Download presentation
Presentation is loading. Please wait.

1
資料採礦方法論(I) 蘇志雄 教授
 蘇志雄 教授")
2
決策樹(Decision Tree)
")
3
Game:Twenty Question

5
Comment from 20.Q

6
分類(Classification) 一、分類的意義 分類模型 資料庫 預測 瞭解類別屬性與 特徵
 一、分類的意義 分類模型 資料庫 預測 瞭解類別屬性與 特徵")
7
二、分類的技術 1.監督式(supervised learning)的機器學習法------ 決策樹(Decision Tree) 資料庫
分類標記 性別 Female Male 年齡 婚姻 <35 ≧35 未婚 已婚 否 是

8
二、分類的技術 2.非監督式(unsupervised learning)的機器學習法-----
集群分析法(Cluster Analysis)
")
9
三、分類的目的 1.尋找影響某一重要變項的因素。 2.了解某一族群的特徵。 3.建立分類規則。
例如: 行銷策略(市場區隔) 銀行(核卡額度) 醫療診斷(肝癌,SARS)
 銀行(核卡額度) 醫療診斷(肝癌,SARS)")
10
四、分類的程序 1.模型建立(Model Building) 2.模型評估(Model Evaluation)
3.使用模型(Use Model) 性別 年齡 婚姻 否 是 Female Male <35 ≧35 未婚 已婚 分類規則 IF 性別=Female AND 年齡<35 THEN 購買RV房車=否 IF 性別=Female AND 年齡≧35 THEN 購買RV房車=是 IF 性別=Male AND 婚姻=未婚 THEN 購買RV房車=否 IF 性別=Male AND 婚姻=已婚 THEN 購買RV房車=是 資料庫 訓練樣本(training samples) 建立模型 測試樣本(testing samples) 評估模型
 性別. 年齡. 婚姻. 否. 是. Female. Male. <35. ≧35. 未婚. 已婚. 分類規則. IF 性別=Female AND 年齡<35 THEN 購買RV房車=否. IF 性別=Female AND 年齡≧35 THEN 購買RV房車=是. IF 性別=Male AND 婚姻=未婚 THEN 購買RV房車=否. IF 性別=Male AND 婚姻=已婚 THEN 購買RV房車=是. 資料庫. 訓練樣本(training samples) 建立模型. 測試樣本(testing samples) 評估模型.")
11
Example X 婚姻 年齡 否 是 未婚 已婚 <35 ≧35 低 高 小康 1.建立模型 2. 模型評估 資料 訓練樣本
家庭 所得 否 是 未婚 已婚 <35 ≧35 低 高 小康 Example 1.建立模型 2. 模型評估 資料 訓練樣本 X 錯誤率為 66.67% 測試樣本 3.使用模型 修改模型

12
五、分類演算法的評估 準確度 速度 品質 可詮釋性 訓練測試法(training-and-testing)
交互驗證法(cross-validation) 速度 建模的速度、預測的速度 品質 可詮釋性
 速度. 建模的速度、預測的速度. 品質. 可詮釋性.")
13
決策樹(Decision Tree)之介紹
根部節點(root node) 中間節點(non-leaf node) (代表測試的條件) 分支(branches) (代表測試的結果) 葉節點(leaf node) (代表分類後所獲得的分類標記)
 中間節點(non-leaf node) (代表測試的條件) 分支(branches) (代表測試的結果) 葉節點(leaf node) (代表分類後所獲得的分類標記)")
14
決策樹的形成 根部節點 中間節點 停止分支 ?

15
ID3 演算法(C4.5,C5.0) Quinlan(1979)提出,以Shannon(1949)的資訊理論(Information theory)為依據。 資訊理論:若一事件有k種結果,對應的機率為Pi。則此事件發生後所得到的資訊量I(視為Entropy)為: I=-(p1*log2(p1)+ p2*log2(p2)+…+ pk*log2(pk)) Example 1: 設 k=4 p1=0.25,p2=0.25,p3=0.25,p4= I=-(.25*log2(.25)*4)=2 Example 2: 設 k=4 p1=0, p2=0.5, p3=0, p4= I=-(.5*log2(.5)*2)=1 Example 3: 設 k=4 p1=1, p2=0, p3=0, p4= I=-(1*log2(1))=0
為: I=-(p1*log2(p1)+ p2*log2(p2)+…+ pk*log2(pk)) Example 1: 設 k=4 p1=0.25,p2=0.25,p3=0.25,p4=0.25 I=-(.25*log2(.25)*4)=2. Example 2: 設 k=4 p1=0, p2=0.5, p3=0, p4=0.5 I=-(.5*log2(.5)*2)=1. Example 3: 設 k=4 p1=1, p2=0, p3=0, p4=0 I=-(1*log2(1))=0.")
16
ID3 演算法(C4.5,C5.0) 資訊獲利(Information Gain) 若分類標記(Y)分為(成功、失敗)兩種,X為預測變項(類別屬性;k類),n為總樣本數(n1為總樣本數中具成功標記的個數),經由X變項將樣本分類後mi為X=i類中的總樣本個數(mi1為X=i類中具成功標記的個數)。根據變項X將n個樣本分為m1,m2,…,mk的資訊獲利為: Gain(X)=I(n,n1)-E(X), 其中 I(n,n1)=-((n1/n)log2(n1/n)+(1-n1/n)log2(1-n1/n)) E(X)=(m1/n)*I(m1,m11)+(m2/n)*I(m2,m21)+…(mk/n)*I(mk,mk1)
 若分類標記(Y)分為(成功、失敗)兩種,X為預測變項(類別屬性;k類),n為總樣本數(n1為總樣本數中具成功標記的個數),經由X變項將樣本分類後mi為X=i類中的總樣本個數(mi1為X=i類中具成功標記的個數)。根據變項X將n個樣本分為m1,m2,…,mk的資訊獲利為: Gain(X)=I(n,n1)-E(X), 其中 I(n,n1)=-((n1/n)log2(n1/n)+(1-n1/n)log2(1-n1/n)) E(X)=(m1/n)*I(m1,m11)+(m2/n)*I(m2,m21)+…(mk/n)*I(mk,mk1)")
17
Example(Gain) n=16 n1=4 Max:作為第一個分類依據 Gain(年齡)=0.0167 Gain(性別)=0.0972
I(16,4)=-((4/16)*log2(4/16)+(12/16)*log2(12/16))=0.8113 E(年齡)=(6/16)*I(6,1)+(10/16)*I(10,3)=0.7946 Gain(年齡)=I(16,4)-E(年齡)=0.0167 Gain(年齡)=0.0167 Gain(性別)=0.0972 Gain(家庭所得)=0.0177 Max:作為第一個分類依據
=-((4/16)*log2(4/16)+(12/16)*log2(12/16))= E(年齡)=(6/16)*I(6,1)+(10/16)*I(10,3)= Gain(年齡)=I(16,4)-E(年齡)= Gain(年齡)= Gain(性別)= Gain(家庭所得)= Max:作為第一個分類依據.")
18
Example(續) Gain(家庭所得)=0.688 Gain(年齡)=0.9852 Gain(年齡)=0.2222
I(7,3)=-((3/7)*log2(3/7)+(4/7)*log2(4/7))=0.9852 Gain(家庭所得)=0.688 Gain(年齡)=0.9852 I(9,1)=-((1/9)*log2(1/9)+(8/9)*log2(8/9))=0.5032 Gain(年齡)=0.2222 Gain(家庭所得)=0.5032
=-((3/7)*log2(3/7)+(4/7)*log2(4/7))= Gain(家庭所得)= Gain(年齡)= I(9,1)=-((1/9)*log2(1/9)+(8/9)*log2(8/9))= Gain(年齡)= Gain(家庭所得)=")
19
Example(end) ID3演算法 Decision Tree 資料 分類規則
IF 性別=Female AND 家庭所得= 低所得 THEN 購買RV房車=否 IF 性別=Female AND 家庭所得= 小康 THEN 購買RV房車=否 IF 性別=Female AND 家庭所得= 高所得 THEN 購買RV房車=是 IF 性別=Male AND 年齡<35 THEN 購買RV房車=否 IF 性別=Male AND 年齡≧35 THEN 購買RV房車=是 Decision Tree 資料

20
Decision Tree的建立過程 (一)決策樹的分割
決策樹是通過遞迴分割(recursive partitioning)建立而成,遞迴分割是一種把資料分割成不同小的部分的疊代過程。 如果有以下情況發生,決策樹將停止分割: 該群資料的每一筆資料都已經歸類到同一類別。 該群資料已經沒有辦法再找到新的屬性來進行節點分割。 該群資料已經沒有任何尚未處理的資料。
建立而成,遞迴分割是一種把資料分割成不同小的部分的疊代過程。 如果有以下情況發生,決策樹將停止分割: 該群資料的每一筆資料都已經歸類到同一類別。 該群資料已經沒有辦法再找到新的屬性來進行節點分割。 該群資料已經沒有任何尚未處理的資料。")
21
(二)決策樹的剪枝(pruning) 但完全成長的樹對新的資料集來說一定是最好嗎?
決策樹學習可能遭遇模型過度配適(overfitting)的問題,過度配適是指模型過度訓練,導致模型記住的不是訓練集的一般性,反而是訓練集的局部特性。 但完全成長的樹對新的資料集來說一定是最好嗎? Data Mining的主要目的,是為了協助企業追求最高利潤而非追求最高準確度。
的問題,過度配適是指模型過度訓練,導致模型記住的不是訓練集的一般性,反而是訓練集的局部特性。 但完全成長的樹對新的資料集來說一定是最好嗎? Data Mining的主要目的,是為了協助企業追求最高利潤而非追求最高準確度。")
22
樹的修剪 修剪是爲了改善決策樹行爲而把一些枝葉修剪的過程。
實際上,修剪後的樹是整個樹的一個子樹,只要有新的分割點被發現,而且它能夠提高樹把訓練集中的記錄分類的能力,決策樹就會持續成長,如果訓練集中的資料用來評估樹,對樹的任何修剪將只會增加錯誤率。

23
樹的修剪 完全成長的樹很容易產生對訓練集的過度擬合的現象。 如何處理過度擬合呢?有幾種解決的方法,主要為修剪法和盆栽法

24
樹的修剪 修剪法 允許初始決策樹長的足夠深,然後用一些規則剪掉不是一般性的節點。
通常的方法是找到初始決策樹的各種各樣的越來越小的子樹相關的分類錯誤率。

25
樹的修剪 修剪法 若用建樹的同一資料計算錯誤率時,它會隨著樹結構的複雜而持續下降。
爲了限制過分的複雜,複雜程度也被加入了誤差內,在這種修剪過程之中,有一個枝節會一直保留,除非在分類效果上的改進足以抵消它素增加的複雜性。

26
樹的修剪 盆栽法 盡力限制樹的成長以免它長得太深。 例如規定每個節點下的最小的記錄數目。 亦可對每一個可能分割用統計檢驗其顯著性。

27
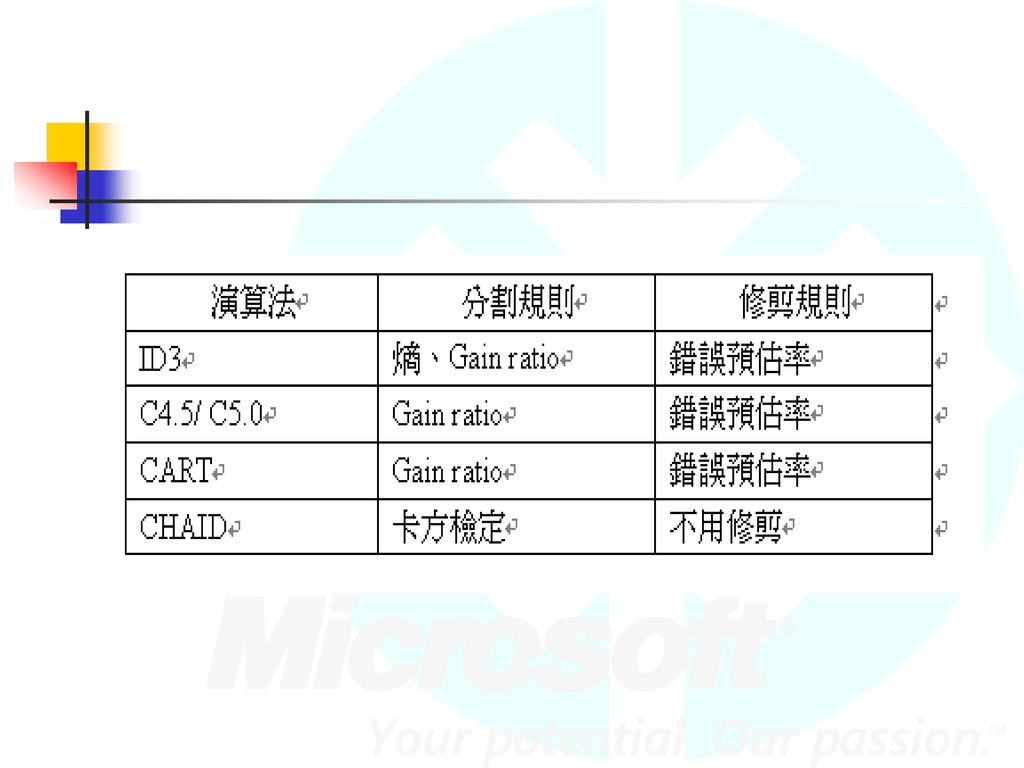
其他演算法 C4.5與C5.0演算法 PRISM 演算法 Gini Index 演算法 CART 演算法 CHAID 演算法

28
C4.5 與 C5.0 演算法 C4.5演算法是ID3演算法的修訂版 ,採用GainRatio來加以改進方法,選取有最大GainRatio的分割變數作為準則,避免ID3演算法過度配適的問題。 C5.0演算法則是C4.5演算法的修訂版 ,適用在處理大資料集,採用Boosting方式提高模型準確率,又稱為Boosting Trees,在軟體上的計算速度比較快,佔用的記憶體資源較少。

29
PRISM 演算法 資訊獲利的定義 : PRISM_Gain(X=x)=log2(mx1/mx)
PRISM_Gain(性別=Female)=log2(1/9)= PRISM_Gain(性別=Male)=log2(3/7)= PRISM_Gain(家庭所得=低)=log2(1/6)=-2.585 PRISM_Gain(家庭所得=小康)=log2(2/7)= PRISM_Gain(家庭所得=高)=log2(1/3)=-1.585 PRISM_Gain(年齡<35)=log2(1/6)= PRISM_Gain(年齡≧35)=log2(3/10)=-1.737
=log2(1/9)= PRISM_Gain(性別=Male)=log2(3/7)= PRISM_Gain(家庭所得=低)=log2(1/6)= PRISM_Gain(家庭所得=小康)=log2(2/7)= PRISM_Gain(家庭所得=高)=log2(1/3)= PRISM_Gain(年齡<35)=log2(1/6)= PRISM_Gain(年齡≧35)=log2(3/10)=")
30
Gini Index 演算法 ID3 and PRISM 適用於類別屬性的分類方法。 Gini Index 針對數值型態屬性的變項來做分類。

31
Gini Index 演算法 集合T包含N個類別的記錄,那麼其Gini指標就是
如果集合T分成兩部分 N1 and N2 。則此分割的Gini就是 提供最小Ginisplit 就被選擇作為分割的標準(對於每個屬性都要經過所有可以的分割方法)。
。")
32
CART 演算法 由Friedman等人提出,1980年代以來就開始發展,是基於樹結構產生分類和迴歸模型的過程,是一種產生二元樹的技術。
CART與C4.5/C5.0演算法的最大相異之處是其在每一個節點上都是採用二分法,也就是一次只能夠有兩個子節點,C4.5/5.0則在每一個節點上可以產生不同數量的分枝。 CART模型適用於目標變數為連續型和類別型的變數,如果目標變數是類別型變數,則可以使用分類樹(classification trees),目標變數是連續型的,則可以採用迴歸樹(regression trees)。
,目標變數是連續型的,則可以採用迴歸樹(regression trees)。")
33
CHAID演算法 Perreault和Barksdale兩人於1980年提出CHAID(Chi-square automatic interaction detector)分析方法,CHAID是由AID演變而來的。 CHAID會防止資料被過度套用並讓決策樹停止繼續分割,依據的衡量標準是計算節點中類別的P值大小,以此決定決策樹是否繼續分割,所以不需要作樹剪枝。

35
Microsoft 決策樹 採礦模型檢視器 放大 /縮小 複製圖

36
Microsoft 決策樹 採礦模型檢視器 滑鼠右鍵 檢視BukeBuyer的比例及其條件式 觀察屬於該節點之觀測值

37
Microsoft 決策樹 採礦模型檢視器 此節點中 BikeBuyer=1的比例有59.59% BikeBuyer=0的比例有40.40%
其特性為 Number Cars Owned=1 Age<=32 Commute Distance=‘0-1 Miles’

38
Microsoft 決策樹 模型相依性網路 各變數與預測變數間的關聯性 弱 強 預測變數 自變數

39
集群分析(Cluster Analysis)
")
40
集群分析的目的 目的在將相似的事物歸類。可以將變數分類,但更多的應用是透過顧客特性做分類,使同類中的事物相對於某些變數來說是相同的、相似的或是同質的;而類與類之間確有著顯著的差異或是異質性。 主要是在檢驗某種相互依存關係,主要是顧客間特性的相似或是差異關係;透過將顧客特性進一步分割成若干類別而達到市場區隔之目的

41
『集群』的形成

43
距離(distance)或稱相似度(similarity)
兩點之間的距離: 歐氏距離(Euclidean distance) 歐氏距離的平方(squared Euclidean distance) 曼哈頓距離(Manhattan distance ; City-Block)
 歐氏距離的平方(squared Euclidean distance) 曼哈頓距離(Manhattan distance ; City-Block)")
44
群與群之間的距離: 單一連接法(single linkage):又稱最短距離法。
完全連接法(complete linkage):又稱最長距離法。 平均連接法(average linkage) 重心法(centroid method) 變異數法(variance method):又稱沃德法(Ward’s procedure)
:又稱最長距離法。 平均連接法(average linkage) 重心法(centroid method) 變異數法(variance method):又稱沃德法(Ward’s procedure)")
45
C B A

46
演算法 集群分析演算法,不需要事先知道資料該分成幾個已知的類型,而可以依照資料間彼此的相關程度來完成分類分群的目的。此法可概分為四大類:
分割演算法 (Partitioning Algorithms), 階層演算法 (Hierarchical Algorithms), 密度型演算法 (Density-Based Algorithms)
, 階層演算法 (Hierarchical Algorithms), 密度型演算法 (Density-Based Algorithms)")
47
分割演算法 資料由使用者指定分割成K個集群群組。每一個分割 (partition) 代表一個集群(cluster),集群是以最佳化分割標準 (partitioning criterion) 為目標,分割標準的目標函數又稱為相似函數 (similarity function)。因此,同一集群的資料物件具有相類似的屬性。 分割演算法中最常見的是K-means及K-medoid兩種。此兩種方法是屬於啟發式 (heuristic),是目前使用相當廣泛的分割演算法。
 代表一個集群(cluster),集群是以最佳化分割標準 (partitioning criterion) 為目標,分割標準的目標函數又稱為相似函數 (similarity function)。因此,同一集群的資料物件具有相類似的屬性。 分割演算法中最常見的是K-means及K-medoid兩種。此兩種方法是屬於啟發式 (heuristic),是目前使用相當廣泛的分割演算法。")
48
K-means演算法:集群內資料平均值為集群的中心
K-means集群演算法,因為其簡單易於瞭解使用的特性,對於球體形狀 (spherical-shaped)、中小型資料庫的資料採礦有不錯的成效,可算是一種常被使用的集群演算法。 1967年由學者J. B. MacQueen 所提出,也是最早的組群化計算技術。
、中小型資料庫的資料採礦有不錯的成效,可算是一種常被使用的集群演算法。 1967年由學者J. B. MacQueen 所提出,也是最早的組群化計算技術。")
49
演算法的進行步驟如下所述: 輸入資料:集群的個數K,n個資料的訊息 輸出資料:K個集群的資料集

50
3、根據步驟二的結果,重新計算各個集群的中心點 (叢集內各物件的平均值)
4、重複步驟二到三,直到所設計的停止條件發生 (一般是以沒有任何物件變換所屬集群為停止絛件,也就是所謂的square-error criterion: mi代表集群i的中心,p是集群i內的物件,Ci則代表集群i)
")
51
K-means 演算法

52
K-medoid演算法:集群內最接近叢集中心者為集群中心。
基本上和K-means類似,不同在於K-means是以集群內各物件的平均值為集群的中心點,而K-medoid是以集群內最接近中心位置的物件為集群的中心點,每一回合都只針對扣除作為集群中心物件外的所有剩餘物件,重新尋找最近似的集群中心。

53
與K-means演算法只有在步驟三計算各個集群中心點的方式略有不同。
將步驟三改為隨意由目前不是當作集群中心的資料中,選取一欲取代某一集群中心的物件,如果因為集群中心改變,導致物件重新分配後的結果較好 (目標函數值較為理想),則該隨意所選取的物件即取代原先的集群中心,成為新的集群中心
,則該隨意所選取的物件即取代原先的集群中心,成為新的集群中心.")
54
K-medoids 演算法

55
需要的計算時間相當地簡潔,只需要O(n. K
需要的計算時間相當地簡潔,只需要O(n*K*t),n為資料物件的個數,K為叢集的數目,t為演算法重複執行的次數,一般而言K,t的值皆遠遠小於n的值。 兩種方法有一共同的缺點,就是事先得表示K值為何。
,n為資料物件的個數,K為叢集的數目,t為演算法重複執行的次數,一般而言K,t的值皆遠遠小於n的值。 兩種方法有一共同的缺點,就是事先得表示K值為何。")
56
K-means對於處理分群資料有明確集中某些地方的情形,有相當不錯的成效,而雜訊或者獨立特行資料的處理, K-medoid要比K-means來得好。

57
階層演算法 此法主要是將資料物件以樹狀的階層關係來看待。依階層建構的方式,一般分成兩種來進行: 凝聚法 (Agglomerative)
分散法 (Divisive)
")
58
凝聚法 (Agglomerative) 首先將各個單一物件先獨自當成一個叢集,然後再依相似度慢慢地將叢集合併,直到停止條件到達或者只剩一個叢集為止,此種由小量資料慢慢聚集而成的方式,又稱為底端向上法(bottom up approach) 。
 首先將各個單一物件先獨自當成一個叢集,然後再依相似度慢慢地將叢集合併,直到停止條件到達或者只剩一個叢集為止,此種由小量資料慢慢聚集而成的方式,又稱為底端向上法(bottom up approach) 。")
59
凝聚法 (Agglomerative) 5 1 4 3 2
")
60
分散法 (Divisive) 此法首先將所有物件全部當成一個叢集,然後再依相似度慢慢地叢集分裂,直到停止條件到達或者每個叢集只剩單一物件為止,此種由全部資料逐步分成多個叢集的方式,又稱為頂端向下法(top down approach) 。
 此法首先將所有物件全部當成一個叢集,然後再依相似度慢慢地叢集分裂,直到停止條件到達或者每個叢集只剩單一物件為止,此種由全部資料逐步分成多個叢集的方式,又稱為頂端向下法(top down approach) 。")
61
密度型演算法 以資料的密度作為同一集群評估的依據。起始時,每個資料代表一個集群,接著對於每個集群內的資料點,根據鄰近區域半徑及臨界值 (threshold),找出其半徑所含鄰近區域內的資料點。如果資料點大於臨界值,將這些鄰近區域內的點全部歸為同一集群,以此慢慢地合併擴大集群的範圍。如果臨界值達不到,則考慮放大鄰近區域的半徑。
,找出其半徑所含鄰近區域內的資料點。如果資料點大於臨界值,將這些鄰近區域內的點全部歸為同一集群,以此慢慢地合併擴大集群的範圍。如果臨界值達不到,則考慮放大鄰近區域的半徑。")
62
密度型演算法 此法不受限於數值資料的問題,可適合於任意形狀資料分佈的集群問題,也可以過濾掉雜訊,較適合於大型資料庫及較複雜的集群問題。
演算法時間的複雜度取決於基本單位的數目多寡,正常狀況下,其時間複雜度可在有限的時間內完成。

63
密度型演算法 缺點是鄰近區域範圍、及門檻值大小的設定;此兩參數的設定直接關係此演算法的效果。

64
通常為了得到比較合理的分類,首先必須採用適當的指標來定量地描述研究物件之間的同質性。
常用的指標為〝距離〞。

65
Microsoft 群集演算法 比例表現,其數字表示最大之比例

66
Microsoft 群集演算法 群集圖表 在群集2中,則無”0-1 Miles”的資料

67
Microsoft 群集演算法 群集設定檔 說明:
了解各群集中,各變數的分佈比例,以圖中為例,群集2中,距離為”0-1 Miles”的有0.4%、 ”1-2 Miles”的有25.7%、 ”2-5 Miles”的有13.6%、 ”5-10 Miles”的有32%、 ”10+Miles”的有28.3%

68
Microsoft 群集演算法 群集特性 說明: 針對各群集中,所有自變數之各選項,其分佈機率值,可看其各群集中,各變數主要分佈比例情形

69
Microsoft 群集演算法 群集辨識 說明:
群集間兩兩比較,了解各變數其值在兩群間之比重分數,以圖中為例,Age在47.7~95之間者,在群集2中的得分為100,而24~47.7在群集1中的分數為100;而Number Cars Owned為2者,主要在群集2,其分數為56.024,而為3者,也是以群集2為主,分數為3.338。

70
Sequence Clustering

71
Sequence Data Sequence data:有順序事件序列組成的資料,相關的變數是以時間區分開來, 但不一定要有時間屬性。
例如瀏覽Web的資料屬於序列資料。

72
Sequence Clustering Sequence Clustering在找出先後發生事物的關係,重點在於分析資料間先後序列關係。
Association則是找出某一事件或資料中會同時出現的狀態,例如項目A是某事件的一部份,則項目B也出現在該事件中的機率有a %。

73
商業應用 顧客通常在購買某類商品後,經過一段時間,會再購買另一類商品
例如: 租過黃飛鴻第一集,經過一段時間,通常會再租黃飛鴻第二集,之後再租黃飛鴻第三集 例如: 買過“棉被、枕頭、床單”之後,經過一段時間 ,通常會再購買“紙尿褲、奶粉” 例如:購買印表機的顧客,有80%的客戶在三個月內購買墨水盒。

74
例子 部分顧客交易資料 顧客編號 交易時間 交易物品編號 1 2004/1/1 2004/2/1 30 60, 90 2 2004/4/10
2004/5/20 10, 20 40,60,70

75
Sequential Pattern ( 2筆 ) :
顧客編號 購買序列 (Sequence Data) 1 (30) (60 90) 2 (10 20) (30) ( ) 3 ( ) 4 (30) (40 70) (90) 5 (90) Sequential Pattern ( 2筆 ) : (30) (90) 、(30) (40 70)
 1. (30) (60 90) 2. (10 20) (30) ( ) 3. ( ) 4. (30) (40 70) (90) 5. (90) Sequential Pattern ( 2筆 ) : (30) (90) 、(30) (40 70)")
76
例子 某序列資料庫假設用戶指定的最小支持度 Min(support) = 2。 Sequence_id Sequence 10
<a(abc)(ac)d(cf)> 20 <(ad)c(bc)(ae)> 30 <(ef)(ab)(df)cb> 40 <eg(af)cbc> 序列<a(bc)df>是序列<a(abc)(ac)d(cf)>的子序列 序列<(ab)c>是長度為3的序列模式
(ac)d(cf)> 20. <(ad)c(bc)(ae)> 30. <(ef)(ab)(df)cb> 40. <eg(af)cbc> 序列<a(bc)df>是序列<a(abc)(ac)d(cf)>的子序列. 序列<(ab)c>是長度為3的序列模式.")
77
Sequence Pattern Mining

78
Sequence Pattern Mining
Sequence Pattern Mining主要研究符號模式(symbolic pattern) 設定時間序列的持續時間(duration) t,限定對某段特定時間內的資料Mining。 例如:t=每年,t=地震發生的前兩週
 設定時間序列的持續時間(duration) t,限定對某段特定時間內的資料Mining。 例如:t=每年,t=地震發生的前兩週.")
79
Sequence Pattern Mining
設定Event folding window (w) 如果w=t,則找出的是與時間無關的模式。例如,某一時間段購買電腦的客戶,同時也買數位相機。 如果w=0,找出的序列模式中每個事件出現在不同的時間。例如,購買電腦的客戶,後續可能買記憶體,再買HD。
 如果w=t,則找出的是與時間無關的模式。例如,某一時間段購買電腦的客戶,同時也買數位相機。 如果w=0,找出的序列模式中每個事件出現在不同的時間。例如,購買電腦的客戶,後續可能買記憶體,再買HD。")
80
Sequence Pattern Mining
設定發現模式的時間間隔(interal,int) int=0,無時間間隔,找出嚴格連續的序列。DNA分析通常需要無時間間隔的連續序列。 Min(interval) ≦int≦Max(interval),例如模式”某人租影片A,可能30天內租影片B”表示,int ≦ 30。 int=c ≠0,具有確定間隔的模式。例如搜索”每次道瓊指數下降超過5%,兩天後可能結果” ,此時搜索間隔int=2天的序列模式。
 int=0,無時間間隔,找出嚴格連續的序列。DNA分析通常需要無時間間隔的連續序列。 Min(interval) ≦int≦Max(interval),例如模式 某人租影片A,可能30天內租影片B 表示,int ≦ 30。 int=c ≠0,具有確定間隔的模式。例如搜索 每次道瓊指數下降超過5%,兩天後可能結果 ,此時搜索間隔int=2天的序列模式。")
81
Sequence Pattern Mining方法
Apriori算法:Association中常用的Apriori算法適用於Sequence Clustering分析。 Database project-based sequential pattern growth

82
Sequence Clustering評估標準

83
Sequence Clustering評估標準
Interest Support Confidence 實施Sequence Clustering分析時,要事先決定最小Support和最小Confidence

84
Interest 規則是否有用,是否夠一般性,需要衡量的指標 當某一規則或序列滿足一定水準的可信度和普遍性,稱為Interest
通常以Support和Confidence來衡量規則或序列的Interest

85
Support Support:測量一個規則在資料集中多常發生的指標,表示一個規則的顯著性。
是一個規則,LHS表示左手規則,RHS表示右手規則。 N表示資料總數,n (LHS)表示包含左手邊的個數。
表示包含左手邊的個數。")
86
Sequence Clustering表示法
序列s=(s1,s2,…..,sn) ,若s包含在一個資料序列中,則稱資料序列支持s。 序列s的Support (s)=(包含s的資料序列總數)/(資料庫中資料序列總數) 若Support (s)大於等於 Min(Support),稱s為頻繁序列 Sequence Clustering目的在找出資料庫中所有頻繁序列的集合。
 ,若s包含在一個資料序列中,則稱資料序列支持s。 序列s的Support (s)=(包含s的資料序列總數)/(資料庫中資料序列總數) 若Support (s)大於等於 Min(Support),稱s為頻繁序列. Sequence Clustering目的在找出資料庫中所有頻繁序列的集合。")
87
Confidence Confidence:表示規則的強度,值介於0和1之間,當接近1時,表示是一個重要的規則。

88
Sequence Clustering的應用

89
Sequence Clustering應用範圍
顧客購買行為模式預測 Web訪問模式預測 疾病診斷 自然災害預測 DNA序列分析

90
Microsoft 時序群集演算法 群集圖表 主要目的: 觀察各群中,各產品的強度

91
Microsoft 時序群集演算法 群集設定檔 列出各群集中所有產品比例 僅列出各群中比例較高之產品及其比例 各群集之個數

92
Microsoft 時序群集演算法 群集特性 可了解各群特色

93
Microsoft 時序群集演算法 觀察各群集中,各產品間的關聯強度

94
問題與討論

Similar presentations







>")









.>")



