Download presentation
Presentation is loading. Please wait.

1
Hu Junfeng 向量空间模型及 k-means 聚类算法 胡俊峰 2016/04/19

2
Hu Junfeng 在 Trie 树上合并同词干的词集 — 问题分析 词干 + 后缀 词干 - 词尾变形 + 后缀 后缀表生成 结果评价? 2

3
Hu Junfeng 手工构造后缀集以及词尾变化(杨明钰) 用户输入词根,程序显示派生词。例如输入 “hope” ,程序输出 “hopes , hoping , hoped” 等派生 词。而如果输入 “hop” ,则显示 “It’s not a word!” 不 会显示 “hopes” 等单词。 char postfix[100][10]={"s","es","ing","er","est","ed","or", "less","ship","ly","y","tion","hood","'s"}; 3
![Hu Junfeng 手工构造后缀集以及词尾变化(杨明钰) 用户输入词根,程序显示派生词。例如输入 hope ,程序输出 hopes , hoping , hoped 等派生 词。而如果输入 hop ,则显示 It’s not a word! 不 会显示 hopes 等单词。 char postfix[100][10]={ s , es , ing , er , est , ed , or , less , ship , ly , y , tion , hood , s }; 3](http://images.slidesplayer.com/40/11087615/slides/slide_3.jpg "Hu Junfeng 手工构造后缀集以及词尾变化(杨明钰) 用户输入词根,程序显示派生词。例如输入 hope ,程序输出 hopes , hoping , hoped 等派生 词。而如果输入 hop ,则显示 It’s not a word! 不 会显示 hopes 等单词。 char postfix[100][10]={ s , es , ing , er , est , ed , or , less , ship , ly , y , tion , hood , s }; 3")
4
Hu Junfeng 我是黄司昊,学号 1400012222 ,附件中有我的按词根配对 的作业。谢谢老师! 另外想问一下,这次按词根配对中怎样的后缀算词尾是由 我们事先定义好是吗?我作业里是按这个写的。还有另外 一种可能,让计算机通过统计自己来判断什么样的后缀算 词根,这个能做到吗?难吗? 4

5
Hu Junfeng 章将国 1400012146 本程序第十五个文件有问题,打不开,所以有更换。 程序中使用 d 和 b 两个变量, b 表示该节点之前的点的选项 个数, d 对打印之后还能继续走的分支进行计数。 程序使用了深度优先的栈结构,所以如果两个单词非同源 部分超过了词尾的一个字母或者在一个很长的单词之后又 出现值钱的单词的同源单词则无法打印出来。应当尝试队 列结构进行广度优先搜索,但期中考试时间不够。 5

6
Hu Junfeng 黄司昊 1400012222 这里是等字典树形成了以后再去将带词尾的和词根配对。大概意思就是,比 如找结尾为 “s” 的复数和原型配对,那么就要满足几个条件: 到某个节点处有单词结束,它的 “s 子树 ” 不是空的,而且 “s 子树 ” 下的节点处也 有单词结束。其他情况以此类推。 用这种方法所有正确的配对应该是都能找出来的,但是还会引入一些额外的 虽然配对但不是我们想要的答案。所以错误率会有极少数,召回率应该是 100% (准确说是与我写下来的变化对应的所有词都能被找出来)。 总结写来发生的错误都是比较短的单词,这些单词加上某种词尾之后的单词 本身可能也是词根,意思完全不相关。但这很难避免,毕竟计算机无法知道 那两个单词含义上是不是真的相关。 可以召回的有,名词复数、名词所有格、动名词,动词第三人称单数、过去 式、过去分词、现在分词。当然,语法条件允许下的所有特殊变化情况都考 虑进去了。 6
。 总结写来发生的错误都是比较短的单词,这些单词加上某种词尾之后的单词 本身可能也是词根,意思完全不相关。但这很难避免,毕竟计算机无法知道 那两个单词含义上是不是真的相关。 可以召回的有,名词复数、名词所有格、动名词,动词第三人称单数、过去 式、过去分词、现在分词。当然,语法条件允许下的所有特殊变化情况都考 虑进去了。 6")
7
Hu Junfeng 刘周泽蕊 1400012130 1 、本程序实现了对单复数( s,es,ves,ies ),过去式 (d,ed,ied) ,现在进行时 (ing, 去 e 加 ing) 的单词合并,结果在 en_word_freq 文档中。 2 、有些不规则动词时态变化则没有实现,如果要实现可考虑多给计算机一些信 息,比如不规则动词表,将其与字符树进行匹配,寻找出现的不规则动词变化 。 3 、在做作业的过程中发现,较短的单词出现错误合并的可能性比长单词更高, 在这一点上程序还可以进行修改。 4 、以及,动词与名词之间的合并,可以用本程序同样的比较方法来找出后缀为 ment,tion,sion 等单词,但由于词性变化形式较多,算法又雷同,故本程序没有涉 及。 5 、由于不是很能够弄懂老师的题目意图,如果是想找出所有可能的后缀形式的 话,下面给出一个算法思想。深搜遍历字符树,当找到一个 cnt!=0, 开始用字符串 记录接下来的的字符,再往下找当又出现 cnt!=0 时,则相当于找到两个单词之间 相差的部分,即为后缀,存入另一个字符树 root1 中。遍历 root1 ,输出所有后缀 。 7
,过去式 (d,ed,ied) ,现在进行时 (ing, 去 e 加 ing) 的单词合并,结果在 en_word_freq 文档中。 2 、有些不规则动词时态变化则没有实现,如果要实现可考虑多给计算机一些信 息,比如不规则动词表,将其与字符树进行匹配,寻找出现的不规则动词变化 。 3 、在做作业的过程中发现,较短的单词出现错误合并的可能性比长单词更高, 在这一点上程序还可以进行修改。 4 、以及,动词与名词之间的合并,可以用本程序同样的比较方法来找出后缀为 ment,tion,sion 等单词,但由于词性变化形式较多,算法又雷同,故本程序没有涉 及。 5 、由于不是很能够弄懂老师的题目意图,如果是想找出所有可能的后缀形式的 话,下面给出一个算法思想。深搜遍历字符树,当找到一个 cnt!=0, 开始用字符串 记录接下来的的字符,再往下找当又出现 cnt!=0 时,则相当于找到两个单词之间 相差的部分,即为后缀,存入另一个字符树 root1 中。遍历 root1 ,输出所有后缀 。 7")
8
Hu Junfeng 林暐韬 1400012132 1. 仅考虑规则的变化,不考虑不规则过去式。由于形态变化多样性,不 深究具体变化情况,也就是说诸如 ment ive ion 等变化都算在内。这样会 引起误判。 2. 考虑到时态变化最长有可能是双写 +ing 形式,因此设置最长后缀为 4 位 。具体实现中有位运算 j&=31 3. 考虑到原型以 e 结尾的情况,进行了特判 具体实现: 修改 dfs 函数为 dfs1 ,用于标记每个前缀的有效节点子孙( j 中 修改 dfs 函数为 dfs2 ,用于访问具有有效节点子孙且本身为词的前缀(并 对 e 尾进行特判)。对每个访问到的节点进行第二次不超过 4 层的 dfs3 , 打印结果。 8
。对每个访问到的节点进行第二次不超过 4 层的 dfs3 , 打印结果。 8.")
9
Hu Junfeng 提纲 概述 文本聚类的流程 主要聚类算法介绍 文本聚类的高级问题 聚类的质量评价 文本聚类的应用

10
Hu Junfeng 提纲 概述 文本聚类的流程 主要聚类算法介绍 文本聚类的高级问题 聚类的质量评价 文本聚类的应用

11
Hu Junfeng 什么是聚类 聚类( Clustering )就是将数据分组成为多个类( Cluster )。在同一个类内对象之间具有较高的相 似度,不同类之间的对象差别较大。 早在孩提时代,人就通过不断改进下意识中的聚 类模式来学会如何区分猫和狗,动物和植物
就是将数据分组成为多个类( Cluster )。在同一个类内对象之间具有较高的相 似度,不同类之间的对象差别较大。 早在孩提时代,人就通过不断改进下意识中的聚 类模式来学会如何区分猫和狗,动物和植物")
12
Hu Junfeng 聚类 VS. 分类 聚类 – 事先并不知道存在什么类别,完全按照反映对象特征 的数据把对象进行分类 – 模型训练:无指导学习 分类 – 事先有了某种分类标准之后,判定一个新的研究对象 应该归属到哪一类别 – 模型训练:有指导学习

13
Hu Junfeng 聚类的应用领域 经济领域: – 帮助市场分析人员从客户数据库中发现不同的客户群,并且用购 买模式来刻画不同的客户群的特征。 – 谁喜欢打国际长途,在什么时间,打到那里? – 对住宅区进行聚类,确定自动提款机 ATM 的安放位置 – 股票市场板块分析,找出最具活力的板块龙头股 – 企业信用等级分类 –…… 生物学领域 – 推导植物和动物的分类; – 对基因分类,获得对种群的认识 数据挖掘领域 – 作为其他数学算法的预处理步骤,获得数据分布状况,集中对特 定的类做进一步的研究

14
Hu Junfeng 概述 聚类时,如何描述一个对象? – 特征 f1, f2, f3, … – 对象可以被描述为一组特征的集合: – 如何量化地说明两个对象(样本)是相似的? – 距离:两个对象距离越小,它们之间越相似
是相似的? – 距离:两个对象距离越小,它们之间越相似")
15
Hu Junfeng 2008 年 8 月 相似性的度量 ( 样本点间距离的计算方法 ) Euclidean 距离 Squared Euclidean 距离 Block 距离 Chebychev 距离 Minkovski 距离
 Euclidean 距离 Squared Euclidean 距离 Block 距离 Chebychev 距离 Minkovski 距离")
16
Hu Junfeng 提纲 概述 文本聚类的流程 主要聚类算法介绍 文本聚类的高级问题 聚类的质量评价 文本聚类的应用

17
Hu Junfeng 文本聚类 聚类分析的对象是一篇篇文档 – 特征:文档中的词 t – 每个文档 d 表示为一个向量 – , m 是特征的个数, tf ti 是词 t i 在 d 中 出现的次数 – 相似度:两个文档对应向量的距离 – 相似度矩阵:两两向量之间相似度构成的矩阵

18
Hu Junfeng 硬聚类和软聚类 硬聚类:每个文档只能属于一类 –C1 ∪ C2 ∪ ⋯ ∪ Ck = DC , Ci ∩ Cj =Φ ,其中, 1 ≤ i ≠ j ≤ k (1) 软聚类:文档集合被划分为 k 个可能相交的文档子 集,即每个文档可能属于多个类别。
 软聚类:文档集合被划分为 k 个可能相交的文档子 集,即每个文档可能属于多个类别。")
19
Hu Junfeng 文本聚类的流程

20
Hu Junfeng 20 文档词汇特征 高频词 TF*IDF Keywords or Key Phrases

21
Hu Junfeng 提纲 文本聚类的流程 主要聚类算法介绍 文本聚类的高级问题 聚类的质量评价 文本聚类的应用

22
Hu Junfeng 主要聚类算法介绍 基于划分的聚类 基于层次的聚类 其他聚类算法

23
Hu Junfeng 基于划分的聚类 K- 均值( K-means )算法 – 是一种基于质心的聚类技术,其基本原理是首先选择 k 个文档作为初始的聚类点,然后根据类中对象的平均 值,将每个文档 ( 重新 ) 赋给最类似的类,并更新类的平 均值,然后重复这一过程,直到类的划分不再发生变 化。 K- 近邻算法 – 每个对象和距离它最近的 K-1 个对象组成一个类 – 是一种软聚类(允许类的重叠)
算法 – 是一种基于质心的聚类技术,其基本原理是首先选择 k 个文档作为初始的聚类点,然后根据类中对象的平均 值,将每个文档 ( 重新 ) 赋给最类似的类,并更新类的平 均值,然后重复这一过程,直到类的划分不再发生变 化。 K- 近邻算法 – 每个对象和距离它最近的 K-1 个对象组成一个类 – 是一种软聚类(允许类的重叠)")
24
Hu Junfeng k- 平均 输入 : 类的数目 k ,包含 n 个文本的特征向量。 输出 : k 个类,使平方误差准则最小。 步骤 : 1) 任意选择 k 个对象作为初始的类中心 ; 2) repeat; 3) 根据类中对象的平均值,将每个对象 ( 重新 ) 赋给最 类似的类 ; 4) 更新类的平均值 ; 5) until 不再发生变化。
 任意选择 k 个对象作为初始的类中心 ; 2) repeat; 3) 根据类中对象的平均值,将每个对象 ( 重新 ) 赋给最 类似的类 ; 4) 更新类的平均值 ; 5) until 不再发生变化。")
25
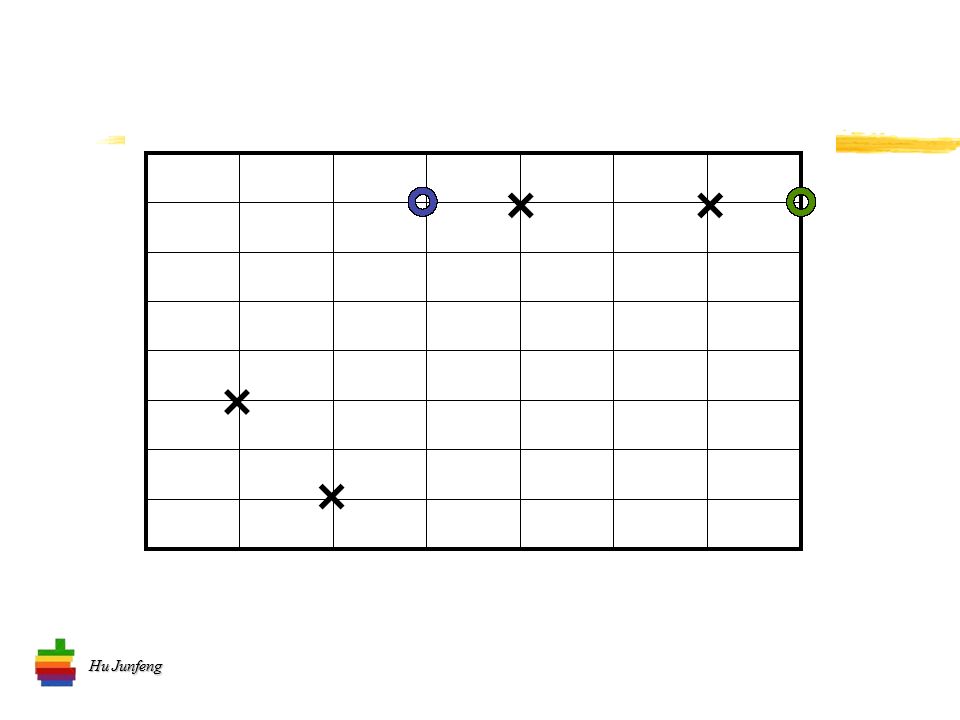
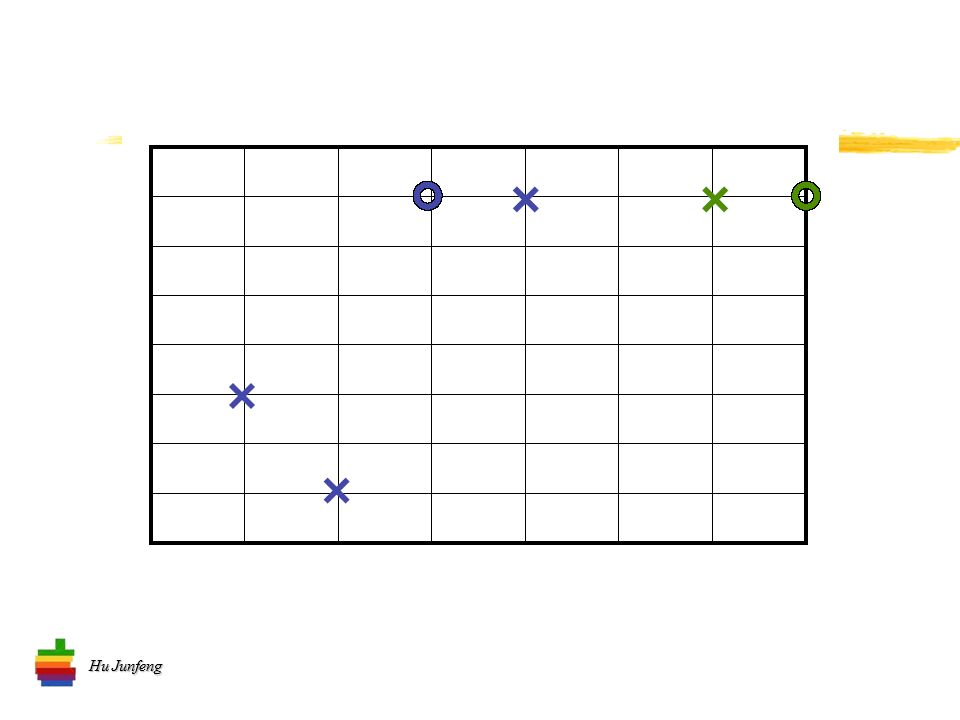
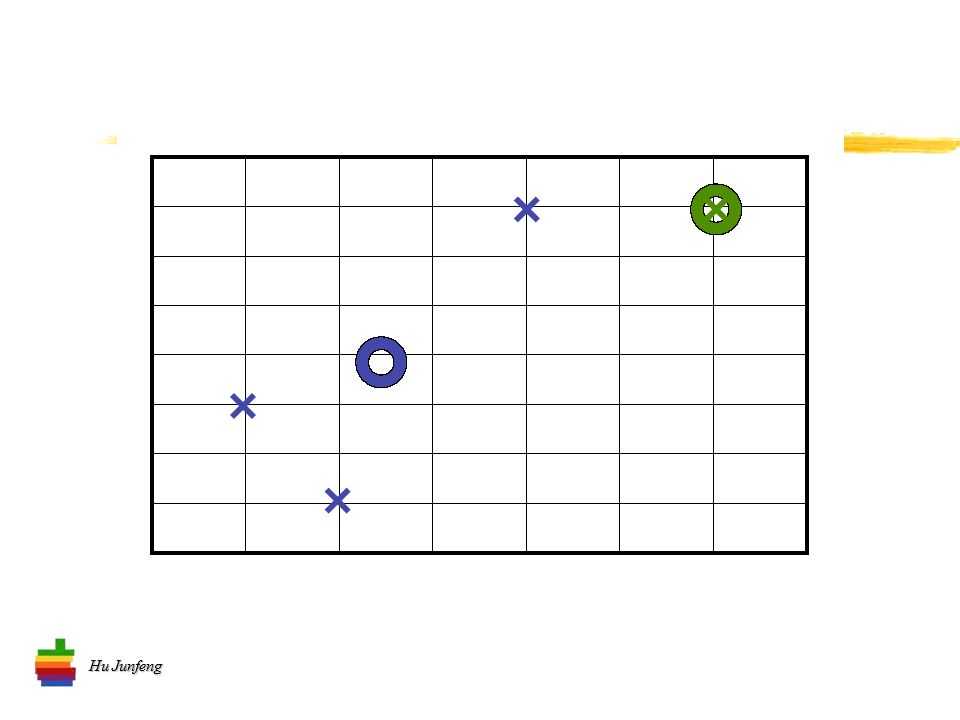
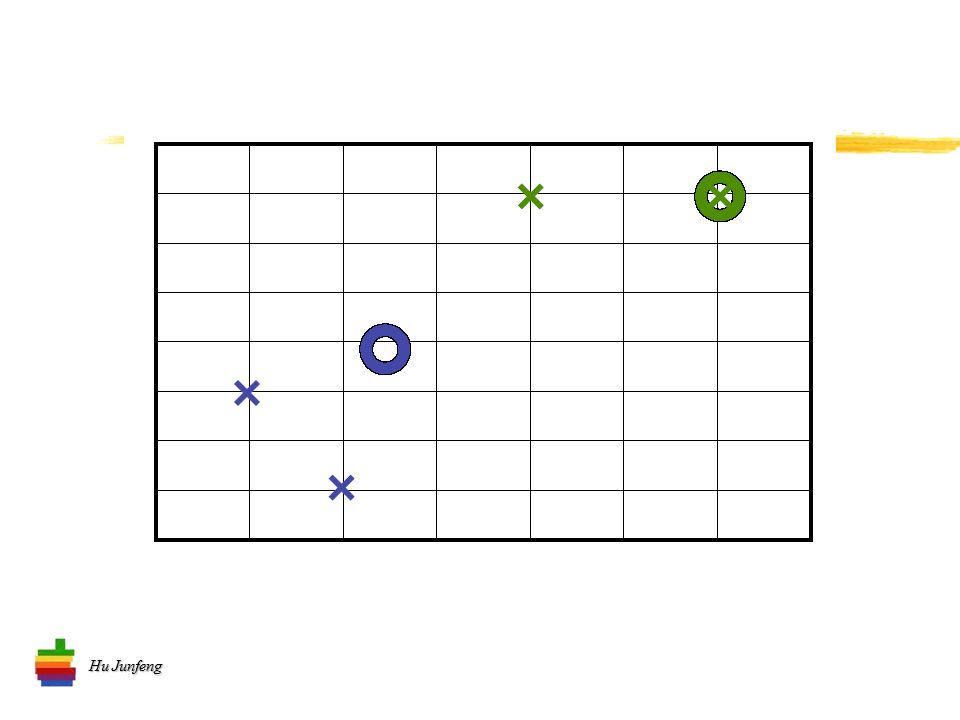
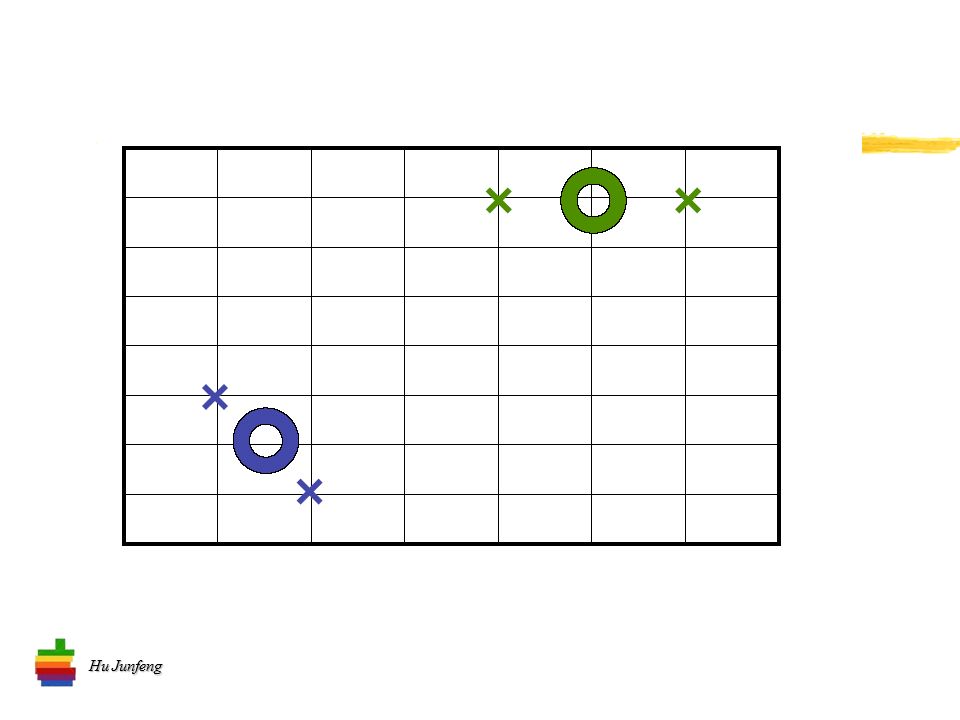
Hu Junfeng K- 均值算法流程 将 n 个向量分到 k 个类别中去 选择 k 个初始中心 计算两项距离 计算均值 确定新的中心 …… 迭代直到 “ 系统稳定 ”

26
Hu Junfeng

32
K- 均值算法 算法复杂度为 O (kln) ,其中 l 为迭代次数, n 为文 档个数, k 为类别个数 K- 均值算法最后一定是可以收敛的 该算法本质上是一种贪心算法。 – 可以保证局部最优,但是很难保证全局最优。 需要预先指定 k 值和初始划分 变种: K-medoids –medoid :离类 r 质心最近的文档向量
 ,其中 l 为迭代次数, n 为文 档个数, k 为类别个数 K- 均值算法最后一定是可以收敛的 该算法本质上是一种贪心算法。 – 可以保证局部最优,但是很难保证全局最优。 需要预先指定 k 值和初始划分 变种: K-medoids –medoid :离类 r 质心最近的文档向量")
33
Hu Junfeng 33

34
Hu Junfeng 34

35
Hu Junfeng 35

36
Hu Junfeng 36

37
Hu Junfeng 37

38
Hu Junfeng 38

39
Hu Junfeng 39

40
Hu Junfeng 40

41
Hu Junfeng K-means 的改进 确定 K – 对于不同的 K 都尝试聚类,取效果最好的 确定初始种子 – 尝试多种初始向量的组合,取效果最好的 – 通过其他方法(如层次聚类)确定初始文档向量 – 对每个类,取若干随机向量( e.g.10 个)的平均值作为 它的初始向量
确定初始文档向量 – 对每个类,取若干随机向量( e.g.10 个)的平均值作为 它的初始向量")
42
Hu Junfeng K- 近邻算法 每个对象和距离它最近的 K-1 个对象组成一个类 是一种软聚类(允许类的重叠) 需要比较每两个对象之间的距离,时间代价为 O(N 2 )
 需要比较每两个对象之间的距离,时间代价为 O(N 2 )")
43
Hu Junfeng 基于层次的聚类 定义:对给定的数据进行层次的分解: 分类: – 凝聚的( agglomerative )方法(自底向上)(案例 介绍) 思想:一开始将每个对象作为单独的一组,然后根 据同类相近,异类相异的原则,合并对象,直到所 有的组合并成一个,或达到一个终止条件为止。 – 分裂的( divisive )方法(自顶向下) 思想:一开始将所有的对象置于一类,在迭代的每 一步中,一个类不断地分为更小的类,直到每个对 象在单独的一个类中,或达到一个终止条件。
方法(自底向上)(案例 介绍) 思想:一开始将每个对象作为单独的一组,然后根 据同类相近,异类相异的原则,合并对象,直到所 有的组合并成一个,或达到一个终止条件为止。 – 分裂的( divisive )方法(自顶向下) 思想:一开始将所有的对象置于一类,在迭代的每 一步中,一个类不断地分为更小的类,直到每个对 象在单独的一个类中,或达到一个终止条件。")
44
Hu Junfeng 基于层次的聚类 特点: – 类的个数不需事先定好 – 需确定类间距离函数 – 运算量要大,适用于处理小样本数据 – 时间代价 O(N 2 )
")
45
Hu Junfeng 广泛采用的类间距离: 最小距离法( single linkage method ) – 极小异常值在实际中不多出现,避免极大值的影响
 – 极小异常值在实际中不多出现,避免极大值的影响")
46
Hu Junfeng 广泛采用的类间距离: 最大距离法( complete linkage method ) – 可能被极大值扭曲,删除这些值之后再聚类
 – 可能被极大值扭曲,删除这些值之后再聚类")
47
Hu Junfeng 广泛采用的类间距离: 类平均距离法( average linkage method )类间所有 样本点的平均距离 – 该法利用了所有样本的信息,被认为是较好的系统聚 类法
类间所有 样本点的平均距离 – 该法利用了所有样本的信息,被认为是较好的系统聚 类法")
48
Hu Junfeng 广泛采用的类间距离: 重心法( centroid hierarchical method ) – 类的重心之间的距离 – 对异常值不敏感,结果更稳定
 – 类的重心之间的距离 – 对异常值不敏感,结果更稳定")
49
Hu Junfeng 基于层次的聚类 优点:能够生成层次化的嵌套类,准确度高 缺点:速度慢,不适合大文本集的聚类

50
Hu Junfeng 提纲 概述 文本聚类的流程 主要聚类算法介绍 文本聚类的高级问题 聚类的质量评价 文本聚类的应用

51
Hu Junfeng 文本聚类的高级问题 高级稀疏问题 – 向量空间的维数变高后,由于数据量有限,分配到每 个维度上的数据将变得非常稀少。 – 停用词过滤和词形还原处理 – 保留其中频率较高的部分词 – 潜在语义索引 (LSI)
")
52
Hu Junfeng 文本聚类的高级问题 语义计算问题 – 近义词和多义词 – 向量空间中只考虑了词频,忽略了词序和语义 – 将特征项映射到概念级 –LSI ,知网,语义内积空间模型

53
Hu Junfeng 提纲 概述 文本聚类的流程 主要聚类算法介绍 文本聚类的高级问题 聚类的质量评价 文本聚类的应用

54
Hu Junfeng 聚类的质量评价 指标:纯度( Purity )和 F 值( F-measure ) 标准答案:一般是人工分好类的文档集合
和 F 值( F-measure ) 标准答案:一般是人工分好类的文档集合")
55
Hu Junfeng 纯度

56
Hu Junfeng F值F值

57
Hu Junfeng F值F值

58
Hu Junfeng 特征相关性 – 特征向量 – 降维( PCA ) 58
 58")
59
Hu Junfeng 59 作业题: 上机布置

Similar presentations
 入帳,或親至出納組辦理。 為因應數位化及現代生活習慣,擬設 置繳費 E 化平台,同時收款通路將增 加全國四大超商、線上刷卡或網路.>")

辦桌文化起始略說: 1. 祭祀宗教 2. 生命禮儀 3. 外燴 --- 老師、師公、師傅、總鋪師 4. 搬桌搬椅時代 (二) 食物食材 1. 靠山考海 2. 基本:炒米粉、糍、檳榔 3. 小吃搬上桌 (三) 變變變 1. 調味不同 2. 師承不同 3. 地點也變.>")


 词的色彩不同 词语色彩----感情色彩 ----语体色彩.>")




 陳可兒 (4F03) 張令宜 (4F05) 何秀欣 (4F14) 潘美玲>")








