Download presentation
Presentation is loading. Please wait.

1
Searching for SuperNovae by LAMOST A-Li Luo, LiangpingTu, Chao Wu et al. LAMOST team, NAOC, CAS Taiyuan, , Nov.28

2
什么是超新星 超新星(supernova,SN)是恒星世界中剧烈的天文现象,超新星爆发时其光度将达到太阳的几十亿甚至百亿倍,也就是和一个银河系(由百亿颗恒星组成的星系)相同的光度,爆发过程中所释放的总能量相当于太阳一生所发射总能量的10倍以上。 超新星爆发时,不仅光学波段 会突然增亮,而且还有强的中微子、gama射线、x射线,有时还有射电辐射产生,天文学家有强烈的愿望要去解释这一剧烈变化的物理过程。通过观测、统计和理论分析,天文学家已给出了超新星爆发物理过程的初步模型。 分类,根据爆发过程中呈现的光谱特征和光变曲线,将超新星分为Ia(SNIa)Ib和II(SNII)三大类,这三类超新星爆发的原因、爆发过程、和结局都大不相同,爆发前也起源于不同类型的天体。 I型超新星的前身星是演化最终阶段的密近双星,它的大质量子星已演化的白矮星,并且开始吸积伴星的物质。当吸积速率到达一定限度是,白矮星表面物质就从氢聚变为氦;然后底部由氦聚变为碳,很快的白矮星的碳核质量迅速达到钱氏极限,碳被点燃,聚变迅速扩展,不到一秒钟就到达表面形成超新星爆发。 II型超新星被认为是大质量恒星演化到晚期的结果。一个大质量恒星在不到3000万年的时间,核心的氢就耗尽了,然后氦聚变为碳和氧,碳变为氖和镁,氖变为氧和镁,氧和镁变为硅和硫,直到最后硅和硫聚变为铁族元素。铁核外面依次为上述聚变的剩余物,核心变为铁族元素后,核反应停止,没有压力来平衡引力,于是引力收缩开始,中心密度和温度迅速上升,电子被压到原子核中形成富中子的原子核,高能粒子又撕裂原子核使它变为alpha粒子,这两个过程大量吸收能量,使得塌缩加速。从引力收缩开始不到一秒钟的时间内,中心密度就超过2.7×10e+14g/cm3的核子的密度,他将阻止塌缩而产生反弹激波,产生超新星爆发。
Ib和II(SNII)三大类,这三类超新星爆发的原因、爆发过程、和结局都大不相同,爆发前也起源于不同类型的天体。 I型超新星的前身星是演化最终阶段的密近双星,它的大质量子星已演化的白矮星,并且开始吸积伴星的物质。当吸积速率到达一定限度是,白矮星表面物质就从氢聚变为氦;然后底部由氦聚变为碳,很快的白矮星的碳核质量迅速达到钱氏极限,碳被点燃,聚变迅速扩展,不到一秒钟就到达表面形成超新星爆发。 II型超新星被认为是大质量恒星演化到晚期的结果。一个大质量恒星在不到3000万年的时间,核心的氢就耗尽了,然后氦聚变为碳和氧,碳变为氖和镁,氖变为氧和镁,氧和镁变为硅和硫,直到最后硅和硫聚变为铁族元素。铁核外面依次为上述聚变的剩余物,核心变为铁族元素后,核反应停止,没有压力来平衡引力,于是引力收缩开始,中心密度和温度迅速上升,电子被压到原子核中形成富中子的原子核,高能粒子又撕裂原子核使它变为alpha粒子,这两个过程大量吸收能量,使得塌缩加速。从引力收缩开始不到一秒钟的时间内,中心密度就超过2.7×10e+14g/cm3的核子的密度,他将阻止塌缩而产生反弹激波,产生超新星爆发。")
3
超新星的研究对恒星形成,星系及其化学元素演化,宇宙学参数测量、暗能量探索等方面具有十分重要的作用。
超新星爆发是大质量恒星和密近双星演化的终极,然而超新星爆发同时又被认为是大质量恒星形成的触发机制; 星爆星系被认为是有大规模恒星正在形成,这又被认为是超新星级联爆发的结果; 超新星爆发过程又是形成重元素的过程,甚至认为铁族以后的重元素也是超新星爆发过程中产生的,因此,超新星爆发关联着化学元素的演化; 超新星在其最高星等处较小的弥散使得它是宇宙的最好的距离指示器,被作为标准烛光使用,来研究宇宙结构。 超新星爆发时释放出中微子、gama射线和X射线,以及在超新星遗迹中有强的gama射线和X射线源,因而它们还是高能天体物理研究的主要对象; 超新星还用来推算或检验哈勃常数, 宇宙学测距的标准烛光

4
要对超新星进行更多和更深的研究就必须获得尽可能多的观测样本,而超新星爆发是偶发性的天文现象,且视星等大都是12等以上,所以早年对超新星的研究并不多,近年来,随着光学观测仪器及电脑的进步,让超新星的发现数量有了大幅度的增长,特别是自2000年以来每年都新发现数百颗超新星,据IAU:CBAT(Central Bureau for Astronomical Telegrams)统计,自1885年起到2008年4月24日止,人类共发现了4672颗超新星,且其中3500余颗是1997年以来发现的,这些发现为超新星的进一步研究提供了极大的便利。 国际上已实行和正在施行的超新星巡天计划有很多,较有影响的有SDSS(Sloan Digital Sky Survey) II Supernova Survey,; Barbary 等人利用哈勃太空望远镜(HST)寻找和跟踪高质量高红移的超新星,大大改善了宇宙膨胀历史的统计限制.在搜寻低红移超新星方面作出大量贡献的有LOSS(Lick Observatory Supernova Search),CSP(Carnegie Supernova Project),SNFactory(Nearby Supernova Factory)和CFA SN Group,这些组织获得了大量高质量的Ia型超新星多波段光变曲线和多时段的光谱。它们可以很好的被用来作为超新星模板,为发现更多的超新星奠定了一定的基础。 国内目前有原北京天文台使用60cm望远镜进行过超新星巡天,1996年开始到2001年结束, 96,97年共发现29颗;还有台湾鹿林天文台用其1米望远镜进 行两年多的超新星巡天,在南天区独立发现了11颗超新星。
 II Supernova Survey,; Barbary 等人利用哈勃太空望远镜(HST)寻找和跟踪高质量高红移的超新星,大大改善了宇宙膨胀历史的统计限制.在搜寻低红移超新星方面作出大量贡献的有LOSS(Lick Observatory Supernova Search),CSP(Carnegie Supernova Project),SNFactory(Nearby Supernova Factory)和CFA SN Group,这些组织获得了大量高质量的Ia型超新星多波段光变曲线和多时段的光谱。它们可以很好的被用来作为超新星模板,为发现更多的超新星奠定了一定的基础。 国内目前有原北京天文台使用60cm望远镜进行过超新星巡天,1996年开始到2001年结束, 96,97年共发现29颗;还有台湾鹿林天文台用其1米望远镜进 行两年多的超新星巡天,在南天区独立发现了11颗超新星。")
5
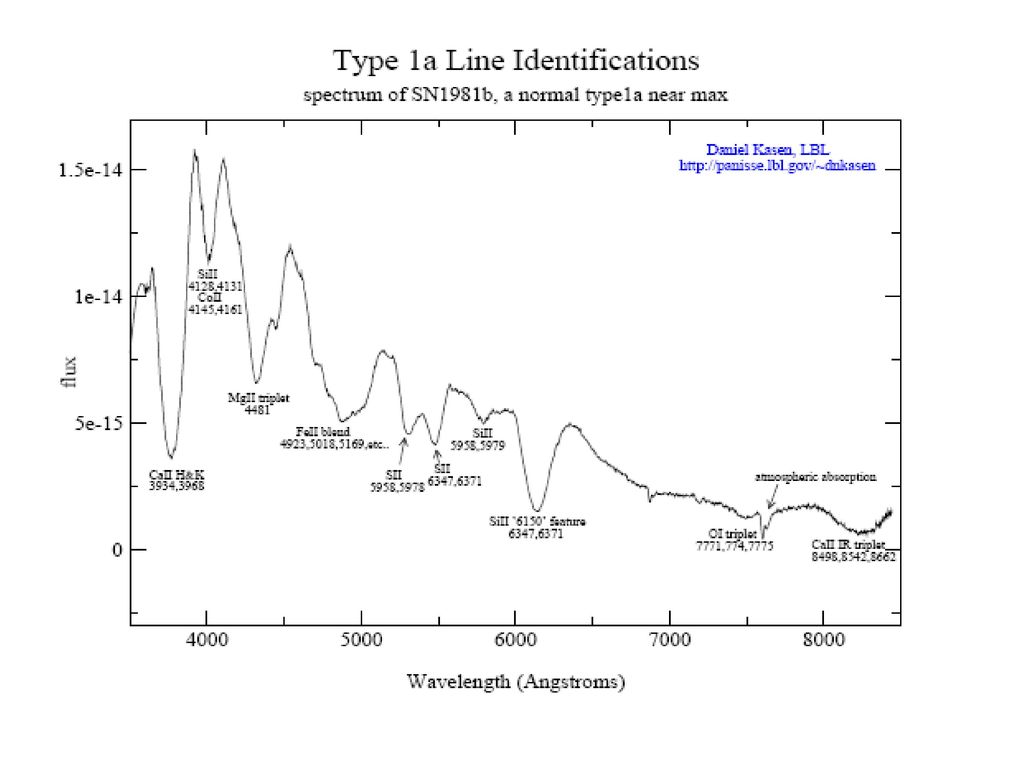
超新星的光谱分类特征: 如果在光极大时刻,其光谱中完全没有氢和氮的特征,而有很强的硅的吸收线,这类超新星被称为Ia型超新星。如果在光极大时刻,其光谱中有氦的特征而没有硅的特征,称为Ib型超新星。如果在光极大时刻,其光谱中既没有氦线也没有硅线。则被称为Ic型超新星。I型超新星光谱缺乏氢的各条光谱线。Ia型在光极大期间最明亮的谱线是一次电离硅(SiII)的6355 Å吸收线,其次是同时出现的从Si到Ca各元素的谱线。在光极大以后几周呈现HeI5876 Å的吸收线,SNIa晚期最主要的光谱是一次和二次电离Fe的禁戒发射线,而氧的光谱线却看不见。Ib型在光极大时最典型明亮的是HeI5876 Å吸收线,而不是SiII6355 Å ,几个月后SNIb铁的光谱线较弱,主要的光谱线是氧、镁等中质量元素的禁线。
的6355 Å吸收线,其次是同时出现的从Si到Ca各元素的谱线。在光极大以后几周呈现HeI5876 Å的吸收线,SNIa晚期最主要的光谱是一次和二次电离Fe的禁戒发射线,而氧的光谱线却看不见。Ib型在光极大时最典型明亮的是HeI5876 Å吸收线,而不是SiII6355 Å ,几个月后SNIb铁的光谱线较弱,主要的光谱线是氧、镁等中质量元素的禁线。")
6
Type Characteristics Type I Type Ia Lacks hydrogen and presents a singly-ionized silicon (Si II) line at 615.0 nm (nanometers), near peak light. Type Ib Non-ionized helium (He I) line at 587.6 nm and no strong silicon absorption feature near 615 nm. Type Ic Weak or no helium lines and no strong silicon absorption feature near 615 nm. Type II Type IIP Reaches a "plateau" in its light curve Type IIL Displays a "linear" decrease in its light curve (linear in magnitude versus time).
 line at nm (nanometers), near peak light. Type Ib. Non-ionized helium (He I) line at nm and no strong silicon absorption feature near 615 nm. Type Ic. Weak or no helium lines and no strong silicon absorption feature near 615 nm. Type II. Type IIP. Reaches a plateau in its light curve. Type IIL. Displays a linear decrease in its light curve (linear in magnitude versus time).")
8
不同类型的超新星光极大一周后的光谱

9
不同类型的超新星不同时刻的光谱

10
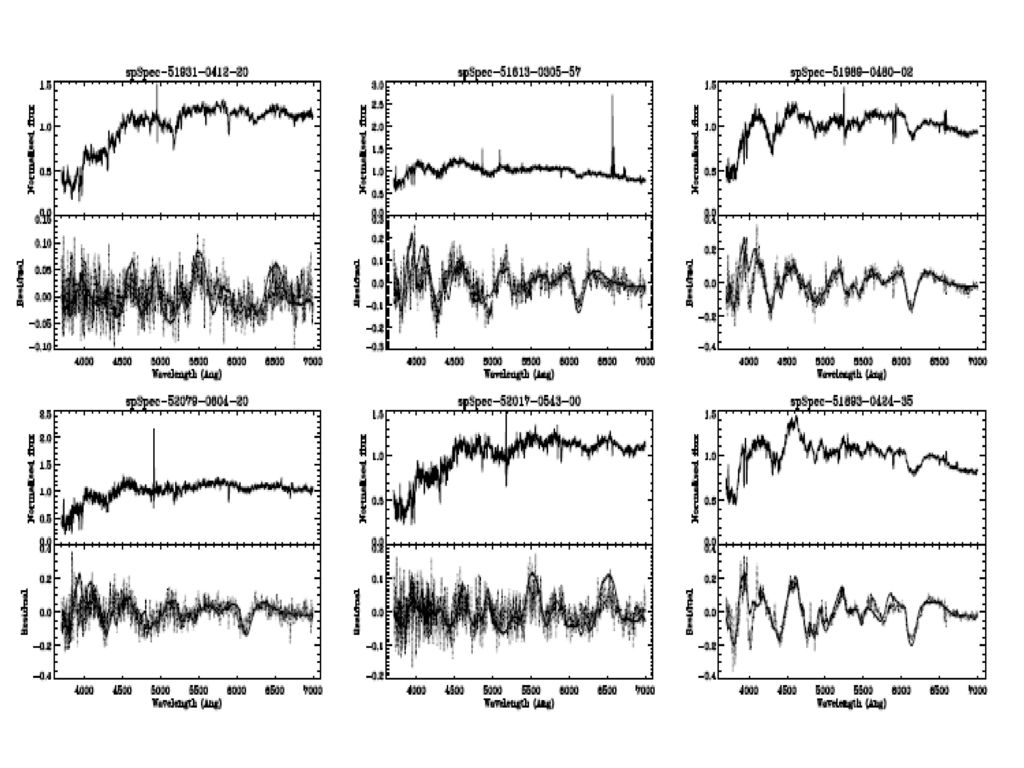
一个Ia型超新星在不同观测时刻的光谱比较

11
超新星另一重要观测特征是光变曲线,一般SNII型光变曲线相差很大,而I型(特别是Ia型)的光变曲线非常相似,而且Ia型在光极大的光度几乎相同,其绝对星等约为-20m。利用此性质Ia型SN可作为标准烛光来测定遥远星系的距离,进而确定哈勃常数。 SNIb与SNII全部都出现在漩涡星系中,而SNIa既可以出现在椭圆星系中,也可出现在漩涡星系中,且他们在漩涡星系中出现的位置和星系旋臂间不存在统计相关性。根据这种特征和其光谱中明显缺乏氢线,人们认为SNIa的前身星是双星系统中吸积的白矮星。统计分析表明,SNIa的爆发频率约100年出现一次。

12
Ia型SN在ugriz波段的光变曲线 griz light curves for SN 2005ff,z=0.088;gri light curves for SN 2005gg,z=0.231. Time is measured in days from the peak of g-band light.

13
Sloan超新星巡天介绍 SDSS-II SN 巡天是 年的三年计划,该计划利用美国APO的2.5m望远镜和其它十家协作天文望远镜进行超新星搜寻,它主要目标是在300sq.deg的天区内搜索红移范围在 内的Ia型超新星,在已释放的 的数据中,共获得327颗已得到光谱证认Ia型SN,30颗怀疑为Ia型SN,14颗证认的Ib/c型,32颗证认的SNII。 科学目标: Cosmological parameters from the SN Ia Hubble diagram; Minimization and evaluation of SN systematics; Anchoring the Hubble diagram and light-curve training; Rest-frame ultraviolet light-curve templates for high-z SN surveys; SN cosmology from multi-band photometry; SN rates, host galaxies, and rare SN types;

14
巡天策略: (1)主要仪器是安装在新墨西哥州APO(Apache Point Observatory)2.5m望远镜上的SDSS CCD摄像机,它可以同时在五个光学波段(ugriz)成像。仪器覆盖速度约为20sq.deg/小时。可以检测到最高星等为:u = 22.5, g = 23.2, r = 22.6, i = 21.9, and z = 20.8恒星源。 (2)巡天区域为南银半球天球赤道附近2.5度宽约300sq.deg区域。此区域大气消光小,在每年的9月到11月可以很好的进行光谱和测光观测。另外这一区域在SDSS-I时有大量的视宁度<1.5的图像,可提供高质量模板用于图像去除和发现超新星,而且大量的高质量背景图像可以改善测光水平。 (3)巡天方式,在每年9月1日到11月30日期间有效的观测夜里(最好是圆月左右五个夜晚)进行观测。然后用五个观测夜的平均图像与背景模板对比搜集瞬变现象,并输入数据库,最后通过其光变曲线等特征确定超新星候选。 (4)所有超新星候选按照光变曲线特征与Ia型超新星光变模板比较确定优先级后分配给10个协作望远镜进行光谱观测并就地进行证认。
主要仪器是安装在新墨西哥州APO(Apache Point Observatory)2.5m望远镜上的SDSS CCD摄像机,它可以同时在五个光学波段(ugriz)成像。仪器覆盖速度约为20sq.deg/小时。可以检测到最高星等为:u = 22.5, g = 23.2, r = 22.6, i = 21.9, and z = 20.8恒星源。 (2)巡天区域为南银半球天球赤道附近2.5度宽约300sq.deg区域。此区域大气消光小,在每年的9月到11月可以很好的进行光谱和测光观测。另外这一区域在SDSS-I时有大量的视宁度<1.5的图像,可提供高质量模板用于图像去除和发现超新星,而且大量的高质量背景图像可以改善测光水平。 (3)巡天方式,在每年9月1日到11月30日期间有效的观测夜里(最好是圆月左右五个夜晚)进行观测。然后用五个观测夜的平均图像与背景模板对比搜集瞬变现象,并输入数据库,最后通过其光变曲线等特征确定超新星候选。 (4)所有超新星候选按照光变曲线特征与Ia型超新星光变模板比较确定优先级后分配给10个协作望远镜进行光谱观测并就地进行证认。")
15
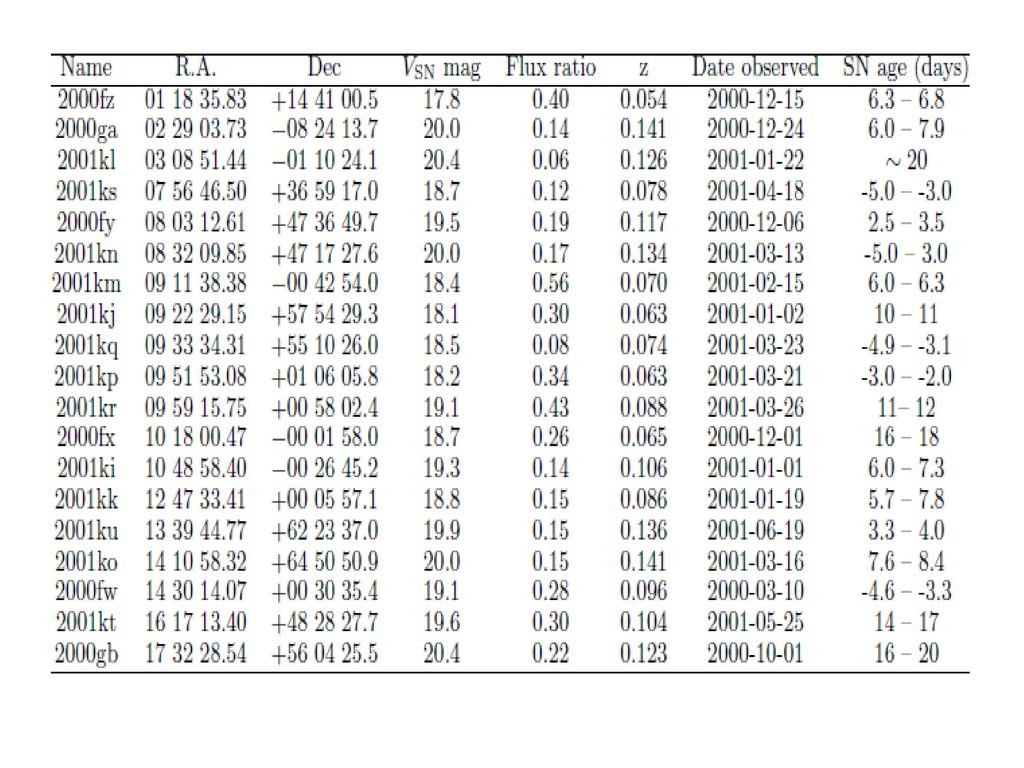
Spectroscopic Detection of Type Ia Supernovae in the SDSS(DR1,2003) (Darren S. Madgwick et al 2003, 作者中有王力帆) Galaxy Subtraction Processing (filter) SNe matching (correlation) Results find 19 Ia SN in galaxies with z<=0.25,Zconfidence>=0.35 in SDSS-DR1
 SNe matching (correlation) Results. find 19 Ia SN in galaxies with z<=0.25,Zconfidence>=0.35 in SDSS-DR1.")
18
SN search by LAMOST 全部巡天有 10^7 星系, 每个观测夜~10000个星系; LAMOST的峰值红移为: 0.2;
估计从LAMOST能够得到的SN: 10^2~10^3; No extra cost except for compute power and our intellect & Idea.

19
LAMOST 寻找超新星侯选体 目前超新星的发现效率较低,因为几乎所有这些巡天观测都是基于图像对比和测光观测的超新星候选体确认,这就需要大量的时间消耗和数据处理消耗,所以迫切需要寻找更有效率的方法去确定超新星候选。 而每年LAMOST大型巡天计划可获得海量的天体光谱,而这些数据经过1D pipeline自动分类后可以获得其中的大量星系光谱,从这些光谱数据发现超新星侯选体, 进而进行后续观测和光谱证认显然更有效率,而且消耗很低。 例用模式识别方面大量数据的统计意义的特征描述,获得了一种不用进行测光和图像对比并有效缩小超新星候选范围的方法,该方法通过计算星系光谱的超新星统计特征描述向量在数据中的孤立性进行离群点搜索,一定程度上克服了红移和时变的问题。实验证明该方法是可行和有效的。本文下面内容安排如下:首先介绍所用数据来源和处理过程,然后介绍了本文所使用的方法,随后给出相应实验结果及分析,最后对我们的工作进行了总结。

20
Plan Step 1: Searching for SN in SDSS DR7, to compute the producing rate of SN at redshift ~0.1; (Demonstrate the project to astronomers) Step 2: Candidate number reducing methods; make a reducing pipeline; Step 3: Migrate SNID to an identification pipeline ; Step 4: provide reliable SN candidate catalog

21
目前的一些实验 实验中我们主要用了两组Ia型超新星光谱数据:413条实测数据和500条模拟数据。实测的是不包含星系成分的,在使用中我们加入了星系成分。 实测数据部分采用The Suspect Database175个超新星中的46个Ia型的413条光谱,同一超新星不同光谱间的时间跨度最高达230天。 模拟数据我们利用来自Kinney在其文章中构造的正常星系模板和Peter Nugents Spectral Templates中的Ia超新星模板,按流量1:1合成了红移覆盖范围为0.001~0.5步长为0.001的500条光谱。星系数据我们采用了SDSS的 天区中的5054个星系。所有数据我们都插值到波长范围4002~7200A(这是因为所有的实测数据都可以覆盖这一范围,间隔3A接近LAMOST的光谱分辨率),并进行归一化处理。
,并进行归一化处理。")
22
Peter模板中的两条不同爆发时间的Ia型超新星模板

23
超新星PCA模板构造 我们将Peter Nugents Spectral Templates的90条Ia模板中的奇数位置共45条光谱进行红移后插值,获得红移范围0~0.3步长为0.001的13545条波长范围为4002~7200A间隔为3A的超新星光谱,然后对这些光谱进行PCA分析,获得其方差贡献率大于0.99的前16个主成分向量,称为Ia超新星的PCA模板,它们所构成的子空间称为超新星的特征子空间,每条光谱在这16个特征分量上的投影构成一个16维向量,称其为对应光谱的超新星统计特征描述。图为应第一第二主分量的显示。

24
基于样本对象孤立性度量(OM)的超新星候选体约减算法
定义:设样本对象,为一正数,称样本对象在集合中的邻域内的样本点到邻域内平均向量的平均距离为样本对象在集合中相对于的孤立性度量Outlier Measurement(OM),特别的,如果该邻域内只有一个样本点,则定义其孤立性度量为无穷大,相应点称为孤立点。 利用上述孤立性度量定义,我们可设计相应的离群样本点搜索算法,即光谱集合中的潜在超新星候选的搜索算法。算法描述如下: 1、 计算所有样本到中心的平均距离meandist; 2、 以aplha×meandist为半径计算每个样本的孤立性度量,其中,alpha~[0,0.3]由人工经验确定,meandist 是集合中所有样本到中心的平均距离; 3、 对所有样本按孤立性度量大小进行由大到小的排序; 4、选取所有样本数目比例beta为[0,0.05](一般,过大则意义不大)的孤立性度量较大的样本为超新星候选体人工选择前的选择范围。需要指出的是本方法中同为孤立点的样本排序先后不表示孤立性差异。
,特别的,如果该邻域内只有一个样本点,则定义其孤立性度量为无穷大,相应点称为孤立点。 利用上述孤立性度量定义,我们可设计相应的离群样本点搜索算法,即光谱集合中的潜在超新星候选的搜索算法。算法描述如下: 1、 计算所有样本到中心的平均距离meandist; 2、 以aplha×meandist为半径计算每个样本的孤立性度量,其中,alpha~[0,0.3]由人工经验确定,meandist 是集合中所有样本到中心的平均距离; 3、 对所有样本按孤立性度量大小进行由大到小的排序; 4、选取所有样本数目比例beta为[0,0.05](一般,过大则意义不大)的孤立性度量较大的样本为超新星候选体人工选择前的选择范围。需要指出的是本方法中同为孤立点的样本排序先后不表示孤立性差异。")
25
基于样本对象局部孤立性因子(LOF)的超新星候选约减算法
OM方法虽说是在局部邻域计算孤立性,但本质意义仍然是一种静态计算的全局孤立性度量,有时不能真正检测到某些孤立点,而且对都为孤立点的样本无法相互比较,Markus M提出了一种局部孤立性因子的概念,利用局部孤立性因子更能体现超新星在星系数据中的异常.

26
实验及结果分析 利用OM度量我们对模拟数据实验40次,实测数据实验30次,下图是两组超新星样本孤立性度量在所有5059个样本中排序位置的统计直方图。 经统计模拟数据结果中有70.50%的结果在前50个范围内,而有98%的结果在前100个范围;实测数据有90%的结果在前50个范围内,93.33%的结果在前100个范围。

27
LOF度量的实验结果 利用LOF度量计算时间消耗较小,我们对所有的数据都进行了测验。模拟数据仍然是500条上述星系加超新星数据合成光谱,实测数据为上述的413条光谱,归一化后计算PCA统计特征描述向量,每次将一个融合在那5054个星系中,并进一步计算相应的局部孤立性因子,最后排序,相应超新星数据的排序位置统计直方图见下图.经统计,模拟数据有100%的结果在前18个范围内,其中更有39.20%排序为1,即在所有数据中局部孤立性因子最大。实测数据中有98.79%的结果在前50个范围内,其中更有67.31%排序为1。

28
这些实验结果表明我们完全可以把超新星候选搜索范围自动降低到初始数据范围的1%-2%比例之内。也就是说按LAMOST每天获得约10000条星系光谱而言,通过我们的方法只需对其中的 条进行详细检验即可,这就大大增加了人工或交互式实时搜寻超新星候选的效率。需要说明的是在OM度量中大多数计算结果其实都是孤立点,也就是说孤立性度量都是无穷大,孤立点之间的排序位置不能说明相对孤立性大小,这与选择的邻域大小有关,由此引入Markus M方法。 另外,我们也分析了孤立性因子较大的其他星系,发现多数是信噪比较低的光谱,其特征描述显然是被噪声污染了,而其中信噪比高的样本中一部分有超新星的宽线特征,另外一些则是有强谱线、宇宙线存在或有较多坏像素存在影响,这会造成特征描述的较大差异。

29
问题和现状 低信噪比光谱的减星系(红移),测光对比法正在尝试; 算法需要进一步验证,并寻找新的聚类算法 (异常数据的挖掘);
SDSS的真实数据正在挖掘中…DR7全部进行了更正; 软硬件的设计.

30
谢谢!

Similar presentations