Minimum Spanning Trees
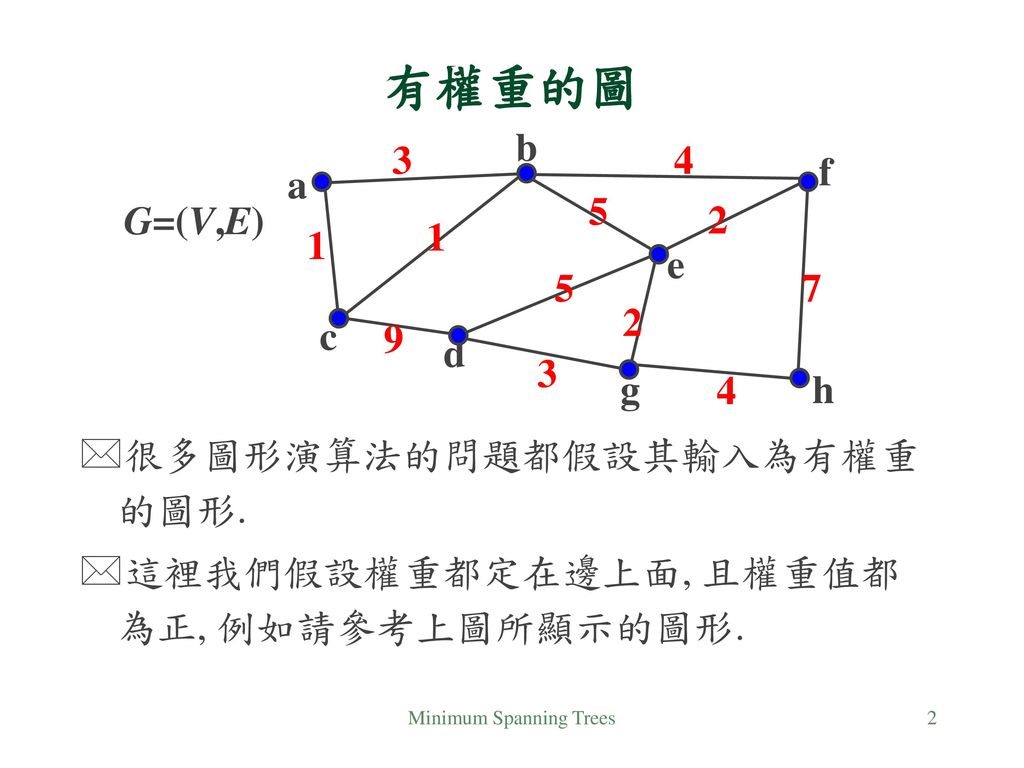
Minimum Spanning Trees 有權重的圖 a b c d e f g h 3 5 1 9 4 7 2 G=(V,E) 很多圖形演算法的問題都假設其輸入為有權重的圖形. 這裡我們假設權重都定在邊上面, 且權重值都為正, 例如請參考上圖所顯示的圖形. 相當多實際的問題可以模式成圖形理論問題,而這些圖形理論問題很多又都考慮在有權重的圖形上,例如最短路徑問題與本章要討論的 minimum spanning tree (MST) 問題。 在此我們假設給定的圖形在每一個邊上都有一權重,而且這些權重都大於 0。在很多應用問題上,例如電路、交通網路、電腦網路,邊的權重都代表建構此一連線的代價,因此權重都大於 0 的假設應該算合理。當然有時候有些問題會模式成一邊有負權重的圖形問題,這時原假設於正權重而設計出的演算法可能會不適用於此新的狀況,我們在後面會再討論這個問題。 一個邊有權重的無向圖可以用投影片所畫的圖形來表示,小圓圈代表頂點,線段代表邊,邊旁的數字代表其權重。 Minimum Spanning Trees
Minimum Spanning Trees (MST) Find the lowest-cost way to connect all of the points (the cost is the sum of weights of the selected edges). The solution must be a tree. (Why ?) A spanning tree : a subgraph that is a tree and connect all of the points. A graph may contains exponential number of spanning trees. (e.g. # spanning trees of a complete graph = nn-2.) MST 問題最早來自於要找一最省成本的方式,將所有的頂點連起來。通常給定的圖形一定本身要連通的,甚至就是完全圖(complete graph;指任何兩點間都有連線),邊的權重代表要將邊的兩端點建立一直接連線所需的代價。所謂將所有的頂點連起來,是指選一些邊使得這些邊與所有頂點形成原圖的一個連通子圖,而所需成本就是這些選定邊的權重和。 因我們假設邊的權重都是正的,因此解一定形成一棵樹。 若一圖的子樹包含原圖所有頂點,我們稱這種樹為 spanning tree。 因此這題就等價於要找一棵邊權重和最小之 spanning tree 即 MST。 一個圖所含的 spanning trees 個數可能為頂點數 n 的指數函數,因此暴力法不可行。 Minimum Spanning Trees
A High-Level Greedy Algorithm for MST while(T=(V,A) is not a spanning tree of G) { select a safe edge for A ; } The algorithm grows a MST one edge at a time and maintains that A is always a subset of some MST. An edge is safe if it can be safely added to without destroying the invariant. How to check that T is a spanning tree of G ? How to select a “safe edge” edge ? 有兩個有名的找 MST 的演算法,分別由 Kruskal 與 Prim 兩人設計出來。他們的演算法都被歸類於 greedy 演算法,而且其本概念可由本張投影片的 pseudo code 來顯示。 演算法每一次加一個邊進來,並保證加進來的邊為某一 MST 的部分集合,這樣的邊稱為 safe edge。 當然這 pseudo code 的層級相當高,還有幾個細節問題待解決。 第一個問題較容易解決,因為一 spanning tree 剛好有 |V|1 個邊,所以只要檢查選進來的邊數是否為 |V|1 即可。 如何保證加進來的邊為 safe edge 較為麻煩,而且兩個演算法用的方式稍有不同,但其基本原理是一樣的,這原理即下一張投影片的主題。 Minimum Spanning Trees
Minimum Spanning Trees MST 基本引理 Let V = V1 + V2, (V1,V2 ) = {uv | u V1& v V2 }. if xy (V1,V2 ) and w(xy) = min {w(uv)| uv (V1,V2 )}, then xy is contained in a MST. a b c d e f g h 3 5 1 9 4 7 2 這個引理(lemma)是兩個 MST 演算法保證選到 safe edge 的基本原理。 符號 V = V1 + V2 代表頂點集 V 的一個分割,即 V1 , V2 的聯集為 V 交集為空。一般我們稱 V1 , V2 間的所有邊為原圖 G 的一個 cut,一個邊xy 的權重只要是某一 cut 的最小權重,即保證 xy 為某一 MST 的一個邊。 可用所附圖例,並隨意畫幾個分割來瞭解這個引理。 V1 V2 Minimum Spanning Trees
Kruskal’s Algorithm (pseudo code 1) for( each edge in order by nondecreasing weight ) if( adding the edge to A doesn't create a cycle ){ add it to A; if( | A| == n1 ) break; } How to check that adding an edge does not create a cycle? Kruskal’s algorithm 乾脆依照邊的權重大小,由小到大一個一個拿進來考量。若加進來的邊與之前選的邊集合會產生一個迴圈,那顯然這個邊不是 safe edge。若是不會產生迴圈,利用 MST 基本引理,可證明這個邊為 safe edge。 因此剩下的問題為:如何有效率的檢查是否加進來的邊會產生一個迴圈。 Minimum Spanning Trees
Kruskal’s Algorithm (例 1/3) b 3 5 1 9 4 7 2 f a e c d g h 這張以及以下幾張投影片用一個例子顯示 Kruskal’s algorithm 建構一 MST 的過程。 紅色的 4 個邊為權重最小的 4 個邊,因為加這 4 個邊不會產生迴圈,因此 Kruskal’s algorithm 會將這 4 個邊加入集合 A 中。 Minimum Spanning Trees
Kruskal’s Algorithm (例 2/3) b 3 5 1 9 4 7 2 f a e c d g h 再來考慮權重為 3 的兩個邊,ab 與 dg,注意加入 ab 會產生迴圈,因此只有 dg 加入 A 中。 Minimum Spanning Trees
Kruskal’s Algorithm (例 3/3) b 3 5 1 9 4 7 2 f a e c d g h 再來被考慮的邊為權重為 4 的邊,注意加入 de 會產生迴圈,但 bf 及 gh 不會。此時已有 n1 = 7 個邊加入 A 中,所以 Kruskal’s algorithm 會停並得一 MST 權重和為 17。 MST cost = 17 Minimum Spanning Trees
Kruskal’s Algorithm (pseudo code 2) A = ; initial(n); // for each node x construct a set {x} for( each edge xy in order by nondecreasing weight) if ( ! find(x, y) ) { union(x, y); add xy to A; if( | A| == n1 ) break; } 這張投影片主要描述:如何有效率的檢查加入一個邊 xy 到邊集合 A 中是否會產生一個迴圈。 會產生迴圈的充要條件為 x 與 y 在子圖 (V, A) 的同一 connected component (c.c.) 裡。一般要檢查這個條件是否成立,只要在子圖中做一次 depth-first search 即可。但這個檢查可能會做 |E| 次,因此做這麼多次depth-first search 太沒效率。 一個漂亮的作法為利用一種實做 disjoint sets 的高級資料結構(請參考 “Data structures for disjoint sets” 一章)。 演算法一開始 A 為空集合,所以可以看成在子圖 (V, A) 中,每一個頂點自成一個 c.c.。依序加入邊到後,子圖的 c.c. 個數漸漸減少,一直到最後演算法停時只剩下一個 c.c.。 投影片裡描述的實做方式,即是把每一個 c.c. 看成是一個由 c.c. 內的頂點所成的集合,顯然這些集合為 disjoint。因此加入邊 xy 會產生一個迴圈等價於 x 與 y 在同一個 c.c.,也等價於 x 與 y 在同一個集合裡。又加入一個邊 xy 到 A,相當於將 x 與 y 所在的集合聯集起來。 find(x, y) = true iff. x and y are in the same set union(x, y): unite the two sets that contain x and y, respectively. Minimum Spanning Trees
Prim’s Algorithm (pseudo code 1) ALGORITHM Prim(G) // Input: A weighted connected graph G=(V,E) // Output: A MST T=(V, A) VT { v0 } // Any vertex will do; A ; for i 1 to |V|1 do find an edge xy (VT, VVT ) s.t. its weight is minimized among all edges in (VT, VVT ); VT VT { y } ; A A { xy } ; Prim’s algorithm 找 A 的 safe edge 的方式稍有不同,此演算法利用一個逐漸增大的頂點集 VT,來構成一個 cut (VT, VVT) ,並找出這 cut 權重最小的邊 xy 加入 A,根據 MST 基本引理 xy 必為某一 MST 的邊,又我們注意到 VT 一直保持為 A 的邊的端點所成的集合,所以 A必包含在某一 MST 內且 xy 為A 的 safe edge。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 1/8) b 3 5 1 9 4 7 2 f a e c d g h 以下我們用一例來說明 Prim’s algorithm 的運作過程。 紫色點代表 VT 內的點。 紫色與藍色點間的最小權重邊為 ac,所以 ac 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 2/8) b 3 5 1 9 4 7 2 f a e c d g h 邊 ac 已加入 A 中 (以紅色邊表示 A 中的邊)。 紫色與藍色點間的最小權重邊為 bc,所以 bc 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 3/8) b 3 5 1 9 4 7 2 f a e c d g h 紫色與藍色點間的最小權重邊為 bf,所以 bf 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 4/8) b 3 5 1 9 4 7 2 f a e c d g h 紫色與藍色點間的最小權重邊為 ef,所以 ef 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 5/8) b 3 5 1 9 4 7 2 f a e c d g h 紫色與藍色點間的最小權重邊為 eg,所以 eg 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 6/8) b 3 5 1 9 4 7 2 f a e c d g h 紫色與藍色點間的最小權重邊為 dg,所以 dg 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 7/8) b 3 5 1 9 4 7 2 f a e c d g h 紫色與藍色點間的最小權重邊為 gh,所以 gh 會被加入 A 中。 Minimum Spanning Trees
Minimum Spanning Trees Prim’s Algorithm (例 8/8) b 3 5 1 9 4 7 2 f a e c d g h 最後已有 n1 = 7 個邊加入 A 中,所以 演算法會停並得一 MST 權重和為 17。 MST cost = 17 Minimum Spanning Trees
Prim’s Algorithm (pseudo code 2) Built a priority queue Q for V with key[u] = uV; key[v0] = 0; [v0] = Nil; // Any vertex will do While (Q ) { u = Extract-Min(Q); for( each v Adj(u) ) if (v Q && w(u, v) < key[v] ) { [v] = u; key[v] = w(u, v); Change-Priority(Q, v, key[v]); } 之前的 pseudo code 1 主要描述 Prim’s algorithm 的運作概念,這裡的pseudo code 2 較偏向實做。 在 pseudo code 1,有一 loop每一次要找 VT 與 V VT 間權重最小之邊,而在 pseudo code 2 則利用一 priority queue Q 來達成這個目標,但要注意 Q 是建構在頂點上而不是在邊上,並利用一陣列 key[u] 來記錄每一點的priority。將 Q 建構在邊上其實也可以,只是運算會複雜很多。 在 while loop 裡面,每一次從 Q 裡面拿一點 u 相當於在 pseudo code 1裡將 u 加入點集VT(亦相當於在範例裡,點由藍色變成紫色)。而所找到的 VT 與 V VT 間權重最小之邊的兩個端點分別為 u 與 [u]。 輸出的 MST 記錄在陣列 [ ] 裡,此樹可看成是一 rooted tree,以 v0 為根,每一點 u 的 [u] 紀錄 u 在此 rooted tree 的父節點。 一個點 u 的 key[u] 值在點還沒從 Q 拿出前可能會改變,因此呼叫副程式 Change-Priority( ) 是需要的。 Minimum Spanning Trees
Minimum Spanning Tree (分析) Let n = |V( G)|, m =|E( G)|. Execution time of Kruskal’s algorithm: (use union-find operations, or disjoint-set unions) O(m log m ) = O(m log n ) Running time of Prim’s algorithm: adjacency lists + (binary or ordinary) heap: O((m+n) log n ) = O(m log n ) adjacency matrix + unsorted list: O(n2) adjacency lists + Fibonacci heap: O(n log n + m) Kruskal’s algorithm 的瓶頸在對邊的權重做排序。 Prim’s algorithm 相當於在給定的圖形上做一種圖形搜尋,可稱為 priority first search,因為演算法根據頂點的 key 值的大小做搜尋,並且每一點與邊,頂多被探測兩次。因此時間複雜度與所用圖形表示的資料結構有很大的關係。照圖形演算法的習慣,當邊相當密集時,可以使用 adjacency matrix 來表示一個圖,當邊較稀疏時一般建議用 adjacency lists 來表示。但時間複雜度還與用哪一種實體資料結構來實做 priority queue 有關,根據 pseudo code 2,演算法總共需呼叫 O(n) 次 Extract-Min( ), O(m)次 Change-Priority( )。而使用不同實做 priority queue 的方式,每一個運算的平均執行時間複雜度不太一樣,總結如下: 使用資料結構 Extract-Min( ) Change-Priority( ) binary heap O(log n) O(log n) unsorted list O(n) O(1) Fibonacci heap O(log n) O(1) 因此,當使用 adjacency matrix表示圖形時,O(n2) 的時間複雜度是逃不掉的,所以此時的 priority queue 不如用最粗糙的 unsorted list 來實做還比較有效率。 Minimum Spanning Trees