Download presentation
Presentation is loading. Please wait.

1
大數據的學習路線 目前做不到的:機率性太高的(博奕) 大數據的核心:預測 預測來自於:分析及樣本 樣本的產生及收集 樣本的儲存 樣本的處理
關聯性的尋找來自於分析 分析所需的處理能力 分析依據的理論 運算能力及儲存能力 雲端運算 虛擬化 容器

2
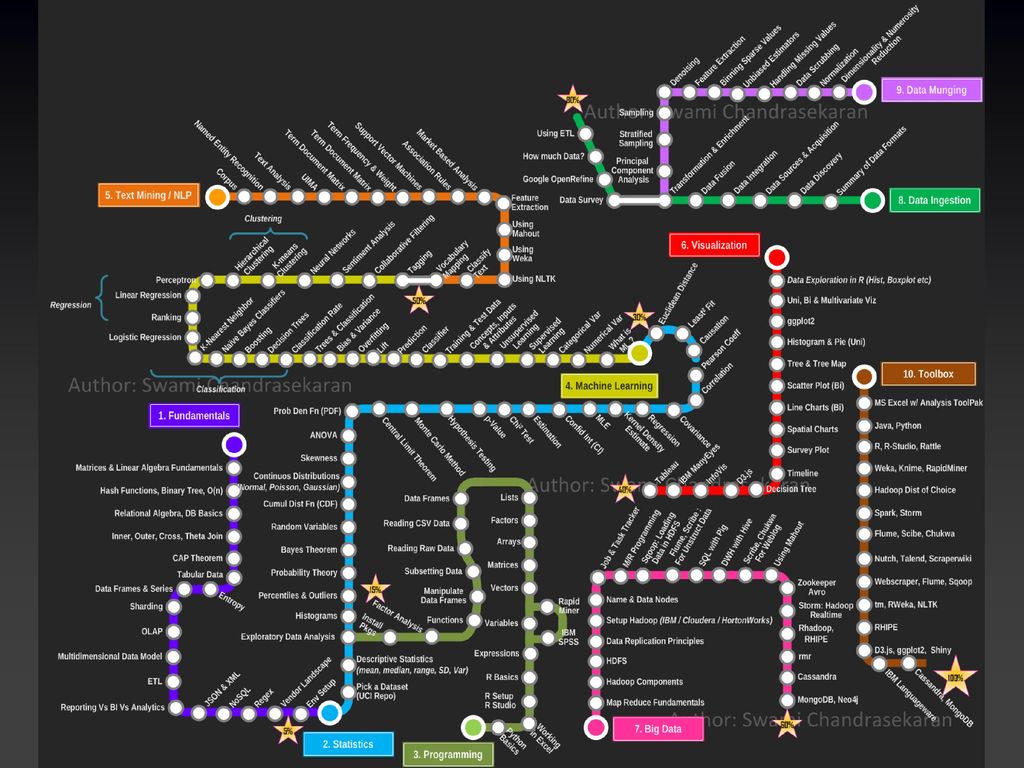
大數據基礎 統計學基礎 程式語言 機器學習 文字探勘 視覺化 大數據 資料匯整 資料轉換 工具集

3
大數據基礎 (5%) 基礎矩陣 線性代數 雜湊 二元數 O(n) 關聯代數 DB基礎 內積外積 CAP理論 表格資料 資料頁框 資料系列
Theta Join CAP理論 表格資料 資料頁框 資料系列 資料分片 OLAP 多維資料模式 報表 商業智慧 分析 JSON XML NoSQL 正規表示 大數據廠商應用 環境設定

4
程式語言 Python 基礎 Excel 程式基礎 R設定 R Studio 快速 資料挖掘 變數 向量 矩陣 Factors Lists
表達式 IBM SPSS 快速 資料挖掘 變數 向量 矩陣 陣列 Factors Lists Data Frames CSV 讀取 原生資料 存取 資料 子分類

5
程式語言 資料頁框 處理 函數 因子分析 套件安裝 (15%)
")
6
統計學基礎 選擇資料集(UCI Repo) 描述性統計學(中數、方差等) 探索資料分析 貝式理論 亂數變數 Cumul Dist Fn
Histogram Percentiles Outliers 貝式理論 亂數變數 Cumul Dist Fn 連續分佈 高斯、帕森、正常 Skewness ANOVA Prob Den Function 中間限制理論 蒙地卡羅 理論 假設測試 P值

7
Chi2測試 評估 CI值 MLE Pearson 因子 最小適用 Euclidean距離 (30%)
")
8
視覺化 (40%) 資料探索 使用R 單雙多資料視覺 ggplot2 Scatter Plot Spatial Charts Survey
Histogram Pie Tree Tree Map Scatter Plot Line Charts Spatial Charts Survey Plot 時間軸 決策樹 D3.js Infovis IBM ManyEyes Tabular

9
機器學習 機器學習 基礎 數值 變數 分類 變數 監督 學習 觀念 輸入 屬性 訓練及 測試資料 分類 預測 OverLift Bias
非監督 學習 觀念 輸入 屬性 訓練及 測試資料 分類 預測 Lift OverLift Bias Variance Trees 分類 分類率 決策樹 Boosting

10
機器學習 (50%) Naïve貝式分類 K近似值 邏輯回歸 Ranking Perception Neutral 網路 科學分析 協作
線性回歸 Perception 階層式 Clustering Neutral 網路 科學分析 K近似 Clustering 協作 過濾 標記 Trees 分類 分類率 決策樹 Boosting

11
文字探勘 (50%) 語料庫 命名個體辨識 文字分析 UIMA 文字分類 使用WEKA 使用Mahout 市場為主分析 關聯規則 支援
字彙對映 文字分類 使用NLTK 使用WEKA 使用Mahout 特徵擷取 市場為主分析 關聯規則 支援 向量機 Term頻率 權重 Term文件 矩陣

12
大數據 Hadoop 資料複製 HDFS 元件 原則 MR 程式設計 Sqoop Pig 資料載入 HIVE For HDFS 語言 SQL
MapReduce YARN Hadoop 元件 HDFS 資料複製 原則 安裝 Hadoop NameNodes DataNodes JobTracker TaskTracker MR 程式設計 Sqoop 資料載入 HDFS 非結構性 Flume Scribe Pig For SQL HIVE 語言 Chukwa Weblog Mahout Zookeeper Avro Storm 即時資料

13
大數據 Spark Streaming RHadoop R MR Cassandra MongoDB Neo4j

14
資料匯整 資料格式 資料來源 簡介 資料發現 資料整合 取得 資料轉換 加工 資料總量 資料調查 ETL 資料混合 Google
OpenRefine 資料總量 ETL

15
資料轉換 (80%) 基本元件 可接受 分析 取樣 去噪 取樣 分散資料 整合 正規化 無偏差 評估器 維度及數量等級降低 特徵擷取
資料擦洗 正規化 維度及數量等級降低

16
(100%) 工具集 R語言 Java R Studio Python Rattle Spark Storm EXCEL 分析工具集
Weka Knime RapidMiner Hadoop 版本選擇 Spark Storm Flume Scribe Chukwa Nutch Talend ScrapperWiki WebScrapper Flume Sqoop Rweka NTLK RHIPE D3.js Ggplot2 Shiny IBM Languageware Cassandra MongoDB

Similar presentations
 成立于 2011 年 9 月, 2013 年完成千万美元 A 轮融资 ( 北极光 领投 ) , 2014 年完成数千万美元的.>")

 温馨提示:编辑幻灯片母版,可以修改每页PPT的厦大校徽和底部文字 林子雨>")






>")






 目前做不到的:機率性太高的(博奕) 大數據的核心:預測 預測來自於:分析及樣本 樣本的產生及收集>")

>")
