Download presentation
1
第十一章 药物生物信息学基础

2
第一节 生物信息学概述

4
生物信息学:生物信息学是一门交叉学科。它包 含了生物信息的获取、管理、分析、解释和应用 在内的所有方面。它综合运用生物学、计算机科 学和数学等多方面知识与方法,来阐明和理解大 量生物数据所包含的生物学意义,并应用于解决 生命科学研究和生物技术相关产业中的各种问 题。

5
主要任务 生物数据库的设计、建立和优化 从数据库中提取有效信息的算法 为用户设计查询信息的界面 开发数据可视化的有效方法
与多种资源和信息库建立有效连接 开发数据分析的新方法 发展预测的算法

6
研究内容 核酸及基因组信息 蛋白质及蛋白组信息 分子相互作用及代谢调控网络 生物进化

7
一级数据库 来源于实验获得的原始数据,只经过简单的归类 整理和注释,如核酸和蛋白质序列数据库、生物 大分子三维结构数据库等。

8
二级数据库(知识库、专用数据库 ) 是在一级数据库、实验数据和理论分析的基础上针 对特定目标衍生而来,是对生物学知识和信息的进 一步加工、提取、综合形成的知识库。
 是在一级数据库、实验数据和理论分析的基础上针 对特定目标衍生而来,是对生物学知识和信息的进 一步加工、提取、综合形成的知识库。")
9
分子生物信息数据库 基因组与功能基因组 : GDB, ACeDB, SGD, TDB
核酸序列: GenBank, EMBL, DDBJ 基因组与功能基因组 : GDB, ACeDB, SGD, TDB 蛋白质序列 : PIR, TrEMBL, SWISS-PROT 蛋白质结构 : PDB, MMDB, SCOP, CATH 蛋白质组 疾病数据库 代谢组数据库 与药物相关的分子设计数据库 集成数据库检索系统

10
核酸序列数据库

11
Genbank 由美国国立生物技术信息中心(NCBI)建立 和维护的。包含了所有已知的核酸序列和蛋白 质序列,以及与它们相关的文献著作和生物学 注释。 NCBI的网址是:
建立 和维护的。包含了所有已知的核酸序列和蛋白 质序列,以及与它们相关的文献著作和生物学 注释。 NCBI的网址是:")
12
EMBL 由欧洲生物信息学研究所(EBI)维护的核酸 序列数据构成,查询检索可以通过因特网上的 序列提取系统(SRS)服务完成。 数据库网址是: SRS的网址是:
维护的核酸 序列数据构成,查询检索可以通过因特网上的 序列提取系统(SRS)服务完成。 数据库网址是: SRS的网址是:")
13
DDBJ 日本DNA数据仓库(DDBJ)也是一个全面的 核酸序列数据库,与Genbank和EMBL核酸库合 作交换数据。使用其主页上提供的SRS工具进 行数据检索和序列分析。 DDBJ的网址是:
也是一个全面的 核酸序列数据库,与Genbank和EMBL核酸库合 作交换数据。使用其主页上提供的SRS工具进 行数据检索和序列分析。 DDBJ的网址是:")
15
三大核心数据库核酸序列增长

16
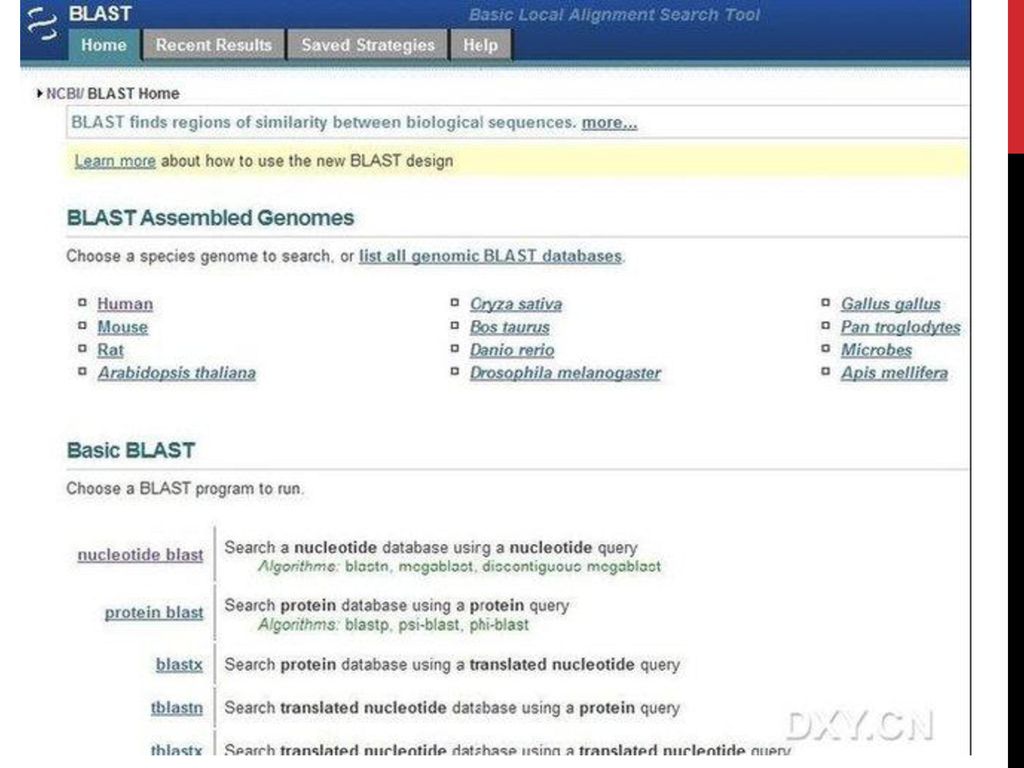
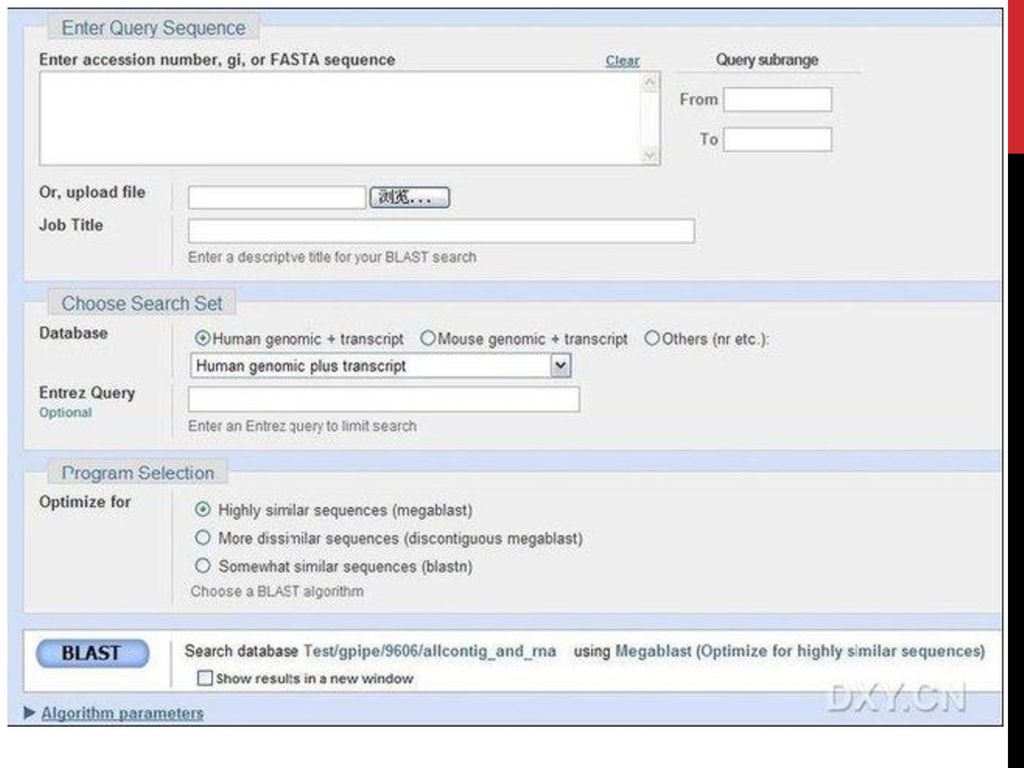
GenBank 使用 GenBank Search (基因序列及其注释资料的提取) BLAST 序列比对
 BLAST 序列比对")
17
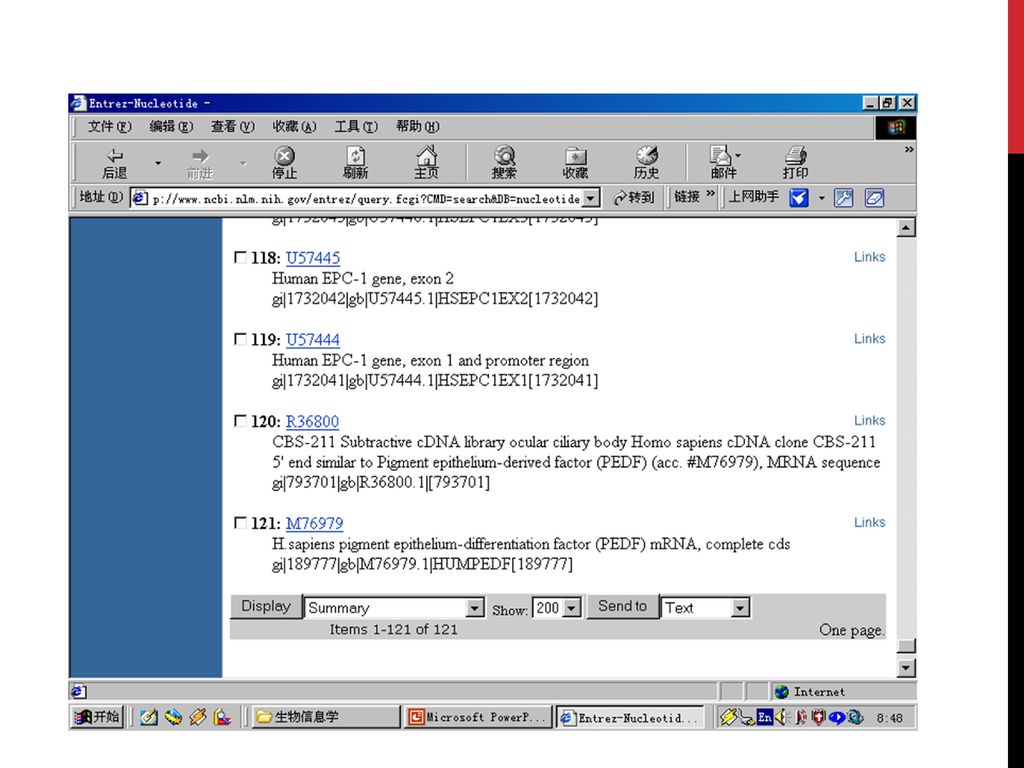
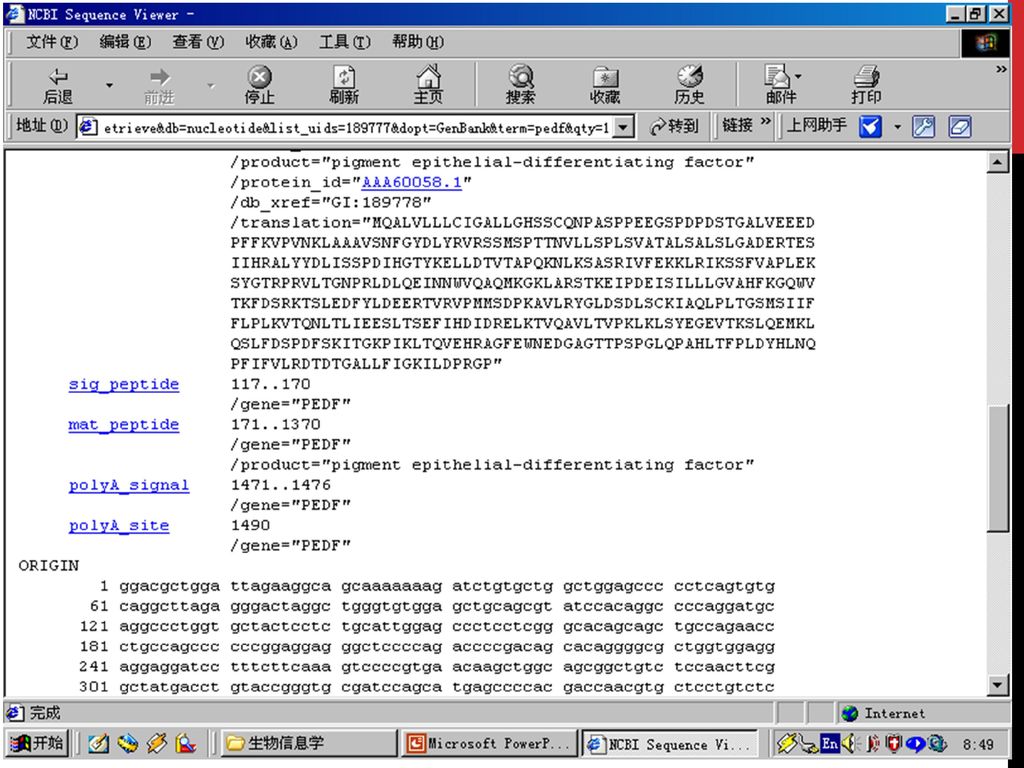
PEDF 基因相关序列及其注释资料的提取举例

20
基因组与功能基因组数据库 基因组数据库是存储生物整个基因组序列的数据 库,包括模式生物基因组、染色体、基因突变、 遗传疾病、放射杂交、比较基因组、基因调控和 表达、基因图谱等。 基因组数据库多是二级数据库,即从一级数据库 中选出的有关同一物种的核酸信息。

21
举例:GDB数据库:人类基因组数据库 ACeDB:线虫基因组数据库 SGD:啤酒酵母基因组数据库 TDB:微生物信息库,也包含人、植物、 微生物等的分类信息。

22
蛋白质序列数据库 PIR是国际上最大的公共蛋白质序列数据库。 PIR提供序列检索标准的序列相似性搜索和蛋白 质家族信息的高级搜索。

23
SWISS-PROT 由欧洲生物信息学研究所(EBI)维护。数据库 包含蛋白质序列、分类学信息、功能、位点、 结构、相似性、残缺与疾病的关系等信息。 SWISS-PROT的网址是: TrEMBL数据库 网址是:

24
序列分析 序列比对和相似性搜索 核酸序列分析 蛋白质序列分析

25
BLAST Basic Local Alignment Search Tool 基于局部的比对搜索工具 原理:待检片段 已知片段 高分值片段
比对结果 两端延伸 计算匹配程度 高分值片段 阈值 动态规划法

26
序列比对和相似性搜索 两两序列比对 双序列比对 多序列比对

30
核酸序列分析 启动子的识别和分析 开放阅读框的识别和分析 内含子 / 外显子的识别和分析 限制性酶切位点的识别和分析 对CpG岛的识别和分析
对重复序列的识别和分析

31
蛋白质序列分析 蛋白质基本性质分析: 蛋白质的分子量和等电点 蛋白质的疏水性分析 蛋白质酶切位点的分析 蛋白质辨识 组成的蛋白质辨识
蛋白质的质谱分析 2D-PAGE

32
跨膜蛋白的跨膜区分析 信号肽的分析 卷曲螺旋结构区的分析

33
第二节 生物信息学在药学中的应用

34
蛋白类结构预测和模拟 蛋白质结构预测的一般流程: 序列比对 二级结构预测 三级结构预测 蛋白质结构建模 蛋白质结构预测的检验

35
蛋白质结构预测的方法 理论分析法或从头算法(Ab initio) 统计分析法
 统计分析法")
36
理论分析法或从头算法(Ab initio)
计算分子力学,分子动力学等的理论参数 假设折叠后蛋白质取能量最低 无同源蛋白质时方用

37
统计分析法 统计分析已知结构的蛋白质 建立映射模型 蛋白质结构预测 氨基酸序列

38
蛋白质二级结构的预测 二级结构:肽链的局部主链骨架原子的空间结构 形式:α-螺旋 β-折叠 β-转角 无规卷曲

39
α-螺旋 右手螺旋 肽链内氢键维持稳定 侧链伸向外侧

40
β-折叠 呈折线状 肽链平行排列 肽链间氢键维持稳定

41
β-转角 肽链180度回折 以远距离力维持

42
蛋白质二级结构的预测 基础:每一段相邻的氨基酸残基具有形成一定 二级结构的倾向 核心问题:模式的识别与分类 目标:二级态的判断

43
蛋白质二级结构的预测 统计-经验法 基于单个氨基酸的统计分析:Chou-Fasman法
基于氨基酸片段的统计分析:基于信息论的GOR 方法或最邻近法 物理-化学方法 机器学习方法 致力于前两种方法的优点的结合,如人工神经网 络法

44
蛋白质二级结构的预测 人工神经网络法 输入层:接受蛋白质序列数据 隐含层:信息处理 输出层:输出蛋白质二级结构

45
蛋白质二级结构的预测 人工神经网络法 PHDsec 同源序列的多重比对排列 进行从序列到结构的映射 进行从结构到结构的映射 二级结构预测结果

46
蛋白质二级结构的预测 人工神经网络法 PHDsec 有自我学习能力 结合其他方法预测的准确度可达到80% 进化信息、长程作用信息和全局信息的
利用还不完全

47
蛋白质三级结构的预测 三级结构:整条肽链所有原子的三维空间排布 位置 维持力:次级键 结构域:三级结构中折叠较为紧密具有功能的 区域

48
肌红蛋白三级结构

49
蛋白质三级结构的预测方法 同源模建 折叠模式识别 从头预测

50
同源建模 数据库搜索及模板的选择 序列比对 确定结构保守区 构建目标蛋白质的主链 构建目标蛋白质的侧链 优化模型

51
目标蛋白与模板同源性 >60%:预测结果可以 完全准确 20%~25%:预测结果 准确性很低 < 20%:无法作出预测

52
折叠模式识别 找到同一家族的远程同源蛋白质:预测结果 比较好 找到非同一家族的远程同源蛋白质:预测结 果难以保证 找到同一家族的远程同源蛋白质的可能性只 有40%左右

53
从头预测 基于蛋白质天然结构是能量最小的构象原 理,将蛋白质的残基作为最基本单元,进行蒙 特卡罗模拟、模拟退火或遗传算法优化,计算 出蛋白质肽链所有可能构象的能量,从中取出 能量最小的构象就是蛋白质的天然构象。

54
药物靶标的发现 药物发现的主要方式是进行药物设计和筛选,特 别是围绕药物作用的靶点进行 药物作用靶点:指具有重要生理或病理功能,能 够与药物相结合并产生药理作用的生物大分子及 其特定的结构位点。 生物大分子主要是蛋白质,也有一些是核苷酸及 其他物质 全世界治疗药物的作用生物靶标分子约有500个, 而预测的可能靶点为5 000~10 000种

55
计算机辅助药物设计 直接药物设计方法 数据库搜寻方法 全新药物设计 间接药物设计 定量构效关系 药效基团模型




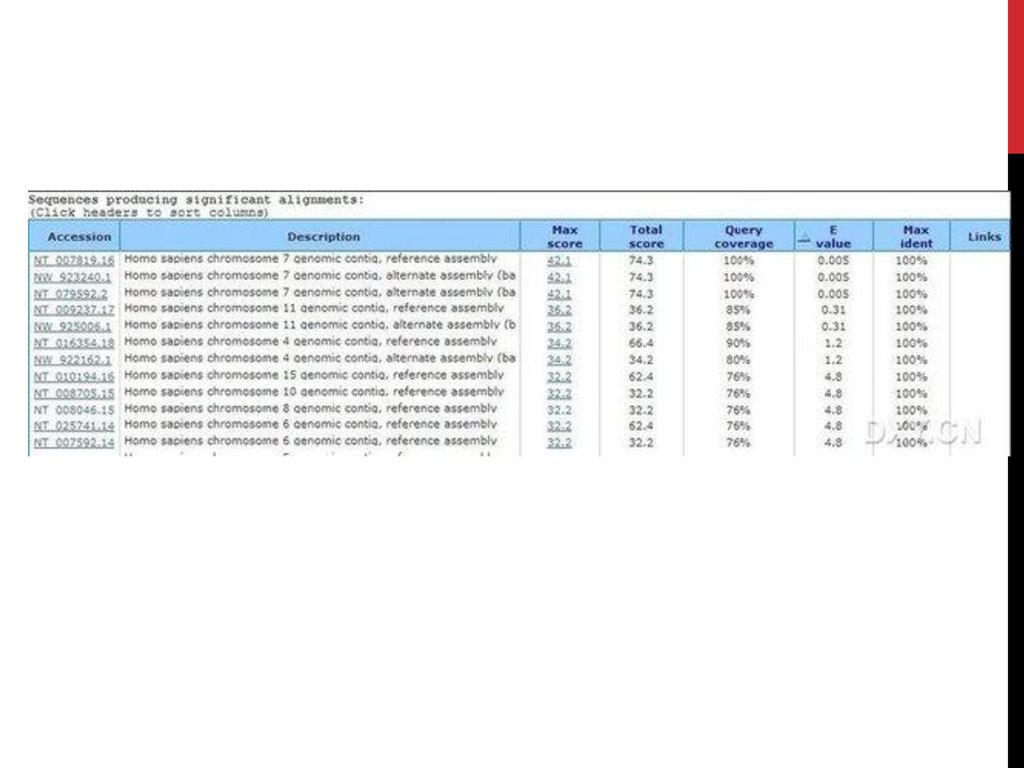
 生物信息学. 检索数据库的方法 用关键词或词组进行数据库检索 (Text-based database searching) 用核苷酸或蛋白质序列进行数据库检索 (Sequence-based database searching) Gene.>")


:核蛋白体组成成分 转移 RNA ( tRNA ):转运氨基酸 信使 RNA ( mRNA ):蛋白质合成模板 不均一核 RNA ( hnRNA ):成熟 mRNA 的前体 小核 RNA ( snRNA ):>")


生物信息学基础 2013年秋季学期通选课程 上课时间:周一 18:30点 上课地点:软件园4区502d>")
>")








 三级结构:所有原子空间位置 四级结构:多亚基蛋白>")


