Download presentation
Presentation is loading. Please wait.

1
五子棋棋略的演化學習法

2
五子棋策略搜尋樹(IF rule Tree) 1.文法定義與演化方式
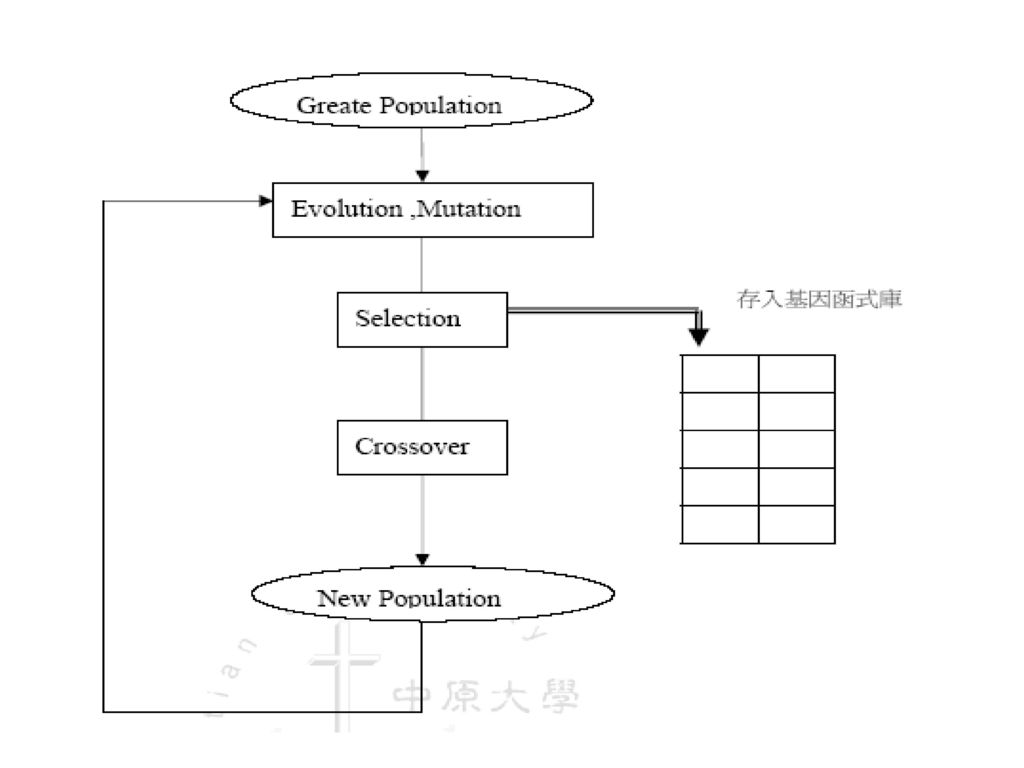
Introduction 基本演算結構 五子棋策略搜尋樹(IF rule Tree) 1.文法定義與演化方式 2.Weight的設定 3.基因函式庫 4.Crossover 五子棋策略搜尋樹(SWITCH tree) 演化完成後的去蕪存菁 實驗數據
 1.文法定義與演化方式. 2.Weight的設定. 3.基因函式庫. 4.Crossover. 五子棋策略搜尋樹(SWITCH tree) 演化完成後的去蕪存菁. 實驗數據.")
3
Introduction ◎母體大小(Population Size) 利用基因演算法,建立一個能自我學習的五子棋程式
建立系統後,更改以下基因演算法的控制參數,以期找到最佳設定 ◎母體大小(Population Size) ◎交配率(Crossover Rate) ◎突變率(Mutation Rate) ◎適應度函數(Fitness fumction)
 ◎交配率(Crossover Rate) ◎突變率(Mutation Rate) ◎適應度函數(Fitness fumction)")
4
基本演算結構 棋盤資料結構:table [size] [size] 0:空位 X,*:各代表其中一方的棋子 評估棋型表:雙方各建立一張棋型表
int computer [size] [size] [4] 0:表直線 1:表橫線 2:表左斜 3:表右斜
![基本演算結構 棋盤資料結構:table [size] [size] 0:空位 X,*:各代表其中一方的棋子 評估棋型表:雙方各建立一張棋型表](http://slidesplayer.com/slide/11317347/61/images/4/%E5%9F%BA%E6%9C%AC%E6%BC%94%E7%AE%97%E7%B5%90%E6%A7%8B+%E6%A3%8B%E7%9B%A4%E8%B3%87%E6%96%99%E7%B5%90%E6%A7%8B%EF%BC%9Atable+%5Bsize%5D+%5Bsize%5D+0%3A%E7%A9%BA%E4%BD%8D+X%EF%BC%8C%EF%BC%8A%EF%BC%9A%E5%90%84%E4%BB%A3%E8%A1%A8%E5%85%B6%E4%B8%AD%E4%B8%80%E6%96%B9%E7%9A%84%E6%A3%8B%E5%AD%90+%E8%A9%95%E4%BC%B0%E6%A3%8B%E5%9E%8B%E8%A1%A8%EF%BC%9A%E9%9B%99%E6%96%B9%E5%90%84%E5%BB%BA%E7%AB%8B%E4%B8%80%E5%BC%B5%E6%A3%8B%E5%9E%8B%E8%A1%A8.jpg "int computer [size] [size] [4] 0:表直線 1:表橫線 2:表左斜 3:表右斜.")
5
例如 computer[4][6][0]=2 computer[4][6][1]=1 computer[4][6][2]=2
以上即表示在座標(4 , 6)的點,在直方向有己方2子相連,橫方向有1己方子, 左斜方向有己方3 子相連, 右斜方向有己方2 子相連,但其末端有對方子阻擋,所以為負值。
![例如 computer[4][6][0]=2 computer[4][6][1]=1 computer[4][6][2]=2](http://slidesplayer.com/slide/11317347/61/images/5/%E4%BE%8B%E5%A6%82+computer%5B4%5D%5B6%5D%5B0%5D%3D2+computer%5B4%5D%5B6%5D%5B1%5D%3D1+computer%5B4%5D%5B6%5D%5B2%5D%3D2.jpg "以上即表示在座標(4 , 6)的點,在直方向有己方2子相連,橫方向有1己方子, 左斜方向有己方3 子相連, 右斜方向有己方2 子相連,但其末端有對方子阻擋,所以為負值。")
6
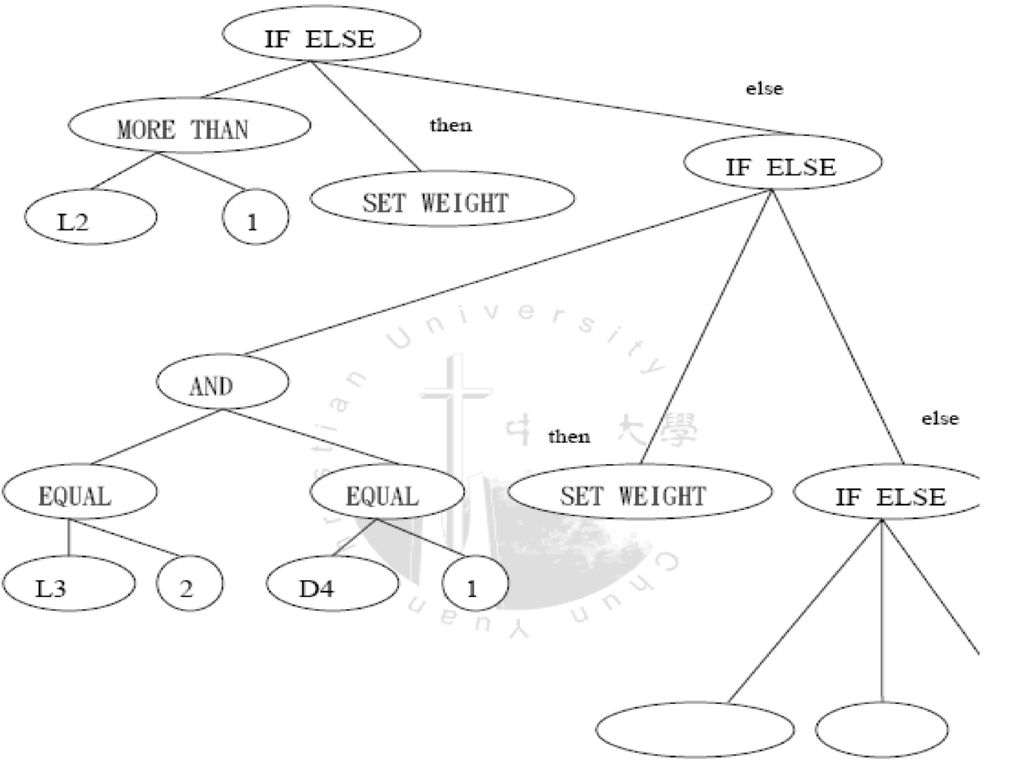
五子棋策略搜尋樹(IF rule Tree)
Definition of Functional argument:

7
Definition of Terminal node:
SET_WEIGHT : 對棋盤上的一點設定weight L1 : 探測棋盤上一點的四個方向, 存在1 個己方棋子的數目 L2 : 探測棋盤上一點的四個方向, 存在2 相鄰己方棋子的數目 L3 : 探測棋盤上一點的四個方向, 存在3 相鄰己方棋子的數目 L4 : 探測棋盤上一點的四個方向, 存在4 相鄰己方棋子的數目 L5 : 探測棋盤上一點的四個方向, 存在5 相鄰己方棋子的數目 D1 : 探測棋盤上一點的四個方向, 存在1 相鄰己方棋子的數目(末端有 對方的子阻擋) D2 : 探測棋盤上一點的四個方向, 存在2 相鄰己方棋子的數目(末端有 D3 : 探測棋盤上一點的四個方向, 存在3 相鄰己方棋子的數目(末端有對 方的子阻擋) D4 : 探測棋盤上一點的四個方向, 存在4 相鄰己方棋子的數目(末端有 D5 : 探測棋盤上一點的四個方向, 存在5 相鄰己方棋子的數目(末端有
 D2 : 探測棋盤上一點的四個方向, 存在2 相鄰己方棋子的數目(末端有. D3 : 探測棋盤上一點的四個方向, 存在3 相鄰己方棋子的數目(末端有對 方的子阻擋) D4 : 探測棋盤上一點的四個方向, 存在4 相鄰己方棋子的數目(末端有. D5 : 探測棋盤上一點的四個方向, 存在5 相鄰己方棋子的數目(末端有.")
9
IF rule tree 演化方式:

10
Gene node 的節構定義: class Gene { int symbolic;
int type; // function or terminal Gene* child; //只有function node 才有child Gene* next; // child->next 便是其第2 個子結點 }

12
Weight值設定: 3 維陣列構成了五子棋的基本資料骨架,之後再加入一些輔助評估的weight變數便可以處裡各種棋盤的局勢!!! 。

13
Integer weight[size][size] //initial all value in array to 0
for( I = 0 to size-1 ) { for( J = 0 to size-1) for( K = 0 to 4) switch(computer[I][J][K]) case 1 weight[I][J]+10 case 2 weight[I][J]+15 case 3 weight[I][J]+40 case 4 weight[I][J]+20000 case -1 weight[I][J]+5 case -2 weight[I][J]+10 case -3 weight[I][J]+35 case -4 weight[I][J]+20000
![Integer weight[size][size] //initial all value in array to 0](http://slidesplayer.com/slide/11317347/61/images/13/Integer+weight%5Bsize%5D%5Bsize%5D+%2F%2Finitial+all+value+in+array+to+0.jpg "for( I = 0 to size-1 ) { for( J = 0 to size-1) for( K = 0 to 4) switch(computer[I][J][K]) case 1 weight[I][J]+10. case 2 weight[I][J]+15. case 3 weight[I][J]+40. case 4 weight[I][J] case -1 weight[I][J]+5. case -2 weight[I][J]+10. case -3 weight[I][J]+35. case -4 weight[I][J]")
14
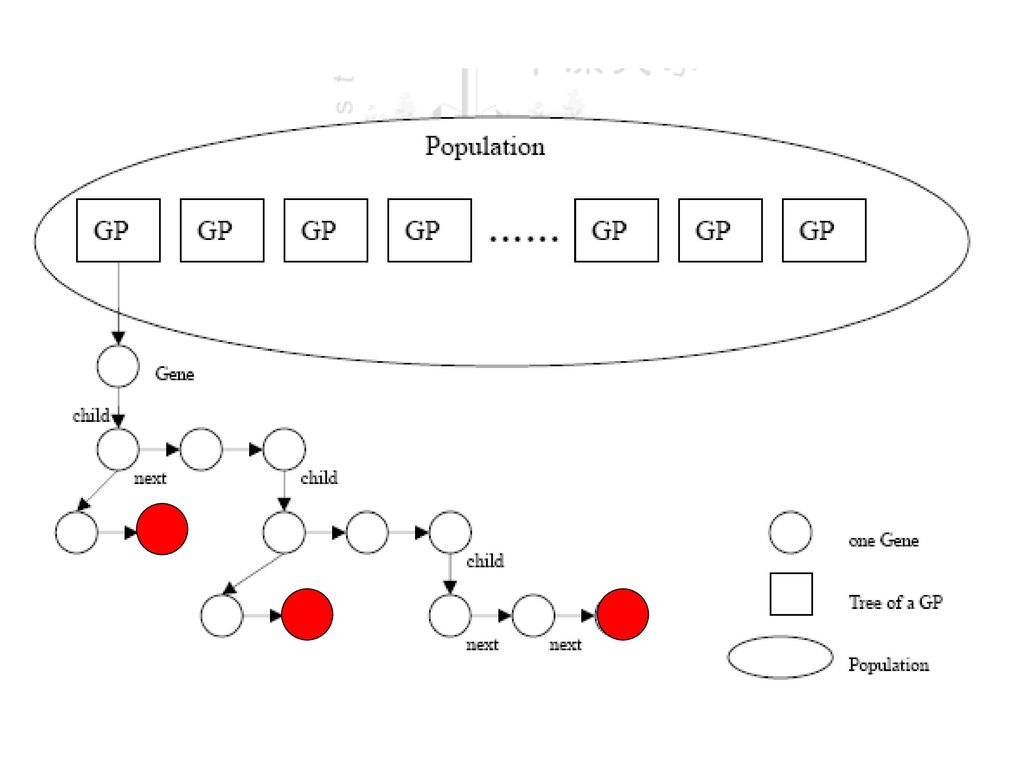
基因函式庫: 利用偵測無用或多餘的sub espression避免演化後的expression 數量過大造成使用過多的記憶體用量和執行效率減低。 將每個subtree 中加入一個記數變數,變數值初設為0,每當各subtree 若被走到時,記數值則加1,並儲存在TABLE裡,如下圖所示

15
將之前記錄的TABLE表中依rank 的前百分比取
出前幾個來放入此函式庫,而存放的內容是只存各 subtree 的condition-expression。 函式庫的內容可供特殊crossover 時引用,而 引用時依照被插接樹將被插接處的深度之深淺參考 到基因函式庫的排序範圍來引用,也就是說深度越 淺的引用基因函式庫排越前面的,即平均使用次數 越多的。

16
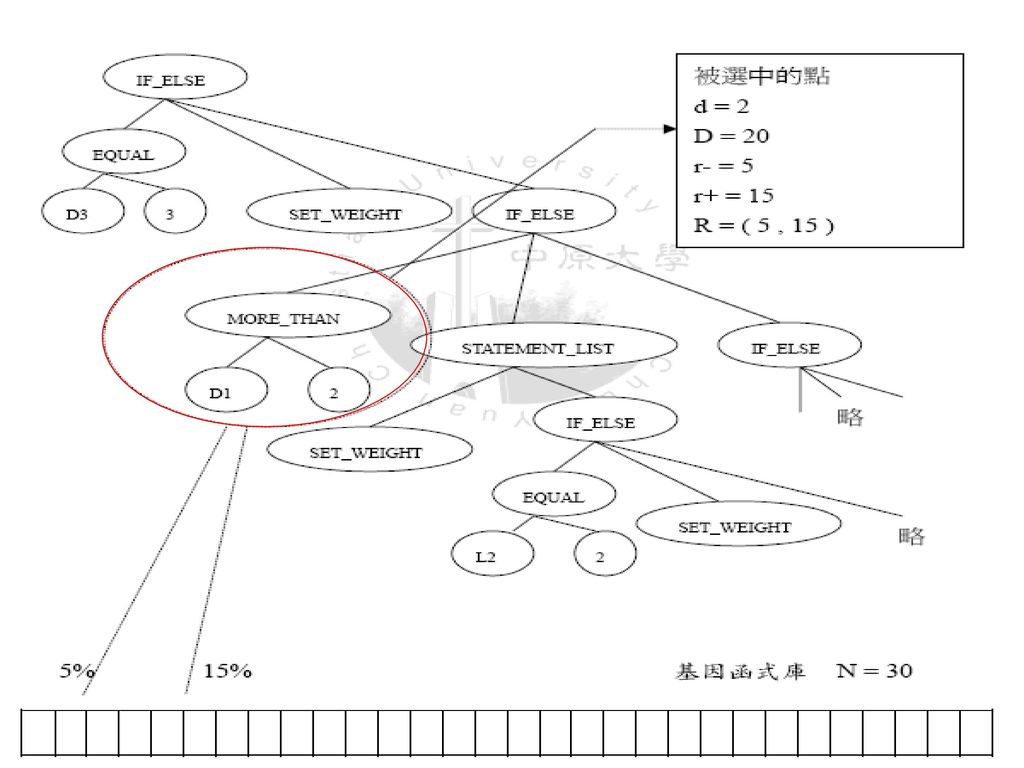
1.選出要被crossover的個體,在個體中選出點
2.依照該點在樹中的depth來印射到基因函式庫 的特定範圍 3.在此範圍中隨機選擇一個函式來插接到該點 4.範圍印射方法如下 D:要被crossover的個體之深度 d:被選中要cross 之點的深度 N:基因函式庫的大小 R:(r-%, r+%),印射到的範圍 r-=[(d/D)*100]-5, r-≧0低於0,以0計 r+=[(d/D)*100]+5,r+≦100,超過100,以100計
,印射到的範圍. r-=[(d/D)*100]-5, r-≧0低於0,以0計. r+=[(d/D)*100]+5,r+≦100,超過100,以100計.")
18
五子棋策略搜尋樹(SWITCH tree)
a.GA 染色體的內容 染色體內放置許多五子棋的棋型,一個棋型代表一個基因,而染色體中基因的排序便可視為棋型重要度的排列。 b.五子棋GA 的演化 由於染色體中基因的排序是為棋型重要度的排列,故調整染色體中基因的排序,便是對棋型重要度的再排序。而GA 經由演化時不斷排列染色體中基因的序列,意即棋型重要地位不斷地排列,最後得到一個最好策略性的棋型排列順序。 c.五子棋策略學習 讓每個在染色體內的棋型擁有一個weight 值,棋型重要度越高其weight 值亦越高,當此套策略輸棋或贏棋時,GA 會對所用過的棋型之weight 的增加或減少,如此便可造成染色體內的棋型順序重新排列。當輸棋時將對手最後幾步的下子點之棋型weight 增加,則相對應的棋型重要度便上升,GA 便從對手學習到棋型間相對的重要性。

20
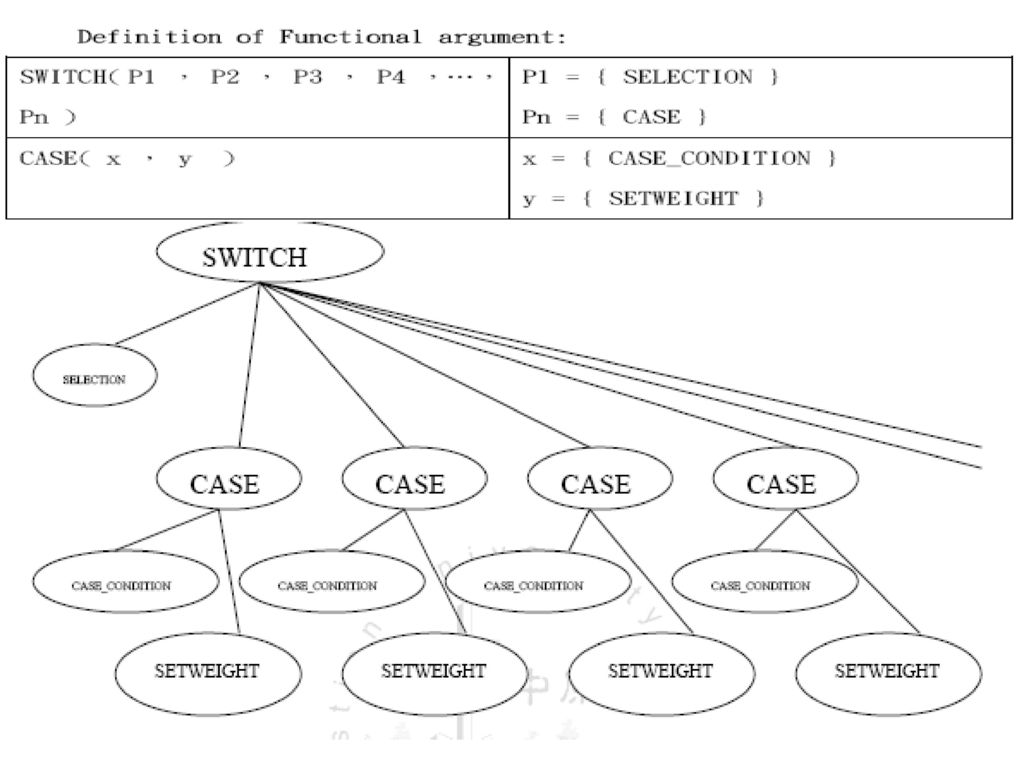
各operator 的詳細說明: (1) SWITCH : SWITCH operator 的參數個數沒有限制,第一個參數接SELECTION operator,而之後的參數接CASE operators。 (2)CASE : CASE operator 有兩個參數,第一個SELECTION,第二個為SETWEIGHT,而CASE operator 會將SELECTION 的內容與其父SWITCH operator 所接的SELECTION 內容作比較,如果內容相符,便執行其SETWEIGHT。 (3) CASE_CONDITION : 內容型態與SELECTION 相同,CASE operator 會將其與SELECTION 作比較。 (4) SETWEIGHT :此terminal node 為設定參考weight。
CASE : CASE operator 有兩個參數,第一個SELECTION,第二個為SETWEIGHT,而CASE operator 會將SELECTION 的內容與其父SWITCH operator 所接的SELECTION 內容作比較,如果內容相符,便執行其SETWEIGHT。 (3) CASE_CONDITION : 內容型態與SELECTION 相同,CASE operator 會將其與SELECTION 作比較。 (4) SETWEIGHT :此terminal node 為設定參考weight。")
21
(5) SELECTION : 此terminal node 內放置一組集合,內容來自於對棋盤上之點的偵測,此集合是供CASE condition 來判斷。格式如下:
{橫,直,左斜,右斜}{2,*3,1,0} 這個空點的橫方向有2 個連續點,*3 則表示直方向有3 子 相連,但其兩末端皆有他子阻擋。 順序問題: {2,2,1,0} 是否等於{0,1,2,2}

22
(5) SELECTION : 此terminal node 內放置一組集合,內容來自於對棋盤上之點的偵測,此集合是供CASE condition 來判斷。格式如下:
{橫,直,左斜,右斜}{2,*3,1,0} 這個空點的橫方向有2 個連續點,*3 則表示直方向有3 子 相連,但其兩末端皆有他子阻擋。 順序問題: {2,2,1,0} {0,1,2,2} 順時針轉45度

23
SELECTION operator 加入”不介意值”
我們希望加入一個偵測符號,其目的在於: 1.希望提高演化學者效能 2.縮小CASE operators 的數量 在棋型資料上另外加入一個”不介意值”,即是 可表示各種棋型,如以下棋型: { 2 , * , -1 , 1 } , { 1 , 4, * , *} “*“符號可代表所有範圍內的元素

24
個體(individual)的fitness評斷方式
輸的時候: 1. 一個走15 步與一個走7 步皆輸的兩個GP,較快輸的則判定為較差。 2. 將其fitness 值直接設定為其走的棋步數。 贏的時候: 1. 一個走12 步與一個走19 步皆贏的兩個GP,較快贏的則判定較優。將其fitness 設為[ 2 倍的棋盤大下 – 步數 ] 。

25
fitness 值的計算方式如下: INTEGER size : (size * size)為棋盤大小 INTEGER W : 當局棋步總數
BOOLEAN R : 結果是輸或贏 IF( R is Win) { Fitness= [ 2 * ( size * size) – W ] } ELSE Fitness = W
 { Fitness= [ 2 * ( size * size) – W ] } ELSE. Fitness = W.")
27
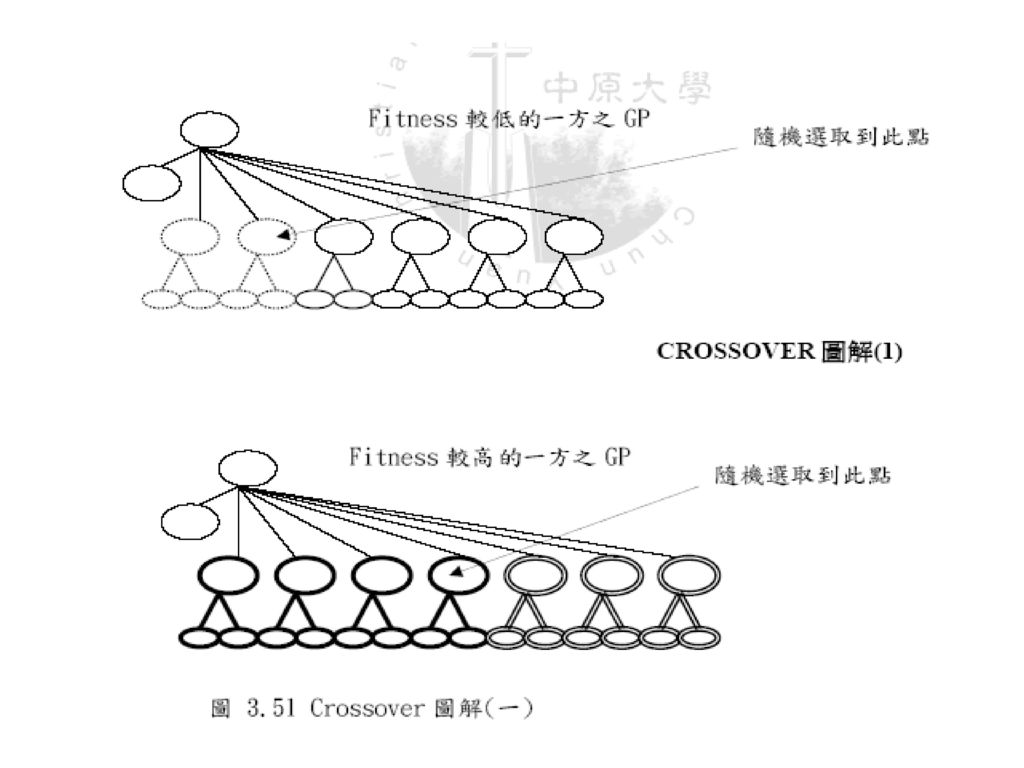
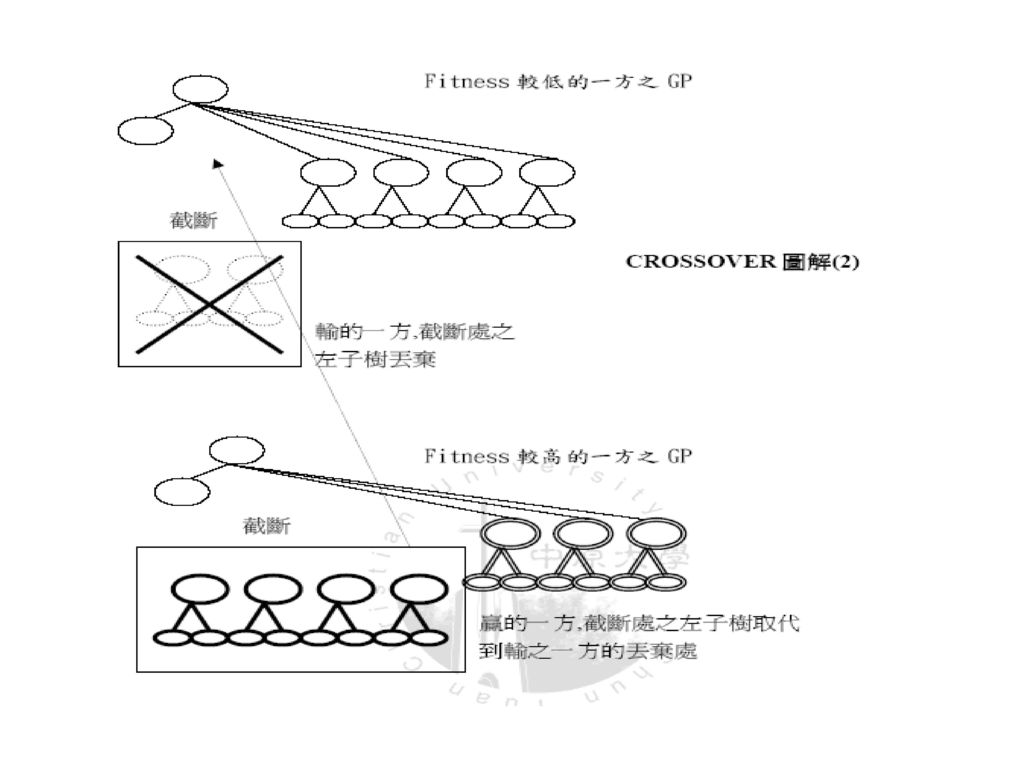
GA Crossover: 1.在population 中隨機選擇兩個GP 2.比較兩者的fitness 高低,低的一方將接受改變
3.在雙方中隨機選取一點,高的一方以其選之點 之前(左)截斷 4.將之插入低的一方所選之點之前 如以下圖例:
截斷. 4.將之插入低的一方所選之點之前. 如以下圖例:")
30
Crossover 修正: crossover 完後必須偵測子GP,將相同的地方去除,還有weight 的排列順序也已經改變,故必須
將之重新排序

31
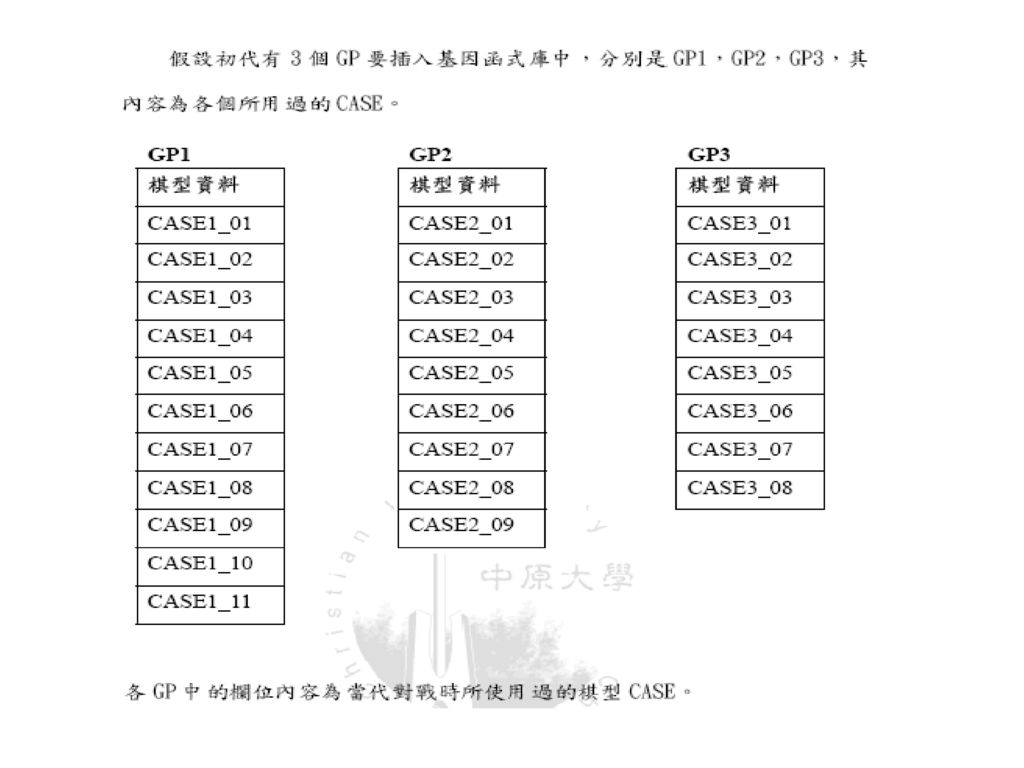
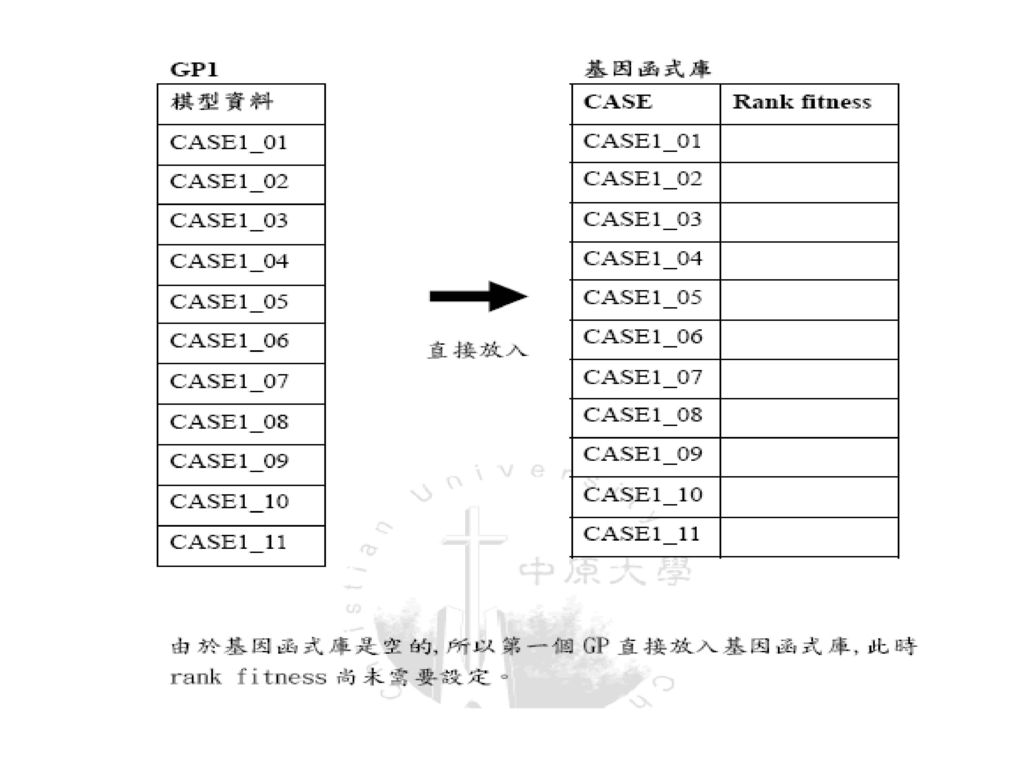
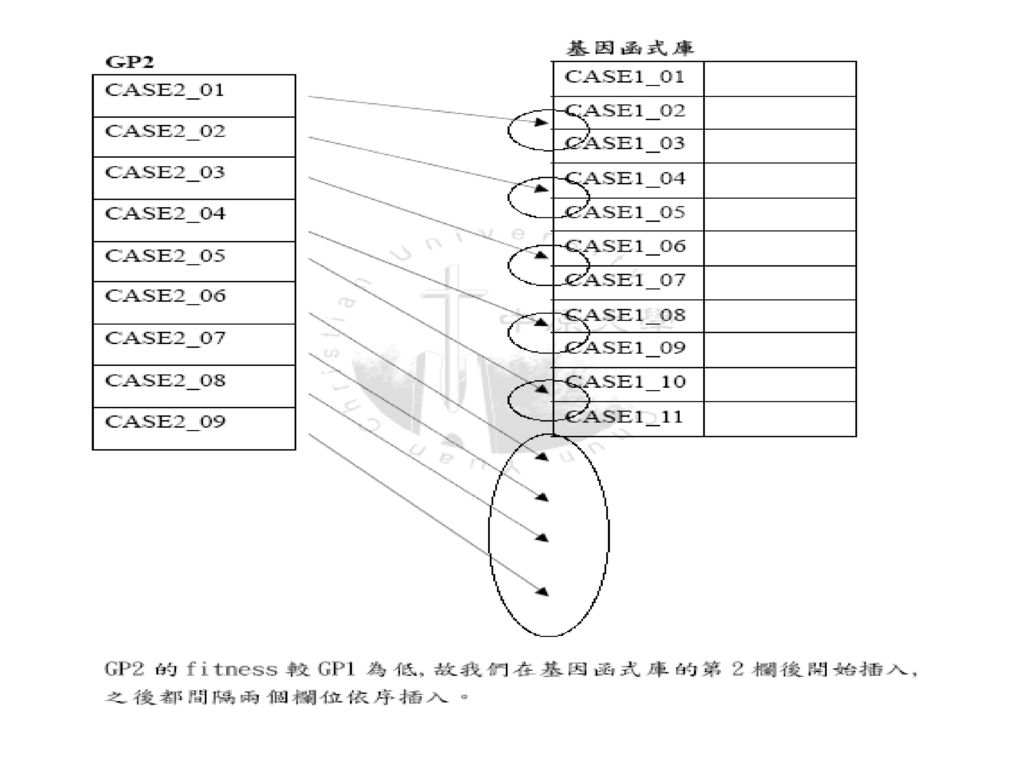
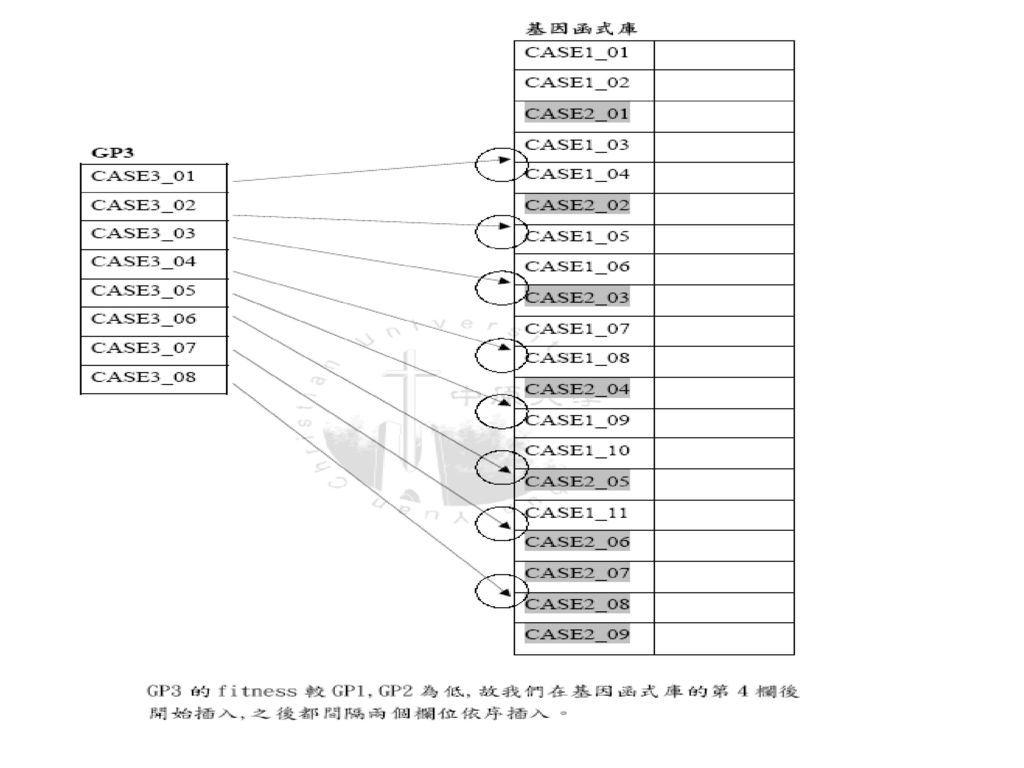
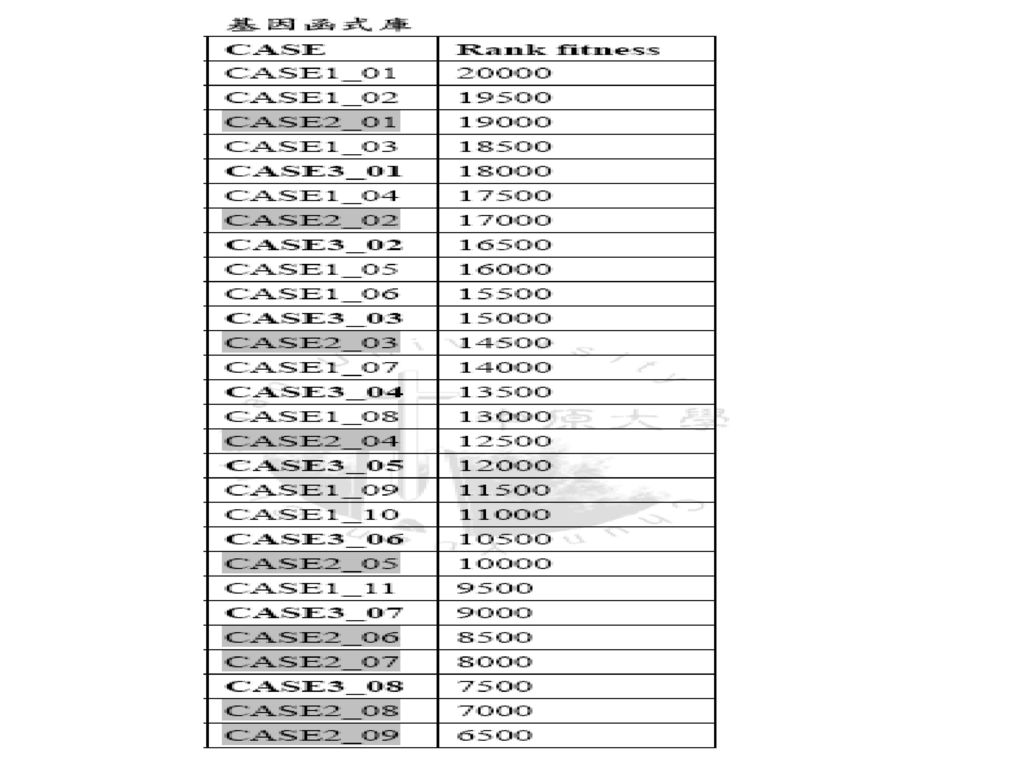
建立基因函式庫: 各individual GP 中有被使用過的CASE 都會被作一個記號,有被使用過的CASE 都會被匯集起來作整理之後送到基因函式庫中存放,但是僅取前30%。 依照GP的fitness值大小,將排序好的CASE放入基因函式庫中,但是並非依序排入,在此以跳格的方式置入函式庫,以此種跳格的方式,可以盡量讓CASE的地位能得到較合理的位置,如以下所示。

37
遇到CASE CONDITION重複時(第二代)
基因函式庫的內容修正: 遇到CASE CONDITION重複時(第二代) CASE記錄為LOSE: 則扣掉一些WEIGHT CASE記錄為WIN: 則加上一些WEIGH 若間隔值 >>weight CASE升降緩慢 若間隔值 <<weight CASE升降快速
 CASE記錄為LOSE: 則扣掉一些WEIGHT. CASE記錄為WIN: 則加上一些WEIGH. 若間隔值 >>weight. CASE升降緩慢. 若間隔值 <<weight. CASE升降快速.")
38
增加一個暫存對手棋步的紀錄器(最後3步棋),若GA輸了可以對基因函式庫做高額的量的加權,以免GA重蹈覆轍。
,若GA輸了可以對基因函式庫做高額的量的加權,以免GA重蹈覆轍。")
39
演化完成後的去蕪存菁 簡化後的好處: 1. 可節省記憶體的儲存空間。 2. 讓下次需要再演化時,效率比之前快。
3. 演化出來的規則,更淺顯易懂。

40
簡化tree 中多餘的分枝或可合併的分枝 何謂多餘的分枝之定義: a. 永遠不會被走到的subtree。
b. 對整棵樹之fitness 不會有影響之subtree。

41
何謂可合併的分枝之定義: a. condition-expression 相同的subtree 可合 併為一枝,其weight 值相加。 b. condition-expression 與子結點的condition- expression 有呼叫相同的terminal node

42
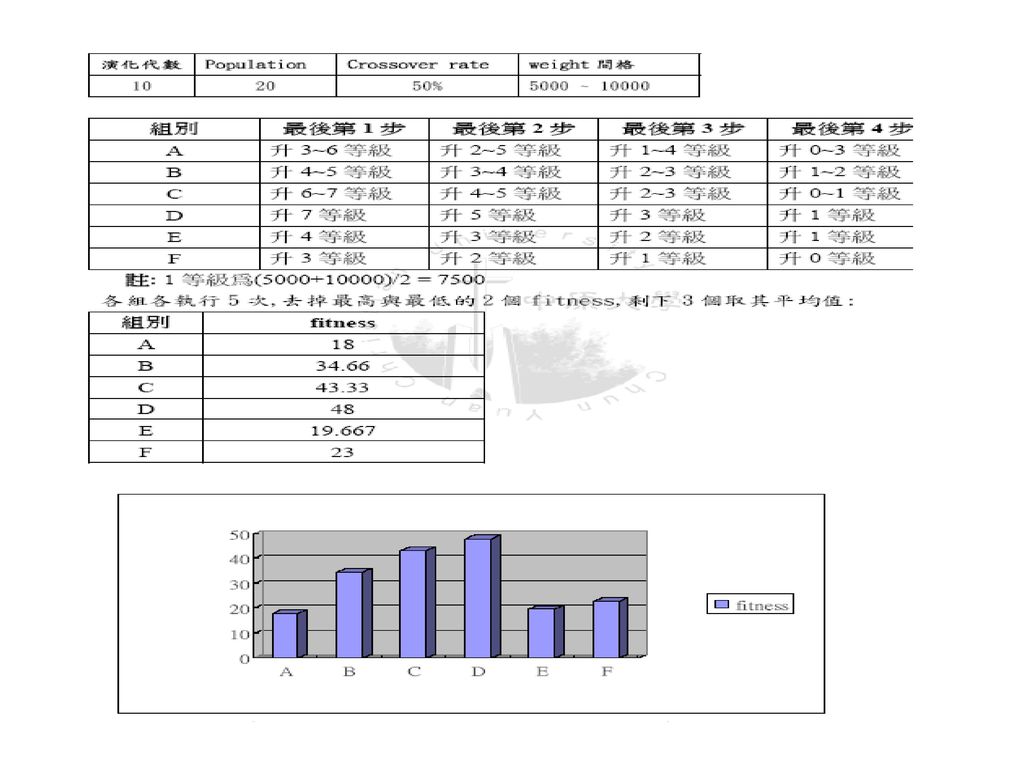
實驗數據

Similar presentations


















 林偉川.>")
