一元线性回归(二)
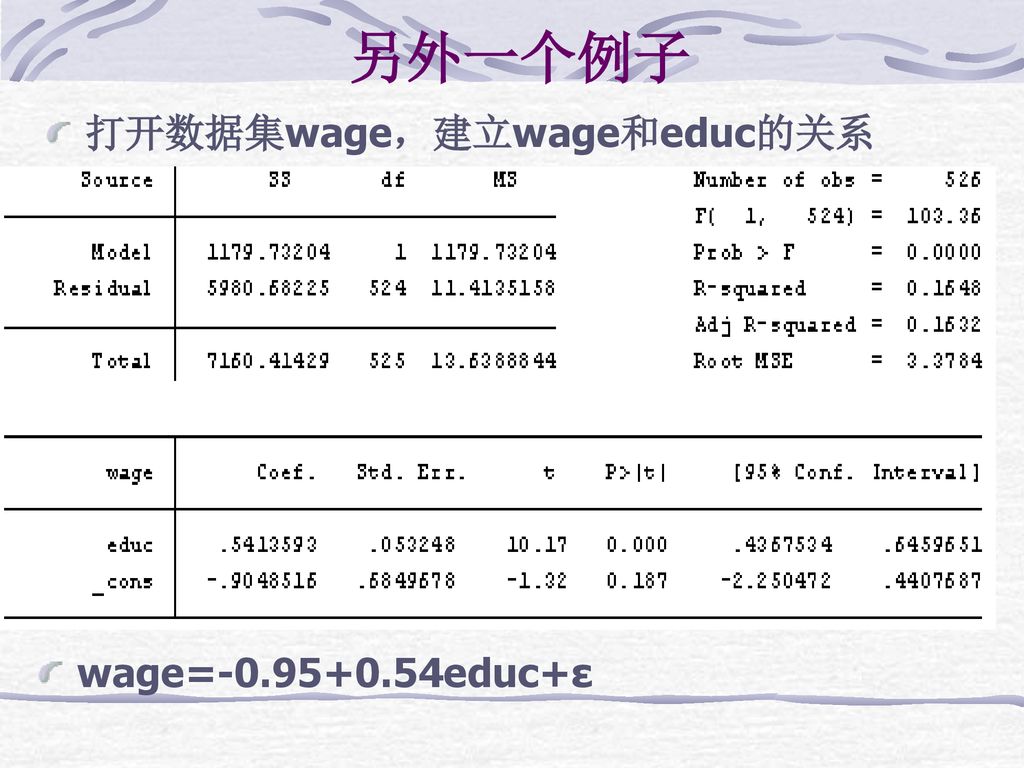
另外一个例子 打开数据集wage,建立wage和educ的关系 wage=-0.95+0.54educ+ε
我们把利用OLS方法估计出的参数α和β称为OLS估计量,用 表示。同时,以后每次做完回归后,我们将使用 作为回归拟合直线的纵坐标,以区分样本点纵坐标Y。
残差和拟合线的概念 残差是每个样本的拟合值和实际值之间的差。用ei或者 表示。 样本拟合线: 残差值:
如何得到残差和拟合值 在stata中做完回归后使用如下命令: predict y_hat,xb predict e,res list y y_hat e 可以发现 e=y-y_hat 因此, 是Y的估计值或拟合值,而残差的大小决定了模型的优劣。
直线上的点的坐标是 ,样本点的坐标是Yi (或者ei)是从样本点到直线的距离。
思考:ei 与ui是否是一回事? 有什么区别和联系?
重写求解步骤,得到重要结论
对上式各项分别求和,并移项可得
第一个方程两边同除以n,可得 将其带入到第二个方程 合并同类项,并移项可得:
使用关系式 将其写成离差的形式:
一些重要结论 1. 从方程可知 样本回归线一定经过 2. 下列方程成立:
写成内积的形式: 分别定义常数向量、残差向量、解释向量以及拟合值向量为:
可得: 故残差向量e与常数向量I正交,而且也与解释向量x正交。
3. 残差向量e也与拟合值 向量正交
4. 可以得到以下结论
OLS方法得到的拟合线一定是所有直线中拟合效果最好的,但由于样本自身的原因,拟合效果有好有坏。 最典型的例子是错误的函数形式
这是一个典型的对数函数的例子,用线性方程,模拟效果较差。
拟合优度 拟合优度R2:描述OLS回归线对样本数据的拟合效果;描述观测值在回归线附近的离散程度;同时描述了样本数据有多大程度可以被回归方程所解释。 R2是指可由Xi解释(或预测)的Yi样本方差的比例。
一个重要的公式:
证明: 其中:
拟合优度
对于所有样本点的平方和,均有下列结论: 总体平方和(Total Sum of Squares) 记 回归平方和(Explained Sum of Squares) 残差平方和(Residual Sum of Squares )
根据平方和分解公式,可将被解释变量的离差平方和分解为模型可以解释与不可解释的部分。 如果模型可以解释的部分所占比重越大,则样本回归线的拟合程度越好。 定义 拟合优度(goodness of fit)为:
Y的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归线(ESS),另一部分则来自随机势力(RSS)。 TSS=ESS+RSS Y的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归线(ESS),另一部分则来自随机势力(RSS)。 在给定样本中,TSS不变, 如果实际观测点离样本回归线越近,则ESS在TSS中占的比重越大,因此 拟合优度:回归平方和ESS/Y的总离差TSS
2、拟合优度R2统计量 称 R2 为(样本)拟合优度/可决系数/判定系数(coefficient of determination)。 拟合优度的取值范围:[0,1] R2越接近1,说明实际观测点离样本线越近,拟合优度越高。
由于每次向回归方程中增加解释变量,R2必然只增不减。为此,可以通过调整自由度对解释变量过多进行“惩罚”,因此,可以定义 “校正的拟合优度”
察看上述例题的拟合优度 注意: 1。拟合优度一定程度上反映了选取变量的对被解释变量的“解释能力”。 2。拟合优度低一般说明方程忽略了某些重要的解释因素。
回归标准误差(SER) 回归标准误差(standard error of the regression. SER)是回归误差u的标准差估计量,是用因变量单位度量的观测值在回归线附近的离散程度。 对于误差项ui,我们更关心它在回归线附近的离散程度,即标准差。希望标准差越小越好。 由于ui本身是不可知的,因此,实际上sui是无法获得的,为了模拟其数值大小,我们用 的标准差作为ui的标准差的估计值,称为回归的标准误差。
为什么要除以n-2?n-2是自由度。
模型中样本值可以自由变动的个数,称为自由度。 自由度 = 样本个数 — 样本数据受约束条件(方程)的个数。 例如,样本数据个数为n,它们受k个方程的约束(系数矩阵秩为k),那么,自由度df = n-k。
其中n-2为自由度。由于随机变量 必须满足k+1个正规方程(一元线形回归模型中有2个方程),故只有n-k-1个是相互独立的。经过这样校正后,才是无偏估计。
如果 无任何特征和规律可言,整个计量模型的建立将无法开展,因此,我们需要人为地为它设定一些假定条件。 如果下列假定条件满足,我们就可以用最小二乘法对模型进行回归估计。 这些假定条件被称为古典线性模型的经典假设
假设1:线性假定(linearity) 线性假设的含义是解释变量对yi的边际效应为常数。
假设2:严格外生性(strict exogeneity) 给定Xi时ui的条件分布均值为零 E(ui|Xi) = 0。 同时: E(Yi|Xi)=E( )=E( )=
理论上,随机误差项被假定为没有被纳入到模型中的微小影响,因此,没有理由相信这样一些影响会以一种系统的方式使被解释变量变大或者变小,可以假定其均值为0。
例如对某一给定的班级规模Xi,如每班20个学生,其他因素ui有时使成绩高于预测值(ui>0),有时使成绩低于预测值(ui<0) ,但就总体平均而言,ui的分布的均值为零。 同时,给定班级规模Xi,由于ui的干扰,某些Y’i的值大于Yi,某些Y’i的值小于Yi,但就总体平均而言,Y’i的分布的均值为E(Yi|Xi)=B0+B1Xi,即总体均值在回归线上。
推论 E(ui|Xi) = 0意味着ui和Xi不相关,即: Corr(ui , Xi)=0 这是最小二乘法最基本的假设,如果