Download presentation
Presentation is loading. Please wait.

1
数据密集型科学环境中 科技期刊的数字化走向
数据密集型科学环境中 科技期刊的数字化走向 李若溪 重庆师范大学编辑出版中心 国家社科基金、教育部人文社科基金课题组

2
数字化、网络化引发了信息爆炸、数据爆炸 信息、数据爆炸导致了科学研究的模式变化 “数据密集型”科学研究——指当今科学研究越来越依赖于数据 的聚集和分析,特别是海量数据分析 无处不在的数据环境——数据场(data space) 科学研究的模式发生着转变,科技期刊也随之转变

3
数据爆炸和应运而生的数据处理技术,使科学走 到了“数据密集型”研究范式

4
Jim Gray 计算机科学家 微软研究院 图灵奖获得者

5
The fourth paradigm: data-intensive scientific discovery USA: Microsoft Research 2009

6
科学研究由假设驱动转向基于探索的科学方法
过去设问“我应该设计什么样的实验来验证这个假设?” 现在设问“从这些数据中我能够看到什么?” “如果把其他领域的数据溶合进来,能够发现什么?” 天文学研究不再用肉眼看望远镜,而是把望远镜观察到的现象以 数据形式记录到计算机,对数据进行分析判断

7
大型天文观察望远镜LSST Large Synoptic Survey Telescope 投入运行后第一年 生产的数据达到1.28PB (1×1015Bytes)
")
8
欧洲分子生物实验室核酸序列数据库EMBL-Bank
收到数据的速度每年递增200% 人类基因组计划2008年生产数据1万亿碱基对 2009年速率又翻一番 医学科学的数据爆炸: 在生物医学文献编目中已经有1800万医学文章 现在每年增加接近百万篇 100年前,一个内科医生知道医学的全面知识 今天,一个基层医生需要知道10000种疾病、3000种药物和 1100多种实验室检查才能跟上发展步伐

9
数据密集型科学就这样开始了 数据密集型科学研究的3个基本活动 数据抓取 ——Capture 分类处理 ——Curation 数据分析 —— Analysis 数据基础设施 ——Data infrasturcture 数据科学家 —— Data scientists

10
2 数据基础设施与数据科学家 大型科研项目有专门的预算用于建立数据和网络基础设施 基层科研人员投入软件的经费预算非常有限
2 数据基础设施与数据科学家 大型科研项目有专门的预算用于建立数据和网络基础设施 基层科研人员投入软件的经费预算非常有限 需要建立通用的“数据基础设施” Jim Gray 为之奋斗了几十年

11
Gray的设计诀窍:某 个学科数据库设计, 必须能够回答这个学 科的科学家想问的20 个关键问题。

12
数据基础设施 (1)数据分类处理: 数据录入 输入信息用算法重新表述 数据分类处理(curation): 建立正确的数据结构 分门别类
数据转换 图表和元数据长期储存 跨实验、跨设施的整合 数据库建模 数据可视化……

13
目前已有的基础设施: 圣迭戈超级计算机中心(SDSC)建立的数据中心站,拥有27PB 的数据 澳大利亚国家数据服务站(ANDS)的目标:使分散孤立的研究数 据转变成相互关联的研究资源 ……、……、……、…… 经过分类处理和整合转换的数据,才能够进行分析利用,才能永 久保存和共享 未经“分类处理”的数据将丢失

14
(2)广泛无缝链接: 数据获取、聚集——高效率全天候、跨学科跨国界 数据储存——永久性、动态性、随时读取
数据交流——开放获取、即时互动、世界共享

15
微软研究院推出的全球望远镜 worldwide telescope WWT
是宇宙探索工具 聚集了大量星云、星座、行星以及宇宙全景等图像数据 免费提供给用户浏览、做研究 用户可在桌面上浏览夜空 数据来自哈勃望远镜及分布于世界各地的10来个天文望远镜 WWT处理的数据实现了远程无缝链接:当观察者注意到一个非同寻常的波 长或位置的数据,他可以点击那里,同时远程链接到相关期刊文章上或数 据库上

16
基于excel 的数据管理、搜索、转换工具。你可以对自己的excel 表 格中关于天体定位、几何形态等数据直接生成图像。你也可以链接远 程的期刊论文、数据库等等

17
给科研人员节省了大量重复操作的时间,大大提高工作效率

18
(3) 数据云,数据流技术 对付海量数据加工难题,云计算是很好的办法 云计算(cloud computing)是一种基于互联网的计算方式, 将庞大的计算程序自动分拆成无数个较小的子程序,交由多部 服务器组成的系统进行搜索和计算,最后又将处理结果返回给 用户 能够在数秒钟之内处理以亿计的信息 其特点,就是把分散的用户电脑要计算的内容全部放到服务器上 运算,个人的电脑只负责显示结果

19
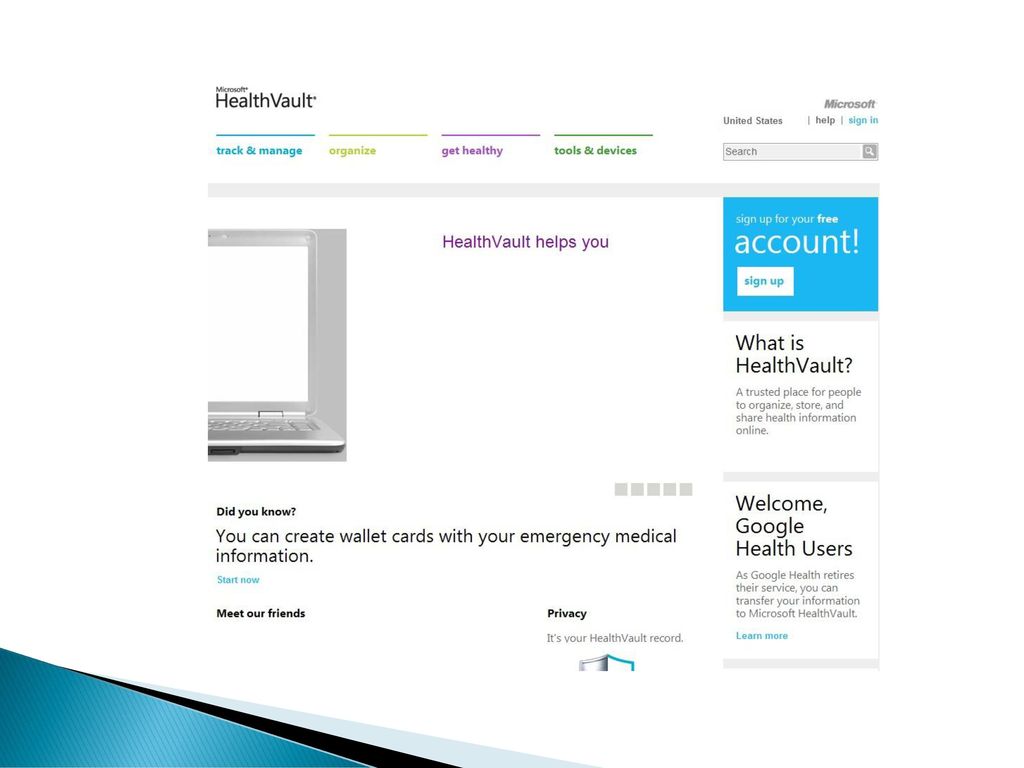
微软卫生库(Microsoft Health Vault)
谷歌卫生(Google Health) 都是基于因特网的“用户数据云” 临床病人的数据输入里面形成云 用户数据云为新医学知识即刻传达至病人提供了可能 维基百科也是用户数据云
 都是基于因特网的 用户数据云 临床病人的数据输入里面形成云. 用户数据云为新医学知识即刻传达至病人提供了可能. 维基百科也是用户数据云.")
21
(4) 工作流技术(Workflow) 是对工作流程及其各操作步骤业务规则的抽象、概括、描述 工作流要解决的主要问题是:为实现业务目标,在多个参与者 之间,按预定规则自动传递文档、信息或者任务 好处是有利于管理数据,对纷繁复杂的数据处理和分析起到提 高效率减少差错等作用

22
数据科学家 美国国家科学委员会(national science board NSB)
“长期保存数字化数据集成:推进21世纪的研究和教育”计划 对“数据科学家”这一新群体的关注和扶持问题 数据科学家——包括信息与计算机科学家、数据库和软件工程师、 学科专家、数据处理员和专业注释员、图书馆员、档案馆员等凡 是从事数据集成的管理人员

23
《第四范式》的作者之一,Tony Hey:
如果你是一位科学家,向计算机科学家谈你的问题和受到的挑 战,反之亦然 如果你是一个学生,一定要同时选专业课和计算机科学课 如果你是教师、辅导员、或家长,除了让你的孩子(学生)作 出专业选择之外,鼓励他们注重跨学科的学习
作 出专业选择之外,鼓励他们注重跨学科的学习.")
24
3 在数据密集型科学环境中期刊的应对策略 全面数字化——Digitalization 推行结构化——Structuralization
全面开放——Opening 推进融合——Integration

25
全面数字化和全面开放 目前我国的科技期刊,绝大多数都作到了分散数字化出版,电子 文本提交给CNKI、万方、维普等大型数据库
不少期刊已建立自己的网站 中国科技核心期刊1800多种有自建网站的占59% 中国大陆学术期刊有自建网的占49% 国际学术期刊有自建网的占73%

26
2001年以来国际上兴起的开放获取运动,在很大程度上促进了期 刊的数字化和开放
现在美国所有的公共资助的科学文献必须在线开放于PubMed Central中心知识库 欧洲发达国家也纷纷跟进 瑞典LUND大学的开放获取期刊目录DOAJ,收录期刊数已经超过 7100种

27
出版的文献仅仅是全部研究数据的冰山一角。期刊数字化,是要达到文献与所有科学数据能够相互融为一体,在英特网上形成数据与文献互动操作的世界平台,这才算是全面数字化

28
数据与文献的融合 文献数据处于塔尖;基础层是大量的原始数据,中间层是抽取出 来的和关联的数据层
三部分在数据场中相互融合,共同有机地构成了全部科学研究的 内容整体 所谓融合:在构建的数据平台上你可以读一篇论文,而同时调取 它的原始数据;你甚至可以重演作者的分析过程;或者你能够在 分析一些数据的同时找出跟数据相关的全部文献

30
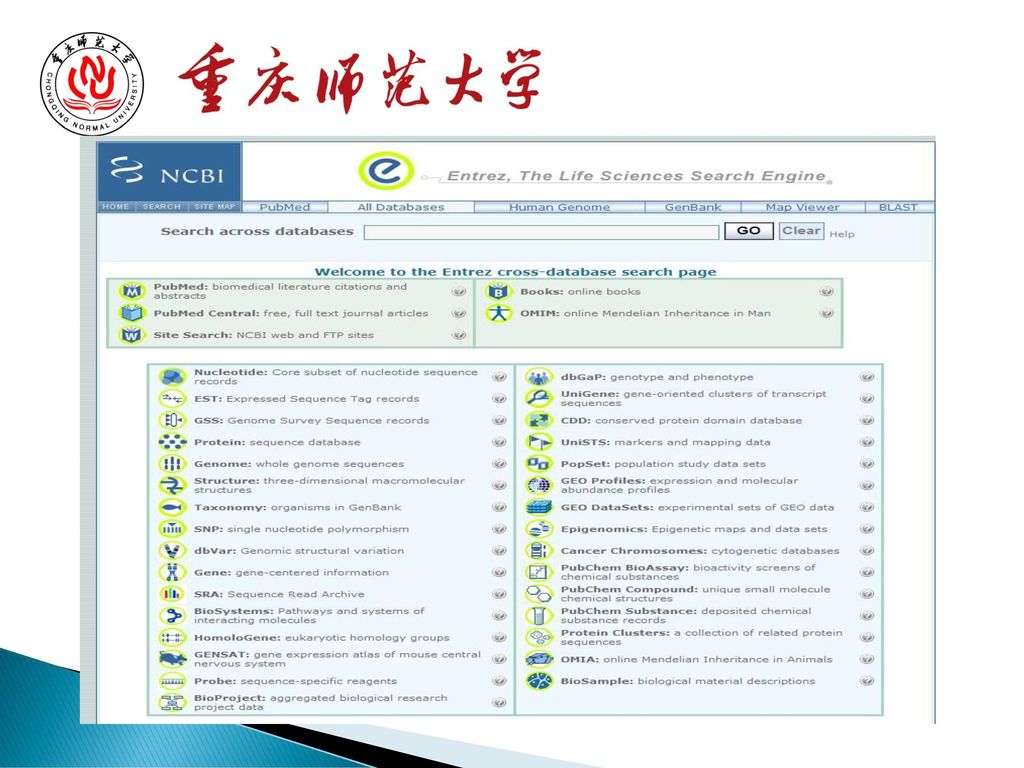
Entrez, 是一个生命科学搜索引擎 它真正实现了数据和文献的交互性操作 用户可以边阅读一篇文章,同时打开基因数据,跟随基因找到这个 疾病,然后又回到文章.它确实非常棒! 微软的WWT,也实行了数据与文献的融合 融合和交互操作可通过统一的链接、统一的标签和ID号而实现 把全世界的数据都集成在一起,形成巨型的动态数据集 一个全球化的数据库将必然诞生

31
文献内容结构化 (1)自动化标引 标引工作在计算机数据处理中属于语义服务 由语义服务指导数据工作者提炼数据
利用自动工具在文本和数据库中形成语义层通道 为数据的处理分析和整合提供有效的解决途径 英国皇家化学学会 Royal Society of Chemistry’s journal Molecular BioSystems 对HTML格式的全文内有关主题词进行标注 把这些标注的词汇链接到外部数据库词目 借助自动化文本挖掘工具的协助 出版环节的标引是出版增值服务的体现

32
(2)先进的文本分析技术 先进的文本分析技术,侧重于提高文本的机器易读性
用文本分析技术从文献中抽取实体(entity)和实体之间的关系 (entity relation) 利用机器定义和识别的语词,嵌入文献中,使文献能够用机器来 分析 让机器去寻找不同学科的文献之间的关联点,从而串联知识点, 触发新视野的产生 美国的一些研究项目鼓励学者们在出版论文时就发布实体或实体 关系信息,以尽量减少后加工过程
和实体之间的关系 (entity relation) 利用机器定义和识别的语词,嵌入文献中,使文献能够用机器来 分析. 让机器去寻找不同学科的文献之间的关联点,从而串联知识点, 触发新视野的产生. 美国的一些研究项目鼓励学者们在出版论文时就发布实体或实体 关系信息,以尽量减少后加工过程.")
33
基于网络和数据场的学术过程记忆 在数据密集型科研环境下,引文索引和评价将不再起主导作用 数据场中信息的类型、来源渠道和获取方式都是多元的
各种数据的流动、交互操作、融合、引用等都将留下轨迹 在网络中记载和显现这种过程 使学术过程以机读信息发布于英特网,称为“过程公开记忆” 把隐性的数据流动转变为显性的,甚至可视化 基于网络和数据场的学术过程记忆将在学术跟踪和评价中大显身 手

34
《自然》杂志的 引文链接图:citation links

35
时代的呼声:让所有的科学文献都在线 所有的科学数据都在线 实现交互操作 期刊的走向:全面数字化 推进结构化 与数据基础设施融合 最大限度实行开放获取

36
谢谢!

Similar presentations





![桐乡市地方税务局 2013 年度社会保险费汇算清缴有 关政策及事项说明. 一、政策规定 根据《中华人民共和国社会保险法》、《桐乡市社会保险费征缴管 理办法》(市政府令第 42 号)、《 关于完善社会保险费征缴管理有关问 题的通知》(桐政办发 [2012]152 号)及《关于完善社会保险费征缴管理.](/40/11070600/big_thumb.jpg "桐乡市地方税务局 2013 年度社会保险费汇算清缴有 关政策及事项说明. 一、政策规定 根据《中华人民共和国社会保险法》、《桐乡市社会保险费征缴管 理办法》(市政府令第 42 号)、《 关于完善社会保险费征缴管理有关问 题的通知》(桐政办发 [2012]152 号)及《关于完善社会保险费征缴管理.>")












 第二十一章数据的整理与初步处理 21.1.4扇形统计图的制作.>")
>")