Download presentation
Presentation is loading. Please wait.

1
第五章 非平稳序列的随机分析

2
本章结构 差分运算 ARIMA模型 Auto-Regressive模型 异方差的性质 方差齐性变化 条件异方差模型

3
5.1 差分运算 差分运算的实质 差分方式的选择 过差分

4
差分运算的实质 差分方法是一种非常简便、有效的确定性信息提取方法 Cramer分解定理在理论上保证了适当阶数的差分一定可以充分提取确定性信息
差分运算的实质是使用自回归的方式提取确定性信息

5
差分方式的选择 序列蕴含着显著的线性趋势,一阶差分就可以实现趋势平稳
序列蕴含着曲线趋势,通常低阶(二阶或三阶)差分就可以提取出曲线趋势的影响 对于蕴含着固定周期的序列进行步长为周期长度的差分运算,通常可以较好地提取周期信息
差分就可以提取出曲线趋势的影响. 对于蕴含着固定周期的序列进行步长为周期长度的差分运算,通常可以较好地提取周期信息.")
6
例5.1 【例1.1】1964年——1999年中国纱年产量序列蕴含着一个近似线性的递增趋势。对该序列进行一阶差分运算
考察差分运算对该序列线性趋势信息的提取作用

7
差分前后时序图 原序列时序图 差分后序列时序图

8
例5.2 尝试提取1950年——1999年北京市民用车辆拥有量序列的确定性信息

9
差分后序列时序图 一阶差分 二阶差分

10
例5.3 差分运算提取1962年1月——1975年12月平均每头奶牛的月产奶量序列中的确定性信息

11
差分后序列时序图 一阶差分 1阶-12步差分

12
过差分 足够多次的差分运算可以充分地提取原序列中的非平稳确定性信息 但过度的差分会造成有用信息的浪费

13
例5.4 假设序列如下 考察一阶差分后序列和二阶差分序列 的平稳性与方差

14
比较 一阶差分 平稳 方差小 二阶差分(过差分) 平稳 方差大
 平稳 方差大")
15
5.2 ARIMA模型 ARIMA模型结构 ARIMA模型性质 ARIMA模型建模 ARIMA模型预测 疏系数模型 季节模型

16
ARIMA模型结构 使用场合 差分平稳序列拟合 模型结构

17
ARIMA(P,d,q)=random walk model
ARIMA(p,d,q)=ARMA(p,q) P=0 ARIMA(P,d,q)=IMA(d,q) q=0 ARIMA(P,d,q)=ARI(p,d) d=1,P=q=0 ARIMA(P,d,q)=random walk model
=ARMA(p,q) P=0. ARIMA(P,d,q)=IMA(d,q) q=0. ARIMA(P,d,q)=ARI(p,d) d=1,P=q=0. ARIMA(P,d,q)=random walk model.")
18
随机游走模型( random walk) 模型结构 模型产生典故
Karl Pearson(1905)在《自然》杂志上提问:假如有个醉汉醉得非常严重,完全丧失方向感,把他放在荒郊野外,一段时间之后再去找他,在什么地方找到他的概率最大呢?
在《自然》杂志上提问:假如有个醉汉醉得非常严重,完全丧失方向感,把他放在荒郊野外,一段时间之后再去找他,在什么地方找到他的概率最大呢?")
19
ARIMA模型的平稳性 ARIMA(p,d,q)模型共有p+d个特征根,其中p个在单位圆内,d个在单位圆上。所以当 时ARIMA(p,d,q)模型非平稳。 例5.5 ARIMA(0,1,0)时序图
时序图.")
20
ARIMA模型的方差齐性 时,原序列方差非齐性 d阶差分后,差分后序列方差齐性

21
ARIMA模型建模步骤 获 得 观 察 值 序 列 分 析 结 束 平稳性 检验 白噪声 检验 Y Y N N 差分 运算 拟合 ARMA

22
例5.6 对1952年——1988年中国农业实际国民收入指数序列建模

23
x1<-scan() 100 101.6 103.3 111.5 116.5 120.1 120.3 100.6 83.6 84.7 88.7 98.9 111.9 122.9 131.9 134.2 131.6 132.2 139.8 142 140.5 153.1 159.2 162.3 159.1 155.1 161.2 171.5 168.4 180.4 201.6 218.7 247 253.7 261.4 273.2 279.4

24
par(mfrow=c(2,2)) ts.plot(x1) x2=diff(x1) ts.plot(x2) acf(x2) pacf(x2)
) ts.plot(x1) x2=diff(x1) ts.plot(x2) acf(x2) pacf(x2)")
25
Box.test(x2,lag=6) Box.test(x2,lag=12) Box.test(x2,lag=18) Box.test(x2,lag=6,type ="Ljung-Box") Box.test(x2,lag=12,type ="Ljung-Box") Box.test(x2,lag=18,type ="Ljung-Box")
")
26
一阶差分序列时序图

27
一阶差分序列自相关图

28
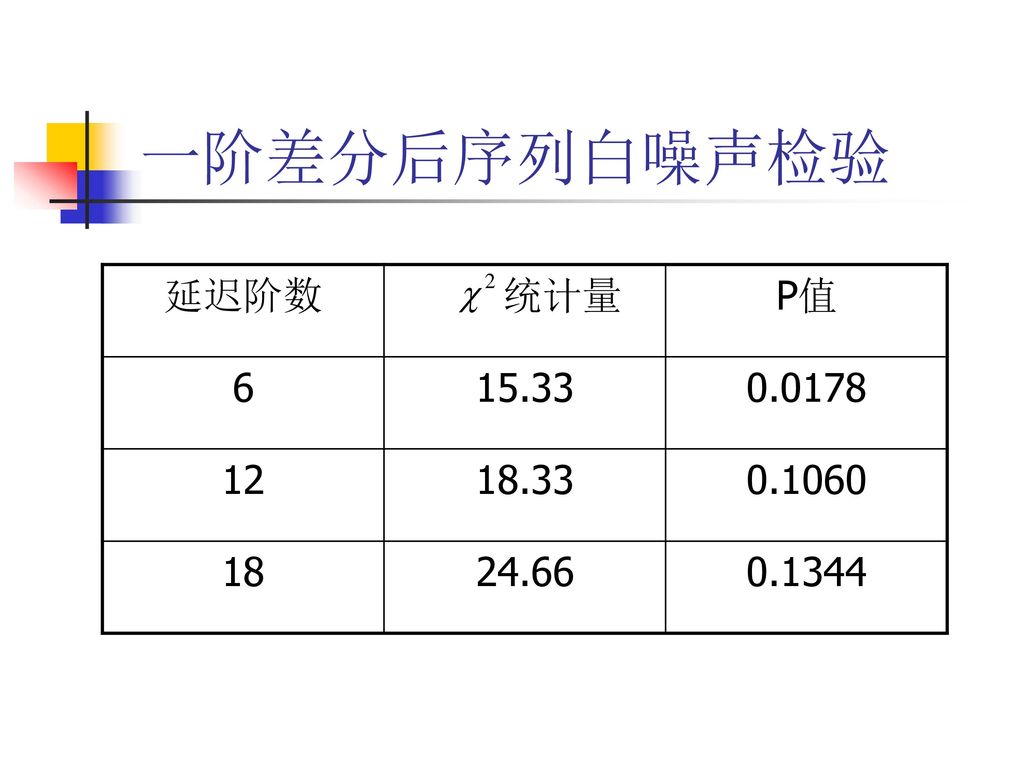
一阶差分后序列白噪声检验 延迟阶数 统计量 P值 6 15.33 0.0178 12 18.33 0.1060 18 24.66
0.1344
29
拟合ARMA模型 偏自相关图

30
mar=arima(x1,order=c(0,1,1))
xr=resid(mar) Box.test (xr, lag = 6, type = "Ljung") Box.test (xr, lag = 12, type = "Ljung") ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)
 Box.test (xr, lag = 6, type = Ljung ) Box.test (xr, lag = 12, type = Ljung ) ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)")
31
mar par(mfrow=c(2,2)) ts.plot(xr) acf(xr) pacf(xr)
) ts.plot(xr) acf(xr) pacf(xr)")
32
mar2=arima(x2,order=c(0,0,1))
xr2=resid(mar2) Box.test (xr2, lag = 6, type = "Ljung") Box.test (xr2, lag = 12, type = "Ljung") ct2=abs(mar2$coef)/sqrt(diag(mar2$var.coef)) 1-pnorm(ct2)
 Box.test (xr2, lag = 6, type = Ljung ) Box.test (xr2, lag = 12, type = Ljung ) ct2=abs(mar2$coef)/sqrt(diag(mar2$var.coef)) 1-pnorm(ct2)")
33
mar2 par(mfrow=c(2,2)) ts.plot(xr2) acf(xr2) pacf(xr2)
) ts.plot(xr2) acf(xr2) pacf(xr2)")
34
建模 定阶 ARIMA(0,1,1) 参数估计 模型检验 模型显著 参数显著
 参数估计 模型检验 模型显著 参数显著")
35
ARIMA模型预测 原则 最小均方误差预测原理 Green函数递推公式

36
预测值

37
例5.7 已知ARIMA(1,1,1)模型为 且 求 的95%的置信区间
模型为 且 求 的95%的置信区间")
38
预测值 等价形式 计算预测值

39
计算置信区间 Green函数值 方差 95%置信区间

40
例5.6续:对中国农业实际国民收入指数序列做为期10年的预测

41
px=predict(arima(x2, order = c(0,0,1)), n.ahead = 10)
xp=c(x2,px$pred) ts.plot(xp) xp1=c(x1[1],xp) for(i in 2:length(xp1)) {xp1[i]=xp1[i-1]+xp[i-1]} ts.plot(xp1)
 ts.plot(xp) xp1=c(x1[1],xp) for(i in 2:length(xp1)) {xp1[i]=xp1[i-1]+xp[i-1]} ts.plot(xp1)")
42
疏系数模型 ARIMA(p,d,q)模型是指d阶差分后自相关最高阶数为p,移动平均最高阶数为q的模型,通常它包含p+q个独立的未知系数:
如果该模型中有部分自相关系数 或部分移动平滑系数 为零,即原模型中有部分系数省缺了,那么该模型称为疏系数模型。

43
疏系数模型类型 如果只是自相关部分有省缺系数,那么该疏系数模型可以简记为 如果只是移动平滑部分有省缺系数,那么该疏系数模型可以简记为
为非零自相关系数的阶数 如果只是移动平滑部分有省缺系数,那么该疏系数模型可以简记为 为非零移动平均系数的阶数 如果自相关和移动平滑部分都有省缺,可以简记为

44
例5.8 对1917年-1975年美国23岁妇女每万人生育率序列建模

45
一阶差分

46
Y1<-scan() 183.1 183.9 163.1 179.5 181.4 173.4 167.6 177.4 171.7 170.1 163.7 151.9 145.4 145 138.9 131.5 125.7 129.5 129.6 132.2 134.1 132.1 137.4 148.1 174.1 174.7 156.7 143.3 189.7 212 200.4 201.8 200.7 215.6 222.5 231.5 237.9 244 259.4 268.8 264.3 264.5 268.1 264 252.8 240 229.1 204.8 193.3 179 178.1 181.1 165.6 159.8 136.1 126.3 123.3 118.5

47
par(mfrow=c(2,2)) ts.plot(Y1) Y2=diff(Y1) ts.plot(Y2) acf(Y2) pacf(Y2)
) ts.plot(Y1) Y2=diff(Y1) ts.plot(Y2) acf(Y2) pacf(Y2)")
48
自相关图

49
mar=arima(Y1,order=c(4,1,0))
yr=resid(mar) Box.test (yr, lag = 6, type = "Ljung") Box.test (yr, lag = 12, type = "Ljung") ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)
 Box.test (yr, lag = 6, type = Ljung ) Box.test (yr, lag = 12, type = Ljung ) ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)")
50
偏自相关图

51
建模 定阶 ARIMA((1,4),1,0) 参数估计 模型检验 模型显著 参数显著
,1,0) 参数估计 模型检验 模型显著 参数显著")
52
Y1<-scan() 183.1 183.9 163.1 179.5 181.4 173.4 167.6 177.4 171.7 170.1 163.7 151.9 145.4 145 138.9 131.5 125.7 129.5 129.6 132.2 134.1 132.1 137.4 148.1 174.1 174.7 156.7 143.3 189.7 212 200.4 201.8 200.7 215.6 222.5 231.5 237.9 244 259.4 268.8 264.3 264.5 268.1 264 252.8 240 229.1 204.8 193.3 179 178.1 181.1 165.6 159.8 136.1 126.3 123.3 118.5

53
Y2=diff(Y1) library(tseries) mar=arma(Y2,lag=list(ar=c(1,4),ma=NULL),include.intercept = F)
 library(tseries) mar=arma(Y2,lag=list(ar=c(1,4),ma=NULL),include.intercept = F)")
54
yr=resid(mar) Box.test (yr, lag = 6, type = "Ljung") Box.test (yr, lag = 12, type = "Ljung") ct=abs(summary(mar)$coef[,1])/summary(mar)$coef[,2] 1-pnorm(ct)
![yr=resid(mar) Box.test (yr, lag = 6, type = Ljung ) Box.test (yr, lag = 12, type = Ljung ) ct=abs(summary(mar)$coef[,1])/summary(mar)$coef[,2]](http://slidesplayer.com/slide/11355061/61/images/54/yr%3Dresid%28mar%29+Box.test+%28yr%2C+lag+%3D+6%2C+type+%3D+Ljung+%29+Box.test+%28yr%2C+lag+%3D+12%2C+type+%3D+Ljung+%29+ct%3Dabs%28summary%28mar%29%24coef%5B%2C1%5D%29%2Fsummary%28mar%29%24coef%5B%2C2%5D.jpg "1-pnorm(ct)")
55
par(mfrow=c(3,1)) ts.plot(yr[-which(is.na(yr))]) acf(yr[-which(is.na(yr))]) pacf(yr[-which(is.na(yr))])
![par(mfrow=c(3,1)) ts.plot(yr[-which(is.na(yr))]) acf(yr[-which(is.na(yr))]) pacf(yr[-which(is.na(yr))])](http://slidesplayer.com/slide/11355061/61/images/55/par%28mfrow%3Dc%283%2C1%29%29+ts.plot%28yr%5B-which%28is.na%28yr%29%29%5D%29+acf%28yr%5B-which%28is.na%28yr%29%29%5D%29+pacf%28yr%5B-which%28is.na%28yr%29%29%5D%29.jpg "par(mfrow=c(3,1)) ts.plot(yr[-which(is.na(yr))]) acf(yr[-which(is.na(yr))]) pacf(yr[-which(is.na(yr))])")
56
季节模型 简单季节模型 乘积季节模型

57
简单季节模型 简单季节模型是指序列中的季节效应和其它效应之间是加法关系
简单季节模型通过简单的趋势差分、季节差分之后序列即可转化为平稳,它的模型结构通常如下

58
例5.9 拟合1962——1991年德国工人季度失业率序列

59
差分平稳 对原序列作一阶差分消除趋势,再作4步差分消除季节效应的影响,差分后序列的时序图如下

60
白噪声检验 延迟阶数 统计量 P值 6 43.84 <0.0001 12 51.71 18 54.48

61
差分后序列自相关图

62
差分后序列偏自相关图

63
模型拟合 定阶 ARIMA((1,4),(1,4),0) 参数估计
,(1,4),0) 参数估计")
64
Z1<-scan() 1.1 0.5 0.4 0.7 1.6 0.6 1.3 1.2 0.9 2.9 2.1 1.7 2 2.7 1 1.5 2.6 2.3 3.6 5 4.5 4.9 5.7 4.3 4 4.4 5.2 4.2 4.1 3.9 4.8 3.5 3.4 5.5 5.4 6.5 8 7 7.4 8.5 10.1 8.9 8.8 9 10 8.7 10.4 10.2 8.6 8.4 9.9 9.8 8.2 7.6 7.5 8.1 7.1 6.9 6.6 6.8 6 6.2

65
par(mfrow=c(2,2)) ts.plot(Z1) Z2=diff(Z1) Z3=diff(Z2,lag=4) ts.plot(Z3) acf(Z3) pacf(Z3)
) ts.plot(Z1) Z2=diff(Z1) Z3=diff(Z2,lag=4) ts.plot(Z3) acf(Z3) pacf(Z3)")
66
mar=arima(Z3,order=c(4,0,0))
yr=resid(mar) Box.test (yr, lag = 6, type = "Ljung") Box.test (yr, lag = 12, type = "Ljung") ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)
 Box.test (yr, lag = 6, type = Ljung ) Box.test (yr, lag = 12, type = Ljung ) ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)")
67
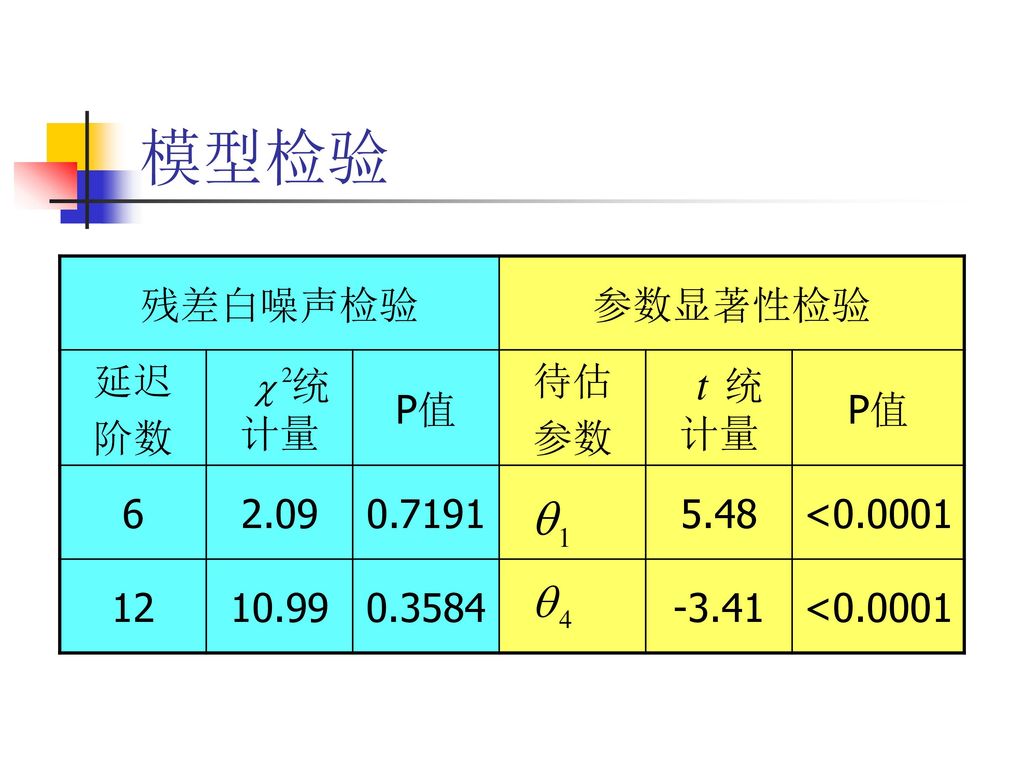
模型检验 残差白噪声检验 参数显著性检验 延迟 阶数 统计量 P值 待估 参数 6 2.09 0.7191 5.48 <0.0001
12 10.99 0.3584 -3.41
68
拟合效果图

69
乘积季节模型 使用场合 构造原理 序列的季节效应、长期趋势效应和随机波动之间有着复杂地相互关联性,简单的季节模型不能充分地提取其中的相关关系
短期相关性用低阶ARMA(p,q)模型提取 季节相关性用以周期步长S为单位的ARMA(P,Q)模型提取 假设短期相关和季节效应之间具有乘积关系,模型结构如下
模型提取. 季节相关性用以周期步长S为单位的ARMA(P,Q)模型提取. 假设短期相关和季节效应之间具有乘积关系,模型结构如下.")
70
其中 记为 R code : arima(x,order=c(p,d,q), seasonal = list(order = c(P,D,Q),period= S))
, seasonal = list(order = c(P,D,Q),period= S))")
71
例如

72
例5.10 :拟合1948——1981年美国女性月度失业率序列

73
差分平稳 一阶、12步差分

74
差分后序列自相关图

75
差分后序列偏自相关图

76
W<-scan() 446 650 592 561 491 604 635 580 510 553 554 628 708 629 724 820 865 1007 1025 955 889 965 878 1103 1092 978 823 827 928 838 720 756 658 684 779 754 794 681 644 622 588 670 746 616 646 678 552 560 578 514 541 576 522 530 564 442 520 484 538 454 404 424 432 458 556 506 633 1013 1031 1101 1061 1048 1005 987 1006 1075 854 1008 777 982 894 795 799 781 776 761 839 842 811 843 753 848 828 857 986 847 801 739 767 941 846 768 709 798 831 833 806 771 951 1156 1332 1276 1373 1325 1326 1314 1343 1225 1133 1023 1266 1237 1180 1046 1010 985 971 1037 1026 947 1097 1018 1054 1067 1132 1019 1110 1262 1174 1391 1533 1479 1411 1370 1486 1451 1309 1316 1319 1233 1113 1363 1245 1205 1084 1131 1138 1271 1244 1139 1030 1300 1198 1147 1140 1216 1200 1254 1203 1272 1073 1375 1400 1322 1214 1096 1193 1163 1120 1164 966 1154 1306 1123 1033 940 1151 1105 1011 963 1040 1012 888 840 880 939 868 1001 956 896 1044 972 897 1056 1055 1287 1231 1076 929 1127 988 903 845 1020 994 1036 1050 977 818 964 967 867 1058 1119 1202 1086 1238 1264 1171 1206 1303 1393 1463 1601 1495 1561 1404 1705 1739 1667 1599 1516 1625 1629 1809 1831 1665 1659 1457 1707 1607 1616 1522 1585 1657 1717 1789 1814 1698 1481 1330 1646 1596 1496 1386 1302 1524 1547 1632 1668 1421 1475 1396 1706 1715 1586 1477 1500 1648 1745 1856 2067 2104 2061 2809 2783 2748 2642 2628 2714 2699 2776 2795 2673 2558 2394 2784 2751 2521 2372 2202 2469 2686 2815 2831 2661 2590 2383 2670 2771 2381 2224 2556 2512 2690 2726 2493 2544 2232 2494 2315 2217 2100 2116 2319 2491 2432 2470 2191 2241 2117 2370 2392 2255 2077 2047 2233 2539 2341 2231 2171 2487 2449 2300 2387 2474 2667 2791 2904 2737 2849 2723 2613 2950 2825 2717 2593 2703 2836 2938 2975 3064 3092 3063 2991

77
par(mfrow=c(2,2)) ts.plot(W) Z2=diff(W) Z3=diff(Z2,lag=12) ts.plot(Z3) acf(Z3) pacf(Z3)
) ts.plot(W) Z2=diff(W) Z3=diff(Z2,lag=12) ts.plot(Z3) acf(Z3) pacf(Z3)")
78
mar=arima(Z3,order=c(1,0,13))
yr=resid(mar) Box.test (yr, lag = 6, type = "Ljung") Box.test (yr, lag = 12, type = "Ljung") ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)
 Box.test (yr, lag = 6, type = Ljung ) Box.test (yr, lag = 12, type = Ljung ) ct=abs(mar$coef)/sqrt(diag(mar$var.coef)) 1-pnorm(ct)")
79
简单季节模型拟合结果 延迟阶数 拟合模型残差白噪声检验 值 P值 AR(1,12) MA(1,2,12) 6 14.58 0.0057
9.5 0.0233 15.77 0.0004 12 16.42 0.0883 14.19 0.1158 17.99 0.0213 结果 拟合模型均不显著

80
乘积季节模型拟合 模型定阶 ARIMA(1,1,1)×(0,1,1)12 参数估计
×(0,1,1)12 参数估计")
81
Pma=arima(W, order = c(1,1,1),
seasonal = list(order = c(0, 1, 1), period = 12))
, period = 12))")
82
yr=resid(Pma) Box.test (yr, lag = 6, type = "Ljung") Box.test (yr, lag = 12, type = "Ljung") ct=abs(Pma$coef)/sqrt(diag(Pma$var.coef)) 1-pnorm(ct)
")
83
par(mfrow=c(3,1)) ts.plot(yr) acf(yr) pacf(yr)
) ts.plot(yr) acf(yr) pacf(yr)")
84
模型检验 残差白噪声检验 参数显著性检验 延迟 阶数 统计量 P值 待估 参数 6 4.50 0.2120 -4.66 <0.0001
9.42 0.4002 23.03 18 20.58 0.1507 -6.81 结果 模型显著 参数均显著

85
乘积季节模型拟合效果图

86
5.3 Auto-Regressive模型 构造思想 首先通过确定性因素分解方法提取序列中主要的确定性信息
然后对残差序列拟合自回归模型,以便充分提取相关信息

87
Auto-Regressive模型结构

88
对趋势效应的常用拟合方法 自变量为时间t的幂函数 自变量为历史观察值

89
对季节效应的常用拟合方法 给定季节指数 建立季节自回归模型

90
例5.6续 使用Auto-Regressive模型分析1952年-1988年中国农业实际国民收入指数序列。

91
趋势拟合 方法一:变量为时间t的幂函数 方法二:变量为一阶延迟序列值

92
趋势拟合效果图

93
x1<-scan() 100 101.6 103.3 111.5 116.5 120.1 120.3 100.6 83.6 84.7 88.7 98.9 111.9 122.9 131.9 134.2 131.6 132.2 139.8 142 140.5 153.1 159.2 162.3 159.1 155.1 161.2 171.5 168.4 180.4 201.6 218.7 247 253.7 261.4 273.2 279.4

94
par(mfrow=c(2,2)) ts.plot(x1) lmx=lm(x1~c(1:length(x1))) lines(fitted(lmx),col="red") ts.plot(x1[-1]) lmx2= lm(formula = x1[-1] ~ x1[-length(x1)] - 1) lines(fitted(lmx2),col="red")
![par(mfrow=c(2,2)) ts.plot(x1) lmx=lm(x1~c(1:length(x1))) lines(fitted(lmx),col= red ) ts.plot(x1[-1])](http://slidesplayer.com/slide/11355061/61/images/94/par%28mfrow%3Dc%282%2C2%29%29+ts.plot%28x1%29+lmx%3Dlm%28x1%7Ec%281%3Alength%28x1%29%29%29+lines%28fitted%28lmx%29%2Ccol%3D+red+%29+ts.plot%28x1%5B-1%5D%29.jpg "lmx2= lm(formula = x1[-1] ~ x1[-length(x1)] - 1) lines(fitted(lmx2),col= red )")
95
library(lmtest) dwtest(x1~c(1:length(x1))) r1=resid(lmx) ar(r1)
 dwtest(x1~c(1:length(x1))) r1=resid(lmx) ar(r1)")
96
dwtest(x1[-1] ~ x1[-length(x1)] - 1)
r2=resid(lmx2) ar(r2)
![dwtest(x1[-1] ~ x1[-length(x1)] - 1)](http://slidesplayer.com/slide/11355061/61/images/96/dwtest%28x1%5B-1%5D+%7E+x1%5B-length%28x1%29%5D+-+1%29.jpg "r2=resid(lmx2) ar(r2)")
97
残差自相关检验 检验原理 回归模型拟合充分,残差的性质 回归模型拟合得不充分,残差的性质

98
Durbin-Waston检验(DW检验)
假设条件 原假设:残差序列不存在一阶自相关性 备择假设:残差序列存在一阶自相关性

99
DW统计量 构造统计量 DW统计量和自相关系数的关系

100
DW统计量的判定结果 正 相 关 相 关 性 待 定 不相关 相 关 性 待 定 负 相 关 2 4

101
例5.6续 检验第一个确定性趋势模型 残差序列的自相关性。

102
DW检验结果 检验结果 检验结论 检验结果显示残差序列高度正自相关。 DW统计量的值 P值 0.1378 1.42 1.53 0.0001

103
Durbin h检验 DW统计量的缺陷 Durbin h检验
当回归因子包含延迟因变量时,残差序列的DW统计量是一个有偏统计量。在这种场合下使用DW统计量容易产生残差序列正自相关性不显著的误判 Durbin h检验

104
例5.6续 检验第二个确定性趋势模型 残差序列的自相关性。

105
Dh检验结果 检验结果 检验结论 检验结果显示残差序列高度正自相关。 Dh统计量的值 P值 2.8038 0.0025

106
残差序列拟合 确定自回归模型的阶数 参数估计 模型检验

107
例5.6续 对第一个确定性趋势模型的残差序列 进行拟合

108
残差序列自相关图

109
残差序列偏自相关图

110
par(mfrow=c(2,2)) acf(r1) pacf(r1) acf(r2) pacf(r2)
) acf(r1) pacf(r1) acf(r2) pacf(r2)")
111
模型拟合 定阶 AR(2) 参数估计方法 极大似然估计 最终拟合模型口径
 参数估计方法 极大似然估计 最终拟合模型口径")
112
例5.6 第二个Auto-Regressive模型的拟合结果

113
r0=diff(x1) arima(r0,order=c(0,0,1)) r1=resid(lm(x1~c(1:length(x1)))) arima(r1,order=c(2,0,0)) r2=resid(lm(x1[-1] ~ x1[-length(x1)] - 1)) arima(r2,order=c(1,0,0))
![r0=diff(x1) arima(r0,order=c(0,0,1)) r1=resid(lm(x1~c(1:length(x1)))) arima(r1,order=c(2,0,0)) r2=resid(lm(x1[-1] ~ x1[-length(x1)] - 1))](http://slidesplayer.com/slide/11355061/61/images/113/r0%3Ddiff%28x1%29+arima%28r0%2Corder%3Dc%280%2C0%2C1%29%29+r1%3Dresid%28lm%28x1%7Ec%281%3Alength%28x1%29%29%29%29+arima%28r1%2Corder%3Dc%282%2C0%2C0%29%29+r2%3Dresid%28lm%28x1%5B-1%5D+%7E+x1%5B-length%28x1%29%5D+-+1%29%29.jpg "arima(r2,order=c(1,0,0))")
114
lmx=lm(x1~c(1:length(x1)))
lines(fitted(lmx),col="red") ts.plot(x1[-1]) lmx2= lm(formula = x1[-1] ~ x1[-length(x1)] - 1)
,col= red ) ts.plot(x1[-1]) lmx2= lm(formula = x1[-1] ~ x1[-length(x1)] - 1)")
115
三个拟合模型的比较 模型 AIC SBC ARIMA(0,1,1)模型: Auto-Regressive模型一: Auto-Regressive模型二:

116
5.4 异方差的性质 异方差的定义 异方差的影响 如果随机误差序列的方差会随着时间的变化而变化,这种情况被称作为异方差
忽视异方差的存在会导致残差的方差会被严重低估,继而参数显著性检验容易犯纳伪错误,这使得参数的显著性检验失去意义,最终导致模型的拟合精度受影响。

117
异方差直观诊断 残差图 残差平方图

118
残差图 方差齐性残差图 递增型异方差残差图

119
残差平方图 原理 残差序列的方差实际上就是它平方的期望。 所以考察残差序列是否方差齐性,主要是考察残差平方序列是否平稳

120
例5.11 直观考察美国1963年4月——1971年7月短期国库券的月度收益率序列的方差齐性。

121
一阶差分后残差图

122
一阶差分后残差平方图

123
异方差处理方法 假如已知异方差函数具体形式,进行方差齐性变化 假如不知异方差函数的具体形式,拟合条件异方差模型

124
5.5 方差齐性变换 使用场合 处理思路 序列显示出显著的异方差性,且方差与均值之间具有某种函数关系 其中: 是某个已知函数
其中: 是某个已知函数 处理思路 尝试寻找一个转换函数 ,使得经转换后的变量满足方差齐性

125
转换函数的确定原理 转换函数 在 附近作一阶泰勒展开 求转换函数的方差 转换函数的确定

126
常用转换函数的确定 假定 转换函数的确定

128
例5.11续 对美国1963年4月——1971年7月短期国库券的月度收益率序列使用方差齐性变换方法进行分析 假定 函数变换

129
对数序列时序图

130
一阶差分后序列图

131
白噪声检验 延迟阶数 LB统计量 P值 6 3.58 0.7337 12 10.82 0.5441 18 21.71 0.2452

132
y1<-scan() 0.0025 0.0026 0.0033 0.0037 0.003 0.0036 0.005 0.0047 0.0055 0.0054

133
par(mfrow=c(2,2)) ts.plot(y1) y2=diff(y1) ts.plot(y2) y3=log(y1) ts.plot(y3) y4=diff(y3) ts.plot(y4)
) ts.plot(y1) y2=diff(y1) ts.plot(y2) y3=log(y1) ts.plot(y3) y4=diff(y3) ts.plot(y4)")
134
par(mfrow=c(2,2)) acf(y2) pacf(y2) acf(y4) pacf(y4)
) acf(y2) pacf(y2) acf(y4) pacf(y4)")
135
Box.test(y2,lag=6) Box.test(y2,lag=12) Box.test(y4,lag=6) Box.test(y4,lag=12)
 Box.test(y2,lag=12) Box.test(y4,lag=6) Box.test(y4,lag=12)")
136
拟合模型口径及拟合效果图

137
5.6 条件异方差模型 ARCH模型 GARCH模型 GARCH模型的变体 EGARCH模型 IGARCH模型 GARCH-M模型
AR-GARCH模型

138
ARCH模型 假定 原理 通过构造残差平方序列的自回归模型来拟合异方差函数 ARCH(q)模型结构
模型结构")
139
GARCH 模型结构 使用场合 模型结构 ARCH模型实际上适用于异方差函数短期自相关过程

140
GARCH模型的约束条件 参数非负 参数有界

141
EGARCH模型(参数无约束)
")
142
IGARCH模型(方差无界)
")
143
GARCH-M模型(条件方差为回归因子)
")
144
AR-GARCH模型

145
GARCH模型拟合步骤 回归拟合 残差自相关性检验 异方差自相关性检验 ARCH模型定阶 参数估计 正态性检验

146
例5.12 使用条件异方差模型拟合某金融时间序列。

147
Z<-scan() 561.1 551.9 558.3 575 569.4 585.2 592 594.8 602.2 605.5 615.1 633.5 626.8 613.1 624.6 647.2 645.7 663.5 674 679.1 685.2 692.8 709.5 740.6 737.5 717.1 723.5 752.5 739.9 744.4 746.8 745 745.2 753.7 756 765.9 764.7 752.1 778.3 763.8 778.8 785.6 781.3 780 780.8 787.1 803.2 793 772.3 775.2 791.3 767.2 773.8 781.7 777.4 778.5 784.5 791.4 811.9 802.4 788.3 796.2 818 797.3 810.8 812.9 814.5 818.9 817.6 826.1 844.3 833.2 823.4 835 852.9 841.9 857.8 861.9 864.2 867.3 875 893.4 916.8 918.1 916.5

148
par(mfrow=c(2,2)) ts.plot(Z) lmz=lm(Z[-1]~Z[-length(Z)]-1) dwtest(Z[-1]~Z[-length(Z)]-1) rz=resid(lmz) Box.test(rz,lag=6,type="L") Box.test(rz,lag=12,type="L")
![par(mfrow=c(2,2)) ts.plot(Z) lmz=lm(Z[-1]~Z[-length(Z)]-1) dwtest(Z[-1]~Z[-length(Z)]-1) rz=resid(lmz)](http://slidesplayer.com/slide/11355061/61/images/148/par%28mfrow%3Dc%282%2C2%29%29+ts.plot%28Z%29+lmz%3Dlm%28Z%5B-1%5D%7EZ%5B-length%28Z%29%5D-1%29+dwtest%28Z%5B-1%5D%7EZ%5B-length%28Z%29%5D-1%29+rz%3Dresid%28lmz%29.jpg "Box.test(rz,lag=6,type= L ) Box.test(rz,lag=12,type= L )")
149
arima(rz,order=c(2,0,0)) ar(rz) ts.plot(rz) acf(rz) pacf(rz) portest(rz,test="LjungBox")
) ar(rz) ts.plot(rz) acf(rz) pacf(rz) portest(rz,test= LjungBox )")
150
回归拟合 拟合模型 参数估计 参数显著性检验 P值<0.0001,参数高度显著

151
残差自相关性检验 残差序列DW检验结果 Durbin h= 拟合残差自回归模型 方法:逐步回归 模型口径

152
异方差自相关检验 Portmantea Q检验 拉格朗日乘子(LM)检验
检验")
153
Portmantea Q检验 假设条件 检验统计量 检验结果 拒绝原假设 接受原假设

154
LM检验 假设条件 检验统计量 检验结果 拒绝原假设 接受原假设

155
例5.12残差序列异方差检验

156
Box.test(rz,lag=6,type="L")
")
157
arf= arima(rz,order=c(2,0,0), include.mean = F)
arima(rz,order=c(2,0,0), include.mean = T) rv=resid(arf) ts.plot(rv)
, include.mean = T) rv=resid(arf) ts.plot(rv)")
158
library(tseries) summary(garch(rz)) Z1=diff(Z) Z1.s=summary(garch(Z1)) zr=Z1.s$residuals acf(zr) pacf(zr)
")
159
arz=arima(Z1,order=c(13,0,0))
zr=resid(arz) acf(zr) pacf(zr)
 acf(zr) pacf(zr)")
160
library(tseries) mar=arma(Z1,order=c(13,0),include.intercept = T) summary(mar)
 mar=arma(Z1,order=c(13,0),include.intercept = T) summary(mar)")
161
zr=resid(mar) Box.test (zr, lag = 6, type = "Ljung") Box.test (zr, lag = 12, type = "Ljung") ct=abs(summary(mar)$coef[,1])/summary(mar)$coef[,2] 1-pnorm(ct)
![zr=resid(mar) Box.test (zr, lag = 6, type = Ljung ) Box.test (zr, lag = 12, type = Ljung ) ct=abs(summary(mar)$coef[,1])/summary(mar)$coef[,2]](http://slidesplayer.com/slide/11355061/61/images/161/zr%3Dresid%28mar%29+Box.test+%28zr%2C+lag+%3D+6%2C+type+%3D+Ljung+%29+Box.test+%28zr%2C+lag+%3D+12%2C+type+%3D+Ljung+%29+ct%3Dabs%28summary%28mar%29%24coef%5B%2C1%5D%29%2Fsummary%28mar%29%24coef%5B%2C2%5D.jpg "1-pnorm(ct)")
162
par(mfrow=c(3,1)) ts.plot(zr[-which(is.na(zr))]) acf(zr[-which(is.na(zr))]) pacf(zr[-which(is.na(zr))])
![par(mfrow=c(3,1)) ts.plot(zr[-which(is.na(zr))]) acf(zr[-which(is.na(zr))]) pacf(zr[-which(is.na(zr))])](http://slidesplayer.com/slide/11355061/61/images/162/par%28mfrow%3Dc%283%2C1%29%29+ts.plot%28zr%5B-which%28is.na%28zr%29%29%5D%29+acf%28zr%5B-which%28is.na%28zr%29%29%5D%29+pacf%28zr%5B-which%28is.na%28zr%29%29%5D%29.jpg "par(mfrow=c(3,1)) ts.plot(zr[-which(is.na(zr))]) acf(zr[-which(is.na(zr))]) pacf(zr[-which(is.na(zr))])")
163
n <- 1100 a <- c(0.1, 0.5, 0.2) # ARCH(2) coefficients e <- rnorm(n) x <- double(n) x[1:2] <- rnorm(2, sd = sqrt(a[1]/(1.0-a[2]-a[3])))
 x <- double(n) x[1:2] <- rnorm(2, sd = sqrt(a[1]/(1.0-a[2]-a[3]))) .")
164
for(i in 3:n) # Generate ARCH(2) process
{ x[i] <- e[i]*sqrt(a[1]+a[2]*x[i-1]^2+a[3]*x[i-2]^2) } x <- ts(x[101:1100])
 } x <- ts(x[101:1100])")
165
par(mfrow=c(2,2)) acf(x);pacf(x) pacf(x^2); acf(x^2)
) acf(x);pacf(x) pacf(x^2); acf(x^2)")
166
x.arch <- garch(x, order = c(0,2))
# Fit ARCH(2) summary(x.arch) # Diagnostic tests plot(x.arch) xr=summary(x.arch)$residuals
 summary(x.arch) # Diagnostic tests. plot(x.arch) xr=summary(x.arch)$residuals.")
167
par(mfrow=c(2,2)) acf(xr);pacf(xr) acf(xr^2); pacf(xr^2)
) acf(xr);pacf(xr) acf(xr^2); pacf(xr^2)")
168
data(EuStockMarkets)
dax <- diff(log(EuStockMarkets))[,"DAX"] acf(dax);pacf(dax) pacf(dax^2); acf(dax^2)
)[, DAX ] acf(dax);pacf(dax) pacf(dax^2); acf(dax^2)")
169
dax.garch <- garch(dax) # Fit a GARCH(1,1) to DAX returns
summary(dax.garch) # ARCH effects are filtered. However, plot(dax.garch) # conditional normality seems to be violated
 # ARCH effects are filtered. However, plot(dax.garch) # conditional normality seems to be violated.")
170
xr=summary(dax.arch)$residuals
par(mfrow=c(2,2)) acf(xr);pacf(xr) acf(xr^2); pacf(xr^2)
) acf(xr);pacf(xr) acf(xr^2); pacf(xr^2)")
171
ARCH模型拟合 定阶:GARCH(1,1) 参数估计:极大似然估计 拟合模型口径:AR(2)-GARCH(1,1)
 参数估计:极大似然估计 拟合模型口径:AR(2)-GARCH(1,1)")
172
模型检验 检验方法:正态性检验 假设条件: 检验统计量 检验结果 拒绝原假设 接受原假设

173
例5.13正态性检验结果 P值=0.5603 AR(2)-GARCH(1,1)模型显著成立
-GARCH(1,1)模型显著成立")
174
拟合效果图

Similar presentations








班 顾韬 景琰杰 指导教师:张成鹏>")



>")







