Download presentation
Presentation is loading. Please wait.

1
本投影片修改自Introduction to Information Retrieval一書之投影片 Ch 16 & 17
Lecture 4 : Clustering 楊立偉教授 本投影片修改自Introduction to Information Retrieval一書之投影片 Ch 16 & 17

2
Clustering : Introduction

3
Clustering: Definition
(Document) clustering is the process of grouping a set of documents into clusters of similar documents. Documents within a cluster should be similar. Documents from different clusters should be dissimilar. Clustering is the most common form of unsupervised learning. Unsupervised = there are no labeled or annotated data. 3
 clustering is the process of grouping a set of documents into clusters of similar documents. Documents within a cluster should be similar. Documents from different clusters should be dissimilar. Clustering is the most common form of unsupervised learning. Unsupervised = there are no labeled or annotated data. 3.")
4
Data set with clear cluster structure
Propose algorithm for finding the cluster structure in this example 4

5
Classification vs. Clustering
Supervised learning Classes are human-defined and part of the input to the learning algorithm. Clustering Unsupervised learning Clusters are inferred from the data without human input. 5

6
Why cluster documents? Whole corpus analysis/navigation
Better user interface 提供文件集合的分析與導覽 For improving recall in search applications Better search results 提供更好的搜尋結果 For better navigation of search results Effective "user recall" will be higher 搜尋結果導覽 For speeding up vector space retrieval Faster search 加快搜尋速度

7
For visualizing a document collection
Wise et al, "Visualizing the non-visual" PNNL ThemeScapes, Cartia [Mountain height = cluster size]

8
For improving search recall
Cluster hypothesis - "closely associated documents tend to be relevant to the same requests". Therefore, to improve search recall: Cluster docs in corpus 先將文件做分群 When a query matches a doc D, also return other docs in the cluster containing D 也建議符合的整群 Hope if we do this: The query “car” will also return docs containing automobile Because clustering grouped together docs containing car with those containing automobile. Why might this happen? 具有類似的文件特徵

9
For better navigation of search results
For grouping search results thematically clusty.com / Vivisimo (Enterprise Search – Velocity)
")
11
Issues for clustering (1)
General goal: put related docs in the same cluster, put unrelated docs in different clusters. Representation for clustering Document representation 如何表示一篇文件 Need a notion of similarity/distance 如何表示相似度 whittle 削切

12
Issues for clustering (2)
How to decide the number of clusters Fixed a priori : assume the number of clusters K is given. Data driven : semiautomatic methods for determining K Avoid very small and very large clusters Define clusters that are easy to explain to the user whittle 削切

13
Clustering Algorithms
Flat (Partitional) algorithms 無階層的聚類演算法 Usually start with a random (partial) partitioning Refine it iteratively 不斷地修正調整 K means clustering Hierarchical algorithms 有階層的聚類演算法 Create a hierarchy Bottom-up, agglomerative 由下往上聚合 Top-down, divisive 由上往下分裂
 algorithms 無階層的聚類演算法. Usually start with a random (partial) partitioning. Refine it iteratively 不斷地修正調整. K means clustering. Hierarchical algorithms 有階層的聚類演算法. Create a hierarchy. Bottom-up, agglomerative 由下往上聚合. Top-down, divisive 由上往下分裂.")
14
Flat (Partitioning) Algorithms
Partitioning method: Construct a partition of n documents into a set of K clusters 將 n 篇文件分到 K 群中 Given: a set of documents and the number K Find: a partition of K clusters that optimizes the chosen partitioning criterion Globally optimal: exhaustively enumerate all partitions 找出最佳切割 → 通常很耗時 Effective heuristic methods: K-means and K-medoids algorithms 用經驗法則找出近似解即可

15
Hard vs. Soft clustering
Hard clustering: Each document belongs to exactly one cluster. More common and easier to do Soft clustering: A document can belong to more than one cluster. For applications like creating browsable hierarchies Ex. Put sneakers in two clusters: sports apparel, shoes You can only do that with a soft clustering approach. *only hard clustering is discussed in this class. 15

16
K-means algorithm

17
K-means Perhaps the best known clustering algorithm
Simple, works well in many cases Use as default / baseline for clustering documents 17

18
K-means In vector space model, Assumes documents are real-valued vectors. Clusters based on centroids (aka the center of gravity 重心 or mean) of points in a cluster, c: Reassignment of instances to clusters is based on distance to the current cluster centroids.
 of points in a cluster, c: Reassignment of instances to clusters is based on distance to the current cluster centroids.")
19
K-means algorithm 1. Select K random docs {s1, s2,… sK} as seeds. 先挑選種子 2. Until clustering converges or other stopping criterion: 重複下列步驟直到收斂或其它停止條件成立 2.1 For each doc di: 針對每一篇文件 Assign di to the cluster cj such that dist(xi, sj) is minimal. 將該文件加入最近的一群 2.2 For each cluster cj sj = (cj) 以各群的重心為種子,再做一次 (Update the seeds to the centroid of each cluster)
 is minimal. 將該文件加入最近的一群. 2.2 For each cluster cj. sj = (cj) 以各群的重心為種子,再做一次. (Update the seeds to the centroid of each cluster)")
20
K-means algorithm

21
K-means example (K=2) Pick seeds Reassign clusters Compute centroids
Converged! 通常做3至4回就大致穩定(但仍需視資料與群集多寡而調整)
")
22
Termination conditions
Several possibilities, e.g., A fixed number of iterations. 只做固定幾回合 Doc partition unchanged. 群集不再改變 Centroid positions don’t change. 重心不再改變

23
Convergence of K-Means
Why should the K-means algorithm ever reach a fixed point? A state in which clusters don’t change. 收斂 K-means is a special case of a general procedure known as the Expectation Maximization (EM) algorithm. EM is known to converge. Number of iterations could be large. 在理論上一定會收斂,只是要做幾回合的問題 (逼近法,且一開始逼近得快)
 algorithm. EM is known to converge. Number of iterations could be large. 在理論上一定會收斂,只是要做幾回合的問題. (逼近法,且一開始逼近得快)")
24
Convergence of K-Means : 證明
Define goodness measure of cluster k as sum of squared distances from cluster centroid: Gk = Σi (di – ck) (sum over all di in cluster k) G = Σk Gk 計算每一群中文件與中心的距離平方,然後加總 Reassignment monotonically decreases G since each vector is assigned to the closest centroid. 每回合的動作只會讓G越來越小
2 (sum over all di in cluster k) G = Σk Gk. 計算每一群中文件與中心的距離平方,然後加總. Reassignment monotonically decreases G since each vector is assigned to the closest centroid. 每回合的動作只會讓G越來越小.")
25
Time Complexity Computing distance between two docs is O(m) where m is the dimensionality of the vectors. Reassigning clusters: O(Kn) distance computations, or O(Knm). Computing centroids: Each doc gets added once to some centroid: O(nm). Assume these two steps are each done once for I iterations: O(IKnm). 執行 I 回合;分 K 群;n 篇文件;m 個詞 → 慢且不scalable 改善方法:用 近似估計, 抽樣, 選擇 等技巧來加速
 distance computations, or O(Knm). Computing centroids: Each doc gets added once to some centroid: O(nm). Assume these two steps are each done once for I iterations: O(IKnm). 執行 I 回合;分 K 群;n 篇文件;m 個詞 → 慢且不scalable. 改善方法:用 近似估計, 抽樣, 選擇 等技巧來加速.")
26
Issue (1) Seed Choice Results can vary based on random seed selection.
Some seeds can result in poor convergence rate, or convergence to sub-optimal clusterings. Select good seeds using a heuristic (e.g., doc least similar to any existing mean) Try out multiple starting points Example showing sensitivity to seeds In the above, if you start with B and E as centroids you converge to {A,B,C} and {D,E,F} If you start with D and F you converge to {A,B,D,E} {C,F}
 Try out multiple starting points. Example showing. sensitivity to seeds. In the above, if you start. with B and E as centroids. you converge to {A,B,C} and {D,E,F} If you start with D and F. you converge to. {A,B,D,E} {C,F}")
27
Issue (2) How Many Clusters?
Number of clusters K is given Partition n docs into predetermined number of clusters Finding the “right” number of clusters is part of the problem 假設 連應該分成幾群都不知道 Given docs, partition into an “appropriate” number of subsets. E.g., for query results - ideal value of K not known up front - though UI may impose limits. 查詢結果分群時通常不會預先知道該分幾群

28
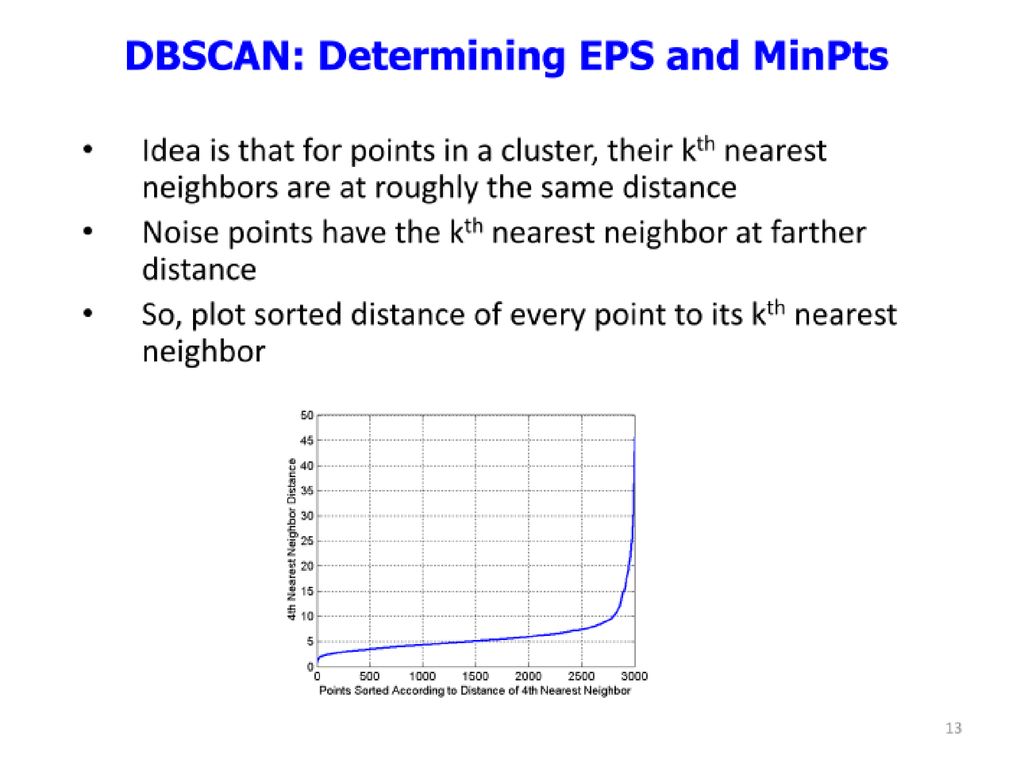
If K not specified in advance
Suggest K automatically using heuristics based on N using K vs. Cluster-size diagram Tradeoff between having less clusters (better focus within each cluster) and having too many clusters 如何取捨
 and having too many clusters. 如何取捨.")
29
方法: 以「組間變異對應 於整體變異的百分比」來 看 (即F檢驗),每增加一 群所能帶來的邊際變異開 始下降的前一點。
Ref: "Determining the number of clusters in a data set", Wikipedia.

30
The Calinski-Harabasz index
群間方差和BGSS越大越好,群內方差和WGSS越小越 好,因此得到的分數越高越好。 Ref: "Clustering Indices", clusterCrit package, R project.

31
K-means variations Recomputing the centroid after every assignment (rather than after all points are re-assigned) can improve speed of convergence of K-means 每個點調整後就重算重心,可以加快收斂 spherical 球面的
 can improve speed of convergence of K-means. 每個點調整後就重算重心,可以加快收斂. spherical 球面的.")
32
Evaluation of Clustering

33
What Is A Good Clustering?
Internal criterion: A good clustering will produce high quality clusters in which: the intra-class (that is, intra-cluster) similarity is high 群內同質性越高越好 the inter-class similarity is low 群間差異大 The measured quality of a clustering depends on both the document representation and the similarity measure used
 similarity is high 群內同質性越高越好. the inter-class similarity is low 群間差異大. The measured quality of a clustering depends on both the document representation and the similarity measure used.")
34
External criteria for clustering quality
Based on a gold standard data set (ground truth) e.g., the Reuters collection we also used for the evaluation of classification Goal: Clustering should reproduce the classes in the gold standard Quality measured by its ability to discover some or all of the hidden patterns 用挑出中間不符合的份子來評估分群好不好
 e.g., the Reuters collection we also used for the evaluation of classification. Goal: Clustering should reproduce the classes in the gold standard. Quality measured by its ability to discover some or all of the hidden patterns. 用挑出中間不符合的份子來評估分群好不好.")
35
External criterion: Purity
Ω= {ω1, ω2, , ωK} is the set of clusters and C = {c1, c2, , cJ} is the set of classes. For each cluster ωk : find class cj with most members nkj in ωk Sum all nkj and divide by total number of points purity是群中最多一類佔該群總數之比例 35

36
Example for computing purity
To compute purity: 5 = maxj |ω1 ∩ cj | (class x, cluster 1) 4 = maxj |ω2 ∩ cj | (class o, cluster 2) 3 = maxj |ω3 ∩ cj | (class ⋄, cluster 3) Purity is (1/17) × ( ) ≈ 0.71. 36
 4 = maxj |ω2 ∩ cj | (class o, cluster 2) 3 = maxj |ω3 ∩ cj | (class ⋄, cluster 3) Purity is (1/17) × ( ) ≈")
37
Rand Index A B C D Number of points Same Cluster in clustering 分在同一群
Different Clusters in clustering 分在不同群 Same class in ground truth 已知同一類 A C Different classes in ground truth 已知不同類 B D

38
Rand index: symmetric version
Compare with standard Precision and Recall.

39
20 24 72 Rand Index example: 0.68 Number of points
Same Cluster in clustering Different Clusters in clustering Same class in ground truth 20 24 Different classes in ground truth 72

40
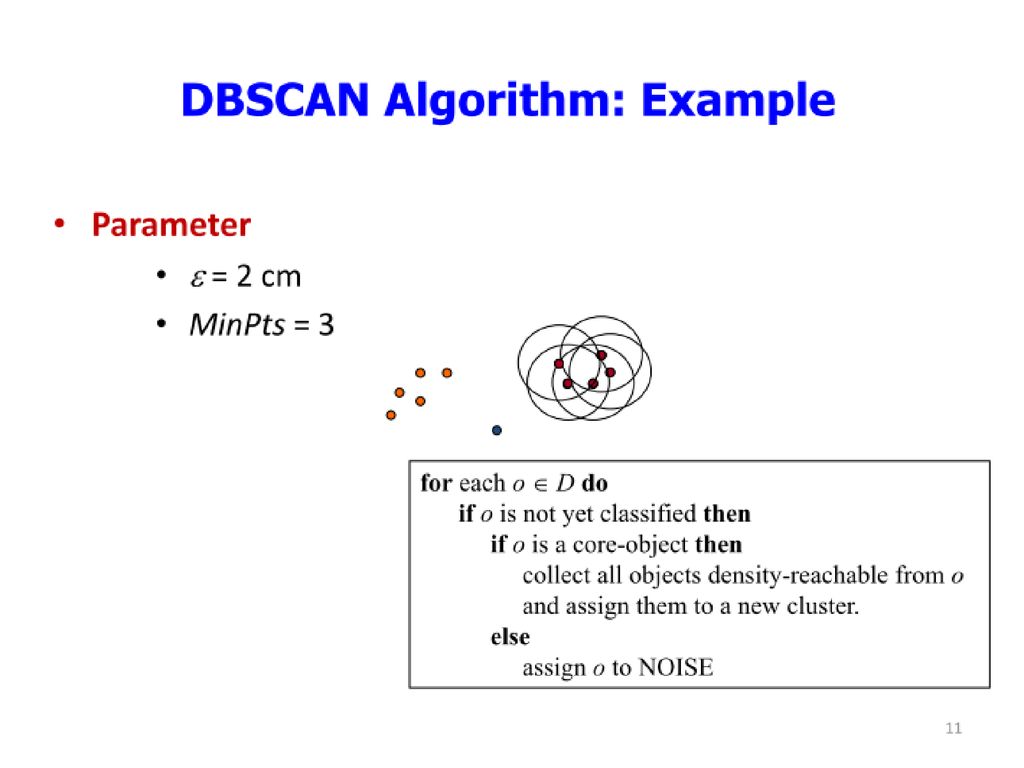
DBSCAN algorithm

41
DBSCAN Density-based clustering : clusters are dense regions in the data space, separated by regions of lower object density. A cluster is defined as a maximal set of density-connected points May discovers clusters of arbitrary shape c.f. K-mean is spherical Ref: Density-Based Spatial Clustering of Applications with Noise 41

42
DBSCAN Definition Eps-neighborhood of point p : points within radius eps from p "High density" : Eps-neighborhood of a point contains at least MinPts of points For radius ɛ, MinPts=4. Density of p is "high" Density of q is "low" 42

43
DBSCAN Core points, Border points, and Noise points
A point is a core point if it has more than a specified number of points (MinPts) within Eps—These are points that are at the interior of a cluster A border point has fewer than MinPts within Eps, but is in the neighborhood of a core point A noise point is any point that is not a core point nor a border point. 43
 within Eps—These are points that are at the interior of a cluster. A border point has fewer than MinPts within Eps, but is in the neighborhood of a core point. A noise point is any point that is not a core point nor a border point. 43.")
44
Example See

45
DBSCAN Directly density-reachable
point q is directly density-reachable from point p if p is a core object and q is in eps-neighborhood of p q is directly density-reachable from p p is not directly density-reachable from q density-reachability is asymmetric MinPts=4 45

51
Visualize the algorithm

52
After clustering.

53
Hierarchical Clustering

54
Hierarchical Clustering
Build a tree-based hierarchical taxonomy (dendrogram) from a set of documents. One approach: recursive application of a partitional clustering algorithm. 可由每一層不斷執行分群演算法所組成 animal vertebrate fish reptile amphib. mammal worm insect crustacean invertebrate Vertebrate 脊索動物
 from a set of documents. One approach: recursive application of a partitional clustering algorithm. 可由每一層不斷執行分群演算法所組成. animal. vertebrate. fish reptile amphib. mammal worm insect crustacean. invertebrate. Vertebrate 脊索動物.")
55
Dendrogram: Hierarchical Clustering
Clustering obtained by cutting the dendrogram at a desired level: each connected component forms a cluster. 另一種思考: 對階層樹橫向切一刀, 留下有連接在一起的, 就構成一群 Dendrogram 樹狀圖

56
Hierarchical Clustering algorithms
Agglomerative (bottom-up): 由下往上聚合 Start with each document being a single cluster. Eventually all documents belong to the same cluster. Divisive (top-down): 由上往下分裂 Start with all documents belong to the same cluster. Eventually each node forms a cluster on its own. Does not require the number of clusters k in advance 不需要先決定要分成幾群 Needs a termination condition
: 由下往上聚合. Start with each document being a single cluster. Eventually all documents belong to the same cluster. Divisive (top-down): 由上往下分裂. Start with all documents belong to the same cluster. Eventually each node forms a cluster on its own. Does not require the number of clusters k in advance. 不需要先決定要分成幾群. Needs a termination condition.")
57
Hierarchical Agglomerative Clustering (HAC) Algorithm
Starts with each doc in a separate cluster 每篇文件剛開始都自成一群 then repeatedly joins the closest pair of clusters, until there is only one cluster. 不斷地將最近的二群做連接 The history of merging forms a binary tree or hierarchy. 連接的過程就構成一個二元階層樹

58
Dendrogram: Document Example
As clusters agglomerate, docs likely to fall into a hierarchy of “topics” or concepts. d3 d5 d1 d3,d4,d5 d4 d2 d1,d2 d4,d5 d3

59
Closest pair of clusters 如何計算最近的二群
Many variants to defining closest pair of clusters Single-link 挑群中最近的一點來代表 Similarity of the most cosine-similar (single-link) Complete-link 挑群中最遠的一點來代表 Similarity of the “furthest” points, the least cosine-similar Centroid 挑群中的重心來代表 Clusters whose centroids (centers of gravity) are the most cosine-similar Average-link 跟群中的所有點計算距離後取平均值 Average cosine between pairs of elements
 Complete-link 挑群中最遠的一點來代表. Similarity of the furthest points, the least cosine-similar. Centroid 挑群中的重心來代表. Clusters whose centroids (centers of gravity) are the most cosine-similar. Average-link 跟群中的所有點計算距離後取平均值. Average cosine between pairs of elements.")
60
Single Link Agglomerative Clustering
Use maximum similarity of pairs: Can result in “straggly” (long and thin) clusters due to chaining effect. 長而鬆散的群集 After merging ci and cj, the similarity of the resulting cluster to another cluster, ck, is:
 clusters due to chaining effect. 長而鬆散的群集. After merging ci and cj, the similarity of the resulting cluster to another cluster, ck, is:")
61
Single Link Example

62
Complete Link Agglomerative Clustering
Use minimum similarity of pairs: Makes “tighter,” spherical clusters that are typically preferable. 緊密一點的群集 After merging ci and cj, the similarity of the resulting cluster to another cluster, ck, is: Ci Cj Ck

63
Complete Link Example

64
Computational Complexity
In the first iteration, all HAC methods need to compute similarity of all pairs of n individual instances which is O(n2). 兩兩文件計算相似性 In each of the subsequent n2 merging iterations, compute the distance between the most recently created cluster and all other existing clusters. 包含合併過程 O(n2 log n)
. 兩兩文件計算相似性. In each of the subsequent n2 merging iterations, compute the distance between the most recently created cluster and all other existing clusters. 包含合併過程 O(n2 log n)")
65
Key notion: cluster representative
We want a notion of a representative point in a cluster 如何代表該群→可以用中心或其它點代表 Representative should be some sort of “typical” or central point in the cluster, e.g.,

66
Example: n=6, k=3, closest pair of centroids
Centroid after second step. d1 d2 Centroid after first step.

67
Outliers in centroid computation
Can ignore outliers when computing centroid. What is an outlier? Lots of statistical definitions, e.g. moment of point to centroid > M some cluster moment. Say 10. Centroid Outlier 簡單說就是距離太遠的點 (ex. 10倍遠),直接忽略
,直接忽略.")
68
Using Medoid As Cluster Representative
The centroid does not have to be a document. Medoid: A cluster representative that is one of the documents 用以代表該群的某一份文件 Ex. the document closest to the centroid Why use Medoid ? Consider the representative of a large cluster (>1000 documents) The centroid of this cluster will be a dense vector The medoid of this cluster will be a sparse vector
 The centroid of this cluster will be a dense vector. The medoid of this cluster will be a sparse vector.")
69
Clustering : discussion

70
Feature selection 選擇好的詞再來做分群
Which terms to use as axes for vector space? IDF is a form of feature selection the most discriminating terms 鑑別力好的詞 Ex. use only nouns/noun phrases

71
Labeling 在分好的群上加標記 After clustering algorithm finds clusters - how can they be useful to the end user? Need pithy label for each cluster 加上簡潔厄要的標記 In search results, say “Animal” or “Car” in the jaguar example. In topic trees (Yahoo), need navigational cues. Often done by hand, a posteriori. 事後以人工編輯
, need navigational cues. Often done by hand, a posteriori. 事後以人工編輯.")
72
How to Label Clusters Show titles of typical documents 用幾份代表文件的標題做標記
Show words/phrases prominent in cluster 用幾個較具代表性的詞做標記 More likely to fully represent cluster Use distinguishing words/phrases 配合自動產生關鍵詞的技術

73
Labeling Common heuristics - list 5-10 most frequent terms in the centroid vector. 通常用5~10個詞來代表該群 Differential labeling by frequent terms Within a collection “Computers”, clusters all have the word computer as frequent term. Discriminant analysis of centroids. 要挑選有鑑別力的詞

74
Topic Model 應用分群在主題建模上
在數量龐大的文件集合中自動地發現某些結構 (主題),並 將每個主題用某些關鍵字的形式表現 (註: 即Bag-of-Word模型); 隨後,還可以知道每篇文章中各個主題占得比重如何,並 據此判斷兩篇文章的相關程度。 分群演算法就可以將關鍵字群聚成若干主題。
,並 將每個主題用某些關鍵字的形式表現 (註: 即Bag-of-Word模型); 隨後,還可以知道每篇文章中各個主題占得比重如何,並 據此判斷兩篇文章的相關程度。 分群演算法就可以將關鍵字群聚成若干主題。")
75
Topic Modelling (with LSA, pLSA, or LDA)
brain computer data dna evolve gene genetic life organism nerve neuron number … Clustering words into topics

Similar presentations






 他被这所学校正式录取 大桥已经落成,日内就可以正式通车 落伍 luòw ǔ 迟到 chídào 他怕迟到,六点就起床了.>")


: Free Response idea: 你周末做了什么?>")













