Download presentation
Presentation is loading. Please wait.

1
树和二叉树(四)
")
2
内容回顾 树的存储方式 孩子兄弟表示法 树与二叉树的转换 树转二叉树 二叉树还原为树

3
本节内容 1 哈夫曼树的相关概念 2.哈夫曼树的构造算法 3.判定树 (哈夫曼树的应用之一) 4.哈夫曼编码(哈夫曼树的应用之二)
5.建立哈夫曼树及求哈夫曼编码的算法

4
1 哈夫曼树的相关概念 A B C D E F G 1)路径和路径长度 若一棵树中存在一个结点序列k1,k2,…,kj,使得ki是kj的双亲(0<i<j),则称此结点序列是从ki~ kj的路径。从k1~kj所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1。
路径和路径长度 若一棵树中存在一个结点序列k1,k2,…,kj,使得ki是kj的双亲(0<i<j),则称此结点序列是从ki~ kj的路径。从k1~kj所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1。")
5
2)结点的权和带权路径长度 例:结点c的路径长度为2,其WPL=2*9=18
a c b d 7 3 9 8

6
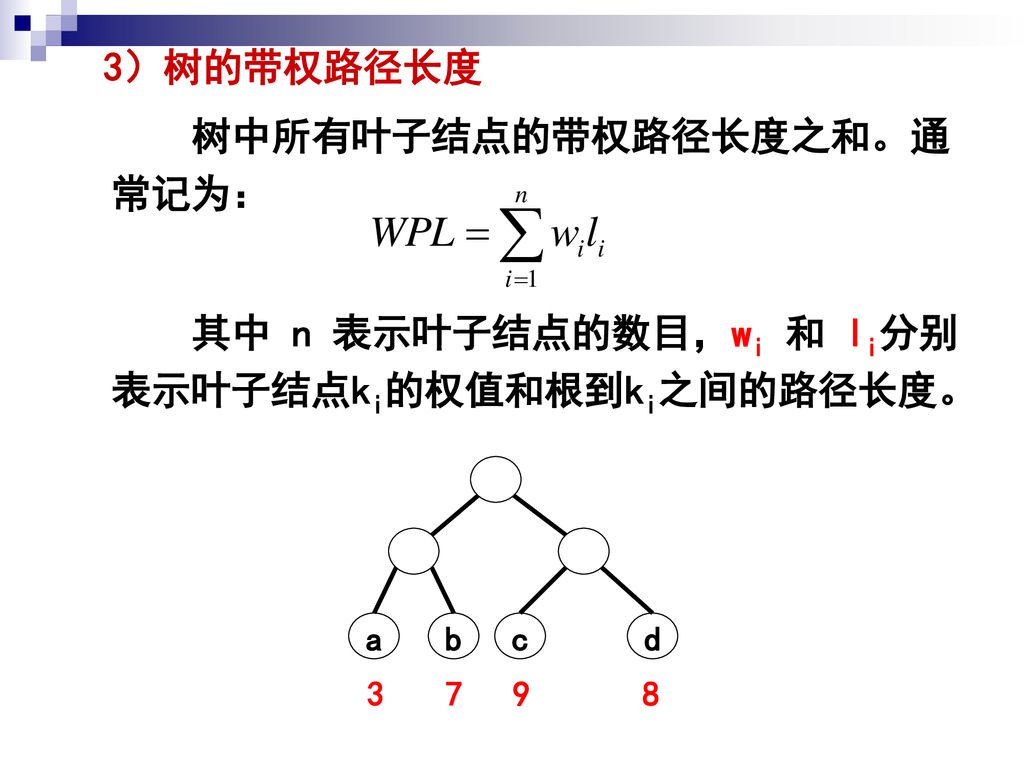
3)树的带权路径长度 树中所有叶子结点的带权路径长度之和。通常记为: 其中 n 表示叶子结点的数目,wi 和 li分别表示叶子结点ki的权值和根到ki之间的路径长度。 a c b d 7 3 9 8
7
4)哈夫曼(Huffman)树 又称最优二叉树。它是 n 个带权叶子结点构成的所有二叉树中,带权路径长度WPL最小的二叉树。
例:有四个叶子结点a,b,c,d,分别带权为9、4、5、2,由它们构成三棵不同的二叉树。

8
a b c a) WPL=9×2 +4×2+5×2+2×2=40 b) WPL=4×1+2×2+5×3+9×3=50
d 4 9 5 2 b c d a 4 9 5 2 a b c d 9 2 4 5 a b c a) WPL=9×2 +4×2+5×2+2×2=40 b) WPL=4×1+2×2+5×3+9×3=50 c) WPL=9×1+5×2+4×3+2×3=37 Huffman树
 WPL=9×2 +4×2+5×2+2×2=40. b) WPL=4×1+2×2+5×3+9×3=50. c) WPL=9×1+5×2+4×3+2×3=37. Huffman树.")
9
3) 从F中删去这两棵树,同时加入刚生成的新树; 4) 重复(2)和(3)两步,直至F中只含一棵树为止。
2.哈夫曼树的构造算法 构造Huffman树的基本思想: 权值大的结点用短路径,权值小的结点用长路径。 构造Huffman树的步骤(即Huffman算法): 1)根据给定的n个权值{w1, w2, …, wn},构造 n棵二叉树的集合 F = {T1, T2, …,Tn},其中每棵二叉树中均只含一个带权值为wi的根结点,其左、右子树为空树; 2) 在F中选取其根结点的权值为最小的两棵二叉树,分别作为左、右子树构造一棵新的二叉树,并置这棵新的二叉树根结点的权值为其左、右子树根结点的权值之和; 3) 从F中删去这两棵树,同时加入刚生成的新树; 4) 重复(2)和(3)两步,直至F中只含一棵树为止。
: 1)根据给定的n个权值{w1, w2, …, wn},构造 n棵二叉树的集合 F = {T1, T2, …,Tn},其中每棵二叉树中均只含一个带权值为wi的根结点,其左、右子树为空树; 2) 在F中选取其根结点的权值为最小的两棵二叉树,分别作为左、右子树构造一棵新的二叉树,并置这棵新的二叉树根结点的权值为其左、右子树根结点的权值之和; 3) 从F中删去这两棵树,同时加入刚生成的新树; 4) 重复(2)和(3)两步,直至F中只含一棵树为止。")
10
第一步: 第二步: 第三步: 第四步: 注:方框表示外结点(叶子) 圆框表示内结点(合并后的结点)。 a b c d 9 2 5 4 a c
6 第二步: a b c d 9 2 4 5 第三步: 6 11 第四步: a 9 b c d 2 4 5 6 11 20 注:方框表示外结点(叶子) 圆框表示内结点(合并后的结点)。
 圆框表示内结点(合并后的结点)。")
11
3.判定树 (哈夫曼树的应用之一) 在解决某些判定问题时,利用哈夫曼树可以得到最佳判定算法。 例:编制一将学生百分成绩按分数段分级的程序。
若学生成绩分布是 均匀的,可用图(a) 二叉树结构来实现。 a<60 a<70 a<80 a<90 不及格 中等 良好 优秀 及格 Y N (a)
 二叉树结构来实现。 a<60. a<70. a<80. a<90. 不及格. 中等. 良好. 优秀. 及格. Y. N. (a)")
12
学生成绩分布不是均匀的情况: 输入10000个数据,则需进行31500次比较。 分数 0—59 60—69 70—79 80—89
90—99 比例 0.05 0.15 0.4 0.3 0.1 a<60 a<70 a<80 a<90 不及格 中等 良好 优秀 及格 Y N (a) 输入10000个数据,则需进行31500次比较。 500*1+1500*2+4000*3+3000*4+1000*4=31500
 输入10000个数据,则需进行31500次比较。 500*1+1500*2+4000*3+3000*4+1000*4=")
13
有没有一种更好的办法来减少比较次数呢?

14
以比例数为权构造一棵哈夫曼树,如(b)判断树所示。
分数 0—59 60—69 70—79 80—89 90—99 比例 0.05 0.15 0.4 0.3 0.1 70≤a<80 a<60 及格 中等 良好 80≤a<90 60≤a<70 不及格 优秀 Y N 以比例数为权构造一棵哈夫曼树,如(b)判断树所示。 再将每一比较框的两次比较改为一次,可得到(c)判定树。 输入10000个数据,仅需进行22000次比较。 不及格 Y a<90 a<80 a<70 a<60 优秀 中等 及格 良好 N (c) (b)
判断树所示。 再将每一比较框的两次比较改为一次,可得到(c)判定树。 输入10000个数据,仅需进行22000次比较。 不及格. Y. a<90. a<80. a<70. a<60. 优秀. 中等. 及格. 良好. N. (c) (b)")
15
4.哈夫曼编码(哈夫曼树的应用之二) 二进制编码 通信中,可以采用0、1的不同排列来表示不同的字符,称为二进制编码。 发送端需要将电文中的字符序列转换成二进制的0、1序列,即编码; 接受端需要把接受的0、1序列转换成对应的字符序列,即译码。
 二进制编码 通信中,可以采用0、1的不同排列来表示不同的字符,称为二进制编码。 发送端需要将电文中的字符序列转换成二进制的0、1序列,即编码; 接受端需要把接受的0、1序列转换成对应的字符序列,即译码。")
16
ABACCDA 字符的两种不同的编码方案 字符 编码 字符 编码 A 000 A 00 B 010 B 01 C 100 C 10
(1) 等长编码 ABACCDA 字符的两种不同的编码方案 字符 编码 字符 编码 A A B B C C D D (a) (b) (a)电文的代码为 ,长度为21 (b)代码为 ,长度为14
 等长编码. ABACCDA. 字符的两种不同的编码方案. 字符 编码 字符 编码. A 000 A 00. B 010 B 01. C 100 C 10. D 111 D 11. (a) (b) (a)电文的代码为 ,长度为21. (b)代码为 ,长度为14.")
17
ABACCDA 字符 编码 A 0 B 00 C 1 D 01 (2) 不等长编码
(2) 不等长编码 ABACCDA 字符 编码 A B C D 电文用二进制序列: 发送,其长度只有9个二进制位
 不等长编码. ABACCDA. 字符 编码. A 0. B 00. C 1. D 01. 电文用二进制序列: 发送,其长度只有9个二进制位.")
18
哈夫曼树编码 例:要传输的电文是{CAS;CAT;SAT;AT} 要传输的字符集是 D={C,A,S,T, ;}
每个字符出现的频率是W={ 2,4, 2,3, 3 } 方法: (1)用{ 2,4, 2,3, 3 }作为叶子结点的权值生成一棵哈夫曼树,并将对应权值wi的叶子结点注明对应的字符; (2)约定左分支表示字符“0”,右分支表示字符‘1’ (3)从根结点到叶子结点的路径上的‘0’或‘1’连接的序列就是结点对应的字符的二进制编码。 各字符编码是 T ; A C S 上述电文编码: 14 6 8 3 4 2 1 T ; A C S 例2:哈夫曼树用于电文编码 要传输的电文是{CAS;CAT;SAT;AT} 要传输的字符集是 D={C,A,S,T, ;} 每个字符出现的频率是W={ 2,4, 2,3, 3 } 以带权字符为叶子结点建立哈夫曼树,得到各字符编码是 T ; A C S 00 上述电文编码: 其总长度为32,恰好等于哈夫曼树的带权路径长。可见哈夫曼编码是使电文具有最短长度的二进制编码。 注意:编码的总长度恰好为哈夫曼树的带权路径长。
用{ 2,4, 2,3, 3 }作为叶子结点的权值生成一棵哈夫曼树,并将对应权值wi的叶子结点注明对应的字符; (2)约定左分支表示字符 0 ,右分支表示字符‘1’ (3)从根结点到叶子结点的路径上的‘0’或‘1’连接的序列就是结点对应的字符的二进制编码。 各字符编码是 T ; A C S 上述电文编码: T. ; A. C. S. 例2:哈夫曼树用于电文编码. 要传输的电文是{CAS;CAT;SAT;AT} 要传输的字符集是 D={C,A,S,T, ;} 每个字符出现的频率是W={ 2,4, 2,3, 3 } 以带权字符为叶子结点建立哈夫曼树,得到各字符编码是. T ; A C S 上述电文编码: 其总长度为32,恰好等于哈夫曼树的带权路径长。可见哈夫曼编码是使电文具有最短长度的二进制编码。 注意:编码的总长度恰好为哈夫曼树的带权路径长。")
19
5.建立哈夫曼树及求哈夫曼编码的算法 哈夫曼树没有度为1的结点,则一棵有n个叶子结点的哈夫曼树共有2n-1个结点,可以存储在一个大小为2n-1的一维数组中。 由于在构造哈夫曼树之后,为求编码需从叶子结点出发走一条从叶子到根的路径;而为译码需从根出发走一条从根到叶子的路径。所以,每个结点既需知道双亲的信息,又需知道孩子结点的信息。 typedef struct { unsigned int weight; unsigned int parent,lchild,rchild; } HTNode, *HuffmanTree; //动态分配数组存储哈夫曼树 typedef char **HuffmanCode;

20
//存放树的叶子结点,n-1个单元存放内部结点 for (p=HT, i=1; i<=n; ++i,++p,++w)
void HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int *w, int n) {//w存放n个字符的权值,构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC if (n<=1) return; // n为字符数目, m=2*n-1; // m为结点数目 HT = (HuffmanTree)malloc((m+1)*sizeof(HTNode)); //HT存放Huffman树结构,0号单元未用,其余前n个单元 //存放树的叶子结点,n-1个单元存放内部结点 for (p=HT, i=1; i<=n; ++i,++p,++w) { p->weight = *w; p->parent=0; p->lchild=0; p->rchild=0; } // *p={*w,0,0,0};初始化HT中的叶结点循环退出时i=n+1;
 {//w存放n个字符的权值,构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC. if (n<=1) return; // n为字符数目, m=2*n-1; // m为结点数目. HT = (HuffmanTree)malloc((m+1)*sizeof(HTNode)); //HT存放Huffman树结构,0号单元未用,其余前n个单元. //存放树的叶子结点,n-1个单元存放内部结点. for (p=HT, i=1; i<=n; ++i,++p,++w) { p->weight = *w; p->parent=0; p->lchild=0; p->rchild=0; } // *p={*w,0,0,0};初始化HT中的叶结点循环退出时i=n+1;")
21
for (; i<=m;++i,++p)
{ p->weight = 0; p->parent=0; p->lchild=0; p->rchild=0; } // *p={0,0,0,0}; 初始化HT中的内部结点 for (i=n+1; i<=m;++i) // 建哈夫曼树,(建立HT链表中的链) { Select(HT,i-1,s1,s2);//在HT[1~i-1]中选择parent // 为0且weight最小的两个结点,序号分别为s1和s2 HT[s1].parent=i; HT[s2].parent = i; HT[i].lchild = s1; HT[i].rchild = s2; HT[i].weight = HT[s1].weight + HT[s2].weight; }
 // 建哈夫曼树,(建立HT链表中的链) { Select(HT,i-1,s1,s2);//在HT[1~i-1]中选择parent. // 为0且weight最小的两个结点,序号分别为s1和s2. HT[s1].parent=i; HT[s2].parent = i; HT[i].lchild = s1; HT[i].rchild = s2; HT[i].weight = HT[s1].weight + HT[s2].weight; }")
22
//从叶子到根逆向求哈夫曼编码 HC= (HuffmanCode)malloc((n+1)*sizeof(char *)); cd = (char *)malloc( n * sizeof(char) ); cd[n-1]=‘\0’; //编码结束符 for (i=1;i<=n;++i) //逐个字符求哈夫曼编码 { start = n-1; //编码结束符位置 for (c=i,f=HT[c].parent; f!=0; c=f,f=HT[f].parent) //从叶子到根逆向求编码 if (HT[f].lchild ==c) cd[--start]='0'; else cd[--start]='1'; HC[i]=(char *)malloc((n-start)*sizeof(char)); strcpy(HC[i],&cd[start]); //从cd复制编码串到HC printf("%s\n",HC[i]); } free(cd); //释放工作空间 } //HuffanCoding
 //逐个字符求哈夫曼编码. { start = n-1; //编码结束符位置. for (c=i,f=HT[c].parent; f!=0; c=f,f=HT[f].parent) //从叶子到根逆向求编码. if (HT[f].lchild ==c) cd[--start]= 0 ; else cd[--start]= 1 ; HC[i]=(char *)malloc((n-start)*sizeof(char)); strcpy(HC[i],&cd[start]); //从cd复制编码串到HC. printf( %s\n ,HC[i]); } free(cd); //释放工作空间. } //HuffanCoding.")
23
例: 已知某系统在通信联络中只可能出现八种字符,其概率分别为0. 05,0. 29,0. 07,0. 08,0. 14,0. 23,0
例: 已知某系统在通信联络中只可能出现八种字符,其概率分别为0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,试设计Huffman编码。 设权w=(5,29,7,8,14,23,3,11),n=8,则m=15 存储结构的初始状态为: 11 3 23 14 8 7 29 5 weight parent lchild rchild 1 2 4 6 9 10 12 13 15 14 13 100 12 2 0(15) 58 11 6 42 10 5 0(14) 29 9 8 0(13) 19 × 4 3 0(12) 15 × 7 1 0(11) 8 × 11 × 0(9) 3 × 23 × 14 × 0(10) 7 × 5× weight parent lchild rchild 15
,n=8,则m=15 存储结构的初始状态为: weight. parent. lchild. rchild (15) (14) (13) 19 × (12) 15 × (11) 8 × 11 × 0(9) 3 × 23 × 14 × 0(10) 7 × 5× weight. parent. lchild. rchild. 15.")
24
HC 1 2 3 4 5 6 7 8 1 0 0 0 1 1 1 23 29 1 1 11 14 1 1 5 3 7 8 cd \0

25
小结:哈夫曼树及其应用 1.Huffman算法的思路: —权值大的结点用短路径,权值小的结点用长路径。

26
本章小结 1、定义和性质 2、存储结构 3、遍历 树 顺序结构 链式结构 森林 先序遍历 中序遍历 后序遍历 哈夫曼树 哈夫曼编码 二叉链表
三叉链表 森林 二叉树 中序遍历 后序遍历 先序遍历 3、遍历 哈夫曼树 哈夫曼编码

27
作业 1. 以数据集{4,5,6,7,10,12,18}为结点权值,画出Huffman树,并计算其带权路径长度。

Similar presentations




 主要内容: 第三部分:树、二叉树、森林.>")





.>")
>")







