Introduction to MapReduce Jazz Wang Yao-Tsung Wang jazz@nchc.org.tw
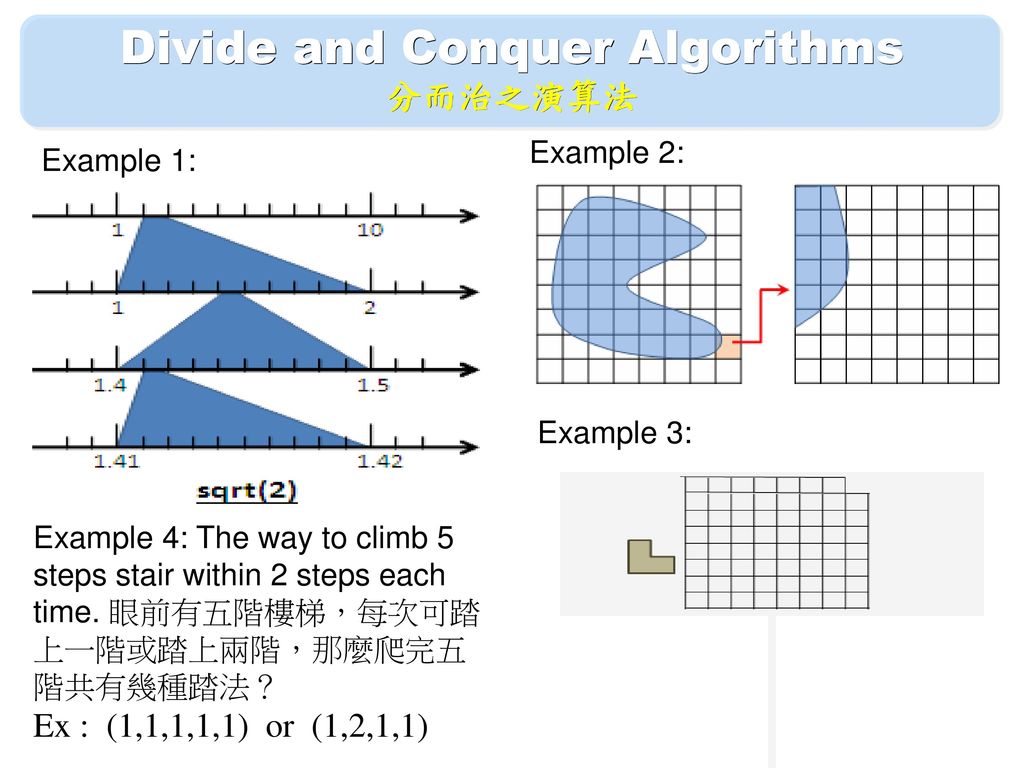
Divide and Conquer Algorithms 分而治之演算法 Example 2: Example 1: Example 3: Example 4: The way to climb 5 steps stair within 2 steps each time. 眼前有五階樓梯,每次可踏上一階或踏上兩階,那麼爬完五階共有幾種踏法? Ex : (1,1,1,1,1) or (1,2,1,1) 2 2
What is MapReduce ?? 什麼是MapReduce ?? MapReduce是Google申請的軟體專利,主要用來處理大量資料 MapReduce is a patented software framework introduced by Google to support distributed computing on large data sets on clusters of computers. 啟發自函數編程中常用的map與reduce函數。 The framework is inspired by map and reduce functions commonly used in functional programming, although their purpose in the MapReduce framework is not the same as their original forms Map(...) : N → N Ex. [ 1,2,3,4 ] – (*2) -> [ 2,4,6,8 ] Reduce(...): N → 1 [ 1,2,3,4 ] - (sum) -> 10 Logical view of MapReduce Map(k1,v1) -> list(k2,v2) Reduce(k2, list (v2)) -> list(v3) Source: http://en.wikipedia.org/wiki/MapReduce
Google's MapReduce Diagram Google的MapReduce圖解 4 4
Google's MapReduce in Parallel Google的MapReduce平行版圖解 5 5
How does MapReduce work in Hadoop Hadoop MapReduce 運作流程 JobTracker選數個TaskTracker來作Map運算,產生些中間檔案 split 0 split 1 split 2 input HDFS JobTracker跟NameNode取得需要運算的blocks part0 part1 output HDFS reduce完後通知JobTracker與Namenode以產生output sort/copy JobTracker將中間檔案整合排序後,複製到需要的TaskTracker去 merge reduce JobTracker派遣TaskTracker作reduce 6 6
MapReduce by Example (1) MapReduce 運作實例 (1) I am a tiger, you are also a tiger a,2 also,1 am,1 are,1 I,1 tiger,2 you,1 reduce JobTracker再選一個TaskTracker作reduce I am a tiger you are also JobTracker先選了三個Tracker做map map I,1 you,1 tiger,1 a,1 also,1 are,1 am,1 sort & shuffle Map結束後,hadoop進行中間資料的重組與排序 I,1 you (1) tiger(1,1) a (1,1) also (1) are (1) am,1 7
MapReduce by Example (2) MapReduce 運作實例 (2) 1.0 0.0 3.0 3.2 0.8 32.0 1.0 14.0 1.0 a b c d sqrt(a + b) sqrt(c + d) ? (0,sqrt(1.0 + 0.0 + 3.0)) (1,sqrt(3.2 + 0.8 + 32.0)) (2,sqrt(1.0 + 14.0 + 1.0)) Input File 0 0 1.0 // A[0][1] = 1.0 0 1 0.0 // A[0][1] = 0.0 0 2 3.0 // A[0][2] = 3.0 1 0 3.2 // A[1][0] = 3.2 1 1 0.8 // A[1][1] = 0.8 1 2 32.0 // A[1][2] = 32.0 2 0 1.0 // A[2][0] = 1.0 2 1 14.0 // A[2][1] = 14.0 2 2 1.0 // A[2][2] = 1.0 ` (0,1.0) (0,0.0) (0,3.0) (1,3.2) (1,0.8) (1,32.0) (2,1.0) (2,14.0) reduce map sort / merge (0,{1.0,0.0,3.0}) (1,{3.2,0.8,32.0}) (2,{1.0,14.0,1.0}) map 8
MapReduce is suitable to .... MapReduce 合適用於 .... 大規模資料集 Large Data Set 可拆解 Parallelization Text tokenization Indexing and Search Data mining machine learning … http://www.dbms2.com/2008/08/26/known-applications-of-mapreduce/ http://wiki.apache.org/hadoop/PoweredBy 9
MapReduce程式設計入門 Jazz Wang Yao-Tsung Wang jazz@nchc.org.tw MapReduce Programing 101 Jazz Wang Yao-Tsung Wang jazz@nchc.org.tw
Other configure 其他的設定參數程式碼 Program Prototype (v 0.20) Class MR{ static public Class Mapper …{ } static public Class Reducer …{ main(){ Configuration conf = new Configuration(); Job job = new Job(conf, “job name"); job.setJarByClass(thisMainClass.class); job.setMapperClass(Mapper.class); job.setReduceClass(Reducer.class); FileInputFormat.addInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }} Mapper 程式碼 Map 區 Reducer 程式碼 Reduce 區 設 定 區 Other configure 其他的設定參數程式碼 11
Other configure 其他的設定參數程式碼 Program Prototype (v 0.18) Class MR{ static public Class Mapper …{ } static public Class Reducer …{ main(){ JobConf conf = new JobConf( MR.class ); conf.setMapperClass(Mapper.class); conf.setReduceClass(Reducer.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); }} Map 區 Map 程式碼 Reduce 區 Reduce 程式碼 設 定 區 Other configure 其他的設定參數程式碼 12
Word Count - mapper itr itr itr itr itr itr itr class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map( LongWritable key, Text value, Context context) throws IOException , InterruptedException { String line = ((Text) value).toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); }}} 1 2 3 4 5 6 7 8 9 Input key <word,one> …………………. ………………… No news is a good news. /user/hadooper/input/a.txt < no , 1 > no news is good a < news , 1 > itr itr itr itr itr itr itr < is , 1 > Input value line < a, 1 > < good , 1 > < news, 1 > 13
Word Count - reducer news 1 1 class MyReducer extends Reducer< Text, IntWritable, Text, IntWritable> { IntWritable result = new IntWritable(); public void reduce( Text key, Iterable <IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for ( IntWritable val : values ) sum += val.get(); result.set(sum); context.write ( key, result); }} 1 2 3 4 5 6 7 8 for ( int i ; i < values.length ; i ++ ){ sum += values[i].get() } <word,one> < a, 1 > news < good, 1 > <key,SunValue> < is, 1 > 1 1 < news , 2 > < news, 11 > < no, 1 > 14
Word Count – main program Class WordCount{ main() Configuration conf = new Configuration(); Job job = new Job(conf, “job name” ); job.setJarByClass(thisMainClass.class); job.setMapperClass(MyMapper.class); job.setReduceClass(MyReducer.class); FileInputFormat.addInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); }} 15
Slides - http://trac.nchc.org.tw/cloud Questions? Slides - http://trac.nchc.org.tw/cloud Jazz Wang Yao-Tsung Wang jazz@nchc.org.tw