Download presentation
Presentation is loading. Please wait.

4
第2章 计算机中的信息表示 2.1 无符号数和有符号数 2.2 数的定点表示和浮点表示 2.3 定点运算 2.4 浮点四则运算
第2章 计算机中的信息表示 2.1 无符号数和有符号数 2.2 数的定点表示和浮点表示 2.3 定点运算 2.4 浮点四则运算 2.5算术逻辑单元 2.6 字符的表示 2.7 指令信息的表示 2.8 校验技术

5
2.1 无符号数和有符号数 2.1.1 无符号数 以机器字长为16位为例,无符号数的表示范围为0 ~ 65535,而有符号数的表示范围为 ~ 。 2.1.2 有符号数 1.机器数与真值 把符号“数字化”的数叫做机器数,而把带“+”或“-”符号的数叫做真值。

6
2.原码表示法

8
如时钟指示6点,欲使它指示3点,既可按顺时针方向将分针转9圈,又可按逆时针方向将分针转3圈,结果是一致的。
3.补码表示法 (1)补数的概念 如时钟指示6点,欲使它指示3点,既可按顺时针方向将分针转9圈,又可按逆时针方向将分针转3圈,结果是一致的。
补数的概念. 如时钟指示6点,欲使它指示3点,既可按顺时针方向将分针转9圈,又可按逆时针方向将分针转3圈,结果是一致的。")
11
(2)补码的定义
补码的定义")
12
小数补码的定义为

15
4.反码表示法

18
例2.1 设机器数字长为8位(其中一位为符号位),对于整数,当其分别代表无符号数、原码、补码和反码时,对应的真值范围各位为多少?
,对于整数,当其分别代表无符号数、原码、补码和反码时,对应的真值范围各位为多少?")
20
5.移码表示法 当真值用补码表示时,由于符号位和数值部分一起编码,与习惯上的表示法不同,因此人们很难从补码的形式上直接判断其真值的大小

24
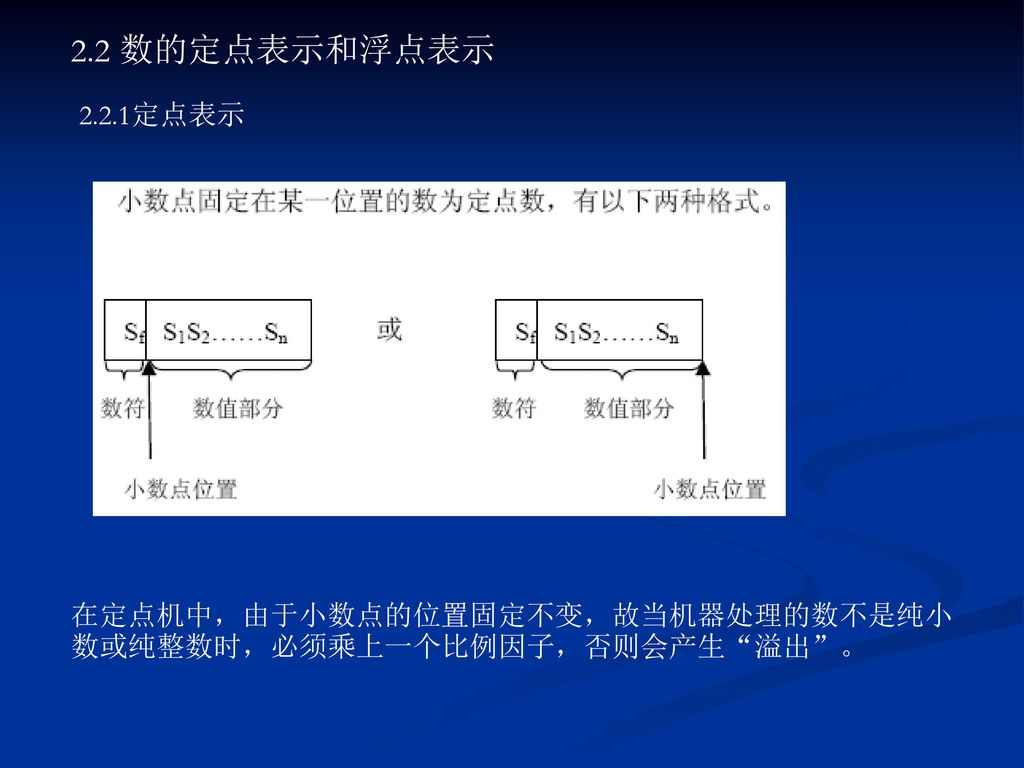
2.2 数的定点表示和浮点表示 2.2.1定点表示 在定点机中,由于小数点的位置固定不变,故当机器处理的数不是纯小数或纯整数时,必须乘上一个比例因子,否则会产生“溢出”。

25
2.2.2浮点表示

26
1. 浮点数的表示形式

27
2. 浮点数的表示范围

28
3.浮点数的规格化

29
2.2.3 定点数和浮点数的比较

30
2.2.4举例

34
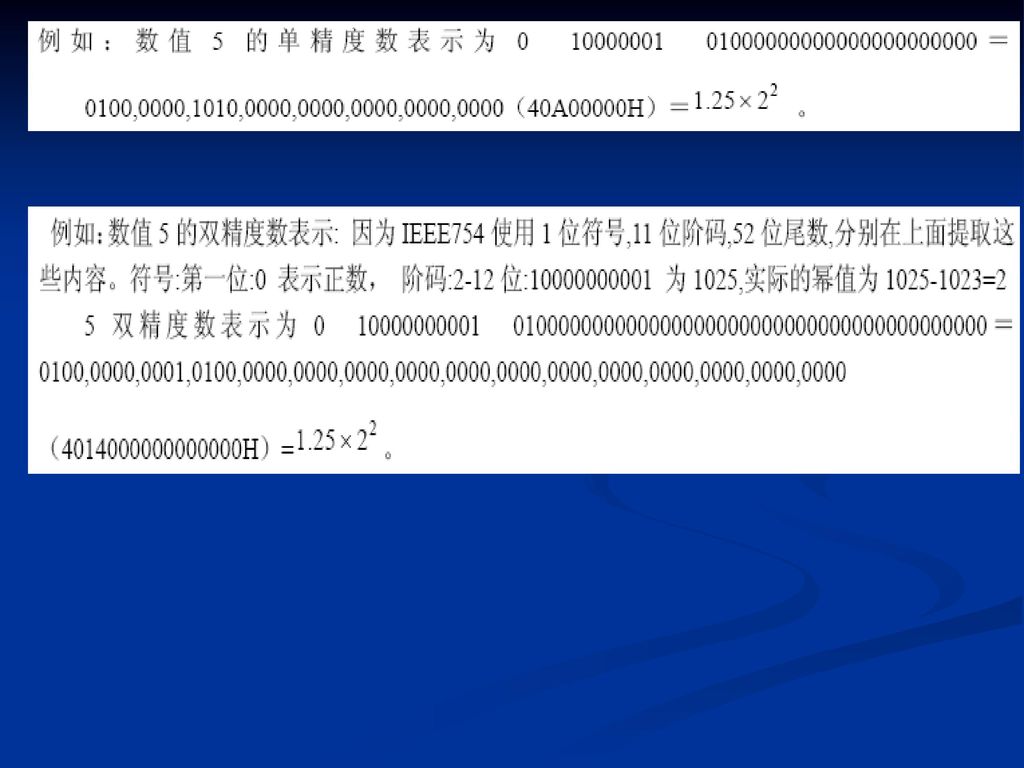
2.2.5 IEEE 754

36
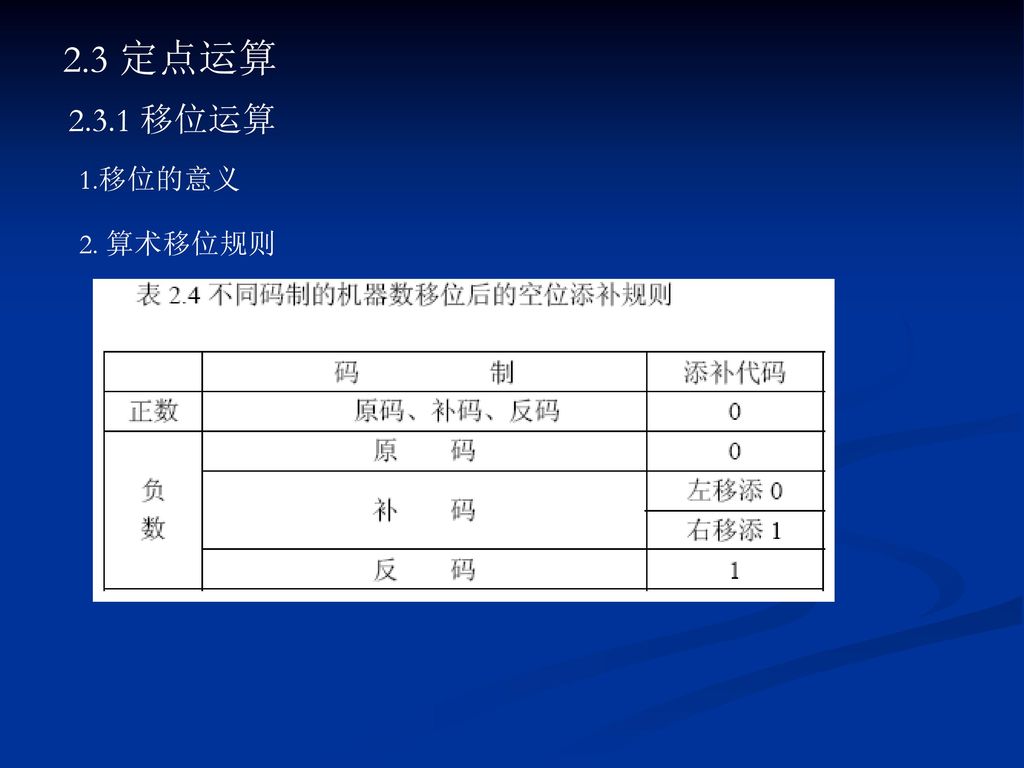
2.3 定点运算 2.3.1 移位运算 移位的意义 2. 算术移位规则

37
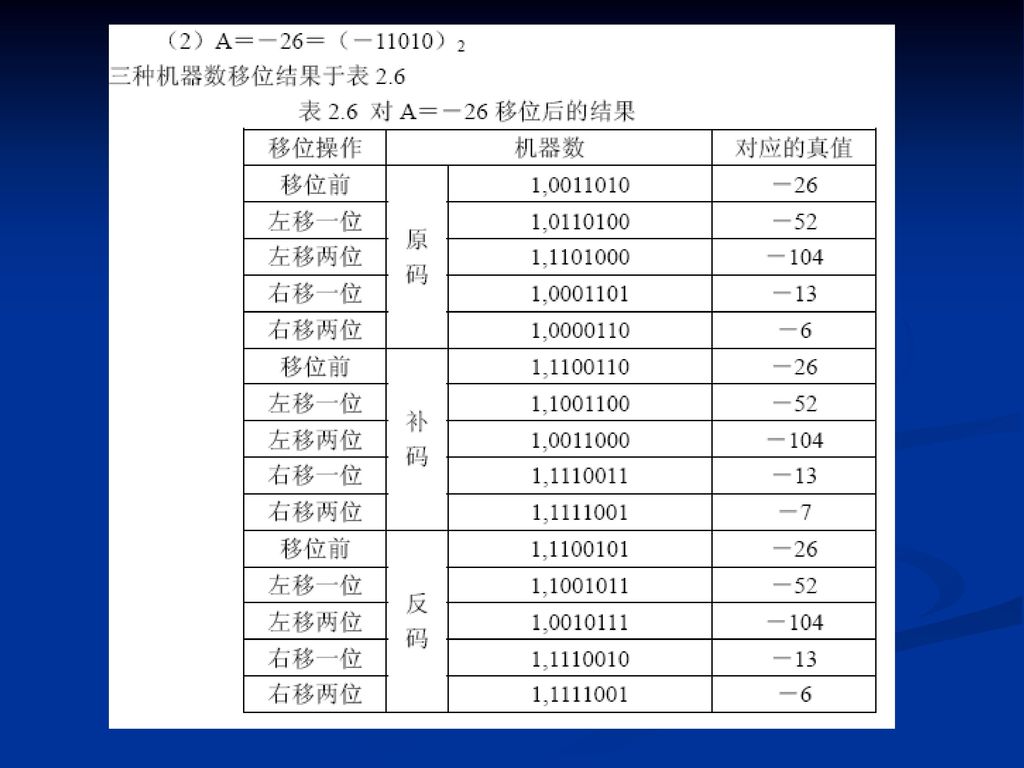
例2.7 设机器数字长为8位(含一符号位),若A=±26,写出三种机器数左、右移一位和两位后的表示形式及对应的真值,并分析结果的正确性。
,若A=±26,写出三种机器数左、右移一位和两位后的表示形式及对应的真值,并分析结果的正确性。")
39
其中(a)真值为正的三种机器数的移位操作;(b)负数原码的移位操作;(c)负数补码的移位操作;(d)负数反码的移位操作。
真值为正的三种机器数的移位操作;(b)负数原码的移位操作;(c)负数补码的移位操作;(d)负数反码的移位操作。")
40
3. 算术移位与逻辑移位的区别 有符号数的移位称为算术移位,无符号数的移位称为逻辑移位。逻辑移位的规则是逻辑左移时,高位移出,低位添0;逻辑右移时,低位移出,高位添0。例如,寄存器内容为 ,逻辑左移为 ,算术左移为 (最高数位“1”移丢)。又如寄存器内容为 ,逻辑右移为 。若将其视为补码,算术右移为 。显然两种移位的结果是不同的。上例中为了避免算术左移时最高位丢1,可采用带进位(CY)的移位,其示意图如图2.4所示。算术左移时,符号位移至CY,最高位可避免移出。
。又如寄存器内容为 ,逻辑右移为 。若将其视为补码,算术右移为 。显然两种移位的结果是不同的。上例中为了避免算术左移时最高位丢1,可采用带进位(CY)的移位,其示意图如图2.4所示。算术左移时,符号位移至CY,最高位可避免移出。")
41
2.3.2 加法与减法运算

46
(2)溢出判断 对于加法,只有正数加正数和负数加负数两种情况下才可能出现溢出,符号不同的两个数相加是不会出现溢出的。 对于减法,只有在正数减负数或负数减正数两种情况下才可能产生溢出,符号相同的两个数相减是不会出现溢出的。 由于减法运算在机器中是用加法器实现的,因此可得如下结论:不论是作加法还是减法,只要实际参加运算的两个数(减法时即为被减数和“求补”以后的减数)符号相同,结果又与原操作数的符号不同,即为溢出。
符号相同,结果又与原操作数的符号不同,即为溢出。")
50
计算机中采用一位符号位判断时,为了节省时间,通常用符号位产生的进位与最高有效位产生的进位异或操作后,按其结果进行判断。若异或结果为1,即为溢出;异或结果为0,则无溢出。例2.12中符号位有进位,最高有效位无进位,即1⊕0=1,故溢出。例2.13中符号位有进位,最高有效位也有进位,即1⊕1=0,故无溢出。

51
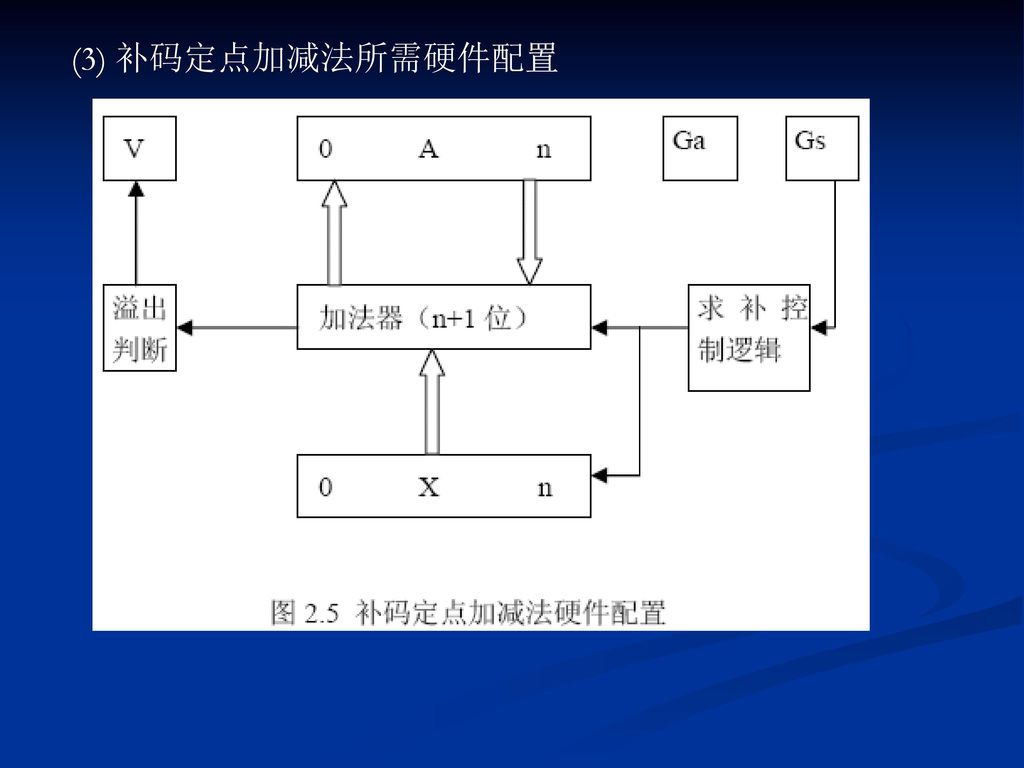
(3) 补码定点加减法所需硬件配置
 补码定点加减法所需硬件配置")
52
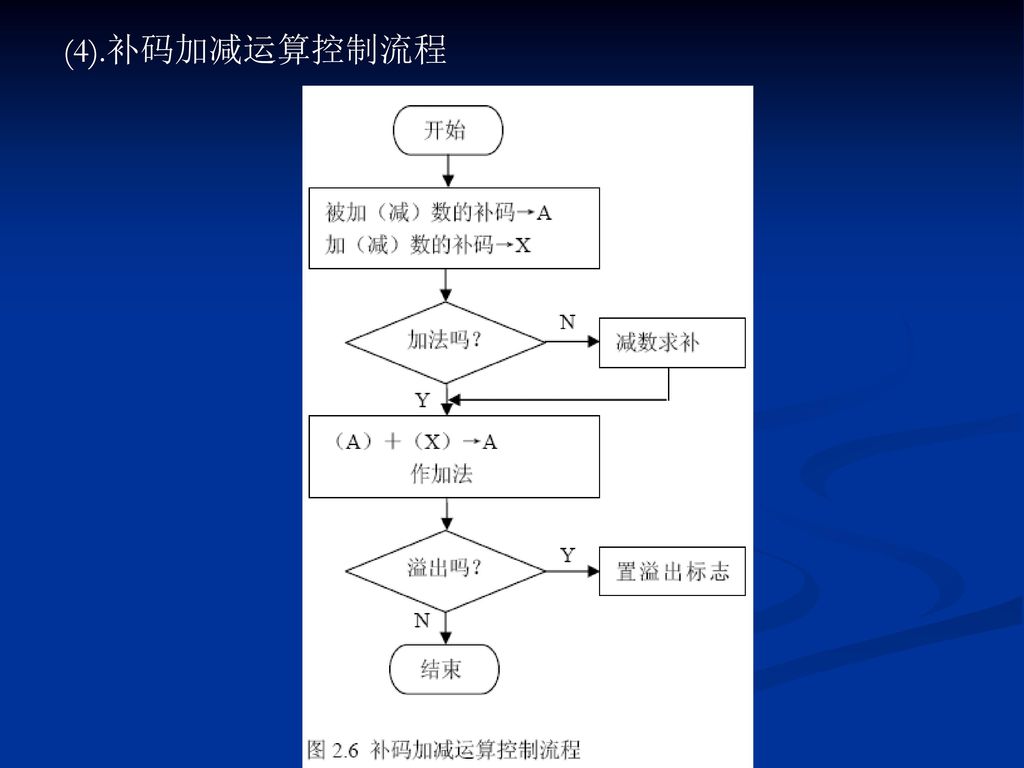
(4).补码加减运算控制流程
.补码加减运算控制流程")
53
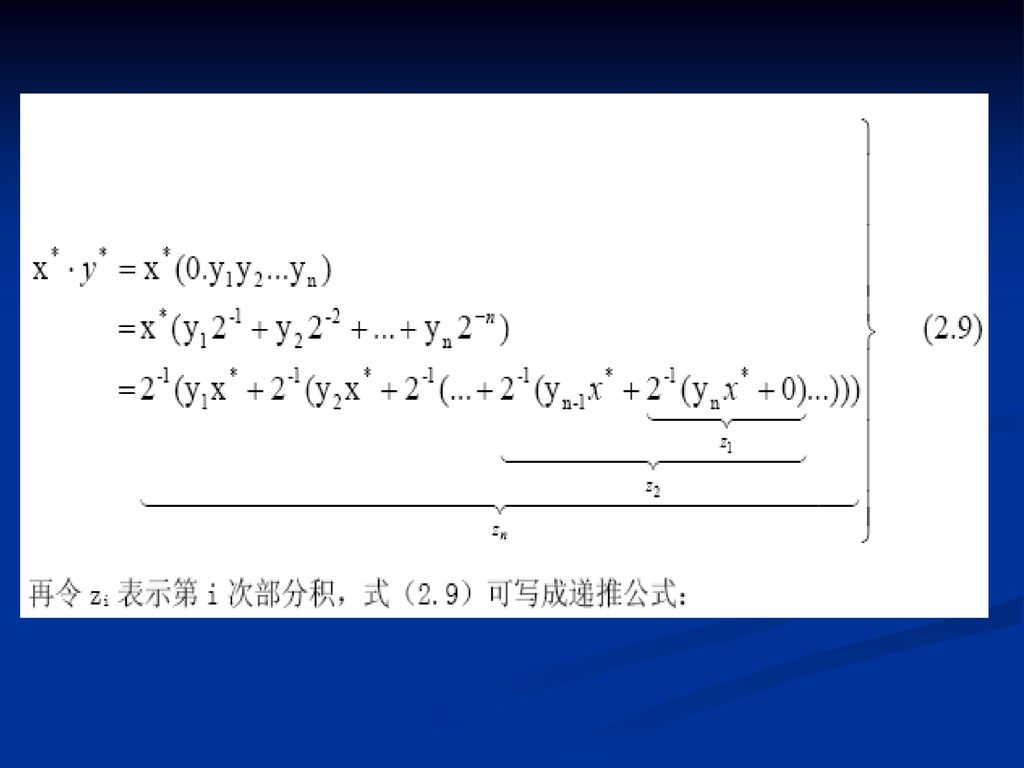
2.3.3 乘法运算

57
上述运算过程可归纳为: ①乘法运算可用移位和加法来实现,当两个四位数相乘,总共需做四次加法和四次移位。 ②由乘数的末位值确定被乘数是否与原部分积相加,然后右移一位,形成新的部分积;同时乘数也右移一位,由次低位作新的末位,空出的最高位放部分积的最低位。 ③每次做加法时,被乘数仅仅与原部分积的高位相加,其低位被移至乘数所空出的高位位置。 实现这种运算比较容易,用一个寄存器存放被乘数,一个寄存器存放乘积的高位,另一个寄存器存放乘积的低位与乘数。再配上加法器及其它相应电路,就可组成乘法器。又因加法只在部分积的高位进行,故这种算法不仅节省硬件资源,而且缩短运算时间。

58
(3)原码乘法
原码乘法")
62
0.0000

63
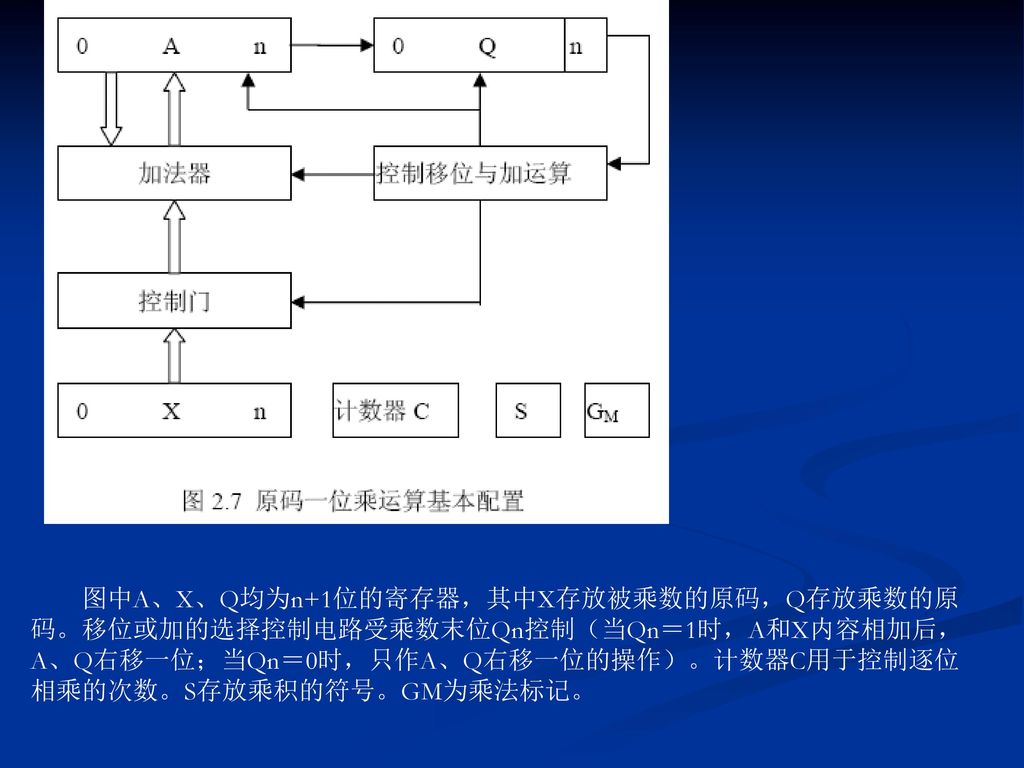
图中A、X、Q均为n+1位的寄存器,其中X存放被乘数的原码,Q存放乘数的原码。移位或加的选择控制电路受乘数末位Qn控制(当Qn=1时,A和X内容相加后,A、Q右移一位;当Qn=0时,只作A、Q右移一位的操作)。计数器C用于控制逐位相乘的次数。S存放乘积的符号。GM为乘法标记。
。计数器C用于控制逐位相乘的次数。S存放乘积的符号。GM为乘法标记。")
64
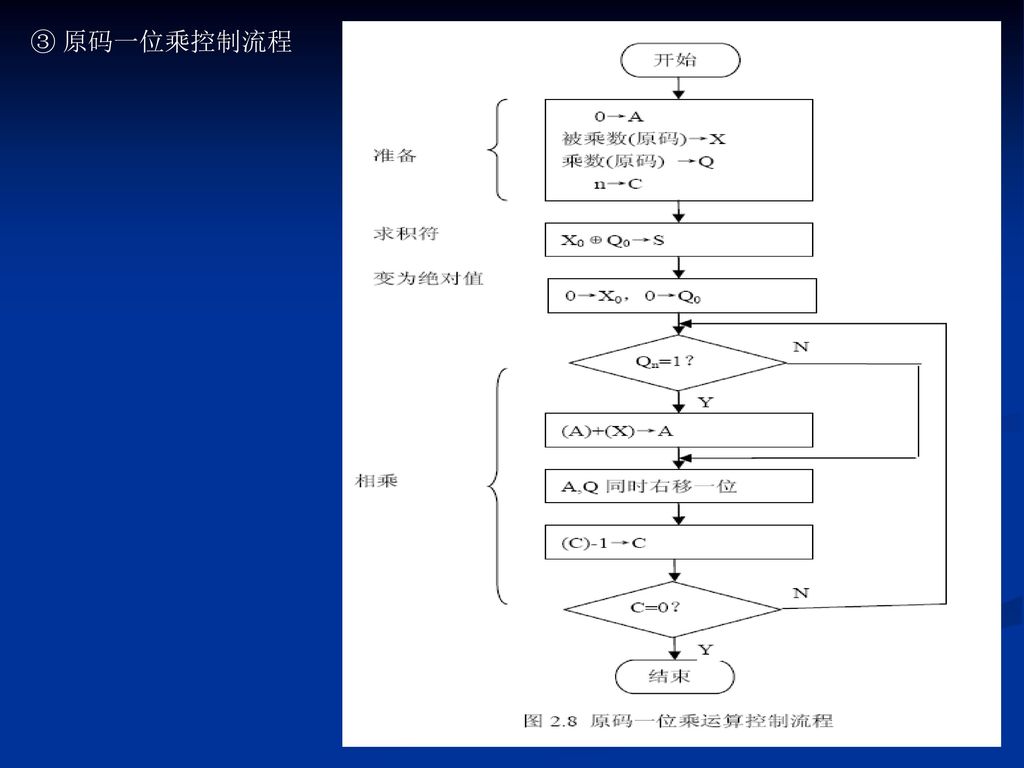
③ 原码一位乘控制流程

65
③原码两位乘 与原码一位乘一样,符号位的运算和数值部分是分开进行的,但原码两位乘是用两位乘数的状态来决定新的部份积如何形成,因此可提高运算的速度。

67
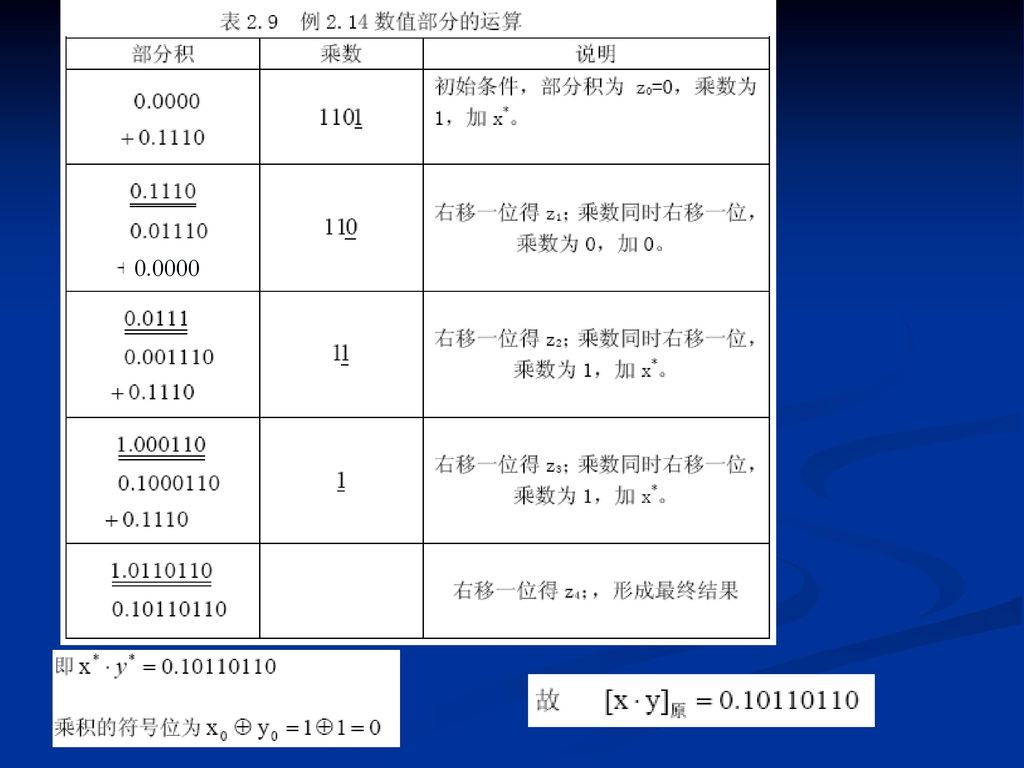
例2.15 设x=0.111111,y= -0.111001,用原码两位乘求[x﹒y]原。
![例2.15 设x= ,y= ,用原码两位乘求[x﹒y]原。](http://slidesplayer.com/slide/11455969/61/images/67/%E4%BE%8B2.15+%E8%AE%BEx%3D+%EF%BC%8Cy%3D+%EF%BC%8C%E7%94%A8%E5%8E%9F%E7%A0%81%E4%B8%A4%E4%BD%8D%E4%B9%98%E6%B1%82%5Bx%EF%B9%92y%5D%E5%8E%9F%E3%80%82.jpg "例2.15 设x= ,y= ,用原码两位乘求[x﹒y]原。")
69
2.3.4除法运算 1.分析笔算除法

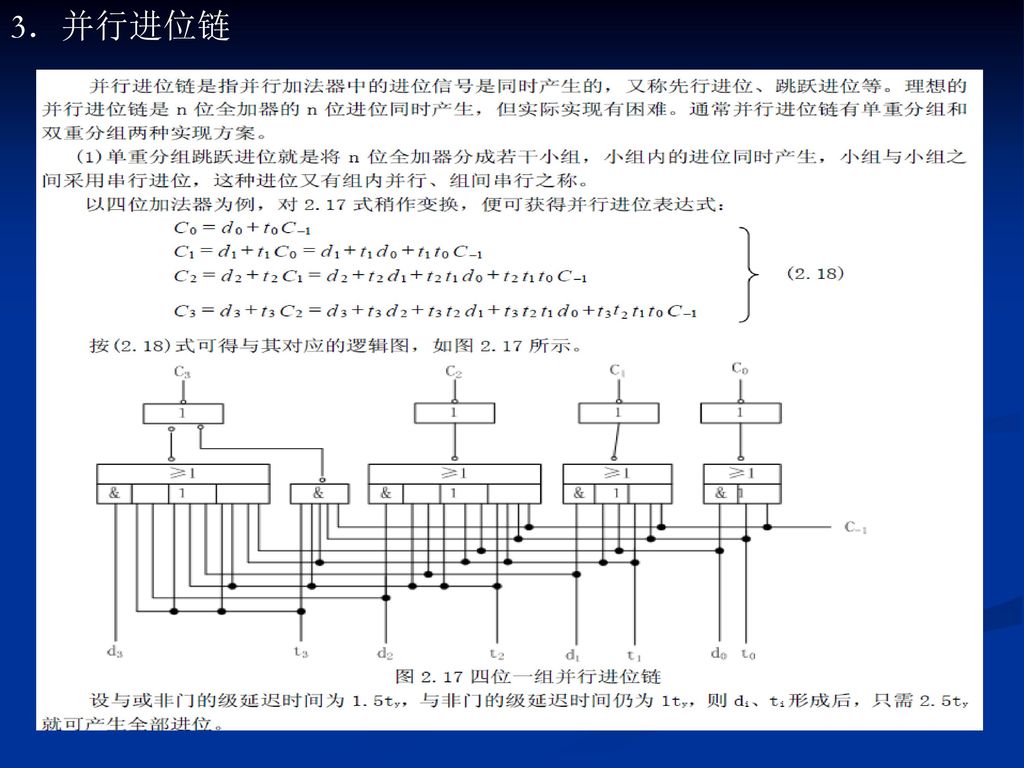
70
②按照每次减法总是保持余数不动低位补0,再减去右移后的除数这一规则,则要求加法器的位数必须为除数的两倍。仔细分析发现,右移除数可以用左移余数的办法代替,其运算结果是一样的,但对线路结构更有利。不过此刻所得到的余数不是真正的余数,只有将它乘上2-n才是真正的余数。 ③笔算求商时是从高位向低位逐位求的,而要求机器把每位商直接写到寄存器的不同位也是不可取的。计算机可将每一位商直接写到寄存器的最低位,并把原来的部分商左移一位。 综上所述,便可得原码除法运算规则。

71
2.4 浮点四则运算 2.4.1 浮点加减运算 由于浮点数尾数的小数点均固定在第一数值位前,所以尾数的加减运算规则与定点数完全相同。但由于其阶码的大小又直接反映尾数有效值的小数点位置,因此当两浮点数阶码不等时,因两尾数小数点的实际位置不一样,尾数部分无法直接进行加减运算。因此,浮点数加减运算必须按以下几步进行: ①对阶,使两数的小数点位置对齐。 ②尾数求和,将对阶后的两尾数按定点加减运算规则求和(差)。 ③规格化,为增加有效数字的位数,提高运算精度,必须将求和(差)后的尾数规格化。 ④舍入,为提高精度,要考虑尾数右移时丢失的数值位。 ⑤判断结果,即判断结果是否溢出。
。 ③规格化,为增加有效数字的位数,提高运算精度,必须将求和(差)后的尾数规格化。 ④舍入,为提高精度,要考虑尾数右移时丢失的数值位。 ⑤判断结果,即判断结果是否溢出。")
72
1.对阶

73
2.尾数求和

74
3.规格化

77
法同样有使尾数变大和变小的两种可能。

79
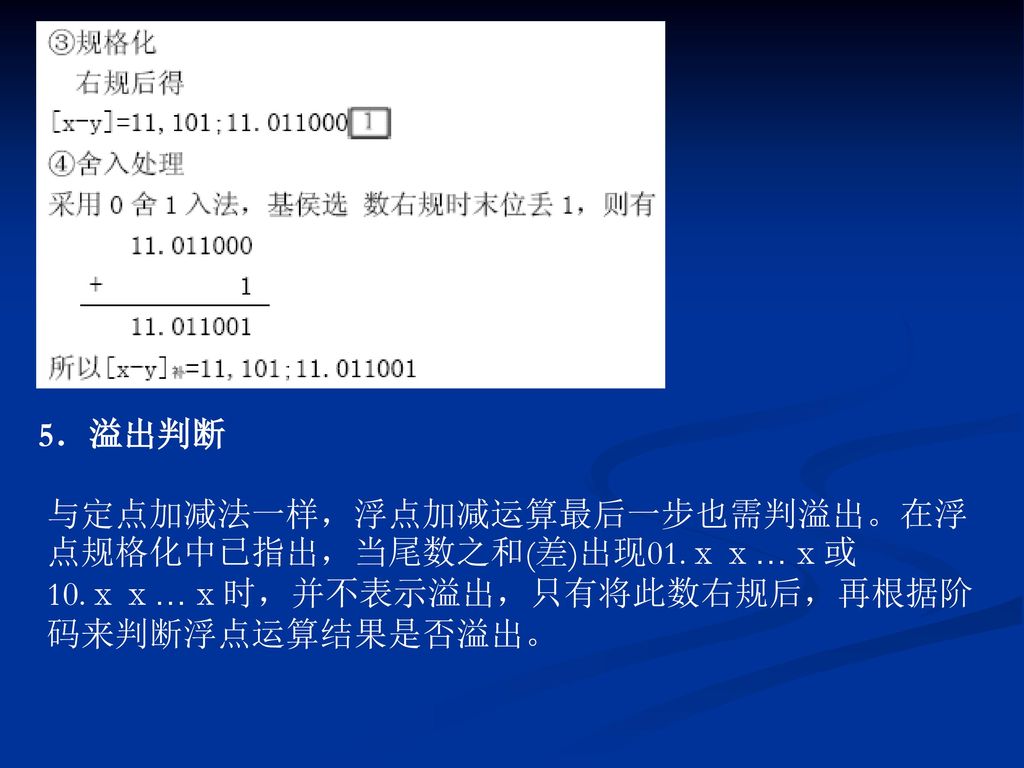
5.溢出判断 与定点加减法一样,浮点加减运算最后一步也需判溢出。在浮点规格化中已指出,当尾数之和(差)出现01.ⅹⅹ…ⅹ或10.ⅹⅹ…ⅹ时,并不表示溢出,只有将此数右规后,再根据阶码来判断浮点运算结果是否溢出。
出现01.ⅹⅹ…ⅹ或10.ⅹⅹ…ⅹ时,并不表示溢出,只有将此数右规后,再根据阶码来判断浮点运算结果是否溢出。")
80
2.4.2浮点乘除法运算

81
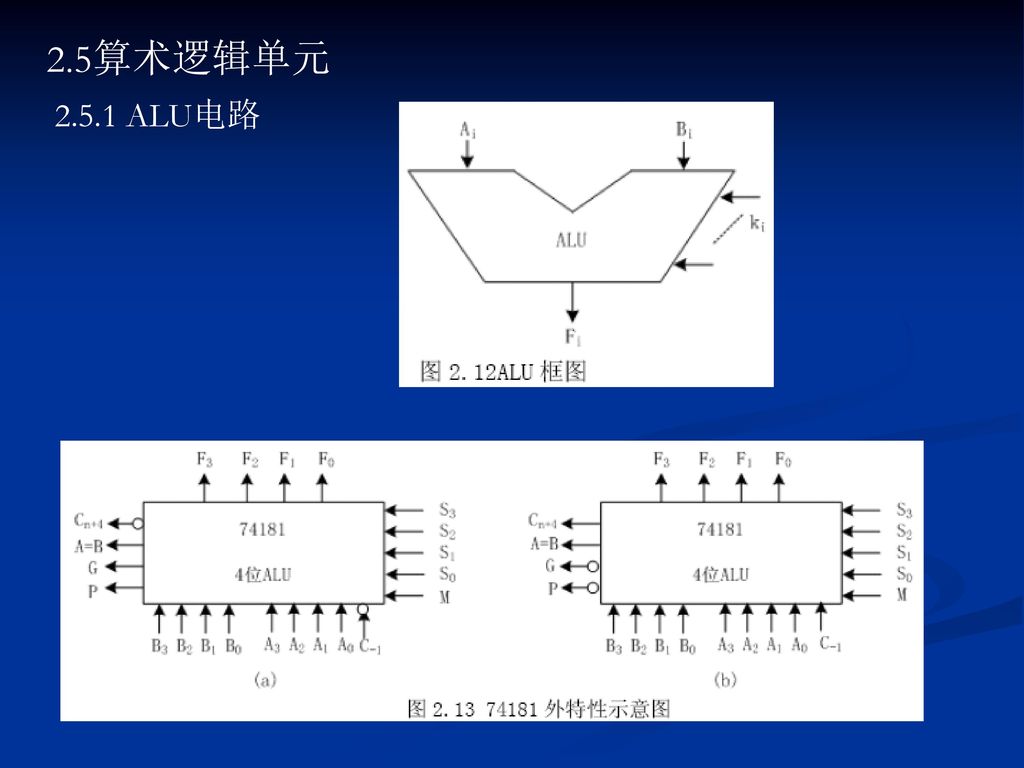
2.5算术逻辑单元 2.5.1 ALU电路

83
2.5.2快速进位链 1.并行加法器

84
2.串行进位链

85
3.并行进位链

86
(1)单重分组跳跃进位就是将n位全加器分成若干小组,小组内的进位同时产生,小组与小组之间采用串行进位,这种进位又有组内并行、组间串行之称。
单重分组跳跃进位就是将n位全加器分成若干小组,小组内的进位同时产生,小组与小组之间采用串行进位,这种进位又有组内并行、组间串行之称。")
87
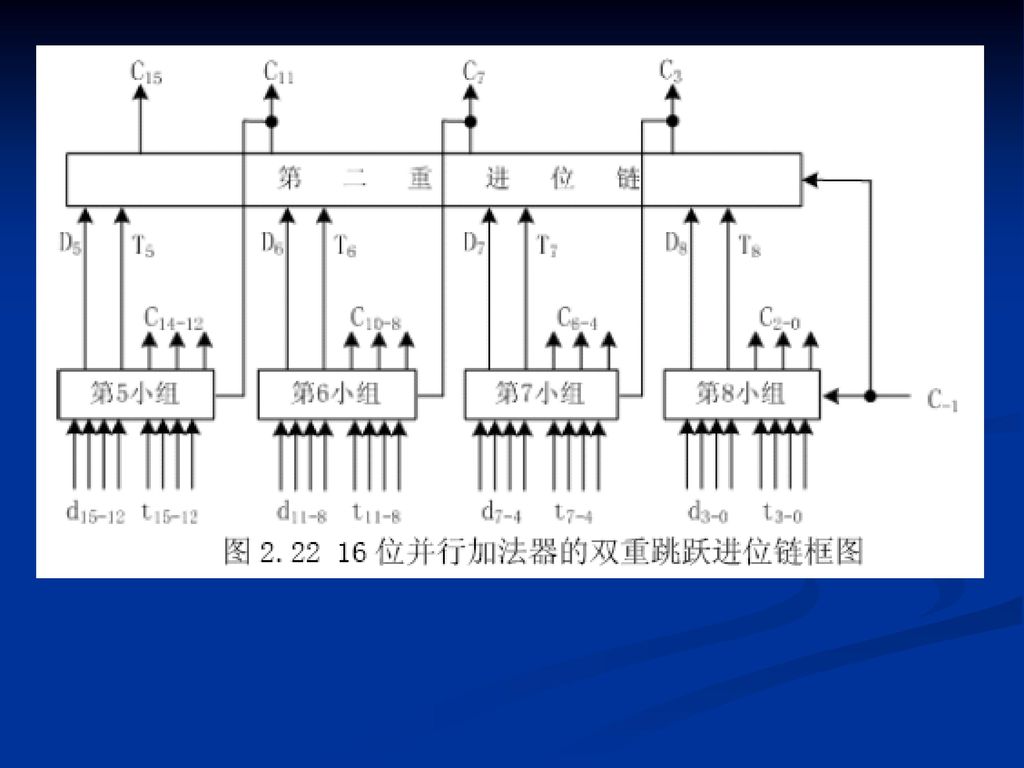
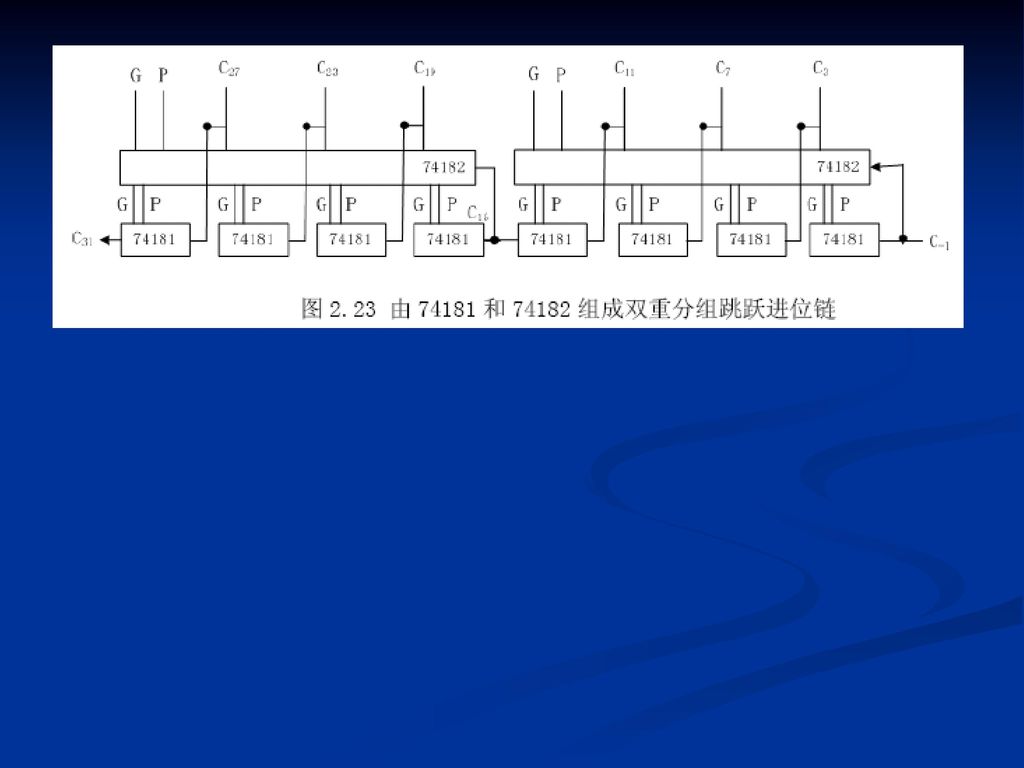
(2)双重分组跳跃进位
双重分组跳跃进位")
93
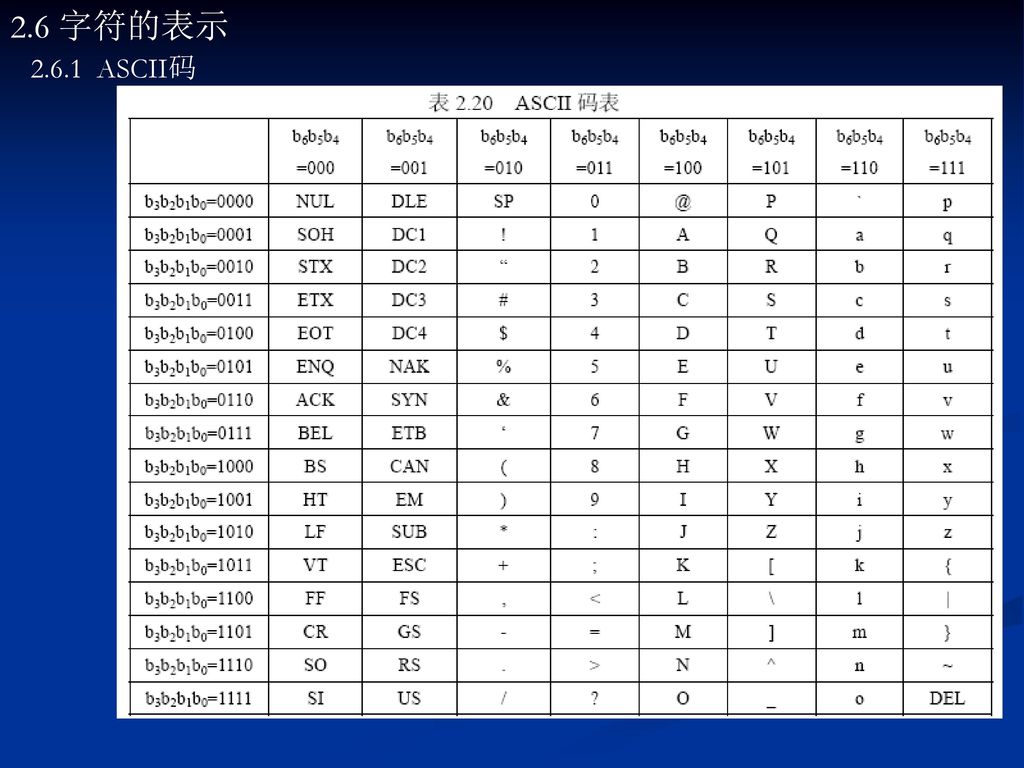
2.6 字符的表示 ASCII码

94
UNICODE编码 UNICODE使任何语言的字符都可以为机器更容易的接受,UNICODE由UC(UNICODE协会)管理并接受其技术上的修改。 UNICODE有双重含义。首先UNICODE是对国际标准ISO/IEC10646编码的一种称谓(ISO/IEC10646是一个国际标准。亦称大字符集。它是ISO于1993年颁布的一项重要国际标准。其宗旨是全球所有文种统一编码)。另外它又是由美国的HP、Microsoft、IBM、Apple等大企业组成的联盟集团的名称。成立该集团的宗旨就是要推进多文种的统一编码。
。另外它又是由美国的HP、Microsoft、IBM、Apple等大企业组成的联盟集团的名称。成立该集团的宗旨就是要推进多文种的统一编码。")
95
2.6.3 汉字编码简介 1.汉字的输入码 2.字符集与汉字内码
汉字编码简介 1.汉字的输入码 2.字符集与汉字内码 汉字通过输入码从键盘或通过语音识别从麦克风或通过联机手写或印刷体文字扫描输入等各种手段被输入到计算机内部后,就按照一种称为“内码”的编码形式在系统中进行存储、查找、传送等处理。对于西文字符数据,它的内码就是ASCII码。对于汉字内码的选择,我们必须考虑以下几个因素:(1)不能有二义性,即不能和ASCII码有相同的编码。(2)要与汉字在字库中的位置有关系,以便于汉字的处理、查找。(3)编码应尽量短。 1981年我国颁布了《信息交换用汉字编码字符集·基本集》(GB2312—80)。该标准选出6763个常用汉字
不能有二义性,即不能和ASCII码有相同的编码。(2)要与汉字在字库中的位置有关系,以便于汉字的处理、查找。(3)编码应尽量短。 1981年我国颁布了《信息交换用汉字编码字符集·基本集》(GB2312—80)。该标准选出6763个常用汉字.")
96
随着亚洲地区计算机应用的普及与深入,汉字字符集及其编码还在发展。国际标准ISO/IEC 10646提出了一种包括全世界现代书面语言文字所使用的所有字符的标准编码,每个字符用4个字节(称为UCS-4)或2个字节(称为UCS-2)来编码。我国(包括香港、台湾地区)与日本、韩国联合制订了一个统一的汉字字符集(CJK编码),共收集了上述不同国家和地区的共约2万多汉字及符号,采用2字节(即:UCS-2)编码,现已被批准为国家标准(GB13000 )。美国微软公司在Windows 95和Windows NT操作系统(中文版)中也已采用了中西文统一编码,收集了中、日、韩三国常用的约2万汉字,称为“Unicode”(2字节编码),它与ISO/IEC 10646的UCS-2编码一致。
或2个字节(称为UCS-2)来编码。我国(包括香港、台湾地区)与日本、韩国联合制订了一个统一的汉字字符集(CJK编码),共收集了上述不同国家和地区的共约2万多汉字及符号,采用2字节(即:UCS-2)编码,现已被批准为国家标准(GB13000 )。美国微软公司在Windows 95和Windows NT操作系统(中文版)中也已采用了中西文统一编码,收集了中、日、韩三国常用的约2万汉字,称为 Unicode (2字节编码),它与ISO/IEC 10646的UCS-2编码一致。")
97
3.汉字的字模点阵码和轮廓描述 经过计算机处理后的汉字,如果需要在屏幕上显示出来或用打印机打印出来,则必须把汉字机内码转换成人们可以阅读的方块字形式,若输出内码,那谁都很难看懂。 每一个汉字的字形都必须预先存放在计算机内,一套汉字(例如GB2312国标汉字字符集)的所有字符的形状描述信息集合在一起称为字形信息库,简称字库(font)。不同的字体(如宋体、仿宋、楷体、黑体等)对应着不同的字库。在输出每一个汉字的时侯,计算机都要先到字库中去找到它的字形描述信息,然后把字形信息送到相应的设备输出。
的所有字符的形状描述信息集合在一起称为字形信息库,简称字库(font)。不同的字体(如宋体、仿宋、楷体、黑体等)对应着不同的字库。在输出每一个汉字的时侯,计算机都要先到字库中去找到它的字形描述信息,然后把字形信息送到相应的设备输出。")
98
2.7 指令信息的表示 指令格式

100
5.指令长度 (1)指令长度应为存储器基本字长的整数倍 (2)指令字长应尽量短 常用寻址方式
指令长度应为存储器基本字长的整数倍 (2)指令字长应尽量短 常用寻址方式")
104
7.相对寻址 8.基址寻址 9.隐含寻址方式 10.其它寻址方式

105
指令类型 指令种类及功能请见第四章

106
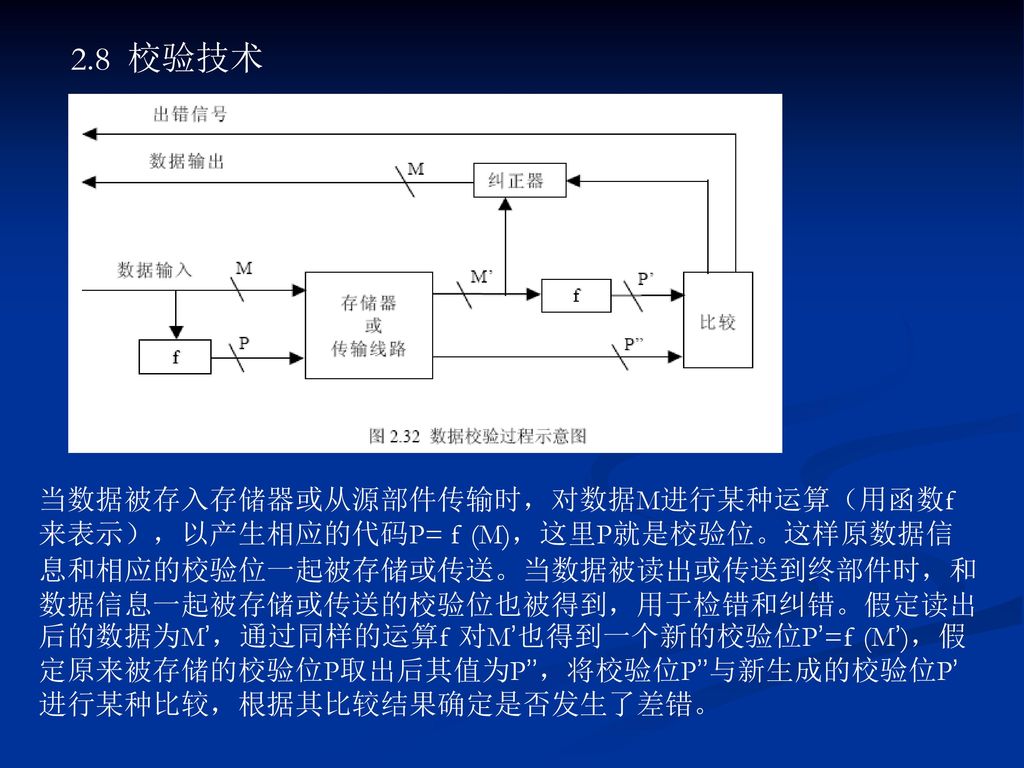
2.8 校验技术 当数据被存入存储器或从源部件传输时,对数据M进行某种运算(用函数f 来表示),以产生相应的代码P= f (M),这里P就是校验位。这样原数据信息和相应的校验位一起被存储或传送。当数据被读出或传送到终部件时,和数据信息一起被存储或传送的校验位也被得到,用于检错和纠错。假定读出后的数据为M’,通过同样的运算f 对M’也得到一个新的校验位P’=f (M’),假定原来被存储的校验位P取出后其值为P’’,将校验位P’’与新生成的校验位P’进行某种比较,根据其比较结果确定是否发生了差错。
,以产生相应的代码P= f (M),这里P就是校验位。这样原数据信息和相应的校验位一起被存储或传送。当数据被读出或传送到终部件时,和数据信息一起被存储或传送的校验位也被得到,用于检错和纠错。假定读出后的数据为M’,通过同样的运算f 对M’也得到一个新的校验位P’=f (M’),假定原来被存储的校验位P取出后其值为P’’,将校验位P’’与新生成的校验位P’进行某种比较,根据其比较结果确定是否发生了差错。")
108
奇偶校验码

110
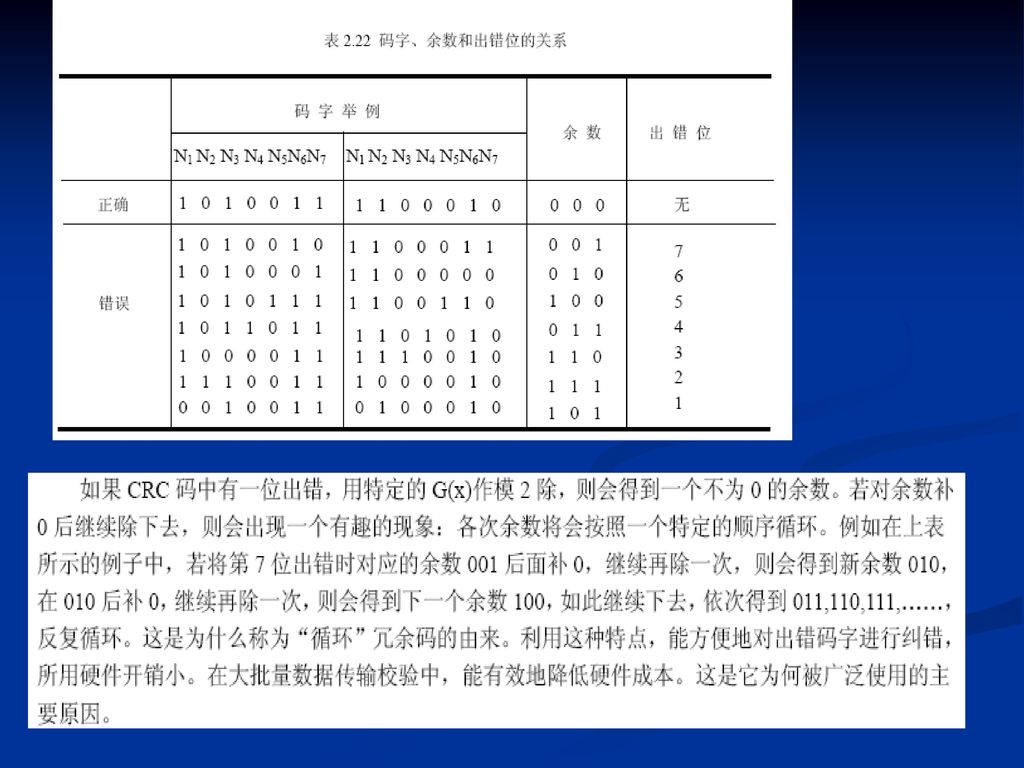
循环冗余校验码 循环冗余校验码(Cyclic Redundancy Check),简称CRC码,是一种具有很强检错、纠错能力的校验码。循环冗余校验码常用于外存储器的数据校验,在计算机通信中,也被广泛采用。
,简称CRC码,是一种具有很强检错、纠错能力的校验码。循环冗余校验码常用于外存储器的数据校验,在计算机通信中,也被广泛采用。 .")
116
本章重点关注的内容: 2.1 无符号数和有符号数 2.2 数的定点表示和浮点表示 2.3 定点运算 2.4 浮点四则运算 2.5算术逻辑单元
2.2 数的定点表示和浮点表示 2.3 定点运算 2.4 浮点四则运算 2.5算术逻辑单元 2.6 字符的表示 2.7 指令信息的表示 2.8 校验技术

Similar presentations

































102 年 1 月 30 日公告施行營業秘密法 ( 一 )102 年 1 月 30 日公告施行營業秘密法 修正案,增加侵害營業秘密之刑事 修正案,增加侵害營業秘密之刑事 責任,對於意圖在境外使用而竊取 責任,對於意圖在境外使用而竊取.>")
 部分申报表的公告(国家税务总局公告 2016 年第 3 号) 一、对《企业基础信息表》( A000000 )及填报说明修改如下: (一) “107 从事国家非限制和禁止行业 ” 修改为 “107 从事国家限制或禁止行业 ”>")
 4. 人事测量的分类及工具 5. 人事测量的实际应用 内 容.>")
 及稅務問題 講師 : 蘇炳章 日期 : 92 年 8 月 12 日.>")
 辅导材料(二) A000000 企业基础信息 A100000 主表.>")

。 二、本系於新生入學二個月內,針對新生辦理「選課輔導說明會」,內容.>")










以外都属于施工机械使用费。 A.购置费 B.安拆费及场外运费 C.折旧费 D.修理费.>")

