Download presentation
Presentation is loading. Please wait.

1
第五章 GIS空间分析技术 1、概述. 2、空间数据(图形)基本量算 3、空间查询 4、栅格数据分析的基本类型 5、矢量数据分析的基本方法
6、网络分析 7、空间插值分析 8、数字地面(地形)分析与DEM模型
分析与DEM模型.")
2
1、概述 空间分析是GIS的主要特征。GIS与一般的计算机辅助制图(CAC/CAD)系统的主要区别在于GIS具有空间分析功能。
GIS的空间分析是指以地理事物的空间位置和形态为基础,以地学原理为依托,以空间数据运算、为特征,提取与产生新的空间信息的技术和过程,如获取关于空间分布、空间形成以及空间演变的信息。空间分析功能是GIS的主要特征与评价GIS软件的主要指标之一 其运用的手段包括各种几何的逻辑运算、数理统计分析,代数运算等数学手段

3
1、概述 另一种分类:①基于空间图形数据的分析运算;②基于非空间属性的数据运算;③空间和非空间数据的联合运算。 基本的空间分析包括以下方面:
空间查询 空间量算 缓冲区分析 叠加分析 网络分析 空间统计分析 空间插值 数字高程模型(数字地形模型) 空间建模与空间决策支持系统 面向应用的分析 简单的空间分析 复杂的空间分析 另一种分类:①基于空间图形数据的分析运算;②基于非空间属性的数据运算;③空间和非空间数据的联合运算。
 空间建模与空间决策支持系统. 面向应用的分析. 简单的空间分析. 复杂的空间分析. 另一种分类:①基于空间图形数据的分析运算;②基于非空间属性的数据运算;③空间和非空间数据的联合运算。")
4
2、图形基本量算 图形量算是GIS空间分析技术中最基本的分析内容之一。基本的图形量算功能包括图形的长度量算、面积量算、等高线地形图中的体积量算。 2.1 质(重)心量算:描述地理目标空间分布最有用的单一量算量,质心是保持目标均匀分布的平衡点。在几何中心基础上的加权计算。 质心的量算,可以跟踪某些地理分布的变化,例如人口的变迁、土地类型的变化,也可以简化某些复杂目标, 在某些情况下,可以方便的导出某些预测模型。 式中,i为离散目标物,Wi为该目标权重,Xc、Yc 为目标。

5
2.2 几何量算 · 点状目标:坐标; · 线状目标:长度、曲率、方向; · 面状目标:面积、周长等; · 体状目标:表面积、体积等。
空间量算是指对空间信息的自动化量算,是地理信息系统所具有的重要功能,也是进行其它空间分析的定量化基础 几何量算对点、线、面、体四类目标物而言,其含义是不同的: · 点状目标:坐标; · 线状目标:长度、曲率、方向; · 面状目标:面积、周长等; · 体状目标:表面积、体积等。

6
2.2 几何量算 长度量算:线由点组成,矢量图形的长度量算基于直线段的两点之间距离公式,设空间两点p1(x1,y1)和p2(x2,y2),则直线段的长度为 由此不难得出折线与多边形周长的长度量算公式 式中,i为折线或多边形的顶点数,含义为依次求出组成折线或多边形的所有线段长度,然后累加求和

7
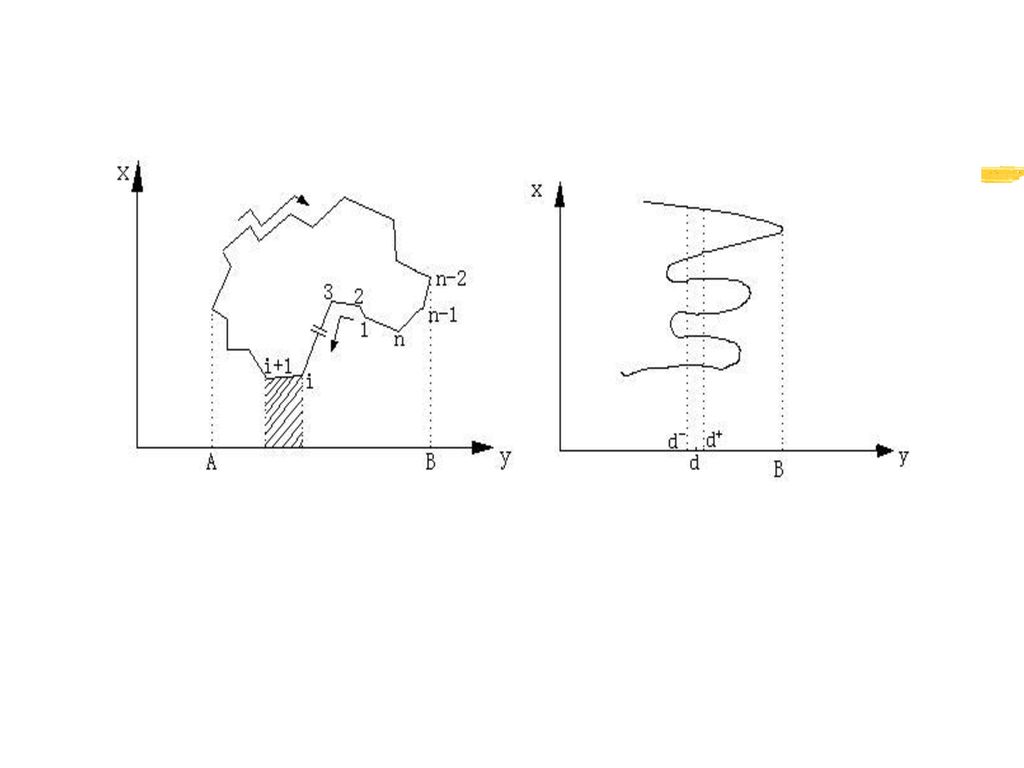
2.2 几何量算 多边形面积计算及其应用:辛普森(Simposion)面积计算公式
在GIS中,梯形法是求面积的主要方法之一。其基本思想是:按照多边形的顶点顺序依次求出多边形所有边与X轴或Y轴组成的梯形面积,然后求其代数和 已知条件: 为多边形顶点坐标,凸、凹多边形均可,顶点顺序顺时针方向、逆时针方向均可。

9
求证:

10
辛普森面积计算公式 由推证过程可看出,顺时针坐标点排列面积为正值,逆时针坐标点排列面积为负值,考虑到面积可能为负值,因而最终取绝对值

11
辛普森面积公式的应用 辛普森求积公式的应用 判断多边形顶点的走向(逆时针或顺时针旋转 面积s为正则为顺时针走向 面积s为负则为逆时针走向

12
多边形顶点走向的简单判别 对于凸多边形事实上任意顺次取3个顶点坐标,计算此3点组成的图形面积s’,即可判断出此多边形的顶点的走向。
对于一般的多边形(包括凹多边形)取一个方向坐标的极值点前后两点组成的三角形面积,即可判断出此多边形的顶点的走向。 任意三点(x2 , y2)、(x1 , y1)、(x3 , y3)组成的三角形面积为: St = x1 (y2-y3) + x2 (y3-y1) + x3 (y1-y2)
取一个方向坐标的极值点前后两点组成的三角形面积,即可判断出此多边形的顶点的走向。 任意三点(x2 , y2)、(x1 , y1)、(x3 , y3)组成的三角形面积为: St = x1 (y2-y3) + x2 (y3-y1) + x3 (y1-y2)")
13
辛普森面积公式的应用 判断点与矢量线段的空间拓扑关系 P在AB的右边; P在AB直线上; P在AB的左边;

14
3. 空间查询 图形查询:图形查属性是根据图形的空间位置来查询有关属性信息;或者实体之间的空间关系查询,实体的属性信息查询等。
属性查询:根据一定的属性条件来查询满足条件的空间实体的位置,是基于实体的属性信息进行查询,与一般的数据库查询相同,只不过最后查询的结果需要再与图形关联起来。 图形属性互查:将空间关系和属性结合起来进行查询,并将最后结果以图形和属性两种方式显示出来。如:查询京九线沿线人口大于100万的城市及各种属性信息。 地址匹配:根据一个地理名字(如学校名字)来定位相关实体并获得其属性信息。其基础是地理编码,即将一个地理名字与一个或若干个空间实体关联起来、或者与实体的某个属性关联起来、或者与某个地理坐标关联起来。
来定位相关实体并获得其属性信息。其基础是地理编码,即将一个地理名字与一个或若干个空间实体关联起来、或者与实体的某个属性关联起来、或者与某个地理坐标关联起来。")
15
3. 空间查询 例如:查询三峡地区长江流域人口大于50万的市或县 Select * From 县或市 Where 县或市人口>50万
and Cross (河流名称=“长江”)
")
16
4.栅格数据分析的基本类型 栅格数据的聚类是根据设定的聚类条件对原有数据系统进行有选择的信息提取而建立新的栅格数据系统的方法。
栅格数据的分析处理方法可以概括为聚类聚合分析、多层面复合叠置分析、窗口分析及追踪分析等几种基本的分析模型类型。 4.1 栅格数据的聚类、聚合分析 聚类分析 栅格数据的聚类是根据设定的聚类条件对原有数据系统进行有选择的信息提取而建立新的栅格数据系统的方法。

17
4.栅格数据分析的基本类型 图6—1(a)为一个栅格数据系统样图,1、2、3、4为其中的四种类型要素, 图6—1(b)为提取其中要素“2”的聚类结果。
为一个栅格数据系统样图,1、2、3、4为其中的四种类型要素, 图6—1(b)为提取其中要素 2 的聚类结果。")
18
4.栅格数据分析的基本类型 聚合分析 栅格数据的聚合分析是指根据空间分辨力和分类表,进行数据类型的合并或转换以实现空间地域的兼并。
空间聚合的结果往往将较复杂的类别转换为较简单的类别,并且常以较小比例尺的图形输出。当从地点、地区到大区域的制图综合变换时常需要使用这种分析处理方法。

19
4.栅格数据分析的基本类型 对于图6—1(a),如给定聚合的标准为1、2类合并为b,3、4类合并为a,则聚合后形成的栅格数据系统如图6—2(a)所示, 如给定聚合的标准为2、3类合并为c,1、4类合并为d,则聚合后形成的栅格数据系统如图6—2(b)所示。
,如给定聚合的标准为1、2类合并为b,3、4类合并为a,则聚合后形成的栅格数据系统如图6—2(a)所示, 如给定聚合的标准为2、3类合并为c,1、4类合并为d,则聚合后形成的栅格数据系统如图6—2(b)所示。")
20
4.栅格数据分析的基本类型 聚类、聚合分析应用 栅格数据的聚类聚合分析处理法在数字地形模型及遥感图象处理中的应用是十分普遍的。
例如,由数字高程模型转换为数字高程分级模型便是空间数据的聚合,而从遥感数字图象信息中提取其一地物的方法则是栅格数据的聚类

21
4.栅格数据分析的基本类型 信息复合模型(overlay)包括两类,简单的视觉信息复合和较为复杂的叠加分类模型
4.2 栅格数据的信息复合(叠加)分析 能够极为便利地进行同地区多层面空间信息的自动复合叠置分析,是栅格数据一个最为突出的优点。正因为如此,栅格数据常被用来进行区域适应性评价、资源开发利用、规划等多因素分析研究工作。在数字遥感图象处理工作中,利用该方法可以实现不同波段遥感信息的自动合成处理;还可以利用不同时间的数据信息进行某类现象动态变化的分析和预测。因此该方法在计算机地学制图与分析中具有重要的意义。 信息复合模型(overlay)包括两类,简单的视觉信息复合和较为复杂的叠加分类模型
分析. 能够极为便利地进行同地区多层面空间信息的自动复合叠置分析,是栅格数据一个最为突出的优点。正因为如此,栅格数据常被用来进行区域适应性评价、资源开发利用、规划等多因素分析研究工作。在数字遥感图象处理工作中,利用该方法可以实现不同波段遥感信息的自动合成处理;还可以利用不同时间的数据信息进行某类现象动态变化的分析和预测。因此该方法在计算机地学制图与分析中具有重要的意义。 信息复合模型(overlay)包括两类,简单的视觉信息复合和较为复杂的叠加分类模型.")
22
4.栅格数据分析的基本类型 4.2.1视觉信息复合:将不同专题的内容叠加显示在结果图件上,以便系统使用者判断不同专题地理实体的相互空间关系,获得更为丰富的信息。 简单视觉信息复合之后,参加复合的平面之间没发生任何逻辑关系,仍保留原来的数据结构 面状图、线状图和点状图之间的复合; 面状图区域边界之间或一个面状图与其他专题区域边界之间的复合; 遥感影像与专题地图的复合; 专题地图与数字高程模型复合显示立体专题图; 遥感影像与DEM复合生成真三维地物景观。

24
4.栅格数据分析的基本类型 4.2.2叠加分类模型 :根据参加复合的栅格数据层不同类别的空间关系重新划分空间区域,每个空间区域内各空间点的属性组合一致。 叠加结果生成新的数据层,该数据层图形数据记录了重新划分的区域,而属性数据库结构中则包含了原来的几个参加复合的数据层的属性数据库中所有的数据项。 叠加分类模型用于多要素综合分类,以划分最小地理景观单元,进一步可进行综合评价以确定各景观单元的等级序列。

25
4.栅格数据分析的基本类型 逻辑判断复合法 设有A、B、C三个层面的栅格数据,一般可以用布尔逻辑算子以及运算结果的文氏图(见图6-3)表示其一般的运算思路和关系
表示其一般的运算思路和关系")
26
逻辑关系运算例 例:有土壤厚度(大于50厘米)和土壤类型(红壤和其他类型)两个二值化图层,不同的逻辑运算结果如下:
AND关系:结果是将土层厚度大于50厘米,且土壤为红壤的土壤单元显示出来; OR关系:结果将土层厚度大于50厘米,或者土壤为红壤的土壤单元显示出来; XOR:结果将土层厚度小于50厘米,或者土壤不是红壤的土壤单元显示出来; NOT:如结果是将土层厚度大于50厘米,但土壤不是红壤的土壤单元显示出来;

27
4.栅格数据分析的基本类型 数学运算复合法 指不同层面的栅格数据逐网格按一定的数学法则进行运算,从而得到新的栅格数据系统的方法。其主要类型有以下几种: 算术运算 指两层以上的对应网格值经加、减运算,而得到新的栅格数据系统的方法。这种复合分析法具有很大的应用范围。图6-4给出了该方法在栅格数据编辑中的应用例证。

28
算术运算

29
4.栅格数据分析的基本类型 函数运算 指两个以上层面的栅格数据系统以某种函数关系作为复合分析的依据进行逐网格运算,从而得到新的栅格数据系统的过程。 这种复合叠置分析方法被广泛地应用到地学综合分析、环境质量评价、遥感数字图像处理等领域中。 只要得到对于某项事物关系及发展变化的函数关系式,便可运用以上方法完成各种人工难以完成的极其复杂的分析运算。这也是目前信息自动复合叠置分析法受到广泛应用的原因。

30
函数运算

31
在Arc View中,使用Map Calculator可以很方便地实现栅格图层的复合(叠加)运算
利用土壤侵蚀通用方程式计算土壤侵蚀量时,就可利用多层面栅格数据的函数运算复合分析法进行自动处理。一个地区土壤侵蚀量的大小是降雨(R)、植被覆度(C)、坡度(S)、坡长(L)、土壤抗蚀性(SR)等因素的函数
、植被覆度(C)、坡度(S)、坡长(L)、土壤抗蚀性(SR)等因素的函数.")
32
4.栅格数据分析的基本类型 值得注意是,信息的复合法只是处理地学信息的一种手段,而其中各层面信息关系模式的建立对分析工作的完成及分析质量的优劣具有决定性作用。这往往需要经过大量的试验研究,而计算机自动复合分析法的出现也为获得这种关系模式创造了有利的条件。

33
4.栅格数据分析的基本类型 4.3 追踪分析 追踪分析一般都是基于栅格数据的,由某一个或多个起点,按照一定的追踪线索进行追踪目标或者追踪轨迹信息提取的空间分析方法。 如栅格所记录的是地面点的海拔高程值,根据地面水流必然向最大坡度方向,由追踪法提取地面水流的路径流动的基本追踪线索,可以得出地面水流的基本轨迹 追踪分析法在扫描图件的矢量化、利用数字高程模型自动提取等高线、污染源的追踪分析等方面都发挥着十分重要的作用。 Arc View中的水文分析及生成等高线的功能就是利用了追踪分析的原理。

34
追踪分析

35
4.栅格数据分析的基本类型 4.4 邻域分析(窗口分析)
邻域分析主要应用于栅格数据模型。地学信息除了在不同层面的因素之间存在着一定的制约关系之外,还表现在空间上存在着一定的关联性。对于栅格数据所描述的某项地学要素,其中的(I,J)栅格往往会影响其周围栅格的属性特征 窗口分析是指对于栅格数据系统中的一个、多个栅格点或全部数据,开辟一个有固定分析半径的分析窗口,并在该窗口内进行诸如极值、均值等一系列统计计算,或与其它层面的信息进行必要的复合分析,从而实现栅格数据有效的水平方向扩展分析。
栅格往往会影响其周围栅格的属性特征. 窗口分析是指对于栅格数据系统中的一个、多个栅格点或全部数据,开辟一个有固定分析半径的分析窗口,并在该窗口内进行诸如极值、均值等一系列统计计算,或与其它层面的信息进行必要的复合分析,从而实现栅格数据有效的水平方向扩展分析。")
36
4.4 邻域分析(窗口分析) 分析窗口的类型 按照分析窗口的形状,可以将分析窗口划分为以下类型:
矩形窗口:是以目标栅格为中心,分别向周围八个方向扩展一层或多层栅格,从而形成矩形分析区域,如3×3、5×5、7×7的矩形窗口。 圆型窗口:是以目标栅格为中心,向周围作一等距离搜索区,构成一圆型分析窗口。 环型窗口:是以目标栅格为中心,按指定的内外半径构成环型分析窗口。 扇型窗口:是以目标栅格为起点,按指定的起始与终止角度构成扇型分析窗口。

37
4.4 邻域分析(窗口分析)
")
38
4.4 邻域分析(窗口分析) 窗口内统计分析的类型 栅格分析窗口内的空间数据的统计分析类型一般有以下几种类型:
(1)Mean;(2)Maximum; (3)Minimum;(4)Median;(5)Sum; (6)Range;(7)Majority;(8)Minority;(9)Variety。 在Arc View软件中,窗口分析的功能是Neighborhood statistic 命令 在实际工作中,为解决某一个具体的应用命题,以上4种栅格数据的分析模式往往综合使用。
Mean;(2)Maximum; (3)Minimum;(4)Median;(5)Sum; (6)Range;(7)Majority;(8)Minority;(9)Variety。 在Arc View软件中,窗口分析的功能是Neighborhood statistic 命令. 在实际工作中,为解决某一个具体的应用命题,以上4种栅格数据的分析模式往往综合使用。")
39
5.矢量数据分析的基本方法 5.1 包含分析 5.2 叠置(加)分析 5.3 缓冲区分析
与栅格数据分析处理方法相比, 矢量数据一般不存在模式化的分析处理方法, 而表现为处理方法的多样性与复杂性。 5.1 包含分析 5.2 叠置(加)分析 5.3 缓冲区分析
分析. 5.3 缓冲区分析.")
40
5.1 包含分析 确定要素之间是否存在着直接的联系,即矢量点、线、面之间是否存在在空间位置上的联系,这是地理信息分析处理中常要提出的问题,也是在地理信息系统中实现图形—属性对应检索的前提条件与基本的分析方法。 例如是否相邻或包含 ,要确定某个井位属于哪个行政区;要测定某条断裂线经过哪些城市建筑;在计算机屏幕上利用鼠标点击对应的点状、线状或面状图形,查询其对应的属性信息; 在包含分析的具体算法中,点与点、点与线的包含分析一般均可以分别通过先计算点到点,点到线之间的距离,然后,利用最小距离阈值判断包含的结果。

41
5.1 包含分析 点与面之间的包含分析,或称为Point-Polygon分析,具有较为典型的意义。可以通过著名的铅垂线算法来解决,如图6-9所示,由Pt点作一条铅垂线。现在要测试Pt是在该多边形之内或之外。其基本算法的思路是,如果该铅垂线与某一图斑有奇数交点,则该Pt点必位于该图斑内(某些特殊条件除外)
")
42
5.1 包含分析 利用这种包含分析方法,还可以解决: 地图的自动分色 地图内容从面向点的制图综合 面状数据从矢量向栅格格式的转换
区域内容的自动计数(例如某个设定的森林砍伐区内,某一树种的颗数) 等等。 例如,确定某区域内矿井的个数,这是点与面之间的包含分析,确定某一县境内公路的类型以及不同级别道路的里程,是线与面之间的包含分析。 分析的方法是:首先对这些矿井、公路要点、线要素数字化,经处理后形成具有拓扑关系的相应图层,然后和已经存放在系统中的多边形进行点与面、线与面的叠加;最后对这个多边形或区域进行这些点或线段的自动计数或归属判断。
 等等。 例如,确定某区域内矿井的个数,这是点与面之间的包含分析,确定某一县境内公路的类型以及不同级别道路的里程,是线与面之间的包含分析。 分析的方法是:首先对这些矿井、公路要点、线要素数字化,经处理后形成具有拓扑关系的相应图层,然后和已经存放在系统中的多边形进行点与面、线与面的叠加;最后对这个多边形或区域进行这些点或线段的自动计数或归属判断。")
43
5.2 基于矢量的叠加分析 原理:就是把同一地区的两幅或两幅以上的图层重叠在一起进行图形运算和属性运算(关系运算),产生新的空间图形和属性的过程 目的:寻找和确定同时具有几种地理属性的地理要素的分布,或是按照确定的地理指标,对叠加后产生的具有不同属性级的多边形进行分类或分级 如了解某区域的森林覆盖面积(行政区与植被图层的叠加)、一个县的公路里程、一个地区的河流密度、降雨与温度的关系等
、一个县的公路里程、一个地区的河流密度、降雨与温度的关系等.")
44
5.2 基于矢量的叠加分析

45
5.2 基于矢量的叠加分析 叠加分析是空间信息系统中最常用的提取隐含信息的手段之一。叠加分析不仅包含空间关系的比较,还包含属性关系的比较:
点与多边形的叠加:实质上是计算多边形对点的包含关系,用于统计或属性赋值。 线与多边形的叠加:主要用于计算线落在哪些多边形中以及各自的部分。 多边形叠加:最常用的叠加分析。

46
5.2 基于矢量的叠加分析 叠加类型: 5.2.1 点与多边形的叠加 5.2.2 线与多边形的叠加 5.2.3 多边形与多边形的叠加
至少涉及两个图层,其中必有一个图层是多边形图层,称基础图层 叠加类型: 5.2.1 点与多边形的叠加 5.2.2 线与多边形的叠加 5.2.3 多边形与多边形的叠加 5.2.4 ARC/INFO常用叠加分析命令

47
矢量图层叠加分析 A B 1 2 3 4 5 1B 2B 1A 2A 4A 3A 5B 3B 4B 降雨量 土壤类型 适宜农作物

48
5.2.1 点与多边形的叠加 叠加图层:将一个含有点的图层(目标图层)叠加在另一个含有多边形的图层(操作图层)上,以确定每个点落在哪个区域内。 叠加方法:通过点在多边形内的点位判别完成。通常得到一张新的属性表,该属性表除了原有属性外,还含有落在那个多边形的目标标识,如果必要的话,还可以在多边形的属性表中提取一些附加属性。

49
5.2.2 线与多边形的叠加 叠加图层:将线的图层(目标图层)叠加在多边形的图层(操作图层)上,以确定一条线落在哪个多边形内。 叠加原理:与前面不同的是,往往一个线目标跨越多个多边形,这时需要先进行线与多边形的求交,并将线目标进行切割,形成一个新的空间目标(新的线目标)的结果集
叠加在多边形的图层(操作图层)上,以确定一条线落在哪个多边形内。 叠加原理:与前面不同的是,往往一个线目标跨越多个多边形,这时需要先进行线与多边形的求交,并将线目标进行切割,形成一个新的空间目标(新的线目标)的结果集.")
50
5.2.3 多边形与多边形的叠加 叠加过程:多边形与多边形的叠加操作要比前面两种复杂得多。需要将两层多边形的边界全部进行边界求交的运算和切割。然后根据切割的弧段重新建立拓扑关系,最后判断叠加后的多边形分别落在原始多边形层的哪个多边形内,建立起新多边形与原多边形的关系 下图是多边形叠加的过程

51
三个主要叠加分析命令 5.2.4 ARC/INFO常用叠加分析命令 UNION:合并操作(OR) IDENTIFY:识别操作
INTERSECT:求交集操作(AND) 三个命令的比较
 三个命令的比较.")
52
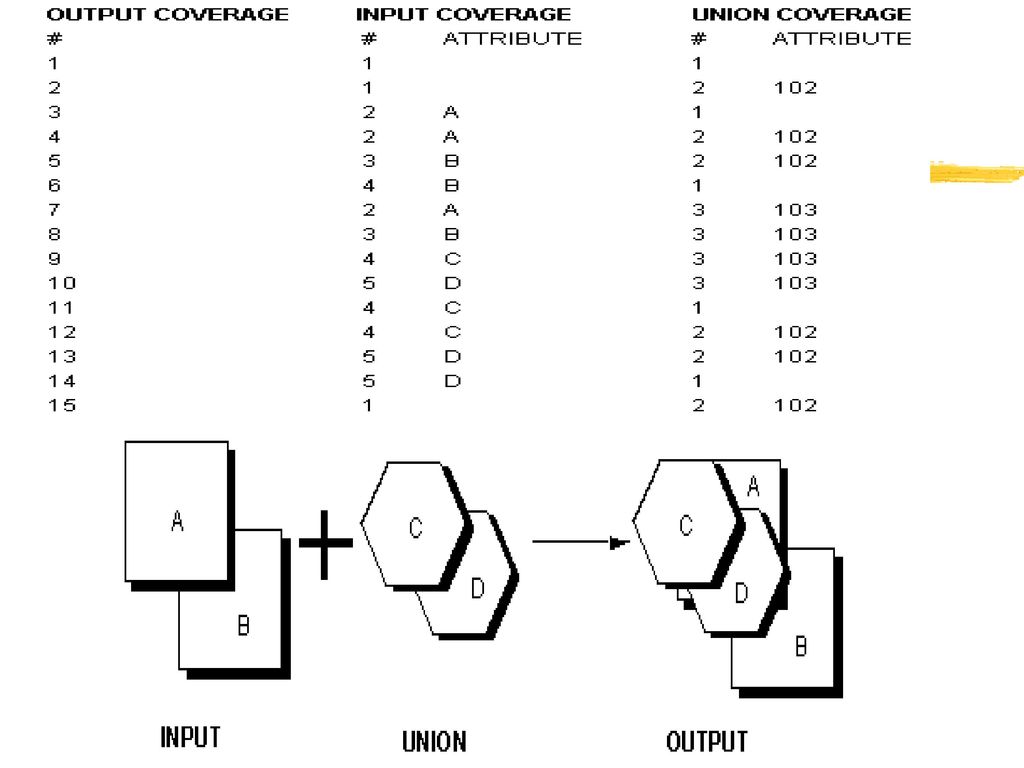
UNION 合并操作(求并集操作):只能进行多边形叠加,保留原来两个Coverage的所有区域
UNION <in_cover> <union_cover> <out_cover> {fuzzy_tolerance} {JOIN | NOJOIN}

54
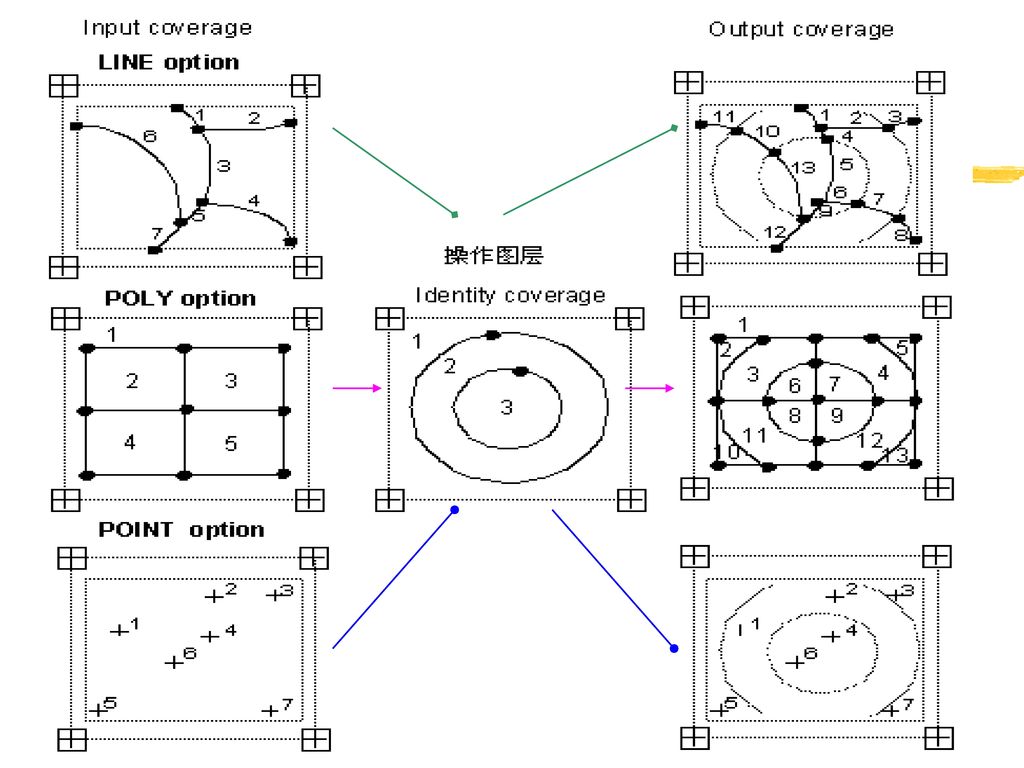
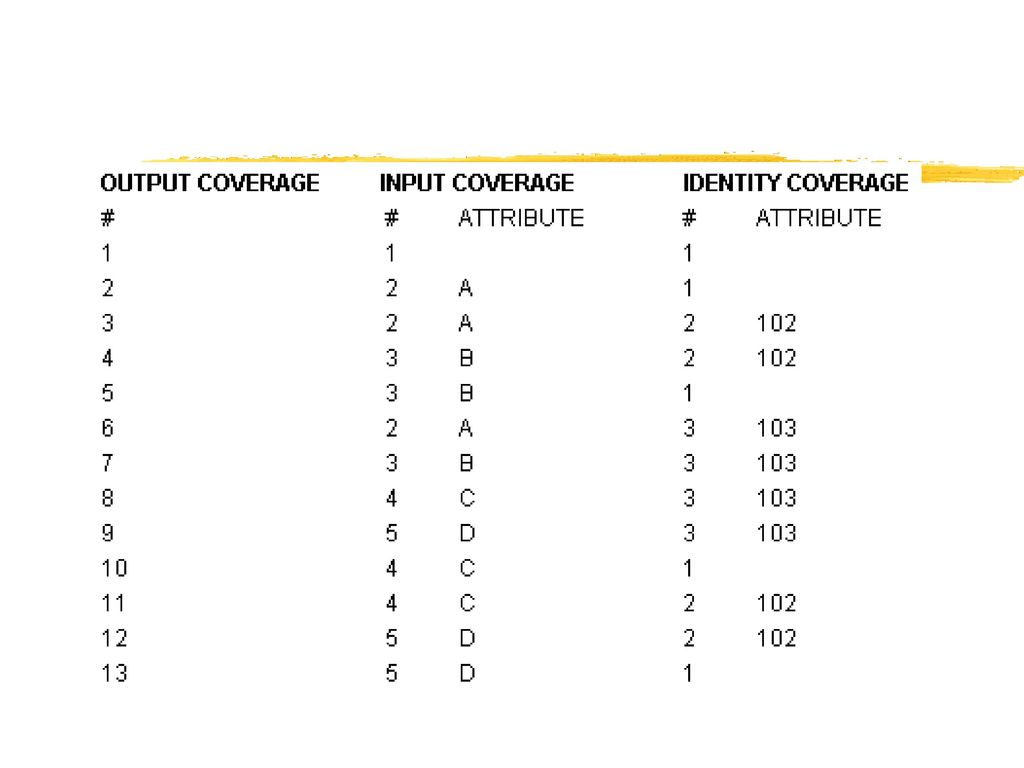
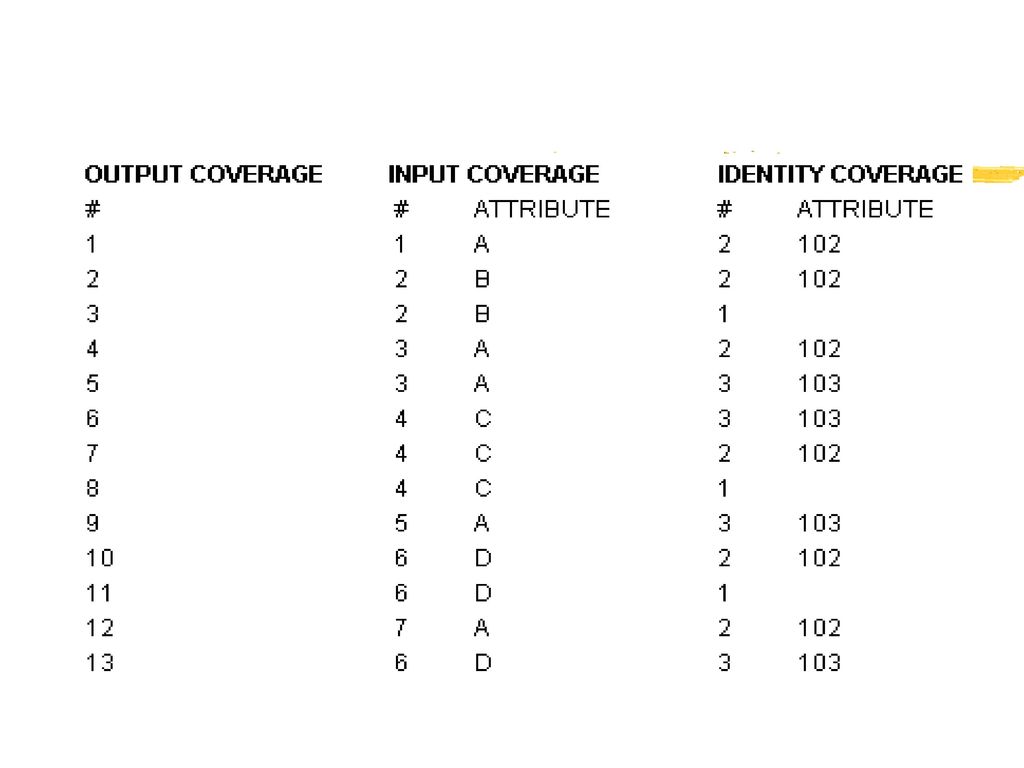
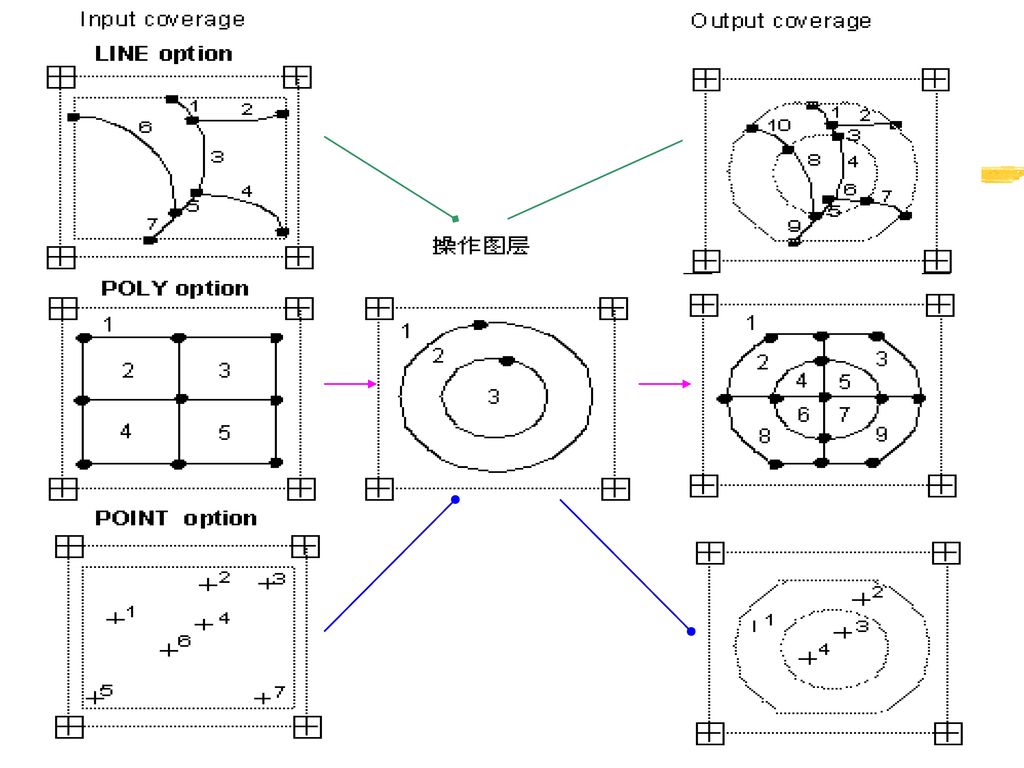
IDENTITY(识别操作) 将点、线或多边形叠加到多边形上,保留所有输入Coverage的特征。
输入图层的可以是多边形、点、线,而操作图层(叠加)要素必须是多边形。 IDENTITY <in_cover> <identity_cover> <out_cover> {POLY | LINE | POINT} {fuzzy_tolerance} {JOIN | NOJOIN}
要素必须是多边形。 IDENTITY <in_cover> <identity_cover> <out_cover> {POLY | LINE | POINT} {fuzzy_tolerance} {JOIN | NOJOIN}")
56
多边形识别操作示意

58
线状要素识别操作示意

60
INTERSECT(求交集操作) 将点、线或多边形叠加到多边形上,两个图层的公共部分予以保留。属性表同时被更新
输入图层的可以是多边形、点、线,而操作图层(叠加)要素必须是多边形。 INTERSECT <in_cover> <intersect_cover> <out_cover> {POLY | LINE | POINT} {fuzzy_tolerance} {JOIN | NOJOIN}
要素必须是多边形。 INTERSECT <in_cover> <intersect_cover> <out_cover> {POLY | LINE | POINT} {fuzzy_tolerance} {JOIN | NOJOIN}")
62
三个命令的比较 相同点:三个命令的执行过程中,ArcInfo自动为输出Coverage创建拓扑关系,输出Coverage的特征属性表中对应于每一条记录,都有关于相交生成此地物特征的两个原始Coverage的地物特征的编号信息,如果使用了JOIN选项,输出Coverage的特征属性表中附加<in_cover>和<out_cover>的特征属性表的所有属性项。 不同点:对输入Coverage的类型有不同的要求。另外输出Coverage中保留哪些输入Coverage的特征的处理标准不同。

63
5.3 缓冲区分析(Buffer) 5.3.1 缓冲区分析原理 缓冲区分析是研究根据数据库的点、线、面实体,自动建立其周围一定宽度范围内的缓冲区多边形实体,从而实现空间数据在水平方向得以扩展的信息分析方法。它是地理信息系统重要的和基本的空间操作功能之一。 缓冲区就是空间实体的一种影响范围或服务范围。缓冲区分析的基本思想就是给定一个空间实体或集合,确定它们的邻域,邻域的大小由领域半径R来确定。 缓冲分析是对一组或一类地物按照缓冲的距离条件,建立缓冲区多边形图,然后将这个图层与需要进行缓冲分析的图层进行叠加分析,得到所需要的结果. 分析过程:一是建立缓冲区图层,二是进行叠加分析

64
5.3.2 缓冲区分析应用 在数据处理和空间分析的某些过程中需要使用Buffer功能来实现。前者如从单线河生成双线河或从街道中心线生成双线街道等;后者如根据污染源求敏感区范围等。城市的噪音污染源所影响的一定空间范围、交通线两侧所划定的绿化带 BUFFER可以以多边形、线、点或结点为输入数据生成缓冲区,这个缓冲区必定为多边形

65
5.3.3 缓冲区的建立 地物缓冲区示意图

66
以点状地物为圆心,以缓冲区距离为半径绘圆 线缓冲区和面缓冲区 以线状地物的边线为参考线,作它们的平行线,再考虑端点圆弧,即可建立缓冲区。
5.3.3 缓冲区的建立 点缓冲区 以点状地物为圆心,以缓冲区距离为半径绘圆 线缓冲区和面缓冲区 以线状地物的边线为参考线,作它们的平行线,再考虑端点圆弧,即可建立缓冲区。 地物缓冲区示意图

67
ARC/INFO中缓冲区的建立

68
5.3.4 缓冲区模型 线性模型:随距离增大影响呈线性衰减 缓冲因素 分析模型 1)主体。分析的目标,点源、面源、线源
2)临近对象。受主体影响的客体,如行政变更涉及的居民区,森林砍伐涉及的水土流失范围 3)作用条件。主体对邻近对象施加作用的影响条件或强度 分析模型 线性模型:随距离增大影响呈线性衰减 二次模型:随距离增大影响呈二次形式衰减 指数模型:随距离增大影响呈指数形式衰减
临近对象。受主体影响的客体,如行政变更涉及的居民区,森林砍伐涉及的水土流失范围. 3)作用条件。主体对邻近对象施加作用的影响条件或强度. 分析模型. 线性模型:随距离增大影响呈线性衰减. 二次模型:随距离增大影响呈二次形式衰减. 指数模型:随距离增大影响呈指数形式衰减.")
69
5.4.5 缓冲区分析实例 道路通达性 条件:研究区域内三条道路,道路为主体,附近的居民出行为为邻近对象 要求:三条道路的通达性 分析过程:
1)计算道路的综合规模化指数(标准化处理) 2)计算道路的最大影响距离(与道路的级别与长度有关) 3)实施缓冲区操作,经过分析道路的影响特点,选择指数模型
计算道路的综合规模化指数(标准化处理) 2)计算道路的最大影响距离(与道路的级别与长度有关) 3)实施缓冲区操作,经过分析道路的影响特点,选择指数模型.")
70
6. 网络分析(NetWork) 网络是用于实现资源运输和信息交流的一系列相互联接的线性特征组合。 6.1 什么是网络分析?
在GIS中,网络分析是指依据网络拓扑关系(结点与弧段拓扑、弧段的连通性),通过考察网络元素的空间及属性数据,以数学理论模型为基础,对网络的性能特征进行多方面研究的一种分析计算。
,通过考察网络元素的空间及属性数据,以数学理论模型为基础,对网络的性能特征进行多方面研究的一种分析计算。")
71
6. 网络分析(NetWork) 6.2.1 网络数据模型 6.2.2 网络分析功能 网络跟踪(Trace)
6.2 网络分析主要内容 6.2.1 网络数据模型 6.2.2 网络分析功能 网络跟踪(Trace) 路径分析(PathFinding) 资源分配(Allocation) 其他网络分析
 路径分析(PathFinding) 资源分配(Allocation) 其他网络分析.")
72
6.2.1网络数据模型 网络模型是对现实世界网络的抽象。在模型中,网络由链(Link)、结点(Node)、站点(Stop)、中心(Center)和转向点(Turn)组成。 建立一个好的网络模型的关键是清楚地认识现实网络的各种特性与以网络模型的要素(Link, Node, Stop, Center, Turn)表示的特性之间的关系。
表示的特性之间的关系。")
73
网络组成要素 结点(Node):网络中任意两条线段的交点,属性如资源数量等
链(Link):连接两个结点的弧段。供物体运营的通道,链间的连接关系由弧段-结点拓扑数据结构来表达。属性如资源流动的时间、速度等 中心(Center):网络中位于结点处,具有沿着链收集和发放资源能力的设施,如邮局、电站、水库等 站点(Stop):资源沿着网络路径流动时被分配或收集的位置,如邮件投放点、公共汽车站,属性如资源需求量 转向点(拐点,Turn):链路相交处,资源流向发生改变的点
:连接两个结点的弧段。供物体运营的通道,链间的连接关系由弧段-结点拓扑数据结构来表达。属性如资源流动的时间、速度等. 中心(Center):网络中位于结点处,具有沿着链收集和发放资源能力的设施,如邮局、电站、水库等. 站点(Stop):资源沿着网络路径流动时被分配或收集的位置,如邮件投放点、公共汽车站,属性如资源需求量. 转向点(拐点,Turn):链路相交处,资源流向发生改变的点.")
74
网络组成要素

75
6.2.2.3 资源分配 6.2.2.5 地址地理编码 6.2.2 网络分析功能 6.2.2.1 网络跟踪 6.2.2.2 路径分析
定位配置分析 地址地理编码

76
6.2.2.1 网络跟踪(Trace) 概念:网络中用于研究网络中资源和信息的流向就是网络跟踪的过程。
在点污染研究中,可以跟踪污染物从污染源开始,沿河流向下游扩散的过程。在电网应用中,可以根据不同开关的开、关状态,确定电力的流向。 数据结构的拓扑基础:网络跟踪中涉及的一个重要概念是“连通性”(Connectivity),这定义了网络中弧段与弧段的连接方式,也决定了资源与信息在网络中流动时的走向。
,这定义了网络中弧段与弧段的连接方式,也决定了资源与信息在网络中流动时的走向。")
77
6.2.2.2 路径分析 在网络分析过程中,路径系统起着相当重要的作用。事实上很多网络分析的结果都是以路径系统的形式体现出来的。
内容:路径分析是用于模拟两个或两个以上地点之间资源流动的路径寻找过程。当选择了起点、终点和路径必须通过的若干中间点后,就可以通过路径分析功能按照指定的条件寻找最优路径

78
路径选择(PathFinding) 应用:在远距离送货、物资派发、急救服务和邮递等服务中,经常需要在一次行程中同时访问多个站点(收货方、邮件主人、物资储备站等),如何寻找到一个最短和最经济的路径,保证访问到所有站点,同时最快最省地完成一次行程,这是很多机构经常遇到的问题。 这类分析中,道路网络的不同弧段(网络模型中的Link)有不同的影响物流通过的因素, 路径选择分析必须充分考虑到这些因素,在保证遍历需要访问的站点的同时,为用户寻找出一条最佳(距离、时间或费用等)的运行路径。
有不同的影响物流通过的因素, 路径选择分析必须充分考虑到这些因素,在保证遍历需要访问的站点的同时,为用户寻找出一条最佳(距离、时间或费用等)的运行路径。")
79
路径选择(PathFinding) 两种方式(Path和Tour)。ArcInfo有两个路径选择分析命令:Path和Tour。
共同点:都是在网络中寻找遍历所有站点最经济的路径。 区别:在遍历网络的所有站点过程中,处理站点的顺序有所不同。 PATH:必须按照指定的顺序访问网站中的所有站点。 例如,救护车必须从急救中心(STOP 1)出发,然后前往事故地点(STOP 2),然后负责将伤员送往最近的医院(STOP 3),最后返回急救中心(STOP 4).
出发,然后前往事故地点(STOP 2),然后负责将伤员送往最近的医院(STOP 3),最后返回急救中心(STOP 4).")
80
路径选择(PathFinding) TOUR:进行路径选择分析时,在保证在一次行程中访问所有站点的前提下,访问站点的次序是由TOUR自己决定的。因此TOUR分析的结果既包括所选择的路径,也包括它所确定的最优的访问次序。例如:卡车司机要在一天时间内向若干个站点送货,只要保证在当天内将货物送到每一个站点就可以了,先送哪个站点,后送哪个站点,完全由司机本人决定。TOUR就负责完成确定访问次序,并寻找最经济路径的任务。

81
资源分配(Allocation) 反映现实世界网络中资源的供需关系模型。可以解决资源的有效利用和合理分配;确定最近中心,实现最佳服务 “供(Supply)”代表一定数量的资源或货物,它们位于被称之为“CENTER”的设施中。“需(Demand)”指对资源的利用。Allocate分析就是在空间中的一个或多个点之间分配资源的过程。 为了实现供需关系,在网络中必然存在资源的运输和流动。资源要么由供方送到需方,要么由需需方到供方索取。
 代表一定数量的资源或货物,它们位于被称之为 CENTER 的设施中。 需(Demand) 指对资源的利用。Allocate分析就是在空间中的一个或多个点之间分配资源的过程。 为了实现供需关系,在网络中必然存在资源的运输和流动。资源要么由供方送到需方,要么由需需方到供方索取。")
82
Supply-To-Demand的例子:负荷设计、时间与距离损耗估算
关于Allocate的两个例子 Supply-To-Demand的例子:负荷设计、时间与距离损耗估算 电能从电站产生,并通过电网传送到客户那里去。在这里,电站就是网络模型中的“Center”,因为它可以提供电力供应。电能的客户沿电网的线路(网络模型中的Link)分布,他们产生了“Demand”。在这种情况下,资源是通过网络由供方传输到需方来实现资源分配。可用来分析输电系统是否超载;停电的社会、经济影响估计等。
分布,他们产生了 Demand 。在这种情况下,资源是通过网络由供方传输到需方来实现资源分配。可用来分析输电系统是否超载;停电的社会、经济影响估计等。")
83
Demand-To-Supply的例子:学校选址
关于Allocate的两个例子 Demand-To-Supply的例子:学校选址 学校与学生的关系也构成一种在网络中供需分配关系。学校是资源提供方,它负责提供名额供适龄儿童入学。适龄儿童是资源的需求方,他们要求入学。作为需求方的适龄儿童沿街道网络分布,他们产生了对作为供给方的学校的资源--学生名额的需求。这种情况下,“资源”的流向是由适龄儿童前往学校

84
Location-Allocation(选址和分区)分析
定位配置分析(选址和分区) Location-Allocation(选址和分区)分析 Location-allocation分析是决定一个或多个服务设施的最优位置的过程,它的定位力求保证服务设施可以以最经济有效的方式为它所服务的人群提供服务。在此分析中,即有定位过程,也有资源分配过程。
 Location-Allocation(选址和分区)分析. Location-allocation分析是决定一个或多个服务设施的最优位置的过程,它的定位力求保证服务设施可以以最经济有效的方式为它所服务的人群提供服务。在此分析中,即有定位过程,也有资源分配过程。")
85
定位配置分析(选址和分区) 定位配置分析的实质是线性规划问题。主要的算法包括:
p-中心问题:在m个候选点中,选择p个供应点,为n个需求点服务,并使得从服务中心到需求点之间的距离(或时间、费用)最小。 中心服务范围的确定:中心服务范围是指一个服务设施在给定的时间或距离内,能够到达的区域。 中心资源的分配范围:资源分配就是将空间网络的边或者结点,按照中心的供应量及网络边和结点的需求量,分配给一个中心的过程,用来模拟空间网络上资源的供需关系(Allocation) 。
最小。 中心服务范围的确定:中心服务范围是指一个服务设施在给定的时间或距离内,能够到达的区域。 中心资源的分配范围:资源分配就是将空间网络的边或者结点,按照中心的供应量及网络边和结点的需求量,分配给一个中心的过程,用来模拟空间网络上资源的供需关系(Allocation) 。")
86
地址编码与匹配(GeoCoding) 地址编码与匹配(GeoCoding)
利用人们习惯的地址(街道门牌号)信息确定它在地图上的确切位置的技术. 地址编码与匹配就是在含地址的表格数据与相关图层之间建立联系,并为表格数据创建一个相应的点要素层。当对表格数据进行编码后,就可以对表格数据进行空间定位查询和分析
信息确定它在地图上的确切位置的技术. 地址编码与匹配就是在含地址的表格数据与相关图层之间建立联系,并为表格数据创建一个相应的点要素层。当对表格数据进行编码后,就可以对表格数据进行空间定位查询和分析.")
87
7. 空间插值分析 概念:从存在的观测数据中找到一个函数关系式,使该关系式最好地逼近这些已知的空间数据,并能根据函数关系式推求出区域范围内其它任意点或任意分区的值,这种根据已知点或分区的数据,推求任意点或任意分区的值的方法称为空间数据内插。 空间插值分析是GIS中数据处理常用方法之一,广泛应用于等值线自动制图、DEM模型建立、不同区域界限现象的相关分析 这一过程实际上是把样本点置于三维空间中,点属性为Z坐标,拟合构造一个连续的光滑曲面函数,任意一点的属性值通过函数求解,因此也称为面插值分析

88
7. 空间插值分析 原因:空间数据往往是根据自己的要求获取采样的观测值,诸如土地类型、地面高程等。这些点的分布往往是不规则的,在用户感兴趣或模型复杂区域可能采样点多,在其它地区则采样点少,由此而导致所形成的多边形的内部变化不可能表达得更精确、更具体,而只能达到一般的平均水平。但用户在某些时候却欲获知未观测点的某种感兴趣特征的更精确值,这就导致了空间内插技术的诞生。

89
7. 空间插值分析 通常,在以下几种情况下要做空间插值: 现有数据的分辨率不够,如遥感图象从一种分辨率转换到另一种分辨率。
现有数据的结构与所需结构不同,如将栅格数据转换到TIN数据。 现有数据没有完全覆盖整个区域,如只有一些离散点数据。 需要进行空间插值处理的原始数据包括:航片/卫片、野外测量采样数据、等值线图等。

90
7. 空间插值分析 连续空间与离散空间 现实空间可以分为具有渐变特征的连续空间和具有跳跃特征的离散空间。举例来讲,土地类型分布属离散空间,而地形表面分布则是连续空间

91
7. 空间插值分析 空间插值的理论假设是空间位置上越靠近的点,越可能具有相似的特征值,而距离越远的点,其特征值相似的可能性越小。
离散空间数据内插 对于离散空间,假定任何重要变化发生在边界上,则在边界内的变化是均匀的,同质的,即在各个方面都是相同的。对于这种空间的最佳内插方法是邻近元法,即以最邻近图元的特征值表征未知图元的特征值。这种方法在边界会产生一定的误差,但在处理大面积多边形时,则十分方便。在Arc View中,无离散数据的内差功能,只有把矢量的离散数据转换为GRID数据的功能。 连续表面的内插技术必须采用连续的空间渐变模型实现这些连续变化,可用一种平滑的数学表面加以描述。分为整体插值方法和部分(局部)插值方法两类。
插值方法两类。")
92
7. 空间插值分析 整体插值:用研究区域所有采样点的数据进行全区域特征拟合,如边界内插法、趋势面分析等。这种内插技术的特点是不能提供内插区域的局部特性,因此,该模型一般用于模拟大范围内的变化 部分(局部)插值:仅仅用邻近的数据点来估计未知点的值,如最邻近点法(泰森多边形方法)、移动平均插值方法(距离倒数插值法)、样条函数插值方法、空间自协方差最佳插值方法(克里金插值)等。局部拟合技术则是仅仅用邻近的数据点来估计未知点的,因此可以提供局部区域的内插值,而不致受局部范围外其它点的影响
插值:仅仅用邻近的数据点来估计未知点的值,如最邻近点法(泰森多边形方法)、移动平均插值方法(距离倒数插值法)、样条函数插值方法、空间自协方差最佳插值方法(克里金插值)等。局部拟合技术则是仅仅用邻近的数据点来估计未知点的,因此可以提供局部区域的内插值,而不致受局部范围外其它点的影响.")
93
泰森多边形 概述 具有离散样本点的问题分析 通过对于具有专业属性的离散样本点分析,如地下水深度、土壤有机质含量,降雨量等。求解在该研究区任意点的专业属性数据值。 解决方法 等值面解决思路——泰森多边形思路 构造曲面函数思路——面插值,模拟解析函数

94
(3)相邻三角形外心的连线或三角形边垂直平分线与图廓线构成泰森多边形
泰森多边形算法思路 (1)用样本点连成三角形,尽量生成锐角三角形,即样本点之间最近样本点的连线 (2)对每个三角形作外心 (3)相邻三角形外心的连线或三角形边垂直平分线与图廓线构成泰森多边形
用样本点连成三角形,尽量生成锐角三角形,即样本点之间最近样本点的连线. (2)对每个三角形作外心. (3)相邻三角形外心的连线或三角形边垂直平分线与图廓线构成泰森多边形.")
95
泰森多边形性质与应用 性质 每个泰森多边形包围一个样本点 泰森多边形内任意一点与其包围样本点的距离为最近 应用 构建等值区,由点的研究扩展到面研究 条件 样本点需要相当数量,并且必须有代表性

96
8 数字地面分析与DEM模型 概念:数字地面(地形)模型(DTM ,Digital Terrain Model )是通过地表点集的空间坐标及其属性数据表示表面特征的地学模型。是带有空间位置特征和地面属性特征的数字描述。 DTM中属性为高程的要素叫数字高程模型(DEM Digital Elevation Model )。 许多大型GIS系统都有专门的DEM模块,如ArcInfo中的TIN、GRID模块
。 许多大型GIS系统都有专门的DEM模块,如ArcInfo中的TIN、GRID模块.")
97
DEM的应用 在数字地形图数据库中存贮高程数据 ; 解决道路设计和其他民用及军用工程中的一些与高程有关的问题 ;
三维地形显示及风景设计和规划; 剖面视觉分析 ; 道路规划、大坝选址等 ; 不同地形之间的静态分析和比较; 产生坡度图、坡向、及坡度剖面图,辅助地貌分析(淹没分析、土方计算等)或建立侵蚀图; 作为专题信息的显示背景或将地形数据与专题数据如土壤、土地利用或植被等进行叠加 ; 为景观的图像模拟和景观处理提供数据 ; 通过将高程替换为其他连续变化的属性,DEM能表示传播时间、费用、人口、污染程度、地下水深等信息
或建立侵蚀图; 作为专题信息的显示背景或将地形数据与专题数据如土壤、土地利用或植被等进行叠加 ; 为景观的图像模拟和景观处理提供数据 ; 通过将高程替换为其他连续变化的属性,DEM能表示传播时间、费用、人口、污染程度、地下水深等信息.")
98
DEM的数据采集与表示 DEM的数据源与采集方法 以航空或航天遥感图像为数据源 ; 以地形图为数据源 以地面实测记录为数据源
数学分块曲面表示法 规则格网表示法 不规则三角网(TIN)表示法
表示法.")
99
DEM的数据采集 以航空或航天遥感图像为数据源 ;

100
DEM的数据采集 以航空或航天遥感图像为数据源 :这种方法是由航空或航天遥感立体像对,用摄影测量的方法建立空间地形立体模型,量取密集数字高程数据,建立DTM。采集数据的摄影测量仪器包括各种解析的和数字的摄影测量与遥感仪器。

101
DEM的数据采集 以地形图为数据源 :主要以比例尺不大于1:1万的国家近期地形图为数据源,从中量取中等密度地面点集的高程数据,建立DEM。

102
DEM的数据采集 以地面实测记录为数据源 用电子速测仪(全站仪)和电子手簿或测距经纬仪配合PC1500等袖珍计算机,在已知点位的测站上,观测到目标点的方向、距离和高差三个要素。计算出目标点的x、y、z三维坐标,存储于电子手簿或袖珍计算机中,成为建立DEM的原始数据。这种方法一般用于建立小范围大比例尺(比例尺大于1:5000)区域的DEM,对高程的精度要求较高。
和电子手簿或测距经纬仪配合PC1500等袖珍计算机,在已知点位的测站上,观测到目标点的方向、距离和高差三个要素。计算出目标点的x、y、z三维坐标,存储于电子手簿或袖珍计算机中,成为建立DEM的原始数据。这种方法一般用于建立小范围大比例尺(比例尺大于1:5000)区域的DEM,对高程的精度要求较高。")
103
DEM数据的表示 数学分块曲面表示法 这种方法把地面分成若干个块,每块用一种数学函数,如傅立叶级数高次多项式、随机布朗运动函数等,以连续的三维函数高平滑度地表示复杂曲面,并使函数曲面通过离散采样点。这种近似数学函数表示的DTM不太适合于制图,但广泛用于复杂表面模拟的机助设计系统。 高程矩阵(规则矩形格网) 表示方法:将区域划分成网格,记录每个网格的高程; 优点:计算机处理以栅格为基础的矩阵很方便,使高程矩阵称为最常见的DEM; 缺点:在平坦地区出现大量数据冗余;若不改变格网大小,就不能适应不同的地形条件;在视线计算中过分依赖格网轴线。
 表示方法:将区域划分成网格,记录每个网格的高程; 优点:计算机处理以栅格为基础的矩阵很方便,使高程矩阵称为最常见的DEM; 缺点:在平坦地区出现大量数据冗余;若不改变格网大小,就不能适应不同的地形条件;在视线计算中过分依赖格网轴线。")
104
DEM数据的表示 高程矩阵(规则矩形格网):DTM来源于直接规则矩形格网采样点或由规则或不规则离散数据点内插产生。由于计算机对矩阵的处理比较方便,特别是以栅格为基础的GIS系统中高程矩阵已成为DTM最通用的形式。
:DTM来源于直接规则矩形格网采样点或由规则或不规则离散数据点内插产生。由于计算机对矩阵的处理比较方便,特别是以栅格为基础的GIS系统中高程矩阵已成为DTM最通用的形式。")
105
规则网格模型 将区域空间分为规则的网格单元(可以是正方形或三角形),每个单元对应一个数值。 91 78 63 50 53 44 94 81
X 将区域空间分为规则的网格单元(可以是正方形或三角形),每个单元对应一个数值。 91 78 63 50 53 44 94 81 64 51 57 62 99 84 66 55 54 95 56 72 71 58 96 82 80 60 79 Y
,每个单元对应一个数值。 Y.")
106
规则网格模型 对于每个网格的数值有两种不同的解释。第一种认为该格网单元的数值是其中所有点的高程,即格网单元对应的地面面积内高程是均一的高度。这种数字高程模型是一个不连续的函数,一般用来表示离散空间。第二种认为该格网单元的数值是网格中心点的高程或该网格单元的平均高程值,这样则需要用一种插值方法来计算每个点的高程。 在Arc View 中,每个网格的值被认为是栅格中心点的值

107
DEM数据的表示 不规则三角网(TIN) 表示方法:将区域划分为相邻的三角面网络,区域中任意点落在三角面顶点、线或三角形内,落在顶点其高程与顶点相同,落在线上则由两个顶点线性插值得到,落在三角形内则由三个顶点插值得到 生成方法:由不规则点、矩形格网或等高线转换而得到 TIN允许在地形复杂地区收集较多的信息,而在简单的地区收集少量信息,避免数据冗余 对于某些类型的运算比建立在数字等高线基础上的系统更有效,如坡度、坡向等

108
DEM数据的表示 不规则三角网(TIN) :TIN表示法利用所有采样点取得的离散数据,按照优化组合的原则,把这些离散点(各三角形的顶点)连接成相互连续的三角面(在连接时,尽可能地确保每个三角形都是锐角三角形或是三边的长度近似相等)
 :TIN表示法利用所有采样点取得的离散数据,按照优化组合的原则,把这些离散点(各三角形的顶点)连接成相互连续的三角面(在连接时,尽可能地确保每个三角形都是锐角三角形或是三边的长度近似相等)")
109
TIN模型 采用不规则三角网减少网格方法的数据冗余。
采用不规则三角网可根据情况减少野外作业量。相对平坦的地方采集点少,地形变化剧烈的地方采集点多.

110
TIN的光照显示

111
DEM模型在GIS中的应用 1)、由TIN获取任意点P的高程 已知Q1、Q2、Q3三个顶点,高程线性内插 求P的Z
x y z 1 x1 y1 z1 1 x2 y2 z2 1 x3 y3 z3 1 =0 平面方程 Z=Z1-(x-x1) (y21z31-y31z21)+(y-y1)(z21x31-z31x21)/(x21y31-x31y21)
 (y21z31-y31z21)+(y-y1)(z21x31-z31x21)/(x21y31-x31y21)")
112
DEM模型在GIS中的应用 2)、由TIN进行曲面拟合 由于在TIN中可以获取任意点高程,进行密集插值可获得拟合的地形曲面.
、由TIN进行曲面拟合 由于在TIN中可以获取任意点高程,进行密集插值可获得拟合的地形曲面.")
113
DEM模型在GIS中的应用 3)、剖面分析与绘制
、剖面分析与绘制")
114
DEM模型在GIS中的应用 剖面分析与绘制 剖面线

115
DEM模型在GIS中的应用 3)、剖面分析与绘制 确定剖面线。既可以人工输入,也可以利用鼠标实时确定。
计算剖面线与所有网格的交点,并对交点进行插值处理,得到各交点高程。 在新的剖面图中,按顺序绘制交点并连接。 如果需要,可进行二次曲线插值,进行光滑处理。 300 200 100

116
DEM模型在GIS中的应用 4)、土石方计算 在DEM基础上进行土石方计算非常方便。
如果是规则网格模型,那么把三维空间实体转变为长方体集合就能方便进行计算。 如果是TIN模型,可通过插值达到规则网格模型的密集度。当然会有一定的误差。

117
DEM模型在GIS中的应用 5)、坡度、坡向分析 在流域提取、泥石流分析和植物生长环境研究中都需要坡度与坡向分析。
、坡度、坡向分析 在流域提取、泥石流分析和植物生长环境研究中都需要坡度与坡向分析。")
118
DEM模型在GIS中的应用 5)、坡度、坡向分析(规则网格模型) DEM原数据 空间还原
、坡度、坡向分析(规则网格模型) DEM原数据 空间还原")
119
DEM模型在GIS中的应用 5)、坡度、坡向分析(规则网格模型) 坡度:规则网格模型中地表基本单元的坡度等于其法向量N与Z轴之夹角。
、坡度、坡向分析(规则网格模型) 坡度:规则网格模型中地表基本单元的坡度等于其法向量N与Z轴之夹角。")
120
DEM模型在GIS中的应用 5)、 ARC/VIEW提取地面坡度坡向图示例
、 ARC/VIEW提取地面坡度坡向图示例")
121
DEM模型在GIS中的应用 6)、利用DEM绘制等高线图:如图所示,利用DEM绘制等高线图,是以格网点高程数据或者将离散的高程数据由栅格追踪法原理转换为矢量等值线所产生的。
、利用DEM绘制等高线图:如图所示,利用DEM绘制等高线图,是以格网点高程数据或者将离散的高程数据由栅格追踪法原理转换为矢量等值线所产生的。")
122
DEM模型在GIS中的应用 7)、利用DEM绘制地面晕渲图 :晕渲图是以通过模拟实际地面本影与落影的方法有效反映地形起伏的重要的地图制图学方法。在各种小比例尺地形图、地理图,以及各类有关专题地图上得到非常广泛的应用。
、利用DEM绘制地面晕渲图 :晕渲图是以通过模拟实际地面本影与落影的方法有效反映地形起伏的重要的地图制图学方法。在各种小比例尺地形图、地理图,以及各类有关专题地图上得到非常广泛的应用。")
123
DEM模型在GIS中的应用 8、透视立体图的绘制 :立体图是表现物体三维模型最直观形象的图形,它可以生动逼真地描述制图对象在平 面和空间上分布的形态特征和构造关系。

124
DEM模型在GIS中的应用 9)、DEM水文分析 :水文分析模型用于研究与地表水流有关的各种自然现象如洪水水位及泛滥情况,或者划定受污染源影响的地区,以及预测当改变某一地区的地貌时对整个地区将造成的后果等。
、DEM水文分析 :水文分析模型用于研究与地表水流有关的各种自然现象如洪水水位及泛滥情况,或者划定受污染源影响的地区,以及预测当改变某一地区的地貌时对整个地区将造成的后果等。")
125
DEM模型在GIS中的应用 10)、基于DEM的可视性分析 :可视性分析也称道视分析,它实质属于对地形进行最优化处理的范畴,比如设置雷达站、 电视台的发射站、道路选择、航海导航等,在军事上如布设阵地(如炮兵阵地、电子对抗阵地)、设置观察哨所、铺架通信线路等。 可视性分析的基本因子有两个,一个是两点之间的通视性(Intervisibility),另一个是可视域(ViewShed),即对于给定的观察点所覆盖的区域。
,另一个是可视域(ViewShed),即对于给定的观察点所覆盖的区域。")
126
DEM模型在GIS中的应用 10)、基于DEM的可视性分析 :
、基于DEM的可视性分析 :")
127
DEM模型在GIS中的应用 10)、基于DEM的可视性分析 :
、基于DEM的可视性分析 :")
128
9、空间信息再分类(Reclassify)
空间信息分类方法是地理信息系统功能组成的重要组成部分。地理信息系统存储的数据具有原始数据的性质,这样用户就可以根据不同的使用目的对数据进行任意提取和分析。对于数据分析来说,采用分类方法不同,得到的结果会有很大的差异。 空间信息的再分类分为两类,一类是基于地理信息的非空间属性如高程、产值、性质等进行再分类,它并不改变地物已有的属性值,而只是根据地物的属性,将它们划分到相应的类别中。此种分类可以通过简单的改变图例表现来完成(如Arc View 中的Legend Edit功能),也可通过使用经典的数理统计方法如主成分分析法,层次分析法,聚类分析法等来完成。
,也可通过使用经典的数理统计方法如主成分分析法,层次分析法,聚类分析法等来完成。")
129
9、空间信息再分类(Reclassify)
另一类在分类的方法是通过对地物属性信息经过分类组织产生新的地物特征。对于矢量数据结构中的点、线地物,可以通过简单的修改属性表中的数值来实现,对面状地物,还需同时改变实体的几何形状和属性。对于栅格数据,也可通过赋值或简单的计算来获取新的地物,来达到重新分类的目的(如ArcView 中的Reclassify功能)
")
130
思考题 1、比较缓冲分析与缓冲查询的概念 2、解释叠加分析与缓冲分析方法的基本思想,并举例说明其用途 3、DTM的概念及其用途
4、栅格数据的叠加与矢量数据的叠加有什么不同 5、对空间数据的查询有哪些形式和手段? 6、泰森多边形有何特点?如何建立?

131
查资料 1、空间内插方法(方法介绍及比较)及其应用实例分析(专业应用特点) 2、DEM水文分析方法(方法介绍)及其应用(如水土流失研究)
3、缓冲分析与叠加分析实例分析(可以结合实验) 4、DEM应用分析(可以结合实验)
 4、DEM应用分析(可以结合实验)")
Similar presentations
















中队读书节 韩茜、蒋霁制作.>")


 营口市第十七中学 杨晋.>")
