncut = FALSE; }
![else if (S1[0] <MAXSTRSIZE)](http://slidesplayer.com/slide/14444313/90/images/31/else+if+%28S1%5B0%5D+%3CMAXSTRSIZE%29.jpg "{ // 截断. T[1..S1[0]] = S1[1..S1[0]]; T[S1[0]+1..MAXSTRLEN] = S2[1..MAXSTRLEN-S1[0]]; T[0] = MAXSTRLEN; uncut = FALSE; }")
32
else { // 截断(仅取S1) T[0..MAXSTRLEN] = S1[0..MAXSTRLEN]; // T[0] == S1[0] == MAXSTRLEN uncut = FALSE; } return uncut; } // Concat
![else { // 截断(仅取S1) T[0..MAXSTRLEN] = S1[0..MAXSTRLEN]; // T[0] == S1[0] == MAXSTRLEN. uncut = FALSE;](http://slidesplayer.com/slide/14444313/90/images/32/else+%7B+%2F%2F+%E6%88%AA%E6%96%AD%28%E4%BB%85%E5%8F%96S1%29+T%5B0..MAXSTRLEN%5D+%3D+S1%5B0..MAXSTRLEN%5D%3B+%2F%2F+T%5B0%5D+%3D%3D+S1%5B0%5D+%3D%3D+MAXSTRLEN.+uncut+%3D+FALSE%3B.jpg "} return uncut; } // Concat.")
33
void Concat( char T[ ], char S1[ ], char S2[ ])
{// 以T返回由S1和S2联接而成的新串 j=0; k=0; while ( S1[j] != '\0') T[k++] = S1[j++]; // 复制串 S1 j = 0; while ( S2[j] != '\0') T[k++] = S2[j++]; // 紧接着复制串 S2 T[k] = '\0'; // 置结果串T的结束标志 } // Concat_Sq
![void Concat( char T[ ], char S1[ ], char S2[ ])](http://slidesplayer.com/slide/14444313/90/images/33/void+Concat%28+char+T%5B+%5D%2C+char+S1%5B+%5D%2C+char+S2%5B+%5D%29.jpg "{// 以T返回由S1和S2联接而成的新串 j=0; k=0; while ( S1[j] != \0 ) T[k++] = S1[j++]; // 复制串 S1 j = 0; while ( S2[j] != \0 ) T[k++] = S2[j++]; // 紧接着复制串 S2 T[k] = \0 ; // 置结果串T的结束标志 } // Concat_Sq.")
34
bool SubString ( char Sub[ ], char S, int pos, int len )
{ // 若参数合法(即1≤pos≤StrLength(S) 且 //0≤len≤StrLength(S)-pos+1),则以Sub带回串S中第pos个字符起 //长度为len的子串,并返回TRUE,否则返回FALSE slen=StrLength(S); // 求串S的长度 if (pos < 1 || pos > slen || len < 0 || len > slen-pos+1) return FALSE; for ( j = 0; j < len; j++ ) Sub[ j ] = S[pos + j -1]; // 向子串Sub复制字符 Sub[len] = '\0'; // 置串Sub的结束标志 return TRUE; } // SubString
![bool SubString ( char Sub[ ], char S, int pos, int len )](http://slidesplayer.com/slide/14444313/90/images/34/bool+SubString+%28+char+Sub%5B+%5D%2C+char+S%2C+int+pos%2C+int+len+%29.jpg "{ // 若参数合法(即1≤pos≤StrLength(S) 且. //0≤len≤StrLength(S)-pos+1),则以Sub带回串S中第pos个字符起. //长度为len的子串,并返回TRUE,否则返回FALSE slen=StrLength(S); // 求串S的长度 if (pos < 1 || pos > slen || len < 0 || len > slen-pos+1) return FALSE; for ( j = 0; j < len; j++ ) Sub[ j ] = S[pos + j -1]; // 向子串Sub复制字符 Sub[len] = \0 ; // 置串Sub的结束标志 return TRUE; } // SubString.")
35
4.2.2 块链存储表示 用链表存储串值 类型定义 ch next #define SIZE 80 typedef struct Node{
char ch[SIZE]; struct Node *next; }Node; typedef struct{ Node *head, *tail; int curlen; }LString; 设立尾指针是为了便于进行联结操作

36
存在结点大小问题:即每个结点的ch域可以存放一个字符,也可以存放多个字符
如:S=“ABCDEFG” 结点大小为1 A B F G … ∧ h

37
h 数据元素所占存储位 存储密度 = 实际分配的存储位 A C ∧ D E F G B
结点大小为4 A C ∧ h D E F G B 当结点大小大于1时,由于串长不一定是结点大小的整数倍,则链表中的最后一个结点的ch域不一定会被串值占满,此时通常补上非串值字符,如:#、空白字符等。 数据元素所占存储位 存储密度 = 实际分配的存储位

38
优点:插入、删除操作容易 结点大小为1时 缺点:存储密度低,存储占用量大,访问效率低 优点:存储密度高,访问效率高 结点大小大于1时 缺点:插入、删除等操作复杂

39
4.2.3 堆分配存储表示 定义:系统将一个容量很大、地址连续的存储空间作为串值的可利用空间,在程序执行过程中动态分配,该存储空间称之为“堆”, 也称为动态存储分配的顺序表。 typedef struct { char *ch; // 若是非空串,则按串实际长度分配存储区,否则 ch 为NULL int length; // 串长度 } HString;

40
通常,C语言中提供的串类型就是以这种存储方式实现的。系统利用函数malloc( ) 和 free( ) 进行串值空间的动态管理,为每一个新产生的串分配一个存储区,称串值共享的存储空间为“堆”。
这类串操作实现的算法为: 先为新生成的串分配一个存储空间,然后进行串值的复制。

41
void StrInsert (HString& S, int pos, HString T)
{ // 1≤pos≤StrLength(S)+1。在串 S 的 // 第 pos 个字符之前插入串 T slen=S.length; tlen=T.length; // 取得S和T的串长 if (pos < 1 || pos > slen+1) return; // 插入位置不合法 S1.ch = new char[slen] ; // S1作为辅助串 S1.ch[0..slen-1] = S.ch[0..slen-1]; // 暂存 S if (tlen>0) // T 非空,则为S重新分配空间并插入T { } } // StrInsert _HSq ……
+1。在串 S 的. // 第 pos 个字符之前插入串 T. slen=S.length; tlen=T.length; // 取得S和T的串长. if (pos < 1 || pos > slen+1) return; // 插入位置不合法. S1.ch = new char[slen] ; // S1作为辅助串. S1.ch[0..slen-1] = S.ch[0..slen-1]; // 暂存 S. if (tlen>0) // T 非空,则为S重新分配空间并插入T. { } } // StrInsert _HSq. ……")
42
S.ch = new char[slen + tlen ];
for ( i=0, k=0; i<pos-1; i++) S.ch[k++] = S1.ch[i]; // 保留插入位置之前的子串 for ( i=0; i<tlen; i++) S.ch[k++] = T.ch[i]; // 插入T for ( i=pos; i<slen; i++ ) S.ch[k++] = S1.ch[i]; // 复制插入位置之后的子串 S.length = slen+tlen; delete S1.ch;
![S.ch = new char[slen + tlen ];](http://slidesplayer.com/slide/14444313/90/images/42/S.ch+%3D+new+char%5Bslen+%2B+tlen+%5D%3B.jpg "for ( i=0, k=0; i<pos-1; i++) S.ch[k++] = S1.ch[i]; // 保留插入位置之前的子串. for ( i=0; i<tlen; i++) S.ch[k++] = T.ch[i]; // 插入T. for ( i=pos; i<slen; i++ ) S.ch[k++] = S1.ch[i]; // 复制插入位置之后的子串. S.length = slen+tlen; delete S1.ch;")
43
bool StrInsert (HString& S, int pos, HString T)
{ // 若1≤pos≤StrLength(S)+1,则改变串S,在串S的第pos个字符之前插入串T,并返回TRUE,否则串S不变,并返回FALSE char S1[S.length] ; // S1 作为辅助串空间用于暂存 S.ch if (pos < 1 || pos > S.length+1) return FALSE; // 插入位置不合法 if (T.length) { // T 非空,则为S重新分配空间并插入 T p=S.ch; i=0; while (i < S.length) S1[i++] = *(p+i) ; // 暂存串S
+1,则改变串S,在串S的第pos个字符之前插入串T,并返回TRUE,否则串S不变,并返回FALSE char S1[S.length] ; // S1 作为辅助串空间用于暂存 S.ch. if (pos < 1 || pos > S.length+1) return FALSE; // 插入位置不合法 if (T.length) { // T 非空,则为S重新分配空间并插入 T p=S.ch; i=0; while (i < S.length) S1[i++] = *(p+i) ; // 暂存串S.")
44
S.ch = new char[S.length + T.length ];
// 为S重新分配串值存储空间 for ( i=0, k=0; i<pos-1; i++ ) S.ch[ k++ ] = S1[ i ]; // 保留插入位置之前的子串 j = 0; while ( j<T.length ) S.ch[k++] = T.ch[ j++]; // 插入 T while ( i<S.length ) S.ch[k++] = S1[i++]; // 复制插入位置之后的子串 S.length+=T.length; // 置串 S 的长度 } // if return TRUE; } // StrInsert
![S.ch = new char[S.length + T.length ];](http://slidesplayer.com/slide/14444313/90/images/44/S.ch+%3D+new+char%5BS.length+%2B+T.length+%5D%3B.jpg "// 为S重新分配串值存储空间 for ( i=0, k=0; i<pos-1; i++ ) S.ch[ k++ ] = S1[ i ]; // 保留插入位置之前的子串 j = 0; while ( j<T.length ) S.ch[k++] = T.ch[ j++]; // 插入 T while ( i<S.length ) S.ch[k++] = S1[i++]; // 复制插入位置之后的子串 S.length+=T.length; // 置串 S 的长度 } // if return TRUE; } // StrInsert.")
45
4.3 串的模式匹配算法 首先,回忆一下串匹配(查找)的定义: Index (S, T, pos)
4.3 串的模式匹配算法 首先,回忆一下串匹配(查找)的定义: Index (S, T, pos) 初始条件:串 S 和 T 存在,T 是非空串, 1≤pos≤StrLength(S)。 操作结果:若主串 S 中存在和模式串 T 值相同的子串,则返回它在主串 S 中第 pos 个字符之后第一次出现的位置;否则函数值为0。
的定义: Index (S, T, pos) 初始条件:串 S 和 T 存在,T 是非空串, 1≤pos≤StrLength(S)。 操作结果:若主串 S 中存在和模式串 T 值相同的子串,则返回它在主串 S 中第 pos 个字符之后第一次出现的位置;否则函数值为0。")
46
定义在串中寻找子串(第一个字符)在串中的位置。
词汇在模式匹配中,子串称为模式,串称为目标。 示例目标T :“Beijing”, 模式P :“jin”, 匹配结果= 3

47
串的模式匹配算法 串的模式匹配算法解决的是在长串中查找短串的一个、多个或所有出现的问题。
(哲学视点:在“外面的世界”寻找“小小的我”的位置) 通常,我们称长串为text,称短串为pattern。 一个长度为m的pattern可被表述为y=y[1..m];长度为n作用的text可被表述为x=x[1..n];而模式匹配的任务是找到y在x中的出现。 模式匹配过程中,程序会查看text中长度为m的窗口,即用pattern串和text的窗口中的子串进行比对。比对完成后,将窗口向右滑动,并不断重复这一过程。直到根据需要找到所需匹配为止。这种机制被称为滑动窗口机制。 我们所讨论的模式匹配算法都是基于滑动窗口机制的算法。
 通常,我们称长串为text,称短串为pattern。 一个长度为m的pattern可被表述为y=y[1..m];长度为n作用的text可被表述为x=x[1..n];而模式匹配的任务是找到y在x中的出现。 模式匹配过程中,程序会查看text中长度为m的窗口,即用pattern串和text的窗口中的子串进行比对。比对完成后,将窗口向右滑动,并不断重复这一过程。直到根据需要找到所需匹配为止。这种机制被称为滑动窗口机制。 我们所讨论的模式匹配算法都是基于滑动窗口机制的算法。")
48
基于顺序存储的串模式匹配算法 一、简单算法(Brute-Force) 二、KMP(D. E. Knuth, V. R. Pratt,
J. H. Morris) 算法
 算法.")
49
BF(Brute-Force)算法 BF算法是最基本的串模式匹配算法,Index函数就是利用BF算法实现的。
其过程是:依次比对pattern 和滑动窗口中的对应位置上的字符;比对完成后将滑动窗口向右移动1,直到找到所需的匹配为止。 22

50
串的模式匹配(基本算法) fail ! fail ! success ! b a c P= a b c P= a b c P= a b c
T= b a c fail ! P= a b c fail ! P= a b c success ! P= a b c

51
Brute-Force算法示例 23 第一轮比较: y x
C G T A G C G T C T C T C A T A T G T C A T G C C G T C T C T C 比较窗口右移 1 个位置 第二轮比较: y x C G T A G C G T C T C T C A T A T G T C A T G C 1 C G T C T C T C 比较窗口右移 1 个位置 第三轮比较: y x C G T A G C G T C T C T C A T A T G T C A T G C 1 C G T C T C T C 比较窗口右移 1 个位置 ... 第六轮比较: y x C G T A G C G T C T C T C A T A T G T C A T G C C G T C T C T C 找到子串,程序结束 Brute-Force算法示例 23

52
int Index(SString S, SString T, int pos)
{// 返回子串T在主串S中第pos个字符之后的位置。若不存在, // 则函数值为0。 其中,T非空,1≤pos≤StrLength(S)。 i = pos; j = 1; while (i <= S[0] && j <= T[0]) { if (S[i] == T[j]) { ++i; ++j; }// 继续比较后继字符 else { i = i-j+2; j = 1; } // 指针(i和j)后退重新开始匹配 } if (j > T[0]) return i-T[0]; else return 0; } // Index O(m*n) 算法速度慢的原因在于回溯
。 i = pos; j = 1; while (i <= S[0] && j <= T[0]) { if (S[i] == T[j]) { ++i; ++j; }// 继续比较后继字符. else { i = i-j+2; j = 1; } // 指针(i和j)后退重新开始匹配. } if (j > T[0]) return i-T[0]; else return 0; } // Index. O(m*n) 算法速度慢的原因在于回溯.")
53
BF算法的特点总结 (1) 不需要预处理过程; (2) 只需固定的存储空间; (3) 滑动窗口的移动每次都为1;
(4) 字符串的比对可按任意顺序进行(从左到 右、从右到左、或特定顺序均可); (5) 算法的时间复杂性为O(m×n); (6) 最大比较次数为(n-m+1)× m。 25
 字符串的比对可按任意顺序进行(从左到. 右、从右到左、或特定顺序均可); (5) 算法的时间复杂性为O(m×n); (6) 最大比较次数为(n-m+1)× m。 25.")
54
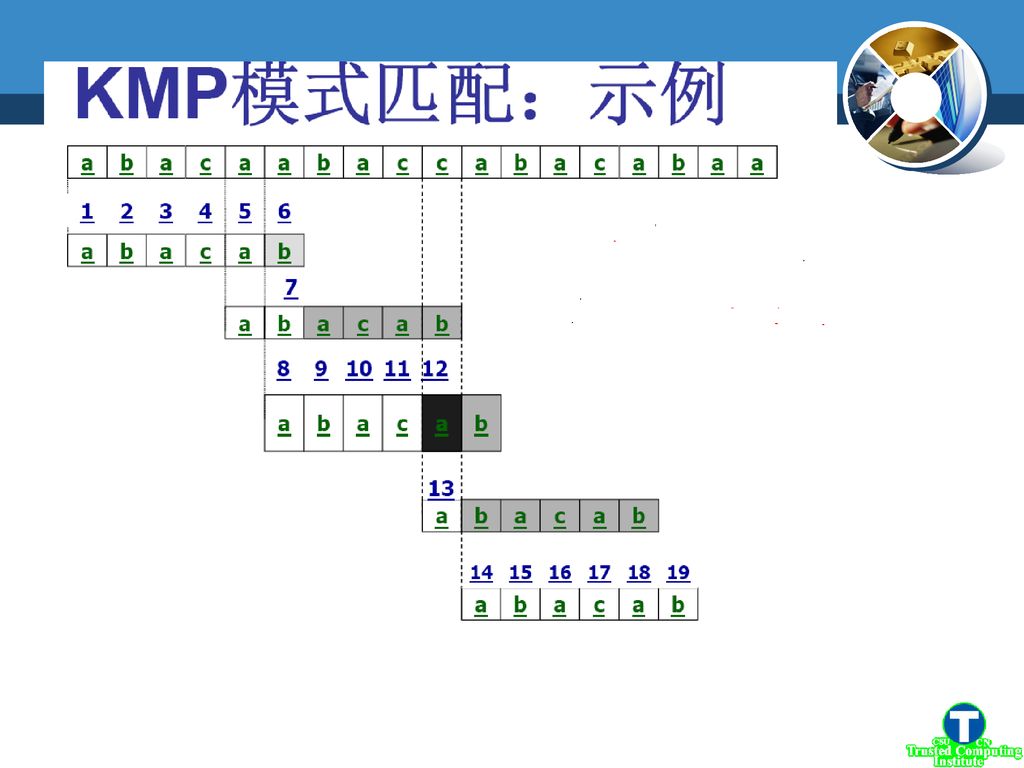
二、KMP 算法 朴素的串匹配算法(BF)存在的不足: 每一轮匹配过程中出现字符比较不等(即失配)时,i指针需要回溯(即模式右移一位)。
KMP算法,旨在利用pattern的内容指导滑动窗口向右滑动距离k。

55
KMP (Knuth-Morris-Pratt)算法
Knuth-Morris-Pratt (KMP) 算法发现每个字符对应 的该k值仅依赖于模式P本身,与目标对象T无关 1970年,S. A. Cook在进行抽象机的理论研究 时证明了在最差情况下模式匹配可在N+M时间 内完成 此后,D. E. Knuth 和V. R. Pratt以此理论为基 础,构造了一种方法来在N+M时间内进行模式 匹配,与此同时,J. H. Morris在开发文本编辑 器时为了避免在检索文本时的回溯也得到了同 样的算法 33
 算法发现每个字符对应. 的该k值仅依赖于模式P本身,与目标对象T无关. 1970年,S. A. Cook在进行抽象机的理论研究. 时证明了在最差情况下模式匹配可在N+M时间. 内完成. 此后,D. E. Knuth 和V. R. Pratt以此理论为基. 础,构造了一种方法来在N+M时间内进行模式. 匹配,与此同时,J. H. Morris在开发文本编辑. 器时为了避免在检索文本时的回溯也得到了同. 样的算法. 33.")
56
KMP (Knuth-Morris-Pratt)算法
BF算法每次比较的窗口向右滑动的距离均为1。 KMP算法,旨在利用pattern的内容指导滑动窗口(模式)向右滑动的距离 k。 32
向右滑动的距离 k。 32.")
57
主要思想:在“失配”发生时,利用已有的工作
KMP 主要思想:在“失配”发生时,利用已有的工作 T= b a c fail ! P= a b c 根据P预先计算 reuse ! P= a b c

58
KMP算法思想 (朴素匹配的)下一趟一定不匹配!可以跳过去,也即模式右 移一位后依然不匹配!
T T1 … Ti-j-1 Ti-j Ti-j+1 Ti-j+2 … Ti-2 Ti-1 Ti … Tn-1 ǁ ǁ ǁ ǁ P 则有 如果 p p2 … pj-2 pj -1 pj Ti-j+1 Ti-j+2 … Ti-1 = p1 p2 …pj-1 p1p2 …pj-2 p2 p3 …pj-1 (1) (2) 则立刻可以断定 p1 p2…pj-2 Ti-j+2 Ti-j+3 … Ti-1 (朴素匹配的)下一趟一定不匹配!可以跳过去,也即模式右 移一位后依然不匹配!
 (2) 则立刻可以断定. p1 p2…pj-2 Ti-j+2 Ti-j+3 … Ti-1. (朴素匹配的)下一趟一定不匹配!可以跳过去,也即模式右. 移一位后依然不匹配!")
59
模式右移j-k-1位 同样,若 p1 p2 …pj-3 p3 p4 …pj-1
KMP算法思想 同样,若 p1 p2 …pj-3 p3 p4 …pj-1 而且 p3 p4 …pj-1= Ti-j+3 Ti-j+4 … Ti-1 则模式右移2位也不匹配,因为有p1 p2 …pj-3 Ti-j+3 Ti-j+4 … Ti-1 直到对于某一个“k”值,使得:p1 p2 …pk pj-k pj-k+1 …pj-1 p1 p2 …pk-1 = pj-k +1 pj-k+2 …pj-1 p1 p2 …pk-1 = Ti-k Ti-k+2 … Ti-1 Ti 且 则 ǁ ǁ ǁ pj-k+1 pj-k+2 … pj-1 pj ǁ ǁ ǁ 模式右移j-k-1位 p1 p2 … pk-1 pk

60
KMP算法的关键:模式本身 模式右移j-k-1位 关键:对每个pj,如何求k值 ??即 当Ti 与pj失配时,Ti应与模式中pk比较。
Ti-j+1 Ti-j+2 Ti-j+3 … Ti-k Ti-k+1 … Ti Ti ǁ ǁ ǁ ǁ ǁ ǁ p p2 p3 … pj-k pj-k+1 … pj-1 pj ǁ ǁ ǁ p1 p2 … pk-1 pk 当Ti 与pj失配时,Ti应与模式中pk比较。 关键:对每个pj,如何求k值 ??即 即特征向量NEXT

61
定义:模式串的特征向量next函数 P= A B A B A B A B C A next[i]=
![定义:模式串的特征向量next函数 P= A B A B A B A B C A next[i]=](http://slidesplayer.com/slide/14444313/90/images/61/%E5%AE%9A%E4%B9%89%EF%BC%9A%E6%A8%A1%E5%BC%8F%E4%B8%B2%E7%9A%84%E7%89%B9%E5%BE%81%E5%90%91%E9%87%8Fnext%E5%87%BD%E6%95%B0+P%3D+A+B+A+B+A+B+A+B+C+A+next%5Bi%5D%3D.jpg "定义:模式串的特征向量next函数 P= A B A B A B A B C A next[i]=")
62
int Index_KMP(SString T, SString P, int pos)
{ // 1≤pos≤StrLength(T) i = pos; j = 1; while (i <= T[0] && j <= P[0]) { if (j = 0 || T[i] == P[j]) { ++i; ++j; } // 继续比较后继字符 else j = next[j]; // 模式串向右移动 }//while if (j > P[0]) return i-P[0]; // 匹配成功 else return 0; } // Index_KMP (算法中,如果i不动,则模式右移,故时间复杂度为O(n+m)
 i = pos; j = 1; while (i <= T[0] && j <= P[0]) { if (j = 0 || T[i] == P[j]) { ++i; ++j; } // 继续比较后继字符. else j = next[j]; // 模式串向右移动. }//while. if (j > P[0]) return i-P[0]; // 匹配成功. else return 0; } // Index_KMP. (算法中,如果i不动,则模式右移,故时间复杂度为O(n+m)")
63
对模式的预处理过程—求特征向量next 求 next 函数值的过程是一个递推过程,分析如下: 已知:next[1] = 0;
假设:next[j] = k; 若: P[j] = P[k],则: next[j+1] = k+1 若: P[j] P[k],则需往前回溯,检查 P[j] == P[ k’]? k’=next[k] 这实际上也是一个匹配的过程,不同在于:主串和模式串是同一个串。
![对模式的预处理过程—求特征向量next 求 next 函数值的过程是一个递推过程,分析如下: 已知:next[1] = 0;](http://slidesplayer.com/slide/14444313/90/images/63/%E5%AF%B9%E6%A8%A1%E5%BC%8F%E7%9A%84%E9%A2%84%E5%A4%84%E7%90%86%E8%BF%87%E7%A8%8B%E2%80%94%E6%B1%82%E7%89%B9%E5%BE%81%E5%90%91%E9%87%8Fnext+%E6%B1%82+next+%E5%87%BD%E6%95%B0%E5%80%BC%E7%9A%84%E8%BF%87%E7%A8%8B%E6%98%AF%E4%B8%80%E4%B8%AA%E9%80%92%E6%8E%A8%E8%BF%87%E7%A8%8B%EF%BC%8C%E5%88%86%E6%9E%90%E5%A6%82%E4%B8%8B%3A+%E5%B7%B2%E7%9F%A5%EF%BC%9Anext%5B1%5D+%3D+0%EF%BC%9B.jpg "假设:next[j] = k; 若: P[j] = P[k],则: next[j+1] = k+1. 若: P[j] P[k],则需往前回溯,检查 P[j] == P[ k’] k’=next[k] 这实际上也是一个匹配的过程,不同在于:主串和模式串是同一个串。")
64
void get_next(SString & P, int &next[] ) { // 求模式串T的next函数值并存入数组next。
j = 1; next[1] = 0; k = 0; while (j < P[0]) { if (k == 0 || P[j] == P[k]) {++j; ++k; next[j] = k; } else k = next[k]; //同样采用KMP算法思想 } } // get_next 算法复杂度:O(m),由于模式通常很短(m相比文本串长度n来说很小),因此,预处理增加的时间可以忽略不计。
![void get_next(SString & P, int &next[] ) { // 求模式串T的next函数值并存入数组next。](http://slidesplayer.com/slide/14444313/90/images/64/void+get_next%28SString+%26+P%2C+int+%26next%5B%5D+%29+%7B+%2F%2F+%E6%B1%82%E6%A8%A1%E5%BC%8F%E4%B8%B2T%E7%9A%84next%E5%87%BD%E6%95%B0%E5%80%BC%E5%B9%B6%E5%AD%98%E5%85%A5%E6%95%B0%E7%BB%84next%E3%80%82.jpg "j = 1; next[1] = 0; k = 0; while (j < P[0]) { if (k == 0 || P[j] == P[k]) {++j; ++k; next[j] = k; } else k = next[k]; //同样采用KMP算法思想. } } // get_next. 算法复杂度:O(m),由于模式通常很短(m相比文本串长度n来说很小),因此,预处理增加的时间可以忽略不计。")
65
i x[i] Next[i] C G T C T C T C
![i x[i] Next[i] C G T C T C T C](http://slidesplayer.com/slide/14444313/90/images/65/i+x%5Bi%5D+Next%5Bi%5D+C+G+T+C+T+C+T+C.jpg "i x[i] Next[i] C G T C T C T C")
68
字符串处理的相关应用 1.遗传算法(GA): 种群(个体)的编码:字符串 选择(selection by rules)个体
交叉(crossover):产生新个体 变异(Mutation) 2. 分段模型( Segmentation Model) 英文分段很简单(如:I am chinese) 中文不好分(如:我明天要去湘潭),怎么分?
:产生新个体. 变异(Mutation) 2. 分段模型( Segmentation Model) 英文分段很简单(如:I am chinese) 中文不好分(如:我明天要去湘潭),怎么分?")
Similar presentations

>")









 6-1 佇列的基礎 6-2 佇列的表示法 6-3 環狀佇列 6-4 雙佇列.>")

.>")




>")

.>")