Download presentation
1
时间序列分析法

2
中国医大基础医学院论文年代分布 关键字段出现频次关键字段出现频次 197814199293 197922199375 198020199449 198117199572 198224199665 198317199759 198414199858 1985341999101 1986292000147 1987272001137 1988452002181 1989622003174 1990522004194 1991862005308 1992932006330

3
中国医大基础医学院论文年代分布 这些数据说明了什么? 如何分析之?

4
文献数量随着时间分布的问题 文献增长模型是怎么来的? 普赖斯是如何分析的? 是否还有别的分析方法?

5
基本定义 时间序列 – 把研究事物的特征值统计数据按其发生时间的先后顺 序排列起来所形成的数列。 某一主题的文献量,每年文献量 医院,门诊量,每日 / 月 – 这种数列能够反映事物发展变化的动态,因此也称为 动态数列。

6
时间序列数据 – 为了保证时间序列分析的准确性, 时间序列数据的编制应该遵循以下 一些原则: 时间序列中的各项数据所代表 的时期长短(或间隔时间)应 该一致且连续; 时间序列中的各项数据所代表 的总体范围应该一致; 时间序列中的各项数据所代表 的质的内容应该前后一致; 统计指标数据的计算方法和计 量单位应该一致。 年代艾滋病文献量 19826 1983160 1984174 1985159 1986154 1987162 1988191 1989161 1990171 1991112 1992135 1993120 199494 199590 199669 199739
应 该一致且连续; 时间序列中的各项数据所代表 的总体范围应该一致; 时间序列中的各项数据所代表 的质的内容应该前后一致; 统计指标数据的计算方法和计 量单位应该一致。 年代艾滋病文献量")
7
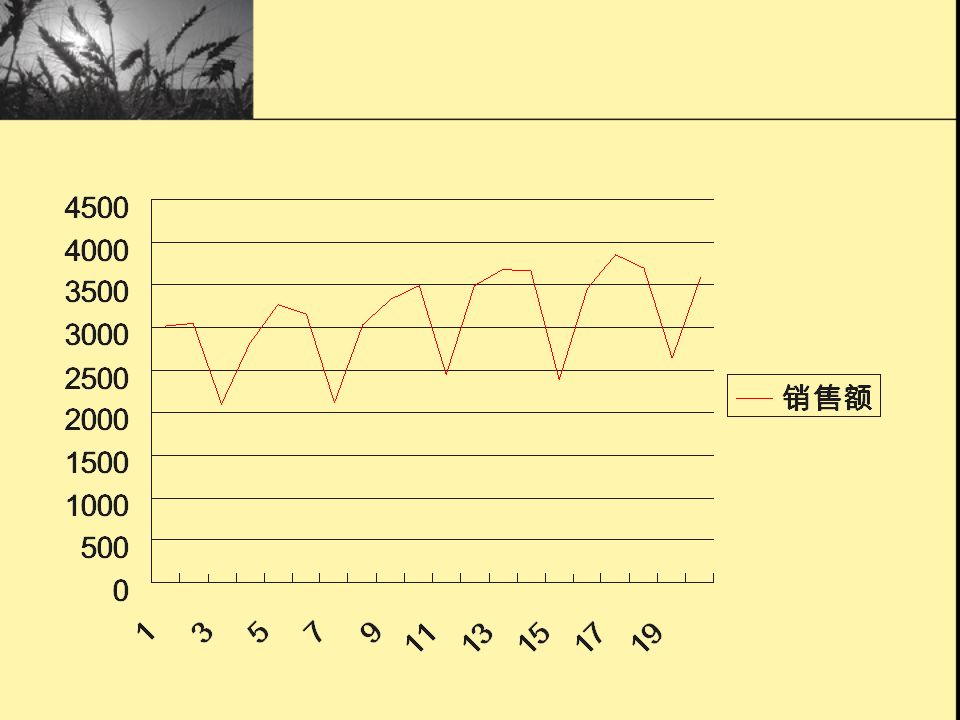
某商店某年前 10 个月的销售额

9
某企业从 1990 年 1 月到 2002 年 12 月的 销售数据 (单位:百万元)
")
10
倾向变动分析预测的方法 时间序列数据岁时间推移而变动的类型: – 倾向变动 / 趋势变动,用 T ( Trend )表示 – 周期变动,用 C ( Cyclical )表示 – 季节变动,用 S ( Seasonal )表示 – 不规则变动 / 随机变动,用 I ( Irregular )表 示
表示 – 周期变动,用 C ( Cyclical )表示 – 季节变动,用 S ( Seasonal )表示 – 不规则变动 / 随机变动,用 I ( Irregular )表 示")
11
时间序列分析的类型

12
时间序列分析的类型 倾向线的拟合: – 回归分析 – 精度高 – 近期和早期数据的区别 – 全部数据的计算 – 运算工作量大,复杂 倾向线的逐步修正 – 对数据进行平滑:将原始数据中的不规则的有 突变的轨迹大致修匀,形成平滑的倾向线。

13
倾向线的拟合 多项式曲线法 指数曲线 : 生长曲线

14
倾向线的逐步修正 移动平均法 – 一次移动平均 – 二次移动平均 指数平滑法 – 一次指数平滑 – 二次指数平滑 – 三次指数平滑

15
算术平均法 最简单的平滑方法,它能有效地排除随机变动的影响。 时间序列数据为 Y 1,Y 2,…,Y N : 对应于时间 t:1,2,…,N 则其算术平均值为: 式中: –y t ----- 第 t 时期的实际值; –t ----- 时间下标变量,表示时期序号; –N ----- 时间序列的时期个数,也即时间序列数据个数。 只能反映时间序列数据的一般情况(平均水平),而不能反映出数据 中的高值和低值,更不能反映时间序列数据的演变过程和发展趋势, 掩盖了可能存在的倾向变动; – 对时序列的近期数据和早期数据同样看待,缺乏对当前数据变动的适应 能力。
,而不能反映出数据 中的高值和低值,更不能反映时间序列数据的演变过程和发展趋势, 掩盖了可能存在的倾向变动; – 对时序列的近期数据和早期数据同样看待,缺乏对当前数据变动的适应 能力。")
16
分段平均法 按时期序号将时间序列数据分成都含有 n 个 时期的段,再取各段数据平均值。 分段平均法能够反映研究对象的总的变化 趋势和各时期大致变化幅度,并且通过取 平均值可以减弱随机因素的影响。 分段平均使得数据点大为减少,只为原来 数据点的 1/n ,使各段平均值呈阶梯状,不 能连续地反映变量的变化过程; 当时期总数不为 n 的整数倍时不便分段。

17
移动平均法 Moving Average 对象:无规则波动的数据 方法:每次在时间序列上移动一步求平均 值,去掉一个头部的数据,加入一个新的 数据。 意义:修匀,消除样本序列中的随机干扰 成分,突出序列本身的固有规律,为进一 步建模和参数估计打下基础。

18
一次移动平均 移动平均法: – 又称为滑动平均法。移动平均法是利用平均过 程所具有的平滑作用,从时间序列数据中去除 局部的不规则性,排除随机影响,从而找出时 间序列数据变动趋势的方法。 – 对时间序列数据分段求出算术平均值,但这时 的分段平均并不是按截然分开的段进行,而是 按根据时期的顺序不断移动得到的段进行,即 它的平均值的计算区段部分的重叠和逐渐移动, 因而能够在一定程度上客观地描述实际的时间 序列数据及其变化趋势。

19
一次移动平均 一次移动平均值的计算公式为: — 第 t 时期及其以前 (n-1) 个时期的数据的移动平均值; —— 时期序号; —— 第 t 时期变量的数值; —— 每段跨越的时期个数,即所包含的数据个数。
 个时期的数据的移动平均值; —— 时期序号; —— 第 t 时期变量的数值; —— 每段跨越的时期个数,即所包含的数据个数。")
20
一次移动平均的计算 艾滋病研究进展的文献计量学分析 – 董建成 申飞驹 南通医学院医学信息学教研

21
一次移动平均

22
一次移动平均 合理的选择分段时期个数 n 是用好移动平均 法的关键。 – 在 n 取较大值时,对波动曲线的 “ 修匀 ” 效果好, 但对变化反应的灵敏度降低; – 当 n 取较小值时,于随机影响的敏感性强,平 滑作用差,适应数据新水平的时间短,容易因 对随机干扰反映过度灵敏而造成错觉。 – 一般可以根据实际时间序列数据的特征和经验 选择模型参数 n 。

23
二次移动平均 一次移动平均只适用于修匀时间序列数据,而不 适用于有线性变动趋势的时间序列数据预测。 因为在时间序列数据具有线性变动趋势时,一次 移动平均值的变化总要落后于实际数据变动,而 形成一种滞后偏差。 二次移动平均是在一次移动平均值的基础上进行 的,二次移动平均数序列也与一次移动平均数序 列存在滞后偏差。 移动平均法正是利用这种滞后偏差的演变规律来 求出平滑系数,建立时间关系的数学模型,以进 行预测。

24
线性平滑时间关系模型 一般公式: t :时期的序号 L :由当前时期 t 到需要预测的时期之间的 时期个数; y t+l :第( t+l )时期的预测值。 b t :斜率,即单位时期的变化量 a t :截距,即当前时期 t 的数据水平
时期的预测值。 b t :斜率,即单位时期的变化量 a t :截距,即当前时期 t 的数据水平")
25
二次移动平均 在一次移动平均值的基础上,对有线性变 动倾向的时间序列数据再进行一次移动平 均 方法与一次移动平均完全相同。二次移动 平均值的计算公式为: :第 t 时期的二次移动平均值; :第 t 时期的一次移动平均值。

26
移动平均法 之所以计算一次移动平均值和二次移动平 均值,是因为需要利用滞后偏差的演变规 律求出平滑系数 a t 、 b t ,而不是直接用于预 测的。

27
移动平均法 必须指出,移动平均法虽然简便、实用,但是它 也有自身不可克服的缺点。 – 第一,与回归分析法(包括时间序列回归分析)的预 测模型相比,移动平均法的预测模型及求平滑系数的 公式并不是根据严格的数学推导建立的,而是根据经 验、作出假设导出的,是经验公式。 – 第二,移动平均法对时间序列不同时期的数据赋以相 同的权重,并未考虑远、近期数据对预测值的不同影 响,主要是根据时间序列数据的近期数据进行的。所 以它比较适合短期预测,而不宜用于长期预测。
的预 测模型相比,移动平均法的预测模型及求平滑系数的 公式并不是根据严格的数学推导建立的,而是根据经 验、作出假设导出的,是经验公式。 – 第二,移动平均法对时间序列不同时期的数据赋以相 同的权重,并未考虑远、近期数据对预测值的不同影 响,主要是根据时间序列数据的近期数据进行的。所 以它比较适合短期预测,而不宜用于长期预测。")
28
指数平滑法 exponential smoothing method 是对移动平均法的进一步改进,它除了具有移动 平均法的优点外,还有下述优点: – 对时间序列的不同时期的数据给以不同权重,更重视 近期数据; – 不损失数据个数,可以充分利用全部数据;运算比较 简单。 因此,在实际工作中,指数平滑法运用十分广泛, 是时间序列分析预测的重要方法。

29
指数平滑法 在时间序列分析与预测中,近期数据对于 研究对象当前发展趋势的影响总要比早期 数据影响大,所以应该给近期数据以较大 的权重,而给早期数据以较小权重。于是, 在移动平均法的基础上,产生了加权移动 平均法。 加权一次移动平均值; 权重数, ,有: ,

30
指数平滑法 对于不同时期数据,按几何级数的形式分 配权重,即按指数形式加权,并使权重数 之和为 1 。于是有:

31
时间序列分析的类型

32
生长曲线 发展过程中的三个阶段 – 发生、发展、成熟(稳定) – 人口的增长、技术的发展、某种产品的销量变 化等 它们的发展过程不能简单地用指数曲线或 修正指数曲线来描述。 – 指数曲线只能反映事物的发生、初期发展和迅 速发展阶段; – 而修正指数曲线则是反映了事物在经过蓬勃发 展之后发展速度逐步减慢趋向稳定的阶段。
 – 人口的增长、技术的发展、某种产品的销量变 化等 它们的发展过程不能简单地用指数曲线或 修正指数曲线来描述。 – 指数曲线只能反映事物的发生、初期发展和迅 速发展阶段; – 而修正指数曲线则是反映了事物在经过蓬勃发 展之后发展速度逐步减慢趋向稳定的阶段。")
33
生长曲线 “S” 型曲线又称为生长曲线( growing curve ),主要包括两种: – 对称型 S 曲线,称为 Logistic 曲线; – 非对称型 S 曲线,称为 Gompertz 曲线
,主要包括两种: – 对称型 S 曲线,称为 Logistic 曲线; – 非对称型 S 曲线,称为 Gompertz 曲线")
34
Logistic 曲线 逻辑曲线 是由比利时数学家 Verhulst 对于人口增长规律的 研究得来的。 他发现社会人口的增长速度最初随着时间的增加 而逐渐加快,在经过一段时间的高速增长之后, 人口增长速度逐渐减慢,最后社会人口总量趋于 一稳定值。 20 世纪初,美国统计学家 Pearl 发现了同样的规 律,所以 Logistic 曲线也称为 Pearl 曲线。

35
Logistic 曲线 如果 a>0, – 当 t → -∞ 时, y → 0 – 当 t → +∞ 时, y → k 如果 a <0 , – 当 t → +∞ 时, y → 0 – 当 t → -∞ 时, y → k →

36
Logistic 曲线 对 t 求一阶导数得 y 的增长速度受到 – 与该时刻的 y 成正比的 “ 力 ” 的推动, – 与 y 2 成正比的 “ 力 ” 的抑制。

37
Logistic 曲线 当 y=0 时, dy/dt=0 ; 在 y 值逐渐增大但数值仍较小时(相当于事物的 发生、发展阶段),推动 “ 力 ” 大于抑制 “ 力 ” , dy/dt 逐渐增大,即增长速度加快; 在 y 值超过某一数量后(相当于事物发展的成熟 阶段), dy/dt 逐渐减小,即增长速度逐渐减慢; 当 y=K 时, dy/dt=0 ,即事物发展趋于一个稳定 值。
,推动 力 大于抑制 力 , dy/dt 逐渐增大,即增长速度加快; 在 y 值超过某一数量后(相当于事物发展的成熟 阶段), dy/dt 逐渐减小,即增长速度逐渐减慢; 当 y=K 时, dy/dt=0 ,即事物发展趋于一个稳定 值。")
38
Logistic 曲线 从数学上可知,上式对除 y=0 和 y=K 以外的 一切 y 值均不为零。所以,在这两个极限值 之间无极大值或极小值,即曲线的变化是 单调的,而存在一拐点。

39
Logistic 曲线 曲线在其单调区间内的 y=k/2 处有唯一的拐 点。 记拐点处的 y 值为 yr ,则 对应于拐点的时间点 tr 因此, logistic 曲线对于点( yr,tr )是对称 的。
是对称 的。")
40
Gompertz 曲线 Gompertz 曲线是由英 国统计学家和数学家 B.Gompertz 于 1825 年 提出的,用下式表示: Gompertz 曲线是 双层指数函数。对 于模型参数的不同 取值, Gompertz 曲 线有四种不同的类 型。其中满足条件 K>0,0<a<1 , 0<b<1 的 Gompertz 曲线适用于某些技 术、经济、社会现 象发展过程的模拟。

41
Gompertz 曲线 Gompertz 曲线的拐点的坐标是

42
时间序列分析:总结

43
More : http://in-spire.pnl.gov/index.stm

44
ThemeRiver showing Castro data from November 1959 through June 1961

45
GeneXproTools 4.0 http://www.gepsoft.com/













 考点作文十大夺魁技法 6-10 ·新课标.>")







